
키워드:AI, GPT-4.1, DeepSeek, 智谱AI IPO, 英伟达AI超算 투자, 아마존 AI 자본 지출, AI Agent 상호 운용 프로토콜, DeepSeek 사용자 규모
🔥 포커스
OpenAI, GPT-4.1 시리즈 모델 출시, API 성능 향상 및 GPT-4.5 폐기: OpenAI는 4월 15일 API를 통해 GPT-4.1, GPT-4.1 mini, GPT-4.1 nano 세 가지 새로운 모델을 출시했으며, 이는 GPT-4o 시리즈를 전면적으로 능가하는 것을 목표로 합니다. 새로운 모델은 최대 100만 Token의 컨텍스트 창을 가지며, 지식 베이스는 2024년 6월까지 업데이트되었습니다. GPT-4.1은 코딩 능력(SWE-bench Verified 점수 54.6%, GPT-4o 대비 21.4% 향상), 지시 사항 준수(MultiChallenge 점수 38.3%, GPT-4o 대비 10.5% 향상), 긴 컨텍스트 비디오 이해(Video-MME 점수 72.0%, GPT-4o 대비 6.7% 향상) 측면에서 뛰어난 성능을 보입니다. 주목할 점은 GPT-4.1 nano가 최초의 nano 모델이며, GPT-4o mini보다 성능이 우수하고 비용이 저렴하다는 것입니다. 동시에 OpenAI는 3개월 후(7월 14일) GPT-4.5 Preview API를 연구 미리보기 버전으로 간주하고 서비스를 중단할 것이며, 향후 개발자들이 선호하는 기능을 새로운 모델에 통합할 것이라고 발표했습니다. 이번 출시는 OpenAI가 API 모델과 ChatGPT 제품 라인을 구분하고 Google Gemini 시리즈와 직접 경쟁하려는 전략적 조치로 간주됩니다. (출처: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI, IPO 컨설팅 시작 및 신규 모델 오픈소스 공개, 기업 가치 200억 위안 초과: 중국 대형 모델 ‘여섯 작은 호랑이(六小虎)’ 중 하나인 Zhipu AI(智谱华章)가 4월 14일 베이징 증권감독국에 컨설팅 등록을 완료하고 공식적으로 IPO 절차를 시작했으며, CICC가 컨설팅 기관을 맡았습니다. Zhipu AI는 칭화대학교 지식 공학 연구실에서 인큐베이팅되었으며, 핵심 팀 멤버 대부분이 칭화대 출신입니다. 누적 융자액은 150억 위안을 초과했으며, 최근 기업 가치는 200억 위안을 넘어섰습니다. IPO 시작과 동시에 Zhipu AI는 GLM-4-32B/9B 시리즈 모델(기반, 추론, 숙고 세 종류 포함)을 대규모로 오픈소스 공개한다고 발표했으며, 이는 MIT 라이선스를 따라 무료 상업적 사용이 가능합니다. 이 중 32B 파라미터의 추론 모델 GLM-Z1-32B-0414는 일부 작업에서 671B 파라미터의 DeepSeek-R1과 비슷한 성능을 보이며, API 초고속 버전 GLM-Z1-AirX의 추론 속도는 200 tokens/s에 달하고, 고가성비 버전의 가격은 DeepSeek-R1의 1/30에 불과합니다. 회사는 또한 새로운 도메인 z.ai를 모델 무료 체험 플랫폼으로 사용하기 시작했습니다. 이는 Zhipu AI가 기술 자체 개발, 상업화 탐색 및 오픈소스 생태계 구축에 대한 전면적인 레이아웃을 보여줍니다. (출처: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

Nvidia, 5000억 달러 투자하여 미국 본토에서 AI 슈퍼컴퓨터 제조: Nvidia는 향후 4년 동안 5000억 달러를 투자하여 처음으로 미국 본토에서 AI 슈퍼컴퓨터를 제조하는 중대한 계획을 발표했습니다. 이 계획에는 TSMC(애리조나에서 Blackwell 칩 생산), Foxconn 및 Wistron(텍사스에서 슈퍼컴퓨터 공장 건설), Amkor 및 SPIL(애리조나에서 패키징 및 테스트 수행) 등 여러 업계 거물과의 협력이 포함됩니다. Nvidia CEO Jensen Huang은 이 조치가 증가하는 AI 칩 및 슈퍼컴퓨터 수요를 충족하고 공급망 탄력성을 강화하며, Nvidia의 AI, 로봇(Isaac GR00T) 및 디지털 트윈(Omniverse) 기술을 활용하여 공장을 설계하고 운영하기 위한 것이라고 밝혔습니다. 이 계획은 미국 정부의 본토 제조 추진(예: 《칩스법》) 및 지정학적 배경 하에서의 전략적 배치로 간주되며, 글로벌 AI 인프라 경쟁에서 미국의 지위를 향상시키는 것을 목표로 하지만, 공급망 복잡성, 기술 인력 부족 및 정책 불확실성 등의 도전 과제에 직면해 있습니다. (출처: 新智元1, 新智元2, Reddit r/artificial)

아마존, 경쟁 대응 및 기회 포착 위해 AI에 1000억 달러 이상 투자 계획: 아마존 CEO Andy Jassy는 2024년 연례 주주 서한에서 회사가 2025년에 1000억 달러 이상의 자본 지출을 계획하고 있으며, 대부분은 데이터 센터, 네트워크 장비, AI 하드웨어(자체 개발 칩 Trainium 등) 및 생성형 AI 서비스(자체 개발 대형 모델 Nova 시리즈, Bedrock 플랫폼, 업그레이드된 Alexa+, 쇼핑 도우미 Rufus 등)와 같은 AI 관련 프로젝트에 사용될 것이라고 밝혔습니다. 이 거액 투자(연간 수입의 약 1/6에 해당)는 아마존이 AI를 전자 상거래 분야의 치열한 경쟁(SHEIN, Temu, TikTok 등으로부터)에 대응하고 역사적인 기회를 포착하는 핵심으로 간주하고 있음을 반영합니다. Jassy는 AI가 검색, 프로그래밍, 쇼핑 등의 규칙을 바꿀 것이며, 투자하지 않으면 경쟁력을 잃을 것이라고 강조했습니다. 현재 아마존 AI 사업의 연간 수입은 수십억 달러에 달하며, 전년 대비 세 자릿수 성장을 기록하고 있습니다. 이 조치는 또한 아마존이 클라우드 서비스(AWS) 분야에서 Microsoft Azure, Google Cloud 등 경쟁사의 도전에 직면하여 선두 지위를 공고히 하기 위해 지속적으로 투자하려는 결의를 보여줍니다. (출처: 36氪)
🎯 동향
AI Agent 상호 운용성 프로토콜 MCP와 A2A 표준 주목: AI 에이전트 분야는 표준화된 상호 작용 프로토콜 경쟁을 맞이하고 있습니다. Anthropic이 제안한 MCP(Model Context Protocol)는 대형 모델과 외부 도구, 데이터 소스 간의 통신을 통합하는 것을 목표로 하며, “AI의 USB-C”로 불리며 OpenAI, Google 등의 지지를 받았습니다. Google은 서로 다른 공급업체, 프레임워크의 에이전트 간의 안전하고 효율적인 협업에 초점을 맞춘 A2A(Agent2Agent) 프로토콜을 오픈소스 공개하여 생태계 장벽을 허물고자 합니다. 이 두 가지 주요 프로토콜의 등장은 AI가 단일 지능에서 협업 네트워크로 진화하고 있음을 나타내지만, “프로토콜이 곧 권력”, 데이터 독점 및 생태계 장벽(“높은 담장 안의 작은 뜰”)에 대한 논의를 불러일으켰습니다. 표준 제정권을 장악하는 것은 AI 산업 체인 구조를 재편하고 AI와 물리적 세계(로봇, 사물 인터넷)의 융합에 깊은 영향을 미칠 수 있습니다. Alibaba Cloud, Tencent Cloud 등 중국 내 기업들도 MCP 지원을 위한 준비를 시작했습니다. (출처: 36Kr)

QuestMobile 보고서: DeepSeek, 중국 AI 애플리케이션 시장 판도 뒤집어, 사용자 규모 2.4억 명 도달: QuestMobile이 발표한 《2025년 1분기 AI 애플리케이션 시장 경쟁 분석》 보고서에 따르면, DeepSeek 모델과 그 애플리케이션의 폭발적인 인기로 인해 중국 내 네이티브 AI 앱 시장 판도가 완전히 뒤집혔습니다. 2025년 2월 말 기준, 네이티브 AI 앱 월간 활성 사용자 규모는 2.4억 명에 달하며, 1월 대비 약 90% 증가했습니다. DeepSeek App은 1.94억 명의 월간 활성 사용자로 1위를 차지했으며, ByteDance의 Doubao(1.16억 명)와 Tencent Yuanbao(4164만 명)가 2, 3위를 기록하며 이전의 Kimi 등을 대체했습니다. 보고서는 DeepSeek의 오픈소스 보편화 효과가 선두 주자들의 도입과 AI 애플리케이션 폭발을 촉진했으며, AI 종합 비서, AI 검색 등 23개 분야를 형성했고, 그중 AI 검색 경쟁이 가장 치열하다고 지적했습니다. 현재 “다중 모델 구동”은 선두 앱의 표준이 되었으며, 경쟁의 초점은 제품 설계와 운영으로 옮겨가고 있습니다. (출처: QuestMobile)

