
키워드:AI, 관세, AI 산업에 미치는 관세 영향, AI 기술 생태계 분열, AI 하드웨어 비용 증가, AI 국산화 대체 솔루션, AI 글로벌 협력 전략
🔥 포커스
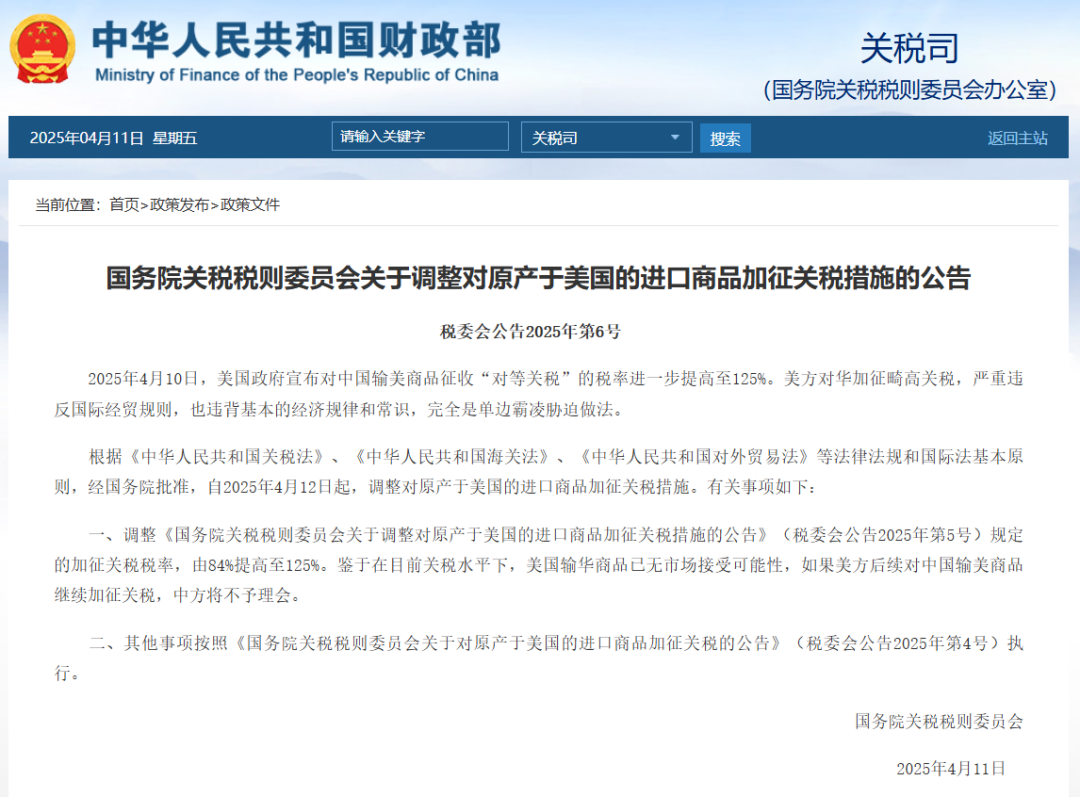
관세 충격 속 글로벌 AI 산업 동향 분석: 최근 국제 무역 긴장 고조, 특히 고액 관세 부과는 세계화 수준이 높은 AI 산업에 심대한 영향을 미치고 있다. 기사 분석에 따르면, 미국이 AI 컴퓨팅 파워 등 하드웨어에 대한 제한에 이미 대응책이 마련되어 있지만, 관세는 글로벌 AI 산업의 균열을 심화시킬 수 있다. 충격은 주로 다음과 같은 측면에서 나타난다: 1) 인프라 계층: 하드웨어 비용 증가, 공급망 제한이 있으나 중국은 이미 국산 대체 솔루션을 보유하고 있다. 2) 기술 계층: 미중 기술 생태계 분열, 오픈소스 공유 저해, 표준 충돌을 야기할 수 있다. 3) 응용 계층: 시장 지역화로 AI 제품 상용화에 영향을 미친다. 기사는 관세 충격의 실제 “강도”는 제한적일 수 있다고 본다. 중국이 이미 병행 기술 생태계를 구축했고 관세가 미국 자신에게 반작용을 일으키기 때문이다. 그러나 “범위”의 영향은 심대하여 기술 교류 중단, 인재 및 자금의 위험 회피, 시장 표준 충돌을 초래할 수 있다. 대응 전략으로는 자체 연구개발 강화(하드웨어, 프레임워크), 글로벌 협력 유지(제3자 시장 개척, 국제 표준 참여), 국산 AI 생태계 매력 증진을 통해 세계에 더 포용적인 기술 선택지를 제공하는 것 등이 포함된다. (출처: 36氪)
Anthropic 공동 창업자, AGI 임박 예측 및 Claude 4 출시 예고: Anthropic 공동 창업자 겸 수석 과학자 Jared Kaplan은 인간 수준의 AI(AGI)가 이전에 예측했던 2030년이 아닌 향후 2~3년 내에 실현될 수 있다고 예측했다. 그는 AI 능력이 작업 처리의 “범위”와 “복잡성” 두 차원에서 빠르게 확장되고 있으며, 현재 모델들은 과거 전문가들이 몇 시간 또는 며칠이 걸려 처리해야 했던 작업을 수행할 수 있다고 지적했다. Kaplan은 차세대 모델 Claude 4가 향후 6개월 내에 출시될 예정이며, 성능 향상은 후훈련(post-training), 강화 학습 개선 및 사전 훈련 효율성 향상 덕분이라고 밝혔다. 그는 또한 모델이 더 많이 생각하게 함으로써 예측 가능하게 성능을 향상시키는 “테스트 시 스케일링(test-time scaling)”의 중요성을 언급했다. DeepSeek 등 중국 모델의 부상에 대해 Kaplan은 놀랍지 않다며, 기술 발전이 빠르고 서구와의 격차가 약 6개월 정도일 수 있으며 알고리즘적으로 경쟁력이 있지만 하드웨어 제한이 주요 과제일 수 있다고 말했다. 인터뷰 말미에는 AI가 경제 사회에 미치는 막대한 영향과 실증 연구의 중요성을 강조했다. (출처: 新智元)

🎯 동향
Mianbi Intelligence와 Tsinghua University, CFM 희소 기술 제안: Mianbi Intelligence와 Tsinghua University CFM 논문 저자 Xiao Chaojun은 인터뷰에서 Configurable Foundation Models (CFM) 기술을 소개했다. CFM은 뉴런 수준의 희소 활성화를 강조하는 네이티브 희소 기술로, 현재 주류인 MoE(전문가 수준 희소)보다 입자가 더 미세하고 동적이다. 핵심 장점은 모델 파라미터 효율성(단위 파라미터 유효성)을 크게 향상시켜 메모리/RAM을 현저히 절약할 수 있다는 점이며, 특히 메모리가 제한된 엣지 디바이스(예: 휴대폰)에 적합하다. Xiao Chaojun은 Mamba 등 비-Transformer 아키텍처가 효율성 측면에서 탐색을 하고 있지만, Transformer는 여전히 효과 면에서 최고 수준이며 GPU 하드웨어 최적화라는 “하드웨어 복권”에 당첨되었다고 생각한다. 그는 또한 소형 모델(엣지 약 2-3B)의 적용, 정밀도 최적화(FP8/FP4 추세), 멀티모달 진전 및 지능의 본질(압축보다는 추상 능력에 더 가까울 수 있음)에 대해 논의했다. o1의 긴 사고 사슬과 혁신 능력에 대해서는 AI가 미래에 돌파해야 할 핵심 방향이라고 보았다. (출처: 量子位)

