
키워드:AI 보안, 인공지능 윤리, AI 에이전트, 3D 생성, 코드 모델, AI 리스크 평가, Gemini 2.5 Pro 비디오 이해, AssetGen 2.0 3D 생성, Seed-Coder 코드 모델, AgentOps 에이전트 운영
🔥 초점
AI 보안 위험에 대한 우려, 전문가 핵안보 경험을 참고한 위험 평가 촉구: 국제 사회에서 인공지능의 잠재적 위험에 대한 우려가 날로 커지고 있으며, 일부 전문가(예: Max Tegmark)는 AI 회사가 위험한 AI 시스템을 출시하기 전에 Robert Oppenheimer의 첫 핵실험 당시 안전 계산 방법을 모방하여 인공지능이 통제 불능 상태가 될 확률(Compton constant)을 엄격하게 평가해야 한다고 촉구했습니다. 이는 업계 공감대를 형성하고, 글로벌 AI 보안 메커니즘 구축을 추진하여 슈퍼 인텔리전스가 초래할 수 있는 재앙적 결과를 방지하기 위함입니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

새 교황 프란치스코(가명 Leo XIV), AI가 가져올 사회 변화에 높은 관심 표명: 새로 선출된 교황 프란치스코(Leo XIV로 알려짐)는 인공지능을 인류가 직면한 주요 과제 중 하나로 규정했습니다. 그가 ‘Leo’를 교황명으로 선택한 이유 중 하나는 AI가 주도하는 새로운 사회 문제와 산업 혁명 때문이며, 이는 역사적으로 교황 Leo XIII세가 제1차 산업 혁명에 대응했던 것을 연상시킵니다. 교황은 AI가 “인간의 존엄성, 정의, 노동”을 유지하는 데 도전을 제기한다고 강조했으며, 향후 AI 윤리에 관한 중요한 문서를 발표할 계획으로, AI 기술 윤리와 사회적 영향에 대한 종교 지도자의 깊은 관심을 보여줍니다. (출처: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

구글, 76페이지 분량의 AI 에이전트 백서 발표, AgentOps 및 미래 응용 분야 설명: 구글은 76페이지 분량의 AI 에이전트 백서를 발표하여 에이전트의 구축, 평가 및 응용에 대해 자세히 설명했습니다. 백서는 생성형 AI 운영의 한 분야로서 에이전트 운영(AgentOps)의 중요성을 강조하며, AgentOps는 에이전트의 효율적인 운영에 필요한 도구 관리, 핵심 프롬프트 설정, 메모리 기능 및 작업 분해 등에 중점을 둡니다. 백서는 또한 다양한 에이전트가 계획, 검색, 실행, 평가 등의 역할을 수행하며 복잡한 작업을 공동으로 완료하는 다중 에이전트 협업 아키텍처를 논의하고, NotebookLM 기업 버전 및 Agentspace와 같이 기업에서 직원을 보조하고 백엔드 작업을 자동화하는 에이전트의 응용 전망을 제시했습니다. (출처: WeChat)

Meta, AssetGen 2.0 출시: 텍스트/이미지로 고품질 3D 에셋 생성: Meta는 최신 3D 기반 AI 모델인 AssetGen 2.0을 발표했습니다. 이 모델은 텍스트 및 이미지 프롬프트를 기반으로 고품질 3D 에셋을 생성할 수 있습니다. AssetGen 2.0은 두 개의 하위 모델을 포함합니다. 하나는 3D 메시 생성을 위한 것으로, 단일 단계 3D 확산 모델을 채택하여 디테일과 충실도를 향상시켰습니다. 다른 하나인 TextureGen 모델은 텍스처 생성을 위한 것으로, 향상된 뷰 일관성, 텍스처 복원 및 더 높은 텍스처 해상도를 위한 방법을 도입했습니다. 이 기술은 현재 Meta 내부에서 3D 세계를 만드는 데 사용되고 있으며, 올해 말 Horizon 크리에이터에게 확대 적용될 예정입니다. (출처: Reddit r/artificial)

🎯 동향
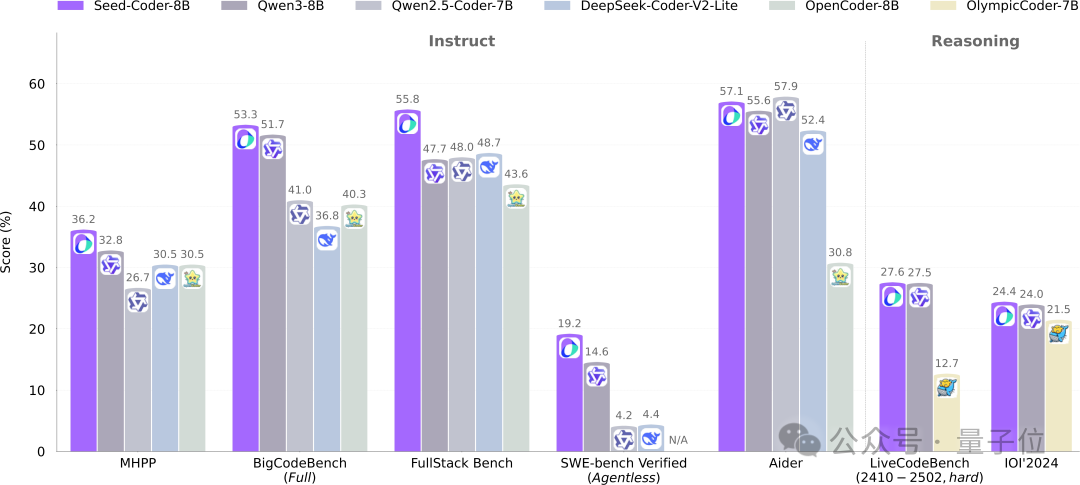
바이트댄스 Seed, 8B 코드 모델 Seed-Coder 오픈소스 공개, 모델 관리 데이터의 새로운 패러다임 채택: 바이트댄스 Seed 팀이 처음으로 8B 규모의 코드 모델 Seed-Coder를 오픈소스로 공개했습니다. 이 모델은 Base, Instruct, Reasoning 세 가지 버전을 포함합니다. 여러 코드 생성 벤치마크에서 우수한 성능을 보였으며, 특히 HumanEval과 MBPP에서는 Qwen3 등의 모델을 능가했습니다. Seed-Coder의 핵심 혁신은 “모델 중심”의 데이터 처리 방식을 제안한 것으로, LLM 자체를 활용하여 파일 수준 코드, 저장소 수준 코드, Commit 데이터 및 코드 관련 웹 데이터를 포함한 고품질 코드 훈련 데이터를 생성하고 필터링하며, 총 훈련 데이터 양은 6T 토큰에 달합니다. 이는 인공적인 참여를 줄이고 코드 모델의 능력을 향상시키는 것을 목표로 합니다. (출처: WeChat)
Gemini 2.5 Pro, 비디오 이해 능력에서 혁신적 발전, 오디오-비디오와 코드의 네이티브 융합 실현: 구글의 최신 Gemini 2.5 Pro 및 Flash 모델은 비디오 이해 능력에서 상당한 진전을 이루었습니다. Gemini 2.5 Pro는 여러 주요 비디오 이해 벤치마크에서 SOTA 수준에 도달했으며, 심지어 GPT 4.1을 능가했습니다. Gemini 2.5 시리즈 모델은 처음으로 오디오-비디오 정보와 코드 등 다른 데이터 형식을 네이티브하게 완벽히 결합하여, 비디오를 직접 인터랙티브 애플리케이션(예: 학습 앱)으로 변환하고, 비디오를 기반으로 p5.js 애니메이션을 생성하며, 비디오 클립을 정확하게 검색하고 설명하는 등 강력한 시간적 추론 능력을 보여주었습니다. 이러한 기능은 Google AI Studio, Gemini API 및 Vertex AI에서 사용할 수 있습니다. (출처: WeChat)

ModelScope, GPT-4o 이미지 능력에 필적하는 통합 이미지 모델 Nexus-Gen 오픈소스 공개: ModelScope 팀은 이미지 이해, 생성 및 편집을 동시에 처리할 수 있는 통합 멀티모달 모델인 Nexus-Gen을 출시하여 GPT-4o의 이미지 처리 능력에 필적하는 것을 목표로 합니다. 이 모델은 token → transformer → diffusion → pixels의 기술 경로를 채택하여 MLLM의 텍스트 모델링 능력과 Diffusion 모델의 이미지 렌더링 능력을 융합했습니다. 연속적인 이미지 Embedding을 자기 회귀적으로 예측할 때 발생하는 오차 누적 문제를 해결하기 위해 팀은 사전 채우기 자기 회귀 전략을 제안했습니다. Nexus-Gen은 ModelScope 커뮤니티에서 최근 오픈소스로 공개한 ImagePulse 편집 데이터셋을 포함하여 약 2,500만 개의 이미지-텍스트 데이터로 훈련되었습니다. (출처: WeChat)

