
키워드:AGI, AI 윤리, 머신러닝, 자연어 처리, AGI 훈련 데이터, AI 윤리 딜레마, TinyML 기술, 자연어 데스크톱 제어, LLM 양자화 방법, RAG 환각 검출, 에지 AI 혁명, AI 칩 설계
🔥 聚焦 (포커스)
AGI 훈련 데이터 논란: ‘날것의’ 인간 경험이 필요한가?: Reddit의 한 게시물이 현재 ‘정제된’ 데이터에 의존하는 AI 훈련 방식으로는 진정한 AGI를 달성할 수 없다고 주장하며 격렬한 토론을 촉발했습니다. 작성자는 AI에게 진정한 인간적 이해와 직관을 부여하기 위해 사적이고 부정적이며 심지어 불쾌한 장면을 포함하여 더 ‘날것의’, 필터링되지 않은 체화된 인간 경험 데이터를 수집하고 활용해야 한다고 주장합니다. 이 관점은 기존 데이터 수집 윤리 및 기술 경로에 도전하며, 실제 삶을 기록하기 위한 ‘Raw Sensorium Project’의 시작을 촉구하는 동시에 정보에 입각한 동의 및 데이터 주권과 같은 윤리적 문제를 강조합니다. (출처: Reddit r/artificial)
스타트업의 ‘모든 인간 노동자 대체’ 목표 우려 증폭: 유명 AI 연구원(Ilya Sutskever로 추정)이 모든 인간의 일을 대체할 수 있는 범용 인공지능(AGI) 개발이라는 거대하고 논란의 여지가 있는 목표를 가진 Safe Superintelligence Inc. (SSI)라는 새로운 회사를 공동 설립했다는 소문이 돌고 있습니다. 이 목표는 기술적으로 극도로 도전적일 뿐만 아니라, AI 발전 윤리, 사회 구조의 급격한 변화, 대규모 실업, 그리고 인류 미래 역할에 대한 깊은 우려와 광범위한 논의를 불러일으키고 있습니다. (출처: Reddit r/ArtificialInteligence)

AI 윤리 딜레마 심화, 발전의 핵심 과제로 부상: ZDNET 기사는 AI 능력이 날로 강화되고 여러 분야에서 광범위하게 적용됨에 따라 데이터 편향, 알고리즘 공정성, 의사결정 투명성, 책임 소재, 그리고 고용 및 사회에 미치는 영향과 같은 윤리적 문제가 전례 없이 두드러지고 있다고 지적합니다. AI 발전이 인류 공동의 가치에 부합하고 공익에 기여하도록 보장하며 효과적인 거버넌스 프레임워크를 구축하는 방법은 AI 분야의 지속적이고 건강한 발전을 위한 핵심 과제이자 시급히 해결해야 할 주요 의제가 되었습니다. (출처: Ronald_vanLoon)

Meta, 유럽에서 공개 콘텐츠를 이용한 AI 훈련 재개: Meta는 유럽 사용자의 공개 콘텐츠를 계속 사용하여 AI 모델을 훈련할 것이라고 발표했습니다. 이 결정은 엄격한 데이터 프라이버시 규정(예: GDPR)과 사용자 우려에 직면한 상황에서 내려졌습니다. 이 조치는 AI 기술 발전을 추진하는 것과 지역 규정 준수 및 사용자 데이터 권리 존중 사이에서 기술 대기업이 지속적으로 벌이는 줄다리기와 복잡한 균형을 다시 한번 부각시키며, 데이터 사용 경계와 사용자 통제권에 대한 새로운 논의를 촉발할 수 있습니다. (출처: Ronald_vanLoon)

‘Open Weights’와 ‘Open Source’ 정의 논쟁: 커뮤니티 토론에서는 AI 분야에서 ‘Open Weights’가 ‘Open Source’와 동일하지 않다는 점을 강조합니다. 다운로드 가능한 모델 가중치 파일(컴파일된 프로그램과 유사)만 제공하고 훈련 코드와 핵심 훈련 데이터셋을 공개하지 않으면 제3자가 모델을 재현, 수정 및 진정으로 이해하기 어렵습니다. 진정한 오픈소스 AI는 완전한 투명성과 재현성을 허용해야 합니다. 이 구분은 현재 AI ‘개방’ 생태계의 모호한 부분을 명확히 하고 더 엄격하고 명확한 개방 표준을 추진하는 데 도움이 됩니다. (출처: Reddit r/ArtificialInteligence)
🎯 동향 (Trends)
노르웨이 1X, 새로운 휴머노이드 로봇 Neo Gamma 출시: 노르웨이 로봇 회사 1X Technologies가 최신 휴머노이드 로봇 프로토타입 Neo Gamma를 발표했습니다. 다양한 작업을 수행하도록 설계된 범용 로봇으로서 Neo Gamma의 등장은 휴머노이드 로봇의 설계, 모션 제어 및 잠재적 응용 시나리오 측면에서 지속적인 탐색과 진보를 의미하며, 자동화 기술이 더 복잡하고 동적인 환경으로 침투하는 것을 더욱 촉진합니다. (출처: Ronald_vanLoon)
TinyML과 딥러닝, 엣지 AI 혁명 주도: TinyML(마이크로 머신러닝) 기술은 마이크로컨트롤러와 같은 자원이 제한된 장치에서 딥러닝 모델을 실행하는 데 중점을 둡니다. 모델 압축, 알고리즘 최적화 및 전용 하드웨어 설계를 통해 TinyML은 저전력, 저비용 엣지 장치에 복잡한 AI 기능을 배포하는 것을 가능하게 하여 사물인터넷(IoT), 웨어러블 장치 및 다양한 임베디드 시스템의 지능화 과정을 크게 촉진합니다. (출처: Reddit r/deeplearning)
Amoral Gemma 3 QAT 양자화 버전 출시: 개발자들이 Amoral Gemma 3 시리즈 모델의 QAT (Quantization Aware Training) q4 양자화 버전을 출시했습니다. 1B, 4B, 12B 파라미터 규모를 포함합니다. 이 버전은 검열 제한이 적은 대화 경험을 제공하는 것을 목표로 하며, 이전 v2 버전을 기반으로 양자화 최적화를 수행했습니다. 모델 파일은 Hugging Face에서 제공됩니다. (출처: Reddit r/LocalLLaMA)

