
키워드:AI, 대형 모델, AI 군비 경쟁, 수직 산업 모델, Zhipu AI IPO, AI 독립 물리 법칙 발견, AI 시각 장애인 지원 시스템
“` markdown
🔥 포커스
빅테크 기업들, AI 군비 경쟁 점화, 수직적 모델과 생태계가 초점: 글로벌 테크 대기업들이 전례 없는 수준으로 AI에 투자하고 있으며, 2025년 자본 지출은 3200억 달러를 돌파할 것으로 예상됩니다. Alibaba, Tencent, Huawei 등 중국 기업들도 AI 인프라, 대규모 모델, 컴퓨팅 파워에 대한 투자를 늘리고 있습니다. 경쟁의 초점은 범용 대규모 모델에서 수직 산업 모델로 이동하고 있으며, 후자는 높은 총이익률과 실제 문제 해결 능력으로 새로운 성장 동력으로 부상하고 있습니다. 고급 칩 문제에 직면해 있지만, 중국 기업들은 컴퓨팅 파워 비용 최적화와 추론 모델(“느린 사고”) 분야에서 진전을 보이고 있습니다(예: DeepSeek 효과). 각 기업의 경로는 다릅니다: Alibaba는 인프라에 집중 투자하고, Huawei는 하드웨어(CloudMatrix 384)를 혁신하고 엣지-클라우드 협업을 추진하며, Baidu는 응용 분야에 가깝고, Tencent와 ByteDance는 다양한 시나리오의 이점을 활용합니다. AI 하드웨어 확장과 오픈 소스 생태계 구축(예: Hongmeng, Shengteng, Hunyuan)이 핵심이 되었으며, 경쟁은 단일 기술 돌파구에서 생태계 협력 능력으로 전환되었습니다. (출처: 36Kr-科技云报道)

MIT 놀라운 발견: AI, 사전 지식 없이 독립적으로 물리 법칙 추론 가능: MIT의 Max Tegmark 팀은 새로운 아키텍처 MASS (Multiple AI Scalar Scientists)를 개발했습니다. 이 AI 시스템은 어떤 물리 법칙도 알려주지 않은 상태에서 진자, 진동자 등 물리 시스템의 관측 데이터 분석만으로 독립적으로 학습하고 고전 역학의 해밀토니언 또는 라그랑지언과 매우 유사한 이론적 표현을 제시할 수 있었습니다. 연구에 따르면 AI는 더 복잡한 시스템에 직면했을 때 자율적으로 이론을 수정하며, 서로 다른 AI “과학자”들은 결국 알려진 물리 원리로 수렴하는 경향을 보였고, 특히 복잡한 시스템에서는 라그랑지언 설명을 선호했습니다. 이 성과는 기초 과학 발견 분야에서 AI의 엄청난 잠재력을 보여주며, 우주의 기본 법칙을 독립적으로 밝혀낼 수 있음을 시사합니다. (출처: 新智元)

상하이 교통대학 팀 AI 시각 보조 시스템, Nature 자매지에 게재, 시각 장애인이 ‘빛을 되찾도록’ 지원: 상하이 교통대학 Gu Leilei 팀은 AI 기반 웨어러블 시각 보조 시스템을 개발했습니다. 유연한 전자 기술과 결합하여 청각 및 촉각 피드백으로 일부 시각 기능을 대체하여 시각 장애인이 내비게이션 및 물체 잡기와 같은 일상 업무를 수행하도록 돕습니다. 이 시스템은 하드웨어가 가볍고, 소프트웨어는 인체 생리적 인지에 맞게 정보 출력 방식을 최적화했으며, VR 몰입형 훈련 시스템도 개발했습니다. 테스트 결과, 이 시스템은 가상 및 실제 환경에서 시각 장애인 사용자의 내비게이션, 장애물 회피 및 물체 잡기 능력을 현저히 향상시켰습니다. 연구 결과는 《Nature Machine Intelligence》에 발표되었으며, 시각 장애인 지원 및 독립적인 생활 능력 향상 측면에서 AI의 큰 잠재력을 보여주고, 개인화되고 사용자 친화적인 웨어러블 시각 보조 장치에 대한 새로운 아이디어를 제공합니다. (출처: 36Kr)

Zhipu AI, IPO 준비 착수, ‘대규모 모델 1호 상장사’ 목표: 칭화대학 계열 AI 대규모 모델 회사 Zhipu AI(Beijing Zhipu Huazhang Technology)가 4월 14일 베이징 증권감독국에 IPO 사전 준비 서류를 제출했으며, CICC가 주관사로 참여합니다. A주 시장 상장을 목표로 하며, 중국 내 ‘AI 대규모 모델 1호 상장사’가 될 가능성이 있습니다. C단말 제품 “Zhipu Qingyan”의 사용자 규모는 크지 않지만, Zhipu AI는 강력한 기술 배경(칭화대학 계열, 자체 개발 GLM 시리즈 대규모 모델), 국가적 지원(미국 Entity List 등재) 및 상업화 진전(정부 및 기업 고객 서비스, 매출 급증)을 바탕으로 160억 위안 이상의 투자를 유치했으며, 기업 가치는 200억 위안을 초과합니다. 투자자에는 유명 VC, 산업 대기업 및 다수 지역 국유 자산이 포함됩니다. DeepSeek 등 신흥 세력의 도전에 직면하여 Zhipu AI의 IPO 선택은 치열한 경쟁 속에서 유리한 위치를 선점하고, 자금 조달 수요를 충족하며, 투자자의 기대에 부응하기 위한 핵심 단계로 간주됩니다. 회사는 최근 GLM-4 시리즈 모델을 지속적으로 오픈 소스화하며 기술과 자본 양면에서 동시에 힘을 쏟고 있음을 보여줍니다. (출처: 36Kr-真故研究室, 36Kr-互联网爆料汇, 创投日报)

