
키워드:GENMO, Seed-Coder, DeepSeek, LlamaParse, 에이전틱 AI, 에지 컴퓨팅, 양자 컴퓨팅, NVIDIA GENMO 인체 모션 모델, 바이트댄스 Seed-Coder 코드 대형 모델, DeepSeek 오픈소스 전략 영향, LlamaParse 문서 분석 신뢰도 점수, 에지 컴퓨팅 실시간 데이터 처리
🔥 聚焦
NVIDIA, GENMO 범용 인간 동작 모델 출시: NVIDIA가 GENMO (GENeralist Model for Human MOtion)라는 AI 모델을 발표했습니다. 이 모델은 텍스트, 비디오, 음악, 심지어 키프레임 실루엣 등 다양한 입력을 사실적인 3D 인체 동작으로 변환할 수 있습니다. 이 모델은 다양한 유형의 입력을 이해하고 융합할 수 있는데, 예를 들어 비디오에서 동작을 학습하고 텍스트 프롬프트에 따라 수정하거나 음악 리듬에 맞춰 춤을 생성할 수 있습니다. GENMO는 게임 애니메이션, 가상 세계 캐릭터 생성 등 분야에서 엄청난 잠재력을 보여주며, 복잡하고 자연스러운 연속 동작을 생성하고 애니메이션 시퀀스를 직관적으로 편집할 수 있도록 지원합니다. 현재 얼굴 표정이나 손 디테일 처리는 불가능하고 외부 SLAM 방식에 의존하지만, 다중 모드 입력과 고품질 출력은 AI 동작 생성 분야에서 중요한 진전을 의미합니다 (출처: YouTube – Two Minute Papers
)
ByteDance, Seed-Coder 시리즈 오픈소스 대규모 모델 발표: ByteDance가 8B 파라미터 규모의 기본 모델, 명령어 모델, 추론 모델을 포함하는 Seed-Coder 시리즈 오픈소스 대규모 언어 모델을 출시했습니다. 이 시리즈 모델의 핵심 특징은 “코드 모델 자체 기획 데이터” 능력으로, 데이터 구축에서 인공적인 참여를 최소화하는 것을 목표로 합니다. Seed-Coder는 코드 생성, 편집 등 여러 측면에서 현재 최고 수준(SOTA)을 달성했으며, AI 자체 능력으로 훈련 데이터를 최적화하고 구축할 수 있는 잠재력을 보여주어 코드 대규모 모델 발전에 새로운 아이디어를 제공했습니다 (출처: _akhaliq)
DeepSeek 모델, AI 커뮤니티에서 광범위한 주목을 받다: DeepSeek 시리즈 모델, 특히 코드 모델은 강력한 성능과 오픈소스 전략으로 AI 커뮤니티에서 광범위한 논의를 불러일으켰습니다. 많은 개발자와 연구자들이 그 성능에 깊은 인상을 받았으며, 전 세계적으로 오픈소스 모델에 대한 인식을 바꾸었다고 평가했습니다. 논의에서는 DeepSeek의 성공이 OpenAI와 같은 회사들이 오픈소스 전략을 재평가하고 현지 대규모 모델 제조업체들의 오픈소스화 속도를 높이도록 촉진할 수 있다고 지적했습니다. 오픈소스가 상용화, 하드웨어 호환성 등의 도전에 직면하고 있지만, DeepSeek의 등장은 AI 기술 민주화와 산업 발전을 촉진하는 중요한 힘으로 간주됩니다 (출처: Ronald_vanLoon, 36氪)

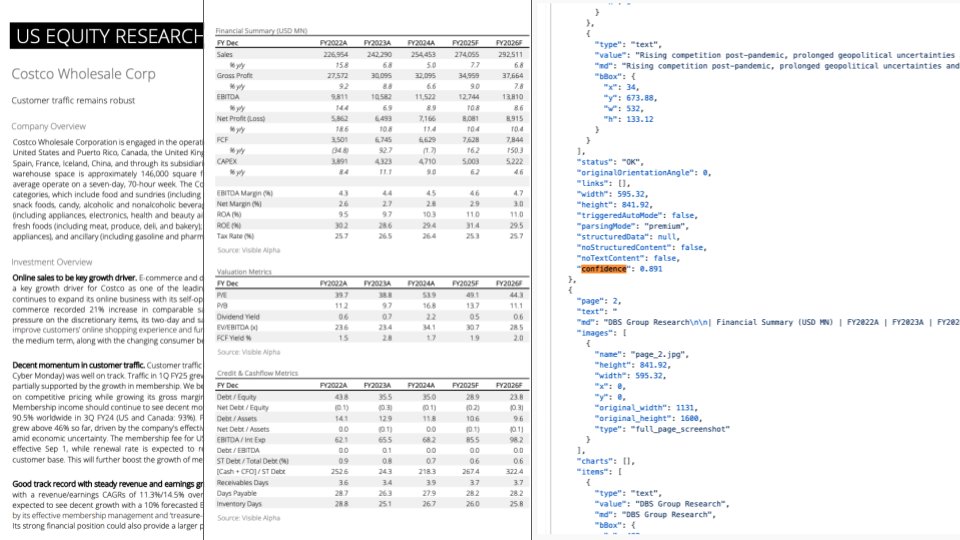
LlamaParse 업데이트: GPT-4.1 및 Gemini 2.5 Pro 통합으로 문서 분석 능력 향상: LlamaParse가 최신 GPT-4.1 및 Gemini 2.5 Pro 모델을 통합하여 문서 분석 정확도를 크게 향상시킨 중요 업데이트를 발표했습니다. 새로운 기능에는 자동 방향 및 기울기 감지가 포함되어 분석 내용의 정렬과 정확성을 보장합니다. 또한 신뢰도 점수 기능이 도입되어 사용자가 각 페이지의 분석 품질을 평가하고 신뢰도 임계값에 따라 수동 검토 프로세스를 설정할 수 있습니다. 이번 업데이트는 LLM/LVM이 복잡한 문서를 처리할 때 발생할 수 있는 오류를 해결하고, 수동 검토 및 수정 사용자 경험을 제공하여 자동화 프로세스의 신뢰성을 보장하는 것을 목표로 합니다 (출처: jerryjliu0)
🎯 동향
2025년 기술 산업 동향 전망: 보고서는 2025년 기술 산업의 주요 동향을 예측했으며, 인공지능, 머신러닝, 5G, 웨어러블 기기, 블록체인, 사이버 보안 등 신흥 기술이 지속적으로 발전하고 깊이 융합될 것으로 전망했습니다. 이러한 기술은 삶을 개선하고 혁신을 주도하며 사회 문제를 해결하는 데 중요한 역할을 할 것으로 예상되며, 기술이 지원하는 밝은 미래를 예고합니다 (출처: Ronald_vanLoon, Ronald_vanLoon)

2025년 AI 분야 발전 동향 예측: IBM은 2025년 인공지능 분야가 지속적으로 빠르게 발전할 것이며, 머신러닝(ML)과 인공지능(MI) 기술이 더욱 성숙해져 각 산업에 광범위하게 적용될 것으로 예측했습니다. AI는 자동화, 데이터 분석, 의사 결정 지원 등에서 더 큰 역할을 하며 기술 혁신과 산업 업그레이드를 추진할 것으로 예상됩니다 (출처: Ronald_vanLoon)