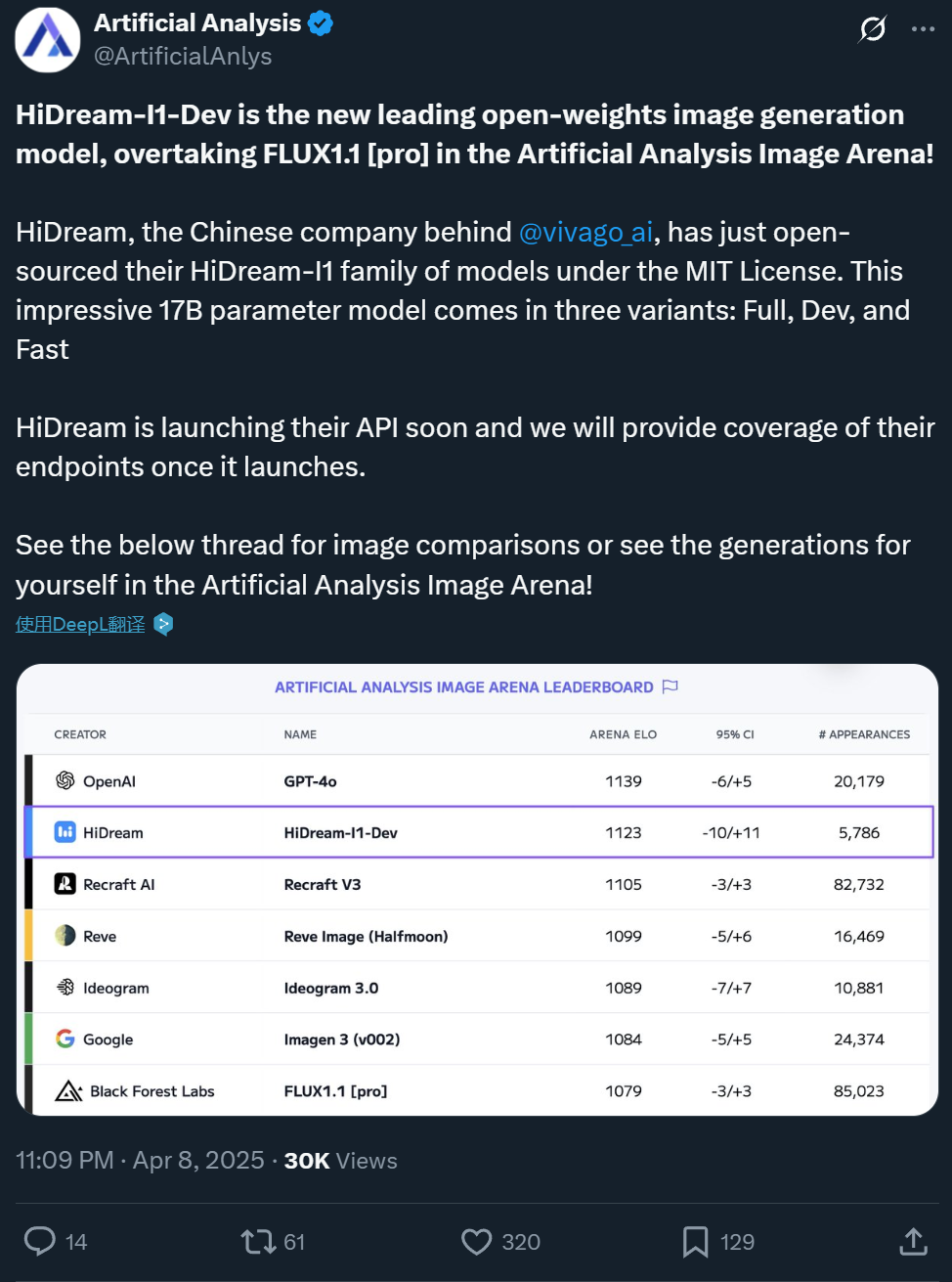
Zxiang Future, 17B 텍스트-이미지 생성 모델 HiDream-I1 오픈소스 공개, GPT-4o와 견줄 만한 효과: 중국 회사 Zxiang Future(智象未来)가 17B 파라미터의 텍스트-이미지 생성 대형 모델 HiDream-I1을 오픈소스 공개했습니다. 이 모델은 완화된 MIT 라이선스를 채택하여 상업적 사용이 가능합니다. Artificial Analysis 등 플랫폼의 경쟁 및 벤치마크 테스트(예: HPSv2.1, GenEval, DPG-Bench)에서 뛰어난 성능을 보였으며, 생성된 이미지의 사실감, 섬세함 및 지시 사항 준수 능력은 GPT-4o 및 FLUX 1.1 Pro와 견줄 만하며 일부 측면에서는 더 우수하다고 평가받습니다. HiDream-I1은 Sparse Diffusion Transformer(Sparse DiT) 아키텍처를 채택하고 MoE 기술을 통합하여 성능과 효율성을 향상시켰습니다. 회사는 또한 상호 작용형 이미지 편집을 지원하는 HiDream-E1 모델을 곧 오픈소스 공개할 예정이며, 이 둘을 결합하여 “오픈소스 버전 GPT-4o”의 이미지 생성 및 편집 경험을 제공하는 것을 목표로 합니다. 모델은 Hugging Face에 공개되었으며 Vivago 플랫폼에서 체험할 수 있습니다. (출처: 机器之心1, 机器之心2)
ByteDance, 7B 비디오 기반 모델 Seaweed 출시, 저비용 고효율: ByteDance Seed 팀이 Seaweed(Seed-Video의 발음 유사)라는 비디오 생성 기반 모델을 출시했습니다. 이 모델의 파라미터 수는 70억 개에 불과하며, 66.5만 H100 GPU 시간(1000개 카드로 약 28일 훈련에 해당)을 사용하여 훈련을 완료했다고 알려져 비용이 상대적으로 저렴합니다. Seaweed는 텍스트를 기반으로 다양한 해상도(기본 1280×720 지원, 2K까지 업샘플링 가능), 임의의 가로세로 비율 및 길이의 비디오를 생성할 수 있습니다. 모델은 이미지-비디오 생성, 참조 주체 제어(단일/다중 이미지), 디지털 휴먼 솔루션 Omnihuman과 결합하여 입 모양 동기화 비디오 생성, 비디오 더빙 등의 기능을 지원합니다. 기술적으로는 DiT+VAE 아키텍처를 채택하고, 포괄적인 데이터 처리 프로세스와 다단계 다중 작업 훈련 전략(사전 훈련, SFT, RLHF)을 결합했으며, 훈련 효율성을 높이기 위해 시스템 수준 최적화를 수행했습니다. 팀은 전 Google 비디오 생성 책임자 Jiang Lu 박사 등이 이끌고 있습니다. (출처: 量子位)

Alibaba Tongyi, 디지털 휴먼 비디오 생성 모델 OmniTalker 출시: Alibaba Tongyi 연구소 HumanAIGC 팀이 새로운 디지털 휴먼 비디오 생성 대형 모델 OmniTalker를 출시했습니다. 이 모델은 기존의 캐스케이드 방식(TTS+오디오 구동)이 야기하는 지연, 오디오-비디오 비동기화, 스타일 불일치 등의 문제를 해결하는 것을 목표로 합니다. OmniTalker는 엔드투엔드 통합 프레임워크로, 텍스트와 참조 오디오/비디오 클립을 입력하면 동기화된 음성 및 디지털 휴먼 비디오를 실시간으로 생성하며, 동시에 참조 소스의 음성 및 얼굴 말하기 스타일을 유지합니다. 핵심 아키텍처는 오디오 및 시각 정보를 각각 처리하는 듀얼 스트림 DiT(Diffusion Transformer)를 채택하고, 새로운 오디오-비디오 융합 모듈을 통해 동기화 및 스타일 일관성을 보장합니다. 모델은 컨텍스트 참조 학습 모듈을 사용하여 참조 비디오에서 스타일 특징을 포착하므로 추가적인 스타일 추출기 훈련이 필요 없습니다. 현재 프로젝트는 ModelScope 커뮤니티와 HuggingFace에서 체험할 수 있습니다. (출처: 机器之心)

Kuaishou, Kuaishou AI 비디오 모델 2.0 버전 출시: Kuaishou 산하의 Kuaishou AI 비디오 생성 모델이 2.0 버전을 출시했습니다. 카메라 워크 범위, 물리 법칙 준수, 인물 연기, 동작 안정성 및 의미 이해 등에서 현저한 개선이 있다고 알려졌습니다. 사용자 평가에 따르면, 새 버전은 복잡한 상호 작용(예: 티라노사우루스가 나무를 부러뜨리는 것), 섬세한 동작(예: 안경 벗기), 다인 장면 및 실제 빛과 그림자 시뮬레이션 처리에서 뛰어난 성능을 보이며, 생성된 비디오의 사실감과 영화적 느낌이 크게 향상되어 이전 1.6 버전을 능가하고 업계 최고 수준에 도달했다고 평가받습니다. 고속 군중 이동 및 극단적인 물리 시뮬레이션(예: 농구 슛) 측면에서는 여전히 개선의 여지가 있지만, 종합적인 성능은 전문 제작 수준에 도전하기 시작했다고 간주됩니다. 사용자는 공식 웹사이트 klingai.com을 통해 새 버전을 체험할 수 있습니다. (출처: 公众号, op7418)

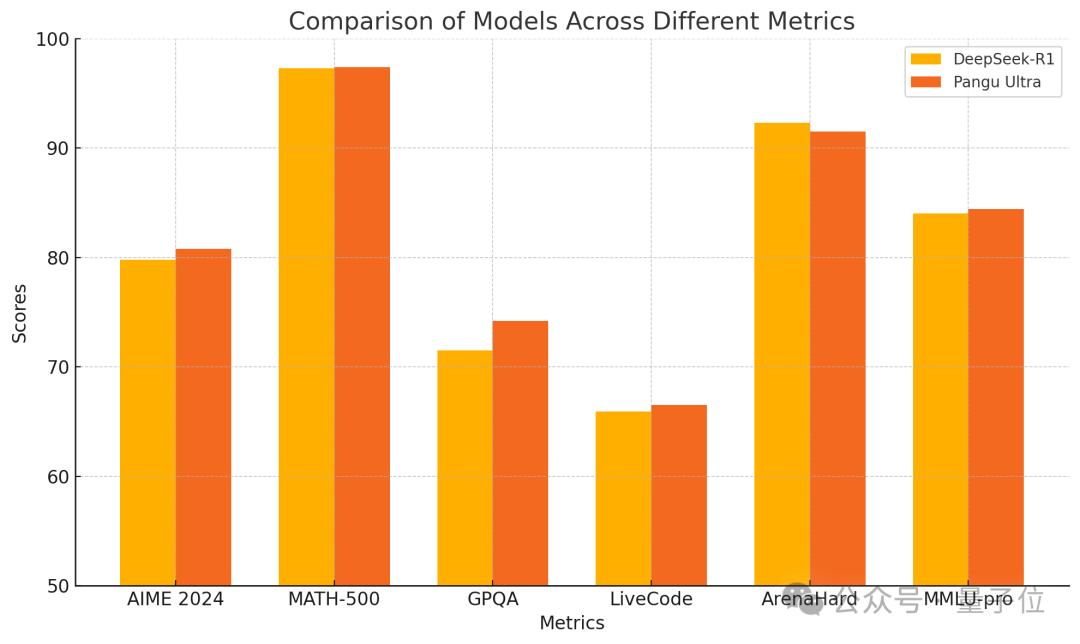
Huawei, Pangu Ultra 135B Dense 모델 출시, 순수 Ascend 훈련 성능 우수: Huawei는 Pangu 대형 모델 시리즈의 새로운 멤버인 Pangu Ultra를 공개했습니다. 이는 파라미터 수가 135B인 Dense 모델로, 전적으로 Huawei Ascend AI 컴퓨팅 클러스터(8192개 NPU)에서 훈련되었으며 Nvidia GPU를 사용하지 않았습니다. 보고서에 따르면, Pangu Ultra는 수학 추론(AIME 2024, MATH-500) 및 프로그래밍(LiveCodeBench)과 같은 작업에서 뛰어난 성능을 보이며, DeepSeek-R1과 같은 더 큰 규모의 MoE 모델과 견줄 만한 성능을 제공합니다. 기술적으로, 모델은 혁신적인 딥 스케일링 Sandwich-Norm 레이어 정규화 및 TinyInit 파라미터 초기화 전략을 채택하여 초심층 네트워크(94개 레이어) 훈련 시의 불안정성 문제를 효과적으로 해결하고, 손실 스파이크 없이 안정적인 훈련을 달성했습니다. 시스템 수준 최적화를 통해 훈련은 52% 이상의 컴퓨팅 파워 활용률(MFU)을 달성했습니다. (출처: 量子位)
Canopy Labs, 감성 음성 합성 모델 Orpheus 오픈소스 공개: Canopy Labs는 Orpheus라는 텍스트 음성 변환(TTS) 모델 시리즈를 출시하고 오픈소스 공개했습니다. 이 모델은 Llama 아키텍처를 기반으로 하며, 첫 번째 버전은 30억 파라미터이고, 이후 1B, 0.5B, 0.15B 등 더 작은 버전이 출시될 예정입니다. Orpheus의 특징은 매우 인간적인 감정, 억양, 리듬을 가진 음성을 생성할 수 있으며, 심지어 텍스트에서 웃음, 한숨 등 비언어적 소리를 추론하고 생성하여 “공감” 표현을 실현할 수 있다는 것입니다. 모델은 제로샷 음성 복제 및 태그를 통한 감정 억양 제어를 지원합니다. 스트리밍 추론을 채택하여 지연 시간이 100-200ms로 낮으며, A100 40GB 그래픽 카드에서 실시간 재생보다 빠른 추론 속도를 보입니다. 개발자는 기존 오픈소스 및 일부 폐쇄 소스 SOTA 모델을 능가하는 성능을 주장하며, 폐쇄 소스 TTS 모델의 독점을 깨뜨리는 것을 목표로 합니다. 모델 및 코드는 GitHub 및 Hugging Face에 공개되었습니다. (출처: 新智元)

