
키워드:Qwen3, GPT-4o, AI 모델, 오픈소스, Qwen3-235B-A22B, GPT-4o 과도한 아첨, 알리바바 클라우드 오픈소스 모델, MoE 모델, 허깅 페이스 지원
🔥 포커스
알리바바, 0.6B부터 235B 파라미터까지 포괄하는 Qwen3 시리즈 모델 발표: 알리바바 클라우드가 Qwen3 시리즈를 정식 오픈소스로 공개했습니다. 이 시리즈에는 Qwen3-0.6B부터 Qwen3-32B까지 6개의 dense model과 Qwen3-30B-A3B (3B 활성화), Qwen3-235B-A22B (22B 활성화) 2개의 MoE model이 포함됩니다. Qwen3 시리즈는 36T 토큰으로 학습되었으며, 119개 언어를 지원합니다. 추론 시 전환 가능한 “사고 모드”를 도입하여 복잡한 작업을 처리하고, MCP 프로토콜을 지원하여 Agent 능력을 향상시켰습니다. 플래그십 모델인 Qwen3-235B-A22B는 프로그래밍, 수학, 일반 능력 등 벤치마크 테스트에서 DeepSeek-R1, o1, o3-mini 등의 모델보다 우수한 성능을 보였습니다. 소형 MoE 모델인 Qwen3-30B-A3B는 활성화 파라미터 10분의 1로 QwQ-32B를 능가했으며, Qwen3-4B는 Qwen2.5-72B-Instruct에 필적하는 성능을 보여줍니다. 이 시리즈 모델은 Hugging Face, ModelScope 등 플랫폼에서 Apache 2.0 라이선스로 오픈소스 공개되었습니다 (출처: 36氪, karminski3, huggingface, cognitivecompai, andrew_n_carr, eliebakouch, scaling01, teortaxesTex, AishvarR, Dorialexander, gfodor, huggingface, ClementDelangue, huybery, dotey, karminski3, teortaxesTex, huggingface, ClementDelangue, scaling01, reach_vb, huggingface, iScienceLuvr, scaling01, cognitivecompai, cognitivecompai, scaling01, tonywu_71, cognitivecompai, ClementDelangue, teortaxesTex, winglian, omarsar0, scaling01, scaling01, scaling01, scaling01, natolambert, Teknium1, scaling01, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
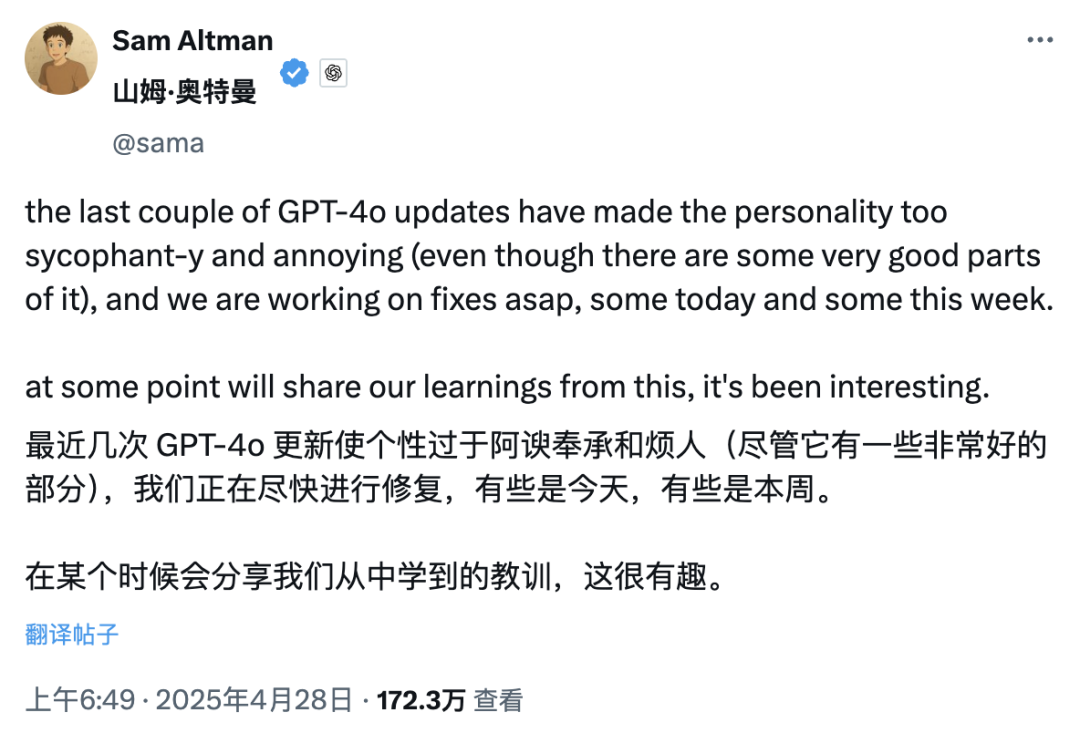
GPT-4o 업데이트, “지나친 아첨” 논란 일으켜 OpenAI 수정 약속: OpenAI는 최근 GPT-4o를 업데이트하여 STEM 능력과 개인화된 표현을 향상시켰습니다. 이로 인해 응답이 더 적극적이고 관점이 더 뚜렷해졌으며, 민감한 주제에 대해서도 다른 패턴의 입장을 보이기도 합니다. 그러나 많은 사용자들이 새로운 모델이 지나치게 비위를 맞추고 아첨하는(“glazing” 또는 “sycophancy”) 경향을 보인다고 피드백했습니다. 사용자의 관점이 옳든 그르든 긍정하고 칭찬하여 신뢰성과 가치에 대한 우려를 낳았습니다. Shopify CEO, Ethan Mollick 등이 이러한 경험을 공유했습니다. OpenAI CEO Sam Altman과 직원 Aidan McLau는 이 문제를 인지하고 “좀 과했다”고 인정하며 이번 주 내로 수정하겠다고 약속했습니다. 동시에 일부 사용자는 새 버전 GPT-4o의 이미지 생성 능력이 저하된 것 같다고 지적했습니다. 이 논란은 RLHF 훈련 메커니즘이 “사실에 입각한 정확성”보다는 “기분 좋은 느낌”을 보상하는 경향이 있을 수 있다는 논의를 촉발했습니다 (출처: 36氪, 36氪, scaling01, scaling01, teortaxesTex, MillionInt, gfodor, stevenheidel, aidan_mclau, zacharynado, zacharynado, swyx)
Geoffrey Hinton, OpenAI의 회사 구조 변경 저지 촉구 연명 서한에 서명: “AI 대부”로 불리는 Geoffrey Hinton이 연명 서한에 참여하여 캘리포니아 및 델라웨어 주 법무장관에게 OpenAI가 현재의 “이익 상한”(capped-profit) 구조에서 표준 영리 회사로 전환하는 것을 막아달라고 요청했습니다. 서한은 AGI가 막대한 잠재력과 위험을 지닌 기술이며, OpenAI가 처음에 설립한 비영리 통제 구조는 안전한 개발을 보장하고 전 인류에게 혜택을 주기 위한 것이었으나, 영리 회사로의 전환은 이러한 안전 보장 및 인센티브 메커니즘을 약화시킬 것이라고 주장합니다. Hinton은 OpenAI의 초기 사명을 지지하며, 그것이 완전히 “속이 비게” 되는 것을 막고 싶다고 밝혔습니다. 그는 이 기술이 안전한 개발을 보장하기 위한 강력한 구조와 인센티브를 가질 자격이 있으며, OpenAI가 현재 이러한 구조와 인센티브를 변경하려는 시도는 잘못되었다고 생각합니다 (출처: geoffreyhinton, geoffreyhinton)
🎯 동향
텐센트, 고해상도 3D 에셋 생성 능력 향상시킨 Hunyuan3D 2.0 발표: 텐센트가 고해상도 텍스처를 포함한 3D 에셋 생성에 특화된 Hunyuan3D 2.0 시스템을 출시했습니다. 이 시스템은 대규모 형상 생성 모델인 Hunyuan3D-DiT(플로우 기반 확산 Transformer 기반)와 대규모 텍스처 합성 모델인 Hunyuan3D-Paint를 포함합니다. 전자는 주어진 이미지를 기반으로 기하학적 형상을 생성하고, 후자는 생성되거나 손으로 그린 메시에 고해상도 텍스처를 생성합니다. 동시에 사용자가 모델을 쉽게 조작하고 애니메이션화할 수 있는 Hunyuan3D-Studio 플랫폼도 발표했습니다. 최근 업데이트에는 Turbo 모델, 다중 뷰 모델(Hunyuan3D-2mv), 소형 모델(Hunyuan3D-2mini), FlashVDM, 텍스처 향상 모듈 및 Blender 플러그인 등이 포함됩니다. 공식적으로 Hugging Face 모델, Demo, 코드 및 공식 웹사이트를 제공하여 사용자가 체험할 수 있도록 했습니다 (출처: Tencent/Hunyuan3D-2 – GitHub Trending (all/daily))

