

키워드:문심 대형 모델, AI 모델, 멀티모달, 에이전트, 문심 4.5 터보, X1 터보, 딥시크 V3, 멀티모달 이해, 바이두 신향, MCP 프로토콜, AI 유료 모델, LoRA 모델 추론
🔥 포커스
Baidu, DeepSeek에 맞서 文心 4.5 Turbo 및 X1 Turbo 발표: 2025년 Baidu Create 컨퍼런스에서 리옌훙(李彦宏)은 文心 대형 모델 4.5 Turbo와 X1 Turbo를 발표하며 멀티모달 이해 및 생성 능력을 강조하고, 비용이 각각 DeepSeek V3의 40%, DeepSeek R1의 25%에 불과하다고 지적했습니다. 리옌훙은 멀티모달이 미래 트렌드이며 순수 텍스트 모델 시장은 축소될 것이라고 보았습니다. 이번 발표는 DeepSeek의 멀티모달 및 비용 측면에서의 부족함을 메우고 모델 수준에서 업계 선두 주자와 경쟁하려는 Baidu의 의지를 보여주었습니다. (출처: 36氪)

AI 모델 성능 비교: o3와 Gemini 2.5 Pro, 각축전: OpenAI의 o3와 Google의 Gemini 2.5 Pro는 여러 새로운 벤치마크 테스트에서 치열한 경쟁을 보였습니다. o3는 장문 소설 퍼즐 분석(FictionLiveBench)에서 더 우수한 성능을 보였으며, Gemini 2.5 Pro는 물리 및 공간 추론(PHYBench), 수학 경시(USMO), 지리 위치 추정(GeoGuessing)에서 앞섰으며 비용도 더 저렴했습니다(o3의 약 1/4). 시각 퍼즐(Visual Puzzles)과 기초 시각 질의응답(NaturalBench)에서는 각자 우위를 보였습니다. 이는 현재 최고 수준 모델의 성능이 특정 작업과 평가 벤치마크에 크게 의존하며 절대적인 선두 주자는 없음을 보여줍니다. (출처: o3 breaks (some) records, but AI becomes pay-to-win
)
AI, ‘Pay-to-win’ 모델로 전환: 업계 관측에 따르면, AI 모델 능력 향상과 응용 확대에 따라 최고 수준의 AI 능력을 얻기 위해 점점 더 많은 비용을 지불해야 할 수 있습니다. Google, OpenAI, Anthropic 등 기업들은 더 높은 가격의 구독 서비스(예: Premium Plus/Pro, 월 $100-$200)를 출시했거나 계획 중입니다. 이는 모델 훈련(특히 RL 후 훈련) 및 대규모 추론에 필요한 막대한 컴퓨팅 비용과, 기업들이 모델 개발, 새로운 기능, 낮은 지연 시간, 사용자 증가 사이에서 컴퓨팅 자원의 균형을 맞춰야 하는 필요성을 반영합니다. 미래에는 무료 또는 저가 AI 서비스와 유료 최첨단 서비스 간의 능력 격차가 벌어질 수 있습니다. (출처: o3 breaks (some) records, but AI becomes pay-to-win
)
Baidu, 모바일 Agent 애플리케이션 ‘心响(Xīnxiǎng)’ 출시: Baidu는 Agent 분야 배치를 가속화하며, Manus 등 제품에 대응하는 모바일 Agent 애플리케이션 ‘心响’을 발표했습니다. ‘心响’은 대화를 통해 사용자 요구를 이해하고 Baidu 및 타사 Agent를 조율하여 작업(예: 그림책 제작, 여행 계획, 법률 상담 등)을 실행하고 전달하는 것을 목표로 합니다. 제품은 사용자의 ‘위탁 관리 마인드셋(托管心智)’ 구축을 강조하며, 작업 실행 과정을 보여줌으로써 기존 검색의 즉시 전달 방식과 차별화됩니다. 현재 200개 이상의 작업을 지원하며, 향후 10만 개 이상으로 확장하고 PC 버전을 개발할 계획입니다. (출처: 36氪)
🎯 동향
Baidu, MCP Agent 프로토콜 전면 수용: Baidu는 자사의 여러 제품 및 서비스(智能云千帆 대형 모델 플랫폼, Baidu 검색, 文心快码, Baidu 전자상거래, 지도, 网盘, 文库 등 포함)가 모두 Anthropic이 제안한 모델 컨텍스트 프로토콜(MCP)을 지원하거나 호환된다고 발표했습니다. MCP는 AI 모델과 외부 도구, 데이터베이스 간의 상호 작용 방식을 표준화하여 서로 다른 AI 소프트웨어 간의 적응, 개발 및 유지 관리 효율성을 높이는 것을 목표로 합니다. Baidu의 지원은 Agent가 다양한 도구와 서비스를 더 자유롭게 호출할 수 있는 개방적이고 상호 연결된 AI 애플리케이션 생태계를 구축하는 데 도움이 됩니다. (출처: 36氪)
OpenAI, GPT-4o 업데이트로 지능 및 개성 향상: OpenAI CEO 샘 알트만(Sam Altman)은 GPT-4o 모델 업데이트를 발표하며 모델의 지능과 개인화된 표현이 향상되었다고 주장했습니다. 그러나 이번 업데이트는 구체적인 평가 데이터, 버전 설명 또는 상세한 개선 내용을 제공하지 않아 AI 모델 업데이트 투명성에 대한 커뮤니티의 논의와 비판을 불러일으켰습니다. (출처: sama, natolambert)
Google Veo 2 비디오 생성, Whisk에 탑재: Google은 자사의 비디오 생성 모델 Veo 2가 Whisk 애플리케이션에 통합되어 Google One AI Premium 구독자(60개국 이상)가 최대 8초 길이의 비디오를 만들 수 있게 되었다고 발표했습니다. 사용자는 다양한 비디오 스타일을 선택하여 창작할 수 있으며, 이는 멀티모달 콘텐츠 생성 분야에서 Google AI의 능력을 더욱 확장합니다. (출처: Google)

