
키워드:GPT-4.1, Hugging Face, GPT-4.1 시리즈 모델 성능 비교, Hugging Face, Pollen Robotics 인수, OpenAI 신규 모델 코딩 능력 향상, GPT-4.1 mini 비용 83% 절감, 오픈소스 로봇 Reachy 2
🔥 포커스
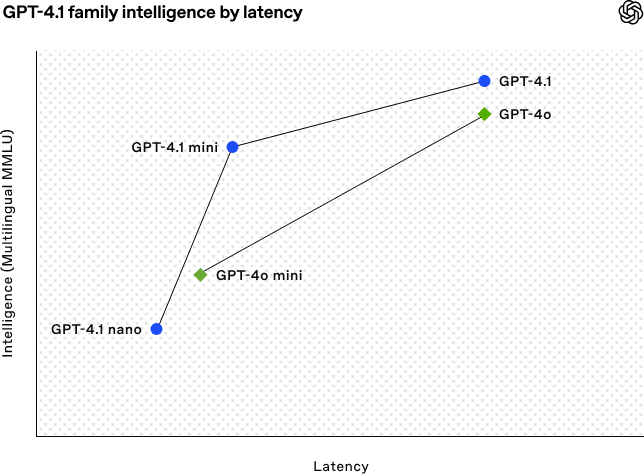
OpenAI, 코딩 및 장문 텍스트 처리 능력 강화된 GPT-4.1 시리즈 모델 발표: OpenAI는 4월 15일 새벽, GPT-4.1 시리즈의 새로운 모델 3종(플래그십 GPT-4.1, 고효율 GPT-4.1 mini, 초소형 GPT-4.1 nano)을 발표했으며, 모두 API를 통해서만 제공됩니다. 이 시리즈 모델은 코딩, 명령어 준수, 장문 컨텍스트 이해 측면에서 뛰어난 성능을 보이며, 컨텍스트 창은 모두 100만 token, 출력 token은 32768에 달합니다. GPT-4.1은 SWE-bench Verified 테스트에서 54.6%의 점수를 얻어 GPT-4o 및 곧 폐기될 GPT-4.5 Preview보다 현저히 우수합니다. GPT-4.1 mini는 GPT-4o를 능가하는 성능을 보이면서 지연 시간은 절반으로 줄고 비용은 83% 절감되었습니다. GPT-4.1 nano는 현재 가장 빠르고 비용이 저렴한 모델로, 낮은 지연 시간이 요구되는 작업에 적합합니다. 이번 발표는 개발자에게 더 강력한 성능, 더 우수한 비용 효율성, 더 빠른 속도의 모델 선택지를 제공하여 복잡한 지능형 시스템 및 에이전트 애플리케이션 구축을 촉진하는 것을 목표로 합니다. (출처: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face, 오픈소스 로봇 회사 Pollen Robotics 인수: AI 커뮤니티 플랫폼 Hugging Face는 프랑스 오픈소스 로봇 스타트업 Pollen Robotics 인수를 발표하며, AI 로봇의 오픈소스화 및 대중화를 추진하고자 합니다. 이번 인수는 Hugging Face의 소프트웨어 플랫폼(예: LeRobot 라이브러리 및 Hub)에서의 강점과 Pollen Robotics의 오픈소스 하드웨어(예: Reachy 2 휴머노이드 로봇) 분야 전문성을 결합할 것입니다. Reachy 2는 연구, 교육, 체화된 지능 실험을 위해 설계된 오픈소스, VR 호환 휴머노이드 로봇으로, 가격은 7만 달러입니다. Hugging Face는 로봇이 AI의 다음 중요 인터페이스이며, 개방적이고 저렴하며 맞춤 설정 가능해야 한다고 생각합니다. 이번 인수는 이러한 비전을 실현하는 중요한 단계이며, 커뮤니티가 폐쇄적이고 값비싼 시스템에 의존하는 대신 자신만의 로봇 동반자를 구축하고 제어할 수 있도록 하는 것을 목표로 합니다. (출처: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 동향
AI, 50년간 풀리지 않은 수학 난제 해결에 기여: 미국 브룩헤이븐 국립 연구소의 중국계 학자 Weiguo Yin은 OpenAI의 추론 모델 o3-mini-high를 이용하여 1차원 J_1-J_2 q-상태 Potts 모델의 정확한 해법 도출에 돌파구를 마련했으며, 특히 q=3인 경우 AI의 도움으로 핵심 증명을 완료했습니다. 이 문제는 통계 역학의 기본 모델과 관련이 있으며, 층상 물질의 원자 적층, 비정상 초전도 등 물리 현상과 연관되어 지난 50년간 정확한 해법이 나오지 않았습니다. 연구진은 최대 대칭 부분 공간(MSS) 방법을 도입하고 AI의 단계적 힌트를 통해 전달 행렬을 처리함으로써, q=3일 때의 9×9 전달 행렬을 효과적인 2×2 행렬로 성공적으로 단순화하고 이 방법을 임의의 q 값으로 일반화했습니다. 이 연구는 오랫동안 존재해 온 수리물리학 난제를 해결했을 뿐만 아니라, 복잡한 과학 연구를 보조하고 새로운 통찰력을 제공하는 AI의 엄청난 잠재력을 보여주었습니다. (출처: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

AI 웹 버전 어시스턴트 부상, 휴대폰 및 자동차 제조사 멀티 디바이스 경험 구축: 화웨이(小艺助手), 리샹 자동차(理想同学), OPPO(小布助手) 등 제조사들이 잇따라 자사 AI 어시스턴트의 웹 버전을 출시하며 주목받고 있습니다. 이러한 웹 버전은 기능 완성도(예: 질문 편집, 레이아웃, 설정 옵션) 면에서 DeepSeek 등 전문 모델 서비스에 미치지 못할 수 있지만, 핵심 목표는 직접적인 경쟁이 아니라 각 브랜드 사용자를 위한 서비스 제공이며, 휴대폰, 차량 인포테인먼트 시스템에서 PC까지 이어지는 통합적인 경험을 제공하는 것입니다. 사용자 계정 연동, 대화 기록 동기화를 통해 이러한 웹 버전은 사용자 충성도를 높이고, 여러 단말기에서 일관된 상호 작용 경험을 제공하며, AI 어시스턴트를 더 넓은 사용자 시나리오에 통합하는 것을 목표로 합니다. 본질적으로 이는 사용자 접점과 데이터 생태계에 대한 경쟁입니다. (출처: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Figure 로봇, 강화 학습 통해 시뮬레이션에서 현실로 제로샷 전이 성공: Figure사는 자사의 Figure 02 휴머노이드 로봇이 순수 시뮬레이션 환경에서의 강화 학습(RL)을 통해 자연스러운 보행을 구현하는 것을 시연했습니다. 효율적인 GPU 가속 물리 시뮬레이터를 이용하여 몇 시간 만에 수년 분량의 훈련 데이터를 생성하고, 다양한 물리적 파라미터와 시나리오(예: 다른 지형, 방해)를 가진 여러 가상 로봇을 제어할 수 있는 단일 신경망 정책을 훈련했습니다. 시뮬레이션 영역 무작위화와 실제 로봇의 고주파 토크 피드백을 결합하여 훈련된 정책은 미세 조정 없이 물리적 로봇으로 제로샷 전이가 가능합니다. 