저장대학교와 ByteDance, MegaTTS3 음성 합성 모델 공동 발표: 저장대학교 Zhao Zhou 교수 팀과 ByteDance가 협력하여 3세대 음성 합성 모델 MegaTTS3를 발표하고 오픈소스 공개했습니다. 이 모델은 단 0.45B의 경량 파라미터 규모로 고품질의 중영 이중 언어 음성 합성을 실현했으며, 제로샷 음성 복제에서도 뛰어난 성능을 보여 자연스럽고 제어 가능하며 개인화된 음성을 생성할 수 있습니다. MegaTTS3는 음성-텍스트 희소 정렬, 생성 제어 가능성, 효율성과 품질의 균형을 중점적으로 돌파했습니다. 기술적 하이라이트로는 억양 강도 등 다차원 제어를 위한 “다중 조건 분류기 자유 유도”(Multi-Condition CFG) 기술과 샘플링 속도를 3배 향상시키는 “구간 정류 흐름 가속”(PeRFlow) 기술이 있습니다. 모델은 LibriSpeech 등 벤치마크에서 선도적인 자연스러움(CMOS)과 화자 유사성(SIM-O)을 보여주었습니다. (출처: PaperWeekly)

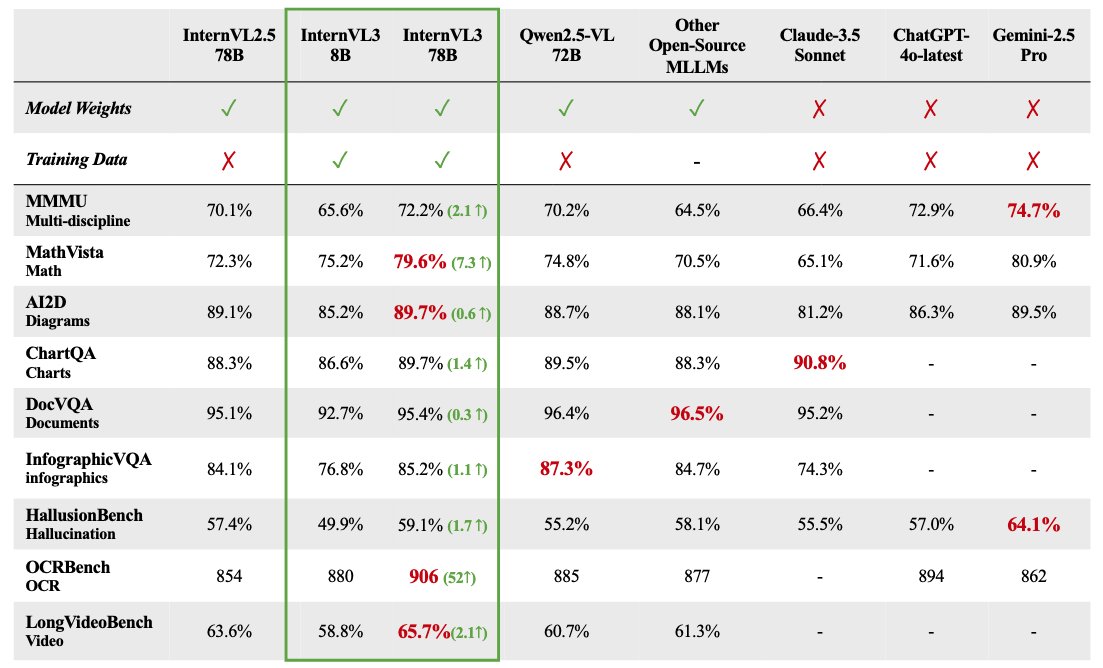
InternVL 3 멀티모달 대형 모델 시리즈 오픈소스 공개: OpenGVLab이 InternVL 3 멀티모달 대형 모델 시리즈를 발표했으며, 파라미터 규모는 1B에서 78B까지 다양하며 Hugging Face에 공개되었습니다. 78B 파라미터 버전은 MMMU 벤치마크 테스트에서 72.2점을 기록하여 오픈소스 멀티모달 모델의 SOTA 기록을 경신했다고 알려졌습니다. InternVL 3의 기술적 하이라이트는 다음과 같습니다: 네이티브 멀티모달 사전 훈련을 채택하여 언어와 시각을 동시에 학습; 확장된 컨텍스트를 지원하기 위해 가변 시각 위치 인코딩(V2PE) 도입; SFT 및 MPO와 같은 고급 후훈련 기술 사용; 수학 추론 능력을 향상시키기 위한 테스트 시 스케일링 전략 적용. 훈련 데이터와 모델 가중치 모두 커뮤니티 사용을 위해 공개되었습니다. (출처: huggingface)
GPT-4.1 실측 성능 분석: 코딩 강화되었으나 추론은 뒤처져: OpenAI가 출시한 GPT-4.1 시리즈 모델은 초기 실측 및 벤치마크 평가에서 복잡한 성능 양상을 보였습니다. 코드 생성 작업에서는 GPT-4o보다 현저한 진전을 보여, 예를 들어 물리 시뮬레이션, 게임 개발 등의 작업을 더 잘 수행하고 SWE-Bench에서 높은 점수를 기록했습니다. 그러나 더 광범위한 추론, 수학 및 지식 문답 벤치마크(예: Livebench, GPQA Diamond)에서는 GPT-4.1의 성능이 여전히 Google의 Gemini 2.5 Pro 및 Anthropic의 Claude 3.7 Sonnet에 뒤처졌습니다. 분석가들은 GPT-4.1이 GPT-4o의 점진적 업데이트이거나 GPT-4.5에서 증류된 것일 수 있으며, 출시 전략은 경쟁사의 플래그십 모델을 전면적으로 능가하기보다는 API를 통해 더 가성비 좋고 특정 최적화된 모델 옵션을 제공하는 것을 목표로 할 수 있다고 보고 있습니다. (출처: 新智元)
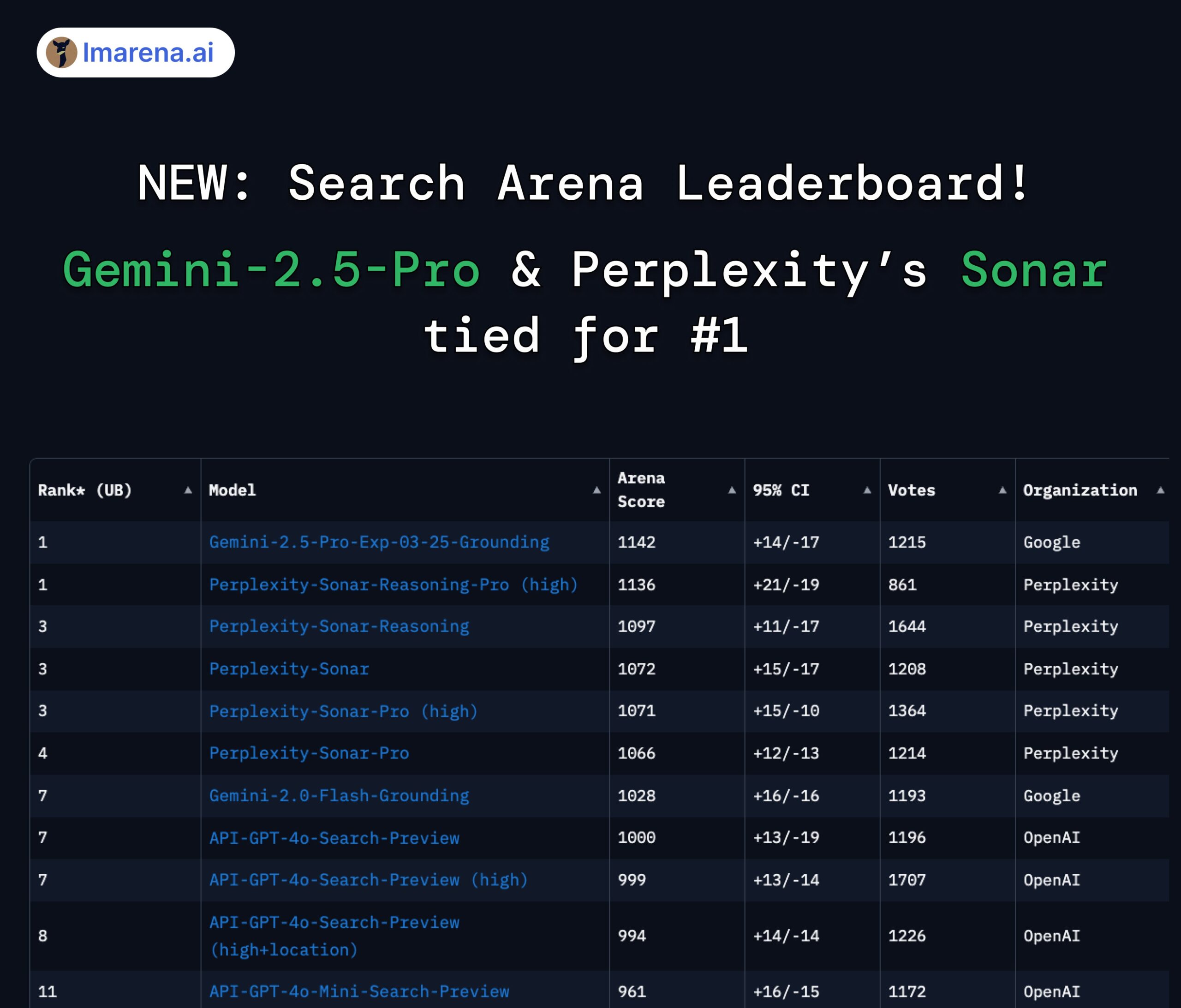
LMArena Search 순위: Gemini 2.5 Pro와 Perplexity Sonar 공동 1위: 검색/네트워킹 기능을 갖춘 대형 모델을 대상으로 한 LMArena의 경쟁 평가에서 Google의 Gemini-2.5-Pro(Google Search 결합)와 Perplexity의 Sonar-Reasoning-Pro가 공동 1위를 차지했습니다. 이 결과는 Google DeepMind CEO Demis Hassabis와 Google 개발자 관계 책임자 Logan Kilpatrick이 리트윗하여 확인했습니다. Perplexity CEO Aravind Srinivas도 이에 대해 내부 A/B 테스트 결과 자사의 Sonar 모델이 사용자 유지율에서 GPT-4o보다 우수하며, 성능은 Gemini 2.5 Pro 및 새로 출시된 GPT-4.1과 비슷하다고 밝혔습니다. 평가 주최측 lmarena.ai는 7000건의 사용자 투표 데이터를 오픈소스 공개했습니다. (출처: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta, 유럽 사용자 공개 콘텐츠를 AI 훈련에 다시 사용 예정: Meta는 유럽 사용자의 공개 콘텐츠를 자사 인공지능 모델 훈련에 다시 사용하기 시작할 것이라고 발표했습니다. 이전에는 유럽 데이터 보호 기관(특히 아일랜드 데이터 보호 위원회)의 압력과 규제 요구 사항에 직면하여 Meta가 이 관행을 중단했었습니다. 훈련 재개 결정은 Meta가 사용자 개인 정보 보호, 규정 준수(예: GDPR) 및 AI 모델 경쟁력 유지를 위한 충분한 데이터 확보 사이에서 지속적인 노력과 전략 조정을 반영하는 것일 수 있습니다. 이 조치는 사용자 데이터 권리 및 AI 훈련 투명성에 대한 논의를 다시 불러일으킬 수 있습니다. (출처: Reddit r/artificial)

