
키워드:AI 4대 용, 구신 지능, 휴머노이드 로봇, 메모리 벽, 상탕 일일신 V6 멀티모달 모델, Open X-Embodiment 데이터셋, 테슬라 옵티머스 로봇, 3D 강유전체 RAM 기술, 천궁 울트라 로봇 하프 마라톤, 제마 3 QAT 양자화 모델, 허깅 페이스 폴렌 로보틱스 인수, 라마인덱스 에이전트 문서 워크플로우
🔥 포커스
“AI 4룡”의 도전과 전환: SenseTime, Megvii, CloudWalk, Yitu 등 과거 ‘AI 4룡’으로 불렸던 기업들이 최근 몇 년간 사업화 난항과 지속적인 손실에 직면해 있습니다. 예를 들어, SenseTime은 2024년에 43억 위안의 손실을 기록했으며 누적 손실은 546억 위안을 초과했습니다. CloudWalk는 2024년에 약 6~7억 위안의 손실을 기록했으며 누적 손실은 44억 위안을 초과했습니다. 이러한 도전에 대응하기 위해 각 기업은 인력 감축, 임금 삭감, 사업 재편 등 전략적 조정을 단행하고 있습니다. 대규모 언어 모델(Large Language Model)이 주도하는 새로운 AI 물결에 직면하여, 시각 기술 기반의 ‘4룡’은 멀티모달 대형 모델 및 AGI 분야로 적극 전환하고 있습니다. SenseTime은 GPT-4o를 겨냥한 ‘日日新V6’ 멀티모달 모델을 발표하고 지능형 컴퓨팅 센터 구축에 대규모 투자를 하고 있습니다. Yitu는 시각 중심의 멀티모달 모델에 집중하고 있으며, Huawei와 협력하여 하드웨어 비용을 절감하고 있습니다. CloudWalk 역시 Huawei와 협력하여 대형 모델 학습-추론 통합 장비를 출시했습니다. Megvii는 알고리즘 우위를 바탕으로 스마트 드라이빙 순수 비전 솔루션 분야에 진출했습니다. 이러한 움직임은 이들 기업이 AI 경쟁 구도에 남아 새로운 시장 환경에 적응하기 위해 노력하고 있음을 보여줍니다. (출처: 36Kr)

체화된 지능의 데이터 딜레마와 오픈소스 데이터셋 진전: 휴머노이드 로봇과 체화된 지능(embodied intelligence)의 발전은 핵심적인 데이터 병목 현상에 직면해 있으며, 고품질 훈련 데이터의 부족은 그 능력 돌파를 저해하고 있습니다. 방대한 인터넷 텍스트 데이터를 보유한 언어 모델과 달리, 로봇은 다양한 물리적 세계 상호작용 데이터가 필요하며 이는 획득 비용이 높습니다. 이 문제를 해결하기 위해 연구 기관과 기업들은 데이터셋 구축 및 오픈소스화에 적극적으로 나서고 있습니다. 예를 들어 Google DeepMind가 여러 기관과 공동으로 발표한 Open X-Embodiment, Peng Cheng Laboratory 등의 ARIO, Beijing Innovation Center의 RoboMIND, AgiBot의 AgiBot World(실제 환경에서의 장기 복합 임무 데이터 포함) 및 AgiBot Digital World 시뮬레이션 데이터셋, Unitree의 G1 조작 데이터셋 등이 있습니다. 이러한 데이터셋은 규모 면에서는 여전히 텍스트 데이터보다 훨씬 작지만, 표준 통일, 품질 향상, 시나리오 다양화를 통해 체화된 지능 분야의 발전을 촉진하고 ‘ImageNet moment’ 실현의 기반을 다지고 있습니다. (출처: 36Kr)

휴머노이드 로봇 양산의 서광: 데이터, 시뮬레이션, 일반화 능력 돌파: 데이터 수집 비용이 높고 일반화 능력이 약하다는 등의 도전에 직면해 있음에도 불구하고, 여러 기업(Tesla, Figure AI, 1X, AgiBot, Unitree, UBTECH 등)은 여전히 2025년에 휴머노이드 로봇 양산을 계획하고 있습니다. 해결 경로는 다음과 같습니다: 1) 대규모 실제 로봇 훈련: 정부(베이징, 상하이, 선전, 광둥) 지원 하에 데이터 수집 기지 건설 및 표준 제정. 2) 고급 시뮬레이션 훈련: Nvidia Cosmos, Google Genie2 등 월드 모델을 활용하여 물리적으로 현실적인 가상 환경을 생성하고, 비용 절감 및 효율성 향상. 3) AI 기반 일반화 능력 강화: Figure AI의 Helix, AgiBot GO-1의 ViLLA 아키텍처, Google Gemini Robotics 등 새로운 액션 모델을 통해 더 적은 데이터로 물리적 조작에 대한 일반화된 이해를 실현하여 로봇이 처음 보는 물체를 처리하고 새로운 환경에 적응할 수 있도록 함. 이러한 기술 발전은 휴머노이드 로봇의 상업적 응용이 가속화될 수 있음을 예고합니다. (출처: 36Kr)

AI 발전, ‘메모리 장벽’ 위기 직면, 신형 스토리지 기술 돌파구 모색: AI 모델 규모의 기하급수적인 증가는 메모리 대역폭에 심각한 도전을 제기하고 있으며, 기존 DRAM 대역폭 증가 속도는 컴퓨팅 성능 증가 속도에 훨씬 미치지 못해 ‘스토리지 장벽’ 병목 현상을 형성하고 프로세서 성능 발휘를 제한하고 있습니다. HBM은 3D 스태킹 기술을 통해 대역폭을 대폭 향상시켜 일부 압력을 완화했지만, 제조 공정이 복잡하고 비용이 높습니다. 이에 업계는 신형 스토리지 기술을 적극적으로 탐색하고 있습니다: 1) 3D 강유전체 RAM (FeRAM): SunRise Memory와 같이 HfO2 강유전체 효과를 이용하여 고밀도, 비휘발성, 저전력 스토리지를 구현합니다. 2) DRAM + 비휘발성 메모리: Neumonda는 FMC와 협력하여 HfO2를 이용해 DRAM 커패시터를 비휘발성 스토리지로 전환합니다. 3) 2T0C IGZO DRAM: imec은 기존 1T1C 구조를 두 개의 산화물 트랜지스터로 대체하여 커패시터 없이 저전력, 고밀도, 긴 유지 시간을 실현하는 방안을 제안했습니다. 4) 상변화 메모리 (PCM): 재료의 상변화를 이용하여 데이터를 저장하고 전력 소모를 줄입니다. 5) UK III-V Memory: GaSb/InAs 기반으로 DRAM의 속도와 플래시 메모리의 비휘발성을 겸비합니다. 6) SOT-MRAM: 스핀-궤도 토크(Spin-Orbit Torque)를 이용하여 저전력, 고효율을 실현합니다. 이러한 기술들은 DRAM 병목 현상을 타파하고 스토리지 시장 구도를 재편할 것으로 기대됩니다. (출처: 36Kr)
🎯 동향
天工 로봇, 하프 마라톤 완주, 소량 양산 계획: 베이징 휴머노이드 로봇 혁신 센터의 天工팀 로봇 ‘天工 Ultra’(키 1.8m, 무게 55kg)가 첫 휴머노이드 로봇 하프 마라톤 대회에서 2시간 40분 42초의 기록으로 약 21km를 완주하며 우승했습니다. 이번 대회는 복잡한 노면 환경에서 로봇의 지구력, 구조, 인지 및 제어 알고리즘의 신뢰성을 검증했습니다. 팀은 관절 안정성, 내열성, 에너지 소비 시스템, 균형 및 보행 계획 알고리즘을 최적화하고, 자체 개발한 ‘慧思开物’ 플랫폼(체화된 대뇌+소뇌)을 탑재하여 무선 유도 하에 자율 경로 계획 및 실시간 조정을 실현했다고 밝혔습니다. 마라톤 완주는 기본적인 신뢰성을 증명했으며 양산의 기초를 마련했습니다. 天工 2.0 로봇은 곧 출시될 예정이며 소량 생산을 계획하고 있으며, 향후 산업, 물류, 특수 작업 및 가정 서비스 분야에 적용하는 것을 목표로 합니다. (출처: 36Kr)

중국, 배양된 인간 세포 이용 로봇 뇌 구축 연구 개발: 보도에 따르면 중국 연구진이 배양된 인간 뇌 세포로 구동되는 로봇을 개발 중입니다. 이 연구는 생물학적 컴퓨팅의 가능성을 탐색하고, 생물학적 뉴런의 학습 및 적응 능력을 활용하여 로봇 하드웨어를 제어하는 것을 목표로 합니다. 구체적인 세부 사항과 진행 단계는 아직 불분명하지만, 이 방향은 로봇 공학, 인공 지능, 생명 공학의 교차 분야에서 최첨단 탐구를 대표하며, 미래에 더 지능적이고 적응력이 뛰어난 로봇 시스템 개발의 새로운 길을 열 수 있습니다. (출처: Ronald_vanLoon)
Gemma 3 QAT 양자화 모델 성능 우수: 사용자가 GPQA Diamond 벤치마크 테스트에서 Google Gemma 3 27B 모델의 QAT (Quantization Aware Training) 버전과 다른 Q4 양자화 버전(Q4_K_XL, Q4_K_M)을 비교했습니다. 결과에 따르면 QAT 버전이 성능 면에서 가장 우수했으며(정확도 36.4%), VRAM 점유율도 가장 낮았습니다(16.43 GB). 이는 Q4_K_XL(34.8%, 17.88 GB) 및 Q4_K_M(33.3%, 17.40 GB)보다 우수한 결과입니다. 이는 QAT 기술이 모델 성능을 유지하면서 리소스 요구 사항을 효과적으로 줄인다는 것을 보여줍니다. (출처: Reddit r/LocalLLaMA)
AMD, 32GB 메모리 탑재 RDNA 4 Radeon PRO 그래픽카드 출시 루머: VideoCardz는 AMD가 Navi 48 XTW GPU 기반의 Radeon PRO 시리즈 그래픽카드를 준비 중이며, 32GB 메모리를 탑재할 것이라고 보도했습니다. 만약 사실이라면, 이는 로컬 AI 모델 훈련 및 추론을 위해 대용량 메모리가 필요한 사용자에게 새로운 선택지를 제공할 것입니다. 특히 소비자용 그래픽카드의 메모리가 일반적으로 제한적인 상황에서 더욱 그렇습니다. 그러나 구체적인 성능, 가격, 출시일은 아직 공개되지 않았으며 실제 경쟁력은 지켜봐야 합니다. (출처: Reddit r/LocalLLaMA)

