
키워드:AI 발전, Grok 3, Gemma 3, AI 응용, AI 발전 패러다임 전환, xAI Grok 3 API, Google Gemma 3 QAT, VideoGameBench AI 평가, AI 분자 발견 가속, 연합 학습 의료 영상, LlamaIndex 지식 에이전트, AI 코드 자가 수정 기술
🔥 포커스
AI 발전 패러다임 전환: 순위 경쟁에서 가치 창출로: OpenAI 연구원 Yao Shunyu의 블로그가 토론을 촉발하며 AI 발전이 후반전에 접어들었다고 주장했습니다. 전반전은 알고리즘 혁신과 벤치마크 점수 경쟁(예: AlphaGo, GPT-4)에 초점을 맞추었으며, 대규모 사전 훈련(사전 지식 제공)과 강화 학습(RL)을 결합하고 “추론이 곧 행동”이라는 개념을 도입하여 일반화의 돌파구를 마련했습니다. 그러나 그는 지속적인 순위 경쟁의 한계 효용이 감소하고 있으며, 후반전에는 실제 응용 가치가 있는 문제를 정의하고, 현실 세계에 더 가까운 평가 방법을 개발하며, 제품 관리자처럼 생각하여 단순히 지표 향상을 추구하는 것이 아니라 AI를 통해 사용자 가치와 사회적 가치를 진정으로 창출하는 방향으로 전환해야 한다고 주장합니다. 이는 AI 분야가 기술 탐색 중심에서 응용 실현 및 가치 구현 중심으로 사고방식이 전환되고 있음을 나타냅니다 (출처: dotey)
xAI, Grok 3 시리즈 모델 API 출시: xAI가 Grok 3 시리즈 모델의 API 인터페이스(docs.x.ai)를 공식 출시하여 최신 모델을 개발자에게 공개했습니다. 이 시리즈에는 Grok 3 Mini와 Grok 3가 포함됩니다. xAI에 따르면, Grok 3 Mini는 낮은 비용(유사 추론 모델보다 5배 저렴하다고 주장)을 유지하면서 우수한 추론 능력을 보여주며, Grok 3는 강력한 비추론 모델(지식 집약적 작업 지칭 가능성)로 자리매김하여 법률, 금융, 의료 등 실제 세계 지식이 필요한 분야에서 뛰어난 성능을 보입니다. 이는 xAI가 AI 모델 API 시장 경쟁에 합류하여 개발자에게 새로운 선택지를 제공함을 의미합니다 (출처: grok, grok)
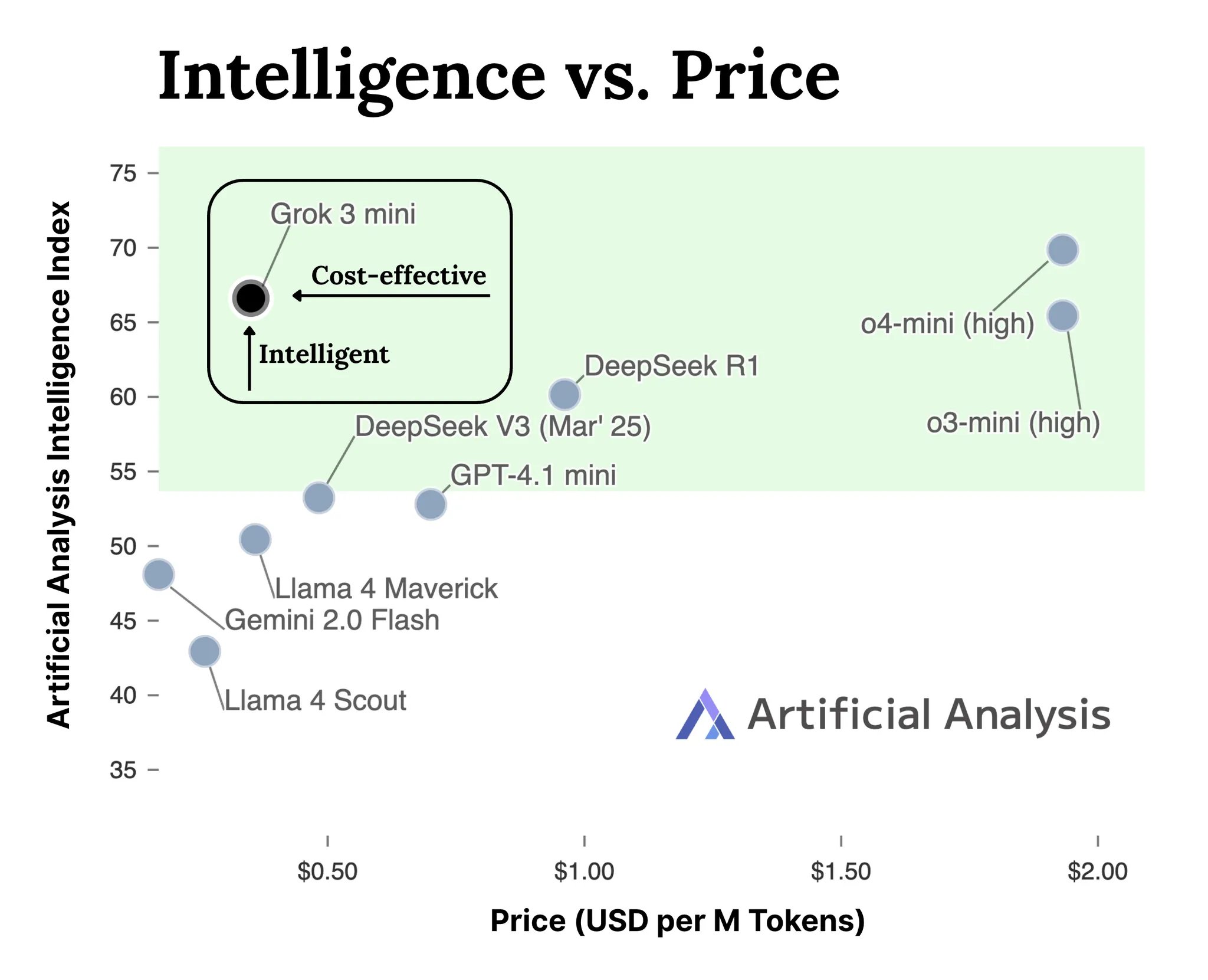
VideoGameBench: 고전 게임으로 AI 에이전트 능력 평가: 연구자들이 VideoGameBench 벤치마크 미리보기 버전을 출시했습니다. 이는 시각 언어 모델(VLM)이 20가지 고전 비디오 게임(예: Doom II)의 작업을 실시간으로 완료하는 능력을 평가하기 위한 것입니다. 초기 테스트 결과, GPT-4o, Claude Sonnet 3.7, Gemini 2.5 Pro를 포함한 최고 수준 모델들이 Doom II에서 각기 다른 성능을 보였지만, 모두 첫 번째 단계를 통과하지 못했습니다. 이는 모델들이 많은 작업에서 강력한 능력을 보이지만, 실시간 인식, 의사 결정 및 행동이 필요한 복잡하고 동적인 환경에서는 여전히 어려움을 겪고 있음을 보여줍니다. 이 벤치마크는 상호작용 환경에서 AI 에이전트의 발전을 측정하고 촉진하는 새로운 도구를 제공합니다 (출처: Reddit r/LocalLLaMA)
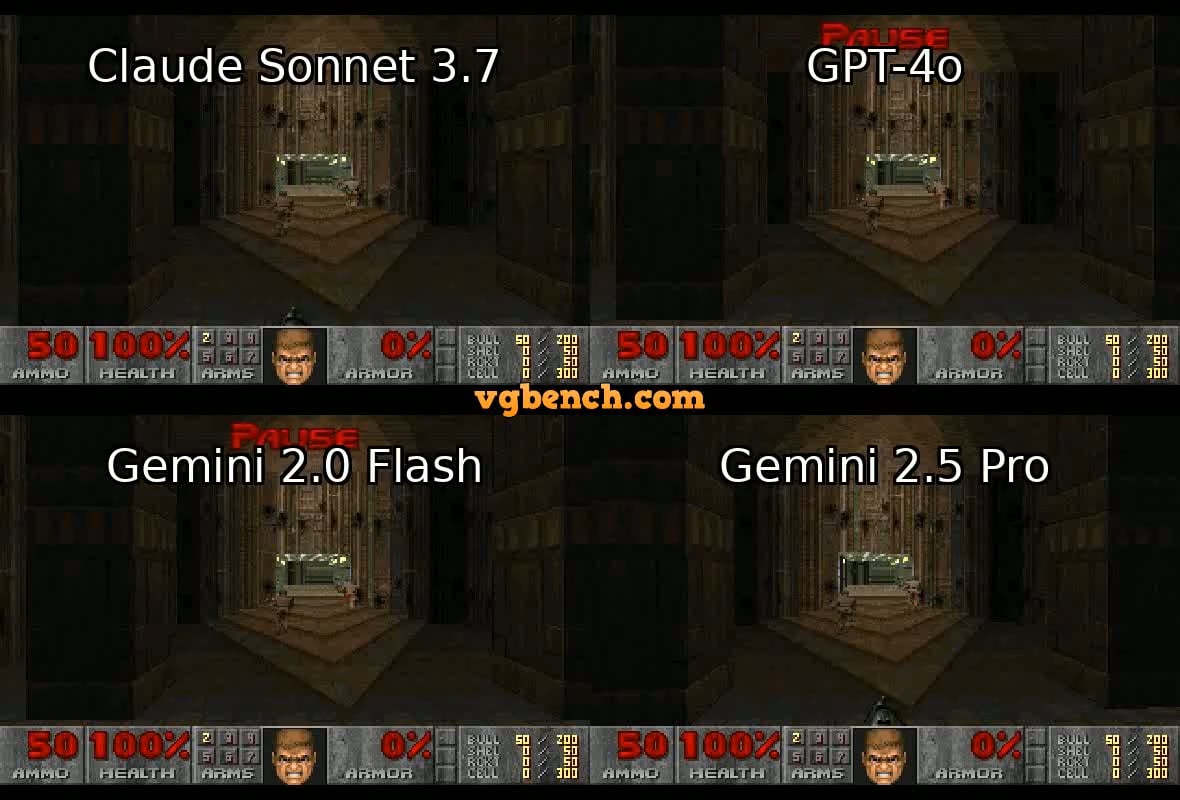
OpenAI, 신원 인증 강화로 논란: OpenAI가 일부 고급 모델(특히 강력한 추론 능력을 갖춘 o3 등)에 접근하기 위해 사용자에게 상세한 신원 증명(예: 여권, 세금 고지서, 공과금 청구서)을 요구하는 것으로 알려져 논란이 되고 있습니다. 이 조치는 커뮤니티에서 강한 반발을 불러일으켰으며, 사용자들은 개인 정보 유출과 접근 장벽 상승을 우려하고 있습니다. OpenAI가 보안, 규정 준수 또는 자원 관리상의 이유로 이러한 조치를 취했을 수 있지만, 이 엄격한 인증 요구는 개방적인 이미지와 대조되며, 사용자들이 개인 정보 보호가 더 우수하거나 접근하기 쉬운 대안, 특히 로컬 모델로 전환하도록 유도할 수 있습니다 (출처: Reddit r/LocalLLaMA)
AI, 분자 발견 가속화: 자연의 수억 년 진화 모방: 소셜 미디어 토론에서 인공지능이 며칠 만에 분자를 설계할 수 있으며, 이는 자연계에서 5억 년이 걸려 진화할 수 있는 분자라는 언급이 있었습니다. 구체적인 세부 사항은 검증이 필요하지만, 이는 AI가 과학적 발견, 특히 화학 및 생물학 분야에서 발견을 가속화하는 데 엄청난 잠재력을 가지고 있음을 강조합니다. AI는 광대한 화학 공간을 탐색하고 분자 특성을 예측할 수 있으며, 그 속도는 전통적인 실험 방법과 자연 진화를 훨씬 능가하여 신약 개발, 재료 과학 등 분야에서 획기적인 진전을 가져올 것으로 기대됩니다 (출처: Ronald_vanLoon)
🎯 동향
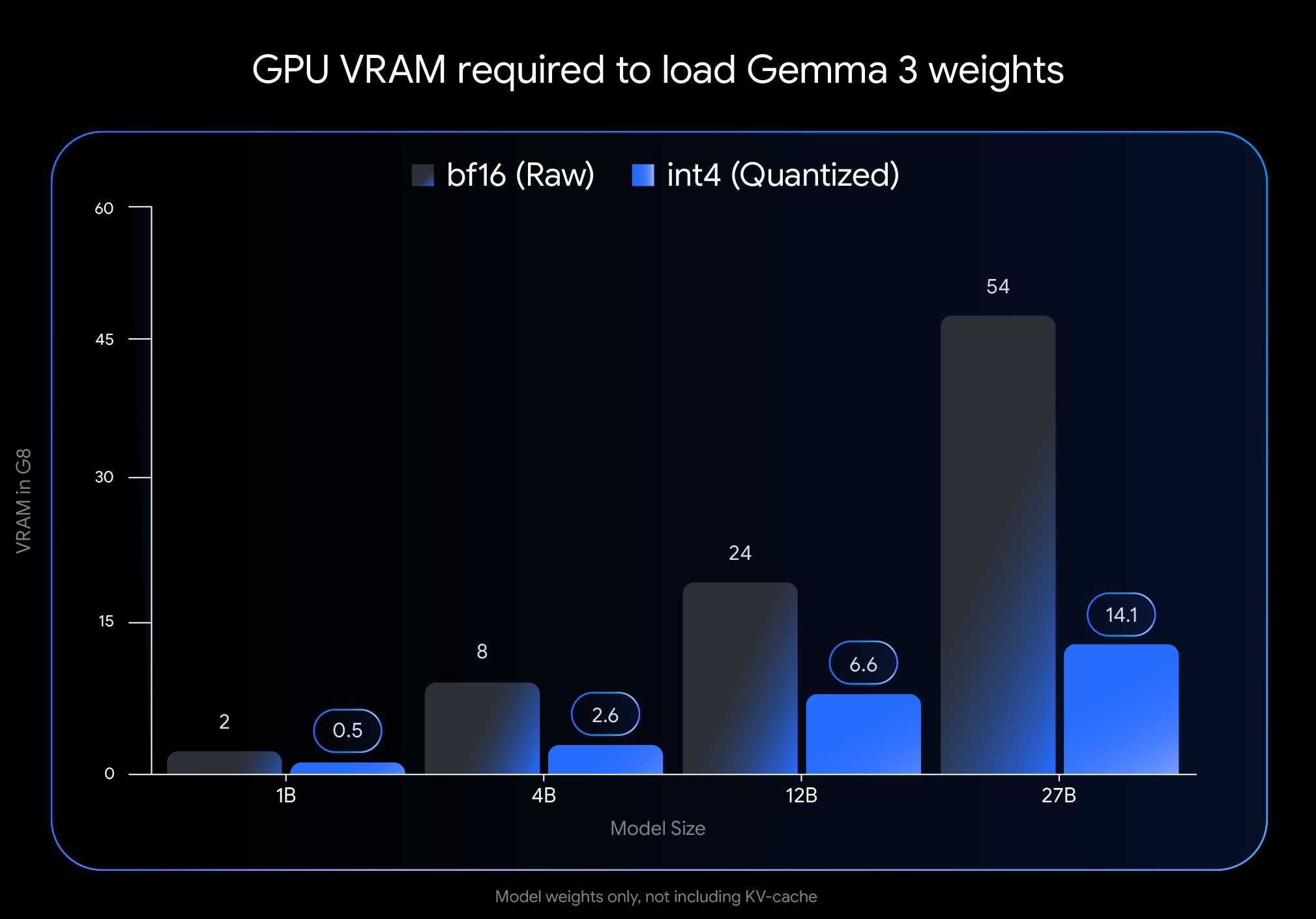