🎯 동향
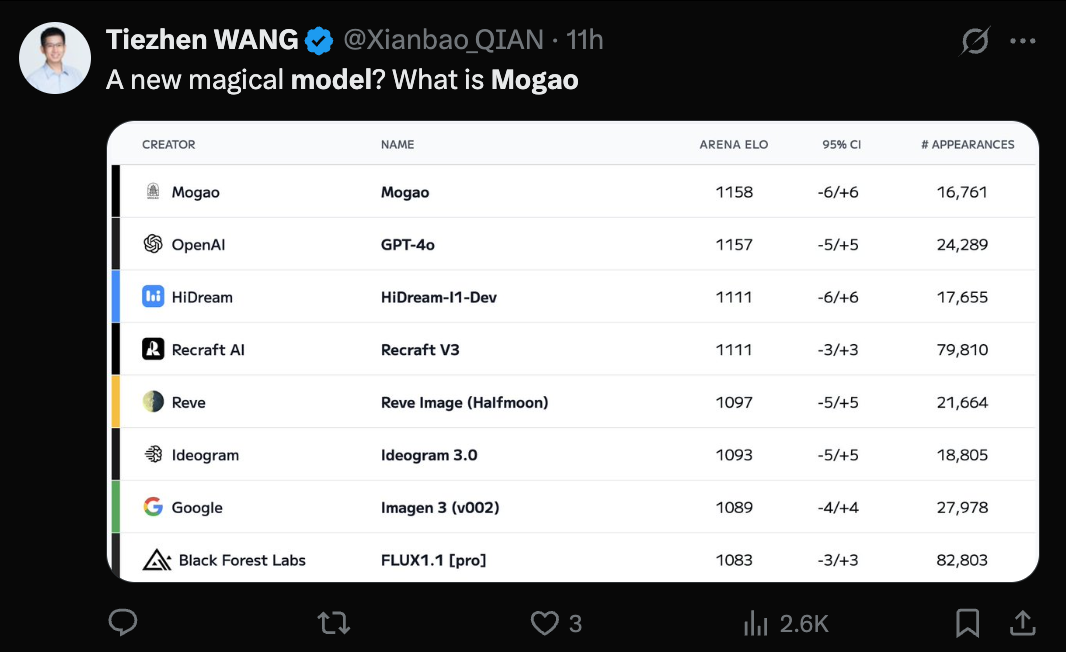
ByteDance Seedream 3.0 (Mogao) 모델 공개, 텍스트-이미지 생성 능력 인정받아: 최근 Artificial Analysis 텍스트-이미지 생성 순위에서 상위권을 차지한 미스터리 모델 Mogao가 ByteDance Seed 팀이 개발한 Seedream 3.0으로 확인되었습니다. 이 모델은 사실성, 디자인, 애니메이션 등 다양한 스타일과 텍스트 생성에서 뛰어난 성능을 보이며, 특히 밀집된 텍스트 처리와 사실적인 인물 사진 생성에 능숙합니다. 중국어 및 영어 문자 사용 가능률은 94%에 달하고, 인물 사진의 사실성은 전문 사진 수준에 가까우며, 네이티브 2K 해상도 이미지 출력을 지원하고 생성 속도가 빠릅니다. 기술 보고서는 데이터 처리(결함 감지 훈련, 이중 축 샘플링), 사전 훈련(MMDiT 아키텍처, 혼합 해상도, 교차 모달 RoPE), 후훈련(지속적 훈련, SFT, RLHF, VLM 보상 모델) 및 추론 가속(Hyper-SD, RayFlow) 등 여러 혁신 기술을 공개했습니다. GPT-4o와 비교할 때 Seedream 3.0은 중국어, 레이아웃 및 색상에서 더 우수합니다. (출처: 36Kr-机器之心)
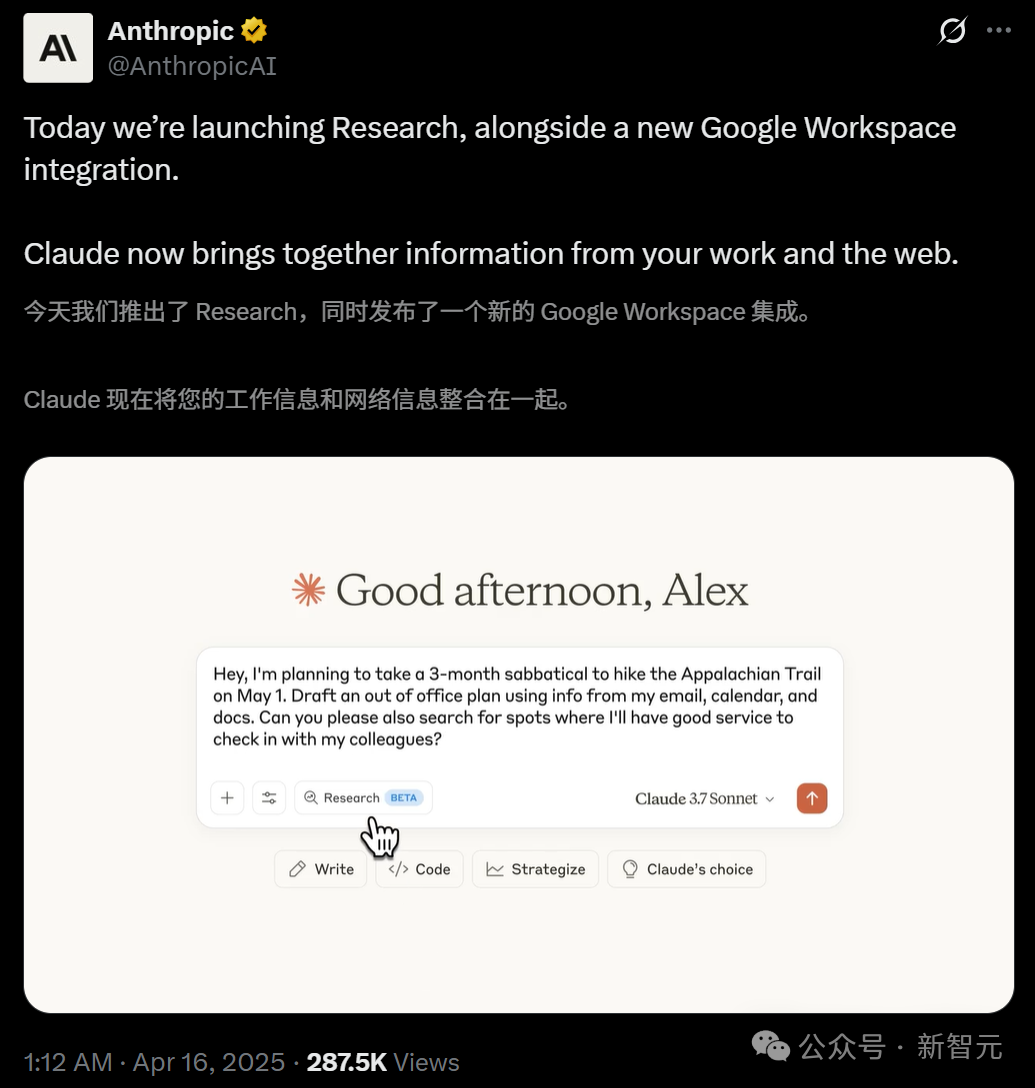
Claude, Research 기능 출시 및 Google Workspace 통합: Anthropic은 자사의 AI 어시스턴트 Claude에 Research와 Google Workspace 통합이라는 두 가지 주요 기능을 추가했습니다. Research 기능은 Claude가 웹에서 정보를 검색하고 사용자 내부 파일(예: Google Docs)과 결합하여 다각적인 분석을 수행하고 종합 보고서를 신속하게 생성할 수 있도록 합니다. Google Workspace 통합은 Gmail, Google Calendar, Google Drive를 연결하여 Claude가 사용자의 일정, 이메일, 문서 내용을 이해하고 정보를 추출하여 작업 수행을 보조할 수 있게 합니다(예: 개인 정보 기반 일정 계획, 이메일 초안 작성 등). 이러한 기능은 사용자 작업 효율성을 대폭 향상시키는 것을 목표로 합니다. Research 기능은 현재 미국, 일본, 브라질의 Max, Team, Enterprise 사용자에게 베타 테스트로 제공되며, Workspace 통합은 모든 유료 사용자에게 베타 테스트로 제공됩니다. 사용자 피드백은 긍정적이며 효율성을 높이고 데이터 간의 연관성을 발견하는 데 도움이 된다고 평가하지만, 데이터 보안에 대한 우려도 있습니다. (출처: 新智元, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
홍콩 중문대와 칭화대, Video-R1 발표, 비디오 추론의 새로운 패러다임 열어: 홍콩 중문대학(CUHK)과 칭화대학 팀이 공동으로 세계 최초로 강화 학습 R1 패러다임을 채택한 비디오 추론 모델 Video-R1을 출시했습니다. 이 모델은 기존 비디오 모델의 시간적 논리 및 깊이 있는 추론 능력 부족 문제를 해결하는 것을 목표로 합니다. 시간 인지 T-GRPO 알고리즘 도입과 이미지 및 비디오 혼합 훈련 데이터셋(Video-R1-COT-165k 및 Video-R1-260k) 결합을 통해, 7B 파라미터의 Video-R1은 Fei-Fei Li가 제안한 VSI-Bench 비디오 공간 추론 벤치마크 테스트에서 GPT-4o보다 우수한 성능을 보였습니다. 모델은 인간과 유사한 “통찰의 순간”을 보여주며, 시계열 정보에 기반한 논리적 추론이 가능합니다. 실험 결과, 입력 프레임 수를 늘리면 추론 정확도가 향상되는 것으로 나타났습니다. 이 프로젝트는 모델, 코드, 데이터셋을 모두 오픈 소스화했으며, 비디오 AI가 “이해”에서 “사고”로 나아가고 있음을 예고합니다. (출처: 新智元)

