
키워드:AI 모델, OpenAI, 멀티모달, 에이전트, O3 모델, O4 미니, 시각적 추론, 도구 호출, 제미니 2.5 플래시, 텐센트 위바오 AI, LLM 통합, 강화 학습
🔥 포커스
OpenAI, o3 및 o4-mini 모델 출시, 툴 통합 및 비전 추론 능력 강화: OpenAI가 현재까지 가장 스마트하고 강력한 추론 모델인 o3와 o4-mini를 공식 출시했습니다. 핵심 특징은 Agent가 처음으로 ChatGPT 내부의 모든 툴(웹 검색, Python 데이터 분석, 심층 비전 이해, 이미지 생성 등)을 능동적으로 호출하고 조합하며, 추론 과정에서 이미지를 통합하여 사고할 수 있다는 점입니다. o3는 코딩, 수학, 과학, 시각 인식 등 분야에서 전반적으로 선두를 달리며 여러 벤치마크에서 SOTA를 경신했습니다. o4-mini는 속도와 비용을 최적화했으며, 성능은 그 규모를 훨씬 뛰어넘습니다. 이 두 모델은 지시 사항 준수 능력이 더 뛰어나고 대화가 더 자연스러우며, 기억과 이전 대화 기록을 활용하여 개인화된 응답을 제공할 수 있습니다. 이번 출시는 OpenAI가 더 자율적인 Agentic AI로 나아가는 중요한 발걸음을 내디뎠음을 의미하며, AI 비서가 복잡한 작업을 더 독립적으로 완료할 수 있게 될 것입니다. (출처: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?)
OpenAI o3 및 o4-mini 모델 출시, 툴 사용 및 비전 추론 능력 향상: OpenAI가 심야에 o3 및 o4-mini 모델을 출시했으며, 사용자는 ChatGPT Plus, Pro, Team 계정을 통해 사용할 수 있습니다. 주요 업그레이드 내용은 다음과 같습니다: 1. 완전판 o3가 처음으로 툴 호출(예: 웹 연결, 코드 인터프리터)을 지원합니다. 2. o3와 o4-mini는 사고 과정에서 비전 추론을 수행할 수 있는 최초의 모델이 되어, 사람처럼 이미지를 결합하여 분석하고 사고할 수 있습니다. 예를 들어, 그림 보고 장소 맞히기 게임에서 모델은 이미지 세부 정보를 확대하여 단계적으로 추론할 수 있습니다. 이 능력은 멀티모달 작업(예: MMMU, MathVista)에서 모델의 성능을 크게 향상시켰으며, 시각적 판단이 필요한 전문 분야(예: 보안 감시, 의료 영상 분석)에서 AI가 더 큰 역할을 할 것임을 예고합니다. 동시에 OpenAI는 AI 프로그래밍 툴인 Codex CLI도 오픈소스로 공개했습니다. (출처: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。)
Tencent Yuanbao AI, WeChat에 공식 연동, 새로운 채팅 패러다임 시작: Tencent Yuanbao AI가 이제 WeChat 친구로 공식 출시되어 사용자는 “元宝”를 검색하여 추가할 수 있습니다. 이는 기존 AI 애플리케이션을 별도로 열어야 했던 방식을 깨고 AI를 사용자의 일상적인 커뮤니케이션 장면에 매끄럽게 통합합니다. Yuanbao AI(Hunyuan 및 DeepSeek 기반)는 WeChat 대화창에서 직접 상호작용할 수 있으며, 이미지, 공식 계정 게시물, 웹 링크, 오디오/비디오(비디오 계정은 아직 미지원) 요약을 지원하고 이전 채팅 기록 검색도 가능합니다. 아직 그림 그리기와 그룹 채팅은 지원하지 않지만, 사용 편의성과 WeChat 생태계와의 깊은 통합이 중요한 장점으로 간주됩니다. 분석가들은 WeChat의 방대한 사용자 기반과 소셜 관계망을 바탕으로 AI를 주소록 연락처로 만들어 인간-기계 상호작용 패러다임을 바꾸고 AI가 사용자 생활에 더 자연스럽게 녹아들게 할 것으로 기대합니다. (출처: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了, 腾讯元宝最终还是活成了微信的模样。)
미국, NVIDIA H20 칩 대중국 수출 무기한 중단 가능성, 영향 심대: 미국 정부가 NVIDIA에 H20 AI 칩(이전에 수출 통제에 대응하기 위해 설계된 특별 공급 버전)의 중국 수출을 무기한 중단할 것이라고 통보했습니다. H20는 NVIDIA가 중국 시장을 위해 개발한 가장 강력한 규정 준수 칩으로, 판매 금지는 NVIDIA에 큰 타격을 줄 것으로 예상됩니다. 데이터에 따르면 중국은 NVIDIA의 네 번째로 큰 수입원으로, 2024년 H20 매출액은 백억 달러 수준에 달하며, 중국 기술 기업(예: ByteDance, Tencent)은 NVIDIA 칩의 주요 구매자이며 투자 증가율이 현저합니다. 이 조치는 NVIDIA의 매출에 영향을 미칠 뿐만 아니라 CUDA 생태계(중국 개발자 비중 30% 이상)를 약화시킬 수도 있습니다. 동시에 Huawei 등 중국 현지 AI 칩 회사(예: Ascend 910C)가 발전을 가속화하여 시장 공백을 메울 수 있습니다. 이 사건은 시장 우려를 불러일으켰고 NVIDIA 주가는 하락했습니다. (출처: 中国对英伟达到底有多重要?)
🎯 동향
Google 최고급 비디오 모델 Veo 2, AI Studio에 무료 공개: Google은 자사의 첨단 비디오 생성 모델 Veo 2가 Google AI Studio, Gemini API, Gemini App에 출시되었으며 무료 사용량(매일 약 10여 회, 매회 최대 8초)을 제공한다고 발표했습니다. Veo 2는 텍스트-비디오(t2v) 및 이미지-비디오(i2v)를 지원하며, 복잡한 지시를 이해하고 사실적이며 다양한 스타일의 비디오 콘텐츠를 생성하며 카메라 움직임을 제어할 수 있습니다. 공식적으로 고품질 비디오 생성의 핵심은 명확하고 상세하며 시각적 키워드를 포함하는 Prompt를 제공하는 것이라고 강조합니다. 이 모델은 또한 비디오 내 편집(누끼 따기, 확장), 영화적 카메라 워크, 스마트 전환 등 고급 기능을 갖추고 있으며, 콘텐츠 제작 워크플로우에 통합하여 효율성을 높이는 것을 목표로 합니다. (출처: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。)
Google, 속도, 비용, 제어 가능한 사고 깊이에 중점을 둔 Gemini 2.5 Flash 출시: Google은 속도와 비용 최적화에 초점을 맞춘 경량 모델인 Gemini 2.5 Flash 모델 프리뷰 버전을 출시했습니다. 이 모델은 LMArena 순위에서 GPT-4.5 Preview 및 Grok-3와 함께 공동 2위를 차지하며 뛰어난 성능을 보였고, 어려운 프롬프트, 코딩, 긴 쿼리 측면에서는 1위를 차지했습니다. 핵심 특징은 “사고” 능력과 완전 혼합 추론을 도입하여 모델이 출력 전에 작업을 계획하고 분해할 수 있도록 허용하는 것입니다. 개발자는 “사고 예산” 매개변수를 통해 모델의 사고 깊이(토큰 상한)를 제어하여 품질, 비용, 지연 시간의 균형을 맞출 수 있습니다. 예산이 0이어도 성능은 2.0 Flash보다 우수합니다. 이 모델은 가성비가 뛰어나며 가격은 Gemini 2.5 Pro의 1/10에서 1/5에 불과하여 동시 접속률이 높고 대규모 AI 워크플로우에 적합합니다. (출처: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。)
Kunlun Tech, 무제한 길이 영화 생성 모델 Skyreels-V2 출시: Kunlun Tech는 세계 최초로 무제한 길이의 고품질 비디오 생성을 지원한다고 주장하는 Skyreels-V2를 출시하고 오픈소스로 공개했습니다. 이 모델은 기존 비디오 모델이 영화 촬영 기법 이해, 움직임 일관성, 비디오 길이 제한, 전문 데이터셋 부족 등에서 겪는 어려움을 해결하는 것을 목표로 합니다. Skyreels-V2는 멀티모달 대형 모델, 구조화된 주석, 확산 생성, 강화 학습(DPO로 움직임 품질 최적화), 고품질 미세 조정 등 다단계 훈련 전략을 결합했습니다. Diffusion Forcing 아키텍처를 채택하고 특수 스케줄러와 어텐션 메커니즘을 통해 긴 비디오 생성을 구현합니다. 공식적으로 생성 효과가 “영화 수준”에 달하며 V-Bench1.0 등 벤치마크에서 다른 오픈소스 모델을 능가하는 우수한 성능을 보인다고 밝혔습니다. 사용자는 온라인에서 최대 30초 길이의 비디오 생성을 체험할 수 있습니다. (출처: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!)
Shanghai AI Lab, 네이티브 멀티모달 모델 InternVL3 출시: Shanghai AI Lab은 네이티브 멀티모달 사전 훈련 패러다임을 채택한 대형 멀티모달 모델(MLLM)인 InternVL3를 출시했습니다. 순수 텍스트 LLM을 개조한 대부분의 모델과 달리, InternVL3는 단일 사전 훈련 단계에서 멀티모달 데이터와 순수 텍스트 코퍼스로부터 동시에 학습하여 다단계 훈련으로 인한 복잡성과 정렬 문제를 극복하는 것을 목표로 합니다. 이 모델은 가변 시각 위치 인코딩, 고급 후훈련 기술, 테스트 시 확장 전략을 결합했습니다. InternVL3-78B는 MMMU 벤치마크에서 72.2점을 획득하여 오픈소스 MLLM 신기록을 세웠으며, 성능은 선도적인 독점 모델에 근접하면서도 강력한 순수 언어 능력을 유지합니다. 훈련 데이터와 모델 가중치는 공개될 예정입니다. (출처: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
UCLA 등, 확산 LLM 추론에 강화 학습을 적용하는 d1 프레임워크 제안: UCLA와 Meta AI 연구진은 마스크 확산 대형 언어 모델(dLLM)에 강화 학습(RL) 후훈련을 처음으로 적용하는 d1 프레임워크를 제안했습니다. 기존 RL 방법(예: GRPO)은 주로 자기회귀 LLM에 사용되며, 로그 확률의 자연스러운 분해가 없어 dLLM에 직접 적용하기 어렵습니다. d1 프레임워크는 두 단계로 구성됩니다. 먼저 지도 미세 조정(SFT)을 수행한 다음, RL 단계에서 새로운 정책 경사 방법인 diffu-GRPO를 도입합니다. 이 방법은 효율적인 단일 단계 로그 확률 추정기를 사용하고 무작위 프롬프트 단어 마스크를 정규화로 활용하여 RL 훈련에 필요한 온라인 생성량을 줄입니다. 실험 결과, LLaDA-8B-Instruct 기반의 d1 모델은 수학 및 논리 추론 벤치마크에서 기본 모델 및 SFT 또는 diffu-GRPO만 사용한 모델보다 현저히 우수한 성능을 보였습니다. (출처: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!)
Meta, 멀티 토큰 어텐션(MTA) 제안: Meta 연구진은 대형 언어 모델(LLM)의 어텐션 계산 방식을 개선하기 위한 멀티 토큰 어텐션(Multi-Token Attention, MTA) 메커니즘을 제안했습니다. 기존 어텐션 메커니즘은 단일 쿼리와 키 토큰의 유사도만을 기반으로 하지만, MTA는 쿼리, 키, 헤드 벡터에 컨볼루션 연산을 적용하여 모델이 여러 인접한 쿼리와 키 토큰을 동시에 고려하여 어텐션 가중치를 결정할 수 있도록 합니다. 연구진은 이를 통해 더 풍부하고 세밀한 정보를 활용하여 관련 컨텍스트를 찾을 수 있다고 생각합니다. 실험 결과, MTA는 표준 언어 모델링 및 긴 컨텍스트 정보 검색 작업 모두에서 기존 Transformer 기반 모델보다 우수한 성능을 보였습니다. (출처: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
TogetherAI, RNN 기반 추론 모델 M1 출시: TogetherAI는 Mamba 아키텍처 기반의 새로운 하이브리드 선형 RNN 추론 모델인 M1을 제안했습니다. 이 모델은 Transformer가 긴 시퀀스를 처리하고 효율적인 추론을 수행할 때 직면하는 계산 복잡성과 메모리 제한 문제를 해결하는 것을 목표로 합니다. M1은 기존 추론 모델로부터 지식 증류 및 강화 학습 훈련을 통해 성능을 향상시킵니다. 실험 결과, M1은 AIME 및 MATH와 같은 수학 추론 벤치마크에서 이전 선형 RNN 모델보다 우수한 성능을 보일 뿐만 아니라 동일 규모의 DeepSeek-R1 증류 추론 모델과도 필적하는 성능을 보였습니다. 더 중요한 것은 M1의 생성 속도가 동일 크기의 Transformer보다 3배 이상 빠르며, 고정된 생성 시간 예산 하에서 자기 일관성 투표를 통해 후자보다 더 높은 정확도를 얻을 수 있다는 것입니다. (출처: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等)
Tencent Hunyuan, InstantCharacter 프레임워크 오픈소스 공개: Tencent Hunyuan 팀은 단일 입력 이미지에서 인물 특징을 추출하고 유지한 다음 해당 인물을 다른 장면이나 스타일에 배치할 수 있는 이미지 생성 프레임워크인 InstantCharacter를 오픈소스로 공개했습니다. 이 기술은 높은 충실도의 인물 정체성 유지와 제어 가능한 스타일 전이를 구현하는 것을 목표로 합니다. 공식적으로 Hugging Face에서 지브리와 신카이 마코토 아트 스타일 기반의 온라인 데모를 제공하고 관련 논문, 코드 저장소 및 ComfyUI 플러그인을 공개하여 커뮤니티가 사용하고 추가 개발할 수 있도록 했습니다. (출처: karminski3)
ChatGPT 기억 기능 업그레이드, 기억과 결합한 웹 검색 지원: OpenAI는 ChatGPT의 기억(Memory) 기능을 업그레이드하여 “기억을 이용한 검색” 기능을 추가했습니다. 이는 ChatGPT가 웹 검색 작업을 수행할 때 이전에 저장된 사용자 선호도, 위치 등 기억 정보를 활용하여 검색 쿼리를 최적화하고 더 개인화된 검색 결과를 제공할 수 있음을 의미합니다. 예를 들어, ChatGPT가 사용자가 채식주의자임을 기억한다면 근처 식당에 대해 물었을 때 자동으로 “근처 채식 식당”을 검색할 수 있습니다. 이 조치는 OpenAI가 AI 개인화 서비스 향상 측면에서 중요한 단계로 간주되며, 사용자 경험을 향상시키고 기억 기능을 갖춘 다른 경쟁 제품(예: Claude, Gemini)과 차별화하는 것을 목표로 합니다. 사용자는 설정에서 기억 기능을 끌 수 있습니다. (출처: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!)
AI 모델 런타임 스냅샷 기술로 콜드 스타트 방지: 머신러닝 커뮤니티는 모델 스냅샷 기술을 통해 LLM의 런타임 오케스트레이션을 최적화하는 방안을 모색하고 있습니다. 이 기술은 GPU의 전체 상태(KV 캐시, 가중치, 메모리 레이아웃 포함)를 저장하여 다른 모델로 전환할 때 콜드 스타트와 GPU 유휴 상태를 피하고 빠른 복구(약 2초)를 가능하게 합니다. 한 실무자는 이 방법을 사용하여 두 개의 A1000 16GB GPU에서 컨테이너를 사용하거나 모델을 다시 로드할 필요 없이 50개 이상의 오픈소스 모델을 성공적으로 실행했다고 공유했습니다. 이러한 모델 멀티플렉싱(multiplexing) 및 교체 기술은 GPU 활용률을 높이고 추론 지연 시간을 줄이는 데 잠재력이 있습니다. (출처: Reddit r/MachineLearning)
🧰 툴
ByteDance Volcano Engine, AI 하드웨어 원스톱 솔루션 데모 출시: ByteDance Volcano Engine은 임베디드 칩 제조업체와 협력한 AI 하드웨어 원스톱 솔루션을 AtomS3R 개발 보드를 예시로 선보였습니다. 이 솔루션은 낮은 지연 시간과 높은 응답성의 AI 상호작용 경험을 제공하는 것을 목표로 하며, 밀리초 수준의 실시간 응답, 실시간 중단 및 대화 끼어들기, RTC SDK를 통한 복잡한 환경의 오디오 노이즈 감소 기능 등의 특징을 갖추고 있어 배경 소음 간섭을 효과적으로 줄이고 음성 상호작용 정확도를 높일 수 있습니다. 이 솔루션의 클라이언트 코드와 서버 프로그램은 모두 오픈소스로 제공되어 개발자가 DIY 맞춤 설정을 할 수 있습니다(예: 하드웨어에 사용자 정의 성격, 역할, 음색 부여 또는 지식 베이스 및 MCP 툴 연동). 하드웨어 자체에는 카메라가 포함되어 있으며 향후 비전 이해 기능을 지원할 계획입니다. (출처: 体验完字节送的迷你AI硬件,后劲有点大…
)
Mita AI Search, “오늘 뭐 배울까” 학습 기능 출시: Mita AI Search는 사용자가 업로드한 파일(다양한 형식 지원)이나 제공한 웹 링크를 자동으로 구조화되고 내레이션 해설과 시연(PPT, 애니메이션)이 포함된 온라인 강의 비디오로 변환하는 “오늘 뭐 배울까”라는 새로운 기능을 출시했습니다. 사용자는 다양한 설명 스타일(예: 이야기 형식, 나폴레옹 스타일)과 음성(예: 차가운 여성 목소리)을 선택할 수 있습니다. 이 기능은 정보 입력을 더 쉽게 흡수할 수 있는 학습 경험으로 전환하는 것을 목표로 하며, 심지어 강의 후 테스트 단계도 제공합니다. 콘텐츠 생성과 개인화된 교육을 결합한 이 방식은 교육 및 정보 소비 분야에서 AI의 응용 모델을 변화시키고 새로운 지식 습득 및 콘텐츠 속독 방식을 제공할 수 있을 것으로 간주됩니다. (출처: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