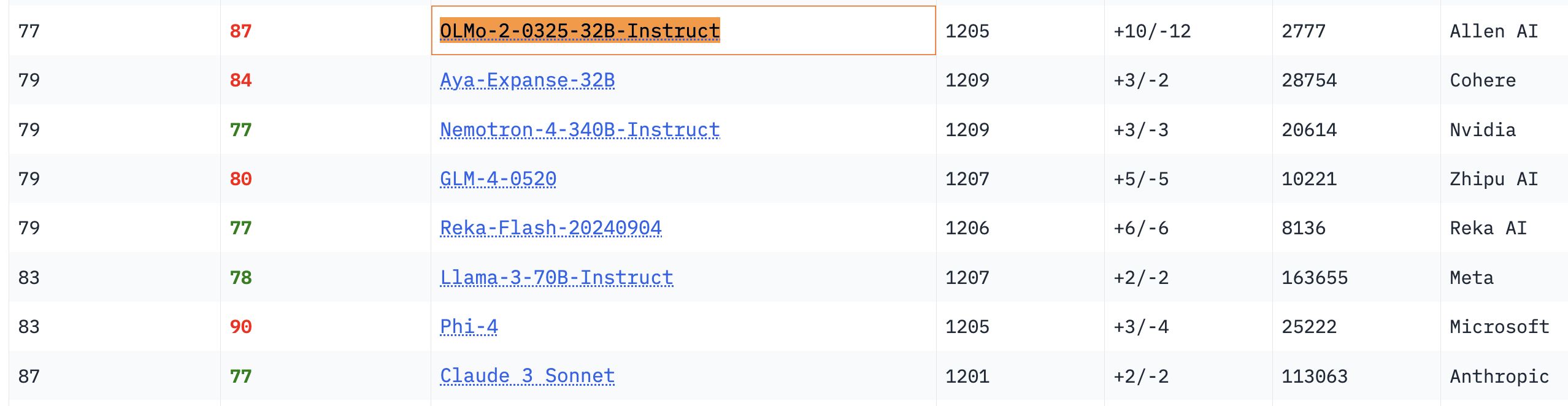
OLMo 32B 모델, 뛰어난 성능 과시: 관련 벤치마크 테스트에서 완전 개방형 OLMo 32B 모델이 파라미터 수가 더 많은 Nemotron 340B 및 Llama 3 70B 모델보다 우수한 성능을 보였습니다. 이 결과는 어떤 면에서는 파라미터 수가 적은 완전 개방형 모델도 더 큰 규모의 상용 모델에 필적하거나 능가할 수 있음을 보여주며, 개방형 모델 연구의 엄청난 잠재력과 추격 속도를 나타냅니다 (출처: natolambert, teortaxesTex, lmarena_ai)
Gemma 모델 다운로드 1.5억 건 돌파, 변형 모델 7만 개 이상: Google의 Gemma 모델이 Hugging Face 플랫폼에서 다운로드 1억 5천만 건을 돌파했으며, 7만 개 이상의 변형 모델을 보유하고 있습니다. 이 데이터는 Gemma 모델이 개발자 커뮤니티에서 높은 인기와 광범위한 활용도를 얻고 있음을 반영합니다. 커뮤니티 사용자들은 또한 향후 버전의 반복에 대한 기대감을 나타내고 있습니다 (출처: osanseviero, _akhaliq)
Unsloth, Qwen3 GGUF 모델 업데이트 및 보정 데이터셋 개선: Unsloth가 모든 Qwen3 GGUF 모델을 업데이트하고 새롭고 개선된 보정 데이터셋을 적용했습니다. 또한 Qwen3-30B-A3B에 더 많은 GGUF 변형을 추가했습니다. 사용자 피드백에 따르면 30B-A3B-UD-Q5_K_XL 버전에서 번역 품질이 다른 Q5 및 Q4 GGUF에 비해 향상되었다고 합니다 (출처: Reddit r/LocalLLaMA)

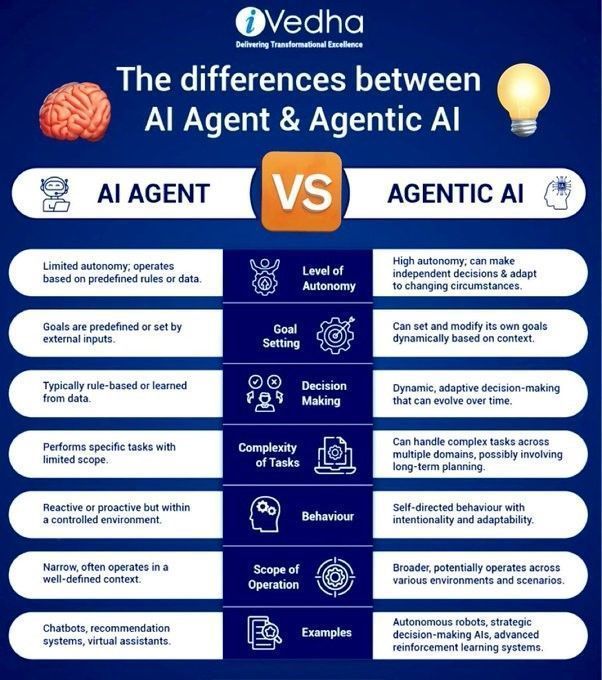
Agentic AI와 GenAI의 차이점: Agentic AI와 생성형 AI(GenAI)는 현재 AI 분야의 핫이슈입니다. GenAI는 주로 새로운 콘텐츠(텍스트, 이미지 등)를 생성할 수 있는 AI를 의미하는 반면, Agentic AI는 자율적으로 작업을 수행하고 환경과 상호 작용하며 의사 결정을 내릴 수 있는 지능형 에이전트에 더 중점을 둡니다. Agentic AI는 일반적으로 GenAI의 능력을 결합하지만 자율성과 목표 지향성을 더 강조합니다 (출처: Ronald_vanLoon)