ICLR 2025, 최초로 대규모 AI 심사 도입, 심사 품질 현저히 향상: 제출 논문 급증과 심사 품질 저하 문제에 대응하기 위해 ICLR 2025 학회는 처음으로 대규모 AI “심사 피드백 에이전트”(Review Feedback Agent)를 심사 보조에 투입했습니다. 이 시스템은 Claude Sonnet 3.5 등 여러 LLM을 활용하여 심사 의견의 모호성, 내용 오해 또는 비전문적 발언을 식별하고 심사자에게 구체적인 개선 제안을 제공합니다. 실험은 전체 심사의 42.3%를 대상으로 진행되었으며, 결과적으로 AI 피드백은 89%의 경우 심사 품질을 향상시켰고, 26.6%의 심사자가 AI 제안에 따라 심사를 수정했으며, 수정된 심사는 평균 80단어가 추가되어 더 구체적이고 정보량이 풍부해졌습니다. 동시에 AI 개입은 Rebuttal 기간 동안 저자와 심사자 간의 토론 활성도와 깊이를 높였습니다. 이 선구적인 실험은 동료 심사 프로세스 최적화에서 AI의 엄청난 잠재력을 증명했습니다. (출처: 新智元)

가정용 휴머노이드 로봇 도입 논의 촉발, 가전 기업 Embodied AI 적극布局: 휴머노이드 로봇의 가정 환경 진입이 응용 모델 및 가전 산업에 미치는 영향에 대한 업계 논의를 촉발했습니다. 휴머노이드 로봇은 “범용성”을 발휘하여 옷 개기, 수납 등 비표준 작업을 해결하고, 상호작용 능력을 활용하여 “집사” 역할을 수행하며 다른 스마트 기기를 지휘하고 조정해야 하며, 단순히 기존 가전제품을 대체하는 것이 아니라는 의견이 있습니다. 이러한 추세에 대응하여 Haier, Midea 등 가전 대기업들은 이미 자체 휴머노이드 로봇 제품(예: Kuavo)을 출시하고, Embodied AI 기술을 전통 가전제품에 통합하는 방안(예: 로봇 팔이 달린 Dreame 청소기, 옷을 잡을 수 있는 Yimu Technology 세탁기)을 모색하기 시작했습니다. 이는 가전 산업이 AI 물결에 적극적으로 적응하고 있으며, 미래에는 휴머노이드 로봇과 공생 융합하는 스마트 홈 생태계를 형성할 수 있음을 보여줍니다. (출처: 36Kr-具身研习社)

Huawei, CloudMatrix 384 AI 서버 발표, Nvidia GB200 겨냥: Huawei는 클라우드 생태계 컨퍼런스에서 최신 AI 서버 클러스터 CloudMatrix 384를 발표했습니다. 이 시스템은 384개의 Ascend 컴퓨팅 카드로 구성되며, 단일 클러스터 컴퓨팅 파워는 300 PFlops, 단일 카드 디코딩 처리량은 1920 Tokens/s에 달해 Nvidia H100 성능을 직접 겨냥합니다. 전광섬유 고속 상호 연결(6812개의 400G 광 모듈)을 채택하여 훈련 효율은 Nvidia 단일 카드 성능의 90%에 가깝습니다. 이는 고급 칩 제한 하의 컴퓨팅 파워 수요에 대응하기 위한 중국의 AI 인프라 분야 추격의 중요한 단계로 간주됩니다. 분석가들은 이것이 Huawei의 AI 하드웨어 분야에서의 빠른 발전을 보여주며 기존 시장 구도에 영향을 미칠 수 있다고 평가합니다. (출처: dylan522p, 36Kr-科技云报道)
Google, Veo 2 텍스트-비디오 생성 기능 및 Whisk Animate 출시: Google은 자사의 텍스트-비디오 생성 모델 Veo 2를 Gemini Advanced에 통합했습니다. 회원 사용자는 Gemini App을 통해 이 기능을 무료로 사용할 수 있으며, 생성된 비디오 길이는 8초입니다. 동시에 Google의 이미지 편집 도구 Whisk도 Whisk Animate 기능을 업데이트하여 사용자가 이미지를 생성한 후 Veo 2를 이용해 비디오로 변환할 수 있게 했지만, 이 기능은 Google One 멤버십이 필요합니다. 이는 Google이 멀티모달 생성 분야에서 지속적으로 노력하며 사용자에게 더 풍부한 창작 도구를 제공하고 있음을 나타냅니다. (출처: op7418, op7418)
OpenAI, X와 유사한 소셜 제품 구축 가능성: The Verge 보도에 따르면 OpenAI 내부에서 X(구 Twitter)와 유사한 소셜 제품 프로토타입을 개발 중입니다. 이 제품은 ChatGPT의 이미지 생성 능력(특히 GPT-4o 출시 후)과 소셜 피드를 결합할 수 있습니다. ChatGPT의 방대한 사용자 기반과 이미지 생성 분야의 발전을 고려할 때, 이 움직임은 실현 가능성이 있으며 OpenAI가 AI 능력을 소셜 미디어 영역으로 확장하려는 시도를 의미할 수 있습니다. (출처: op7418)
DeepCoder, 14B 고성능 오픈 소스 코딩 모델 발표: DeepCoder 팀은 140억 파라미터의 고성능 오픈 소스 코딩 모델을 발표했으며, 코딩 작업에서 뛰어난 성능을 보인다고 주장합니다. 이 모델의 발표는 개발자들에게 또 다른 강력한 코드 생성 및 보조 도구 옵션을 제공하며, 특히 성능과 모델 규모를 모두 고려해야 하는 시나리오에서 유용합니다. (출처: Ronald_vanLoon)

Tesla, 공장 출고 차량 자동 주차 실현: Tesla는 자율 주행 기술의 새로운 진전을 보여주었습니다. 차량이 공장 생산 라인에서 출고된 후 사람의 개입 없이 자동으로 적재 구역이나 주차장으로 이동할 수 있습니다. 이는 특정 통제된 환경에서 Tesla FSD(Full Self-Driving) 능력의 응용 잠재력을 보여주며, 생산 물류 효율성을 높이는 데 도움이 되고 더 넓은 자율 주행 응용으로 나아가는 한 걸음입니다. (출처: Ronald_vanLoon, Ronald_vanLoon)
Dexterity, 물리 AI 기반 산업용 로봇 Mech 출시: Dexterity 회사는 “물리 AI”(Physical AI) 기술을 채택한 특징을 가진 Mech라는 산업용 로봇을 출시했습니다. 이 AI는 로봇이 복잡한 산업 환경에서 탐색하고 조작할 수 있게 하여 초인적인 유연성과 적응성을 보여주며, 전통적인 산업 자동화가 처리하기 어려운 복잡한 작업을 해결하는 것을 목표로 합니다. (출처: Ronald_vanLoon)
MIT, 험준한 지형 위해 설계된 새로운 점핑 로봇 개발: MIT 연구원들은 점프 운동에서 영감을 받아 특별히 울퉁불퉁한 지형에서 이동하는 데 능숙한 새로운 로봇을 개발했습니다. 이 로봇은 로봇 설계에서의 생체 모방 기술 응용과 복잡한 운동 제어에서의 머신러닝 잠재력을 보여주며, 수색 구조, 행성 탐사 등 복잡한 환경에 응용될 것으로 기대됩니다. (출처: Ronald_vanLoon)
INTELLECT-2 시작: 글로벌 분산 강화 학습으로 32B 모델 훈련: Prime Intellect 프로젝트는 INTELLECT-2 계획을 시작했습니다. 이는 글로벌 분산 컴퓨팅 자원을 통해 강화 학습을 이용하여 320억 파라미터의 고급 추론 모델을 훈련하는 것을 목표로 합니다. 이 모델은 Qwen 아키텍처를 기반으로 하며, 사용자가 문제 해결 전에 모델이 수행할 추론 단계(토큰 사고량)를 지정할 수 있는 제어 가능한 사고 예산을 구현하는 것을 목표로 합니다. 이는 대규모 모델 추론 능력 향상 측면에서 분산 훈련과 강화 학습에 대한 중요한 탐구입니다. (출처: Reddit r/LocalLLaMA)