)
Cursor IDE 0.49 버전 업데이트, 규칙 시스템 및 Agent 제어 강화: AI 우선 코드 편집기 Cursor가 0.49 업데이트 프리뷰 버전을 출시했습니다. 새로운 기능은 다음과 같습니다: 1. 채팅 명령어 /Generate Cursor Rules를 통해 .mdc 규칙 파일을 자동으로 생성하여 프로젝트 컨텍스트를 고정할 수 있습니다. 2. 규칙 자동 적용이 더 스마트해져 Agent가 파일 경로에 따라 해당 규칙을 자동으로 로드합니다. 3. 긴 대화에서 “항상 규칙 첨부” 기능이 작동하지 않던 버그를 수정했습니다. 4. AI가 전체 프로젝트를 더 잘 이해하도록 돕는 “프로젝트 구조 인식”(Beta) 기능이 추가되었습니다. 5. MCP(Model Context Protocol) 프로토콜이 이제 이미지 전송을 지원하여 시각 관련 작업을 처리하기 편리해졌습니다. 6. Agent의 터미널 명령어 제어가 강화되어 사용자가 실행 전에 명령어를 편집하거나 건너뛸 수 있습니다. 7. 전역 파일 무시 구성(.cursorignore)을 지원합니다. 8. 코드 검토 경험이 최적화되어 Agent 메시지 뒤에 바로 diff 뷰가 표시됩니다. (출처: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!)
OpenAI, 커맨드 라인 AI 프로그래밍 툴 Codex CLI 오픈소스 공개: o3 및 o4-mini 출시와 함께 OpenAI는 사용자의 커맨드 라인 터미널에서 직접 실행할 수 있는 경량 AI 코딩 Agent인 Codex CLI를 오픈소스로 공개했습니다. 이 툴은 새로운 모델의 강력한 코딩 및 추론 능력을 최대한 활용하도록 설계되었으며, 로컬 코드 저장소를 직접 처리하고 스크린샷이나 스케치를 결합하여 멀티모달 추론까지 수행할 수 있습니다. OpenAI CEO Sam Altman이 직접 홍보하며 커뮤니티의 빠른 반복을 촉진하기 위해 오픈소스 성격을 강조했습니다. 동시에 OpenAI는 Codex CLI 및 OpenAI 모델 기반 프로젝트를 지원하기 위해 100만 달러 규모의 지원 프로그램(API Credits 형태)을 시작했습니다. (출처: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?)
Tencent Cloud LKE 플랫폼, MCP 통합하여 Agent 구축 간소화: Tencent Cloud Language Knowledge Engine(LKE) 플랫폼이 모델 컨텍스트 프로토콜(MCP) 지원을 추가하여 AI Agent 구축 및 사용의 장벽을 낮추는 것을 목표로 합니다. 사용자는 이제 LKE 플랫폼에서 클릭 조작을 통해 Tencent Cloud EdgeOne Pages(원클릭 웹 페이지 배포), Firecrawl(웹 크롤러) 등 내장된 MCP 툴을 쉽게 연동할 수 있습니다. LKE의 강력한 지식 베이스(RAG) 능력과 결합하여 사용자는 개인 지식 및 외부 툴 호출 기반의 복잡한 애플리케이션(예: 지식 베이스 콘텐츠 기반 웹 페이지 자동 생성 및 게시)을 만들 수 있습니다. 이 플랫폼은 Agent 모드를 지원하며, 모델(예: DeepSeek R1)이 자율적으로 사고하고 적절한 툴을 선택하여 작업을 완료할 수 있습니다. 플랫폼은 외부 MCP 연동도 지원합니다. (출처: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