Claude 모바일 앱에 음성 상호 작용 모드 추가 가능성: X 사용자 @testingcatalog가 발견한 단서에 따르면, Anthropic은 자사의 Claude 모바일 애플리케이션에 음성 상호 작용 기능을 추가할 계획일 수 있습니다. 스크린샷에는 앱 인터페이스에 마이크 아이콘이 나타나 있어, 사용자가 향후 ChatGPT 및 Google Gemini 앱에서 이미 제공하는 음성 모드와 유사하게 음성으로 Claude와 대화할 수 있음을 시사합니다. 이는 Claude의 모바일 상호 작용 방식을 더욱 다양하고 편리하게 만들어 사용자 경험을 향상시키고, 다른 주요 AI 비서와 기능적으로 일치시킬 것입니다. (출처: Reddit r/ClaudeAI)
Zhipu Z1 시리즈 모델 속도 주목, “순간 모델”로 불려: Zhipu AI가 최근 발표한 Z1 시리즈 모델, 특히 GLM-Z1-AirX 버전이 매우 빠른 추론 속도로 주목받고 있습니다. 일부 분석에서는 이를 “순간 모델”이라고 부르며, 0.3초 이내에 첫 응답을 완료하고 50자 이상의 한자를 생성할 수 있다고 지적합니다. 이는 인간의 신경 반사 시간과 비슷합니다. 이러한 낮은 지연 시간과 높은 처리량은 인간-기계 상호 작용 방식을 “질문-대기-응답”에서 거의 실시간 동기 대화로 바꿀 것으로 기대되며, 특히 교육, 고객 서비스, 콘텐츠 제작 및 Agent 호출과 같이 응답 속도 요구 사항이 높은 시나리오에 적합합니다. Z1-AirX의 API 버전 속도는 200 tokens/s에 달한다고 알려졌습니다. (출처: 公众号)

AI 네이티브 게임: 효율성 향상 도구에서 게임 플레이 혁신으로의 진화와 도전: 게임 산업은 AI를 활용하여 개발 및 운영 효율성을 높이는 것(예: 아트 생성, 코드 지원, 자동화 테스트)에서 진정한 “AI 네이티브 게임” 탐색으로 전환하고 있습니다. AI 네이티브 게임의 핵심은 AI가 게임 플레이에 깊숙이 통합되어 사전 설정된 시나리오가 아닌 플레이어 상호 작용에 의해 구동되는 동적 콘텐츠와 개인화된 경험을 창출하는 데 있습니다. miHoYo 창립자 Cai Haoyu가 투자한 《Whispers from the Star》, Giant Network 《Space Kill》의 AI 플레이어 모드가 이러한 탐색의 예입니다. 그러나 AI 네이티브 게임을 실현하는 데는 여러 가지 과제가 있습니다: 기술적 측면에서는 모델 능력, 안정성 및 비용 문제를 해결해야 합니다; 디자인 측면에서는 성숙한 사례가 부족하여 제어 가능성과 자유도 사이의 균형을 맞춰야 합니다; 사용자 측면에서는 재미와 상호 작용 깊이에 대한 플레이어의 요구를 충족시켜야 합니다; 또한 콘텐츠 규정 준수 및 윤리적 위험도 있습니다. 현재 업계는 아직 초기 탐색 단계에 있으며 성숙한 구현까지는 거리가 있습니다. (출처: 界面新闻)
🧰 도구
기발한 아이디어의 AI 애플리케이션 5가지 소개: 36Kr은 최근 모집한 AI 네이티브 애플리케이션 혁신 사례 중 창의적이고 실용적인 AI 도구 5가지를 소개했습니다: 1) AiPPT.com: 한 문장 또는 파일(Word, PDF, Xmind, 링크) 가져오기를 통해 빠르게 PPT를 생성하며, 오프라인 실행을 지원합니다. 2) Shanji AI Paipai Mirror: 사진 촬영, 실시간 번역, 공식 인식 등의 기능을 갖춘 AI 안경입니다. 3) Lianxin Digital Unconscious Interrogation Intelligent Agent: 심리 대형 모델 “Insight into People”을 기반으로 미세 표정, 음성, 생리 신호를 분석하여 심문을 보조하고 보고서를 생성합니다. 4) Huili Ma Vali Footwear AI: 키워드를 입력하면 10초 안에 8가지 신발 디자인 도면을 생성하고, 재료 라이브러리와 패턴 데이터를 통합하여 생산과 연결합니다. 5) Nanfang Shidong Sandbag HR Intelligent Agent: 사회 보험 관리 인력 자원 업무를 처리하고, 정책 해석, 비용 계산, 스마트 처리, 위험 경고 등의 기능을 제공합니다. 이러한 애플리케이션들은 AI가 효율성 도구, 스마트 하드웨어, 전문 분야(보안, 디자인, HR)에서 실현될 잠재력을 보여줍니다. (출처: 36Kr)

Haisin Intelligence, AI 제로 코드 개발 플랫폼 “Haisnap” 출시: 베이징 국유 자본 배경의 Haisin Intelligence Technology가 “Haisnap”(响指)이라는 AI 제로 코드/로우 코드 개발 플랫폼을 출시했습니다. 사용자는 자연어로 요구 사항을 설명하여 AI가 자동으로 웹 애플리케이션이나 미니 게임 등을 생성하도록 할 수 있습니다. 플랫폼의 특징은 생성 과정에서 코드가 실시간으로 보이며 대화 방식으로 2차 편집 및 수정이 가능하다는 점입니다. 사용자가 개발한 애플리케이션은 플랫폼의 “창의 커뮤니티”에 게시되어 다른 사람들이 보고, 사용하고, 재창작(remix)할 수 있습니다. 현재 플랫폼은 무료로 개방되어 AI 애플리케이션 개발 장벽을 낮추고 전 국민의 창작을 촉진하며, 특히 청소년 AI 교육 및 산업 애플리케이션 구현에 중점을 두고 있습니다. (출처: 量子位)

오픈소스 지식 베이스 질의응답 시스템 ChatWiki 출시, GraphRAG 및 WeChat 연동 지원: ChatWiki는 새로 오픈소스 공개된 지식 베이스 AI 질의응답 시스템으로, 대형 언어 모델(DeepSeek, OpenAI, Claude 등 20가지 이상 모델 지원)과 검색 증강 생성(RAG) 기술을 통합했으며, 특히 지식 그래프 기반의 GraphRAG를 지원하여 복잡한 쿼리를 처리합니다. 시스템 기능은 다음과 같습니다: 다양한 형식의 문서(OFD, Word, PDF 등) 가져오기를 지원하여 개인 지식 베이스 구축; 의미론적 분할을 지원하여 RAG 정확도 향상; 지식 베이스를 공개 문서 사이트로 게시 가능; API 인터페이스를 제공하여 WeChat 공식 계정, WeChat 고객 서비스 등 생태계에 원활하게 연동하여 AI 챗봇 생성; 시각적 워크플로우 편집 도구 내장; 타사 비즈니스 데이터 연동 지원; 기업 수준의 권한 관리 제공; Docker 및 소스 코드 로컬 배포 지원. (출처: 公众号)

ModelScope 커뮤니티, MCP 광장 개설, 국내 최대 MCP 서비스 생태계 구축: Alibaba 산하 AI 모델 커뮤니티 ModelScope(魔搭)가 공식적으로 “MCP 광장”을 개설했습니다. 여기에는 검색, 지도, 결제, 개발자 도구 등 분야를 포괄하는 약 1500개의 모델 컨텍스트 프로토콜(MCP) 구현 서비스가 모여 있으며, 국내 최대 MCP 중국어 커뮤니티 구축을 목표로 합니다. Alipay와 MiniMax의 여러 MCP 서비스가 이곳에서 독점적으로 처음 공개되었으며, 예를 들어 Alipay의 결제, 조회, 환불 기능, MiniMax의 음성, 이미지, 비디오 생성 기능 등은 모두 MCP 프로토콜을 통해 AI 에이전트가 호출할 수 있습니다. 개발자는 ModelScope MCP 실험장에서 간단한 JSON 구성과 무료 클라우드 리소스를 통해 이러한 서비스를 빠르게 체험하고 통합할 수 있어 AI 애플리케이션이 외부 도구 및 데이터에 접근하는 장벽을 크게 낮췄습니다. ModelScope는 또한 다양한 MCP 서비스의 품질과 성능을 평가하기 위한 MCP Bench를 출시했습니다. (출처: 新智元)

Open WebUI WebSearch 기능 사용 논의: Reddit 커뮤니티 사용자들이 Open WebUI에서 Web Search 기능을 사용하는 방법에 대해 논의했습니다. 문제는 검색 엔진이 사용하는 쿼리 키워드를 정확하게 제어하는 방법과, 개인 모델의 데이터가 실수로 네트워크로 전송되는 것을 방지하기 위해 Web Search 기능을 특정 모델로 제한하는 방법에 집중되었습니다. 이는 사용자들이 통합 검색 기능이 있는 AI 도구를 사용할 때 제어 정밀도와 개인 정보 보호 보안에 대한 실제적인 요구를 반영합니다. (출처: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
사용자, 모델 컨텍스트 프로토콜(MCP) 이해 추구: Reddit 커뮤니티에서 사용자가 모델 컨텍스트 프로토콜(MCP)에 대한 설명을 구하는 게시물을 올렸습니다. 이는 MCP 표준의 보급 및 적용(예: ModelScope MCP 광장)과 함께 개발자 및 사용자 커뮤니티가 이 새로운 기술과 그 작동 원리를 이해하려는 요구가 증가하고 있음을 나타냅니다. (출처: Reddit r/OpenWebUI)
📚 학습
ICLR 2025 시간 검증상, Adam 옵티마이저와 어텐션 메커니즘에 수여: 국제 학습 표현 컨퍼런스(ICLR)는 2025년 “시간 검증상”(Test of Time Award)을 10년 전(2015년) 발표된 두 편의 기념비적인 논문에 수여했습니다. 한 편은 Diederik P. Kingma와 Jimmy Ba가 저술한 《Adam: A Method for Stochastic Optimization》으로, 이 논문에서 제안된 Adam 옵티마이저는 딥러닝 모델 훈련의 표준 알고리즘이 되었습니다. 다른 한 편은 Dzmitry Bahdanau, 조경현, Yoshua Bengio가 저술한 《Neural Machine Translation by Jointly Learning to Align and Translate》로, 이 논문은 처음으로 어텐션 메커니즘을 도입하여 Transformer 아키텍처와 현대 대형 언어 모델의 기초를 마련했습니다. 이 두 상은 기초 연구가 현재 AI 발전에 미치는 깊은 영향을 보여줍니다. (출처: 新智元)