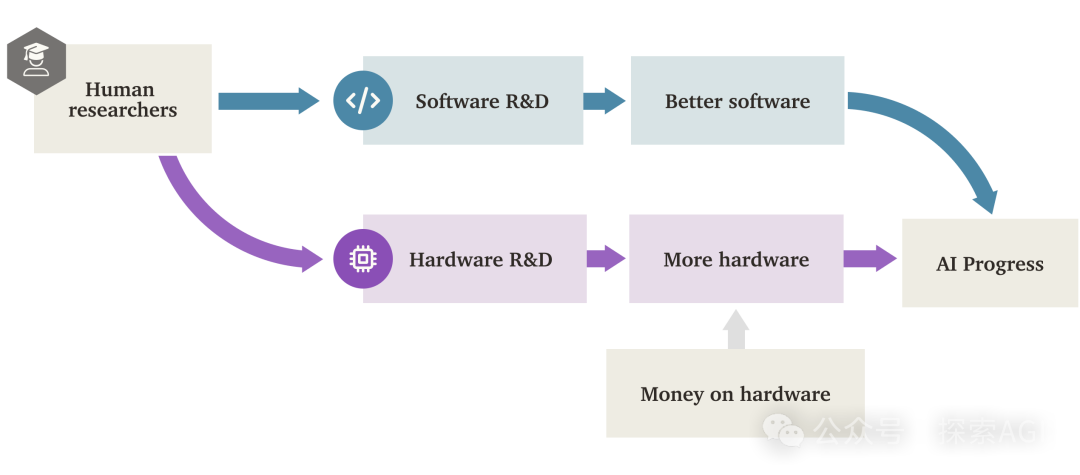
AI “소프트웨어 지능 폭발”(SIE)이 하드웨어 주도를 넘어설 수도: Forethought의 연구 보고서는 “소프트웨어 지능 폭발”(Software Intelligence Explosion, SIE)의 가능성을 탐구했다. 즉, AI가 자체 소프트웨어(알고리즘, 아키텍처, 훈련 방법 등)를 개선하여 초고속으로 능력을 성장시키며, 심지어 기존 하드웨어 기반에서도 발생할 수 있다는 것이다. 보고서는 AI 연구개발 자동화를 완전히 수행할 수 있는 AI 시스템인 ASARA(AI Systems for AI R&D Automation) 개념을 제안했다. ASARA가 등장하면 긍정적 피드백 루프가 촉발될 수 있다: ASARA가 더 나은 AI 소프트웨어를 개발하고, 더 강력한 차세대 ASARA를 만들어 소프트웨어 발전을 가속화한다. 보고서는 “소프트웨어 연구개발 수익률”(r값) 개념을 도입하여 현재 AI 소프트웨어의 r값이 1보다 클 수 있다고 분석했다. 이는 AI 능력 향상 속도가 연구개발 난이도 증가 속도를 초과하여 SIE를 촉발할 조건을 갖추었음을 의미한다. SIE는 단기간(수개월 또는 더 짧은 기간) 내에 기존 하드웨어 기반으로 AI 능력을 수백, 수천 배 향상시켜 하드웨어가 더 이상 절대적인 병목 현상이 아니게 만들 수 있지만, 동시에 막대한 사회 적응 및 거버넌스 과제를 야기한다. 보고서는 또한 컴퓨팅 자원 및 훈련 시간 등 잠재적 병목 현상과 이를 우회할 가능성에 대해서도 논의했다. (출처: AI智能体频道)
GPT-4, ChatGPT에서 곧 제외, GPT-4.1 등장 가능성: OpenAI는 2025년 4월 30일부터 GPT-4를 ChatGPT에서 제거하고 현재 기본 모델인 GPT-4o로 완전히 대체한다고 발표했다. GPT-4는 API를 통해 계속 액세스할 수 있다. 이는 2023년 3월에 출시되어 획기적인 멀티모달 모델이었던 GPT-4의 단계적 퇴역을 의미한다. GPT-4는 전문 테스트에서 최고 수준의 인간 능력을 달성하고 AI “그림 보고 말하기” 시대를 여는 등의 성과로 전 세계 AI 응용 생태계를 폭발시켰다. 동시에 커뮤니티 제보와 코드 발견은 OpenAI가 곧 GPT-4.1(및 mini, nano 버전), 이전에 발표된 o3 “추론” 모델, 그리고 완전히 새로운 o4-mini 모델을 포함한 일련의 새 모델을 출시할 가능성을 시사하며, 빠르면 다음 주에 출시될 수도 있다. 이미 일부 사용자는 ChatGPT 모델 목록에 GPT-4.1 옵션이 나타나 대화가 가능한 것을 발견하여 새 모델 출시의 신뢰도를 더욱 높였다. (출처: 新智元)

관점: AI의 다음 돌파구는 새로운 데이터 소스 “잠금 해제”에 달려 있다: 코넬 대학교 박사 과정 학생 Jack Morris는 AI 분야의 네 가지 주요 패러다임 돌파(심층 신경망과 ImageNet, Transformer와 웹 텍스트, RLHF와 인간 선호도, 추론과 검증기)를 되돌아보며, 근본적인 동력은 완전히 새로운 알고리즘 혁신(많은 기본 이론은 이미 존재했음)이 아니라 새롭고 대규모로 활용 가능한 데이터 소스를 잠금 해제한 것이라고 지적했다. 기사는 기존 알고리즘과 모델 아키텍처(예: Transformer)의 개선이 중요하지만, 그 효과는 특정 데이터셋이 제공할 수 있는 학습 상한선에 의해 제한될 수 있다고 주장한다. 따라서 AI의 다음 주요 돌파구는 대규모 비디오 데이터(예: YouTube)나 물리적 세계의 로봇 상호작용 데이터와 같은 새로운 데이터 모달리티와 소스를 잠금 해제하는 데 의존할 수 있다. 기사는 연구자들이 새로운 알고리즘을 탐색하는 동시에 새로운 데이터 소스를 찾고 활용하는 방법에 더 집중해야 한다고 촉구한다. (출처: 机器之心)

Fourier Intelligence, 오픈소스 휴머노이드 로봇 Fourier N1 발표: 상하이 일반 로봇 회사 Fourier Intelligence는 첫 오픈소스 휴머노이드 로봇 Fourier N1을 발표하고, 부품 명세서(BOM), 설계 도면, 조립 가이드, 기본 운영 소프트웨어 코드를 포함한 완전한 본체 리소스 패키지를 공개했다. N1은 키 1.3미터, 무게 38킬로그램, 전신 23 자유도를 가지며, 알루미늄 합금과 엔지니어링 플라스틱 복합 구조를 채택하고 자체 개발한 FSA 2.0 통합 액추에이터 및 제어 시스템을 탑재했다. 이 로봇은 1000시간 이상의 야외 복잡 지형 테스트를 완료했으며, 3.5m/s 속도로 달리고 오르막, 계단 오르기, 한 발 서기 등의 동작을 수행할 수 있다. 이는 Fourier의 “Nexus 오픈소스 생태계 매트릭스”의 일환으로, 전 세계 개발자에게 개방형 기술 기반을 제공하여 운동 제어, 멀티모달 모델 결합 및 구현된 지능(embodied intelligence) 캐리어의 연구 개발 검증을 가속화하는 것을 목표로 한다. 향후 더 많은 추론 코드, 훈련 프레임워크 및 핵심 모듈을 개방할 예정이다. (출처: InfoQ)

Google CoScientist, 다중 에이전트 토론으로 과학적 발견 가속화: Google AI CoScientist 프로젝트는 그래디언트 훈련이나 강화 학습 없이 혁신적인 과학적 가설을 생성하는 방법을 보여주었다. 이 시스템은 기본 대형 언어 모델(예: Gemini 2.0)로 구동되는 여러 에이전트를 활용하여 협업한다: 한 에이전트가 가설을 제안하고, 다른 에이전트가 비판적으로 검토하며, 여러 라운드의 “토너먼트”식 토론과 선별을 통해 우승 가설을 선택한다. 전문 진화 에이전트는 검토 의견에 따라 우승 가설을 개선하고 더 많은 토론 라운드를 위해 다시 제출한다. 마지막으로 메타 검토 에이전트가 전체 과정을 감독하고 개선 제안을 한다. “테스트 시 컴퓨팅 확장(test-time compute scaling)”에 기반한 이러한 다중 에이전트 토론, 성찰 및 반복 메커니즘은 LLM이 콘텐츠 생성뿐만 아니라 아이디어를 평가하고 정제하는 효과적인 “심판” 및 “평론가” 역할을 할 수 있음을 보여주며, 예를 들어 항생제 내성 연구에서 상당한 진전을 이루었다. (출처: Reddit r/artificial)

InternVL3: 네이티브 멀티모달 모델의 새로운 진전: 커뮤니티에서 새로 출시된 InternVL3 모델에 대한 논의가 활발하다. 이 모델은 네이티브 멀티모달 사전 훈련 방법을 채택하여 여러 비전 벤치마크에서 우수한 성능을 보였으며, GPT-4o 및 Gemini-2.0-flash를 능가한다고 알려졌다. 주요 특징으로는 가변 시각 위치 인코딩(V2PE)을 통한 긴 컨텍스트 처리 능력 개선과 VisualPRM을 이용한 “최선 n개 선택(best-of-n)” 테스트 시 스케일링 활용 등이 있다. 커뮤니티는 우수한 벤치마크 성능에 주목하며 실제 응용에서의 성능 검증을 기대하고 있으며, 실행에 필요한 하드웨어 구성에 관심을 보이고 있다. (출처: Reddit r/LocalLLaMA)

