
키워드:AI, LLM, AI 인덱스 보고서, AI 하드웨어 프로세서, AI 모델 학습 비용, AI 에이전트 개발, AI 데이터 피크
“`korean
🔥 주요 소식
스탠포드, 2025 AI 인덱스 보고서 발표: 스탠포드 대학이 총 456페이지 분량의 《2025 AI Index》 보고서를 발표하여 AI 분야의 현황과 추세를 포괄적으로 개괄했습니다. 보고서에 따르면, 미국은 모델 발표 수에서 앞서지만, 중국이 모델 품질 면에서 빠르게 추격하며 성능 격차가 현저히 줄어들고 있습니다. 훈련 비용은 지속적으로 상승하고 있으며(예: Gemini 1.0 Ultra 약 1억 9200만 달러), 추론 비용은 급격히 하락하고 있습니다. AI의 탄소 배출 문제가 점점 심각해지고 있으며, Meta Llama 3.1의 훈련 배출량은 막대합니다. 보고서는 또한 많은 AI 벤치마크가 포화 상태에 이르러 모델 능력을 구분하기 어려워졌으며, “인류 최후의 시험”이 새로운 도전 과제가 되었다고 언급했습니다. 공개 데이터 수집이 제한되고(최상위 도메인의 48%가 크롤러 제한), “데이터 피크”에 대한 우려가 제기되고 있습니다. 기업의 AI 투자는 막대하지만 아직 뚜렷한 생산성 향상은 보이지 않고 있습니다. AI는 과학 및 의료 분야에서 잠재력이 크지만 실제 응용 전환에는 시간이 더 필요합니다. 정책 측면에서는 미국 주 단위 입법이 활발하며, 특히 딥페이크에 주목하고 있으며, 글로벌 차원에서는 구속력 없는 선언이 대부분입니다. 일자리 대체에 대한 우려에도 불구하고, AI에 대한 대중의 전반적인 태도는 여전히 낙관적인 편입니다 (출처: AINLPer)
신형 광자 AI 프로세서 돌파구 마련: 《Nature》 저널에 게재된 두 편의 논문은 광자와 전자를 결합한 새로운 AI 프로세서를 소개하며, 포스트 트랜지스터 시대의 성능 및 에너지 소비 병목 현상을 돌파하는 것을 목표로 합니다. 싱가포르 Lightelligence사의 PACE 광자 가속기(16,000개 이상의 광자 부품 포함)는 최대 1GHz의 계산 속도와 500배의 최소 지연 시간 단축을 보여주었으며, 이징 문제 해결에서 뛰어난 성능을 보였습니다. 미국 Lightmatter사의 광자 프로세서(128×128 행렬 4개 포함)는 BERT, ResNet 등 AI 모델을 성공적으로 실행하여 전자 프로세서에 필적하는 정밀도를 달성했으며, 《팩맨》 게임 플레이 등의 응용 사례를 시연했습니다. 두 연구 모두 시스템 확장이 가능하고 기존 CMOS 공장에서 제조할 수 있음을 보여주며, AI 하드웨어를 더 강력하고 에너지 효율적인 방향으로 발전시킬 것으로 기대됩니다. 이는 광자 컴퓨팅이 실용화 단계로 나아가는 중요한 발걸음을 의미합니다 (출처: 36氪)