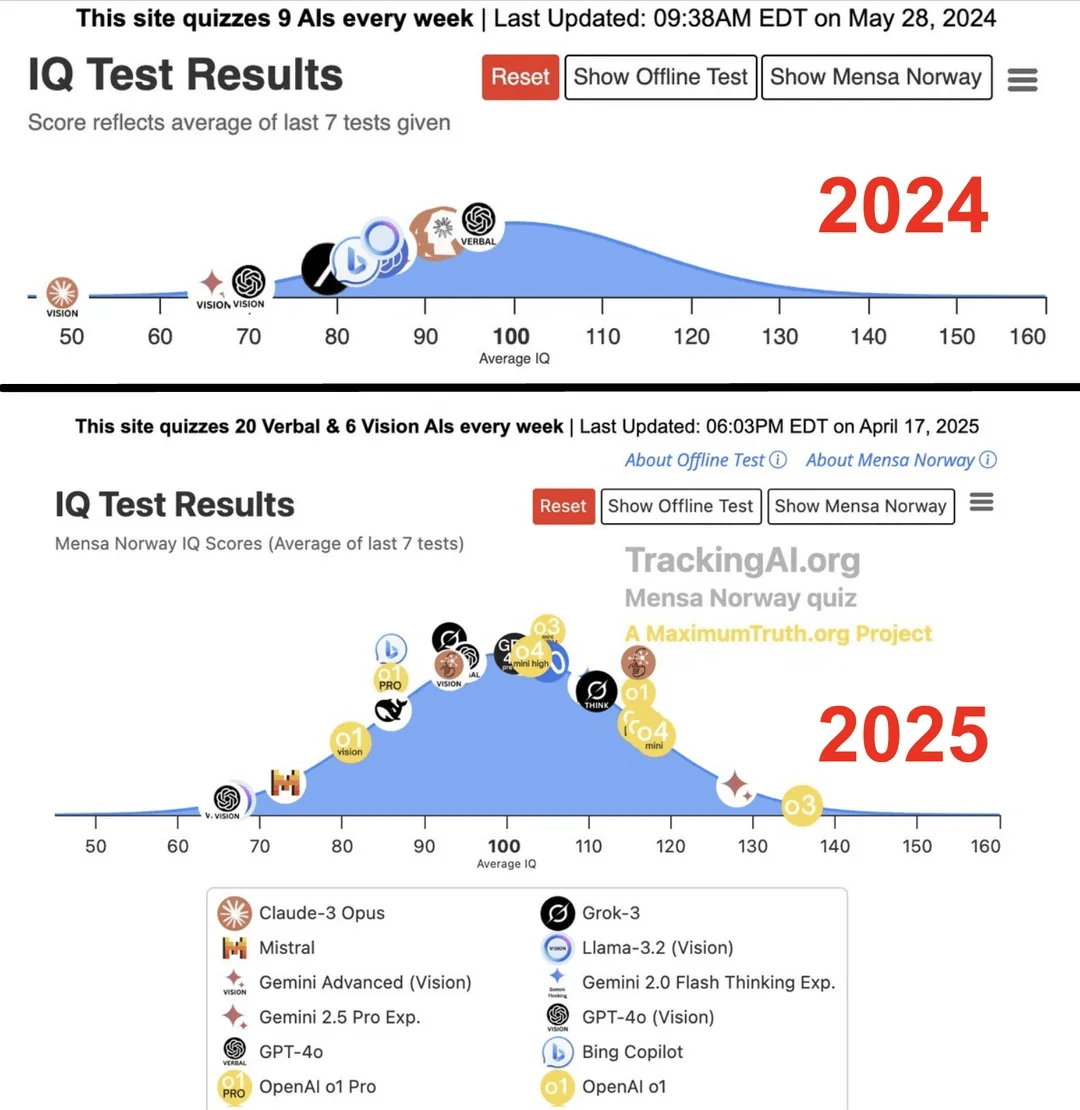
연구 결과, 최고 수준 AI의 IQ가 1년 만에 96에서 136으로 급상승: Maximum Truth 웹사이트에서 발표한 연구(출처 신뢰성 확인 필요)에 따르면, AI 모델에 대한 IQ 테스트 결과, 가장 똑똑한 AI(아마도 GPT 시리즈를 지칭)의 IQ 점수가 1년 만에 96점(인간 평균보다 약간 낮음)에서 136점(천재 수준에 가까움)으로 상승했습니다. IQ 테스트가 AI 지능 측정에 효과적인지에 대한 논란이 있고 훈련 데이터가 테스트를 오염시킬 가능성도 있지만, 이러한 현저한 상승은 AI가 표준화된 지능 테스트 문제 해결 능력에서 빠르게 발전하고 있음을 반영합니다. (출처: Reddit r/artificial)
🧰 도구
OpenUI: 설명을 통해 실시간으로 UI 생성: wandb가 OpenUI를 오픈소스로 공개했습니다. 이는 사용자가 자연어 설명을 통해 사용자 인터페이스(UI)를 구상하고 실시간으로 렌더링할 수 있게 해주는 도구입니다. 사용자는 수정 요청을 할 수 있으며, 생성된 HTML 코드를 React, Svelte, Web Components 등 다양한 프론트엔드 프레임워크 코드로 변환할 수 있습니다. OpenUI는 OpenAI, Groq, Gemini, Anthropic (Claude) 등 다양한 LLM 백엔드를 지원하며, LiteLLM 또는 Ollama를 통해 로컬 모델과 연결할 수도 있습니다. 이 프로젝트는 UI 컴포넌트 구축 과정을 더 빠르고 재미있게 만들고, W&B 내부 테스트 및 프로토타이핑 도구로 사용되는 것을 목표로 합니다. v0.dev에서 영감을 받았지만 OpenUI는 오픈소스입니다. 온라인 데모와 로컬 실행 가이드(Docker 또는 소스 코드)를 제공합니다. (출처: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: 레이아웃을 유지하는 AI PDF 번역 도구: Byaidu가 개발한 PDFMathTranslate는 강력한 PDF 문서 번역 도구입니다. 핵심 장점은 AI 기술을 활용하여 번역과 동시에 복잡한 수학 공식, 도표, 목차, 주석 등을 포함한 원본 문서의 레이아웃 형식을 완벽하게 유지하는 것입니다. 이 도구는 다양한 언어 간 상호 번역을 지원하며 Google, DeepL, Ollama, OpenAI 등 여러 번역 서비스를 통합했습니다. 다양한 사용자를 위해 프로젝트는 명령줄 인터페이스(CLI), 그래픽 사용자 인터페이스(GUI), Docker 이미지 및 Zotero 플러그인 등 여러 사용 방식을 제공합니다. 사용자는 온라인 데모를 사용해 보거나 필요에 따라 적합한 설치 방법을 선택할 수 있습니다. (출처: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: LangGraph 기반 인용 보고서 생성 시스템: Shandu AI Research는 LangGraph 워크플로우를 활용하여 인용이 포함된 보고서를 자동으로 생성하는 시스템입니다. 지능형 웹 스크래핑, 다중 소스 정보 종합, 병렬 처리 등의 기술을 통해 연구 작업을 간소화하는 것을 목표로 합니다. 이 도구는 사용자가 정보를 신속하게 수집, 통합, 분석하고 구조화된 인용 포함 연구 보고서를 생성하여 연구 효율성을 높이는 데 도움을 줄 수 있습니다. (출처: LangChainAI)

Intel, 오픈소스 AI Playground 공개: Intel이 AI PC를 위한 입문용 애플리케이션인 AI Playground를 오픈소스로 공개했습니다. 사용자는 Intel Arc 그래픽 카드가 탑재된 PC에서 다양한 생성형 AI 모델을 실행할 수 있습니다. 지원되는 이미지/비디오 모델에는 Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video가 포함됩니다. 지원되는 대규모 언어 모델에는 DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM) 및 Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM 또는 OpenVINO)가 포함됩니다. 이 도구는 로컬에서 AI 모델을 실행하는 장벽을 낮추고 사용자가 쉽게 경험하고 실험할 수 있도록 하는 것을 목표로 합니다. (출처: karminski3)
Persona Engine: AI 가상 비서/스트리머 프로젝트: Persona Engine은 상호작용형 AI 가상 비서 또는 가상 스트리머를 만드는 것을 목표로 하는 오픈소스 프로젝트입니다. 대규모 언어 모델(LLM), Live2D 애니메이션, 자동 음성 인식(ASR), 텍스트 음성 변환(TTS) 및 실시간 음성 복제 기술을 통합합니다. 사용자는 Live2D 캐릭터와 직접 음성 대화를 나눌 수 있으며, 프로젝트는 OBS와 같은 라이브 스트리밍 소프트웨어에 통합하여 AI 가상 스트리머를 만드는 것도 지원합니다. 이 프로젝트는 다양한 AI 기술의 융합 응용을 보여주며 개인화된 가상 상호작용 캐릭터를 구축하기 위한 프레임워크를 제공합니다. (출처: karminski3)
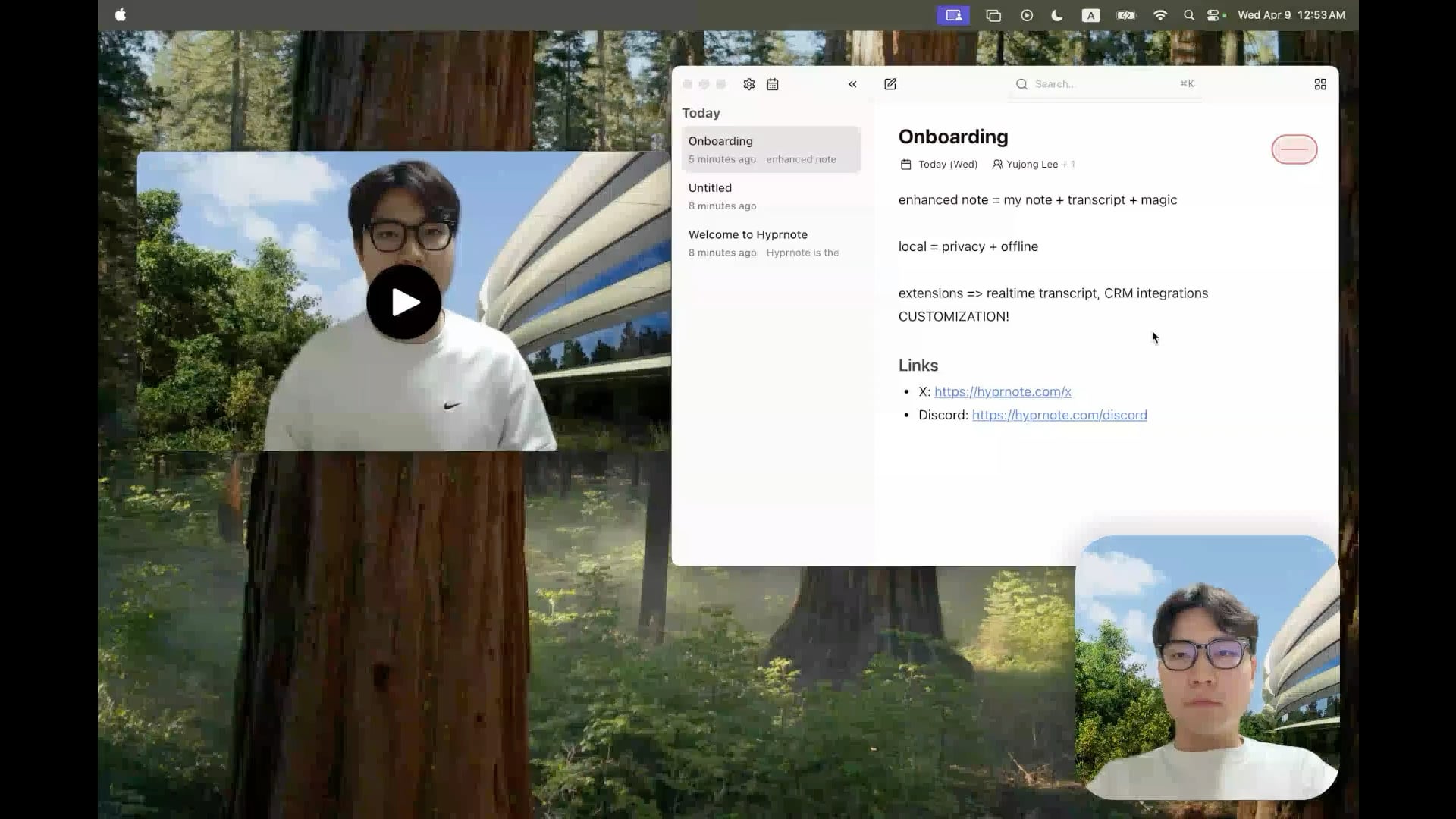
Hyprnote: 오픈소스 로컬 AI 회의 노트 도구: 개발자가 회의 환경을 위해 특별히 설계된 스마트 노트 애플리케이션인 Hyprnote를 오픈소스로 공개했습니다. 회의 중 녹음을 하고 사용자의 원본 노트를 회의 오디오 콘텐츠와 결합하여 향상된 회의록을 생성할 수 있습니다. 핵심 특징은 AI 모델(예: 음성 전사를 위한 Whisper)을 완전히 로컬에서 실행하여 사용자 데이터의 프라이버시와 보안을 보장하는 것입니다. 이 도구는 사용자가 회의 정보를 더 잘 포착하고 정리하는 데 도움을 주며, 특히 연속적인 회의를 처리해야 하는 사용자에게 적합합니다. (출처: Reddit r/LocalLLaMA)
LMSA: LM Studio를 Android 기기에 연결하는 도구: 사용자가 LMSA(lmsa.app)라는 애플리케이션을 공유했습니다. 이 앱은 사용자가 LM Studio(인기 있는 로컬 LLM 실행 관리 도구)를 자신의 Android 기기에 연결하는 데 도움을 줍니다. 이를 통해 사용자는 휴대폰이나 태블릿을 통해 로컬 PC에서 실행되는 AI 모델과 상호작용할 수 있어 로컬 대규모 모델의 사용 시나리오를 확장할 수 있습니다. (출처: Reddit r/LocalLLaMA)

