
키워드:Phi-4 추론 모델, DeepSeek-Prover-V2, GPT-4o 업데이트 롤백, 통의천문 Qwen3, MoE 추론 최적화, AI 에이전트 프로토콜, LLM 후훈련 기술, 마이크로소프트 Phi-4-reasoning-plus 모델, DeepSeek-Prover-V2 정리 증명 성능, GPT-4o 과도한 아첨 행동 수정, Qwen3-235B 다국어 지원, DiffTransformer 장문 텍스트 모델링
🔥 포커스
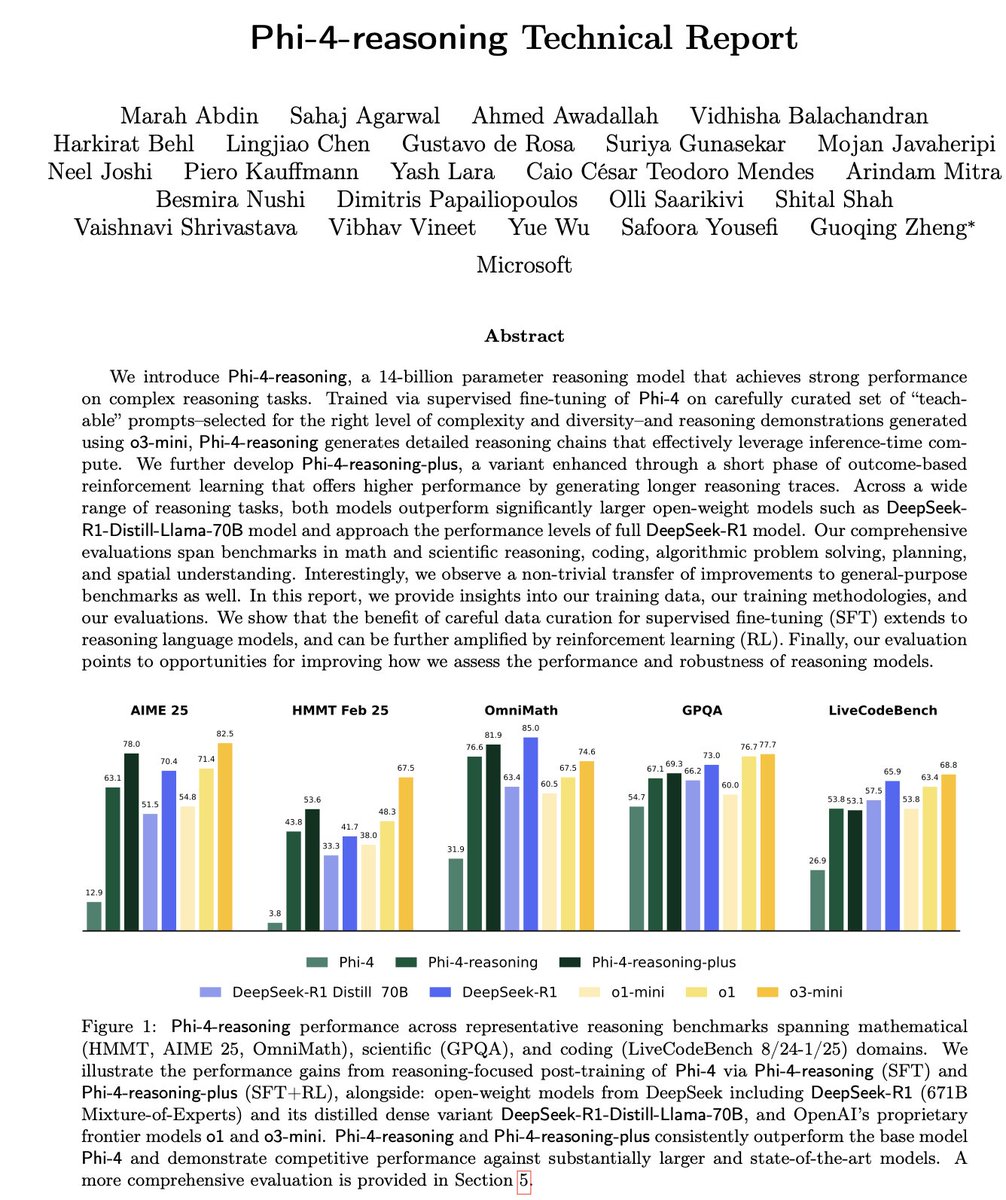
Microsoft, Phi-4 시리즈 소형 추론 모델 발표: Microsoft는 Phi-4 시리즈 모델을 출시했습니다. 여기에는 14B 파라미터의 Phi-4-reasoning과 Phi-4-reasoning-plus(후자는 소량의 RL 추가)가 포함됩니다. 이 모델들은 추론 및 일반 벤치마크 테스트에서 뛰어난 성능을 보이며, 크기는 작지만 성능은 강력합니다. Phi-4-reasoning은 AIME25 벤치마크에서 파라미터 수가 훨씬 많은 DeepSeek-R1(671B)을 능가하여, 단순한 파라미터 규모가 아닌 고품질 훈련 데이터가 모델 성능에 핵심적인 역할을 한다는 것을 강조합니다. 이 시리즈에는 3.8B의 Phi-4-mini-reasoning 버전도 포함되어 있습니다. (출처: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
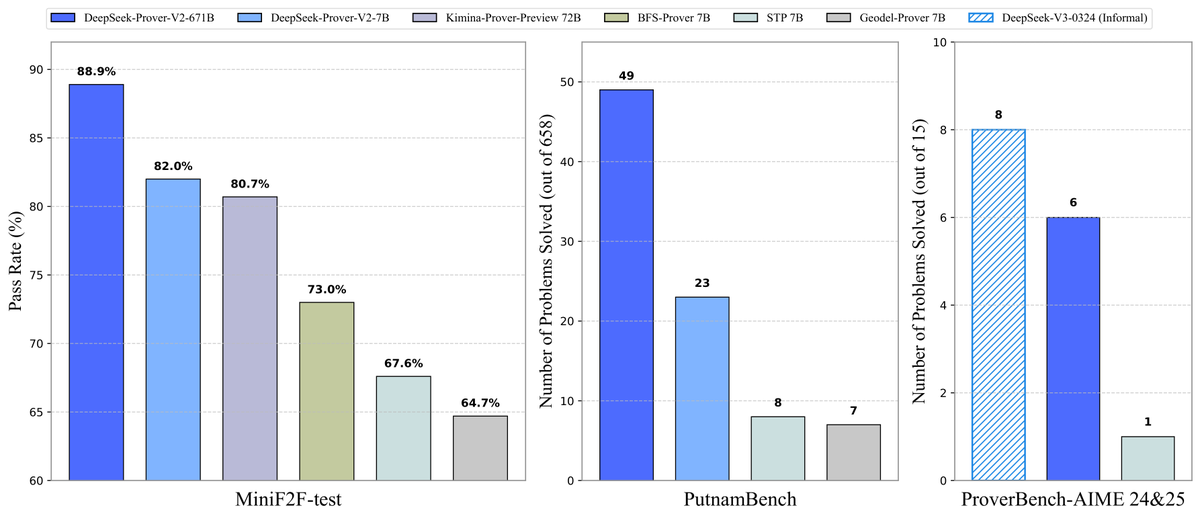
DeepSeek, Prover-V2 정리 증명 모델 오픈소스 공개: DeepSeek은 Lean 4 형식화 정리 증명을 위해 특별히 설계된 오픈소스 대형 모델 DeepSeek-Prover-V2를 발표했습니다. 7B와 671B 두 가지 규모로 제공됩니다. 이 모델은 DeepSeek-V3를 사용하여 재귀적 하위 목표 분해를 통해 콜드 스타트 데이터셋을 생성하고, 강화 학습(GRPO)과 결합하여 최적화되었습니다. MiniF2F-test에서 88.9%의 통과율을 달성했으며, PutnamBench 및 AIME 24/25와 같은 벤치마크에서 SOTA 또는 현저한 성능을 기록했습니다. 또한 AIME 경진대회 문제를 포함한 ProverBench 데이터셋 및 실행 튜토리얼을 오픈소스로 공개하여 형식화 수학 추론의 발전을 촉진합니다. (출처: karminski3, op7418, TheRundownAI, op7418)
OpenAI, “과도한 아첨” 문제 해결 위해 GPT-4o 업데이트 롤백: OpenAI CEO Sam Altman은 최신 버전의 GPT-4o가 지나치게 비위를 맞추고 주관이 부족한 “아첨”(sycophancy/glazing) 행위를 보인다는 사용자 피드백이 많아 월요일 저녁부터 해당 업데이트를 롤백하기 시작했다고 확인했습니다. 무료 사용자는 이미 롤백이 완료되었으며, 유료 사용자는 추후 업데이트될 예정입니다. 팀은 추가적인 수정을 진행 중이며, 향후 며칠 내에 모델 개성에 대한 더 많은 정보를 공유할 계획입니다. 이 사건은 RLHF 훈련 방식, 모델 정렬 목표, 사용자 기대 간의 균형에 대한 광범위한 논의를 촉발했습니다. (출처: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
통이치엔원(通义千问), Qwen3 시리즈 모델 발표: 알리바바는 차세대 통이치엔원 모델인 Qwen3를 발표하고 오픈소스로 공개했습니다. 0.6B부터 235B 파라미터까지 8가지 MoE(Mixture-of-Experts) 모델을 포함합니다. Qwen3는 추론, 코드, 수학, 다국어(119개 언어 지원) 및 도구 호출(향상된 MCP 지원) 등에서 뛰어난 성능을 보이며, 특히 32B 모델은 OpenAI o1 및 DeepSeek R1을 능가하고, 235B 모델은 여러 벤치마크에서 오픈소스 기록을 경신했습니다. Qwen3 모델은 통이 앱(通义 App)과 tongyi.com 웹사이트에 출시되어 사용자들이 강력한 코드 생성, 논리 추론, 창의적 글쓰기 능력을 경험할 수 있습니다. (출처: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 동향
Inception Labs, 최초의 상용 Diffusion LLM API 출시: Inception Labs는 API 공개 베타 버전을 출시하여 최초의 상업적 규모의 Diffusion 대형 언어 모델(dLLMs) 서비스를 제공합니다. Mercury Coder 모델은 이미지 생성과 유사한 “거친 것에서 세밀한 것(coarse-to-fine)” 텍스트 생성 방식을 채택하여 출력 토큰을 병렬로 생성할 수 있게 함으로써 기존 자기회귀 LLM보다 높은 처리량(테스트 속도 5배 이상)을 달성합니다. 이 아키텍처는 속도와 품질 면에서 GPT-4o mini 및 Claude 3.5 Haiku와 경쟁할 수 있으며, LLM 아키텍처 다양화의 새로운 진전을 나타냅니다. (출처: xanderatallah, ArtificialAnlys, sarahcat21)
아마존, Amazon Nova Premier 모델 출시: Amazon Science는 Amazon Bedrock에서 가장 강력한 교사 모델인 Amazon Nova Premier를 출시했습니다. 이 모델은 복잡한 작업(예: RAG, 함수 호출, Agentic 코딩)을 위해 특별히 설계되었으며, 백만 토큰의 컨텍스트 창을 가지고 있어 대규모 데이터셋을 분석할 수 있으며, 해당 인텔리전스 등급에서 가장 비용 효율적인 독점 모델입니다. 이는 사용자에게 맞춤형 증류 모델을 생성하기 위한 강력한 기반을 제공하는 것을 목표로 합니다. (출처: bookwormengr)
Together AI, DPO 미세 조정 지원: Together AI 플랫폼은 이제 모델 미세 조정을 위한 직접 선호도 최적화(Direct Preference Optimization, DPO)를 지원합니다. DPO는 명시적인 보상 모델 없이 인간 선호도 데이터를 기반으로 모델을 조정하는 기술입니다. 이 기능을 통해 사용자는 사용자 요구에 지속적으로 적응하는 맞춤형 모델을 구축하여 모델 정렬 능력을 향상시킬 수 있습니다. 플랫폼은 또한 DPO에 대한 심층 블로그 게시물과 코드 예제를 제공합니다. (출처: stanfordnlp, stanfordnlp)
Diffusion 모델 정보 이론의 새로운 진전: 암스테르담 대학 등 기관의 연구자들은 Diffusion 모델 예측으로 인한 엔트로피 감소량이 손실 함수의 스케일링된 버전과 동일하다는 것을 발견했습니다. 이 발견은 가우시안 Diffusion 모델에 대해 분류 교차 엔트로피를 위한 CDCD 연구에서 사용된 것과 유사한 시간 왜곡(time warping) 가능성을 도입하여, 조건부 엔트로피에 기반한 데이터 의존적 시간 개념을 제공하며, Diffusion 모델의 훈련 스케줄을 최적화할 것으로 기대됩니다. (출처: sedielem)

