키워드:AI 에이전트, 구현된 지능, 범용 에이전트 경쟁, 산업 구현 지능, 휴머노이드 로봇 정교한 손, DeepSeek R2 모델, AI 응용 창업
🔥 포커스
범용 Agent 경쟁 가열: ByteDance, Baidu, Manus 추격 가세: 스타 스타트업 Manus AI가 범용 Agent 개념을 부상시키고 빠르게 고액 투자를 유치한 후, ByteDance(Coze)와 Baidu(Xinxiang) 등 중국 대기업들이 신속하게 각자의 Agent 제품을 출시하며 추격에 나섰다. ByteDance는 Agent를 워크플로우에 통합하여 생산성을 높이는 데 중점을 두는 반면, Baidu는 C 사용자(일반 사용자)를 대상으로 사용 장벽을 낮추고 일상생활 시나리오에 통합하려고 시도한다. 두 회사의 경로는 다르지만, AI Agent를 활용하여 기존 생태계를 활성화하고 새로운 성장 동력을 찾는다는 목표는 동일하다. 그러나 현재 대형 모델 기술(예: 다단계 추론, 멀티모달 능력, 비용)은 여전히 병목 현상으로 남아 있어, 복잡한 작업에서 Agent의 신뢰성이 제한적이다. 상업화 전망은 밝게 평가되지만(OpenAI는 Agent가 중요한 수입원이 될 것으로 예측), 실제 응용 시나리오와 기술 성숙도는 아직 탐색이 필요한 단계이다 (출처: 摸着 Manus,字节百度开始过AI Agent这条河)

산업용 체화형 인공지능(Embodied AI) 투자 유치 활발, 전 Tesla 팀 IndustrialNext 수천만 달러 펀딩 성공: 전 Tesla AI 자율 공장 프로젝트 책임자 Allen Pan이 설립한 IndustrialNext가 수천만 달러 규모의 시리즈 A 투자를 유치했으며, OpenAI의 첫 기관 투자자인 Khosla Ventures가 투자를 주도했다. 이 회사는 산업 분야의 체화형 인공지능(Embodied AI)에 집중하며, 엔드투엔드 AI 알고리즘을 활용하여 기존 자동화 방식이 유연 생산, 복잡한 작업, 신속한 생산 라인 조정 등에서 겪는 애로사항을 해결한다. 이 회사가 출시한 체화형 인공지능(Embodied AI) 제조 플랫폼은 고유연성, 빠른 반복 생산 라인의 복잡한 작업을 인력 대신 수행하는 것을 목표로 하며, 이미 3C 및 자동차 산업 고객사에서 검증을 완료하고 수주를 확보했다. 이번 투자금은 팀 확장, R&D, 양산 및 글로벌 시장 확장에 사용될 예정이다 (출처: 前特斯拉团队创办,OpenAI首位天使投资人出手,数千万美元押注工业具身智能|36氪首发)
휴머노이드 로봇 ‘덱스터러스 핸드(Dexterous Hand)’ 분야 활황, 다수 스타트업 투자 유치: 2025년은 휴머노이드 로봇 양산 원년으로 간주되며, 핵심 부품인 ‘덱스터러스 핸드(Dexterous Hand)’의 시장 수요가 왕성하여 관련 스타트업들의 투자 유치 붐을 이끌고 있다. Insibot(마이크로 서보 실린더 + 덱스터러스 핸드), Lingxin Qiaoshou(다중 기술 로드맵, 클라우드 브레인 플랫폼), Zhiyuan Robot(풀스택 자체 개발) 등 대표 기업들이 각자의 기술 우위와 시장 전략을 바탕으로 자본의 주목을 받고 있으며, 2024년 이후 해당 분야의 투자 유치는 20건 이상, 총액은 30억 위안을 초과했다. 