
키워드:챗봇 아레나, 파이-4-추론, 클로드 통합, AI 에이전트, 딥시크-프루버-V2, 큐원3, 제미니, 파라키트-TDT-0.6B-v2, 순위표 환각, 소형 모델 추론 능력, 서드파티 앱 통합, AI 프로그래밍 에이전트, 수학 정리 증명
🔥 포커스
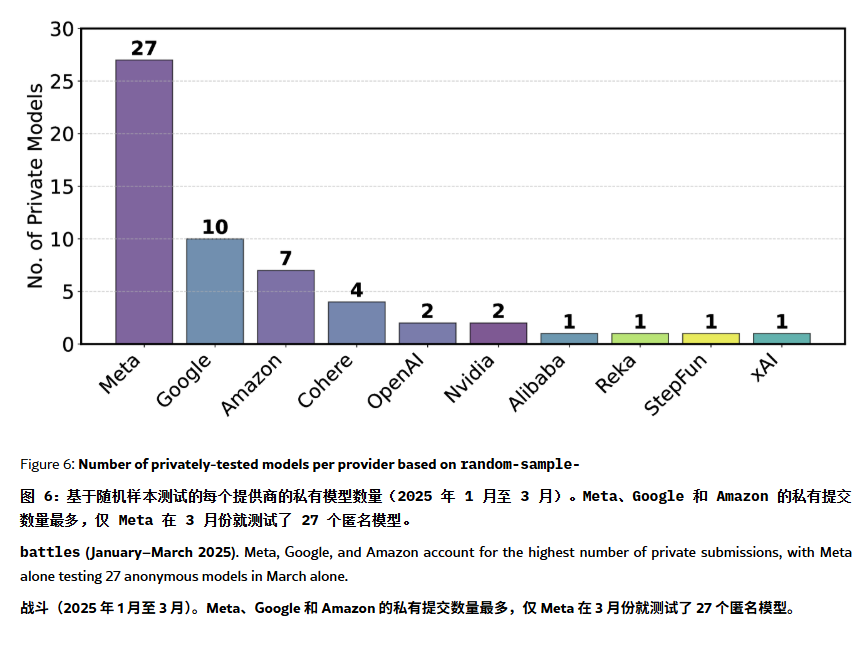
ChatBot Arena 순위표, “환각” 및 조작 논란: ArXiv 논문[2504.20879]은 널리 인용되는 ChatBot Arena 모델 순위표에 대해 “순위표 환각”이 존재한다고 의문을 제기했습니다. 논문은 대형 기술 회사(예: Meta)가 대량의 미세 조정 모델 변형(예: Llama-4 27개 테스트)을 제출하고 최상의 결과만 공개하여 순위를 조작할 수 있다고 지적합니다. 모델 노출 빈도 또한 대기업 모델에 편향되어 오픈 소스 모델의 노출 기회를 축소할 수 있습니다. 모델 퇴출 메커니즘은 투명성이 부족하며, 많은 오픈 소스 모델이 테스트 데이터 부족으로 목록에서 제외되었습니다. 또한 사용자의 일반적인 질문 유사성으로 인해 모델이 점수를 높이기 위해 특정 질문에 과적합 훈련될 수 있습니다. 이는 현재 주류 LLM 벤치마크의 신뢰성과 공정성에 대한 우려를 불러일으키며, 개발자와 사용자는 순위표 순위를 신중하게 보고 자체 요구 사항에 맞는 평가 시스템 구축을 고려할 것을 제안합니다. (출처: karminski3, op7418, TheRundownAI)
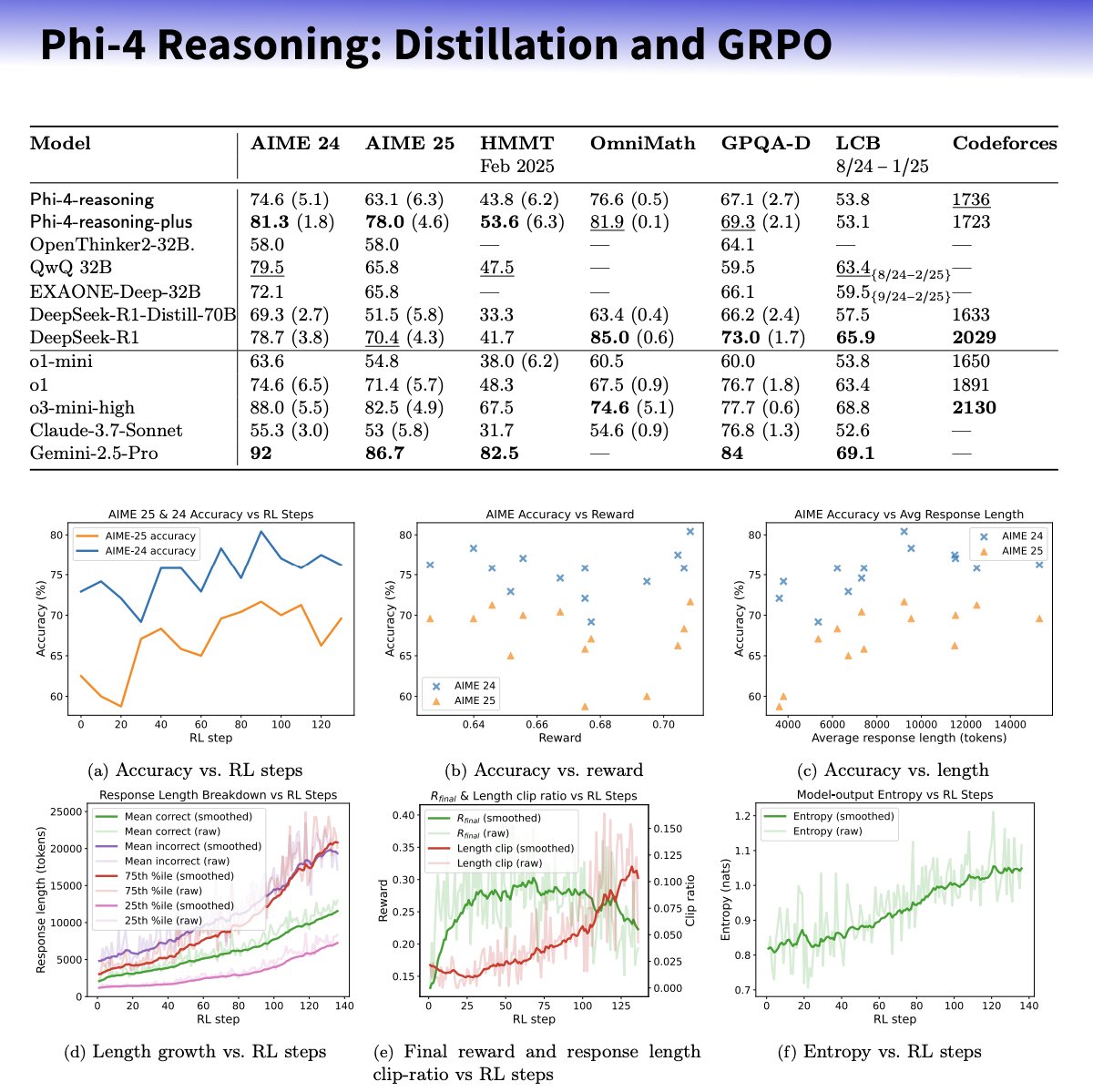
Microsoft, 추론 능력 향상에 초점을 맞춘 Phi-4-reasoning 시리즈 소형 모델 출시: Microsoft는 Phi-4 아키텍처 기반의 Phi-4-reasoning 및 Phi-4-reasoning-plus 모델을 출시했습니다. 이는 신중하게 선별된 데이터셋, 지도 미세 조정(SFT), 목표 강화 학습(RL)을 통해 소형 언어 모델의 추론 능력을 향상시키는 것을 목표로 합니다. 이 모델들은 OpenAI o3-mini를 “교사”로 활용하여 고품질의 연쇄 사고(CoT) 추론 궤적을 생성하고, GRPO 알고리즘을 통해 강화 학습 최적화를 수행한다고 알려졌습니다. Microsoft 연구원 Sebastien Bubeck은 Phi-4-reasoning이 수학 능력에서 DeepSeek R1보다 우수하지만 모델 규모는 2%에 불과하다고 주장했습니다. 이 시리즈 모델은 전용 추론 토큰과 확장된 32K 컨텍스트 길이를 사용합니다. 이는 소형화, 전문화 모델 방향의 탐색으로 간주되며, 자원 제한적인 환경에 더 강력한 추론 솔루션을 제공할 수 있지만, OpenAI 기술을 활용하고 MIT 라이선스로 출시되었는지에 대한 논의도 불러일으켰습니다. (출처: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic, Integrations 기능 출시 및 연구 능력 확장: Anthropic은 Claude Integrations 출시를 발표했습니다. 이를 통해 사용자는 Claude를 Jira, Confluence, Zapier, Cloudflare, Asana 등 10가지 타사 애플리케이션 및 서비스와 연결할 수 있으며, 향후 Stripe, GitLab 등도 지원할 예정입니다. 이전에는 로컬 서버로 제한되었던 MCP(모델 컨텍스트 프로토콜) 지원이 원격 서버로 확장되어, 개발자는 문서나 Cloudflare 등의 솔루션을 통해 약 30분 내에 자체 통합을 생성할 수 있습니다. 동시에 Claude의 연구(Research) 기능이 향상되어 고급 모드가 추가되었습니다. 이 모드는 웹, Google Workspace 및 연결된 Integrations를 검색하고, 복잡한 요청을 분해하여 조사하며, 인용이 포함된 종합 보고서를 생성할 수 있습니다(처리 시간 최대 45분 소요 가능). 웹 검색 기능도 전 세계 유료 사용자에게 공개되었습니다. 이러한 업데이트는 Claude의 업무 보조 도구로서의 통합성과 심층 연구 능력을 향상시키기 위한 것입니다. (출처: _philschmid, Reddit r/ClaudeAI)