이 방법은 개발 시간을 단축하고 실제 환경에서의 안정성을 높였을 뿐만 아니라, 하나의 정책으로 전체 로봇 군단을 제어할 수 있어 대규모 상업적 응용에서의 잠재력을 보여줍니다. (출처: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek, 추론 엔진 최적화 일부 오픈소스화 예정: DeepSeek은 vLLM 기반으로 수정한 고성능 추론 엔진의 일부 최적화 및 기능을 커뮤니티에 기여할 계획이라고 발표했습니다. 완전히 맞춤화된 추론 스택 전체를 공개하는 대신, 핵심 개선 사항(예: 최신 모델 아키텍처 지원, 성능 최적화)을 vLLM 및 SGLang과 같은 주류 오픈소스 추론 프레임워크에 통합하여 커뮤니티가 처음부터 새로운 모델과 기술에 대한 SOTA급 지원을 받을 수 있도록 하는 것을 목표로 합니다. 이 조치는 커뮤니티로부터 환영받았으며, 단순한 구두 선전이 아닌 진정한 오픈소스 기여에 대한 의지로 평가받고 있습니다. (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
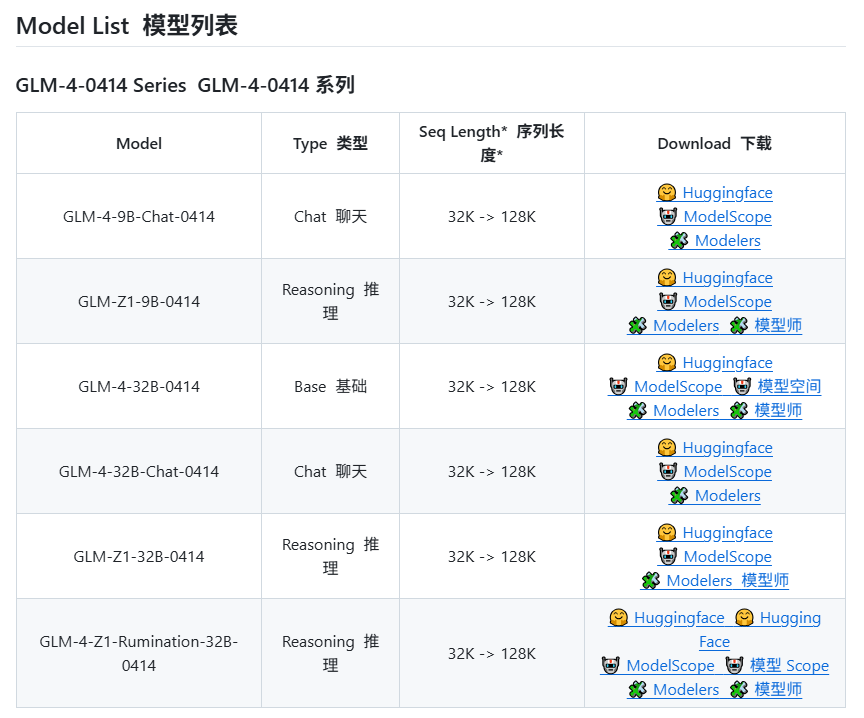
Zhipu AI, GLM-4 시리즈 신규 모델 출시 예정 추정: GitHub에 유출된 정보(이후 삭제됨)에 따르면, Zhipu AI가 GLM-4 시리즈 신규 모델을 출시할 준비를 하고 있는 것으로 보입니다. 이 시리즈는 다양한 파라미터 규모(예: 9B, 32B)와 기능을 가진 버전들을 포함할 수 있으며, 예를 들어 기본 모델(GLM-4-32B-0414), 대화 모델(Chat), 추론 모델(GLM-Z1-32B-0414), 그리고 더 깊은 사고 능력을 갖춘 “Rumination” 모델(OpenAI의 Deep Research에 대응 가능성) 등이 있습니다. 또한, 시각 멀티모달 모델(GLM-4V-9B)도 포함될 수 있습니다. 유출된 벤치마크 테스트 데이터에 따르면, GLM-4-32B-0414는 일부 지표에서 DeepSeek-V3 및 DeepSeek-R1보다 우수할 수 있습니다. 관련 추론 엔진 지원 코드는 이미 transformers/vllm/llama.cpp에 병합되었습니다. 커뮤니티는 이에 대해 높은 관심을 보이며 공식 발표와 평가를 기대하고 있습니다. (출처: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA, Nemotron 시리즈 신규 모델 발표: NVIDIA는 Hugging Face에 새로운 Nemotron-H 시리즈 기본 모델을 발표했습니다. 56B, 47B, 8B 세 가지 파라미터 규모를 포함하며, 모두 8K 컨텍스트 창을 지원합니다. 이 모델들은 하이브리드 Transformer 및 Mamba 아키텍처를 기반으로 합니다. 현재는 기본 모델(Base)만 발표되었으며, 명령어 미세 조정(Instruct) 버전은 아직 제공되지 않았습니다. Nemotron 시리즈는 새로운 아키텍처의 언어 모델링 잠재력을 탐색하는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)

🧰 도구
GitHub Copilot, Windows Terminal Canary 버전에 통합: Microsoft는 GitHub Copilot 기능을 Windows Terminal의 Canary 프리뷰 버전에 통합하여 “터미널 채팅”(Terminal Chat)이라는 새로운 기능을 출시했습니다. 이 기능을 통해 사용자는 터미널 환경에서 직접 AI와 상호 작용하여 명령어 제안 및 설명을 얻을 수 있습니다. 사용자는 GitHub Copilot을 구독하고 최신 Canary 버전 터미널을 설치한 후 계정을 인증하면 사용할 수 있습니다. 이 조치는 AI 지원 기능을 개발자가 자주 사용하는 명령줄 환경에 직접 통합하여 컨텍스트 전환을 줄이고, 복잡하거나 익숙하지 않은 작업 처리 효율성을 높이며, 학습 과정을 가속화하고 오류를 줄이는 데 도움이 되는 것을 목표로 합니다. (출처: GitHub Copilot 现可在 Windows 终端中运行了)

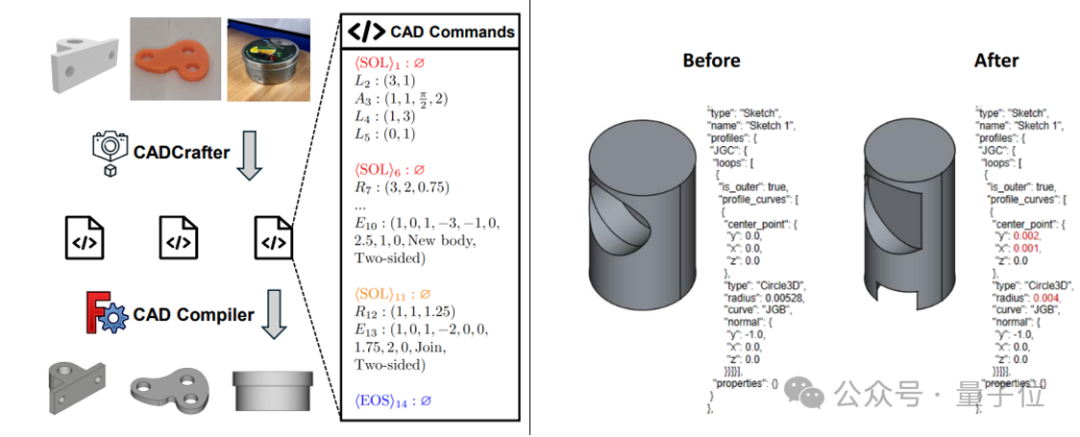
CADCrafter: 단일 이미지로 편집 가능한 CAD 파일 생성: KOKONI 3D(魔芯科技), 난양 공과대학교 등 기관의 연구진이 CADCrafter라는 새로운 프레임워크를 제안했습니다. 이는 단일 이미지(렌더링 이미지, 실제 사진 등)로부터 직접 파라미터화되고 편집 가능한 CAD 엔지니어링 파일(CAD 명령어 시퀀스로 표현)을 생성할 수 있게 하여, 기존의 이미지-3D 변환 방법(Mesh 또는 3DGS 생성)이 생성한 모델의 정밀한 편집이 어렵고 표면 품질이 높지 않은 문제를 해결합니다. 이 방법은 VAE와 Diffusion Transformer를 결합한 2단계 생성 아키텍처를 채택하고, 다중 뷰에서 단일 뷰로의 증류 전략 및 DPO 기반 컴파일 가능성 검사 메커니즘을 통해 생성 품질과 성공률을 향상시킵니다. 연구 성과는 CVPR 2025에 채택되었으며, AI 보조 산업 디자인에 새로운 패러다임을 제공합니다. (출처: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain, GraphRAG와 MongoDB Atlas 통합 출시: LangChain은 MongoDB와 협력하여 그래프 기반 RAG(GraphRAG) 시스템을 출시한다고 발표했습니다. 이 시스템은 MongoDB Atlas를 사용하여 데이터를 저장하고 처리하며, LangChain을 통해 구현되어 전통적인 유사성 검색 기반 RAG를 넘어서 개체 간의 관계를 이해하고 추론할 수 있습니다. LLM을 통한 개체 및 관계 추출을 지원하고 그래프 순회를 이용하여 연결된 컨텍스트 정보를 얻음으로써, 깊이 있는 관계 이해가 필요한 애플리케이션에 더 강력한 질의응답 및 추론 능력을 제공하는 것을 목표로 합니다. (출처: LangChainAI)