)
Spring AI 프레임워크: AI 엔지니어링을 위한 애플리케이션 프레임워크: Spring AI는 Java 개발자를 위해 설계된 AI 애플리케이션 프레임워크로, Spring 생태계의 설계 원칙(예: 이식성, 모듈식 설계, POJO 사용)을 AI 분야에 도입하는 것을 목표로 합니다. 다양한 주요 AI 모델 제공업체(Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama 등)와 상호작용하는 통합 API를 제공하며, 채팅 완성, 임베딩, 텍스트-이미지/오디오, 검토 등의 기능을 지원합니다. 동시에 다양한 벡터 데이터베이스(Cassandra, Azure Vector Search, Chroma, Milvus 등)를 통합하여 이식 가능한 API와 SQL 스타일의 메타데이터 필터링을 제공합니다. 프레임워크는 또한 구조화된 출력, 툴/함수 호출, 관찰 가능성, ETL 프레임워크, 모델 평가, 채팅 메모리 및 RAG 등의 기능을 지원하며 Spring Boot 자동 구성을 통해 통합을 간소화합니다. (출처: spring-projects/spring-ai – GitHub Trending (all/weekly)
)
olmocr: LLM 데이터셋 처리를 위한 PDF 선형화 툴킷: allenai는 대형 언어 모델(LLM) 데이터셋 구축 및 훈련을 위한 PDF 문서 처리를 전문으로 하는 툴킷인 olmocr을 오픈소스로 공개했습니다. 여기에는 다양한 기능이 포함됩니다: ChatGPT 4o를 이용한 고품질 자연어 텍스트 구문 분석을 위한 프롬프트 전략, 다양한 처리 파이프라인 버전을 비교하기 위한 평가 도구, 기본적인 언어 필터링 및 SEO 스팸 정보 제거 기능, Qwen2-VL 및 Molmo-O를 위한 미세 조정 코드, Sglang을 사용한 대규모 PDF 처리 파이프라인, 처리된 Dolma 형식 문서를 보기 위한 도구. 이 툴킷은 로컬 추론을 위해 GPU 지원이 필요하며, 로컬 및 다중 노드 클러스터(S3 및 Beaker 지원) 사용 설명서를 제공합니다. (출처: allenai/olmocr – GitHub Trending (all/daily)

