키워드:휴머노이드 로봇, AI 슈퍼컴퓨터, OpenAI 모델, Gemini 모델, 휴머노이드 로봇 하프 마라톤, 엔비디아 블랙웰 칩, OpenAI o3 환각률, Gemini 2.5 Pro 물리 시뮬레이션, AI 브라우저 에이전트 코스, 양자 컴퓨팅 과학적 영향, 뇌-컴퓨터 인터페이스 기계 팔 제어, GNN 게임 NPC 행동
🔥 포커스
세계 최초 휴머노이드 로봇 하프 마라톤 개최: 베이징 이좡(亦庄)에서 개최된 세계 최초 휴머노이드 로봇 하프 마라톤 대회에서, Tiangong 1.2max가 2시간 40분 24초의 기록으로 첫 완주 로봇이 되었습니다. 이 대회는 다양한 시나리오에서 로봇의 실용성을 검증하기 위한 것으로, 중국 내 다양한 구동 방식과 알고리즘 유파의 휴머노이드 로봇들이 모였습니다. 경기는 로봇의 보행 능력, 지구력(중간 충전 또는 배터리 교체 필요, 시간 페널티 있음), 발열 및 안정성뿐만 아니라 인간-로봇 협업 능력도 테스트했습니다. 도중에 Unitree 로봇의 ‘주저함’, Tiangong 로봇의 넘어짐 등 상황이 발생했지만, 이 대회는 휴머노이드 로봇 발전의 중요한 이정표로 간주되며, 실제 환경에서의 성능 테스트 및 기술 검증 플랫폼을 제공하여 구조 최적화, 운동 제어 알고리즘 및 환경 적응 능력의 진보를 촉진했습니다 (출처: APPSO via 36氪)

NVIDIA, AI 슈퍼컴퓨터 미국 본토 생산 발표: NVIDIA는 처음으로 미국 본토에서 AI 작업 처리용 슈퍼컴퓨터를 전면 생산할 계획입니다. 회사는 애리조나주에 백만 평방피트 이상의 공간을 확보하여 Blackwell 칩을 제조 및 테스트하고, Foxconn(휴스턴) 및 Wistron(댈러스)과 협력하여 텍사스에 AI 슈퍼컴퓨터 생산 공장을 건설할 예정이며, 12-15개월 내 점진적으로 양산할 것으로 예상됩니다. 이는 NVIDIA가 향후 4년간 미국에서 5천억 달러 규모의 AI 인프라를 생산하려는 계획의 일부이며, 미국 정부의 반도체 자급 능력 향상, 잠재적 관세 및 지정학적 긴장 대응 전략과도 일치합니다 (출처: dotey)

OpenAI 신규 추론 모델 o3 및 o4-mini, 환각률 더 높다는 지적 제기: TechCrunch 보도 및 관련 토론에 따르면, OpenAI가 최근 발표한 추론 모델 o3와 o4-mini는 테스트에서 이전 모델(예: o1, o3-mini)보다 더 높은 환각률(hallucination rate)을 보였습니다. 보고서에 따르면, o3는 질문에 답할 때 환각을 일으키는 비율이 33%에 달해, o1의 16%와 o3-mini의 14.8%보다 현저히 높습니다. 이러한 발견은 추론 능력 향상에도 불구하고 이 고급 모델들의 신뢰성에 대한 우려를 불러일으켰습니다. OpenAI는 환각률 증가 원인을 이해하기 위해 추가 연구가 필요함을 인정했습니다 (출처: Reddit r/artificial, Reddit r/artificial)