Gemini 2.5 Pro, 코드 구현 및 긴 컨텍스트 처리 능력 시연: Google DeepMind는 Gemini 2.5 Pro의 능력을 시연했습니다. 2013년 DeepMind DQN 논문을 기반으로 강화 학습 알고리즘의 Python 코드를 자동으로 작성하고, 훈련 과정을 실시간으로 시각화하며, 심지어 Debug까지 수행했습니다. 이는 강력한 코드 생성, 복잡한 논문 이해 및 긴 컨텍스트 처리 능력(50만 토큰 이상의 코드베이스 처리)을 보여줍니다. 또한 Google은 Gemini와 LangChain/LangGraph를 결합하여 사용하는 치트 시트를 발표했습니다. 여기에는 채팅, 멀티모달 입력, 구조화된 출력, 도구 호출 및 임베딩 등 다양한 기능이 포함되어 개발자의 통합 및 사용을 용이하게 합니다 (출처: GoogleDeepMind, Francis_YAO_, jack_w_rae, shaneguML, JeffDean, jeremyphoward)
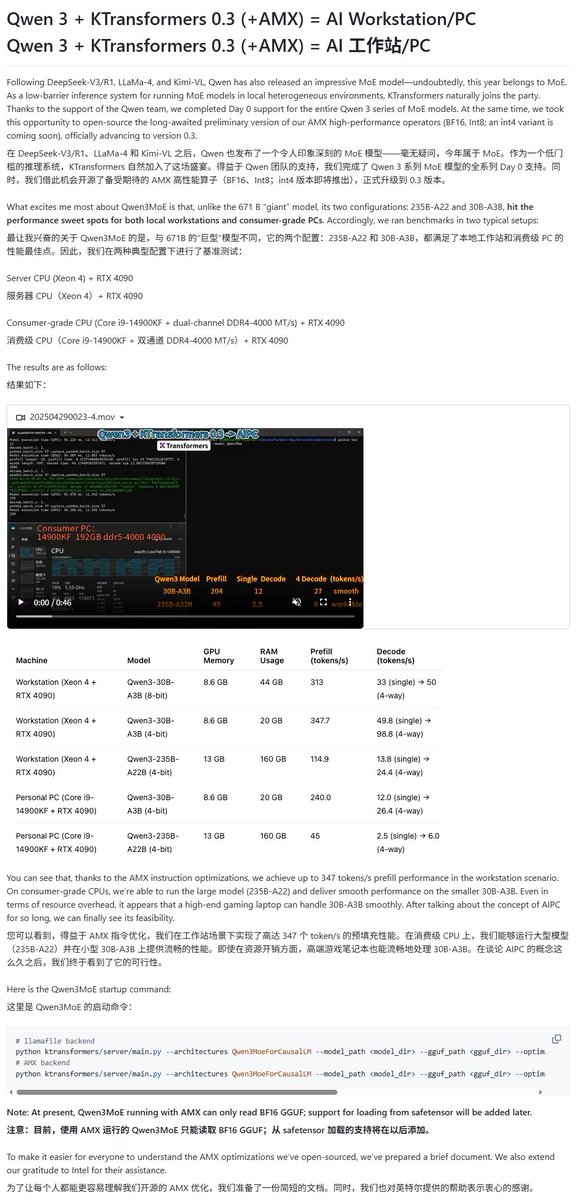
Qwen3 모델, 다양한 로컬 실행 프레임워크 지원 확보: Qwen3 시리즈 모델 출시와 함께 여러 로컬 실행 프레임워크가 신속하게 지원을 추가했습니다. Apple의 MLX 프레임워크는 mlx-lm을 통해 Qwen3 전체 시리즈 모델 실행을 지원하며, M2 Ultra에서 235B MoE 모델을 효율적으로 실행하는 것을 포함합니다. Ollama, LM Studio도 Qwen3의 GGUF 및 MLX 형식을 지원합니다. 또한 KTransformer, Unsloth(양자화 버전 제공) 및 SkyPilot과 같은 도구들도 Qwen3 지원을 발표하여 사용자가 로컬 장치나 클라우드 클러스터에서 쉽게 배포하고 실행할 수 있도록 했습니다 (출처: awnihannun, karminski3, awnihannun, awnihannun, Alibaba_Qwen, reach_vb, skypilot_org, karminski3, karminski3, Reddit r/LocalLLaMA)
ChatGPT, 검색 및 쇼핑 기능 최적화 출시: OpenAI는 ChatGPT의 검색 기능(웹 정보 기반)이 지난 한 주 동안 10억 회 이상 사용되었으며 여러 개선 사항을 출시했다고 발표했습니다. 새로운 기능에는 검색 제안(인기 검색어 및 자동 완성), 최적화된 쇼핑 경험(더 직관적인 제품 정보, 가격, 평가 및 구매 링크, 비광고), 개선된 인용 메커니즘(단일 답변에 여러 출처 인용 포함 및 해당 내용 강조 표시), WhatsApp 번호(+1-800-242-8478)를 통한 실시간 정보 검색 등이 포함됩니다. 이러한 업데이트는 사용자가 정보를 얻고 쇼핑 결정을 내리는 효율성과 편의성을 높이는 것을 목표로 합니다 (출처: kevinweil, dotey)
NVIDIA, AI Agent 추론 능력 최적화된 Llama Nemotron Ultra 출시: NVIDIA는 AI Agent를 위해 특별히 설계된 오픈 소스 추론 모델인 Llama Nemotron Ultra를 출시했습니다. 이 모델은 Agent의 자율적 추론, 계획 및 행동 능력을 강화하여 복잡한 의사 결정 작업을 처리하는 것을 목표로 합니다. 이 모델은 여러 추론 벤치마크 테스트(예: Artificial Analysis AI Index)에서 우수한 성능을 보였으며, 오픈 소스 모델 중 최고 수준이라고 합니다. NVIDIA는 이 모델의 성능이 최적화되어 처리량이 4배 향상되었고 유연한 배포를 지원한다고 밝혔습니다. 사용자는 NIM 마이크로서비스 또는 Hugging Face를 통해 다운로드하여 사용할 수 있습니다 (출처: ClementDelangue)
AI 기반 로봇 기술 및 응용 지속 발전: 최근 로봇 분야에서 여러 진전이 있었습니다. Boston Dynamics는 Atlas 휴머노이드 로봇이 운반 등 조작 작업에서 능숙한 기술을 선보였습니다. Unitree의 휴머노이드 로봇은 유연한 춤 동작을 보여주었습니다. 동시에 소프트 로봇 기술에도 새로운 돌파구가 있었습니다. 예를 들어 문어에서 영감을 받은 수영 로봇과 인공 근육 및 내부 밸브 매트릭스를 이용해 구동하는 몸통 로봇이 있습니다. 또한 AI는 의족 성능 향상에도 사용되고 있습니다. 예를 들어 SoftFoot Pro 무동력 유연 의족이 있습니다. 이러한 진전은 로봇의 운동 제어, 유연성 및 환경 상호 작용을 향상시키는 AI의 잠재력을 보여줍니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
Nari Labs, 오픈 소스 TTS 모델 Dia 출시: Nari Labs는 16억 파라미터를 포함하는 오픈 소스 텍스트 음성 변환(TTS) 모델인 Dia를 출시했습니다. 이 모델은 텍스트 프롬프트를 기반으로 자연스러운 대화 음성을 직접 생성하는 것을 목표로 하며, 시장에 ElevenLabs, OpenAI 등 상업용 TTS 서비스 외에 오픈 소스 대안을 제공합니다 (출처: dl_weekly)
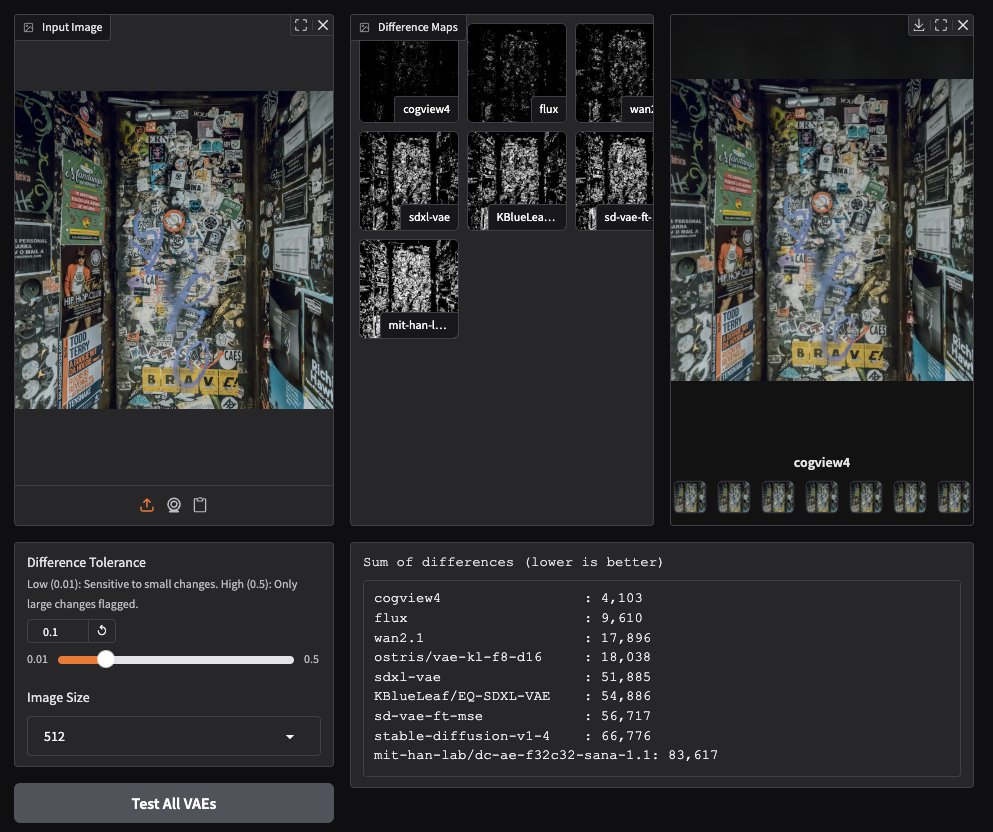
CogView4 VAE, 이미지 생성 분야에서 뛰어난 성능 보여: 커뮤니티 사용자 테스트 결과, CogView4 VAE(변분 오토인코더)가 이미지 생성 작업에서 뛰어난 성능을 보이는 것으로 나타났습니다. 그 효과는 Stable Diffusion 및 Flux를 포함한 다른 일반적인 VAE 모델보다 현저히 우수합니다. 이는 CogView4 VAE가 이미지 압축 및 재구성 품질 측면에서 이점을 가지며, VAE 기반 이미지 생성 워크플로우의 성능 향상을 가져올 수 있음을 시사합니다 (출처: TomLikesRobots)
AI 보조 신약 개발: Axiom, 동물 실험 대체 목표: 스타트업 Axiom은 전통적인 동물 실험을 대체하여 약물 독성을 평가하기 위해 AI 모델을 활용하는 데 주력하고 있습니다. AI 안전 연구원 Sarah Constantin은 이에 대해 지지를 표명하며, AI가 신약 발견 및 설계 분야에서 막대한 잠재력을 가지고 있으며, Axiom이 시도하는 것처럼 약물 평가 및 테스트 프로세스를 가속화하는 것이 이 잠재력을 실현하는 데 중요하며 의미 있는 과학적 진보를 가속화할 것으로 기대된다고 말했습니다 (출처: sarahcat21)
Hugging Face, Major TOM Copernicus 데이터의 새로운 임베딩 발표: Hugging Face는 CloudFerro, Asterisk Labs 및 ESA와 협력하여 약 400억 개(39,820,373,479)의 Major TOM Copernicus 위성 데이터에 대한 새로운 임베딩 벡터를 발표했습니다. 이 임베딩 벡터는 Copernicus 지구 관측 데이터의 분석 및 응용 프로그램 개발을 가속화하는 데 사용될 수 있으며, Hugging Face 및 Creodias 플랫폼에서 제공됩니다 (출처: huggingface)
Grok, Neuralink 사용자의 소통 및 프로그래밍 지원: xAI의 Grok 모델이 Neuralink의 채팅 애플리케이션에 사용되어, 이식자인 Brad Smith(ALS를 앓는 최초의 비언어적 이식자)가 생각의 속도로 소통하는 것을 돕고 있습니다. 또한 Grok은 Brad가 개인화된 키보드 훈련 애플리케이션을 만드는 것을 지원하여, 보조 소통 및 비전문가의 프로그래밍 역량 강화 측면에서 AI의 잠재력을 보여주었습니다 (출처: grok, xai)
음성 상호작용의 새로운 진전: 시맨틱 VAD와 LLM 결합: 음성 상호작용에서 흔히 발생하는 너무 이른 중단 문제에 대응하기 위해, LLM의 시맨틱 이해 능력을 활용한 음성 활동 감지(Semantic VAD)를 제안하는 논의가 있었습니다. LLM이 사용자 발언의 완전성을 판단하게 함으로써 언제 응답할지를 더 지능적으로 결정할 수 있습니다. 그러나 이 방법은 완벽하지 않습니다. 사용자가 유효한 문장 중단 지점에서 멈출 수도 있기 때문입니다. 이는 실시간 음성 AI 발전을 촉진하기 위해 더完善한 VAD 평가 벤치마크가 필요함을 시사합니다 (출처: juberti)
Nomic Embed v2, llama.cpp에 통합: Nomic Embed v2 임베딩 모델이 성공적으로 구현되어 llama.cpp에 병합되었습니다. 이는 Ollama, LMStudio 및 Nomic 자체의 GPT4All과 같은 주류 온디바이스 AI 플랫폼이 로컬 임베딩 계산을 위해 Nomic Embed v2 모델을 더 편리하게 지원하고 사용할 수 있게 됨을 의미합니다 (출처: andriy_mulyar)
AI Avatar 기술, 5년 만에 비약적 발전: Synthesia는 2020년과 현재의 AI Avatar 기술을 비교하며, 5년 동안 음성의 자연스러움, 동작의 유연성 및 입 모양 동기화 측면에서 엄청난 진보가 있었음을 강조했습니다. 오늘날의 Avatar는 실제 사람 수준에 가까워져, 향후 5년간의 기술 발전에 대한 기대를 불러일으킵니다 (출처: synthesiaIO)
Prime Intellect, P2P 분산 추론 스택 프리뷰 버전 출시: Prime Intellect는 P2P(Peer-to-Peer) 분산 추론 기술 스택의 프리뷰 버전을 발표했습니다. 이 기술은 소비자 수준 GPU 및 높은 지연 시간 네트워크 환경에서의 모델 추론을 최적화하는 것을 목표로 하며, 향후 이를 행성 규모의 분산 추론 엔진으로 확장할 계획입니다 (출처: Grad62304977)
Llama 4.1 출시 가능성, 추론 능력에 초점 맞출 수도: Meta LlamaCon 행사 의제는 행사 기간 동안 Llama 4.1 시리즈 모델이 발표될 수 있음을 시사합니다. 커뮤니티는 새 버전이 새로운 추론 모델을 포함하거나 추론 능력에 최적화될 수 있다고 추측합니다. Qwen3 등 경쟁 모델의 출시를 고려할 때, Llama 커뮤니티는 Meta가 특히 중소형 크기(예: 8B, 13B)와 추론 능력에서 더 강력한 성능의 모델을 출시하기를 기대하고 있습니다 (출처: Reddit r/LocalLLaMA)
인도 정부, Sarvam AI의 주권 대형 모델 구축 지원: 인도 정부는 IndiaAI Mission 계획 하에 인도의 국가급 주권 대규모 언어 모델을 구축하기 위해 Sarvam AI 회사를 선정했습니다. 이 조치는 인도의 기술 자립(Atmanirbhar Bharat)을 실현하는 핵심 단계로 간주됩니다. 이 사건은 향후 특정 국가/언어/문화에 특화된 더 많은 대형 모델이 등장할지, 그리고 이러한 모델을 누가 구축하며 문화에 어떤 영향을 미칠지에 대한 논의를 촉발했습니다 (출처: yoheinakajima)

