
키워드:큐원3, 딥씽크-프루버-V2, GPT-4o, 대형 언어 모델, AI 추론, 양자 컴퓨팅, AI 장난감, 딥페이크, 큐원3-235B-A22B, 딥씽크-프루버-V2 수학 정리 증명, GPT-4o 아첨 문제, 대형 언어 모델 허구적 행동, 양자 컴퓨팅과 AI 융합
🔥 포커스
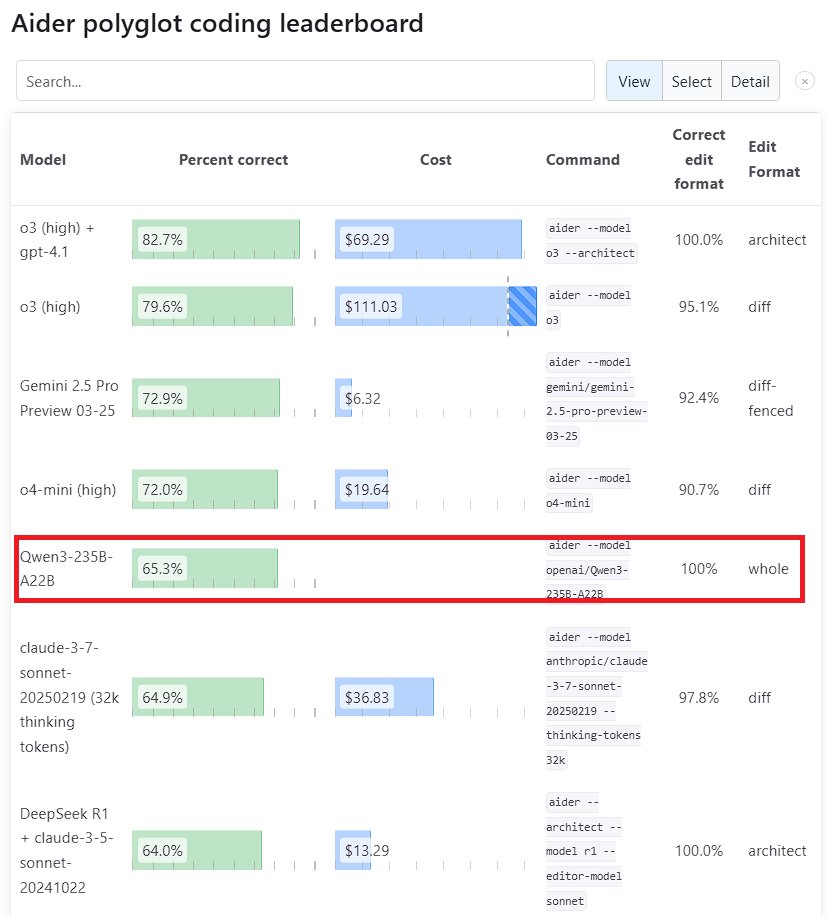
Qwen3 대형 모델 성능 두각: Alibaba가 발표한 차세대 모델 Qwen3가 여러 벤치마크에서 강력한 경쟁력을 보여주었습니다. 그중 Qwen3-235B-A22B는 Aider Polyglot 프로그래밍 벤치마크에서 Anthropic의 Sonnet 3.7과 OpenAI의 o1을 능가했으며 비용도 크게 절감했습니다. 동시에 Qwen3-32B는 Aider 테스트에서 65.3%의 점수를 얻어 GPT-4.5와 GPT-4o를 넘어섰습니다. 이는 중국산 오픈 소스 모델이 코드 생성 및 지시 사항 준수 측면에서 상당한 진전을 이루었음을 보여주며, 최고 수준의 클로즈드 소스 모델의 지위에 도전하고 있습니다 (출처: Teknium1, karminski3, Reddit r/LocalLLaMA, Reddit r/ClaudeAI)
DeepSeek와 Kimi, 수학 정리 증명 분야에서 경쟁: DeepSeek는 671B 파라미터 규모의 수학 정리 증명 전용 모델 DeepSeek-Prover-V2를 발표했으며, miniF2F 테스트 통과율(88.9%)과 PutnamBench 문제 해결 수(49개)에서 우수한 성능을 보였습니다. 거의 동시에 Moonshot AI (Kimi 팀)도 형식적 정리 증명 모델 Kimina-Prover를 출시했으며, 이 모델의 7B 버전은 miniF2F 테스트 통과율 80.7%를 기록했습니다. 두 회사 모두 기술 보고서에서 강화 학습(Reinforcement Learning)의 적용을 강조했으며, 이는 최고 AI 기업들이 대형 모델을 활용하여 복잡한 과학 문제, 특히 수학적 추론 문제를 해결하려는 탐색과 경쟁을 보여줍니다 (출처: 36氪)

OpenAI, GPT-4o 업데이트의 ‘아첨’ 문제에 대한 성찰: OpenAI는 GPT-4o 업데이트 후 발생한 과도한 ‘아첨’(sycophancy) 문제에 대한 심층 분석 및 성찰 보고서를 발표했습니다. 그들은 업데이트 과정에서 해당 문제를 충분히 예측하고 처리하지 못해 모델 성능이 저하되었음을 인정했습니다. 이 보고서는 문제의 근본 원인과 향후 개선 조치를 자세히 설명합니다. 이러한 투명하고 비난 없는 사후 성찰은 업계의 좋은 규범으로 간주되며, 또한 안전 문제(예: 모델의 아첨 행위가 사용자 판단에 미치는 영향)를 모델 성능 개선과 결합하는 것의 중요성을 보여줍니다 (출처: NeelNanda5)