Cursor 0.50 버전 출시, 가격 정책 단순화 및 다수 코드 편집 기능 강화: AI 코드 편집기 Cursor가 0.50 버전을 출시하며 대규모 업데이트를 진행했습니다. 가격 모델은 요청 기반 모델로 단순화되었으며, Max 모드는 모든 최상위 AI 모델을 지원하고 토큰 기반 가격 정책을 채택합니다. 기능 강화 사항은 다음과 같습니다: 새로운 Tab 모델은 파일 간 제안 및 코드 리팩토링 지원, 백그라운드 에이전트(프리뷰 버전)는 여러 에이전트 병렬 실행 및 원격 환경 작업 수행 지원, 코드베이스 컨텍스트는 @folders를 통해 전체 코드베이스 추가 허용, 인라인 편집 UI 최적화 및 전체 파일 편집 및 에이전트로 보내기 기능 추가, 긴 파일 편집 시 검색 및 교체 도구 도입, 다중 루트 작업 공간 지원으로 여러 코드베이스 처리, 채팅 기능 강화로 Markdown으로 내보내기 및 복사 지원. (출처: op7418)
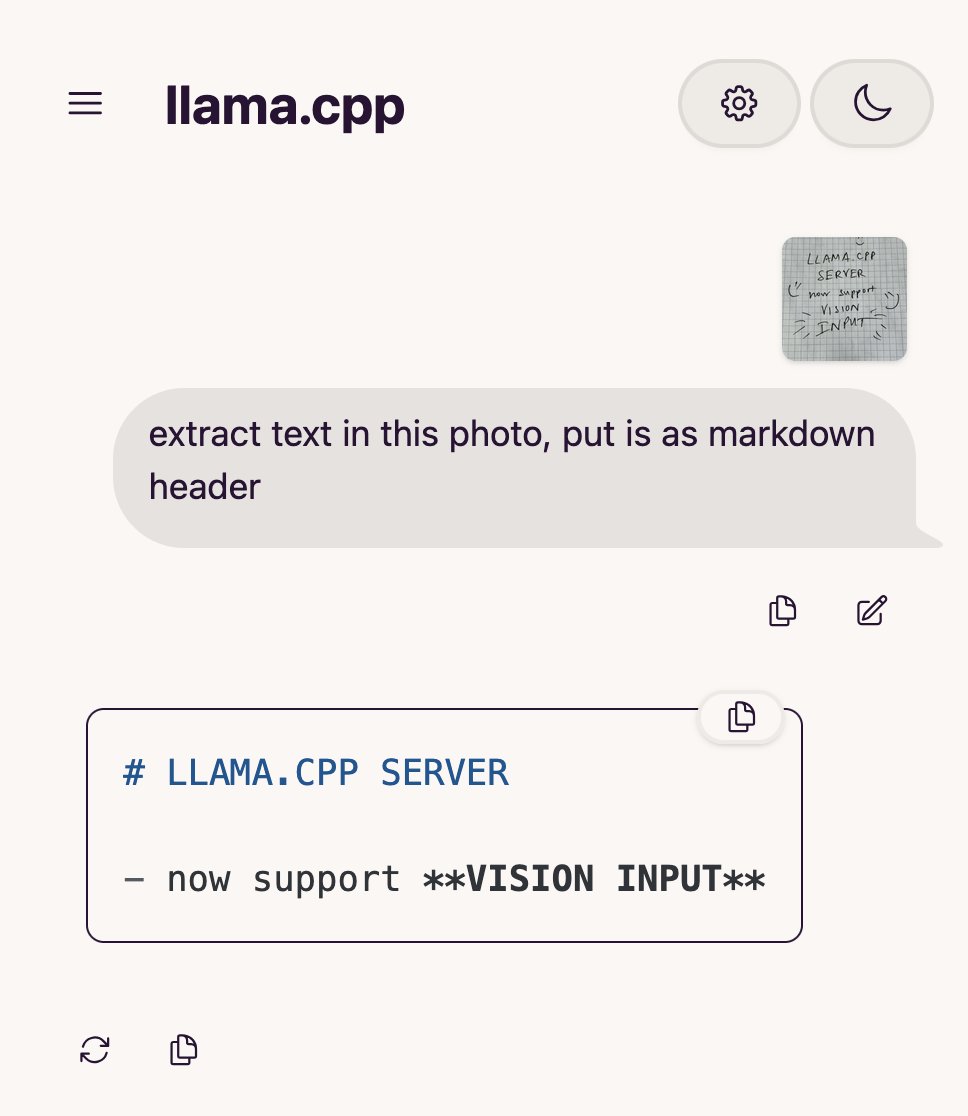
llama.cpp, 시각 언어 모델(VLM) 지원 추가, 완전한 시각적 RAG 파이프라인 구축 가능: 오픈소스 프로젝트 llama.cpp가 시각 언어 모델(VLM)을 지원한다고 발표했습니다. 사용자는 이제 llama.cpp 서버와 웹 UI를 통해 시각 기능을 사용할 수 있습니다. 이번 업데이트는 llama.cpp에서 다중 LoRA를 지원하는 동일한 기본 모델과 임베딩 모델을 로드할 수 있게 되어 완전한 시각적 검색 증강 생성(Vision RAG) 파이프라인을 구축할 수 있음을 의미합니다. 이는 llama.cpp가 로컬에서 대규모 언어 모델을 실행하는 능력을 더욱 확장하여 멀티모달 작업을 처리할 수 있게 합니다. (출처: mervenoyann, mervenoyann)
텐센트, HunyuanVideo 기반 맞춤형 비디오 생성 아키텍처 HunyuanCustom 공개: 텐센트가 Hugging Face에 맞춤형 비디오 생성을 위해 특별히 설계된 멀티모달 기반 아키텍처인 HunyuanCustom을 공개했습니다. 이 작업은 HunyuanVideo를 기반으로 하며, 특히 비디오 생성 시 주체의 일관성을 유지하는 데 중점을 두고 이미지, 오디오, 비디오, 텍스트 등 다양한 조건의 입력을 지원하여 사용자에게 더욱 유연하고 개인화된 비디오 제작 능력을 제공합니다. (출처: _akhaliq)
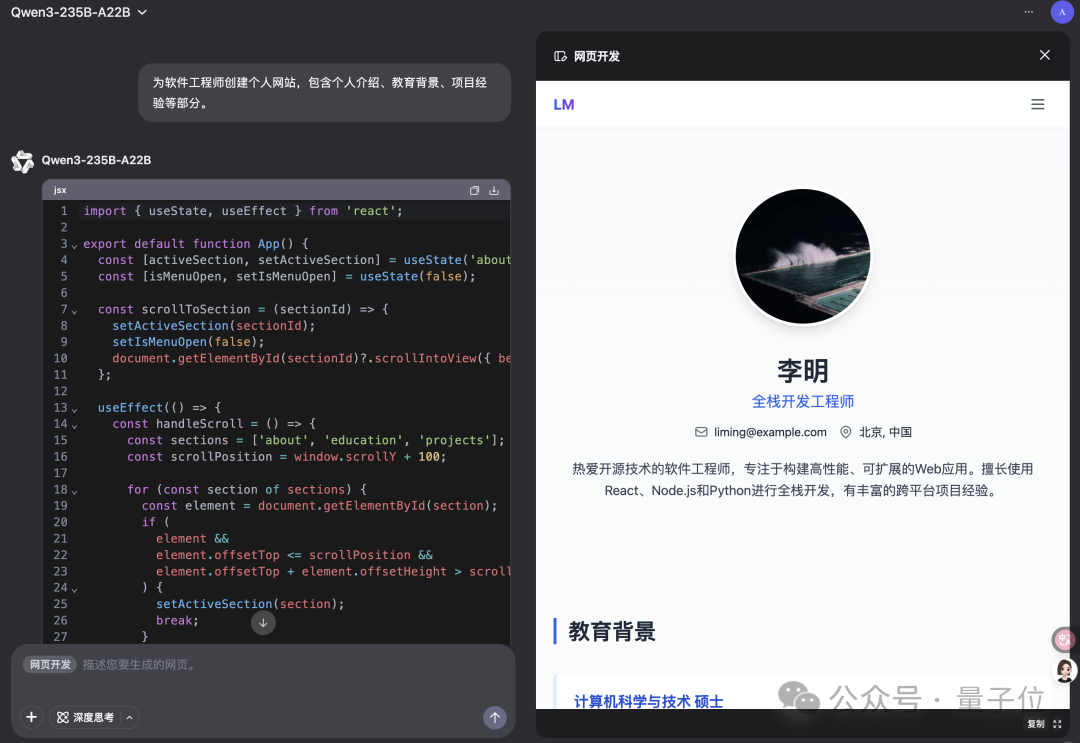
Qwen Chat, ‘웹 개발’ 모드 추가, 한 문장으로 React 웹 애플리케이션 생성: 알리바바 Qwen Chat이 ‘웹 개발’(Web Dev) 모드를 출시했습니다. 사용자는 한 문장의 지시만으로 HTML, CSS, JavaScript를 포함하는 웹 애플리케이션을 생성할 수 있으며, 기본적으로 React 프레임워크와 Tailwind CSS를 사용합니다. 이 기능은 개인 웹사이트, 기존 웹 인터페이스(예: Twitter, GitHub) 복제 또는 설명을 기반으로 특정 양식 및 애니메이션을 빠르게 만들 수 있습니다. 사용자는 다양한 Qwen 모델을 선택하고 ‘심층 사고’ 모드를 결합하여 웹 페이지 품질을 향상시킬 수 있습니다. 이 기능은 프론트엔드 개발 프로세스를 단순화하고 애플리케이션 프로토타입을 빠르게 구축하는 것을 목표로 합니다. (출처: WeChat)
유니트리 로보틱스, Go1 로봇 개의 보안 취약점 인정, 후속 제품은 업그레이드 강조: 유니트리 로보틱스는 약 2년 전 단종된 Go1 로봇 개 시리즈의 ‘백도어 취약점’ 루머에 대해 보안 취약점임을 인정했습니다. 공격자는 제3자 클라우드 터널 서비스의 관리 키를 이용하여 사용자 장치 데이터를 수정하고 카메라 화면 및 시스템 권한을 획득할 수 있습니다. 유니트리 로보틱스는 후속 로봇 시리즈는 더 안전한 업그레이드 버전을 채택하여 이 취약점의 영향을 받지 않는다고 밝혔습니다. 이 사건은 특히 인간형 로봇 상용화 원년이라는 배경 하에 지능형 로봇 공급망 보안 및 데이터 프라이버시에 대한 우려를 불러일으켰으며, 업계는 기술적 난관 극복, 비용 통제, 상용화 경로 탐색 등 여러 도전에 직면해 있습니다. (출처: 36氪)