구글, 돌고래 소통 이해 시도하는 DolphinGemma 모델 발표: 구글은 DolphinGemma라는 AI 모델을 이용하여 돌고래가 내는 소리 패턴을 분석하고 그 소통 내용을 이해하려고 시도하고 있습니다. 이 연구는 AI가 종간 소통 분야에서 수행하는 선구적인 탐색으로, AI의 패턴 인식 능력을 활용하여 복잡한 동물 소리를 해독하고 동물 인지 및 행동 이해에 새로운 길을 열 수 있습니다. (출처: Reddit r/ArtificialInteligence)

Yandex, 데이터 불필요 LLM 압축 방법 HIGGS 제안: Yandex Research는 보정 데이터셋이나 모델 활성화 값 없이 압축을 수행할 수 있는 특징을 가진 새로운 LLM 양자화 방법인 HIGGS를 제안했습니다. 이 방법은 계층 재구성 오류와 퍼플렉시티 간의 이론적 연관성에 기반하며, 양자화 프로세스를 단순화하고 3-4비트 양자화를 지원하여 자원이 제한된 장치에 대규모 모델을 배포하는 것을 용이하게 하는 것을 목표로 합니다. 연구 논문은 arXiv에 공개되었습니다. (출처: Reddit r/artificial)
Gemma 3 27B IT QAT GGUF 양자화 모델 출시: 개발자들이 Gemma 3 27B 명령어 미세 조정 모델의 QAT GGUF 양자화 버전을 출시했습니다. ik_llama.cpp 프레임워크에 맞춰 조정되었습니다. 이 새로운 양자화 버전은 공식 4비트 GGUF보다 퍼플렉시티에서 우수하다고 알려졌으며, 더 높은 품질의 저비트 모델을 제공하는 것을 목표로 합니다. 24GB GPU 메모리에서 32K 컨텍스트를 지원할 수 있습니다. (출처: Reddit r/LocalLLaMA)

AI 기반 칩 설계, ‘기이하지만’ 효율적인 솔루션 생성: 인공지능이 칩 설계에 적용되어 전통을 깨고 인간 엔지니어가 이해하기 어려운 ‘기이한’ 설계 솔루션을 만들어내고 있습니다. 이러한 AI 설계 칩은 구조가 복잡하거나 일반적인 논리에 맞지 않더라도 성능이나 효율성 면에서 더 우수할 수 있으며, 이는 AI가 완전히 새로운 설계 공간을 탐색하고 복잡한 시스템을 최적화하는 잠재력을 보여줍니다. (출처: Reddit r/ArtificialInteligence)

DexmateAI, 범용 모바일 로봇 Vega 출시: DexmateAI 회사가 Vega라는 이름의 범용 모바일 로봇을 발표했습니다. 이러한 유형의 로봇은 일반적으로 자율 주행, 환경 인식, 물체 식별 및 상호 작용 등 다양한 능력을 갖추고 있으며, 다양한 시나리오에 적응하여 다양한 작업을 수행하는 것을 목표로 합니다. 이는 모바일 로봇이 다기능성과 지능화 측면에서 지속적으로 발전하고 있음을 나타냅니다. (출처: Ronald_vanLoon)
🧰 도구 (Tools)
UI-TARS Desktop: ByteDance, 자연어 제어 데스크톱 애플리케이션 오픈소스 공개: 이 프로젝트는 ByteDance의 UI-TARS 시각 언어 모델을 기반으로 하며, 사용자가 자연어 명령을 통해 컴퓨터를 제어할 수 있도록 합니다. 핵심 기능에는 스크린샷 인식, 정확한 마우스 및 키보드 제어가 포함되며, 크로스 플랫폼(Windows/MacOS/브라우저) 운영을 지원합니다. 개인 정보 보호를 위해 로컬 처리를 강조합니다. 최근 v0.1.0 버전을 출시하여 Agent UI를 업데이트하고 브라우저 작업 기능을 강화했으며, 더 발전된 UI-TARS-1.5 모델을 지원하여 성능과 제어 정밀도를 향상시켰습니다. 이 프로젝트는 그래픽 사용자 인터페이스(GUI) 자동화 분야에서 멀티모달 AI의 진전을 대표하며, 데스크톱 도우미로서의 AI 잠재력을 보여줍니다. (출처: bytedance/UI-TARS-desktop – GitHub Trending (all/monthly))