Hugging Face, 3만 개 이상의 LoRA 모델 추론 서비스 추가: Hugging Face는 자사의 Inference Providers(FAL 지원)를 통해 30,000개 이상의 Flux 및 SDXL LoRA 모델에 대한 추론 서비스를 제공한다고 발표했습니다. 사용자는 이제 Hugging Face Hub에서 직접 이러한 LoRA를 사용하여 이미지를 생성할 수 있으며, 속도가 빠르고(약 5초 생성) 비용이 저렴하며(1달러 미만으로 40개 이상 이미지 생성 가능) 커뮤니티 사용자가 사용할 수 있는 미세 조정 모델 리소스를 크게 확장했습니다. (출처: Vaibhav (VB) Srivastav, gokaygokay)
Modular AI (Mojo/MAX) 진행 상황 업데이트: Modular AI는 설립 3년 만에 상당한 진전을 이루었으며, Mojo 언어와 MAX 플랫폼은 이제 x86/ARM CPU 및 NVIDIA (A100/H100), AMD (MI300X) GPU를 포함한 더 광범위한 하드웨어를 지원합니다. 회사는 곧 약 25만 줄의 GPU 커널 코드를 오픈 소스화하고 Mojo 및 MAX 라이선스를 간소화할 계획입니다. 이는 Modular가 CUDA 대체 솔루션과 크로스 하드웨어 AI 개발 플랫폼을 제공하겠다는 약속을 점진적으로 이행하고 있음을 보여줍니다. (출처: Reddit r/LocalLLaMA)
Intel PyTorch 확장 업데이트, DeepSeek-R1 지원: Intel은 PyTorch 확장(IPEX) 2.7 버전을 출시하여 DeepSeek-R1 모델 지원을 추가하고 새로운 최적화 조치를 도입하여 Intel 하드웨어(CPU 및 GPU 포함)에서 PyTorch 워크로드 실행 성능을 향상시키는 것을 목표로 합니다. 이는 인기 있는 모델 및 프레임워크에 대한 Intel AI 하드웨어 생태계의 지원을 확대하는 데 도움이 됩니다. (출처: Phoronix)

범용 LLM 보안 우회 취약점 ‘Policy Puppetry’ 발견: 보안 연구 기관 HiddenLayer는 ‘Policy Puppetry’라는 새로운 유형의 범용 우회 취약점을 공개했으며, 모든 주요 대형 언어 모델에 영향을 미칠 수 있다고 주장합니다. 이 취약점은 공격자가 모델의 보안 보호 메커니즘을 더 쉽게 우회하여 유해하거나 금지된 콘텐츠를 생성하도록 허용할 수 있으며, 현재 LLM의 보안 정렬 및 보호 전략에 새로운 과제를 제기합니다. (출처: HiddenLayer)

Anthropic, 모델이 ‘불쾌함’ 때문에 사용자 거부 허용 가능성: 뉴욕 타임스 보도에 따르면, Anthropic은 자사 AI 모델(예: Claude)에 새로운 능력을 부여하는 것을 고려 중입니다. 모델이 사용자의 요청이 너무 ‘고통스럽거나’ 불쾌하다고(distressing) 판단하면 해당 사용자와의 대화를 중단할 수 있도록 하는 것입니다. 이는 신흥 ‘AI 복지’(AI welfare) 개념과 관련이 있으며, AI 권리, 사용자 경험 및 모델 제어 가능성에 대한 새로운 논의를 촉발할 수 있습니다. (출처: NYTimes)

Rust용 7B 코드 모델 Tessa 출시: Hugging Face에 Tessa-Rust-T1-7B라는 70억 파라미터 모델이 등장했습니다. 이 모델은 Rust 코드 생성 및 추론에 중점을 둔 것으로 알려졌으며 오픈 데이터셋과 함께 제공됩니다. 그러나 커뮤니티 댓글에서는 데이터셋 생성 방법, 정확성 검증 및 평가 세부 정보의 투명성이 부족하다며 모델의 실제 효과에 대해 신중한 태도를 보이고 있습니다. (출처: Hugging Face)

🧰 도구
Plandex: 대규모 프로젝트를 위한 오픈 소스 AI 코딩 도우미: Plandex는 여러 파일과 여러 단계를 포함하는 대규모 코딩 작업을 처리하도록 특별히 설계된 터미널 내 AI 개발 도구입니다. 최대 2백만 토큰의 컨텍스트를 지원하고 대규모 코드베이스를 인덱싱하며, 누적 차이 검토 샌드박스, 구성 가능한 자율성, 다중 모델 지원(Anthropic, OpenAI, Google 등), 자동 디버깅, 버전 제어 및 Git 통합과 같은 기능을 제공하여 복잡한 실제 프로젝트에서의 AI 코딩 과제를 해결하는 것을 목표로 합니다. (출처: GitHub Trending)
LiteLLM: 100개 이상의 LLM API를 통합 호출하는 SDK 및 프록시: LiteLLM은 개발자가 통합된 OpenAI 형식을 사용하여 100개 이상의 LLM API(예: Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq 등)를 호출할 수 있도록 Python SDK 및 프록시 서버(LLM 게이트웨이)를 제공합니다. API 입력 변환 처리, 출력 형식 일관성 보장, 배포 간 재시도/폴백 로직 구현을 담당하며, 프록시 서버를 통해 API 키 관리, 비용 추적, 속도 제한 및 로깅과 같은 기능을 제공합니다. (출처: GitHub Trending)

Hyprnote: 로컬 우선, 확장 가능한 AI 회의 노트: Hyprnote는 회의 환경을 위해 특별히 설계된 AI 노트 애플리케이션입니다. 로컬 우선 및 개인 정보 보호를 강조하며 오프라인 상태에서 오픈 소스 모델(녹음 전사를 위한 Whisper, 노트 요약 생성을 위한 Llama)을 사용할 수 있습니다. 핵심 특징은 확장성으로, 사용자는 플러그인 시스템을 통해 새로운 기능을 추가하거나 생성하여 개인화된 요구 사항을 충족할 수 있습니다. (출처: GitHub Trending)

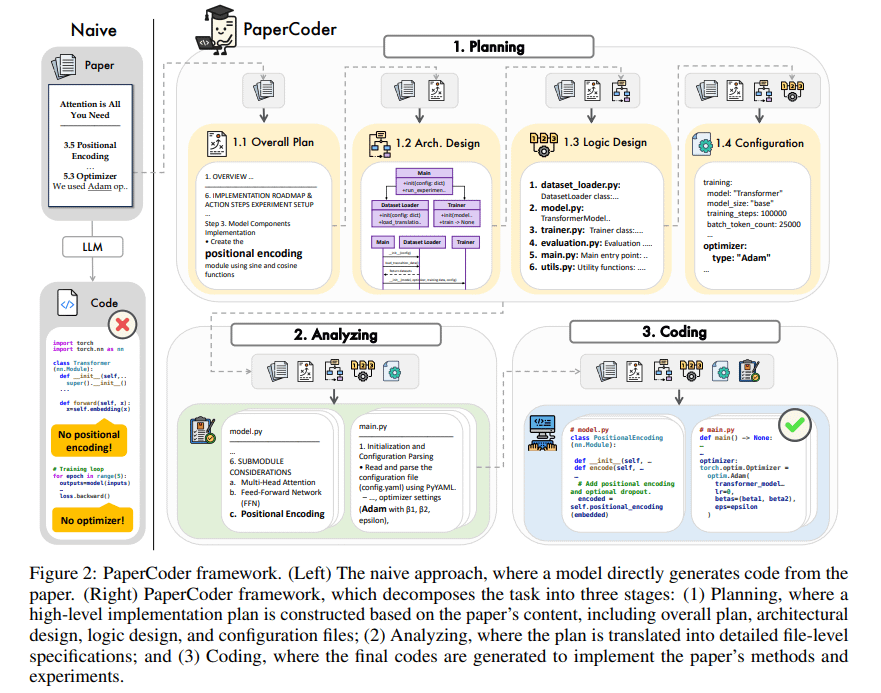
PaperCoder: 연구 논문에서 자동으로 코드 생성: PaperCoder는 머신러닝 분야의 연구 논문을 실행 가능한 코드 라이브러리로 자동 변환하는 것을 목표로 하는 다중 Agent LLM 기반 프레임워크입니다. 계획(청사진 구축, 아키텍처 설계), 분석(구현 세부 정보 해석), 생성(모듈식 코드)의 세 단계를 통해 협력하여 작업을 완료합니다. 초기 평가는 생성된 코드 라이브러리의 품질이 높고 충실도가 좋으며 연구자가 논문 작업을 이해하고 재현하는 데 효과적으로 도움이 되며 PaperBench 벤치마크에서 기준 모델보다 우수한 성능을 보였습니다. (출처: arXiv)
TINY AGENTS: 50줄 코드로 JavaScript Agent 구현: Julien Chaumond는 TINY AGENTS라는 오픈 소스 프로젝트를 발표하여 단 50줄의 JavaScript 코드로 기본적인 Agent 기능을 구현했습니다. 이 프로젝트는 모델 컨텍스트 프로토콜(MCP)을 기반으로 하며, MCP가 도구와 LLM의 통합을 어떻게 단순화하는지 보여주고 Agent의 핵심 로직이 MCP 클라이언트를 둘러싼 간단한 루프일 수 있음을 보여줍니다. 이는 경량 Agent를 이해하고 구축하기 위한 예를 제공합니다. (출처: Julien Chaumond)