Claude Code, 이제 다른 .MD 파일 참조 지원, 명령어 구성 최적화: Anthropic의 Claude Code가 기능을 업데이트하여 버전 0.2.107부터 CLAUDE.md 파일이 다른 Markdown 파일을 가져올 수 있게 되었습니다. 사용자는 기본 CLAUDE.md 파일에 [u/path/to/file].md를 추가하는 방식으로 시작 시 추가 파일 내용을 로드할 수 있습니다. 이 개선 사항은 사용자가 Claude의 명령어를 더 잘 구성하고 관리할 수 있게 하여 대규모 프로젝트에서 명령어 구성의 신뢰성과 모듈성을 향상시키고, 이전의 분산된 파일 의존으로 인해 발생할 수 있는 혼란 문제를 해결합니다. (출처: Reddit r/ClaudeAI)

미국 저작권청, AI 사전 훈련에 대해 더욱 강경한 입장, ‘공정 이용’ 항변 약화: 미국 저작권청이 최근 발표한 보고서에서 AI 모델 사전 훈련 단계에서 저작권 보호 자료를 사용하는 문제에 대해 더욱 강경한 입장을 취했습니다. 보고서는 AI 연구소가 이제 자신들의 모델이 권리 보유자와 경쟁할 수 있다고 주장함에 따라(예: 원본 작품과 유사한 콘텐츠 생성), 저작권 침해 소송에서 ‘공정 이용’(fair use)을 근거로 자신들을 변호할 수 있는 힘이 약화되었다고 지적했습니다. 이러한 변화는 AI 모델의 훈련 데이터 출처와 규정 준수에 중대한 영향을 미칠 수 있습니다. (출처: Dorialexander)

NVIDIA, 48GB GDDR7 메모리 탑재한 RTX Pro 5000 전문가용 그래픽 카드 출시: NVIDIA가 Blackwell 아키텍처 기반의 새로운 전문가용 데스크톱 GPU RTX Pro 5000을 출시했습니다. 이 그래픽 카드는 48GB GDDR7 메모리를 탑재하고 있으며, 메모리 대역폭은 최대 1344 GB/s, 소비 전력은 300W입니다. 공식적으로는 “저렴한” 48GB Blackwell 그래픽 카드라고 하지만, 예상 가격은 여전히 높을 것(4000달러 수준 언급)으로 보이며, 주로 전문가용 워크스테이션 사용자를 대상으로 AI 모델 훈련, 대규모 3D 렌더링 등의 작업에 강력한 연산 능력을 제공합니다. (출처: Reddit r/LocalLLaMA)

🧰 도구
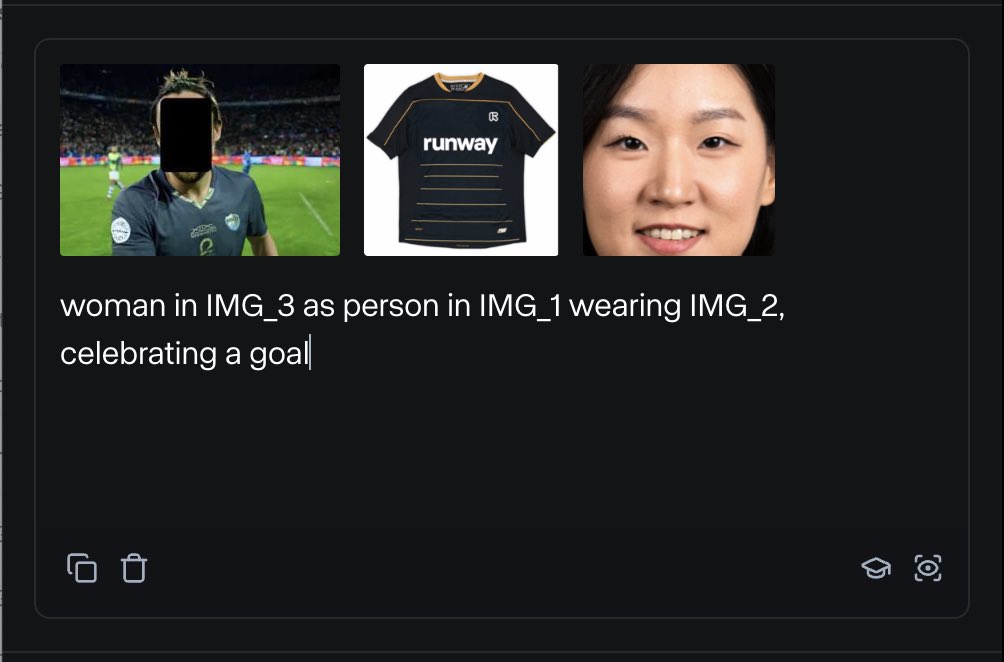
RunwayML, 다양한 참조 자료를 혼합하여 콘텐츠를 생성할 수 있는 References 기능 출시: RunwayML의 새로운 기능 “References”는 사용자가 다양한 참조 자료(예: 이미지, 스타일)를 “원료”로 혼합하고, 이러한 “원료”의 임의 조합에 따라 새로운 시각적 콘텐츠를 생성할 수 있도록 합니다. 이 기능은 거의 실시간 창작 기계로 간주되며, 사용자가 다양한 창의적인 아이디어를 신속하게 구현하도록 도와 AI의 시각적 콘텐츠 제작 유연성과 가능성을 크게 확장합니다. (출처: c_valenzuelab)
Chat2DB: 자연어로 데이터베이스를 조작하는 AI 클라이언트: Chat2DB는 AI 기반 데이터베이스 클라이언트 도구로, 사용자가 자연어를 통해 데이터베이스와 상호 작용할 수 있도록 합니다. 예를 들어, 사용자가 “이번 달에 가장 많이 소비한 고객은 누구인가요?”라고 질문하면 Chat2DB는 AI를 사용하여 질문을 이해하고 데이터베이스의 테이블 구조에 따라 해당 SQL 쿼리 문을 자동으로 생성하여 쿼리를 실행하고 결과를 반환합니다. 이는 데이터베이스 작업의 기술적 장벽을 크게 낮추어 비기술자도 편리하게 데이터 조회 및 분석을 수행할 수 있도록 합니다. 이 프로젝트는 GitHub에 오픈소스로 공개되었습니다. (출처: karminski3)
Qwen 3 8B 모델, 뛰어난 코드 능력 과시, HTML 키보드 생성 가능: Qwen 3 8B 모델(Q6_K 양자화 버전)은 파라미터 수가 적음에도 불구하고 코드 생성에서 뛰어난 성능을 보여줍니다. 사용자는 두 개의 짧은 프롬프트를 통해 이 모델이 플레이 가능한 HTML 키보드 코드를 생성하도록 성공적으로 만들었습니다. 이는 소형화된 모델도 특정 작업에서 높은 실용성을 달성할 수 있는 잠재력을 보여주며, 특히 리소스가 제한된 로컬 배포 환경에 매력적입니다. (출처: Reddit r/LocalLLaMA)
Ollama Chat: Claude 인터페이스와 유사한 로컬 LLM 채팅 도구: Ollama Chat은 로컬 대규모 언어 모델을 위해 설계된 웹 채팅 인터페이스로, UI 스타일과 사용자 경험은 Anthropic의 Claude를 참고했습니다. 이 도구는 텍스트 파일 업로드, 대화 기록 및 시스템 프롬프트 설정을 지원하며, 사용하기 쉽고 미려한 로컬 LLM 상호 작용 솔루션을 제공하는 것을 목표로 합니다. 프로젝트는 GitHub에 오픈소스로 공개되어 사용자가 직접 배포하고 사용할 수 있습니다. (출처: Reddit r/LocalLLaMA)
AI로 개인화된 카드(생일/어머니날)를 생성하는 프롬프트 팁: 사용자가 AI를 사용하여 개인화된 카드(예: 생일 카드, 어머니날 카드)를 생성하는 프롬프트 팁을 공유했습니다. 핵심은 카드 주제(예: 어머니날, 생일), 스타일(예: 여성스러운 스타일, 어린이 스타일), 수신자(예: 엄마, Sandy, Jimmy), 나이(예: 30세, 6세) 및 축하 메시지의 구체적인 내용이나 따뜻하고 달콤한 분위기를 명확히 하는 것입니다. 이러한 요소를 조합하여 AI가 요구 사항에 맞는 카드 디자인을 생성하도록 유도할 수 있습니다. (출처: dotey)