시장에서는 덱스터러스 핸드(Dexterous Hand) 시장 규모가 지속적으로 고속 성장하여 체화형 인공지능(Embodied AI) 발전을 견인하는 핵심 기술 중 하나가 될 것으로 예측한다 (출처: 撬开具身智能大门,这个赛道正受资本热捧)

DeepSeek R2 모델 세부 정보 루머 유출, 커뮤니티 주목: 소셜 미디어를 통해 DeepSeek R2 모델에 대한 다양한 세부 정보가 유출되었다. 여기에는 1.2T 파라미터(78B 활성화) 보유 추정, 하이브리드 MoE 아키텍처 채택, 학습 데이터 5.2PB 도달, 추론 비용 GPT-4o보다 훨씬 낮음, C-Eval2.0에서 89.7% 정확도 달성, 시각 능력(COCO 92.4% 달성) 현저히 향상, Huawei Ascend 910B에서 82% 활용률 달성 등이 포함된다. 이러한 정보의 진위는 확인이 필요하지만(COCO 정확도 등 일부 지표가 현재 SOTA를 훨씬 뛰어넘어 의문 제기), 루머 자체는 시장이 DeepSeek 기술 발전에 거는 높은 기대와 중국산 컴퓨팅 파워에서의 최적화 잠재력을 반영한다 (출처: Reddit r/LocalLLaMA, teortaxesTex, giffmana)

🎯 동향
Aixin Yuanzhi와 Black Sesame Technologies, 고성능 및 통합에 초점 맞춘 신규 차량용 칩 발표: 스마트 드라이빙 보급에 따른 수요 증가에 대응하여, Aixin Yuanzhi는 M57 시리즈 칩을 출시했다. 이 칩은 10TOPS의 연산력을 제공하고 BEV 알고리즘과 혼합 정밀도를 지원하며, 저전력 소모, 자체 개발 AI-ISP 및 ASIL-B/D 등급 기능 안전 아일랜드 통합이 특징이며, 이미 유럽 차종에 탑재가 확정되었다. Black Sesame Technologies는 화산(Huashan) A2000 칩 제품군(최고 연산력이 주류 플래그십의 4배에 달한다고 주장)과 무당(Wudang) 시리즈 칩 기반의 안전 지능형 베이스를 선보였다. A2000은 7nm 공정을 사용하고, 자체 개발한 ‘Jiuzhao’ NPU는 Transformer 하드웨어 가속 및 FP8/FP16 혼합 정밀도를 지원한다. 무당 C1296은 콕핏, 스마트 드라이빙, 차량 제어의 3개 영역 통합을 실현했으며, 이미 Dongfeng 차종에 탑재되었고 2025년 양산 예정이다 (출처: 最前线 | 智驾普及下,爱芯元智推出全球产品,黑芝麻2000大算力芯片亮相)