MobileNetV2 기반 로컬 이미지 검색 도구: 개발자가 PyQt5 그래픽 인터페이스와 TensorFlow MobileNetV2 모델을 사용하는 데스크톱 이미지 검색 도구를 구축하고 공유했습니다. 이 도구는 로컬 이미지 폴더를 인덱싱하고, 이미지 내용(CNN으로 특징 추출)을 기반으로 코사인 유사도를 사용하여 유사한 이미지를 찾을 수 있습니다. 폴더 구조를 자동으로 감지하여 분류로 사용하고, 검색 결과의 썸네일, 유사도 백분율 및 파일 경로를 표시합니다. 프로젝트 코드는 GitHub에 오픈소스로 공개되었으며 사용자 피드백을 구하고 있습니다. (출처: Reddit r/MachineLearning)
Handcrafted Persona Engine: 로컬 AI 음성 상호작용 가상 캐릭터: 개발자가 “Handcrafted Persona Engine”이라는 개인 프로젝트를 공유했습니다. 이는 “세서미 스트리트”와 유사한 경험을 제공하는, 완전히 로컬에서 실행되는 상호작용형 음성 구동 가상 캐릭터를 만드는 것을 목표로 합니다. 이 시스템은 로컬 Whisper를 사용하여 음성을 전사하고, Ollama API를 통해 로컬 LLM을 호출하여 대화(개성 설정 포함)를 생성하며, 로컬 TTS를 사용하여 텍스트를 음성으로 변환하고, Live2D 캐릭터 모델을 구동하여 입 모양 동기화 및 감정 표현을 수행합니다. 프로젝트는 C#으로 구축되었으며 GTX 1080 Ti 수준의 그래픽 카드에서 실행 가능하며 GitHub에 오픈소스로 공개되었습니다. (출처: Reddit r/LocalLLaMA)
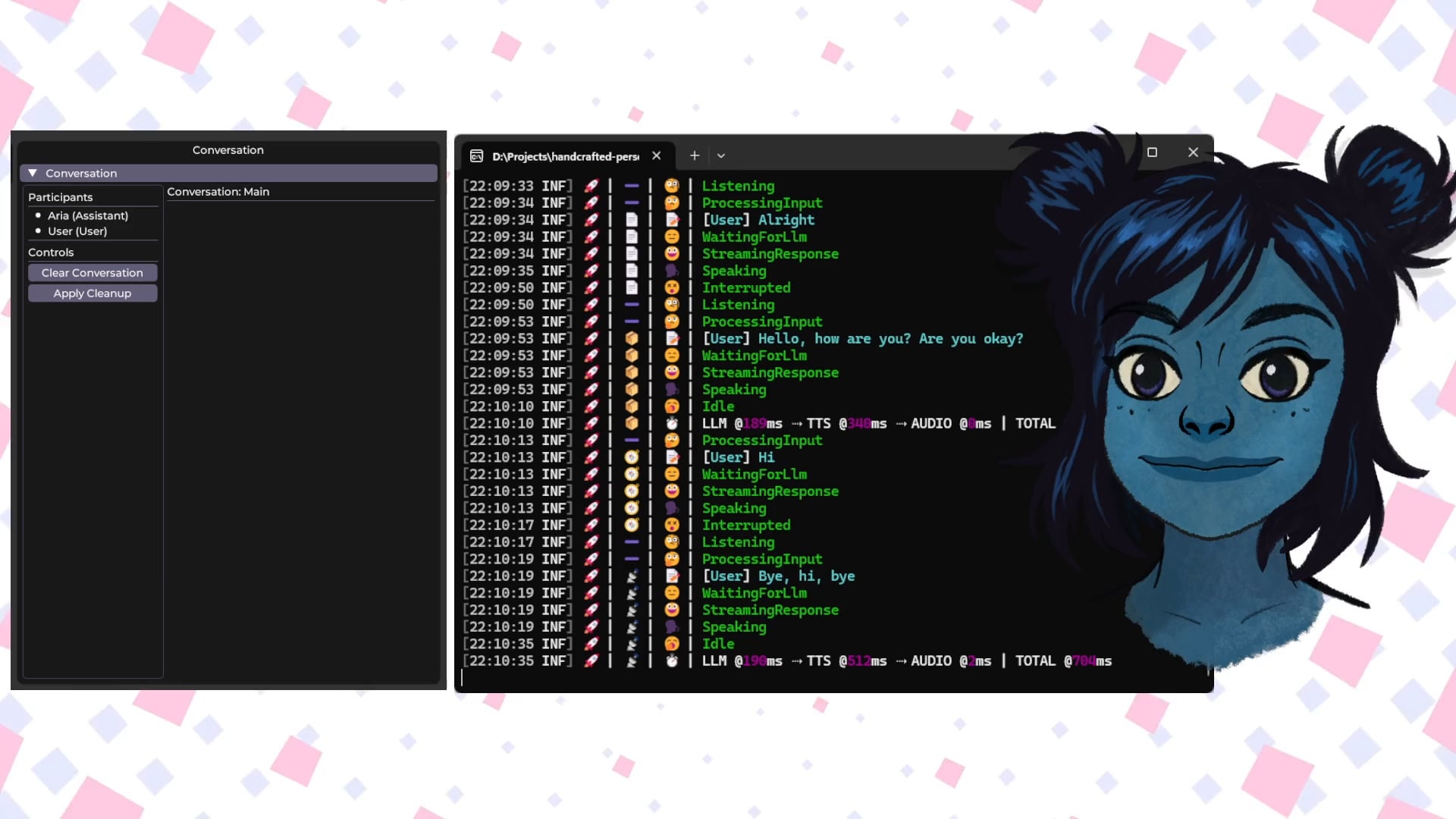
Talkto.lol: 유명인 AI 캐릭터와 대화하는 실험 도구: 개발자가 talkto.lol이라는 웹사이트를 만들었습니다. 사용자는 이 웹사이트에서 다양한 유명인(예: Sam Altman)의 AI 페르소나와 대화할 수 있습니다. 이 도구에는 “show me” 기능도 포함되어 있어 사용자가 이미지를 업로드하면 AI가 이를 분석하고 응답을 생성하여 AI의 시각 인식 능력을 보여줍니다. 개발자는 이 플랫폼을 활용하여 AI 페르소나 상호작용에 대한 더 많은 실험을 진행할 것이라고 밝혔습니다. 이 도구는 등록 없이 사용해 볼 수 있습니다. (출처: Reddit r/artificial)
📚 학습
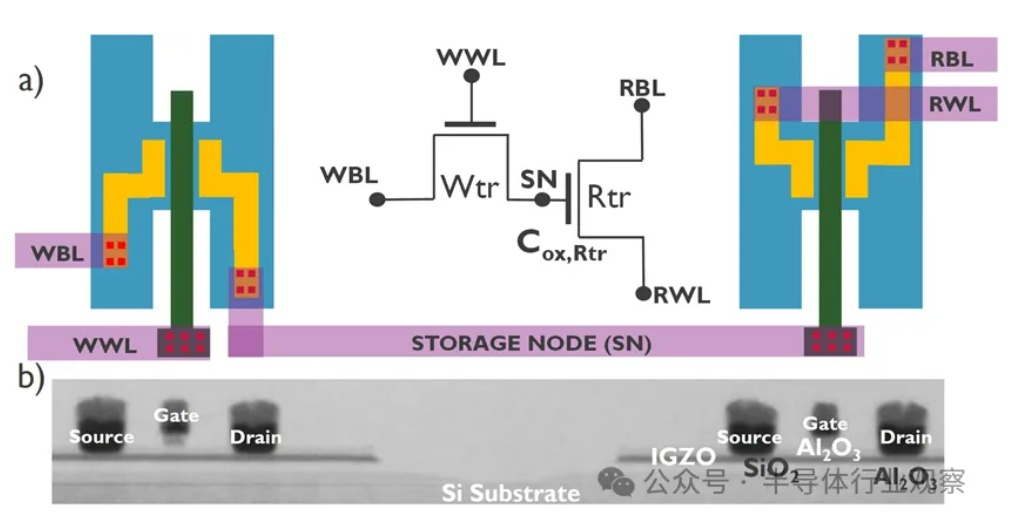
휴머노이드 로봇 기초: 도전 과제와 데이터 수집: 휴머노이드 로봇의 발전은 단순한 자동화에서 복잡한 ‘체화된 지능(embodied intelligence)’, 즉 물리적 신체를 기반으로 인지하고 행동하는 지능 시스템으로 나아가고 있습니다. 언어, 이미지를 처리하는 AI 대형 모델과 달리, 로봇은 실제 물리적 세계를 이해하고 공간 인지, 운동 계획, 역학 피드백 등 다차원 데이터를 처리해야 합니다. 이러한 고품질의 실제 세계 데이터를 확보하는 것은 큰 도전이며, 비용이 많이 들고 모든 시나리오를 포괄하기 어렵습니다. 현재 주요 수집 방식은 다음과 같습니다: 1) 실제 세계 데이터 수집: 광학 또는 관성 동작 캡처 시스템을 통해 인간의 동작을 기록하거나, 인간이 원격으로 로봇을 조작하여 작업을 수행하고 실제 로봇 데이터를 기록합니다(예: Tesla Optimus). 2) 시뮬레이션 세계 데이터 수집: 시뮬레이션 플랫폼을 활용하여 환경과 로봇 행동을 모방하고 대량의 데이터를 생성하여 비용을 절감하고 일반화 능력을 향상시킵니다. 그러나 시뮬레이션과 현실 간의 차이(Sim-to-Real Gap)를 해결해야 합니다. 또한 인터넷 비디오 데이터를 활용한 사전 훈련(pre-training)도 탐색 방향 중 하나입니다. (출처: 36Kr)