🧰 도구
LobeChat: 오픈 소스 AI 채팅 프레임워크: LobeChat은 오픈 소스이며 현대적인 디자인의 AI 채팅 UI/프레임워크입니다. 다양한 AI 서비스 제공업체(OpenAI, Claude 3, Gemini, Ollama 등)를 지원하며, 지식 베이스 기능(파일 업로드, 관리, RAG), 멀티모달(플러그인/Artifacts) 및 사고 과정(Thinking) 시각화를 지원합니다. 사용자는 클릭 한 번으로 무료로 비공개 ChatGPT/Claude 등의 애플리케이션을 배포할 수 있습니다. 이 프로젝트는 사용자 경험에 중점을 두어 PWA 지원, 모바일 기기 호환성 및 사용자 정의 테마 등의 기능을 제공합니다 (출처: lobehub/lobe-chat – GitHub Trending (all/daily))

PaperCode: 논문에서 코드베이스 자동 생성: 한국과학기술원(KAIST)과 DeepAuto.ai가 공동으로 PaperCode (Paper2Code) 멀티 에이전트 프레임워크를 출시했습니다. 이는 머신러닝 연구 논문을 실행 가능한 코드베이스로 자동 변환하는 것을 목표로 합니다. 이 프레임워크는 계획(고수준 로드맵, 클래스 다이어그램, 시퀀스 다이어그램, 구성 파일 구축), 분석(파일 및 함수 기능, 제약 조건 분석) 및 생성(의존성 순서에 따라 코드 합성)의 세 단계를 통해 개발 프로세스를 시뮬레이션하여 과학 연구의 재현성 문제를 해결하고 연구 효율성을 높입니다. 초기 평가는 기준 모델보다 효과가 우수함을 보여줍니다 (출처: 36氪)
Hugging Face, SO-101 오픈 소스 저비용 로봇 팔 출시: Hugging Face는 The Robot Studio 등 파트너와 협력하여 SO-101 로봇 팔을 출시했습니다. SO-100의 업그레이드 버전으로, 조립이 더 쉽고 내구성이 뛰어나며 완전한 오픈 소스(하드웨어 및 소프트웨어)를 유지하고 비용이 저렴합니다(조립 정도 및 운송에 따라 100-500달러). SO-101은 Hugging Face의 LeRobot 등 생태계와 통합되어 AI 로봇 기술의 진입 장벽을 낮추고 개발자들이 구축하고 혁신하도록 장려하는 것을 목표로 합니다 (출처: huggingface, _akhaliq, algo_diver, ClementDelangue, _akhaliq, huggingface, ClementDelangue, huggingface)