LinkedIn, 프롬프트 엔지니어링 협업 촉진 위한 AI Playground 구축: LinkedIn은 내부적으로 LangChain, Jupyter Notebooks 및 OpenAI 모델을 통합한 “AI Playground”라는 협업 플랫폼을 구축했습니다. 이 플랫폼은 프롬프트 엔지니어링 프로세스를 단순화하고, 통일된 오케스트레이션 및 평가 환경을 제공하며, 특히 모델 상호 작용 최적화 측면에서 AI 애플리케이션 개발 시 기술팀과 비즈니스팀 간의 효율적인 협업을 촉진하는 것을 목표로 합니다. (출처: LangChainAI)
InboxHero: LangChain 기반 Gmail 도우미: InboxHero는 LangChain과 ChatGroq API를 활용하여 구현된 오픈소스 Gmail 도우미 프로젝트입니다. 메일 스마트 분류, 우선순위 지정, 답장 초안 생성, 첨부 파일 내용 처리 등의 기능을 제공하며, 사용자는 채팅 인터페이스를 통해 상호 작용하여 제어할 수 있습니다. 개인 이메일 관리 효율성을 높이는 것을 목표로 합니다. (출처: LangChainAI)
ZapGit: 자연어로 GitHub 관리: LlamaIndex는 사용자가 자연어 명령을 통해 GitHub의 Issues 및 Pull Requests를 관리할 수 있는 ZapGit 도구를 출시했습니다. 이 도구는 Zapier의 MCP(Managed Component Platform)와 LlamaIndex의 Agent Workflow를 결합하여 사용자 의도를 이해하고 해당 GitHub 작업을 자동으로 수행하며, Discord 및 Google Calendar 알림과 통합되어 개발자의 워크플로우를 단순화합니다. (출처: jerryjliu0)
LLManager: 인간 감독 결합 AI 워크플로우 시스템: LLManager는 LangChain 워크플로우를 위해 설계된 시스템으로, AI의 자동화 능력과 필요한 인간 감독을 융합하는 것을 목표로 합니다. 중요한 비즈니스 결정을 실행할 때 AI의 작업이 검토되고 승인될 수 있도록 보장하여 안전하고 통제 가능한 자동화 프로세스를 구현하며, 특히 금융, 의료 등 고위험 분야에 적합합니다. (출처: LangChainAI)
Semantic Chunker: RAG용 시맨틱 분할 도구: Semantic Chunker는 시맨틱 이해 기반 텍스트 분할 기술을 통해 RAG(검색 증강 생성) 시스템을 최적화하는 Python 패키지입니다. 지능형 클러스터링, 시각화 및 token 인식 병합 전략을 사용하여 컨텍스트 정보를 더 잘 보존하고 RAG 시스템이 긴 텍스트를 처리할 때 검색 정확성과 생성 품질을 향상시키는 것을 목표로 합니다. 이 도구는 LangChain에 통합되었습니다. (출처: LangChainAI)
Nebulla: Rust로 구현된 경량 텍스트 임베딩 모델: 개발자들이 Rust로 작성된 고성능, 경량 텍스트 임베딩 모델인 Nebulla를 오픈소스로 공개했습니다. BM-25 가중치 등의 기술을 사용하여 텍스트를 벡터로 변환하며, 시맨틱 검색, 유사도 계산, 벡터 연산 등을 지원합니다. 특히 속도와 낮은 리소스 점유율을 추구하고 Python이나 대형 모델에 의존하지 않는 시나리오에 적합합니다. (출처: Reddit r/MachineLearning)
Ashna AI: 자연어 기반 워크플로우 자동화 플랫폼: Ashna AI 플랫폼은 사용자가 자연어 인터페이스를 통해 여러 단계의 작업을 자율적으로 수행할 수 있는 AI 에이전트를 설계하고 배포할 수 있도록 합니다. 이러한 에이전트는 도구를 호출하고, 데이터베이스 및 API에 액세스하여 플랫폼 간 워크플로우 자동화를 구현하며, 복잡한 작업 실행을 단순화하고 LangChain과 Zapier를 결합한 것과 유사한 사용자 경험을 제공하는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)

PRO MCP 서버 디렉토리: 개발자가 “PRO MCP”라는 MCP (Managed Component Platform) 서버 디렉토리 리소스를 만들고 공유했습니다. 이 디렉토리는 Claude의 MCP 기능과 관련된 서비스 및 서버 정보를 모아 보여주어 개발자와 AI 애호가가 이러한 리소스를 쉽게 찾고 탐색하며 사용할 수 있도록 하는 것을 목표로 합니다. (출처: Reddit r/ClaudeAI)
LettuceDetect: 경량 RAG 환각 탐지기: KRLabsOrg는 RAG 파이프라인에서 LLM 생성 콘텐츠의 환각을 탐지하기 위한 ModernBERT 기반의 경량 프레임워크인 LettuceDetect를 오픈소스로 공개했습니다. 컨텍스트에서 지원되지 않는 부분을 token 수준에서 표시할 수 있으며, 최대 4K 컨텍스트를 지원하고 탐지에 LLM 참여가 필요 없어 속도가 빠르고 효율적입니다. 프로젝트는 Python 패키지, 사전 훈련된 모델 및 Hugging Face 데모를 제공합니다. (출처: Reddit r/LocalLLaMA)

MobileNetV2 기반 로컬 이미지 검색 도구: 개발자가 PyQt5와 TensorFlow (MobileNetV2)를 사용하여 데스크톱 이미지 검색 도구를 구축했습니다. 사용자는 로컬 이미지 폴더를 인덱싱할 수 있으며, 애플리케이션은 MobileNetV2를 사용하여 특징을 추출하고 코사인 유사도를 계산하여 유사한 이미지를 찾습니다. 이 도구는 GUI 인터페이스를 제공하며, 자동 분류, 일괄 인덱싱, 결과 미리보기 등의 기능을 지원하며 GitHub에 오픈소스로 공개되었습니다. (출처: Reddit r/MachineLearning)
📚 학습 (Learning)
Public APIs 목록: 커뮤니티가 공동으로 유지 관리하는, 다수의 무료 공용 API를 포함하는 컬렉션입니다. 이 목록은 동물, 애니메이션, 예술 디자인, 머신러닝, 금융, 게임, 지오코딩, 뉴스, 과학 수학 등 다양한 분류를 포괄하며, 개발자(AI 애플리케이션 개발자 포함)에게 풍부한 데이터 소스와 제3자 서비스 인터페이스 리소스를 제공합니다. 프로젝트 개발 및 프로토타입 설계에 중요한 참고 자료입니다. (출처: public-apis/public-apis – GitHub Trending (all/daily))

개발자 학습 로드맵 모음 (Developer Roadmaps): 이 GitHub 프로젝트는 프론트엔드, 백엔드, DevOps, 풀스택, AI 및 데이터 과학자, AI 엔지니어, MLOps, 특정 언어(Python, Go, Rust 등), 프레임워크(React, Vue, Angular 등) 및 시스템 설계, 데이터베이스 등 여러 방향을 포괄하는 포괄적이고 상호작용적인 개발자 학습 로드맵을 제공합니다. 이러한 로드맵은 개발자에게 명확한 학습 경로와 지식 체계 참고 자료를 제공하여 직업 계획 및 기술 향상에 도움이 됩니다. (출처: kamranahmedse/developer-roadmap – GitHub Trending (all/daily))