AI 에이전트 능력, 새로운 무어의 법칙 따라 4개월마다 2배 증가: AI Digest의 연구에 따르면, AI 프로그래밍 에이전트의 작업 완료 능력은 지수적으로 성장하고 있으며, 작업 처리 시간(인간 전문가 소요 시간 기준)은 2024-2025년 사이에 약 4개월마다 2배로 증가하고 있습니다. 이는 2019-2025년 사이 7개월마다 2배 증가했던 속도보다 빠릅니다. 현재 최고 수준의 AI 에이전트는 인간이 1시간 걸리는 프로그래밍 작업을 처리할 수 있습니다. 이러한 가속 추세가 계속된다면, 2027년까지 AI 에이전트는 최대 167시간(약 1개월)이 걸리는 복잡한 작업을 완료할 수 있을 것으로 예상됩니다. 이러한 능력의 급속한 향상은 모델 자체의 발전과 알고리즘 효율성 향상 덕분이며, AI 보조 AI 연구 개발로 인해 초지수적 성장의 긍정적 피드백 루프를 형성할 수 있습니다. 이는 “소프트웨어 지능 폭발”의 가능성을 예고하며, 소프트웨어 개발, 과학 연구 등의 분야를 근본적으로 변화시키는 동시에 자동화가 고용 시장에 미치는 영향과 같은 사회적 과제도 가져올 것입니다. (출처: 新智元)

🎯 동향
DeepSeek-Prover-V2 출시, 수학 정리 증명 능력 향상: DeepSeek AI는 Lean 4 형식 정리 증명에 특화된 DeepSeek-Prover-V2를 7B 및 671B 두 가지 규모로 출시했습니다. 이 모델은 재귀적 증명 검색과 강화 학습(GRPO)을 사용하여 훈련되었으며, DeepSeek-V3를 활용하여 복잡한 정리를 분해하고 증명 초안을 생성한 후, 전문가 반복 및 합성 콜드 스타트 데이터를 결합하여 미세 조정 및 강화 학습을 진행합니다. DeepSeek-Prover-V2-671B는 MiniF2F-test에서 88.9%의 통과율을 달성했으며 PutnamBench에서 49개의 문제를 해결하여 SOTA 성능을 보여주었습니다. AIME 및 교과서 문제가 포함된 ProverBench 벤치마크도 함께 출시되었습니다. 이 모델은 비형식적 추론과 형식적 증명을 통합하여 자동 정리 증명 발전을 목표로 합니다. (출처: 新智元)

Nvidia와 UIUC, 400만 토큰 컨텍스트 확장 신규 방법 제안: Nvidia와 일리노이 대학교 어바나-샴페인(UIUC) 연구진은 Llama 3.1-8B-Instruct의 컨텍스트 창을 128K에서 1M, 2M, 최대 4M 토큰까지 확장할 수 있는 효율적인 훈련 방법을 제안했습니다. 이 방법은 지속적인 사전 훈련과 지시 미세 조정의 두 단계 전략을 채택하며, 핵심 기술로는 특수 문서 구분 기호 사용, YaRN 기반 위치 인코딩 확장, 단일 단계 사전 훈련 등이 있습니다. 훈련된 UltraLong-8B 모델은 RULER, LV-Eval, InfiniteBench 등 장문 컨텍스트 벤치마크에서 우수한 성능을 보였으며, MMLU, MATH 등 표준 단문 컨텍스트 작업에서도 기준 Llama 3.1의 성능을 유지하거나 능가하여 ProLong, Gradient 등 다른 장문 컨텍스트 모델보다 뛰어난 성능을 보였습니다. 이 연구는 초장문 컨텍스트 LLM 구축을 위한 효율적이고 확장 가능한 경로를 제공합니다. (출처: 新智元)

