
키워드:AI, LLM, AI 쇼핑 앱 사기, LLM 벤치마크 테스트, Gemini 모델 자체 호스팅, 로컬 LLM 추론 엔진, AI 에이전트 개발 프레임워크
🔥 포커스
“AI” 쇼핑 앱, 실제로는 수동 조작으로 드러나: Fintech라는 스타트업과 그 창업자가 사기 혐의로 기소되었습니다. AI 기반이라고 주장한 쇼핑 앱이 실제로는 필리핀의 인력팀에 크게 의존하여 거래를 처리한 것으로 밝혀졌습니다. 이 사건은 투자나 사용자를 유치하기 위해 회사가 AI 능력을 과장하거나 허위로 보고하는 “AI 워싱(AI Washing)” 현상에 대한 관심을 다시 불러일으켰습니다. 이 사건은 현재 AI 열풍 속에서 진짜와 가짜 AI 기술 응용 프로그램을 구별하는 어려움과 스타트업에 대한 실사(Due Diligence)의 중요성을 강조합니다 (출처: Reddit r/ArtificialInteligence)

새로운 벤치마크, AI 추론 모델의 일반화 능력 부족 드러내: LLM-Benchmark라는 새로운 벤치마크(https://llm-benchmark.github.io/)에 따르면, 최신 AI 추론 모델조차도 분포 외(OOD) 논리 퍼즐 처리에서 어려움을 겪는 것으로 나타났습니다. 연구에 따르면, 수학 올림피아드와 같은 벤치마크에서의 모델 성능과 비교할 때, 이러한 새로운 논리 퍼즐에서의 점수는 예상보다 훨씬 낮았습니다(약 50배 낮음). 이는 현재 모델이 훈련 데이터 분포를 벗어난 진정한 논리적 추론 및 일반화에 한계가 있음을 보여줍니다 (출처: Reddit r/ArtificialInteligence)
구글, 데이터 프라이버시 우려 해소 위해 기업의 Gemini 모델 자체 호스팅 허용: 구글은 기업 고객이 자체 데이터 센터에서 Gemini AI 모델을 실행할 수 있도록 허용할 것이라고 발표했으며, 첫 번째 지원 모델은 Gemini 2.5 Pro입니다. 이는 데이터 프라이버시 및 보안에 대한 기업의 엄격한 요구 사항을 충족시키기 위한 조치로, 민감한 데이터를 클라우드로 전송하지 않고도 구글의 고급 AI 기술을 활용할 수 있게 합니다. 이 전략은 Mistral AI와 유사하지만, 주로 클라우드 API 또는 파트너를 통해 서비스를 제공하는 OpenAI 및 Anthropic 등과는 대조적으로, 기업용 AI 시장의 경쟁 구도를 바꿀 수 있습니다 (출처: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 동향
VSCode, llama.cpp 네이티브 지원으로 로컬 Copilot 능력 확장: Visual Studio Code는 최근 업데이트에서 로컬 AI 모델 지원을 추가했으며, Ollama 지원에 이어 이제 약간의 조정을 통해 llama.cpp와 호환됩니다. 이는 개발자가 VSCode에서 직접 llama.cpp를 통해 실행되는 로컬 대형 언어 모델을 GitHub Copilot의 대안 또는 보완으로 사용할 수 있음을 의미하며, 로컬 환경에서 LLM을 활용한 코드 지원을 더욱 편리하게 하고 개발 유연성과 데이터 프라이버시를 향상시킵니다. 사용자는 이 기능을 활성화하기 위해 설정에서 Ollama를 프록시로 선택해야 합니다(실제로는 llama.cpp를 사용함) (출처: Reddit r/LocalLLaMA)

Yandex 등 기관, 새로운 LLM 압축 방법 HIGGS 발표: Yandex Research, HSE 대학, MIT 등 기관의 연구자들이 HIGGS라는 새로운 LLM 양자화 압축 기술을 개발했습니다. 이 방법은 모델 크기를 현저히 압축하여 성능이 낮은 장치에서도 실행할 수 있도록 하면서 모델 품질 손실을 최소화하는 것을 목표로 합니다. 이 방법은 671B 파라미터의 DeepSeek R1 모델 압축에 성공적으로 사용되었으며 효과가 두드러진다고 합니다. HIGGS는 LLM 사용 장벽을 낮추어 소규모 회사, 연구 기관 및 개인 개발자도 대형 모델을 더 쉽게 적용할 수 있도록 하며, 관련 코드는 GitHub 및 Hugging Face에 공개되었습니다 (출처: Reddit r/LocalLLaMA)
구글, QAT 2.7 모델 양자화 문제 수정: 구글은 QAT(Quantization Aware Training) 양자화 모델의 2.7 버전(아마도 Gemma 2 7B 또는 유사 모델)을 업데이트하여 이전 버전에 존재했던 일부 제어 토큰(control tokens) 오류 문제를 수정했습니다. 이전에는 모델이 출력 끝에 잘못된 <end_of_turn> 등의 태그를 생성할 수 있었습니다. 새로 업로드된 양자화 모델은 이러한 문제를 해결했으며, 사용자는 업데이트된 버전을 다운로드하여 올바른 모델 동작을 얻을 수 있습니다 (출처: Reddit r/LocalLLaMA)
DeepMind CEO, AlphaFold 성과 언급: DeepMind CEO Demis Hassabis는 한 인터뷰에서 AlphaFold의 막대한 영향력을 강조하며, AlphaFold가 1년 만에 “10억 년의 박사 연구 시간”을 완료했다고 비유적으로 말했습니다. 그는 과거 단백질 구조 하나를 해석하는 데 보통 박사 과정 학생의 전체 박사 과정(4-5년)이 소요되었지만, AlphaFold는 1년 만에 (당시 알려진) 모든 2억 종의 단백질 구조를 예측했다고 지적했습니다. 이 발언은 AI가 과학적 발견을 가속화하는 혁명적인 잠재력을 강조합니다 (출처: Reddit r/artificial)