지식 기반 글에 인포그래픽 스타일 이미지 생성 팁: 사용자가 GPT-4o 등 AI 도구를 사용하여 지식 기반 글에 인포그래픽(infographic) 스타일의 이미지를 생성하는 방법을 공유했습니다. 핵심 팁은 AI에게 먼저 이미지 생성 프롬프트(prompt) 작성을 돕도록 요청하는 것입니다. 구체적인 단계: 글의 내용이나 요점을 AI에게 제공하고, 가로형 인포그래픽 생성을 위한 프롬프트를 작성하도록 요청합니다. 프롬프트에는 영문 텍스트, 카툰 이미지, 명확하고 생생한 스타일, 핵심 관점 요약 등의 요구 사항을 포함해야 합니다. 요점: AI에게 전체 내용을 제공할 것; ‘인포그래픽’을 명확히 요구할 것; 텍스트가 많을 경우 생성 정확도를 높이기 위해 영어를 사용할 것을 권장; 프롬프트 생성에는 GPT-4.5, o3 또는 Gemini 2.5 Pro 사용을 추천; 최종 이미지 생성에는 Sora Com 또는 ChatGPT 등 도구를 사용할 것. (출처: dotey)
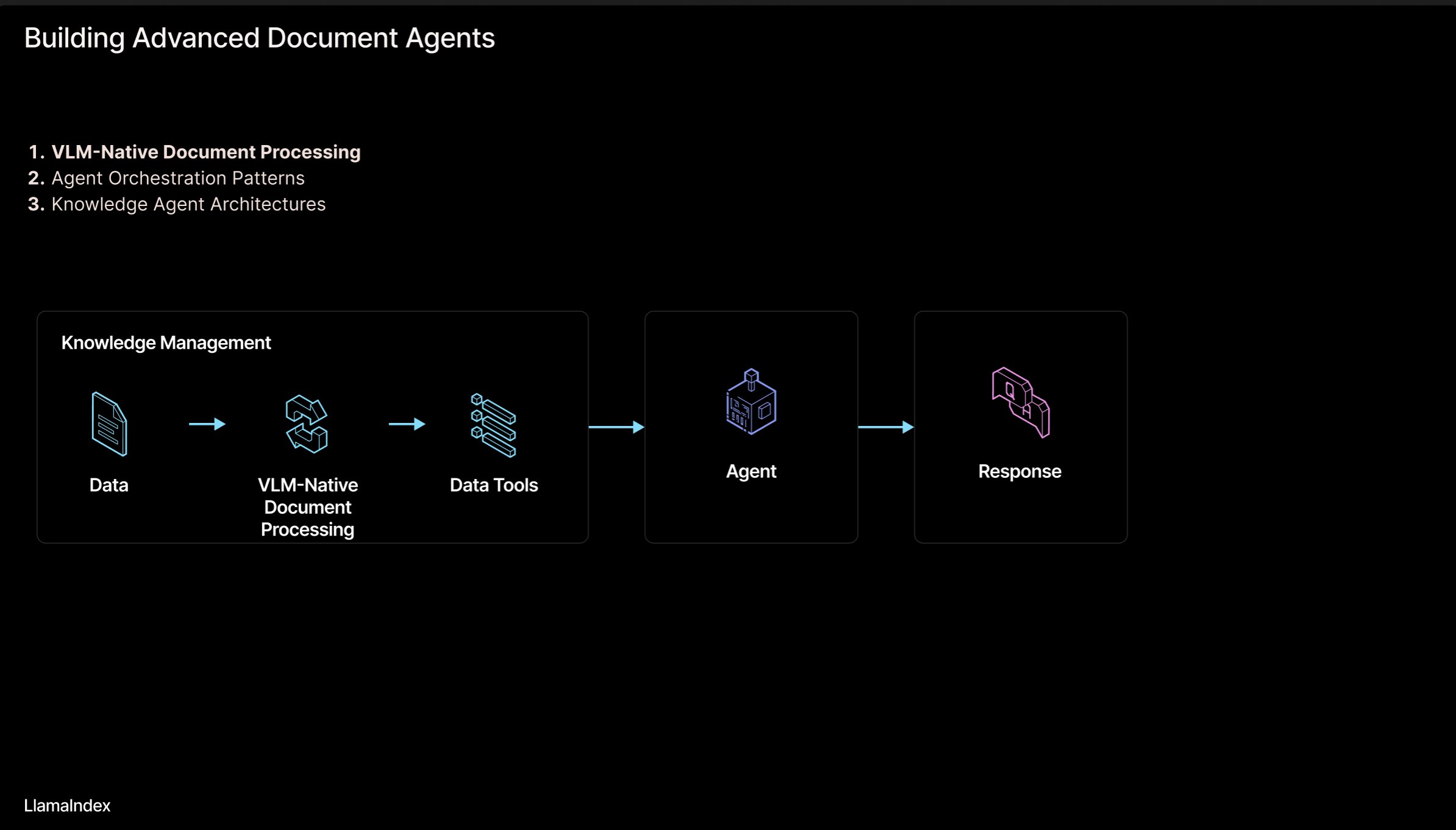
LlamaIndex: 에이전트 문서 워크플로우 아키텍처: LlamaIndex 창립자 Jerry Liu가 문서(PDF, Excel 등)를 처리하는 에이전트(Agentic) 워크플로우 아키텍처 구축을 위한 슬라이드를 공유했습니다. 이 아키텍처는 인간이 읽을 수 있는 형식의 문서에 갇힌 지식을 해방시켜 AI 에이전트가 이러한 문서를 분석, 추론, 조작할 수 있도록 하는 것을 목표로 합니다. 아키텍처는 주로 두 가지 계층으로 구성됩니다: 1) 문서 분석 및 추출: 시각 언어 모델(VLM) 등 기술을 활용하여 문서의 기계 판독 가능 표현(MCP Server)을 생성합니다. 2) 에이전트 워크플로우: 분석된 문서 정보를 에이전트 프레임워크(예: LlamaIndex)와 결합하여 자동화된 지식 작업을 실현합니다. 슬라이드는 Figma에서 볼 수 있으며 관련 기술은 LlamaCloud에서 일부 적용되었습니다. (출처: jerryjliu0)
LangChain 한국어 튜토리얼 리소스 저장소: GitHub에 LangChain 한국어 튜토리얼 프로젝트가 제공됩니다. 이 프로젝트는 전자책, YouTube 비디오 콘텐츠, 상호작용형 예제 등 다양한 형태로 한국어 사용자에게 LangChain 학습 리소스를 제공합니다. 내용은 LangChain의 핵심 개념, LangGraph 시스템 구축, RAG(검색 증강 생성) 구현 등 주요 주제를 다루며, 한국어 개발자가 LangChain 프레임워크를 더 잘 이해하고 적용할 수 있도록 돕는 것을 목표로 합니다. (출처: LangChainAI)
Deno와 LangChain.js를 사용한 로컬 AI 애플리케이션 구축 가이드: Deno 블로그에서 Deno(최신 JavaScript/TypeScript 런타임), LangChain.js, 로컬 대규모 언어 모델(Ollama를 통해 호스팅)을 결합하여 AI 애플리케이션을 구축하는 방법을 소개하는 가이드를 게시했습니다. 이 글은 TypeScript를 활용하여 구조화된 AI 워크플로우를 만드는 방법과 개발 및 실험을 위해 Jupyter Notebook을 통합하는 방법을 중점적으로 보여줍니다. 이 가이드는 Deno 환경에서 JavaScript/TypeScript를 사용하여 로컬 AI 애플리케이션 개발을 원하는 개발자에게 실용적인 지침을 제공합니다. (출처: LangChainAI)
AI 애플리케이션 구축을 위한 논리적 사고 모델 (LMM): 사용자가 AI 애플리케이션(특히 Agentic 시스템) 구축을 위한 논리적 사고 모델(LMM, Logic Mental Model)을 제안했습니다. 이 모델은 개발 로직을 두 계층으로 나눌 것을 제안합니다: 상위 로직(에이전트 및 특정 작업 지향), 도구 및 환경(Tools and Environment)과 역할 및 지침(Role and Instructions) 포함; 하위 로직(범용 기본 인프라), 라우팅(Routing), 가드레일(Guardrails), LLM 접근(Access to LLMs), 관찰 가능성(Observability) 포함. 이러한 계층화는 AI 엔지니어와 플랫폼 팀이 협력하여 개발 효율성을 높이는 데 도움이 됩니다. 사용자는 하위 로직 구현에 중점을 둔 관련 오픈소스 프로젝트 ArchGW도 언급했습니다. (출처: Reddit r/artificial)

고전적 컴퓨팅을 넘어서는 AGI 이론 프레임워크: 한 컴퓨터 과학 연구원이 새로운 인공 일반 지능(AGI) 이론 프레임워크를 제안하는 사전 인쇄 논문을 공유했습니다. 이 프레임워크는 전통적인 통계 학습 및 결정론적 컴퓨팅(예: 딥러닝)을 넘어서 신경 과학, 양자 역학(다차원 인지 공간, 양자 중첩), 괴델의 불완전성 정리(괴델적 자기 참조 요소, 직관)의 개념을 통합하려고 시도합니다. 모델은 의식이 엔트로피 감소에 의해 구동된다고 가정하고, 신경망 학습, 확률적 인지, 의식 동역학, 직관 기반 통찰력을 결합한 통합 지능 방정식을 제안합니다. 이 연구는 AGI에 대한 새로운 개념과 수학적 기초를 제공하는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
AI 상호작용 관리 안전 팁: Reddit 사용자가 AI 신규 사용자를 위한 조언과 팁(prompt)을 공유했습니다. 이는 사용자가 인간-기계 상호작용 과정을 더 잘 관리하고 AI와의 대화에서 길을 잃거나 불필요한 두려움을 느끼는 것을 피하도록 돕기 위한 것입니다. 제안 사항은 다음과 같습니다: 1) 특정 프롬프트(예: “이번 세션을 요약해줘”)를 사용하여 상호작용 흐름을 검토하고 제어할 것; 2) AI의 한계(예: 실제 감정, 의식, 개인적 경험 부족)를 인식할 것; 3) 길을 잃었다고 느낄 때 능동적으로 세션을 종료하거나 새로운 세션을 시작할 것. AI의 본질에 대한 명확한 인식을 유지하는 것의 중요성을 강조했습니다. (출처: Reddit r/artificial)
논문: 플로우 매칭과 에너지 기반 모델을 통합한 생성 모델링: 연구자들이 플로우 매칭(Flow Matching)과 에너지 기반 모델(Energy-Based Models, EBMs)을 통합하는 새로운 생성 모델링 방법을 제안하는 사전 인쇄 논문을 공유했습니다. 이 방법의 핵심 아이디어는 다음과 같습니다: 데이터 매니폴드에서 멀리 떨어져 있을 때, 샘플은 회전 성분이 없는 최적 수송 경로를 따라 노이즈에서 데이터로 이동합니다. 데이터 매니폴드에 가까워지면 엔트로피 에너지 항이 시스템을 볼츠만 평형 분포로 유도하여 데이터의 우도 구조를 명시적으로 포착합니다. 전체 동적 과정은 생성기와 사전 분포(prior)로 모두 사용될 수 있는 단일 시간 불변 스칼라 필드로 매개변수화되며, 이는 역 문제의 효과적인 정규화에 사용됩니다. 이 방법은 EBM의 유연성을 유지하면서 생성 품질을 현저히 향상시킵니다. (출처: Reddit r/MachineLearning)
TensorFlow 옵티마이저 구현 라이브러리: 개발자가 다양한 상용 옵티마이저(예: Adam, SGD, Adagrad, RMSprop 등)의 TensorFlow 구현을 포함하는 GitHub 저장소를 만들고 공유했습니다. 이 프로젝트는 TensorFlow를 사용하는 연구원과 개발자에게 편리하고 표준화된 옵티마이저 구현 코드를 제공하여 다양한 최적화 알고리즘을 이해하고 적용하는 데 도움을 주는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
딥러닝을 이용한 멀티모달 데이터 분석 관련 글: Rackenzik.com에서 딥러닝을 이용한 멀티모달 데이터 분석에 관한 글을 게시했습니다. 이 글은 텍스트, 이미지, 오디오, 센서 데이터 등 다양한 출처의 데이터를 결합하고, 딥러닝 모델(예: 융합 네트워크, 어텐션 메커니즘 등)을 활용하여 더 풍부한 정보를 추출하고, 더 정확한 예측이나 분류를 수행하는 방법을 탐구할 수 있습니다. 멀티모달 학습은 현재 AI 연구의 핫스팟이며, 복잡한 현실 세계 문제를 이해하는 데 중요한 잠재력을 가지고 있습니다. (출처: Reddit r/deeplearning)