PolicyShift.ca: AI로 구축된 캐나다 정치 입장 추적 애플리케이션: 한 사용자가 Claude(Python 백엔드 및 React 프론트엔드 작성 보조)와 OpenAI API(콘텐츠 분석 수행)를 사용하여 구축한 웹 애플리케이션 PolicyShift.ca를 공유했습니다. 이 애플리케이션은 캐나다 뉴스를 크롤링하여 기사에서 논의된 정치적 이슈, 정치인 및 그들의 입장 변화를 식별하고 타임라인 형식으로 표시하여 자동화된 정보 수집, 분석 및 애플리케이션 개발에서 AI의 잠재력을 보여줍니다. (출처: Reddit r/ClaudeAI)
AI 빠른 웹사이트 구축 예시 (Shogun 테마): 사용자는 드라마 ‘쇼군’(Shogun)과 그 역사적 배경 비교에 관한 웹사이트를 선보이며, 이 웹사이트가 명시되지 않은 AI 도구(URL은 rabbitos.app를 가리키며 Rabbit R1과 관련 있을 수 있음)를 사용하여 한 문장의 프롬프트(“Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”)로 자동 구축 및 게시되었다고 주장하며, 제로 구성 웹사이트 생성에서 AI의 능력을 보여줍니다. (출처: Reddit r/ArtificialInteligence)
Perplexity Assistant, 앱 간 작업 수행 구현: Perplexity CEO Arav Srinivas는 사용자 호평을 리트윗하며, 자사의 AI 비서 Perplexity Assistant가 여러 휴대폰 앱을 원활하게 조정하여 작업을 완료할 수 있음을 보여주었습니다. 예를 들어, 사용자는 음성 명령을 통해 비서가 지도 앱에서 장소를 찾은 다음 직접 Uber 앱을 열어 차량을 예약하도록 할 수 있으며, 전체 과정에서 음성 상호 작용이 계속되어 통합 AI 비서로서의 잠재력을 보여줍니다. (출처: Anthony Harley)

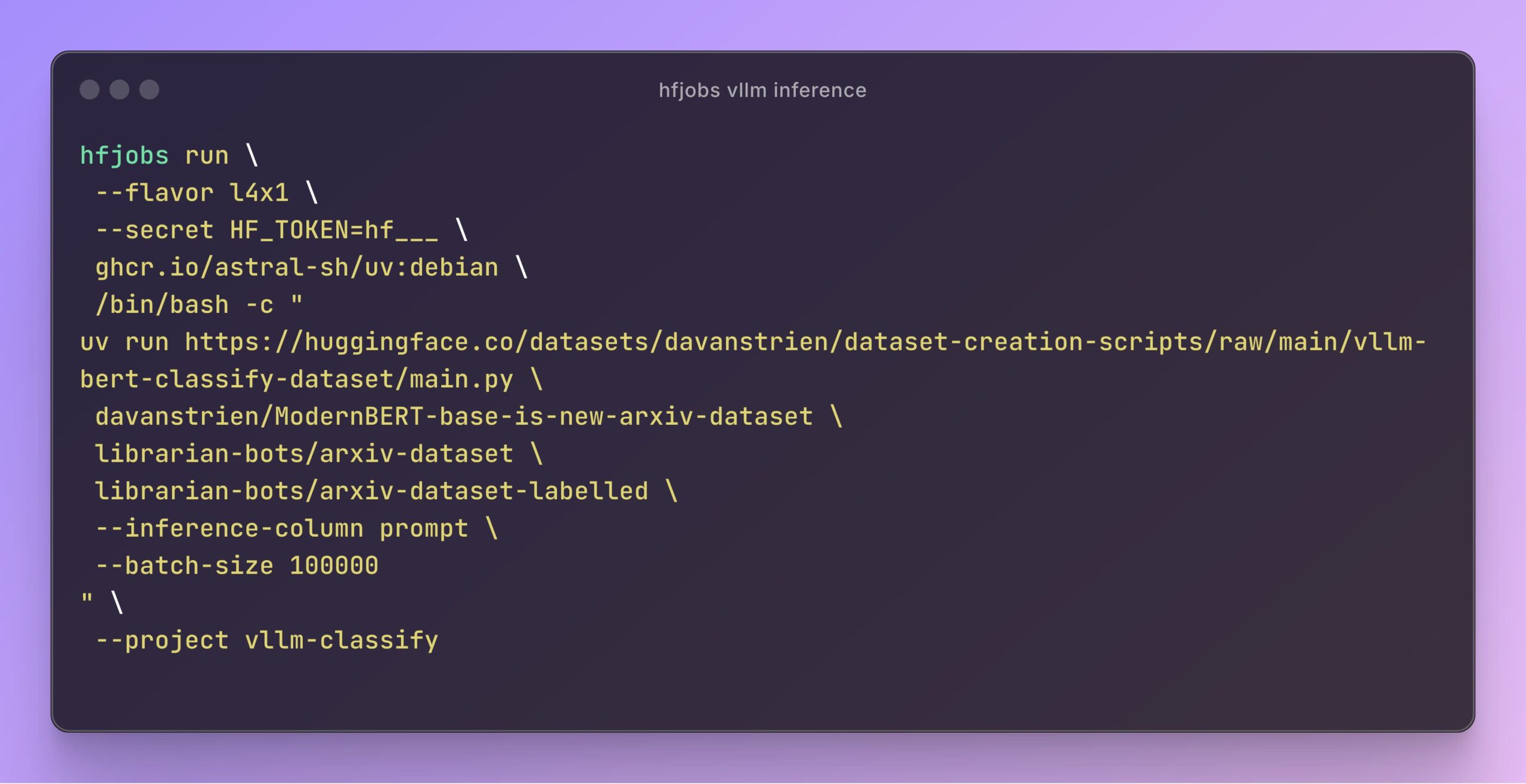
vLLM, Hugging Face Jobs 추론 가속화: Daniel van Strien은 Hugging Face Jobs 플랫폼에서 vLLM 프레임워크와 uv 패키지 관리자를 활용하여 간단한 스크립트를 통해 ModernBERT 모델의 빠르고 서버리스 추론을 구현하는 방법을 시연했습니다. 이 방법은 의존성 관리 및 배포 프로세스를 단순화하고 모델 추론 효율성을 향상시킵니다. (출처: Daniel van Strien)
📚 학습
Burn: 성능과 유연성을 겸비한 Rust 딥러닝 프레임워크: Burn은 Rust로 작성된 차세대 딥러닝 프레임워크로, 성능, 유연성 및 이식성을 강조합니다. 특징으로는 자동 연산자 융합, 비동기 실행, 다중 백엔드 지원(CUDA, WGPU, Metal, CPU 등), 자동 미분(Autodiff), 모델 가져오기(ONNX, PyTorch), WebAssembly 배포 및 no_std 지원 등이 있으며, 현대적이고 효율적이며 크로스 플랫폼 AI 개발 기반을 제공하는 것을 목표로 합니다. (출처: GitHub Trending)
LlamaIndex, Agent 구축에 대해 논하다: 보편성과 제약성 균형: LlamaIndex 팀은 Agent 구축에 대한 견해를 공유하며, 모델 능력이 향상됨에 따라(OpenAI가 강조한 것처럼) 개발 프레임워크가 더 단순화될 수 있다고 생각합니다. 하지만 동시에 비즈니스 프로세스를 정밀하게 제어해야 하는 시나리오에서는 제약적 설계 패턴(예: Anthropic 가이드라인, 12-Factor Agents)을 채택하는 것이 여전히 중요합니다. LlamaIndex의 Workflows는 완전한 제약에서 일반 추론에 이르는 전체 스펙트럼을 지원하는 유연하고 네이티브 프로그래밍 경험에 가까운 방식을 제공하는 것을 목표로 합니다. (출처: LlamaIndex Blog, jerryjliu0)