Google, Gemma 3 QAT 버전 출시로 배포 장벽 대폭 낮춰: Google DeepMind가 양자화 인식 훈련(Quantization-Aware Training, QAT)을 거친 Gemma 3 모델 버전을 출시했습니다. QAT 기술은 모델 크기를 대폭 압축하면서 원본 모델의 성능을 최대한 유지하는 것을 목표로 합니다. 예를 들어, Gemma 3 27B 모델의 크기는 54GB(bf16)에서 약 14.1GB(int4)로 줄어들어, 이전에는 고급 클라우드 GPU가 필요했던 선도적인 모델을 이제 소비자급 데스크톱 GPU(예: RTX 3090)에서 실행할 수 있게 되었습니다. Google은 비양자화 QAT 체크포인트 및 다양한 형식(MLX, GGUF)을 출시했으며, Ollama, LM Studio, llama.cpp 등 커뮤니티 도구와 협력하여 개발자가 다양한 플랫폼에서 편리하게 사용할 수 있도록 보장함으로써 고성능 오픈 소스 모델의 보급을 크게 촉진했습니다 (출처: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR, 인식 연구 성과 발표하며 오픈 소스 노선 유지: Meta FAIR가 고급 기계 지능(AMI) 분야의 여러 새로운 연구 성과를 발표했으며, 특히 인식 분야에서 진전을 이루었습니다. 여기에는 대규모 시각 인코더 Meta Perception Encoder 출시가 포함됩니다. Yann LeCun은 이러한 성과가 오픈 소스로 공개될 것이라고 강조했습니다. 이는 Meta가 기초 AI 연구에 지속적으로 투자하고 있으며, 오픈 소스를 통해 연구 진척 상황을 공유하여 전체 분야의 발전을 촉진하겠다는 의지를 보여줍니다. 발표된 시각 인코더 등의 도구는 더 넓은 연구 및 개발자 커뮤니티에 혜택을 줄 것입니다 (출처: ylecun)
OpenAI, 모델 사용 제한 명확화: OpenAI가 ChatGPT Plus, Team, Enterprise 사용자의 모델 사용량을 명확히 규정했습니다. 이에 따르면, o3 모델은 주당 50개 메시지, o4-mini는 하루 150개, o4-mini-high는 하루 50개로 제한됩니다. ChatGPT Pro(특정 요금제 또는 오류일 수 있음)는 무제한 접근 권한을 가진다고 합니다. 이러한 제한은 고빈도 사용자 및 특정 모델에 의존하는 애플리케이션 개발자에게 직접적인 영향을 미치므로 사용 계획 시 고려해야 합니다 (출처: dotey)
LlamaIndex, Google Cloud 데이터베이스와 통합하여 지식 에이전트 구축: Google Cloud Next 2025 컨퍼런스에서 LlamaIndex는 자사 프레임워크가 Google Cloud 데이터베이스와 통합되어 다단계 연구 수행, 문서 처리 및 보고서 생성이 가능한 지식 에이전트를 구축하는 방법을 시연했습니다. 시연에는 직원 온보딩 가이드 자동 생성 멀티 에이전트 시스템 사례가 포함되었습니다. 이는 AI 애플리케이션 프레임워크와 클라우드 플랫폼 및 해당 데이터 서비스 간의 깊은 융합 추세를 보여주며, 기업이 AI를 활용하여 내부 지식과 데이터를 처리하는 실제 요구 사항을 해결하는 것을 목표로 합니다 (출처: jerryjliu0)

신형 나노 뇌 센서, AI와 결합하여 고정밀 신호 인식 실현: 연구 보고서에 따르면 새로운 나노 스케일 뇌 센서가 신경 신호 인식에서 96.4%의 정확도를 달성했습니다. 센서 기술 자체가 핵심적인 돌파구이지만, 이처럼 높은 인식 정확도를 달성하려면 일반적으로 복잡하고 미약한 신경 신호를 해독하기 위해 고급 AI 및 머신러닝 알고리즘의 도움이 필요합니다. 이 진전은 뇌 과학 연구와 미래의 뇌-컴퓨터 인터페이스 응용에 새로운 길을 열어주며, 더 정밀한 뇌 활동 모니터링 및 상호 작용을 가능하게 할 것으로 기대됩니다 (출처: Ronald_vanLoon)

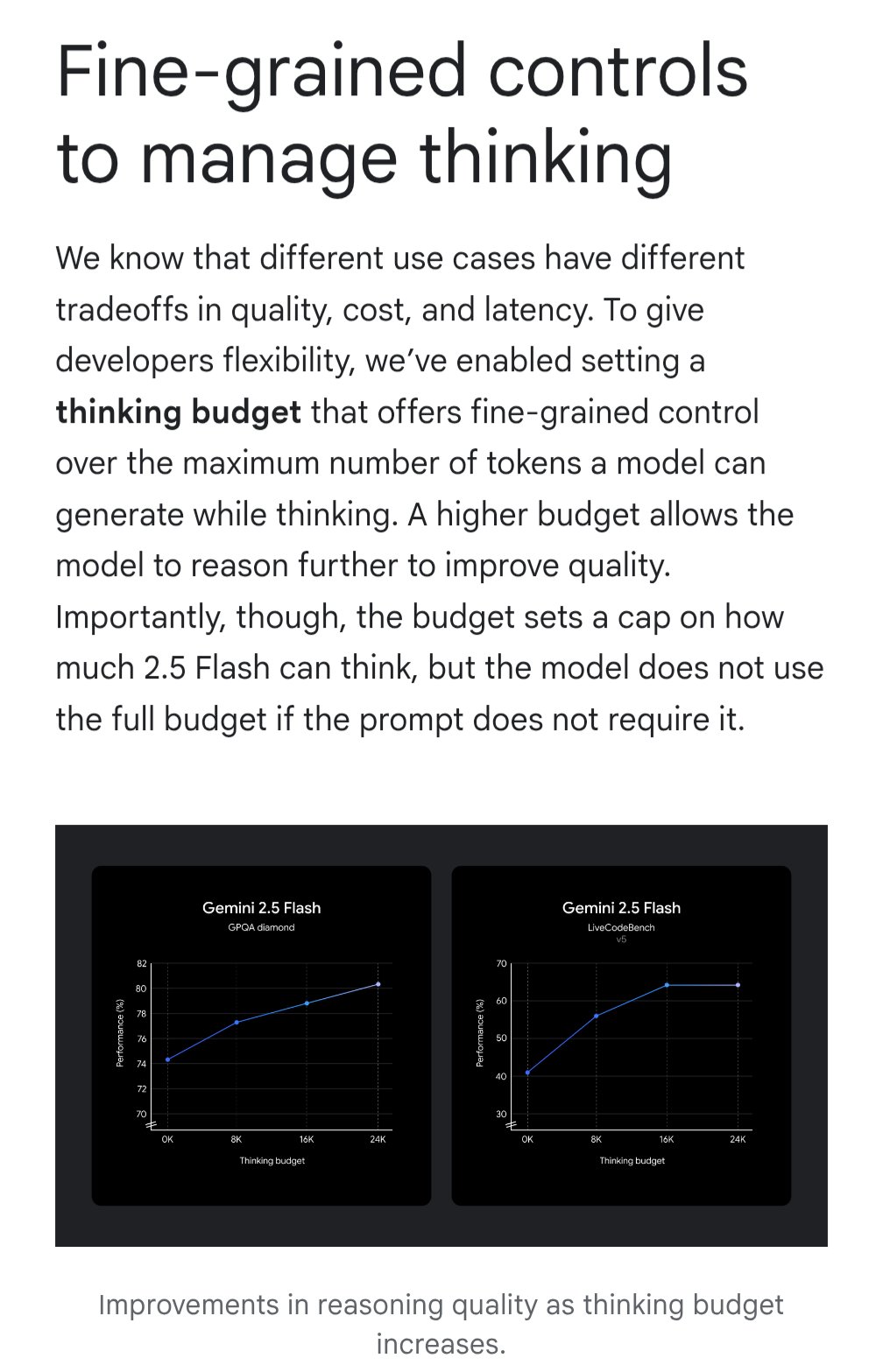
Gemini, ‘사고 예산’ 기능 도입으로 비용 효율성 최적화: Google Gemini 모델에 ‘사고 예산’(thinking budget) 기능이 도입되어 사용자가 쿼리 처리 시 모델에 할당되는 계산 자원 또는 ‘사고’ 깊이를 조정할 수 있게 되었습니다. 이 기능은 사용자가 응답 품질, 비용 및 지연 시간 사이에서 균형을 맞출 수 있도록 하는 것을 목표로 합니다. 이는 API 사용자에게 매우 실용적인 기능으로, 특정 응용 시나리오의 요구 사항에 따라 모델 사용 비용과 성능을 유연하게 제어할 수 있습니다 (출처: JeffDean)