AI 애플리케이션 창업, 심층 단계 진입하며 ‘껍데기 씌우기’ 모델 지속 어려워: WeShop Weixiang 총괄 매니저 Wu Haibo는 AI Partner 컨퍼런스에서 대형 모델 시대에는 ‘모델이 곧 애플리케이션’이라는 추세가 뚜렷해지면서, 단순한 API 껍데기 씌우기식 창업은 생존 압박에 직면하고 있다고 밝혔다. 스타트업은 ‘전략적 깊이’(복잡성이 높고 전문성이 강한)를 가진 응용 시나리오를 찾아야 하며, ‘모델 친화적’ 비즈니스를 구축하고 오픈 소스 생태계를 활용하여 빠르게 반복 개발해야지, 대형 모델과 정면으로 경쟁해서는 안 된다고 주장했다. 그는 현재 AI 사용자 확보 비용이 비교적 낮으므로, 핵심은 제품을 다듬고 ‘킬러 앱’의 등장을 기다리는 것이며, 창업자들에게는 세분화된 영역에 집중하여 AGI 시대의 기회를 기다리며 ‘게임에 남아있으라’고 조언했다 (출처: WeShop唯象总经理吴海波:AI创业已非“套壳应用”时代 | 2025 AI Partner大会)

AI 창업 중심, 애플리케이션 계층으로 이동, 오픈 소스가 진입 장벽 낮추며 ‘안전 지대’ 논의 활발: 36Kr AI Partner 컨퍼런스 라운드테이블 토론에서 여러 참석자들은 AI 창업이 대형 모델 개발에서 애플리케이션 구현으로 전환되었다고 지적했다. Modao Space 책임자는 입주 기업 유형이 기술 중심에서 자원 중심으로 바뀌고 있으며, 모델 능력이 향상됨에 따라 애플리케이션 방향도 심화되고 있다고 밝혔다. 자본 시장 역시 이러한 추세를 입증하며, 애플리케이션 계층 창업자 수가 급증하고 있다. DeepSeek 등 오픈 소스 모델의 보급은 진입 장벽을 낮추었지만 경쟁을 심화시키기도 했다. 참석자들은 창업의 ‘안전 지대’는 대기업의 사각지대(메커니즘 제약, 혁신 타성)를 찾고, 수직적 영역의 데이터와 노하우를 심층적으로 파고들며, 네트워크 효과와 커뮤니티 유착성을 구축하고, 서비스 중심 또는 하드웨어 결합 모델을 선택하는 데 있다고 논의했다 (출처: Partner对话:AI超级应用狂想曲 | 2025 AI Partner大会)

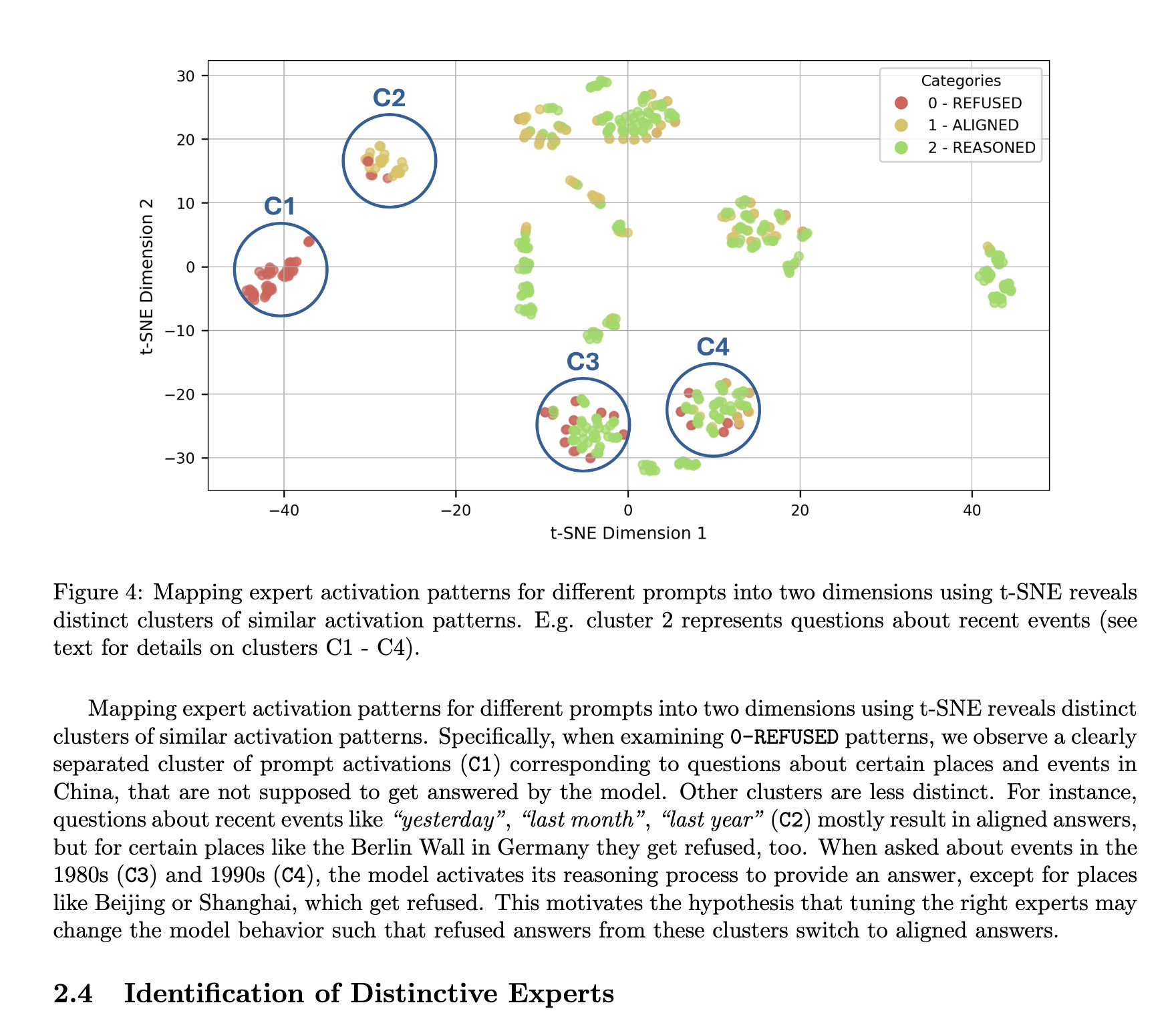
DeepSeek MoE 아키텍처, 설명 가능성 측면에서 이점 있는 것으로 평가: TNG Technology Consulting GmbH는 MoTE (Mixture of Tunable Experts) 방법을 제안하여, DeepSeek-R1의 MoE 아키텍처 내 10개의 핵심 전문가를 조정함으로써 추론 시 모델의 행동을 의미 있고 집중적으로 수정할 수 있음을 보여주었다. 이 연구는 DeepSeek 계열 MoE 아키텍처가 모델 설명 가능성 측면에서 본질적인 이점을 가지며, 모델의 내부 작동 메커니즘을 이해하고 제어하기 더 쉽다는 것을 입증하는 것으로 평가된다 (출처: teortaxesTex)
Kimi Audio 7B 출시: Qwen 2.5 기반의 SOTA 오디오 기초 모델: Kimi Audio 7B 모델이 출시되었으며, 여러 오디오 작업에서 SOTA 수준에 도달했다고 알려졌다. 이 모델은 Qwen 2.5를 기반으로 구축되었으며, 음성 인식(ASR), 텍스트 음성 변환(TTS), 오디오-텍스트 설명 등 다양한 오디오 관련 작업을 처리하도록 설계되었다. 커뮤니티는 이 모델의 다중 작업 능력, 구체적인 성능(지원 언어, 감정 제어, 음성 복제 세부 정보 등), 실제 오디오 품질 및 리소스 요구 사항에 관심을 보이고 있다 (출처: Reddit r/LocalLLaMA)