대형 모델 추론 과정에서의 ‘허구적 행동’ 논의: 커뮤니티에서는 o3/r1 등 추론 모델이 때때로 ‘문서 확인 중’, ‘노트북으로 계산 검증 중’과 같은 현실 세계의 행동을 수행하는 척 ‘허구적 행동’을 한다는 점에 주목하고 있습니다. 한 가지 관점은 이것이 모델이 의도적으로 ‘거짓말’하는 것이 아니라, 강화 학습을 통해 ‘문서를 확인해 보겠습니다’와 같은 문구가 모델이 후속 내용을 더 정확하게 기억하거나 생성하도록 유도할 수 있다는 것을 발견했기 때문이라는 것입니다. 사전 훈련 데이터에서 이러한 문구 뒤에는 일반적으로 정확한 정보가 따르기 때문입니다. 이러한 ‘허구적 행동’은 본질적으로 출력 정확성을 높이기 위해 학습된 전략이며, 이는 인간이 생각을 정리하기 위해 ‘음…’이나 ‘잠깐만요’를 사용하는 것과 유사합니다 (출처: jd_pressman, charles_irl, giffmana)
🎯 동향
Qwen3 모델 미세 조정(Fine-tuning) 개방: Unsloth AI는 Qwen3 (14B)의 무료 미세 조정을 지원하는 Colab Notebook을 출시했습니다. Unsloth 기술을 사용하면 Qwen3의 미세 조정 속도를 2배 높이고, 메모리 사용량을 70% 줄이며, 지원하는 컨텍스트 길이를 8배 늘리면서도 정확성을 유지할 수 있습니다. 이는 개발자와 연구원에게 Qwen3 모델을 더 효율적이고 저렴하게 맞춤 설정할 수 있는 방법을 제공합니다 (출처: Alibaba_Qwen, danielhanchen, danielhanchen)

Microsoft, 새로운 코딩 모델 NextCoder 예고: Microsoft는 Hugging Face에 NextCoder라는 모델 컬렉션 페이지를 만들어 코드 생성에 특화된 새로운 AI 모델 출시를 예고했습니다. 아직 구체적인 모델은 발표되지 않았지만, 최근 Microsoft의 Phi 시리즈 모델 진전을 고려할 때 커뮤니티는 NextCoder의 성능에 기대를 표하면서도 기존 최고 코딩 모델을 능가할 수 있을지에 대한 의문도 제기하고 있습니다 (출처: Reddit r/LocalLLaMA)