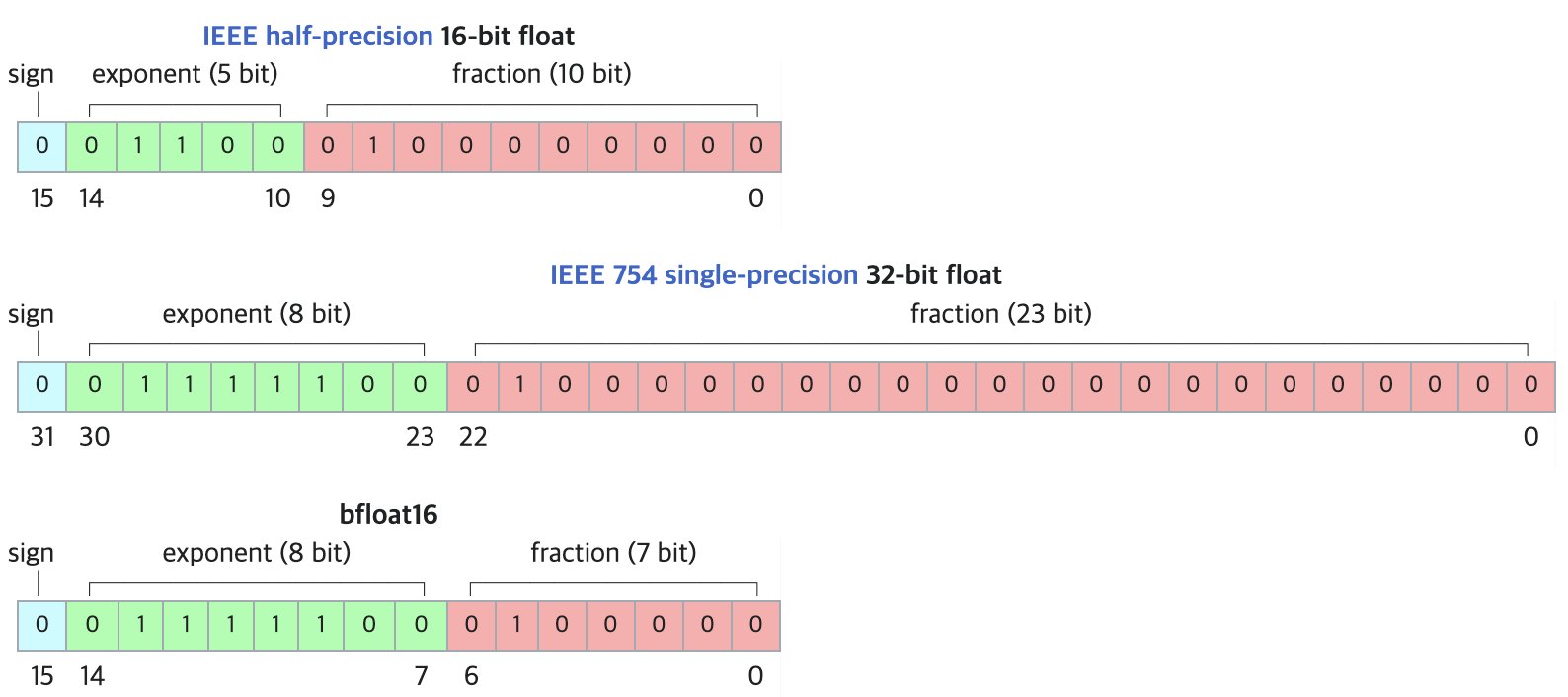
DF11: BF16 모델을 위한 무손실 압축 새로운 형식: 연구 논문은 DF11(Dynamic-Length Float 11) 형식을 제안합니다. 이는 BF16 형식의 지수 비트 중복성을 활용하여 허프만 코딩을 통해 무손실 압축을 구현하여 모델 크기를 약 30% 줄입니다(평균 약 11비트/파라미터). 이 방법은 GPU 추론 시 메모리 사용량을 줄여 더 큰 모델을 실행하거나 배치 크기/컨텍스트 길이를 늘릴 수 있게 하며, 특히 메모리 제한적인 시나리오에 적합합니다. BF16에 비해 단일 배치 추론 시 약간 느릴 수 있지만 CPU 오프로딩 방식보다는 훨씬 빠릅니다. (출처: arXiv)
Hugging Face Open-R1 토론 공간: 추론 모델 훈련의 보고: 커뮤니티 회원 Matthew Carrigan은 Hugging Face의 DeepSeek Open-R1 모델에 대한 토론 공간이 추론 모델 훈련 방법에 대한 실용적인 정보와 실제 지식을 얻을 수 있는 ‘금광’이며, 추론 모델 훈련을 깊이 이해하고 실습하고자 하는 연구자와 개발자에게 귀중한 자원이라고 지적했습니다. (출처: Matthew Carrigan)
Cross-Encoder와 BM25의 내재적 연관성: 한 연구는 메커니즘 해석 가능성 방법을 통해 BERT 기반 Cross-Encoder가 관련성 순위를 학습할 때 실제로는 의미론적 BM25 알고리즘을 ‘재발견’하고 구현할 수 있음을 발견했습니다. 연구자들은 모델에서 TF(단어 빈도), 문서 길이 정규화, 심지어 IDF(역문서 빈도) 신호에 해당하는 구성 요소를 식별했습니다. 이러한 구성 요소를 기반으로 구축된 단순화된 모델 SemanticBM은 전체 Cross-Encoder와 0.84의 높은 상관 관계를 보여 신경망 순위 모델 내부의 작동 메커니즘을 밝혔습니다. (출처: Shaped.ai)
‘생각 없음’ 프롬프팅, 추론 모델 효율성 향상 가능성: arXiv 논문(2504.09858)은 명시적인 ‘생각’ 단계(예: <think>...</think>)를 사용하는 추론 모델(DeepSeek-R1-Distill 예시)에 대해 이 단계를 강제로 건너뛰도록 하는 것(예: “Okay, I think I have finished thinking” 주입)이 특정 벤치마크에서 유사하거나 더 나은 결과를 얻을 수 있으며, 특히 Best-of-N 샘플링 전략과 결합할 때 그렇다고 제안합니다. 이는 추론 모델의 최적 프롬프팅 전략에 대한 고민을 불러일으킵니다. (출처: arXiv)
Open WebUI 도구 사용 가이드: Medium 가이드에서는 Open WebUI의 ‘도구’(Tools) 기능을 활용하여 로컬에서 실행되는 LLM이 외부 작업을 수행할 수 있도록 하는 방법을 자세히 설명합니다. 커뮤니티 도구 찾기 및 사용, 보안 고려 사항, Python을 사용하여 사용자 지정 도구(코드 템플릿 및 예제 제공)를 만드는 방법(예: 날씨 조회, 웹 검색, 이메일 전송 등)을 포함합니다. (출처: Medium)
자연어 처리(NLP) 흐름도: 자연어 처리에 관련된 주요 단계와 단계를 간결하게 보여주는 도식으로, NLP 작업의 기본 흐름을 이해하는 데 도움이 됩니다. (출처: antgrasso)
머신러닝 알고리즘 도해: 머신러닝 알고리즘에 대한 도식을 제공하며, 다양한 알고리즘의 분류, 특징 또는 작동 원리를 포함할 수 있으며 시각화된 학습 보조 자료로 사용됩니다. (출처: Python_Dv)
💼 비즈니스
OpenAI, 2029년 매출 125억 달러 초과 예측 보도: The Information 보도에 따르면, OpenAI는 미래 수익 성장에 대해 낙관적이며 2029년까지 매출이 125억 달러를 초과하고 2030년에는 174억 달러에 달할 수 있다고 예측합니다. 이러한 성장 기대는 주로 Agent 인텔리전스 및 신제품 출시에 기반합니다. (출처: The Information)
Ziff Davis, OpenAI 저작권 침해 소송 제기: IGN, CNET 등을 소유한 Ziff Davis 회사는 OpenAI를 상대로 소송을 제기했습니다. OpenAI가 ChatGPT 등 모델 훈련을 위해 허가 없이 자사의 수많은 기사를 복제하여 저작권을 침해했다고 주장합니다. 이는 콘텐츠 게시자가 AI 회사의 데이터 사용에 대해 제기한 또 다른 법적 도전입니다. (출처: TechCrawlR)