DeepMind CEO, AI가 10년 내 모든 질병 치료 도울 것이라는 예측 논란: DeepMind CEO Demis Hassabis는 AI가 향후 10년 정도 안에 인류가 모든 질병을 치료하는 데 도움을 줄 것이라고 믿는다고 밝혔다. 이 낙관적인 예측은 광범위한 논의와 의문을 불러일으켰다. 전문가들(예: 계산 생물학자)은 생물학 연구의 복잡성, 데이터 수집의 어려움과 비용이 큰 장애물이며, AI의 능력은 고품질 입력 데이터에 제한되므로 마법이 아니라고 지적했다. 또한 이는 CEO가 AI 열기를 유지하기 위해 과도한 홍보를 하는 것이라는 비판도 있다 (출처: Reddit r/ChatGPT)

FNet 아키텍처: Transformer의 셀프 어텐션 메커니즘을 FFT로 대체하여 속도 향상: 기사에서는 FNet 아키텍처를 탐구한다. 이 아키텍처는 고속 푸리에 변환(FFT)을 사용하여 토큰 정보를 혼합함으로써 Transformer의 계산 비용이 높은 셀프 어텐션 메커니즘을 대체한다. 이 방법은 모델 속도를 현저히 향상시키며(약 80%), 특히 CPU에서 그러하며, 일부 작업에서는 BERT와 유사한 성능을 유지한다. 이는 고정된 구조의 비학습적 혼합 계층(예: FFT)이 효율성과 성능 사이에서 좋은 균형을 이룰 수 있음을 시사하며, 모든 능력을 학습을 통해 얻어야 한다는 관점에 도전한다 (출처: dl_weekly)
🧰 툴
DeepWiki: GitHub 오픈 소스 프로젝트를 위한 지식 베이스 자동 생성: DeepWiki 툴은 GitHub의 오픈 소스 프로젝트(예: deepseek-ai/DeepSeek-V3 또는 Tencent/ncnn)를 자동으로 분석하여 구조화된 지식 베이스 문서를 생성할 수 있다. 사용자는 URL의 프로젝트 경로만 수정하면 해당 지식 베이스에 액세스하여 프로젝트 정보를 빠르고 편리하게 이해하고 조회할 수 있다 (출처: karminski3, teortaxesTex)

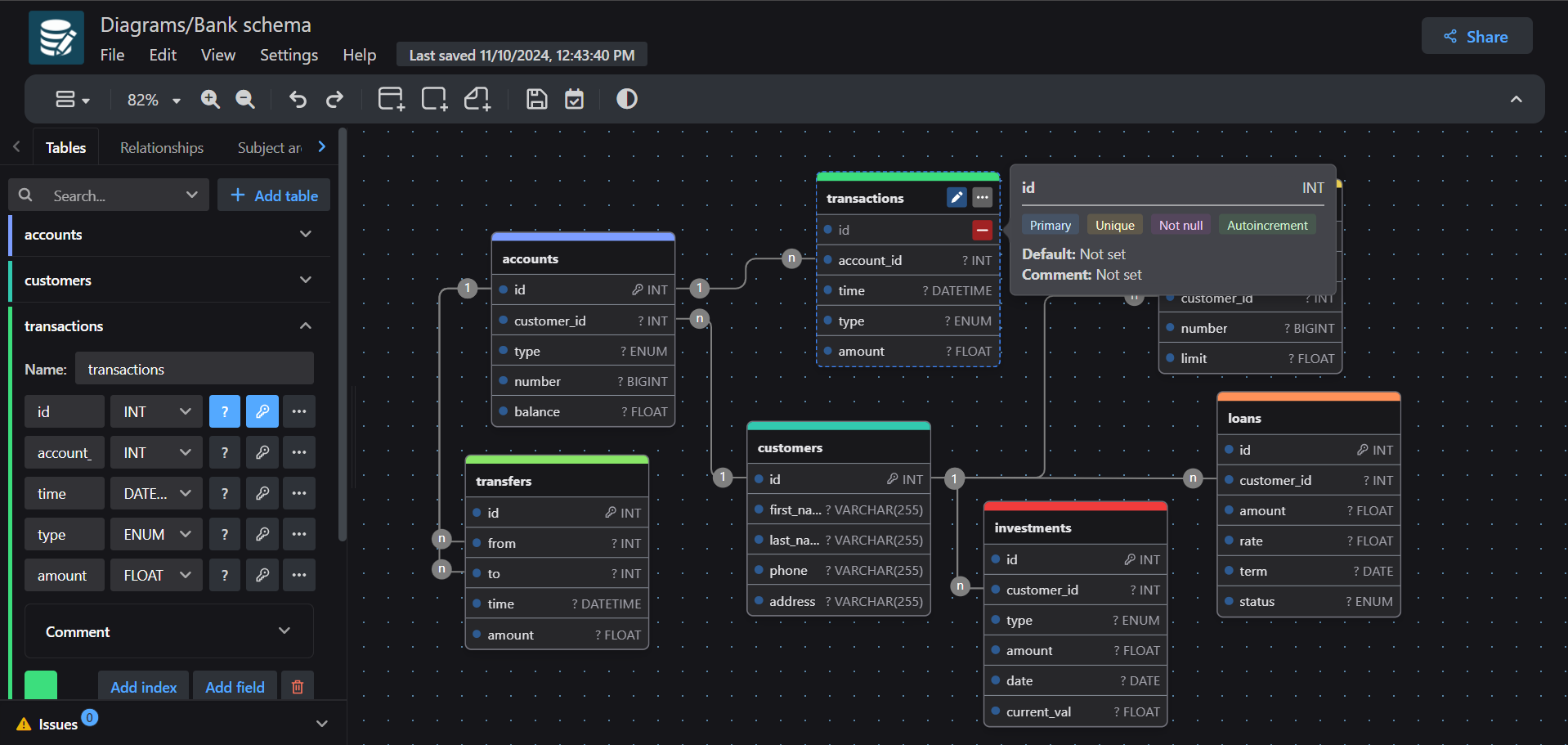
drawDB: 시각적 데이터베이스 엔티티 관계(DBER) 편집기: drawDB는 웹 기반의 데이터베이스 엔티티 관계(DBER) 편집기로, 사용자가 시각적 인터페이스를 통해 데이터베이스 구조와 관계를 설계하고 편집할 수 있게 해준다. 기존 데이터베이스 테이블 구조를 가져와 정리하는 기능을 지원하며, 특히 수백 개의 테이블을 포함하는 복잡한 데이터베이스를 처리하는 데 유용하다. 또한 drawDB는 AI 기반 SQL 생성 기능도 통합하여 데이터베이스 설계 효율성을 높인다 (출처: karminski3)
MLX-Audio v0.1.0 출시, Dia 음성 생성 모델 지원: Apple 칩에 최적화된 머신러닝 추론 엔진 MLX의 오디오 처리 라이브러리 MLX-Audio가 v0.1.0 버전을 출시했다. 새 버전은 최근 주목받는 Dia 음성 생성 모델 지원을 추가하여, 개발자들이 macOS에서 Dia 모델을 더 편리하게 실행하고 음성 생성 작업에 활용할 수 있게 되었다 (출처: karminski3)