🎯 동향
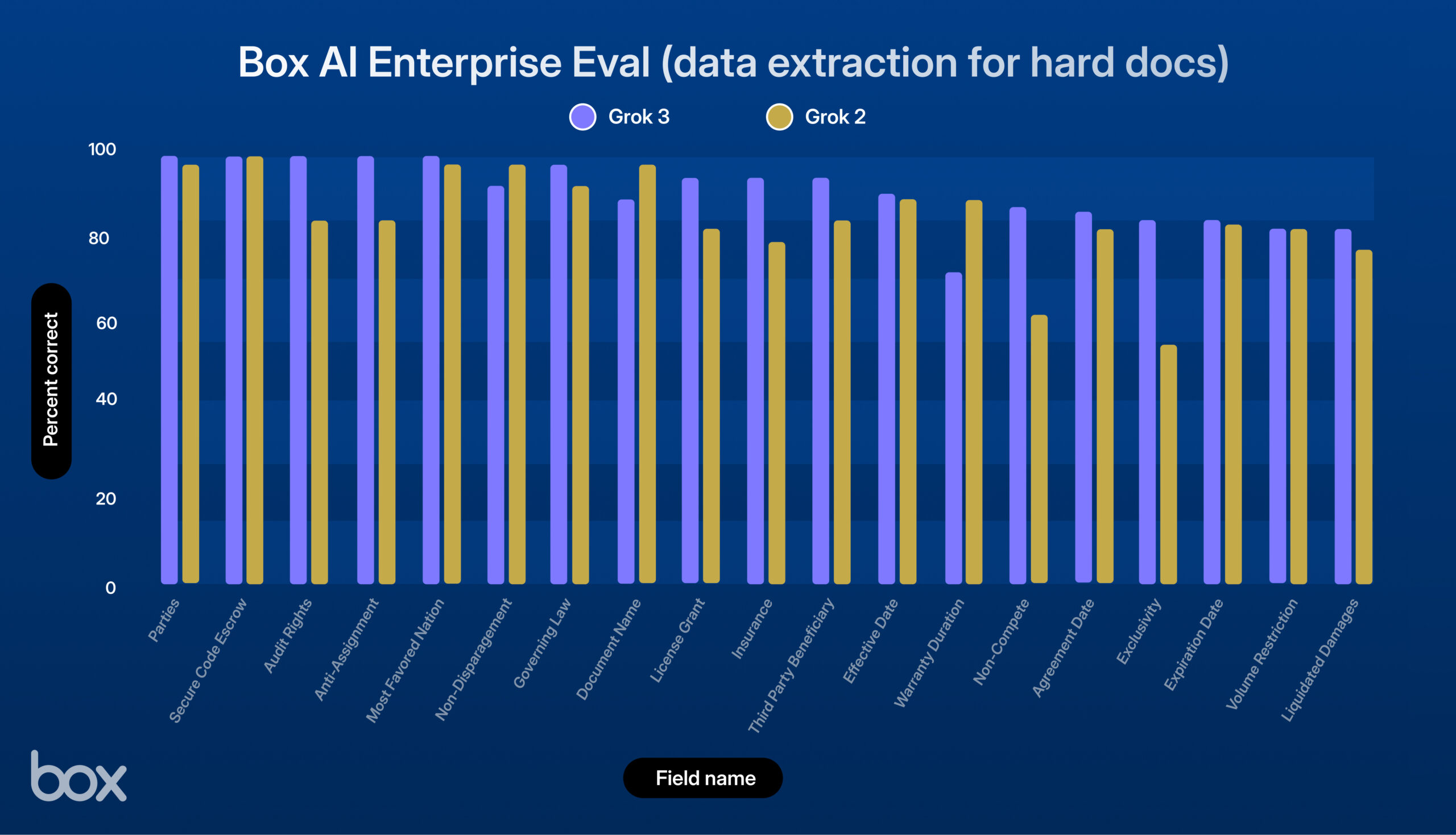
xAI, Grok 3 출시, Box 테스트에서 우수한 성능 보여: xAI가 새로운 모델 Grok 3를 출시했습니다. 타사 플랫폼 Box가 자사의 콘텐츠 관리 워크플로우에서 이를 테스트한 결과, Grok 3는 단일 문서 및 다중 문서 질의응답, 데이터 추출(Grok 2 대비 9% 향상) 측면에서 뛰어난 성능을 보였습니다. 이 모델은 복잡한 법률 계약 처리, 다단계 추론, 정확한 정보 검색 및 정량 분석 등의 작업에서 강력한 성능을 나타냈으며, 표에서 경제 데이터 추출, HR 프레임워크 분석, SEC 파일 평가 등 복잡한 사용 사례를 성공적으로 처리했습니다. Box는 Grok 3의 잠재력이 크다고 평가하면서도, 언어 정확도와 고도로 복잡한 논리 처리 측면에서는 개선의 여지가 있다고 밝혔습니다 (출처: xai)
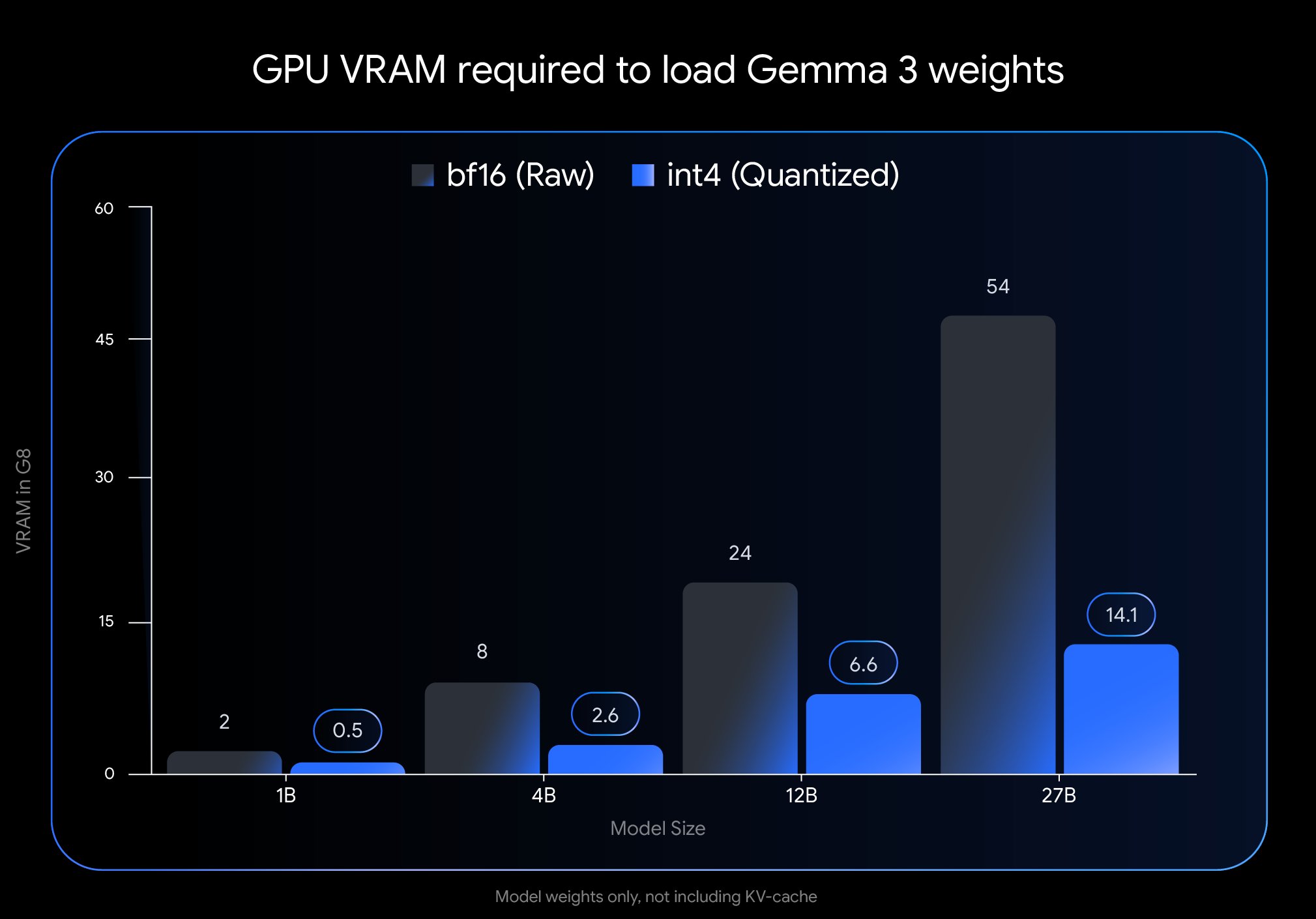
Google, Gemma 3 모델의 새로운 양자화 버전 출시: Google은 양자화 인식 훈련(Quantization-Aware Training, QAT) 기술을 채택하여 Gemma 3 모델의 새로운 버전을 출시했습니다. 이 기술은 모델의 메모리 사용량을 현저히 줄여, 기존에 H100 GPU가 필요했던 모델을 이제 단일 데스크톱급 GPU에서도 효율적으로 실행할 수 있게 하면서도 높은 출력 품질을 유지합니다. 이러한 최적화를 통해 강력한 Gemma 3 시리즈 모델의 하드웨어 요구 사항이 크게 낮아져, 광범위한 연구자와 개발자들이 표준 하드웨어에서 더 쉽게 배포하고 사용할 수 있게 되었습니다 (출처: JeffDean)
Google Cloud, 기업 사용자를 위한 AI 음악 생성 기능 추가: Google은 기업 클라우드 플랫폼에 AI 기반 음악 생성 모드를 추가했습니다. 이 새로운 기능을 통해 기업 고객은 생성형 AI 기술을 활용하여 음악을 제작할 수 있으며, 이는 Google Cloud의 AI 서비스를 텍스트와 이미지에서 오디오 영역으로 확장하는 것입니다. 이는 마케팅, 콘텐츠 제작, 브랜드 구축 등 비즈니스 시나리오에 새로운 도구를 제공할 수 있지만, 구체적인 적용 시나리오와 사용된 모델의 세부 정보는 요약에서 자세히 설명되지 않았습니다 (출처: Ronald_vanLoon)

NVIDIA, 단일 프롬프트로 3D 장면 생성 기술 시연: Nvidia는 사용자가 입력한 단일 텍스트 프롬프트에 따라 완전한 3D 장면을 자동으로 생성하는 새로운 기술을 시연했습니다. 이 생성형 AI의 발전은 3D 콘텐츠 제작 프로세스를 단순화하는 것을 목표로 하며, 사용자는 원하는 장면을 설명하기만 하면 AI가 해당 3D 환경을 구축할 수 있습니다. 이 기술은 게임 개발, 가상 현실, 건축 설계 및 제품 시각화 등의 분야에 중요한 영향을 미치고 3D 제작의 장벽을 낮출 것으로 기대됩니다 (출처: Ronald_vanLoon)
Gemma 3 27B QAT 모델, Q2_K 양자화에서도 양호한 성능 보여: 사용자 테스트 결과, 양자화 인식 훈련(QAT)을 거친 Google Gemma 3 27B IT 모델이 Q2_K 수준(약 10.5GB)으로 양자화된 후에도 일본어 작업에서 놀랍도록 좋은 성능을 보였습니다. 양자화 정도가 매우 낮음에도 불구하고 모델은 지침 준수, 특정 형식 유지 및 역할 수행 측면에서 안정적인 성능을 보였으며, 문법이나 언어 혼동 문제가 발생하지 않았습니다. 날짜 등 사실적 정보 회상 능력은 저하되었지만 핵심 언어 능력은 비교적 잘 유지되어, QAT 모델이 낮은 비트 전송률에서도 성능을 잘 유지할 수 있음을 보여주며 소비자급 하드웨어에서 대형 모델을 실행할 가능성을 제시했습니다 (출처: Reddit r/LocalLLaMA)