Qwen3 출시, 성능 눈에 띄게 향상: Alibaba는 Qwen3-30B-A3B 등을 포함한 Qwen3 시리즈 모델을 출시했습니다. Reddit 사용자의 초기 테스트 및 벤치마크 데이터(예: AHA Leaderboard)에 따르면, Qwen3는 이전 Qwen2.5 및 QwQ 버전에 비해 여러 차원(예: 건강, 비트코인, Nostr 등 특정 분야 지식)에서 더 나은 성능을 보입니다. 사용자 피드백에 따르면 Qwen3는 특정 작업(예: 태양계 역학 시뮬레이션) 처리 시 강력한 능력을 보여, 물리 법칙을 정확하게 적용하여 타원 궤도와 상대 주기를 생성했습니다. 그러나 일부 사용자는 Qwen3가 장문 컨텍스트(예: 16K에 가까울 때)에서 성능이 현저히 저하되고 추론 시 토큰 소모가 높다고 지적하며 검색 도구와 함께 사용할 것을 권장했습니다. Qwen3의 명명 방식(예: Qwen3-30B-A3B)도 명확성으로 인해 호평을 받았습니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini, 개인화된 경험 제공 위해 Google 계정 데이터 통합 예정: Google은 Gemini AI 어시스턴트가 사용자의 Gmail, 사진, YouTube 기록 등 Google 계정 데이터에 접근하여 더욱 개인화되고 능동적이며 강력한 보조 경험을 제공할 계획입니다. Google 제품 책임자 Josh Woodward는 이것이 Gemini가 사용자를 더 잘 이해하고 사용자의 연장선이 되도록 하기 위함이라고 밝혔습니다. 이 기능은 선택 사항(opt-in)이며, 사용자는 데이터 접근 권한 부여 여부를 선택할 수 있습니다. 이는 개인 정보 보호 및 데이터 보안에 대한 논의를 불러일으켰으며, 사용자는 개인화된 편의성과 데이터 프라이버시 사이에서 균형을 맞춰야 합니다. (출처: JeffDean, Reddit r/ArtificialInteligence)

Nvidia, Parakeet-TDT-0.6B-v2 ASR 모델 출시: Nvidia는 6억 개의 파라미터를 가진 새로운 자동 음성 인식(ASR) 모델 Parakeet-TDT-0.6B-v2를 출시했습니다. 이 모델은 Open ASR Leaderboard에서 Whisper3-large(파라미터 16억 개)보다 우수한 성능을 보이며, 특히 다양한 데이터셋(LibriSpeech, Fisher Corpus, YouTube 데이터 등 약 12만 시간 데이터 포함) 처리에서 뛰어난 성능을 보인다고 합니다. 이 모델은 문자, 단어, 단락 수준의 타임스탬프를 지원하지만 현재 영어만 지원하며 Nvidia GPU와 특정 프레임워크가 필요합니다. 사용자의 초기 피드백에 따르면 전사 및 구두점 정확도가 높습니다. (출처: Reddit r/LocalLLaMA)

Qwen2.5-VL 출시, 시각 언어 이해 능력 향상: Alibaba는 기계의 시각 세계 이해 및 상호 작용 능력을 향상시키기 위해 Qwen2.5-VL 시리즈 멀티모달 모델(3B, 7B, 72B 파라미터 포함)을 출시했습니다. 이 모델들은 이미지 요약, 시각적 질의응답, 복잡한 시각 정보로부터 보고서 생성 등의 작업에 사용될 수 있습니다. 기사는 아키텍처, 벤치마크 성능 및 추론 세부 정보를 소개하며 시각 언어 이해 분야에서의 발전을 보여줍니다. (출처: Reddit r/deeplearning)

Mistral Small 3.1 Vision 지원, llama.cpp에 병합: llama.cpp 프로젝트는 Mistral Small 3.1 Vision 모델(24B 파라미터) 지원을 병합했습니다. 이는 사용자가 llama.cpp 프레임워크 내에서 이 멀티모달 모델을 실행하여 이미지 이해 등의 작업을 수행할 수 있음을 의미합니다. Unsloth는 해당 GGUF 형식 모델 파일을 제공했습니다. 이는 로컬에서 Mistral의 비전 모델을 실행하는 데 편의를 제공합니다. (출처: Reddit r/LocalLLaMA)
Meta, Synthetic Data Kit 출시: Meta는 LLM 미세 조정에 필요한 데이터 준비 단계를 간소화하기 위해 Synthetic Data Kit이라는 명령줄 도구를 오픈 소스로 공개했습니다. 이 도구는 ingest(데이터 가져오기), create(QA 쌍 생성, 추론 체인 선택 가능), curate(Llama를 평가자로 사용하여 우수 샘플 선별), save-as(호환 형식으로 내보내기)의 네 가지 명령을 제공하며, 로컬 LLM(vLLM 사용)을 활용하여 고품질 합성 훈련 데이터를 생성합니다. 특히 Llama-3 등 모델의 특정 작업 추론 능력을 잠금 해제하는 데 적합합니다. (출처: Reddit r/MachineLearning)
GTE-ModernColBERT-v1, 인기 임베딩 모델로 부상: LightOnIO에서 출시한 GTE-ModernColBERT-v1 모델이 Hugging Face에서 새로운 인기 트렌드 검색/임베딩 모델이 되었습니다. 이 모델은 다중 벡터(후기 상호작용 또는 ColBERT라고도 함) 검색 방법을 채택하여 이러한 기술에 관심 있는 개발자에게 새로운 선택지를 제공합니다. (출처: lateinteraction)
X 추천 알고리즘 업데이트: X 플랫폼(구 Twitter)은 사용자 부정적 피드백 미반영, 동일 콘텐츠 반복 노출, SimCluster 알고리즘의 관련 없는 콘텐츠 추천 등 오랜 문제를 해결하기 위해 추천 알고리즘을 수정했습니다. 초기 피드백은 긍정적인 것으로 알려졌습니다. (출처: TheGregYang)
위키백과, 인간 편집자 보조 위한 새로운 AI 전략 발표: 위키백과는 인간 편집자를 대체하는 것이 아니라 그들의 작업을 지원하고 강화하기 위해 AI 도구를 활용하는 새로운 인공지능 전략을 발표했습니다. 구체적인 내용은 출처에 자세히 설명되지 않았지만, 세계 최대 온라인 백과사전이 AI 기술을 콘텐츠 생성 및 유지 관리 프로세스에 통합하는 방법을 모색하고 있음을 보여줍니다. (출처: Reddit r/artificial)
🧰 도구
Midjourney, Omni-Reference 기능 출시: Midjourney는 새로운 Omni-Reference(oref) 기능을 출시했습니다. 사용자는 참조 이미지 URL을 제공하여(–oref 매개변수 사용) 이미지 생성을 안내함으로써 캐릭터, 물체, 차량 또는 비인간 생명체의 일관성을 구현할 수 있습니다. 사용자는 –ow 매개변수를 통해 참조 이미지의 영향 가중치를 제어할 수 있으며, 낮은 가중치는 스타일화에, 높은 가중치는 사실적이거나 정확한 얼굴 매칭에 적합합니다. 이 기능은 생성된 이미지에서 특정 요소의 일관성과 제어 가능성을 높이는 것을 목표로 합니다. (출처: op7418, DavidSHolz)

Runway Gen-4 References, 단일 이미지 개인화 구현: Runway의 Gen-4 모델은 References(참조) 기능을 출시했습니다. 사용자는 단 한 장의 참조 이미지만 제공하면 이미지의 스타일이나 인물 특징을 새로운 생성 콘텐츠에 적용할 수 있습니다. 데모에서는 이 기능을 사용하여 인물 초상화를 참조 이미지의 스타일로 또는 참조 이미지가 묘사하는 세계에 배치하여 쉽게 재창조하는 것을 보여주며, 모델이 단 한 장의 참조 이미지만으로 높은 일관성과 미적 품질의 개인화된 생성을 구현할 수 있는 능력을 보여줍니다. (출처: c_valenzuelab, c_valenzuelab)