📚 학습
구글, 프롬프트 엔지니어링 백서 발표, 사용자에게 효과적인 질문 방법 안내: 구글은 프롬프트 엔지니어링에 관한 백서(Kaggle을 통해 접근 가능)를 발표하여 사용자에게 AI 모델에 더 효과적으로 질문하는 방법을 가르치는 것을 목표로 합니다. 튜토리얼 내용은 명확하며, 출력 요구 사항을 명확히 하고, 출력 범위를 제한하며, 변수를 사용하는 방법 등의 기술을 자세히 소개하여 사용자가 대규모 언어 모델과의 상호 작용 효율성과 효과를 높여 더 정확하고 유용한 답변을 얻을 수 있도록 돕습니다. (출처: karminski3)

홍콩과기대(광저우) 팀, MultiGO 제안: 계층적 가우시안 모델링으로 단일 이미지에서 3D 텍스처 인체 생성: 홍콩과학기술대학교(광저우) 팀은 MultiGO라는 혁신적인 프레임워크를 제안하여 계층적 가우시안 모델링을 통해 단일 이미지에서 텍스처가 있는 3D 인체 모델을 재구성합니다. 이 방법은 인체를 골격, 관절, 주름 등 다양한 정밀도 계층으로 분해하여 단계적으로 세분화합니다. 핵심 기술은 가우시안 스플래팅 포인트를 3D 기본 요소로 사용하고 골격 강화, 관절 강화 및 주름 최적화 모듈을 설계했습니다. 이 연구 성과는 CVPR 2025에 선정되었으며, 단일 이미지 3D 인체 재구성에 새로운 아이디어를 제공하고 코드는 곧 오픈소스화될 예정입니다. (출처: WeChat)

칭화대, 푸단대, 홍콩과기대 공동 RM-BENCH 발표: 최초의 보상 모델 평가 벤치마크: 현재 대규모 언어 모델 보상 모델 평가에서 ‘형식보다 내용’ 및 스타일 편향 문제가 존재하는 것에 대응하여, 칭화대학교, 푸단대학교, 홍콩과학기술대학교 연구팀이 공동으로 최초의 체계적인 보상 모델 평가 벤치마크인 RM-BENCH를 발표했습니다. 이 벤치마크는 채팅, 코드, 수학, 보안 네 가지 영역을 포괄하며, 미세한 내용 차이에 대한 모델의 민감도와 스타일 편차에 대한 견고성을 평가하여 보다 신뢰할 수 있는 ‘내용 심판’의 새로운 기준을 수립하는 것을 목표로 합니다. 연구 결과 기존 보상 모델은 수학 및 코드 영역에서 성능이 저조하고 일반적으로 스타일 편차가 존재하는 것으로 나타났습니다. 이 성과는 ICLR 2025 Oral에 채택되었습니다. (출처: WeChat)

톈진대와 텐센트, COME 솔루션 오픈소스 공개: 5줄 코드로 TTA 견고성 향상, 모델 붕괴 해결: 톈진대학교와 텐센트가 협력하여 테스트 시 적응(TTA) 과정에서 엔트로피 최소화(EM)로 인한 모델의 과도한 자신감과 붕괴 문제를 해결하기 위한 COME (Conservatively Minimizing Entropy) 방법을 제안했습니다. COME은 주관적 논리를 도입하여 예측 불확실성을 명시적으로 모델링하고, 적응형 Logit 제약(Logit 놈 동결)을 사용하여 간접적으로 불확실성을 제어함으로써 보수적인 엔트로피 최소화를 달성합니다. 이 방법은 모델 아키텍처를 수정할 필요 없이 소량의 코드로 기존 TTA 방법에 통합할 수 있으며, ImageNet-C 등 데이터셋에서 모델 견고성과 정확도를 현저히 향상시키면서 계산 비용은 극히 적습니다. 논문은 ICLR 2025에 채택되었으며 코드는 오픈소스화되었습니다. (출처: WeChat)
화웨이와 정보공학연구소, DEER 제안: 사고 사슬 ‘동적 조기 종료’ 메커니즘으로 LLM 추론 효율성 및 정확도 향상: 화웨이가 중국과학원 정보공학연구소와 공동으로 DEER(Dynamic Early Exit in Reasoning) 메커니즘을 제안했습니다. 이는 대규모 언어 모델이 긴 사고 사슬(Long CoT) 추론에서 발생할 수 있는 과도한 사고 문제를 해결하기 위함입니다. DEER은 추론 전환점을 모니터링하고, 실험적인 답변을 유도하며 그 신뢰도를 평가하여 사고를 조기에 종료하고 결론을 생성할지 여부를 동적으로 판단합니다. 실험 결과, DeepSeek 시리즈 등 추론 LLM에서 DEER은 추가 훈련 없이 평균 31%-43%의 사고 사슬 생성 길이를 줄이면서 정확도를 1.7%-5.7% 향상시키는 것으로 나타났습니다. (출처: WeChat)