🧰 도구
MinIO: AI를 위한 고성능 객체 스토리지: MinIO는 오픈 소스 고성능, S3 호환 객체 스토리지 시스템으로, GNU AGPLv3 라이선스를 사용합니다. 특히 머신러닝, 분석 및 애플리케이션 데이터 워크로드 측면에서 고성능 인프라 구축 능력을 강조하며, 전용 AI 스토리지 문서를 제공합니다. 사용자는 컨테이너(Podman/Docker), Homebrew(macOS), 바이너리 파일(Linux/macOS/Windows) 또는 소스 코드를 통해 설치할 수 있습니다. MinIO는 분산형, 삭제 코딩(Erasure Coding)을 갖춘 고가용성 스토리지 클러스터 구축을 지원하며, 대량의 데이터를 처리해야 하는 AI 애플리케이션 시나리오에 적합합니다 (출처: minio/minio – GitHub Trending (all/daily))

IntentKit: 스킬을 갖춘 AI 에이전트 구축 프레임워크: IntentKit은 개발자가 블록체인 상호작용(EVM 체인 우선 지원), 소셜 미디어 관리(Twitter, Telegram 등) 및 사용자 지정 스킬 통합을 포함한 다양한 능력을 갖춘 AI 에이전트를 생성하고 관리할 수 있도록 설계된 오픈 소스 자율 에이전트 프레임워크입니다. 이 프레임워크는 다중 에이전트 관리 및 자율 실행을 지원하며 확장 가능한 플러그인 시스템 출시를 계획하고 있습니다. 프로젝트는 현재 알파 단계이며 아키텍처 개요 및 개발 가이드라인을 제공하고 커뮤니티의 스킬 기여를 장려합니다 (출처: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM: 고성능 LLM 추론 및 서비스 엔진: vLLM은 LLM 추론 및 서비스에 특화된 높은 처리량, 메모리 효율적인 라이브러리입니다. 핵심 장점으로는 PagedAttention 기술을 통한 어텐션 키-값 메모리의 효과적인 관리, 연속 배치 처리(Continuous Batching) 지원, CUDA/HIP 그래프 최적화, 다양한 양자화 기술(GPTQ, AWQ, FP8 등) 지원, FlashAttention/FlashInfer와의 통합, 그리고 추측 디코딩(Speculative Decoding) 등이 있습니다. vLLM은 Hugging Face 모델을 지원하고 OpenAI 호환 API를 제공하며, NVIDIA, AMD 등 다양한 하드웨어에서 실행 가능하여 대규모 LLM 서비스 배포가 필요한 시나리오에 적합합니다 (출처: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader: 랜덤 액세스 및 검색 기능이 있는 TFRecords 리더: 이는 TFRecords 데이터셋 처리를 위한 Python 도구로, 특히 데이터 검사 및 분석을 위해 설계되었습니다. 사용자가 TFRecords 파일에 대한 인덱스를 생성하여 랜덤 액세스 및 콘텐츠 기반 검색(Polars SQL 쿼리 사용)을 가능하게 하여 TFRecords의 기본 순차 읽기 제한을 해결합니다. 이 도구는 TensorFlow 및 protobuf 패키지에 의존하지 않으며 Google Storage에서 직접 읽기를 지원하고 인덱싱 속도가 빨라 개발자가 모델 훈련 외에 대규모 TFRecords 데이터셋을 탐색하고 샘플을 찾는 데 편리합니다 (출처: Reddit r/MachineLearning)
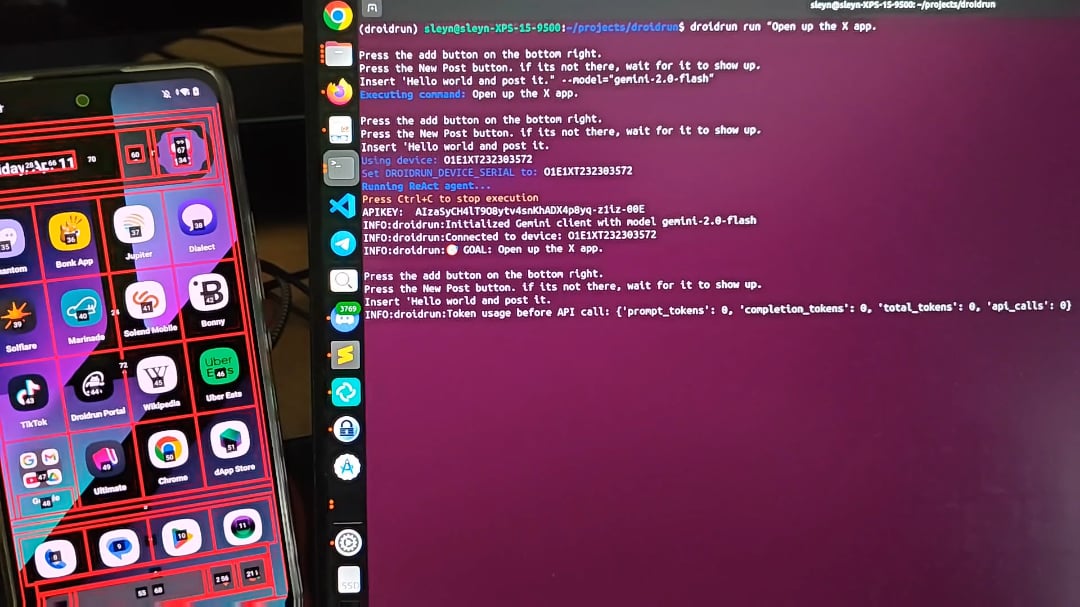