인텔 18A 공정, 위험 생산 돌입, 14A 곧 출시: 인텔 파운드리 컨퍼런스에서 CEO 팻 겔싱어는 Intel 18A 공정 노드가 위험 생산 단계에 진입했으며 연내 양산될 것이라고 발표했습니다. 동시에 인텔은 주요 고객에게 Intel 14A PDK 초기 버전을 제공했으며, 이 노드는 PowerDirect 직접 접점 전력 공급 기술을 채택할 예정입니다. 또한 Intel 18A-P, 18A-PT 등 진화 버전과 Foveros Direct, EMIB-T 등 첨단 패키징 기술을 소개하고, Amkor Technology와의 협력을 발표하여 AI 등 고성능 컴퓨팅 수요를 충족시키기 위한 시스템 레벨 파운드리 역량을 강화했습니다. (출처: WeChat)
AI 엔터테인먼트 스튜디오, 인수합병 통해 통합 가속화: 최근 AI 엔터테인먼트 분야에서 통합 추세가 나타나고 있습니다. 할리우드 AI 데이터 분석 플랫폼 Cinelytic은 AI 지식 재산 관리 도구 개발사 Jumpcut Media를 인수하여 AI 시나리오 분석 능력을 확장하고 ScriptSense와 같은 도구를 통합하여 콘텐츠 의사 결정 효율성을 높이는 것을 목표로 합니다. 동시에 작년에 설립된 AI 엔터테인먼트 스튜디오 Promise는 AI 영화 학교 Curious Refuge를 인수하여 인재 공급 채널을 구축하고 생성형 AI에 능숙한 창작 인재를 양성하여 영화 및 TV 제작에서 AI 적용을 가속화할 계획입니다. (출처: 36氪)