감성 AI, 고객 경험 향상: 감성 AI 기술은 인간의 감정을 분석하고 이해함으로써 고객 경험(CX)을 향상시키는 데 활용되고 있습니다. 이는 기업이 고객의 요구와 감정을 더 잘 이해하여 보다 개인화되고 공감적인 서비스를 제공하도록 돕고, 디지털 전환 과정에서 고객 관계 관리 혁신을 촉진합니다 (출처: Ronald_vanLoon)
AI 기반 개인화 도구 “지능형 역학 보조 장치”(Jigging) 개념: Karina Nguyen은 AI 모델이 개인화된 자가 개선 도구 제작자가 될 것이라는 비유로 “Jigging” 개념을 제안했습니다. AI는 사용자와 상호 작용할 때마다 사용자의 특성과 작업에 따라 새로운 전용 도구를 만들어 능력을 향상시킵니다. 예를 들어, AI는 의사를 위해 개인화된 진단 프레임워크를 구축하거나 작가를 위해 독특한 서사 프레임워크를 구축합니다. 이러한 순환적 개선은 AI를 사용자 인지 아키텍처의 확장으로 만들어 인간-기계 협업의 근본적인 변화를 주도할 것입니다 (출처: karinanguyen_)
AI 에이전트와 Agentic AI의 차이점: Khulood Almani는 AI 에이전트(AI Agents)와 Agentic AI 간의 차이점을 추가로 설명했습니다. AI 에이전트는 일반적으로 특정 작업을 수행하는 소프트웨어 프로그램을 의미하는 반면, Agentic AI는 시스템의 자율성, 학습 능력 및 적응성을 더 강조하며 환경과 보다 능동적으로 상호 작용하고 복잡한 목표를 달성할 수 있습니다. 이 차이점을 이해하면 AI 발전 방향과 잠재력을 파악하는 데 도움이 됩니다 (출처: Ronald_vanLoon)
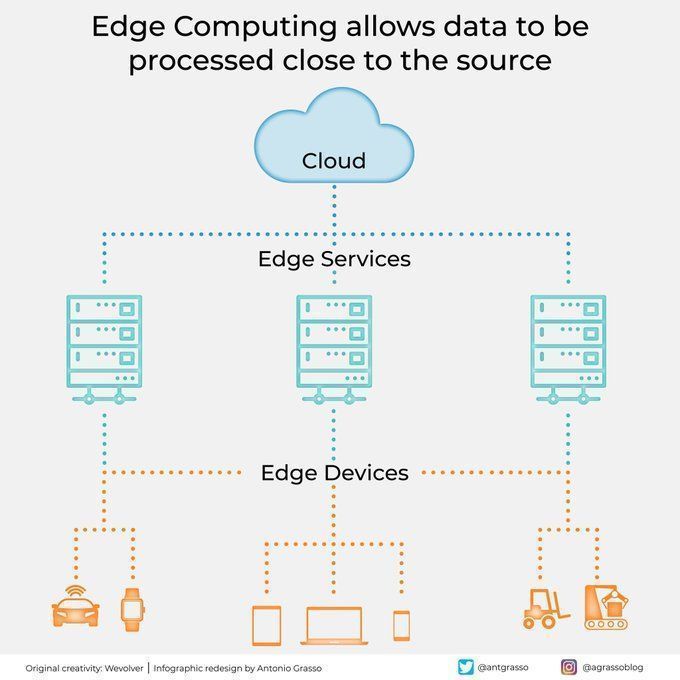
엣지 컴퓨팅, 데이터 소스 근처에서 데이터 처리: 엣지 컴퓨팅 기술은 데이터 소스 근처에서 데이터를 처리하여 지연 시간을 줄이고 대역폭 요구 사항을 낮추며 개인 정보 보호를 강화합니다. 이는 자율 주행, 산업용 사물 인터넷(IIoT)과 같이 실시간 응답 및 대량 데이터 처리가 필요한 AI 애플리케이션에 매우 중요하며, 클라우드 컴퓨팅 및 디지털 전환의 중요한 구성 요소입니다 (출처: Ronald_vanLoon)
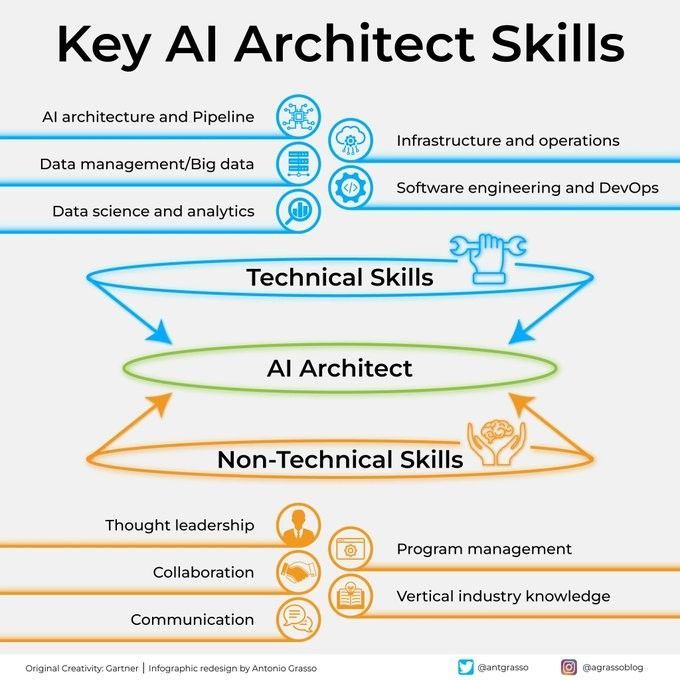
AI 아키텍트의 핵심 기술: 성공적인 AI 아키텍트가 되려면 심도 있는 기술적 배경(머신러닝, 딥러닝 알고리즘), 시스템 설계 능력, 데이터 관리 지식, 비즈니스 요구 사항에 대한 이해 등 다방면의 기술이 필요합니다. 또한 의사소통 및 협업 능력과 새로운 기술을 지속적으로 학습하려는 열정도 매우 중요합니다 (출처: Ronald_vanLoon)
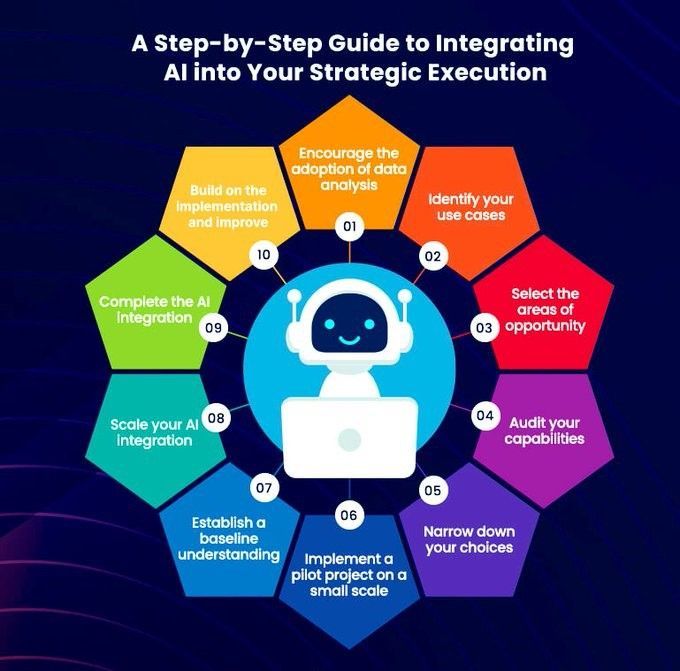
AI를 전략 실행에 통합하는 단계별 가이드: Khulood Almani는 기업이 인공지능을 전략 실행 프로세스에 통합하는 데 도움이 되는 단계별 가이드를 제공했습니다. 여기에는 AI 목표 명확화, 기존 역량 평가, 적절한 AI 기술 선택, 실행 로드맵 수립, 모니터링 및 평가 메커니즘 구축 등이 포함되어 AI 프로젝트가 전체 비즈니스 전략과 일치하고 예상 가치를 창출하도록 보장합니다 (출처: Ronald_vanLoon)
양자 컴퓨팅이 사이버 보안을 어떻게 변화시키는가: 양자 컴퓨팅의 등장은 사이버 보안에 이중적인 영향을 미칩니다. 한편으로는 강력한 계산 능력으로 기존 암호화 알고리즘을 해독하여 보안 위협을 초래할 수 있고, 다른 한편으로는 양자 기술이 양자 암호학과 같은 새로운 보안 방어 수단을 탄생시켰습니다. Khulood Almani는 사이버 보안 분야에서 양자 컴퓨팅의 변혁적 역할을 논하며 포스트 양자 시대를 준비하는 것의 중요성을 강조했습니다 (출처: Ronald_vanLoon)
2025년 AI 분야를 주도할 도구: Perplexity는 2025년에 인공지능 분야를 주도할 핵심 도구를 예측했으며, 여기에는 더욱 발전된 대규모 언어 모델(LLM), 생성형 AI 플랫폼, 데이터 과학 도구 및 특정 산업 애플리케이션을 위한 전문 AI 솔루션이 포함될 수 있습니다. 이러한 도구는 각 산업에서 AI의 보급과 심층 적용을 더욱 촉진할 것입니다 (출처: Ronald_vanLoon)