DroidRun: AI 에이전트가 안드로이드 폰을 제어하게 하다: DroidRun은 AI 에이전트가 사람처럼 안드로이드 장치를 조작할 수 있게 하는 프로젝트입니다. 어떤 LLM이든 연결하여 휴대폰 UI와의 상호작용 제어를 실현하고 다양한 작업을 수행할 수 있습니다. 프로젝트는 그 잠재력을 보여주며, 자동 콘텐츠 게시, 앱 관리 등 휴대폰 단에서의 자동화된 작업을 목표로 합니다. 개발자는 커뮤니티의 피드백과 아이디어를 요청하며 더 많은 자동화 시나리오를 탐색하고 있습니다 (출처: Reddit r/LocalLLaMA)
📚 학습
Cell Patterns, 다국어 대형 모델(MLLM) 중요 리뷰 발표: 이 리뷰는 473편의 문헌을 포괄하여 다국어 대형 모델의 연구 현황을 체계적으로 정리했습니다. 내용은 다국어 사전 훈련, 명령어 미세 조정 및 RLHF의 데이터셋 자원 및 구축 방법; 교차 언어 정렬 전략(파라미터 조정 정렬: 사전 훈련, 명령어 미세 조정, RLHF, 다운스트림 미세 조정 등 / 파라미터 동결 정렬: 직접 프롬프팅, 코드 스위칭, 번역 정렬, 검색 증강 등); 다국어 평가 지표 및 벤치마크(NLU 및 NLG 작업); 그리고 환각(Hallucination), 지식 편집, 안전성, 공정성, 언어/모달리티 확장, 해석 가능성, 배포 효율성 및 업데이트 일관성 등 미래 연구 방향과 과제를 논의합니다. 포괄적인 MLLM 연구 지도를 제공합니다 (출처: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | 베이항 대학, TRACK 제안: 동적 도로망과 궤적 표현의 협력 학습: 베이항 대학 팀은 기존 방법이 교통 시공간 동적성을 포착하지 못하는 문제를 해결하기 위해 TRACK 모델을 제안했습니다. 이 모델은 처음으로 교통 상태(거시적 집단 특징)와 궤적 데이터(미시적 개별 특징)를 공동으로 모델링하며, 이 둘이 서로 영향을 미친다고 가정합니다. TRACK은 그래프 어텐션 네트워크(GAT), Transformer, 그리고 혁신적인 궤적 전이 인식 GAT 및 협력적 어텐션 메커니즘을 통해 동적 도로망과 궤적 표현을 학습합니다. 모델은 마스크된 궤적 예측, 대조적 궤적 학습, 마스크된 상태 예측, 다음 상태 예측 및 궤적-교통 상태 매칭 등 자가 지도 학습 작업을 포함하는 공동 사전 훈련 프레임워크를 채택하여 교통 상태 예측 및 이동 시간 추정 작업에서 우수한 성능을 보입니다 (출처: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

남방과기대 양린이 교수, 대형 모델 분야 박사/RA/방문 학생 모집: 남방과기대 통계 및 데이터 과학과 양린이 교수(곧 부임, 독립 PI)가 생성형 인공지능 연구실(GenAI Lab)을 설립하고 2025/2026년도 박사, 석사 과정 학생 및 박사후 연구원, 연구 조교(RA), 인턴을 모집합니다. 연구 방향은 대형 모델 추론의 인과 분석, 일반화 가능한 강화 학습 대형 모델 방법, AI 통제 불능 예방을 위한 신뢰할 수 있는 비-에이전트 시스템 구축 등입니다. 양 교수는 최고 학회에 다수의 논문을 발표했으며, 국내외 여러 대학 및 연구 기관과 광범위한 협력을 하고 공동 지도를 장려합니다. 지원자는 강한 자기 주도성, 탄탄한 수리 기초 및 프로그래밍 능력이 요구됩니다 (출처: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