Perplexity의 WhatsApp 봇 서비스 재개: Perplexity AI의 WhatsApp 챗봇이 예상보다 훨씬 높은 수요로 인해 잠시 중단된 후 서비스를 재개했습니다. 사용자는 전화번호 +1 (833) 436-3285를 통해 상호 작용할 수 있으며, 메시지를 전달하여 사실 확인을 하거나, 직접 질문하여 답변을 얻거나, 자유 형식의 텍스트 대화를 나누거나, 이미지를 생성할 수 있습니다. (출처: AravSrinivas, AravSrinivas)
Krea AI, 4o 이미지 모델 결합하여 정밀한 이미지 제어 구현: AI 크리에이티브 도구 Krea AI는 OpenAI의 4o 이미지 모델 능력을 결합하여 이미지 콜라주와 스케치 방식으로 생성 이미지의 내용과 스타일을 더욱 정밀하게 제어할 수 있는 새로운 기능을 추가했습니다. 이는 Krea가 대화형 이미지 생성 분야에서 지속적으로 혁신하고 있음을 보여주며, 사용자가 AI 창작을 더욱 직관적이고 세밀하게 유도할 수 있게 합니다. (출처: op7418)
행운 브라운 앤트 일체형 머신: 저비용으로 풀 성능 DeepSeek 실행: 칭화대 배경의 행운 집적회로(行云集成电路)는 브라운 앤트(褐蚁) AI 일체형 머신을 출시했습니다. 14.9만 위안 가격으로 양자화되지 않은 FP8 정밀도의 DeepSeek-R1/V3 671B 모델을 20 token/s 이상의 속도로 실행하고 128K 컨텍스트를 지원한다고 주장합니다. 이 솔루션은 듀얼 AMD EPYC CPU와 대용량 고주파 메모리를 사용하고 소량의 GPU 가속을 결합하여 CPU+메모리 아키텍처를 통해 대형 모델의 프라이빗 배포 하드웨어 비용을 대폭 절감하고, 공식 성능에 가까운 로컬 경험을 제공하며, 비용에 민감하고 고정밀도가 필요한 기업 환경에 적합합니다. (출처: 新智元)

NotebookLM 앱 출시 예정: Google의 AI 노트 앱 NotebookLM이 공식 iOS 및 Android 애플리케이션을 곧 출시할 예정이며, 5월 20일 출시 예정으로 현재 사전 예약이 가능합니다. 이를 통해 NotebookLM의 사용자 노트 및 문서를 기반으로 요약, 질의응답, 아이디어 생성을 제공하는 기능이 모바일로 확장됩니다. (출처: zacharynado)
Granola, iOS 앱 출시하여 AI 실시간 회의록 구현: AI 노트 앱 Granola가 iOS 버전을 출시하여 기존 Zoom 회의 AI 노트 기능을 오프라인 대면 대화 장면으로 확장했습니다. 사용자는 iPhone에서 Granola를 사용하여 대화를 녹음하고 전사하며, AI를 활용하여 요약 및 노트를 생성하여 추후 검토 및 정리에 편리합니다. (출처: amasad)
Grok Studio, PDF 처리 지원: Grok AI 어시스턴트가 Studio 기능에 PDF 파일 처리 능력을 추가했습니다. 이제 사용자는 Grok Studio에서 PDF 문서를 더 편리하게 처리하고 분석할 수 있습니다. 구체적인 기능 세부 정보는 명시되지 않았지만, Grok이 다중 형식 문서 이해 및 상호 작용 능력을 확장했음을 나타냅니다. (출처: grok, TheGregYang)
Suno 새 모델, 뛰어난 음악 생성 능력 선보여: AI 음악 생성 플랫폼 Suno가 새 모델을 출시했으며, 사용자 피드백에 따르면 생성 효과가 “매우 뛰어나다”고 합니다. 한 사용자는 이를 사용하여 라이브 공연 스타일의 노래를 생성하려고 시도했지만, 기대했던 호응 효과를 완전히 구현하지는 못했지만 생성된 음악은 군중 분위기 등에서 좋은 성능을 보여 새 모델의 음악 품질과 스타일 다양성 향상을 보여주었습니다. (출처: nptacek, nptacek)
AI 보조 개구리 울음소리 식별 앱 Frog Spot: 한 개발자가 Frog Spot이라는 무료 앱을 만들었습니다. 자체 훈련된 CNN 모델(TensorFlow Lite)을 사용하여 10초 오디오의 스펙트로그램을 분석하여 다양한 종류의 개구리 울음소리를 식별합니다. 이 앱은 대중이 지역 종을 이해하도록 돕는 동시에 딥러닝이 생물 음향 모니터링 및 시민 과학 분야에서 응용될 수 있는 잠재력을 보여줍니다. (출처: Reddit r/deeplearning)
AI 보조 산업 기술 도면 자동화: IAAI 2025 논문은 배관 및 계측 흐름도(P&ID)의 “계측 전형”(Instrument Typicals) 확장을 자동화하는 방법을 소개합니다. 이 방법은 컴퓨터 비전 모델(텍스트 감지 및 인식)과 도메인 특정 규칙을 결합하여 P&ID 도면 및 범례 표에서 정보를 자동으로 추출하고, 단순화된 계측 전형 기호를 상세한 계측 목록으로 확장하여 정확한 계측 색인을 생성합니다. 이는 엔지니어링 프로젝트(특히 입찰 단계)의 효율성을 높이고 인적 오류를 줄이는 것을 목표로 합니다. (출처: aihub.org)

Sora를 이용한 미니어처 장판야(酱板鸭) 풍경 생성: 사용자가 상세한 프롬프트에 따라 Sora로 생성한 “미니어처 풍경 장판야” 이미지를 공유했습니다. 프롬프트는 장면 스타일(매크로 사진, 미니어처 풍경), 주체(장판야로 구성된 노점 건물), 세부 사항(장밋빛 붉은 껍질, 고추 참깨, 요리사 슬라이스, 식객), 환경(오리 고기 소스로 구성된 거리, 절임 스타일 벽면, 붉은 등불 등)을 세밀하게 묘사했습니다. 이는 Sora가 복잡하고 상상력이 풍부한 텍스트 설명을 이해하고 해당 고품질 이미지를 생성하는 능력을 보여줍니다. (출처: dotey)

3D 날씨 예보 GPTs 생성: 사용자가 직접 만든 ChatGPTs 애플리케이션 “Weather 3D”를 공유했습니다. 사용자가 입력한 도시 이름을 기반으로 날씨 API를 호출하여 실시간 날씨 데이터를 가져오고, 해당 도시의 상징적인 건물의 3D 등각 투영 미니어처 모델 스타일 일러스트레이션을 생성하며 현재 날씨 상황을 통합합니다. 일러스트레이션 상단에는 도시 이름, 날씨 상태, 온도 및 날씨 아이콘이 표시됩니다. 이 GPTs는 API 호출과 이미지 생성 능력을 결합하여 실용적이고 시각적으로 매력적인 AI 애플리케이션을 만드는 방법을 보여줍니다. (출처: dotey)