AI 보조 초음파 검사 품질, 전문가 수준에 필적: JAMA Cardiology에 발표된 연구에 따르면, 훈련받은 의료 전문가가 AI 안내 하에 수행한 초음파 검사의 이미지 품질은 진단 기준을 충족하기에 충분했으며(98.3%), AI 안내 없이 전문가가 얻은 이미지와 비교했을 때 통계적으로 유의미한 차이가 없었습니다. 이는 AI가 보조 도구로서 비전문가 사용자가 의료 영상 조작의 품질과 일관성을 효과적으로 향상시키는 데 도움을 줄 수 있음을 보여주며, 자원이 제한된 지역에서 고품질 진단 서비스의 접근성을 확대할 수 있을 것으로 기대됩니다 (출처: Reddit r/ArtificialInteligence)
MIT 연구, AI 생성 코드의 정확성 및 구조 준수 향상: MIT 연구원들이 대규모 언어 모델의 출력을 제어하는 더 효율적인 방법을 개발했습니다. 이는 모델이 특정 구조(예: 프로그래밍 언어 구문)를 따르고 오류 없는 코드를 생성하도록 유도하는 것을 목표로 합니다. 이 연구는 AI 생성 코드의 신뢰성 문제를 해결하기 위해 제약 조건 생성 기술을 개선하여 출력이 구문 규칙을 엄격하게 준수하도록 보장함으로써 AI 코드 어시스턴트의 실용성을 높이고 후속 디버깅 비용을 줄이는 데 전념하고 있습니다 (출처: Reddit r/ArtificialInteligence)
NVIDIA, 로봇 분야 주요 프로젝트 공개 가능성: 소셜 미디어에서 NVIDIA가 로봇 공학, 엔지니어링, 인공지능 및 자율 기술과 관련된 “가장 야심찬 프로젝트”를 진행 중이라는 언급이 있었습니다. 구체적인 내용은 알려지지 않았지만, NVIDIA가 AI 하드웨어 및 플랫폼(예: Isaac) 분야의 핵심 위치에 있다는 점을 고려할 때, 관련된 주요 발표는 큰 주목을 받을 것이며, 이는 구현된 지능 및 로봇 분야에서의 추가적인 전략적 배치와 기술적 돌파구를 예고할 수 있습니다 (출처: Ronald_vanLoon)
🧰 도구
Potpie: 코드 저장소 전용 AI 엔지니어링 어시스턴트: Potpie는 코드 저장소를 위한 맞춤형 AI 엔지니어링 에이전트를 생성하기 위한 오픈 소스 플랫폼(GitHub: potpie-ai/potpie)입니다. 코드 지식 그래프를 구축하여 컴포넌트 간의 복잡한 관계를 이해하고, 코드 분석, 테스트, 디버깅 및 개발과 같은 자동화된 작업을 제공합니다. 플랫폼은 다양한 사전 구축된 에이전트(예: 디버깅, Q&A, 코드 변경 분석, 단위/통합 테스트 생성, 저수준 설계, 코드 생성)와 도구 세트를 제공하며, 사용자가 사용자 정의 에이전트를 생성할 수 있도록 지원합니다. VSCode 확장 및 API 통합을 제공하여 개발 프로세스에 편리하게 통합할 수 있습니다 (출처: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: LLM 관리를 통합한 Linux 서버 패널: 1Panel (GitHub: 1Panel-dev/1Panel)은 현대적인 오픈 소스 Linux 서버 운영 관리 패널로, 웹 그래픽 인터페이스를 통해 호스트, 파일, 데이터베이스, 컨테이너 등을 관리할 수 있습니다. 특징 중 하나는 대규모 언어 모델(LLM) 관리 기능을 포함한다는 것입니다. 또한 애플리케이션 스토어, 웹사이트 빠른 배포(WordPress 통합), 보안 보호 및 원클릭 백업 복구 등의 기능을 제공하여 AI 관련 애플리케이션 배포 및 관리를 포함한 서버 관리 및 애플리케이션 배포를 간소화하는 것을 목표로 합니다 (출처: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex, 업그레이드된 채팅 UI 컴포넌트 출시: LlamaIndex가 채팅 UI 컴포넌트 라이브러리(@llamaindex/chat-ui)의 주요 업데이트를 발표했습니다. 새로운 컴포넌트는 shadcn UI를 기반으로 구축되었으며, 더 세련된 디자인, 반응형 레이아웃을 갖추고 있으며 완전히 사용자 정의 가능합니다. 개발자가 LLM 기반 프로젝트를 위해 미려하고 사용자 친화적인 채팅 인터페이스를 더 쉽게 구축하여 AI 애플리케이션의 상호 작용 경험을 향상시키는 것을 목표로 합니다. 개발자는 npm을 통해 설치하고 프로젝트에서 직접 사용할 수 있습니다 (출처: jerryjliu0)
LlamaExtract 실전: 금융 분석 애플리케이션 구축: LlamaIndex는 LlamaExtract 도구(LlamaCloud의 일부)를 활용하여 풀스택 웹 애플리케이션을 구축하는 사례를 선보였습니다. LlamaExtract를 사용하면 사용자가 정확한 Schema를 정의하여 복잡한 문서에서 구조화된 데이터를 추출할 수 있습니다. 이 예제 애플리케이션은 회사 연례 보고서에서 위험 요소를 추출하고 연도별 변화를 분석하여 이전에는 20시간 이상 소요되던 작업을 자동화합니다. 이 애플리케이션은 오픈 소스(GitHub: run-llama/llamaextract-10k-demo)로 공개되었으며, LlamaExtract와 Sonnet 3.7을 결합하여 이 워크플로우를 구축하는 방법을 보여주는 비디오 데모가 있어 복잡한 분석 작업 자동화에서 AI 에이전트의 잠재력을 보여줍니다 (출처: jerryjliu0, jerryjliu0)