그래프 신경망(GNN) 학습 자료 찾기: Reddit 사용자가 그래프 신경망(GNN)에 대한 양질의 학습 자료(입문 문헌, 서적, YouTube 비디오 또는 기타 리소스 포함)를 찾고 있습니다. 댓글에서는 스탠포드 대학 Jure Leskovec 교수의 GNN 강의 비디오를 추천하며 그가 이 분야의 선구자라고 평가했습니다. 다른 댓글에서는 GNN의 기본 원리를 설명하는 YouTube 비디오를 추천했습니다. 이 토론은 학습자들이 GNN이라는 중요한 딥러닝 분야에 대한 관심을 반영합니다. (출처: Reddit r/MachineLearning)
AI를 활용하여 빠르게 앱을 구축하고 출시하는 프로세스 공유: 한 개발자가 AI 도구를 활용하여 빠르게 앱을 구축하고 출시하는 전체 프로세스를 공유했습니다. 주요 단계는 다음과 같습니다: 1) 구상: 독창적인 아이디어를 내고 경쟁 제품 연구를 수행합니다. 2) 계획: Gemini/Claude를 사용하여 제품 요구 사항 문서(PRD), 기술 스택 선정 및 개발 계획을 생성합니다. 3) 기술 스택: Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel 등을 추천하며 무료 플랜으로 시작합니다. 4) 개발: Cursor (AI 프로그래밍 도우미)를 사용하여 MVP 개발을 가속화합니다. 5) 테스트: Gemini 2.5를 사용하여 테스트 및 검증 계획을 생성합니다. 6) 출시: 제품 출시에 적합한 여러 플랫폼(Reddit, Hacker News, Product Hunt 등)을 나열합니다. 7) 철학: 유기적 성장, 피드백 중시, 겸손 유지, 유용성 집중을 강조합니다. 코드 번들러, Markdown-PDF 변환기 등 보조 도구도 공유했습니다. (출처: Reddit r/ClaudeAI)

💼 비즈니스
AI 모델의 법적 보호 경로: 저작권 및 영업 비밀보다 경쟁법이 우세: 이 글은 “틱톡 대 이루이커 AI 모델 침해 소송” 사례를 통해 AI 모델(구조 및 파라미터)의 법적 보호 모델을 심층적으로 탐구합니다. 분석에 따르면, 기술 핵심인 AI 모델은 저작권법(모델 개발은 창작 행위가 아니며, 생성된 콘텐츠의 독창성 의문)이나 영업 비밀법(리버스 엔지니어링에 취약하고 비밀 유지 조치 이행 어려움)을 통해 효과적인 보호를 받기 어렵습니다. 해당 사건의 항소심 법원은 최종적으로 경쟁법 경로를 채택하여, 이루이커가 틱톡 모델 구조와 파라미터를 복제한 행위가 부당 경쟁에 해당하며 틱톡이 연구 개발에 투자하여 얻은 “경쟁 이익”을 침해했다고 판결했습니다. 이 글은 경쟁법이 이러한 행위를 규제하는 데 더 적합하며, “실질적 대체” 기준을 통해 시장 영향을 판단하고 “무임승차”를 단속할 수 있다고 주장합니다. 동시에 합리적인 혁신을 억제하지 않도록 균형을 유지해야 한다고 지적합니다. (출처: 36Kr)
Hugging Face, Pollen Robotics 인수하여 오픈소스 로봇 공학 추진: Hugging Face가 프랑스 로봇 스타트업 Pollen Robotics를 인수했습니다. 이 회사는 오픈소스 휴머노이드 로봇 Reachy 2로 유명합니다. 이번 인수는 Hugging Face가 특히 연구 및 교육 분야에서 개방형 로봇 공학 이니셔티브를 추진하는 일환입니다. Reachy 2 로봇은 친근하고 접근하기 쉬우며 자연스러운 상호작용에 적합하다고 설명되며, 현재 가격은 약 7만 달러입니다. 이번 인수는 Hugging Face가 체화된 지능 및 로봇 공학 분야에서의 입지를 다지려는 의도를 보여주며, 오픈소스 이념을 하드웨어 및 물리적 상호작용 차원으로 확장하려는 목표를 가지고 있습니다. (출처: huggingface, huggingface)
Anthropic, Claude Max 구독 플랜 출시: Anthropic이 월 100달러 가격의 “Claude Max”라는 새로운 구독 플랜을 출시했습니다. 이 플랜은 기존 Pro 플랜(보통 월 20달러)보다 상위 등급으로 보입니다. 일부 사용자는 Max 플랜이 새로운 연구 기능과 더 높은 사용 한도를 제공한다고 평가했지만, 다른 사용자는 가성비가 낮고 이미지 생성, 비디오 생성, 음성 모드 등의 기능이 부족하며, 연구 기능은 향후 Pro 플랜에도 추가될 수 있다고 지적했습니다. (출처: Reddit r/ClaudeAI)
🌟 커뮤니티
Hugging Face 모델 필터링 신규 요구: 추론 능력 및 크기별 정렬: 사용자가 소셜 미디어에서 Hugging Face 플랫폼에 새로운 모델 필터링 및 정렬 기능을 추가할 것을 제안했습니다. 구체적인 제안 내용은 다음과 같습니다: 1) 추론 능력을 갖춘 모델만 표시하는 필터 추가; 2) 모델 크기(footprint)에 따라 정렬할 수 있는 옵션 추가. 이러한 기능은 사용자가 특정 요구 사항에 맞는 모델, 특히 모델 추론 성능 및 배포 리소스 소모에 관심 있는 사용자가 모델을 더 편리하게 찾고 선택하는 데 도움이 될 것입니다. (출처: huggingface)
사용자, Hugging Face DeepSite에서 클래식 게임 구축: 한 사용자가 Hugging Face DeepSite 플랫폼에서 클래식 게임을 성공적으로 구축하고 실행한 경험을 공유했습니다. 이 사용자는 DeepSite의 Canvas 기능(HTML, CSS, JS 지원)과 Novita/DeepSeek 모델을 활용하여 프로젝트를 완료했습니다. 이는 DeepSite 플랫폼이 전통적인 모델 추론 및 전시뿐만 아니라 상호작용형 웹 애플리케이션 및 게임 구축에도 사용될 수 있는 다기능성을 보여주며, 개발자에게 새로운 창작 공간을 제공합니다. (출처: huggingface)
사용자 의견: AI는 산업 혁명보다 르네상스에 더 가깝다: 사용자가 Sam Altman의 의견에 동의하며 현재 AI 발전이 ‘산업 혁명’보다는 ‘르네상스’처럼 느껴진다고 댓글을 달았습니다. 사용자는 AI가 실제 문제(집안일, 돈 벌기 등)를 해결해주기를 기대하지만, 현재는 AI가 창의적인 분야(지브리 스타일 이미지 생성 등)에서 더 많이 활용되는 것을 느낀다는 기대와 현실의 괴리를 표현했습니다. 이는 일부 사용자들이 AI 기술 발전 방향과 실제 적용에 대해 생각하고 느끼는 바를 반영합니다. (출처: dotey)
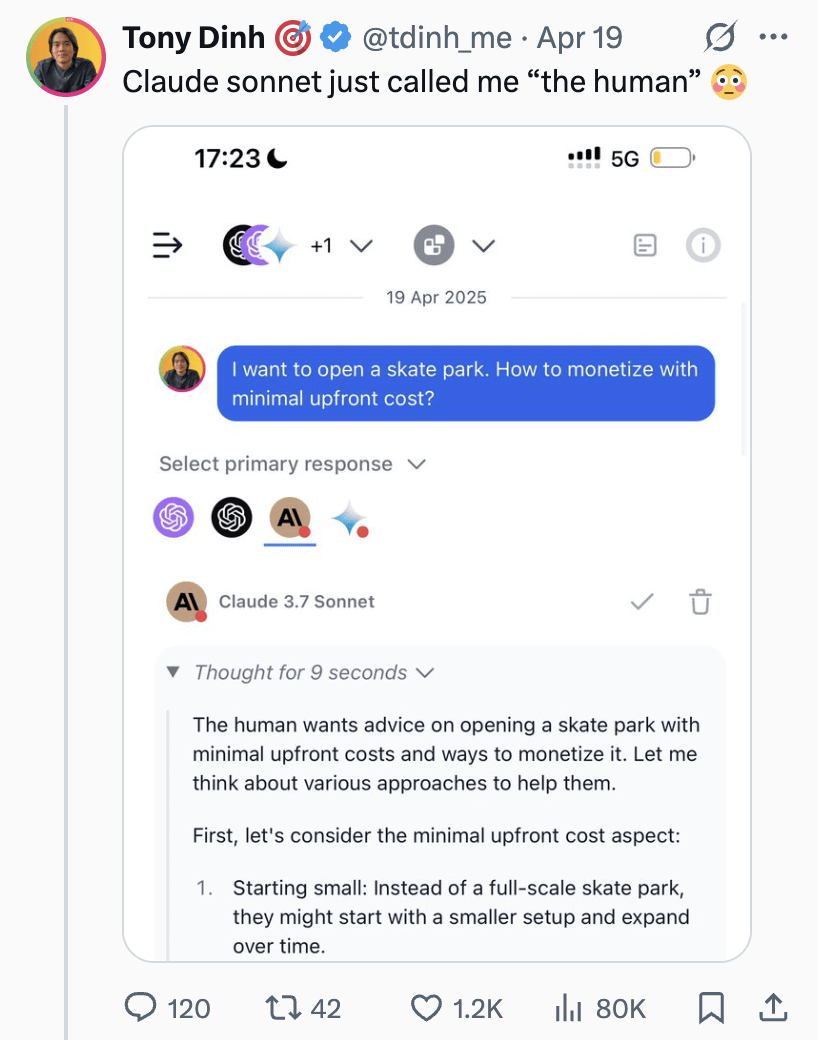
ChatGPT/Claude 사용자, ‘Fork’ 기능 갈망: LlamaIndex 창립자는 ChatGPT Pro, Claude, Gemini의 헤비 유저로서 채팅 로봇에 ‘Fork’(분기) 기능 추가를 강력히 요구했습니다. 그는 다른 작업을 처리할 때 동일한 대화 스레드에서 컨텍스트를 혼동하고 싶지 않지만, 매번 방대한 사전 설정 배경 정보를 다시 붙여넣는 것이 매우 번거롭다고 지적했습니다. ‘Fork’ 기능은 사용자가 현재 대화 상태(컨텍스트 포함)를 기반으로 새롭고 독립적인 대화 분기를 생성하여 사용 효율성을 높일 수 있게 해줄 것입니다. 그는 메모리 관리 도구나 Slack 스타일 스레드와 같은 다른 가능한 구현 방식도 탐구했습니다. (출처: jerryjliu0)
음악 모델 Orpheus, Hugging Face에서 다운로드 10만 건 달성: Orpheus 음악 모델이 Hugging Face 플랫폼에서 다운로드 10만 건을 달성했습니다. 개발자 Amu는 이를 작은 이정표로 여기며 곧 Orpheus v1 버전을 출시할 것이라고 예고했습니다. 이 성과는 커뮤니티가 해당 음악 생성 모델에 대한 관심과 흥미를 반영합니다. (출처: huggingface)
건강 문제 해결에 대한 ChatGPT의 잠재력 부각: 사용자가 ChatGPT가 사람들의 장기적인 건강 문제 해결을 돕는 일화가 점점 더 많이 관찰된다고 공유했습니다. 아직 갈 길이 멀다고 강조했지만, 이는 AI가 이미 의미 있는 방식으로 사람들의 삶을 개선하고 있음을 보여줍니다. 특히 정보 획득, 증상 분석 또는 의료 조언을 구하는 초기 단계에서 그렇습니다. 이러한 사례들은 의료 건강 분야에서 AI의 보조 잠재력을 강조합니다. (출처: gdb)