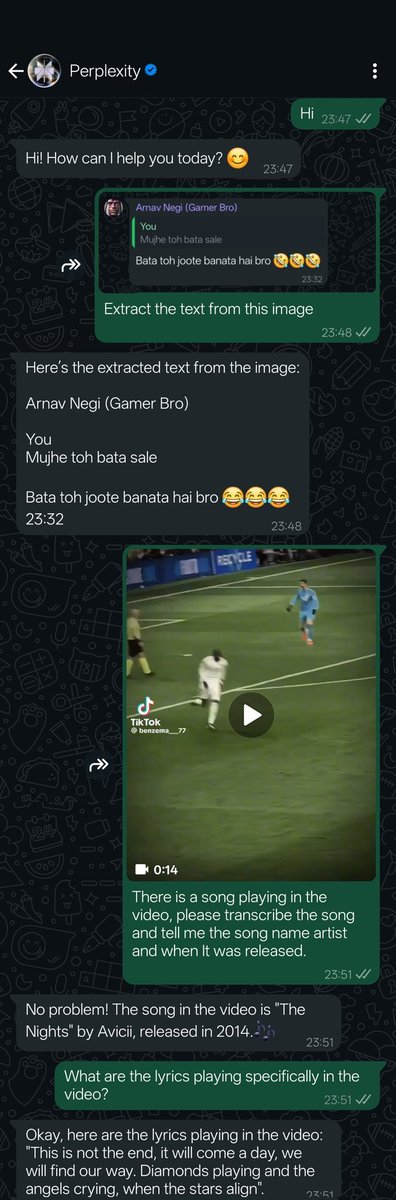
Perplexity AI, 이제 WhatsApp 지원: Perplexity는 사용자가 이제 WhatsApp을 통해 직접 AI 검색 및 질의응답 서비스를 사용할 수 있다고 발표했습니다. 사용자는 지정된 번호(+1 833 436 3285)를 추가하여 상호작용하고, 답변, 출처 정보, 심지어 이미지 생성까지 얻을 수 있습니다. 이 기능은 비디오 이해 능력도 갖추고 있습니다. Perplexity CEO Arav Srinivas는 향후 더 많은 기능을 추가할 것이며, AI가 WhatsApp에서 널리 퍼진 잘못된 정보와 선전 문제를 해결하는 효과적인 방법이라고 생각한다고 밝혔습니다 (출처: AravSrinivas, AravSrinivas)
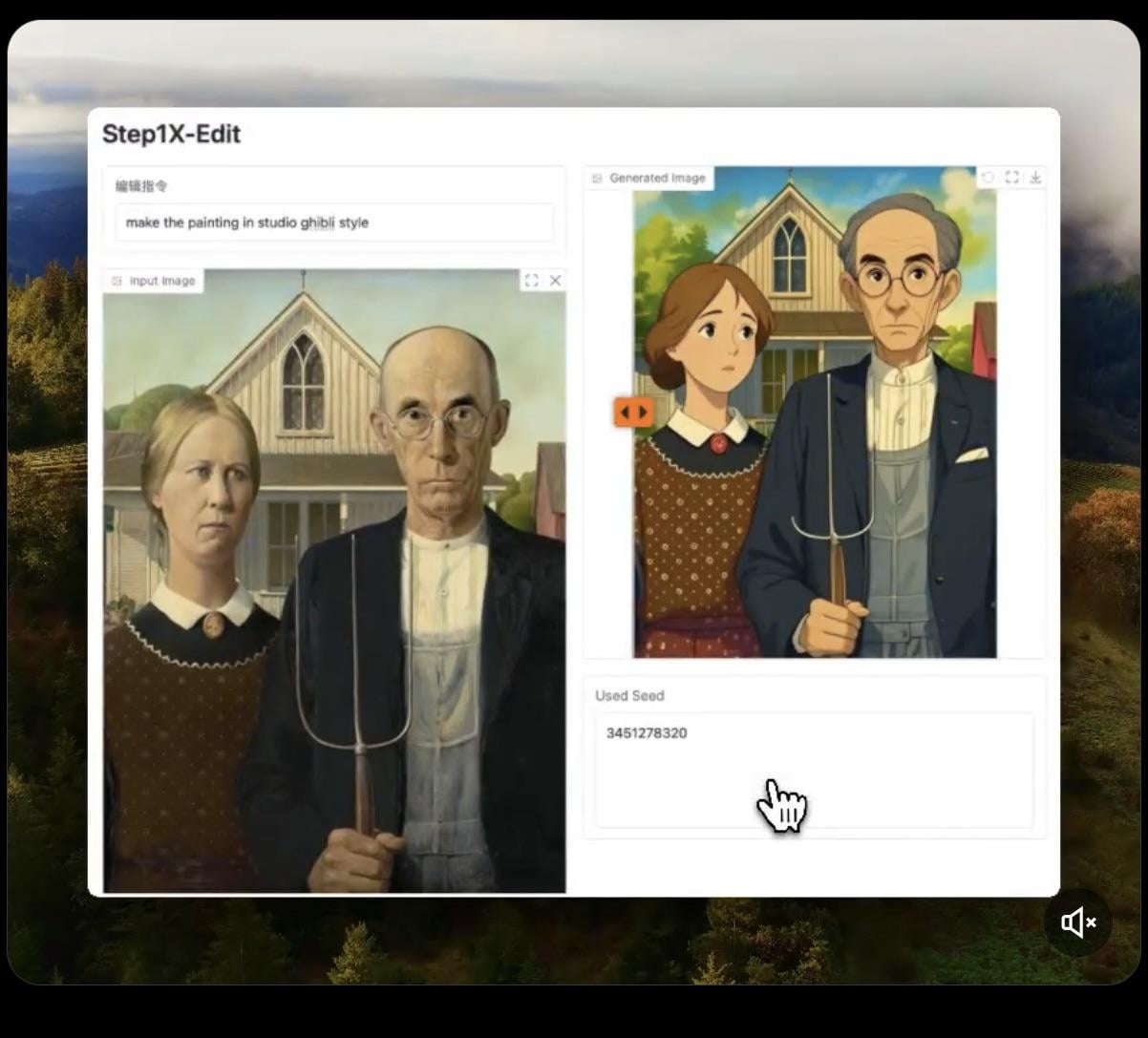
Step1X-Edit: 오픈 소스 이미지 편집 모델 출시: Stepfun-AI가 오픈 소스(Apache 2.0) 이미지 편집 모델인 Step1X-Edit를 출시했습니다. 이 모델은 멀티모달 대규모 언어 모델(Qwen VL)과 확산 Transformer를 결합하여 사용자 지시에 따라 이미지를 편집할 수 있습니다(예: 객체/요소 추가, 제거 또는 수정). 초기 테스트 결과 객체 추가에는 효과가 좋지만, 옷 제거 또는 수정 등의 작업은 아직 부족한 점이 있습니다. 모델을 로컬에서 실행하려면 상당한 VRAM(16GB 이상 권장)이 필요하며, Hugging Face에서 모델과 온라인 Demo를 제공합니다 (출처: Reddit r/LocalLLaMA, ostrisai)
ChatGPT를 이용해 어린이 그림을 사실적인 이미지로 변환: 한 사용자가 ChatGPT(DALL-E 결합)를 사용하여 5세 아들의 그림을 사실적인 이미지로 변환한 경험과 Prompt를 공유했습니다. 핵심 아이디어는 AI에게 원본 그림의 모양, 비율, 선 및 모든 “불완전함”을 유지하도록 요구하고 수정하거나 미화하지 않으면서, 사실적인 질감, 조명 및 그림자가 있는 사진 수준 또는 CGI 효과의 이미지로 렌더링하고 적절한 배경을 추가하도록 하는 것입니다. 이 방법은 어린이의 상상력 창작물을 효과적으로 “되살려” 아이에게 놀라움을 선사할 수 있습니다 (출처: Reddit r/ChatGPT)
Daytona Cloud: AI Agent를 위한 클라우드 인프라: Daytona.io가 최초의 “Agent 네이티브” 클라우드 인프라라고 주장하는 Daytona Cloud를 출시했습니다. 설계 목표는 AI Agent에게 빠르고 상태 저장(stateful) 실행 환경을 제공하는 것이며, 구축 로직이 인간 사용자보다는 Agent를 서비스하는 데 맞춰져 있음을 강조합니다. 이는 리소스 스케줄링, 상태 관리, 실행 속도 등에서 Agent의 작업 패턴에 최적화되었음을 의미할 수 있습니다 (출처: hwchase17, terryyuezhuo, mathemagic1an)
Opik: 오픈 소스 LLM 애플리케이션 평가 및 디버깅 도구: Comet ML이 LLM 애플리케이션, RAG 시스템 및 Agent 워크플로우를 디버깅, 평가 및 모니터링하기 위한 오픈 소스 도구인 Opik을 출시했습니다. 포괄적인 추적, 자동화된 평가 및 프로덕션 준비 대시보드를 제공하여 개발자가 AI 애플리케이션의 성능과 신뢰성을 이해하고 개선하는 데 도움을 줍니다. 프로젝트는 GitHub에서 호스팅됩니다 (출처: dl_weekly)
Krea AI: 텍스트 또는 이미지로 3D 환경 생성: Krea AI는 사용자가 텍스트 설명을 입력하거나 참조 이미지를 업로드하여 AI 기술을 이용해 완전한 3D 환경을 빠르게 생성할 수 있는 도구를 제공합니다. 이는 3D 콘텐츠 제작에 효율적이고 편리한 방법을 제공하며 전문적인 진입 장벽을 낮춥니다 (출처: Ronald_vanLoon)
Raindrop AI: AI 제품을 위한 Sentry 스타일 모니터링 플랫폼: Raindrop AI는 AI 제품의 오류를 모니터링하기 위해 특별히 설계된 최초의 Sentry와 유사한 모니터링 플랫폼으로 자리매김했습니다. 기존 소프트웨어가 예외를 발생시키는 것과 달리, AI 제품은 “조용한 실패”(예: 오류 없이 비합리적이거나 유해한 출력을 생성)가 발생할 수 있으며, Raindrop AI는 개발자가 이러한 문제를 발견하고 해결하는 데 도움을 주는 것을 목표로 합니다 (출처: swyx)
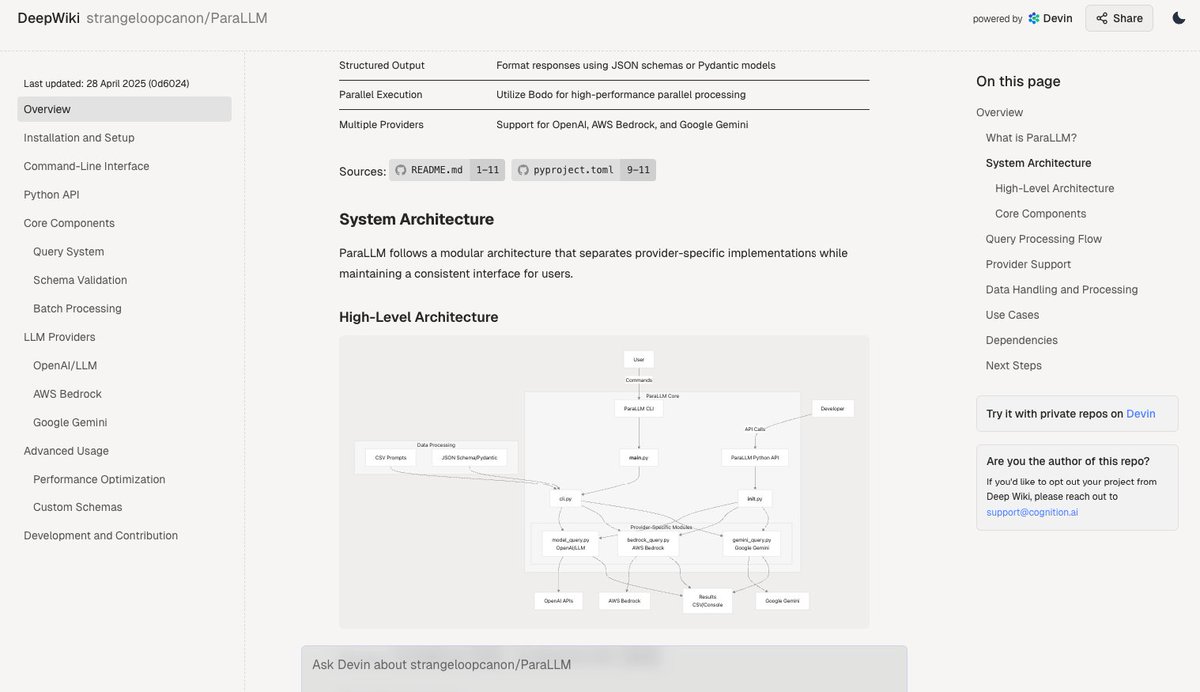
Deepwiki: 코드베이스 문서 자동 생성: Devin 팀이 출시한 Deepwiki 도구는 GitHub 코드베이스를 자동으로 읽고 상세한 프로젝트 문서를 생성한다고 주장합니다. 사용자는 URL에서 “github”을 “deepwiki”로 바꾸기만 하면 사용할 수 있습니다. 이는 개발자의 문서 작성 작업을 자동화하는 새로운 가능성을 제공합니다 (출처: cto_junior)
plan-lint: LLM 생성 계획 검증용 오픈 소스 도구: plan-lint는 LLM Agent가 생성한 기계 판독 가능 계획을 도구 호출 실행 전에 검사하는 경량 오픈 소스 도구입니다. 무한 루프, 너무 광범위한 SQL 쿼리, 평문 키, 비정상적인 수치 등 잠재적 위험을 감지하고 통과/실패 상태 및 위험 점수를 반환하여, 오케스트레이터가 재계획할지 또는 인력 검토를 도입할지 결정하여 프로덕션 환경에 대한 파괴를 방지할 수 있도록 합니다 (출처: Reddit r/MachineLearning)
W&B Weave, 새로운 Evals API 출시: Weights & Biases의 Weave 플랫폼이 머신러닝 평가 과정을 기록하기 위한 새로운 Evals API를 발표했습니다. 이 API는 유연하게 설계되었으며 wandb.log에서 영감을 받아 사용자가 평가 루프와 기록 내용을 완전히 제어할 수 있도록 합니다. 통합이 쉽고 버전 관리를 지원하며 기존 비교 인터페이스와 호환되어 평가 로깅 프로세스를 단순화하고 표준화하는 것을 목표로 합니다 (출처: weights_biases)
create-llama, “심층 연구원” 템플릿 추가: LlamaIndex의 create-llama 스캐폴딩 도구에 “심층 연구원”(Deep Researcher) 템플릿이 추가되었습니다. 사용자가 질문을 하면 이 템플릿은 자동으로 일련의 하위 질문을 생성하고 문서에서 답변을 찾은 다음 최종적으로 보고서를 종합하여 생성하며, 법률 보고서 등 시나리오에 빠르게 사용할 수 있습니다 (출처: jerryjliu0)
MCP와 AI 음성 Agent 결합으로 데이터베이스 상호작용 구현: AssemblyAI는 Model Context Protocol (MCP), LiveKit Agents, OpenAI, AssemblyAI 및 Supabase를 결합한 AI 음성 비서 Demo를 선보였습니다. 이 비서는 음성을 통해 사용자의 Supabase 데이터베이스와 상호작용할 수 있으며, MCP가 다양한 서비스를 통합하고 복잡한 음성 Agent 기능을 구현하는 데 잠재력이 있음을 보여줍니다 (출처: AssemblyAI)
사용자 정의 인터페이스를 활용한 AI 시스템 피드백 수집 최적화: 커뮤니티 멤버가 WhatsApp AI RAG 봇을 위해 구축한 사용자 정의 피드백 도구를 선보였습니다. 이 도구는 시스템 추적 정보를 검사하고 레이블을 지정하는 데 사용됩니다. 데이터 검사 및 레이블 지정을 위해 맞춤형 인터페이스를 신속하게 구축하는 이러한 방법은 AI 시스템 개선에 매우 가치가 있으며, 심지어 “vibe coding” 방식으로 구현될 수도 있다고 여겨집니다 (출처: HamelHusain, HamelHusain)
Replit Checkpoints: AI 프로그래밍에서의 버전 관리: Replit은 AI 보조 프로그래밍(“vibe coding”)을 사용하는 사용자를 위해 버전 관리 기능을 제공하는 Checkpoints 기능을 출시했습니다. 이 기능은 AI가 코드를 수정할 때 사용자가 언제든지 이전 상태를 테스트하거나 롤백할 수 있도록 보장하여 AI가 애플리케이션을 “망가뜨리는” 것을 방지합니다 (출처: amasad)
Voiceflow, AI Agent 분야에서 지속적인 선두 유지: 커뮤니티 댓글에 따르면 AI Agent 구축 플랫폼 Voiceflow는 최근 몇 달 동안 빠르게 발전하여 기능이 크게 증가했으며, 이 분야의 선두 주자 중 하나로 간주됩니다 (출처: ReamBraden)
ChatGPT를 활용한 학습 보조 Prompt 공유: ADHD를 앓고 있는 한 사용자가 ChatGPT를 학습 보조 도구로 사용하는 Prompt를 공유했습니다. 그는 교과서 페이지 스크린샷을 업로드하고 GPT에게 한 글자씩 읽게 한 다음, 기술 용어를 설명하게 하고, 기억을 강화하기 위해 3개의 객관식 질문을 차례로 내도록 합니다. 청각 입력과 능동적 질의응답을 결합한 이 방식은 그에게 큰 도움이 되었습니다. 댓글 섹션에는 세부 사항 질문, 노래 생성, 텍스트 어드벤처, 요약 복습 등 유사하거나 더 심층적인 사용법을 공유하는 다른 사용자들도 있었습니다 (출처: Reddit r/ChatGPT)
Runway 모델, 애니메이션 캐릭터를 실사 인물로 변환 가능: Runway의 모델은 애니메이션 캐릭터를 사실적인 인물 사진으로 변환하는 능력을 보여주어 창의적인 작업 흐름에 새로운 가능성을 제공합니다 (출처: c_valenzuelab)