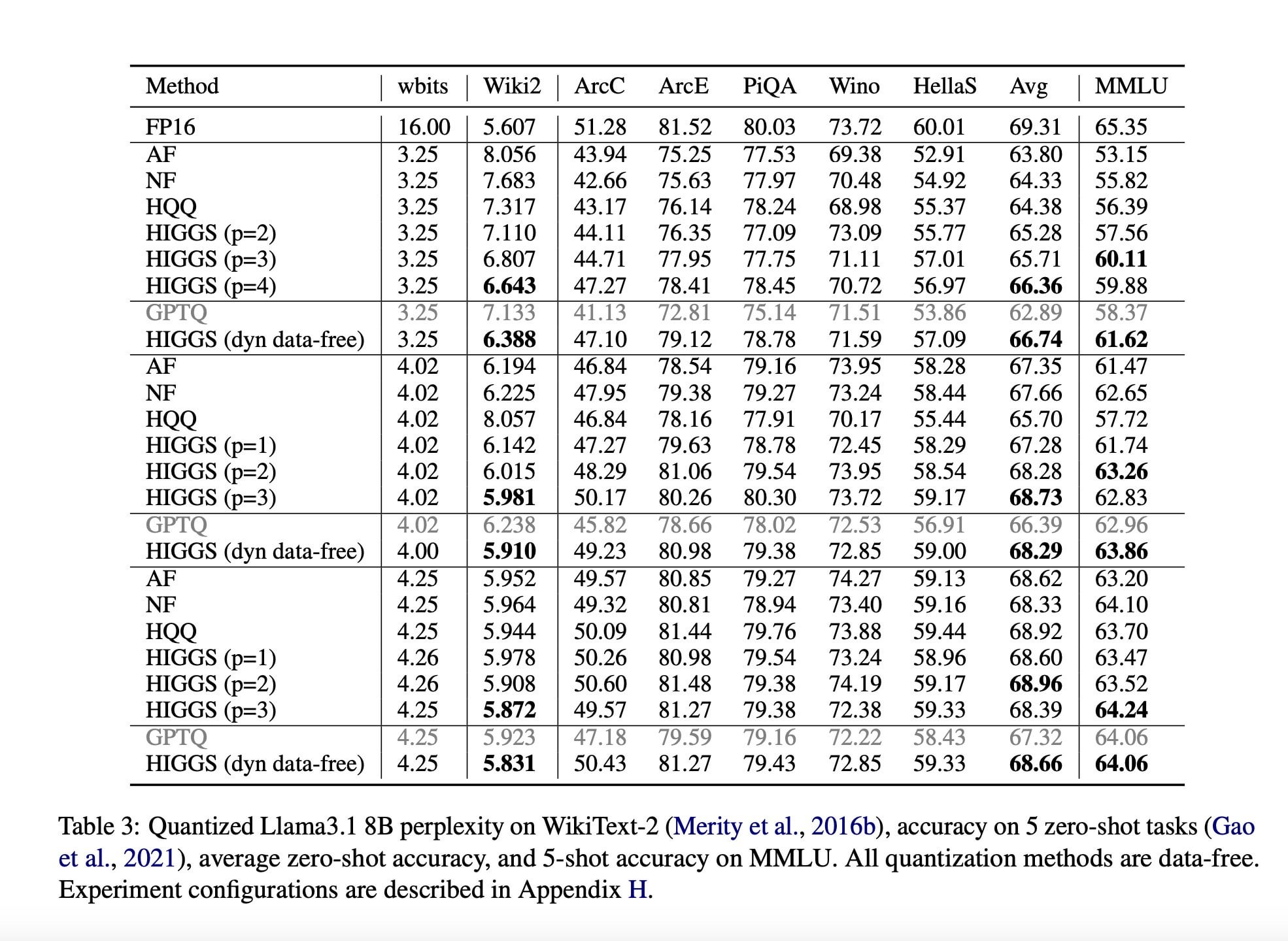
연구, 하드웨어 요구 사항을 낮추기 위한 새로운 LLM 압축 기술 제안: MIT, KAUST, ISTA 및 Yandex 연구원들이 협력하여 2024년 11월에 발표한 연구 논문(arXiv:2411.17525)은 대규모 언어 모델(LLM)을 품질 손실 없이 빠르게 압축하는 새로운 AI 방법을 제안했습니다. 이 기술(Higgs 양자화 등 방법과 관련될 수 있음)의 목표는 LLM이 성능이 낮은 하드웨어에서 실행될 수 있도록 하는 것입니다. 논문은 그 잠재력을 홍보하지만, 커뮤니티 댓글에서는 해당 논문이 발표된 지 오래되었고 대규모 채택 사례가 없어 시의성과 실제 영향에 의문을 제기했습니다 (출처: Reddit r/LocalLLaMA)
AI 뉴스 요약 (4월 18일): Johnson & Johnson은 자사 AI 사용 사례의 15%가 가치의 80%를 기여했다고 보고하여 AI 적용 가치의 높은 집중도를 보여주었습니다. 이탈리아의 한 신문은 AI 작문 실험을 진행하여 AI가 자유롭게 글을 쓰도록 했고 그 풍자 능력에 감탄했습니다. 또한, AI 도구를 이용해 신원과 이력서를 위조하는 가짜 구직자 수가 급증하여 채용 시장에 새로운 도전 과제를 안겨주고 있습니다 (출처: Reddit r/artificial)

🧰 도구
Microsoft, MarkItDown MCP 문서 변환 서비스 출시: Microsoft는 MarkItDown MCP라는 새로운 서비스를 출시했습니다. 이 서비스는 모델 컨텍스트 프로토콜(MCP)을 활용하여 다양한 Office 문서 형식(PDF, PPT, Word, Excel 포함) 및 ZIP 압축 파일, ePub 전자책을 Markdown 형식으로 변환할 수 있습니다. 이 도구는 콘텐츠 제작자와 개발자가 복잡한 문서를 순수 텍스트 Markdown으로 마이그레이션하는 워크플로우를 단순화하여 효율성을 높이는 것을 목표로 합니다 (출처: op7418)