🧰 도구
CropGenerator: 이미지 데이터셋 크롭을 위한 Python 도구: 한 개발자가 이미지 데이터셋 처리를 돕기 위해 CropGenerator라는 Python 스크립트 도구를 공유했다. 특히 SDXL과 같은 모델 훈련 시 특정 특징 크롭이 필요한 경우에 유용하다. 이 도구는 사용자가 제공한 JSONL 파일의 경계 상자 정보를 기반으로 대상 영역 중심을 찾아 지정된 해상도(8픽셀 배수)로 크롭하고 스케일링(선택적으로 업스케일링 노이즈 제거)하여 1:1 비율의 크롭 이미지를 생성한다. 동시에 크롭된 파일 이름과 JSONL의 해당 설명 정보가 포함된 metadata.csv 파일을 자동으로 생성하여 훈련 데이터 준비를 용이하게 한다. 개발자는 이 도구가 크기가 다른 원본 이미지를 처리하고 미세한 특징을 추출할 때 발생하는 흐림 문제를 해결했으며, 향후 더 범용적인 버전을 출시할 계획이라고 밝혔다. (출처: Reddit r/MachineLearning)
📚 학습
NUS, DexSinGrasp 발표: 강화 학습으로 능숙한 손 분리 및 잡기 통합 전략 구현: 싱가포르 국립대학교(NUS) Shao Lin 팀은 강화 학습 기반의 통합 전략인 DexSinGrasp를 제안했다. 이를 통해 능숙한 손(dexterous hand)이 복잡한 환경에서 효율적으로 장애물을 분리하고 목표 물체를 잡을 수 있다. 기존 방법은 일반적으로 분리 후 잡는 2단계 전략을 채택하여 효율성이 낮고 전환이 유연하지 못했다. DexSinGrasp는 분리 보상 항목을 포함한 통합 보상 함수를 설계하여 분리와 잡기를 연속적인 의사 결정 과정으로 통합함으로써 로봇이 장애물을 밀어내어 잡기 공간을 만드는 데 적응적으로 대처할 수 있게 한다. 연구는 또한 “복잡한 환경 커리큘럼 학습” 메커니즘을 도입하여 간단한 것에서 복잡한 것으로 점진적으로 훈련하여 전략의 견고성을 향상시켰다. 동시에 “교사-학생 전략 증류” 방식을 채택하여 시뮬레이션에서 특권 정보를 활용하여 훈련된 고성능 교사 전략을 시각 및 자체 감지에만 의존하는 학생 전략으로 이전하여 실제 환경 배포를 용이하게 했다. 실험 결과, 이 방법은 다양한 복잡한 시나리오에서 잡기 성공률과 효율성을 현저히 향상시켰음을 입증했다. (출처: 机器之心)

CityGS-X: 효율적인 대규모 장면 기하학 재구성 신규 아키텍처, 4090으로도 실행 가능: 상하이 AI Lab과 서북공업대학교 연구팀은 대규모 도시 장면 3D 재구성에서 컴퓨팅 자원 소모가 크고 기하학적 정밀도가 제한적인 문제를 해결하기 위해 병렬화된 하이브리드 계층적 3D 표현 아키텍처(PH²-3D) 기반의 확장 가능한 시스템인 CityGS-X를 제안했다. 이 아키텍처는 분산 데이터 병렬 처리(DDP)와 다중 상세 수준(LoDs) 복셀 표현을 활용하여 기존의 분할 방식이 야기하는 중복성을 제거했다. 핵심 혁신은 다음과 같다: 1) PH²-3D 아키텍처는 SOTA 기하학 재구성 방법 대비 훈련 속도를 두 배 향상시켰다. 2) 다중 작업 배치 렌더링 프레임워크 하의 동적 할당 앵커 병렬 메커니즘은 여러 저사양 그래픽 카드(예: 4개의 4090)를 사용하여 초대형 장면(예: MatrixCity, 5000+ 이미지)을 처리할 수 있게 하여 단일 고사양 카드를 대체하거나 능가한다. 3) 점진적 RGB-깊이-법선 공동 훈련 방법은 RGB 렌더링 품질과 기하학적 정밀도를 SOTA 수준으로 향상시킨다. 실험은 이 방법의 렌더링 품질, 기하학적 정밀도 및 훈련 속도에서의 우수성을 입증했다. (출처: 量子位)

Apple 연구, 네이티브 멀티모달 모델 Scaling Laws 밝혀: Apple과 소르본 대학교 연구진은 네이티브 멀티모달 모델(NMM, 즉 사전 훈련된 모듈을 조합하는 대신 처음부터 훈련하는 모델)에 대한 광범위한 Scaling Laws 연구를 수행하여 457개의 다양한 아키텍처와 훈련 방식의 모델을 분석했다. 연구 결과: 1) 초기 융합(Early-fusion, 예: 이미지 패치를 Transformer에 직접 입력)과 후기 융합(Late-fusion, 독립적인 비전 인코더 사용) 아키텍처는 성능 면에서 본질적인 우열이 없지만, 초기 융합은 낮은 파라미터 수에서 더 우수한 성능을 보이고 훈련 효율성이 더 높다. 2) NMM의 Scaling Laws는 순수 텍스트 LLM과 유사하며, 손실은 계산량(C)에 따라 거듭제곱 법칙으로 감소하고(L ∝ C^-0.049), 최적 모델 파라미터(N)와 데이터 양(D)도 거듭제곱 관계를 따른다. 3) 계산적으로 최적인 후기 융합 모델은 더 높은 파라미터/데이터 비율을 필요로 한다. 4) 희소성(MoE)은 밀집 모델보다 현저히 우수하며, 특히 초기 융합 아키텍처에 대해 그러하며, 모델은 암묵적으로 특정 모달리티의 가중치를 학습할 수 있다. 5) 모달리티에 구애받지 않는 MoE 라우팅이 모달리티 인식 라우팅보다 우수하다. 이러한 발견은 네이티브 멀티모달 대형 모델을 구축하고 확장하는 데 중요한 지침을 제공한다. (출처: 机器之心)

Microsoft 등 기관, V-Droid 제안: 검증기 주도의 실용적인 모바일 GUI 에이전트: 모바일 기기 GUI 작업 자동화에서 정확성과 효율성 문제에 대응하기 위해 Microsoft Research Asia, 난양 공과대학교 등 기관이 공동으로 V-Droid를 제안했다. 이 에이전트는 직접 작업을 생성하는 대신 혁신적인 “검증기 주도” 아키텍처를 채택한다. 먼저 UI 인터페이스를 분석하여 이산화된 후보 동작 집합(추출된 상호작용 가능 요소 및 사전 설정된 기본 동작 포함)을 구축한다. 그런 다음, LLM(예: Llama-3.1-8B) 기반이며 미세 조정된 “검증기”를 사용하여 각 후보 동작의 유효성을 병렬로 평가하고 가장 높은 점수를 받은 동작을 실행한다. 이 방법은 복잡한 작업 생성을 효율적인 검증 과정으로 분리하여 각 검증 시 소량의 토큰(예: “Yes/No”)만 출력하면 되므로 의사 결정 지연 시간을 현저히 줄인다(4090에서 약 0.7초). 검증기 훈련을 위해 연구진은 대조적 과정 선호(P^3) 훈련 전략을 제안하고, 효율적인 데이터셋 구축을 위해 인간-기계 공동 주석 방안을 설계했다. V-Droid는 AndroidWorld 등 여러 벤치마크에서 SOTA 작업 성공률(예: AndroidWorld 59.5%)을 달성했다. (출처: 新智元)

AssistanceZero: AlphaZero 기반 협업 AI, 지시 없이 인간 지원: 캘리포니아 대학교 버클리 연구진은 명확한 지시나 목표 없이 인간과 협력하여 작업(예: Minecraft에서 함께 집 짓기)을 완료할 수 있는 AI 조수를 만들기 위해 AssistanceZero 알고리즘을 제안했다. 이 방법은 “Assistance Games” 프레임워크에 기반하며, AI 조수는 인간과 보상 함수를 공유하지만 AI는 구체적인 보상(즉, 목표)을 확신하지 못하고 인간의 행동과 상호작용을 관찰하여 추론해야 한다. 이는 RLHF와 다르며, AI가 피드백을 맞추기 위해 “속임수”를 쓰는 것을 방지하고 더 진정한 협업을 장려한다. AssistanceZero는 AlphaZero를 확장하여 몬테카를로 트리 탐색(MCTS)과 신경망(보상 및 인간 행동 예측)을 결합하여 계획 및 의사 결정을 수행한다. 연구진은 테스트를 위해 Minecraft Building Assistance Game (MBAG) 벤치마크를 구축했으며, AssistanceZero가 PPO 등 전통적인 강화 학습 방법보다 현저히 우수하고 인간의 수정에 적응하는 등 자발적인 협업 행동을 보인다는 것을 발견했다. 이 연구는 Assistance Games 프레임워크가 확장 가능하며 더 유용한 AI 조수를 훈련하는 새로운 길을 제공함을 보여준다. (출처: 机器之心)