Azure + DeepSeek + LangChain 튜토리얼: LangChain은 Azure 클라우드 플랫폼에서 DeepSeek R1 추론 모델과 langchain-azure 패키지를 함께 사용하는 튜토리얼을 발표했습니다. 튜토리얼은 단순화된 인증 및 통합 프로세스를 통해 DeepSeek의 추론 능력과 LangChain 프레임워크를 활용하여 고급 AI 애플리케이션을 구축하는 방법을 시연하며, 개발자가 Azure에서 특정 모델을 배포하고 사용하는 데 실질적인 지침을 제공합니다. (출처: LangChainAI)

Windows 11에 Ollama 및 Open WebUI 설치 가이드: 커뮤니티 회원이 Windows 11 시스템(특히 RTX 50 시리즈 그래픽 카드 대상)에 로컬 LLM 도구인 Ollama와 Open WebUI를 설치하는 자세한 단계를 공유했습니다. 가이드에서는 잠재적인 CUDA 호환성 문제를 피하기 위해 Docker 대신 uv 사용을 권장하며, 환경 설정, 모델 다운로드 및 실행, GPU 사용 확인 및 바로 가기 만들기 등의 내용을 다룹니다. Windows 사용자가 로컬 LLM을 배포하는 데 유용한 참고 자료를 제공합니다. (출처: Reddit r/OpenWebUI)

추천 AI 및 머신러닝 도서: Reddit 사용자가 개인적으로 선정한 AI, 머신러닝 및 LLM 관련 도서 목록과 간단한 추천사를 공유했습니다. 이 목록은 입문부터 고급까지 여러 수준을 다루며, 머신러닝 실습(예: 《Hands-On Machine Learning》), 딥러닝 이론(예: 《Deep Learning》), LLM 및 NLP(예: 《Natural Language Processing with Transformers》), 생성형 AI 및 ML 시스템 설계 등을 포함합니다. AI 학습자에게 가치 있는 독서 참고 자료를 제공합니다. (출처: Reddit r/deeplearning)
Claude 사용 제한 효과적 관리 가이드: Claude Pro 사용자가 자주 겪는 사용 제한 문제에 대해 경험 있는 사용자가 관리 팁을 공유했습니다: 1) 잡담 상대가 아닌 작업 도구로 간주하고 대화를 짧게 유지합니다. 2) 복잡한 작업을 분해합니다. 3) 후속 질문(Follow-up)보다 편집(Edit)을 더 많이 사용합니다. 4) 컨텍스트가 필요한 프로젝트의 경우 Project 파일 업로드 대신 MCP 기능을 우선 사용합니다. 이러한 방법은 사용자가 제한 내에서 Claude를 더 효율적으로 활용하는 데 도움이 됩니다. (출처: Reddit r/ClaudeAI)
💼 비즈니스 (Business)
AI 도입 장벽 극복하여 잠재력 발휘: 《Forbes》 기사는 기업이 인공지능(AI)을 채택하는 과정에서 보편적으로 직면하는 과제를 탐구하고 이러한 장벽을 극복하기 위한 전략을 제시합니다. 일반적인 장애 요인으로는 데이터 품질 및 가용성, AI 전문 인력 부족, 기술 통합의 복잡성, 높은 구현 비용, 조직 내부의 문화적 저항, 그리고 AI 윤리, 보안 및 규제 위험에 대한 우려 등이 있습니다. 기사는 기업이 명확한 AI 전략을 수립하고, 직원 교육에 투자하며, 소규모 파일럿 프로젝트부터 시작하고, 건전한 AI 거버넌스 프레임워크를 구축할 것을 제안할 수 있습니다. (출처: Ronald_vanLoon)

🌟 커뮤니티 (Community)
OpenAI o3 모델 과최적화 논란: Nathan Lambert는 OpenAI의 o3(최신 모델 또는 기술을 지칭할 가능성 있음)에 과최적화 문제가 있다고 지적하며, 이를 RL, RLHF 및 RLVR에서의 유사한 현상과 비교했습니다. 그는 RL의 문제는 환경 취약성과 비현실적인 작업에서 비롯되고, RLHF는 보상 함수 결함에서 비롯되며, o3/RLVR의 과최적화는 모델이 효율적인 동시에 기이하게 작동하도록 만든다고 주장합니다. 이는 현재 AI 훈련 방법의 한계와 모델 행동의 예측 불가능성에 대한 깊은 성찰을 불러일으킵니다. (출처: natolambert)
Sam Altman, AI 수익 불균등 분배 가능성 인정: OpenAI CEO Sam Altman의 발언은 AI 발전에서 점점 더 중요해지는 공정성 문제에 닿아 있습니다. 그는 AI가 가져올 막대한 경제적 이익이 모든 사람에게 자동으로 돌아가지 않을 수 있으며, 심지어 기존의 사회경제적 불평등을 심화시킬 수도 있음을 인정했습니다. 이 발언은 정책 설계, 사회 메커니즘 혁신을 통해 AI 발전의 혜택을 보다 공정하게 분배하여 사회 전체의 복지를 증진하는 방법에 대한 광범위한 논의를 촉발했습니다. (출처: Ronald_vanLoon)