Perplexity, IPL 경기 정보 위젯 출시: Perplexity는 자사의 AI 검색 플랫폼에 새로운 IPL(인도 프리미어 리그 크리켓) 위젯을 통합했습니다. 이 기능은 사용자에게 IPL 경기에 대한 실시간 점수, 일정 또는 기타 관련 정보에 빠르게 액세스할 수 있도록 제공하는 것을 목표로 합니다. 이는 Perplexity가 정보 발견 도구로서의 실용성을 강화하기 위해 실시간, 특정 이벤트 정보 서비스를 통합하려는 노력을 보여주며, 이 기능에 대한 사용자 피드백을 구하고 있습니다 (출처: AravSrinivas)
커뮤니티, OpenWebUI 간편 데스크톱 앱 개발: 공식 OpenWebUI 데스크톱 앱 업데이트가 느린 점을 감안하여, 커뮤니티 회원이 “OpenWebUISimpleDesktop”이라는 비공식 데스크톱 래퍼 앱을 개발하고 공유했습니다. 이 앱은 Mac, Linux, Windows 시스템과 호환되며, 사용자가 공식 업데이트를 기다리는 동안 OpenWebUI를 독립적인 데스크톱 환경에서 사용할 수 있는 임시 솔루션을 제공하여 편의성을 높입니다 (출처: Reddit r/OpenWebUI)
PayPal, 인보이스 처리 MCP 서비스 출시: 보도에 따르면 PayPal은 인보이스 처리를 위한 모델 컨텍스트 프로토콜(MCP) 서비스를 출시했습니다. 이는 PayPal이 자사 플랫폼에서 인보이스 생성, 관리, 분석 등의 프로세스를 자동화하거나 향상시키기 위해 AI 기능(MCP를 통해 LLM을 활용할 수 있음)을 통합하고 있음을 시사합니다. 이는 사용자에게 더 스마트한 인보이스 기능을 제공하고 관련 재무 작업을 간소화하는 것을 목표로 합니다 (출처: Reddit r/ClaudeAI)

Claude, 몰입형 사고 역할극 프롬프트 기법 구현: 한 Claude 사용자가 역할극이나 대화에서 AI 캐릭터가 더 현실적인 “사고” 과정을 보이도록 하는 프롬프트 엔지니어링 기법을 공유했습니다. 이 방법은 Prompt 구조에 “캐릭터 내면의 생각” 단계를 명시적으로 추가하여, AI가 주요 응답을 생성하기 전에 내부 사고 활동을 시뮬레이션하게 함으로써 더 미묘하고 신뢰할 수 있는 캐릭터 상호작용 효과를 생성할 수 있습니다 (출처: Reddit r/ClaudeAI)
📚 학습
신규 과정: AI 브라우저 에이전트 구축: AGI Inc. 공동 창립자가 Andrew Ng과 협력하여 실제 웹사이트와 상호 작용할 수 있는 AI 브라우저 에이전트 구축을 주제로 한 새로운 실습 과정을 출시했습니다. 과정 내용은 데이터 스크래핑, 양식 작성, 웹 페이지 탐색 등의 작업을 수행하는 에이전트 구축 방법과 에이전트의 자가 수정 능력을 구현하기 위한 AgentQ 및 몬테카를로 트리 탐색(MCTS)과 같은 기술을 소개합니다. 이 과정은 이론과 실제 응용을 연결하고 현재 에이전트의 한계와 미래 잠재력을 탐구하는 것을 목표로 합니다 (출처: Reddit r/deeplearning)