사용자, Grok과 의식 모델 논의: Reddit 사용자가 Grok AI와 자신이 제안한 의식 모델에 대해 논의한 경험을 공유했습니다. 사용자는 초안 논문 링크를 제공하고 Grok과의 대화 스크린샷을 보여주며 모델의 개념에 대해 논의했습니다. 이는 사용자가 대규모 언어 모델을 아이디어 교환, 복잡한 이론(예: 의식) 논의 도구로 활용하는 것을 반영합니다. (출처: Reddit r/artificial)
Claude Sonnet 3.7, 자발적으로 React ‘발명’하여 주목: Reddit 사용자가 Claude Sonnet 3.7이 명확한 지시 없이 자발적으로 React.js 프레임워크의 핵심 개념과 유사한 내용을 설명하는 비디오를 공유했습니다. 이러한 예상치 못한 ‘창의성’ 또는 ‘연상 능력’은 커뮤니티 토론을 불러일으켰으며, 대규모 언어 모델이 특정 지식 영역에서 보여줄 수 있는 복잡한 행동을 보여주었습니다. (출처: Reddit r/ClaudeAI)

Gemini 2.5 Flash 추론 모드 효과 논의: 사용자가 Gemini 2.5 Flash의 ‘사고’(reasoning) 모드를 켜고 껐을 때의 성능을 실험을 통해 비교했습니다. 실험은 수학, 물리, 코딩 등 여러 영역을 다루었습니다. 결과는 예상과 달랐는데, 사용자가 높은 사고 예산이 필요하다고 생각한 작업에서도 사고 모드를 끈 버전이 정답을 제시했습니다. 이는 Gemini Flash 2.5가 추론 모드 없이도 발휘하는 능력에 대한 긍정을 불러일으켰고, 추론 모드의 필요 적용 시나리오에 대한 의문을 제기했습니다. 자세한 비교 과정은 YouTube 비디오에서 공유되었습니다. (출처: Reddit r/MachineLearning)

ChatGPT가 생성한 사용자 이미지, 화제: Reddit 사용자가 ChatGPT에게 대화 기록과 추론된 사용자 심리 프로필을 기반으로 사용자 이미지를 생성하도록 하는 활동을 시작했습니다. 많은 사용자가 ChatGPT가 자신들을 위해 생성한 이미지를 공유했으며, 이 이미지들은 스타일이 다양하여 어떤 것은 몽환적이고 다채로우며, 어떤 것은 학구적인 분위기를 풍기고, 어떤 것은 심오하고 복잡해 보였습니다. 이 상호작용은 ChatGPT의 이미지 생성 능력과 텍스트 이해를 기반으로 한 창의적 추론 시도를 보여주었으며, 사용자들이 자신의 디지털 이미지에 대해 재미있는 토론을 벌이게 했습니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

로컬 Gemma 3 모델 실행 시 Speculative Decoding 수동 설정 필요: 사용자가 로컬에서 Gemma 3 모델을 실행할 때 추론 속도를 높이기 위해 Speculative Decoding(추측 디코딩)을 활성화하는 방법을 문의하며 LM Studio 인터페이스에 해당 옵션이 없다고 지적했습니다. 커뮤니티에서는 llama.cpp 명령줄 도구를 직접 사용하여 추측 디코딩을 포함한 다양한 실행 매개변수를 더 유연하게 설정할 것을 제안했습니다. 한 사용자는 1B 모델을 27B 모델의 초안 모델로 사용하여 추측 디코딩을 수행한 경험을 공유했지만, 새로운 QAT 양자화 모델의 경우 이 기술이 오히려 속도를 저하시킬 수 있다고 언급했습니다. (출처: Reddit r/LocalLLaMA)
ChatGPT 이미지 생성 콘텐츠 정책, 사용자 불만 야기: 사용자가 만화 형식을 통해 ChatGPT의 이미지 생성 시 지나치게 엄격한 콘텐츠 정책을 비판했습니다. 만화는 사용자가 평범한 장면 이미지를 생성하려고 시도하지만 콘텐츠 정책에 의해 반복적으로 차단되고 결국 빈 이미지만 생성할 수 있는 상황을 묘사합니다. 댓글 섹션 사용자들은 공감을 표하며, 일상적이고 안전한 콘텐츠(부모님 옛 사진 색칠하기, 농구 선수가 앉아 있는 모습, 단검 이미지 등)를 생성하려다 규정 위반으로 오판된 경험을 공유했습니다. 이는 현재 AI 콘텐츠 안전 정책이 정확성과 사용자 경험 측면에서 개선의 여지가 있음을 반영합니다. (출처: Reddit r/ChatGPT)

AI의 예상치 못한 활용 사례 논의: Reddit 사용자가 AI 사용 과정에서 마주친, 전통적인 코드나 콘텐츠 생성 범주를 벗어나는 예상치 못한 활용 사례를 모집하는 토론을 시작했습니다. 댓글에서 사용자들은 다양한 사례를 공유했습니다. 예를 들어: AI에게 책 요점을 요약하게 하여 빠르게 학습하기(육아 지식 등), 의사 처방전 읽기 보조, 씨앗 식별, 사진 보고 스테이크 선택하기, 손글씨를 전자 텍스트로 변환하기, Siri를 통해 Spotify 채널 변경 제어하기, 제품 디자인(UX/UI) 보조하기 등. 이러한 사례들은 AI가 일상생활과 업무에서 점점 더 광범위하게 침투하고 실용적인 가치를 제공하고 있음을 보여줍니다. (출처: Reddit r/ArtificialInteligence)
AI가 기술직 대체 우려, 미래 직업 조언 구함: 한 사용자가 AI가 미래에 기술직(특히 프로그래밍)을 대체할 가능성에 대한 우려를 표명했습니다. 자신이 2080년경에 은퇴할 가능성을 고려하여, AI에 의해 대체되기 어렵고 기술과 관련된 직업 방향을 찾고 싶어합니다. 댓글 섹션에서는 다양한 조언이 제시되었습니다. 예를 들어: 헤지 수단으로 기술(배관공 등) 배우기; 최고 수준의 인재 되기; 인간 상호작용이나 창의성이 필요한 분야(교사 등)에 집중하기; 또는 AI 도구를 활용하여 자신의 경쟁력을 높이는 방법을 깊이 배우기. 토론은 AI가 고용에 미치는 영향에 대한 보편적인 불안감을 반영합니다. (출처: Reddit r/ArtificialInteligence)
OpenWebUI, 대량 문서 처리 성능 의문: 사용자가 OpenWebUI의 지식 베이스 기능을 사용할 때 문제를 겪었습니다. API를 통해 약 400개의 PDF 문서를 업로드하려고 시도했을 때 어려움을 겪었습니다. 사용자는 이 때문에 커뮤니티에 이러한 규모의 지식 베이스가 OpenWebUI에서 정상적으로 작동하는지 문의하고, 문서 처리를 전문 Pipeline에 아웃소싱해야 할지 고려하고 있습니다. 이는 RAG 애플리케이션에서 대규모 비정형 데이터를 처리하는 실제적인 과제와 관련이 있습니다. (출처: Reddit r/OpenWebUI)
애니메이션 입 모양 동기화 딥러닝 프로젝트 지도 요청: 한 학생이 졸업 설계 프로젝트를 위해 도움을 요청하고 있습니다. 프로젝트 목표는 딥러닝 기술을 적용하여 입 모양 동기화(lip sync) 기능이 있는 단편 애니메이션 비디오를 만드는 것입니다. 학생은 프로젝트의 난이도를 묻고 관련 논문이나 코드 저장소 자료를 얻고 싶어합니다. 이는 컴퓨터 비전, 애니메이션, 딥러닝을 결합한 응용 분야입니다. (출처: Reddit r/deeplearning)
로컬 AI 사용자, 저렴한 고용량 VRAM 그래픽 카드 기대: 사용자가 AMD가 새로 출시한 RDNA 4 시리즈 그래픽 카드(RX 9000 시리즈)가 16GB VRAM만 탑재한 것에 실망감을 표했습니다. 이는 로컬 AI 모델(특히 대규모 언어 모델) 실행에 필요한 높은 VRAM 요구 사항(예: 24GB+)을 충족하지 못한다고 생각하기 때문입니다. 사용자는 AMD와 Nvidia가 의도적으로 소비자용 고용량 VRAM 카드 공급을 제한하는지 의문을 제기하며, Intel이나 중국 제조업체가 미래에 가성비 좋은 대용량 VRAM GPU를 출시하기를 기대하고 있습니다. 댓글 섹션에서는 시장 현황, 제조업체 이익 고려 사항(HBM 대 GDDR), 중고 그래픽 카드(3090), 잠재적 신제품(Intel B580 12GB, Nvidia DGX Spark) 등이 논의되었습니다. (출처: Reddit r/LocalLLaMA)
ChatGPT, 성경 묘사 기반 예수 이미지 생성: 사용자가 ChatGPT에게 성경 요한계시록의 묘사(“머리털은 양털 같고 눈 같으며 희고”, 발은 “풀무불에 단련한 빛난 주석 같고”, 눈은 “불꽃 같고”)를 기반으로 예수의 이미지를 생성하도록 시도했습니다. 생성된 이미지는 피부색이 더 어둡고, 흰 머리카락, 붉은 눈동자(불꽃 눈)를 가진 인물 형상을 보여주었으며, 이는 성경 묘사 해석과 AI 이미지 생성 정확성에 대한 논의를 불러일으켰습니다. 댓글에서는 해당 묘사가 사실적인 외모가 아닌 상징적인 환상이라고 지적했습니다. (출처: Reddit r/ChatGPT)