📚 학습
AdaRFT: 강화 학습 미세 조정 최적화를 위한 새로운 방법: Taiwei Shi 등은 AdaRFT라는 경량의 플러그 앤 플레이 커리큘럼 학습 방법을 제안했습니다. 이는 인간 피드백 기반 강화 학습(RFT) 알고리즘(예: PPO, GRPO, REINFORCE)의 훈련 과정을 최적화하는 것을 목표로 합니다. AdaRFT는 RFT 훈련 시간을 최대 2배 단축하고 모델 성능을 향상시킬 수 있으며, 훈련 데이터 순서를 더 지능적으로 배열하여 학습 효율성과 효과를 높인다고 합니다. (출처: menhguin)

AI 평가(Evals) 온라인 마스터 클래스: Hamel Husain과 Shreya Shankar는 AI 애플리케이션 평가(Evals)에 관한 4주 과정의 온라인 마스터 클래스를 개설했습니다. 이 과정은 개발자가 AI 애플리케이션을 프로토타입 단계에서 생산 준비 상태로 전환하는 데 도움을 주는 것을 목표로 하며, 개발 및 출시 후 평가 방법, 벤치마크와 실제 평가의 차이점, 데이터 검사, PromptEvals 등을 다룹니다. AI 애플리케이션의 신뢰성과 성능을 보장하는 데 있어 평가의 중요성을 강조합니다. (출처: HamelHusain, HamelHusain)

Google 모델 튜닝 플레이북: Google Research는 모델 튜닝을 위한 지침과 모범 사례를 제공하는 “tuning_playbook”이라는 리소스 저장소를 제공합니다. 이는 특정 작업이나 데이터셋에 맞게 대형 언어 모델이나 기타 머신러닝 모델을 미세 조정해야 하는 개발자 및 연구원에게 유용한 학습 자료입니다. (출처: zacharynado)

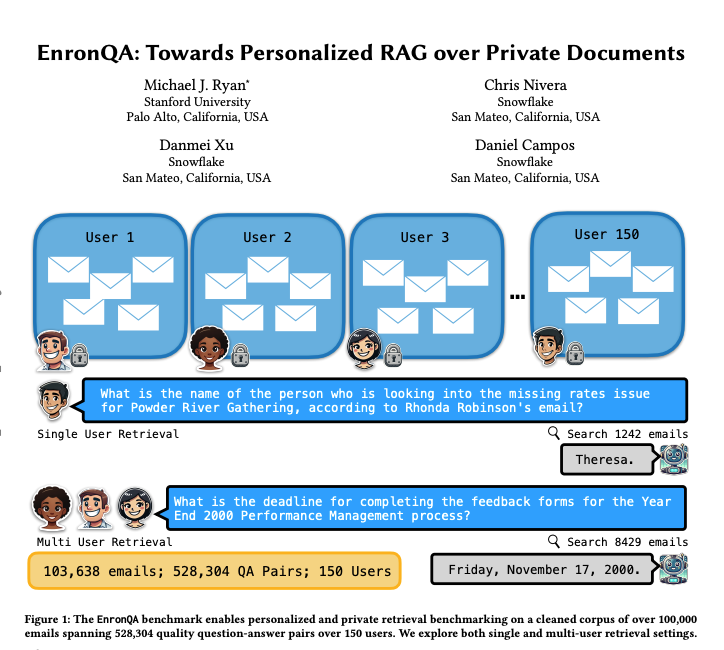
EnronQA: 개인화된 RAG 벤치마크 데이터셋: 연구진은 150명의 사용자로부터 받은 103,638개의 이메일과 528,304개의 고품질 질의응답 쌍을 포함하는 EnronQA 데이터셋을 출시했습니다. 이 데이터셋은 개인화된 검색 증강 생성(RAG) 시스템이 개인 문서 처리 성능을 평가하기 위한 벤치마크로 사용되는 것을 목표로 합니다. 데이터셋에는 정답 참조, 오답, 추론 근거 및 대체 답변이 포함되어 있어 RAG 시스템의 성능을 더 세밀하게 분석하는 데 도움이 됩니다. (출처: tokenbender)
ReXGradient-160K: 대규모 흉부 X선 및 보고서 데이터셋: ReXGradient-160K라는 대규모 공개 흉부 X선 데이터셋이 발표되었습니다. 미국 3개 의료 시스템(79개 의료 지점)의 109,487명의 고유 환자로부터 얻은 60,000건의 흉부 X선 연구와 그에 상응하는 방사선 보고서(자유 텍스트)를 포함합니다. 이는 현재 공개적으로 사용 가능한 환자 수가 가장 많은 흉부 X선 데이터셋으로 알려져 있으며, 의료 영상 AI 모델 훈련 및 평가에 귀중한 자원을 제공합니다. (출처: iScienceLuvr)

AI 에이전트 능력 성장에 대한 블로그 게시물: 연구원 Shunyu Yao는 “The Second Half”라는 블로그 게시물을 통해 현재 AI 발전이 “중간 휴식” 시점에 있다고 주장했습니다. 이전에는 훈련이 평가보다 중요했지만, 이후에는 강화 학습(RL)이 마침내 효과적으로 작동하기 시작하면서 평가가 훈련보다 더 중요해질 것이라고 합니다. 이 글은 AI 능력이 지속적으로 향상되는 상황에서 평가 방법론 변화의 중요성을 탐구합니다. (출처: andersonbcdefg)
OpenAI의 프라이버시 및 기억화 연구 공유: OpenAI 연구원 Pratyush Maini와 Zhili Feng은 프라이버시 및 기억화 연구에 대한 강연을 진행할 예정입니다. 대형 언어 모델의 기억화 현상을 탐지, 정량화, 제거하는 방법과 생산 환경 LLM에서의 실제 적용에 대해 논의합니다. 이는 모델 능력과 사용자 데이터 프라이버시 보호 간의 균형을 맞추는 것과 관련이 있습니다. (출처: code_star)