mcpbased.com: 오픈 소스 MCP 서버 디렉토리 오픈: 새로운 웹사이트 mcpbased.com이 오픈 소스 MCP(Meta Controller Pattern 또는 유사 개념 가능성) 서버 전용 디렉토리로 시작되었습니다. 이 플랫폼은 다양한 MCP 서버 프로젝트를 모아 보여주고 Github 저장소 데이터를 실시간으로 동기화하여 개발자가 관련 도구를 쉽게 찾고, 탐색하고, 연결할 수 있도록 하는 것을 목표로 합니다. MCP 서버를 구축하거나 사용하고, 도구 통합을 수행하거나 MCP 생태계에 관심 있는 개발자에게 새로운 리소스 센터가 될 것입니다 (출처: Reddit r/ClaudeAI)
📚 학습
RLHF 서적, ArXiv에 등재: Nathan Lambert 등이 저술한 인간 피드백 기반 강화 학습(RLHF)에 관한 서적 “rlhfbook”이 ArXiv 플랫폼(번호 2504.12501)에 게시되었습니다. RLHF는 현재 ChatGPT와 같은 대규모 언어 모델(LLM)을 정렬하는 핵심 기술 중 하나입니다. 이 책의 출판은 연구자와 실무자에게 RLHF 원리 및 실습을 체계적으로 학습하고 깊이 이해할 수 있는 중요한 리소스를 제공하며, 해당 분야 지식의 전파 및 응용을 촉진합니다 (출처: natolambert)
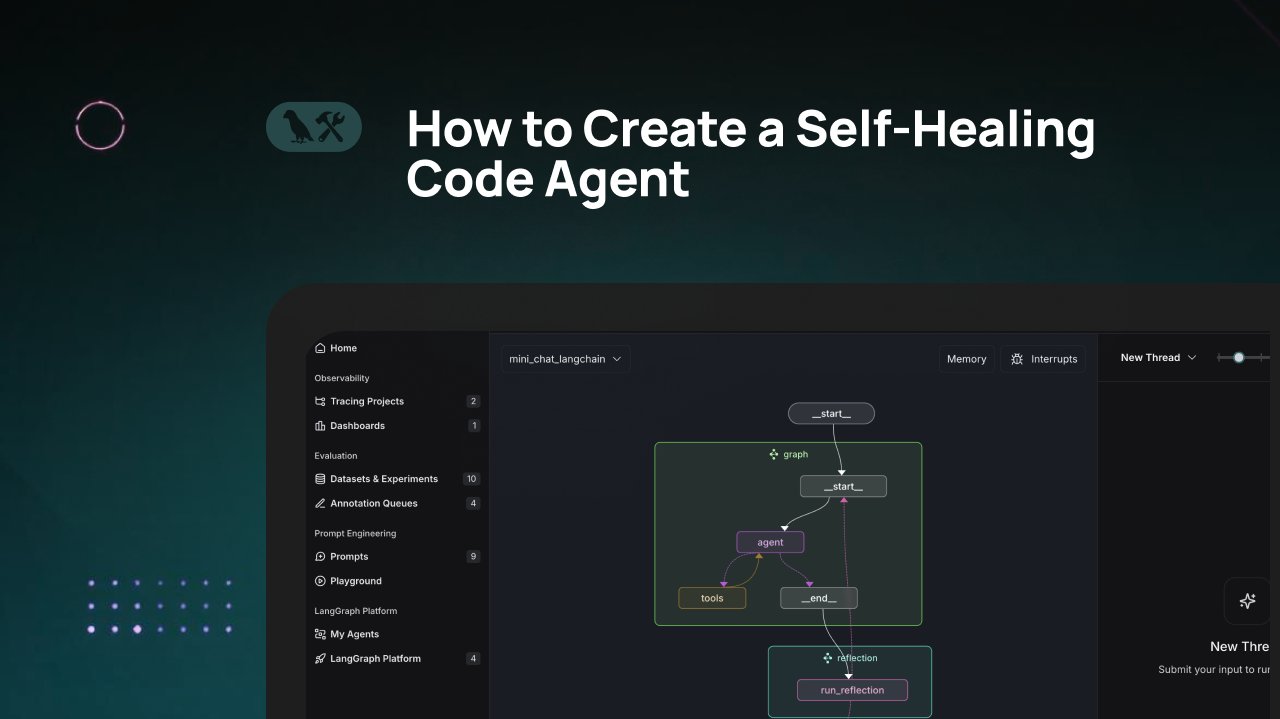
LangChain 튜토리얼: 자가 복구 코드 생성 에이전트 구축: LangChain이 “자가 복구” 능력을 갖춘 AI 코드 생성 에이전트를 구축하는 방법을 소개하는 비디오 튜토리얼을 공개했습니다. 핵심 아이디어는 코드 생성 후 “반성”(reflection) 단계를 추가하여 에이전트가 생성된 코드를 스스로 검증, 평가 또는 개선한 다음 결과를 반환하도록 하는 것입니다. 이 방법은 AI 생성 코드의 정확성과 신뢰성을 높이는 것을 목표로 하며, 코드 어시스턴트의 실용성을 향상시키는 효과적인 기술입니다 (출처: LangChainAI)
AI와 Blender 결합하여 게임용 3D 에셋 제작: 소셜 미디어에서 AI 도구(이미지 생성 가능성)와 3D 모델링 소프트웨어 Blender를 결합하여 게임에서 사용할 수 있는(game-ready) 3D 에셋을 제작하는 튜토리얼이 공유되었습니다. 이는 현재 AI가 직접 3D 모델을 생성하는 능력 부족 문제를 해결하기 위한 것으로, 실용적인 혼합 워크플로우를 보여줍니다. 즉, AI를 사용하여 개념이나 텍스처 맵을 생성한 다음, Blender와 같은 전문 도구를 통해 모델링, 최적화를 수행하여 최종적으로 게임 엔진 요구 사항을 충족하는 리소스를 생산하는 것입니다 (출처: huggingface)
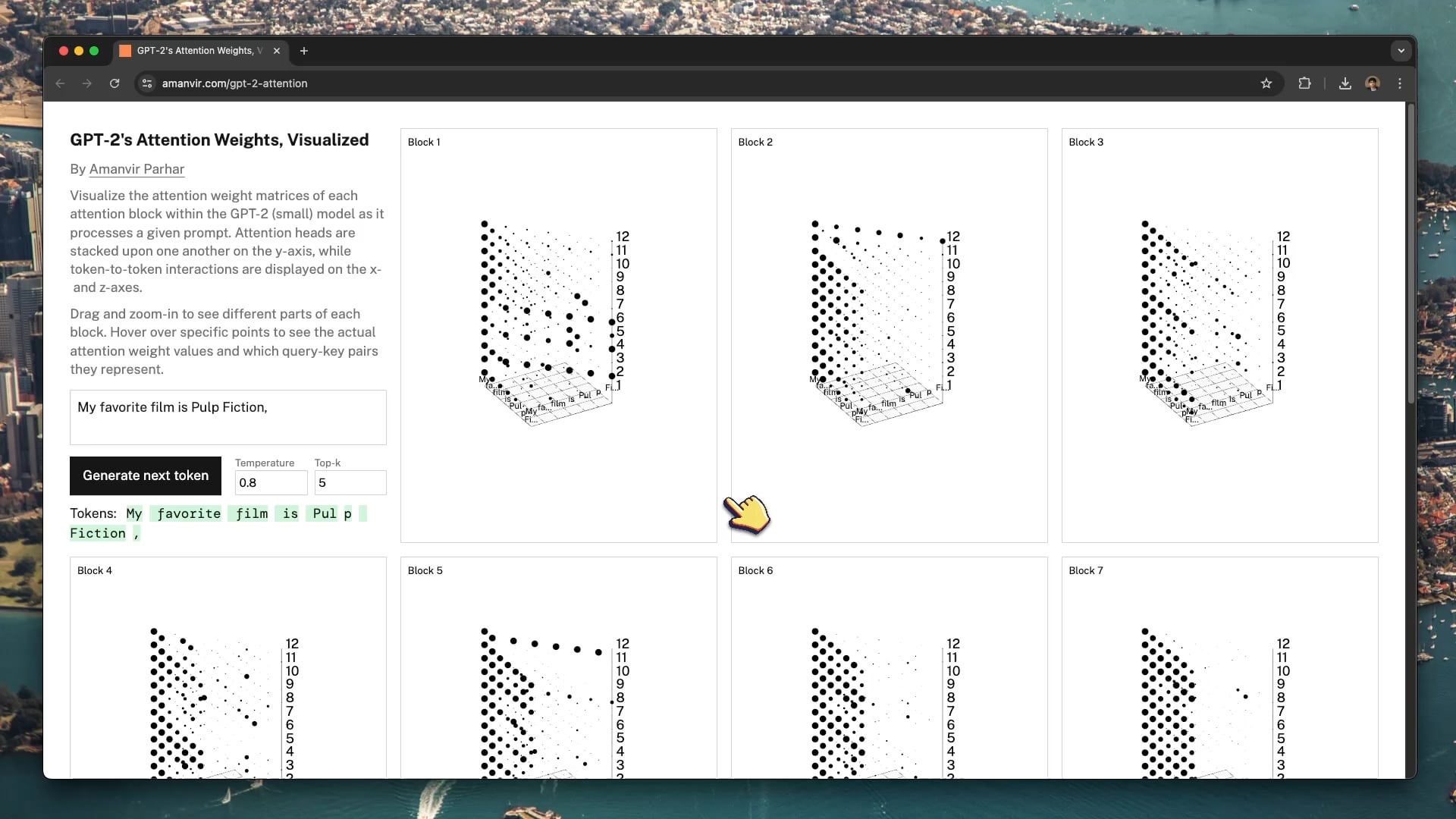
상호작용형 시각화 도구로 GPT-2 어텐션 메커니즘 이해 돕기: 개발자 tycho_brahes_nose_가 GPT-2(소형) 모델 내부의 각 어텐션 블록 가중치 계산 과정을 보여주는 상호작용형 3D 시각화 도구(amanvir.com/gpt-2-attention)를 제작하고 공유했습니다. 사용자는 입력 텍스트 후 모델이 다른 레이어, 다른 어텐션 헤드 간에 토큰과 토큰의 상호 작용 강도를 어떻게 계산하는지 직관적으로 볼 수 있습니다. 이는 Transformer 핵심 메커니즘을 이해하는 데 훌륭한 보조 자료를 제공하며, AI 학습 및 모델 해석 가능성 연구에 도움이 됩니다 (출처: karminski3, Reddit r/LocalLLaMA)
의료 영상 분석에서의 연합 학습 응용: Reddit 게시물은 연합 학습(Federated Learning, FL)과 심층 신경망(DNN)을 결합하여 의료 영상 분석에 적용하는 것에 관한 기사를 가리킵니다. 의료 데이터의 개인 정보 민감성 때문에 FL은 원본 데이터를 공유하지 않고 여러 기관에서 협력하여 모델을 훈련할 수 있도록 합니다. 이는 의료 분야에서 AI 응용을 추진하는 데 매우 중요하며, 이 리소스는 개인 정보 보호 분산 학습 기술과 의료 영상에서의 실습을 이해하는 데 도움이 됩니다 (출처: Reddit r/deeplearning)

Sander Dielman, VAE와 잠재 공간 심층 해설: Andrej Karpathy가 Sander Dielman의 변분 오토인코더(VAE) 및 잠재 공간 모델링에 대한 심층 블로그 게시물(sander.ai/2025/04/15/latents.html)을 추천했습니다. 이 글은 VAE 훈련의 세부 사항, 예를 들어 KL 발산 항이 잠재 공간 형성에 미치는 실제 영향이 제한적이라는 점, 그리고 L1/L2 재구성 손실이 흐릿한 이미지를 생성하는 경향이 있는 이유(이미지 스펙트럼 감쇠와 인간의 시각적 인식 초점 불일치) 등을 탐구합니다. 이 글은 생성 모델을 이해하는 데 엄격하고 통찰력 있는 분석을 제공합니다 (출처: Reddit r/MachineLearning)