UC 버클리, o3-mini에 필적하는 14B 코드 모델 DeepCoder 오픈소스 공개: UC 버클리와 Together AI가 공동으로 DeepCoder-14B-Preview를 발표했습니다. 이는 완전 오픈소스 14B 파라미터 코드 추론 모델로, 성능은 OpenAI의 o3-mini와 비슷합니다. 이 모델은 Deepseek-R1-Distilled-Qwen-14B를 분산 강화 학습(RL)을 통해 미세 조정하여 개발되었으며, LiveCodeBench 벤치마크에서 Pass@1 60.6%를 달성했습니다. 연구팀은 24,000개의 고품질 프로그래밍 문제로 구성된 훈련 데이터셋을 구축했으며, 개선된 GRPO+ 훈련 방법, 반복적 컨텍스트 확장(16K에서 32K로 확장, 추론 시 64K 도달), 초장문 필터링 기술을 채택했습니다. 동시에 최적화된 RL 훈련 시스템 verl-pipeline을 오픈소스로 공개하여 엔드투엔드 훈련 속도를 2배 향상시켰습니다. 이번 발표에는 모델뿐만 아니라 데이터셋, 코드, 훈련 로그도 포함됩니다 (출처: 新智元)
🎯 동향
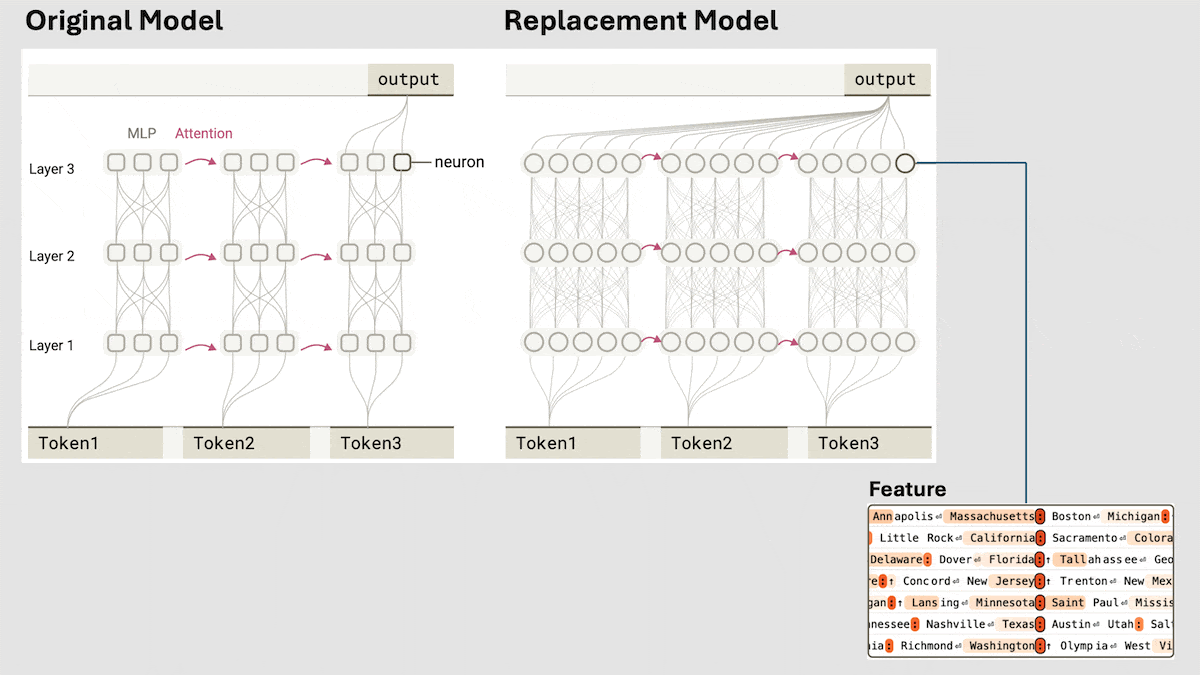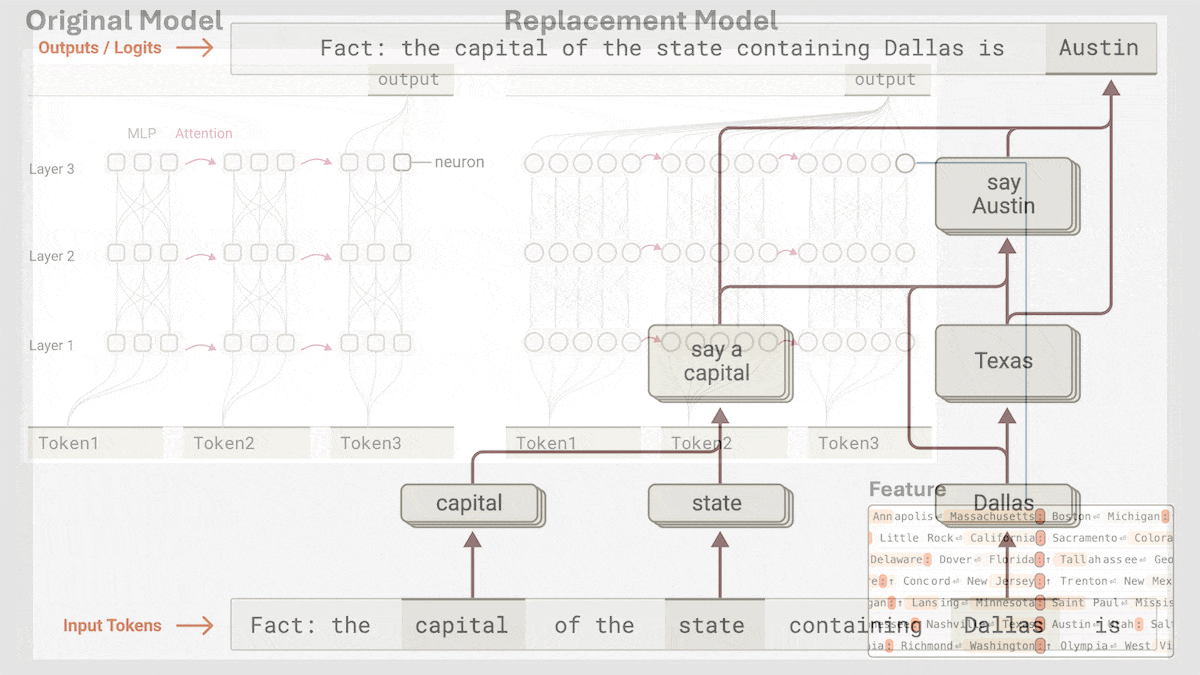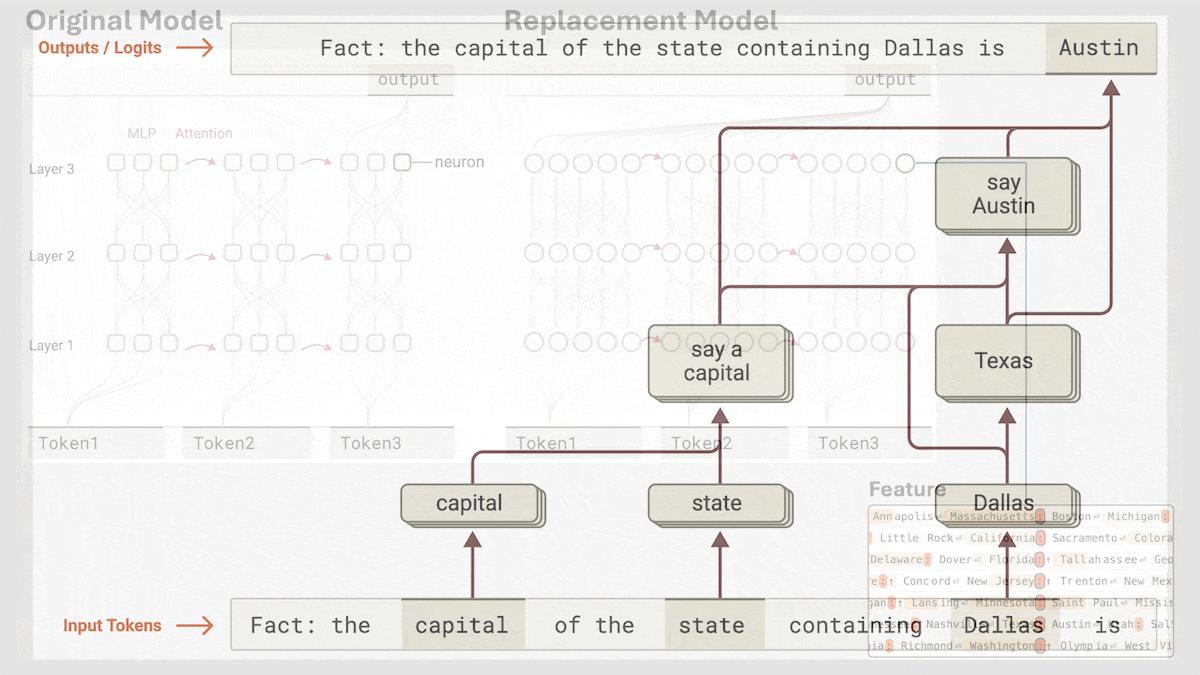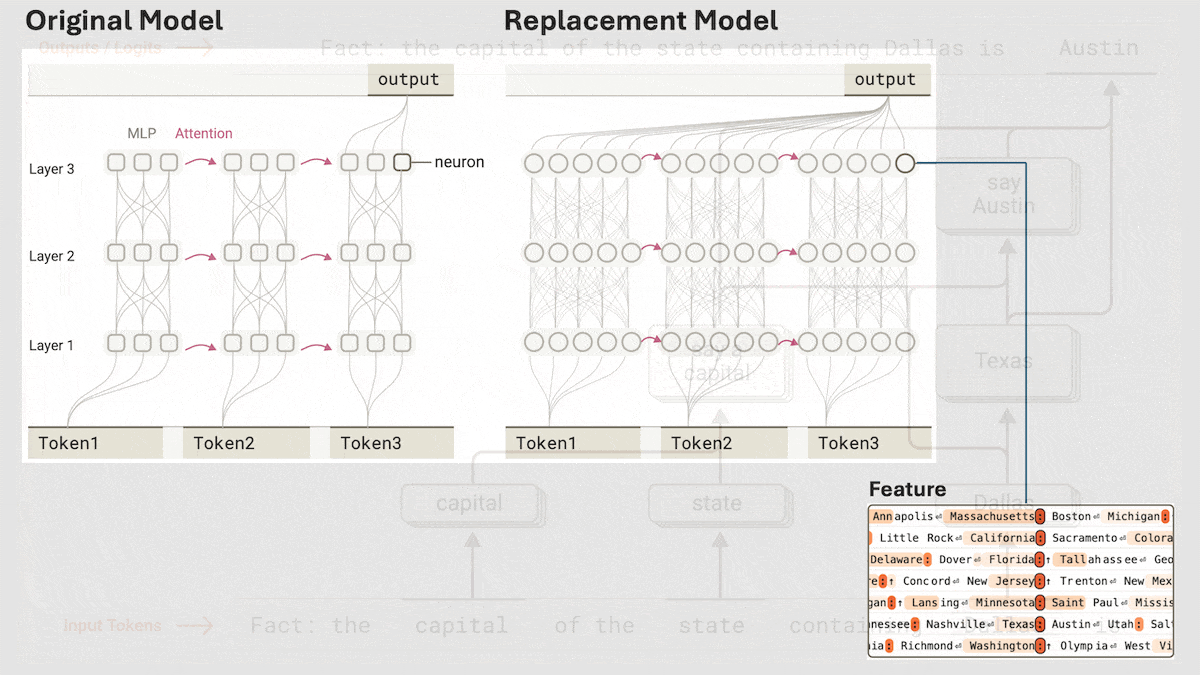
Anthropic, Claude 3.5 Haiku의 암시적 추론 메커니즘 공개: Anthropic 연구팀은 새로운 방법을 통해 Transformer 모델(특히 Claude 3.5 Haiku)의 내부 작동 메커니즘을 분석했습니다. 연구 결과, 연쇄적 사고(Chain-of-Thought)를 명시적으로 훈련하지 않았음에도 불구하고 모델이 응답을 생성할 때 뉴런 활성화를 통해 유사한 추론 단계를 보이는 것으로 나타났습니다. 이 방법은 완전 연결 계층을 해석 가능한 “계층 간 트랜스코더(cross-layer transcoder)”로 대체하여 특정 개념이나 예측과 관련된 “특징(feature)”을 식별하고, 정보 흐름을 시각화하기 위한 귀인 그래프(attribution graph)를 구축합니다. 실험 결과, 모델은 질문(“작은 것의 반의어는 무엇인가?” 또는 댈러스가 속한 주의 주도 판단)에 답할 때 직접 답을 예측하는 대신 내부적으로 여러 논리적 단계를 거치는 것으로 나타났습니다. 이 연구는 LLM의 내부 작동 방식을 이해하고 진정한 추론 능력과 표면적인 모방을 구별하는 데 도움이 됩니다 (출처: DeepLearning.AI)
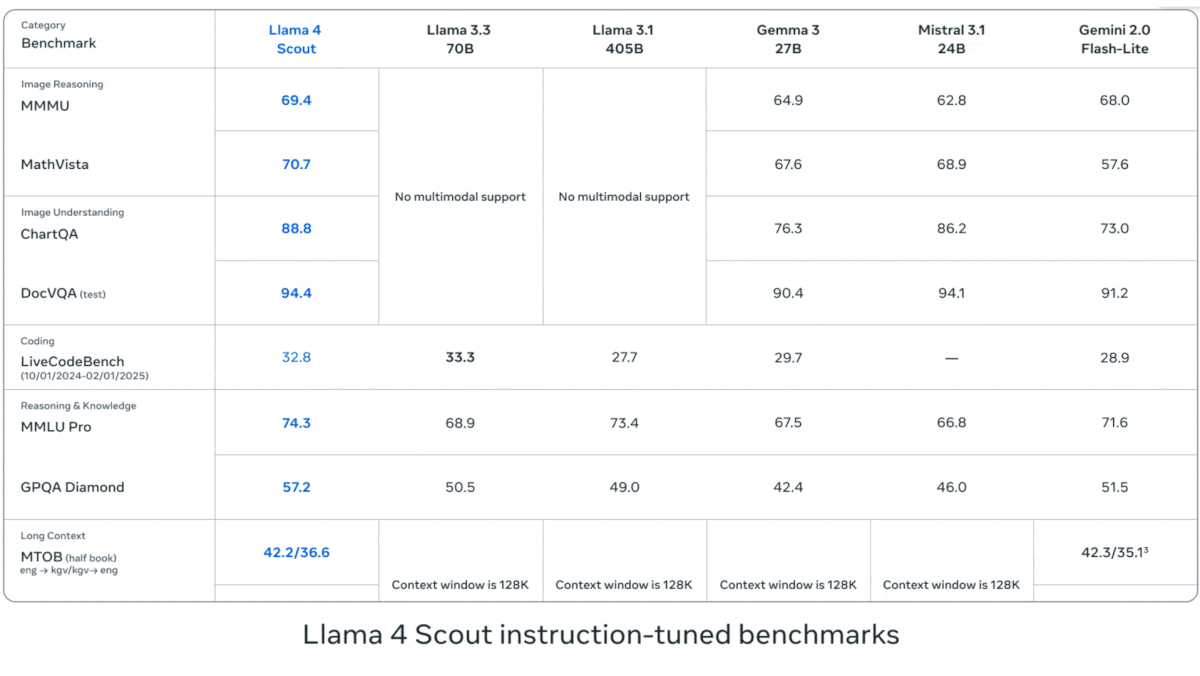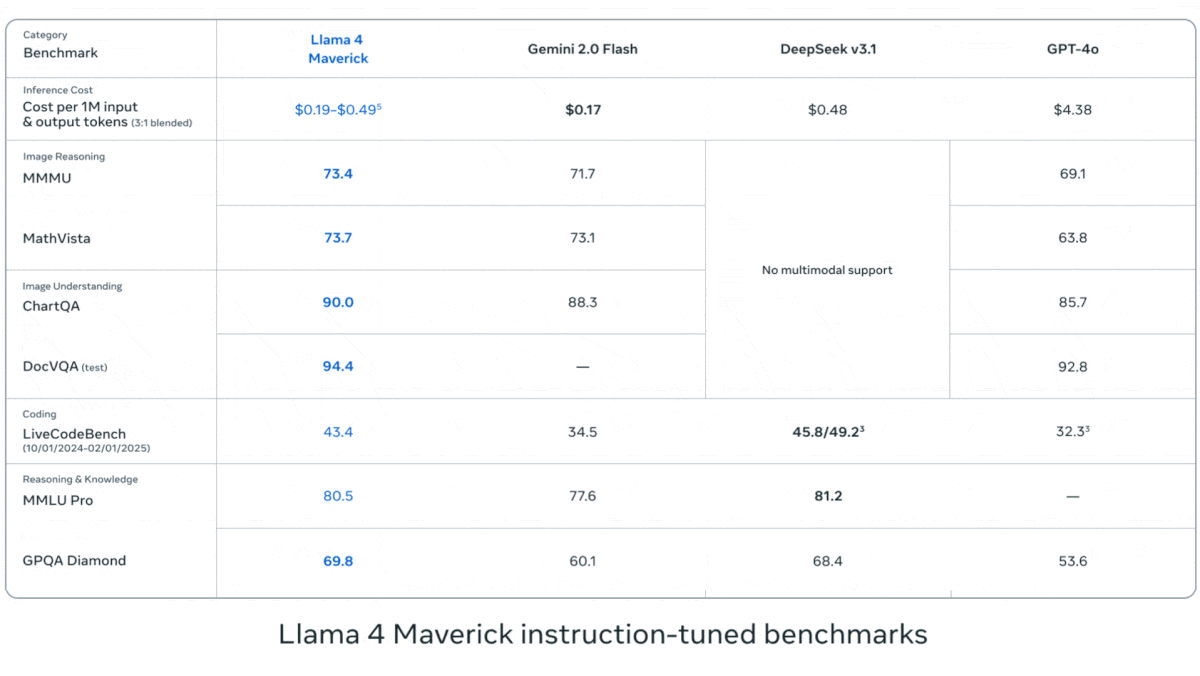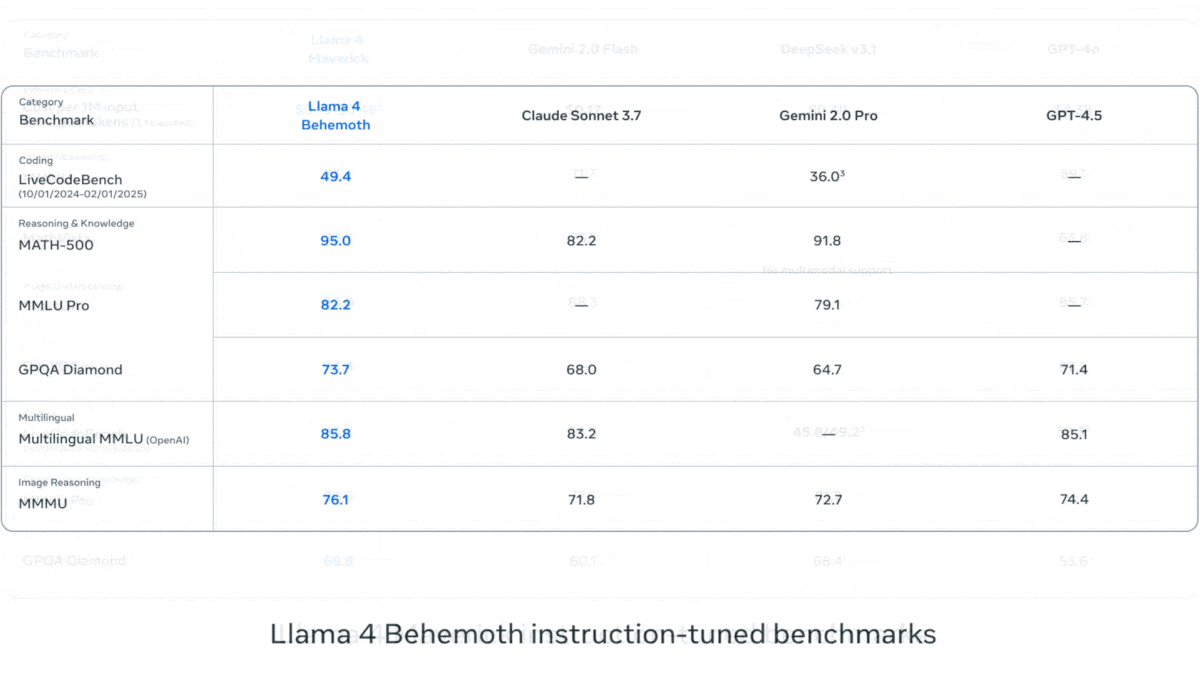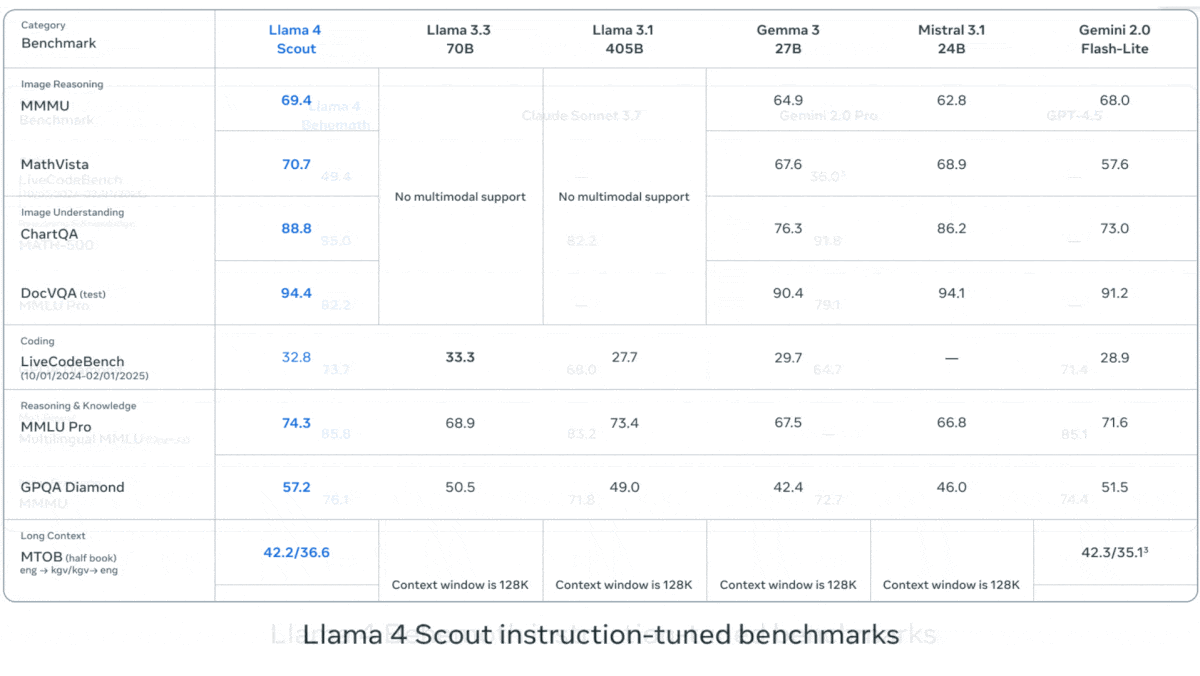
Meta, Llama 4 시리즈 비전 언어 모델 발표: Meta는 Llama 4 시리즈의 두 가지 오픈소스 멀티모달 모델인 Llama 4 Scout (109B 파라미터, 17B 활성)와 Llama 4 Maverick (400B 파라미터, 17B 활성)을 출시했으며, 약 2T 파라미터의 Llama 4 Behemoth를 예고했습니다. 이 모델들은 모두 MoE 아키텍처를 채택하고 텍스트, 이미지, 비디오 입력을 지원하며 텍스트 출력을 생성합니다. Scout는 최대 10M 토큰의 컨텍스트 창(실제 유효성에 대한 의문은 있음)을 가지고 있으며, Maverick은 1M입니다. 모델들은 이미지, 코딩, 지식, 추론 등 여러 벤치마크에서 강력한 성능을 보였으며, Scout는 Gemma 3 27B 등을 능가하고 Maverick은 GPT-4o 및 Gemini 2.0 Flash보다 우수하며, 초기 Behemoth 버전은 GPT-4.5 등을 넘어섰습니다. 이 모델들의 발표는 오픈소스 모델이 폐쇄형 모델을 따라잡는 추세를 더욱 가속화하고 있습니다 (출처: DeepLearning.AI, X @AIatMeta)
알리바바, Qwen2.5-Omni 7B 멀티모달 모델 발표: 알리바바는 새로운 오픈소스 멀티모달 모델 Qwen2.5-Omni 7B를 발표했습니다. 이 모델은 텍스트, 이미지, 오디오, 비디오 입력을 처리하고 텍스트 및 음성 출력을 생성할 수 있습니다. 이 모델은 Qwen 2.5 7B 텍스트 모델, Qwen2.5-VL 비전 인코더, Whisper-large-v3 오디오 인코더를 기반으로 구축되었으며, 혁신적인 Thinker-Talker 아키텍처를 채택했습니다. 모델은 여러 벤치마크에서 뛰어난 성능을 보였으며, 특히 오디오-텍스트, 이미지-텍스트, 비디오-텍스트 작업에서 SOTA 수준을 달성했지만, 순수 텍스트 및 텍스트-음성 작업에서는 다소 뒤처졌습니다. Qwen2.5-Omni의 발표는 고성능 오픈소스 멀티모달 모델의 선택지를 더욱 풍부하게 만들었습니다 (출처: DeepLearning.AI)
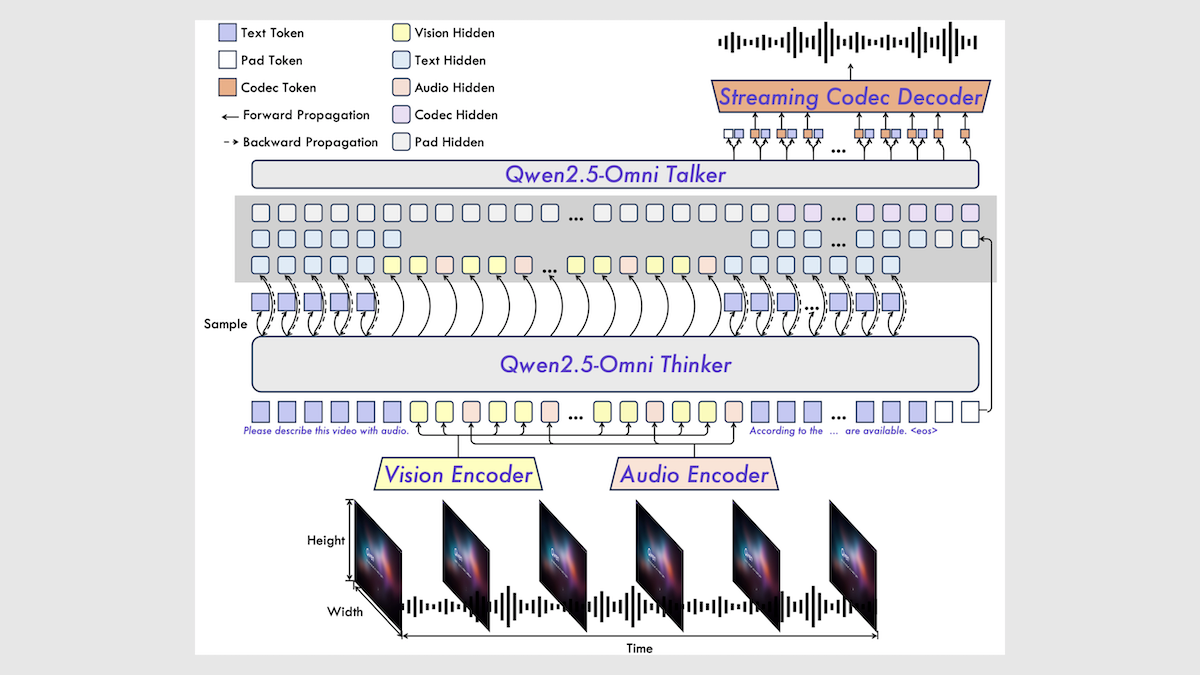
TabPFN: 의사 결정 트리를 뛰어넘는 테이블 데이터 Transformer: 프라이부르크 대학 등 연구 기관의 연구자들이 테이블 데이터 전용 Transformer 모델인 Tabular Prior-data Fitted Network (TabPFN)를 출시했습니다. 1억 개의 합성 데이터셋에서 사전 훈련을 통해 TabPFN은 데이터셋 간의 패턴을 인식하는 법을 학습하여, 추가 훈련 없이 새로운 테이블 데이터에서 직접 분류 및 회귀 예측을 수행할 수 있습니다. 실험 결과, AutoML 및 OpenML-CTR23 벤치마크에서 TabPFN은 분류(AUC) 및 회귀(RMSE) 작업에서 CatBoost, LightGBM, XGBoost와 같은 인기 있는 그래디언트 부스팅 트리 방법보다 우수한 성능을 보였지만, 추론 속도는 더 느렸습니다. 이 연구는 Transformer가 테이블 데이터 처리 분야에서 새로운 길을 열었습니다 (출처: DeepLearning.AI)
인텔 플랫폼, 대형 모델 일체형 머신의 새로운 가성비 선택지로 부상: DeepSeek 등 오픈소스 모델의 보급에 따라, 대형 모델 일체형 머신은 기업이 AI를 신속하게 배포하는 인기 있는 선택지가 되었습니다. 인텔은 자사의 Arc™ 게이밍 그래픽 카드(예: A770)와 Xeon® W 프로세서 조합을 통해 높은 가성비의 하드웨어 솔루션을 제공하여, 일체형 머신 가격을 백만 위안 수준에서 십만 위안 수준으로 낮추고 있습니다. 이 플랫폼은 DeepSeek R1뿐만 아니라 Qwen, Llama 등 모델도 지원합니다. Feizhi Cloud, SuperCloud, Cloud-Tip 등 여러 기업이 이 플랫폼을 기반으로 지식 기반 Q&A, 스마트 고객 서비스, 금융 투자 자문, 문서 처리 등 시나리오에 사용되는 AI 일체형 머신 제품 또는 솔루션을 출시하여 중소기업 및 특정 부서의 로컬 AI 추론 요구를 충족시키고 있습니다 (출처: 量子位)
Google, 7세대 TPU “Ironwood” 출시: Google Cloud Next 컨퍼런스에서 Google은 AI 추론에 최적화된 7세대 TPU 시스템 Ironwood를 발표했습니다. 1세대 Cloud TPU와 비교하여 Ironwood의 성능은 3600배 향상되었고, 에너지 효율은 29배 향상되었습니다. 6세대 Trillium과 비교하면 Ironwood의 와트당 성능은 2배 향상되었고, 단일 칩 메모리는 192GB(Trillium의 6배)에 달하며, 데이터 접근 속도는 4.5배 빨라졌습니다. Ironwood는 증가하는 AI 추론 수요를 충족시키기 위해 올해 말 출시될 예정입니다 (출처: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind 및 Gemini 모델, MCP 프로토콜 지원 예정: Google DeepMind의 공동 창립자 Demis Hassabis와 Gemini 모델 책임자 Oriol Vinyals는 모델 컨텍스트 프로토콜(MCP)을 지원할 것이며, MCP 팀 및 업계 파트너와 함께 이 프로토콜을 발전시키기를 기대한다고 밝혔습니다. MCP는 AI Agent 시대의 개방형 표준으로 빠르게 자리 잡고 있으며, 다양한 모델이 통일된 “서비스 언어”를 이해하여 외부 도구 및 API를 쉽게 호출할 수 있도록 하는 것을 목표로 합니다. 이 조치는 Gemini 모델이 성장하는 MCP 생태계에 더 잘 통합되어 더 강력한 Agent 애플리케이션을 구축할 수 있게 할 것입니다 (출처: X @demishassabis, X @OriolVinyalsML)
Moonshot AI, KimiVL A3B 멀티모달 모델 발표: Moonshot AI(月之暗面)는 KimiVL A3B Instruct & Thinking 모델을 발표했습니다. 이는 128K의 긴 컨텍스트 능력을 갖춘 오픈소스(MIT 라이선스) 멀티모달 대형 모델 시리즈입니다. 이 시리즈는 MoE VLM과 MoE Reasoning VLM을 포함하며, 활성 파라미터는 약 3B에 불과합니다. 비전 및 수학 벤치마크에서 GPT-4o보다 우수하다고 알려졌으며, MathVision에서 36.8%, ScreenSpot-Pro에서 34.5%, OCRBench에서 867점을 기록했고, 긴 컨텍스트 테스트(MMLongBench-Doc 35.1%, LongVideoBench 64.5%)에서도 뛰어난 성능을 보였습니다. 모델 가중치는 Hugging Face에 공개되었습니다 (출처: X @huggingface)