Hugging Face, 추론 플레이그라운드(Inference Playground) 오픈소스화: Hugging Face는 모델 추론 테스트 및 비교에 사용되는 온라인 도구인 Inference Playground를 오픈소스화했습니다. 이는 웹 기반 LLM 채팅 인터페이스로, 사용자가 다양한 추론 설정(예: temperature, top-p 등)을 제어하고, AI 응답을 수정하며, 다른 모델 및 제공 업체의 성능을 비교할 수 있게 합니다. 이 프로젝트는 Svelte 5, Melt UI, Tailwind를 사용하여 구축되었으며, 코드는 GitHub에 공개되어 개발자에게 맞춤 설정 및 확장이 가능한 로컬 또는 온라인 모델 상호 작용 및 평가 플랫폼을 제공합니다. (출처: huggingface)
Flowith 플랫폼 ARR 백만 달러 돌파, AI Agent 웹 페이지 생성 능력 시연: AI Agent 플랫폼 Flowith의 연간 반복 매출(ARR)이 100만 달러를 넘어섰으며, 이는 인력을 대체할 수 있는 만능 AI Agent 플랫폼에 대한 시장의 강한 수요를 보여줍니다. 사용자는 Flowith의 Oracle 기능을 사용하여 간단한 자연어 설명(“소셜 미디어 이미지/텍스트 미리보기 프로그램 웹 페이지를 만들고 싶어요…”)만으로 기능이 완벽하고 스타일이 정확하게 재현된(예: Twitter 스타일) 이미지 미리보기를 지원하는 웹 페이지 소형 도구를 빠르게 생성하는 경험을 공유했습니다. GitHub 연결이나 복잡한 구성 없이도 가능하며, 이는 AI Agent가 로우코드/노코드 웹 페이지 생성 분야에서 가진 잠재력을 보여줍니다. (출처: karminski3)
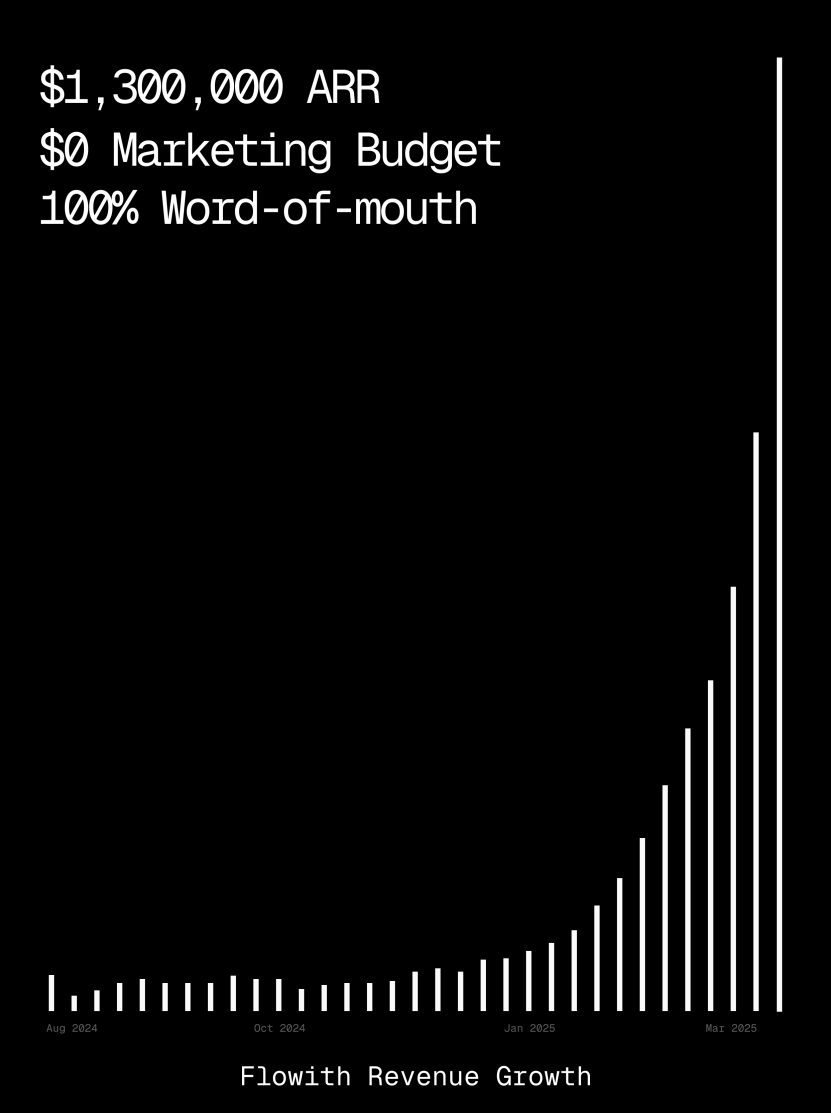
자율 디버깅 에이전트 Deebo 출시: 연구진은 Deebo라는 자율 디버깅 에이전트 MCP 서버를 구축했습니다. 이는 로컬 데몬으로 실행되며, 프로그래밍 에이전트는 까다로운 오류 처리 작업을 비동기적으로 이 에이전트에 위임할 수 있습니다. Deebo는 다양한 수정 가설을 가진 여러 하위 프로세스를 생성하고, 각 시나리오를 격리된 git 브랜치에서 실행하며, “마더 에이전트”가 순환 테스트, 추론을 수행하여 최종적으로 진단 결과와 제안된 패치를 반환합니다. 실제 tinygrad $100 현상금 버그 테스트에서 Deebo는 문제의 근본 원인을 성공적으로 식별하고 두 가지 구체적인 수정 방안을 제시하여 테스트를 통과했습니다. (출처: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 학습
Nabla-GFlowNet: 다양성과 효율성을 모두 고려한 확산 모델 보상 파인튜닝 신규 방법: 확산 모델 파인튜닝에서 전통적인 강화 학습의 느린 수렴, 직접적인 보상 최대화 시 과적합 및 다양성 손실 문제를 해결하기 위해, 홍콩 중문대(선전) 등 기관의 연구진이 Nabla-GFlowNet을 제안했습니다. 이 방법은 생성 흐름 네트워크(GFlowNet) 프레임워크를 기반으로 확산 과정을 흐름 균형 시스템으로 간주하여 Nabla-DB 균형 조건 및 해당 손실 함수를 도출합니다. 파라미터화 설계를 통해 단일 단계 노이즈 제거로 잔차 그래디언트를 추정하여 추가적인 네트워크 추정을 피합니다. 실험 결과, 미적 점수, 명령어 준수 등 보상 함수로 Stable Diffusion을 파인튜닝할 때 Nabla-GFlowNet은 ReFL, DRaFT 등 방법보다 더 빠르게 수렴하고 과적합되기 어려우며, 동시에 생성 샘플의 다양성을 유지하는 것으로 나타났습니다. (출처: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: 371B Tokens 규모의 최대 오픈소스 수학 추론 데이터셋 공개: LLM360이 출시한 MegaMath 데이터셋은 3710억 Tokens를 포함하며, 오픈소스 커뮤니티에 대규모 고품질 수학 추론 사전 훈련 데이터가 부족한 문제를 해결하는 것을 목표로 합니다. 이 데이터셋은 수학 중심 웹 페이지(279B), 수학 관련 코드(28.1B), 고품질 합성 데이터(64B) 세 부분으로 구성됩니다. 구축 과정에서는 혁신적인 데이터 처리 파이프라인을 채택했으며, 여기에는 수학 공식에 최적화된 HTML 파싱, 2단계 텍스트 추출, 동적 교육 가치 채점, 코드 데이터의 다단계 정밀 리콜, 그리고 다양한 대규모 합성 방법(Q&A, 코드 생성, 텍스트-코드 인터리빙)이 포함됩니다. Llama-3.2(1B/3B)에서 100B Tokens 사전 훈련 검증 결과, MegaMath는 GSM8K, MATH 등 벤치마크에서 15-20%의 절대 성능 향상을 가져오는 것으로 나타났습니다. (출처: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