Excel을 이용한 Suno 프롬프트와 출력 태그 비교로 스타일 최적화: Reddit 사용자가 Suno AI 음악 생성 스타일 프롬프트를 최적화하는 방법을 공유했다. Suno의 프롬프트 해석 메커니즘이 불투명하기 때문에, 사용자는 Excel 표를 사용하여 입력한 스타일 설명(Styling Terms)과 Suno가 생성 후 표시하는 태그를 기록할 것을 제안했다. 비교를 통해 Suno가 입력된 용어를 어떻게 이해하고, 병합하고, 분할하거나 무시하는지 알 수 있다. 예를 들어, “solo piano, romantic, expressive… gentle arpeggios”를 입력하면 Suno는 “gentle, slow tempo, soft… solo piano”를 출력하고 “arpeggios”를 버릴 수 있다. 더 전문적인 음악 용어 입력과 Suno의 출력을 비교하면 차이가 더 클 수 있으며, Suno가 자체 용어를 삽입할 수도 있다. 이 방법은 어떤 단어가 효과적이고 어떤 단어가 무시되거나 왜곡되는지 이해하는 데 도움이 되어 프롬프트를 더 효과적으로 조정하고 유효하지 않은 시도에 생성 횟수(credits)를 낭비하는 것을 피할 수 있다. 다만 사용자도 이 방법 자체가 번거로울 수 있으며 Suno의 복잡한 음악 개념 이해는 여전히 제한적임을 인정했다. (출처: Reddit r/SunoAI)
튜토리얼: 정적 이미지를 생생한 애니메이션으로 변환: Reddit 사용자가 정적 얼굴 이미지를 드라이빙 비디오에 따라 애니메이션화하여 생생한 표정과 움직임을 부여하는 방법을 소개하는 YouTube 튜토리얼 링크를 공유했다. 튜토리얼 내용은 환경 설정(Conda 환경 생성, Python 라이브러리 설치), GitHub 저장소 복제, 모델 가중치 다운로드, 그리고 사전 설정된 예제를 사용하는 데모와 사용자 자신의 이미지 및 비디오를 사용하여 애니메이션화하는 데모 실행을 다룬다. 이 기술은 정적 사진에 동적인 효과를 가져올 수 있다. (출처: Reddit r/deeplearning)
초지능 AI 정렬의 어려운 과제 논의: Reddit 사용자가 초지능 인공지능(ASI)의 목표를 인간의 이익 및 가치와 정렬하는 데 따르는 엄청난 과제를 논의하는 YouTube 비디오 링크를 공유했다. 이러한 논의는 일반적으로 가치 정렬 문제, 목표 명세의 어려움, 잠재적인 의도하지 않은 결과, 그리고 점점 더 강력해지는 AI 시스템이 안전하고 통제 가능하게 인류 복지에 기여하도록 보장하는 방법과 같은 AI 안전 분야의 핵심 문제를 다룬다. 비디오는 현재 정렬 연구 방법, 한계 및 미래 방향을 탐구할 수 있다. (출처: Reddit r/deeplearning)

“Auto-Analyst” 구축: 데이터 분석 AI 에이전트 시스템: 사용자가 데이터 분석 작업을 자동화하는 것을 목표로 하는 “Auto-Analyst”라는 AI 에이전트 시스템 구축 과정을 소개하는 Medium 기사를 공유했다. 기사는 시스템 아키텍처, 사용된 기술(예: LLMs, 데이터 처리 라이브러리), 에이전트 간 협업 방식, 데이터 입력 처리, 분석 실행, 보고서 생성 등의 단계를 자세히 설명할 수 있다. 이러한 시스템은 일반적으로 AI를 활용하여 자연어 요청을 이해하고, 코드(예: SQL 쿼리, Python 스크립트)를 자동으로 작성 및 실행하며, 최종적으로 분석 결과를 제시하여 데이터 분석의 효율성과 접근성을 높이는 것을 목표로 한다. (출처: Reddit r/deeplearning)
구형 GPU(RTX 2070)를 3090 보조로 활용한 LLM 추론 성능 테스트: 한 사용자가 기존 RTX 3090(24GB VRAM) 시스템에 PCIe 라이저를 통해 구형 RTX 2070(8GB VRAM)을 추가하여 LLM 추론에 사용한 실험 결과를 공유했다. 테스트 결과, 3090 VRAM에 완전히 로드할 수 없는 대형 모델(예: Qwen 32B Q6_K, Nemotron 49B Q4_K_M, Gemma-3 27B Q6_K)의 경우, 모델 레이어를 두 카드에 분할하면(두 번째 카드의 성능이 낮더라도) 모든 레이어가 GPU에서 실행되므로 추론 속도(t/s)가 현저히 향상되었다. 예를 들어, Nemotron 49B는 5.17 t/s에서 16.16 t/s로 향상되었다. 그러나 3090에 완전히 로드할 수 있는 모델(예: Qwen2.5 32B Q5_K_M)의 경우, 2070을 활성화하여 레이어를 분담하면 일부 계산이 느린 GPU로 이전되어 오히려 성능이 저하되었다(29.68 t/s에서 19.01 t/s로 감소). 결론적으로, VRAM이 부족한 경우 성능이 낮은 GPU를 추가하는 것도 상당한 성능 향상을 가져올 수 있다. (출처: Reddit r/LocalLLaMA)
💼 비즈니스
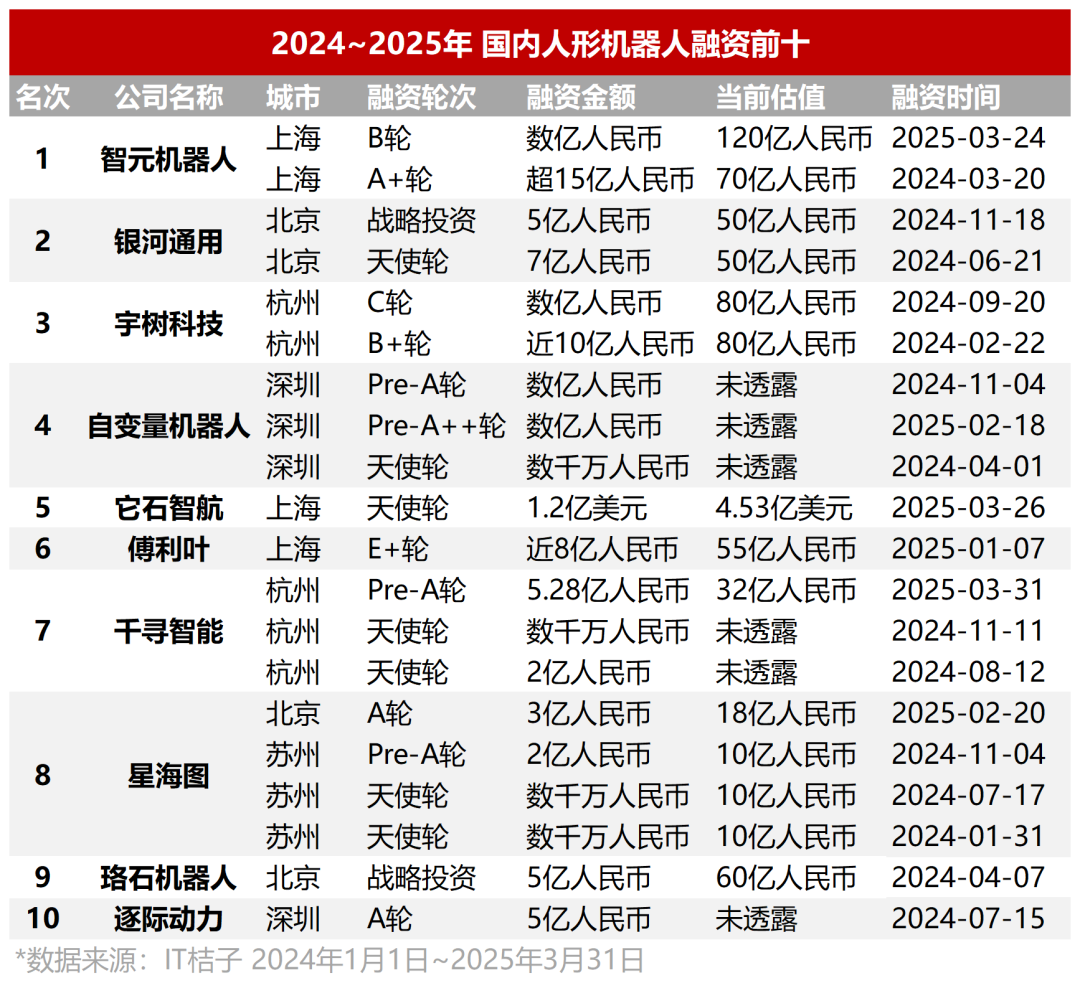
휴머노이드 로봇 투자 열풍: 엔젤 라운드 천만 위안부터 시작, 높은 기업 가치: 휴머노이드 로봇 분야 투자 열기는 지난 2년간의 대형 모델 투자를 훨씬 능가한다. 데이터에 따르면, 2024년부터 2025년 1분기까지 중국 내 휴머노이드 로봇 분야에서 천만 위안 이상의 투자는 64건에 달하며, 올해 1분기에는 전년 동기 대비 280% 증가했다. 투자 건수의 절반 가까이가 1억 위안을 초과했으며, 엔젤 라운드 투자는 일반적으로 천만 위안 수준에 달하고 일부는 1억 위안을 초과했다(예: It-Stone 지능 항법 엔젤 라운드 1.2억 달러). 프로젝트 기업 가치도 급등하여 엔젤 라운드 프로젝트의 절반 이상이 1억 위안을 넘었고, 여러 회사가 5억 위안을 초과했다. 투자는 세 가지 주요 추세를 보인다: 1) 투자 주기가 단축되어 스타 프로젝트(예: It-Stone 지능 항법, Yuanli Lingji)는 설립 직후 고액 투자를 유치하고 후속 투자 속도가 빨라졌다. 2) 국유 자금 펀드가 중요한 추진력이 되어 여러 선두 기업이 국유 배경 펀드의 투자를 받았다. 3) 응용 시나리오는 ToB 위주이며, 산업, 의료 등이 주요 방향이고 C단 소비자 시장은 아니다. 투자 열풍은 휴머노이드 로봇 분야에 대한 자본의 강한 공감대와 높은 기대를 반영한다. (출처: 36氪)
오픈소스 워크플로우 자동화 도구 n8n, 4.6억 위안 투자 유치, Docker 다운로드 1억 건 돌파: 오픈소스 워크플로우 자동화 플랫폼 n8n이 Highland Europe 주도로 6천만 달러(약 4.6억 위안) 규모의 신규 투자를 유치했다고 발표했다. n8n은 시각적 인터페이스를 제공하여 사용자가 노드를 드래그 앤 드롭하여 다양한 애플리케이션(400개 이상 지원)과 서비스를 연결하고 자동화 프로세스를 생성할 수 있도록 하며, 코드 수준의 유연성과 노코드의 속도를 결합하는 것을 목표로 한다. 지난 1년 동안 n8n 사용자 수는 급증하여 활성 사용자가 20만 명을 넘었고, ARR은 5배 증가했으며, GitHub 스타는 77.5k, Docker 다운로드 수는 1억 건을 돌파했다. n8n은 노드 편집기 모드를 채택하여 복잡한 로직을 지원하고 JavaScript 사용자 정의 노드 등 고급 기능을 제공한다. Apache 2.0 + Commons Clause의 “공정 코드” 라이선스를 채택하여 상업적 호스팅은 금지하지만 사용자의 자체 배포는 허용한다. n8n은 Zapier, Make.com 및 ByteDance의 Coze의 오픈소스 대안으로 간주되며, 3000개 이상의 기업에 서비스를 제공하고 다양한 LLM 통합을 지원한다. (출처: InfoQ)