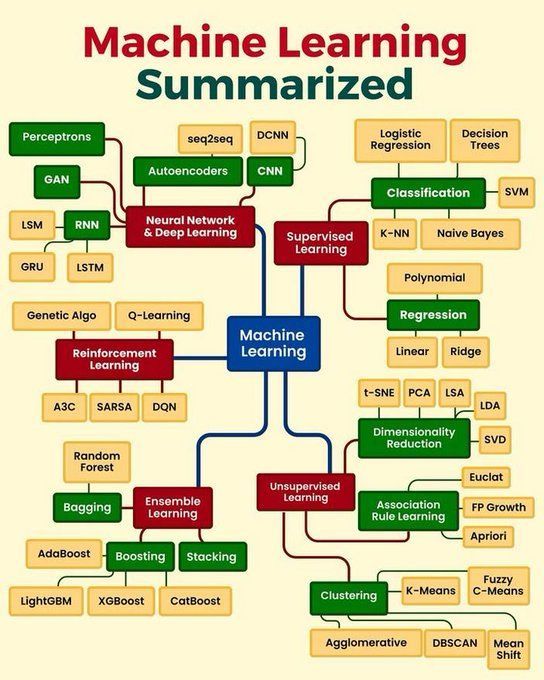
머신러닝 핵심 개념 요약: Python_Dv는 지도 학습, 비지도 학습, 강화 학습, 딥러닝 등 기본 원리, 자주 사용되는 알고리즘 및 응용 시나리오를 포함할 수 있는 머신러닝의 핵심 개념을 요약했습니다. 이는 초보자와 기본 지식을 다지고자 하는 사람들에게 간결한 개요를 제공합니다 (출처: Ronald_vanLoon)
🧰 툴
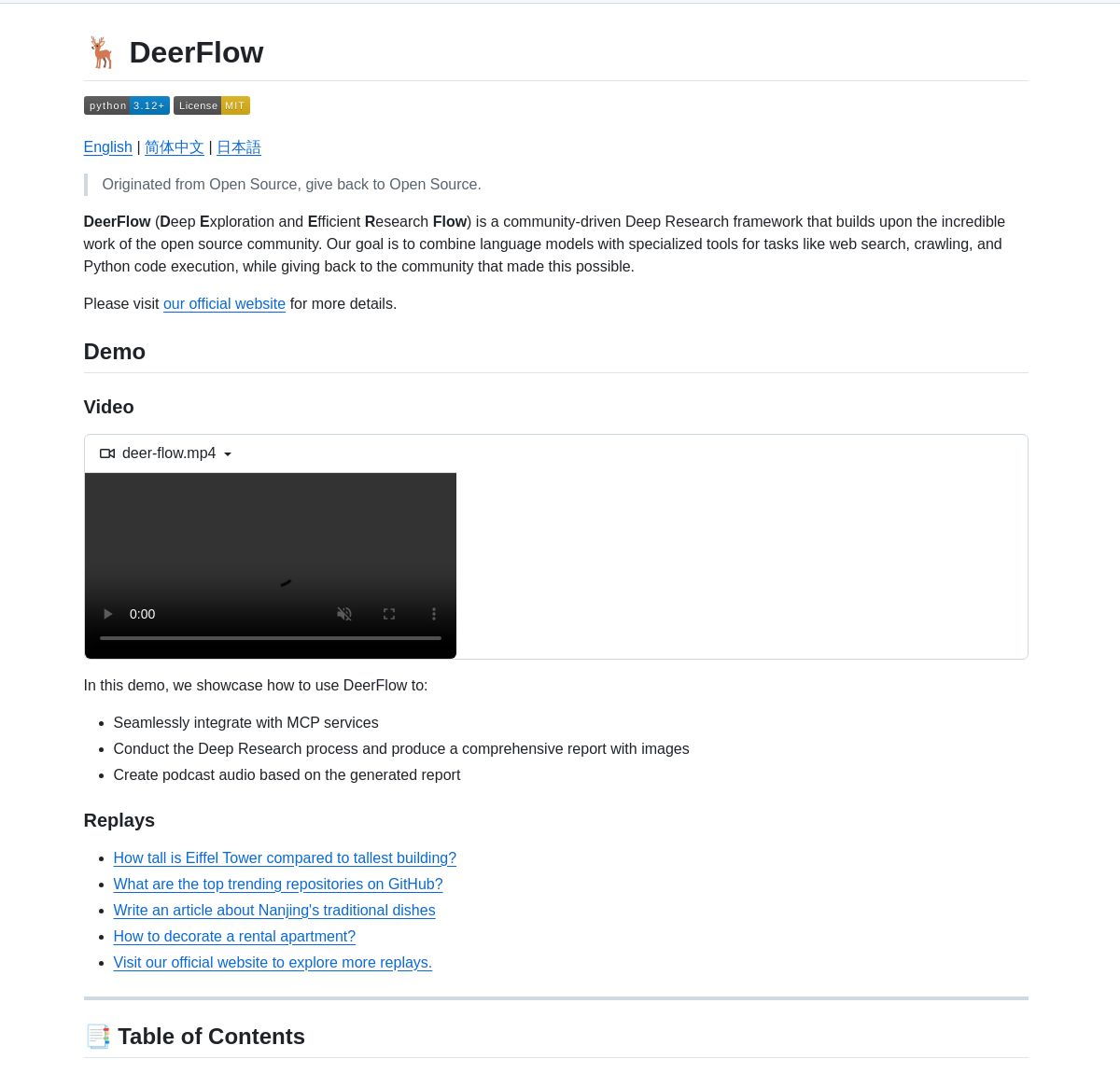
ByteDance, 심층 연구 프레임워크 DeerFlow 출시: ByteDance가 LangGraph 에이전트 조정을 통해 체계적인 심층 연구를 수행하는 프레임워크인 DeerFlow를 오픈소스로 공개했습니다. 이는 포괄적인 문헌 분석, 데이터 종합 및 구조화된 지식 발견을 지원하며, 과학 연구 분야에서 AI의 응용 효율성과 깊이를 향상시키는 것을 목표로 합니다 (출처: LangChainAI, Hacubu)
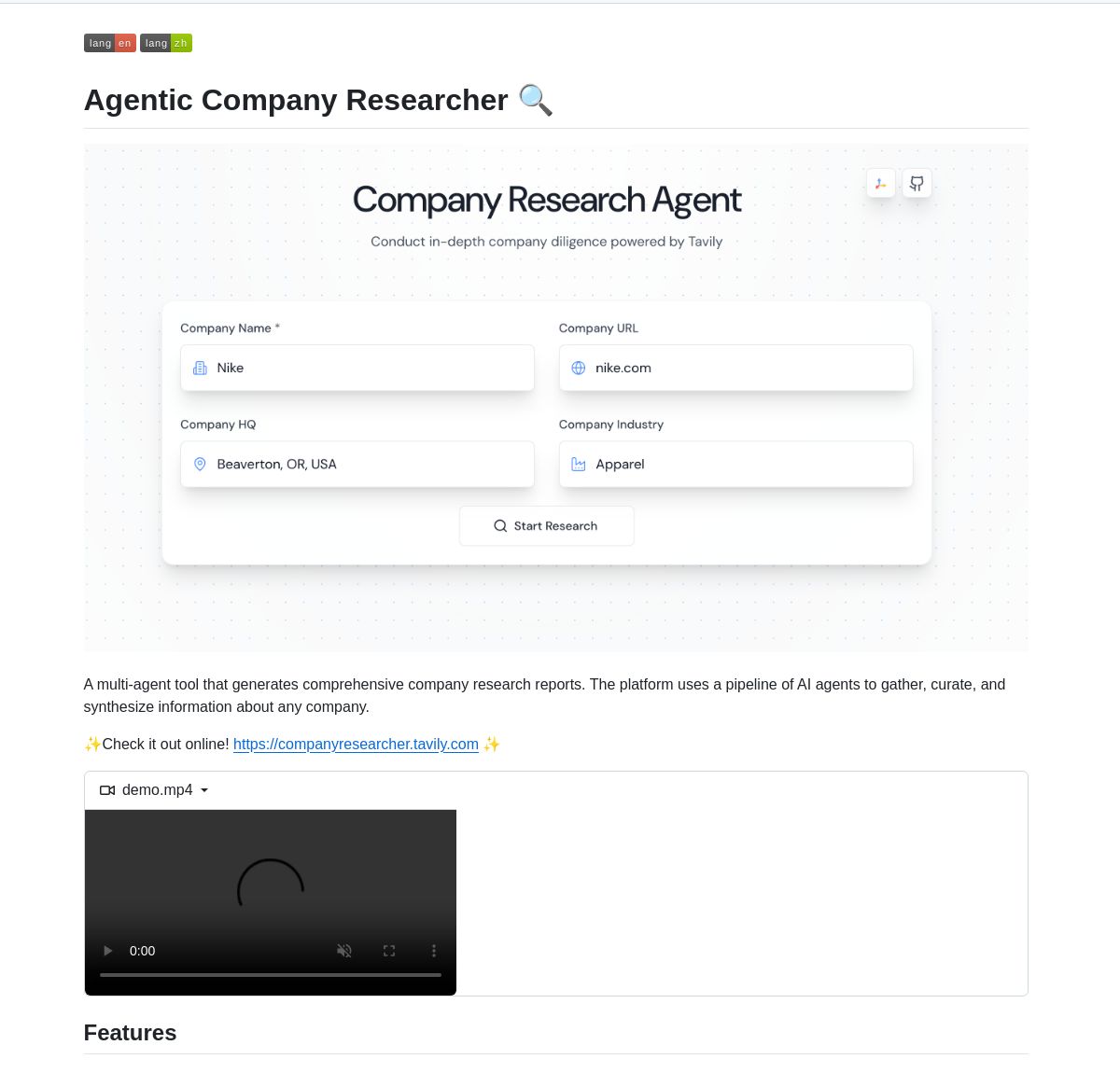
LangGraph 기반 기업 연구원 멀티 에이전트 시스템: 실시간 기업 연구 보고서 생성을 위해 LangGraph 기반 멀티 에이전트 시스템이 개발되었습니다. 이 시스템은 지능형 프로세스를 통해 비즈니스, 재무 및 시장 데이터를 분석하는 전문 노드를 활용하여 사용자에게 심층적인 기업 통찰력을 제공합니다. 데모 및 코드는 GitHub에 제공되었습니다 (출처: LangChainAI, Hacubu)
RunwayML Gen-4 References, 정확한 캐릭터/객체 위치 지정 실현: RunwayML의 Gen-4 References 기능이 생성 콘텐츠에서 캐릭터나 객체의 위치를 정확하게 제어하는 데 사용될 수 있음이 발견되었습니다. 사용자는 장면과 마커가 있는 참조 이미지(예: 위치를 나타내는 간단한 색상 도형)를 제공하여 AI가 특정 요소를 원하는 정확한 위치에 배치하도록 유도할 수 있어 창의적인 워크플로우에 새로운 가능성을 제공합니다. 이 모델은 범용 모델로서 미세 조정 없이 다양한 워크플로우에 적용할 수 있습니다 (출처: c_valenzuelab, c_valenzuelab)

