
키워드:OpenAI, 아마존 AWS, AI 연산 능력, 스탠포드 AgentFlow, 메이티안 LongCat-Flash-Omni, 알리바바 Qwen3-Max-Thinking, 삼성 TRM 모델, Unity AI 그래프, OpenAI와 아마존 연산 능력 협력, AgentFlow 프레임워크 강화 학습, LongCat-Flash-Omni 전모달 모델, Qwen3-Max-Thinking 추론 능력, TRM 재귀 추론 아키텍처
🔥 포커스
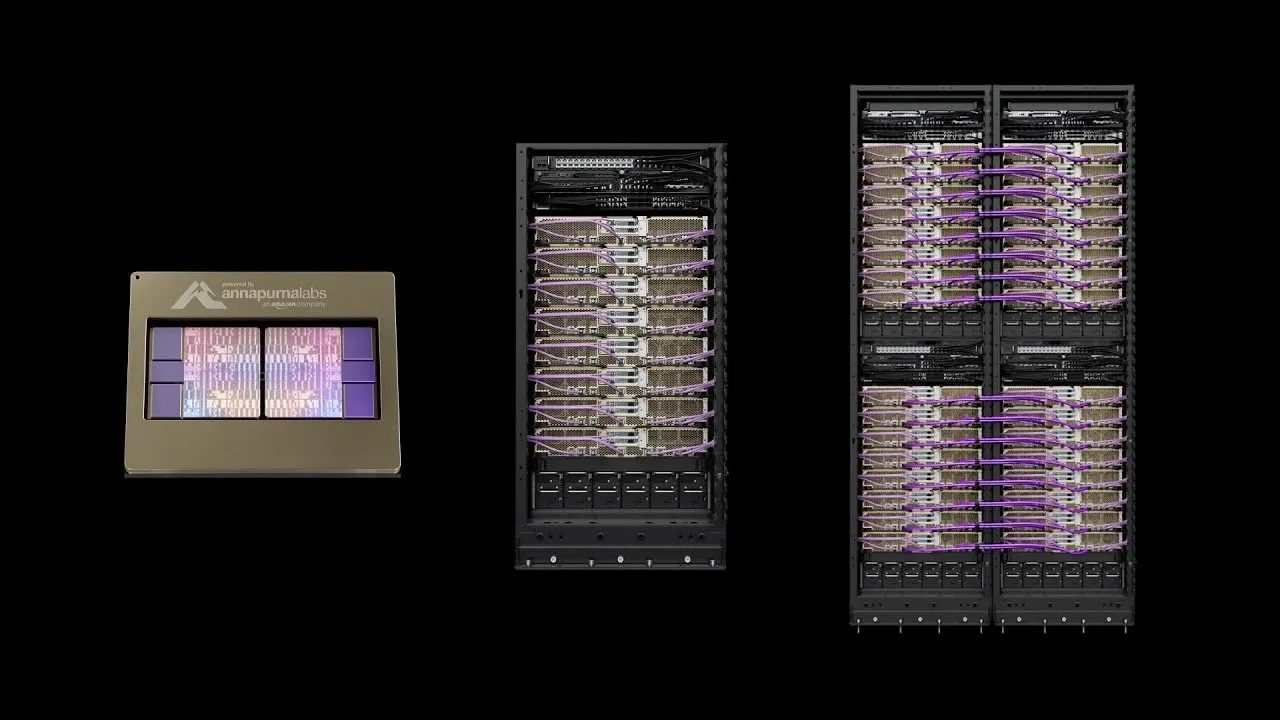
OpenAI와 아마존, 380억 달러 규모의 컴퓨팅 파워 협력 체결: OpenAI와 아마존 AWS는 380억 달러 규모의 컴퓨팅 파워 계약을 체결했습니다. 이는 AI 모델 인프라 구축 및 AI 목표 달성을 위한 NVIDIA GPU 자원 확보를 목표로 합니다. 이번 조치는 OpenAI가 클라우드 서비스 제공업체를 다각화하고, Microsoft에 대한 독점적 의존도를 줄이며, 향후 IPO를 위한 발판을 마련하는 중요한 단계입니다. 아마존은 이 협력을 통해 AI 인프라 분야에서 리더십을 공고히 하는 동시에 OpenAI의 경쟁사인 Anthropic과의 협력도 유지합니다. 이 계약은 OpenAI에 AI 추론 및 차세대 모델 훈련을 위한 확장 가능한 컴퓨팅 파워를 제공하고, AWS 플랫폼에서 기본 모델의 적용을 촉진할 것입니다. (출처: Ronald_vanLoon, scaling01, TheRundownAI)

스탠포드 AgentFlow 프레임워크: 소규모 모델이 GPT-4o를 능가: 스탠포드 대학 등 연구팀이 AgentFlow 프레임워크를 발표했습니다. 이 프레임워크는 모듈형 아키텍처와 Flow-GRPO 알고리즘을 통해 AI 에이전트 시스템이 추론 흐름에서 온라인 강화 학습을 수행하여 지속적인 자체 최적화를 달성하게 합니다. 7B 파라미터의 AgentFlow는 검색, 수학, 과학 등 다양한 작업에서 GPT-4o(약 200B 파라미터) 및 Llama-3.1-405B를 능가하며 HuggingFace Paper 일간 차트에서 1위를 차지했습니다. 이 연구는 에이전트 시스템이 온라인 강화 학습을 통해 대규모 모델과 유사한 학습 능력을 얻을 수 있으며, 특정 작업에서 더 효율적이라는 것을 증명하여 AI 발전에 ‘작지만 강력한’ 새로운 길을 열었습니다. (출처: HuggingFace Daily Papers)
AWS, Project Rainier 가동: 세계 최대 AI 컴퓨팅 클러스터 중 하나: AWS는 Project Rainier를 시작했습니다. 이는 1년도 채 안 되어 구축된 약 50만 개의 Trainium2 칩을 갖춘 AI 컴퓨팅 클러스터로, Anthropic은 이미 이곳에서 새로운 Claude 모델을 훈련했으며 2025년 말까지 100만 개의 칩으로 확장할 계획입니다. Trainium2는 AWS가 대규모 신경망 처리를 위해 맞춤 제작한 AI 훈련 프로세서입니다. 이 프로젝트는 UltraServer 아키텍처를 채택하여 NeuronLinks와 EFA 네트워크를 통해 연결되며, 최대 83.2 petaflops의 희소 FP8 모델 컴퓨팅 능력을 제공하고 100% 재생 에너지로 전력을 공급하여 고효율 에너지 소비를 실현합니다. Project Rainier는 AWS가 AI 인프라 분야에서 선두적인 위치를 차지하고 있음을 보여주며, 맞춤형 칩부터 데이터센터 냉각까지 수직 통합 솔루션을 제공합니다. (출처: TheTuringPost)