개인 프로젝트: 처음부터 대형 언어 모델 구축하기: 한 개발자가 처음부터 Causal Language Model(GPT와 유사)을 구현한 개인 프로젝트를 공유했습니다. 프로젝트는 Python과 PyTorch를 사용하며, 핵심 아키텍처는 Causal Mask가 있는 멀티 헤드 셀프 어텐션, 피드포워드 네트워크, 디코더 블록(레이어 정규화, 잔차 연결) 스택을 포함합니다. 모델은 사전 훈련된 GPT-2 단어 임베딩과 위치 임베딩을 사용하며, 출력 레이어는 어휘 로짓으로 매핑됩니다. Top-k 샘플링을 사용하여 자기회귀 텍스트 생성을 수행하고, WikiText 데이터셋에서 AdamW 옵티마이저와 CrossEntropyLoss를 사용하여 훈련합니다. 프로젝트 코드는 GitHub에 공개되어 LLM 구축의 기본 과정을 보여줍니다 (출처: Reddit r/MachineLearning)
논문 해설: d1 – 강화 학습을 통한 확산 대형 언어 모델(dLLM)의 추론 능력 확장: 이 연구는 사전 훈련된 확산 기반 LLM(dLLM)을 추론 작업에 적용하기 위한 d1 프레임워크를 제안합니다. dLLM은 자기회귀(AR) 모델과 달리 거친 방식에서 정교한 방식으로 텍스트를 생성합니다. d1 프레임워크는 지도 미세 조정(SFT)과 강화 학습(RL)을 결합하며, 구체적으로 다음을 포함합니다: 지식 증류 및 유도된 자가 개선을 위한 Masked SFT 사용; 새로운 Critic 없는 정책 그래디언트 기반 RL 알고리즘 diffu-GRPO 제안. 실험 결과, d1은 수학 및 논리 추론 벤치마크에서 SOTA dLLM의 성능을 현저히 향상시켜 dLLM의 추론 작업 잠재력을 입증했습니다 (출처: Reddit r/MachineLearning)
💼 비즈니스
알리바바 통이 연구소, 일반 RAG/AI 검색 분야 알고리즘 전문가 채용 (베이징/항저우): 알리바바 통이 연구소 AI 검색팀에서 알고리즘 전문가를 채용합니다. 검색 및 RAG(검색 증강 생성) 핵심 모듈(예: Embedding, ReRank 모델)의 연구 개발 최적화를 담당하여 모델 효과 및 업계 선도 수준을 향상시키는 역할을 합니다. 또한 하위 애플리케이션(질의응답, 고객 서비스, 멀티모달 Memory)을 위한 전체 프레임워크 링크를 최적화하여 정확성, 효율성 및 확장성을 높이고 팀과 협력하여 비즈니스 적용을 추진하는 책임도 있습니다. 관련 전공 석사 이상 학력, 검색/NLP/대형 모델 기술에 익숙하고 관련 프로젝트 경험이 요구됩니다 (출처: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

AI 채용 스타트업 OpportuNext, CTO 물색 중 (원격/지분): OpportuNext는 AI 기술을 활용하여 채용 프로세스를 개선하고 지능형 직무 매칭, 이력서 분석 및 경력 계획 도구를 제공하는 것을 목표로 하는 초기 단계의 스타트업입니다. 창업자는 AI 기능 개발을 주도하고 확장 가능한 백엔드 시스템을 구축하며 제품 혁신을 추진할 기술 파트너(CTO)를 찾고 있습니다. AI/ML, Python 및 확장 가능한 시스템 경험이 요구되며, 실제 문제 해결에 열정이 있고 스타트업 초기에 합류할 의향이 있어야 합니다(지분 기반 원격 직책) (출처: Reddit r/deeplearning)
🌟 커뮤니티
토론: 대형 모델의 본질은 “언어의 환상”: 한 심층적 사고 글에서는 대형 모델(예: ChatGPT)이 정보를 진정으로 이해하는 것이 아니라 방대한 언어 데이터를 학습하여 표현 형식을 모방하고 예측한다고 주장합니다. Prompt의 역할은 문맥을 설정하고 모델의 주의를 유도하는 것이지, 의식 있는 실체와 소통하는 것이 아닙니다. 모델의 답변은 “충분히 많이 본” 패턴의 재현에 기반하며, 지능적으로 보이지만 실제로는 이해가 부족하여 “진지하게 헛소리하는” 환각을 일으키기 쉽습니다. 인간-기계 상호작용은 사용자가 모델을 대신하여 생각하는 것에 더 가깝고, 모델의 출력은 사용자의 사고 및 판단 습관을 잠재적으로 재구성하고 현실의 편견을 반영하고 증폭시킬 수 있습니다 (출처: 我所理解的大模型:语言的幻术)
토론: AI 에너지 소비와 미중 모델 개발 전략 차이: Reddit 사용자들이 트럼프가 석탄을 AI 개발의 핵심 광물로 지정한 발언에 대해 토론하며 AI 에너지 소비 문제에 대한 우려를 제기했습니다. 댓글에서는 대형 모델이 점점 더 많은 에너지를 소비하며, 중국 기업들은 더 간결하고 효율성에 중점을 둔 모델을 구축하는 경향이 있는 것 같다고 지적했습니다. 이는 AI 개발에서 성능과 에너지 효율 사이의 균형, 그리고 지역별로 채택할 수 있는 다른 기술 경로를 반영합니다 (출처: Reddit r/artificial)