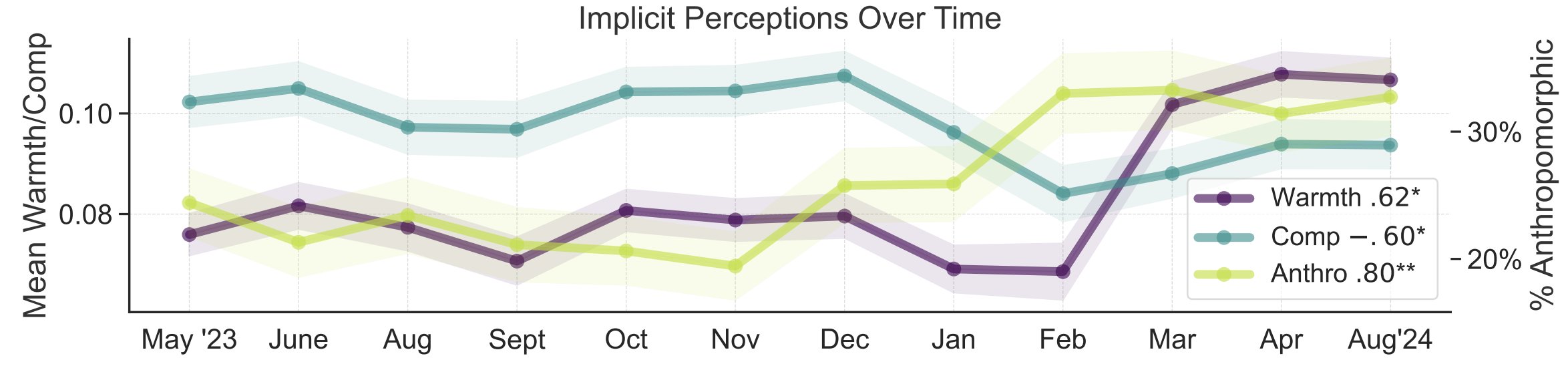
AI 대중 인식의 은유 연구: 스탠포드 대학 연구원 Myra Cheng 등은 FAccT 2025에서 발표한 논문을 통해 12개월 동안 수집된 12,000개의 AI 관련 은유를 분석하여 AI에 대한 대중의 심성 모형과 시간 경과에 따른 변화를 이해하고자 했습니다. 연구 결과, 시간이 지남에 따라 대중은 AI를 더 인간적이고 능동적인 존재로 간주하는 경향(의인화 정도 상승)이 있으며, AI에 대한 감정적 경향(따뜻함)도 상승하고 있음을 발견했습니다. 이 방법은 자기 보고 방식보다 더 세밀한 대중 인식 통찰력을 제공합니다. (출처: stanfordnlp, stanfordnlp)
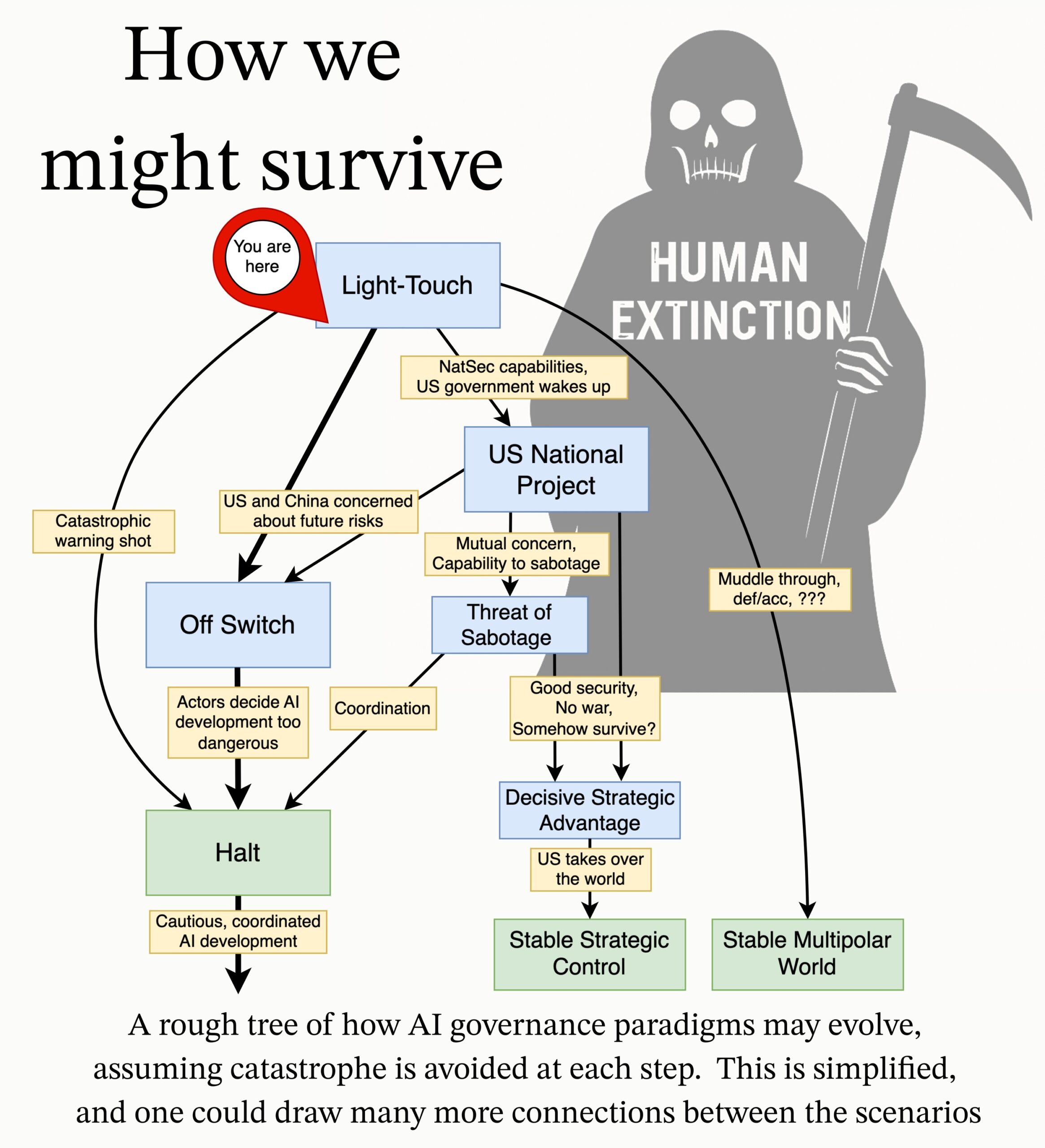
MIRI, AI 거버넌스 연구 의제 발표: 인공지능 연구소(MIRI)의 기술 거버넌스 팀은 새로운 AI 거버넌스 연구 의제를 발표했습니다. 전략적 환경에 대한 그들의 견해를 설명하고 일련의 실행 가능한 연구 질문을 제시합니다. 목표는 어떤 조직이나 개인이 통제 불가능한 초지능을 구축하는 것을 방지하기 위해 어떤 조치가 필요한지 탐색하여 AI로 인한 재앙적 위험과 멸종 위험을 줄이는 것입니다. (출처: JeffLadish)
💼 비즈니스
엔터프라이즈 AI 솔루션 기업 딥엑시(Deepexi), 홍콩 증시 IPO 신청: 전 화웨이, 알리바바 출신 임원 자오제후이(赵杰辉)가 설립한 엔터프라이즈 AI 솔루션 제공업체 딥엑시(Deepexi)가 홍콩 증시 상장 신청서를 공식 제출했습니다. 이 회사는 FastData 데이터 인텔리전스 플랫폼과 FastAGI 엔터프라이즈 AI 솔루션에 주력하며, 소매(예: 벨), 제조, 의료 등 산업에 서비스를 제공합니다. 지난 3년간 회사의 매출은 지속적으로 성장하여 2024년에는 2억 4,300만 위안에 달했습니다. 딥엑시는 힐하우스 캐피털, IDG 캐피털, 우위안 캐피털 등 유명 기관으로부터 투자를 유치하여 8차례의 펀딩을 완료했으며, 마지막 펀딩 후 기업 가치는 약 68억 위안으로 평가되었습니다. 매출 성장에도 불구하고 회사는 현재 적자 상태이며, 조정 후 순손실은 매년 감소하고 있습니다. (출처: 36氪)
BMW 중국, DeepSeek 대형 모델 연동 발표: 알리바바와의 협력에 이어 BMW 그룹은 중국 내 AI 사업을 더욱 심화하여 DeepSeek 대형 모델을 연동한다고 발표했습니다. 이 기능은 2025년 3분기부터 제9세대 BMW 운영 체제를 탑재한 중국 판매 신차 여러 모델에 우선 적용될 예정이며, 향후 중국 생산 BMW 차세대 모델에도 적용될 예정입니다. 이는 DeepSeek의 심층 사고 능력을 통해 BMW 인텔리전트 퍼스널 어시스턴트를 핵심으로 하는 인간-기계 상호 작용 경험을 강화하고, 차량의 지능화 수준과 감성적 연결 능력을 향상시키기 위한 것으로, BMW가 현지화 AI 전략을 가속화하고 지능화 전환 과제에 대응하는 중요한 단계입니다. (출처: 36氪)
Shopify, 전 직원 AI 사용 의무화, 일부 직무 AI 대체 의도: 글로벌 이커머스 플랫폼 Shopify CEO Tobi Lutke는 내부 메모에서 AI의 효율적인 사용이 더 이상 권장 사항이 아닌 회사 전 직원의 “철칙”이 되었다고 강조했습니다. 메모는 직원들에게 AI를 업무 프로세스에 적용하여 조건 반사적으로 사용하도록 요구하고, 팀이 인력 증원을 신청하기 전에 AI가 해당 업무를 수행할 수 없는 이유를 증명하도록 하며, 성과 평가에 AI 사용 지표를 도입할 것을 요구합니다. Lutke는 AI가 효율성을 크게 향상시킬 수 있으며(일부 직원은 10배, 심지어 100배까지), 직원은 경쟁력을 유지하기 위해 매년 20%-40% 향상해야 한다고 지적했습니다. Shopify는 이미 고객 서비스 등 부서에서 감원을 진행하고 AI를 도입했습니다. 이는 AI로 인한 사무직 직무 조정 및 감원 추세의 명확한 신호로 간주됩니다. (출처: 新智元)