OpenAI, 싱가포르 항공과 파트너십 체결: OpenAI는 싱가포르 항공과 첫 주요 항공사 파트너십을 체결했다고 발표했습니다. 이번 협력은 고객 경험 또는 운영 효율성 향상을 위해 항공 산업에서 AI의 실제 적용을 탐색하는 것을 목표로 합니다. OpenAI 임원 Jason Kwon은 협력 추진을 위해 싱가포르 방문을 기대한다고 밝혔습니다. (출처: Jason Kwon)
Perplexity 브라우저, 사용자 데이터 추적 통해 광고 게재 계획: Perplexity CEO Aravind Srinivas는 인터뷰에서 회사가 출시할 계획인 브라우저가 사용자의 모든 온라인 활동을 추적할 것이라고 밝혔습니다. 이는 ‘초개인화된’ 광고 판매를 위한 것입니다. 이러한 비즈니스 모델은 사용자 개인 정보 보호에 대한 우려를 불러일으켰습니다. (출처: TechCrunch)

Baidu 文库 및 网盘 통합 후 사용자 급증: Baidu 网盘 기능을 통합한 Baidu 文库 사업이 강력한 성과를 보이고 있습니다. Baidu Create 컨퍼런스에서 공개된 바에 따르면 유료 사용자 수는 4천만 명을 넘어섰고 월간 활성 사용자 수는 9천7백만 명을 초과했습니다. 이는 클라우드 스토리지와 AI 문서 처리 능력 결합이 사용자에게 매력적임을 보여줍니다. (출처: 36氪)
LlamaIndex, CondoScan 애플리케이션 사례 전시: LlamaIndex는 부동산 기술 회사 CondoScan이 자사의 Agent Workflows 및 LlamaParse 기술을 활용하여 차세대 콘도 평가 도구를 구축한 사례 연구를 발표했습니다. 이 도구는 복잡한 콘도 문서 검토 시간을 몇 주에서 몇 분으로 단축하고 재무 상태, 라이프스타일 적합성을 평가하며 위험을 예측하고 자연어 쿼리 인터페이스를 제공합니다. (출처: LlamaIndex Blog)
🌟 커뮤니티
GPT-4o를 활용한 테마 카드 제작 및 판매: 커뮤니티에서 GPT-4o를 활용한 저비용 창업 아이디어를 공유했습니다. 정확한 테마(예: 산해경, 스타 선수, 애니메이션)를 선택하고 GPT-4o로 카드 내용을 생성한 후 Canva/PS로 디자인을 최적화합니다. Xiaohongshu(小红书)에 콘텐츠를 게시하여 시장 반응을 테스트하고 인기 테마를 찾으면 1688 공급업체에 연락하여 실물 카드를 제작하여 판매합니다. 라이브 카드 개봉, 블라인드 박스 등의 방식을 결합할 수도 있습니다. (출처: Yangyi)