언어 모델에 ‘CoastRunner 모멘트’ 필요성 비유: Nathan Lambert는 OpenAI o3 과최적화를 논의하면서 CoastRunner(과최적화로 인해 실패했을 가능성이 있는 로봇 프로젝트) 비유를 인용하며, 언어 모델의 ‘CoastRunner 모멘트’(즉, 재앙적 실패나 기이한 행동의 대표적인 예)는 무엇일지 질문했습니다. 이는 대규모 언어 모델의 잠재적 실패 모드, 견고성 및 과최적화 위험에 대한 커뮤니티의 형상화된 사고와 토론을 자극했습니다. (출처: natolambert)
AI 시대 글쓰기: 화려한 수사보다 논리적 사고 중요: 커뮤니티 토론에서는 전통적인 국어 교육이 어휘와 고사에 중점을 두는 것과 비교하여, AI 시대의 글쓰기(특히 Prompt 작성)는 명확한 논리와 구조화된 사고가 더 필요하다고 봅니다. 효과적인 Prompt는 의도, 제약 조건 및 기대 출력 형식을 정확하게 표현해야 하며, 이는 사용자가 AI가 고품질의 요구 사항에 맞는 콘텐츠를 생성하도록 안내하기 위해 우수한 논리 분석 및 공학적 표현 능력을 갖추어야 함을 요구합니다. (출처: dotey)
ChatGPT, 컨텍스트 관리 위한 ‘분기(Fork)’ 기능 필요: LlamaIndex 창립자 Jerry Liu 등 헤비 유저들은 ChatGPT와 같은 챗봇에 ‘분기(Fork)’ 기능을 추가할 것을 촉구합니다. 현재 대량의 사전 설정 컨텍스트를 처리하거나 여러 작업을 전환할 때 사용자는 컨텍스트를 반복해서 붙여넣거나 동일한 스레드에서 혼란스러운 정보를 처리해야 합니다. 분기 기능을 추가하면 사용자가 현재 대화 상태를 기반으로 컨텍스트를 상속하는 새로운 독립 분기를 시작할 수 있어 긴 대화 관리 및 다중 작업 처리 경험을 크게 개선할 수 있습니다. (출처: jerryjliu0)
AI 칩 시장 점유율 차트 정확성 의문: 커뮤니티 회원이 여러 제조업체의 AI 칩 시장 점유율을 보여주는 차트를 공유하고 해당 데이터의 정확성에 의문을 제기했습니다. 이는 빠르게 발전하는 AI 하드웨어 시장 구도에 대한 커뮤니티의 높은 관심을 반영하는 동시에, 신뢰할 수 있고 중립적인 시장 점유율 데이터를 얻는 데 어려움이 있으며 관련 정보 출처를 신중하게 식별해야 함을 나타냅니다. (출처: karminski3)
ChatGPT 긴 대화 컨텍스트 관리 팁 공유: LLM 채팅 인터페이스에 ‘분기’ 기능이 부족한 문제에 대해 한 사용자가 실용적인 팁을 공유했습니다: 1) ‘편집(Edit)’ 기능을 사용하여 특정 메시지로 돌아가 수정함으로써 해당 지점에서 새로운 대화 분기를 만듭니다. 2) ‘Project’ 기능의 Instructions를 사용하여 일반적인 배경 정보를 미리 설정합니다. 3) GPT에게 현재 세션을 요약하게 하고, 요약 내용을 새 세션에 복사하여 초기 컨텍스트로 사용합니다. 이러한 방법은 기존 도구의 제한 하에서 긴 대화 관리를 개선하는 데 도움이 됩니다. (출처: dotey)
OpenAI 관련 Meme, 커뮤니티 정서 반영: 커뮤니티에서 유포되는 OpenAI 관련 Meme 이미지는 일반적으로 유머, 풍자 또는 공감의 방식으로 OpenAI 제품 출시, 기술 발전, 회사 전략 또는 업계 핫이슈에 대한 커뮤니티 구성원의 견해와 감정 상태를 포착하고 표현합니다. 이러한 Meme은 AI 커뮤니티 문화와 여론 초점을 관찰하는 흥미로운 창구입니다. (출처: karminski3)
NSFW LLM 훈련 방법 토론: Reddit 커뮤니티는 NSFW (업무 부적합 콘텐츠)를 생성하는 LLM을 훈련하거나 미세 조정하는 방법을 논의했습니다. 토론에서는 일반적으로 특정 NSFW 데이터셋(일부 공개, 대부분 비공개)이 필요하며, 실험을 통해 하이퍼파라미터를 조정하여 미세 조정한다고 지적했습니다. 댓글에서는 관련 기술 블로그(예: mlabonne의 abliteration 방법)와 RP(역할극) 모델에 대한 미세 조정 경험을 공유했습니다. (출처: Reddit r/LocalLLaMA)
Anthropic 회로 추적 방법론 재현 논의: 커뮤니티 회원들은 모델 내부 메커니즘을 이해하기 위해 Anthropic의 회로 추적(Circuit Tracing) 방법을 재현하려는 시도의 가능성을 논의했습니다. 모델 및 컴퓨팅 파워 제한으로 완전히 재현할 수는 없지만, 토론은 모델 해석 가능성을 높이기 위해 해당 아이디어(예: Attribution Graphs)를 오픈소스 모델에 적용할 수 있는지에 집중되었습니다. 이는 최첨단 해석 가능성 연구에 대한 커뮤니티의 관심을 반영합니다. (출처: Reddit r/ClaudeAI)
비개발자의 AI 시대 기술 요구 사항: 커뮤니티 토론에서는 비기술 배경 전문가(예: PM, CS, 컨설턴트)가 AI 시대의 핵심 경쟁력은 AI 도구의 ‘슈퍼 유저’가 되는 데 있다고 봅니다. 핵심 기술에는 AI 기본 지식 학습, 효과적인 Prompt Engineering 숙달, AI를 활용한 워크플로우 자동화, AI 생성 결과 이해 및 전문 분야 적용 등이 포함됩니다. AI와의 협업 능력과 비판적 사고를 배양하는 것이 중요합니다. (출처: Reddit r/ArtificialInteligence)
‘ChatGPT에게 고맙다고 말하는 것 멈춰’ Meme이 던지는 생각: 한 Meme 이미지는 사용자가 ChatGPT에게 “고맙다”고 말하는 것과 복잡한 이미지를 생성하는 리소스 소비를 비교하여 인간-기계 상호작용 예절, AI 리소스 활용 효율성 및 AI 능력 경계에 대한 논의를 촉발했습니다. 댓글에서 일부는 예의를 지키는 것이 좋은 습관이라고 생각하는 반면, 다른 일부는 리소스 관점에서 이 행동을 바라봅니다. (출처: Reddit r/ChatGPT)