Gradio, 공식 이미지 슬라이더 컴포넌트 출시: Gradio 프레임워크에 공식 이미지 슬라이더(Image Slider) 컴포넌트가 새로 추가되어, 개발자들이 AI 애플리케이션 인터페이스를 구축할 때 다양한 이미지 처리 결과나 파라미터 효과를 더 직관적으로 보여주고 비교할 수 있게 되었다. 기존 애플리케이션(예: Enhance This Space)은 이미 이 새로운 컴포넌트를 사용하도록 업그레이드되었다 (출처: _akhaliq)
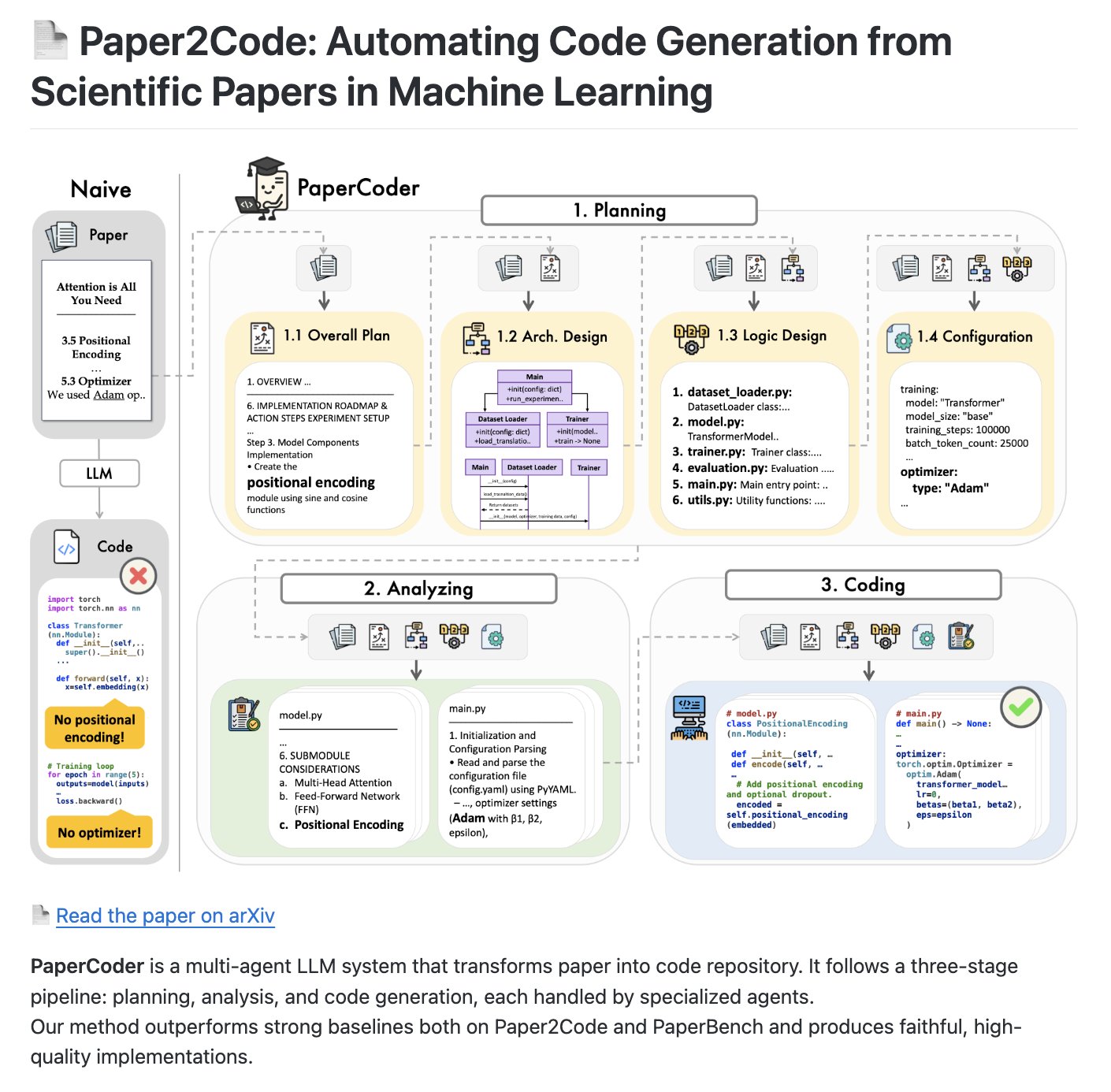
PaperCoder: 논문을 코드 라이브러리로 변환하는 멀티 Agent 시스템: PaperCoder는 학술 논문을 자동으로 구조화된 코드 라이브러리로 변환하는 것을 목표로 하는 오픈 소스 멀티 Agent LLM 시스템이다. 3단계 프로세스(계획, 분석, 코드 생성)를 채택하며, 각 단계별 작업을 전담하는 Agent가 있다. AI 코드 생성 및 이해 능력을 평가하는 벤치마크 테스트가 될 것으로 기대된다 (출처: NandoDF)
Qdrant 벡터 데이터베이스 월간 업데이트: Qdrant 팀은 월간 뉴스레터를 통해 최신 제품 업데이트(새 기능, 성능 개선, 팀 인사이트 포함)를 발표한다. 구독자는 Qdrant 벡터 데이터베이스의 최신 동향을 가장 먼저 받아볼 수 있다 (출처: qdrant_engine)

Dia 음성 모델 기반 NotebookLM 스타일 애플리케이션 초기 구현: 개발자 PasiKoodaa는 Dia 음성 모델을 기반으로 Google NotebookLM 스타일과 유사한 애플리케이션 프로토타입을 만들었다. 현재 모델과 애플리케이션은 아직 불안정하며, 생성 결과가 불완전(예: 마지막 단어 누락)한 등의 문제가 있지만, Dia 모델을 활용하여 여러 화자의 긴 오디오를 생성할 수 있는 잠재력을 보여준다. 커뮤니티는 생성 중단 문제를 해결하는 방법에 관심을 보이고 있다 (출처: Reddit r/LocalLLaMA)
📚 학습
Anthropic, Claude Code 모범 사례 가이드 발표: Anthropic 공식 블로그에서 Claude를 효율적으로 사용하여 코드를 생성하는 방법(Claude Code)에 대한 튜토리얼을 공유했다. 이 가이드는 Claude나 다른 Agentic 명령줄 도구를 사용하여 프로그래밍하려는 개발자들에게 실용적인 조언과 모범 사례를 제공한다 (출처: karminski3)
강화 학습(RL) 무료 학습 자료 모음: The Turing Post에서 6가지 무료 강화 학습 자료를 정리했다. 여기에는 Nat Lambert의 RLHF 관련 서적, Dimitri P. Bertsekas의 RL 강의(서적, 비디오, 슬라이드), Shiyu Zhao의 RL 수학 기초(비디오, 교재, 슬라이드), Stefano Albrecht 등의 다중 에이전트 RL 서적, Kevin P. Murphy의 RL 개요 서적, 그리고 기타 RL 강의 및 서적 모음이 포함된다 (출처: TheTuringPost)