OS Agents 개요: 멀티모달 대형 모델 기반 컴퓨터, 휴대폰, 브라우저 에이전트 연구: 저장대학교가 OPPO, 01.AI 등 기관과 협력하여 운영체제 에이전트(OS Agents)에 대한 개요 논문을 발표했습니다. 이 논문은 멀티모달 대형 언어 모델(MLLM)을 이용하여 컴퓨터, 휴대폰, 브라우저 등 환경에서 자동으로 작업을 완료할 수 있는 에이전트(예: Anthropic의 Computer Use, Apple의 Apple Intelligence) 연구 현황을 체계적으로 정리합니다. 내용은 OS Agents의 기초(환경, 관찰 공간, 행동 공간, 핵심 능력), 구축 방법(기본 모델 아키텍처 및 훈련 전략, 에이전트 프레임워크의 인식/계획/기억/행동 모듈), 평가 프로토콜 및 벤치마크, 관련 상용 제품 및 미래 과제(보안 프라이버시, 개인화 및 자가 진화)를 다룹니다. 연구팀은 250개 이상의 관련 논문을 포함하는 오픈소스 저장소를 유지하며 이 분야의 발전을 촉진하고자 합니다. (출처: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: MAE 손실과 최적 수송을 결합한 강건한 프롬프트 학습 방법: 상하이 과학기술대학교 YesAI Lab은 CVPR 2025 Highlight 논문에서 NLPrompt를 제안하여 시각 언어 모델 프롬프트 학습에서의 레이블 노이즈 문제를 해결하고자 합니다. 연구 결과, 프롬프트 학습 시나리오에서 평균 절대 오차(MAE) 손실(PromptMAE)을 사용하는 것이 교차 엔트로피(CE) 손실보다 노이즈 레이블의 영향에 더 강하며, 특징 학습 이론 관점에서 그 강건성을 증명했습니다. 또한, 프롬프트 기반 최적 수송 데이터 정화 방법(PromptOT)을 제안하여 텍스트 특징을 프로토타입으로 사용하여 데이터셋을 깨끗한 하위 집합(CE 손실로 훈련)과 노이즈가 있는 하위 집합(MAE 손실로 훈련)으로 나누어 두 손실의 장점을 효과적으로 융합합니다. 실험 결과 NLPrompt는 합성 및 실제 노이즈 데이터셋 모두에서 우수한 성능을 보였으며 우수한 일반화 능력을 갖추고 있음을 증명했습니다. (출처: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
DeepSeek-R1 추론 메커니즘 분석: 맥길 대학교 연구진은 DeepSeek-R1과 같은 대형 추론 모델의 추론 과정을 분석했습니다. 직접 답을 제시하는 LLM과 달리, 추론 모델은 상세한 다단계 추론 체인을 생성합니다. 연구는 추론 체인 길이와 성능 간의 관계(최적 지점이 존재하며, 너무 길면 성능 저하 가능성), 장문 컨텍스트 관리, 문화 및 보안 문제(비추론 모델 대비 더 강한 보안 취약점 존재), 그리고 인간 인지 현상과의 연관성(예: 이미 탐색한 문제에 계속 집착)을 탐구했습니다. 이 연구는 현재 추론 모델 작동 메커니즘의 일부 특징과 잠재적 문제를 밝혀냈습니다. (출처: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MoE 대형 모델 테스트 시점 최적화 방법 C3PO: 존스 홉킨스 대학교 연구진은 전문가 혼합(MoE) LLM에 전문가 경로 차선화 문제가 있음을 발견하고, 테스트 시점 최적화 방법 C3PO(핵심 계층, 핵심 전문가, 협력 경로 최적화)를 제안했습니다. 이 방법은 실제 레이블에 의존하지 않고 참조 샘플 집합의 “성공적인 이웃”을 통해 대체 목표를 정의하여 모델 성능을 최적화합니다. 패턴 찾기, 커널 회귀, 유사 샘플 평균 손실 등의 알고리즘을 사용하며, 비용 절감을 위해 핵심 계층의 핵심 전문가 가중치만 최적화합니다. MoE LLM에 적용한 결과, C3PO는 6개 벤치마크 테스트에서 기본 모델 정확도를 7-15% 향상시켜 일반적인 테스트 시점 학습 기준선을 능가했으며, 소규모 파라미터 MoE 모델의 성능을 더 큰 파라미터 LLM보다 뛰어나게 하여 MoE 효율성을 높였습니다. (출처: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
양자화가 추론 모델 성능에 미치는 영향 연구: 칭화대학교 연구팀은 양자화 기술이 추론형 언어 모델(예: DeepSeek-R1 시리즈, Qwen, LLaMA) 성능에 미치는 영향을 처음으로 체계적으로 탐색했습니다. 연구는 다양한 비트 폭(W8A8, W4A16 등)의 가중치, KV 캐시 및 활성화 양자화 알고리즘이 수학, 과학, 프로그래밍 등 추론 벤치마크에서 어떤 성능을 보이는지 평가했습니다. 결과에 따르면, W8A8 또는 W4A16 양자화는 일반적으로 성능 손실 없이 구현 가능하지만, 더 낮은 비트 폭은 상당한 정확도 저하 위험을 초래합니다. 모델 크기, 출처 및 작업 난이도는 양자화 후 성능에 영향을 미치는 핵심 요소입니다. 양자화된 모델의 출력 길이는 크게 증가하지 않았으며, 모델 크기를 합리적으로 조정하거나 추론 단계를 늘리면 성능을 향상시킬 수 있습니다. 관련 양자화 모델과 코드는 오픈소스로 공개되었습니다. (출처: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: 에이전트가 보안 정책을 준수하도록 강제하는 가드레일: 시카고 대학교는 SHIELDAGENT 프레임워크를 제안하여, 논리적 추론을 통해 AI 에이전트의 행동 궤적이 명확한 보안 정책을 준수하도록 강제하는 것을 목표로 합니다. 이 프레임워크는 먼저 정책 문서에서 검증 가능한 규칙을 추출하여 보안 정책 모델(확률적 규칙 회로 기반)을 구축합니다. 그런 다음 에이전트 실행 과정에서 행동 궤적에 따라 관련 규칙을 검색하고 보호 계획을 생성하며, 도구 라이브러리와 실행 가능한 코드를 사용하여 형식적 검증을 수행하여 에이전트 행동이 보안 규정을 위반하지 않도록 보장합니다. 동시에 3K개의 보안 관련 명령어 및 궤적 쌍으로 구성된 데이터셋 SHIELDAGENT-BENCH를 공개했습니다. 실험 결과, SHIELDAGENT는 여러 벤치마크에서 SOTA를 달성하여 보안 준수율과 재현율을 크게 향상시켰으며, 동시에 API 쿼리 및 추론 시간을 단축했습니다. (출처: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: 강화 학습을 통해 의료 VLM 추론 능력 촉진: 뮌헨 공과대학교, 옥스퍼드 대학교 등 기관이 협력하여 MedVLM-R1을 제안했습니다. 