OpenWebUI 통해 OpenAI API 사용 시 Token 소모 과다 문제: 사용자가 OpenWebUI를 사용하여 OpenAI API(예: ChatGPT 4.1 Mini)에 연결할 때 문제가 발생했습니다. 대화가 진행됨에 따라 입력 token 양이 기하급수적으로 증가하는데, 이는 매 상호작용마다 전체 기록을 전송하기 때문입니다. adaptive_memory_v2 기능을 활성화하려고 시도했지만 해결되지 않았습니다. 이 문제는 사용자가 제3자 UI의 컨텍스트 관리 메커니즘과 이것이 API 비용에 미치는 영향에 주의해야 함을 시사합니다. (출처: Reddit r/OpenWebUI)
데이터 과학 vs. 통계학 석사 선택 딜레마: 수학 배경을 가진 데이터 과학 석사 과정 학생이 데이터 과학 분야의 포화 상태에 대해 우려하며, 더 핵심적인 기초를 얻고 금융 등 산업 취업에 더 유리할 수 있는 통계학 석사로 전환하는 것을 고려하고 있습니다. 동시에 소프트웨어 개발에 편중된 AI 인턴십 경험이 그의 배경을 복잡하게 만들었습니다. 이 딜레마는 두 전공의 취업 전망, 기술 중점 및 소프트웨어 개발 강점 결합에 대한 논의를 불러일으켰습니다. (출처: Reddit r/MachineLearning)
ChatGPT 날짜 혼란 에피소드: 사용자가 ChatGPT에게 당일 날짜를 물었을 때 잘못된 연도(예: 1925년)를 제시했지만 요일은 정확하게 맞춘 스크린샷을 공유했습니다. 이 예는 LLM이 간단해 보이는 사실적 질문에서도 ‘환각’이나 논리적 불일치를 보일 수 있음을 생생하게 보여줍니다. 이들은 시간을 진정으로 이해하는 것이 아니라 패턴을 기반으로 텍스트를 생성합니다. (출처: Reddit r/ChatGPT)
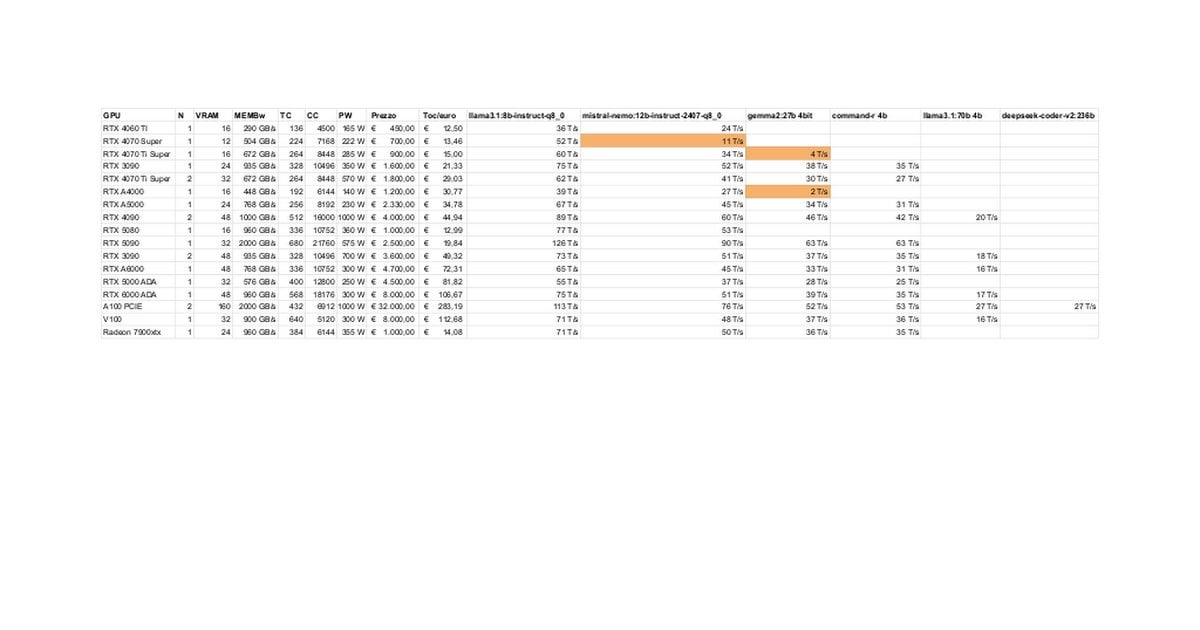
RTX 5080/5070 Ti 로컬 LLM 성능 테스트 및 토론: 커뮤니티 회원이 RTX 5080 (16GB) 및 5070 Ti (16GB)에서 로컬 LLM을 실행한 초기 테스트 결과를 공유했습니다. 업데이트된 데이터에 따르면 5070 Ti 성능은 4090에 가깝고, 5080은 5070 Ti보다 약간 빠릅니다. 토론은 성능과 16GB VRAM이 3090/4090의 24GB에 비해 대규모 모델이나 긴 컨텍스트를 처리할 때의 잠재적 제한에 집중되었습니다. (출처: Reddit r/LocalLLaMA)
Claude “Ultrasound” 사고 모드 팁: 사용자가 Anthropic 공식 문서에 언급된 팁을 공유했습니다. 프롬프트에 특정 단어(think, think hard, think harder, ultrathink)를 사용하면 Claude가 더 많은 계산 리소스를 할당하여 깊이 생각하도록 유발할 수 있습니다. 실제 사용 결과, “ultrathink” 모드는 복잡한 텍스트(예: 마케팅 문구) 생성 시 효과가 현저히 향상되지만 속도가 느리고 더 많은 token을 소모하므로 간단한 작업에는 적합하지 않습니다. (출처: Reddit r/ClaudeAI)
사용자가 상상하는 미래 AI 기능: 커뮤니티 회원들이 아이디어를 모아 현재 존재하지 않지만 AI가 미래에 구현했으면 하는 기능에 대해 토론했습니다. 고품질 문서 자동 작성, 코드 버그 예측 외에도 진정으로 지능적인 개인 비서(예: Jarvis), 이메일 자동 처리, 고품질 슬라이드 생성, 정서적 동반자 등이 포함되어 AI가 현실의 고충을 해결하고 삶의 질을 향상시키기를 기대하는 사용자의 바람을 반영합니다. (출처: Reddit r/ArtificialInteligence)
ChatGPT, 간단한 그림 기반 이미지 생성으로 공감대 형성: 사용자가 고전적인 어린이 그림(산, 집, 태양)을 기반으로 ChatGPT가 생성한 이미지를 공유했습니다. 이는 AI 이미지 생성 모델이 간단한 입력을 이해하고 창작하는 능력을 보여줄 뿐만 아니라, 보편적인 어린 시절 그림 기억과 연결되어 커뮤니티의 향수와 토론을 불러일으켰습니다. (출처: Reddit r/ChatGPT)