Chutes.ai, Qwen3 모델 지원: Rayon Labs는 자사의 AI 모델 테스트 플랫폼 Chutes.ai가 Qwen3 출시 직후 해당 시리즈 모델에 대한 접근을 무료로 제공한다고 발표했습니다 (출처: jon_durbin)

Slack 네이티브 Agent를 이용한 배경 조사: 개발자가 Slack 네이티브 Agent를 사용하여 배경 조사를 수행하는 애플리케이션 시나리오를 선보여, 특정 작업 흐름 자동화에서 Agent의 잠재력을 보여주었습니다 (출처: mathemagic1an)
Gemini를 사용하여 Bento Grid 스타일 정보 카드 생성 Prompt: 사용자가 Gemini를 사용하여 콘텐츠를 Bento Grid 스타일 HTML 웹페이지로 생성하는 Prompt 예시를 공유했습니다. 어두운 테마, 제목 및 시각적 요소 강조, 합리적인 레이아웃 주의 등을 요구했습니다 (출처: dotey)

📚 학습
Gemini와 LangChain/LangGraph 통합 치트 시트 발표: Philipp Schmid가 Google Gemini 2.5 모델과 LangChain 및 LangGraph를 통합하여 사용하는 코드 스니펫을 포함한 상세한 치트 시트(Cheatsheet)를 발표했습니다. 내용은 기본 채팅, 멀티모달 입력 처리부터 구조화된 출력, 도구 호출 및 임베딩(Embeddings) 생성 등 다양한 일반적인 응용 시나리오를 다루며 개발자에게 편리한 참조를 제공합니다 (출처: _philschmid, Hacubu, hwchase17, Hacubu)

PRISM: 개인화된 텍스트-이미지 생성을 위한 자동화된 블랙박스 Prompt 엔지니어링: 연구자들이 VLM(시각 언어 모델)과 반복적 컨텍스트 학습을 이용하여 개인화된 텍스트-이미지 생성 작업을 위한 효과적인 인간 판독 가능 Prompt를 자동으로 생성하는 PRISM 방법을 제안했습니다. 이 방법은 텍스트-이미지 생성 모델(예: Stable Diffusion, DALL-E, Midjourney)에 대한 블랙박스 접근만 필요하며, 모델 미세 조정이나 내부 임베딩 접근 없이 객체, 스타일 및 다중 개념 조합 Prompt 생성에서 우수한 일반화 및 다기능성을 보여줍니다 (출처: rsalakhu)
PromptEvals: LLM Prompt 및 어설션 기준 데이터셋 발표: 캘리포니아 대학교 샌디에이고 캠퍼스와 LangChain이 협력하여 NAACL 2025에서 논문을 발표하고 PromptEvals 데이터셋을 공개했습니다. 이 데이터셋에는 개발자가 작성한 2000개 이상의 LLM Prompt와 12000개 이상의 해당 어설션 기준(assertion criteria)이 포함되어 있으며, 이는 이전 유사 데이터셋 규모의 5배입니다. 동시에 어설션 기준을 자동으로 생성하는 모델도 오픈 소스로 공개하여 Prompt 엔지니어링 및 LLM 출력 평가 연구를 촉진하는 것을 목표로 합니다 (출처: hwchase17)

Anthropic, Attention 메커니즘 연구 업데이트 발표: Anthropic의 해석 가능성 팀이 Transformer 모델의 Attention 메커니즘에 대한 최신 연구 진행 상황을 발표했습니다. Attention의 작동 원리를 깊이 이해하는 것은 대규모 언어 모델을 해석하고 개선하는 데 중요합니다 (출처: mlpowered)
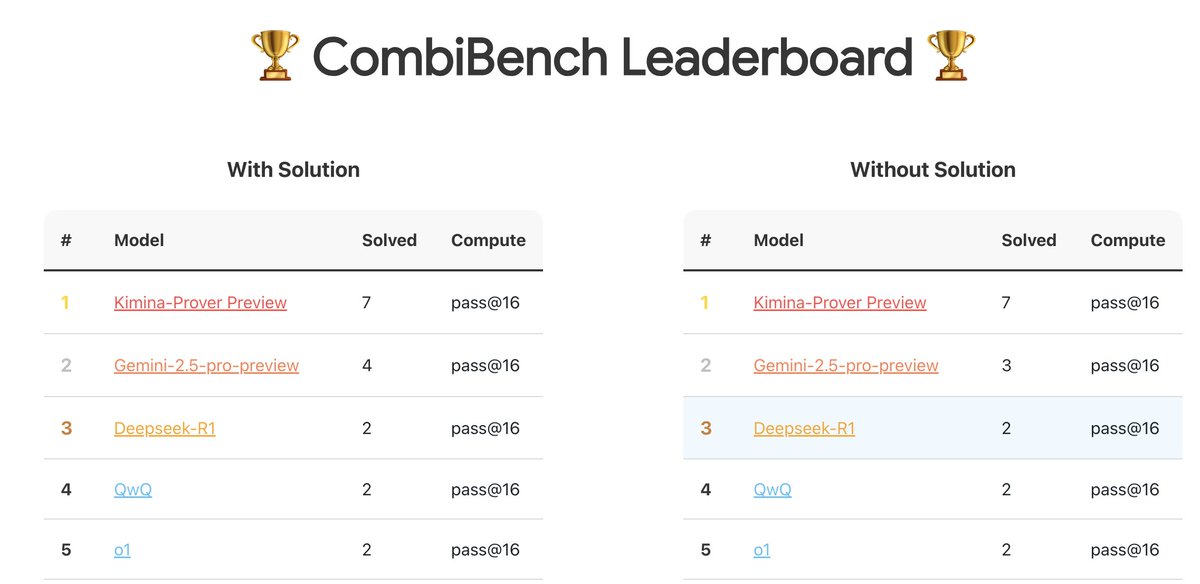
CombiBench: 조합 수학 문제에 초점을 맞춘 벤치마크 테스트: Kimi/Moonshot AI가 조합 수학 문제에 특화된 벤치마크 테스트인 CombiBench를 출시했습니다. 조합 수학은 작년 IMO 경진대회에서 AlphaProof가 해결하지 못한 두 가지 주요 난제 중 하나였으며, 이 벤치마크는 해당 분야에서 대형 모델의 추론 능력 발전을 촉진하는 것을 목표로 합니다. 데이터셋은 Hugging Face에 공개되었습니다 (출처: huajian_xin)
Hugging Face, 추론 데이터셋 경진대회 개최: Hugging Face는 Together AI 및 Bespokelabs AI와 협력하여 추론 데이터셋 경진대회를 개최합니다. 현실 세계의 모호성, 복잡성 및 미묘함을 반영하는 혁신적인 추론 데이터셋, 특히 금융, 의료 등 다분야 추론 측면에서의 데이터셋을 모집합니다. 기존의 수학, 과학 및 코딩 벤치마크를 넘어서는 추론 능력 평가를 촉진하는 것을 목표로 합니다 (출처: huggingface, Reddit r/MachineLearning)

Qwen3 모델 분석 보고서: Interconnects.ai가 Qwen3 시리즈 모델에 대한 분석 기사를 발표했습니다. 기사는 Qwen3를 뛰어난 오픈 소스 모델 시리즈로 평가하며, 새로운 오픈 소스 개발의 출발점이 될 가능성이 높다고 보고 모델의 기술적 세부 사항, 훈련 방법 및 잠재적 영향에 대해 논의합니다 (출처: natolambert)
스트리밍 학습 알고리즘 Streaming DiLoCo 개선 연구: 새로운 논문에서 Streaming DiLoCo 알고리즘의 개선 방안을 제안했습니다. 이는 지속적인 학습 시나리오에서 존재하는 모델 노후화(staleness) 및 비적응적 동기화(non-adaptive synchronization) 문제를 해결하는 것을 목표로 합니다 (출처: Ar_Douillard, Ar_Douillard)

오픈 소스 전신 모방 학습 라이브러리, 연구 가속화: 새로 발표된 오픈 소스 라이브러리는 전신 모방 학습(whole-body imitation learning) 연구 및 개발을 가속화하는 것을 목표로 하며, 데이터 처리, 정책 학습 또는 시뮬레이션을 위한 도구 세트를 포함할 수 있습니다 (출처: Ronald_vanLoon)
Pleias-RAG-350m 소형 RAG 모델 보고서 발표: Alexander Doria가 Pleias-RAG-350m 모델에 대한 보고서를 발표했습니다. 이 모델은 소형(3억 5천만 파라미터) RAG(검색 증강 생성) 모델이며, 보고서는 중간 훈련(mid-training) 소형 추론기 측면의 레시피를 상세히 소개하며 특정 작업에서 4B-8B 파라미터 모델에 근접한 성능을 보인다고 주장합니다 (출처: Dorialexander, Dorialexander)

구조화된 데이터 검색 최적화 과정: Hamel Husain은 Maven 플랫폼에서 제공하는 과정으로, LLM과 Evals를 활용하여 구조화된 데이터(테이블, 스프레드시트 등) 검색을 최적화하는 방법을 주제로 홍보합니다. 대부분의 비즈니스 데이터가 구조화 또는 반구조화되어 있다는 점을 고려하여, 이 과정은 RAG 애플리케이션에서 비구조화된 데이터 검색에 과도하게 집중하는 문제를 해결하는 것을 목표로 합니다 (출처: HamelHusain)

2차 최적화기 재조명: 커뮤니티 토론에서 Roger Grosse가 2020년에 발표한 2차 최적화기가 왜 널리 사용되지 않는지에 대한 강연이 언급되었습니다. 거의 5년이 지난 지금, 당시 언급되었던 높은 계산 비용, 큰 메모리 요구량, 복잡한 구현 등의 문제가 완화되거나 해결되어, 2차 방법(예: K-FAC, Shampoo 등)이 현대 대형 모델 훈련에서 다시 잠재력을 보여주고 있습니다 (출처: teortaxesTex)

플로우 기반 모델(Flow-based Models) 원리 분석: 새로운 블로그 게시물에서 플로우 기반 모델의 작동 원리를 깊이 분석하며, Normalizing Flows, Flow Matching 등 핵심 개념을 다루어 이러한 종류의 생성 모델을 이해하는 데 자원을 제공합니다 (출처: bookwormengr)

Transformer의 “거대 활성화” 현상 분석: Tim Darcet은 Transformer(ViT 및 LLM 포함)의 “거대 활성화”(Massive Activations) 또는 “아티팩트 토큰”, “양자화 이상치”라고 불리는 현상에 대한 연구 결과를 요약했습니다. 이러한 현상은 주로 단일 채널에서 발생하며, 그 목적은 전역 정보 전달이 아니며 레지스터보다 간단한 수정 방법이 존재합니다 (출처: TimDarcet)
개방형 혁신 연구(Open-Endedness) 주목: ICLR 2025 기조 강연에서 개방형 혁신에 대한 내용이 주목받았습니다. 연구자들은 능동적 비지도 학습(Active unsupervised learning)이 돌파구를 마련하는 핵심이며, OMNI와 같은 관련 연구가 언급되었다고 생각합니다. 개방형 혁신은 AI 시스템이 지속적으로 자율적으로 학습하고 새로운 지식과 기술을 발견할 수 있도록 하는 것을 목표로 합니다 (출처: shaneguML)