이는 명확한 자연어 추론 과정을 생성하는 것을 목표로 하는 의료 시각 언어 모델(VLM)입니다. 이 모델은 DeepSeek의 집단 상대 정책 최적화(GRPO) 강화 학습 프레임워크를 채택하여 최종 답변만 포함된 데이터셋에서 훈련되었음에도 불구하고 인간이 해석 가능한 추론 경로를 자율적으로 발견합니다. 단 600개의 MRI VQA 샘플만 사용하여 훈련한 후, 이 2B 파라미터 모델은 MRI, CT, X-ray 벤치마크 테스트에서 78.22%의 정확도를 달성하여 기준선을 크게 능가했으며, 강력한 도메인 외 일반화 능력을 보여주어 Qwen2-VL-72B와 같은 더 큰 규모의 모델을 능가하기도 했습니다. 이 연구는 신뢰할 수 있고 해석 가능한 의료 AI 구축에 새로운 방향을 제시합니다. (출처: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
연구 결과, 강화 학습 훈련이 추론 모델의 장황한 응답을 유발할 수 있음: Wand AI의 한 연구는 추론 모델(예: DeepSeek-R1)이 더 긴 응답을 생성하는 원인을 분석했습니다. 연구 결과, 이러한 행동은 문제 자체가 더 긴 추론을 필요로 하기 때문이 아니라 강화 학습(특히 PPO 알고리즘) 훈련 과정에서 비롯될 수 있다는 것을 발견했습니다. 모델이 잘못된 답변으로 부정적인 보상을 받을 때, PPO 손실 함수는 각 token의 처벌을 희석하기 위해 더 긴 응답을 생성하는 경향이 있으며, 추가 내용이 정확도 향상에 도움이 되지 않더라도 마찬가지입니다. 연구는 또한 간결한 추론이 종종 더 높은 정확도와 관련이 있음을 보여줍니다. 해결 가능한 문제의 일부만 사용하여 두 번째 강화 학습 훈련을 수행하면 응답 길이를 줄이면서 정확도를 유지하거나 심지어 향상시킬 수 있으며, 이는 배포 효율성 향상에 중요한 의미를 갖습니다. (출처: 更长思维并不等于更强推理性能,强化学习可以很简洁)

중국과기대와 ZTE, Curr-ReFT 제안: 소형 VLM 추론 및 일반화 능력 향상: 소형 시각 언어 모델(VLM)이 복잡한 작업에서 겪는 “훈련 병목 현상”과 도메인 외 일반화 능력 부족 문제를 해결하기 위해, 중국과기대와 ZTE는 커리큘럼 강화 학습 후훈련 패러다임(Curr-ReFT)을 제안했습니다. 이 패러다임은 커리큘럼 학습(CL)과 강화 학습(RL)을 결합하여 난이도 인지 보상 메커니즘을 설계하여 모델이 쉬운 것부터 어려운 것(이진 결정 → 다지선다 → 개방형 답변)으로 점진적으로 학습하도록 합니다. 동시에, 거부 샘플링 기반 자가 개선 전략을 채택하여 고품질 멀티모달 및 언어 샘플을 사용하여 모델의 기본 능력을 유지합니다. Qwen2.5-VL-3B/7B 모델에서의 실험 결과, Curr-ReFT는 모델의 추론 및 일반화 성능을 크게 향상시켰으며, 7B 모델은 일부 벤치마크에서 InternVL2.5-26B/38B를 능가하기도 했습니다. (출처: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: 생성적 추론을 통한 프로세스 보상 모델 확장: 칭화대학교와 상하이 AI Lab은 생성적 프로세스 보상 모델(GenPRM)을 제안하여, 전통적인 프로세스 보상 모델(PRM)이 스칼라 점수에 의존하고 해석 가능성이 부족하며 테스트 시점 확장이 불가능한 문제를 해결하고자 합니다. GenPRM은 생성적 방법을 채택하여 사고의 연쇄(CoT) 추론과 코드 검증을 결합하여 각 추론 단계에 대해 자연어 분석 및 Python 코드 실행 검증을 수행하여 더 깊고 해석 가능한 프로세스 감독을 제공합니다. 또한, GenPRM은 테스트 시점 확장 메커니즘을 도입하여 여러 추론 경로를 병렬로 샘플링하고 보상 값을 집계하여 평가 정확도를 향상시킵니다. 단 23K의 합성 데이터로 훈련된 1.5B 모델은 테스트 시점 확장을 통해 ProcessBench에서 GPT-4o를 능가했으며, 7B 버전은 72B의 Qwen2.5-Math-PRM-72B를 능가했습니다. GenPRM은 또한 비평 모델로서 정책 모델 최적화를 지도할 수 있습니다. (출처: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
연구 결과, 추론 AI가 전제 누락 문제에서 “과도한 사고” 현상 보임: 메릴랜드 대학교와 리하이 대학교의 연구 결과, 현재의 추론 모델(예: DeepSeek-R1, o1)은 필요한 전제 정보가 누락된 문제(Missing Premise, MiP)에 직면했을 때 “과도한 사고” 경향을 보이는 것으로 나타났습니다. 이들은 정상적인 문제보다 2-4배 더 긴 응답을 생성하며, 문제를 반복적으로 검토하고 의도를 추측하며 자기 의심에 빠지는 순환에 갇히는 경향이 있습니다. 문제를 해결할 수 없음을 빠르게 인식하고 멈추는 대신 말입니다. 이에 비해 비추론 모델(예: GPT-4.5)은 MiP 문제에 대해 더 짧은 응답을 보이며 전제 누락을 더 잘 인식합니다. 연구는 추론 모델이 전제 누락을 감지할 수는 있지만, 비효율적인 추론을 단호하게 중단하는 “비판적 사고”가 부족하며, 이러한 행동 패턴은 강화 학습 훈련 중 길이 제약 부족에서 비롯되어 증류를 통해 전파될 수 있음을 시사합니다. (출처: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

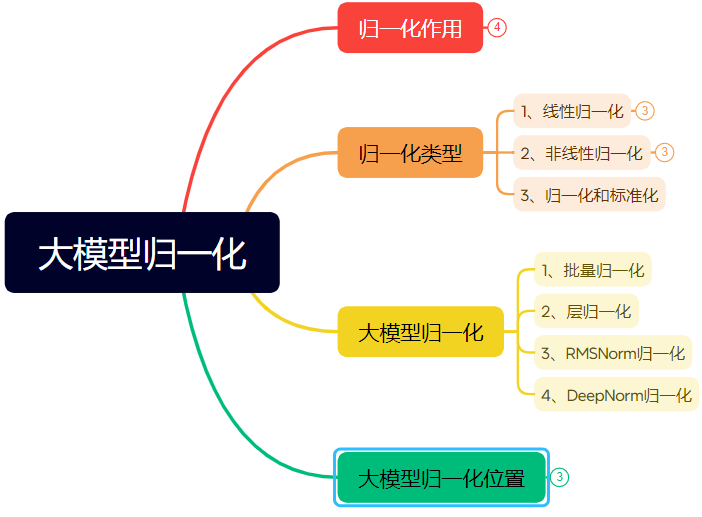