🎯 동향
메이투안(美团), LongCat-Flash-Omni 멀티모달 모델 발표: 메이투안(美团)은 최신 멀티모달 모델인 LongCat-Flash-Omni를 오픈소스화했습니다. 이 모델은 Omni-Bench와 WorldSense 등 종합 벤치마크 테스트에서 오픈소스 SOTA(State-Of-The-Art) 수준에 도달했으며, 클로즈드소스인 Gemini-2.5-Pro와 견줄 만합니다. LongCat-Flash-Omni는 총 560B 파라미터, 27B 활성화 파라미터의 MoE 아키텍처를 채택하여 높은 추론 효율성과 낮은 지연 시간의 실시간 상호작용을 구현했으며, 멀티모달 실시간 상호작용을 구현한 최초의 오픈소스 모델입니다. 이 모델은 텍스트, 음성, 이미지, 비디오 및 임의 조합의 멀티모달 입력을 지원하며, 128K tokens의 컨텍스트 창을 갖춰 8분 이상의 오디오-비디오 상호작용을 지원합니다. (출처: WeChat, ZhihuFrontier)

알리바바 Qwen3-Max-Thinking 추론 버전 발표: 알리바바 Qwen 팀은 Qwen3-Max-Thinking의 초기 프리뷰 버전을 발표했습니다. 이 모델은 현재 훈련 중인 중간 체크포인트 모델입니다. 이 모델은 도구 사용을 강화하고 테스트 시간 계산을 확장한 후 AIME 2025 및 HMMT와 같은 도전적인 추론 벤치마크에서 100% 점수를 획득했습니다. Qwen3-Max-Thinking의 출시는 알리바바의 AI 추론 능력에 대한 상당한 진전을 보여주며, 사용자에게 더욱 강력한 사고 연쇄(chain-of-thought) 및 문제 해결 능력을 제공합니다. (출처: Alibaba_Qwen, op7418)
삼성 TRM 모델: 재귀 추론이 Transformer 패러다임에 도전: 삼성 SAIL 몬트리올 연구소는 Tiny Recursive Model(TRM)을 제안했습니다. 이는 단 700만 개의 파라미터와 두 개의 신경망 레이어로 구성된 새로운 재귀 추론 아키텍처입니다. TRM은 ‘답변’과 ‘잠재적 사고 변수’를 재귀적으로 업데이트하여 여러 차례의 자체 수정 과정을 통해 올바른 결과에 근접하며, Sudoku-Extreme과 같은 작업에서 DeepSeek R1 및 Gemini 2.5 Pro와 같은 대규모 모델을 능가하는 기록을 세웠습니다. 이 모델은 아키텍처적으로 심지어 자체 주의(self-attention) 레이어(TRM-MLP 변형)를 포기했는데, 이는 소규모 고정 입력 작업의 경우 MLP가 과적합을 줄일 수 있음을 보여주며, AI 업계의 ‘모델이 클수록 강하다’는 경험적 법칙에 도전하여 경량 AI 추론을 위한 새로운 아이디어를 제공합니다. (출처: 36氪)