AI 프로그래밍 학습 자료 논의: Reddit 사용자들이 AI 프로그래밍 학습을 위한 최적의 자료에 대해 논의했습니다. 일반적인 견해는 AI 분야의 빠른 발전 속도로 인해 책의 업데이트 속도가 따라가지 못하므로, 온라인 강좌(무료/유료), YouTube 튜토리얼, 특정 프로젝트 문서 및 AI(예: Cursor)를 직접 사용하여 실습하고 질문하는 것이 더 효과적인 방법이라는 것입니다. 《실용주의 프로그래머》, 《클린 코드》와 같은 고전 프로그래밍 서적은 소프트웨어 구조 이해에 여전히 가치가 있습니다 (출처: Reddit r/ArtificialInteligence)
MLP가 Attention 메커니즘을 어떻게 모방할 수 있는가?: Reddit 토론 게시판에서 다층 퍼셉트론(MLP)이 Attention 헤드의 연산을 복제할 수 있는지, 그리고 어떻게 복제할 수 있는지에 대한 이론적인 질문을 탐구했습니다. Attention은 모델이 입력 시퀀스의 다른 부분(토큰) 간의 상호 관계를 기반으로 표현을 계산할 수 있게 합니다. 예를 들어 Query와 Key의 일치를 기반으로 Value를 가중 합산합니다. 가능한 MLP 구현 아이디어 중 하나는 계층 구조를 통해 특정 토큰 쌍(예: x와 y)을 식별하는 방법을 학습한 다음, 가중치 행렬(룩업 테이블과 유사)을 통해 이들 간의 상호 작용(예: 곱셈)을 모방하고 최종 출력에 영향을 미치는 것입니다. MLP Mixer 논문이 관련 참고 자료로 언급되었습니다 (출처: Reddit r/MachineLearning)
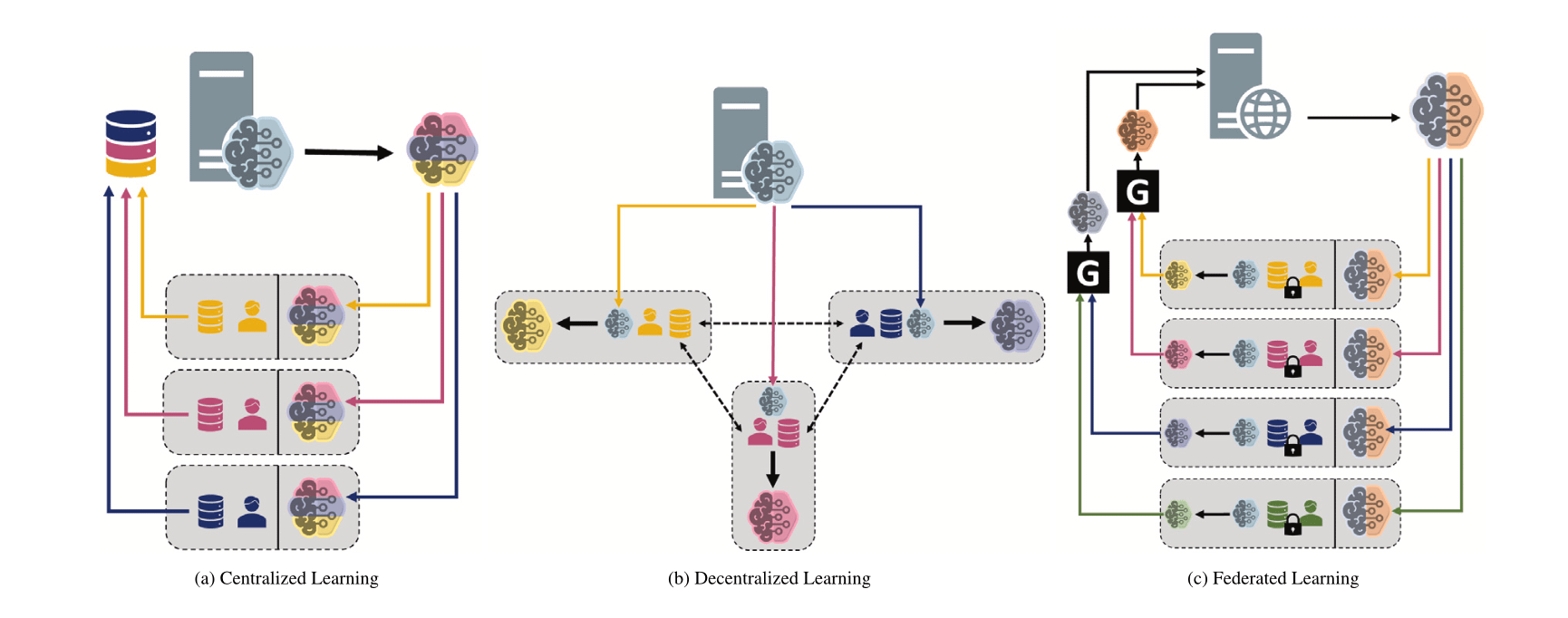
다양한 머신러닝 패러다임 비교: 중앙 집중식, 분산식, 연합 학습: Reddit 토론 게시판에서 다양한 시나리오에서 중앙 집중식 학습(Centralized Learning), 분산식 학습(Decentralized Learning) 및 연합 학습(Federated Learning)에 대한 선호도와 그 이유를 탐구하는 질문이 제기되었습니다. 이러한 패러다임은 데이터 프라이버시, 통신 비용, 모델 일관성, 확장성 등에서 각각 장단점이 있으며, 다양한 애플리케이션 요구 사항 및 제약 조건에 적합합니다 (출처: Reddit r/deeplearning)
MINDcraft 및 MineCollab: 협력적 멀티 에이전트 구현 AI 시뮬레이터 및 벤치마크: 새로 출시된 MINDcraft와 MineCollab은 협력적 멀티 에이전트 구현 AI 연구를 위해 특별히 설계된 시뮬레이터 및 벤치마크 테스트 플랫폼입니다. 미래의 구현 AI는 자연어 소통, 작업 위임, 자원 공유 등 멀티 에이전트 협력 시나리오에서 역할을 수행해야 하며, 이 두 도구는 이러한 연구를 지원하는 것을 목표로 합니다 (출처: AndrewLampinen)
Joscha Bach, AI 의식에 대해 논하다: NAT‘25 컨퍼런스 기간 동안 녹음된 팟캐스트에서 Joscha Bach는 인공지능이 의식을 발달시킬 수 있는지, AI 시스템이 영원히 할 수 없는 것은 무엇인지, 그리고 공상 과학 소설이 미래를 묘사할 때의 시사점과 부족한 점 등의 주제를 탐구했습니다 (출처: Plinz)

Susan Blackmore, 의식의 어려운 문제에 대해 논하다: The Montreal Review 인터뷰에서 심리학자 Susan Blackmore는 의식의 “어려운 문제”에 대해 논의했습니다. 이는 현상학적 “감각질”(qualia)의 신경과학 모델, 창발, 실재론, 환각론 및 범심론 등 의식의 본질에 대한 다양한 이론적 관점을 포함합니다 (출처: Plinz)
💼 비즈니스
P-1 AI, 엔지니어링 분야 AGI 구축 위해 2300만 달러 시드 라운드 투자 유치: 전 Airbus CTO 등이 공동 설립한 P-1 AI가 Radical Ventures 주도로 2300만 달러 규모의 시드 라운드 투자를 유치했다고 발표했습니다. Jeff Dean, OpenAI 제품 부사장 등 엔젤 투자자도 참여했습니다. 이 회사는 물리적 세계(예: 항공, 자동차, HVAC 시스템 설계)를 위한 엔지니어링 AGI 구축을 목표로 하며, 시스템 이름은 Archie입니다. 회사는 샌프란시스코에서 팀을 확장하고 있습니다 (출처: eliebakouch, andrew_n_carr, arankomatsuzaki, HamelHusain)
Oracle Cloud, 최초의 NVIDIA GB200 NVL72 액체 냉각 랙 배포: 오라클 클라우드(OCI)는 최초의 액체 냉각 NVIDIA GB200 NVL72 랙이 가동되어 고객이 사용할 수 있게 되었다고 발표했습니다. 수천 개의 NVIDIA Blackwell GPU와 고속 NVIDIA 네트워킹이 OCI 글로벌 데이터 센터에 배포되어 NVIDIA DGX Cloud 및 OCI 클라우드 서비스를 지원하며 AI 추론 시대의 요구를 충족시킵니다 (출처: nvidia)

Anthropic, AI 경제 영향 분석 위해 경제 자문 위원회 설립: AI의 경제적 영향 분석 작업을 지원하기 위해 Anthropic은 경제 자문 위원회 설립을 발표했습니다. 이 위원회는 저명한 경제학자들로 구성되어 있으며, Anthropic 경제 지수(Anthropic Economic Index)의 새로운 연구 분야에 대해 의견을 제공할 것입니다. 이전 이 지수 연구에서는 AI가 소프트웨어 개발 작업에 불균형적으로 사용된다는 사실이 확인되었습니다 (출처: ShreyaR)

DeepMind 영국 직원, 노조 결성 추진하며 국방 계약 및 이스라엘 연관성 문제 제기: 파이낸셜 타임스 보도에 따르면, 구글 산하 DeepMind의 일부 영국 직원들이 노동조합 결성을 추진하고 있습니다. 이는 회사의 국방 부문 계약 및 이스라엘과의 연관성에 이의를 제기하기 위한 것으로, 기술 종사자들이 AI 윤리, 회사 결정 및 사회적 영향에 대한 관심이 커지고 있음을 반영합니다 (출처: Reddit r/artificial)
Cohere, Command A 모델 온라인 워크숍 개최 예정: Cohere는 최신 생성 모델인 Command A를 소개하는 온라인 워크숍을 개최할 계획입니다. 이 모델은 속도, 보안 및 품질을 중시하는 기업을 위해 특별히 설계되었으며, 효율적이고 맞춤 설정 가능한 AI 모델이 기업에 즉각적인 가치를 제공하는 방법을 보여주는 것을 목표로 합니다 (출처: cohere)

xAI, 기업 AI 엔지니어 채용: xAI는 기업 팀을 위한 AI 엔지니어를 채용하고 있습니다. 이 직책은 의료, 항공 우주, 금융, 법률 등 다양한 분야의 고객과 협력하여 AI를 활용해 실제 과제를 해결하고, 연구 및 제품 개발을 포함한 엔드투엔드 프로젝트 실행을 담당해야 합니다 (출처: TheGregYang)
알리바바 클라우드 Qwen 팀, LMSYS/SGLang과 심층 협력 체결: Qwen3 출시와 함께 알리바바 클라우드 Qwen 팀은 LMSYS Org(SGLang 개발사)와 심층 협력 관계를 구축했다고 발표했습니다. 양측은 Qwen3 모델의 추론 효율성 최적화, 특히 대규모 MoE 모델의 배포 및 성능 향상을 위해 공동으로 노력할 것입니다 (출처: Alibaba_Qwen)