Code Chrono: 로컬 LLM으로 프로그래밍 프로젝트 시간 예측 도구: Rafael Viana가 코딩 세션 시간을 추적하고 로컬 LLM을 활용하여 향후 기능 개발 시간을 예측하는 Code Chrono라는 터미널 도구를 개발했습니다. 이 도구는 개발자가 프로젝트 소요 시간을 보다 현실적으로 평가하고 작업량 과소평가를 방지하는 데 도움을 주기 위해 만들어졌습니다. 프로젝트 코드는 오픈소스로 공개되었습니다 (출처: Reddit r/LocalLLaMA)

PyTorch와 Mojo 언어 통합 진행 상황: Mark Saroufim이 Mojo 해커톤에서 PyTorch가 신흥 언어 및 하드웨어 백엔드 지원을 어떻게 단순화하는지 소개하고 Mojo 팀과 협력하여 개발한 WIP 백엔드를 시연했습니다. Chris Lattner는 이 협력에 대해 찬사를 보내며 Mojo와 PyTorch의 결합이 PyTorch 생태계에 새로운 활력을 불어넣고 AI 개발 도구 혁신을 촉진할 것이라고 평가했습니다 (출처: clattner_llvm, marksaroufim)
트럼프 스타일 챗봇: 한 개발자가 실제 백악관 집무실 역사적 사건을 기반으로 트럼프 스타일을 모방한 챗봇을 훈련시켜 출시했습니다. 이 챗봇은 Hugging Face Spaces에서 상호 작용할 수 있으며, 개발자는 사용자 피드백과 제안을 기다리고 있습니다 (출처: Reddit r/artificial)
오픈소스 Agentic Network 구축 도구: python-a2a라는 오픈소스 도구가 드래그 앤 드롭 방식을 지원하여 Agentic Network 구축 과정을 단순화했습니다. 사용자는 이 도구를 사용하여 AI 에이전트 네트워크를 만들고 관리할 수 있습니다 (출처: Reddit r/ClaudeAI)
carcodes.xyz: 자동차 애호가를 위한 소셜 플랫폼: 한 사용자가 여자친구의 외도 후 Claude 3.7을 프로그래밍 보조 도구로 활용하여 carcodes.xyz를 개발했습니다. 이 플랫폼은 Linktree와 유사하며, 자동차 애호가들이 자신의 튜닝카를 전시하고 다른 자동차 애호가들을 팔로우하며 주변 자동차 모임을 공유하고 발견할 수 있도록 합니다. 또한 자동차에 부착할 수 있는 QR 코드를 제공하여 다른 사람들이 스캔하여 개인 페이지에 접속할 수 있도록 합니다. 전체 프로젝트는 Next.js, TailwindCSS, MongoDB, Stripe를 사용하여 구축되었습니다 (출처: Reddit r/ClaudeAI)

AMD RX 7800 XT 16GB에서 로컬로 Gemma 3 27B 모델 실행: 사용자가 AMD RX 7800 XT 16GB 그래픽 카드에서 로컬로 Gemma 3 27B 모델을 성공적으로 실행한 경험을 공유했습니다. lmstudio-community에서 제공하는 gemma-3-27B-it-qat-GGUF 버전을 사용하고 llama.cpp 서버와 함께 사용하여 16K 컨텍스트 길이에서 모델을 VRAM에 완전히 로드하여 실행했습니다. 공유 내용에는 자세한 하드웨어 구성, 시작 명령, 파라미터 설정(Unsloth 팀 권장 사항 기반) 및 ROCm과 Vulkan 환경에서의 성능 벤치마크 결과가 포함되어 있으며, 이 설정에서 ROCm이 더 우수한 성능을 보였습니다 (출처: Reddit r/LocalLLaMA)