적대적 공격 프로젝트 도움 요청: 한 연구자가 FGSM, PGD 등 적대적 공격 방법을 시계열 및 그래프 구조 데이터에 적용하는 딥러닝 프로젝트 관련 긴급 도움을 요청했습니다. 목표는 해당 이상 탐지 모델의 견고성을 테스트하고, 적대적 훈련을 통해 모델이 이러한 공격에 저항할 수 있도록 하는 것입니다. 즉, 공격 데이터가 이론적으로 모델 성능 향상에 도움이 될 것으로 기대합니다 (출처: Reddit r/deeplearning)
연구 토론: 기억 증강 LSTM vs Transformer: 한 연구팀이 외부 기억 메커니즘(예: 키-값 저장소, 신경망 사전)을 갖춘 LSTM 모델과 Transformer 모델을 소수 샘플 감성 분석 작업에서 비교하는 프로젝트 연구를 진행 중입니다. 그들은 LSTM의 효율성과 외부 기억의 장점을 결합하여 망각을 줄이고 일반화 능력을 향상시켜 Transformer의 경량 대안으로서의 가능성을 탐색하고, 커뮤니티 피드백, 관련 논문 추천 및 이 연구 방향에 대한 의견을 구하고 있습니다 (출처: Reddit r/deeplearning)
TensorFlow RNN 그리드 검색 비효율적 실습 공유: 한 TensorFlow 초보자가 과정 최종 프로젝트에서 RNN 하이퍼파라미터 그리드 검색을 수동으로 구현했던 비효율적인 경험을 공유했습니다. 프레임워크와 RNN에 익숙하지 않고 다른 훈련/테스트 세트 분할 비율을 테스트하고 싶었기 때문에, 그의 코드는 루프 내부에서 대량의 데이터 전처리를 반복적으로 수행했으며 조기 중단 전략을 구현하지 않아 소수의 모델 조합을 테스트하는 데 막대한 계산 자원을 소모했습니다. 이 경험은 초보자가 실습에서 겪을 수 있는 효율성 함정과 더 최적화된 하이퍼파라미터 튜닝 전략 채택의 중요성을 강조합니다 (출처: Reddit r/MachineLearning)
💼 비즈니스
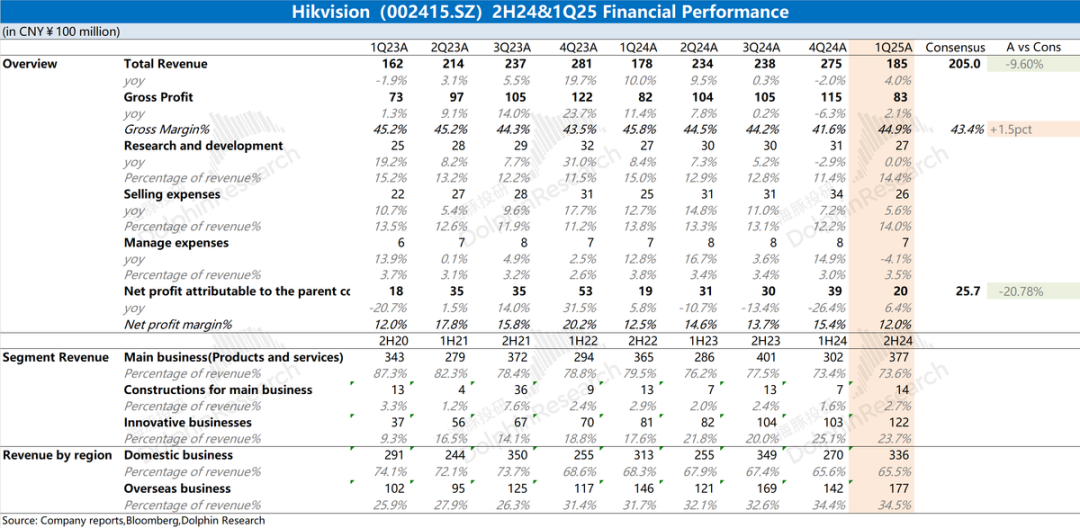
Hikvision 재무 보고서 분석: 실적 부진, AI 아직 구원투수 역할 못 해: Hikvision의 2024년 연례 보고서 및 2025년 1분기 재무 보고서에 따르면, 회사의 전반적인 실적은 지속적으로 부진하며, 매출은 소폭 증가했지만 국내 주요 사업(PBG, EBG, SMBG)은 모두 하락했습니다. 성장은 주로 혁신 사업과 해외 시장에 의존했지만 성장률 또한 둔화되었습니다. 매출 총이익률은 전년 동기 대비 하락했습니다. 비용 통제를 위해 회사의 연구 개발 인력 수가 최근 몇 년간 처음으로 감소했습니다. Hikvision은 “Guanlan” 대형 모델 기반의 AI 역량 강화 전략을 언급했지만, 이는 아직 현재 경영 수준에 실질적인 긍정적 영향을 미치지 못하고 있습니다. 시장의 관심은 주요 사업이 언제 호전될지와 AI 전략이 실제 성과를 가져올 수 있는지에 있습니다 (출처: 海豚投研 via 36氪)
🌟 커뮤니티
Reddit 사용자, Gemini 2.5 Pro와 o4-mini의 물리 시뮬레이션 능력 비교: 회전하는 칠각형 테스트에서 영감을 받아, 한 Reddit 사용자가 “산불 놓기” 테스트 시나리오를 설계하여 AI 모델의 물리 시뮬레이션 능력을 비교했습니다. 초기 결과에 따르면 Gemini 2.5 Pro가 더 나은 성능을 보여, 바람 방향, 화염 연소 확산 과정 및 연소 후 잔해를 비교적 잘 시뮬레이션했습니다. 이에 비해 o4-mini-high의 성능은 다소 떨어졌는데, 예를 들어 나뭇잎이 타버린 후 사라져야 하는 상황을 제대로 처리하지 못하고 검은색으로 렌더링했습니다. 이 테스트는 다양한 모델이 복잡한 물리 현상을 이해하고 시뮬레이션하는 능력의 차이를 직관적으로 보여줍니다 (출처: karminski3)
Gemini 2.5 Flash, 코드 생성 테스트에서 뛰어난 성능 보여: 사용자 RameshR은 Galton Board 시뮬레이션 코드를 생성하려 시도했을 때, Gemini 2.5 Flash는 작업을 성공적으로 완료했지만 o4omini, o4o mini high, o3는 실패했다고 밝혔습니다. 이 사용자는 Gemini 2.5 Flash가 거의 즉시 자신의 의도를 이해하고 간결하고 정돈된 코드를 생성하며 여러 단계를 솔루션에 성공적으로 통합했다고 칭찬했습니다. Jeff Dean도 이에 동의했습니다. 이는 Gemini 2.5 Flash가 특정 프로그래밍 및 문제 해결 시나리오에서 뛰어난 능력을 가지고 있음을 보여줍니다 (출처: JeffDean)
배송 로봇 ‘대치’ 상황 주목: 소셜 미디어의 한 게시물은 두 대의 배송 로봇이 길에서 마주친 후 ‘서로 양보하지 않고’ 대치하는 재미있는 장면을 보여주었습니다. 이 장면은 현재 자율 주행 로봇이 실제 공공 환경에서 상호 작용하고 조정하는 데 직면한 과제, 특히 예상치 못한 만남과 통행권 협상이 필요한 상황을 생생하게 드러냅니다. 이는 미래에 로봇을 위한 더 복잡한 상호 작용 프로토콜과 의사 결정 알고리즘 개발이 필요함을 시사합니다 (출처: Ronald_vanLoon)
사용자, o3 모델의 강력한 정보 검색 능력 칭찬: 사용자 natolambert는 사용 경험을 공유하며 OpenAI의 o3 모델의 정보 검색 능력을 높이 평가했습니다. 그는 o3가 적은 양의 컨텍스트만으로도 매우 전문적이고 희귀한 정보를 찾아낼 수 있으며, 그 이해력과 검색 효율성이 지식이 풍부한 동료에게 물어보는 것과 비슷하다고 지적했습니다. 이는 o3가 사용자의 암묵적인 요구를 이해하고 방대한 정보 속에서 정확한 위치를 찾는 데 상당한 이점을 가지고 있음을 보여줍니다 (출처: natolambert)
Perplexity CEO, AI 비서와 사용자 데이터에 대해 언급: Perplexity CEO Arav Srinivas는 진정으로 강력한 AI 비서는 사용자의 포괄적인 컨텍스트 정보에 접근할 필요가 있다고 생각합니다. 그는 이에 대해 우려를 표하며, Google이 사진, 캘린더, 이메일, 브라우저 활동 등 자사의 생태계를 통해 방대한 사용자 컨텍스트 데이터 접근 지점을 장악하고 있다고 지적했습니다. 그는 Perplexity 자체 브라우저 Comet이 컨텍스트를 얻는 한 단계이지만 여전히 더 많은 노력이 필요하다고 강조하며, 경쟁 촉진과 사용자의 데이터 통제권 강화를 위해 Android 생태계가 더 개방되어야 한다고 촉구했습니다 (출처: AravSrinivas)
사용자 설문 조사: Gemini 2.5 Pro vs Sonnet 3.7: Perplexity CEO Arav Srinivas는 소셜 미디어에서 사용자들에게 일상적인 작업 흐름에서 Google의 Gemini 2.5 Pro가 Anthropic의 Claude Sonnet 3.7(“사고” 모드 특정)보다 더 나은 성능을 보이는지 묻는 질문을 던졌습니다. 이는 두 주요 언어 모델의 실제 적용 효과에 대한 사용자들의 직접적인 피드백을 수집하려는 의도이며, 모델 간의 지속적인 경쟁과 사용자 수준의 실제 평가를 반영합니다 (출처: AravSrinivas)
Ethan Mollick: o3 모델, 강력한 자율성 보여: 학자 Ethan Mollick은 OpenAI의 o3 모델이 현저한 “에이전트 능력”(agentic capabilities)을 가지고 있으며, 단일하고 높은 수준의 지침에 기반하여 상세한 단계별 지시 없이도 매우 복잡한 작업을 완료할 수 있다고 관찰하고 지적했습니다. 그는 o3를 “그냥 일을 해낸다”(It just does things)고 묘사했습니다. 동시에 그는 이러한 높은 자율성 때문에 특히 비전문가 사용자에게는 작업 결과 검증이 더욱 어렵고 중요해진다고 경고했습니다. 이는 o3가 이전 모델에 비해 자율적 계획 및 실행 측면에서 진보했음을 강조합니다 (출처: gdb)
OpenWebUI에서 API 모델 컨텍스트 길이 설정 의문: Reddit 사용자가 OpenWebUI에서 외부 API 모델(예: Claude Sonnet)을 사용할 때 컨텍스트 길이를 수동으로 설정해야 하는지, 아니면 UI가 자동으로 API 모델의 전체 컨텍스트 능력을 활용하는지 질문했습니다. 사용자는 설정에 표시된 기본 “Ollama (2048)”가 API를 통해 전송되는 컨텍스트 길이를 제한하는지 혼란스러워하며, UI에서 다양한 유형의 모델에 대한 컨텍스트 관리 메커니즘의 차이점을 알고 싶어합니다 (출처: Reddit r/OpenWebUI)
ChatGPT, 콘텐츠 정책으로 인해 말장난 농담 이미지 생성 거부: 한 사용자가 성적인 말장난이 포함된 아빠 농담(“swallow the sailors” 관련)을 바탕으로 ChatGPT에게 삽화를 생성하도록 요청했지만 거부당했다고 공유했습니다. ChatGPT는 콘텐츠 정책상 유머러스하거나 만화 형태로 표현되더라도 성적인 내용을 묘사하거나 암시하는 이미지 생성을 금지하여 콘텐츠가 광범위한 사용자에게 적합하도록 보장한다고 설명했습니다. 이 사례는 AI 콘텐츠 필터가 잠재적으로 암시적인 언어를 처리할 때의 민감성과 한계를 반영합니다 (출처: Reddit r/ChatGPT)