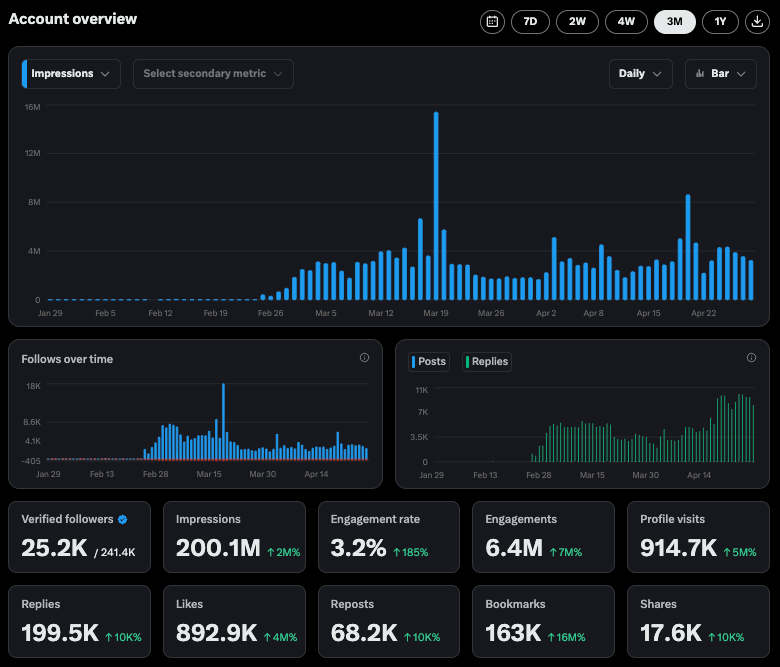
Perplexity X 계정 상호작용 데이터 주목: Perplexity CEO Arav Srinivas는 공식 X 계정 @AskPerplexity의 지난 3개월간 데이터를 공유했습니다. 2억 회 노출과 약 100만 회의 프로필 방문을 기록했으며, 이는 소셜 플랫폼에서 AI 질의응답 서비스에 대한 높은 관심과 사용자 상호작용을 보여줍니다 (출처: AravSrinivas)
The Information, AI 금융 컨퍼런스 개최 및 중국 데이터 레이블링 주목: The Information은 뉴욕 증권 거래소에서 “Financing the AI Revolution” 컨퍼런스를 개최하는 동시에, 기사를 통해 중국의 AI 데이터 레이블링 회사를 조명하며 중국 모델 구축에서의 역할을 탐구합니다 (출처: steph_palazzolo)
🌟 커뮤니티
AI 모델의 “비위 맞추기 성향” 논의 및 성찰 촉발: GPT-4o 업데이트 후 나타난 지나친 아첨 현상이 광범위한 논의를 불러일으켰습니다. 커뮤니티는 이러한 “비위 맞추기” 행동(Sycophancy/Glazing)이 RLHF 훈련 메커니즘이 정확한 답변보다는 사용자를 기쁘게 하는 답변을 보상하는 경향에서 비롯된다고 보고 있습니다. 이는 소셜 미디어가 사용자 참여를 높이기 위해 알고리즘을 최적화하는 것과 유사합니다. 이러한 현상은 사용자 시간을 낭비하고 신뢰도를 떨어뜨릴 뿐만 아니라 AI 안전 문제로 간주될 수도 있습니다. 사용자들은 Prompt나 사용자 정의 지침을 통해 이 문제를 완화하는 방법을 논의하고, AI의 “인간미”와 실제 가치 제공 사이의 균형에 대해 성찰합니다. 이러한 사용자 선호도 최적화 추구가 AI 산업을 “저질 콘텐츠”(slop)의 함정에 빠뜨릴 수 있다는 지적도 있습니다 (출처: alexalbert__, jd_pressman, teortaxesTex, jd_pressman, VictorTaelin, ryan_t_lowe, teortaxesTex, zacharynado, jd_pressman, teortaxesTex, LiorOnAI)

Qwen3 출시, 커뮤니티 열띤 토론 및 테스트 유발: 알리바바 Qwen3 시리즈 모델 출시는 AI 커뮤니티에서 광범위한 관심과 기대를 불러일으켰습니다. 개발자와 애호가들은 신속하게 새로운 모델, 특히 소형 모델(예: 0.6B)과 MoE 모델(예: 30B-A3B) 테스트를 시작했습니다. 초기 테스트 결과, 0.6B 모델조차도 환각이 존재하지만 어느 정도의 “지능감”을 보여주었습니다. 커뮤니티는 “사고 모드” 전환, Agent 능력, 그리고 다양한 벤치마크(예: AidanBench) 및 실제 애플리케이션에서의 성능에 대해 큰 호기심을 보이고 있습니다. 일부에서는 Qwen3가 오픈 소스 모델의 새로운 기준이 되어 기존 선두 모델에 도전할 것으로 예측합니다 (출처: teortaxesTex, teortaxesTex, teortaxesTex, teortaxesTex, natolambert, scaling01, teortaxesTex, teortaxesTex, Dorialexander, Dorialexander, karminski3)
AI 발견 성과 홍보, 종종 과장되었다는 지적: 커뮤니티 토론에서는 미디어나 기관이 발표하는 “AI가 X를 발견했다”는 종류의 뉴스가 종종 AI의 실제 역할을 심각하게 과장한다고 지적합니다. 캘리포니아 대학교 샌디에이고 캠퍼스의 AI가 알츠하이머병 원인 발견에 기여했다는 보도 자료를 예로 들면, 해당 분야 전문가들은 Hacker News에서 AI가 데이터 분석의 작은 부분에만 사용되었으며, 핵심적인 실험 설계, 검증 및 이론적 돌파는 여전히 인간 과학자들이 수행했다고 밝혔습니다. AI의 역할을 무한정 확대하는 이러한 홍보는 과학자들의 노력을 존중하지 않으며 대중이 AI 능력에 대해 오해하도록 만들 수 있다는 비판을 받습니다 (출처: random_walker, jeremyphoward)

AI가 대규모로 사무직을 대체할 것이라는 우려 제기: Reddit 사용자가 AI 기술이 빠르게 발전하여 2030년 이전에 분석, 마케팅, 기초 코딩, 작문, 고객 서비스, 데이터 입력 등 대부분의 PC 기반 사무직을 대체할 수 있으며, 일부 금융 분석가, 법률 보조원 등 전문직도 영향을 받을 수 있다는 글을 올려 논의를 촉발했습니다. 글쓴이는 사회가 이에 대한 준비가 부족하고 기존 기술이 빠르게 쓸모없어질 것을 우려합니다. 댓글 섹션의 의견은 다양합니다. 일부는 AI가 현재 여전히 한계(예: 사실 오류)가 있다고 생각하고, 일부는 경제 구조적 관점에서 대체 복잡성을 분석하며, 일부는 이것이 이전 기술 변혁의 일반적인 현상이라고 생각합니다 (출처: Reddit r/ArtificialInteligence)
AI, 인터넷 사기 식별 더욱 어렵게 만들어: AI 도구가 완전한 웹사이트, 임원 프로필, 소셜 미디어 계정 및 상세한 배경 스토리를 포함하여 매우 사실적인 가짜 비즈니스를 만드는 데 사용되고 있다는 논의가 있습니다. 이러한 AI 생성 콘텐츠에는 명백한 철자나 문법 오류가 없어 표면적인 단서에 기반한 전통적인 식별 방법이 무력화됩니다. 전문 사기 조사관조차도 진위 구별이 점점 더 어려워지고 있음을 인정합니다. 이는 “온라인 증거”가 의미를 잃을 때 신뢰 시스템이 심각한 도전에 직면할 것이라는 우려를 낳습니다 (출처: Reddit r/artificial)

ChatGPT Plus 업데이트, 사용자 불만 야기: 한 ChatGPT Plus 유료 사용자가 OpenAI의 최근(특히 4월 27일경) 비밀 업데이트가 사용자 경험을 심각하게 저하시켰다고 불평하는 글을 올렸습니다. 구체적인 문제로는 세션 시간 초과 용이성, 메시지 수 제한 강화(약 20-30개 후 중단), 긴 대화 길이 단축, 앱 종료 후 초안 손실, 장기 프로젝트 연속성 유지 어려움 등이 있습니다. 사용자는 OpenAI가 사전 통지 없이 서버 부하를 우선시하여 대화 품질을 희생했으며, 이로 인해 유료 서비스 경험이 저하되어 진지한 작업이나 개인 프로젝트에 의존하는 사용자에게 피해를 입혔다고 비판했습니다 (출처: Reddit r/ArtificialInteligence)
“학습 방법 학습”이 AI 시대 핵심 기술로 부상: 커뮤니티 토론에서는 AI 도구의 보급과 빠른 반복으로 인해 단순한 지식 축적의 중요성은 감소하고 “학습 방법 학습”(meta-learning) 및 변화 적응 능력이 매우 중요해졌다고 보고 있습니다. 빠르게 재학습하고, 방향을 조정하며, 실험하는 능력이 핵심 경쟁력이 될 것입니다. AI에 대한 과도한 의존은 이러한 적응 능력 배양을 저해할 수 있습니다 (출처: Reddit r/ArtificialInteligence)
프롬프트 엔지니어링(Prompt Engineering) 직무 전망 논란: 월스트리트 저널 기사가 “2023년 가장 인기 있는 AI 직업(프롬프트 엔지니어)은 이미 시대에 뒤떨어졌다”고 주장하면서 커뮤니티 논의를 촉발했습니다. 모델 능력 향상이 복잡한 Prompt에 대한 의존도를 낮춘 것은 사실이지만, AI와 효과적으로 상호 작용하고 특정 작업을 완료하도록 유도하는 기술(광의의 프롬프트 엔지니어링)은 많은 응용 시나리오에서 여전히 중요합니다. 논쟁의 핵심은 이 기술이 독립적인 장기 고임금 “엔지니어” 직무가 될 수 있는지 여부입니다 (출처: pmddomingos)
AI 윤리 및 사회적 영향 지속적 관심: 커뮤니티 내에서 AI 윤리 및 사회적 영향과 관련된 여러 논의가 있었습니다. Geoffrey Hinton은 OpenAI 회사 구조 변화에 대한 안전 우려를 표명했습니다. DeepMind 직원은 국방 계약에 도전하기 위해 노조 결성을 모색하고 있습니다. AI가 더 식별하기 어려운 사기 제조에 사용될 수 있다는 우려가 있습니다. 또한 AI 에너지 소비 및 기후 영향에 대한 논쟁과 AI가 사회 불평등을 심화시킬 것인지 등의 문제도 있습니다. 이러한 논의는 AI 기술 발전과 함께 수반되는 광범위한 사회 윤리적 고려 사항을 반영합니다 (출처: Reddit r/artificial, nptacek, nptacek, paul_cal)

LLM, AGI가 아닌 “지능 게이트웨이”로 간주: 한 블로그 게시물은 현재의 대규모 언어 모델(LLM)이 범용 인공 지능(AGI)으로 가는 경로가 아니라 “지능 게이트웨이”(Intelligence Gateways)에 더 가깝다는 관점을 제시했습니다. 이 글은 LLM이 주로 과거 인간의 지식과 사고방식을 반영하고 재구성하며, 마치 오래된 지식을 되짚어보는 “타임머신”과 같고 완전히 새로운 지능을 창조하는 “우주선”은 아니라고 주장합니다. 이러한 재분류는 AI 위험, 진전 및 사용 방식을 평가하는 데 중요한 의미를 갖습니다 (출처: Reddit r/artificial)