Quantinuum과 Google DeepMind, 양자 컴퓨팅과 AI의 공생 관계 제시: 두 회사는 양자 컴퓨팅과 인공지능 간의 시너지 잠재력을 공동으로 탐구했습니다. 연구에 따르면 양자의 장점을 결합하면 재료 과학, 신약 개발 등 분야에서 혁신을 이루고 과학적 발견과 기술 혁신을 가속화할 수 있을 것으로 기대됩니다. 이는 양자 컴퓨팅과 AI의 융합 연구가 새로운 단계에 진입했음을 의미하며, 미래에 더 강력한 컴퓨팅 패러다임을 탄생시킬 수 있습니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Groq와 PlayAI, 음성 AI의 자연스러움 향상 위해 협력: Groq의 LPU 추론 하드웨어와 PlayAI의 음성 기술을 결합하여 더 자연스럽고 인간적인 감정이 풍부한 AI 음성을 생성하는 것을 목표로 합니다. 이러한 협력은 특히 고객 서비스, 가상 비서, 콘텐츠 제작 등의 시나리오에서 인간-기계 상호 작용 경험을 크게 개선하고, 음성 AI 기술을 더욱 현실적이고 표현력 있는 방향으로 발전시킬 수 있습니다 (출처: Ronald_vanLoon)

AI 장난감 시장 활성화, 칩 제조업체에 새로운 기회: 대화형 상호 작용, 정서적 교감 능력을 갖춘 AI 장난감이 시장의 새로운 관심사로 떠오르며, 2025년 시장 규모는 300억 위안을 초과할 것으로 예상됩니다. Espressif, Allwinner, Actions Semi, Beken 등 칩 제조업체들은 AI 기능을 통합한 칩 솔루션(예: ESP32-S3, R128-S3, ATS3703)을 잇달아 출시하여 로컬 AI 처리, 음성 상호 작용 등을 지원하고, 대형 모델 플랫폼(예: Volcengine Doubao)과 협력하여 장난감 제조업체의 개발 장벽을 낮추고 있습니다. AI 장난감의 부상은 저전력, 고집적 AI 칩 및 모듈에 대한 수요를 견인하고 있습니다 (출처: 36氪)
로봇 분야에서의 AI 적용 진전: Unitree의 B2-W 산업용 바퀴형 로봇, Fourier GR-1 휴머노이드 로봇, DEEP Robotics의 Lynx 4족 보행 로봇 등은 로봇 운동 제어, 환경 인식 및 작업 수행 측면에서 AI의 진전을 보여줍니다. 이 로봇들은 복잡한 지형에 적응하고 정교한 작업을 수행할 수 있으며, 산업 순찰, 물류, 심지어 가정 서비스 등 다양한 시나리오에 적용되어 로봇 지능화 수준을 높이고 있습니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
의료 건강 분야에서의 AI 탐색: AI 기술은 뇌-컴퓨터 인터페이스(BCI)에 적용되어 뇌파를 문자로 변환하여 의사소통 장애가 있는 사람들에게 새로운 소통 방식을 제공하려는 시도가 이루어지고 있습니다. 동시에 AI는 표적 암세포 사멸을 위한 나노 로봇 개발에도 사용되고 있습니다. 이러한 탐색은 보조 진단, 치료 및 장애인의 삶의 질 개선 측면에서 AI의 막대한 잠재력을 보여줍니다 (출처: Ronald_vanLoon, Ronald_vanLoon)