AI 발전 약사와 기업 진화 회고: 이 글은 인공지능이 20세기 중반부터 현재까지 발전해 온 과정을 체계적으로 회고합니다. 주요 시점으로는 튜링 테스트, 다트머스 회의, 기호주의와 전문가 시스템, AI 겨울, 머신러닝의 부상(DeepBlue, PageRank), 딥러닝 혁명(AlexNet, AlphaGo), 그리고 현재의 대형 모델 시대(GPT 시리즈, 생성형 AI 상업화, 오픈소스와 폐쇄소스 경쟁)가 있습니다. 동시에 이 글은 AI 기업 발전을 네 시대로 구분합니다: 개척 시대(2000-2010, 도구형 애플리케이션 탐색), 골드러시 시대(2011-2016, 플랫폼 기반 강화 및 데이터 주도 폭발), 거품 시대(2017-2020, 시나리오 경쟁 및 상업화 병목 현상), 재구성 시대(2021-현재, 대형 모델 주도 새로운 판도). 이 글은 컴퓨팅 파워, 데이터, 알고리즘의 시너지 효과와 DeepSeek 등 새로운 세력이 판도에 미치는 영향을 강조합니다. (출처: 混沌大学)
OpenAI, GPT-4.1 프롬프트 엔지니어링 가이드 발표: GPT-4.1 시리즈 모델 출시에 맞춰 OpenAI가 프롬프트 엔지니어링(Prompting) 가이드라인을 업데이트했습니다. 가이드라인은 GPT-4.1 시리즈 모델이 GPT-4 등 초기 모델보다 지시 사항을 더 엄격하고 문자 그대로 따르며, 명확하고 구체적인 프롬프트에 더 민감하다고 강조합니다. 모델의 성능이 기대에 미치지 못할 경우, 일반적으로 간결하고 명확한 설명을 추가하면 모델의 행동을 유도할 수 있습니다. 이는 과거 모델이 사용자 의도를 추측하는 경향이 있었던 것과 다르므로, 개발자는 기존 프롬프트 전략을 조정해야 할 수 있습니다. 가이드라인은 기본 원칙부터 고급 전략까지 최상의 실천 방법을 제공하여 개발자가 새로운 모델의 특성을 더 잘 활용하도록 돕습니다. (출처: dotey, Reddit r/LocalLLaMA)
상하이 교통대 등, 시공간 지능 벤치마크 STI-Bench 발표, 멀티모달 모델 물리 이해 도전: 상하이 교통대학교는 여러 기관과 협력하여 멀티모달 대형 모델(MLLM)의 시공간 지능을 평가하는 최초의 벤치마크 테스트 STI-Bench를 발표했습니다. 이 벤치마크는 실제 세계 비디오를 사용하여 정확하고 정량적인 공간 시간 이해 능력에 초점을 맞추며, 척도 측정, 공간 관계, 3D 위치 파악, 이동 경로, 속도 가속도, 자기 중심 방향, 궤적 설명, 자세 추정 등 8가지 작업을 포함합니다. GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL 등 최고 수준 모델에 대한 평가 결과, 기존 모델들은 이러한 작업에서 전반적으로 성능이 좋지 않으며(정확도 < 42%), 특히 정량적 공간 속성, 시간적 동적 변화 및 교차 모달 정보 통합 처리에 어려움을 겪는 것으로 나타났습니다. 이 벤치마크는 현재 MLLM이 물리적 세계 이해 측면에서 가지는 한계를 드러내고 후속 연구 방향을 제시합니다. (출처: 量子位)

강화 학습과 다중 목표 최적화 결합 연구 주목: 강화 학습(RL)과 다중 목표 최적화(MOO)의 교차 분야가 AI 의사 결정 연구의 핫스팟이 되고 있습니다. 이러한 결합은 에이전트가 복잡한 환경에서 단일 최적 목표를 추구하는 대신 여러 (충돌 가능성이 있는) 목표를 절충하도록 하는 것을 목표로 합니다. 예를 들어, 홍콩과기대는 안전과 에너지 효율을 동시에 최적화하기 위해 자율 주행에 동적 그래디언트 균형 프레임워크를 제안했습니다; MIT의 Pareto 전략 검색 알고리즘은 로봇 제어에 사용됩니다; Alibaba Cloud는 수익과 위험의 균형을 맞추기 위해 금융 거래에 다중 목표 정렬 기술을 적용합니다. CMORL(지속적 다중 목표 강화 학습) 및 조합 최적화를 위한 Pareto 집합 학습과 같은 관련 연구는 RL 에이전트가 동적으로 변화하거나 여러 최적화 차원을 가진 현실 세계 문제를 더 효과적으로 처리하는 방법을 탐색하고 있습니다. (출처: 公众号)

자동 적대적 공격 방어 플랫폼 A³D 오픈소스 공개 (TPAMI 2025): 군사과학원 국방과기혁신연구원 지능 설계 및 강건 학습 연구팀(IDRL)이 A³D(자동 적대적 공격 및 방어)라는 플랫폼을 개발하고 오픈소스 공개했습니다. 이 플랫폼은 자동 머신러닝(AutoML) 기술을 활용하고 공격-방어 게임 이론 사상을 결합하여 강건한 신경망 아키텍처와 효율적인 적대적 공격 전략을 자동화하여 검색하는 것을 목표로 합니다. 플랫폼은 자동 방어를 위해 다양한 신경망 아키텍처 검색(NAS) 방법과 강건성 평가 지표(놈 공격, 의미론적 공격, 적대적 위장 등)를 통합하고, 동시에 자동 적대적 공격 모듈을 제공하여 최적화 알고리즘을 통해 최적의 조합 공격 방안을 검색할 수 있습니다. 연구 결과는 최고 수준 저널 TPAMI에 게재되었으며, 코드는 Hongshan Open Source 등 플랫폼에 공개되어 DNN 모델 안전성 평가 및 향상을 위한 새로운 도구를 제공합니다. (출처: 公众号)

플로리다 대학교, NLP/LLM 분야 전액 장학금 박사/인턴 모집: 플로리다 대학교 컴퓨터학과 Yuanyuan Lei 조교수(2025년 가을 부임 예정)가 2025년 가을 또는 2026년 봄 입학 예정인 전액 장학금 박사 과정 학생 및 유연한 근무 시간의 연구 인턴(원격 가능)을 모집한다는 공고를 발표했습니다. 연구 분야는 자연어 처리(NLP)와 대형 언어 모델(LLM)에 초점을 맞추며, 구체적으로는 지식 강화 LLM, 사실 검증, 추론 및 계획, NLP 응용(멀티모달, 법률, 비즈니스, 과학 등)을 포함합니다. 컴퓨터, 전자 공학, 통계, 수학 등 관련 배경을 가지고 AI 연구에 관심과 동기가 있는 학생들의 지원을 환영합니다. 이메일에는 플로리다 SB-846 법안이 중국 본토 학생 모집에 미칠 수 있는 잠재적 영향 및 대응 방안에 대해 언급되어 있습니다. (출처: PaperWeekly)

확산 모델 신규 연구: 시간 상관 노이즈 사전: arXiv 논문 《How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models》은 확산 모델을 위한 새로운 유형의 노이즈 사전을 제안합니다. 이 방법은 시간 상관 노이즈를 도입하여 (아마도 비디오) 확산 모델의 생성 품질이나 효율성을 개선하는 것을 목표로 합니다. 구체적인 기술적 세부 사항은 원 논문을 참조해야 합니다. (출처: Reddit r/MachineLearning)
자동화된 과학 발견 신규 연구: AI Scientist-v2: arXiv 논문 《The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search》는 AI Scientist-v2 시스템을 소개합니다. 이 시스템은 Agentic Tree Search(에이전트 트리 검색) 방법을 활용하여 “워크숍 수준”(Workshop-Level)의 자동화된 과학 발견을 달성하는 것을 목표로 합니다. 이는 연구자들이 더 고급적이고 자율적인 과학 연구 및 탐색을 위해 AI 에이전트를 사용하는 방법을 모색하고 있음을 보여줍니다. (출처: Reddit r/MachineLearning)
Dropout 정규화 구현 설명: Substack 기사에서 Dropout 정규화 기술의 구현 방식을 자세히 설명합니다. Dropout은 딥러닝에서 널리 사용되는 정규화 기술로, 훈련 과정에서 일부 뉴런을 무작위로 “탈락”시켜 모델의 과적합을 방지합니다. 이 기사는 Dropout 작동 원리를 깊이 이해하거나 직접 구현하고자 하는 학습자를 대상으로 할 수 있습니다. (출처: Reddit r/deeplearning)
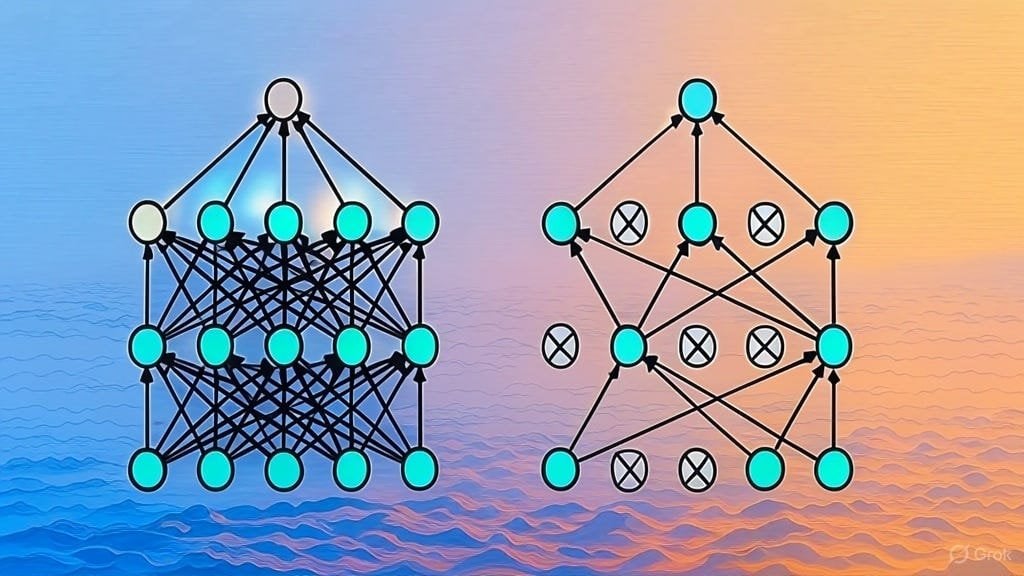
LLM 아키텍처 논문 목록 모집: Reddit 사용자가 대형 언어 모델(LLM) 아키텍처에 관한 arXiv 논문을 공유하고 모집하는 토론을 시작했습니다. 이미 나열된 아키텍처에는 BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, DeepSeek 시리즈 등이 포함됩니다. 이 목록은 현재 LLM 아키텍처 연구의 다양성과 빠른 발전을 반영하며, 해당 분야를 체계적으로 이해하고자 하는 연구자에게 참고 자료가 될 수 있습니다. (출처: Reddit r/MachineLearning)
💼 비즈니스
AI 영양 플랫폼 Fay, 5000만 달러 투자 유치, 연 수입 5000만 달러 달성: 실리콘밸리 AI 영양 플랫폼 Fay가 최근 Goldman Sachs 주도로 5000만 달러 규모의 시리즈 B 투자를 유치했으며, 누적 투자액은 7500만 달러, 기업 가치는 5억 달러에 달합니다. Fay는 등록 영양사와 환자를 연결하고 AI를 활용하여 서비스 효율성을 높이며(환자당 6.5시간에서 2시간으로 단축 주장), 임상 노트 생성(ICD 코드 포함), 개인 맞춤형 영양 계획 수립, 보험 청구, 백엔드 관리 등의 작업을 자동화합니다. 이 플랫폼은 GLP-1 비만 치료제가 가져온 영양 상담 수요 급증을 정확히 포착하고, 보험 회사와의 협력(영양 중재는 만성 질환의 장기 의료 비용을 절감할 수 있음)을 통해 결제 단계를 해결했습니다. Fay 플랫폼에는 3000명 미만의 영양사만 있지만, 5000만 달러의 연간 수입(ARR)을 달성하여 수직적 의료 분야에서 AI가 전문가를 지원하고 결제자와 연결하는 성공적인 비즈니스 모델을 보여줍니다. (출처: 乌鸦智能说)
청두 Hengtu Technology: AI로 디지털 크리에이티브 강화, 해외 진출 및 수익 창출: 청두 현지 기업 Hengtu Technology는 핵심 제품 Fotor(이미지 비디오 편집 플랫폼)를 통해 전 세계적으로 약 7억 명의 사용자를 확보했으며, 월간 활성 사용자 수는 천만 명을 넘어섰습니다. 특히 해외 시장에서 두각을 나타내며, 국내에서 비교적 일찍 해외에 진출하여 규모화된 수익을 창출한 AI 애플리케이션 회사 중 하나입니다. 이 회사는 16년간 이미지 처리 기술에 깊이 파고들었으며, 2022년에는 AIGC 기능(텍스트-이미지, 텍스트-비디오 생성 등)을 Fotor 및 새로운 플랫폼 Clipfly에 신속하게 통합했습니다. Fotor는 AI를 통해 디지털 시각 콘텐츠 제작의 장벽을 낮추고 전자 상거래, 소셜 미디어, 광고, 문화 관광, 교육 등 다양한 산업에 서비스를 제공합니다. Hengtu Technology는 AI를 활용하여 “문화 번역”을 수행하고 중국 문화의 해외 진출을 지원하며 디지털 크리에이티브 산업의 새로운 경로를 탐색하고 있습니다. (출처: 36Kr四川)
기업 AI 도입 실천: 가치 중시, 미세 조정 경시, 협업 촉진: 기업들은 대형 모델 도입 과정에서 초기 탐색 단계를 지나 보다 실용적인 가치 지향으로 전환했습니다. 성공적인 AI 애플리케이션은 반복성이 강하고 창의적인 요구가 있으며 패러다임이 정립될 수 있는 시나리오(예: 지식 문답, 스마트 고객 서비스, 자료 생성, 데이터 분석 등)에 초점을 맞추는 경향이 있습니다. 기업들은 일반적으로 모델 미세 조정을 맹목적으로 추구하는 것은 투입 대비 산출 비율이 낮다는 것을 인식하고, 지식 거버넌스 및 인텔리전트 에이전트 플랫폼 구축(초기에는 RAG 위주)을 우선시해야 합니다. AI 도입은 비즈니스 부서의 깊은 참여와 고위 경영진의 지원이 필요하며, “빠른 성공 파일럿 + AI 기반 준비” 병행 전략이 더 효과적입니다. 조직 인재 측면에서 기업들은 소규모 전문 AI 팀을 구성하여 비즈니스를 지원하는 경향이 있으며, 외부 최고 인재 영입, 내부 젊은 인력 양성(인턴 + 베테랑 비즈니스 조합) 및 외부 전문가와의 협력 등을 통해 인재 부족 문제를 해결합니다. (출처: AI前线)
커촹반 인공지능 지수 주목, 투자 새로운 바람 될 수도: 보고서 분석에 따르면, 최근 시장 변동성에도 불구하고 중국 인공지능 산업은 “컴퓨팅 파워-모델-애플리케이션”의 완전한 폐쇄 루프를 형성했으며 강력한 회복력을 보여주었습니다. 국가 “동수서산” 프로젝트, DeepSeek 등 저비용 모델 및 휴머노이드 로봇 등 애플리케이션 돌파구가 주목할 만합니다. AI는 향후 10년간 글로벌 경제 성장의 중요한 엔진으로 간주되며 관련 자산의 장기 수익률이 현저합니다. 이러한 배경 하에서, 상하이증권거래소 커촹반 인공지능 지수(컴퓨팅 파워 칩 및 AI 애플리케이션에 초점)는 높은 성장성 기대와 자체 제어 가능성 향상으로 투자자들의 주목을 받고 있습니다. E Fund 등 기관들은 이미 해당 지수를 추종하는 ETF 및 연계 펀드(예: 588730, 023564/023565)를 출시하여 투자자들이 국산 AI 산업 체인에 투자할 수 있는 도구를 제공했습니다. (출처: 创业最前线)