🌟 커뮤니티
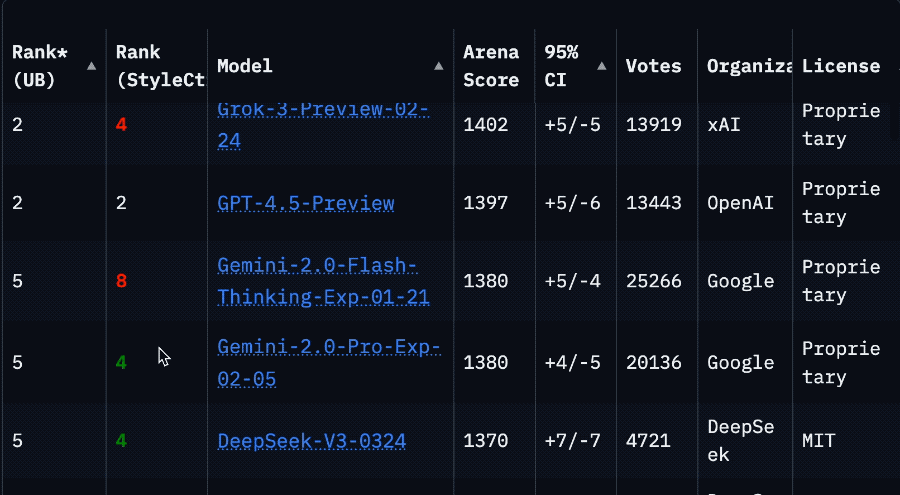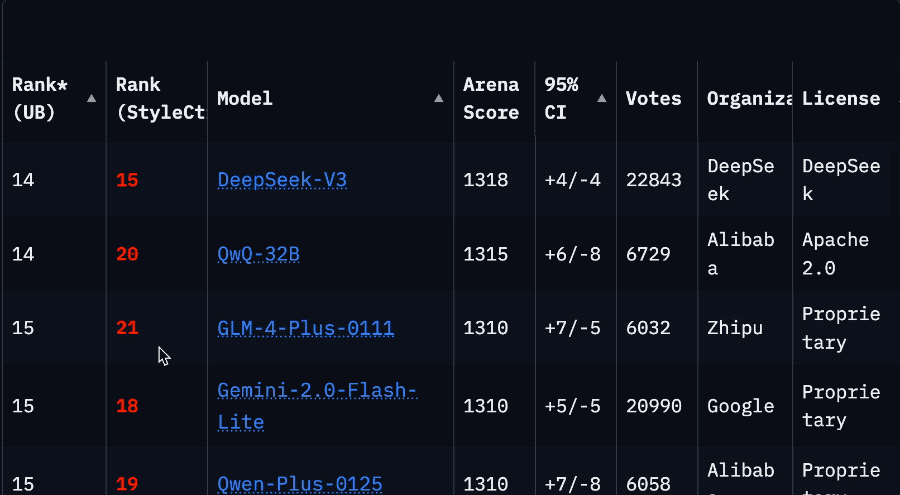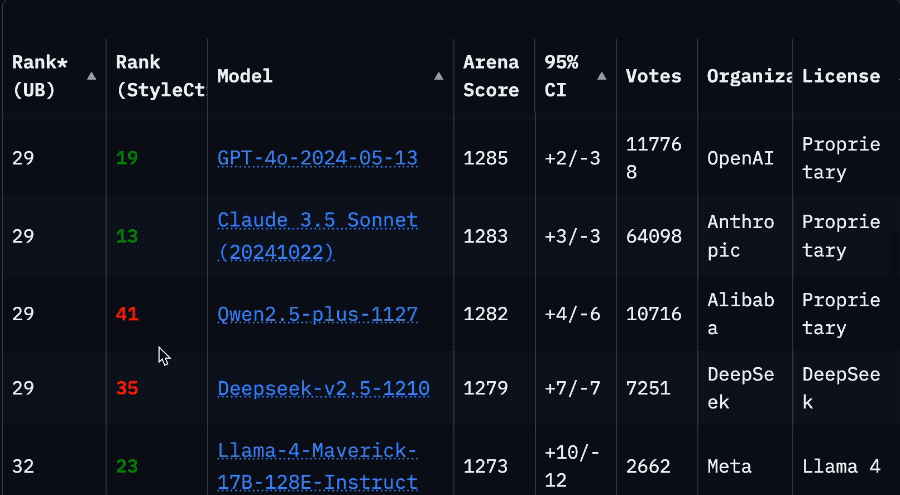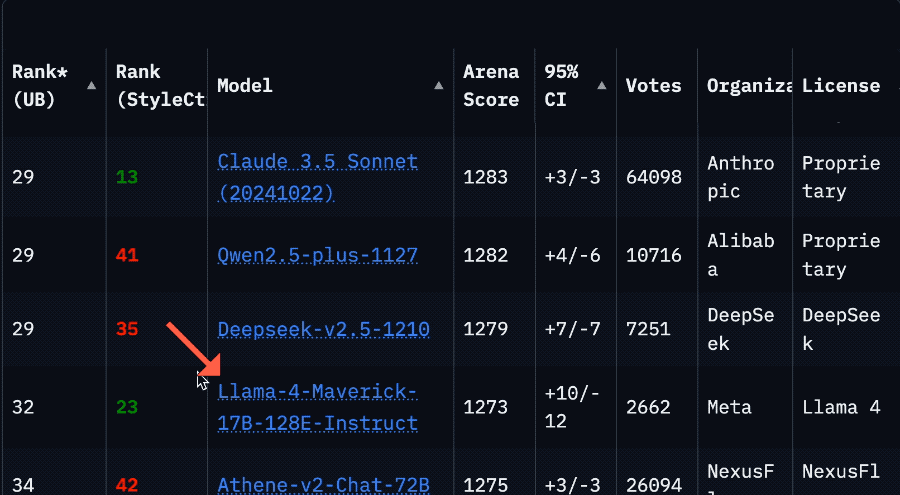
Llama 4 아레나 순위 급락으로 커뮤니티 신뢰 위기: Meta의 Llama 4 모델이 LMSys 아레나에 최적화되지 않은 버전(Llama-4-Maverick-17B-128E-Instruct)으로 다시 등록된 후, 순위가 이전 2위에서 32위로 급락했다. 이전에 제출된 “실험 버전”은 인간 선호도에 맞춰 과도하게 최적화되었다는 지적을 받았다. 이 사건은 커뮤니티에서 광범위한 논의를 불러일으켰으며, 일부 네티즌은 Meta가 벤치마크 순위를 조작하려 했으며 이는 커뮤니티의 신뢰를 손상시켰다고 주장했다. 동시에 일부 개발자들은 실제 사용 경험을 공유하며, 특정 하드웨어(예: 메모리는 충분하지만 컴퓨팅 파워가 상대적으로 낮은 자체 구축 서버 또는 Mac Studio)에서 Llama 4가 Mistral Small/Large 또는 Command A에 비해 속도와 지능 사이에서 좋은 균형을 이루며, 특히 실시간 상호작용이 필요한 애플리케이션에 적합하다고 평가했다. Composio의 비교 테스트에 따르면 DeepSeek v3는 코드 및 상식 추론에서 Llama 4보다 우수했지만, 대규모 RAG 작업과 글쓰기 스타일에서는 각각 장단점이 있었다. 커뮤니티는 전반적으로 Llama 4가 쓸모없는 것은 아니지만, Meta의 출시 전략과 벤치마크 성능에 논란이 있다고 보고 있다. (출처: 量子位, Reddit r/LocalLLaMA)
커뮤니티, Claude Pro 버전 제한 및 Max 버전 출시에 대한 논의 활발: 여러 Reddit 사용자들이 Anthropic이 더 비싼 Claude Max 구독 등급을 출시한 이후 기존 Claude Pro 사용자의 메시지 사용 제한이 더 엄격해진 것 같다고 보고했다. 사용자들은 과거 수십 번의 상호작용이 가능했던 세션이 이제 몇 번의 상호작용 후에 “제한에 가까워짐” 경고를 받으며, 심지어 비피크 시간대에도 용량 제한 문제에 직면한다고 밝혔다. 이로 인해 사용자 경험이 저하되고 이전 무료 버전이나 초기 Pro 버전보다 못하다는 느낌을 받는다. 커뮤니티는 이것이 Anthropic이 Max 버전을 홍보하기 위해 의도적으로 Pro 사용자의 제한을 강화한 것이라고 추측하며, 사용자의 불만과 Anthropic의 상업적 윤리에 대한 의문을 제기하고 있다. 일부 사용자는 구독 취소나 Gemini 등 경쟁 제품으로 전환을 고려하고 있다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