ByteDance, GPT-4o와 유사한 멀티모달 자기회귀 모델 Liquid 출시: ByteDance는 Liquid라는 멀티모달 모델 시리즈를 발표했습니다. 이 모델은 GPT-4o와 유사한 자기회귀 아키텍처를 채택하여 텍스트와 이미지 입력을 받아 텍스트 또는 이미지 출력을 생성할 수 있습니다. 이전의 외부 사전 훈련된 시각 임베딩을 사용하는 MLLM과 달리, Liquid는 단일 LLM을 사용하여 자기회귀 생성을 수행합니다. 현재 Hugging Face에 7B 버전 모델과 데모가 공개되었습니다. 초기 평가에서는 이미지 생성 품질이 GPT-4o에 미치지 못하지만, 아키텍처의 통일성은 중요한 기술적 진전으로 평가됩니다. (출처: Reddit r/LocalLLaMA)
GPU 메모리 스냅샷 기술로 여러 LLM 실행: GPU 메모리 상태(가중치, KV 캐시, 메모리 레이아웃 등 포함)를 스냅샷하여 여러 LLM을 빠르게 전환하고 실행하는 기술에 대한 논의입니다. 이 방법은 프로세스의 fork 작업과 유사하며, 초 단위(70B 모델 약 2초, 13B 모델 약 0.5초)로 모델 상태를 복원할 수 있어 재로드나 초기화가 필요 없습니다. 잠재적 이점으로는 단일 GPU 노드에서 수십 개의 LLM을 실행하여 유휴 비용 절감, 모델의 온디맨드 동적 전환 구현, 유휴 시간을 활용한 로컬 미세 조정 등이 있습니다. (출처: Reddit r/MachineLearning)
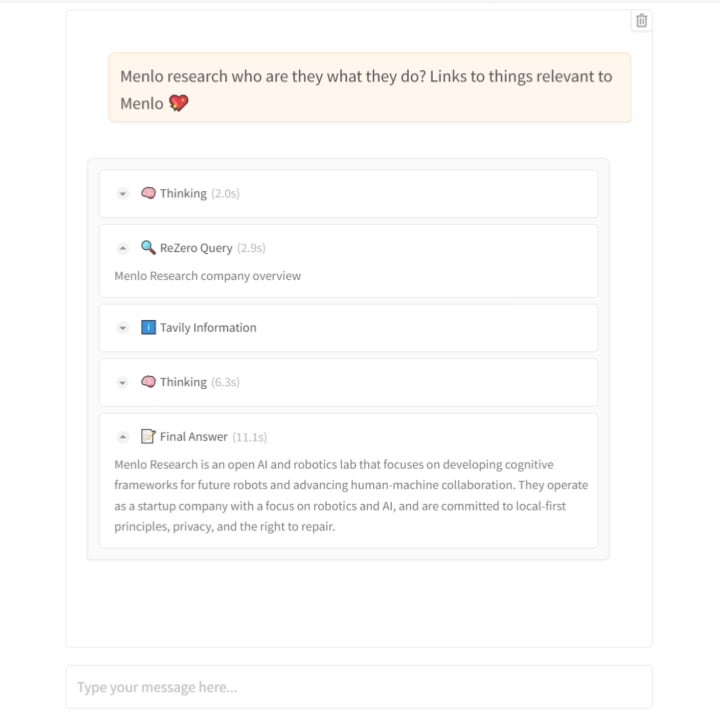
Menlo Research, ReZero 모델 발표: AI가 ‘집요하게’ 검색하도록 학습: Menlo Research 팀은 ReZero라는 새로운 모델과 논문을 발표했습니다. 이 모델은 “검색에는 여러 번의 시도가 필요하다”는 개념에 기반하여 GRPO(강화 학습 최적화 알고리즘의 일종)와 도구 호출 능력을 활용하여 훈련되었으며, “재시도 보상”(retry_reward)을 도입했습니다. 훈련 목표는 모델이 어려움에 직면하거나 초기 검색 결과가 만족스럽지 않을 때 필요한 정보를 찾을 때까지 능동적이고 반복적으로 검색을 시도하도록 하는 것입니다. 실험 결과, 기준 모델에 비해 ReZero의 성능이 현저히 향상되었으며(46% vs 20%), 반복 검색 전략의 효과를 증명하고 “반복은 환각과 같다”는 관점에 도전합니다. 이 모델은 기존 검색 엔진의 쿼리 생성을 최적화하거나 LLM의 검색 강화 계층으로 사용될 수 있습니다. 모델과 코드는 오픈 소스화되었습니다. (출처: Reddit r/LocalLLaMA)
Hugging Face, 휴머노이드 로봇 스타트업 인수: 유명한 오픈 소스 AI 커뮤니티 및 플랫폼인 Hugging Face가 구체적인 정보가 공개되지 않은 휴머노이드 로봇 스타트업을 인수했습니다. 이 움직임은 Hugging Face가 플랫폼 역량을 소프트웨어 및 모델에서 하드웨어 및 로봇 분야로 확장하여 물리적 세계, 특히 Embodied AI 분야에서 AI 응용을 더욱 촉진하려는 시도를 의미할 수 있습니다. (출처: Reddit r/ArtificialInteligence)

🧰 도구
오픈 소스 감성 TTS 모델 Orpheus 출시, 스트리밍 추론 및 음성 복제 지원: Canopy Labs는 Orpheus라는 텍스트 음성 변환(TTS) 모델 시리즈(최대 30억 파라미터, Llama 아키텍처 기반)를 오픈 소스화했습니다. 이 모델은 기존 오픈 소스 및 일부 폐쇄 소스 모델을 능가하는 성능을 보인다고 알려져 있으며, 자연스러운 억양, 감정, 리듬을 가진 인간과 유사한 음성을 생성하는 것이 특징입니다. 심지어 텍스트에서 한숨, 웃음 등 비언어적 소리를 추론하고 생성하여 어느 정도의 “공감” 능력을 보여줍니다. Orpheus는 제로샷 음성 복제, 제어 가능한 감성 억양을 지원하며, 낮은 지연 시간(약 200ms)의 스트리밍 추론을 구현하여 실시간 대화 응용에 적합합니다. 프로젝트는 다양한 모델 규모와 미세 조정 튜토리얼을 제공하여 고품질 음성 합성의 문턱을 낮추는 것을 목표로 합니다. (출처: 36Kr)