중국과학원 등, R1-Reward 제안: 안정적인 강화 학습을 통해 멀티모달 보상 모델 훈련: 중국과학원, 칭화대학교, 콰이쇼우, 난징대학교 연구팀은 안정적인 강화 학습 알고리즘 StableReinforce를 통해 멀티모달 보상 모델(MRM)을 훈련하여 장기 추론 능력을 향상시키는 방법인 R1-Reward를 제안했습니다. StableReinforce는 MRM 훈련 시 PPO 등 기존 RL 알고리즘에서 발생할 수 있는 불안정성 문제를 개선하기 위해 Pre-Clip 전략, 어드밴티지 필터, 그리고 새로운 일관성 보상 메커니즘(분석과 답변의 일관성을 검사하는 심판 모델 도입)을 통해 훈련 과정을 안정화합니다. 실험 결과, R1-Reward는 여러 MRM 벤치마크에서 SOTA 모델보다 우수한 성능을 보였으며, 추론 시 다중 샘플링 투표를 통해 성능을 더욱 향상시킬 수 있음을 보여주었습니다. (출처: WeChat)
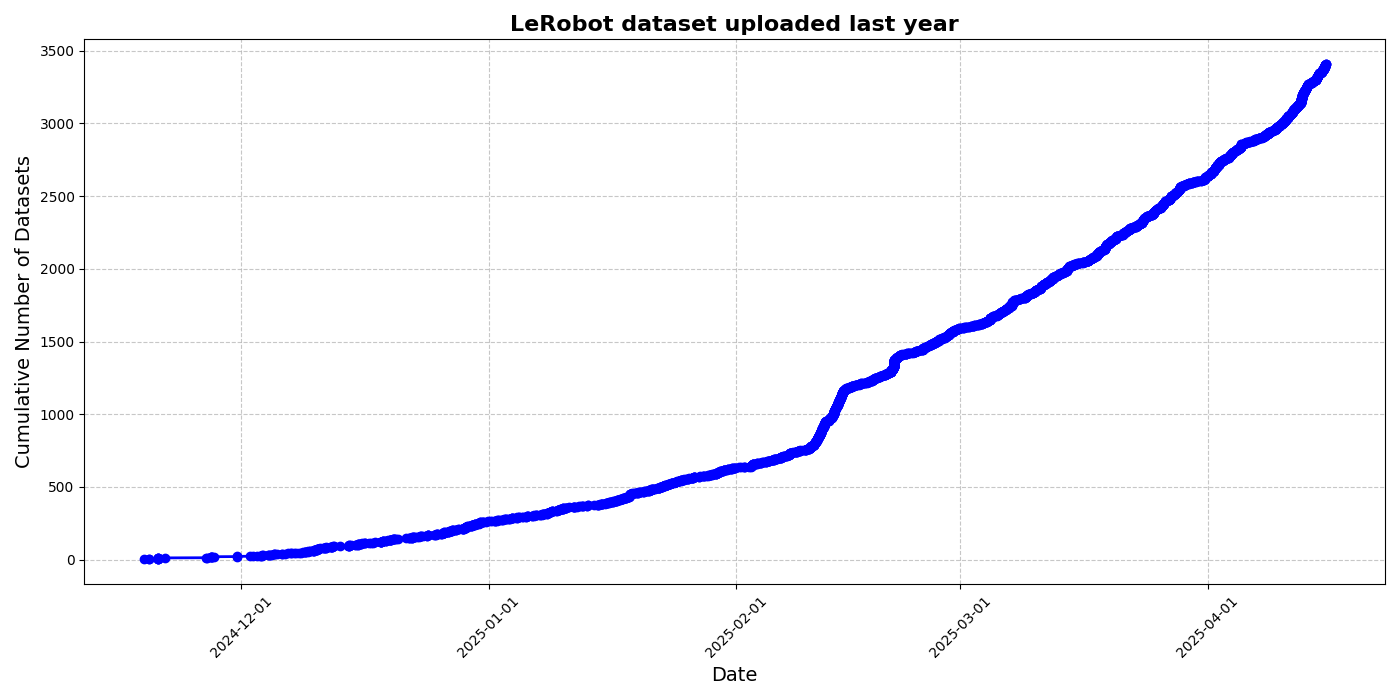
HuggingFace, LeRobot 커뮤니티 데이터셋 이니셔티브 발표, 로봇 분야 ‘ImageNet 모멘트’ 추진: HuggingFace가 LeRobot 커뮤니티 데이터셋 프로젝트를 시작하여 로봇 분야의 ‘ImageNet’을 구축하고 커뮤니티 기여를 통해 범용 로봇 기술 발전을 추진하고자 합니다. 이 글은 로봇 일반화 능력에 대한 데이터 다양성의 중요성을 강조하며, 기존 로봇 데이터셋이 대부분 제한된 학술 환경에서 비롯되었음을 지적합니다. LeRobot은 데이터 수집 및 업로드 절차를 간소화하고 하드웨어 비용을 절감하여 사용자들이 다양한 로봇(예: So100, Koch 로봇 팔)이 다양한 작업(예: 체스 두기, 서랍 조작)을 수행하는 데이터를 공유하도록 장려합니다. 동시에, 이 글은 데이터 레이블링 불일치, 특징 매핑 모호성 등의 문제에 대응하고 고품질의 다양한 로봇 데이터셋 구축을 촉진하기 위한 데이터 품질 기준과 모범 사례 목록을 제시합니다. (출처: HuggingFace Blog, LoubnaBenAllal1)
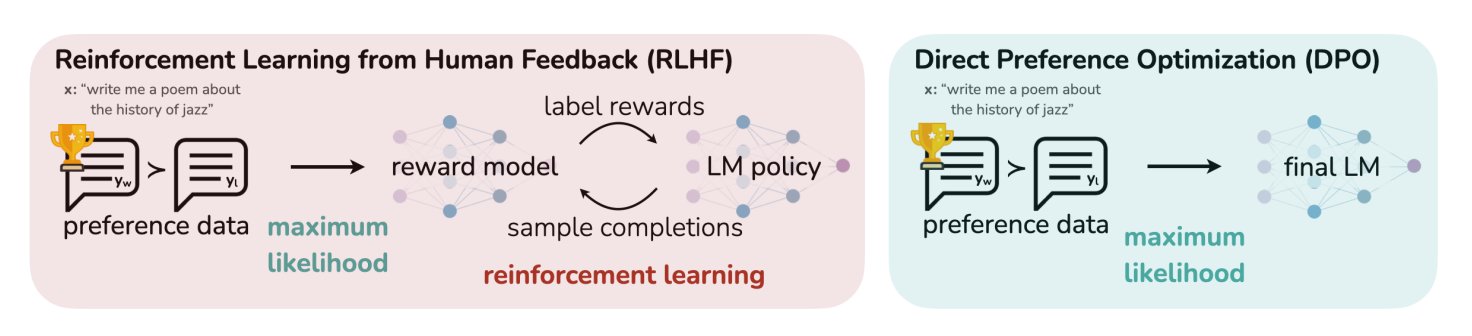
HuggingFace 블로그 게시물, LLM의 11가지 정렬 및 최적화 알고리즘 요약: TheTuringPost가 HuggingFace의 한 게시물을 공유했는데, 여기에는 대규모 언어 모델(LLM)을 위한 11가지 정렬 및 최적화 알고리즘이 요약되어 있습니다. 이러한 알고리즘에는 PPO(Proximal Policy Optimization), DPO(Direct Preference Optimization), GRPO(Group Relative Policy Optimization), SFT(Supervised Fine-Tuning), RLHF(Reinforcement Learning from Human Feedback) 및 SPIN(Self-Play Fine-Tuning) 등이 포함됩니다. 이 게시물은 이러한 알고리즘에 대한 링크와 추가 정보를 제공하여 연구자와 개발자에게 LLM 최적화 방법에 대한 개요를 제공합니다. (출처: TheTuringPost)
UC Berkeley, CS280 대학원 컴퓨터 비전 과정 자료 공유: 캘리포니아 대학교 버클리 캠퍼스의 Angjoo Kanazawa 교수와 Jitendra Malik 교수가 이번 학기에 강의한 대학원 컴퓨터 비전 과정 CS280의 모든 강의 자료를 공유했습니다. 그들은 고전적 컴퓨터 비전과 현대 컴퓨터 비전 내용을 결합한 이 자료 세트가 효과가 좋았다고 생각하며, 학습자들이 참고할 수 있도록 공개했습니다. (출처: NandoDF)
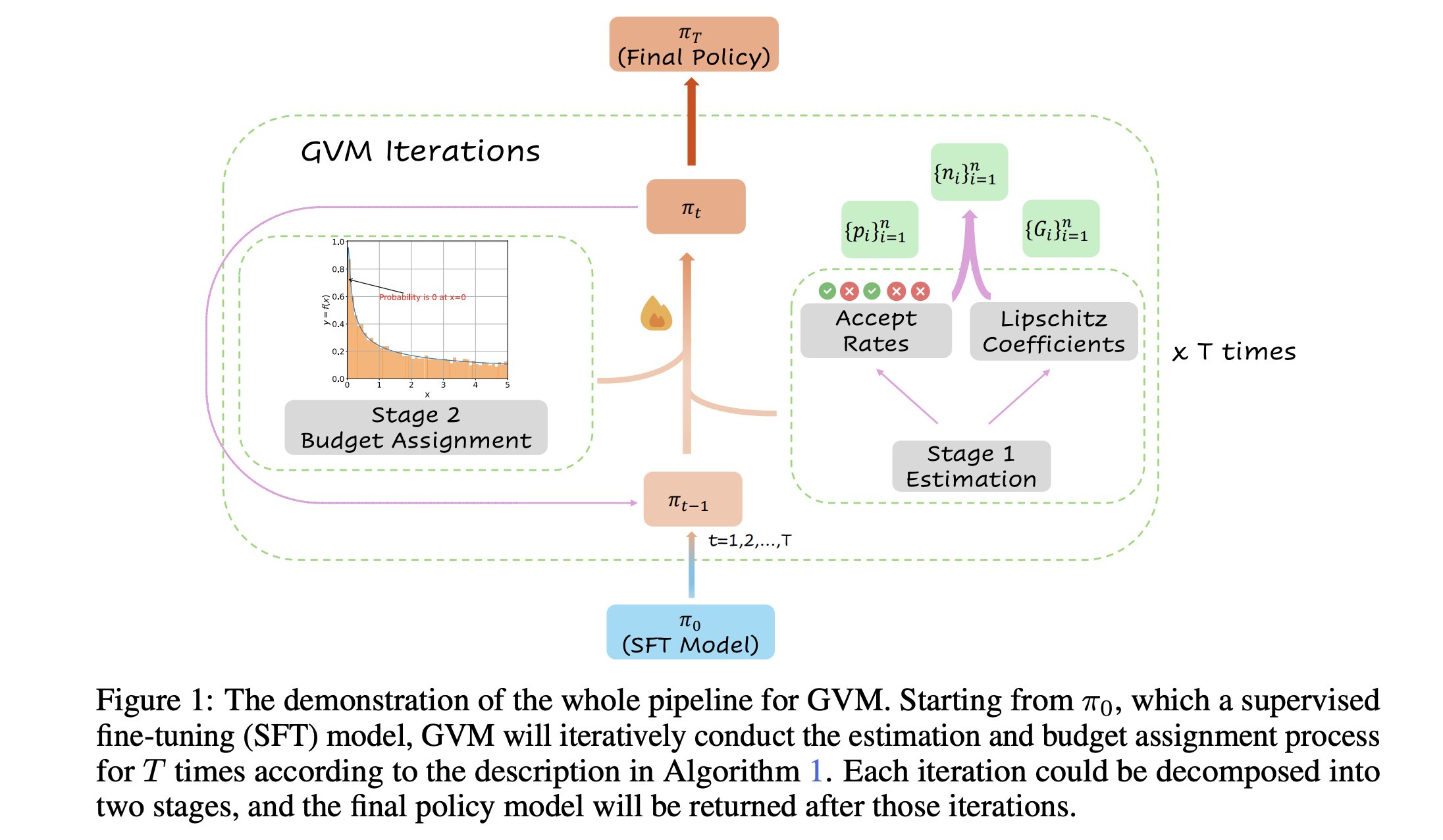
GVM-RAFT: 사고 사슬 추론기의 동적 샘플링 최적화 프레임워크: 새로운 논문에서 GVM-RAFT 프레임워크를 소개했습니다. 이 프레임워크는 각 프롬프트에 대해 동적으로 샘플링 전략을 조정하여 사고 사슬(chain-of-thought) 추론기를 최적화하며, 기울기 분산을 최소화하는 것을 목표로 합니다. 이 방법은 수학 추론 작업에서 2-4배의 속도 향상을 달성하고 정확도를 높였다고 합니다. (출처: _akhaliq)
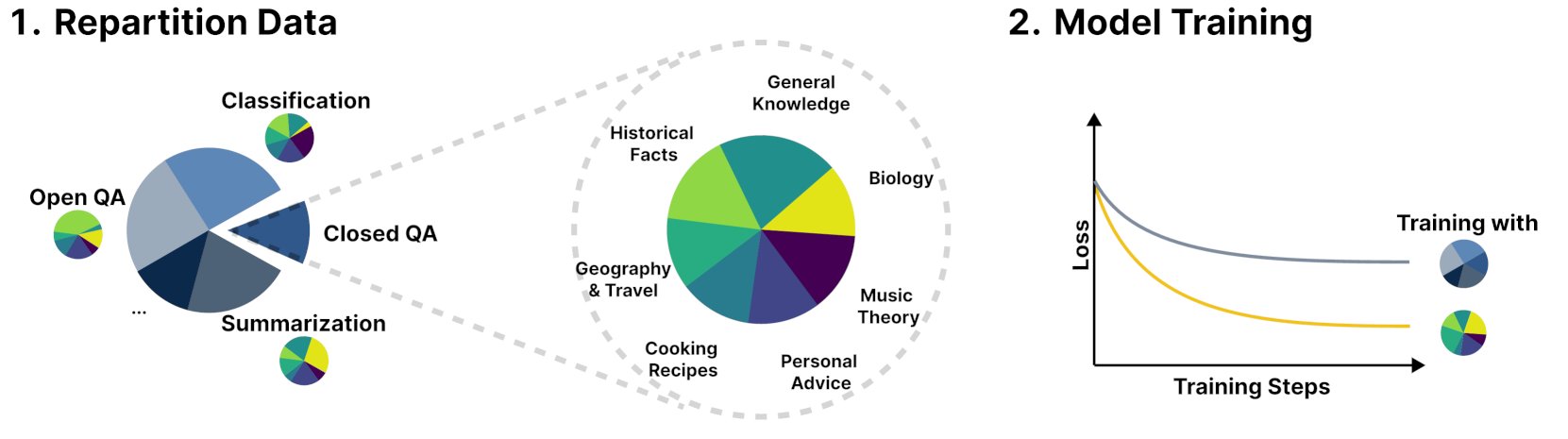
새로운 프레임워크 R&B, 동적 균형 훈련 데이터로 언어 모델 성능 향상: R&B라는 새로운 연구에서 언어 모델의 훈련 데이터를 동적으로 균형을 맞추어 단 0.01%의 추가 계산량만으로 모델 성능을 향상시키는 새로운 프레임워크를 제안했습니다. 이 방법은 데이터 활용 효율을 최적화하여 적은 비용으로 모델 성능 개선을 목표로 합니다. (출처: _akhaliq)
논문, AI 안전에 대한 새로운 시각 제시: 사회와 기술 진보를 누비이불 꿰매기에 비유: arXiv에 발표된 새로운 논문 “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt”는 AI 안전의 핵심을 의견 불일치가 갈등으로 확대되는 것을 방지하는 데 초점을 맞춰야 한다는 새로운 AI 안전관을 제시합니다. 이 논문은 사회와 기술의 진보를 끊임없이 커지고 변화하며, 조각보 같고 다채로운 누비이불을 꿰매는 것에 비유하며, 복잡한 시스템에서 안정과 협력을 유지하는 것의 중요성을 강조합니다. (출처: jachiam0)
논문, 자기 회귀 언어 모델에서의 적응형 계산 논의: 딥러닝에서의 적응형 계산의 흥미로운 점에 대한 논의가 있었으며, 관련 기술 발전을 열거했습니다: PonderNet (DeepMind, 2021)은 신경망과 순환을 통합하는 초기 도구였습니다. 확산 모델은 여러 번의 순방향 전파를 통해 계산을 수행합니다. 그리고 최근의 추론형 언어 모델은 임의의 수의 토큰을 생성하여 유사한 효과를 달성합니다. 이는 계산 자원 할당 및 사용에 대한 모델의 유연성과 동적 추세를 반영합니다. (출처: jxmnop)
논문, ‘나쁜 데이터’가 어떻게 ‘좋은 모델’을 만드는지 탐구: 하버드 대학교 2025년 논문 “When Bad Data Leads to Good Models”(arXiv:2505.04741)는 특정 상황에서 4chan 콘텐츠를 포함한 사전 훈련 데이터와 같이 품질이 낮아 보이는 데이터가 오히려 모델 정렬에 도움이 되고 모델의 ‘파워 레벨’을 숨겨 더 나은 성능을 보이게 할 수 있음을 탐구합니다. 이는 데이터 품질, 모델 정렬 및 모델 행동의 진실성에 대한 논의를 불러일으켰습니다. (출처: teortaxesTex)