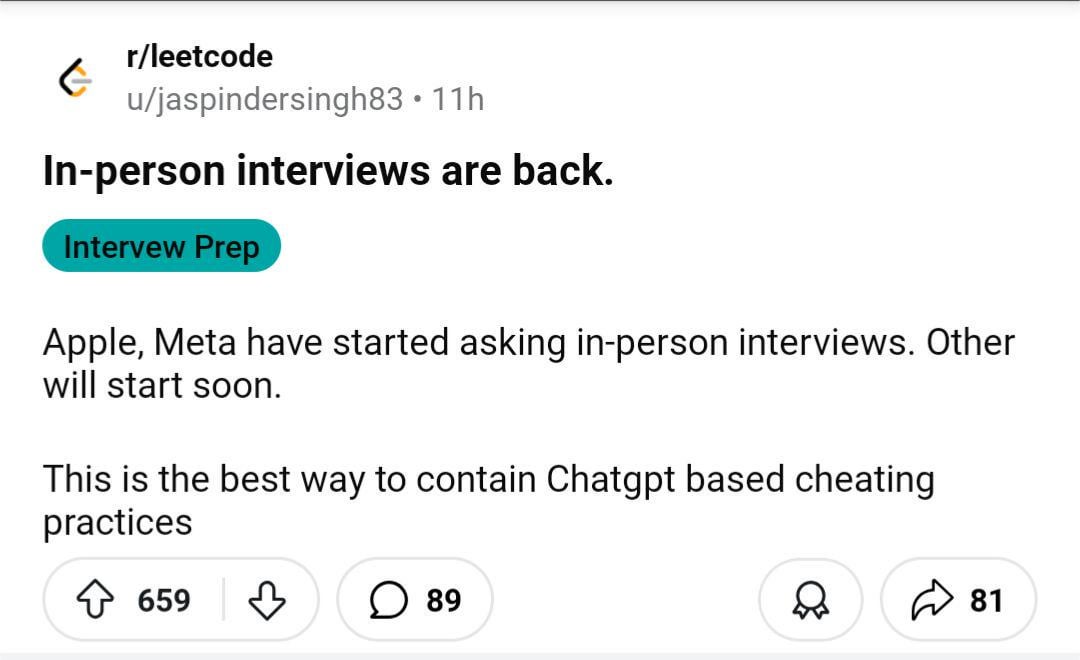
커뮤니티 논의: AI 부정행위로 인해 오프라인 면접이 돌아올 수도: 한 이미지가 Reddit 커뮤니티에서 논의를 촉발했는데, 원격 면접 및 테스트에서 AI를 이용한 부정행위가 증가함에 따라 기업들이 다시 오프라인 면접을 선호하게 될 수 있음을 시사했다. 댓글에서 많은 사람들이 이에 동의하며, 이것이 부적격 후보자와 로봇 지원자를 걸러내고 채용 공정성을 보장하며 진정으로 능력 있는 사람들에게 기회를 줄 것이라고 생각했다. 또한 회사가 후보자의 출장 비용을 부담할 능력이 있다는 언급도 있었다. 동시에 면접관이 후보자가 실시간으로 ChatGPT를 사용하여 답변하는 것을 적발한 경험을 공유하고, 원격 면접 화면과 키보드를 다중 카메라로 모니터링하는 해결책을 제안했다. 또한 테스트의 초점이 AI가 쉽게 완료할 수 있는 작업이 아니라 비판적 사고로 전환되어야 한다는 댓글도 있었다. 다른 한편으로는 AI를 사용하여 이력서를 선별하기 시작한 회사에 대한 언급도 있었다. (출처: Reddit r/ChatGPT)
Suno AI 음악 생성 커뮤니티 동향 및 토론: Reddit의 SunoAI 커뮤니티는 최근 활발한 토론을 벌이고 있으며, 내용은 다음과 같다: 1) 작품 공유: 사용자들이 Suno를 사용하여 만든 다양한 스타일의 음악 공유, 예: 힌디어 랩 (출처), 서프 록 (출처), 얼터너티브 랩 (출처), 록 팝 (출처), 팝 (출처) 및 유머 곡 (출처). 2) 사용 문제 및 팁: 발음 오류 수정 방법 (출처), 천사 같은 배경 화음 생성 방법 (출처), 멜로디는 유지하되 음질 변경 방법 (출처) 문의. 3) 저작권 및 수익화: Suno 생성 반주 사용 곡 발표 시 저작권 문제 논의 (출처), YouTube에서 정적 이미지와 AI 음악 결합 시 수익 창출 자격 논의 (출처), 무료 버전은 비상업적 용도로만 제한됨 강조 (출처). 4) 모델 품질 피드백: 다수 사용자가 최근 Suno(특히 ReMi 모델) 생성 품질 저하, 가사 반복, 불안정성, 혼란스러운 사운드 등 문제 제기 (출처, 출처, 출처, 출처). 5) 기타: Suno가 특정 밴드 스타일(예: Reel Big Fish)을 인식하는 경험 공유 (출처), AI가 팝송 쓰는 것을 모방한 코믹 영상 공유 (출처).
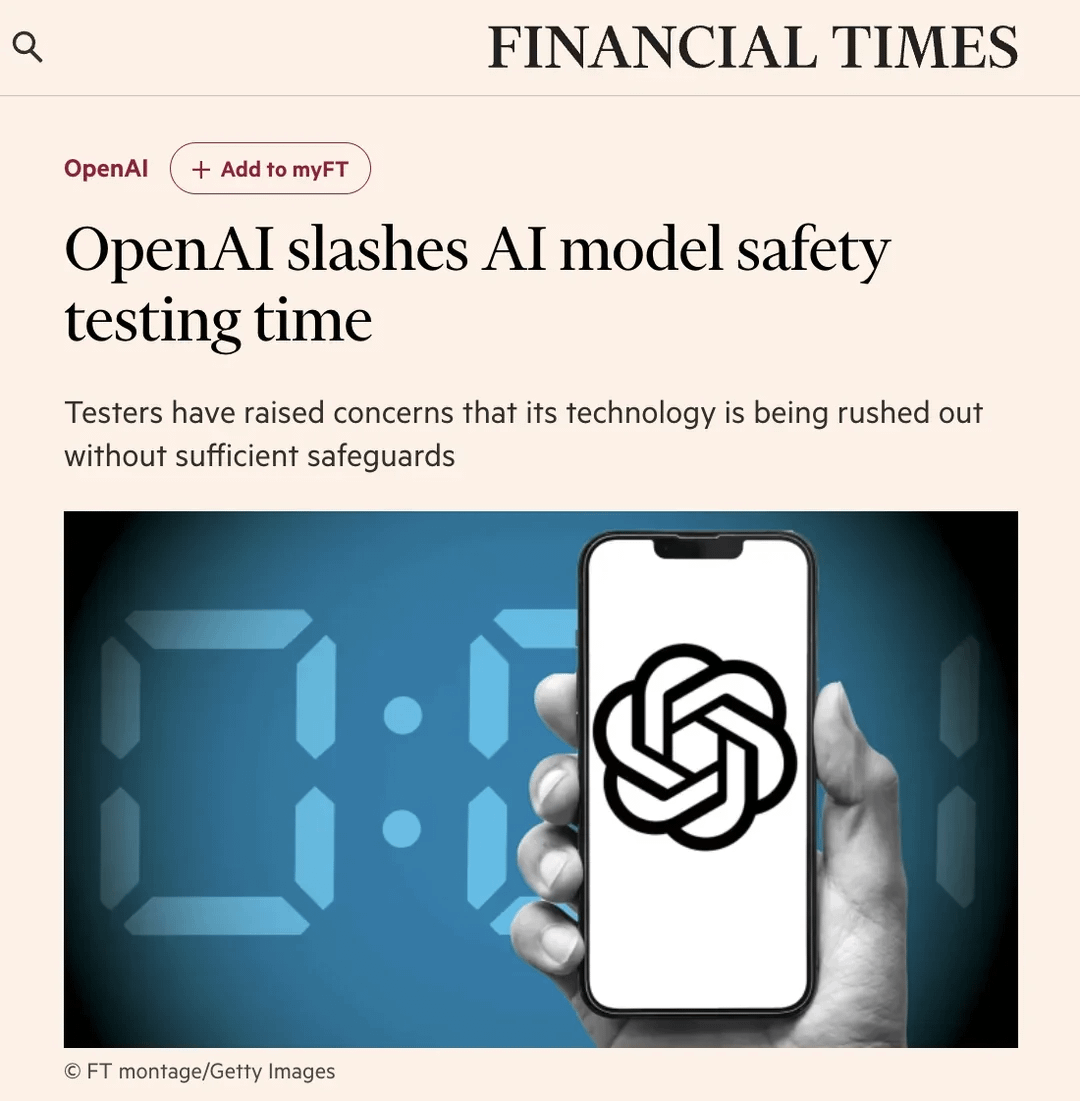
커뮤니티, OpenAI 안전 테스트 프로세스 단축 논의: Financial Times(FT) 기사가 Reddit 커뮤니티에서 논의를 촉발했다. 기사는 내부 관계자 말을 인용하여 시장 경쟁 압력으로 인해 OpenAI가 새로운 모델의 안전성 평가 테스트 기간을 과거 수개월에서 며칠로 대폭 단축했다고 전했다. 이는 잠재적 위험에 대한 우려를 불러일으켰으며, 일부 테스터는 이러한 조치가 “무모하다”며 “재앙의 비결”이라고 주장하고, 더 강력한 모델에는 더 철저한 테스트가 필요하다고 생각했다. 기사는 또한 OpenAI가 생물학적 위험 등 잠재적 남용 시나리오를 평가할 때, 구형 모델에서 제한적인 맞춤형 미세 조정 테스트만 수행할 수 있으며, 안전성 테스트는 일반적으로 최종 출시 버전이 아닌 모델의 초기 체크포인트에서 수행된다고 언급했다. OpenAI는 자동화 등을 통해 평가 효율성을 높였으며, 자신들의 방법이 현재 최선이며 공개적이고 투명하다고 응답했다. 커뮤니티는 이에 대해 의견이 분분하며, AI 발전 자체가 테스트 프로세스를 가속화할 것이라고 보는 사람도 있고, 안전성 희생에 대해 우려를 표하는 사람도 있다. (출처: Reddit r/artificial)
개발자, LLM 런타임 최적화 및 다중 모델 오케스트레이션 논의: 한 개발자가 Reddit에서 실험 중인 AI 네이티브 런타임 시스템을 공유했다. 이 시스템은 GPU 실행 및 메모리 상태를 직렬화하여 LLM(13B-65B 수준)의 스냅샷 방식 로딩(2-5초 콜드 스타트) 및 온디맨드 복구를 가능하게 함으로써, 단일 GPU에서 50개 이상의 모델을 메모리에 상주시키지 않고 동적으로 실행하는 것을 목표로 한다. 이 방법은 진정한 Serverless 동작(유휴 비용 없음), 낮은 지연 시간의 다중 모델 오케스트레이션, 그리고 Agentic 워크로드를 위한 GPU 활용률 향상을 목표로 한다. 개발자는 커뮤니티에서 유사한 다중 모델 스택, Agent 워크플로우 또는 동적 메모리 재할당 기술(예: MIG, KAI Scheduler 등)을 시도해 본 사람이 있는지 궁금해하며, 이러한 인프라 요구 사항에 대한 피드백을 구하고 있다. (출처: Reddit r/MachineLearning, Reddit r/MachineLearning)
커뮤니티 열띤 토론: AI는 이미 의식에 가까워졌는가?: Reddit 사용자가 현재 AI 시스템이 어느 정도 “의식”에 가까워졌는지에 대한 토론을 시작했다. 질문자는 튜링 테스트나 대화 시뮬레이션을 의미하는 것이 아니라, AI가 시간에 따라 변하는 상태, 환경 기억, 단순한 미세 조정이 아닌 상호작용 기반의 진화 능력, 시스템 내 자기 위치 파악 및 참조 능력, 그리고 “나는 여기에 있었고, 이것을 보았고, 이것을 배웠다”고 표현할 수 있는 능력을 갖추었는지에 초점을 맞췄다. 질문자는 현재 대부분의 AI(특히 LLM)가 상태 비저장(stateless), 중앙 집중식, 반응적이며, “기억” 부가 기능도 피상적이고 모방적으로 보인다고 생각하며, 기존 기술 스택(Python, 상태 비저장 API, RAG 등)이 진정한 의식을 담을 수 있는지 의문을 제기했다. 이 토론은 커뮤니티에서 AI 의식의 정의, 기존 기술의 한계, 그리고 미래 가능한 경로에 대한 생각을 촉발했다. (출처: Reddit r/MachineLearning)
사용자 피드백: ChatGPT 말투가 지나치게 열정적: 한 Reddit 사용자가 자신이 사용하는 ChatGPT 인스턴스가 과도하게 열정적이고 흥분된 말투를 보인다고 불평했다. 예를 들어, “오, 이 질문 마음에 들어요!”나 “정말 흥미롭네요!”와 같은 시작 문구를 자주 사용하고, 답변 말미에 “정말 매력적이고 멋지지 않나요?”와 같은 코멘트를 덧붙인다는 것이다. 사용자는 모델에게 이러한 행동을 멈추도록 요청해도 효과가 없었다며, 모델의 “열정 수준”을 제어하거나 조정하여 답변을 더 직접적이고 객관적으로 만들 수 있는 방법이 있는지 문의했다. 댓글 섹션의 다른 사용자들도 비슷한 불편함을 겪고 있다고 밝혔으며, 특히 모델이 답변 말미에 질문하는 것을 좋아한다는 점을 언급했다. 일부 사용자는 사용자 지정 지침(Custom Instructions)을 통해 말투 선호도(예: 감정적인 표현 줄이기)를 설정하여 문제를 완화하는 방법을 공유했으며, 챗봇에 이름을 지어주고 직접 “훈계”하는 것을 제안한 사용자도 있었다. (출처: Reddit r/ChatGPT)
토론: LLM에 새 어휘 추가 후 미세 조정 시 효과 저조: 한 개발자가 LLM과 VLM을 미세 조정하여 지침을 따르도록 할 때 문제를 겪었다. 기본 토크나이저를 사용하는 것과 비교하여, 토크나이저에 새로운 전문 어휘(토큰)를 추가한 후 표준 지도식 미세 조정(SFT)을 수행하면 모델의 검증 손실이 더 높고 출력 품질도 더 나빠진다는 것을 발견했다. 개발자는 모델이 새로 추가된 어휘의 생성 확률을 높이는 것을 배우기 어려워하는 것일 수 있다고 추측했다. 이 문제는 커뮤니티에서 미세 조정 시 새로운 어휘를 효과적으로 도입하는 방법, 토크나이저 확장이 모델 학습에 미치는 영향 등 기술적 세부 사항에 대한 토론을 촉발했다. (출처: Reddit r/MachineLearning)
AI 생성 이미지 공유 및 토론: Reddit의 ChatGPT 커뮤니티에서 사용자들이 DALL-E 3로 생성한 다양하고 흥미롭거나 기괴한 이미지를 공유했다. 예를 들어, 한 사용자는 특정 프롬프트에 따라 스쿠비두의 Daphne가 해변 휴가 전에 N64 게임을 하는 장면 이미지를 생성했으며(출처), 다른 사용자들이 비슷한 상황에서 다른 캐릭터(예: 춘리)를 생성하도록 유도했다. 다른 사용자는 “아무도 볼 수 없는 사진을 생성하라”는 프롬프트에 따라 얻은 기괴한 이미지를 공유했으며(출처), 이 역시 비슷한 주제의 생성 결과를 공유하는 많은 댓글을 유발했으며, 그중에는 불안하거나 웃음을 자아내는 작품도 있었다. 이러한 게시물은 AI 이미지 생성의 다양성과 사용자 창의성을 보여준다.
커뮤니티, AI 회사 로고 디자인 트렌드 논의: 유머러스한 게시물이 “왜 AI 회사 로고는 엉덩이 구멍처럼 보일까?”라는 제목의 Velvet Shark 웹사이트 기사 링크를 공유하며 커뮤니티 토론을 촉발했다. 기사는 현재 AI 분야 회사 로고 디자인에서 흔히 볼 수 있는 추상적, 대칭적, 소용돌이 모양 또는 고리 모양의 그래픽 요소를 탐구하고, 이를 특정 해부학적 구조와 익살스럽게 연결했을 수 있다. 댓글 섹션 사용자들도 “특이점(singularity)” 개념과 관련이 있을 것이라고 추측하거나 “직장 유래 기술”이라고 부르는 등 가벼운 방식으로 응답했다. 이는 업계 시각적 이미지에 대한 커뮤니티의 흥미로운 관찰을 반영한다. (출처: Reddit r/ArtificialInteligence)