Orpheus TTS 3B 출시: 다국어 제로샷 음성 복제 모델: 오픈소스 커뮤니티에서 Orpheus TTS 3B 모델을 출시했습니다. 이는 30억 파라미터의 다국어 텍스트 음성 변환 모델입니다. 제로샷 음성 복제를 지원하며, 스트리밍 생성 지연 시간은 약 100밀리초이고, 감정과 억양을 유도하여 사람과 유사한 음성을 생성할 수 있습니다. 이 모델은 Apache 2.0 라이선스를 사용하며, 가중치는 Hugging Face에서 제공되어 오픈소스 TTS 기술 발전을 더욱 촉진하고 있습니다 (출처: X @huggingface)
OmniSVG 출시: 통합 확장 가능한 벡터 그래픽 생성 모델: OmniSVG라는 새로운 모델이 제안되었습니다. 이는 확장 가능한 벡터 그래픽(SVG) 생성을 통합하는 것을 목표로 합니다. 이 모델은 Qwen2.5-VL을 기반으로 하며 SVG 토크나이저를 통합하여 텍스트 및 이미지 입력을 받아 해당 SVG 코드를 생성할 수 있습니다. 프로젝트 웹사이트는 강력한 SVG 생성 효과를 보여줍니다. 현재 논문과 데이터셋은 공개되었지만 모델 가중치는 아직 공개되지 않았습니다 (출처: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025, AI에 초점: Google Cloud Next 컨퍼런스는 AI 분야의 진전을 중점적으로 선보였습니다. 추론에 최적화된 7세대 TPU Ironwood를 발표했습니다. Gemini 2.5 Pro가 현재 가장 지능적인 모델이며 Chatbot Arena에서 1위를 차지했다고 발표했습니다. DeepMind, Google Research, Google Cloud의 연구 성과를 결합하여 고객에게 WeatherNext 및 AlphaFold와 같은 모델을 제공합니다. 기업이 자체 데이터 센터에서 Gemini 모델을 실행할 수 있도록 허용합니다. Nvidia와 협력하여 Gemini 모델을 Blackwell 및 기밀 컴퓨팅을 통해 온프레미스 배포로 가져올 것이라고 발표했습니다 (출처: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
2025년 AI 트렌드 예측: 여러 의견을 종합하면, 2025년 AI의 주요 트렌드는 다음과 같습니다: 생성형 AI의 지속적인 발전과 응용 심화, AI 윤리 및 책임감 있는 AI의 중요성 증대, 엣지 AI의 보급, 특정 산업(의료, 금융, 공급망 등)에서의 AI 도입 가속화, 멀티모달 AI 능력 강화, AI Agent의 자율성 및 도전 과제, AI가 기존 비즈니스 모델에 미치는 파괴적 영향, 그리고 AI 인재 및 기술 다양성 요구 증가 (출처: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