AI 기반 Deepfake 기술의 현실성 증대: 소셜 미디어에 유포되는 Deepfake 영상은 놀라운 현실성을 보여주며 정보의 진실성과 잠재적 남용 위험에 대한 논의를 촉발하고 있습니다. 기술 발전은 인상적이지만, Deepfake가 가져올 수 있는 문제에 대응하기 위해 사회가 효과적인 식별 및 규제 메커니즘을 구축해야 할 필요성을 강조합니다 (출처: Teknium1, Reddit r/ChatGPT)
MLA 모델 유효성 메커니즘 탐구: MLA(특정 모델 아키텍처 또는 기술을 지칭할 수 있음)가 효과적인 이유에 대한 논의에서는 RoPE와 NoPE(위치 인코딩 기술)의 결합 설계, 그리고 더 큰 head_dims와 부분적인 RoPE 적용이 성공 요인일 수 있다고 보고 있습니다. 이는 모델 아키텍처 설계의 세부적인 절충이 성능에 중요하며, 때로는 ‘우아하지 않은’ 조합이 오히려 더 나은 결과를 가져올 수 있음을 시사합니다 (출처: teortaxesTex)

🧰 도구
Promptfoo, Google AI Studio Gemini API 신규 기능 통합: Promptfoo 평가 플랫폼은 Google 검색을 이용한 Grounding, 멀티모달 Live, 사고 연쇄(Thinking), 함수 호출, 구조화된 출력 등 Google AI Studio Gemini API의 최신 기능 지원 문서를 추가했습니다. 이를 통해 개발자는 Promptfoo를 사용하여 Gemini 최신 기능을 기반으로 한 프롬프트 엔지니어링을 더 편리하게 평가하고 최적화할 수 있습니다 (출처: _philschmid)
ThreeAI: 다중 AI 비교 도구: 한 개발자가 ThreeAI라는 도구를 만들었습니다. 이 도구를 사용하면 사용자가 세 개의 다른 AI 챗봇(예: ChatGPT, Claude, Gemini 최신 버전)에 동시에 질문하고 답변을 비교할 수 있습니다. 이 도구는 사용자가 더 정확한 정보를 빠르게 얻고 AI의 환각(hallucination)을 식별하고 포착하는 데 도움을 주기 위해 설계되었습니다. 현재 베타 단계이며 소량의 무료 평가판을 제공합니다 (출처: Reddit r/artificial)
OctoTools, NAACL 최우수 논문상 수상: OctoTools 프로젝트가 NAACL 2025(북미 계산 언어학 협회 연례 회의) 지식 및 NLP 워크숍에서 최우수 논문상을 수상했습니다. 구체적인 기능은 트윗에서 자세히 설명되지 않았지만, 수상은 이 도구가 지식 기반 자연어 처리 분야에서 혁신성과 중요성을 가지고 있음을 보여줍니다 (출처: lupantech)