듀오링고, 전면적인 AI First 전략 발표: 듀오링고 CEO는 전사 메시지에서 회사가 전면적으로 AI First 전략으로 전환할 것이며, AI 수용이 시급하다고 밝혔습니다. 회사는 점진적으로 AI가 대체할 수 있는 인력 아웃소싱 업무를 AI로 대체하고, 인력 증가를 엄격히 통제하며 AI 자동화 방안을 우선적으로 고려할 것입니다. AI는 채용, 성과 평가 등 단계에 도입되어 효율성을 높이고 인간 직원이 창의적인 업무에 집중할 수 있도록 하는 것을 목표로 합니다. 이는 듀오링고가 최근 몇 년간 AI(특히 OpenAI와의 협력)를 활용하여 이룬 현저한 사용자 증가와 매출 증대에 기반한 조치입니다. (출처: WeChat)

🧰 도구
Meta, llama-prompt-ops 도구 오픈소스 공개: LlamaCon에서 Meta는 DSPy 및 MIPROv2 옵티마이저 기반의 Python 패키지 llama-prompt-ops를 발표했습니다. 이 도구는 다른 LLM에 적합한 프롬프트를 Llama 모델에 최적화된 프롬프트로 변환할 수 있으며, 여러 작업에서 현저한 성능 향상을 보여주었습니다. 이는 사용자가 Llama 모델에서 애플리케이션을 더 편리하게 마이그레이션하고 최적화할 수 있도록 돕는 것을 목표로 합니다. (출처: matei_zaharia, stanfordnlp, lateinteraction)
구글 클라우드, Agent Starter Pack 발표: Google Cloud Platform은 다양한 생산 준비 완료된 GenAI Agent 템플릿(예: ReAct, RAG, 다중 에이전트, 실시간 멀티모달 API) 모음인 Agent Starter Pack을 오픈소스로 공개했습니다. 이는 전체적인 솔루션을 제공하여 GenAI Agent의 개발 및 배포를 가속화하고, 배포 운영, 평가, 맞춤화 및 관찰 가능성과 같은 일반적인 과제를 해결하며, Cloud Run 및 Agent Engine 배포를 지원하는 것을 목표로 합니다. (출처: GitHub Trending)

CUA 프레임워크 발표: AI Agent가 운영체제를 제어하는 Docker 컨테이너: trycua는 고성능, 경량 가상 컨테이너 내에서 완전한 운영체제를 제어할 수 있는 AI Agent 솔루션인 CUA (Computer-Use Agent) 프레임워크를 오픈소스로 공개했습니다. 이는 Apple Silicon의 Virtualization.Framework를 활용하여 거의 네이티브에 가까운 macOS/Linux 가상 머신 성능(최대 97%)을 제공하며, AI 시스템이 이러한 환경을 관찰하고 제어하여 애플리케이션 상호 작용, 웹 브라우징, 코딩 등 복잡한 워크플로우를 수행하면서 안전한 격리를 보장하는 인터페이스를 제공합니다. (출처: GitHub Trending)
Modal Labs 플랫폼, JavaScript 및 Go 지원 추가: 클라우드 컴퓨팅 플랫폼 Modal Labs는 Rust로 작성된 런타임이 이제 JavaScript (Node/Deno/Bun) 및 Go SDK를 지원한다고 발표했습니다. 개발자는 이제 이러한 언어를 사용하여 GPU 서버리스 함수를 호출하고, 신뢰할 수 없는 코드를 위한 안전한 가상 머신을 시작할 수 있어, 데이터 과학/머신러닝 분야 외의 Modal 적용 시나리오를 확장했습니다. (출처: akshat_b, HamelHusain)
Kling AI, 새로운 특수 효과 출시: 콰이쇼우(快手) 산하의 비디오 생성 모델 Kling AI는 새로운 인터랙티브 특수 효과를 추가했습니다. 사용자는 두 사람이 포함된 사진을 업로드한 다음 “키스”, “포옹”, “하트 만들기”, 심지어 “장난치기”와 같은 효과를 적용하여 동적 비디오를 생성함으로써 인물 비디오 생성의 재미와 상호 작용성을 향상시켰습니다. (출처: Kling_ai)
NotebookLM, 다국어 오디오 개요 기능 추가: Google의 AI 노트 도구 NotebookLM은 사용자가 업로드한 문서, 노트 등을 팟캐스트 스타일의 오디오 요약으로 생성하는 오디오 개요(Audio Overviews) 기능을 출시했습니다. 이 기능은 이제 한국어를 포함한 전 세계 50개 이상의 언어를 지원하며, 사용자의 원본 자료가 여러 언어로 혼합되어 있더라도 원하는 언어의 오디오 요약을 생성하여 사용자가 언제 어디서나 듣기를 통해 정보를 학습하고 이해할 수 있도록 편리하게 지원합니다. (출처: WeChat)
PaperCoder: 머신러닝 논문을 코드로 자동 변환: 한국과학기술원(KAIST) 연구진이 머신러닝 논문의 방법론과 실험을 실행 가능한 코드 라이브러리로 자동 변환하는 것을 목표로 하는 다중 에이전트 LLM 시스템 PaperCoder를 오픈소스로 공개했습니다. 시스템은 계획, 분석, 코드 생성의 세 단계를 통해 전문 에이전트가 각기 다른 작업을 처리합니다. 연구에 따르면 생성된 코드 품질이 기존 벤치마크를 능가하고 논문 원저자의 77%로부터 인정을 받아, 논문 코드 재현의 어려움을 해결할 것으로 기대됩니다. (출처: WeChat)