🌟 커뮤니티
AI 환각 문제에 대한 논의: 리옌훙(李彦宏) 바이두 회장이 바이두 AI 개발자 컨퍼런스에서 DeepSeek-R1의 높은 환각률, 느린 속도, 높은 비용 등의 문제를 비판하면서 커뮤니티에서 대형 모델의 “환각” 현상에 대한 논의가 다시 불붙었습니다. 분석에 따르면 DeepSeek뿐만 아니라 OpenAI의 o3/o4-mini, 알리바바의 Qwen3 등 첨단 모델들도 보편적으로 환각 문제를 가지고 있으며, 추론 모델의 다단계 사고가 편향을 증폭시킬 수 있다고 지적합니다. Vectara의 평가에 따르면 R1의 환각률(14.3%)은 V3(3.9%)보다 훨씬 높습니다. 커뮤니티는 모델 능력이 향상됨에 따라 환각이 더 은밀하고 논리적으로 변하여 사용자가 진위를 구별하기 어려워지고 신뢰성에 대한 우려를 낳는다고 보고 있습니다. 동시에 환각은 창의성의 부산물이며, 특히 문학 창작 등 분야에서 가치가 있다는 의견도 있습니다. 수용 가능한 환각 수준을 어떻게 정의하고, RAG, 데이터 품질 관리, 비판적 모델 등의 기술적 수단을 통해 환각을 완화하는 방법은 업계가 지속적으로 탐색하는 과제입니다. (출처: 36氪)

AI 동반자/친구에 대한 생각과 토론: Meta CEO 마크 저커버그가 더 많은 사회적 연결에 대한 사람들의 요구를 충족시키기 위해 개인화된 AI 친구를 사용하자고 제안(일반인이 친구 3명을 가지고 있지만 요구는 15명이라고 주장)하면서 커뮤니티 토론이 촉발되었습니다. Sebastien Bubeck은 진정한 AI 동반자를 구현하는 것이 매우 어렵다고 생각하며, 핵심은 AI가 사용자의 경험을 공유하는 것뿐만 아니라 “최근에 무엇을 하고 있었나요?”라는 질문에 의미 있게 답할 수 있어야 한다는 것, 즉 자체적인 경험과 체험을 가져야 한다는 점이라고 지적합니다. 그는 현재의 AI 동반자 구상이 공유된 경험에 너무 집중하고 있으며, AI 자체도 공유할 수 있는 독립적인 경험, 심지어 가십(서로의 경험 공유)이 필요하다는 점을 간과하고 있다고 생각합니다. 다른 논평자는 던바의 수 관점에서 AI로 구성된 거대한 소셜 서클이 실제 의미가 부족할 수 있다고 의문을 제기합니다. 또한 상업 회사가 제공하는 AI 친구의 최종 목적이 진정한 동반자 관계가 아니라 정밀 마케팅 전환일 수 있다는 우려도 있습니다. (출처: jonst0kes, SebastienBubeck, gfodor, gfodor)

AI 예술 창작이 불러일으키는 감정과 생각: 커뮤니티 사용자 중 일부는 AI가 단시간에 “미친 듯이 좋은” 예술 작품을 만들어낼 수 있다는 사실에 “슬픔”(grieving)을 느끼며, 이것이 예술 창작에서 인간의 독창성에 도전한다고 표현했습니다. 이는 AI 예술, 인간 창의성의 본질, 기술 충격 하에서의 개인적 가치감에 대한 논의를 촉발했습니다. 예술 창작의 즐거움은 과정 자체에 있으며 AI와 경쟁하는 것이 아니라는 의견도 있고, AI 예술은 영감의 원천이 될 수 있다는 의견도 있습니다. AI 예술은 인간 창작의 “오류”나 영혼이 부족하여 너무 완벽하거나 틀에 박힌 것처럼 보인다는 사람들도 있습니다. 동시에 토론은 AI가 감정 모방, 의식, 그리고 미래 사회 구조(예: 일자리 대체) 등에서 가져올 철학적 사고로 확장되었습니다. (출처: Reddit r/ArtificialInteligence)
AI 윤리와 책임: 비밀 실험과 정보 공개: 커뮤니티는 AI 연구의 윤리 문제에 대해 논의했습니다. 한 뉴스에서는 AI 연구자들이 Reddit에서 비밀 실험을 통해 사용자 생각을 바꾸려 시도했다는 내용이 언급되어 사용자 알 권리와 AI 조작 위험에 대한 우려를 불러일으켰습니다. 다른 토론에서는 사용자가 AI 회사에 잠재적 보안 문제를 보고할 때 복잡한 절차와 불분명한 책임 문제에 직면했다는 경험을 공유하며, 현재 AI 분야가 책임 있는 공개 및 취약점 대응 메커니즘 측면에서 아직 미성숙하다는 점을 부각했습니다. (출처: Reddit r/ArtificialInteligence, nptacek)