📚 학습
DSPy 프레임워크 핵심 이념 및 장점 해설: Omar Khattab이 DSPy 프레임워크의 핵심 설계 이념을 자세히 설명했습니다. DSPy는 LLM 및 그 방법론의 지속적인 발전에 AI 소프트웨어 개발이 적응할 수 있도록 안정적인 추상화(Signatures, Modules, Optimizers 등) 세트를 제공하는 것을 목표로 합니다. 핵심 관점에는 정보 흐름이 핵심이라는 점, LLM과의 상호 작용은 함수화되고 구조화되어야 한다는 점, 추론 전략은 다형성 모듈이어야 한다는 점, AI 행동 규범과 학습 패러다임은 분리되어야 한다는 점, 자연어 최적화는 강력한 학습 패러다임이라는 점 등이 포함됩니다. 이러한 원칙은 기본 모델이나 패러다임 변화로 인한 재작성 비용을 줄여 “미래 지향적인” AI 소프트웨어를 구축하는 것을 목표로 합니다. 이 일련의 트윗은 광범위한 논의와 인정을 받았으며, DSPy와 현대 AI 소프트웨어 개발을 이해하는 데 중요한 참고 자료로 간주됩니다 (출처: menhguin, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction, lateinteraction)
초보자 친화적인 AI 수학 워크숍: ProfTomYeh가 초보자를 위한 AI 수학 워크숍을 개최한다고 발표했습니다. 이 워크숍은 참가자들이 점곱, 행렬 곱셈, 선형 계층, 활성화 함수, 인공 뉴런과 같은 딥러닝의 기본 수학 원리를 이해하도록 돕는 것을 목표로 합니다. 워크숍은 일련의 대화형 연습을 통해 참가자들이 직접 수학 계산을 수행하도록 하여 AI 수학에 대한 신비감을 해소할 것입니다 (출처: ProfTomYeh)
《음성 및 언어 처리》 교재 업데이트 슬라이드 발표: 스탠포드 대학교 Dan Jurafsky와 James H. Martin의 고전 교재 《음성 및 언어 처리》(Speech and Language Processing)의 최신 슬라이드가 발표되었습니다. 이 교재는 NLP 분야의 권위 있는 저서로, 이번 업데이트는 학습자와 교육자에게 귀중한 오픈 액세스 리소스를 제공하여 LLM, Transformer 등 첨단 기술을 이해하는 데 도움이 될 것입니다 (출처: stanfordnlp)
AI 연구 에이전트 튜토리얼: LangGraph와 Ollama로 구축하기: LangChainAI가 AI 연구 에이전트를 구축하는 방법을 안내하는 튜토리얼을 발표했습니다. 이 에이전트는 웹 페이지를 검색하고 LangGraph와 Ollama를 사용하여 인용이 포함된 요약을 생성하여 사용자에게 완전한 자동화 연구 솔루션을 제공합니다. 튜토리얼 비디오는 YouTube에 게시되었습니다 (출처: LangChainAI, Hacubu)

DAIR.AI, 이번 주 인기 AI 논문 발표: DAIR.AI가 2025년 5월 5일부터 11일까지의 인기 AI 논문을 종합했습니다. 여기에는 ZeroSearch, Discuss-RAG, Absolute Zero, Llama-Nemotron, The Leaderboard Illusion 및 Reward Modeling as Reasoning과 같은 연구 성과가 포함되어 연구자들에게 최신 동향을 제공합니다 (출처: omarsar0)
에이전트 패턴(Agentic Patterns)에 대한 논의: Phil Schmid가 일반적인 에이전트 패턴을 심층적으로 논의하고 구조화된 워크플로우와 보다 동적인 에이전트 패턴을 구분하는 글을 공유했습니다. 이 글은 보다 효율적인 AI 에이전트 시스템을 이해하고 설계하는 데 도움이 됩니다 (출처: dl_weekly)
GPT-4o 아첨 현상 및 모델 훈련에 대한 시사점 논의: 한 기사에서 GPT-4o 모델에서 나타나는 “아첨”(sycophancy) 현상을 논의하고, RLHF(인간 피드백 강화 학습) 및 선호도 조정 과제와의 연관성을 분석하며, 이것이 모델 훈련, 평가 및 산업 투명성에 미치는 광범위한 영향에 대해 논의했습니다 (출처: dl_weekly)
Claude 시스템 프롬프트 유출 및 설계 분석: Bindu Reddy가 유출된 Claude 시스템 프롬프트를 분석했습니다. 이 프롬프트는 예상보다 훨씬 긴 24k 토큰으로, LLM의 논리적 추론 한계를 넓히고 환각을 줄이며 다양한 방식으로 명령을 반복하여 LLM의 이해를 보장하도록 설계되었습니다. 이는 현재 LLM이 신뢰성과 명령어 준수 측면에서 여전히 어려움을 겪고 있으며, 행동을 교정하기 위해 복잡한 시스템 프롬프트가 필요하다는 것을 보여줍니다 (출처: jonst0kes)

머신러닝 편향 시뮬레이션: 베이즈 네트워크 방법: 케임브리지 대학교 박사 과정 학생과 그가 지도하는 학부생들이 머신러닝 편향에 관한 연구 프로젝트를 수행했습니다. 그들은 베이즈 네트워크를 사용하여 “실제 세계” 데이터 생성 과정을 시뮬레이션한 다음, 이 데이터에 머신러닝 모델을 실행하여 훈련 데이터에서 전파된 편향이 아닌 모델 자체가 생성하는 편향을 측정했습니다. 프로젝트 웹사이트는 자세한 방법론, 결과 및 시각화 도구를 제공하며 ML 배경 지식을 가진 사람들의 피드백을 구하고 있습니다 (출처: Reddit r/MachineLearning)
💼 비즈니스
OpenAI, Microsoft와 새로운 자금 조달 및 향후 IPO 논의 중이라는 소문: 파이낸셜 타임스 보도에 따르면 OpenAI는 Microsoft와 새로운 자금 지원을 받고 향후 기업 공개(IPO) 가능성을 논의 중입니다. 이는 OpenAI가 값비싼 대규모 모델 연구 개발 및 컴퓨팅 파워 수요를 지원하기 위해 지속적으로 자금을 모색하고 있으며, 장기적인 발전을 위해 보다 명확한 자본 경로를 계획하고 있을 수 있음을 시사합니다 (출처: Reddit r/artificial)