Unity 개발자 컨퍼런스: AI+게임 미래 트렌드: 2025 Unity 개발자 컨퍼런스에서는 AI가 게임 창의성과 효율성의 엔진이 될 것이라고 강조했습니다. Unity 엔진은 텐센트 혼원(Tencent Hunyuan)과 협력하여 AIGC 워크플로우를 깊이 통합한 AI Graph 플랫폼을 출시했으며, 이를 통해 2D 디자인 효율성을 30%, 3D 자산 생산 효율성을 70% 향상시킬 수 있습니다. 아마존 웹 서비스(AWS) 또한 게임의 전체 수명 주기(구축, 실행, 성장)에 걸쳐 AI의 역량 강화, 특히 코드 생성 분야에서 AI가 보조 역할에서 자율적인 생성으로 전환되고 있음을 보여주었습니다. 3D 생성형 AI 창작 도구인 Meshy는 확산 모델과 자기회귀 모델을 통해 개발자들이 비용을 절감하고 프로토타입 제작을 가속화하도록 돕고 있으며, 특히 VR/AR 및 UGC 시나리오에서 큰 잠재력을 가지고 있습니다. (출처: WeChat)

Cartesia, Sonic-3 음성 모델 발표: 음성 AI 기업 Cartesia는 최신 음성 모델 Sonic-3를 발표했습니다. 이 모델은 일론 머스크의 목소리를 복제하는 데 놀라운 효과를 보여주었으며, NVIDIA 등 투자자로부터 1억 달러 규모의 시리즈 B 투자를 유치했습니다. Sonic-3는 전통적인 Transformer 아키텍처가 아닌 상태 공간 모델(SSM)을 기반으로 구축되어, 지속적으로 컨텍스트와 대화 분위기를 감지하여 더 자연스럽고 적은 노력으로 AI 응답을 구현합니다. 이 모델의 지연 시간은 90밀리초에 불과하며, 엔드투엔드 응답 시간은 190밀리초로 현재 가장 빠른 음성 생성 시스템 중 하나입니다. (출처: WeChat)

MiniMax, Speech 2.6 음성 모델 발표: MiniMax는 최신 음성 모델 MiniMax Speech 2.6을 발표했습니다. 이 모델은 ‘빠르고 유창하게 말하는’ 특성을 강조합니다. 응답 지연 시간을 250ms 이내로 단축했으며, 40가지 이상의 언어와 모든 악센트를 지원하고, URL, 이메일, 금액, 날짜, 전화번호 등 다양한 ‘비표준 텍스트’를 정확하게 인식할 수 있습니다. 이는 악센트가 강하고 말하는 속도가 빠르며 정보가 복잡한 입력 상황에서도 모델이 한 번에 이해하고 명확하게 말할 수 있음을 의미하며, 음성 상호작용의 효율성과 정확성을 크게 향상시킵니다. (출처: WeChat)
Amazon Chronos-2: 범용 예측 기반 모델: 아마존은 임의의 예측 작업을 처리하도록 설계된 기반 모델인 Chronos-2를 출시했습니다. 이 모델은 단변량, 다변량 및 공변량 정보 예측을 지원하며, 제로샷 방식으로 작동할 수 있습니다. Chronos-2의 출시는 아마존이 시계열 예측 분야에서 중요한 진전을 이루었음을 의미하며, 기업과 개발자에게 더 유연하고 강력한 예측 능력을 제공하여 복잡한 예측 프로세스를 간소화하고 의사 결정 효율성을 높일 것으로 기대됩니다. (출처: dl_weekly)