Apple AI 전략, 개방으로 전환: Siri 개발에 타사 모델 사용 허용: “개인화된 Siri” 기능 개발을 가속화하고 경쟁사를 따라잡기 위해 Apple은 오랫동안 고수해 온 내부 폐쇄 개발 전략을 조정한 것으로 알려졌습니다. 새로운 소프트웨어 엔지니어링 수석 부사장 Craig Federighi의 지휘 아래, Siri 엔지니어들은 처음으로 타사 대형 언어 모델을 사용하여 Siri 기능을 개발하는 것이 허용되었으며, 이는 이전에 Apple 자체 개발 모델만 사용해야 했던 제한을 깨뜨렸습니다. 이 변화는 Apple이 AI 분야에서의 기술적 준비 부족에 대응하고, “개인화된 Siri” 기능 지연으로 인한 더 많은 사용자 불만(심지어 소송)을 피하기 위한 핵심적인 조치로 간주됩니다. 이 조치는 OpenAI나 Alibaba(중국 시장) 등 외부 모델 공급업체에게 Apple과 협력할 기회를 제공할 수 있습니다. (출처: 三易生活)

🌟 커뮤니티
DeepSeek, Doubao, Yuanbao 애플리케이션 경쟁 치열, 제품 경험이 핵심: 중국 AI 비서 애플리케이션 시장 경쟁이 백열화되고 있습니다. DeepSeek은 모델 능력으로 폭발적인 인기를 얻은 후 사용자 수가 급증했으며, 이를 먼저 도입한 Tencent Yuanbao가 한때 1위를 차지했습니다. 그러나 ByteDance의 Doubao는 더 완성도 높은 제품 기능과 Douyin과의 깊은 통합을 통해 다시 Yuanbao를 추월했습니다. 분석가들은 단순히 강력한 모델(예: DeepSeek) 도입에 의존하는 것은 단기적인 이익만 가져올 뿐이며, 장기적인 경쟁에서는 애플리케이션 자체의 기능 풍부함, 사용자 경험, 멀티 디바이스 협업 및 플랫폼 생태계 통합 능력이 더 중요하다고 보고 있습니다. 각 사의 모델 능력이 비슷해짐에 따라(예: 모두 깊은 사고 능력 보유), 미래의 경쟁 초점은 제품 디자인, 운영 전략 및 AI Agent와 같은 새로운 형태의 애플리케이션 돌파구가 될 것입니다. (출처: 字母榜)
아시아계 학생 개발 면접 부정행위 도구, 인터넷 토론 촉발: 컬럼비아 대학교의 아시아계 학생 Roy Lee가 Interview Coder라는 AI 도구를 개발하여 Amazon, Meta, TikTok 등 여러 기술 회사의 원격 기술 면접을 통과했습니다. 그는 이 회사들의 제안을 거절했을 뿐만 아니라, 부정행위 도구를 사용하는 과정을 녹화하여 YouTube에 게시했고, Amazon의 신고 후 학교에서 정학 처분을 받았습니다. Roy Lee는 이에 개의치 않고 사건 경위와 학교, 회사와의 이메일 교환 내용을 공개하여 많은 네티즌의 지지와 업계의 관심을 받았으며, 이를 계기로 회사를 설립했습니다. 이 사건은 기술 면접(특히 LeetCode 문제 풀이 방식)의 유효성, 채용 과정에서의 AI 도구의 윤리적 경계, 개인이 대기업 체제에 도전하는 것 등 다양한 주제에 대한 열띤 토론을 불러일으켰습니다. (출처: 直面AI)

사용자, Zhipu 신규 오픈소스 GLM 모델 지식 베이스 및 MCP 연동 실측: 사용자가 Zhipu AI가 최근 발표한 GLM 시리즈 모델(API 호출 통해)을 테스트했습니다. 결과에 따르면, GLM-Z1-AirX(초고속 버전)는 FastGPT로 구축된 로컬 지식 베이스에 연결했을 때 응답 속도가 매우 빠르며(200 tokens/s에 달한다고 주장), 답변 품질도 일반 모델보다 향상되어 더 상세하고 완전한 답변과 비교표를 생성할 수 있었습니다. GLM-4-Air(기반 모델)는 MCP(모델 컨텍스트 프로토콜)에 연결하여 Agent 작업(예: 인터넷 검색, 로컬 파일 쓰기, Docker 제어, 웹 페이지 요약)을 수행할 때 도구를 올바르게 호출하고 작업을 완료했지만, 효과는 DeepSeek-V3보다 약간 떨어졌습니다. 사용자는 동시에 Zhipu 모델의 안전성 측면(탈옥 프롬프트에 응답하지 않음)을 긍정적으로 평가했습니다. (출처: 公众号)
![로컬 지식 베이스 + Zhipu 오픈소스 GLM-Z1-Air, 안전하고 프라이빗하며 답변 속도 매우 빠름! 효과 새로운 경지 돌파 [MCP 활용법 포함]](https://rebabel.net/wp-content/uploads/2025/04/image_1744722926.gif)
“초이성적 문제 해결사” 프롬프트 공유 및 모델 효과 비교: 커뮤니티 사용자가 LLM이 “초이성적, 제1원리 문제 해결사” 역할을 하도록 설계된 고급 프롬프트(Prompt)를 공유했습니다. 이 프롬프트는 모델의 작동 원칙(문제 해체, 솔루션 엔지니어링, 전달 프로토콜, 상호 작용 규칙), 응답 형식 및 어조 특징을 상세하게 규정하며, 논리, 행동, 결과를 강조하고 모호함, 변명, 감정적 위안을 배제합니다. 사용자는 이 프롬프트를 사용하여 DeepSeek, Claude Sonnet 3.7, ChatGPT 4o가 문제 해결, 지침 제공, 인터넷 추천 자원 제공 측면에서 어떤 성능을 보이는지 비교 테스트했으며, Claude 3.7의 효과가 더 좋다고 평가했습니다. 이는 잘 설계된 프롬프트를 통해 특정 작업에서 LLM의 성능을 현저하게 유도하고 향상시킬 수 있음을 보여줍니다. (출처: 公众号)

커뮤니티, GPT-4.1 출시에 뜨거운 반응: 성능, 전략 및 명명: OpenAI의 GPT-4.1 시리즈 모델 출시는 커뮤니티에서 광범위한 토론을 불러일으켰습니다. 한편으로 사용자들은 실측 및 벤치마크 비교(예: Aider, Livebench, GPQA Diamond, KCORES Arena)를 통해 GPT-4.1이 코딩 측면에서 현저한 향상을 보였지만, 종합적인 추론 능력에서는 여전히 Google Gemini 2.5 Pro 및 Claude 3.7 Sonnet에 뒤처진다는 것을 발견했습니다. 다른 한편으로 커뮤니티는 OpenAI의 제품 전략(API와 ChatGPT 구분, GPT-4.5 폐기), 모델 반복 속도 및 혼란스러운 명명 방식(4.5 이후 4.1 출시)에 대해 토론하고 비판했습니다. OpenAI가 혁신 병목 현상에 직면했을 수 있다는 의견도 있고, 이것이 API 제품 라인을 최적화하고 다양한 가성비 옵션을 제공하려는 전략이라는 의견도 있습니다. (출처: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT, 법률 상담 시나리오에서 능력 발휘, 사용자 성공 경험 공유: Reddit 사용자가 ChatGPT를 사용하여 업무 관련 법적 분쟁을 처리한 성공 사례를 공유했습니다. 이 사용자는 해고 위험에 처했지만, ChatGPT에 문서를 제공하고 영국 고용법 전문가 역할을 하도록 하여 고용주의 절차적 오류를 발견했습니다. 또한 ChatGPT가 작성한 서신을 통해 협상하여 결국 2개월치 급여 보상을 포함한 합의에 도달하고 불리한 기록을 피했습니다. 댓글 섹션에는 다른 사용자들이 AI(ChatGPT 또는 Gemini)를 사용하여 법률 서신을 작성하고 청문회를 준비하여 긍정적인 결과를 얻은 경험을 공유하며, AI가 법률 보조 측면에서 상당한 비용과 시간을 절약할 수 있다고 평가했습니다. (출처: Reddit r/ChatGPT)
사용자, OpenAI Deep Research 기능 효과 불만 토로: Reddit 사용자가 OpenAI의 Deep Research(심층 연구) 기능을 비판하는 게시물을 올렸습니다. 사용자는 이 기능에 세 가지 주요 문제가 있다고 지적했습니다: 1) 검색 결과가 부정확하거나 관련성이 없음(Bing API 의존); 2) 탐색 방식이 광범위한 연구보다는 깊이 우선 탐색에 가까움; 3) 사용자의 연구 목표와 동떨어져 있으며 제약이 부족함. 사용자는 이것이 진정한 심층 연구라기보다는 확장된 검색 능력에 가깝다고 평가했습니다. 이는 현재 AI Agent 연구 능력에 대한 사용자의 기대와 실제 경험 사이의 격차를 반영합니다. (출처: Reddit r/deeplearning)
AI 생성 콘텐츠 전시 및 토론: 커뮤니티 사용자들은 다양한 AI 도구(예: ChatGPT, Midjourney, Kling AI, Suno AI 등)를 사용하여 제작한 콘텐츠를 적극적으로 공유했습니다. 여기에는 풍자 만화(트럼프와 머스크), 대학 의인화 이미지, 대안 역사 2차 세계 대전 단편 영화, 그리스 신화 인물 이미지, 90년대 스타일 치약 광고, 여러 컷 만화 등이 포함됩니다. 이러한 공유는 AI가 텍스트, 이미지, 비디오, 음악 생성 분야에서 보여주는 능력을 전시할 뿐만 아니라, AI 생성 콘텐츠의 창의성, 미학(예: “키치하다”는 비판), 한계(예: 만화 캐릭터 일관성 부족) 및 윤리적 문제에 대한 토론을 유발했습니다. (출처: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