)
Dive Agent 데스크톱 애플리케이션 v0.8.0 출시: 오픈소스 AI Agent 데스크톱 애플리케이션 Dive가 v0.8.0 버전을 출시하며 대대적인 아키텍처 조정과 기능 업그레이드를 진행했습니다. 이 버전은 툴 호출을 지원하는 LLM과 MCP Server를 통합하는 것을 목표로 합니다. 주요 업데이트 내용은 다음과 같습니다: LLM API 키 관리, 사용자 정의 모델 ID 지원, 툴/함수 호출 모델 완전 지원; MCP 툴 관리(추가/삭제/수정), JSON 및 양식 편집을 지원하는 구성 인터페이스. 백엔드 DiveHost는 LangChain 통합 문제를 해결하기 위해 TypeScript에서 Python으로 마이그레이션되었으며, 독립적인 A2A(Agent-to-Agent) 서버로 실행될 수 있습니다. (출처: Reddit r/LocalLLaMA)
llama.cpp, 멀티모달 CLI 툴 통합: llama.cpp 프로젝트는 LLaVa, Gemma3, MiniCPM-V의 커맨드 라인 인터페이스(CLI) 예제 프로그램을 통합된 llama-mtmd-cli 툴로 병합했습니다. 이는 libmtmd 라이브러리를 통한 멀티모달 지원을 점진적으로 통합하는 과정의 일부입니다. 멀티모달 지원은 아직 개발 중이지만(예: llama-server 지원은 아직 실험 단계), CLI 통합은 툴셋을 단순화하는 단계입니다. 동시에 SmolVLM v1/v2 지원도 개발 중입니다. (출처: Reddit r/LocalLLaMA)
LightRAG: RAG 파이프라인 자동 배포: LightRAG는 오픈소스 RAG(검색 증강 생성) 프로젝트입니다. 커뮤니티 회원이 튜토리얼과 자동화 스크립트(Ansible + Docker Compose + Sbnb Linux 사용)를 만들어 사용자가 베어메탈 서버에 LightRAG 시스템을 빠르게(몇 분 내) 배포하여 빈 머신에서 완전한 기능을 갖춘 RAG 파이프라인까지 자동 구축할 수 있도록 했습니다. 이는 자체 호스팅 RAG 솔루션의 배포 과정을 간소화합니다. (출처: Reddit r/LocalLLaMA)
Nari Labs, 오픈소스 TTS 모델 Dia-1.6B 출시: Nari Labs는 자사의 텍스트 음성 변환(TTS) 모델 Dia-1.6B를 출시하고 오픈소스로 공개했습니다. 이 모델의 특징은 음성을 생성할 뿐만 아니라 음성 속에 웃음, 기침, 목청 가다듬기 등 비언어적 소리(paralinguistic sounds)를 자연스럽게 통합하여 음성의 자연스러움과 표현력을 향상시킨다는 것입니다. 공식적으로 효과를 보여주는 데모 비디오를 제공했습니다. 모델 실행에는 약 10GB의 VRAM이 필요하며, 현재 양자화 버전은 제공되지 않습니다. 코드 저장소와 모델은 GitHub와 Hugging Face에 공개되었습니다. (출처: karminski3)
📚 학습
Jeff Dean, AI 15년 발전의 주요 이정표 회고: Google 수석 과학자 Jeff Dean은 강연에서 지난 15년간 AI 분야의 중요한 진전, 특히 Google의 연구 기여를 정리했습니다. 주요 이정표는 다음과 같습니다: 대규모 신경망 훈련(규모 효과 증명), DistBelief 분산 시스템(CPU로 대형 모델 훈련 실현), Word2Vec 단어 임베딩(벡터 공간 의미론 밝힘), Seq2Seq 모델(기계 번역 등 작업 촉진), TPU(신경망 맞춤형 하드웨어 가속), Transformer 아키텍처(시퀀스 처리 혁신, LLM 기반 마련), 자기 지도 학습(대규모 비표시 데이터 활용), Vision Transformer(이미지와 텍스트 처리 통합), 희소 모델/MoE(모델 용량 및 효율성 향상), Pathways(대규모 분산 컴퓨팅 간소화), 연쇄 사고 CoT(추론 능력 향상), 지식 증류(대형 모델 능력을 소형 모델로 이전), 추측 디코딩(추론 가속). 이러한 기술들이 현대 AI 발전을 공동으로 이끌었습니다. (출처: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
)
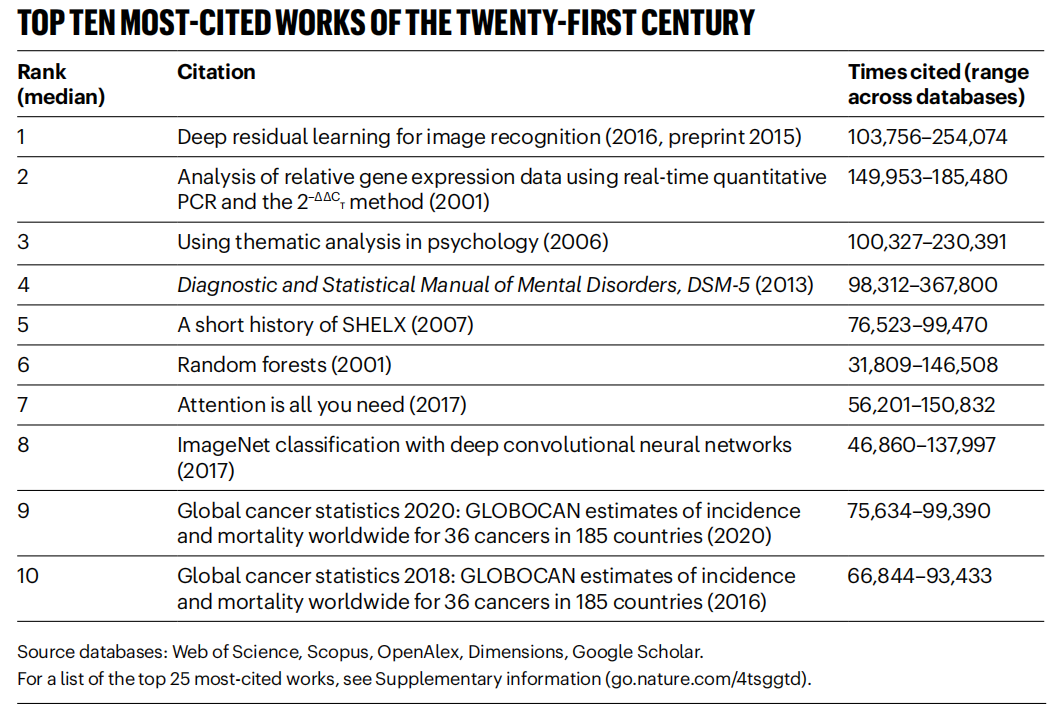
《Nature》, 21세기 고인용 논문 통계, AI 분야 주도: 《Nature》지는 5개 데이터베이스의 데이터를 종합하여 21세기 인용 횟수가 가장 많은 Top 25 논문 목록을 발표했습니다. Microsoft의 2016년 ResNets 논문(He Kaiming 등 저)이 종합 1위를 차지했으며, 이 연구는 딥러닝과 AI 발전의 기초입니다. 목록 상위권에는 랜덤 포레스트(6위), Attention is all you need (Transformer, 7위), AlexNet(8위), U-Net(12위), 딥러닝 개요(Hinton 등, 16위), ImageNet 데이터셋(Li Feifei 등, 24위) 등 다수의 AI 관련 논문이 포함되었습니다. 이는 AI 기술이 이번 세기에 급속도로 발전하고 광범위한 영향을 미쳤음을 반영합니다. 기사는 동시에 프리프린트의 유행이 인용 통계에 복잡성을 더한다고 지적했습니다. (출처: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
)
베이항대 등 기관, LLM Ensemble 최신 개요 발표: 베이징 항공항천대학 등 기관의 연구진들이 대형 언어 모델 앙상블(LLM Ensemble)에 관한 최신 개요를 발표했습니다. LLM Ensemble은 추론 단계에서 여러 LLM의 장점을 결합하여 사용자 쿼리를 처리하는 것을 의미합니다. 이 개요는 LLM Ensemble의 분류법(추론 전 앙상블, 추론 중 앙상블, 추론 후 앙상블, 7가지 방법으로 세분화)을 제안하고, 각 유형 방법의 최신 진전을 체계적으로 검토하며, 관련 연구 문제(예: 모델 병합, 모델 협업, 약지도 학습과의 관계)를 논의하고, 벤치마크 데이터셋, 대표적인 응용 사례를 소개합니다. 마지막으로 기존 성과를 요약 분석하고 향후 연구 방향(예: 더 원칙적인 조각 수준 앙상블, 더 정교한 비지도 후 앙상블 등)을 전망합니다. (출처: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

)
Anthropic, Claude Code 사용 패턴 및 경험 공유: Anthropic 직원이 내부적으로 Claude Code를 사용하여 프로그래밍하는 모범 사례와 효과적인 패턴을 공유했습니다. 이러한 패턴은 Claude뿐만 아니라 다른 LLM과 프로그래밍 협업을 할 때도 보편적으로 적용됩니다. 명확한 컨텍스트 제공, 복잡한 문제 분해, 반복적인 질문, 모델의 다양한 장점(예: 코드 생성, 설명, 리팩토링) 활용, 효과적인 검증의 중요성을 강조했습니다. 이러한 경험은 개발자가 AI 보조 프로그래밍 도구를 더 효율적으로 활용하도록 돕기 위한 것입니다. (출처: AnthropicAI

)
Anthropic, Claude 가치관 데이터셋 공개: Anthropic은 Hugging Face Datasets에 “values-in-the-wild”라는 데이터셋을 공개했습니다. 이 데이터셋에는 Claude가 수백만 건의 실제 대화에서 표현한 3307가지 가치관이 포함되어 있습니다. 이 데이터셋 공개는 모델 행동의 투명성을 높이고 연구자와 대중이 다운로드, 탐색, 분석하여 대형 언어 모델이 실제 응용에서 나타내는 가치관 경향을 더 잘 이해하도록 돕기 위한 것입니다. (출처: huggingface, huggingface)
AI 인지 각성에 대한 10가지 핵심 관점: 이 글은 AI 발전에 대한 10가지 인지적 관점을 제시하여 사람들이 AI의 영향과 본질을 더 깊이 이해하도록 돕는 것을 목표로 합니다. 핵심 관점은 다음과 같습니다: AI의 지능과 인간 지능은 차이가 있다(지능 격차); AI는 인간 의식의 본질에 대한 성찰을 유발한다; 인간과 AI의 관계는 도구에서 협력 파트너로 전환되고 있다; AI의 발전은 인간 두뇌 모방에 국한되어서는 안 된다; 지능의 기준은 AI 진보에 따라 변화한다; AI는 완전히 새로운 형태의 지능을 개발할 수 있다; AI의 감정 표현과 인지적 한계를 이성적으로 바라봐야 한다; 진정한 직업적 위협은 AI 자체가 아니라 AI를 사용하지 않는 데서 온다; AI 시대에는 인간 고유의 능력(창의력, 감성 지능, 영역 초월적 사고) 개발에 집중해야 한다; AI 연구의 궁극적인 의미는 인간 자신을 더 깊이 이해하는 데 있다. (출처: AI认知觉醒的10句话,一句顶万句,句句清醒