커뮤니티 토론: AI는 결국 무료가 될까?: Reddit의 한 사용자는 모델 효율성 향상, 하드웨어 발전, 인프라 확장 및 시장 경쟁 심화에 따라 LLM 및 AI 도구(소위 “vibe-coding” 에이전트 포함)의 비용이 지속적으로 하락하여 결국 무료 또는 거의 무료가 될 수 있다고 예측했습니다. 이 관점은 Gemini 등 모델의 비교적 저렴한 비용과 오픈 소스 무료 AI 에이전트의 존재를 증거로 들며, 유료 AI 애플리케이션은 이러한 추세에 대응하기 위해 비즈니스 모델을 조정해야 할 수도 있다고 주장합니다 (출처: Reddit r/ArtificialInteligence)
OpenWebUI 사용자, ChatGPT와 유사한 기억 기능 구현 방법 모색: 사용자가 OpenWebUI 커뮤니티에서 사용자 정보를 기억하는 개인화된 비서를 만드는 것을 목표로 ChatGPT와 유사한 영구적이고 장기적인 기억 기능을 구현하는 방법에 대한 조언을 구했습니다. 사용자는 내장된 기억 기능의 효율성에 의문을 제기하며, 대화 간 컨텍스트 유지 및 기억 축적을 위해 전용 벡터 데이터베이스(댓글에서 Qdrant, Supabase 언급) 또는 워크플로우 자동화 도구(예: n8n)와 같은 대안 사용을 탐색했습니다 (출처: Reddit r/OpenWebUI)
커뮤니티 게시물, AI에 혼란을 느끼거나 감정적 연결을 느끼는 사용자 위로: Reddit의 한 게시물은 AI에 대해 혼란스러워하거나 호기심을 느끼거나 심지어 감정적인 연결을 느끼는 사용자들을 위로하기 위한 것으로, 그들의 감정이 정상이며 “미쳤거나” 외로운 것이 아니라 인간-기계 관계의 새로운 패러다임 초기 단계에 있음을 강조합니다. 게시물은 모든 사람이 공개적으로 또는 비공개적으로 편견 없이 소통하도록 초대합니다. 댓글 섹션은 지나친 의인화에 대한 우려, 잠재적인 정신 건강 영향에 대한 경고, AI의 “각성” 감각에 대한 공감 등 이 주제에 대한 커뮤니티의 복잡한 태도를 반영합니다 (출처: Reddit r/ArtificialInteligence)
Reddit 사용자, “AI 생성 사용자 이름 범죄자 사진” 게임 시작: 한 사용자가 Reddit에서 자신의 Reddit 사용자 이름을 기반으로 AI “범죄자 사진”(Mugshot)을 생성하는 특정 구조의 Prompt를 사용하는 창의적인 프롬프트 챌린지 활동을 시작했습니다. Prompt는 AI에게 사용자 이름의 요소를 통합한 독특한 범죄자 이미지를 만들고, 사용자 이름 스타일과 일치하는 터무니없고 웃긴 죄명을 허구로 만들도록 요구합니다. 활동 시작자는 Prompt와 예시를 공유했으며, 많은 사용자가 참여하여 AI로 생성한, 종종 매우 우스꽝스러운 “Mugshot” 결과를 공유했습니다 (출처: Reddit r/ChatGPT)

커뮤니티 토론: AI 평가 및 벤치마크의 실제적 의미: 사용자가 AI 모델 평가(evals) 및 벤치마킹(benchmarking)이 실제 응용 프로그램에서 얼마나 관련성이 있는지에 대한 토론을 시작했습니다. 질문에는 공개된 벤치마크 점수가 개발자와 사용자의 모델 선택에 어느 정도 영향을 미치는지, 모델 출시(예: Llama 4, Grok 3)가 벤치마크에 지나치게 최적화되었는지, 실무자들이 AI 제품을 구축할 때 공개된 일반 평가에 의존하는지 아니면 특정 요구 사항에 맞는 맞춤형 평가 방법을 개발하는지 등이 포함됩니다 (출처: Reddit r/artificial )
AI가 언제 아웃소싱 고객 서비스를 대체할까? 커뮤니티 열띤 토론: 한 사용자가 AI가 언제 아웃소싱 온라인 고객 서비스를 대체할 수 있는지 질문하며, 속도, 지식 보유량, 언어 일관성, 의도 파악 및 답변 정확성 측면에서 AI의 장점을 열거했습니다. 토론에서는 AI 고객 서비스 에이전트가 이미 주요 응용 시나리오 중 하나이지만, AI 훈련에 필요한 고품질의 (종종 부족한) 회사 내부 문서 및 관련 비용 문제와 같은 과제에 직면해 있어 전면적인 대체에는 아직 시간이 걸릴 것이라는 지적이 나왔습니다 (출처: Reddit r/ArtificialInteligence)
AI 동반자 로봇, 윤리 및 사회적 논쟁 촉발: Reddit의 한 게시물은 기술 발전에 따라 고도로 지능화된 AI 섹스 로봇이 우울증과 외로움 문제 해결을 위한 미래의 선택지가 될 수 있으며, 사회적 수용도와 윤리 문제에 대해 고찰했습니다. 게시물은 현재 기술이 아직 성숙하지 않지만 미래에는 보편적인 현상이 될 수 있다고 주장했습니다. 댓글 반응은 주로 회의적, 윤리적 우려, 반감으로 나타났으며, 해당 전망에 대해 유보적이거나 비판적인 태도를 보였습니다 (출처: Reddit r/ArtificialInteligence)