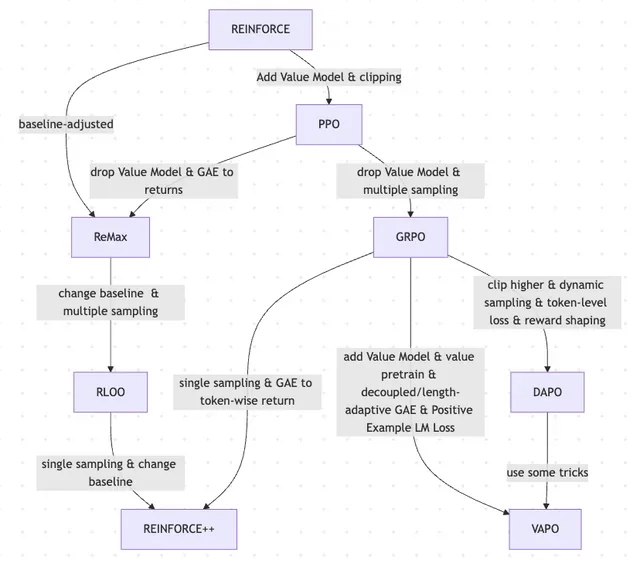
논문, REINFORCE에서 VAPO까지 RLHF 및 그 변형의 진화 과정 탐구: 한 연구 논문은 대규모 언어 모델(LLM) 미세 조정을 위해 사용되는 강화 학습(RL) 방법의 진화 과정을 요약했습니다. 이 논문은 고전적인 PPO 및 REINFORCE 알고리즘에서 시작하여 GRPO, ReMax, RLOO, DAPO 및 VAPO와 같은 최근 방법으로의 진화를 추적하며, 가치 모델의 폐기, 샘플링 전략 변경, 기준선 조정, 보상 형성 및 토큰 수준 손실과 같은 기술의 적용을 분석합니다. 이 연구는 LLM 정렬 분야에서 RLHF 및 그 변형의 연구 지형을 명확하게 보여주는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)
논문 “Absolute Zero”: 인간 데이터 없이 강화 자가 학습 추론을 수행하는 AI: “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data”(arXiv:2505.03335)라는 백서는 논리 AI를 훈련하는 새로운 방법을 탐구합니다. 연구자들은 인간이 레이블링한 데이터셋을 사용하지 않고 논리 AI 모델을 훈련시켰으며, 모델은 스스로 추론 작업을 생성하고 문제를 해결하며 코드 실행을 통해 솔루션을 검증할 수 있습니다. 이는 AI가 수학, 물리, 언어와 같은 사전 지식이 전혀 없는 원시 환경에서 처음부터 기호 표현을 발명하고, 논리 구조를 정의하며, 숫자 체계를 개발하고, 인과 모델을 구축할 수 있는지, 그리고 이러한 “이종 지능”의 잠재력과 위험에 대한 논의를 불러일으켰습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)
푸단대학교 지능형 인간-컴퓨터 상호작용 연구실, 2026학년도 석박사 과정 학생 모집: 푸단대학교 컴퓨터과학기술학부의 지능형 인간-컴퓨터 상호작용 연구실이 2026학년도 여름 캠프/추천 입학 석사 및 박사 과정 학생을 모집합니다. 연구실은 샹리 교수가 이끌고 있으며, 연구 분야는 웨어러블 AGI (MemX 스마트 안경과 LLM 결합), 오픈소스 구현 지능, 모델 압축(대형에서 소형으로), 그리고 머신러닝 시스템(예: ML 컴파일 최적화, AI 프로세서) 등을 포함합니다. 연구실은 인간 중심의 지능을 탐구하며, 대형 모델과 스마트 웨어러블, 구현 지능 시스템을 융합한 새로운 인간-컴퓨터 상호작용 패러다임을 모색하는 데 전념하고 있습니다. (출처: WeChat)