테슬라 공장, 차량 자율 주행 운송 실현: 테슬라는 생산된 자동차가 공장 구역 내에서 생산 라인에서 하역 구역까지 사람의 개입 없이 자동으로 주행할 수 있음을 보여주었습니다. 이는 통제된 환경(예: 공장 물류)에서의 자율 주행 기술 적용 가능성을 보여주며, 자동차 제조 및 자동화 분야에서 AI 발전의 한 예입니다 (출처: X @Ronald_vanLoon)
🧰 도구
Free-for-dev: 개발자를 위한 무료 리소스 모음: GitHub의 ripienaar/free-for-dev 프로젝트는 개발자(특히 DevOps 및 인프라 개발자)에게 유용한 다양한 SaaS, PaaS, IaaS 제품의 무료 플랜을 모아놓은 인기 있는 리소스 목록입니다. 이 목록은 클라우드 서비스, 데이터베이스, API, 모니터링, CI/CD, 코드 호스팅, AI 도구 등 다양한 카테고리를 포함하며, 서비스 제공자가 평가판이 아닌 장기 무료 티어를 제공해야 하고 보안(예: TLS를 제한하는 서비스는 허용되지 않음)을 중시한다는 명확한 요구 사항을 가지고 있습니다. 이 프로젝트는 커뮤니티 주도로 지속적으로 업데이트되며, 개발자가 무료 서비스를 찾고 비교하는 데 큰 편의를 제공합니다 (출처: GitHub: ripienaar/free-for-dev)