만 자 분량의 장문으로 신경망 정규화 기술 발전 상세 설명: 이 글은 정규화(Normalization)가 신경망, 특히 Transformer 및 대형 모델에서 수행하는 역할과 그 발전을 체계적으로 정리합니다. 정규화는 데이터를 고정된 범위로 제한함으로써 데이터 비교 가능성 문제를 해결하고, 최적화 속도를 향상시키며, 활성화 함수 포화 영역 및 내부 공변량 변화(ICS) 문제를 완화합니다. 이 글은 일반적인 선형(Min-max, Z-score, Mean) 및 비선형 정규화 방법을 소개하고, 딥러닝 모델에 적합한 배치 정규화(BN), 레이어 정규화(LN), RMSNorm 및 DeepNorm을 중점적으로 설명하며, Transformer 아키텍처에서의 적용 차이(왜 LN/RMSNorm이 NLP에 더 적합한지)를 분석합니다. 또한, Transformer 계층 내 정규화 모듈의 다양한 배치 위치(Post-Norm, Pre-Norm, Sandwich-Norm)와 이것이 훈련 안정성 및 성능에 미치는 영향을 논의합니다. (출처: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
AI를 이용한 특정 스타일 폰트 디자인 Prompt 엔지니어링: 이 글은 저자가 즉몽(即梦) AI 3.0을 사용하여 특정 스타일의 문자 디자인을 생성한 경험과 프롬프트 템플릿을 공유합니다. 저자는 폰트 이름(예: 송체, 해서체)을 직접 지정하는 것이 효과적이지 않으며 AI 모델의 이해도가 제한적이라는 것을 발견했습니다. 따라서 저자는 폰트 스타일 특징, 감성적 분위기, 시각적 효과를 설명하고 다양한 스타일의 참조 예를 결합하여 “고급 문자 스타일 디자인 프롬프트 생성기”라는 Prompt 템플릿을 구축했습니다. 사용자는 문자 내용만 입력하면 이 템플릿이 문자 내포 의미에 따라 지능적으로 여러 사전 설정 스타일(예: 빛 운율 밤 그림자, 산업적 소박함, 동심 낙서, 금속 공상 과학 등)을 매칭하거나 융합하여, 텍스트-이미지 생성 모델에 사용할 상세한 프롬프트를 생성함으로써 비교적 안정적인 품질의 텍스트-이미지 디자인 효과를 얻을 수 있습니다. (출처: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: LLM 사전 훈련을 위한 적응형 그래디언트 스파이크 억제 방법: 연구진은 LLM 훈련 과정에서의 손실 스파이크를 줄여 훈련 안정성을 높이기 위한 경량의 적응형 그래디언트 클리핑 방법인 ZClip을 제안했습니다. 고정된 임계값을 사용하는 전통적인 그래디언트 클리핑과 달리, ZClip은 z-score 기반 방법을 사용하여 비정상적인 그래디언트 스파이크, 즉 최근 이동 평균에서 현저하게 벗어난 그래디언트를 감지하고 클리핑합니다. 이 방법은 수렴을 방해하지 않으면서 훈련 안정성을 유지하는 데 도움이 되며, 어떤 훈련 루프에도 쉽게 통합될 수 있습니다. 코드와 논문이 공개되었습니다. (출처: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 비즈니스
인텔 Arc 그래픽 카드 + Xeon W 프로세서 솔루션, 저비용 AI 올인원 PC/서버 지원: 인텔은 Arc™ 그래픽 카드와 Xeon® W 프로세서 조합을 통해 시장에 비용 효율적(10만 위안 수준)이면서 실용적인 성능의 대형 모델 올인원 PC/서버 솔루션을 제공합니다. Arc™ 그래픽 카드는 Xe 아키텍처와 XMX AI 가속 엔진을 채택하고 주류 AI 프레임워크 및 Ollama/vLLM을 지원하며, 전력 소모가 낮고 다중 카드 병렬 연결을 지원합니다. Xeon® W 프로세서는 높은 코어 수와 메모리 확장 능력을 제공하며 AMX 가속 기술을 내장하고 있습니다. IPEX-LLM, OpenVINO™, oneAPI 등 소프트웨어 최적화와 결합하여 CPU와 GPU의 효율적인 협업을 실현했습니다. 실제 테스트 결과, 이 솔루션 기반 올인원 PC/서버는 Qwen-32B 모델을 단일 사용자 사용 시 32 tokens/s에 도달하고, 671B DeepSeek R1 모델(FlashMoE 최적화 필요)을 실행 시 약 10 tokens/s에 도달하여 오프라인 추론 요구를 충족시키며 AI 추론의 대중화를 촉진합니다. (출처: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA, 미국 본토에서 AI 슈퍼컴퓨터 제조 예정: NVIDIA는 처음으로 미국 본토에서 AI 슈퍼컴퓨터를 완전히 설계하고 구축할 것이며, 주요 제조 파트너와 협력할 것이라고 발표했습니다. 동시에 차세대 Blackwell 칩은 애리조나의 TSMC 공장에서 생산을 시작했습니다. NVIDIA는 향후 4년 동안 미국에서 최대 5천억 달러 상당의 AI 인프라를 생산할 계획이며, 파트너로는 TSMC, Foxconn, Wistron, Amkor, SPIL 등이 있습니다. 이 조치는 AI 칩 및 슈퍼컴퓨터 수요를 충족하고 공급망을 강화하며 탄력성을 높이는 것을 목표로 합니다. (출처: nvidia, nvidia)

Horizon Robotics, 3D 재구성/생성 인턴 채용: Horizon Robotics 체화 지능 팀은 상하이/베이징에서 3D 재구성/생성 분야 알고리즘 인턴을 채용합니다. 직무에는 로봇 Real2Sim 알고리즘 솔루션 설계 및 개발 참여(3D GS 재구성, 피드포워드 재구성, 3D/비디오 생성 결합), Real2Sim 시뮬레이터 성능 최적화(유체, 촉각 시뮬레이션 등 지원), 최첨단 연구 추적 및 최고 학회 논문 발표 등이 포함됩니다. 석사 이상 학력, 컴퓨터/그래픽스/AI 관련 전공, 3D 비전/비디오 생성 또는 멀티모달/확산 모델 경험, Python/Pytorch/Huggingface 능숙 사용자를 요구합니다. 최고 학회 논문 발표, 시뮬레이션 플랫폼 또는 오픈소스 프로젝트 경험자는 우대합니다. 정규직 전환 기회, GPU 클러스터 및 경쟁력 있는 급여를 제공합니다. (출처: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan 호텔/여행 부문, L7-L8 대형 모델 알고리즘 엔지니어 채용: Meituan 호텔/여행 공급 알고리즘 팀은 베이징에서 L7-L8 레벨의 대형 모델 알고리즘 엔지니어(경력직)를 채용합니다. 