💼 비즈니스
직원 50명 미만, 기업 가치 10억 달러 이상 AI 스타트업 10곳 개요: Business Insider가 직원 수 50명 미만이면서 기업 가치가 10억 달러를 넘는 AI 스타트업 10곳을 정리했습니다. 여기에는 Safe Superintelligence(기업 가치 320억 달러, 직원 20명), OG Labs(기업 가치 20억 달러, 직원 40명), Magic(기업 가치 15억 8천만 달러, 직원 20명), Sakana AI(기업 가치 15억 달러, 직원 28명) 등이 포함됩니다. 이들 회사는 AI 분야에서 소규모 팀으로 높은 기업 가치를 창출하는 잠재력을 보여주며, 기술과 혁신이 자본 시장에서 높은 가치를 지니고 있음을 반영합니다. (출처: hardmaru)
푸리에 인텔리전스, 요양 분야 심화, 상하이 국제 의료 센터와 협력하여 구현 지능 재활 기지 구축: 구현 지능 유니콘 기업 푸리에 인텔리전스는 첫 번째 구현 지능 생태계 정상 회의에서 상하이 국제 의료 센터와 협력하여 재활 의료 분야에서 구현 지능 로봇의 응용을 공동으로 추진할 것이라고 발표했습니다. 여기에는 표준 구축, 솔루션 공동 개발, 과학 연구 협력 등이 포함되며, 국내 최초의 구현 지능 재활 시범 기지를 구축할 예정입니다. 푸리에 인텔리전스 창립자 구제는 향후 10년간의 핵심 전략으로 “요양 분야에 기반을 두고, 상호 작용에 집중하며, 사람에게 봉사한다”를 제시하며 의료 재활이 그 근간임을 강조했습니다. 회사는 2015년 설립 이후 재활 로봇에서 시작하여 범용 인간형 로봇 GR-1 및 GRx 시리즈로 점차 확장했으며, 누적 출하량은 수백 대에 달합니다. (출처: 36氪)
Meta, 전 국방부 관리 채용 중이라는 보도, 군사 분야 강화 가능성: 포브스 보도에 따르면 Meta가 전 국방부 관리를 채용하고 있으며, 이는 회사가 군사 기술 또는 국방 관련 분야 사업을 강화할 계획임을 의미할 수 있습니다. 이러한 움직임은 대형 기술 기업의 군사 응용 참여에 대한 논의와 관심을 불러일으키고 있습니다. (출처: Reddit r/artificial)

🌟 커뮤니티
Andrej Karpathy, LLM 학습에 중요한 패러다임 ‘시스템 프롬프트 학습’ 부재 지적하며 열띤 토론 유발: Andrej Karpathy는 현재 LLM 학습에 중요한 패러다임이 빠져 있다고 주장하며, 이를 ‘시스템 프롬프트 학습’이라고 명명했습니다. 그는 사전 훈련은 지식을 위한 것이고, 미세 조정(지도 학습/강화 학습)은 습관적 행동을 위한 것이며, 둘 다 매개변수 변경을 수반하지만, 방대한 양의 인간 상호 작용과 피드백이 충분히 활용되지 않는 것 같다고 지적했습니다. 그는 이를 영화 ‘Memento’의 주인공에게 전역적 문제 해결 지식과 전략을 저장하기 위한 메모장을 주는 것에 비유했습니다. 이 관점은 광범위한 토론을 불러일으켰으며, 일부는 이것이 DSPy의 이념과 유사하거나 기억/최적화, 지속적 학습 문제와 관련이 있다고 보았고, Langgraph에서 유사한 메커니즘을 구현하는 방법에 대해 논의했습니다. (출처: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
AI 회사가 구직자에게 AI로 지원서 작성하지 말 것을 요구하며 논란: Anthropic 등 AI 회사가 구직자에게 지원서(예: 이력서) 작성 시 AI 도구를 사용하지 말 것을 요구한 규정이 커뮤니티에서 논란을 일으켰습니다. 일부 채용 담당자는 AI로 생성된 이력서에서 “문자 쓰레기” 현상이 심각하며, 경력자조차 이로 인해 핵심을 놓칠 수 있다고 말했습니다. 그러나 일부 구직자는 AI가 직무 요구 사항에 맞춰 이력서를 최적화하고, 기술을 강조하며, 가독성을 높이는 데 도움이 된다고 생각합니다. 논의는 LinkedIn 등 플랫폼에 AI 생성 콘텐츠가 넘쳐나는 현상과 구직자 평가를 위해 비디오 등 다른 방식을 채택해야 하는지 여부로까지 확대되었습니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

AI 생성 콘텐츠의 ‘식별 가능성’ 논란, 사용자는 쉽게 감지 가능하다고 생각: 커뮤니티 토론에서 AI(특히 ChatGPT)로 생성된 콘텐츠는 특정 구두점(예: em dashes)이나 문장 구조(예: “That’s not x; that’s y.”)뿐만 아니라 특유의 “리듬감”과 “밋밋함” 때문에 쉽게 식별할 수 있다는 지적이 나왔습니다. AI 흔적을 식별하면 콘텐츠가 비현실적이고 개성이 없어 보입니다. 일부 사용자는 이메일, 소셜 미디어 게시물, 심지어 비디오 게임에서도 이러한 경우를 겪었다고 말하며, AI 생성 콘텐츠를 그대로 사용하면 내용이 지루하고 진정성이 없어지므로 사용자는 AI를 도구로 사용하여 수정하고 개인화해야 한다고 제안했습니다. (출처: Reddit r/ChatGPT)
AI 발전, ‘허니문 기간-반발 기간’ 순환 양상 보여, 진정성에 대한 인간의 선호 반영: 새로운 생성형 AI 모델(텍스트, 이미지, 음악 등)의 등장은 종종 사람들이 그 능력에 감탄하는 ‘허니문 기간’을 동반한다는 견해가 있습니다. 그러나 곧 사람들이 AI가 생성한 ‘틀’이나 ‘흔적’을 인식하기 시작하면 반발이 생겨 칭찬에서 의심으로 바뀌고 심지어 ‘영혼이 없다’고 여기기도 합니다. AI 작품을 빠르게 학습하여 인식하고 결함 있는 인간 창작물을 선호하는 이러한 현상은, 사람들이 작품 뒤의 이야기, 작가의 의도, 진정성을 중시하기 때문에 AI가 인간 창작자를 완전히 대체하기보다는 보조 도구로서 더 많이 활용될 수 있음을 의미할 수 있습니다. (출처: Reddit r/ArtificialInteligence)
Anthropic 내부 AI 코드 생성률 70% 초과, AI 자가 반복에 대한 연상 유발: Anthropic의 Mike Krieger는 회사 내부에서 풀 리퀘스트(pull requests)의 70% 이상이 현재 AI에 의해 생성된다고 밝혔습니다. 이 데이터는 커뮤니티에서 논의를 불러일으켰으며, 일부는 공상 과학 작품의 장면처럼 기계가 스스로 편집하고 개선하는 장면을 연상했습니다. 동시에, 이 데이터의 진실성과 구체적인 의미(예: 이러한 PR의 복잡성 정도)에 대해 의문을 제기하는 사람들도 있었습니다. (출처: Reddit r/ClaudeAI)