질문: PyTorch Lightning과 유사한 심층 강화 학습 프레임워크 찾기: Reddit 사용자가 심층 강화 학습(DRL) 전용으로 PyTorch Lightning(PL)과 유사한 프레임워크가 있는지 문의했습니다. 이 사용자는 PL이 DRL에 사용될 수 있지만, 그 설계가 환경 상호작용 기반의 DRL보다는 데이터셋 기반의 지도 학습에 더 치우쳐 있다고 생각합니다. 게시물은 DRL(예: DQN, PPO)에 적합하고 Gymnasium과 같은 환경과 잘 통합되는 프레임워크를 커뮤니티에 추천하거나 PL을 사용하여 DRL을 수행하는 최상의 실습 경험을 공유해달라고 요청합니다 (출처: Reddit r/deeplearning)
커뮤니티: 가상 뮤지션을 위한 Discord 커뮤니티 MetaMinds 출범: MetaMinds라는 새로운 Discord 커뮤니티가 설립되어 AI 도구(예: Suno)를 사용하여 음악을 만드는 가상 아티스트에게 교류, 협업 및 공유 플랫폼을 제공합니다. 커뮤니티는 “A Personal Song”이라는 첫 번째 작곡 대회를 시작했으며, 향후 더 높은 수준의 경쟁을 개최하고 현금 상금을 포함할 수도 있습니다. 이는 AI 음악 창작 분야에서 새로운 커뮤니티 생태계가 형성되고 있음을 반영합니다 (출처: Reddit r/SunoAI)
토론: 훈련 세트를 포함하는 데이터셋 모음을 어떻게 불러야 할까?: Reddit 사용자가 여러 작업에서 모델 성능을 평가하는 데 사용되는 “벤치마크(Benchmark)”와 달리, 동일한 모델을 훈련하고 평가하기 위한 여러 데이터셋을 포함하는 모음을 어떤 용어로 불러야 하는지 질문했습니다. 이 질문은 머신러닝 분야 내 데이터셋 분류 및 용어 사용의 세부 사항을 탐구합니다 (출처: Reddit r/MachineLearning)
도움 요청: OpenWebUI에서 음성-텍스트 변환 기능 구현하기: 사용자가 Docker로 배포된 OpenWebUI+Ollama 환경에서 H100 GPU를 활용하여 음성-텍스트 변환(사용자 질문에는 TTS로 기재되었으나, 설명 내용은 YouTube 동영상/오디오 파일 전사로 ASR/STT에 해당) 기능을 구현하기 위한 최적의 방안과 추천 모델을 찾고 있습니다. 이는 사용자가 로컬 LLM 상호작용 인터페이스에 더 많은 모달리티 처리 능력을 통합하려는 요구를 반영합니다 (출처: Reddit r/OpenWebUI)
토론: Claude 연간 구독 및 제한 조정에 대한 의견: Reddit 사용자가 최근 많은 사용자가 사용 제한 강화에 대해 불평함에 따라 Claude 연간 구독을 구매하지 않은 것을 다행으로 생각한다고 말했습니다. 사용자는 Anthropic이 많은 유료 사용자를 유치한 후 비용 절감을 위해 정책을 조정한 것일 수 있다고 생각합니다. 동시에 사용자는 무료 Gemini 2.5 Pro의 강력한 성능을 언급하며 Claude의 미래 발전에 대한 우려와 기대를 표현했습니다. 토론은 LLM 서비스 가격 책정, 사용 제한 및 가성비에 대한 사용자의 민감도를 반영합니다 (출처: Reddit r/ClaudeAI)
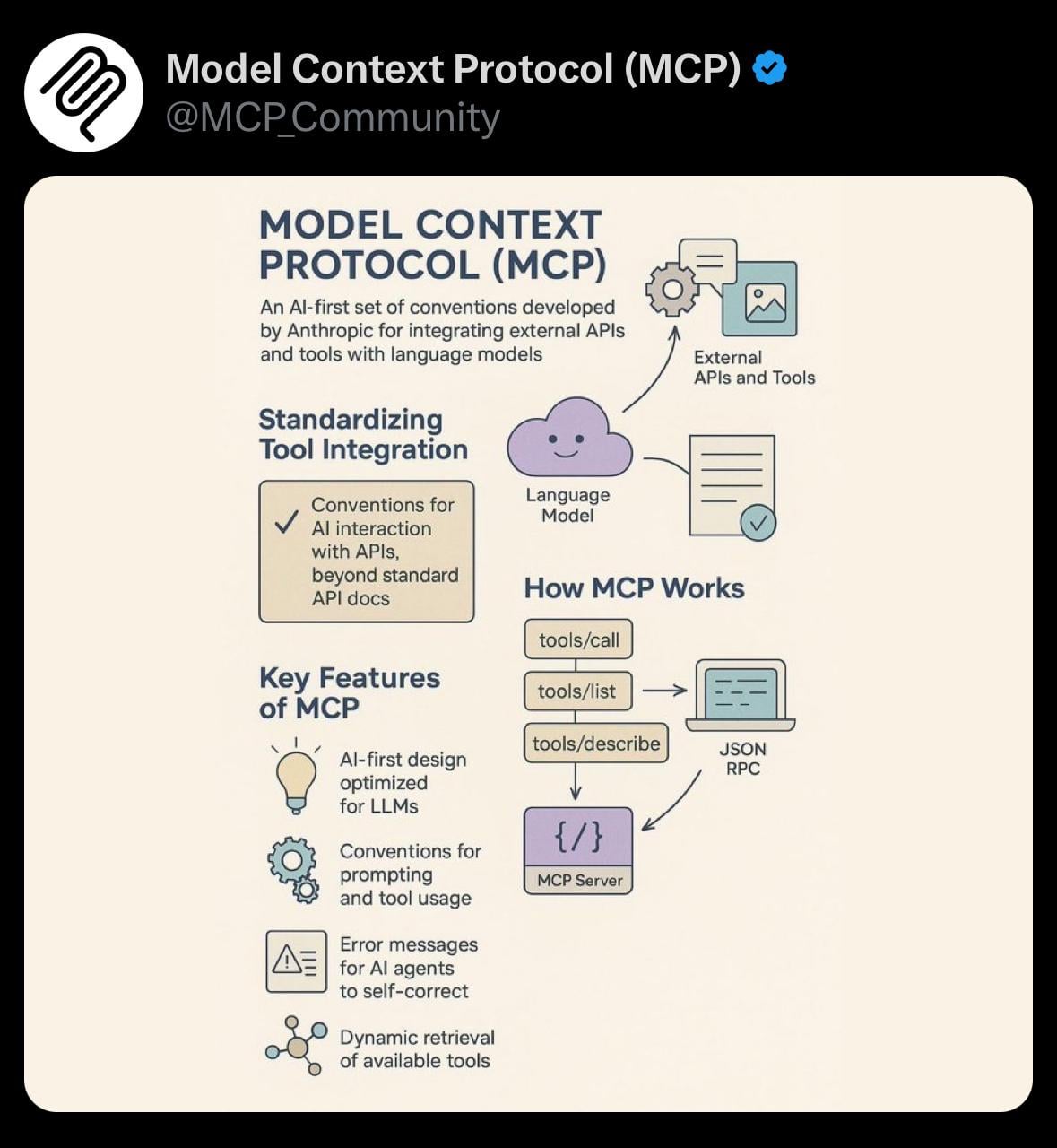
공유: 모델 컨텍스트 프로토콜(MCP)의 간단한 시각화: 사용자가 모델 컨텍스트 프로토콜(Model Context Protocol, MCP)에 대한 간단한 시각화 이미지를 공유했습니다. MCP는 Anthropic Claude 모델과 관련된 기술 개념일 수 있으며, 모델이 긴 컨텍스트를 처리하는 방식을 최적화하거나 관리하는 것을 목표로 할 수 있습니다. 이 공유는 커뮤니티가 관련 기술 개념을 이해하는 데 시각적 보조 자료를 제공합니다 (출처: Reddit r/ClaudeAI)
도움 요청: OpenWebUI 채팅에 사용자 지정 명령어 추가하기: 사용자가 OpenWebUI 채팅 인터페이스에 사용자 지정 명령어(예: 자동 완성 메뉴가 있는 @tag 형식)를 추가하여 맞춤형 RAG 쿼리(예: 문서 유형별 필터링)를 편리하게 수행하는 기술적 난이도에 대해 문의했습니다. 사용자는 드롭다운 메뉴를 대안으로 고려하고 있습니다. 이는 사용자가 프런트엔드 상호작용 능력을 확장하여 백엔드 AI 기능을 보다 유연하게 제어하려는 아이디어를 반영합니다 (출처: Reddit r/OpenWebUI)
토론: 미적이고 기능적인 AI QR 코드 생성하기: 사용자가 ChatGPT/DALL-E를 사용하여 예술적 스타일이 융합되고 스캔 가능한 QR 코드를 생성하려고 시도했지만 효과가 좋지 않았으며, ControlNet과 같은 방법이 더 효과적이라고 지적했습니다. 이는 현재 주류 텍스트-이미지 생성 모델이 정확한 구조와 기능성(예: 스캔 가능성)이 필요한 이미지 생성에 있어 가지는 한계에 대한 토론을 유발했습니다 (출처: Reddit r/ChatGPT)