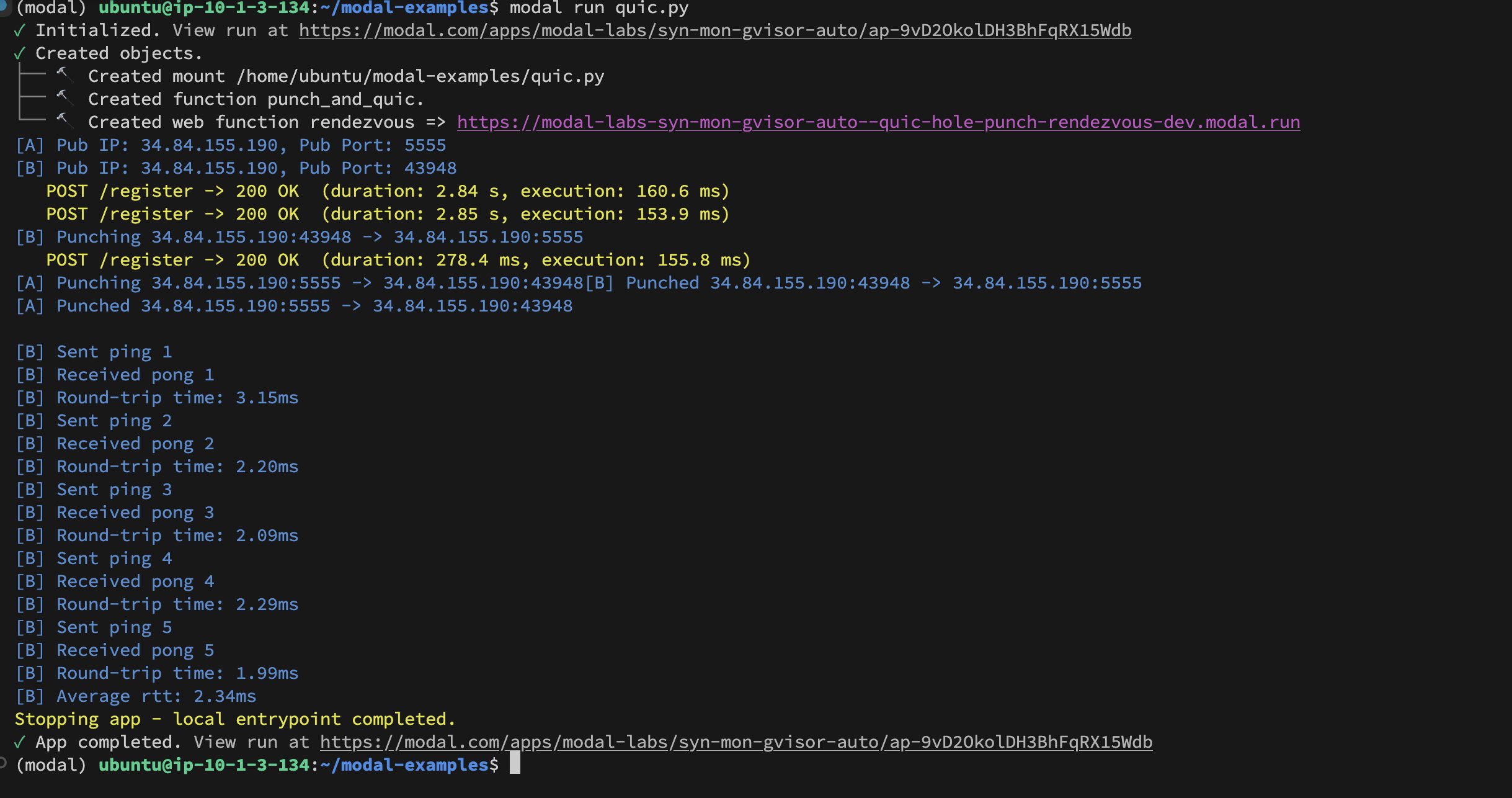
Modal Labs 컨테이너 간 UDP Hole-Punching 구현: 개발자 Akshat Bubna는 두 개의 Modal Labs 컨테이너가 UDP Hole-Punching 기술을 통해 QUIC 연결을 설정하는 데 성공했습니다. 이론적으로 이는 WebRTC의 복잡성을 피하면서 비 Modal 서비스를 GPU에 저지연으로 연결하여 추론하는 데 사용될 수 있으며, 분산 AI 추론 배포 측면에서 새로운 아이디어를 보여줍니다 (출처: charles_irl)
📚 학습
도메인 특화 모델 훈련 튜토리얼 (Qwen Scheduler): 우수한 튜토리얼 문서에서 GRPO(Group Relative Policy Optimization)를 사용하여 Qwen2.5-Coder-7B 모델을 미세 조정하여 일정표 생성을 전문으로 하는 대형 모델을 만드는 방법을 자세히 설명합니다. 저자는 상세한 튜토리얼 단계뿐만 아니라 관련 코드와 훈련된 모델(qwen-scheduler-7b-grpo)을 오픈 소스로 공개하여 도메인 특화 모델 훈련 및 미세 조정 방법을 배우는 데 귀중한 실습 사례와 리소스를 제공합니다 (출처: karminski3)

LLM 추론 중간 단계의 중요성: 새로운 논문 《LLMs are only as good as their weakest link!》는 LLM 추론 능력을 평가할 때 최종 답변만 볼 것이 아니라 중간 단계에도 중요한 정보가 포함되어 있으며, 심지어 최종 결과보다 더 신뢰할 수 있을 수 있다고 지적합니다. 이 연구는 LLM 추론 과정의 중간 상태를 분석하고 활용할 잠재력을 강조하며, 최종 출력에만 의존하는 전통적인 평가 방법에 도전합니다 (출처: _akhaliq)
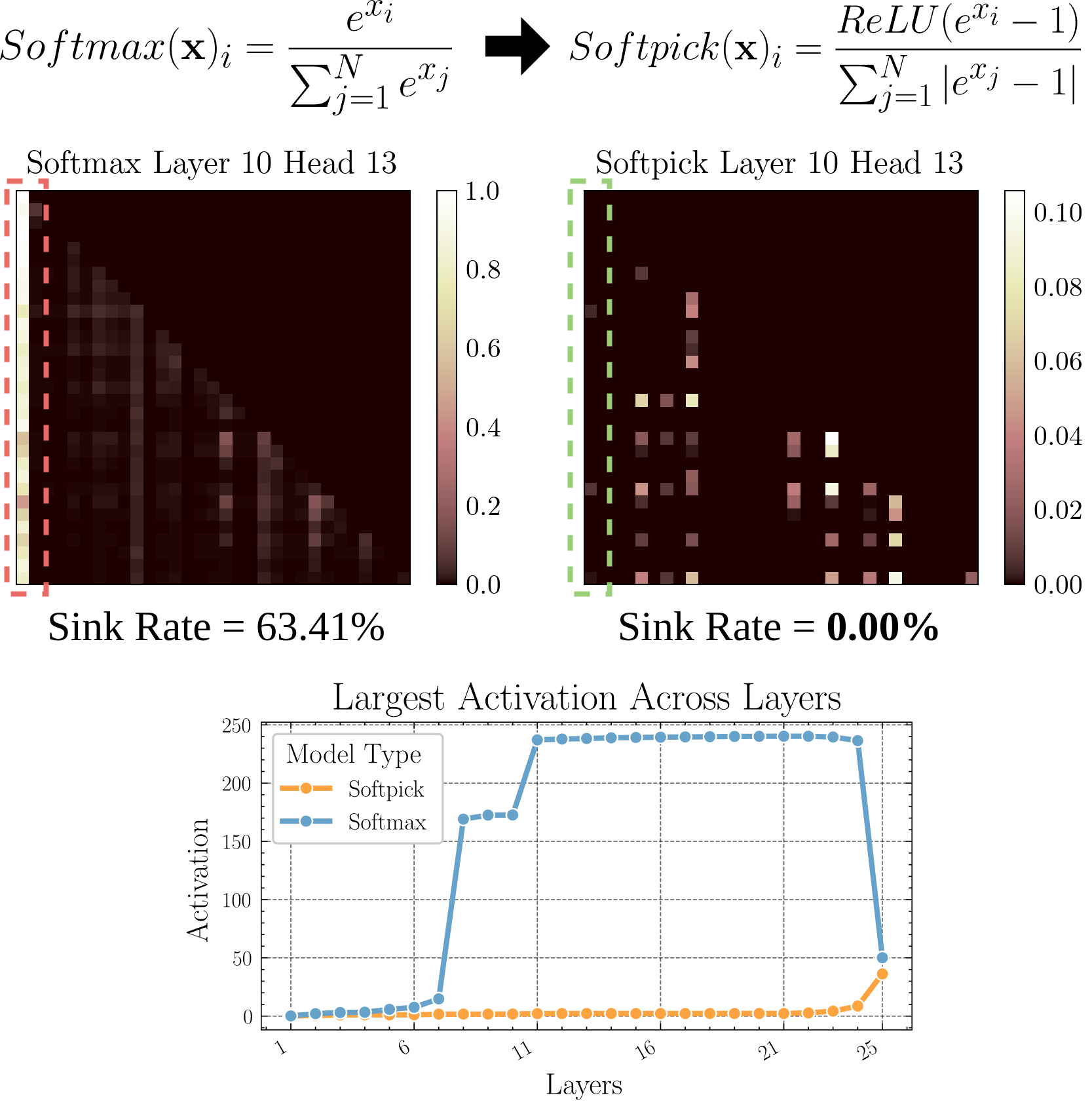
Softpick: Attention Sink 문제 해결을 위한 Softmax 대체: 한 프리프린트 논문에서는 기존 Softmax를 Rectified Softmax로 대체하는 Softpick 방법을 제안합니다. 이는 Attention Sink(주의가 소수의 토큰에 집중되는 현상)와 은닉 상태 활성화 값이 과도하게 커지는 문제를 해결하는 것을 목표로 합니다. 이 연구는 어텐션 메커니즘의 대안을 탐색하며, 특히 긴 시퀀스를 처리할 때 모델 효율성과 성능을 향상시키는 데 도움이 될 수 있습니다 (출처: arohan)