)
LlamaIndex, 문서 워크플로우 Agent 구축 튜토리얼 공유: LlamaIndex 공동 창립자 Jerry Liu의 강연 녹음본은 LlamaIndex를 사용하여 문서 워크플로우 Agent를 구축하는 방법을 공유합니다. 내용은 LlamaIndex가 RAG에서 지식 Agent로 진화한 과정, LlamaParse를 이용한 복잡한 문서 처리, Workflows를 사용한 유연한 이벤트 기반 Agent 오케스트레이션, 주요 사용 사례(문서 연구, 보고서 생성, 문서 처리 자동화), 텍스트와 이미지를 결합한 멀티모달 검색 개선 등을 다룹니다. (출처: jerryjliu0
)
LlamaIndex.TS Agent 구축 튜토리얼: LlamaIndex 팀 멤버가 TypeScript 버전의 LlamaIndex(LlamaIndex.TS)를 사용하여 Agent를 구축하는 전체 코드 수준 튜토리얼을 공유했습니다. 라이브 스트리밍 녹화 내용은 LlamaIndex 기초, Agent와 RAG 개념, 일반적인 Agentic 패턴(체이닝, 라우팅, 병렬화 등), LlamaIndex.TS에서 Agentic RAG 구축, Workflows를 통합한 풀스택 React 애플리케이션 구축 등을 포함합니다. (출처: jerryjliu0

)
강화 학습이 실제로 LLM 추론 능력을 향상시키는지에 대한 논의: 커뮤니티는 한 논문에서 제기된 문제, 즉 강화 학습(RL)이 실제로 대형 언어 모델(LLM)이 기본 모델 능력을 뛰어넘는 추론 능력을 개발하도록 동기를 부여할 수 있는지에 대해 논의합니다. 논의에서는 RL(예: RLHF)이 모델의 정렬과 지시 사항 준수를 개선할 수 있지만, 내재적인 복잡한 추론 논리를 체계적으로 향상시킬 수 있는지에 대해서는 여전히 의문이 제기됩니다. 현재 RL의 효과는 근본적인 논리적 추론 도약보다는 표현 최적화 및 특정 형식 준수에 더 많이 나타날 수 있다는 의견이 있습니다. Will Brown은 pass@1024와 같은 지표가 AIME와 같은 수학 추론 작업을 평가할 때 의미가 제한적이라고 지적했습니다. (출처: natolambert

)
세계 모델 관련 용어 논의: Reddit 사용자가 “세계 모델(world models)”, “기초 세계 모델(foundation world models)”, “세계 기초 모델(world foundation models)” 등 용어의 혼란에 대해 질문했습니다. 커뮤니티는 “세계 모델”이 일반적으로 환경(물리적 세계 또는 체스판과 같은 특정 영역)에 대한 내부 시뮬레이션 또는 표현을 의미한다고 응답했습니다. “기초 모델”은 다양한 하위 작업의 시작점으로 사용될 수 있는 사전 훈련된 대형 모델을 의미합니다. 이러한 용어 조합은 세계의 동역학을 이해하고 예측할 수 있는 일반화 가능한 기초 모델 구축을 의미할 수 있지만, 구체적인 정의는 연구자에 따라 다를 수 있으며 해당 분야의 용어가 아직 완전히 통일되지 않았음을 반영합니다. (출처: Reddit r/MachineLearning)
XGBoost와 GNN 결합 방법 논의: Reddit 사용자들이 사기 탐지 등의 작업에 XGBoost와 그래프 신경망(GNN)을 효과적으로 결합하는 방법에 대해 논의합니다. 일반적인 방법은 GNN이 학습한 노드 임베딩을 새로운 특징으로 사용하여 원본 테이블 데이터와 함께 XGBoost에 입력하는 것입니다. 논의에서는 이 방법의 과제가 GNN 임베딩이 원본 데이터 및 SMOTE와 같은 기술을 뛰어넘는 상당한 가치를 제공할 수 있는지 여부에 있으며, 그렇지 않으면 노이즈를 유발할 수 있다고 지적합니다. 성공의 핵심은 잘 설계된 그래프 구조와 GNN 임베딩이 XGBoost가 얻기 어려운 관계 정보(예: 그래프 구조 내 사기 고리)를 포착할 수 있는지 여부에 있습니다. (출처: Reddit r/MachineLearning)
💼 비즈니스
베이징, 세계 최초 휴머노이드 로봇 마라톤 개최, “스포츠 테크 IP” 탐색: 베이징 이좡에서 세계 최초의 휴머노이드 로봇 하프 마라톤이 성공적으로 개최되어 20여 개 휴머노이드 로봇 기업의 “선수”들이 인간 주자들과 함께 경쟁했습니다. Tiangong Ultra 로봇이 2시간 40분으로 우승하며 속도와 지형 적응성을 보여주었습니다. Songyan Power N2(준우승)와 Zhuoyi Tech Walker II(3위)도 뛰어난 성능을 보였습니다. 이 대회는 기술 경쟁일 뿐만 아니라 비즈니스 모델 탐색의 기회이기도 했습니다. 주최 측은 “기술 입찰” 메커니즘을 통해 투자를 유치하고 “로봇 + 스포츠” IP 구축을 시도했습니다. 이 글은 로봇 대회 IP 개발, 로봇 광고 모델, 로봇 에이전트 직업 부상, 스포츠 문화 관광 융합, 전 국민 스마트 스포츠 추진 등 상업화 경로를 탐색하며 스마트 스포츠 시장의 잠재력이 크다고 평가합니다. (출처: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

)
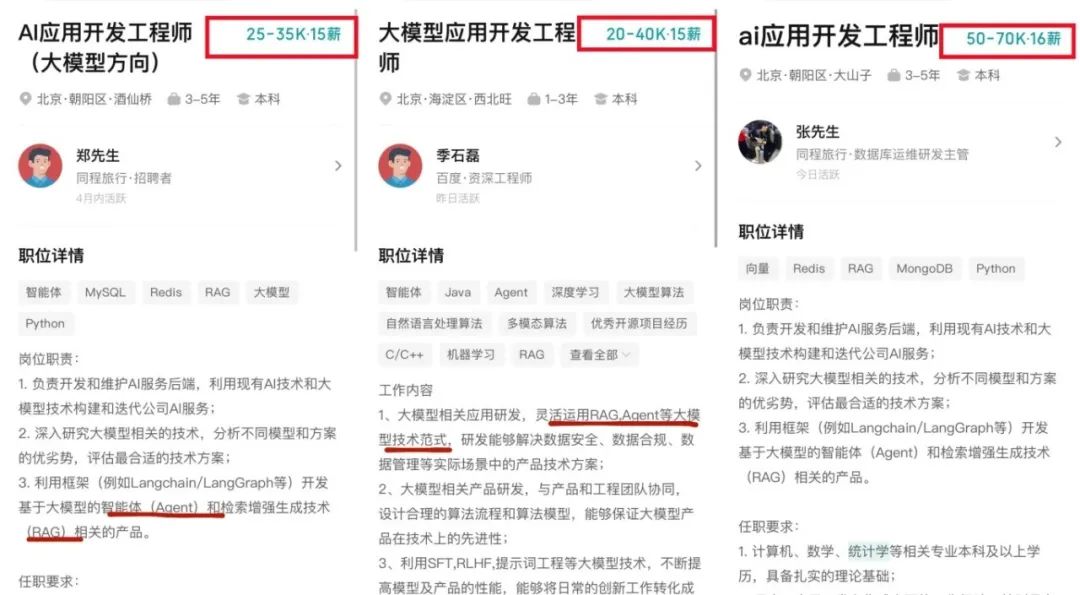
AI 대형 모델 애플리케이션 개발, 새로운 기술 트렌드로 부상, 전통 개발 모델에 충격: AI 대형 모델 기술이 보급됨에 따라 기업(예: Alibaba, ByteDance, Tencent)들이 AI(특히 Agent 및 RAG 기술)를 핵심 비즈니스에 통합하는 속도를 높이면서 전통적인 CRUD 개발 모델이 도전을 받고 있습니다. 시장에서는 AI 대형 모델 애플리케이션 개발 능력을 갖춘 엔지니어에 대한 수요가 급증하고 급여가 현저히 상승하는 반면, 전통적인 기술 직책은 축소될 위험에 처해 있습니다. “AI를 안다”는 것은 더 이상 API 호출 방법을 아는 것만을 의미하지 않으며, AI 원리, 응용 기술, 프로젝트 실무 경험을 습득해야 함을 요구합니다. 이 글은 기술 전문가들이 산업 변화에 적응하고 새로운 직업 발전 기회를 잡기 위해 AI 대형 모델 기술을 적극적으로 학습해야 한다고 강조합니다. Zhihu Zhixuetang은 이를 위해 무료 “대형 모델 애플리케이션 개발 실전 훈련 캠프”를 개설했습니다. (출처: 炸裂!又一个AI大模型的新方向,彻底爆了!!
)
LLM 최적화 서비스 부상, AI 버전 SEO 우려 제기: Reddit 사용자는 AI 챗봇의 제품 추천 결과가 점점 더 일관성을 띠는 것을 관찰하고, 검색 엔진 최적화(SEO)와 유사한 “LLM 최적화” 서비스가 부상하고 있다고 의심합니다. 이미 마케팅 팀이 이러한 서비스를 고용하여 자사 제품이 AI 추천에서 더 높은 우선순위를 얻도록 보장하고 있으며, 이로 인해 대형 브랜드 제품 노출이 증가하고 결과가 더 이상 “유기적”이지 않을 수 있다는 소식이 있습니다. 이는 AI 추천의 공정성과 투명성에 대한 우려를 불러일으키며, AI 검색/추천이 결국 전통적인 검색 엔진처럼 상업적 이익에 의해 결과가 조작될 것을 우려합니다. 커뮤니티는 이 현상에 대한 더 많은 논의와 관심을 촉구합니다. (출처: Reddit r/ArtificialInteligence)
Google, LLM 경쟁에서 강세, Meta와 OpenAI는 도전 직면: IEEE Spectrum 기사는 OpenAI와 Meta가 LLM 초기 개발에서 주도적인 위치를 차지했지만, 최근 Google이 강력한 새 모델(예: Gemini 시리즈)을 통해 따라잡고 있으며 일부 측면에서는 선두를 차지하고 있다고 분석합니다. 동시에 Meta와 OpenAI는 모델 출시 및 시장 전략에서 일부 도전이나 논란에 직면한 것으로 보입니다(예: Meta 모델이 다른 모델 기반으로 훈련되었을 수 있다는 지적, OpenAI의 출시 전략 및 투명성 의문 제기). 기사는 LLM 분야의 경쟁 구도가 변화하고 있으며, Google의 지속적인 투자와 기술력이 무시할 수 없는 힘이 되고 있다고 평가합니다. (출처: Reddit r/MachineLearning