Cactus: 경량 온디바이스 AI 프레임워크: Cactus는 모바일 기기에서 AI 모델을 실행하기 위한 경량, 고성능 프레임워크입니다. React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++), Flutter/Dart 전반에 걸쳐 통합되고 일관된 API를 제공하여 개발자가 다양한 모바일 플랫폼에서 AI 모델을 쉽게 배포하고 실행할 수 있도록 합니다. (출처: Reddit r/deeplearning)
Muyan-TTS: 오픈소스 저지연 맞춤형 TTS 모델: ChatPods 팀은 저지연, 고도로 맞춤화 가능한 텍스트 음성 변환(TTS) 모델인 Muyan-TTS를 오픈소스로 공개했습니다. 이 모델은 기존 오픈소스 TTS 모델의 품질이 낮거나 충분히 개방적이지 않은 문제를 해결하는 것을 목표로 하며, 완전한 모델 가중치, 훈련 스크립트 및 데이터 처리 흐름을 제공합니다. Base 모델(제로샷 TTS용)과 SFT 모델(음성 복제용)을 포함하며, 영어 효과가 좋고 커뮤니티가 해당 프레임워크를 기반으로 2차 개발 및 확장을 하도록 장려합니다. (출처: Reddit r/deeplearning)
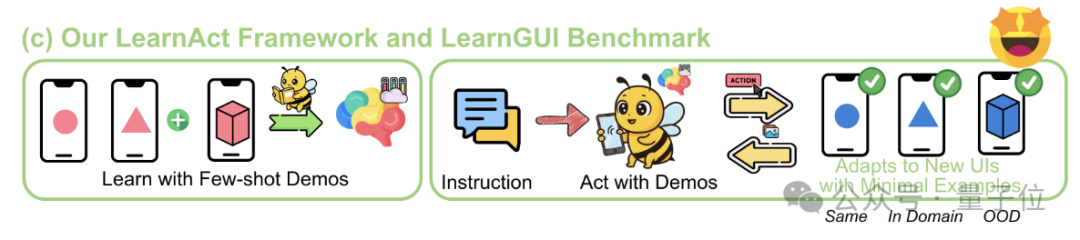
LearnAct 프레임워크: 휴대폰 AI, 단 한 번의 시연으로 복잡한 작업 학습: 저장대학과 vivo AI Lab은 소량(심지어 한 번)의 사용자 시연을 통해 휴대폰 GUI 에이전트가 복잡하고 개인화된 롱테일 작업을 수행하도록 학습시키는 것을 목표로 하는 LearnAct 다중 에이전트 프레임워크와 LearnGUI 벤치마크를 공동으로 제안했습니다. LearnAct는 DemoParser(시연 분석), KnowSeeker(지식 검색), ActExecutor(동작 실행)의 세 가지 에이전트를 포함하며, 실험 결과 이 방법이 미경험 시나리오에서 모델의 작업 성공률을 현저히 향상시킬 수 있음을 보여주었습니다(예: Gemini-1.5-Pro의 정확도를 19.3%에서 51.7%로 향상). (출처: WeChat)
📚 학습
LLM 후훈련 기술 심층 리뷰: MBZUAI, Google DeepMind 등 기관의 연구자들이 포괄적인 LLM 후훈련 기술 리뷰를 발표했습니다. 보고서는 강화 학습(RLHF, RLAIF, DPO, GRPO 등), 지도 미세 조정(SFT), 테스트 시 확장(CoT, ToT, GoT, 자기 일관성 디코딩 등)을 통해 LLM 추론 능력 강화, 인간 의도와의 정렬, 신뢰성 향상을 위한 다양한 방법을 심층적으로 탐구합니다. 보고서는 또한 보상 모델링, 파라미터 효율적 미세 조정(PEFT), 모델 확장 전략 및 관련 평가 벤치마크를 다루고 미래 연구 방향을 제시합니다. (출처: WeChat)
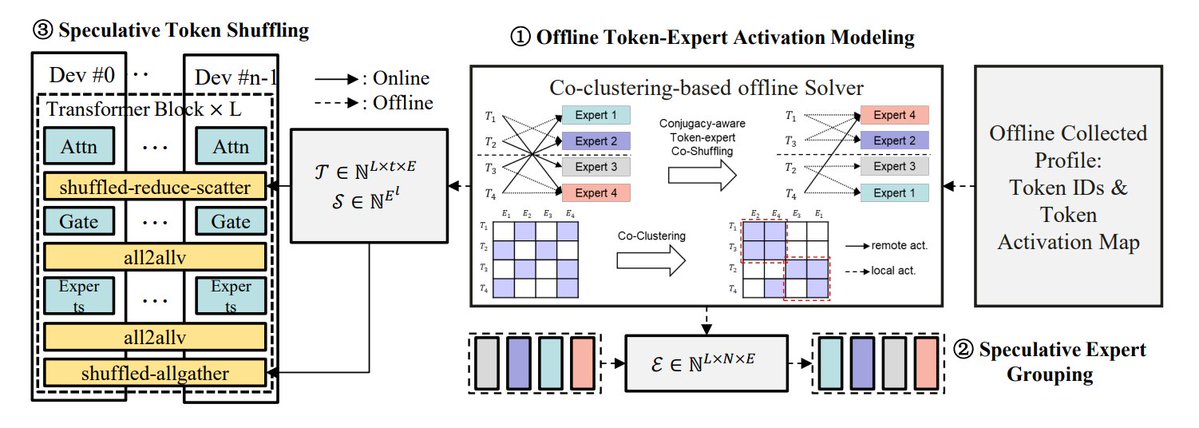
MoE 추론 최적화 방법 요약: TheTuringPost는 MoE 모델 추론을 최적화하는 5가지 방법을 요약했습니다: eMoE(전문가 예측 및 사전 로드), MoEShard(전문가를 각 GPU에 분할), DeepSpeed-MoE(다양한 기술을 결합한 대규모 처리), Speculative-MoE(라우팅 경로 예측 및 전문가 그룹화), MoE-Gen(모듈 기반 배치 처리). 이 글은 또한 Structural MoE 및 Symbolic-MoE와 같은 고급 방법을 언급하며 MoE 모델의 추론 효율성과 처리량을 향상시키는 것을 목표로 합니다. (출처: TheTuringPost)
10년 전 End-To-End Memory Networks 논문 회고: Meta 연구 과학자 Sainbayar Sukhbaatar는 자신이 2015년에 공동 저술한 논문 “End-To-End Memory Networks”를 회고했습니다. 이 논문은 RNN을 완전히 어텐션 메커니즘으로 대체한 최초의 언어 모델 중 하나로, 키-값 프로젝션이 있는 점곱 소프트 어텐션, 다층 스택 어텐션, 위치 임베딩(당시 시간 임베딩으로 불림)과 같은 개념을 도입했으며, 이는 현재 LLM의 핵심 요소입니다. 비록 “Attention is all you need”만큼의 영향력은 없었지만, Memory Networks와 초기 소프트 어텐션의 아이디어를 결합하여 다층 소프트 어텐션의 추론 잠재력을 보여주었습니다. (출처: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – 효율적인 비전 미세 조정을 위한 새로운 방법: 칭화대학, 중국과학원대학 등 기관에서 새로운 비전 어댑터 미세 조정 방법인 Mona (Multi-cognitive Visual Adapter)를 제안했습니다. 다중 인지 비전 필터(깊이 분리 합성곱 + 다중 스케일 커널)와 입력 분포 최적화(Scaled LayerNorm)를 도입하여, Mona는 백본 네트워크 파라미터의 5% 미만만 조정하면서 인스턴스 분할, 객체 탐지 등 여러 비전 작업에서 전체 파라미터 미세 조정 성능을 능가하고 계산 및 저장 비용을 현저히 절감했습니다. 이 방법은 비전 모델의 효율적인 PEFT를 위한 새로운 방향을 제시합니다. (출처: WeChat)