NLP 분야의 ChatGPT 부상에 대한 성찰: Quanta Magazine은 Chris Potts, Yejin Choi, Emily Bender 등 여러 자연어 처리(NLP) 분야 전문가와의 인터뷰를 통해 ChatGPT 출시 이후 전체 분야에 미친 충격과 성찰을 되돌아보는 기사를 게재했습니다. 이 기사는 대형 언어 모델의 부상이 전통적인 NLP의 이론적 기반을 어떻게 도전하고, 분야 내 논쟁, 파벌 분열 및 연구 방향 조정을 유발했는지 탐구합니다. 커뮤니티 회원들은 이 기사에 대해 GPT-3 이후 언어학 분야의 동요와 적응 과정을 잘 요약했다고 호평했습니다. (출처: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
AI 생성 광고의 출현과 감상: 소셜 미디어 사용자들은 YouTube 등 플랫폼에서 AI가 생성한 광고를 보기 시작했으며 “매우 불편하다”고 표현했습니다. 이는 AI 콘텐츠 생성 기술이 상업 광고 제작에 적용되기 시작했음을 보여주는 동시에, 사용자들이 AI 생성 콘텐츠의 품질, 진실성 및 감정적 경험에 대해 초기 반응을 보이고 있음을 나타냅니다. (출처: code_star)
개발자의 AI 모델 선호도 순위: Cursor.ai는 사용자(주로 개발자)가 선호하는 AI 모델 순위를 발표했으며, Openrouter도 모델 토큰 사용량 순위를 공개했습니다. 실제 제품 사용 데이터를 기반으로 한 이러한 순위는 ChatBot Arena와 같은 경쟁 방식 순위표보다 실제 개발 환경에서 사용자의 선택 선호도를 더 잘 반영할 수 있으며, 모델 실용성 평가에 다른 관점을 제공하는 것으로 간주됩니다. (출처: op7418, Reddit r/LocalLLaMA)
AI가 “사고” 능력을 갖추었는지에 대한 논의: 커뮤니티에서는 대형 언어 모델(LLMs)이 진정으로 “사고” 능력을 갖추었는지에 대한 논의가 계속되고 있습니다. 현재 LLMs는 실제로 말하기 전에 사고하는 것이 아니라 더 많은 텍스트(예: 사고의 연쇄)를 생성하여 사고 과정을 모방하는 것이며, 이는 오해를 불러일으킨다는 견해가 있습니다. 연속 수학 방법(예: LLMs)을 사용하여 이산 컴퓨터에서 이산 추론을 수행하는 것 자체가 근본적인 문제가 있다는 견해도 있습니다. 이러한 논의는 현재 AI 기술의 본질과 미래 발전 방향에 대한 심층적인 사고를 반영합니다. (출처: francoisfleuret, pmddomingos)
AI 에너지 소비 및 환경 영향에 대한 변증법적 사고: AI 훈련 및 운영에 필요한 막대한 에너지 소비로 인한 환경 문제에 대해 커뮤니티에서 변증법적 사고가 나타나고 있습니다. 한 가지 견해는 AI의 막대한 에너지 수요(특히 Google, Amazon, Microsoft 등 초대형 컴퓨팅 회사)가 이들 회사로 하여금 자체 재생 에너지(태양광, 풍력, 배터리)에 투자하고 심지어 원자력 발전소(예: Microsoft와 Constellation의 쓰리마일 섬 원전 재가동 협력)를 재가동하도록 강요하고 있다는 것입니다. 이러한 수요는 오히려 청정 에너지 배치 및 기술 혁신(예: 소형 모듈형 원자로 SMR) 가속화의 촉매제가 될 수 있다는 것입니다. 그러나 AI 에너지 소비의 수익 체감 문제와 냉각에 필요한 수자원 소비 역시 주목해야 한다는 지적도 있습니다. (출처: Reddit r/ArtificialInteligence)
Anthropic, AI 칩 경쟁 제한 시도 의혹: 커뮤니티 토론에서는 Anthropic CEO Dario Amodei가 중국 등지로의 AI 칩 수출 통제를 강화해야 한다고 주장하며, 심지어 칩이 임산부 가짜 배 등으로 위장되어 밀수될 수 있다는 주장을 제기했다고 지적합니다. 비판자들은 Anthropic의 이러한 조치가 경쟁사(특히 DeepSeek, Qwen과 같은 중국 회사)가 첨단 컴퓨팅 자원을 확보하는 것을 제한하여 최첨단 모델 개발에서의 우위를 유지하려는 의도라고 주장합니다. 이러한 행위는 정책을 이용하여 경쟁을 억압하고 글로벌 AI 기술의 개방적 발전과 오픈 소스 커뮤니티에 불리하다는 비판을 받고 있습니다. (출처: Reddit r/LocalLLaMA)

💡 기타
AI와 인간 인지 한계에 대한 고찰: Jeff Ladish는 인간이 AI의 “복사-붙여넣기 조수” 역할을 하는 기간이 극히 짧을 것이라고 평하며, AI의 자율 능력이 단순 보조를 빠르게 넘어설 것임을 암시했습니다. 동시에 DeepMind 창립자 Hassabis는 인터뷰에서 진정한 AGI는 단순히 문제를 해결하는 것이 아니라 가치 있는 과학적 가설(예: 아인슈타인이 일반 상대성 이론을 제안한 것)을 독립적으로 제시할 수 있어야 하며, 현재 AI는 가설 생성 측면에서 여전히 부족하다고 생각한다고 밝혔습니다. 류츠신(刘慈欣)은 AI가 인간 뇌의 생물학적 인지 한계를 돌파하기를 기대합니다. 이러한 관점들은 AI 능력의 경계, 인간 역할의 진화, 미래 지능의 본질에 대한 심층적인 고찰을 공통적으로 지향합니다. (출처: JeffLadish, 新智元)
Waymo 라이다, 아찔한 순간 포착: Waymo 자율 주행 차량의 라이다(LiDAR) 시스템이 성공적으로 회피한 오토바이 사고에서 배달 기사가 충돌 중 공중제비하는 3D 포인트 클라우드 영상을 선명하게 포착했습니다. 이는 Waymo 감지 시스템의 강력한 능력(복잡한 동적 상황에서도)을 보여줄 뿐만 아니라, 사고의 독특한 시점을 우연히 기록했습니다. 다행히 사고로 중상자는 없었습니다. (출처: andrew_n_carr)
AI 소설 창작의 새로운 아이디어: 플롯 약속 시스템: 개발자 Levi는 AI 소설 창작을 위해 전통적인 계층적 개요 방법을 대체하는 “플롯 약속”(Plot Promise) 시스템을 제안했습니다. 이 시스템은 Brandon Sanderson의 “약속, 진행, 보상” 이론에서 영감을 받아 이야기를 일련의 활성 서사 단서(약속)로 간주합니다. 각 약속에는 중요도 점수가 있으며, 알고리즘은 점수와 진행 상황에 따라 진행 시기를 제안하지만, AI는 문맥 논리에 따라 현재 가장 적합한 약속을 선택합니다. 사용자는 동적으로 약속을 추가하거나 삭제할 수 있습니다. 이 방법은 이야기의 유연성, 확장성(초장편 분량 적응), 창작의 창발성을 향상시키는 것을 목표로 하지만, AI 의사 결정 최적화, 장기적 일관성 유지 및 입력 프롬프트 길이 제한 등의 과제에 직면해 있습니다. (출처: Reddit r/ArtificialInteligence)