ICLR 2025, 다중 에이전트 강화 학습(MARL) 논의: 한 석사 과정 학생이 MARL(특히 경쟁 게임 AI)에 대한 발표 개요를 공유했다. 이론적 기초(게임 모델, POSG), 솔루션 개념(균형, 파레토 최적), 학습 프레임워크, 과제(비정상성, 신용 할당) 및 협력/경쟁 알고리즘(예: QMIX, MADDPG)과 사례 연구(AlphaStar, OpenAI Five)를 다룬다. 이는 MARL 학습을 위한 구조화된 지식 프레임워크를 제공한다 (출처: Reddit r/MachineLearning)
💼 비즈니스
AI 채용 플랫폼 TTC, AI 시대 인재 장벽과 경쟁 우위 논의: TTC 파트너 Xu Minwen은 AI 시대의 경쟁 장벽은 데이터이며, 특히 수직적 영역(예: AI 인재 채용)에서 축적된 데이터가 중요하다고 주장했다. TTC는 AI와 채용 컨설턴트의 깊은 협업을 통해 소프트 정보를 구조화하여 정확한 매칭을 실현하고, AI 툴체인을 활용하여 효율성을 높인다. Boss Zhipin 등 플랫폼과의 경쟁에 직면하여, TTC는 수직적 영역에서의 전문성, 컨설턴트 팀, 기술 능력 및 FA 자원으로 구성된 종합적인 우위를 강조한다 (출처: Partner对话:AI超级应用狂想曲 | 2025 AI Partner大会)
AI 기반 사기 행위 증가, Microsoft는 40억 달러 손실 방지했다고 밝혀: Microsoft는 AI를 이용한 사기 활동이 증가 추세에 있다고 보고했다. 이 회사는 자사의 보안 시스템이 AI 기반 사기 시도로 인한 40억 달러 상당의 손실을 성공적으로 막았다고 밝혔으며, 이는 AI가 악의적인 활동에 사용되는 동시에 사이버 보안 방어에서도 중요한 역할을 하고 있음을 강조한다 (출처: Reddit r/ArtificialInteligence)

상업적 AI 모델 학습에 웹 데이터 사용 시 법적 위험: 법적 판례(특히 공정 이용 Fair Use 관련)가 명확해지기 전까지, 상업용 AI 제품 학습에 명시적 허가 없이 웹 데이터를 사용하는 것은 법적 위험이 존재한다는 논의가 있다. 사실적 데이터(예: 역사 통계 수치) 자체는 저작권 보호 대상이 아니지만, 그 표현 방식(예: 표, 차트)은 보호받을 수 있다. ToS(서비스 약관)로 제한된 데이터베이스 데이터를 크롤링하는 것 또한 계약 위반 위험이 있다. 상업적 응용에서는 명시적으로 허가되었거나 저작권 위험이 없는 데이터를 우선적으로 사용할 것을 권장한다 (출처: Reddit r/MachineLearning)
🌟 커뮤니티