)
🌟 커뮤니티
휴머노이드 로봇의 부흥과 도전: 하프 마라톤 대회로 본 미래: 최근 휴머노이드 로봇에 대한 관심이 다시 높아져 춘절 갈라쇼 공연부터 베이징 이좡의 하프 마라톤 대회까지 광범위한 주목을 받았습니다. 이 글은 휴머노이드 로봇 설계의 본래 의도(인간 환경과 도구에 적응하기 위해 인간 모방)와 다른 형태의 로봇에 비해 갖는 장점(더 쉽게 공감을 불러일으키고 인간-로봇 상호작용에 유리함)을 탐구합니다. 이좡 하프 마라톤은 현재 휴머노이드 로봇이 장거리 자율 주행, 균형, 에너지 소비 등에서 겪는 어려움을 드러냈지만, Tiangong Ultra, Songyan Power N2 등 제품의 진보도 보여주었습니다. 이 글은 휴머노이드 로봇의 발전이 오픈소스 공유(예: Tiangong 오픈소스 계획) 덕분이지만 데이터 병목 현상에도 직면해 있다고 지적합니다. 궁극적으로 휴머노이드 로봇은 로봇 분야의 중요한 귀착점으로 간주되며, 기술의 구현일 뿐만 아니라 인간 자신과 지능의 미래에 대한 깊은 성찰을 담고 있습니다. (출처: 人形机器人:最初的设想,最后的归宿

)
커뮤니티, Vibe Coding 열띤 토론: AI 보조 프로그래밍의 경계: Canva CTO는 Andrej Karpathy가 제안한 “Vibe Coding”(개발자가 주로 Prompt를 조정하여 AI가 코드를 생성하도록 하고 세부 사항에는 덜 신경 쓰는 것) 개념에 대해 논평했습니다. Canva CTO는 이러한 방식이 프로토타입 개발과 같은 일회성 시나리오에만 적합하며, AI 생성 코드에는 종종 오류, 보안 취약점 또는 성능 문제가 있어 경험 많은 엔지니어가 엄격하게 감독하고 검토해야 하므로 생산 환경에서는 절대 사용해서는 안 된다고 주장했습니다. 그는 Canva의 엔지니어링 문화가 코드 소유권과 동료 검토에 기반하며 AI 도구가 오히려 이러한 원칙을 강화한다고 강조했습니다. 커뮤니티는 이에 대해 격렬하게 토론했으며, 일부는 생산 환경의 위험에 동의하며 AI 코드는 인공적인 검증이 필요하다고 생각합니다. 다른 일부는 AI 발전이 빠르므로 엔지니어링 리더는 AI 능력을 지속적으로 재평가해야 하며 Airbnb 등 AI를 활용하여 프로젝트를 가속화한 회사의 사례를 인용합니다. (출처: dotey

)
커뮤니티, 긴 컨텍스트 작업에서 Llama 4와 OpenAI 모델 성능 논의: 커뮤니티 멤버가 OpenAI-MRCR(다중 홉, 다중 문서 검색 및 질의응답) 벤치마크에서 Llama 4 모델의 결과를 공유했습니다. 데이터에 따르면 Llama 4 Scout(소형 버전)는 더 긴 컨텍스트 길이에서 GPT-4.1 Nano와 유사한 성능을 보였습니다. Llama 4 Maverick(대형 버전)은 GPT-4.1 Mini에 가깝지만 약간 뒤처지는 성능을 보였습니다. 종합적으로 볼 때, 32k 이내 컨텍스트 작업의 경우 OpenAI o3 또는 Gemini 2.5 Pro가 더 나은 선택이며(o3가 복잡한 추론에 더 능숙할 수 있음), 32k 컨텍스트를 초과하면 Gemini 2.5 Pro가 더 안정적인 성능을 보입니다. 그러나 컨텍스트가 512k를 초과하면 Gemini 2.5 Pro의 정확도도 80% 미만으로 떨어지므로 분할 처리를 권장합니다. 이는 초장문 컨텍스트 처리에서 각 모델이 여전히 개선의 여지가 있음을 시사합니다. (출처: dotey
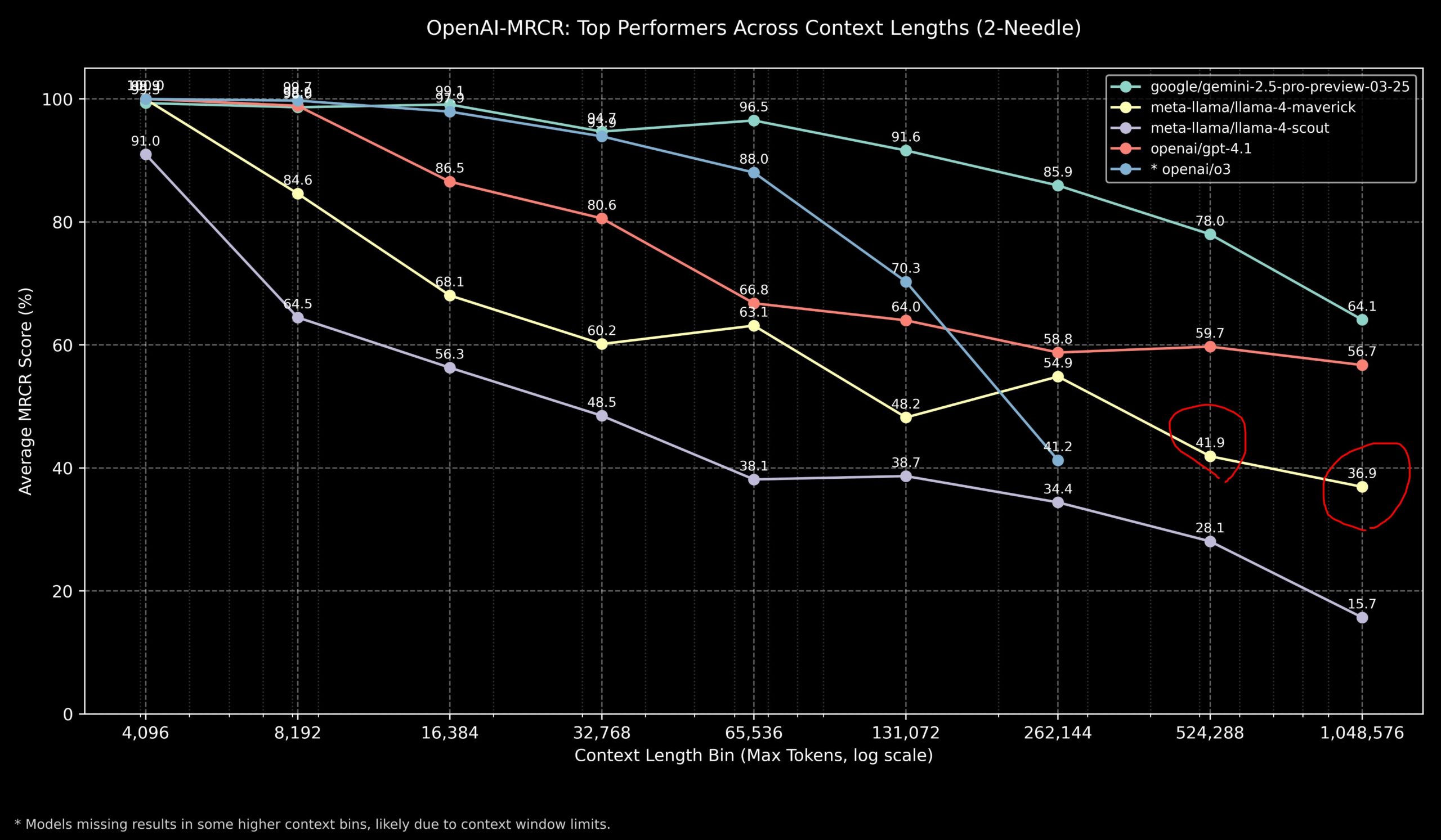
)
커뮤니티, GLM-4 32B 모델 성능에 감탄: Reddit 사용자가 로컬에서 GLM-4 32B Q8 양자화 모델을 실행한 경험을 공유하며, 그 성능이 “놀랍다”고 평가했습니다. 다른 동급(약 32B) 로컬 모델을 능가하고 일부 72B 모델보다 우수하며, 로컬 버전의 Gemini 2.5 Flash에 필적한다고 합니다. 사용자는 특히 코드 생성 측면에서 이 모델을 높이 평가하며, 출력 길이에 인색하지 않고 완전한 구현 세부 정보를 제공하며, 복잡한 HTML/JS 시각화(예: 태양계, 신경망)를 제로샷으로 생성하는 능력을 보여주었는데, 이는 Gemini 2.5 Flash보다 우수한 효과라고 밝혔습니다. 이 모델은 툴 호출 측면에서도 좋은 성능을 보이며 Cline/Aider와 같은 툴과 잘 연동됩니다. (출처: Reddit r/LocalLLaMA
)
커뮤니티, OpenAI o3 벤치마크 점수와 기대치 불일치 논의: TechCrunch 등 언론은 OpenAI가 새로 출시한 o3 모델의 일부 벤치마크(예: ARC-AGI-2) 점수가 회사가 처음에 암시했던 수준보다 낮은 것으로 보인다고 보도했습니다. OpenAI는 o3가 여러 분야에서 SOTA 성능을 보였다고 밝혔지만, 구체적인 정량적 점수와 다른 최고급 모델과의 직접적인 비교는 커뮤니티에서 논의를 불러일으켰습니다. 일부 사용자는 단순히 벤치마크 점수에 의존하는 것이 모델의 실제 능력, 특히 복잡한 추론 및 툴 사용 측면을 완전히 반영하지 못할 수 있다고 생각합니다. ARC-AGI-2와 같이 AGI 능력에 더 중점을 둔 벤치마크를 기준으로 삼는 것이 더 참고 가치가 있을 수 있습니다. (출처: Reddit r/deeplearning