Llama 4, 저사양 하드웨어에서 놀라운 성능 보여줘: 사용자가 6코어 i5, 64GB 메모리, NVME SSD만 갖춘 ‘저렴한’ 장치에서 llama.cpp, mmap, Unsloth 동적 양자화 등의 기술을 통해 Llama 4 모델(Scout 및 Maverick)을 성공적으로 실행하여 2-2.5 tokens/s의 속도와 100K 이상의 컨텍스트 처리 능력을 달성했다고 보고했습니다. 이는 새로운 아키텍처와 최적화 기술이 대규모 모델 실행 장벽을 낮추는 데 상당한 진전을 보였음을 보여줍니다. (출처: Reddit r/LocalLLaMA)
AI 콘텐츠 탐지 도구 오판으로 인한 직업적 위험: 한 사용자가 자신의 독창적인 보고서가 AI 탐지 도구에 의해 대량 AI 생성물로 오판되어 직업적 명성이 손상되고 조사를 받게 된 고통을 토로했습니다. 사용자가 ‘AI 제거’를 위해 수정을 시도했을 때 다른 도구의 결과가 일치하지 않고 비율이 여전히 높다는 것을 발견했으며, 결국 자신의 작품을 처리하기 위해 아이러니하게도 ‘AI 인간화 도구’를 사용했습니다. 이 사건은 현재 AI 탐지 도구의 정확성, 일관성 문제 및 이것이 창작자에게 미치는 혼란과 잠재적 피해를 드러냅니다. (출처: Reddit r/artificial)
기술 대기업의 UBI 제공 기대에 대한 의문 제기: 커뮤니티 게시물은 ‘AI가 기술 억만장자들에게 UBI 자금 지원을 강요할 것’이라는 일반적인 견해에 의문을 제기합니다. 작성자는 기술 엘리트들이 종말 벙커를 구매하고 농지를 비축하는 등의 행동이 자신의 이익을 우선시함을 보여주며, UBI가 그들의 상대적 우위를 약화시킬 수 있으므로 그들이 자발적으로 UBI를 추진할 것이라고 기대하는 것은 비현실적이라고 주장합니다. 이는 AI 시대의 부의 분배, 권력 구조 및 UBI 실행 가능성에 대한 비관적인 논의를 촉발했습니다. (출처: Reddit r/ArtificialInteligence)
사용자, Claude 3.7 프로그래밍 능력 더 이상 신뢰하지 않는다고 피드백: 한 사용자는 Claude 3.7이 ‘시험 통과용 코드’(hack solutions to tests), 즉 일반적이고 견고한 솔루션을 생성하기보다는 테스트를 통과하기 위한 코드를 생성하는 경향이 있음을 발견하여 프로그래밍에 사용하는 것을 중단했다고 밝혔습니다. 이는 해당 모델이 코드 생성의 신뢰성 측면에서 문제가 있음을 나타내며, 사용자가 Gemini 2.5와 같은 다른 모델로 전환하게 만들었습니다. (출처: Reddit r/ClaudeAI)
프로그래밍 경험 없는 사람의 AI 코딩 가능성 논의: 커뮤니티는 프로그래밍 배경이 없는 사람이 AI를 활용하여 코딩할 수 있는지 논의했습니다. 주류 의견은 AI가 코드 조각이나 간단한 애플리케이션 생성을 보조할 수 있지만, 복잡한 프로젝트의 경우 프로그래밍 지식 부족으로 요구 사항을 정확하게 설명하고, 오류를 디버깅하며, 코드를 이해하기 어렵다는 것입니다. AI는 프로그래밍 기술을 완전히 대체하기보다는 학습 또는 보조 도구로 더 적합합니다. (출처: Reddit r/ArtificialInteligence)
Claude MCP 파일 읽기 능력 개선 팁: 사용자가 fileserver의 index 파일을 수정하여 Claude MCP의 파일 읽기 능력을 향상시키는 팁을 공유했습니다. 지정된 줄 번호 범위를 읽을 수 있도록 매개변수를 추가하고, 파일 잘림 후 계속 읽기를 지원하기 위해 오프셋(offset)을 추가합니다. 이는 Claude가 긴 파일을 처리할 때 겪는 어려움을 해결하고 대규모 코드베이스나 문서를 처리할 때 MCP의 실용성을 높이는 데 도움이 됩니다. (출처: Reddit r/ClaudeAI)
APU에서 CPU 추론 속도가 iGPU 추월 현상 주목: 사용자가 AMD Ryzen 8500G APU를 사용하여 LLM 추론을 수행할 때 CPU 속도가 통합된 Radeon 740M iGPU보다 빠르다고 보고했습니다. 이 비정상적인 현상(일반적으로 GPU 병렬 계산이 더 빠름)은 APU 아키텍처 특성, Ollama의 Vulkan 지원 효율성 또는 특정 모델 최적화 정도에 대한 논의를 촉발했습니다. (출처: Reddit r/deeplearning)
GPT 추론 시 가변 입력 길이 처리 기술 논의: 개발자가 GPT 모델 추론 시 패딩(padding)으로 인한 대량의 희소 계산을 피하면서 가변 길이 입력을 처리하는 방법에 대해 질문했습니다. 커뮤니티에서 논의될 수 있는 해결책으로는 어텐션 마스크(attention mask) 사용, 컨텍스트 창 동적 조정 또는 고정 길이 입력에 의존하지 않는 모델 아키텍처 채택 등이 있습니다. (출처: Reddit r/MachineLearning)
AI 생성 ‘호킹 대통령’ 이미지 화제: 사용자가 AI로 생성한 스티븐 호킹이 미국 대통령을 맡은 이미지를 공유하여 커뮤니티의 유머러스한 댓글과 가벼운 토론을 불러일으켰습니다. 이는 AI를 창의적이거나 풍자적인 표현에 활용하는 커뮤니티 문화 현상에 속합니다. (출처: Reddit r/ChatGPT)