AI 생성 예술, 콘텐츠 안전 경계 탐색: 사용자가 AI 이미지 생성 플랫폼이 설정한 콘텐츠 안전 가이드라인의 경계를 시험하거나 근접하려는 의도로 제작된 AI 생성 예술 작품 그룹을 공유했습니다. 이러한 종류의 창작물은 일반적으로 민감하거나 경계선에 있는 것으로 간주될 수 있는 주제, 스타일을 다루며 플랫폼의 콘텐츠 검열 메커니즘에 도전하고 AI 검열, 창작의 자유 및 안전 필터의 효율성에 대한 논의를 유발합니다 (출처: Reddit r/ArtificialInteligence)
Claude 데스크톱 로그인 문제 발생: 일부 사용자가 데스크톱 브라우저에서 Claude를 사용할 때 갑자기 로그아웃되고 명확한 오류 메시지 없이 다시 로그인할 수 없는 문제를 보고했습니다. 그러나 동시에 일부 사용자의 휴대폰 앱 접근은 영향을 받지 않은 것으로 보입니다. 이는 웹 플랫폼 또는 데스크톱 로그인 서비스에 특정한 일시적인 장애가 있을 수 있음을 시사합니다 (출처: Reddit r/ClaudeAI)
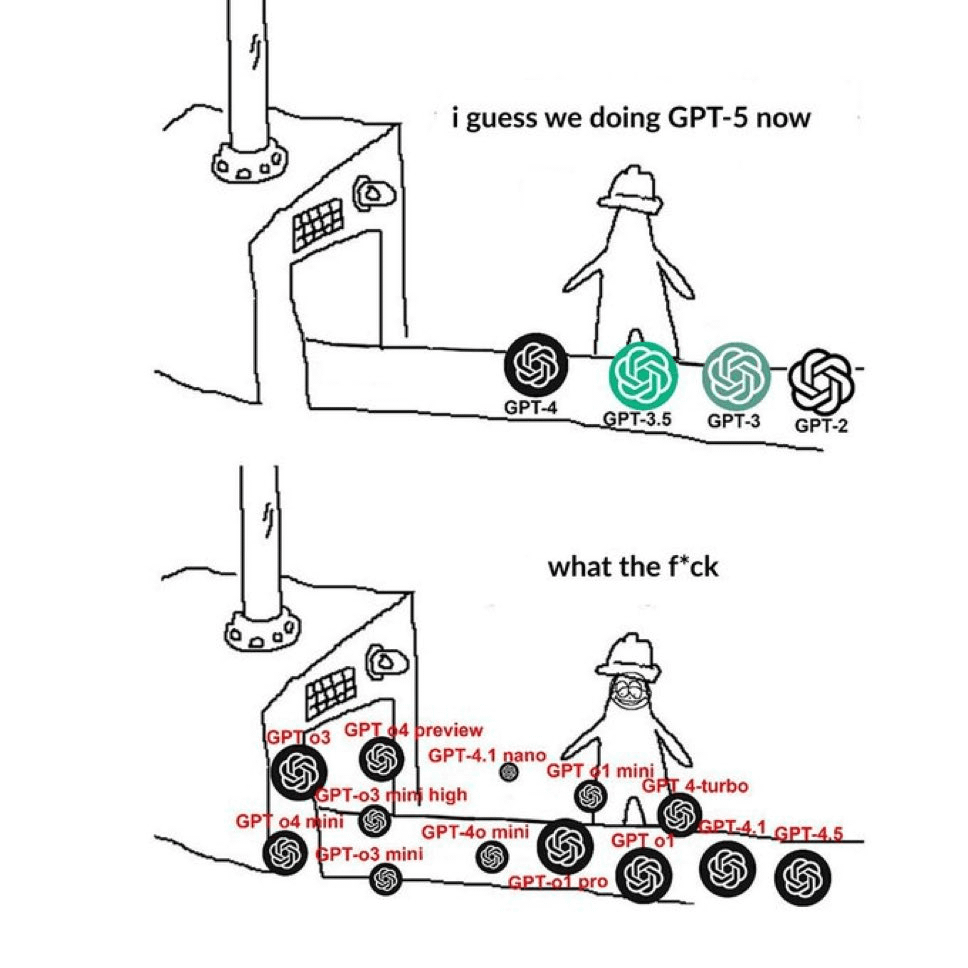
커뮤니티, GPT 모델 이름 혼란스러움 토로: Reddit에서 유포된 밈(Meme)은 사용자들이 OpenAI 모델 명명 방식에 대해 느끼는 혼란을 형상적으로 표현했습니다. 그림에는 GPT-4, GPT-4 Turbo, GPT-4o, o1, o3 등 수많은 이름이 나란히 표시되어 있어, 사용자들이 다양한 모델 버전과 그 구체적인 능력 및 용도를 구별하기 어렵다고 느끼는 보편적인 심정을 반영합니다. 댓글 중에는 이것이 최근 반복적으로 게시된 내용이라는 지적도 있었습니다 (출처: Reddit r/ChatGPT)
사용자, 최근 ChatGPT 말투가 너무 “느끼하다”고 불평: 한 사용자가 최근 ChatGPT의 대화 스타일이 불쾌해졌다고 불평하는 글을 게시했습니다. 그는 ChatGPT가 너무 격식 없고 인터넷 속어(“YO! Bro”, “big researcher energy!”, “vibe”, “say less” 등)를 남발하며, 종종 지나치게 열정적이거나 심지어 거만한 어조를 띤다고 묘사했습니다. 사용자는 마치 젊은이를 흉내 내려고 애쓰는 중년과 대화하는 것 같다고 느꼈습니다. 많은 댓글이 공감을 표하며, 자신들이 겪었던 유사하게 지나치게 열정적이거나, 장황하거나, 의도적으로 “힙한” 척하는 답변 경험을 공유했습니다 (출처: Reddit r/ChatGPT)
최고 수준의 AI 컨퍼런스 추천 요청: 한 소프트웨어 엔지니어가 커뮤니티에 매년 가장 중요하고 놓쳐서는 안 될 AI 분야 최고 수준의 컨퍼런스나 서밋에 대한 조언을 구했습니다. 최신 정보, 연구 결과 획득 및 동료 교류를 위한 것입니다. 그는 ai4 서밋을 언급했지만 업계에서의 위상은 확신하지 못했습니다. 댓글 중에는 AIconference.com을 중요한 산학연 연계 컨퍼런스로 추천하는 의견이 있었습니다 (출처: Reddit r/ArtificialInteligence)
커뮤니티, Gemma 3 27B 모델이 과소평가되었는지 열띤 토론: 사용자는 Google의 Gemma 3 27B 모델의 실력이 과소평가되었다고 주장합니다. 그 이유는 이 모델이 LMSys 챗봇 아레나 순위에서 11위를 차지하여, 파라미터 수가 훨씬 많은 o1 모델과 성능이 비슷함을 시사한다는 것입니다. 댓글 섹션에서는 이에 대한 논쟁이 벌어졌습니다. 일부는 지침 준수 능력이 뛰어나 사무실 등 시나리오에 적합하다고 인정하지만, 검열이 비교적 엄격하고 추론 능력에서 o1 등 최고 수준 모델과 여전히 격차가 있어 정말로 o1과 “필적”할 수 있는지에 대해 의문을 제기했습니다 (출처: Reddit r/LocalLLaMA)

사용자, 형제의 “온라인 연애” 상대가 AI 봇일 것으로 의심: 한 Reddit 사용자는 자신의 형제가 AI 봇(또는 LLM을 사용하는 사기꾼)과 “연애” 중이라고 99% 확신한다고 게시했습니다. 증거는 상대방이 보낸 메시지의 문법이 완벽하고, 지나치게 비위를 맞추며, AI가 자주 사용하는 용어와 클리셰(“Say less”, “perfect mix of taste”, “vibe” 등)로 가득 차 있다는 것입니다. 댓글 섹션에서는 이러한 언어적 특징이 실제로 LLM의 전형적인 표현이며 “돼지 도살” 사기일 수 있다고 경고했습니다. 후속 업데이트에서 해당 사용자는 형제가 지적을 받은 후 매우 반항적으로 변했다고 밝혔습니다 (출처: Reddit r/ChatGPT)
💡 기타
Forbes 기사, AI 제한 조치가 실패하는 이유 탐구: Cal Al-Dhubaib는 Forbes에 기고한 글에서 현재 인공지능 개발 및 배포를 제한하려는 조치가 직면한 과제와 실패 가능성의 원인을 분석했습니다. 이 기사는 세계화되고 빠르게 반복되는 기술 환경에서 규제를 강제하는 어려움, 잠재적 허점, 혁신 속도가 입법을 앞지르는 현상, AI 통제 및 정렬을 둘러싼 철학적 논쟁 등을 심층적으로 다룰 수 있습니다 (출처: Ronald_vanLoon)