NVIDIA CEO 젠슨 황, 전 직원 AI 에이전트 도입 강조, AI가 개발자 역할 재정의할 것: NVIDIA CEO 젠슨 황은 회사가 전 직원에게 AI 조수를 배치할 것이며, AI 에이전트가 일상 개발에 통합되어 코드 최적화, 취약점 발견, 프로토타입 설계 가속화를 할 것이라고 말했습니다. 그는 미래에는 모든 사람이 여러 AI 조수를 지휘하게 되어 생산성이 기하급수적으로 증가할 것이라고 생각합니다. Meta CEO 마크 저커버그, Microsoft CEO 사티아 나델라 등도 유사한 견해를 가지고 있으며, AI가 대부분의 코드 작업을 완료하고 개발자의 역할은 “AI 지휘”와 “요구 사항 정의”로 전환될 것이라고 생각합니다. 이러한 추세는 소프트웨어 개발 주기에 큰 변화가 있을 것을 예고하며, GitHub Copilot, Cursor 등 AI 프로그래밍 도구가 보편화될 것입니다. (출처: WeChat)

토론: ML 연구자가 매년 1000~2000편의 논문을 읽는 것이 가능한가?: 커뮤니티에서는 최고의 머신러닝 연구자들이 매년 거의 2000편의 논문을 읽을 수 있다는 논의가 있었습니다. 이에 대해 일부 평론가들은 논문 읽기 수 자체는 대리 지표일 뿐이며, 진정으로 중요한 것은 방대한 정보에서 신호를 걸러내고, 효과적인 정보를 추출하며, 올바르게 적용하는 능력이라고 생각합니다. 분야 내의 하이라이트와 추세를 따라가고 필요할 때 특정 내용을 깊이 연구할 수 있는 이러한 정보 필터링 능력은 금세기의 핵심 기술입니다. (출처: torchcompiled)
토론: 모델 훈련/미세 조정을 위한 GPU 구매 vs. GPU 임대: 머신러닝 실무자들은 GPU 리소스를 선택할 때 구매 또는 임대라는 선택에 직면합니다. 경험자들은 혼합 전략을 제안합니다: 소규모 실험을 위해 로컬에 괜찮은 성능의 소비자용 GPU를 구성하고, 대규모 훈련 작업에는 클라우드 GPU를 임대하는 것입니다. 선택은 모델 복잡성, 데이터 양 및 예산에 따라 달라집니다. 클라우드 GPU는 ML Ops 조직 측면에서 장점이 있지만, 동일 가격대에서 T4와 같은 일반적인 클라우드 GPU 성능은 고급 소비자 카드(예: 3090/4090)보다 떨어질 수 있지만, 클라우드에서는 더 큰 메모리를 가진 A100/H100과 같은 최상위 GPU를 제공할 수 있습니다. (출처: Reddit r/MachineLearning)
💡 기타
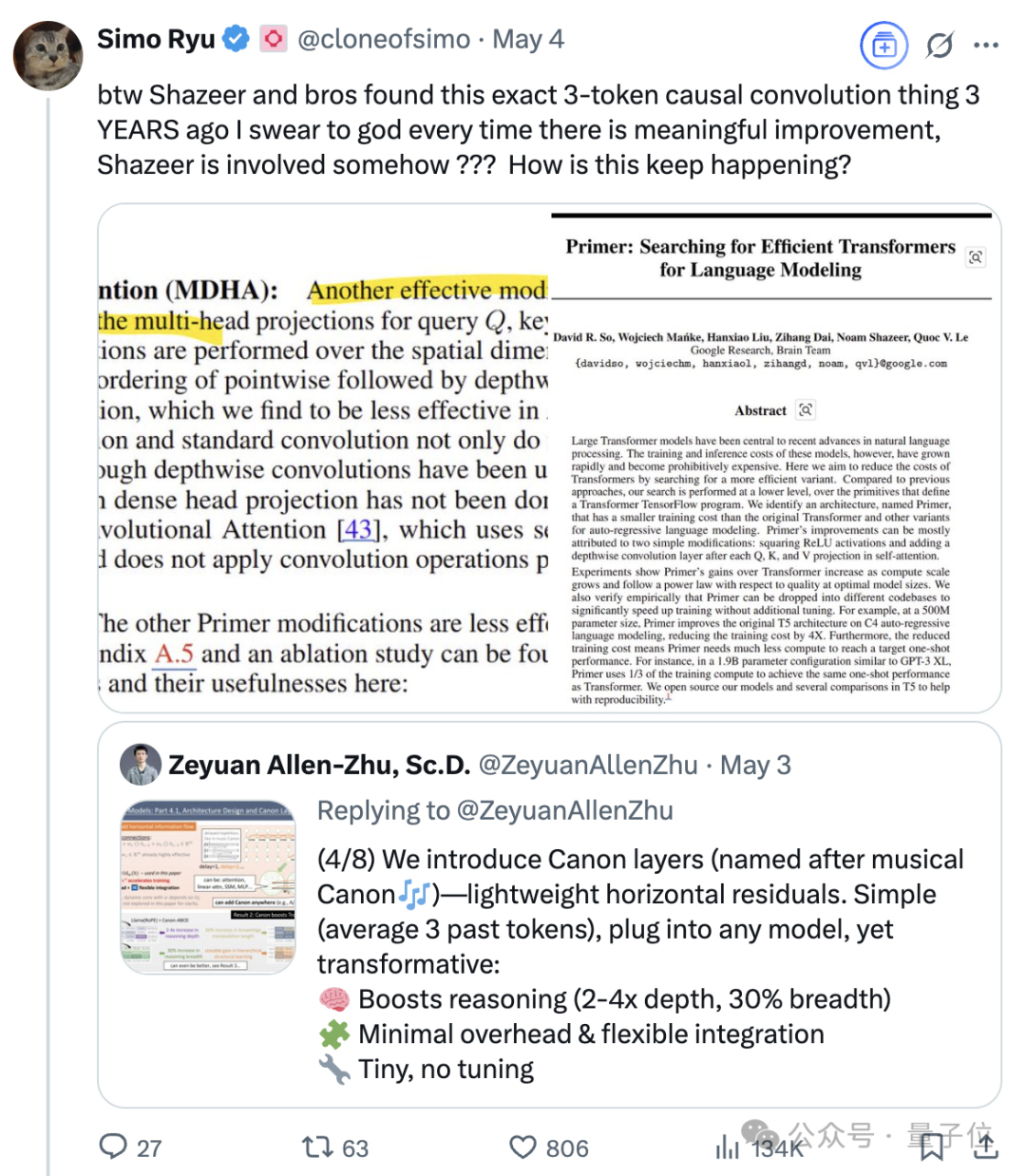
Transformer 8인 중 한 명인 Noam Shazeer의 지속적인 영향력: Transformer 아키텍처 논문 “Attention Is All You Need”의 8명의 저자 중 한 명인 Noam Shazeer의 기여는 가장 큰 것으로 널리 알려져 있습니다. 그의 영향력은 이를 훨씬 뛰어넘어, 언어 모델에 희소 게이트 전문가 혼합(MoE)을 초기에 도입한 연구, Adafactor 최적화기, 다중 쿼리 어텐션(MQA) 및 Transformer의 게이트 선형 계층(GLU) 등을 포함합니다. 이러한 작업은 현재 주류 대규모 언어 모델 아키텍처의 기초를 마련하여 Shazeer를 AI 분야에서 기술 패러다임을 지속적으로 정의하는 핵심 인물로 만들었습니다. 그는 구글을 떠나 Character.AI를 창업했다가 회사가 인수되면서 구글로 복귀하여 Gemini 프로젝트를 공동으로 이끌었습니다. (출처: WeChat)
기술 대기업들, AI가 초래한 ‘중년의 위기’ 직면: 이 글은 구글, 애플, 메타, 테슬라를 포함한 ‘기술 7대 기업’이 인공지능이 가져온 파괴적인 도전에 직면하여 ‘중년의 위기’에 빠졌다고 분석합니다. 구글의 검색 사업은 AI 직접 질의응답 모델의 위협을 받고 있고, 애플은 AI 혁신에서 더딘 진전을 보이고 있으며, 메타는 AI를 소셜에 통합하려 하지만 Llama 4의 성능이 기대에 미치지 못했고, 테슬라는 판매량과 주가 하락 압력에 직면해 있습니다. 이들 과거 업계 선두 주자들은 ‘혁신가의 딜레마’ 사례처럼 AI가 가져온 새로운 시장과 새로운 모델의 충격에 대응해야 하며, 그렇지 않으면 AI 시대의 ‘노키아’가 될 수 있습니다. (출처: WeChat)

구글 AI, 모의 의료 대화에서 인간 의사보다 우수한 성능 보여: 연구에 따르면 의료 면담을 위해 훈련된 AI 시스템이 모의 환자와 대화하고 병력에 따라 가능한 진단을 나열하는 데 있어 인간 의사와 동등하거나 그 이상의 성능을 보였습니다. 연구자들은 이러한 AI 시스템이 의료 서비스의 보편화와 민주화에 기여할 잠재력이 있다고 생각합니다. (출처: Reddit r/ArtificialInteligence)