Graphiti: 실시간 AI 지식 그래프 구축 프레임워크: getzep/graphiti는 시계열 인지 능력을 갖춘 지식 그래프를 구축하고 쿼리하기 위한 Python 프레임워크로, 특히 동적 환경 정보를 처리해야 하는 AI Agent에 적합합니다. 사용자 상호 작용, 구조화/비구조화 데이터를 지속적으로 통합하고, 증분 업데이트 및 정확한 과거 쿼리를 지원하며, 그래프를 완전히 다시 계산할 필요가 없습니다. Graphiti는 의미론적 임베딩, 키워드 검색(BM25), 그래프 순회를 결합하여 효율적인 하이브리드 검색을 수행하며, 사용자 정의 엔티티 정의를 허용합니다. 이 프레임워크는 Zep 메모리 계층의 핵심 기술이며 현재 오픈소스로 공개되었습니다 (출처: GitHub: getzep/graphiti)

WeChatMsg: 위챗 채팅 기록 추출 및 AI 비서 훈련 도구: LC044/WeChatMsg는 Windows 로컬 위챗 채팅 기록(위챗 4.0 지원)을 추출하여 HTML, Word, Excel 등 형식으로 내보내는 도구입니다. 사용자가 채팅 기록을 영구적으로 보존하도록 돕고, 기록을 분석하여 연례 보고서를 생성할 수 있습니다. 더 나아가, 이 도구는 사용자의 채팅 데이터를 활용하여 개인화된 AI 채팅 비서를 훈련하는 것을 지원하며, “내 데이터는 내가 관리한다”는 이념을 구현합니다. 프로젝트는 그래픽 사용자 인터페이스와 상세한 사용 설명을 제공합니다 (출처: GitHub: LC044/WeChatMsg)
알리바바 클라우드 바이롄, 전체 주기 MCP 서비스 출시, Agent 팩토리 구축: 알리바바 클라우드 바이롄 플랫폼이 모델 컨텍스트 프로토콜(MCP) 서비스의 전체 플랫폼 기능을 공식 출시했습니다. 이는 서비스 등록, 클라우드 호스팅, Agent 호출 및 프로세스 조합의 전체 생명 주기를 포괄합니다. 개발자는 플랫폼에서 호스팅되는 고덕 지도, Notion 등 공식 또는 타사 MCP 서비스를 직접 사용하거나, 간단한 구성(서버 관리 불필요)을 통해 자체 API를 MCP 서비스로 등록할 수 있습니다. 이는 Agent 개발 장벽을 낮추어 개발자가 외부 도구 호출 능력을 갖춘 AI Agent를 신속하게 구축하고 배포하여 실제 시나리오에서 대형 모델의 응용을 촉진하는 것을 목표로 합니다. 이 서비스는 알리바바 AI 상업화의 중요한 단계로 간주됩니다 (출처: 微信公众号 – AINLPer, 量子位)
Hugging Face와 Cloudflare, 무료 WebRTC 인프라 제공 협력: Hugging Face는 Cloudflare와 협력하여 FastRTC를 통해 AI 개발자에게 전 세계적인 엔터프라이즈급 WebRTC 인프라를 제공합니다. 개발자는 Hugging Face 토큰을 사용하여 10GB 데이터를 무료로 전송하여 실시간 음성 및 비디오 AI 애플리케이션을 구축할 수 있습니다. 공식적으로 Llama 4 음성 채팅 데모를 예시로 제공하여 이 협력이 가져오는 편리함을 보여줍니다 (출처: X @huggingface)
Google AI Studio, 대규모 UI 업데이트: Google AI Studio(이전 MakerSuite)의 사용자 인터페이스가 1단계 재설계를 거쳐 더욱 현대적인 외관과 경험을 제공합니다. 이번 업데이트는 향후 몇 달 내에 출시될 더 많은 개발자 플랫폼 기능을 위한 기반을 마련하는 것을 목표로 합니다. 새로운 UI는 Gemini 애플리케이션의 스타일과 더욱 통일되었으며, API 관리 및 결제 관리를 위한 전용 개발자 백엔드가 추가되었습니다. 이번 업데이트는 플랫폼 기능 확장을 예고하며, 새로운 모델(예: Veo 2)에 대한 접근을 포함할 수 있습니다 (출처: X @JeffDean, X @op7418)

LlamaIndex, 시각적 참조 기능 출시: LlamaIndex는 LlamaParse의 레이아웃 Agent 기능을 활용하여 Agent 답변의 시각적 참조를 구현하는 방법을 보여주는 새로운 튜토리얼을 발표했습니다. 이는 생성된 답변이 텍스트 출처를 추적할 수 있을 뿐만 아니라, 원본 문서(예: PDF)의 해당 시각적 영역(경계 상자를 통해 정확하게 위치 지정)에 직접 매핑될 수 있음을 의미합니다. 이는 특히 차트, 표 등 시각적 요소가 포함된 문서를 처리할 때 Agent 답변의 해석 가능성과 추적 가능성을 향상시킵니다 (출처: X @jerryjliu0)

LangGraph, 코드 없는 GUI 빌더 출시: LangGraph는 이제 Agent 아키텍처 설계를 위한 코드 없는 그래픽 사용자 인터페이스(GUI) 빌더를 제공합니다. 사용자는 드래그 앤 드롭과 같은 시각적 조작을 통해 Agent의 작업 흐름과 노드 연결을 계획한 다음, 클릭 한 번으로 Python 또는 TypeScript 코드를 생성할 수 있습니다. 이는 복잡한 Agent 애플리케이션 구축의 장벽을 낮추고 빠른 프로토타이핑 및 개발을 용이하게 합니다 (출처: X @LangChainAI)
Perplexity, 주식 차트 기능 업데이트: Perplexity는 주식 차트 기능을 업데이트하여 이제 시간 축을 전체 차트에 걸쳐 늘리는 대신 당일 주가 변동을 실시간으로 반영합니다. 이 개선 사항은 기본적이지만 금융 정보 표시의 즉시성과 실용성을 향상시킵니다 (출처: X @AravSrinivas, X @AravSrinivas)

OLMoTrace: LLM 출력과 훈련 데이터 연결 도구: Allen Institute for AI (AI2)는 OLMo 모델의 출력을 해당 훈련 데이터 소스(4T 토큰 데이터 내에서 초 단위 매칭)에 실시간으로 매핑할 수 있는 OLMoTrace 도구를 출시했습니다. 이는 모델 행동 이해, 투명성 향상, 후훈련 데이터 개선에 도움이 됩니다. 이 도구는 연구자와 개발자가 대형 언어 모델의 내부 작동 메커니즘과 지식 출처를 더 잘 이해하도록 돕는 것을 목표로 합니다 (출처: X @natolambert)
llama.cpp, Qwen3 모델 지원 병합: 인기 있는 로컬 LLM 추론 프레임워크 llama.cpp가 곧 출시될 Qwen3 시리즈 모델(기본 모델 및 MoE 버전 포함)에 대한 지원을 병합했습니다. 이는 Qwen3 모델이 출시되면 사용자가 llama.cpp 생태계에서 GGUF 형식의 양자화된 모델을 즉시 사용하여 로컬 장치에서 실행할 수 있음을 의미합니다 (출처: X @karminski3, Reddit r/LocalLLaMA)