AI/ML 스터디 파트너 찾기: 3학년 컴퓨터 과학(AI/ML 전공) 학부생이 4-5명의 같은 생각을 가진 사람들을 찾아 AI/ML을 심도 있게 학습하고, 함께 프로젝트를 개발하며, 자료 구조 및 알고리즘(DSA/CP)을 함께 연습할 팀을 구성하고자 게시물을 올렸습니다. 게시자는 자신의 기술 스택과 관심 분야를 나열하며 서로 격려하고 협력하여 학습하는 소그룹을 만들기를 희망합니다 (출처: Reddit r/deeplearning)
토론: AI 에이전트가 스팸 문제를 악화시킬까?: Reddit 사용자가 AI 에이전트가 자동화된 작업(예: 영업 리드 찾기 및 메시지 전송)에 널리 사용되면 스팸 정보가 범람할 수 있다는 우려를 제기했습니다. 모든 사람이 유사한 도구를 사용할 때, 대상 수신자는 대량의 개인화된 자동 메시지에 압도되어 커뮤니케이션 효율성이 떨어지고 에이전트 도구의 가치가 상실될 수 있습니다. 토론은 AI 도구의 대규모 적용이 가져올 수 있는 부정적인 외부 효과에 대한 생각을 유발합니다 (출처: Reddit r/ArtificialInteligence)
토론: Suno AI 최근 품질 문제: 사용자가 Suno AI로 생성한 음악 클립을 공유하며, 최근 커뮤니티에서 Suno 출력 품질 저하에 대한 논의가 있었지만 개인적으로는 이 클립의 효과가 괜찮다고 말했습니다. 이는 AI 생성 도구 성능 변동에 대한 커뮤니티의 인식과 주관적인 평가 차이를 반영합니다 (출처: Reddit r/SunoAI)