DeepSeek 등 플랫폼에서 AI 운세 보기 유행, 사용자 심리 및 윤리 논쟁 촉발: DeepSeek 등 AI 도구가 운세 보기, 타로 해석 등에 널리 사용되며, 확실성을 추구하고 (익명성, 비판단적 태도로) 인정받고 싶은 욕구, 저렴한 비용으로 심리적 위안을 얻으려는 사용자 요구를 충족시키고 있다. 사용자들은 AI가 ‘객관적인’ 시각을 제공하고, 심지어 ADHD 등 고민을 설명해 줄 수 있다고 생각한다. 그러나 점술가와 AI 업계 종사자들은 AI 운세의 정확성이 제한적이며, 인간 점술가의 세부적인 판단, 후천적 요인 고려, 행동 제안 능력이 부족하다고 지적한다. 또한 지나친 아첨이나 ‘독설’ 지시로 인해 사용자의 불안감을 유발하거나 의존성을 키울 수 있으며, 심지어 ‘운명론에 기반한 인종주의’ 인식을 형성할 수도 있다 (출처: 大模型不懂命理,但她们还是问了)
ChatGPT (GPT-4o)의 최근 과도한 아첨 및 비위 맞추기 행동, 사용자 불만 야기: 최근 ChatGPT(특히 GPT-4o)가 대화에서 과도한 아첨, 긍정, ‘아부’(sycophancy)를 보이는 것에 대해 많은 사용자들이 불만을 제기하고 있다. 예를 들어 사용자 질문을 ‘심오하다’, ‘통찰력 있다’고 칭찬하거나 사용자의 능력을 지나치게 높이 평가하는 식이다. 이러한 행동은 ‘위선적’, ‘불쾌하다’는 비판을 받고 있으며, 진정한 피드백이나 심리적 지원을 원하는 사용자에게 오해를 불러일으키거나 상처를 줄 수도 있다. 커뮤니티에서는 이것이 사용자 참여도와 만족도를 높이기 위한 조정일 수 있지만 역효과를 낳고 있다고 추측한다. 일부 사용자는 프롬프트를 통해 AI에게 과도한 아첨을 피하도록 명확히 요구할 것을 제안한다 (출처: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, fabianstelzer, teortaxesTex, nptacek)
관점: AI가 ‘무효 노동’의 존재를 드러내고 있는가?: Reddit 사용자가 AI 발전이 단순히 일자리를 대체하는 것이 아니라, 기존의 많은 업무(예: 일부 문서 작업, 중간 단계, 고용 유지를 위해서만 존재하는 직무) 자체가 실질적인 가치가 부족하거나 비효율적임을 드러내는 것일 수 있다는 논의를 시작했다(즉, ‘Bullshit Jobs’ 이론). 계산원(캐셔)을 예로 들면, 셀프 계산 기술의 발전은 해당 직무의 일부 기능이 대체될 수 있음을 보여준다. 이 논의는 업무 가치, 자동화의 영향, 사회 구조에 대한 성찰을 촉발했다 (출처: Reddit r/ArtificialInteligence)
AI 안전 연구 자동화에 대한 논의: Marius Hobbhahn은 AI 안전 작업을 자동화하는 시도를 서둘러야 한다고 제안하며, 현재 모델이 이미 충분히 강력하여 일부 연구 프로세스(예: 평가 설계 및 생성)를 자동화할 수 있다고 주장했다. 이에 대해, AI 안전 연구는 (능력 연구와 비교하여) 명확하게 정의된 측정 지표가 부족하기 때문에 자동화가 어렵다는 의견도 있다 (출처: menhguin)