💼 비즈니스
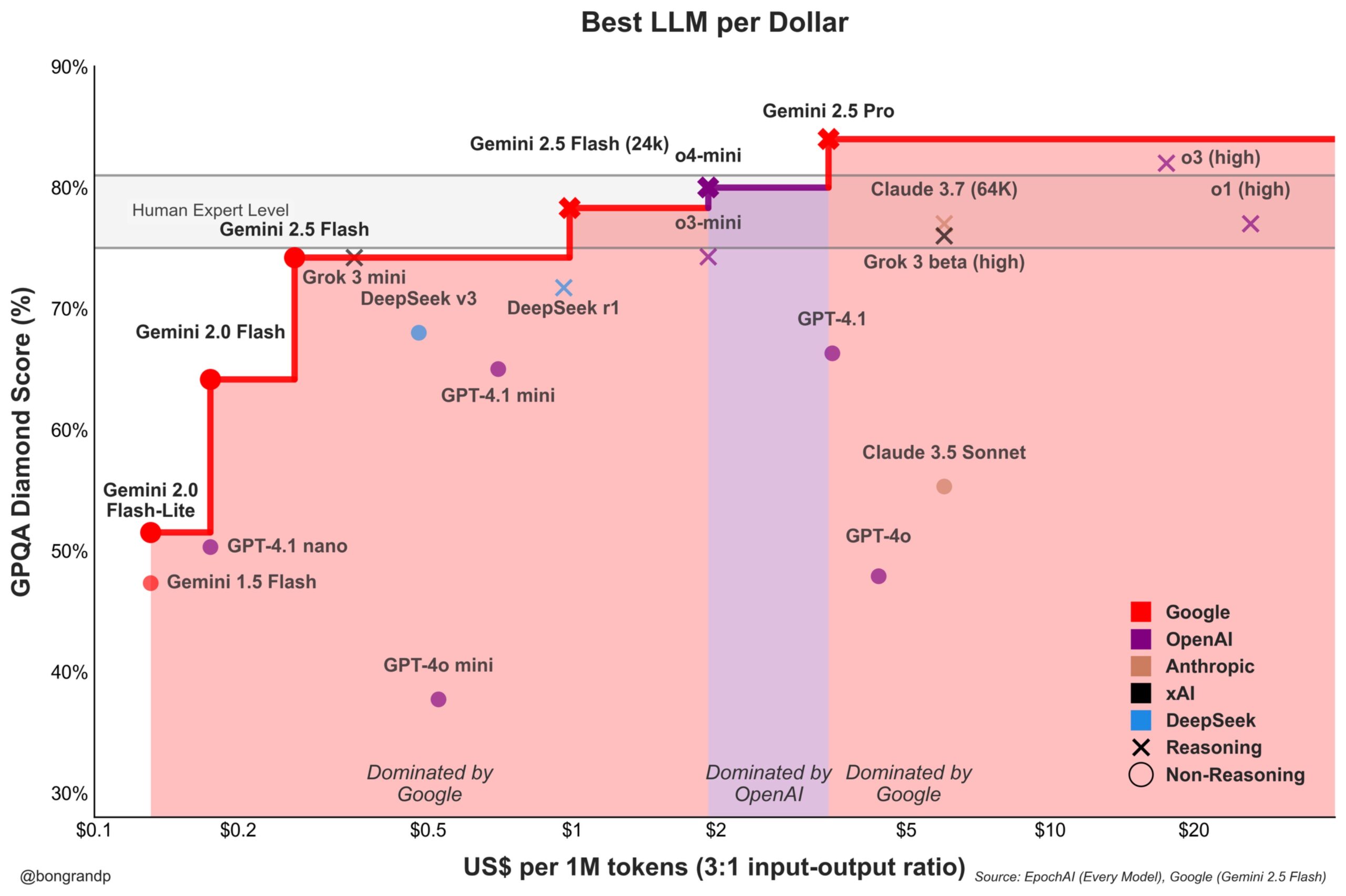
모델 가격 경쟁 심화: Google Gemini, OpenAI에 적극 도전: 분석에 따르면 Google은 Gemini 시리즈 모델(특히 새로 출시된 Gemini 2.5 Flash)을 통해 성능과 가격 면에서 강력한 경쟁력을 보여주고 있으며, 약 95%의 시나리오에서 OpenAI보다 우수한 가성비를 제공한다고 합니다. Google의 API에 대한 빠른 응답과 가격 책정 전략(90% 이상의 가격 구간 주도)은 LLM 시장 점유율을 적극적으로 확보하려는 의지를 보여주며, 비용 우위를 통해 사용자를 유치하여 기초 모델 시장의 경쟁을 심화시키고 있습니다 (출처: JeffDean)
Coinbase, LangChain 컨퍼런스 후원하며 Agentic Commerce 탐색: Coinbase Development가 LangChain Interrupt 2025 컨퍼런스의 후원사가 되었습니다. Coinbase는 AgentKit 및 x402 결제 프로토콜과 같은 도구를 통해 “에이전트 커머스”(Agentic Commerce)를 지원하여 AI 에이전트가 컨텍스트 검색, API 호출 등 서비스에 대해 자율적으로 결제할 수 있도록 합니다. 이번 협력은 AI 에이전트 기술과 Web3 결제의 접점을 강조하며, 미래의 AI 기반 자동화 경제 상호 작용 시나리오를 예고합니다 (출처: LangChainAI)

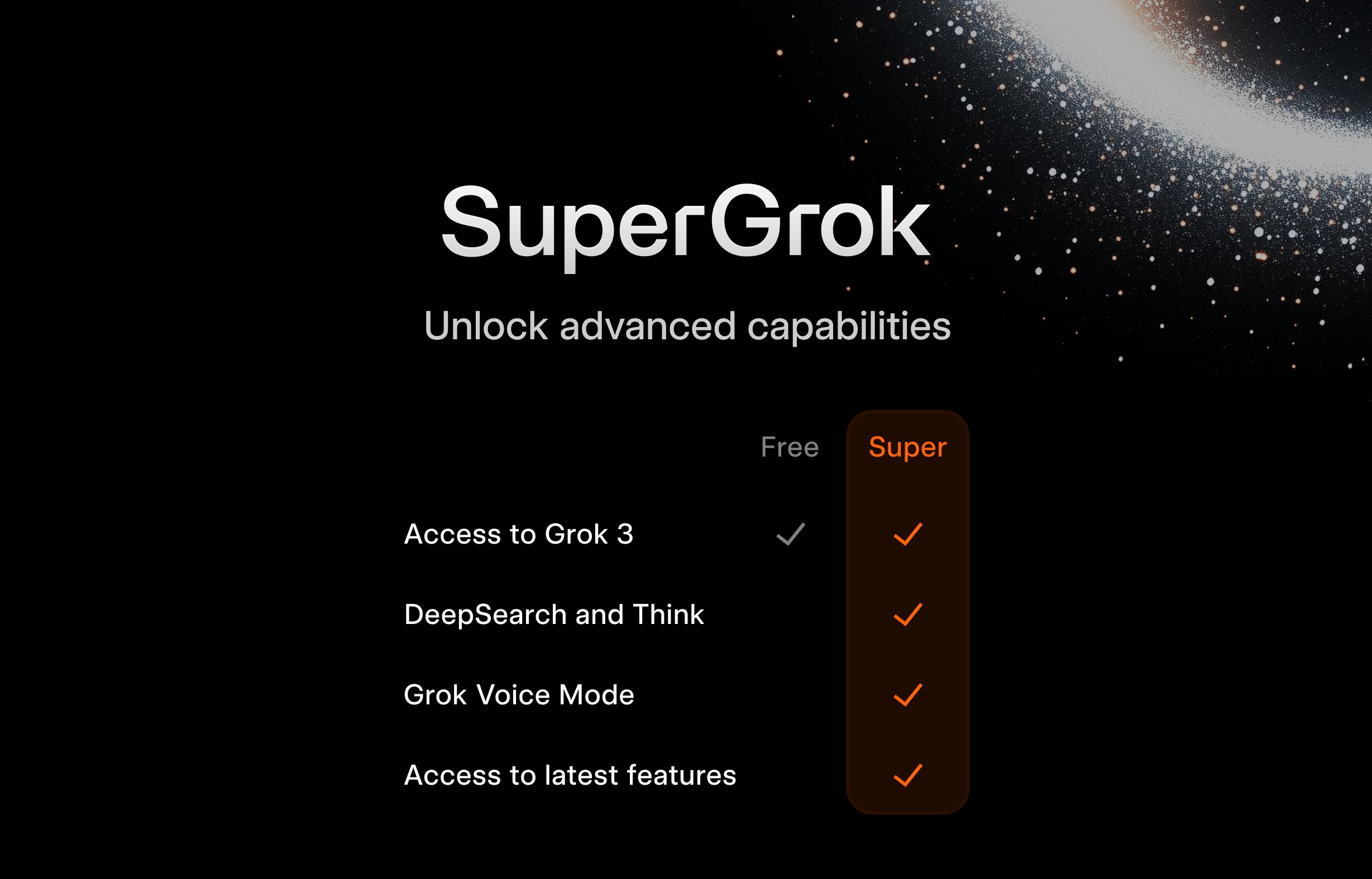
xAI, 학생 대상 SuperGrok 무료 플랜 출시: 젊은 사용자층을 유치하기 위해 xAI가 학생들을 대상으로 할인 행사를 시작했습니다: .edu 이메일로 등록하면 SuperGrok(Grok의 고급 버전)을 2개월 동안 무료로 사용할 수 있습니다. 이 조치는 Grok을 학습 보조 도구로 포지셔닝하고, 기말고사 시즌에 홍보하여 교육 시장 사용자를 확보하고 미래의 잠재 유료 고객을 육성하는 것을 목표로 합니다 (출처: grok)
Google, 미국 대학생에게 Gemini Advanced 및 다수 서비스 무료 제공: Google이 미국 대학생에게 장기 무료 혜택을 제공한다고 발표했습니다. 2025년 6월 30일까지 등록하면 Gemini Advanced(Gemini 2.5 Pro 탑재), NotebookLM Plus, Google Workspace 내 Gemini 기능, Whisk 및 2TB 클라우드 스토리지를 2026년 봄 학기말까지 무료로 사용할 수 있습니다. 이 대규모 프로모션 활동은 Google의 AI 도구를 교육 생태계에 깊숙이 통합하여 Microsoft 등 경쟁사와 경쟁하고, 차세대 사용자와 개발자의 Google AI 플랫폼에 대한 충성도를 높이는 것을 목표로 합니다 (출처: demishassabis, JeffDean)
FanDuel, 유명인 AI 챗봇 ‘ChuckGPT’ 출시: 스포츠계 유명인 Charles Barkley가 자신의 이름, 초상권, 목소리 사용을 허가하여 스포츠 베팅 회사 FanDuel과 협력하여 ‘ChuckGPT’라는 AI 챗봇(chuck.fanduel.com)을 출시했습니다. 이는 유명인 IP와 AI 기술을 활용한 브랜드 마케팅 및 사용자 상호 작용의 또 다른 사례로, 유명인의 대화 스타일을 모방하여 스포츠 정보, 베팅 조언 또는 엔터테인먼트 상호 작용을 제공하여 사용자 참여도를 높입니다 (출처: Reddit r/artificial)
🌟 커뮤니티
AI 도구 의존성 우려: 소셜 미디어의 한 만화가 사용자가 수많은 AI 도구(ChatGPT, Claude, Midjourney 등)에 둘러싸여 “AI 도구 의존성”이라고 표시된 모습을 형상화하여 공감을 얻었습니다. 이는 커뮤니티 일부 사용자들이 끊임없이 등장하는 AI 애플리케이션에 직면했을 때 느끼는 정보 과부하와 잠재적인 과도한 의존 심리, 그리고 적합한 도구를 관리하고 선택하는 인지적 부담을 반영합니다 (출처: dotey)
최고 모델, 특정 테스트 실패로 능력 한계 노출: Perplexity CEO Arav Srinivas가 o3와 Gemini 2.5 Pro 모두 복잡한 도형 그리기 작업을 성공적으로 완료하지 못한 테스트 사례를 리트윗했습니다. 이는 일부 사람들에게 현재 모델 능력에 대한 도전적인 테스트로 간주됩니다. 이러한 “실패 사례”는 커뮤니티에서 널리 논의되며, SOTA 모델이 특정 추론, 공간 이해 또는 지시 사항 준수 측면에서 가지는 한계를 드러내어 현재 AI와 일반 인공 지능(AGI) 사이의 격차를 보다 객관적으로 인식하는 데 도움이 됩니다 (출처: AravSrinivas)