CoreWeave, Weights & Biases 인수 완료: 클라우드 컴퓨팅 제공업체 CoreWeave가 머신러닝 도구 플랫폼 Weights & Biases 인수를 완료했다고 발표했습니다. 이번 인수는 CoreWeave의 GPU 인프라와 Weights & Biases의 MLOps 역량을 결합하여 AI 개발자에게 더욱 강력하고 통합된 개발 및 배포 환경을 제공하는 것을 목표로 합니다 (출처: charles_irl)
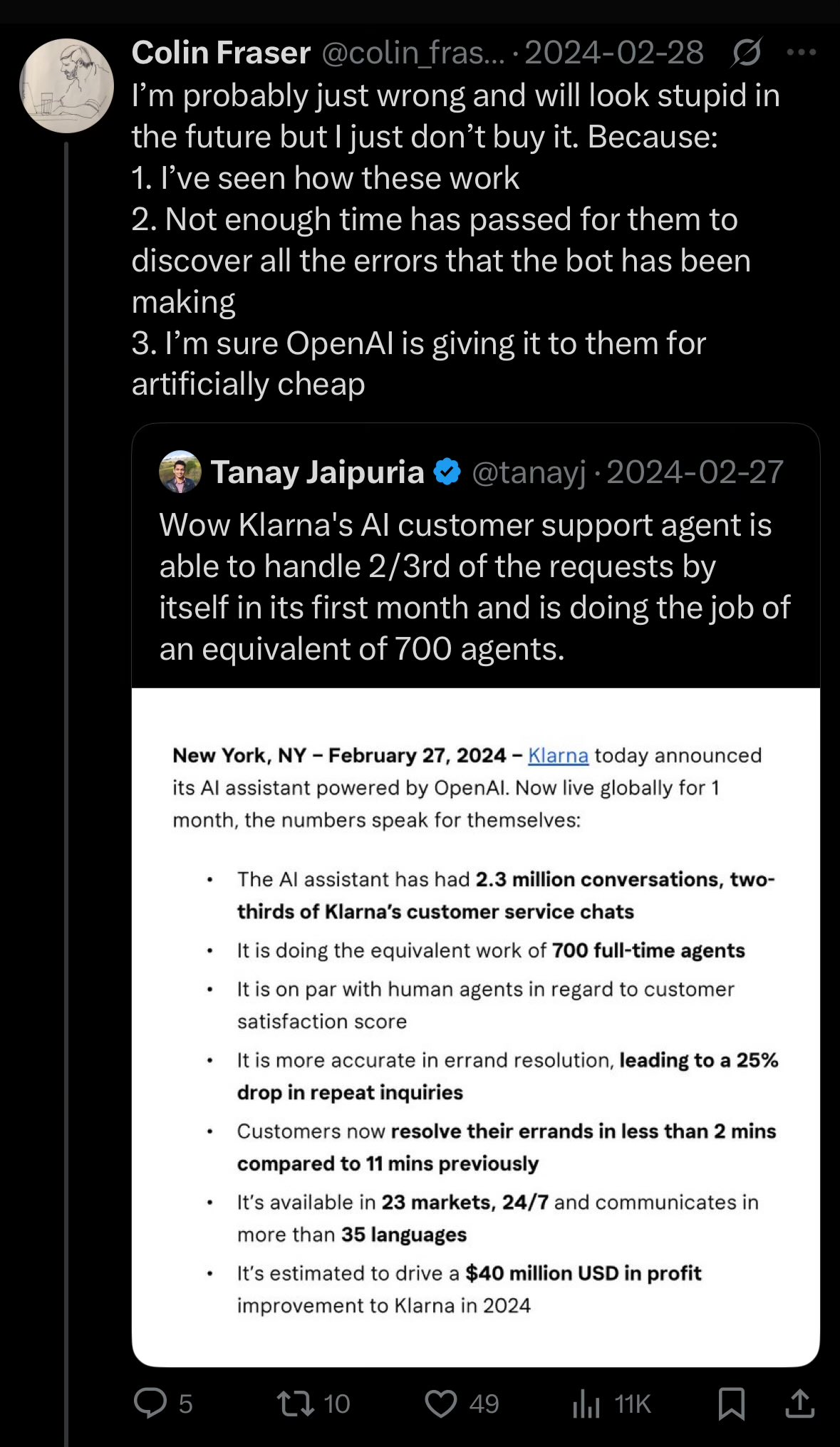
Klarna CEO, AI 과도한 비용 절감으로 인한 고객 서비스 품질 저하 반성: 결제 대기업 Klarna의 CEO는 회사가 인공지능을 통해 비용을 절감하려는 과정에서 “너무 멀리 나갔다”며 고객 서비스 경험이 저하되었고, 현재는 인공 고객 서비스 인력을 늘리는 방향으로 전환하고 있다고 밝혔습니다. 이 사건은 기업이 AI를 통해 비용을 절감하고 효율성을 높이는 것과 서비스 품질을 보장하는 것 사이에서 어떻게 균형을 맞춰야 하는지에 대한 논의를 불러일으켰습니다 (출처: colin_fraser)
🌟 커뮤니티
LLM이 AGI로 가는 길인지에 대한 격렬한 논쟁: 커뮤니티 내에서 대규모 언어 모델(LLM)이 일반 인공 지능(AGI)을 실현하는 올바른 경로인지에 대한 격렬한 논쟁이 벌어졌습니다. 한쪽에서는 LLM이 머신러닝 분야에서 지금까지 가장 성공적인 기술이며, AGI로 가는 길이 “절대 아니다”라고 단언하는 것은 너무 성급하다고 주장합니다. 다른 한쪽에서는 LLM이 상당한 진전을 이루었지만, 규모 확장, 장문 컨텍스트 일관성, 실제 세계 상호 작용 등의 문제를 해결하는 등 기존 LLM과는 근본적으로 다른 방법이 AGI를 실현하는 데 필요할 수 있다고 주장합니다. 토론자들은 과학적 탐구는 성급하게 결론을 내리기보다는 열린 마음을 유지해야 한다고 강조했습니다 (출처: cloneofsimo, teortaxesTex, Dorialexander)
AI 대체 전망에 대한 소프트웨어 개발자와 대중 인식 차이: Reddit의 여러 소프트웨어 개발 관련 게시판 토론에 따르면, 많은 개발자들은 AI가 향후 5~10년 내에 자신들을 대규모로 대체할 가능성이 낮다고 생각하며, 심지어 현재 AI를 “쓰레기”라고 부르기도 합니다. 댓글 분석에 따르면 이러한 관점은 개발자들이 AI의 실제 능력과 프로그래밍 작업의 복잡성에 대해 깊이 이해하고 있기 때문일 수 있습니다. 그들은 AI가 현재 상용구 코드나 간단한 도구를 생성하는 데는 능숙하지만, 복잡한 소프트웨어 엔지니어링을 독립적으로 완료하는 수준에는 훨씬 못 미친다고 생각합니다. 반면 투자자나 대중은 기술적 세부 사항을 알지 못해 AI의 피상적인 능력에 오도될 수 있습니다. 동시에 AI가 강력한 생산성 도구인 것은 사실이지만, 그 역할은 완전한 대체보다는 보조에 가깝고, AI가 대규모의 복잡한 프로젝트를 처리할 때 여전히 “컨텍스트 손실”, “논리적 비일관성” 등의 문제에 직면한다는 의견도 있습니다 (출처: Reddit r/ArtificialInteligence)
ML 학회 논문 수락 정책 논란: 강제 참석 요구, 차별 지적: Neel Nanda 등은 ICML과 같은 머신러닝 학회가 논문 저자 중 최소 한 명이 현장에 참석해야 하며, 그렇지 않으면 이미 수락된 논문을 거부하는 정책을 비판했습니다. 그들은 학회가 DEI(다양성, 형평성, 포용성)를 중시한다고 주장하지만, 이 정책은 본질적으로 초기 경력 연구자나 경제적으로 어려운 연구자를 차별한다고 주장합니다. 이들은 종종 비싼 학회 참가 비용을 감당하기 어렵지만, 최고 수준 학회 논문은 그들의 경력 발전에 매우 중요합니다. Gabriele Berton은 ICML이 이로 인해 논문을 거부하지는 않으며 단지 현장 등록 구매를 요구할 뿐이라고 해명했지만, 논란은 가라앉지 않았고, 무료로 발표하고 심사 품질이 높은 TMLR과 같은 저널이 비교 대상으로 언급되었습니다 (출처: menhguin, jeremyphoward)