YOLOv11을 이용한 건물 인스턴스 분할 및 높이 분류: 한 논문은 위성 이미지에서 건물 인스턴스 분할 및 이산 높이 분류에 YOLOv11을 적용한 사례를 자세히 분석했습니다. YOLOv11은 더 효율적인 아키텍처를 통해 다양한 스케일의 특징을 결합하여 객체 위치 정확도를 높였으며, 복잡한 도시 환경에서 뛰어난 성능을 보였습니다. 이 모델은 DFC2023 Track 2 데이터셋에서 60.4% mAP@50 및 38.3% mAP@50-95의 인스턴스 분할 성능을 달성했으며, 동시에 다섯 가지 사전 정의된 높이 레벨에 대한 견고한 분류 정확도를 유지했습니다. YOLOv11은 가려짐, 복잡한 건물 형태 및 클래스 불균형 처리에서 우수한 성능을 보여 실시간 대규모 도시 매핑에 적합합니다. (출처: HuggingFace Daily Papers)
🧰 도구
PageIndex: 추론형 RAG 문서 인덱싱 시스템: VectifyAI는 벡터 데이터베이스와 청킹(chunking)이 필요 없는 추론형 RAG(검색 증강 생성) 시스템인 PageIndex를 발표했습니다. PageIndex는 문서의 트리 구조 인덱스를 구축하여 인간 전문가가 지식을 탐색하고 추출하는 방식을 모방함으로써 LLM이 다단계 추론을 수행하고 더 정확한 문서 검색을 달성할 수 있도록 합니다. 이 시스템은 FinanceBench 벤치마크에서 98.7%의 정확도를 달성하여 기존 벡터 RAG 시스템을 훨씬 능가하며, 특히 금융 보고서, 법률 문서 등 전문적인 장문 분석에 적합합니다. PageIndex는 자체 호스팅, 클라우드 서비스 및 API 등 다양한 배포 옵션을 제공합니다. (출처: GitHub Trending)

LocalAI: 로컬 오픈소스 OpenAI 대체 솔루션: LocalAI는 무료 오픈소스 OpenAI 대체 솔루션으로, OpenAI API와 호환되는 REST API를 제공하며, 소비자용 하드웨어에서 LLM, 이미지, 오디오, 비디오 생성 및 음성 복제를 로컬로 실행할 수 있도록 지원합니다. 이 프로젝트는 GPU 없이 gguf, transformers, diffusers 등 다양한 모델을 지원하며, WebUI, P2P 추론 및 Model Context Protocol(MCP) 등의 기능이 이미 통합되어 있습니다. LocalAI는 AI 추론의 로컬화 및 분산화를 목표로 사용자에게 더 유연하고 사적인 AI 배포 옵션을 제공하며, 다양한 하드웨어 가속을 지원합니다. (출처: GitHub Trending)
DeepAnalyze: 데이터 과학 Agentic LLM: 중국 인민대학과 칭화대학 연구팀은 데이터 과학을 위한 최초의 Agentic LLM인 DeepAnalyze를 출시했습니다. 이 모델은 수동으로 설계된 워크플로우 없이 단 하나의 LLM만으로 데이터 준비, 분석, 모델링, 시각화, 통찰력 도출 등 복잡한 데이터 과학 작업을 자율적으로 완료하고, 분석가 수준의 연구 보고서를 생성할 수 있습니다. DeepAnalyze는 커리큘럼 학습 방식의 Agentic 훈련 패러다임과 데이터 중심의 궤적 합성 프레임워크를 통해 실제 환경에서 학습하며, 보상 희소성 및 장기 체인 문제 해결 궤적 부족 문제를 해결하여 데이터 과학 분야에서 자율적인 심층 연구를 실현했습니다. (출처: WeChat)