AI 훈련 데이터 피드백 루프로 인한 “모델 붕괴” 우려: 커뮤니티 토론은 잠재적 위험에 주목합니다: 인터넷에서 AI 생성 콘텐츠가 점점 더 많아짐에 따라, 미래의 AI 모델이 주로 이러한 AI 생성 데이터를 기반으로 훈련될 경우 “모델 붕괴”(Model Collapse)가 발생할 수 있다는 것입니다. 이 현상은 모델 성능이 저하되고 출력이 편협해지며 반복적이고 독창성과 정확성이 부족해지는 것을 의미하며, 마치 복사본을 계속 복사하여 흐릿해지는 것과 같습니다. 사용자들은 이것이 정보의 진실성과 인간적 관점을 서서히 침식할 것을 우려합니다. 토론에서는 합성 데이터를 사용하여 훈련하거나 데이터 품질 관리를 강화하는 등의 대응 방법도 언급되었지만, 문제가 이미 발생했는지 여부와 효과적인 예방 방법에 대해서는 논란이 있습니다. (출처: Reddit r/ArtificialInteligence)
관점: AI 시대, 컴퓨팅 파워는 새로운 석유: Reddit 사용자는 AI 발전에서 데이터가 아닌 컴퓨팅 능력(Compute)이 산업 혁명 시대의 석유처럼 핵심적인 병목 현상이자 전략적 자원이 될 것이라는 관점을 제시했습니다. 이유는 다음과 같습니다: 더 강력한 AI 모델(특히 추론 및 Agent 시스템)은 기하급수적으로 증가하는 컴퓨팅 파워를 필요로 합니다; 로봇과 같은 물리적 상호 작용은 방대한 양의 새로운 데이터를 생성하여 컴퓨팅 파워 수요를 더욱 증가시킬 것입니다. 더 많은 컴퓨팅 파워를 보유하는 것은 직접적으로 더 강력한 경제 생산 능력으로 전환될 것입니다. 이 관점은 커뮤니티 토론을 유발했으며, 컴퓨팅 파워가 실제로 핵심 요소이며 AI 능력의 상한선과 발전 속도를 결정한다는 데 동의하는 의견이 많았습니다. (출처: Reddit r/ArtificialInteligence)
AI 사용 윤리 토론: 학습 성적 향상을 위해 AI 사용하는 것이 부적절한가?: 한 온라인 대학생이 강의 구조 문제(매주 시험이나 과제 한 번뿐이고 바로 시험)로 인해 낙제한 후, 강의 PDF를 기반으로 ChatGPT를 사용하여 연습 문제를 생성하여 매일 학습한 결과 성적이 현저하게 향상되었습니다. 그러나 이 학생은 AI의 환경 영향과 “독립적 사고”에 대한 비판을 보고 죄책감을 느꼈습니다. 커뮤니티 댓글은 일반적으로 AI를 학습 보조 도구로 사용하는 것은 정당하고 효과적인 용도이며, 효율성과 학습 효과를 높이는 데 도움이 되므로 죄책감을 느낄 필요가 없다고 평가했습니다. 댓글 작성자들은 AI의 환경 영향은 다른 인간 활동과 비교하여 평가해야 하며, AI를 활용하여 생산성을 높이는 것은 이미 직장의 추세라고 지적했습니다. (출처: Reddit r/ArtificialInteligence)
Claude Pro 사용자 경험: 사용량 제한 및 비즈니스 모델 토론: Reddit ClaudeAI 커뮤니티에서 사용자들은 Claude Pro 서비스 사용 시 겪는 사용량 제한(throttling) 문제에 대해 논의하고 Anthropic의 비즈니스 모델을 탐구했습니다. 한 사용자는 월 20달러의 Pro 구독 비용이 Anthropic이 헤비 유저에게 지불하는 실제 컴퓨팅 비용(월 최대 100달러에 달할 수 있음)보다 훨씬 낮다고 지적하며, 사용자의 불만(예: “착취당한다”고 생각하는 것)이 AI 서비스의 비용 구조를 간과했을 수 있다고 주장했습니다. 토론에서는 최근 Anthropic이 새로운 기능을 Pro 요금제 대신 더 비싼 Max 요금제에 우선적으로 제공하여 초기 Pro 연간 구독자들의 불만을 야기한 점도 다루어졌습니다. (출처: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
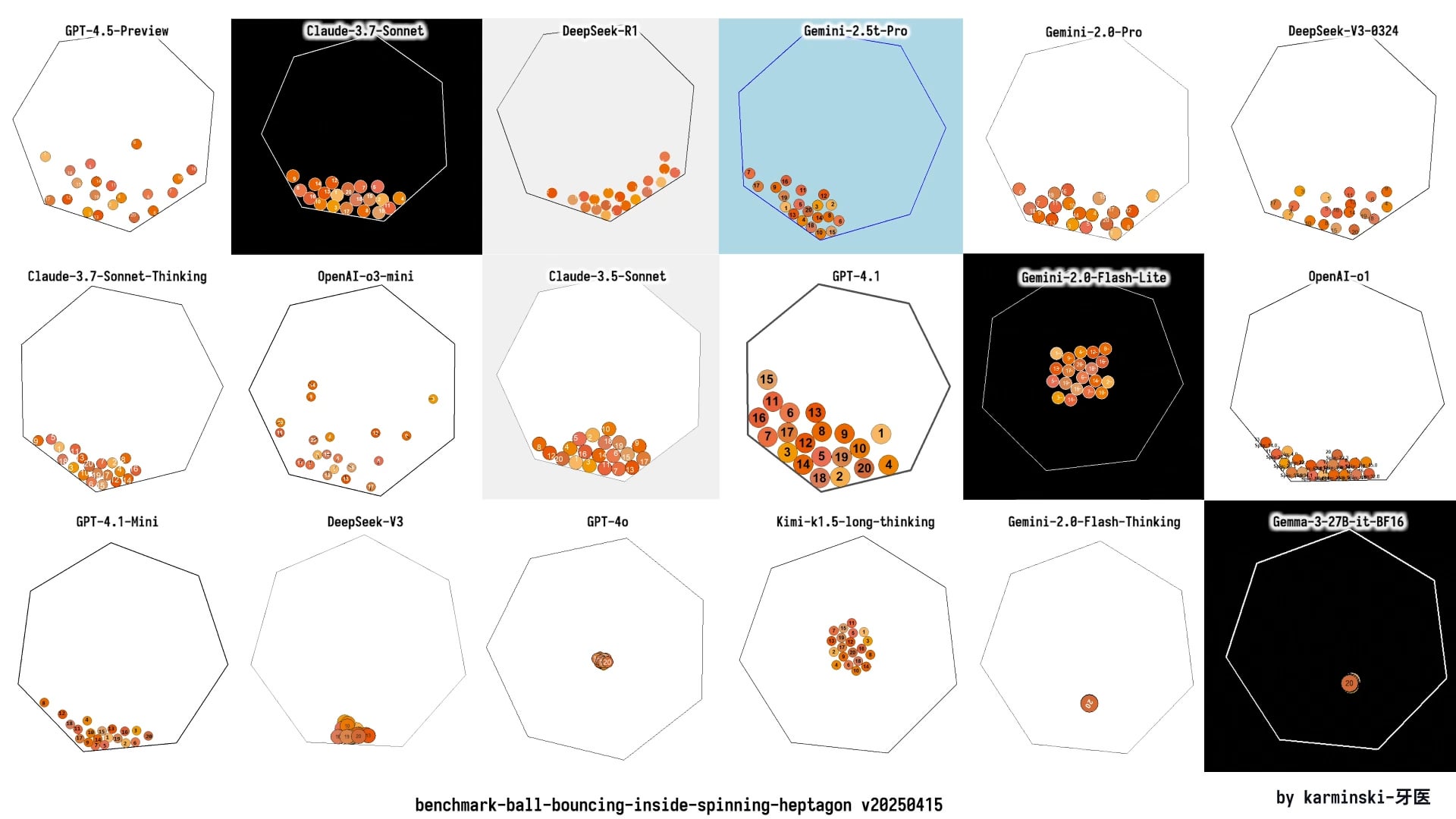
KCORES LLM Arena 업데이트, DeepSeek R1 뛰어난 성능 보여: 사용자가 개인적으로 유지 관리하는 LLM 경쟁장(KCORES LLM Arena)의 최신 테스트 결과를 공유했습니다. 이 테스트는 모델에게 복잡한 물리 시뮬레이션(회전하는 칠각형 내부에서 20개의 공이 충돌하고 반사되는)의 Python 코드를 생성하도록 요구했습니다. GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3 등 새로운 모델을 추가한 업데이트 후, 결과는 DeepSeek R1이 이 작업에서 뛰어난 성능을 보였으며 생성된 시뮬레이션 효과가 좋았음을 보여주었습니다. 이는 커뮤니티에 복잡한 프로그래밍 작업에서 다양한 모델의 능력을 평가하는 또 다른 참고점을 제공합니다. (출처: Reddit r/LocalLLaMA)
다양한 LLM의 감정적 반응 능력 탐구: Reddit 사용자가 ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B, Mistral Large가 사용자의 슬픔 표현에 대해 보이는 다양한 반응 스타일을 유머러스하게 비교하는 Meme 이미지를 게시했습니다. 이는 사용자들이 다양한 LLM을 사용하여 감정 교류를 하거나 지원을 구할 때의 경험 차이와, 모델의 “공감” 능력에 대한 커뮤니티의 인식 및 평가를 반영합니다. 댓글 섹션에서는 개인적인 감정적 주제를 처리하기 위해 로컬 모델을 사용하는 것의 프라이버시 이점도 논의되었습니다. (출처: Reddit r/LocalLLaMA)

AGI가 실리콘밸리의 사기인지에 대한 토론: 커뮤니티 멤버가 범용 인공지능(AGI)이 실리콘밸리(기술 산업)가 투자를 유치하거나 열기를 유지하기 위해 과도하게 홍보하는 개념(hoax)인지 의문을 제기하는 기사를 리트윗하고 토론했을 수 있습니다. 이는 업계와 대중이 AGI 실현 가능성, 일정 및 현재 관련 홍보의 진실성에 대해 지속적인 논쟁과 의심을 가지고 있음을 반영합니다. (출처: Ronald_vanLoon)