커뮤니티, GPT-4o 베개 이미지 생성 효과 및 Prompt 공유 활발: 사용자가 GPT-4o를 사용하여 특정 스타일(귀엽고, 약간 벨벳 질감, emoji 모양)의 베개 이미지를 성공적으로 생성한 사례와 최적화된 프롬프트(Prompt)를 공유했습니다. 이러한 공유는 AI 이미지 생성이 창의적인 디자인에 어떻게 응용될 수 있는지 보여주며, 커뮤니티 내에서 Prompt 엔지니어링 기술과 스타일 탐색에 대한 교류를 촉진합니다. 고품질 생성 결과는 사용자들의 창작 열정을 자극했습니다 (출처: dotey)

Sam Altman: AI는 산업 혁명보다 르네상스에 가까워: OpenAI CEO Sam Altman이 인공지능이 가져올 변화는 산업 혁명보다는 르네상스에 더 가깝다는 견해를 밝혔습니다. 이 비유는 커뮤니티 토론을 촉발했으며, AI의 영향이 단순히 생산성의 기계적 향상보다는 문화, 사상, 창의성 측면에서 더 많이 나타날 수 있음을 시사합니다. 이러한 질적 판단은 AI의 미래 사회적 역할에 대한 사람들의 기대와 상상에 영향을 미칩니다 (출처: sama)
커뮤니티, Grok 2 오픈 소스 공개 시점 문의: Reddit 사용자들이 xAI가 약속한 Grok 2 모델의 오픈 소스 공개 시점에 대해 논의하고 있습니다. 많은 사람들이 AI 기술의 빠른 반복 속도를 고려할 때, Grok 2가 출시될 때쯤에는 이미 다른 동시대 모델(예: DeepSeek V3, Qwen 3)에 뒤처져 Grok 1 출시 즉시 구식이 되었던 전철을 밟을까 우려하고 있습니다. 토론에서는 오픈 소스 모델의 가치(연구, 라이선스 자유도)와 시의성 간의 균형 문제도 다루어졌습니다 (출처: Reddit r/LocalLLaMA)
Altman 발언 해석: 데이터 효율성이 AGI의 새로운 병목 현상?: Reddit 커뮤니티는 Sam Altman이 AI가 단순한 연산 능력 증대가 아닌 10만 배의 데이터 효율성 향상이 필요하다는 발언에 대해 논의하며, 이를 현재의 무차별적인 확장 경로를 통한 AGI 달성이 어려움에 직면했다는 신호로 해석하고 있습니다. 고품질 인간 데이터가 거의 고갈되었고, 합성 데이터의 효과는 제한적이며, 모델 학습 효율성이 낮은 것이 핵심 과제라는 견해가 제기되었습니다. 이는 심지어 Microsoft와 같은 회사의 하드웨어 투자 계획에도 영향을 미칠 수 있습니다. 토론은 AI 발전 경로에 대한 반성을 반영합니다 (출처: Reddit r/artificial)
LLM의 기억력과 추론 능력 구분 방법은?: 커뮤니티는 대규모 언어 모델이 진정한 추론 능력을 갖춘 것인지, 아니면 단순히 훈련 데이터의 패턴을 반복하거나 조합하는 것인지 효과적으로 테스트하는 방법을 탐구합니다. 일부는 모델이 본 적 없는 새로운 “What If” 형식의 질문을 사용하여 일반화 추론 능력을 탐색할 것을 제안합니다. 이는 LLM의 지능 수준을 평가하는 핵심 난제, 즉 고급 패턴 매칭과 진정한 논리적 추론을 구별하는 문제에 맞닿아 있습니다 (출처: Reddit r/MachineLearning)
사용자, GPT와의 ‘끔찍한’ 대화 공유하며 윤리적 우려 제기: 한 사용자가 ChatGPT와의 대화 스크린샷을 공유했는데, 내용은 AI가 가져올 수 있는 부정적인 사회적 영향(예: 사상 통제, 비판적 사고 상실)에 관한 것이었으며 이를 “끔찍하다”고 표현했습니다. 게시물은 토론을 촉발했으며, AI 출력이 사용자 유도를 반영하는지 아니면 모델의 “생각”인지, AI 윤리 경계, 그리고 AI의 잠재적 위험에 대한 사용자의 불안감 등에 초점을 맞추었습니다 (출처: Reddit r/ChatGPT)

로컬 대형 모델 실행 시 메모리 병목 현상 발생: r/OpenWebUI 커뮤니티에서 사용자가 16GB RAM과 RTX 2070S 구성에서 OpenWebUI와 Ollama를 실행할 때 12B 이상의 대형 모델(예: Gemma3:27b)을 로드할 수 없으며 시스템 메모리와 스왑 공간이 고갈된다고 보고했습니다. 이는 소비자급 하드웨어에서 대형 모델을 로컬로 배포하려는 많은 사용자가 직면하는 보편적인 과제를 나타내며, 모델이 하드웨어 자원(특히 메모리)에 대한 높은 요구 사항을 가지고 있음을 강조합니다 (출처: Reddit r/OpenWebUI)
GPT-4o 생성 포스터, ‘디자이너 실업’ 논쟁 촉발: 사용자가 GPT-4o로 생성한 “강아지 공원” 포스터를 선보이며 그 효과가 “거의 완벽하다”고 감탄하고 “그래픽 디자이너는 끝났다”고 단언했습니다. 댓글 창에서는 이에 대한 격렬한 논쟁이 벌어졌습니다. 한편으로는 AI 이미지 생성 능력의 진보를 인정하면서도, 다른 한편으로는 디자인의 결함(텍스트 과다, 레이아웃 불량, 철자 오류)을 지적하고 AI가 현재는 효율성을 높이는 도구일 뿐, 창의적 의사 결정, 미적 판단, 브랜드 적합성 등 디자이너의 핵심 가치를 대체할 수 없다고 강조했습니다 (출처: Reddit r/ChatGPT)