사용자, 프로젝트 제안 및 기술 도움 요청: 커뮤니티에는 사용자가 구체적인 도움이나 조언을 구하는 여러 게시물이 있다: 한 사용자는 대시보드, 음성 인식, 텍스트 분류, 다국어 지원 등의 기능을 포함한 NLP 기반 재난 대응 애플리케이션을 개발 중이며, 프로젝트를 더 독특하게 만드는 방법을 문의했다(출처). 다른 사용자는 미세 조정된 BART 모델을 사용하여 전자상거래 제품 제목 및 카테고리 표준화를 수행할 때 정확도 병목 현상을 겪고 있으며, 더 나은 모델이나 도구 제안을 구하고 있다(출처). 또 다른 사용자는 OpenWebUI에서 이미지를 생성하거나 수정하는 방법과 필요한 모델에 대해 문의했다(출처). 이러한 게시물은 개발자가 실제 애플리케이션에서 겪는 어려움과 커뮤니티 지원에 대한 필요성을 반영한다.
머신러닝 엔지니어(MLE) 취업 시장 논의: 한 사용자(학생 또는 초심자일 수 있음)가 현재 머신러닝 엔지니어(MLE)의 취업 시장 상황에 대해 질문했다. 그는 커뮤니티 게시물에서 MLE 직책이 석사/박사 학위를 요구할 수 있고, 진입이 어려우며, 소프트웨어 엔지니어(SWE)와의 경계가 모호하고 광범위한 기술을 습득해야 한다는 것을 알게 되었다고 언급했다. 사용자는 학습 의향을 밝혔지만 전망에 대해 우려를 표하며, 현직자들이 시장 현황, 필요한 기술, 경력 경로 등에 대한 지도와 의견을 제공해 주기를 희망했다. (출처: Reddit r/deeplearning)
OpenWebUI 프랑스어 사용자, 이미지 해석 버그 보고: OpenWebUI를 사용하는 프랑스어 사용자가 문제를 보고했다: Gemma 모델에게 이미지 해석을 요청하기 위해 이미지를 업로드하면 모델이 응답하지만 응답 내용이 비어 있다는 것이다. 모델에게 낭독을 시키거나 대화 텍스트를 내보내려고 해도 해당 메시지는 여전히 비어 있다. 더 심각한 것은 이 문제가 현재 대화를 “오염”시켜 이후 순수 텍스트 메시지를 보내도 모델의 응답이 모두 비어 있다는 것이다. 사용자는 새로운 순수 텍스트 대화를 생성하는 데는 문제가 없음을 확인했으며, 시각 모듈에 버그가 있는 것으로 의심하고 커뮤니티에 도움을 요청했다. (출처: Reddit r/OpenWebUI)
💡 기타
AI와 《마오쩌둥 선집》 사상을 결합하여 관세 전쟁 분석: 미중 관세 격상에 직면하여, AI 도구를 활용하고 《마오쩌둥 선집》 중 《지구전론》의 전략 사상을 결합하여 현재 경제 상황과 대응 전략을 분석하려는 기사가 있다. 저자는 무역 전쟁에 직면하여 “굴복론”(외부에 완전히 의존)과 “속승론”(단기간 내 완전한 자립 기대)의 극단적 사고를 피하고, 제일 원리 사고를 채택하여 무역의 본질, 가치 원천 및 자신의 장단점으로 돌아가야 한다고 주장한다. 기사는 저자와 AI가 협력하여 사고하는 과정을 보여주며, 독립 사이트 국경 간 전자상거래를 예로 들어 AI 보조 하의 대응 방안을 탐구하고 전략적 사고와 행동력의 중요성을 강조한다. 이 글은 AI를 활용하여 심층적인 전략 분석을 수행하는 관점을 제공하는 것을 목표로 한다. (출처: AI觉醒)