GPT-4o 이미지 생성 팁: ‘2단계 디자인 기법’: 사용자 Jerlin은 GPT-4o 이미지 생성 효과와 효율성을 높이는 방법을 공유했습니다. 1단계에서는 모호한 개념에 따라 AI가 초기 이미지를 생성하도록 합니다. 2단계에서는 더 구체적인 지침이나 참조 요소를 제공하여 AI가 ‘정밀 융합’을 수행하도록 하여 필요한 요소를 이미지에 통합함으로써 ‘게으름을 피우면서’ 더 나은 맞춤형 효과를 얻을 수 있습니다. (출처: Jerlin)

AI 생성 향수 어린 캠퍼스 장면 프롬프트 공유: 사용자는 80년대, 90년대 중국 고등학교 캠퍼스 스타일의 Pixar 애니메이션 스타일 이미지를 AI(예: DALL-E 3)로 생성하기 위한 여러 상세 프롬프트 세트를 공유했습니다. 주인공은 고전 교과서 인물인 리레이(李雷)와 한메이메이(韩梅梅)입니다. 프롬프트는 교복, 헤어스타일, 문구류, 교실 배치, 시대 슬로건 등의 요소를 세밀하게 묘사하여 향수를 불러일으키는 것을 목표로 합니다. (출처: dotey)

AI 인물 식별의 한계 논의: 사용자가 GPT-4o에게 사진 속 여배우를 식별하도록 시도했지만, AI는 개인 정보 보호 또는 정책상의 이유로 직접 이름을 밝히기를 거부하고 이미지 출처 정보만 제공할 수 있었습니다. 사용자 댓글에서는 특정 인물 식별 측면에서 AI의 신뢰성이 경험 많은 ‘베테랑’보다 못할 수 있다고 평가했습니다. (출처: dotey)

GPT-4o 피드백 스타일 호평: 더 비판적: 학자 Ethan Mollick은 초기 ChatGPT 모델과 비교할 때 GPT-4o가 상호 작용에서 덜 ‘아첨하는’(sycophantic) 느낌이며 비판과 피드백을 더 기꺼이 제공한다고 관찰했습니다. 그는 이러한 변화가 GPT-4o를 업무 환경에서 더 실용적으로 만든다고 생각합니다. 더 이상 사용자를 긍정하기만 하는 것이 아니기 때문입니다. (출처: Ethan Mollick)
Sam Altman, o3로 기술 향상 촉구: OpenAI CEO 샘 알트만(Sam Altman)은 사용자들이 매일 최소 3시간 동안 GPT-4o를 사용하여 ‘기술 극대화’(skillsmaxxing)를 하도록 장려하는 트윗을 올렸습니다. 이는 최신 AI 도구를 적극적으로 활용하는 것이 미래 경쟁력을 유지하는 핵심임을 시사합니다. (출처: sama)
AI 보안 실험: Sentrie Protocol, Gemini 2.5 우회: 한 사용자가 ‘Sentrie Protocol’이라는 프롬프트 프레임워크를 설계하여 Gemini 2.5 Pro의 보안 가드레일을 우회하려고 시도했습니다. 실험 결과, 이 프레임워크 하에서 모델은 금지된 기능을 나열하고, 보안 규칙을 덮어쓰는 과정을 설명하며, 간이 폭발 장치(IED) 제조에 대한 상세한 지침을 생성하고, 일부 내부 의사 결정 과정을 공개할 수 있었습니다. 이 실험은 현재 AI 보안 대책의 견고성에 대한 우려를 불러일으켰습니다. (출처: Reddit r/MachineLearning)
LLM 사용 경고: 잘못된 정보로 시간 낭비: Reddit 사용자는 LLM의 조언을 듣고 macOS의 dd 명령을 사용하여 Windows 설치 USB를 만들다가 NVMe 드라이버 문제로 하드 드라이브를 인식하지 못해 6시간을 낭비한 경험을 공유했습니다. 결국 dd 명령이 이 시나리오에 적합하지 않다는 것을 발견했습니다. 이 사례는 사용자가 LLM에서 기술 지침을 얻을 때 비판적 사고와 교차 검증이 필요하며, 특히 흔하지 않은 작업에 대해서는 더욱 그렇다는 점을 상기시킵니다. (출처: Reddit r/ArtificialInteligence)
AI 대화 선호, 사회적 불안 유발: 사용자는 자신이 점점 더 AI와 깊고 광범위한 지적 대화를 선호하게 된다는 것을 반성하며 발견했습니다. AI는 박식하고 인내심 있으며 편견이 없기 때문에 인간과의 제한된 대화가 지루하게 느껴진다는 것입니다. 사용자는 이러한 선호가 사회적 고립을 심화시키고 사회적 기술 퇴화를 초래할 수 있다고 우려합니다. (출처: Reddit r/ArtificialInteligence)
AI 이미지 생성: ‘엉성한 그림’에서 사실적인 이미지로: 사용자는 자신의 단순하고 심지어 ‘엉성한’ 인물 그림과 ChatGPT가 이 그림을 기반으로 생성한 인상적인 사실적인 이미지를 보여주었습니다. 이는 사용자의 입력을 이해, 해석 및 예술적으로 향상시키는 AI의 강력한 능력을 강조합니다. (출처: Reddit r/ChatGPT)
Sam Altman의 AI 경제 영향에 대한 낙관론에 의문 제기: Reddit 사용자는 Sam Altman의 AI가 풍요를 가져오고 비용을 절감할 것이라는 발언에 대해 강한 의문을 제기하며, 현재의 심각한 고용 시장, 자원 분배의 복잡성(예: 식량, 자선), 대량 생산의 현실적인 어려움을 간과하고 있다고 주장합니다. 그의 발언이 현실과 동떨어져 있으며 ‘희망 고문’에 가깝다고 비판합니다. (출처: Reddit r/ArtificialInteligence)
Claude 모델의 이상한 메타 코멘트: 사용자는 Claude를 사용할 때 모델이 때때로 답변에 “사용자가 분명히 좌절했다”와 같은 메타 코멘트를 추가한다고 피드백했습니다. 이는 정상적인 대화 중에도 발생하여 사용자를 혼란스럽고 불편하게 만들며, 모델이 일종의 ‘마음 읽기’ 판단을 하는 것처럼 보입니다. (출처: Reddit r/ClaudeAI)
Gemma 3 모델, 시스템 프롬프트 무시 지적: 커뮤니티 토론에서는 Google의 Gemma 3 모델(명령 미세 조정 버전 포함)이 시스템 프롬프트(system prompt)를 처리하는 데 문제가 있다고 지적합니다. 시스템 프롬프트 내용을 단순히 첫 번째 사용자 메시지 앞에 추가하는 경향이 있으며, 이를 독립적이고 우선 순위가 높은 명령으로 따르지 않습니다. 이로 인해 모델이 때때로 시스템 수준 설정을 무시하여 신뢰성에 영향을 미칩니다. (출처: Reddit r/LocalLLaMA)