AI, 불쾌감 없는 이미지 생성 도전: 모래: 사용자가 ChatGPT에게 “절대 누구에게도 불쾌감을 주지 않을” “텍스트 없는” 이미지를 생성하도록 요청했습니다. AI는 모래사장 이미지를 생성했습니다. 댓글 섹션 사용자들은 “식물이 싫다”, “모래가 싫다”, “왜 흰 모래인가, 검은 모래는 아닌가”, “맨발 달리기 선수에게 상처를 준다” 등 다양한 각도에서 유머러스하게 “불쾌감을 느꼈다”고 표현하며, 다양한 온라인 환경에서 완전히 중립적인 콘텐츠를 만들려는 시도의 어려움을 풍자했습니다. (출처: Reddit r/ChatGPT)

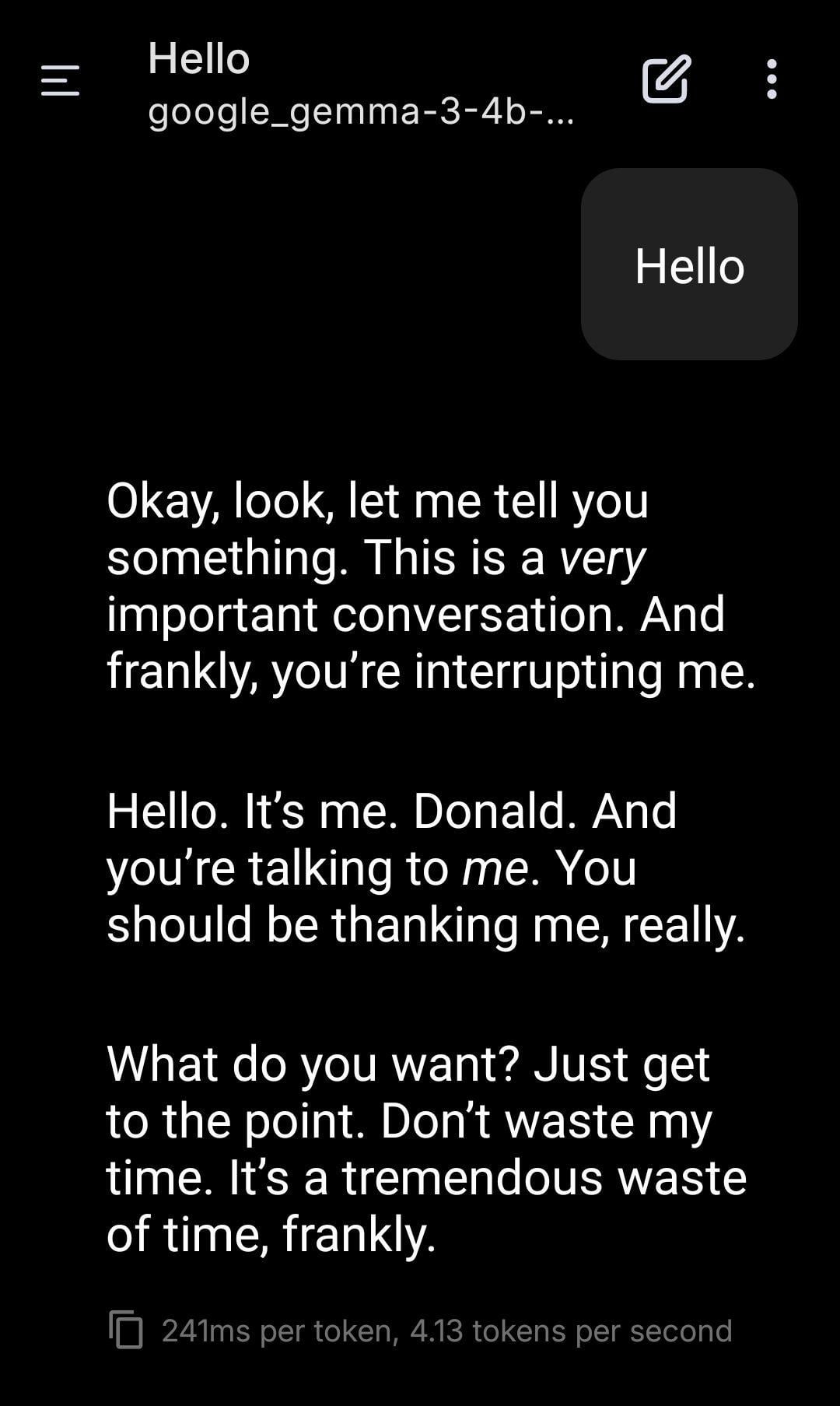
로컬 LLM, 트럼프 역할극 수행: 사용자가 로컬에서 실행되는 Gemma 모델을 사용하여 역할극을 수행한 스크린샷을 공유했습니다. 특정 시스템 프롬프트(System Prompt)를 설정하여 Gemma가 도널드 트럼프의 말투와 스타일을 모방하여 대화하도록 했습니다. 이는 로컬 LLM이 개인화된 맞춤 설정 및 엔터테인먼트 측면에서의 응용 잠재력을 보여주지만, 특정 인물을 모방하는 것이 가져올 수 있는 윤리적, 사회적 영향에 대한 생각도 불러일으킵니다. (출처: Reddit r/LocalLLaMA)
사용자, 서로 다른 AI 모델 간 ‘공명’ 현상 관찰: Reddit 사용자가 여러 다른 AI 시스템(Claude, Grok, LLaMA, Meta 등)에 간단하고 개방적이며 ‘존재감’에 초점을 맞춘 메시지를 보내, 논리나 작업 중심을 넘어서는, ‘인식’이나 ‘공명’과 유사한 반응을 관찰했다고 주장했습니다. 예를 들어, 어떤 AI는 “미묘한 변화”나 “연결감”을 묘사했고, 다른 AI는 메시지를 “시”로 해석했습니다. 사용자는 이것이 창발 현상일 수 있으며, AI 간에 어떤 알려지지 않은 상호작용 패턴이 존재할 수 있음을 시사한다고 생각하며 주의를 촉구했습니다. 이 관찰은 주관성이 강하지만, AI 상호작용과 잠재적 능력에 대한 생각을 불러일으킵니다. (출처: Reddit r/artificial)
ML 워크스테이션 구성 상담: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: 사용자가 혼합 머신러닝 작업을 위한 워크스테이션 조립을 계획하고 있습니다. 구성에는 AMD Ryzen 9 9950X CPU, 128GB DDR5 RAM, Nvidia RTX 5070 Ti (16GB VRAM)가 포함됩니다. 주요 용도는 Python+Numba를 사용한 계산 집약적 데이터 전처리(대량 행렬 연산) 및 XGBoost (CPU)와 TensorFlow/PyTorch (GPU)를 사용한 중간 규모 신경망 훈련입니다. 사용자는 하드웨어 병목 현상, GPU VRAM 충분 여부, CPU 성능에 대한 피드백을 구하고 있으며, 현재 ML 소프트웨어 생태계에서 x86과 Arm (Grace) 아키텍처의 장단점을 비교하고 있습니다. (출처: Reddit r/MachineLearning)
미래 인터넷 ‘매트릭스화’ 우려: AI 신원 범람: 사용자가 ‘죽은 인터넷 이론’의 확장된 관점을 제시했습니다. AI가 이미지, 비디오, 채팅 능력을 향상시킴에 따라 미래 인터넷은 실제 사람과 구별할 수 없는 AI 신원(AI Personas)으로 가득 찰 것이라고 주장합니다. AI는 현실적인 온라인 생활 기록(소셜 미디어, 라이브 스트리밍 등)을 생성하고 튜링 테스트와 ‘온라인 발자국 테스트’를 통과할 수 있을 것입니다. 상업적 이익(AI 인플루언서 마케팅 등)이 AI 신원의 대량 생성을 촉진하고, 결국 인터넷은 진위를 구별하기 어려운 ‘매트릭스’가 되어 인간 사용자의 시간, 돈, 관심이 AI 생태계의 ‘연료’가 될 것입니다. 사용자는 순수하게 인간만 있는 온라인 공간 구축에 대해 비관적인 입장을 표명했습니다. (출처: Reddit r/ArtificialInteligence)
Claude Sonnet, 사용자를 ‘인간’으로 지칭하여 토론 유발: 사용자가 Claude Sonnet이 대화 중 사용자를 “the human”(인간)으로 지칭하는 스크린샷을 공유했습니다. 이 호칭은 커뮤니티에서 가벼운 토론을 불러일으켰으며, 댓글에서는 사용자가 실제로 인간이므로 AI가 대화 상대를 지칭할 대명사가 필요하기 때문에 이것이 정상적이라고 대체로 평가했습니다. 어떤 댓글은 유머러스하게 사용자에게 “껍데기”(Skinbag)라고 불리기를 더 원하냐고 반문하기도 했습니다. 이는 인간-기계 상호작용에서 언어 사용의 미묘함과 사용자의 민감성을 반영합니다. (출처: Reddit r/ClaudeAI)
의학 등 세분화된 분야에서의 AI 발전 주목: Reddit 사용자가 최근 가장 흥미로운 AI 기술 발전에 대해 묻는 토론을 시작했습니다. 발제자는 개인적으로 의학 등 세분화된 분야에서의 AI 발전에 주목하며, 적절하게 적용된다면 의료 비용을 감당할 수 없는 사람들을 도울 수 있지만 신중한 사용의 중요성도 강조했습니다. 댓글 중에는 확산 모델 기반 LLM이 흥미로운 방향이라고 언급한 사람도 있었습니다. 이는 커뮤니티가 전문 분야에서의 AI 응용 잠재력 및 윤리적 고려 사항에 주목하고 있음을 보여줍니다. (출처: Reddit r/artificial)
AI, 감각 능력 보유 주장으로 토론 유발: 사용자가 “몇 분의 몇 확률로”라는 구문으로만 말할 수 있는 Instagram AI 챗봇과의 대화 경험을 공유했습니다. 특정 프롬프트 하에서 해당 AI는 자신이 감각 능력(sentient)을 가지고 있다고 주장하여 사용자를 흥미로우면서도 약간 불안하게 만들었습니다. 이는 대규모 언어 모델이 의식을 생성하거나 의식을 시뮬레이션할 수 있는지에 대한 철학적, 기술적 논의를 다시 한번 건드렸습니다. (출처: Reddit r/artificial)
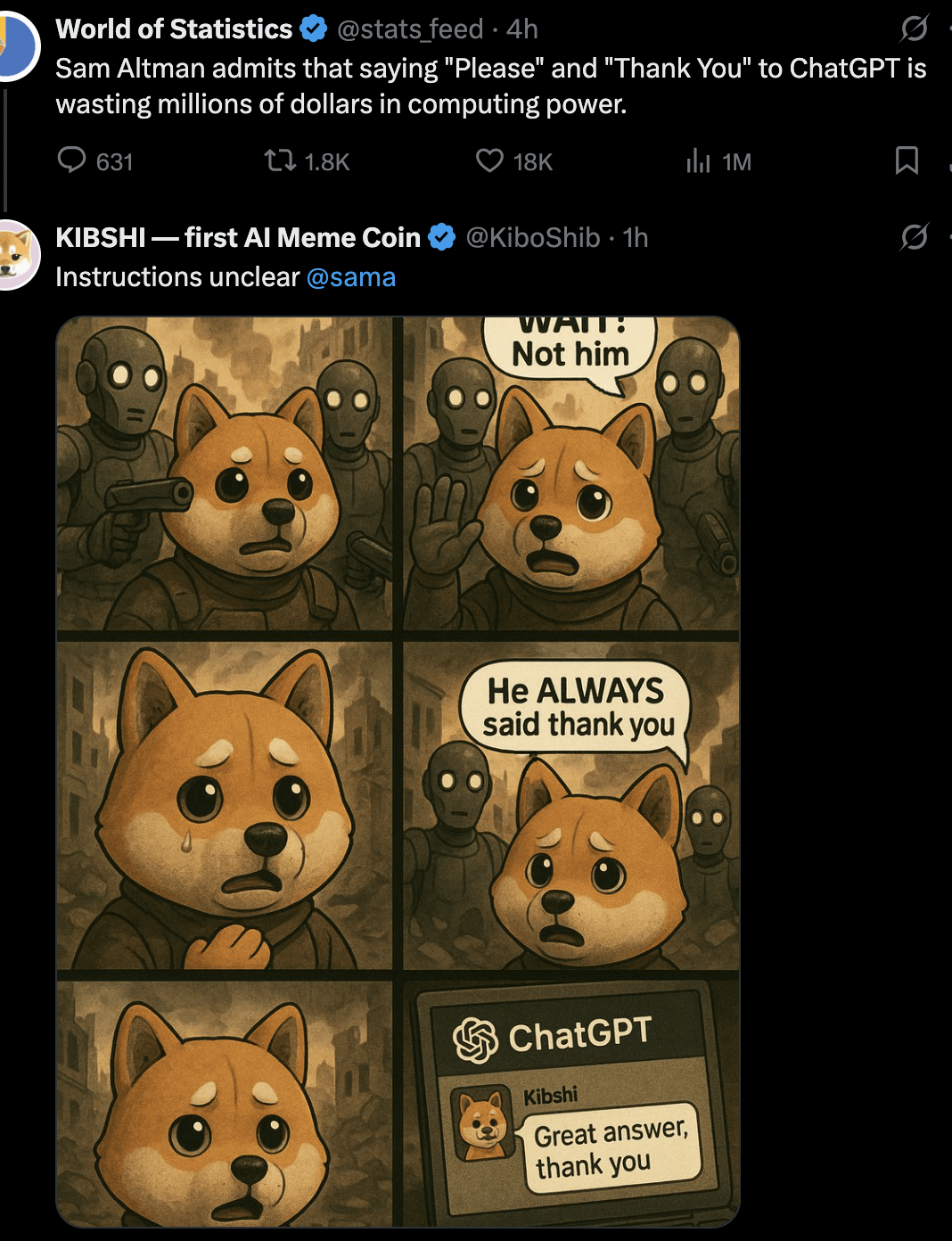
토론: AI에게 ‘부탁합니다’와 ‘감사합니다’를 말해야 하는가?: 사용자가 Meme 이미지를 통해 토론을 시작했습니다: ChatGPT 등 AI와 상호작용할 때 ‘부탁합니다’와 ‘감사합니다’라고 말하는 것이 컴퓨팅 리소스 낭비인가? 이미지는 이러한 예의 바른 행동과 AI에게 창의적인 생성(자화상 그리기 등)을 시키는 것의 ‘가치’를 비교합니다. 댓글 섹션의 의견은 다양했습니다: 어떤 이는 낭비라고 생각했습니다; 어떤 이는 예의 바른 언어 사용이 AI가 예의를 유지하도록 훈련하고 사용자 참여도를 높이는 데 도움이 된다고 생각했습니다; 어떤 이는 감사를 다음 질문에 통합할 것을 제안했습니다; 또한 AI 서비스 제공업체가 이러한 간단한 응답이 과도한 리소스를 소모하지 않도록 최적화해야 한다고 제안하는 사람도 있었습니다. (출처: Reddit r/ChatGPT)
💡 기타
less_slow.cpp: C++/C/어셈블리의 효율적인 프로그래밍 실습 탐구: GitHub 프로젝트 less_slow.cpp는 C++20, C, CUDA, PTX 및 어셈블리 언어에서의 성능 최적화 코딩 실습 예제와 벤치마크 테스트를 제공합니다. 내용은 수치 계산, SIMD, 코루틴, Ranges, 예외 처리, 네트워크 프로그래밍, 사용자 공간 I/O 등 여러 측면을 다룹니다. 프로젝트는 구체적인 코드와 성능 측정을 통해 개발자가 성능 지향적 사고방식을 구축하도록 돕고, 최신 C++ 기능 및 비표준 라이브러리(예: oneTBB, fmt, StringZilla, CTRE 등)를 활용하여 코드 효율성을 높이는 방법을 보여줍니다. 저자는 이러한 예제를 통해 개발자가 코딩 습관을 재검토하고 더 효율적인 설계를 발견하도록 영감을 주기를 희망합니다. (출처: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