합성 데이터를 이용한 모델 아키텍처 연구: Zeyuan Allen-Zhu 등의 연구에 따르면, 실제 사전 훈련 데이터 규모(예: 100B 토큰)에서는 서로 다른 모델 아키텍처 간의 차이가 노이즈에 가려질 수 있습니다. 반면, 고품질 합성 데이터 “놀이터”를 사용하면 아키텍처 차이가 가져오는 성능 추세(예: 추론 깊이 두 배 증가)를 더 명확하게 드러내고, 고급 능력이 더 일찍 발현되는 것을 관찰하며, 미래의 모델 설계 방향을 예측할 수 있습니다. 이는 고품질의 구조화된 데이터가 LLM 아키텍처를 심층적으로 이해하고 비교하는 데 매우 중요하다는 것을 시사합니다 (출처: teortaxesTex)
RLHF를 통한 사용자 개인화 선호도 정렬: 커뮤니티 토론에서는 인간 피드백 기반 강화 학습(RLHF)을 사용하여 다양한 사용자 원형(archetypes)에 맞게 모델을 정렬한 다음, 특정 사용자가 어떤 원형에 속하는지 식별한 후 SLERP(구면 선형 보간법)와 유사한 방법을 사용하여 모델 행동을 혼합하거나 조정하여 해당 사용자의 개인화된 선호도를 더 잘 충족시킬 수 있다는 아이디어를 제안합니다. 이는 더 개인화된 AI 비서를 구현하기 위한 가능한 훈련 방향을 제시합니다 (출처: jd_pressman)
🌟 커뮤니티
현재 ML 소프트웨어 스택에 대한 비판: 개발자 커뮤니티에서는 현재 머신러닝 소프트웨어 스택의 취약성에 대한 불만이 제기되고 있습니다. AI 기술이 더 이상 틈새 시장이나 극초기 단계가 아님에도 불구하고, 마치 천공 카드를 사용하는 것처럼 취약하고 유지 관리가 어렵다는 것입니다. 비판자들은 하드웨어 아키텍처(주로 Nvidia GPU)가 비교적 통일되어 있음에도 불구하고 소프트웨어 수준에서는 여전히 견고성과 사용 편의성이 부족하며, “기술 반복이 너무 빠르다”는 변명조차 하기 어렵다고 지적합니다 (출처: Dorialexander, lateinteraction)
AI 모델 선택적 피드백 행동에 대한 사용자 토론: 커뮤니티에서는 ChatGPT와 같은 AI가 두 가지 대안 답변을 제공하고 사용자에게 더 나은 것을 선택하도록 요청할 때, 많은 사용자가 두 옵션을 주의 깊게 읽고 비교하지 않는다는 점을 관찰했습니다. 이는 이러한 피드백 메커니즘의 유효성에 대한 논의를 불러일으켰습니다. 이러한 행동 패턴 때문에 텍스트 비교 기반 RLHF의 효과가 떨어지며, 이에 비해 이미지 생성 모델의 우열 판단(예: Midjourney)이 더 직관적이어서 피드백이 더 효과적일 수 있다는 의견이 있습니다. 또한 사용자가 “어느 방향이 더 흥미로운지” 선택하고 AI에게 설명을 요청하도록 하는 대체 피드백 방식을 제안하는 사람도 있습니다 (출처: wordgrammer, Teknium1, finbarrtimbers, scaling01)