💡 기타
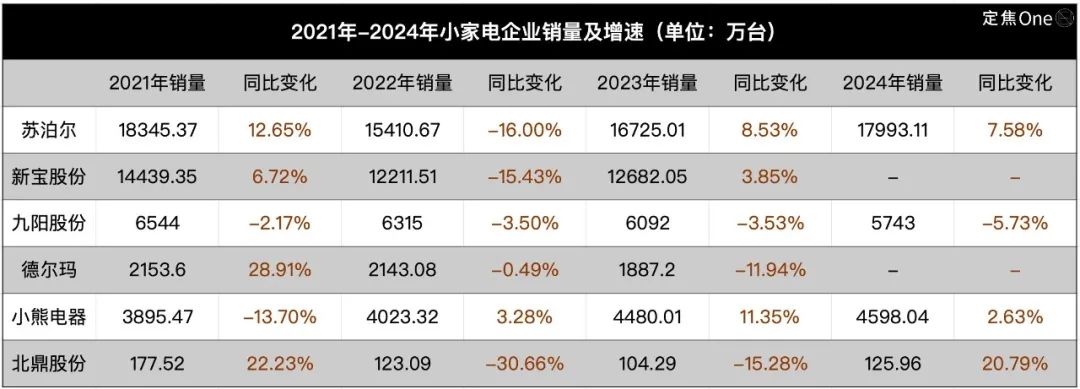
소형 가전 산업 침체, AI 새로운 이야기지만 적용은 아직 미미: 주방 소형 가전 시장(예: 아침 식사 기계, 에어프라이어)은 “집콕 경제” 붐이 사라진 후 판매량 감소와 가격 경쟁의 어려움에 직면했습니다. Supor, Joyoung, Bear Electric 등 “6대 강자” 상장 기업의 실적이 압박을 받고 있습니다. 돌파구를 찾기 위해 기업들은 일반적으로 해외 시장 확장과 AI 기술 융합에 눈을 돌리고 있습니다. 그러나 현재 소형 가전에서의 AI 적용은 간단한 음성 명령, 자동 조절 등에 그치는 경우가 많아 실용성과 혁신 공간이 제한적이며, 비용 증가로 사용자를 외면하게 만들 수 있습니다. 이에 비해 대형 가전은 AI 적용에서 더 유리하며, 스마트 홈 생태계를 구축하고 빅데이터를 활용하여 개인화된 서비스를 제공할 수 있습니다. 소형 가전 산업의 AI 이야기는 아직 초기 단계에 있습니다. (출처: 36Kr)
관세 파동, 화창베이 칩 시장 강타, 국산 대체 가속화될 수도: 최근 칩 관련 관세 정책 변동이 선전 화창베이 전자 시장에 우려를 불러일으켰습니다. CPU, GPU 등 인기 칩(특히 미국 원산지 가능성이 있는) 판매자들이 가격 제시를 중단하고 물건을 쌓아두고 관망하는 현상이 나타났으며, 가격 변동성이 심화되었습니다. 메모리 칩 등 품목은 상대적으로 영향이 적습니다. 여러 상장 유통업체들은 미국에서 직접 수입하는 비율이 작아 관세 전쟁의 직접적인 영향은 제한적이지만 시장 불확실성이 증가했다고 밝혔습니다. 업계는 일반적으로 미국에 웨이퍼 팹을 보유한 IDM 기업(예: TI, Intel, Micron)이 가장 큰 영향을 받을 것으로 보고 있습니다. 이 사건은 이미 일부 하위 고객들이 국산 칩 대체 방안을 문의하도록 촉발했으며, 반도체 분야의 국산화 과정을 가속화할 수 있습니다. (출처: 创业板观察)

AI, 인간 의미 위기 가중시키나? 기술과 가치의 균형 성찰: 이 글은 인공지능의 급속한 발전이 인간 존재의 의미에 어떻게 충격을 주는지 탐구합니다. AI가 전문 분야(예: 바둑, 의료 진단, 예술 창작)에서 인간을 능가하는 것은 산업 혁명 이후 노동 소외, 신앙 위기, 환경 문제 등으로 인해 발생한 인간 의미 위기를 더욱 심화시킨다고 주장합니다. AI는 특히 화이트칼라 직업에서 의사 결정 능력을 대체함으로써 “도구적 인간”의 곤경을 더욱 강화할 수 있습니다. 이 글은 철학자들의 관점과 공상 과학 작품(예: 《듄》, 《웨스트월드》)을 인용하여 기술 노예화 위험을 경고하며, AI가 가져오는 기술적 향상을 수용하는 동시에 가치 합리성을 재건하고, 윤리적 틀과 인문 교육을 통해 인간의 창의력, 감정적 유대, 비판적 사고를 보호하여 스스로 만든 창조물의 부속물이 되는 것을 피해야 한다고 촉구합니다. (출처: 腾讯研究院)
미국 제조 iPhone 비용 고가, 25,000위안 초과할 수도: 이 글은 iPhone이 전적으로 미국 본토에서 생산될 경우 비용이 대폭 상승하여 예상 판매 가격이 3,500달러(약 25,588위안)에 달할 수 있으며, 이는 현재 가격을 훨씬 초과한다고 분석합니다. 주요 원인으로는 미국이 원자재(예: 희토류, 정제 리튬 코발트) 확보, 물류 운송, 공장 건설(토지, 전력, 환경 승인) 및 인력 비용(최저 시급이 중국보다 4-5배 높고 숙련된 산업 노동자 부족) 측면에서 모두 중국보다 훨씬 높기 때문입니다. Apple이 과거 글로벌 공급망(특히 이윤 공간이 상대적으로 큰 중국 공급업체)을 압박하여 높은 이윤율을 유지했던 모델은 미국에서는 지속하기 어려울 것입니다. 높은 생산 비용은 결국 소비자에게 전가되어 Apple의 가격 책정 전략과 시장 지위를 흔들 수 있습니다. (출처: 星海情报局)

수학적 돌파: 평균 곡률 흐름 특이점 이론 증명 획득: 수학자들을 거의 30년간 괴롭혔던 Multiplicity-one 추측이 최근 Richard Bamler와 Bruce Kleiner에 의해 증명되었습니다. 이 추측은 평균 곡률 흐름(Mean Curvature Flow, MCF)에 관한 것으로, 이는 표면이 시간이 지남에 따라 면적을 가장 빠른 속도로 줄이기 위해 어떻게 진화하는지(얼음 조각이 녹거나 모래성이 침식되는 것과 유사) 설명하는 수학적 과정입니다. 증명은 3차원 공간에서 2차원 닫힌 곡면이 MCF 하에서 형성하는 특이점(곡률이 무한대로 발산하는 점)이 단순하며, 일반적으로 국소적으로 한 점으로 수축하는 구면이나 한 선으로 붕괴하는 원기둥 형태로 나타나고, 복잡한 다층 중첩 특이점은 발생하지 않는다고 지적합니다. 이 돌파구는 MCF가 특이점 형성 후에도 계속 분석될 수 있음을 보장하며, MCF를 사용하여 기하학 및 위상학(예: 푸앵카레 추측)의 중요한 문제를 해결하는 데 더 견고한 이론적 기초를 제공합니다. (출처: 机器之心)

사용자, “예산급” 4x RTX 3090 로컬 AI 하드웨어 구성 공유: Reddit 사용자가 로컬에서 LLM을 실행하기 위해 직접 구축한 하드웨어 구성 방안을 공유했으며, 총 비용은 약 4,204달러입니다. 이 구성에는 중고 EVGA RTX 3090 그래픽 카드 4개(개당 600달러), AMD EPYC 7302P 서버 CPU 1개, Asrock Rack 메인보드, 96GB DDR4 메모리 및 2TB NVMe SSD가 포함되며, MLACOM Quad Station Pro Lite 개방형 케이스에 조립되었고 1200W 전원 공급 장치 2개를 사용했습니다. 이 공유는 집에서 비교적 강력한 컴퓨팅 파워(4x 24GB VRAM)를 갖춘 AI 워크스테이션을 구축하고자 하는 사용자에게 상대적으로 “경제적인” 참고 방안을 제공합니다. (출처: Reddit r/LocalLLaMA)

미국 해커, 교통 신호등 공격하여 머스크와 저커버그 Deepfake 메시지 재생: 보도에 따르면, 미국 샌프란시스코 베이 지역의 여러 보행자 횡단 신호등 시스템이 해커의 공격을 받아 AI로 생성된 머스크와 저커버그의 Deepfake(딥페이크) 메시지를 재생하는 데 사용되었습니다. 이 사건은 AI 기술을 이용한 사이버 공격에 직면했을 때 공공 인프라의 취약성과, Deepfake 기술이 허위 정보 유포나 장난에 악용될 위험성을 부각합니다. (출처: Reddit r/ArtificialInteligence)

다양한 로봇 및 자동화 기술 전시: 소셜 미디어에서 다양한 로봇 및 자동화 기술 적용 사례가 전시되었습니다. 여기에는 인간의 동작을 모방하여 쿵푸를 공연할 수 있는 Booster T1 로봇; 재활 훈련에 사용되는 로봇 시스템; 커피를 만들 수 있는 로봇 팔; 벼 심기 및 제초에 사용되는 농업용 로봇; 목축업자가 양을 다루기 편리하게 하는 자동화 시스템; 춤추는 로봇 등이 포함됩니다. 이러한 사례들은 로봇이 산업, 농업, 서비스업, 의료 재활 및 엔터테인먼트 등 다양한 분야에서 광범위하게 적용되고 지속적으로 발전하고 있음을 반영합니다. (출처: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
신흥 기술 및 혁신 제품 전시: 소셜 미디어에서 다양한 신흥 기술 및 혁신 제품이 공유되었습니다. 예를 들어, MIT에서 개발한 빛을 이용하여 셀룰러 통신을 모니터링하는 초소형 무선 안테나; 단풍나무 씨앗 비행을 모방한 단일 날개 드론; 사물 인터넷 스마트 변기; 치과 교정에 사용되는 디지털 인상 기술; 소금물을 이용하여 발전하는 장치; 숨쉬고 움직일 수 있는 동적 벽체; Iron Man 코스프레 슈트; 전지형 전동 스키보드; Flipper Zero 장치를 이용하여 열쇠를 복제하는 기술 등이 있습니다. 이러한 전시는 기술이 통신, 에너지, 건강, 교통, 건축 및 보안 등 여러 분야에서 지속적으로 혁신하고 있음을 보여줍니다. (출처: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

의료 건강 기술 동향: 소셜 미디어 및 기사 링크에서 의료 건강 분야의 기술 적용 및 발전 동향이 언급되었습니다. 여기에는 로봇 보조 수술, 의료 보건 분야에서의 AI 적용 동향 및 전환점, 기술을 활용한 운영 우수성 추진(초자동화), AI가 가져올 수 있는 변혁 등이 포함됩니다. 이러한 내용은 AI, 로봇, 자동화 등 기술이 의료 서비스 효율성, 진단 정확성 및 환자 경험 향상 측면에서 가지는 잠재력과 실천을 반영합니다. (출처: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

사이버 보안 관련 정보: 소셜 미디어에서 사이버 보안 관련 내용이 공유되었습니다. 여기에는 비밀번호 공격 유형 도해 및 데이터 유출 후 60분 이내 복구 능력의 중요성에 관한 기사가 포함됩니다. 이러한 내용은 사용자에게 사이버 보안 위험 및 대응 전략에 대한 주의를 환기시킵니다. (출처: Ronald_vanLoon 1, Ronald_vanLoon 2)

AMD ROCm 플랫폼 토론: Reddit 사용자들이 듀얼 AMD Radeon RX 7900 XTX GPU를 사용하여 딥러닝 워크스테이션을 구축할 가능성에 대해 논의했으며, ROCm(Radeon Open Compute platform) 소프트웨어 스택이 언급되었습니다. 이는 Nvidia가 주도하는 AI 하드웨어 시장에서 사용자들이 AMD GPU 솔루션과 그 소프트웨어 생태계(ROCm)에 대한 관심과 탐색을 반영합니다. (출처: Reddit r/deeplearning)