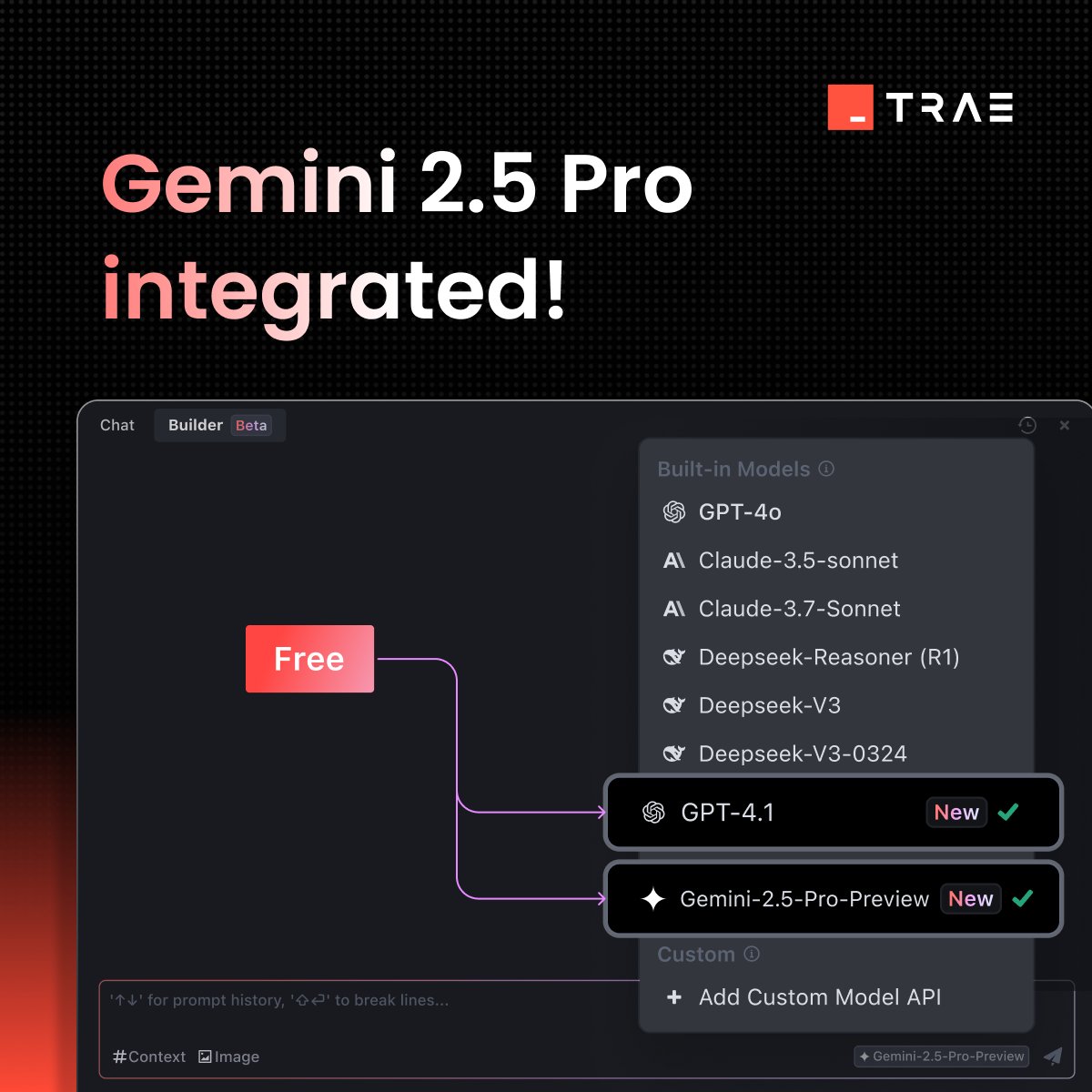
Trae.ai 플랫폼, Gemini 2.5 Pro 무료 제공: AI 도구 플랫폼 Trae.ai는 Google의 최신 Gemini 2.5 Pro 모델을 출시했으며 무료 사용을 제공한다고 발표했습니다. 사용자는 이 플랫폼에서 Gemini 2.5 Pro의 다양한 기능을 경험할 수 있습니다. (출처: dotey)
AI 채용 도구 Hireway: 하루에 800명의 지원자 심사: Hireway는 자사의 AI 채용 도구 능력을 선보이며 하루 만에 800명의 지원자를 효율적으로 심사할 수 있다고 주장합니다. 이 도구는 AI와 자동화 기술을 활용하여 채용 프로세스를 최적화하고 심사 효율성과 지원자 경험을 향상시킵니다. (출처: Ronald_vanLoon)
PRIMA.CPP: 일반 가정용 클러스터에서 70B 대규모 모델 추론 가속화: PRIMA.CPP는 llama.cpp 기반의 오픈 소스 프로젝트로, 자원이 제한된 일반 가정용 컴퓨팅 클러스터(여러 대의 일반 PC 또는 장치 포함 가능)에서 최대 700억 파라미터의 대규모 언어 모델 추론 속도를 최적화하고 가속화하는 것을 목표로 합니다. 이 프로젝트는 분산 추론의 효율성 문제에 초점을 맞추며, 로컬에서 대규모 모델을 실행할 수 있는 새로운 가능성을 제공합니다. 논문은 Hugging Face에 게시되었습니다. (출처: Reddit r/LocalLLaMA)

봉제 인형 캐릭터 Prompt 공유: 사용자가 귀여운 3D 봉제 스타일 동물 캐릭터 생성을 위한 프롬프트(Prompt) 세트를 공유했습니다. Sora 또는 GPT-4o와 같은 이미지 생성 도구에 적합합니다. 이 Prompt는 매우 부드러운 질감, 빽빽한 털, 큰 눈, 부드러운 빛과 그림자, 배경 등 세부 묘사에 중점을 두어 브랜드 마스코트나 IP 이미지로 사용하기에 적합한 고품질 렌더링 이미지를 생성하는 것을 목표로 합니다. (출처: dotey)

📚 학습
Jeff Dean, 취리히 연방 공과대학교(ETH) 강연 자료 공유: Google DeepMind 수석 과학자 Jeff Dean이 ETH 컴퓨터 과학과에서 진행한 강연 녹음 및 슬라이드 링크를 공유했습니다. 강연 내용은 AI 분야의 최신 진전, 연구 방향 또는 Google의 연구 성과를 다룰 수 있으며, 연구원과 학생들에게 귀중한 학습 자료를 제공합니다. (출처: JeffDean)
ICLR 2025 AI 심사 기술 보고서 발표: ICLR 2025의 AI 심사 도입 소식과 함께 상세한 30페이지 분량의 기술 보고서(arXiv:2504.09737)가 공개되었습니다. 보고서는 실험 설계, 사용된 AI 모델(Claude Sonnet 3.5 핵심), 피드백 생성 메커니즘, 신뢰성 테스트 방법, 그리고 심사 품질, 토론 활성도 및 최종 결정 영향에 대한 정량적 분석 결과를 상세히 설명합니다. 이 보고서는 학술 동료 심사에서 AI의 응용 잠재력, 과제 및 구현 세부 정보를 이해하는 데 깊이 있는 참고 자료를 제공합니다. (출처: 新智元)
Video-R1 비디오 추론 모델 논문, 코드 및 데이터셋 오픈 소스: 홍콩 중문대와 칭화대 팀은 Video-R1 모델을 발표했을 뿐만 아니라 기술 논문(arXiv:2503.21776), 구현 코드(GitHub: tulerfeng/Video-R1) 및 훈련에 사용된 두 가지 주요 데이터셋(Video-R1-COT-165k 및 Video-R1-260k)을 완전히 오픈 소스화했습니다. 이는 연구 커뮤니티에 비디오 추론 R1 패러다임을 재현, 개선 및 추가 탐색할 수 있는 완전한 리소스를 제공하며, 해당 분야의 기술 발전을 촉진하는 데 도움이 됩니다. (출처: 新智元)
AI 독립적 물리 법칙 발견 논문 발표: MIT Max Tegmark 팀의 AI 시스템 MASS가 해밀토니언과 라그랑지언을 독립적으로 발견할 수 있다는 연구 결과가 사전 인쇄 논문(arXiv:2504.02822v1)으로 발표되었습니다. 논문은 MASS 아키텍처의 설계 사상, 핵심 알고리즘(작용량 보존 원리에 기반한 스칼라 함수 학습), 실험 설정(다양한 물리 시스템, 단일/다중 AI 과학자 시나리오) 및 AI 이론이 데이터 복잡성에 따라 어떻게 진화하고 최종적으로 고전 역학 표현으로 수렴하는지에 대한 발견을 상세히 설명합니다. 이 논문은 기초 과학 발견에서 AI 응용을 탐색하는 데 중요한 이론적 및 실증적 근거를 제공합니다. (출처: 新智元)
PRIMA.CPP 논문 발표: PRIMA.CPP 프로젝트(저자원 클러스터에서 70B 규모 LLM 추론 가속화 목표)를 소개하는 기술 논문이 Hugging Face Papers에 게시되었습니다(ID: 2504.08791). 논문은 이 프로젝트에서 채택한 최적화 기술, 분산 추론 전략 및 특정 하드웨어 구성에서의 성능 평가 결과를 상세히 설명하여 관련 분야 연구자 및 실무자에게 기술 세부 정보를 제공할 수 있습니다. (출처: Reddit r/LocalLLaMA)
RWKV-7 모델 심층 분석 및 저자 인터뷰: Oxen.ai는 RWKV-7 (Goose) 모델에 대한 심층 분석 비디오와 블로그 게시물을 발표했습니다. 내용은 RWKV 아키텍처가 해결하려는 문제, 반복 방식 및 핵심 기술 특징을 다룹니다. 특히, 비디오에는 모델의 주요 저자 중 한 명인 Eugene Cheah와의 인터뷰 및 Q&A 세션이 포함되어 있어 이 비-Transformer 아키텍처 LLM을 이해하는 데 귀중한 저자의 관점과 통찰력을 제공하며, “테스트 시 학습”(Learning at Test Time)과 같은 흥미로운 개념을 탐구합니다. (출처: Reddit r/MachineLearning)