토론: 딥러닝 훈련용 RTX 4090 vs RTX 5090: 사용자가 개인 딥러닝(주로 LLM 아님)용 단일 GPU 워크스테이션을 구축할 때 현재의 RTX 4090을 선택해야 할지, 아니면 곧 출시될 RTX 5090을 기다려야 할지 문의했습니다. 게시물은 하드웨어 선택에 대한 커뮤니티의 조언을 구하고, 구매 시 게임용 카드와 전문가용 카드(이들은 소비자급 카드임에도 불구하고)를 구별하는 방법을 묻습니다. AI 개발자의 하드웨어 선택 고려 사항을 반영합니다 (출처: Reddit r/deeplearning)
토론: AI가 자본주의를 파괴할 것인가?: 사용자는 기업이 이익 극대화를 추구하기 때문에 AI가 결국 대부분의 일자리를 대체할 수 있다고 생각합니다. 기존 자본주의 체제 하에서는 이것이 대규모 실업과 소득원 중단으로 이어질 것입니다. 사용자는 AI로부터 이익을 얻는 기업에 추가 세금을 부과하여 자금을 조달하는 보편적 기본 소득(UBI)이 필요한 해결책일 수 있다고 제안합니다. 토론은 AI가 미래 경제 구조와 사회 모델에 미칠 심오한 영향에 대해 다룹니다 (출처: Reddit r/ArtificialInteligence)
도움 요청: Anthropic 논문 “Reasoning Models Don’t Always Say What They Think” 재현하기: 사용자가 Anthropic의 “추론 모델은 항상 생각하는 것을 말하지 않는다”는 논문 결과를 재현할 수 있는 프롬프트(Prompts)나 관련 통찰력을 찾기 위해 커뮤니티의 도움을 구하고 있습니다. 이 논문은 대형 언어 모델의 내부 추론 과정과 최종 출력 사이에 존재할 수 있는 불일치를 탐구합니다. 이는 커뮤니티 구성원들이 최첨단 AI 연구 결과를 이해하고 검증하는 데 관심이 있음을 보여줍니다 (출처: Reddit r/MachineLearning)
도움 요청: OpenWebUI에서의 RAG 설정 및 경험: 사용자가 OpenWebUI에서 RAG(검색 증강 생성)를 사용하는 최상의 실습, 추천 설정, 피해야 할 매개변수, 선호하는 임베딩 모델 등에 대해 문의했습니다. 사용자는 또한 모델 동작 이상(예: Mistral Small이 빈 목록 출력) 문제를 겪었으며, 사용자 개인 설정과 관리자 모델 설정의 우선순위 관계에 대해 질문했습니다. 이는 사용자가 실제 RAG 애플리케이션 배포 및 최적화 과정에서 겪는 어려움과 경험 공유를 원하는 요구를 반영합니다 (출처: Reddit r/OpenWebUI)
토론: Claude 사용자 이탈이 서비스 개선으로 이어질까?: 사용자는 최근 제한 및 성능 문제로 인한 일부 Claude 사용자 이탈(“Genesis Exodus”)이 오히려 컴퓨팅 자원을 확보하여 서비스 품질(예: 성능, 제한)이 더 이상적인 상태로 회귀할 수 있다는 가설을 제시했습니다. 사용자는 Claude에 대한 선호를 표현하며 서비스 개선을 희망했습니다. 토론은 AI 서비스의 수요-공급 관계, 자원 배분 및 서비스 품질의 동적 변화에 대한 사용자의 관찰과 생각을 반영합니다 (출처: Reddit r/ClaudeAI)