직무에는 호텔/여행 공급 이해 체계 구축(상품 태그, 핫스팟 식별, 유사 공급 발굴 등), 전시 소재 최적화(제목, 이미지/텍스트, 추천 이유 생성), 휴가 패키지 조합 구축(상품 선정, 판매량 예측, 가격 책정), 최첨단 대형 모델 기술 탐색 및 적용(미세 조정, RL, Prompt 최적화) 등이 포함됩니다. 석사 이상 학력, 2년 이상 경력, 컴퓨터/자동화/수리 통계 관련 전공, 탄탄한 알고리즘 기초 및 코딩 능력을 요구합니다. (출처: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta, EU 사용자 데이터 AI 훈련에 사용 예정: Meta는 EU 지역 Facebook 및 Instagram 사용자의 공개 데이터(예: 게시물, 댓글, 비공개 메시지 제외)를 AI 모델 훈련에 사용하기 시작할 준비가 되었다고 발표했습니다. 18세 이상 사용자에게만 해당됩니다. 회사는 앱 내 알림과 이메일을 통해 사용자에게 알리고 반대(opt-out) 링크를 제공할 예정입니다. 이전에 Meta는 아일랜드 규제 기관의 요구로 유럽에서 사용자 데이터를 AI 훈련에 사용하는 계획을 중단한 바 있습니다. (출처: Reddit r/artificial)

Tencent Cloud, MCP 호스팅 서비스 출시: Tencent Cloud도 MCP(Managed Cloud Platform) 호스팅 서비스를 제공하기 시작하여 기업에 더 편리하고 효율적인 클라우드 리소스 관리 및 운영 솔루션을 제공하는 것을 목표로 합니다. 이는 이 분야에서 주류 클라우드 공급업체 간의 경쟁이 심화됨을 의미합니다. 구체적인 서비스 세부 정보와 “WeChat 특색”은 아직 자세히 설명되지 않았습니다. (출처: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 커뮤니티
튜링상 수상자 LeCun, AI 발전에 대해 논하다: 인간 지능은 범용적이지 않으며, 차세대 돌파구는 비생성 모델에서 나올 수도: 최근 팟캐스트 인터뷰에서 Yann LeCun은 AGI라는 용어가 오해의 소지가 있다고 다시 한번 강조하며, 인간 지능은 고도로 전문화되어 있으며 범용적이지 않다고 주장했습니다. 그는 AI의 다음 주요 돌파구가 비생성 모델에서 나올 수 있으며, 기계가 물리적 세계를 진정으로 이해하고 추론 계획 능력과 지속적인 기억을 갖추는 데 중점을 둘 것이라고 예측했습니다. 이는 그가 제안한 JEPA 아키텍처와 유사합니다. 그는 현재 LLM이 진정한 추론 능력과 물리적 세계 모델링 능력이 부족하며, 고양이 수준의 지능에 도달하는 것만으로도 큰 진전이라고 생각합니다. Meta의 LLaMA 오픈소스화에 대해서는 전체 AI 생태계 발전을 촉진하는 올바른 선택이라고 평가하며, 혁신은 전 세계에서 나오며 오픈소스가 돌파구를 가속화하는 핵심이라고 강조했습니다. 그는 또한 스마트 안경을 AI 비서의 중요한 매개체로 유망하게 보고 있습니다. (출처: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

GitHub, 중국 IP 일시적 “차단” 논란, 공식 입장은 “구성 오류”: 4월 12일부터 13일까지 일부 중국 사용자들이 GitHub에 접속할 수 없게 되었고, 페이지에 “IP 주소 접근 제한”이라는 메시지가 표시되어 커뮤니티에 공포와 논의를 불러일으켰으며, 특정 대상 차단에 대한 우려가 제기되었습니다. 이전에 GitHub는 미국 제재로 인해 러시아, 이란 등 국가 개발자 계정을 차단한 적이 있습니다. GitHub 공식 측은 이후 이번 사건이 구성 변경 오류로 인해 로그인하지 않은 사용자가 일시적으로 접근할 수 없었던 것이며, 문제는 4월 13일에 해결되었다고 밝혔습니다. 기술적 결함이었음에도 불구하고, 이 사건은 코드 호스팅 플랫폼의 지정학적 위험과 국내 대안(예: Gitee, CODING, Jihu GitLab 등)에 대한 논의를 다시 한번 촉발했습니다. (출처: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

AI Agent, 사이버 보안 우려 야기: MIT 테크놀로지 리뷰 기사는 AI 기반의 자율 사이버 공격이 임박했다고 지적합니다. AI 능력이 향상됨에 따라 악의적인 행위자들이 AI Agent를 이용하여 자동으로 취약점을 발견하고 더 복잡하고 대규모의 사이버 공격을 계획 및 실행하여 개인, 기업, 심지어 국가 안보에 새로운 위협을 가할 수 있습니다. 이는 사이버 보안 분야가 AI 기반 공격에 대응할 수 있는 방어 전략과 기술 연구 및 배포를 서둘러야 함을 요구합니다. (출처: Ronald_vanLoon)

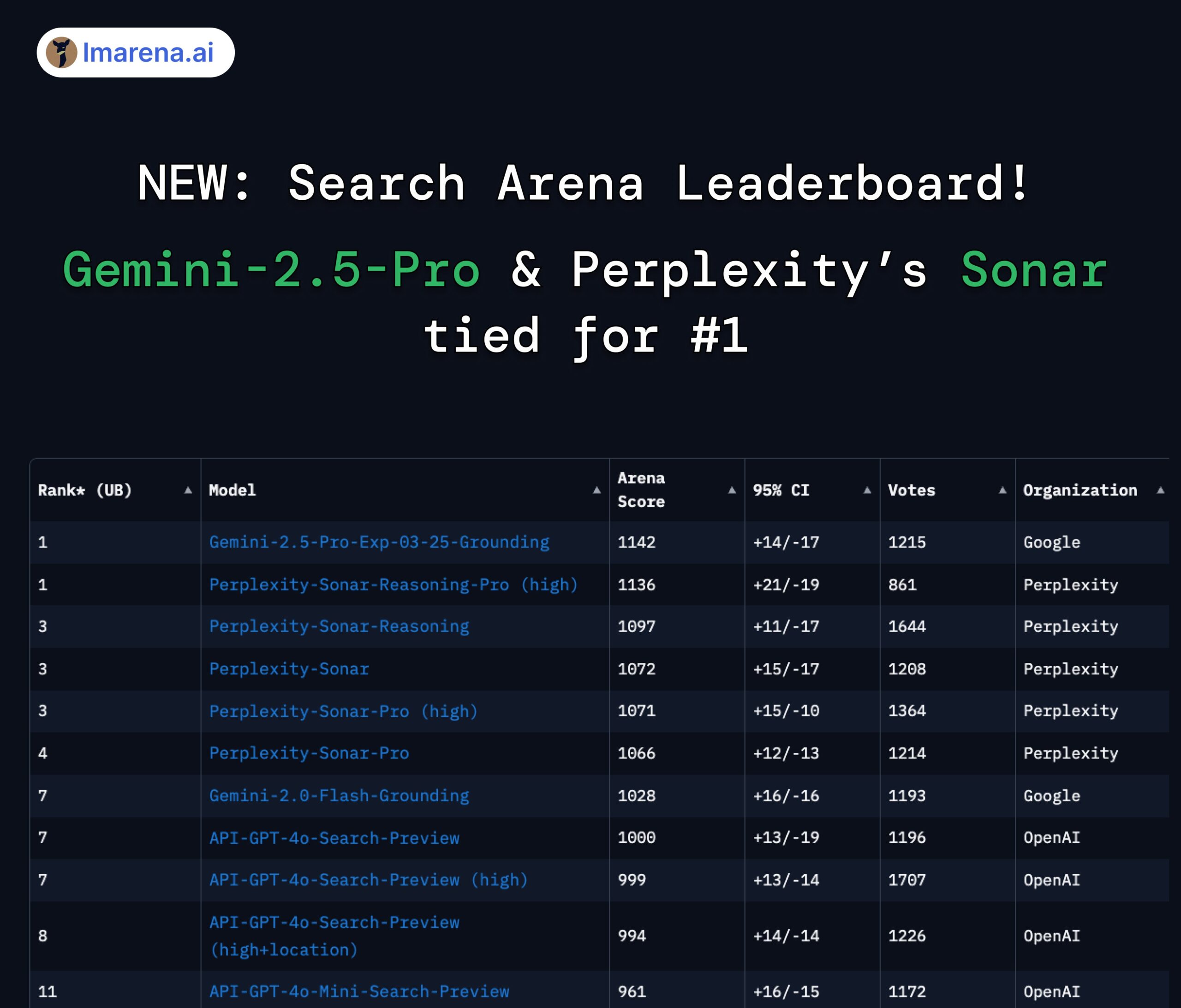