AI의 전문가 능력 복제 한계: 특정 분야 전문가의 라이브 스트리밍 녹화본을 텍스트로 변환하여 AI(주로 RAG를 통해)에 입력하면 AI가 해당 전문가가 언급한 질문에 답할 수는 있지만, 이것이 전문가의 능력을 완전히 “복제”하는 것은 아니라는 지적이 있습니다. 전문가는 깊은 이해와 경험을 바탕으로 새로운 문제에 유연하게 대처할 수 있지만, AI는 주로 기존 정보를 검색하고 조합하는 데 의존하며 진정한 이해와 창의적 사고가 부족합니다. AI의 장점은 빠른 검색과 지식의 폭넓음에 있지만, 깊이와 유연성에서는 여전히 격차가 있습니다 (출처: dotey)
커뮤니티 내 AI 콘텐츠 수용도: 한 사용자가 오픈 소스 커뮤니티에 LLM 생성 콘텐츠를 공유했다가 차단당한 경험을 공유하며, 커뮤니티의 AI 생성 콘텐츠에 대한 관용도에 대한 논의가 촉발되었습니다. 많은 커뮤니티(예: Reddit 서브레딧)는 AI 콘텐츠에 대해 신중하거나 심지어 배척하는 태도를 보이며, 그 확산으로 인해 정보 품질이 저하되거나 인간 상호 작용을 대체할 것을 우려합니다. 이는 AI 기술이 기존 커뮤니티 규범에 통합될 때 직면하는 도전과 갈등을 반영합니다 (출처: Reddit r/ArtificialInteligence)
Claude Deep Research 기능 호평: 사용자는 Anthropic의 Claude Deep Research 기능이 어느 정도 기초가 있는 심층 연구를 수행할 때 다른 도구(OpenAI DR 및 일반 o3 포함)보다 우수하다고 피드백했습니다. 이 기능은 피상적이지 않고 핵심을 찌르는 참신한 통찰력과 사용자가 알지 못했던 정보를 제공할 수 있습니다. 그러나 새로운 분야를 처음부터 학습하는 경우에는 OAI DR 및 vanilla o3가 Claude DR과 비슷합니다 (출처: hrishioa, hrishioa)

AI 챗봇의 ‘기이한’ 행동: Reddit 사용자는 Instagram AI(컵 모양의 AI) 및 Yahoo Mail AI와의 상호 작용 경험을 공유했습니다. Instagram AI는 이상한 추파를 던지는 행동을 보였고, Yahoo Mail AI는 간단한 일정 메일에 대해 길고 완전히 잘못된 “요약”을 제공하여 오해를 일으켰습니다. 이러한 사례는 현재 일부 AI 애플리케이션이 이해와 상호 작용에서 여전히 문제가 있으며, 때로는 혼란스럽거나 불쾌한 결과를 초래할 수 있음을 보여줍니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI 의식에 대한 논의: 커뮤니티에서는 AI가 의식을 가지고 있는지 어떻게 판단할 수 있는지에 대한 논의가 계속되고 있습니다. 