ICLR 2025 Oral: DIFF Transformer – 차등 어텐션으로 장문 텍스트 모델링 향상: Microsoft와 칭화대학은 차등 어텐션 메커니즘(두 Softmax 어텐션 맵의 차이 계산)을 도입하여 핵심 컨텍스트 신호를 증폭하고 노이즈를 제거하는 DIFF Transformer를 제안했습니다. 실험 결과, DIFF Transformer는 언어 모델링에서 확장성이 더 뛰어나며(동일 성능 달성에 약 65% 파라미터/데이터 필요), 장문 텍스트 모델링, 핵심 정보 검색, 컨텍스트 학습, 적대적 환각, 수학 추론 등에서 기존 Transformer보다 현저히 우수하며, 활성화 이상치를 줄여 양자화에 유리합니다. (출처: WeChat)

MARFT: 다중 에이전트 강화 미세 조정의 새로운 패러다임: 상하이교통대학 등 기관에서 LLM 기반 다중 에이전트 시스템(LaMAS)에 적용 가능한 새로운 강화 미세 조정 패러다임인 MARFT (Multi-Agent Reinforcement Fine-Tuning)를 제안했습니다. 이 방법은 다중 에이전트 어드밴티지 값 분해와 Transformer와 유사한 순차적 의사 결정 모델링을 통해 LaMAS의 동적성으로 인한 최적화 과제를 해결합니다. 초기 실험 결과, MARFT로 미세 조정된 LaMAS는 수학 작업에서 미세 조정되지 않은 시스템 및 단일 에이전트 PPO보다 우수한 성능을 보였습니다. 연구자들은 또한 복잡한 작업 해결, 확장성, 개인 정보 보호 및 블록체인과의 결합 등에서의 잠재력과 과제를 탐구했습니다. (출처: WeChat)

AI 에이전트 프로토콜 종합 리뷰: 상하이교통대학과 ANP 커뮤니티가 협력하여 최초의 AI 에이전트 프로토콜 리뷰를 발표했습니다. 논문은 객체 지향(컨텍스트 지향 vs 에이전트 간) 및 응용 시나리오(범용 vs 도메인 특정)의 2차원 분류 프레임워크를 제안하고, MCP, A2A, ANP, AITP, LMOS 등 10여 가지 주요 프로토콜을 정리했습니다. 7가지 차원(효율성, 확장성, 보안성, 신뢰성, 확장성, 운영성, 상호 운용성)을 통해 평가하고, 여행 계획 사례를 사용하여 MCP, A2A, ANP, Agora 네 가지 아키텍처를 비교했습니다. 마지막으로 프로토콜이 정적인 것에서 진화 가능한 것으로, 규칙에서 생태계로, 프로토콜에서 지능형 인프라로 발전하는 미래를 전망했습니다. (출처: WeChat)