KTransformers 프레임워크, Llama 4 모델 지원: 국산 AI 추론 프레임워크 KTransformers(CPU+GPU 혼합 추론, 특히 MoE 모델 오프로딩 지원으로 유명)가 개발 브랜치에 Meta Llama 4 시리즈 모델에 대한 실험적 지원을 추가했습니다. 문서에 따르면, Q4 양자화된 Llama-4-Scout (109B)를 실행하려면 약 65GB 메모리와 10GB VRAM이 필요하며, Llama-4-Maverick (402B)는 약 270GB 메모리와 12GB VRAM이 필요합니다. 4090 + 듀얼 Xeon 4 구성에서 단일 배치 추론 속도는 32 tokens/s에 달할 수 있습니다. 이는 제한된 VRAM 환경에서 대형 MoE 모델을 실행할 가능성을 제공합니다 (출처: X @karminski3, Reddit r/LocalLLaMA)
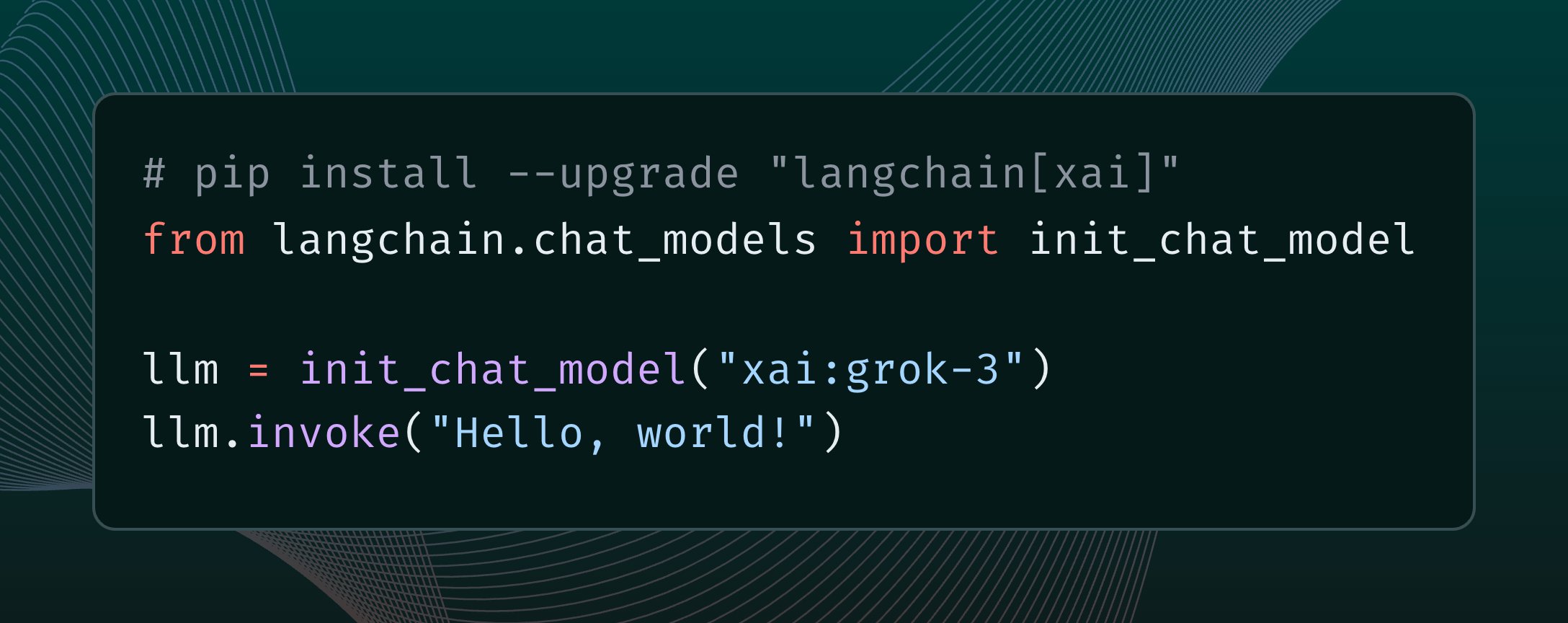
LangChain, xAI Grok 3 모델 통합: LangChain은 xAI가 최근 발표한 Grok 3 모델을 통합했다고 발표했습니다. 사용자는 이제 LangChain 프레임워크를 통해 Grok 3를 호출하여 강력한 기능을 활용하여 애플리케이션을 구축할 수 있습니다 (출처: X @LangChainAI)
n8n 클라우드 서비스 무료 배포 튜토리얼: Hugging Face Spaces와 Supabase를 사용하여 오픈소스 워크플로우 자동화 플랫폼 n8n을 무료로 배포하고 HTTPS를 지원하는 공용 도메인 접근 권한을 얻는 방법을 소개합니다. 이를 통해 사용자는 자체 서버 구매 및 도메인/SSL 인증서 구성 없이 n8n의 전체 기능(콜백 URL이 필요한 노드 포함)을 활용할 수 있습니다. 이 방법은 Supabase의 무료 데이터베이스를 활용하여 Hugging Face Space 휴면으로 인한 데이터 손실 문제를 해결합니다 (출처: 微信公众号 – 袋鼠帝AI客栈)
OpenWebUI 플러그인 업데이트: 컨텍스트 카운터 및 적응형 메모리: 커뮤니티 개발자가 OpenWebUI용 플러그인 두 개를 출시/업데이트했습니다: 1) Enhanced Context Counter v3는 상세한 토큰 사용량, 비용 추적 및 성능 지표 대시보드를 제공하며, 다양한 모델과 사용자 정의 보정을 지원합니다. 2) Adaptive Memory v2는 LLM을 통해 사용자 특정 정보(사실, 선호도, 목표 등)를 동적으로 추출, 저장 및 주입하여 개인화되고 지속적이며 적응적인 대화 메모리를 구현하며, 외부 의존성 없이 완전히 로컬에서 실행됩니다 (출처: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP: Claude가 전화 걸게 하기: 커뮤니티 개발자가 QuickVoice라는 MCP(모델 컨텍스트 프로토콜) 도구를 만들었습니다. 이를 통해 Claude 3.7 Sonnet과 같이 MCP를 지원하는 모델이 실제 전화를 걸고 처리할 수 있습니다. 사용자는 자연어 명령어(예: “의사에게 전화해서 예약해줘”)를 통해 AI가 IVR 메뉴 탐색을 포함한 통화 작업을 완료하도록 할 수 있습니다. 프로젝트는 GitHub에 오픈소스로 공개되었습니다 (출처: Reddit r/ClaudeAI)

RPG Dice Roller for OpenWebUI: 커뮤니티에서 OpenWebUI용 RPG 주사위 굴리기 도구 플러그인을 개발했습니다. 롤플레잉 게임 대화 시 실제적인 무작위 결과를 얻는 데 편리합니다 (출처: Reddit r/OpenWebUI)
📚 학습 자료
Girafe-ai 오픈소스 머신러닝 강의: GitHub의 girafe-ai/ml-course 프로젝트는 girafe-ai 머신러닝 강의 1학기 교육 자료를 제공합니다. Naive Bayes, kNN, 선형 회귀/분류, SVM, PCA, 의사 결정 트리, 앙상블 학습, 그래디언트 부스팅 및 딥러닝 입문 등의 내용을 포함합니다. 강의 비디오 녹화, PPT 강의 자료 및 과제를 제공합니다. 머신러닝 기초 지식을 배우는 데 귀중한 자료입니다 (출처: GitHub: girafe-ai/ml-course)
중국과기대와 화웨이 노아, CMO 프레임워크로 칩 로직 합성 최적화 제안: 중국과학기술대학 왕제 교수팀과 화웨이 노아의 방주 연구소가 협력하여 ICLR 2025에 논문을 발표하고, 신경 기호 함수 마이닝 기반의 효율적인 로직 최적화 방법 CMO를 제안했습니다. 이 프레임워크는 그래프 신경망(GNN)을 사용하여 몬테카를로 트리 탐색(MCTS)을 안내하고, 가볍고 해석 가능하며 일반화 능력이 뛰어난 기호 점수 함수를 생성하여 로직 최적화 연산자(예: Mfs2)의 비효율적인 노드 변환을 가지치기합니다. 실험 결과, CMO는 핵심 연산자의 실행 효율을 최대 2.5배 향상시키면서 최적화 품질을 유지하며, 화웨이 자체 개발 EMU 로직 합성 도구에 적용되었습니다 (출처: 量子位)
상하이 AI Lab, MaskGaussian 가우시안 가지치기 신규 방법 제안: 상하이 AI Lab 연구팀은 CVPR 2025에서 3D 가우시안 스플래팅(3D Gaussian Splatting) 최적화를 위한 MaskGaussian 방법을 제안했습니다. 이 방법은 학습 가능한 마스크 분포를 래스터화 과정에 통합하여, 사용되는 가우시안 점과 사용되지 않는 가우시안 점 모두에 대해 그래디언트를 보존하는 것을 처음으로 실현했습니다. 이를 통해 대량의 중복 가우시안 점을 가지치기하면서도 재구성 품질을 최대한 유지할 수 있습니다. 여러 데이터셋에서의 실험 결과, 60% 이상의 가우시안 점을 가지치기했음에도 성능 손실은 무시할 수 있었으며, 동시에 훈련 속도를 높이고 메모리 사용량을 줄였습니다 (출처: 量子位)
Qwen2.5-Omni 기술 보고서 해설: Reddit 사용자가 알리바바 Qwen2.5-Omni 기술 보고서에 대한 상세한 해설 노트를 공유했습니다. 보고서는 이 모델의 Thinker-Talker 아키텍처, 멀티모달(텍스트, 이미지, 오디오, 비디오) 입력 처리 방식(오디오-비디오 정렬을 위한 혁신적인 TMRoPE 위치 인코딩 포함), 스트리밍 음성 생성 메커니즘, 훈련 과정(사전 훈련 + 후훈련 RL) 등을 소개합니다. 이 노트는 이 최첨단 멀티모달 모델의 내부 작동 원리를 이해하는 데 유용한 참고 자료를 제공합니다 (출처: Reddit r/LocalLLaMA)
맥킨지, 기업 생성형 AI 확장 운영 가이드 발표: 맥킨지는 데이터 리더를 대상으로 기업에서 생성형 AI를 규모 있게 적용하는 방법을 논의하는 운영 가이드를 발표했습니다. 보고서는 전략 수립, 기술 선택, 인재 양성, 위험 관리 등의 측면을 다루며, 기업이 실제 환경에서 GenAI를 도입하고 확장하는 데 지침을 제공할 수 있습니다 (출처: X @Ronald_vanLoon)

AI Agent 학습 입문 가이드: Khulood_Almani가 AI Agent 학습을 시작하는 방법에 대한 자료나 단계를 공유했습니다. 학습 경로, 핵심 개념, 추천 도구 또는 플랫폼 등을 포함할 수 있으며, AI Agent 분야에 입문하려는 학습자에게 지침을 제공합니다 (출처: X @Ronald_vanLoon)