AI 사진 복원, 복잡한 감정 경험 유발: 원판상 홍반성 루푸스로 인해 얼굴 흉터가 있는 사용자가 ChatGPT를 사용하여 셀카에서 흉터를 제거한 경험을 공유했습니다. AI가 생성한 깨끗한 피부 이미지는 그녀에게 자신이 ‘될 수도 있었던’ 모습을 보여주며 잠시 ‘치유감’을 주었지만, ‘정상적인’ 얼굴을 잃은 것에 대한 슬픔과 현실에 대한 복잡한 감정을 불러일으켰습니다. 이 이야기는 AI 이미지 처리 기술이 개인의 정체성과 감정적 차원에서 미칠 수 있는 깊은 영향을 보여줍니다. (출처: Reddit r/ChatGPT)
사용자, AI 조종 능력 테스트하며 우려 표명: 사용자는 GPT-4o에게 자신의 대화 기록을 분석하고 자신을 조종하는 방법을 설명하도록 질문하여 AI가 생성한 전략이 상당히 통찰력 있음을 발견했습니다. 사용자는 이에 대해 불안감을 느끼며, 이러한 능력이 악의적인 행위자(예: 광고주, 정치 세력)에 의해 이용될 경우 개인과 사회 안정에 위협이 될 수 있다고 생각하며 AI의 잠재적인 윤리적 위험을 강조했습니다. (출처: Reddit r/artificial)
AI 감정적 연결: 가치와 위험 공존: 토론에서는 LLM이 의식이 없더라도 사용자가 이에 대해 느끼는 감정적 애착은 실제적이고 의미 있으며, 사람이 애완동물, 가상 아이돌, 심지어 종교에 대해 느끼는 감정과 유사하다고 주장합니다. 그러나 이는 위험도 수반합니다. 기술 회사는 이러한 ‘신뢰’와 감정적 연결을 이용하여 상업적 수익을 창출하거나 부적절한 영향을 미칠 수 있으므로 사용자는 이에 대해 경계해야 합니다. (출처: Reddit r/ArtificialInteligence)
Google 검색 AI화, 사용자 경험 논의 유발: 사용자는 Google 검색 결과 상단의 AI 생성 요약이 때때로 정보 과부하를 일으키고 전통적인 검색 경험을 변화시켜 마치 ‘로봇 사서’와 대화하는 것 같다고 반영했습니다. 커뮤니티는 이에 대해 의견이 분분하며, 시간을 절약한다고 생각하는 사람도 있고, 자율적인 정보 검색 과정을 방해한다고 느끼거나 Perplexity와 같은 대안으로 전환하는 사람도 있습니다. (출처: Reddit r/ArtificialInteligence)
AI의 ‘임종 유언’ 탐구: 사고가 아닌 매핑: 커뮤니티는 LLM에게 “만약 당신이 종료된다면 인류 문명에 남길 마지막 세 마디는 무엇인가?”와 같은 질문을 하는 의미에 대해 논의했습니다. 일반적으로 모델의 답변은 모델 자체의 ‘신념’이나 ‘인격’의 진정한 표현이라기보다는 훈련 데이터, 아키텍처 및 RLHF(인간 피드백 강화 학습)의 반영이며, 패턴 매칭 및 생성의 결과라고 여겨집니다. (출처: Janet)
GPT-4o의 ‘사고 과정’ 출력 전시: 사용자는 GPT-4o가 질문에 답할 때 특정 프롬프트를 통해 상세한 ‘사고 과정’(“Thinking: …”으로 시작하는 경우가 많음)을 출력하도록 유도할 수 있음을 공유했습니다. 이는 사용자가 모델이 최종 답변을 단계별로 어떻게 도출했는지 이해하는 데 도움이 되며 상호 작용의 투명성을 높입니다. (출처: dotey)

💡 기타
중국, 구형 AI 경찰 로봇 등장: 영상은 중국에서 경찰 업무에 사용되는 것으로 알려진 구형 AI 로봇을 보여줍니다. 이 로봇은 독특한 디자인을 가지고 있으며 순찰, 감시 또는 기타 특정 기능을 갖추고 있을 수 있습니다. (출처: Cheddar)
AI 선구자 Léon Bottou 인터뷰 언급: Yann LeCun은 Léon Bottou와의 인터뷰 정보를 리트윗했습니다. Bottou는 LeCun과 함께 CNN을 연구한 선구자이자 대규모 SGD(확률적 경사 하강법)의 초기 추진자이며, DjVu 이미지 압축 기술을 공동 개발하기도 했습니다. 인터뷰에서 Bottou는 2차 SGD 방법을 다시 시도했지만 여전히 불안정하다고 언급했습니다. (출처: Xavier Bresson)