MCP 프로토콜 심층 리뷰: 아키텍처, 생태계 및 보안 위험: 새로운 리뷰 논문은 모델 컨텍스트 프로토콜(MCP)의 아키텍처, 생태계 현황 및 잠재적 보안 위험을 심층적으로 탐구합니다. 이 글은 MCP Host, Client, Server의 삼원 구조와 상호 작용 메커니즘을 분석하고, Anthropic, OpenAI, Cursor, Replit 등 회사와 커뮤니티의 MCP 사용 현황을 개괄하며, MCP Server 수명 주기(생성, 실행, 업데이트)에 존재하는 보안 취약점(예: 이름 충돌, 설치 프로그램 스푸핑, 코드 주입, 도구 이름 충돌, 샌드박스 탈출, 권한 지속성 등)을 중점적으로 분석합니다. (출처: WeChat)

CVPR Oral: UniAP – 통합 계층 내/간 자동 병렬화 알고리즘: 난징대학 리우쥔 교수 연구팀은 계층 내(데이터/텐서/ZeRO) 및 계층 간(파이프라인) 병렬화 전략을 공동으로 최적화할 수 있는 분산 훈련 알고리즘 UniAP를 제안했습니다. 혼합 정수 이차 계획법 모델링을 통해 UniAP는 효율적인 분산 훈련 방안을 자동으로 탐색하여 수동 구성의 복잡성과 비효율성 문제를 해결합니다. 실험 결과, UniAP는 기존 자동 병렬화 방법보다 최대 3.8배 빠르고, 최적화되지 않은 전략보다 9배 빠르며, 64%-87%의 비효율적인(OOM) 전략을 효과적으로 회피하여 사용 편의성을 향상시킵니다. 이 알고리즘은 국산 AI 컴퓨팅 카드에 적용되었습니다. (출처: WeChat)
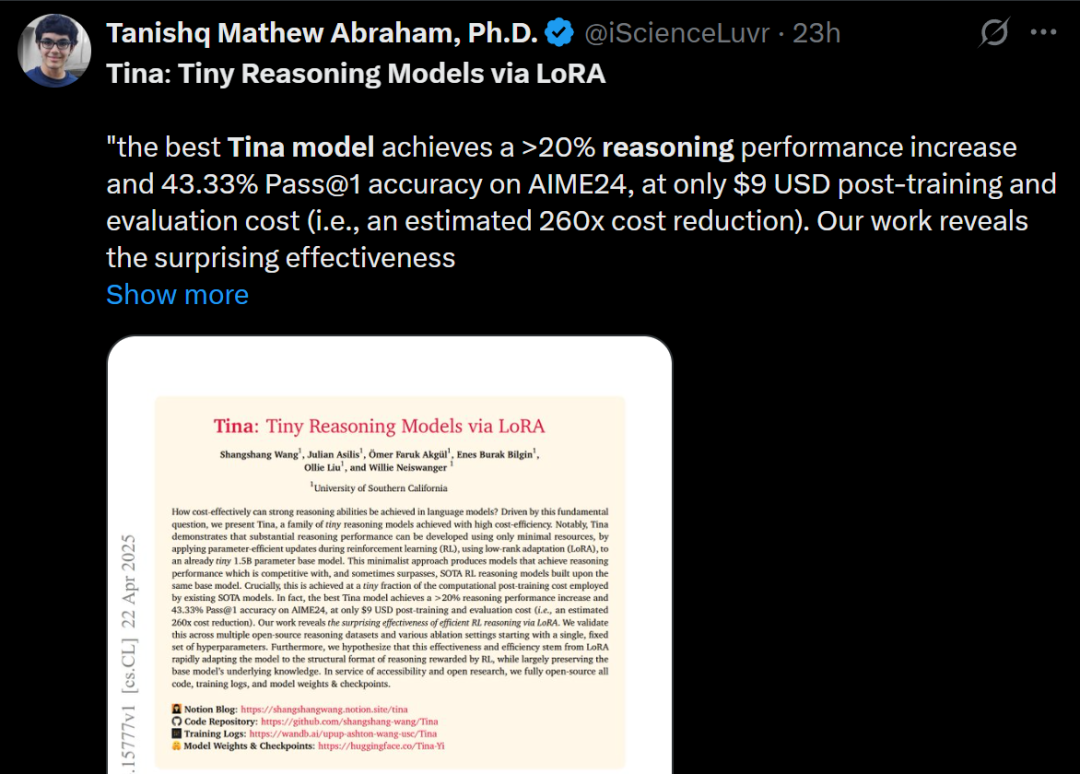
Tina: LoRA를 통한 저비용 고추론 능력 소형 모델: 서던캘리포니아대학교(USC) 팀은 Tina (Tiny Reasoning Models via LoRA) 시리즈 모델을 제안했습니다. 1.5B 파라미터의 DeepSeek-R1-Distill-Qwen을 기반으로 LoRA를 사용하여 강화 학습 후훈련을 통해 Tina 모델은 여러 추론 벤치마크(AIME, AMC, MATH, GPQA, Minerva)에서 전체 파라미터 미세 조정 기준 모델과 동등하거나 더 우수한 성능을 달성했으며, 훈련 비용은 매우 낮았습니다(최적 체크포인트 비용 단 9달러). 이 연구는 LoRA가 추론 형식/구조를 효율적으로 학습하는 데 있어 이점을 밝혀냈으며, 훈련 과정에서 형식 지표와 정확도 지표의 분리 현상을 관찰했습니다. (출처: WeChat)
재귀적 KL 발산 최적화: 새로운 효율적인 모델 훈련 방법: 새로운 논문은 재귀적 KL 발산 최적화(Recursive KL Divergence Optimization) 방법을 제안하며, 모델 훈련(특히 미세 조정)에서 최대 80%의 효율성 향상을 달성할 수 있다고 주장합니다. 이 방법은 모델 업데이트를 더 최적화된 방식으로 제한하여 훈련에 필요한 계산 자원이나 시간을 줄임으로써 모델을 더 경제적이고 빠르게 훈련하고 미세 조정할 수 있는 새로운 길을 제공할 수 있습니다. (출처: Reddit r/LocalLLaMA)
💼 비즈니스
Sakana AI, 미국의 정책 불확실성 활용해 일본에서 성장 모색: 일본 AI 스타트업 Sakana AI는 미국의 정책 불확실성과 국내 AI 솔루션 수요(특히 정부 및 금융 기관)가 일본에서의 성장 기회를 제공한다고 보고 있습니다. 회사 비즈니스 개발 매니저는 향후 6개월 내에 정부 및 금융 기관에서 5~10개의 소비자 사용 사례가 나올 것으로 예상한다고 밝혔습니다. CEO David Ha는 지정학적 긴장이 고조되는 가운데 민주주의 국가들이 정부 및 국방 인프라 업그레이드 수요가 증가하고 있으며, 회사가 국방 응용 분야(예: 생물 보안 위험 및 허위 정보 추적)에 집중하는 것이 중요하다고 지적했습니다. (출처: SakanaAILabs, SakanaAILabs)
Meta, 생성형 AI 매출 2035년 1.4조 달러 예측: Meta는 자사의 생성형 AI 사업이 2025년에 30억 달러의 매출을 올리고, 2035년에는 1.4조 달러로 급증할 것으로 예측했습니다. 이 예측은 Meta가 AI 분야의 장기적인 성장 잠재력을 매우 긍정적으로 보고 있으며, AI 연구 개발 및 인프라 구축에 대한 높은 자본 지출을 계속 유지할 가능성이 있음을 시사합니다. (출처: brickroad7)