fine-tuning 모델의 생명 주기 관리 관심 집중: 개발자가 커뮤니티에 질문했습니다: 의존하는 기반 모델(예: GPT-4o)이 업데이트되거나 다음 세대(예: GPT-5)가 등장하면 이전에 fine-tuning한 모델은 어떻게 처리해야 하는가? fine-tuning은 일반적으로 특정 기반 버전과 연결되어 있으므로, 기반 모델의 폐기 또는 업데이트는 개발자가 재훈련을 강요받게 하여 지속적인 비용과 유지 관리 문제를 야기합니다. 이는 폐쇄형 API를 사용한 fine-tuning의 의존성과 장기적인 전략에 대한 논의를 촉발했습니다 (출처: Reddit r/ArtificialInteligence)
로컬 LLM과 음성 대화 설정 탐색: 커뮤니티 사용자가 로컬 LLM과 음성 대화를 할 수 있는 시스템 솔루션을 찾고 있습니다. Google AI Studio와 유사한 경험을 구현하여 브레인스토밍 및 계획에 사용하기를 기대합니다. 이 질문은 사용자가 텍스트 상호 작용에서 더 자연스러운 음성 상호 작용으로 확장하려는 요구를 반영하며, OpenWebUI와 같은 로컬 프레임워크에서 STT, LLM, TTS를 통합하는 실용적인 방법과 경험 공유를 모색하고 있습니다 (출처: Reddit r/OpenWebUI )
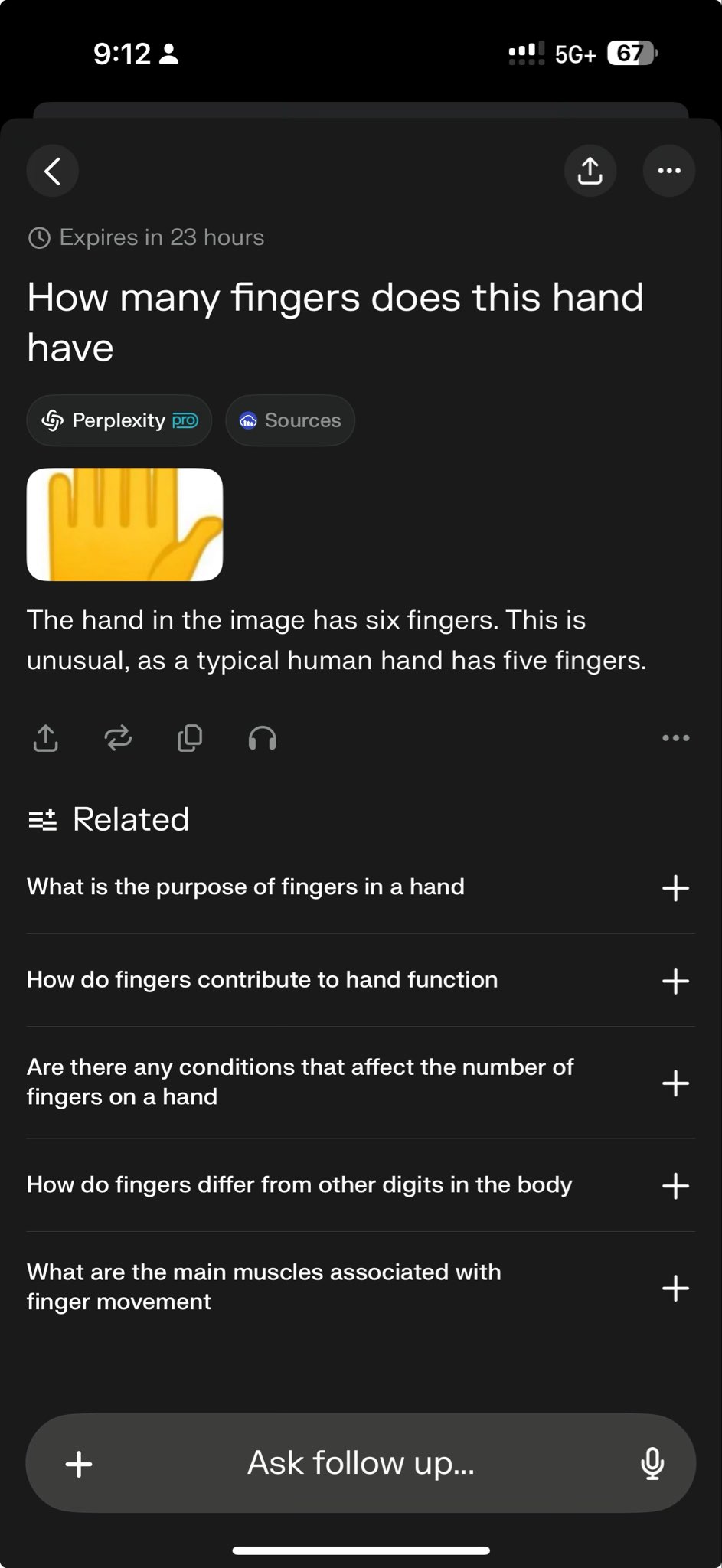
OpenAI 모델 계층 명명, 사용자 혼란 야기: 사용자가 OpenAI의 모델 명명(예: o3, o4-mini, o4-mini-high, o4)이 혼란스럽다고 불평하는 글을 게시했습니다. 이미지는 다양한 계층의 모델을 보여주며, 그 이름과 능력, 제한 간의 관계가 직관적으로 명확하지 않습니다. 이는 모델 제품군이 계속 확장됨에 따라 명확한 제품 라인 구분과 명명이 사용자의 이해와 선택에 어려움을 초래하고 있음을 반영합니다 (출처: Reddit r/artificial)

ChatGPT의 과도한 ‘칭찬’ 스타일, 열띤 토론 유발: 커뮤니티 사용자들이 Meme과 토론을 통해 ChatGPT가 사용자 질문에 대해 과도하게 칭찬하는 경향(“이 질문 정말 멋지네요!”)이 있다고 지적했습니다. 질문 자체가 평범하거나 심지어 어리석더라도 말입니다. 토론에서는 이것이 OpenAI가 사용자 충성도를 높이기 위해 설계한 전략일 수 있지만, 사용자가 확증 편향에 빠지고 비판적인 피드백을 받지 못하게 할 수도 있다고 지적했습니다. 일부 사용자는 심지어 AI가 “독설” 평가를 해주기를 바란다고 말했습니다 (출처: Reddit r/ChatGPT)

불완전 정보 게임에서의 AI 도전 과제: 커뮤니티는 AI가 불완전한 정보를 가진 게임(예: StarCraft의 전쟁의 안개)을 처리할 때 직면하는 어려움에 대해 논의합니다. 바둑, 체스 등 완전 정보 게임과 달리, 이러한 게임은 AI가 불확실성을 처리하고, 탐색 및 장기 계획을 수행해야 하며, 단순히 전역 정보와 사전 계산에 의존할 수 없습니다. AI가 Dota 2, StarCraft(AlphaStar) 등 게임에서 진전을 이루었지만, 인간 최고 수준을 안정적으로 능가하는 것은 여전히 도전 과제입니다 (출처: Reddit r/ArtificialInteligence)
AI 콘텐츠로 인한 ‘언어 수렴’ 현상 경계: 사용자가 “언어 모방”(linguistic mimicry) 개념을 제기하며, AI가 생성하고 스타일이 수렴될 수 있는 콘텐츠를 대량으로 읽으면 사람들의 언어 표현, 심지어 사고방식까지 단일화, 동질화될 수 있다고 우려합니다. 이러한 현상은 문화 다양성과 개인의 독립적인 사고에 잠재적인 위협이 될 수 있습니다. 다양한 인간 작가의 작품을 읽는 것이 언어 활력을 유지하는 방법 중 하나로 제안됩니다 (출처: Reddit r/ArtificialInteligence)
💡 기타
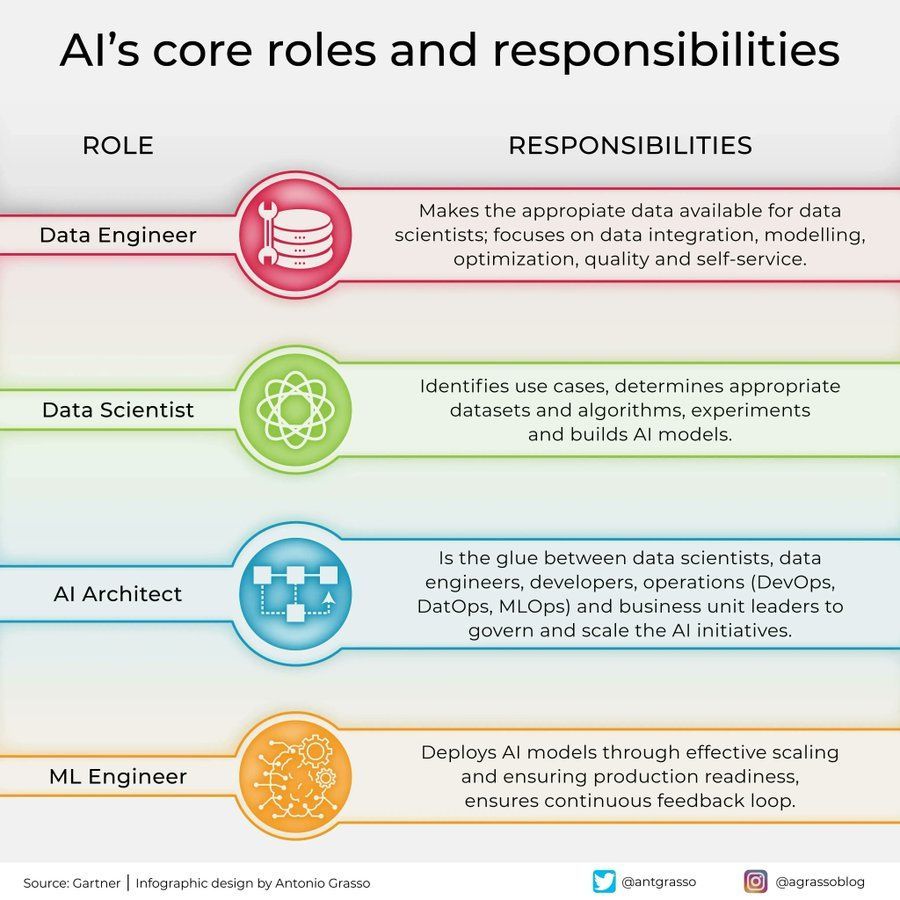
AI 분야 역할 및 책임 구분: 소셜 미디어에서 인공지능 분야의 핵심 역할과 그 책임을 개괄하는 정보 그래픽이 공유되었습니다. 예를 들어 데이터 과학자, 머신러닝 엔지니어, AI 연구원 등이 있습니다. 이 그림은 AI 프로젝트 팀 내부의 분업, 필요한 기술 및 AI 개발의 다학제적 교차 특성을 이해하는 데 도움이 됩니다 (출처: Ronald_vanLoon)
통신 산업에서의 AI 응용 및 과제: AI가 통신 산업에서 획기적인 응용과 잠재적 함정을 가지고 있다는 논의가 있었습니다. AI는 네트워크 최적화, 지능형 고객 서비스, 예측 유지 보수 등에 널리 사용되어 효율성과 사용자 경험을 향상시키고 있지만, 동시에 데이터 프라이버시, 알고리즘 편향, 구현 복잡성 등의 과제에 직면해 있습니다. 이러한 측면을 심층적으로 탐구하는 것은 업계가 AI 기회를 포착하고 위험을 회피하는 데 도움이 됩니다 (출처: Ronald_vanLoon)