Perplexity Sonar와 Gemini 2.5 Pro, 검색 아레나 순위 공동 1위: LMArena.ai(구 LMSYS)가 새로 출시한 Search Arena 순위표에서 Perplexity의 Sonar-Reasoning-Pro-High 모델과 Google의 Gemini-2.5-Pro-Grounding이 공동 1위를 차지했습니다. 이 순위표는 웹 검색 기반 LLM 답변 품질을 전문적으로 평가합니다. Perplexity CEO Arav Srinivas는 이에 대해 축하하며 Sonar 모델과 검색 인덱스를 계속 개선할 것이라고 강조했습니다. 커뮤니티는 이것이 검색 증강 LLM 분야에서 경쟁이 주로 Google과 Perplexity 사이에서 벌어지고 있음을 보여준다고 평가합니다. (출처: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Claude 모델 사용 제한에 대한 논의: Reddit r/ClaudeAI 커뮤니티에서 사용자들이 Claude Pro 버전의 사용 제한(예: 메시지 양 상한, 용량 제한)에 대해 논쟁하고 있습니다. 일부 사용자는 잦은 제한에 부딪혀 작업 흐름에 영향을 받고 모델 교체를 고려한다고 불평하는 반면, 다른 사용자들은 제한에 거의 부딪히지 않으며 사용 방식(예: 매우 큰 컨텍스트 로드)이나 과장된 주장 때문일 수 있다고 생각합니다. 이는 사용자들이 Anthropic 모델 사용 정책 및 안정성에 대해 서로 다른 경험과 견해를 가지고 있음을 반영합니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AI와 고용 미래에 대한 논의: Reddit r/ChatGPT의 한 비교 이미지가 논의를 촉발했습니다: AI는 인간 능력을 향상시켜 풍요로운 삶을 가져올 것인가, 아니면 인간의 일자리를 대체하여 대규모 실업을 초래할 것인가? 댓글에서 많은 사용자들이 AI가 일자리를 대체하는 것에 대한 우려를 표명했으며, 특히 창의적인 직업(프로그래밍, 예술)에 대해 우려했습니다. 일부는 AI가 사회 불평등을 심화시킬 것이라고 생각합니다. 이익이 주로 AI 소유자에게 돌아가고 세수 기반 감소로 UBI 실현이 어려워질 수 있기 때문입니다. 다른 이들은 더 낙관적인 태도를 보이며, AI는 효율성을 높이고 새로운 일자리(예: 프롬프트 엔지니어)를 창출하는 강력한 도구이며, 핵심은 AI를 활용하는 방법을 배우고 적응하는 것이라고 생각합니다. (출처: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

AI 데이터 수집, 프라이버시 우려 제기: 한 정보 그래픽이 다양한 AI 챗봇(ChatGPT, Gemini, Copilot, Claude, Grok)이 수집하는 사용자 데이터 유형을 비교하며 커뮤니티에서 프라이버시 문제에 대한 논의를 촉발했습니다. 그림에 따르면 Google Gemini가 가장 많은 유형의 데이터를 수집하는 반면, Grok(계정 필요)과 ChatGPT(계정 불필요)는 상대적으로 적습니다. 사용자 댓글은 무료 서비스 이면의 데이터 수집 보편성(“공짜 점심은 없다”)을 강조하고 데이터 수집의 구체적인 목적(예: 행동 예측)에 대한 우려를 표명했습니다. (출처: Reddit r/artificial)

모델 증류, 저비용 고성능 재현의 효과적인 경로로 간주: Reddit 사용자는 모델 증류 기술을 통해 대형 모델(예: GPT-4o)을 사용하여 소형, 미세 조정된 모델을 훈련함으로써 특정 영역(감성 분석)에서 14배 저렴한 비용으로 GPT-4o에 가까운 성능(92% 정확도)을 달성한 경험을 공유했습니다. 댓글에서는 증류가 널리 사용되는 기술이지만, 여러 영역에 걸친 일반화 능력에서는 소형 모델이 일반적으로 대형 모델보다 떨어진다고 지적합니다. 특정하고 안정적인 영역의 경우 증류는 효과적인 비용 절감 및 효율성 향상 방법이지만, 지속적으로 새로운 데이터에 적응하거나 여러 영역을 다루어야 하는 복잡한 시나리오의 경우 대형 API를 직접 사용하는 것이 더 경제적일 수 있습니다. (출처: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 기타
OceanBase, 제1회 AI 해커톤 대회 개최: 분산 데이터베이스 공급업체 OceanBase가 Ant Open Source, Jiqizhixin 등과 협력하여 제1회 AI 해커톤 대회를 개최하며, 4월 10일에 참가 신청을 시작하여 5월 7일에 마감합니다. 대회는 “DB+AI”를 주제로 두 가지 방향을 설정했습니다: 하나는 OceanBase를 데이터 기반으로 사용하여 AI 애플리케이션을 구축하는 것이고, 다른 하나는 OceanBase와 AI 생태계(예: CAMEL AI, FastGPT, OpenDAL)의 결합을 탐색하는 것입니다. 대회는 총 10만 위안의 상금을 제공하며 개인 및 팀에게 참가 신청 기회를 열어 개발자들이 데이터베이스와 AI의 깊은 융합을 통한 혁신적인 애플리케이션을 탐색하도록 장려하는 것을 목표로 합니다. (출처: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

칭화대학교 Liu Xinjun 교수, 병렬 로봇 라이브 강연 예정: 칭화대학교 기계공학과 설계공학연구소 소장이자 IFToMM 중국위원회 주석인 Liu Xinjun 교수가 4월 15일 저녁 온라인 강연을 진행합니다. 주제는 “병렬 로봇 기구학 기초 및 장비 혁신”입니다. 강연에서는 병렬 로봇의 기초 이론과 최첨단 장비 혁신에서의 응용을 탐구할 예정입니다. 사회자는 하얼빈 공업대학교 Liu Yingxiang 교수입니다. (출처: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

제3회 중국 AIGC 산업 서밋 가이드 발표: 4월 16일 베이징에서 개최되는 제3회 중국 AIGC 산업 서밋의 상세 일정과 하이라이트가 발표되었습니다. 서밋은 AI 기술과 응용 구현에 초점을 맞추며, 의제는 컴퓨팅 인프라, 교육/문화 엔터테인먼트/기업 서비스/AI4S 등 수직적 시나리오에서의 대형 모델 응용, AI 보안 및 제어 가능성 등을 다룹니다. 연사로는 Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, Ant Group 등이 참여합니다. 서밋에서는 2025년 주목할 만한 AIGC 기업 및 제품 목록과 중국 AIGC 응용 전체 지형도도 발표될 예정입니다. (출처: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