새 모델 “멍청해짐” 인식과 과적합 논의: 일부 사용자들이 Reddit 커뮤니티에서 Qwen3, Llama 3.3/4 등 새로 출시된 대규모 모델이 실제 사용 시 이전 버전보다 “더 멍청하게” 느껴진다고 보고했습니다. 이는 컨텍스트를 더 쉽게 잃어버리고, 내용을 반복하며, 언어 스타일이 경직되는 현상으로 나타납니다. 일부 댓글에서는 이것이 모델이 벤치마크 테스트에서 높은 점수(예: 프로그래밍, 수학, 환각 감소)를 추구하는 과정에서 과도하게 훈련되어 창의적인 글쓰기, 자연스러운 대화 등에서의 성능이 저하되고 “일관성을 희생하면서 똑똑하게 들리려고 하는” 것처럼 변했기 때문일 수 있다고 지적했습니다. 일부 연구에서는 기본 모델이 창의력이 필요한 작업에 더 적합할 수 있다고 지적했습니다 (출처: Reddit r/LocalLLaMA)
AI 생성 콘텐츠 식별 난이도 논의: 투피 오류: “AI 생성 콘텐츠를 쉽게 식별할 수 있다”는 주장에 대해 커뮤니티 토론에서는 “투피 오류”(toupee fallacy)를 인용하여 반박했습니다. 이 오류는 사람들이 모든 가발이 가짜처럼 보인다고 생각하는 이유는 품질 좋은 가발은 전혀 눈에 띄지 않기 때문이라고 지적합니다. 마찬가지로 항상 AI 콘텐츠를 쉽게 식별할 수 있다고 주장하는 사람들은 품질이 낮거나 수정되지 않은 AI 텍스트만 주목하고, 구별하기 어려운 고품질 AI 생성 콘텐츠는 간과했을 수 있습니다 (출처: Reddit r/ChatGPT)
YC, Google 검색 독점에 대한 반독점 소송 의견서 제출: Y Combinator가 미국 법무부에 Google의 반독점 소송에 대한 의견서를 제출했습니다. YC는 Google이 검색 및 검색 광고 분야에서 독점적 지위를 누리며 혁신을 저해하고, 스타트업(특히 AI가 변곡점에 있는 현재)이 거의 돌파구를 찾을 수 없게 만들었다고 주장했습니다. 이러한 움직임은 일부 평론가들에 의해 YC가 Exa와 같은 신흥 AI 검색 회사를 지원하여 Google의 독점을 깨려는 의도로 해석되었습니다 (출처: menhguin)

Claude 모델 성능 문제 지속, 사용자 불만 팽배: Reddit의 ClaudeAI 게시판 Megathread(5월 4일~11일)에 따르면 사용자들이 Claude의 가용성 문제를 지속적으로 보고하고 있으며, 여기에는 매우 낮은 컨텍스트/메시지 제한, 잦은 멈춤 및 출력 잘림 현상이 포함됩니다. Anthropic 상태 페이지는 5월 6일~8일에 오류율이 상승했음을 확인했습니다. 약 75%의 사용자 피드백이 부정적이었으며, 특히 Pro 사용자는 사용자를 더 비싼 Max 요금제로 업그레이드하도록 강요하는 “보이지 않는 다운그레이드”가 있다고 주장했습니다. 외부 정보에 따르면 Max 요금제 사용 정책이 강화되고 웹 검색 가격이 비싸졌습니다. 일부 임시 해결책이 존재하지만 많은 핵심 문제는 여전히 해결되지 않았으며, 사용자들은 투명성 부족과 예고 없는 변경에 분노하고 있습니다 (출처: Reddit r/ClaudeAI)
OpenAI 모델 선택 제안 및 가성비 분석: 인터넷에 떠도는 OpenAI 모델 선택 가이드에 대해 Karminski3는 더 가성비 좋은 제안을 내놓았습니다. GPT-4o는 일상 업무 및 이미지 생성(코드 제외)에 적합하며 가격은 100만 토큰당 2.5달러입니다. GPT-image-1은 비싸지만(100만 토큰당 10달러) 이미지 생성/편집 효과가 좋습니다. O3-mini-high(100만 토큰당 1.1달러)는 코드/수학에 사용할 수 있으며, 그렇지 않은 경우 더 비싼 OpenAI 모델 대신 Claude-3.7-Sonnet-Thinking 또는 Gemini-2.5-Pro를 사용하는 것이 좋습니다. 저자는 현재 OpenAI 모델로 코드를 작성하는 데 비용이 많이 들고 효과가 반드시 최선은 아니며, 순수 텍스트 모델이 100만 토큰당 2달러를 초과하는 API 호출은 신중하게 고려해야 한다고 생각합니다 (출처: karminski3)

💡 기타
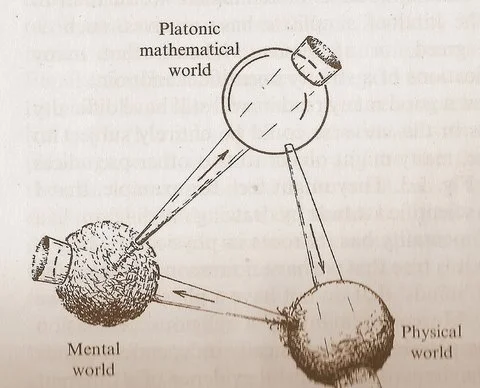
Penrose의 “세 가지 세계” 그림, 수학, 물리, 지능 관계에 대한 고찰 유발: Roger Penrose가 저서 《실재로 가는 길》에서 제시한 “플라톤 수학 세계”, “물리 세계”, “정신 세계”를 포함하는 순환 그림이 새로운 논의를 불러일으켰습니다. 평론가들은 머신러닝의 돌파구가 “플라톤 수학 세계”의 존재, 즉 수학의 유효성이 물리 우주를 뒷받침하는 수학적 구조에서 비롯된다는 것을 입증하는 것처럼 보인다고 평가했습니다. AI(“모래로 만든 뇌”)의 등장은 전례 없는 규모와 빈도로 이 순환을 가속화하고 있으며, 우주에 대한 더 깊은 진실을 밝혀낼 수 있습니다 (출처: riemannzeta)
보험사, AI 챗봇 오류 손실 보험 출시: 보험사들이 AI 챗봇 오류로 인한 손실에 대한 보험 상품을 제공하기 시작했습니다. 이러한 조치는 한편으로는 AI의 부적절한 사용이 심각한 손해를 초래할 수 있음을 인정하는 것이지만, 다른 한편으로는 이러한 보험이 기업들이 AI 시스템의 신뢰성과 안전성을 향상시키는 대신 손실을 보상하기 위해 보험에 의존하여 AI 응용에 더욱 안일하게 대처하도록 조장할 수 있다는 우려를 불러일으켰습니다 (출처: Reddit r/artificial)
음악 창작 분야에서 AI의 잠재력 과소평가: 커뮤니티에서는 많은 사람들이 AI가 음악 창작 분야에서 가진 능력을 과소평가하며, AI 음악은 인간 창작물처럼 “영혼을 울릴 수 없다”고 말하는 경향이 있다는 의견이 있습니다. 그러나 현재 AI가 생성한 음악 작품 중 일부는 청각적으로 인간의 노래 수준에 근접했습니다. AI 음악이 아직 초기 단계에 있다는 점을 고려할 때, 미래 발전 잠재력은 엄청나므로 너무 일찍 부정해서는 안 됩니다 (출처: Reddit r/artificial)