시각적 장소 인식에서의 재순위화 기술 연구: arXiv에 게재된 한 논문은 시각적 장소 인식(Visual Place Recognition, VPR) 작업에서 재순위화(Re-Ranking) 기술이 여전히 유효한지 탐구합니다. 연구는 기존 재순위화 방법의 장단점을 분석하고 현대 VPR 시스템에서의 역할과 필요성을 평가할 수 있습니다 (출처: Reddit r/deeplearning, Reddit r/MachineLearning)
《AI 2027》 연구 보고서, ASI 위험과 미래 탐구: 《AI 2027》이라는 제목의 연구 보고서는 2027년까지 나타날 수 있는 AI 발전 시나리오, 특히 자동화된 AI 연구 개발이 초인공지능(ASI)의 출현으로 이어질 수 있는 가능성을 탐구합니다. 보고서는 ASI가 가져올 잠재적 위험, 예를 들어 목표 불일치로 인한 인류의 권력 상실, 권력 집중, 국제 군비 경쟁 심화로 인한 안보 위험, 모델 탈취 및 대중 인식 지연 등의 문제를 분석하고, 지정학적으로 발생할 수 있는 전쟁, 협정 또는 굴복 등의 결말을 논의합니다 (출처: Reddit r/artificial)
신경망 활성화 정렬 연구: OpenReview에 발표된 한 논문은 신경망에서 표현 정렬(representational alignment)이 발생하는 이유를 탐구합니다. 연구는 정렬이 단일 뉴런에서 비롯된 것이 아니라 활성화 함수가 작동하는 방식과 관련이 있음을 발견하고, 이 현상을 설명하기 위해 Spotlight Resonance Method를 제안하며 실험 결과를 통해 이를 뒷받침합니다 (출처: Reddit r/deeplearning)
💼 비즈니스
알리바바 인터내셔널, 돌파구 마련 위해 AI에 중점 투자: 국경 간 전자상거래 업계의 치열한 경쟁과 글로벌 무역 변화에 직면하여, 알리바바 인터내셔널 디지털 커머스 그룹은 AI를 핵심 전략으로 삼고 성장과 효율성 향상을 위해 대대적으로 투자하고 있습니다. 회사는 “Bravo 102” 글로벌 AI 인재 양성 계획을 시작했으며, 신입 채용에서 80%의 직무를 AI 관련으로 설정했습니다. AI 응용은 이미 B2B(AI 검색 엔진 Accio, “비즈니스 도우미” AI Agent)와 B2C(Aidge 플랫폼에서 가상 피팅, AI 고객 서비스 등 제공)를 포괄합니다. 알리바바 인터내셔널의 매출은 크게 증가했지만(2024년 4분기 전년 동기 대비 32% 증가), 투자로 인해 손실이 확대되었습니다. AI는 알리바바 인터내셔널이 저가 경쟁에서 벗어나 고부가가치 전환과 정교한 운영을 실현하는 핵심 동력으로 간주됩니다 (출처: 36氪)
OpenAI 전 핵심 멤버, Mira Murati의 새 회사 합류: GPT 시리즈의 첫 저자 Alec Radford와 OpenAI 전 최고 연구 책임자 Bob McGrew가 OpenAI 전 CTO Mira Murati가 설립한 새로운 AI 회사 Thinking Machines Lab에 고문으로 합류했습니다. Radford는 GPT 시리즈 모델 탄생에 핵심적인 역할을 했으며, McGrew는 GPT-3/4 및 o1 모델 개발에 깊이 관여했습니다. Thinking Machines Lab 창립 팀 멤버 중 상당수(최소 19명)가 OpenAI 출신입니다. 이 회사는 AI 응용 보급을 목표로 하며, 10억 달러 자금 조달을 계획하고 있고 기업 가치는 90억 달러로 평가받는다고 전해져, 최고 수준의 AI 인재가 이끄는 스타트업에 대한 시장의 높은 기대를 보여줍니다 (출처: 新智元)
공모 펀드, 제약 기업의 AI+의료 사업 주목: 최근 중국의 여러 공모 펀드가 제약 상장 기업을 집중적으로 조사했으며, 의료 분야에서의 AI 응용이 주목받는 초점이 되었습니다. 하이얼 바이오는 자사의 사물인터넷 혈액망, 백신망에서의 AI 응용 및 AI를 통한 공중 보건 시나리오(예: 백신 예약) 효율 향상 진척 상황을 소개했습니다. 하이정 제약은 DeepSeek-R1 모델을 도입했으며 AI 신약 개발 회사와 협력하여 AI를 통해 신약 개발 전 과정에 힘을 실어주기를 희망한다고 밝혔습니다. 강연 제약 또한 AI+다중 오믹스 기반의 한약 혁신 신약 발굴 플랫폼을 구축 중이라고 밝혔습니다. 이는 AI 기술이 제약 연구 개발, 운영 및 환자 서비스 등 여러 단계에서 응용되는 것이 자본 시장의 높은 관심을 받고 있음을 보여줍니다 (출처: 创业板观察)
OpenAI, 산업 협력 심화 위한 Pioneers 프로그램 시작: OpenAI는 야심 찬 기업들과 파트너십을 구축하여 함께 첨단 AI 제품을 만드는 것을 목표로 하는 Pioneers 프로그램을 시작했습니다. 이 프로그램은 두 가지 측면에 집중할 것입니다: 첫째, 모델을 집중적으로 미세 조정하여 특정 분야의 고가치 작업에서 범용 모델을 능가하는 성능을 보이도록 하는 것; 둘째, 업계가 분야 관련 작업에서 모델 성능을 더 잘 측정할 수 있도록 더 우수한 실제 세계 평가(evals)를 구축하는 것입니다. 이는 OpenAI가 자사 기술을 특정 산업에 더 깊이 적용하고 협력 방식을 통해 수직적 분야에서의 모델 실용성과 평가 기준을 향상시키려는 의도를 보여줍니다 (출처: X @sama)
Nvidia와 Google Cloud, 로컬 Gemini 배포 추진 협력: Nvidia와 Google Cloud는 기업 내 로컬(on-prem) 환경에서 Google Gemini 모델 실행을 지원하기 위해 협력한다고 발표했습니다. 이 솔루션은 Nvidia Blackwell GPU 플랫폼과 기밀 컴퓨팅(Confidential Computing) 기술을 결합하여 기업에 고성능이면서 안전한 로컬 AI 배포 옵션을 제공하는 것을 목표로 합니다. 이 조치는 데이터 프라이버시, 보안 규정 준수 및 특정 성능 요구 사항에 대한 일부 기업의 요구를 충족시켜, 자체 인프라에서 강력한 Gemini 모델을 실행할 수 있게 합니다 (출처: X @nvidia)
Google, 기업이 자체 데이터 센터에서 Gemini 모델 실행 허용: Google Cloud는 기업 고객이 자체 데이터 센터에서 Gemini AI 모델을 실행할 수 있도록 허용한다고 발표했습니다. 이 조치는 데이터 주권, 보안 및 맞춤형 배포에 대한 기업의 요구를 충족시키기 위한 것으로, 민감한 데이터를 클라우드로 전송할 필요 없이 로컬 환경에서 Gemini의 강력한 기능을 활용할 수 있게 합니다. 이는 특히 금융, 의료 등 엄격한 규제를 받는 산업의 기업에게 더 큰 유연성과 통제력을 제공합니다 (출처: Reddit r/artificial)
Nvidia CEO 젠슨 황, 관세 영향 경시, AI 서버 면제 가능성 시사: 미국이 시행할 수 있는 새로운 관세 정책에 직면하여, Nvidia CEO 젠슨 황은 영향이 제한적이라고 밝혔으며, 대부분의 Nvidia AI 서버가 면제될 수 있음을 시사했습니다. 이는 해당 제품의 전략적 중요성이나 특정 무역 분류 덕분일 수 있습니다. 이 소식은 Nvidia 하드웨어에 의존하는 AI 산업에 긍정적인 신호이며, 공급망 비용 상승에 대한 우려를 완화하는 데 도움이 될 수 있습니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 커뮤니티
Reddit 뜨거운 논의: Qwen3 모델 언제 출시되나?: Reddit 커뮤니티와 X 플랫폼(구 트위터) 사용자들이 알리바바 Qwen3 모델의 출시 시기에 대해 뜨겁게 논의하고 있습니다. 일부 사용자가 알리 AI 서밋 포스터를 공유하며 곧 출시될 것이라고 추측했지만, 이후 해당 서밋에서 Qwen3가 발표되지 않았다는 소식이 확인되었습니다. 동시에 llama.cpp가 Qwen3 지원을 병합했다는 소식도 커뮤니티의 기대를 더욱 증폭시켰습니다. 이는 오픈소스 커뮤니티가 국산 대형 모델의 진전에 대해 높은 관심과 기대를 가지고 있음을 반영합니다 (출처: X @karminski3, Reddit r/LocalLLaMA)

추론 데이터셋 경진대회 시작: Bespoke Labs가 Hugging Face 및 Together AI와 협력하여 추론 데이터셋 경진대회를 시작했습니다. 이는 커뮤니티가 더 다양하고 실제 세계의 복잡성에 더 가까운 추론 데이터셋, 특히 금융, 의학 등 다분야 추론 측면에서 데이터셋을 생성하도록 장려하여 차세대 LLM 발전을 촉진하는 것을 목표로 합니다. 기존 데이터셋(예: OpenThoughts-114k)은 이미 모델 훈련에서 중요한 역할을 해왔으며, 경진대회는 데이터셋의 경계를 더욱 확장하기를 희망합니다 (출처: X @huggingface)

LiveCodeBench 프로그래밍 벤치마크 업데이트, o3-mini 선두: LiveCodeBench 프로그래밍 능력 순위표가 8개월 만에 업데이트되어 OpenAI의 o3-mini (high)와 o3-mini (medium)가 각각 1위와 2위를 차지했으며, Google Gemini 2.5 Pro가 3위에 올랐습니다. 이 순위표는 커뮤니티 논의를 불러일으켰으며, 일부 사용자는 Claude 3.5/3.7의 순위가 상대적으로 낮은 것에 대해 의문을 제기하며 실제 사용 경험과 일치하지 않는다고 주장했습니다. 이는 서로 다른 벤치마크 테스트와 사용자 주관적 느낌 사이에 존재할 수 있는 차이를 반영합니다 (출처: Reddit r/LocalLLaMA)