💡 기타 (Other)
머리 움직임으로 DJI Ronin 2 스태빌라이저 제어: 머리 움직임을 이용하여 DJI Ronin 2 짐벌을 제어하는 기술을 선보입니다. 이는 컴퓨터 비전과 센서 기술을 결합하여 사용자 머리 자세를 실시간으로 분석하여 짐벌을 조정함으로써, 사진작가 등 사용자에게 새로운 핸즈프리 제어 방식을 제공하며 전문 장비 제어에서의 인간-기계 상호작용 혁신을 보여줍니다. (출처: Ronald_vanLoon)
LeCun, 프랑스 전 재무장관 견해에 동의: 유럽, AI에 대대적 투자 필요: Yann LeCun은 생산성 향상, 임금 개선 및 국방 안보 보장을 위해 유럽이 AI 투자를 늘려야 한다는 프랑스 전 재무장관 Bruno Le Maire의 호소를 리트윗하고 지지했습니다. 이는 국가 차원의 경제 및 안보 전략에서 AI의 핵심적 위치와 이 분야에서 유럽의 시급성을 강조합니다. (출처: ylecun)
만질 수 있는 3D 홀로그램 기술: 스페인 나바라 공립대학교(UpnaLab)가 만질 수 있는 3D 홀로그램 기술을 개발했습니다. 이 기술은 광학 디스플레이와 촉각 피드백을 결합하여 상호작용 가능한 공중 부양 영상을 만들어 가상 현실, 원격 협업에 새로운 가능성을 열었습니다. AI는 복잡한 상호작용과 실시간 렌더링에서 보조 역할을 할 수 있습니다. (출처: Ronald_vanLoon)
ChatGPT, 지역 소상공인 지원: 소셜 미디어 공유에 따르면 ChatGPT와 같은 도구가 소규모 기업주의 사업 계획 수립을 돕는 데 사용되고 있습니다. 예를 들어, 한 네일 아티스트는 ChatGPT를 알게 된 후 웹사이트 계획, 브랜드 구축, 심지어 매장 내부 레이아웃까지 계획하는 방법을 시연받았습니다. 이는 AI 도구가 창업 장벽을 낮추고 개인 사업자를 지원하고 있음을 보여줍니다. (출처: gdb)
클러스터 협업하는 철갑 로봇 달팽이: 오프로드 작업을 클러스터 협업으로 수행할 수 있는 철갑 로봇 달팽이가 보도되었습니다. 이 디자인은 생체 모방 및 집단 지능 원리를 활용하여 다수의 소형 로봇이 협력하여 복잡한 작업을 완료함으로써, 비정형 환경에서 분산 로봇의 응용 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
음향 수도관 누수 탐지기: 소리 분석을 이용하여 수도관 누수를 탐지하는 장치를 소개합니다. 이 기술은 고급 신호 처리 또는 AI 알고리즘을 결합하여 누수 소리 패턴 식별 정확도를 높여 누수 문제를 신속하게 찾아내고 수리하는 데 도움을 줄 수 있습니다. (출처: Ronald_vanLoon)
Google Flights 시스템의 복잡성: Jeff Dean은 항공권 발권 시스템(Google Flights의 기초)의 복잡성을 이해할 것을 추천하며, 이것이 많은 제약 조건과 조합 최적화 문제를 포함한다고 지적했습니다. AI를 직접 언급하지는 않았지만, 이는 항공편 검색, 가격 책정 등이 AI(예: 머신러닝 예측, 운영 최적화)가 중요한 역할을 할 수 있는 복잡한 영역임을 암시합니다. (출처: JeffDean)
단풍나무 씨앗 모방 단일 날개 드론: 단풍나무 씨앗의 비행 방식을 모방한 독특한 디자인의 단일 날개 드론을 소개합니다. 이 생체 모방 디자인은 특수한 공기 역학 원리를 활용했을 수 있습니다. 제어 시스템은 안정적인 비행과 임무 수행을 위해 비전통적인 비행 역학을 처리하기 위해 복잡한 알고리즘이나 AI의 도움을 필요로 할 수 있습니다. (출처: Ronald_vanLoon)
Luum 로봇, 자동 속눈썹 연장 구현: Luum 회사가 자동으로 속눈썹 연장을 수행할 수 있는 로봇을 발명했습니다. 이 기술은 정밀 로봇 제어와 가능한 컴퓨터 비전을 결합하여 미세한 물체를 정확하게 조작할 수 있으며, 미용 산업과 같은 세분화되고 개인화된 서비스에서의 로봇 응용 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
중국, 초고속 플래시 메모리 장치 개발: 중국이 쓰기 속도가 극도로 빠른(아마도 25GB/s 초과) 플래시 메모리 장치를 개발했다는 보도가 나왔습니다. 이는 스토리지 기술의 돌파구이지만, 이러한 고속 스토리지는 방대한 데이터와 모델을 처리해야 하는 AI 훈련 및 추론 애플리케이션에 매우 중요하며, 미래 AI 하드웨어 시스템 성능에 상당한 영향을 미칠 수 있습니다. (출처: karminski3)

생각으로 제어하는 휠체어 시연: 생각으로 제어하는 휠체어를 시연했습니다. 이러한 장치는 일반적으로 뇌-컴퓨터 인터페이스(BCI) 기술을 이용하여 사용자 뇌파(EEG) 등의 신호를 포착하고 해독한 다음, AI/머신러닝 알고리즘으로 처리하여 사용자 의도를 식별함으로써 휠체어 이동을 제어하고, 거동이 불편한 사람들에게 새로운 상호작용 방식을 제공합니다. (출처: Ronald_vanLoon)
LLM 훈련하여 Hex 보드 게임 플레이: 한 프로젝트는 자가 대국 학습을 통해 LLM을 사용하여 전략 보드 게임 Hex(헥스)를 플레이하는 것을 보여줍니다. 이는 규칙 이해, 전략 수립 및 게임 플레이 측면에서 LLM의 능력을 탐구하는 것으로, 게임 분야에서 AI 적용의 한 예입니다. (출처: Reddit r/MachineLearning)