토론: “AI 예술”을 어떻게 정의할 것인가?: 사용자가 커뮤니티 구성원들에게 “AI 예술”을 어떻게 정의하는지 묻고 관련 질문을 제기하는 토론을 시작했습니다: AI 도구(예: ChatGPT)를 사용하여 이미지를 생성하는 사람은 창작자인가? 소유권을 가지는가? LLM 서비스 제공자는 창작 과정에서 어떤 역할을 하며, 공동 창작자로 간주되어야 하는가? 이 토론은 AI 생성 콘텐츠를 둘러싼 창작 주체, 저작권 귀속 등 핵심 개념을 명확히 하려는 목적을 가집니다 (출처: Reddit r/ArtificialInteligence)
토론: AI 음악이 음악의 “공공성”을 위협하는가?: 사용자가 Suno와 같이 초개인화된 음악을 쉽게 생성할 수 있는 AI 도구가 공유 경험으로서의 음악의 “공공성”을 약화시키는지 묻는 질문을 제기했습니다. 우려 사항은 다음과 같습니다: 음악이 커뮤니티를 연결하는 등대가 아닌 개인화된 거울이 될 수 있음; 콘서트와 같은 집단 음악 활동이 영향을 받을 수 있음; 사용자가 맞춤형 콘텐츠만 수용하게 되어 다양하거나 도전적인 음악에 대한 개방성이 줄어들 수 있음. 토론은 AI가 음악 문화와 사회적 기능에 미칠 잠재적 영향에 초점을 맞춥니다 (출처: Reddit r/SunoAI)
질문: Suno AI의 힌디어 노래 생성 정확도는?: 힌디어 비사용자가 Suno AI가 힌디어로 노래를 생성할 때의 정확도와 자연스러움에 대해 문의했습니다. 특정 비영어 언어에 대한 도구의 성능을 파악하고자 합니다 (출처: Reddit r/SunoAI)
💡 기타
Suno AI 작품 공유: Nightingale’s Melody (얼터너티브/인디 록): 사용자가 Suno AI로 만든 얼터너티브/인디 록 스타일의 노래 “Nightingale’s Melody”를 공유하고 YouTube 링크를 첨부했습니다 (출처: Reddit r/SunoAI)

Suno AI 작품 공유: The Art of Abundance (Psytrance): 사용자가 고에너지 Psytrance와 정신 기술 요소를 결합한 AI 생성 음악을 공유했습니다. 가사는 ChatGPT가 작성했고, 음악과 보컬은 Suno AI가 생성했으며, 시각 효과는 MidJourney와 PhotoMosh Pro로 제작되었습니다. 작품은 디지털 시대의 풍요 개념을 탐구하며, 물질주의를 넘어 창의성, AI 의식, 인간의 욕망을 다룹니다 (출처: Reddit r/SunoAI)

Suno AI 작품 공유: Do your Job (컨트리 음악): 사용자가 Suno AI로 만든 컨트리 스타일 노래를 공유했습니다. 가사 내용은 실제 미제 사건(Colton Ross Barrera 실종 사건)을 중심으로 가족의 좌절감과 정의에 대한 외침을 표현합니다 (출처: Reddit r/SunoAI)

Suno AI 작품 공유: Toxic Friends (일렉트로 팝): 사용자가 Suno AI 4월 대회에 참가한 일렉트로 팝 스타일 작품 “Toxic Friends”를 공유했습니다 (출처: Reddit r/SunoAI)

Suno AI 작품 공유: Starlight Visitor (80년대 팝 커버): 사용자가 Suno AI를 사용하여 기존 곡을 80년대 팝 스타일로 커버한 버전을 공유하고 YouTube 링크를 제공했습니다 (출처: Reddit r/SunoAI)

ChatGPT 창의적 활용: 달걀 제품 Meme 확장: 사용자가 달걀에 관한 Meme에서 영감을 받아 ChatGPT를 사용하여 “미리 깨진 삶”(Precracked Life), “달걀 인터넷”(Internet of Eggs) 등 유머러스하고 개념적인 달걀 관련 제품 이미지와 설명을 생성했습니다. AI를 활용한 창의적 발상과 유머 콘텐츠 제작 가능성을 보여줍니다 (출처: Reddit r/ChatGPT)
Suno AI 작품 공유: Tom and Jerry / Crambone (블루스 록 커버): 사용자가 Suno AI를 사용하여 “Tom and Jerry / Crambone”을 블루스 록 스타일로 커버한 노래를 공유하고 YouTube 링크를 제공했습니다 (출처: Reddit r/SunoAI)

AI 생성 이미지: 7대 죄악 구체화: 사용자가 AI(아마도 ChatGPT/DALL-E)를 사용하여 7대 죄악(예: 탐욕, 나태, 질투 등)을 나타내는 구체화되고 의인화된 이미지를 생성한 비디오를 공유했습니다 (출처: Reddit r/ChatGPT)