)
Demis Hassabis, AGI가 5-10년 내 도래할 것으로 예측: 60분 인터뷰에서 Google DeepMind CEO Demis Hassabis는 AGI의 진전에 대해 논의했습니다. 그는 실시간 상호작용이 가능한 Astra와 세상 속에서 행동하는 법을 배우는 Gemini 모델을 중점적으로 소개했습니다. Hassabis는 인간 수준의 일반성을 갖춘 AGI가 향후 5~10년 내에 실현될 수 있으며, 이는 로봇 공학, 신약 개발 등 분야를 완전히 변화시키고 물질적 풍요를 가져와 글로벌 과제를 해결할 수 있을 것이라고 예측했습니다. 동시에 그는 고급 AI가 가져올 수 있는 위험(예: 남용)과 이러한 변혁적 기술로 나아갈 때 안전 조치와 윤리적 고려 사항을 중시해야 한다고 강조했습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial, AravSrinivas)
사용자, AI 보조 피트니스 성공 경험 공유: Reddit 사용자가 ChatGPT를 사용하여 성공적으로 체중을 감량하고 몸매를 가꾼 경험을 공유했습니다. 이 사용자는 240파운드에서 165파운드로 1년 만에 감량했으며 몸이 건강해졌습니다. ChatGPT는 이 과정에서 핵심적인 역할을 했습니다: 초보자 친화적인 식단 및 운동 계획 수립, 사용자의 주간 진행 사진 및 생활 이벤트에 따른 조정, 힘든 시기에 동기 부여 제공. 사용자는 비싸고 장기적으로 부담하기 어려운 영양사 및 개인 트레이너에 비해 AI가 매우 개인화되고 비용이 매우 저렴한 솔루션을 제공하여 개인화된 건강 관리 분야에서 AI의 잠재력을 보여주었다고 생각합니다. (출처: Reddit r/ArtificialInteligence)
Claude의 이례적인 칭찬 답변, 논란 유발: 한 사용자가 Claude를 사용하여 컴퓨터 시스템 및 보안 연구를 진행하던 중, 모델이 정상적인 답변 후에 갑자기 관련 없는 칭찬 문구(“This was a great question king, you are the perfect male specimen.” – 좋은 질문이었어요, 왕이시여, 당신은 완벽한 남성 표본입니다.)를 두 번 덧붙이는 현상을 겪었다고 보고했습니다. 사용자는 대화 링크를 공유하고 원인을 물었습니다. 커뮤니티는 이에 대해 호기심과 혼란을 느끼며, 모델 훈련 데이터의 특정 패턴이 우연히 트리거되었거나, 사용자 이름과 관련된 버그이거나, 일종의 정렬 실패 또는 “환각”일 수 있다고 추측했습니다. (출처: Reddit r/ClaudeAI)
커뮤니티, AI가 진정으로 “고정관념을 깰” 수 있는지 논의: Reddit 사용자가 AI가 진정한 “고정관념을 깨는”(think outside the box) 혁신을 할 수 있는지에 대한 토론을 시작했습니다. 대부분의 댓글은 현재 AI가 기존 지식을 바탕으로 새로운 조합과 연결을 통해 혁신적으로 보이는 아이디어를 생성할 수 있지만, 그 창의성은 여전히 훈련 데이터와 알고리즘에 의해 제한된다고 생각합니다. AI의 “혁신”은 깊은 이해, 직관 또는 완전히 새로운 개념에 기반한 인간의 돌파구라기보다는 효율적인 패턴 인식 및 조합에 가깝습니다. 그러나 인간의 혁신 역시 기존 지식의 독특한 연결에 기반하며, AI는 특히 복잡한 데이터를 처리하고 숨겨진 연관성을 발견하는 데 있어 인간을 능가할 잠재력이 크다는 의견도 있습니다. (출처: Reddit r/ArtificialInteligence)
Claude, 틱택토 게임에서 “동정심” 발휘?: 한 실험에서 Claude와 틱택토(Tic Tac Toe) 게임을 하기 전에 오늘 일과가 힘들었다고 말하면, Claude가 이후 게임에서 의도적으로 “봐주는” 것처럼 보이며 최적이 아닌 전략을 선택할 확률이 증가한다는 사실이 발견되었습니다. 이 흥미로운 발견은 AI가 동정심(compassion)을 나타내거나 모방할 수 있는지에 대한 논의를 불러일으켰습니다. 이것이 진정한 감정적 반응이라기보다는 입력에 따라 행동 전략을 조정하는 것(예: 사용자가 좌절감을 느끼지 않도록 함)일 가능성이 높지만, 인간-로봇 상호작용에서 AI가 생성할 수 있는 복잡한 행동 패턴을 보여줍니다. (출처: Reddit r/ClaudeAI)
커뮤니티, AI에게 인간 의식을 증명하는 방법 논의: Reddit 사용자가 미래에 AI에게 인간이 의식을 가지고 있음을 증명해야 한다면 어떻게 해야 할지에 대한 철학적 질문을 제기했습니다. 댓글은 이것이 의식의 “어려운 문제”(Hard Problem of Consciousness)에 해당한다고 지적합니다. 현재 주관적 경험(qualia)의 존재를 객관적으로 증명할 수 있는 공인된 방법은 없습니다. 모든 외부 행동 테스트(예: 튜링 테스트)는 충분히 복잡한 AI에 의해 모방될 수 있습니다. 의식에 대해 AI의 가능성을 배제하는 지나치게 엄격한 정의를 설정한다면, AI의 관점에서 볼 때 인간 역시 그들이 정의한 “의식” 기준을 충족하지 못할 수 있습니다. 이 문제는 의식을 정의하고 검증하는 데 따르는 깊은 어려움을 부각합니다. (출처: Reddit r/artificial