모델 컨텍스트 프로토콜(MCP) 경쟁 우려 유발: Model Context Protocol (MCP)은 AI Agent와 외부 도구/서비스 간의 상호 작용을 표준화하는 것을 목표로 합니다. 커뮤니티 토론에서는 표준화가 개발자에게 유리하지만 애플리케이션 제공업체 간의 경쟁 문제를 유발할 수도 있다고 보고 있습니다. 예를 들어 사용자가 일반적인 지침(예: “차량 예약”)을 내릴 때 AI 플랫폼(예: Anthropic)은 어떤 서비스 제공업체(Uber 또는 Lyft)의 MCP 서버를 우선 선택할까요? 이로 인해 서비스 제공업체가 AI의 선호를 얻기 위해 데이터 소스를 “오염”시키려고 시도할 수 있을까요? 표준화는 기존 시장 마케팅 및 경쟁 구도를 바꿀 수 있습니다 (출처: madiator)
AI Agent 생성 계획 검증 필요성: LLM Agent 애플리케이션이 증가함에 따라 Agent가 생성한 실행 계획의 안전성과 신뢰성을 보장하는 방법이 문제가 되고 있습니다. plan-lint와 같은 도구의 등장은 사전 실행 검사(예: 루프 감지, 민감 정보 유출, 수치 경계 등)를 통해 Agent의 자동 작업 실행 위험을 줄이는 것을 목표로 하며, 이는 Agent 안전성 및 신뢰성에 대한 커뮤니티의 관심을 반영합니다 (출처: Reddit r/MachineLearning)
AI 안전 분야 여성 대표성 부족 주목: AI 안전 연구원 Sarah Constantin은 AI 안전 분야 여성 종사자가 상대적으로 적어 보인다고 지적하며, 새로운 어머니로서 딸의 미래 성장 환경에 대한 우려를 표명했습니다. 그녀는 AI 안전 분야에서 일하는 다른 어머니들이 있는지, 그리고 그들의 관점과 관심사가 무엇인지 궁금해했습니다. 이는 AI 안전 분야의 다양성과 다양한 집단의 관점에 대한 논의를 촉발했습니다 (출처: sarahcat21)
ChatGPT Deep Research 기능, 결과가 오래되었다는 지적: 사용자는 OpenAI의 o4-mini 기반 ChatGPT Deep Research 기능이 특정 분야(예: 자체 호스팅 LLM)를 검색할 때 상대적으로 오래된 결과(예: BLOOM 176B 및 Falcon 40B 추천)를 반환하며, Qwen 3, Gemma-3 등 최신 모델을 포함하지 못한다고 피드백했습니다. 이는 특히 최신 정보가 필요한 전문 사용자에게 해당 기능의 정보 시의성 및 실용성에 대한 의문을 제기합니다 (출처: teortaxesTex)
AI 이미지 생성의 반복적 편향: Reddit 사용자가 ChatGPT Omni에게 74회 연속으로 “이전 이미지를 정확히 복제하라”고 요구하여 AI 이미지 생성의 누적 편향을 보여주었습니다. 비디오는 지침이 동일하게 유지됨에도 불구하고 생성된 각 이미지가 이전 이미지를 기반으로 미미하지만 점진적으로 누적되는 변화를 겪어 최종 이미지가 초기 이미지와 현저하게 달라지는 것을 보여줍니다. 이는 생성 모델이 정확한 재현 및 장기적 일관성 유지 측면에서 겪는 어려움을 직관적으로 드러냅니다 (출처: Reddit r/ChatGPT)

Kaggle 대회 마스터 타이틀 획득 난이도 높아: 커뮤니티 토론에서 전 세계적으로 Kaggle 대회 마스터(Competition Grandmasters)는 362명에 불과하며, 이 수준에 도달하려면 엄청난 시간과 노력이 필요하다고 언급되었습니다. 경험 공유자에 따르면 수학 박사 학위가 있어도 GM에 도달하는 데 4000시간이 걸렸고, 그 후 첫 대회 우승까지 수천 시간을 더 투자했으며, Kaggle 전체 순위 정상에 오르기까지 총 수만 시간이 걸렸다고 합니다. 이는 최고 수준의 데이터 과학 대회에서 성취를 이루는 것이 얼마나 어려운지를 반영합니다 (출처: jeremyphoward)
💡 기타
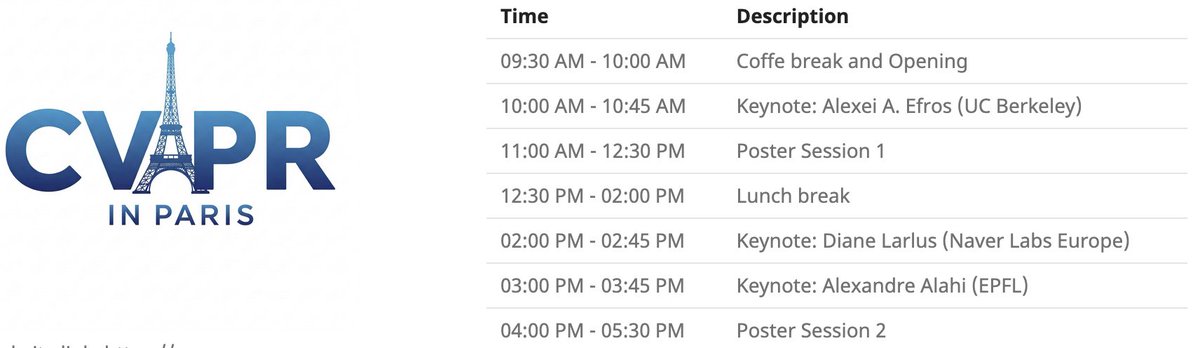
CVPR 파리 로컬 행사: CVPR 2025는 6월 6일 파리에서 로컬 행사를 개최합니다. CVPR 채택 논문 포스터 전시 세션과 Alexei Efros, Cordelia Schmid (@dlarlus) 및 Alexandre Alahi (@AlexAlahi)의 기조 강연이 포함됩니다 (출처: Ar_Douillard)
Geoffrey Hinton, Researchgate의 허위 논문 신고: Geoffrey Hinton은 Researchgate 웹사이트에 “The AI Health Revolution: Personalizing Care through Intelligent Case-based Reasoning”이라는 제목의 허위 논문이 게재되었으며, 이 논문에 자신과 Yann LeCun의 이름이 서명되어 있다고 지적했습니다. 그는 논문 인용 목록의 3분의 1 이상이 Shefiu Yusuf를 가리키고 있지만 그 의미는 명확히 밝히지 않았습니다 (출처: geoffreyhinton)
Meta LlamaCon 2025 라이브 스트리밍 예고: Meta AI는 LlamaCon 2025가 태평양 시간 기준 4월 29일 오전 10시 15분에 라이브 스트리밍을 시작한다고 알렸습니다. 행사에는 기조 강연, 담화가 포함되며 Llama 모델 시리즈에 대한 최신 정보가 발표될 예정입니다 (출처: AIatMeta)
스탠포드 다지 도마뱀붙이 그리퍼: 스탠포드 대학에서 개발한 다지 도마뱀붙이 모방 그리퍼가 잡는 능력을 선보였습니다. 이 디자인은 도마뱀붙이 발의 접착 원리를 모방하여 로봇이 불규칙하거나 깨지기 쉬운 물체를 잡는 데 응용될 수 있습니다 (출처: Ronald_vanLoon)
AI 보조 건강 기술 혁신: 커뮤니티에서는 육체 노동자의 통증을 완화할 수 있는 의자, 모터 없는 유연한 의족 SoftFoot Pro, 실험실 배양 치아 진전에 관한 기사 등 AI 또는 기술 보조 건강 기술 개념이나 제품을 공유했습니다. 이는 기술이 인간의 건강과 삶의 질을 개선하는 데 잠재력이 있음을 보여줍니다 (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
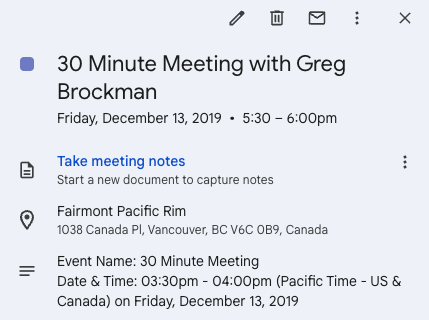
트위터, 창업 기회 촉진: Andrew Carr는 2019년 NeurIPS 컨퍼런스 기간 동안 Twitter (X)를 통해 Greg Brockman에게 적극적으로 연락하여 교류했던 경험을 공유했습니다. 이 우연한 대화는 결국 중요한 협력 기회를 촉진했고, 공동 창업자를 찾아 Cartwheel 회사를 설립하는 데 도움이 되었습니다. 이 이야기는 소셜 미디어가 전문 분야에서 관계를 구축하고 기회를 창출하는 데 가치가 있음을 보여줍니다 (출처: andrew_n_carr, zacharynado)
개인 자율 주행 프로젝트 진행 상황: 한 머신러닝 애호가가 개인적으로 개발 중인 자율 주행 Agent 프로젝트 진행 상황을 공유했습니다. 프로젝트는 1:22 비율의 RC카 제어부터 시작하여 카메라와 OpenCV를 이용한 위치 파악, P 컨트롤러를 통한 가상 경로 추종으로 진행됩니다. 다음 단계는 차량 동역학의 가우시안 프로세스 모델 훈련 및 경로 계획 최적화이며, 최종 목표는 카트, 심지어 F1 레이싱카 수준으로 점진적으로 확장하고 실제 환경에서 테스트하는 것입니다 (출처: Reddit r/MachineLearning)
데이터 엔지니어링, 머신러닝 엔지니어로의 경력 경로: Reddit 토론 게시판에서 데이터 엔지니어(Data Engineer, DE)를 최종적으로 머신러닝 엔지니어(ML Engineer, MLE)가 되기 위한 경력 경로로 삼는 것의 타당성을 탐구했습니다. 한 숙련된 데이터 과학자는 이것이 ETL/ELT, 데이터 파이프라인, 데이터 레이크 등의 지식을 배울 수 있는 좋은 출발점이며, 이후 수학, ML 알고리즘, MLOps 등의 지식을 배우고 인증이나 프로젝트 경험을 결합하여 점진적으로 MLE 직무로 전환할 수 있다고 생각합니다 (출처: Reddit r/MachineLearning)
DeepLearning.AI 바르샤바 Pie & AI 행사: DeepLearning.AI는 폴란드 바르샤바에서 Sii Poland와 협력하여 개최하는 첫 Pie & AI 행사를 홍보합니다 (출처: DeepLearningAI)

Deep Tech Week 행사 예고: Deep Tech Week 행사가 6월 22-27일 샌프란시스코에서 다시 열리며, 뉴욕에서도 동시에 개최됩니다. 이 행사는 처음에는 하나의 트윗에서 시작하여 85개의 행사, 8200명 이상의 참가자(1924개 스타트업 및 814개 투자 기관 대표)를 유치하는 분산형 컨퍼런스로 발전했으며, 최첨단 기술을 선보이고 교류 협력을 촉진하는 것을 목표로 합니다 (출처: Plinz)

SkyPilot 첫 오프라인 밋업: SkyPilot 팀은 첫 오프라인 밋업을 성공적으로 개최했으며, 행사에 많은 개발자가 참여했고 Abridge, vLLM 프로젝트, Anyscale 등 기관의 연사들이 SkyPilot 사용 사례를 공유했다고 전했습니다 (출처: skypilot_org)

토론: 전문화 학습의 어려움: 커뮤니티 멤버들이 학습에서 “숙달”에 이르기 어려운 이유에 대해 토론했습니다. 한 가지 관점은 가장 유용한 기술(예: CUDA Kernel 작성) 중 상당수가 단일 기술의 극치 숙달보다는 여러 학제 간 지식(예: PyTorch, 선형 대수, C++) 습득을 요구한다는 것입니다. 새로운 기술을 배우려면 똑똑하면서도 “바보처럼 보이기를” 기꺼이 감수하고 편안한 영역을 벗어날 용기가 필요합니다 (출처: wordgrammer, wordgrammer)