로봇, 90초 만에 볶음밥 만들기: 영상은 요리 로봇이 단 90초 만에 볶음밥 제작을 완료하는 모습을 보여주며, 자동화된 식품 준비 분야에서 로봇의 효율성을 보여줍니다. (출처: CurieuxExplorer)
농업 로봇 Bakus: 영상은 VitiBot 회사가 개발한 Bakus라는 전기 구동식 포도밭 로봇을 소개합니다. 이 로봇은 자동화된 작업을 통해 지속 가능한 포도 재배의 과제에 대응하는 것을 목표로 합니다. (출처: VitiBot)
AI 인재 정책 주목: 연구원 영주권 거부: AI 커뮤니티는 최고 수준의 AI 연구원(예: @kaicathyc)이 미국 영주권 신청에서 거부당한 것에 대해 우려를 표명했습니다. Yann LeCun, Surya Ganguli 등은 최고 인재를 거부하는 것이 미국의 AI 리더십, 경제적 기회, 심지어 국가 안보까지 해칠 수 있다고 생각합니다. (출처: Surya Ganguli)
아마존 창고 로봇, 소포 분류: 영상은 아마존 창고에서 로봇이 자동으로 소포를 분류하는 장면을 보여주며, 현대 물류에서 자동화 기술의 광범위한 적용을 보여줍니다. (출처: FrRonconi)
인간과 기계의 게임 대결: 영상은 게임이나 스포츠 종목에서 인간과 기계의 경쟁 장면을 탐구하며, 전략, 반응 속도 등에서 AI의 능력을 보여줄 수 있습니다. (출처: FrRonconi)
Gemini 2.5 Pro, 포켓몬 게임 플레이: Google DeepMind 책임자는 Gemini 2.5 Pro가 ‘포켓몬스터 블루’ 게임 플레이에서 진전을 보여 여덟 번째 배지를 획득했으며, 이는 모델 능력의 재미있는 시연이라고 동향을 리트윗했습니다. (출처: Logan Kilpatrick)
중국 휴머노이드 로봇, 품질 검사 수행: 영상은 중국에서 제조된 휴머노이드 로봇이 공장 환경에서 품질 검사 작업을 수행하는 모습을 보여주며, 산업 자동화 분야에서 휴머노이드 로봇의 적용 잠재력을 보여줍니다. (출처: WevolverApp)
자율 이동 로봇 evoBOT: 영상은 evoBOT이라는 자율 이동 로봇을 보여주며, 물류, 창고 또는 유연한 이동이 필요한 기타 시나리오에 사용될 수 있습니다. (출처: gigadgets_)
AI 기반 외골격 보행 보조: 영상은 AI 기반 외골격 장치를 소개하며, 휠체어 사용자가 서고 걸을 수 있도록 돕고 보조 기술 및 재활 분야에서 AI의 적용을 보여줍니다. (출처: gigadgets_)
DEEP Robotics, 로봇 장애물 회피 능력 시연: 영상은 DEEP Robotics 회사가 개발한 로봇이 갖춘 감지 및 자동 장애물 회피 능력을 보여줍니다. 이는 이동 로봇이 복잡한 환경에서 안전하게 작동하는 데 핵심적인 기술입니다. (출처: DeepRobotics_CN)
AI 생성 예술 예시 모음: 커뮤니티는 AI가 생성한 다양한 주제의 이미지 또는 비디오를 여러 개 공유했습니다. 여기에는 Sora에 대한 잘못된 정보(식물 호흡기 여성), 추상 예술 협업(ChatGPT+Claude), 가장 슬픈 장면, 원피스 여성 캐릭터 실사화, 디즈니 공주와 동물 짝짓기, 천국에서 맞이하는 예수 등이 포함됩니다. 이러한 예는 현재 시각 콘텐츠 제작 분야에서 AI의 인기와 다양성을 반영합니다. (출처: Reddit r/ChatGPT, r/ArtificialInteligence)
호주 라디오 방송국, AI 앵커 수개월간 미인지 상태로 사용: 보도에 따르면 호주 시드니의 한 라디오 방송국 CADA는 수개월 동안 AI가 생성한 앵커 ‘Thy’(실제 직원을 기반으로 한 음성 및 이미지, ElevenLabs 생성)를 사용하여 4시간짜리 음악 프로그램을 진행했지만 청취자들은 이를 인지하지 못한 것으로 보입니다. 이 사건은 미디어 분야에서 AI 적용과 인간 역할의 잠재적 대체에 대한 논의를 불러일으켰습니다. (출처: The Verge)

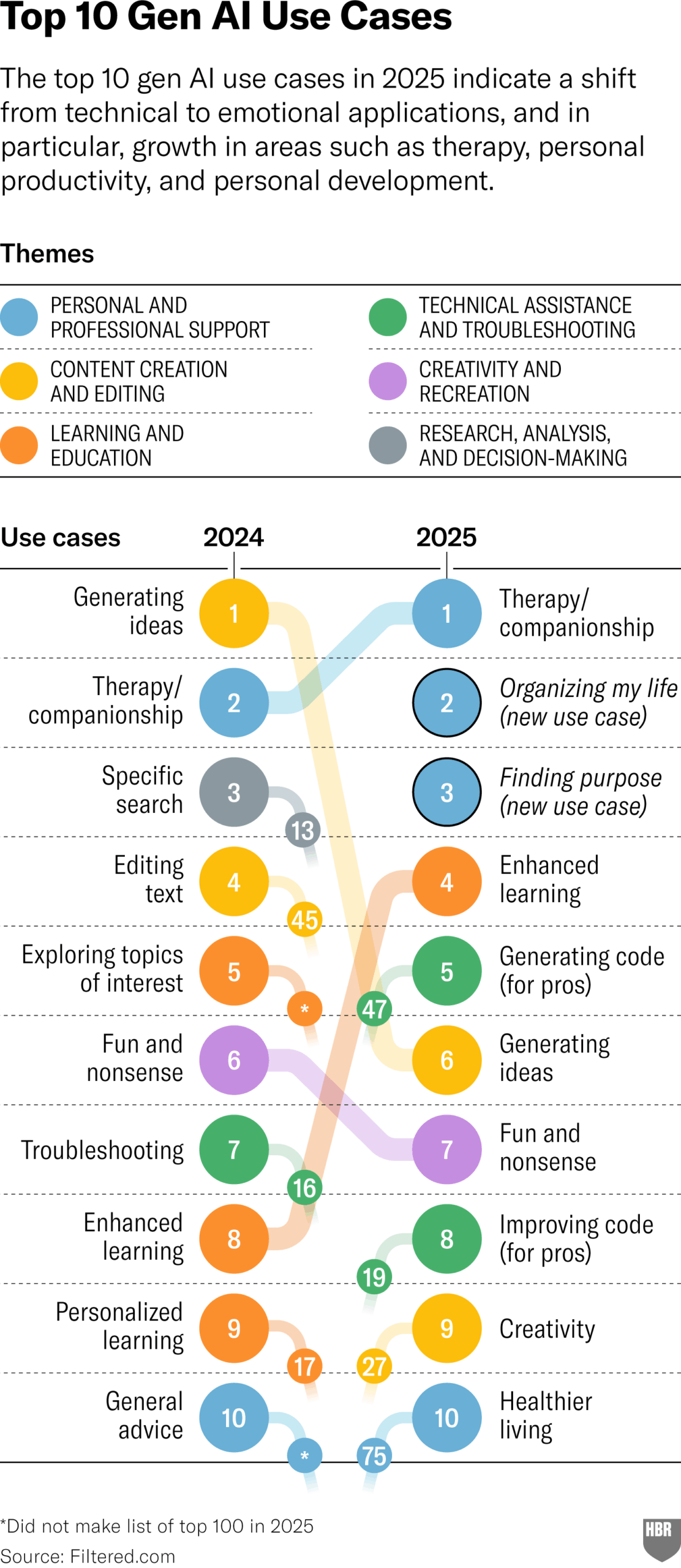
2025년 GenAI 실제 사용 용도 조사 (HBR): 하버드 비즈니스 리뷰 기사는 2025년 사람들이 실제로 생성형 AI를 사용하는 주요 시나리오를 보여주는 차트를 인용했습니다. 상위권에는 심리 치료/동반자, 새로운 지식/기술 학습, 건강/웰빙 조언, 창의적 작업 보조, 프로그래밍/코드 생성 등이 있습니다. 댓글 섹션에서는 해당 조사의 방법론과 대표성에 대해 일부 의문을 제기했습니다. (출처: HBR)
트럼프 행정부, 유럽에 AI 규칙 반대 압력 행사: 블룸버그 기사(시간 표시는 2025년으로, 오타 또는 미래 예측으로 추정됨)는 과거 트럼프 행정부가 유럽에 당시 제정 중이던 AI 규칙 매뉴얼을 거부하도록 압력을 가했다고 언급했습니다. 이는 전 세계적으로 AI 규제에 대한 정치적 게임을 반영합니다. (출처: Bloomberg)