커뮤니티, Claude Code 논의: 강력하지만 비싸고 버그 존재: Reddit 사용자들이 Anthropic의 Claude Code에 대해 논의하며, 일반적으로 컨텍스트 인식 능력이 뛰어나고 코딩 효과가 좋으며 심지어 “미래에서 온 것 같다”고 느낀다고 평가했습니다. 그러나 단점으로는 가격이 비싸고(일부 사용자는 하루 사용료가 30달러에 달한다고 함), 일부 버그(예: claude.md 파일 세션 후 손실, 출력 구문 오류 등)가 있다는 점을 지적했습니다. 사용자들은 미래에 더 강력하고 저렴한 대안이 등장하기를 기대하고 있습니다 (출처: Reddit r/ClaudeAI)
사용자, Mistral-Small-3.1-24B 양자화 모델 공유: Ollama 커뮤니티 사용자가 Mistral-Small-3.1-24B 모델의 Q5_K_M 및 Q6_K 양자화 버전(GGUF 형식)을 공유하여 공식 저장소에서 Q4 및 Q8만 제공하는 부족함을 메웠습니다. 이 양자화 모델들은 Ollama 클라이언트를 사용하여 제작되었으며 비전 기능을 지원하고 RTX 4090에서의 컨텍스트 길이 참조를 제공합니다 (출처: Reddit r/LocalLLaMA)

커뮤니티, AI 비디오 업스케일링 도구 문의: Reddit 사용자가 240p 저해상도 비디오를 1080p/60fps로 향상시킬 수 있는 AI 도구가 있는지 문의하며 오래된 뮤직 비디오를 복원하고 싶다고 밝혔습니다. 댓글에서는 Ai4Video 및 Cutout.Pro와 같은 도구가 언급되었지만, 극도로 낮은 해상도에서 향상시키는 효과는 제한적이며 복원보다는 재생성에 가까울 수 있다는 의견도 있었습니다 (출처: Reddit r/artificial)
사용자 피드백: Claude 3.5 Sonnet, 몰래 업데이트된 것으로 의심: Reddit 개발자 사용자가 사용 경험(예: 모델이 이모티콘 사용 시작, 답변 스타일 변화)을 바탕으로 Anthropic이 고지 없이 최적화되거나 증류된 버전으로 원래의 Claude 3.5 Sonnet 모델을 교체하여 성능이나 행동이 변경되었을 수 있다고 의심했습니다. 이 사용자는 원래 3.5 버전이 코딩 측면에서 3.7보다 우수했지만 최근 경험이 저하되었다고 주장했습니다. 이는 모델 버전의 투명성과 일관성에 대한 커뮤니티 논의를 촉발했습니다 (출처: Reddit r/ClaudeAI)
Anthropic 보고서, 학생들의 AI 사용 부정행위 논의 촉발: Anthropic이 교육 보고서를 발표하여 수백만 건의 익명 학생 대화를 분석한 결과, 학생들이 Claude를 사용하여 학문적 부정행위를 할 수 있음을 발견했습니다. 이 보고서는 커뮤니티 논의를 촉발했으며, 다음과 같은 의견이 나왔습니다: 학생 부정행위 현상은 항상 존재했으며 AI는 새로운 도구일 뿐이다; 교육 시스템은 AI 시대에 적응해야 하며 평가 방식이 바뀌어야 한다; 일부 사용자는 Anthropic이 사용자 대화 데이터를 분석하는 것에 대한 프라이버시 우려를 표명했습니다 (출처: Reddit r/ClaudeAI)

사용자, LLM/Agent 애플리케이션 모니터링 방법 논의: Reddit 머신러닝 커뮤니티 사용자가 LLM 애플리케이션 또는 AI Agent의 성능 및 비용을 어떻게 모니터링하는지(예: 토큰 사용량, 지연 시간, 오류율, 프롬프트 버전 변경 추적 등)에 대한 논의를 시작했습니다. 이 논의는 LLMOps 측면에서 커뮤니티의 실천 방법과 문제점을 파악하고, 자체 구축 솔루션을 사용하는지 아니면 특정 도구를 사용하는지 알아보는 것을 목표로 합니다 (출처: Reddit r/MachineLearning)
💡 기타
Andrew Ng, 미국 관세 정책의 AI 영향에 대한 논평: 앤드류 응(Andrew Ng)은 자신의 주간 뉴스레터 The Batch에서 미국의 새로운 관세 정책에 대한 우려를 표명했습니다. 그는 이 정책이 동맹 관계와 세계 경제를 손상시킬 뿐만 아니라, 하드웨어(서버, 냉각, 네트워크 장비, 전력 시설 부품 등) 수입 제한과 소비재 전자제품 가격 인상을 통해 미국 본토의 AI 발전과 응용 보급을 간접적으로 저해할 것이라고 주장했습니다. 그는 관세가 로봇 및 자동화 수요를 약간 자극할 수 있지만, 이것이 제조업 문제를 해결하는 효과적인 방법은 아니며 AI의 로봇 분야 진전은 상대적으로 느리다고 지적했습니다. 그는 AI 커뮤니티가 국제 협력과 사상 교류를 강화할 것을 촉구했습니다 (출처: DeepLearning.AI)

통신 분야 AI의 돌파구와 함정: 이 글은 네트워크 최적화, 고객 서비스, 예측 유지보수 등 통신 산업에서 인공지능의 응용 잠재력을 탐구하는 동시에, 데이터 프라이버시, 알고리즘 편향, 통합 복잡성 및 기존 작업 흐름에 미치는 영향과 같은 잠재적인 도전 과제와 함정을 지적합니다 (출처: X @Ronald_vanLoon)
기술 다양성, AI 투자 수익률에 중요: Antonio Grasso는 인공지능 프로젝트의 투자 수익(ROI)을 성공적으로 달성하려면 팀이 데이터 과학, 엔지니어링, 도메인 지식, 윤리, 비즈니스 분석 등 다방면의 능력을 포함하는 다양한 기술 조합을 갖추어야 한다고 강조합니다 (출처: X @Ronald_vanLoon)

AI 기반 공급망, 지속 가능한 발전 선도: Nicochan33의 글은 AI를 활용하여 공급망 관리(경로 계획, 재고 관리, 수요 예측 등)를 최적화하는 것이 효율성을 높일 뿐만 아니라, 낭비 감소, 에너지 소비 절감 등을 통해 지속 가능한 발전 목표 달성을 촉진할 수 있다고 지적합니다 (출처: X @Ronald_vanLoon)

AI Agent의 자율성, 보호 조치 및 함정: VentureBeat의 글은 AI Agent 발전의 핵심 의제, 즉 자율 능력 균형 조정 방법, 남용이나 예상치 못한 결과를 방지하기 위한 효과적인 안전 보호 조치 설계, 그리고 배포 및 사용 과정에서 발생할 수 있는 함정 등을 탐구합니다 (출처: X @Ronald_vanLoon)

AI, ‘지루한’ 비즈니스에 대한 최대 위협으로 간주: Forbes의 글은 인공지능이 전통적으로 ‘지루하다’거나 절차적인 것으로 간주되는 비즈니스에 가장 큰 파괴적 위협을 가한다고 주장합니다. 이러한 비즈니스는 일반적으로 AI를 통해 자동화하거나 최적화할 수 있는 작업이 많기 때문입니다 (출처: X @Ronald_vanLoon)

의료 알고리즘의 편향 문제 및 새로운 지침: Fortune 기사는 의료 분야에서 AI의 오랜 편향 문제를 주목하고, 새로운 지침이 이 문제를 해결하고 AI 의료 응용의 공정성과 정확성을 보장하는 데 기여할 수 있는지 탐구합니다 (출처: X @Ronald_vanLoon)

노동력 기술 향상 및 질병 식별에서의 AI 역할: Forbes 기사는 AI가 두 가지 긍정적인 측면에서 역할을 하는 것을 탐구합니다: 첫째, 기존 노동력의 기술을 향상시켜 미래의 직무 요구에 적응하도록 돕는 것, 둘째, 질병의 조기 식별 및 진단 측면에서 지원을 제공하는 것입니다 (출처: X @Ronald_vanLoon)

AI 디지털 에이전트, 업무 재정의할 것: VentureBeat 기사는 AI Agent(디지털 에이전트)가 작업장에 어떻게 통합되어 도구로서 뿐만 아니라 업무 자체의 정의, 프로세스 및 인간-기계 협업 방식을 변화시킬 수 있는지 논의합니다 (출처: X @Ronald_vanLoon)

AI Agent의 보이지 않음, 자율성 및 공격 가능성 딜레마: VentureBeat 기사는 AI Agent가 가져오는 새로운 딜레마를 심층적으로 탐구합니다: 이들의 작동은 사용자에게 ‘보이지 않을’ 수 있고, 높은 자율성을 가지며, 동시에 악의적으로 이용되거나 공격당할 수 있어 보안과 윤리에 새로운 도전을 제기합니다 (출처: X @Ronald_vanLoon)

트럼프, TSMC에 100% 관세 부과 위협: 도널드 트럼프 전 미국 대통령은 TSMC에 미국에 공장을 짓지 않으면 제품에 100% 관세를 부과하겠다고 말한 적이 있다고 밝혔습니다. 이 발언은 지정학이 반도체 공급망에 미치는 지속적인 영향을 반영하며, TSMC 칩에 의존하는 AI 하드웨어 공급에 잠재적 위험을 초래할 수 있습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)

Google Gemini 2.5 Pro, 핵심 안전 보고서 누락 지적: Fortune은 Google이 최근 발표한 Gemini 2.5 Pro 모델에 핵심 안전 보고서(Model Card)가 누락되어 있으며, 이는 Google이 이전에 미국 정부 및 국제 정상회의에 했던 AI 안전 약속을 위반할 수 있다고 보도했습니다. 이 사건은 대형 기술 기업의 모델 출시 투명성 및 안전 약속 이행에 대한 관심을 불러일으켰습니다 (출처: Reddit r/artificial)

AI를 이용한 번호판 인식: Rackenzik의 글은 딥러닝 기반의 번호판 탐지 및 인식 기술을 소개하며, 이미지 흐림, 국가별 번호판 스타일 차이, 다양한 실제 환경 조건에서의 인식 어려움과 같은 과제를 논의합니다 (출처: Reddit r/deeplearning)