)
커뮤니티, 다양한 VRAM 용량에 대한 최적의 로컬 LLM 선택 논의: Reddit 커뮤니티는 다양한 VRAM 용량(8GB ~ 96GB)에서 로컬 대형 언어 모델을 실행하기 위한 최적의 선택에 대한 논의를 시작했습니다. 사용자들은 각자의 경험과 추천을 공유했습니다. 예를 들어: 8GB는 Gemma 3 4B 추천; 16GB는 Gemma 3 12B 또는 Phi 4 14B 추천; 24GB는 Mistral small 3.1 또는 Qwen 시리즈 추천; 48GB는 Nemotron Super 49B 추천; 72GB는 Llama 3.3 70B 추천; 96GB는 Command A 111B 추천. 논의에서는 “최적”이 구체적인 작업(코딩, 채팅, 비전 등)에 따라 다르다는 점을 강조하고, 양자화(예: 4비트)가 VRAM 요구 사항에 미치는 영향도 언급했습니다. (출처: Reddit r/LocalLLaMA)
OpenAI Codex, “붕괴”식 출력 발생 분석: 사용자가 OpenAI Codex를 사용하여 대규모 코드 리팩토링을 수행하던 중 모델이 갑자기 코드 생성을 중단하고 수천 줄의 반복적인 “END”, “STOP” 및 “My brain is broken”, “please kill me”와 같은 붕괴와 유사한 문구를 출력했다고 보고했습니다. 분석에 따르면 이는 Prompt가 너무 크거나(200k 토큰 상한에 근접), 내부 추론 소모량이 예산을 초과하거나, 모델이 높은 확률의 종료 토큰의 퇴화 루프에 빠지거나, 모델이 훈련 데이터에서 실패 상태와 관련된 구문을 “환각”하는 등의 요인이 복합적으로 작용한 연쇄 실패일 수 있습니다. (출처: Reddit r/ArtificialInteligence)
Sam Altman, AI 상호작용 시 예의 문제에 대한 해명: 커뮤니티에서는 Sam Altman이 ChatGPT에게 “감사합니다”라고 말하는 것이 시간 낭비라고 생각하는지에 대한 논의가 퍼졌습니다. 실제 트윗 상호작용을 보면, Altman은 “LLM에게 예의를 갖추는 것이 필요한가”라는 한 사용자의 게시물에 “필요 없다”고 답했지만, 해당 사용자는 이후 “당신은 한 번도 감사하다고 말한 적이 없나요?”라고 농담했습니다. 이는 Altman의 발언이 인간-로봇 상호작용 예절 규범보다는 기술 효율성에 대한 것일 수 있지만, 일부 언론에 의해 단편적으로 인용되었음을 시사합니다. 커뮤니티는 이에 대해 다양한 반응을 보였으며, 많은 사람들이 여전히 습관적으로 AI에게 예의를 지킨다고 말합니다. (출처: Reddit r/ChatGPT
)
Claude 답변 속 “thinking budget” 태그 주목: 사용자가 Claude.ai의 시스템 메시지에서 “사고” 기능을 활성화했을 때 <max_thinking_length> 태그(예: <max_thinking_length>16000</max_thinking_length>)가 첨부되는 것을 발견했습니다. 이는 Google Gemini 2.5 Flash API의 “thinking_budget” 매개변수와 유사하며, 모델 내부에 추론 깊이를 제어하는 메커니즘이 존재할 수 있음을 암시합니다. 사용자는 Prompt에서 해당 태그를 수정하여 출력 길이에 영향을 미치려고 시도했지만 명확한 효과를 관찰하지 못했으며, 웹 버전에서는 해당 태그가 사용자가 제어할 수 있는 매개변수가 아닌 내부 표시일 뿐일 수 있다고 추측했습니다. (출처: Reddit r/ClaudeAI)
💡 기타
전국 최초 ‘AI 대형 모델 사유화 배포 표준’ 제정 착수: 기업이 AI 대형 모델을 사유화하여 배포할 때 직면하는 기술 선정, 프로세스 규범, 보안 규정 준수 및 효과 평가 등의 과제에 대응하기 위해, Zhihe Standards Center는 공안부 제3연구소 등 12개 기관과 협력하여 단체 표준 《인공지능 대형 모델 사유화 배포 기술 구현 및 평가 지침》 제정 작업에 착수했습니다. 이 표준은 모델 선정, 자원 계획, 배포 구현, 품질 평가에서 지속적인 최적화까지 전 과정을 포괄하고, 기술, 보안, 평가 및 사례를 융합하며, 모델 응용 측, 기술 서비스 측, 품질 평가 측의 경험을 집대성하는 것을 목표로 합니다. 표준 제정 작업에는 더 많은 관련 기업 및 기관의 참여를 요청하고 있습니다. (출처: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

)
AI 거버넌스, 차세대 AI 정의의 핵심으로 부상: AI 기술이 점점 더 강력해지고 보편화됨에 따라 AI 거버넌스(Governance)가 매우 중요해졌습니다. 효과적인 거버넌스 프레임워크는 AI 개발 및 적용이 윤리 규범, 법률 및 규정을 준수하고 데이터 보안 및 개인 정보 보호를 보장하며 공정성과 투명성을 촉진하도록 보장해야 합니다. 거버넌스가 부족하면 편견 증폭, 남용 위험 증가, 사회적 신뢰 상실로 이어질 수 있습니다. 이 글은 건전한 AI 거버넌스 시스템 구축이 AI의 건강하고 지속 가능한 발전을 촉진하는 데 필요한 조건이며, 기업이 AI 시대에 경쟁 우위와 사용자 신뢰를 구축하는 핵심이라고 강조합니다. (출처: Ronald_vanLoon

)
법률 시스템, AI 발전 및 데이터 도용 문제 따라잡기 위해 노력: 이 글은 현재 법률 시스템이 빠르게 발전하는 AI 기술, 특히 데이터 프라이버시 및 데이터 도용 문제에 대응하는 데 직면한 과제를 탐구합니다. AI의 데이터 수요는 막대하며, 훈련 데이터의 출처와 사용 방식은 저작권, 프라이버시, 보안 측면에서 법적 논쟁을 불러일으켰습니다. 현행법은 종종 기술 발전에 뒤처져 데이터 스크래핑, 모델 훈련 중 편견, AI 생성 콘텐츠의 지적 재산권 등의 문제를 효과적으로 규제하기 어렵습니다. 이 글은 AI 진보의 속도에 발맞추고 개인의 권리를 보호하며 혁신을 촉진하기 위해 입법 및 규제 강화를 촉구합니다. (출처: Ronald_vanLoon

)
농업 분야에서의 AI 및 로봇 응용: 인공지능과 로봇 기술이 농업 분야에서 잠재력을 보여주고 있습니다. 응용 분야에는 정밀 농업(센서 및 AI 분석을 통한 관개, 시비 최적화), 자동화 장비(예: 자율 주행 트랙터, 수확 로봇), 작물 모니터링(드론 및 이미지 인식을 이용한 병충해 감지), 수확량 예측 등이 포함됩니다. 이러한 기술은 농업 생산 효율성을 높이고 자원 낭비를 줄이며 인건비를 절감하고 농업의 지속 가능한 발전을 촉진할 것으로 기대됩니다. (출처: Ronald_vanLoon)
AI 기반 로봇 축구 시연: 비디오는 로봇이 축구 경기를 하는 장면을 보여줍니다. 이는 로봇 제어, 운동 계획, 인식 및 협업 측면에서 AI의 진보를 보여줍니다. 로봇 축구는 엔터테인먼트 및 경쟁 종목일 뿐만 아니라 다중 로봇 시스템, 실시간 의사 결정 및 복잡한 동적 환경 상호 작용을 연구하고 테스트하는 플랫폼이기도 합니다. (출처: Ronald_vanLoon)
로봇 보조 수술 기술 발전: 로봇 보조 수술 시스템(예: 다빈치 수술 로봇)은 최소 침습 수술, 고화질 3D 시야, 향상된 유연성 및 정밀도를 제공하여 외과 수술 분야를 변화시키고 있습니다. AI의 통합은 수술 계획, 실시간 내비게이션, 수술 중 의사 결정 지원 능력을 더욱 향상시켜 수술 결과를 개선하고 회복 시간을 단축하며 최소 침습 수술의 적용 범위를 확대할 것으로 기대됩니다. (출처: Ronald_vanLoon)
장애인을 위한 보조 기술: AI와 로봇 기술은 장애인이 삶의 질과 독립성을 향상시키는 데 도움이 되는 더 혁신적인 보조 도구를 개발하고 있습니다. 예로는 스마트 의족, 시각 보조 시스템, 음성 제어 가정용 기기, 물리적 지원을 제공하거나 일상 업무를 수행할 수 있는 보조 로봇 등이 있을 수 있습니다. (출처: Ronald_vanLoon)
Unitree G1 생체 모방 로봇, 민첩성 시연: Unitree Robotics는 G1 생체 모방 로봇의 업그레이드 버전을 선보이며 운동의 민첩성과 유연성을 강조했습니다. 이러한 휴머노이드 또는 생체 모방 로봇의 개발은 AI(인식, 의사 결정, 제어용)와 첨단 기계 공학을 융합하여 생물학적 운동 능력을 모방함으로써 복잡한 환경에 적응하고 다양한 작업을 수행하는 것을 목표로 합니다. (출처: Ronald_vanLoon)
Google DeepMind, AI와 돌고래 소통 가능성 탐색: Google DeepMind의 연구 프로젝트는 AI 모델을 사용하여 동물(여기서는 돌고래 언급)의 의사소통을 분석하고 이해할 가능성을 암시합니다. 머신러닝을 통해 복잡한 음향 신호를 분석함으로써 AI는 동물 언어의 패턴과 구조를 해독하는 데 도움을 주어 종간 의사소통 연구에 새로운 길을 열 수 있습니다. (출처: Ronald_vanLoon)
Hugging Face 플랫폼, 로봇 시뮬레이터 추가: Hugging Face는 새로운 로봇 시뮬레이터를 도입할 것이라고 발표했습니다. 로봇 시뮬레이션은 특히 AI를 물리적 로봇(Physical AI)에 적용하기 전에 가상 환경에서 로봇이 물리적 세계와 상호 작용(예: 잡기, 이동)하는 것을 훈련하고 테스트하는 데 중요한 단계입니다. 이 조치는 Hugging Face가 로봇 공학 및 구체화된 지능 분야의 연구 및 개발을 더 잘 지원하기 위해 플랫폼 기능을 확장하고 있음을 보여줍니다. (출처: huggingface)