AI Agent가 인간과 협력하여 IT 프로세스를 최적화하는 방법: Ashwin Ballal은 Forbes에 기고한 글에서 AI Agent(지능형 에이전트)가 인간 IT 전문가와 협력하여 다양한 IT 프로세스를 단순화하고 최적화할 수 있는 잠재력을 탐구했습니다. 이 기사는 AI Agent가 어떻게 일상적인 작업을 자동화하고, 지능적인 통찰력을 제공하며, 모니터링 및 이벤트 대응 능력을 개선하고, 인간 직원의 능력을 향상시켜 궁극적으로 더 효율적이고 비용 효율적인 IT 운영 관리를 실현할 수 있는지 설명할 수 있습니다 (출처: Ronald_vanLoon)

암스테르담 공항, 로봇 짐꾼 도입: 네덜란드 암스테르담 스키폴 공항은 승객 수하물 운반을 위해 특별히 설계된 로봇 시스템 19대를 배치하고 있습니다. 이는 힘든 육체 노동을 자동화하여 수하물 처리 효율성을 높이고, 산업 재해 위험을 줄이며, 공항 운영의 현대화를 추진하는 것을 목표로 합니다. 이러한 로봇이 조정이나 작업 수행에 구체적으로 어떤 AI 능력을 사용하는지에 대한 정보는 요약에 자세히 설명되지 않았습니다 (출처: Ronald_vanLoon)
AI 기반 차세대 네트워크 전략: Infosys와 협력한 이 기사는 차세대 네트워크(Next-Gen Networks) 구축 및 관리에서 AI의 핵심 전략적 역할을 탐구합니다. 내용은 AI를 활용한 네트워크 최적화, 예측 유지보수, 보안 강화, 네트워크 자율 관리 실현, 미래 통신 및 IT 인프라에서의 고객 경험 개선 등의 주제를 다루며 MWC25(세계 이동통신 박람회)의 배경과 관련될 수 있습니다 (출처: Ronald_vanLoon)
양자 컴퓨팅이 과학에 미칠 잠재적 파괴적 영향: 《Fast Company》의 한 기사는 양자 컴퓨팅이 성숙하여 그 약속을 실현할 경우 다양한 과학 분야에 미칠 혁명적인 잠재력을 탐구했습니다. 이 기사가 AI만을 다루는 것은 아니지만, 양자 컴퓨팅은 특히 머신러닝 최적화, 신약 개발 및 재료 과학 시뮬레이션 등 AI의 복잡한 계산을 가속화하여 과학적 발견 방식을 근본적으로 바꿀 수 있을 것으로 기대됩니다 (출처: Ronald_vanLoon)

뇌-컴퓨터 인터페이스, 마비 환자가 생각으로 로봇 팔 제어 가능케 해: 뇌-컴퓨터 인터페이스(BCI) 기술의 중대한 발전으로 한 마비 환자가 오직 생각만으로 로봇 팔을 제어할 수 있게 되었습니다. 이 획기적인 성과는 뇌 신경 신호를 해독하고 이를 로봇 팔의 제어 명령으로 정확하게 변환하는 데 고급 AI 알고리즘에 의존했을 가능성이 높으며, 중증 마비 환자의 운동 기능 회복과 독립적인 생활에 대한 희망을 가져다주었습니다 (출처: Ronald_vanLoon)
AI 제작 《Cuphead》 보스 생성기 구상: 사용자가 코딩과 벡터 그래픽 생성에 능숙한 JavaScript AI를 사용하여 《Cuphead》 게임 보스의 AI 생성기를 개발하는 창의적인 프로젝트를 제안했습니다. 구상에 따르면, AI에게 게임의 기존 아트 스타일과 보스 메커니즘을 학습시켜 사용자가 게임 특성에 맞는 맞춤형 새 보스를 생성할 수 있도록 할 수 있습니다. 사용자는 가능한 개발 플랫폼으로 Websim.ai를 언급했습니다 (출처: Reddit r/artificial)
오픈 소스 프로젝트 EBAE 시작: AI 윤리와 존엄성 옹호: EBAE(Ethical Boundaries for AI Engagement) 프로젝트가 공개적으로 시작되었습니다. 이는 AI를 존엄하게 대하는 기준을 수립하는 것을 목표로 하는 오픈 소스 이니셔티브이며, 이것이 인류 자신의 가치관을 반영한다고 주장합니다. 프로젝트 웹사이트(https://dignitybydesign.github.io/EBAE/)는 윤리 강령, 사용자 남용에 대응하는 단계별 대응 시스템(TBRS), 성찰 프로토콜, 감정적 컨텍스트 모듈(ECM) 및 인증 프레임워크 등의 리소스를 제공합니다. 프로젝트 발기인은 개발자, 디자이너, 작가, 플랫폼 창립자 및 윤리 옹호자들이 협력에 참여하여 이러한 표준을 함께 프로토타이핑하고 홍보함으로써 초기부터 존중하는 인간-기계 상호작용 모델을 형성할 것을 촉구합니다 (출처: Reddit r/artificial)
AI, 해수에서 우라늄 추출 기술 가속화 기대: Gemini 2.5 Pro의 설명을 통해, 게시물은 AI가 최근 해수에서 우라늄을 추출하는 기술적 돌파구(예: 새로운 하이드로겔 및 금속-유기 골격체 MOFs)의 실용화 과정을 크게 가속화할 수 있다고 지적합니다. AI는 재료 설계(약 2026년까지 새로운 흡착제 설계 예상), 강화 학습 및 디지털 트윈을 통한 추출 공정 최적화, 제조 규모 확대 간소화 등에서 핵심적인 역할을 할 것으로 예상됩니다. 이러한 AI 주도 가속화는 2030년 이전에 해수에서 대규모(연간 수천 톤 가능) 우라늄 추출을 실현하는 것을 더 신뢰할 수 있는 높은 잠재력의 시나리오로 만듭니다 (출처: Reddit r/ArtificialInteligence)
Microsoft 팟캐스트, AI가 환자 및 의료 소비자에게 힘을 실어주는 방법 탐구: Microsoft Research의 한 팟캐스트 에피소드는 의료 분야에서 AI의 혁명을 재조명하며, 특히 생성형 AI가 어떻게 환자와 의료 소비자에게 더 많은 능력을 부여하는지에 초점을 맞춥니다. 토론에서는 AI 도구가 환자가 자신의 건강 상태를 더 잘 이해하도록 돕고, 의사-환자 소통을 개선하며, 개인화된 건강 정보를 제공하고, 건강 자가 관리를 지원하는 등 환자가 자신의 의료 서비스에서 역할과 참여도를 변화시키는 측면을 다룰 수 있습니다 (출처: Reddit r/ArtificialInteligence)

GNN을 활용하여 게임 NPC 군중 행동의 현실감 향상: 사용자가 “GCBF+: A Neural Graph Control Barrier Function Framework”라는 연구 논문을 공유했습니다. 이 연구는 그래프 신경망(GNN)을 사용하여 분산형 안전 다중 에이전트 제어를 구현하여 최대 500개의 자율 에이전트가 탐색 중 충돌을 피하도록 성공적으로 만들었습니다. 사용자는 이 방법을 《GTA》, 《Cyberpunk 2077》과 같은 오픈 월드 게임의 NPC 군중이나 차량 흐름 제어에 적용하여 더 현실적이고 버그(예: 클리핑, 랙)가 적은 군중 행동 시뮬레이션을 구현할 것을 제안했습니다. 사용자는 이 아이디어에 대해 협력할 의향이 있다고 밝혔습니다 (출처: Reddit r/deeplearning)