AI PC: 인텔 코어 Ultra 200H 시리즈 프로세서 탑재: 인텔 코어 Ultra 200H 시리즈 프로세서를 탑재한 AI PC는 업무 및 생활 효율성을 높이는 새로운 선택지가 되고 있습니다. 이 시리즈 프로세서는 강력한 NPU(신경망 처리 장치)를 통합하여 에너지 효율성을 최대 21% 향상시켰으며, 실시간 배경 소음 제거, 스마트 배경 제거, AI 비서 문서 정리 등 장시간 저전력 AI 작업을 처리할 수 있고, 네트워크 연결 없이도 완료할 수 있습니다. CPU, GPU, NPU의 하이브리드 아키텍처는 AI PC가 얇고 가벼우며 휴대성이 좋고, 긴 배터리 수명과 오프라인 작업에서 뛰어난 성능을 발휘하게 하여 사무, 학습, 게임 환경에 부드럽고 자연스러운 AI 경험을 제공합니다. (출처: WeChat)

Claude Skills: 2300개 이상의 스킬 디렉토리: skillsmp.com이라는 웹사이트는 2300개 이상의 Claude Skills를 수집하여 Claude AI 사용자에게 검색 가능한 스킬 디렉토리를 제공합니다. 이 스킬들은 개발 도구, 문서, AI 강화, 데이터 분석 등 카테고리별로 정리되어 있으며, 미리보기, ZIP 다운로드 및 CLI 설치 기능을 제공합니다. 이 플랫폼은 Claude 사용자가 AI 스킬을 더 편리하게 발견하고 활용하여 에이전트의 능력을 향상시키고 더 효율적인 자동화 작업을 달성하며, 커뮤니티에 유용한 도구를 제공하는 것을 목표로 합니다. (출처: Reddit r/ClaudeAI)
AI Chatbots for Websites: 2025년 웹사이트를 위한 최고의 AI 챗봇 10가지: 한 보고서는 2025년 웹사이트를 위한 최고의 AI 챗봇 10가지를 선정하여 스타트업과 개인 창업자가 적합한 도구를 선택하는 데 도움을 주고자 합니다. ChatQube는 즉각적인 ‘지식 공백’ 알림 및 컨텍스트 인식 능력으로 가장 흥미로운 신규 도구로 평가되었습니다. Intercom Fin은 대규모 지원팀에 적합하며, Drift는 마케팅 및 리드 확보에 중점을 둡니다. Tidio는 소규모 기업 및 전자상거래에 적합합니다. Crisp, Chatbase, Zendesk AI, Botpress, Flowise, Kommunicate 등 다른 챗봇들도 각각의 특징을 가지고 있으며, 간단한 설정부터 고도로 맞춤화된 다양한 요구 사항을 충족하여 AI 챗봇이 더욱 실용적이고 보편화되었음을 보여줍니다. (출처: Reddit r/artificial)
Perplexity Comet: AI 코딩 Agent: Perplexity Comet은 효율적인 AI 코딩 에이전트로 칭찬받고 있으며, 사용자가 작업을 부여하기만 하면 자율적으로 완료할 수 있습니다. 예를 들어, 사용자는 GitHub 저장소에 대한 접근 권한을 부여하고 푸시 이벤트를 감지하는 Webhook을 설정하도록 요청할 수 있으며, Comet은 다른 탭에서 Webhook URL을 정확하게 가져와 올바르게 구성할 수 있습니다. 이는 Perplexity Comet이 복잡한 지시를 이해하고, 애플리케이션 간 작업을 수행하며, 개발 프로세스를 자동화하는 데 강력한 능력을 가지고 있음을 보여주며, 개발자의 작업 효율성을 크게 향상시킵니다. (출처: AravSrinivas)