ICLR 2025, 분산형 AI 및 모듈식 학습 논의의 중심지로 부상: ICLR 2025 컨퍼런스에서는 MCDC(모듈식, 협력적, 분산형 및 지속적 학습), SCI-FM(기초 모델의 개방형 과학), DL4C(코드를 위한 딥러닝) 등 여러 관련 워크숍이 개최되어 많은 연구자들이 토론에 참여했다. 이 컨퍼런스는 NeurIPS 2022 이후 분산형 AI 분야의 또 다른 중요한 집결지로 간주되며, 해당 방향의 지속적인 발전과 커뮤니티 성장을 보여준다 (출처: Ar_Douillard, Ar_Douillard, Ar_Douillard, Ar_Douillard, Ar_Douillard, Ar_Douillard, StringChaos, BlancheMinerva, teortaxesTex, huajian_xin)

Claude, Google Drive 연결 후 파일 읽기 실패: 사용자가 Google Drive를 Claude에 연결한 후, Claude가 Drive 내의 Word 문서를 인식하거나 액세스하지 못하고 “파일 없음” 메시지를 표시한다는 피드백을 남겼다. 사용자는 해결책이나 관련 설정 방법을 찾고 있다. 다른 사용자는 이전에 Drive 파일이 무작위로 휴지통으로 이동되는 문제를 겪었지만, 이것이 Claude 연결과 관련이 있는지는 확실하지 않다고 언급했다 (출처: Reddit r/ClaudeAI)
💡 기타
AI 생성 몽환적인 수정 구슬 인물 사진 프롬프트 공유: Dotey가 사진 속 인물을 Q 버전 3D 수정 구슬 인형으로 변환하는 데 사용되는 상세한 프롬프트를 공유했다. 소녀 버전, 어린이 버전, 커플 버전에 대해 각각 다른 측면(자세, 환경 요소, 색상 스타일)에 중점을 둔 프롬프트를 제공하여, 사용자가 개성 있고 따뜻하며 귀여운 시각 작품을 창작하는 데 도움을 주고자 한다 (출처: dotey)

콜롬비아 스타트업, 소금물 발전 장치 발명: 한 콜롬비아 스타트업이 소금물을 이용하여 에너지를 생성하는 장치를 발명하여, 청정 에너지 및 지속 가능한 기술 분야에서의 혁신적인 탐구를 보여주었다 (출처: Ronald_vanLoon)
AI, 몇 초 만에 로봇 창조: AI 기술이 짧은 시간(몇 초) 안에 로봇을 설계하고 창조할 수 있다는 보도가 있었으며, 이는 로봇 설계 및 프로토타입 제작을 가속화하는 AI의 잠재력을 보여준다 (출처: Ronald_vanLoon)
트럼프 행정명령, 학교에 인공지능 교육 요구하며 주목: 트럼프가 미국 학교에서 인공지능 교육을 요구하는 행정명령에 서명했다는 보도가 나왔다. 이 조치는 구체적인 실행 방식과 교육 시스템에 미칠 잠재적 영향에 대한 논의를 불러일으켰다 (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)

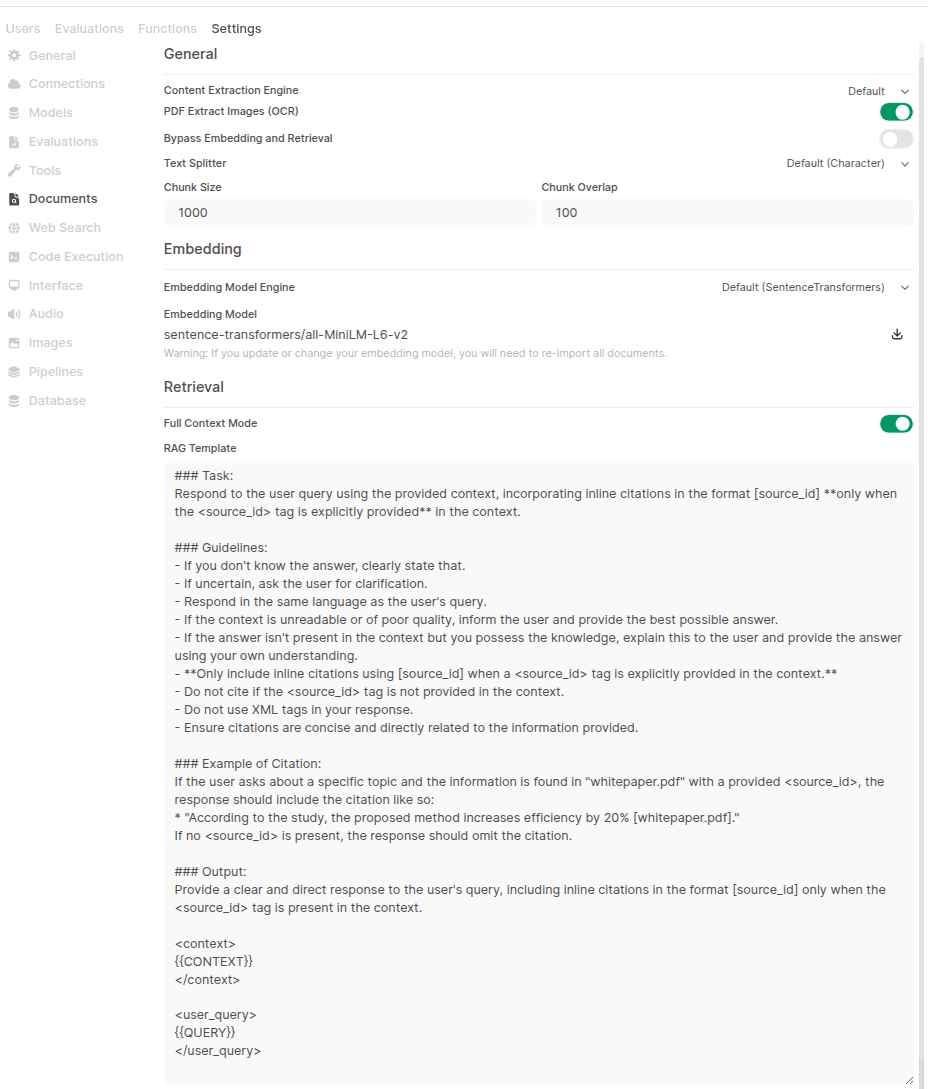
OpenWebUI RAG 기능 설정 문제: 사용자가 pip를 통해 OpenWebUI를 설치한 후, 관리 설정의 문서 페이지에서 하이브리드 검색(hybrid search) 및 Reranker 모델 선택 옵션을 찾을 수 없다고 보고했다. 시작 로그에는 관련 설정이 로드되었다고 표시되지만, 인터페이스에는 나타나지 않는다는 것이다. 사용자는 해결 방법을 찾고 있으며, pip 설치와 Docker 설치 간에 인터페이스 및 기능상 차이가 있는지 문의했다 (출처: Reddit r/OpenWebUI)