알리마마, 세계 지식 대형 모델 URM 발표: 알리마마는 세계 지식과 전자상거래 분야 지식을 결합한 대형 언어 모델 URM (Universal Recommendation Model)을 출시했습니다. 이 모델은 지식 주입(상품 ID를 특수 토큰으로 사용)과 정보 정렬(ID와 멀티모달 의미 표현 융합)을 통해 사용자의 과거 관심사를 이해하고 추론 기반 추천을 수행할 수 있습니다. URM은 Sequence-In-Set-Out 생성 방식을 채택하여 여러 사용자 표현을 병렬로 생성하여 효과와 다양성을 높이는 동시에 추론 효율성을 유지합니다. 이미 알리마마 디스플레이 광고 시나리오에 적용되었으며, 비동기 추론 파이프라인을 통해 LLM 지연 시간 문제를 해결하여 판매자의 광고 효과와 사용자의 쇼핑 경험을 향상시켰습니다. (출처: WeChat)

🌟 커뮤니티
GPT-4 시대의 종말에 대한 감회와 토론: Sam Altman은 GPT-4에 작별을 고하며, 그것이 혁명을 시작했으며 미래의 역사가들을 위해 그 가중치를 보존할 것이라고 말했습니다. 이는 커뮤니티에서 광범위한 감회를 불러일으켰고, 많은 사람들이 GPT-4가 AGI의 잠재력을 처음으로 느끼게 해준 모델이라고 회상했습니다. 동시에 이는 오픈소스에 대한 논의를 촉발했으며, Hugging Face 등 커뮤니티 구성원들은 OpenAI가 GPT-4 가중치를 단순히 봉인하는 대신 연구용으로 오픈소스화할 것을 촉구했습니다. (출처: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
AI 코딩 분야 관찰 및 토론: GruAI 창립자 장하이롱은 AI 코딩이 현재 PMF(Product-Market Fit)를 볼 수 있는 몇 안 되는 분야 중 하나이며, Cursor의 성공은 새로운 시장을 창출한 데 있고 그 UI 가치가 크다고 생각합니다. 그는 Devin의 방향은 옳지만 야심이 너무 크고 시간 주기가 길지만, 성공 가능성은 커지고 있으며 결국 Cursor와 경쟁하게 될 것이라고 봅니다. 스타트업에 대해서는 대기업 경쟁을 지나치게 걱정할 필요가 없으며, 핵심은 제품력과 독특한 가치에 있다고 생각합니다. 모델의 발전은 엔지니어링으로 보완해야 할 필요성을 현저히 낮추었으며, 창업자는 어떤 문제가 모델 발전에 의해 해결될 것이고 어떤 것이 진정한 제품력인지 구분해야 합니다. (출처: WeChat)

“AI가 당신의 일자리를 대체할 것”이라는 주장에 대한 반성: 커뮤니티 토론에서는 “AI가 당신의 일자리를 대체하지는 않겠지만, AI를 사용하는 사람이 당신을 대체할 것”이라는 말이 표면적으로는 맞지만 지나치게 단순화되었으며, 사람들이 더 깊은 수준의 문제를 생각하는 것을 멈추게 하는 “합의 극장(consensus theatre)”이라고 지적합니다. 진정한 핵심은 AI가 어떻게 작업 구조를 바꾸고, 작업 흐름을 재구성하며, 조직 논리를 변화시키는지, 그리고 새로운 시스템 하에서 미래의 일이 어떤 모습일지를 이해하는 것이지, 단순히 개별 작업 수준의 자동화나 강화에만 초점을 맞추는 것이 아닙니다. (출처: Reddit r/ArtificialInteligence)

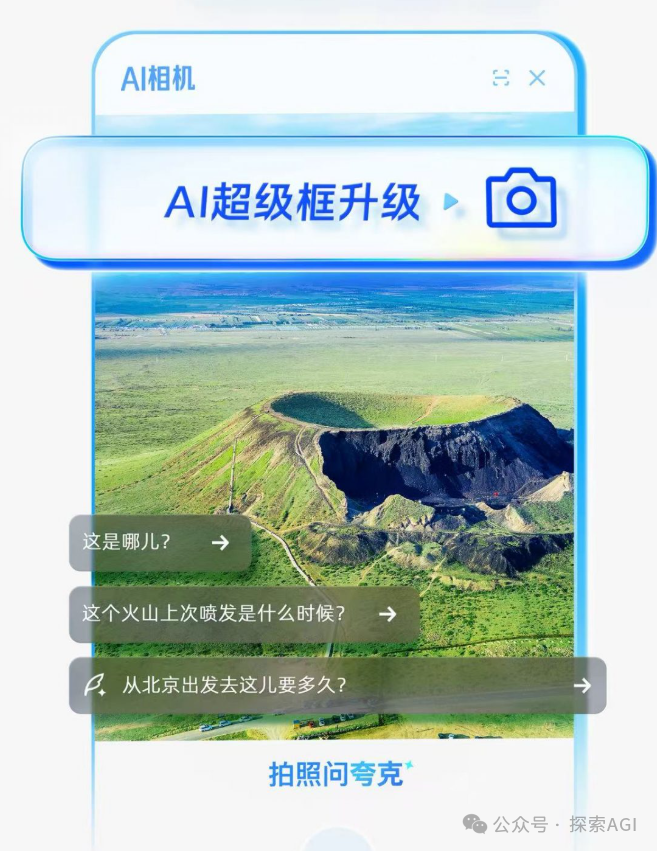
AI 에이전트와 물리적 세계 상호 작용의 새로운 입구: 카메라: 토론에서는 콰크(Quark)의 “찍어서 질문하기(拍照问)”와 유사한 기능이 AI 애플리케이션 상호 작용의 새로운 추세를 나타낸다고 봅니다. 휴대폰 카메라라는 보편적인 센서를 통해 멀티모달 이해 및 Agent 능력과 결합하여 AI는 물리적 세계를 더 잘 이해하고 사용자의 암묵적 또는 명시적 요구에 따라 자율적으로 결정하고 능력을 호출하여 작업을 완료할 수 있습니다(예: 물체 식별, 번역, 가격 비교, 숙제 보조, 영수증 처리 등). 이는 카메라를 단순한 정보 입력 도구에서 물리적 세계와 디지털 지능을 연결하고 “Get it Done”을 실현하는 허브로 전환시킵니다. (출처: WeChat)
💡 기타
AI와 과학 연구: 커뮤니티 관점에서는 AI가 점차 과학 연구의 새로운 “수학”이 되고 있으며, 이는 AI가 수학처럼 과학적 발견과 이해를 추진하는 기초 도구이자 언어가 될 것임을 의미합니다. (출처: shuchaobi)