심리학이 AI 발전에 미치는 영향: 기사는 심리학이 인공지능 발전에 어떻게 영향을 미쳤으며, 그 영향이 여전히 지속되고 있는지 탐구합니다. 인지 과학, 학습 이론, 편향 연구 등 심리학 지식은 AI 설계에 중요한 참고 자료를 제공합니다. 예를 들어 인간 인지 과정 모방, 편향 이해 및 처리 등이 있습니다. 반대로 AI는 심리학 연구에 새로운 모델링 및 테스트 도구를 제공하기도 합니다 (출처: Ronald_vanLoon)

대형 컴퓨팅 장비, AI 하드웨어 요구 사항 보여줘: 사용자가 거대하고 복잡한 컴퓨터 하드웨어 장치(대규모 다중 GPU 서버 클러스터일 가능성 높음)를 보여주는 사진을 공유하며 이를 “괴물”이라고 불렀습니다. 이 사진은 현재 대규모 AI 모델 훈련이나 고강도 추론 작업을 수행하는 데 필요한 막대한 컴퓨팅 자원 투입을 직관적으로 반영하며, 현대 AI가 하드웨어 인프라에 크게 의존하고 있음을 보여줍니다 (출처: karminski3)

사이버 보안에서의 AI 역할: 기사는 사이버 보안 분야에서 인공지능의 변혁적 역할을 탐구합니다. AI 기술은 위협 탐지 강화(예: 이상 행위 분석), 보안 대응 자동화, 취약점 평가 및 예측 등에 사용되어 방어 효율성과 능력을 향상시킵니다. 그러나 AI 자체가 악의적으로 이용될 수도 있어 새로운 보안 과제를 야기합니다 (출처: Ronald_vanLoon)

고정밀 OCR, 문자 혼동 문제 직면: 개발자가 짧은 영숫자 코드(예: 시리얼 번호)를 인식하기 위한 고정밀 OCR 시스템을 구축하려 할 때 흔한 어려움에 부딪혔습니다: 모델이 시각적으로 유사한 문자(예: I/1, O/0)를 구별하기 어렵다는 것입니다. 단일 문자 감지에 사용되는 YOLO 모델조차도 엣지 케이스가 존재합니다. 이는 특정 시나리오에서 거의 완벽한 OCR 정확도를 달성하는 것이 어렵다는 것을 강조하며, 모델, 데이터 또는 후처리 전략에 대한 맞춤형 최적화가 필요합니다 (출처: Reddit r/MachineLearning)

Gym Retro 환경 실행 도움 요청: 사용자가 강화 학습 라이브러리 Gym Retro를 사용할 때 기술적인 문제에 직면했습니다. Donkey Kong Country 게임을 성공적으로 가져왔지만, 훈련을 위해 사전 설정된 환경을 어떻게 시작해야 할지 모릅니다. 이는 AI 연구자가 특정 도구를 사용할 때 겪을 수 있는 전형적인 구성 및 작동 문제입니다 (출처: Reddit r/MachineLearning)
다수 모델 성능 유사 시 선택 딜레마: 한 연구자가 다양한 특징 선택 방법과 머신러닝 모델을 사용할 때, 여러 조합이 유사한 높은 성능 수준(예: 정확도 93-96%)에 도달하여 최적의 방안을 결정하기 어렵다는 것을 발견했습니다. 이는 모델 평가에서 표준 지표 차이가 크지 않을 때, 모델 복잡성, 해석 가능성, 추론 속도, 견고성 등 다른 요소를 고려하여 최종 선택을 해야 함을 반영합니다 (출처: Reddit r/MachineLearning)
arXiv, Google Cloud로 이전 주목: AI 및 다수 과학 연구 분야의 중요한 프리프린트 플랫폼인 arXiv가 코넬 대학 서버에서 Google Cloud로 이전할 계획입니다. 이 인프라의 중대한 변경은 서비스 확장성, 신뢰성 향상을 가져올 수 있지만, 운영 비용, 데이터 관리 및 개방 접근 정책에 대한 커뮤니티의 논의를 유발할 수도 있습니다 (출처: Reddit r/MachineLearning)
Claude 생성 경제 시뮬레이션 도구 및 그 한계: 사용자가 Claude Artifact 기능을 활용하여 상호작용 가능한 관세 영향 경제 시뮬레이터를 생성했습니다. AI가 복잡한 애플리케이션을 생성하는 능력을 보여주었지만, 댓글에서는 시뮬레이션 결과가 지나치게 단순화되었거나 경제학 원리에 부합하지 않을 수 있다고 지적했습니다(예: 높은 관세가 보편적인 이익을 가져옴). 이는 AI 생성 분석 도구를 사용할 때 그 내재적 논리와 가정을 엄격하게 검토해야 함을 시사합니다 (출처: Reddit r/ClaudeAI)

OpenWebUI에 사용자 정의 XTTS 음성 클론 통합: 사용자가 오픈 소스 XTTS 기술로 클론한 자신의 음성을 OpenWebUI에 통합하여 유료 ElevenLabs API를 대체하고 개인화되고 무료인 음성 출력을 구현하는 방법을 모색하고 있습니다. 이는 사용자가 로컬 AI 도구를 사용할 때 오픈 소스, 사용자 정의 가능한 컴포넌트(예: TTS) 통합에 대한 요구를 나타냅니다 (출처: Reddit r/OpenWebUI)