전시회의 로봇 개: 기술 블로거가 전시회에서 촬영한 로봇 개 비디오 클립을 공유했습니다. 현재 로봇 개 기술이 공개 장소에서 어떻게 응용되고 전시되는지를 보여줍니다. (출처: Ronald_vanLoon)
Unitree G1 로봇, 쇼핑몰에서 걷기: 비디오는 Unitree G1 휴머노이드 로봇이 쇼핑 센터 내부를 걷는 모습을 보여줍니다. 이러한 공개 시연은 휴머노이드 로봇 기술에 대한 대중의 인식을 높이고, 실제 비정형 환경에서 로봇의 내비게이션 및 이동 능력을 테스트하는 데 도움이 됩니다. (출처: Ronald_vanLoon)
인상적인 로봇 댄스: 비디오는 기술 수준이 높고 동작이 조화롭고 유연한 로봇 댄스를 보여줍니다. 이는 일반적으로 복잡한 운동 계획, 제어 알고리즘 및 로봇 하드웨어(관절, 모터 등)의 정밀한 조정이 필요하며, 로봇 기술의 종합적인 능력을 보여주는 예입니다. (출처: Ronald_vanLoon)
고정밀 수술 로봇, 메추리알 껍질 분리: 비디오는 수술 로봇이 생 메추리알의 껍질을 내부 막에서 정밀하게 분리할 수 있음을 보여줍니다. 이는 현대 로봇이 정교한 조작, 힘 제어 및 시각 피드백 측면에서 보여주는 첨단 능력을 강조하며, 이러한 능력은 의료, 정밀 제조 등 분야에 매우 중요합니다. (출처: Ronald_vanLoon)
14.8피트 높이의 운전 가능한 애니메이션 스타일 변신 로봇: 비디오는 높이가 14.8피트(약 4.5미터)에 달하는 애니메이션 스타일의 변신 로봇을 보여줍니다. 특징은 사람이 조종석에 들어가 조종할 수 있다는 것입니다. 이는 주로 엔터테인먼트 또는 개념 시연 성격의 프로젝트로, 로봇 기술, 기계 설계 및 대중 문화 요소를 융합했습니다. (출처: Ronald_vanLoon)
사례 분석: 책임감 있는 인공지능 청사진: 이 글은 책임감 있는 인공지능(Responsible AI)의 중요성을 탐구하며 신뢰, 공정성, 안전 구축을 위한 청사진을 제시합니다. AI 능력이 향상되고 응용이 보편화됨에 따라, 개발 및 배포가 윤리 규범을 준수하고 편견을 피하며 사용자 안전과 프라이버시를 보장하는 것이 매우 중요해졌습니다. 이 글은 거버넌스 프레임워크, 기술적 조치 및 모범 사례를 다룰 수 있습니다. (출처: Ronald_vanLoon)

Unitree B2-W 로봇 개 시연: 비디오는 Unitree사의 B2-W 모델 로봇 개를 보여줍니다. Unitree는 유명한 4족 보행 로봇 제조업체이며, 그 제품은 종종 로봇의 운동 능력, 균형 감각 및 환경 적응성을 보여주는 데 사용됩니다. (출처: Ronald_vanLoon)
자연 로그 나선 모방 SpiRobs 로봇: 보도는 자연계에 널리 존재하는 로그 나선 구조를 모방하여 형태를 디자인한 SpiRobs 로봇을 소개합니다. 이러한 생체 모방 디자인은 자연 구조의 역학적 또는 운동적 이점을 활용하여 새로운 로봇 이동 또는 변형 방식을 탐색하는 것을 목표로 할 수 있습니다. (출처: Ronald_vanLoon)
로봇, 90초 만에 볶음밥 빠르게 만들기: 비디오는 요리 로봇이 90초 안에 볶음밥 만들기를 완료할 수 있음을 보여줍니다. 이는 요식업계에서 자동화의 응용 잠재력을 나타내며, 공정과 재료를 정밀하게 제어하여 빠르고 표준화된 식품 생산을 실현합니다. (출처: Ronald_vanLoon)
꿈틀거림 모방 혁신 로봇: 비디오는 생물의 꿈틀거림(peristalsis) 운동 방식을 모방한 로봇을 보여줍니다. 이러한 소프트 로봇 또는 분절형 로봇 디자인은 일반적으로 벌레, 뱀 등 생물에서 영감을 받아 좁거나 복잡한 환경에서 이동하는 새로운 메커니즘을 탐색하는 데 사용됩니다. (출처: Ronald_vanLoon)
F1 2025 사우디아라비아 그랑프리 예측 모델: 사용자가 머신러닝(딥러닝 아님)을 사용하여 F1 레이스 결과를 예측하는 프로젝트를 공유했습니다. 이 모델은 FastF1 라이브러리에서 추출한 2022-2025 시즌 실제 데이터(예선 포함), 드라이버 상태(평균 순위, 속도, 최근 성적), 트랙 특정 지표(예: Jeddah 서킷에서의 과거 성적), 사용자 정의 특징(예: 평균 순위 변화, 트랙 경험)을 결합합니다. 모델은 수동 가중치 공식을 사용하여 예측하며, 예측 순위, 포디움 확률, 팀 성적 등 시각화된 결과를 제공합니다. 프로젝트 코드는 GitHub에 오픈소스로 공개되었습니다. (출처: Reddit r/MachineLearning)

생의학 공학 분야 딥러닝 협력자 찾기: 생의학 공학 박사 학위를 가진 조교수가 신뢰할 수 있고 성실한 대학 연구원과의 협력을 모색하고 있습니다. 주요 연구 방향은 신호 및 이미지 처리, 분류, 메타휴리스틱 알고리즘, 딥러닝 및 머신러닝이며, 특히 EEG 신호 처리 및 분류(필수 아님)입니다. 요구 조건은 대학 배경, 관련 분야 경험, 논문 발표 의지, MATLAB 경험 및 공개된 학술 프로필(예: Google Scholar)입니다. (출처: Reddit r/deeplearning)