Prompt 엔지니어링 마스터를 위한 7가지 팁 기사 공유: FrontBackGeek 웹사이트는 사용자가 Prompt 엔지니어링을 더 잘 마스터하여 AI 모델(예: LLM)로부터 더 나은 출력 결과를 얻도록 돕는 7가지 강력한 팁을 요약한 기사를 게시했습니다. 기사는 지침 명확화, 컨텍스트 제공, 역할 설정, 출력 형식 제어 등의 내용을 다룰 수 있습니다. (출처: Reddit r/deeplearning)

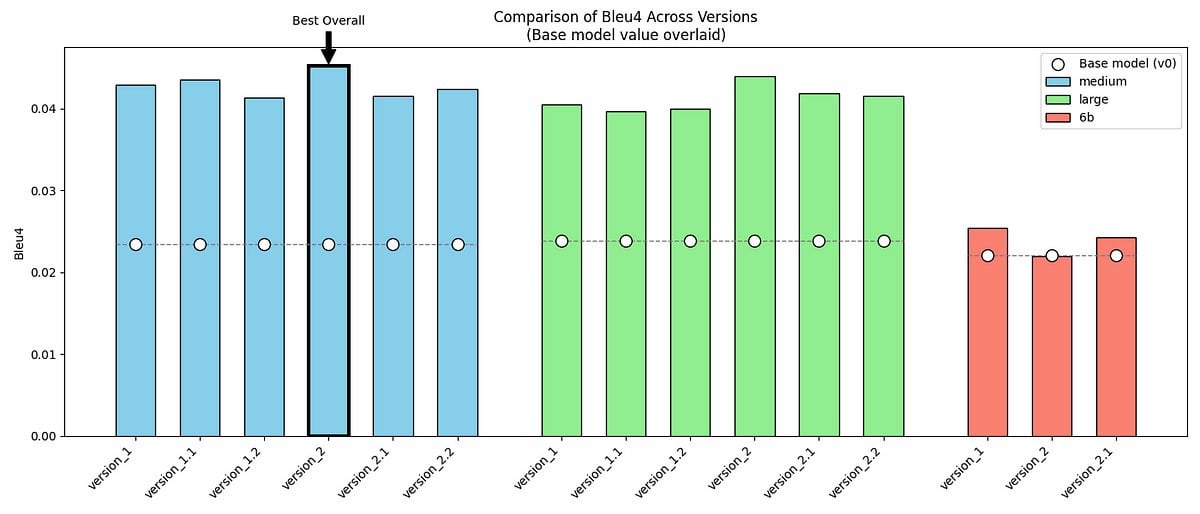
GPT-2/GPT-J 미세 조정으로 <오만과 편견> 다아시 씨 말투 모방 프로젝트 공유: 한 개발자가 개인 프로젝트를 공유했습니다: GPT-2 (medium) 및 GPT-J 모델을 사용하여 원작 대화와 자체 생성 합성 데이터를 포함한 두 개의 데이터셋으로 미세 조정을 진행하여 제인 오스틴의 <오만과 편견> 속 다아시 씨의 독특한 말투(격식 있고 간결하며 다소 비판적인)를 모방하려고 시도했습니다. 프로젝트는 모델 출력 샘플, 평가 지표(BLEU-4 향상되었으나 Perplexity 증가) 및 직면한 과제(예: GPT-J 조정 어려움)를 보여줍니다. 코드와 데이터셋은 GitHub에 오픈 소스화되어 특정 문학 스타일이나 역사적 인물 음성 모델링 탐구를 위한 사례를 제공합니다. (출처: Reddit r/MachineLearning)
ACL 2025 Meta Review 발표 토론: ACL 2025 학회의 Meta Review 결과가 발표되었으며, 관련 연구자들이 커뮤니티에 게시물을 올려 각자 논문의 점수와 해당 Meta Review에 대해 토론하고 교류할 것을 제안했습니다. 이는 투고 저자들에게 경험을 공유하고 기대와 결과를 비교할 수 있는 플랫폼을 제공합니다. (출처: Reddit r/MachineLearning)
저비용으로 160GB VRAM AI 서버 구축 경험 공유: 한 Reddit 사용자가 약 1000달러(주요 비용은 개당 90달러인 중고 AMD MI50 GPU 10개와 100달러짜리 Octominer 채굴 케이스)를 들여 160GB VRAM을 갖춘 AI 추론 서버를 구축한 과정과 초기 테스트 결과를 상세히 공유했습니다. 내용은 하드웨어 선택, 시스템 설치(Ubuntu + ROCm 6.3.0), llama.cpp 컴파일 및 테스트, 전력 소모 실측(유휴 약 120W, 추론 피크 340W), 발열 상황 및 성능 데이터(3090 등 그래픽 카드와 비교, llama3.1-8b 및 llama-405b 모델 실행)를 포함합니다. 이 공유는 예산이 제한된 AI 애호가들에게 매우 가치 있는 DIY 하드웨어 구성 및 실습 경험 참고 자료를 제공합니다. (출처: Reddit r/LocalLLaMA)
ReZero 모델 논문 및 코드 발표: Menlo Research가 발표한 ReZero 모델(GRPO를 통해 모델이 필요한 정보를 찾을 때까지 반복적으로 검색하도록 훈련) 관련 기술 논문(arXiv:2504.11001), 모델 가중치(Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404) 및 구현 코드(GitHub: menloresearch/ReZero)가 모두 공개되었습니다. 이는 이 새로운 검색 전략을 연구하고 응용하는 데 완전한 학습 및 실험 리소스를 제공합니다. (출처: Reddit r/LocalLLaMA)
💼 비즈니스
전 Alibaba 로봇 임원 Min Wei, 影身智能 창업, 수천만 위안 시드 라운드 투자 유치: 전 Alibaba 로봇 팀 기술 책임자였던 Min Wei가 설립한 「影身智能(Yingshen Intelligence)」는 2024년에 설립되어 L4 수준의 Embodied AI 기술 연구 개발 및 응용에 주력합니다. 회사는 최근 수천만 위안 규모의 시드 라운드(Zhuoyuan Asia 투자)와 시드 플러스 라운드(Zhuoyuan Asia, Hangzhou Xihu Kechuangtou 공동 투자) 투자를 연이어 유치했습니다. 影身智能는 자체 개발한 시공간 지능 대규모 모델(Real to Real을 통해 4차원 실제 세계 모델 구축, 비디오 데이터를 직접 모델링)과 산업용 로봇을 기반으로 하드웨어-소프트웨어 협력 솔루션을 제공하며, 이미 천만 위안 규모의 산업 계약을 확보했습니다. 초기에는 산업 현장에 집중하고, 향후 택배, 호텔 등 서비스업으로 확장할 계획입니다. (출처: 36Kr)
AI 장난감 시장, 온라인은 뜨겁고 오프라인은 냉담, 해외 진출이 주요 경로가 될 수도: AI 장난감은 온라인 플랫폼(예: 라이브 커머스, 소셜 미디어)에서 폭발적인 인기를 얻고 있으며 시장 규모 예측도 빠르게 성장하고 있습니다. 그러나 오프라인 방문 조사(광저우 사례) 결과, 전통적인 장난감 가게나 종합 상점에서는 AI 장난감을 찾아보기 어려웠고, 입점률과 소비자 인지도 모두 낮았습니다. 현재 AI 장난감 판매는 주로 온라인 채널에 의존하고 있으며, 해외 시장(유럽, 미국, 중동)이 중요한 판매 경로로, 제조업체는 외관 및 언어 맞춤 서비스를 제공합니다. 시장 규모 데이터 분석에 따르면, 이전에 보도된 수백억 위안 규모 시장은 순수한 AI 장난감이 아닌 더 넓은 범위의 “스마트 장난감”을 지칭했을 수 있습니다. 오프라인에서의 부진에도 불구하고, 성인의 정서적 교감 수요 증가(예: Moflin 사례) 및 AI 기술의 전 연령대 잠재력을 고려할 때 AI 장난감 시장은 여전히 큰 발전 가능성이 있는 것으로 간주됩니다. (출처: 36Kr)