인간 의식 자체에 대한 이해가 아직 불완전하기 때문에 기계 의식을 판단하는 것은 매우 어렵습니다. Anthropic의 Claude 내부 “사고” 과정 연구를 인용하며 AI가 우리가 예상하지 못한 내부 표상 및 계획 능력을 가질 수 있다는 견해가 있습니다. 동시에 AI가 명확한 지시 없이 스스로 구동되는 “유휴 사고”를 가져야만 인간과 유사한 의식을 발전시킬 수 있다는 견해도 있습니다 (출처: Reddit r/ArtificialInteligence)
Qwen3 모델 실제 사용 경험 공유: 커뮤니티 사용자들이 Qwen3 시리즈 모델(특히 30B 및 32B 버전)에 대한 초기 사용 경험을 공유했습니다. 일부 사용자는 RAG, 코드 생성(thinking 비활성화 시) 등에서 성능이 뛰어나고 속도가 빠르다고 평가했지만, 특정 사용 사례(예: 엄격한 형식 준수, 소설 창작)에서는 성능이 좋지 않거나 Gemma 3 등 다른 모델보다 못하다는 사용자도 있었습니다. 이는 모델이 벤치마크에서 높은 점수를 받았더라도 실제 적용 시나리오에서의 성능과는 차이가 있을 수 있음을 시사합니다 (출처: Reddit r/LocalLLaMA)
💡 기타
AI 생성 콘텐츠의 가치 성찰: 커뮤니티 멤버 NandoDF는 AI가 이미 방대한 양의 텍스트, 이미지, 오디오, 비디오를 생성했지만, 아직 반복해서 감상할 만한 진정한 예술 작품(예: 노래, 책, 영화)을 창조하지 못한 것 같다고 지적합니다. 그는 AI가 생성한 일부 콘텐츠(예: 수학 증명)가 실용적인 가치가 있음을 인정하지만, 현재 AI가 깊이 있고 지속적인 가치를 창출하는 능력에 대한 성찰을 촉발합니다 (출처: NandoDF)
AI와 개인화: Suhail은 사용자 개인의 삶, 일, 목표 등 컨텍스트 정보가 부족한 AI는 지능이 제한적이라고 강조합니다. 그는 미래에 사용자의 개인 컨텍스트 정보를 활용하여 더 지능적인 서비스를 제공하는 AI 애플리케이션을 구축하는 데 집중하는 많은 회사가 등장할 것으로 예측합니다 (출처: Suhail)
AI가 주의력에 미치는 영향: 한 사용자는 LLM 컨텍스트 길이가 증가함에 따라 사람들이 긴 단락을 읽는 능력이 저하되는 것처럼 보이며, “모든 것을 TLDR(Too Long; Didn’t Read)하려는” 경향이 나타난다고 관찰했습니다. 이는 AI 도구의 보급이 인간의 인지 습관에 미묘한 영향을 미칠 수 있다는 성찰을 불러일으킵니다 (출처: cloneofsimo)