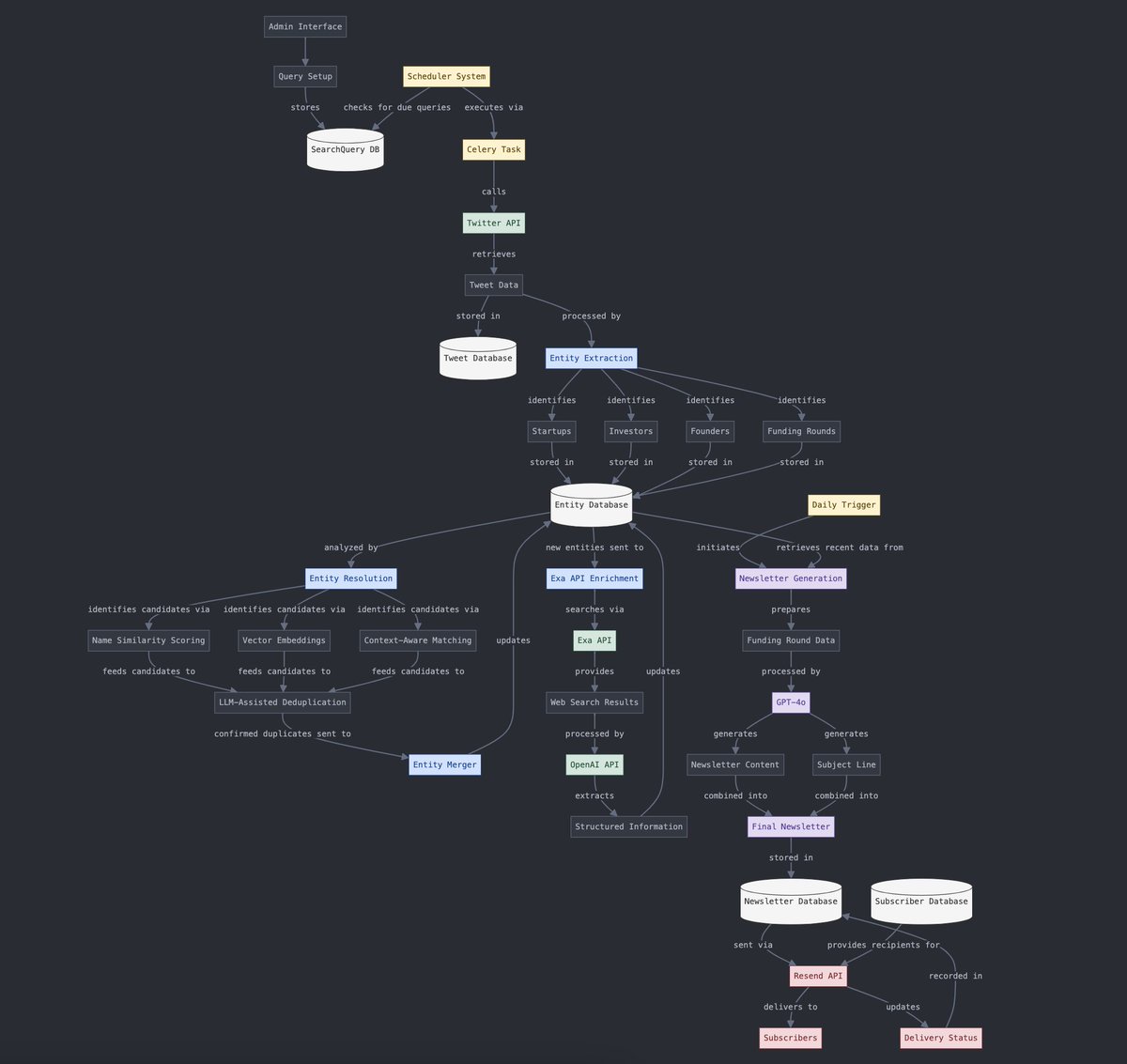
구조화된 데이터와 비구조화된 데이터 변환: Yohei Nakajima는 AI를 사용하여 비구조화된 트윗 데이터를 구조화된 데이터로 변환하고, 이를 다시 비구조화된 일일 뉴스레터로 변환하는 과정을 보여주며 정보 처리 및 콘텐츠 생성 프로세스에서 AI의 응용을 보여줍니다. (출처: yoheinakajima)
AI와 VR 결합의 미래: 커뮤니티 토론은 AI와 VR 결합의 잠재력을 전망하며, 미래에는 자연어 또는 생각만으로 VR의 “화이트보드 공간”에서 3D 객체를 직접 생성하고 조작하여 인지 기반 창작을 실현할 수 있을 것으로 상상합니다. Meta는 이 방향을 추진하는 핵심 참여자로 간주됩니다. (출처: Reddit r/ArtificialInteligence)