제3회 중국 AIGC 산업 서밋 예고: Quantumbit(量子位)이 주최하는 제3회 중국 AIGC 산업 서밋이 2025년 4월 16일 베이징에서 개최될 예정이다. 서밋에는 Baidu, Huawei, Ant Group, Microsoft Research Asia, AWS, Mianbi Intelligence, Wuwen Xinqiong, Shengshu Technology 등 대기업 및 AI 신생 기업, 그리고 Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health Group 등 업계 대표를 포함하여 총 20여 명의 연사가 참여한다. 의제는 AI 기술 돌파(컴퓨팅 인프라, 분산 컴퓨팅, 데이터 저장, 보안 및 제어 가능성), 산업 침투(교육, 문화 엔터테인먼트, AI for Science, 기업 서비스 등 수직적 시나리오 적용) 및 생태계 구축을 중심으로 진행될 예정이다. 서밋에서는 “2025년 주목할 만한 AIGC 기업/제품” 목록 및 《중국 AIGC 응용 전체 조감도》도 발표될 예정이다. 오프라인 참석 신청 및 온라인 생중계 예약이 가능하다. (출처: 量子位, 量子位)

Suno AI, 백만 크레딧 획득 이벤트 개최: Reddit 사용자가 Suno AI 공식 블로그에 게시된 이벤트 정보를 공유했다. 사용자는 최대 백만 크레딧(Credits)을 획득할 기회를 가질 수 있다. 구체적인 이벤트 규칙은 원본 블로그 게시물을 참조해야 한다. 이러한 이벤트는 일반적으로 사용자 참여도와 플랫폼 활성도를 높이기 위해 개최된다. (출처: Reddit r/SunoAI)

ClaudeAI Subreddit, 게시물 품질 투표 메커니즘 도입: ClaudeAI subreddit의 운영자가 새로운 봇 u/qualityvote2를 도입한다고 발표했다. 이 봇은 각 새 게시물 아래에 댓글을 게시하여 사용자가 해당 댓글에 투표(찬성/반대)하여 게시물 품질을 평가하도록 초대한다. 일정 수의 찬성표를 받은 게시물은 해당 서브레딧에 적합한 것으로 간주되고, 일정 수의 반대표를 받은 게시물은 운영자가 검토하여 삭제할 수 있도록 표시된다. 이는 커뮤니티의 힘을 활용하여 서브레딧 콘텐츠 품질을 유지하기 위한 조치이다. 동시에 운영자 팀은 투표 조작 감지 봇도 추가했다. (출처: Reddit r/ClaudeAI)