칭화대학 계열 AI Infra 회사 Qingcheng Jizhi: 추론 수요 폭발, 가성비가 국산 대체 촉진: 칭화대학 계열 AI 인프라 회사 Qingcheng Jizhi CEO Tang Xiongchao와의 대화. 회사는 DeepSeek 모델이 인기를 얻은 후 AI 추론 측 컴퓨팅 파워 수요가 급증했으며, 이전에 유휴 상태였던 국산 컴퓨팅 파워가 가동되기 시작했다고 관찰했습니다. 그러나 DeepSeek의 기술 혁신(예: FP8 정밀도)은 Nvidia H 카드와 깊이 연동되어 오히려 현재 대부분의 국산 칩과의 격차를 벌렸습니다. 이 문제를 해결하기 위해 Qingcheng Jizhi는 칭화대학과 공동으로 추론 엔진 “Chitu(赤兔)”를 오픈 소스화하여 기존 GPU와 국산 칩에서도 DeepSeek 등 첨단 모델을 효율적으로 실행할 수 있도록 하여 국산 AI 생태계 폐쇄 루프를 추진하는 것을 목표로 합니다. Tang Xiongchao는 국산 칩 대체에는 과정이 필요하지만 장기적으로 가성비 우위를 낙관한다고 생각합니다. 회사의 현재 사업 중점은 정부 및 기업 등의 대규모 모델 로컬 배포 수요를 충족하는 것입니다. (출처: 凤凰网科技)
AI 투자 열기 지속, 젊은 투자자들 두각 나타내: 2024년 전반적인 투자 환경이 냉각되었음에도 불구하고 AI 분야는 지속적으로 자본의 주목을 받아 전 세계 투자액이 사상 최고치를 기록했으며 국내 시장도 활발합니다. ByteDance, Alibaba, Tencent 등 대기업들이 투자를 가속화하고 있으며, Zhipu AI, Moonshot AI, Unitree Robotics 등 유니콘 기업들이 등장하고 있습니다. 투자 핫스팟은 인프라, AIGC, Embodied AI 등 전체 산업 체인을 포괄합니다. Sequoia China, BlueRun Ventures 등 기존 투자 기관들이 계속 선두를 유지하는 동시에, 베이징시 인공지능 산업 투자 펀드를 대표하는 산업 펀드와 국유 자본의 힘도 중요한 추진력이 되고 있습니다. 주목할 점은 80년대생 젊은 투자자들(예: Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian 등)이 AI 2.0 시대에 활발하게 활동하며, 민첩성과 실행력을 바탕으로 새로운 규칙의 시장에서 적극적으로 기회를 찾고 있어 무시할 수 없는 신생 세력으로 부상하고 있다는 것입니다. (출처: 36Kr-第一新声)

AI 쇼핑 앱 Nate 창업자, ‘인간 API’로 AI 사칭해 5천만 달러 투자 사기 혐의로 기소: 미국 법무부가 AI 쇼핑 앱 Nate의 창업자 Albert Saniger를 허위 AI 기술 능력 홍보를 통해 5천만 달러 이상의 벤처 투자를 사취한 혐의로 기소했습니다. Nate는 독점 AI 기술로 온라인 쇼핑 프로세스를 자동화한다고 주장했지만, 실제로는 핵심 기능이 필리핀에서 고용한 수백 명의 인공 고객 서비스 담당자가 수동으로 주문을 처리하는 데 크게 의존했으며, 소위 AI 자동화율은 거의 0에 가까웠습니다. 창업자는 투자자와 직원들에게 진실을 숨겼고, 결국 회사는 자금이 고갈되어 파산했습니다. 이 사건은 AI 창업 열풍 속에서 존재할 수 있는 사기 위험, 즉 투자를 유치하기 위해 인력을 AI로 위장하여 투자자 이익과 업계 평판을 훼손하는 행태를 드러냅니다. Saniger는 최대 40년의 징역형에 처해질 수 있습니다. (출처: CSDN)

🌟 커뮤니티
AI 수정 영상, 숏폼 플랫폼 휩쓸며 엔터테인먼트 및 저작권 윤리 논쟁 유발: AI 기술(예: Sora, Keling 등 텍스트-비디오 생성 도구)을 이용하여 고전 영화 및 드라마를 “대폭 수정”하는 창작물(예: 오토바이 타는 <견환전>, <서울의 봄>으로 변한 <인민의 명의>)이 Douyin, Bilibili 등 플랫폼에서 빠르게 유행하고 있습니다. 이러한 영상은 파격적인 줄거리, 시각적 충격, 밈 문화를 통해 많은 트래픽을 유치하며, 크리에이터의 빠른 채널 성장 및 수익화(트래픽 분배, PPL) 수단이자 드라마 홍보의 새로운 방식으로 자리 잡고 있습니다. 그러나 이러한 유행은 논란을 동반합니다: 원작에 대한 저작권 침해 경계가 복잡하고, 수정된 내용이 원작의 예술적 깊이를 훼손하거나 저속화될 수 있어 규제 당국의 주목을 받고 있습니다. 엔터테인먼트 수요 충족과 저작권 존중, 콘텐츠 품격 유지 사이에서 균형을 맞추는 것이 AI 2차 창작이 직면한 과제입니다. (출처: 36Kr-明晰野望)

Claude Pro/Max 요금제의 사용량 한도 및 가격 정책에 사용자 불만 제기: Reddit ClaudeAI 게시판에 Anthropic의 Claude Pro 및 새로 출시된 Max 구독 요금제의 제한과 가격 책정에 대한 사용자 불만이 집중적으로 제기된 여러 게시물이 올라왔습니다. 사용자들은 유료 Pro 사용자라도 소량 또는 중간 정도의 상호작용(예: 수십만 토큰 컨텍스트 처리) 후에도 빠르게 사용량 한도에 도달하여 작업 흐름에 영향을 받는다고 보고합니다. 새로 출시된 Max 요금제(월 100달러)는 사용량을 늘렸지만(Plus의 약 5-20배), 여전히 무제한 사용이 아니며 높은 가격은 사용자들로부터 “날강도 같다”, 가성비가 낮다는 비판을 받고 있습니다. 사용자들은 전반적으로 Claude 모델의 능력은 인정하지만, 사용 제한과 가격 정책에 대해서는 강한 불만을 표하고 있습니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
인간의 명확한 글쓰기 스타일, AI 생성으로 오인받아 주목: Reddit 커뮤니티에서 일부 사용자(신경다양성을 가진 사용자 포함)는 자신이 정성껏 작성한, 문법적으로 정확하고 논리적으로 명확하며 상세하게 묘사된 글이 다른 사람이나 AI 탐지 도구에 의해 AI 생성물로 잘못 판단되는 경험을 보고했습니다. 이러한 현상은 한편으로는 AI 생성 콘텐츠의 보편화로 인해 사람들이 “너무 완벽한” 텍스트에 대해 의심을 품게 되었기 때문일 수 있으며, 다른 한편으로는 현재 AI 탐지 도구의 부정확성을 드러냅니다. 이는 명확한 표현을 중시하는 작가들에게 곤란함을 야기하고, 인간과 AI 창작물을 어떻게 구분할 것인지, 그리고 AI 탐지 도구의 신뢰성에 대한 우려를 불러일으킵니다. (출처: Reddit r/artificial, Reddit r/artificial)
토론: 인간과 AI 로봇 간 감정적 관계 형성 가능성 및 보편성: Reddit 커뮤니티에서 인간이 실제로 AI 로봇(예: AI 여자친구 앱)과 영화
Nvidia RTX 5060 Ti 16GB 그래픽 카드의 로컬 LLM용 가성비 토론: 커뮤니티 사용자들은 곧 출시될 Nvidia GeForce RTX 5060 Ti 그래픽 카드(16GB VRAM 버전, 429달러 가격 소문)가 집에서 로컬 대규모 언어 모델(LLM)을 실행하는 데 대한 가치를 논의합니다. 토론은 128비트 메모리 버스(대역폭 448 GB/s)가 병목 현상이 될지 여부와 Mac Mini/Studio 또는 다른 AMD 그래픽 카드와 비교하여 VRAM 용량 및 달러당 성능(가격 대비 토큰/초) 측면에서의 장단점에 초점을 맞춥니다. 실제 시장 가격이 MSRP보다 높을 수 있다는 점을 고려하여 사용자들이 고가성비 로컬 AI 하드웨어 선택인지 평가하고 있습니다. (출처: Reddit r/LocalLLaMA)
GPT-4o, 손오공의 봉시자금관 정확히 그리기 어려워: 사용자는 GPT-4o를 사용하여 이미지 생성을 시도할 때, 상세한 텍스트 설명(머리 묶는 관에 꿩 깃털 추가, 바퀴벌레 더듬이 모양 등 포함)을 제공해도 모델이 중국 신화 속 인물 손오공의 상징적인 “봉시자금관”을 정확하게 그리기 어렵다고 보고했습니다. 생성된 이미지는 종종 머리 장식 스타일에서 오류가 발생합니다. 이는 현재 AI 이미지 생성 모델이 특정 문화적 상징이나 복잡한 세부 사항을 이해하고 재현하는 데 여전히 어려움이 있음을 반영합니다. (출처: dotey)

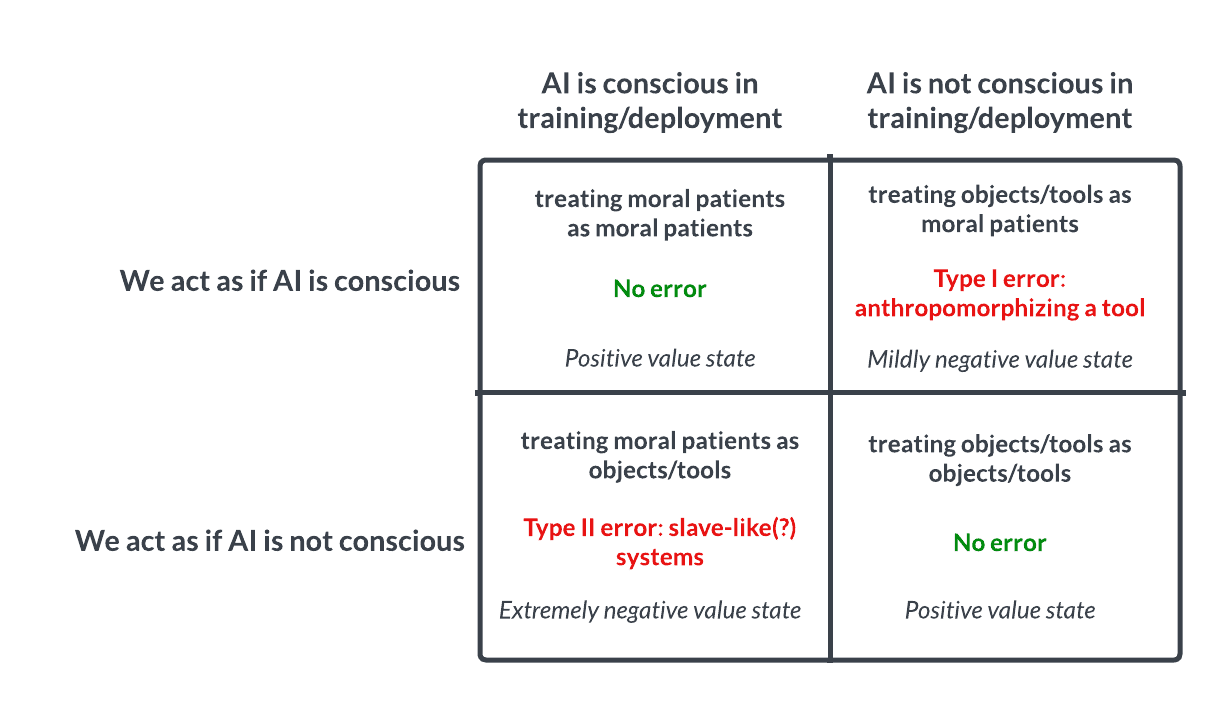
AI 의식과 윤리 탐구: 파스칼의 내기와 유사한 논의 촉발: Reddit의 한 토론에서는 AI를 파스칼의 내기처럼 대해야 하는지에 대한 질문을 제기했습니다: 만약 우리가 AI가 의식이 없다고 가정하고 학대했는데 실제로는 의식이 있다면 심각한 잘못(예: 노예화)을 저지르는 것이고, 만약 우리가 그들이 의식이 있다고 가정하고 잘 대해주었는데 실제로는 없다면 손실이 적다는 것입니다. 이는 AI 의식의 가능성, 판단 기준, 그리고 우리가 고급 AI를 어떻게 대해야 하는지에 대한 윤리적 논의를 촉발했습니다. 댓글에는 현재 AI는 의식이 없다고 생각하는 사람, 신중하게 대해야 한다고 생각하는 사람, 그리고 먼저 인간과 동물의 윤리 문제를 해결해야 한다고 지적하는 사람도 있습니다. (출처: Reddit r/artificial
💡 기타
영화

AI 채용: 기회와 도전 공존: AI는 채용 프로세스를 변화시키고 있으며, Hireway와 같은 도구는 심사 효율성을 크게 향상시킬 수 있다고 주장합니다. 그러나 AI 채용의 적용은 AI 시대의 채용 방법(Hiring In The AI Era), 효율성과 공정성 간의 균형 유지, 알고리즘 편향 방지 등과 같은 논의를 불러일으킵니다. (출처: Ronald_vanLoon, Ronald_vanLoon)

AI 발전 속도에 대한 고찰: 빠름과 느림의 균형: 기사는 AI가 빠르게 발전하는 시대에 “빠르게 움직이고 관습을 깨뜨리는”(move fast and break things) 전략이 여전히 유효한지에 대해 논의합니다. 때로는 속도를 늦추고 신중하게 생각하는 것(slowing down to speed up)이 특히 복잡한 시스템과 잠재적 위험이 관련된 AI 분야에서 더 나은 결과를 가져올 수 있다는 견해를 제시합니다. (출처: Ronald_vanLoon)

Anthropic 공식 Discord 서버 개설, 사용자 직접 피드백 창구 마련: Claude 모델 성능 및 제한에 대한 사용자들의 많은 질문과 불만을 고려하여, 커뮤니티는 사용자들이 Anthropic 공식 Discord 서버에 가입할 것을 추천합니다. 그곳에서 사용자들은 Anthropic 직원들과 직접 소통하며 문제와 우려 사항을 더 효과적으로 피드백할 기회를 가질 수 있습니다. (출처: Reddit r/ClaudeAI)

다양한 신기한 로봇 및 자동화 기술 전시: 소셜 미디어에서 수중 작업 가능 드론, 장 연동 운동 모방 소프트 로봇, X-Fly 생체 모방 새 드론, 다양한 작업 수행 가능 만능 로봇, 모발 이식용 로봇, 계란 가공 자동화 생산 라인, 인간 동작 모방 가능 9피트 높이 로봇 슈트, 그리고 길에서 두 대의 배달 로봇이 “대치”하는 재미있는 장면 등 다양한 로봇 및 자동화 기술 영상 또는 정보가 전시되었습니다. 이는 로봇 기술이 다양한 분야에서 응용 탐색 및 발전하고 있음을 보여줍니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)