LazyCraft: Dify의 오픈소스 Agent 플랫폼 경쟁자: LazyCraft는 Dify의 강력한 경쟁자로 평가되는 새로운 오픈소스 AI Agent 애플리케이션 개발 및 관리 플랫폼입니다. 이 플랫폼은 지식 기반, Prompt 관리, 추론 서비스, MCP 도구(로컬 및 원격 지원), 데이터셋 관리 및 모델 평가 등 핵심 모듈을 내장한 더 완벽한 폐쇄 루프 시스템을 제공합니다. LazyCraft는 다중 테넌트/다중 워크스페이스 관리를 지원하여 기업 환경에서 세분화된 권한 제어 및 팀 관리 요구 사항을 해결합니다. 또한, 로컬 모델 미세 조정 및 관리 기능을 통합하여 사용자가 모델 효과를 과학적으로 비교할 수 있도록 하며, 데이터 프라이버시 및 심층 맞춤화 요구 사항이 있는 기업에 강력한 지원을 제공합니다. (출처: WeChat)
📚 학습
HuggingFace Smol Training Playbook: LLM 훈련 가이드: HuggingFace는 Smol Training Playbook을 발표했습니다. 이는 SmolLM3 훈련의 비하인드 과정을 자세히 설명하는 포괄적인 LLM 훈련 가이드입니다. 이 가이드는 시작 전 전략 및 비용 결정, 사전 훈련(데이터, 어블레이션 연구, 아키텍처 및 튜닝), 후처리 훈련(SFT, DPO, GRPO, 모델 병합)부터 인프라(GPU 클러스터 설정, 통신, 디버깅)까지 전체 과정을 다룹니다. 200페이지가 넘는 이 가이드는 LLM 개발자에게 투명하고 실용적인 훈련 경험을 제공하여 자체 훈련 모델의 진입 장벽을 낮추고 오픈소스 AI의 발전을 촉진하는 것을 목표로 합니다. (출처: TheTuringPost, ClementDelangue)

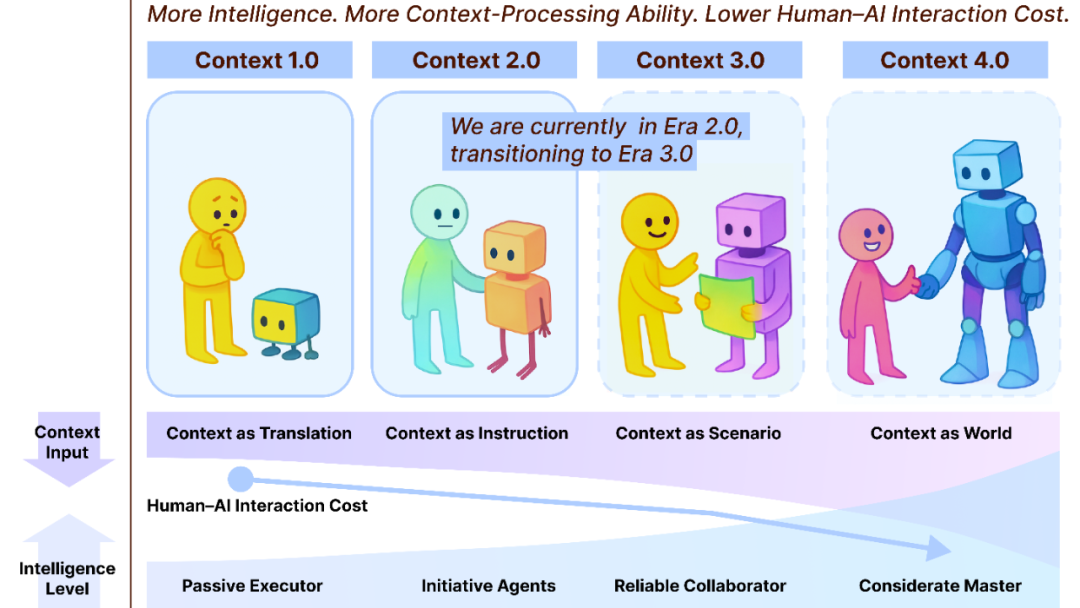
Context Engineering 2.0: 30년 진화의 길: 상하이 창즈 학원(Shanghai Chuangzhi Academy)의 류펑페이(Liu Pengfei) 팀은 ‘컨텍스트 엔지니어링 2.0’ 프레임워크를 제안하며 컨텍스트 엔지니어링의 본질, 역사 및 미래를 분석했습니다. 이 연구는 컨텍스트 엔지니어링이 인간과 기계 사이의 인지적 격차를 해소하기 위한 30년간의 엔트로피 감소 과정임을 지적합니다. 1.0 시대의 센서 기반에서 2.0 시대의 스마트 비서 및 멀티모달 융합, 그리고 3.0 시대에 예측되는 무감각 수집 및 원활한 협업에 이르기까지, 컨텍스트 엔지니어링의 진화는 인간-기계 상호작용의 혁명을 이끌었습니다. 이 프레임워크는 ‘수집, 관리, 사용’의 세 가지 차원을 강조하며, AI가 인간을 능가한 후 컨텍스트가 어떻게 새로운 인간 정체성을 구성하는지에 대한 철학적 문제도 탐구합니다. (출처: WeChat)
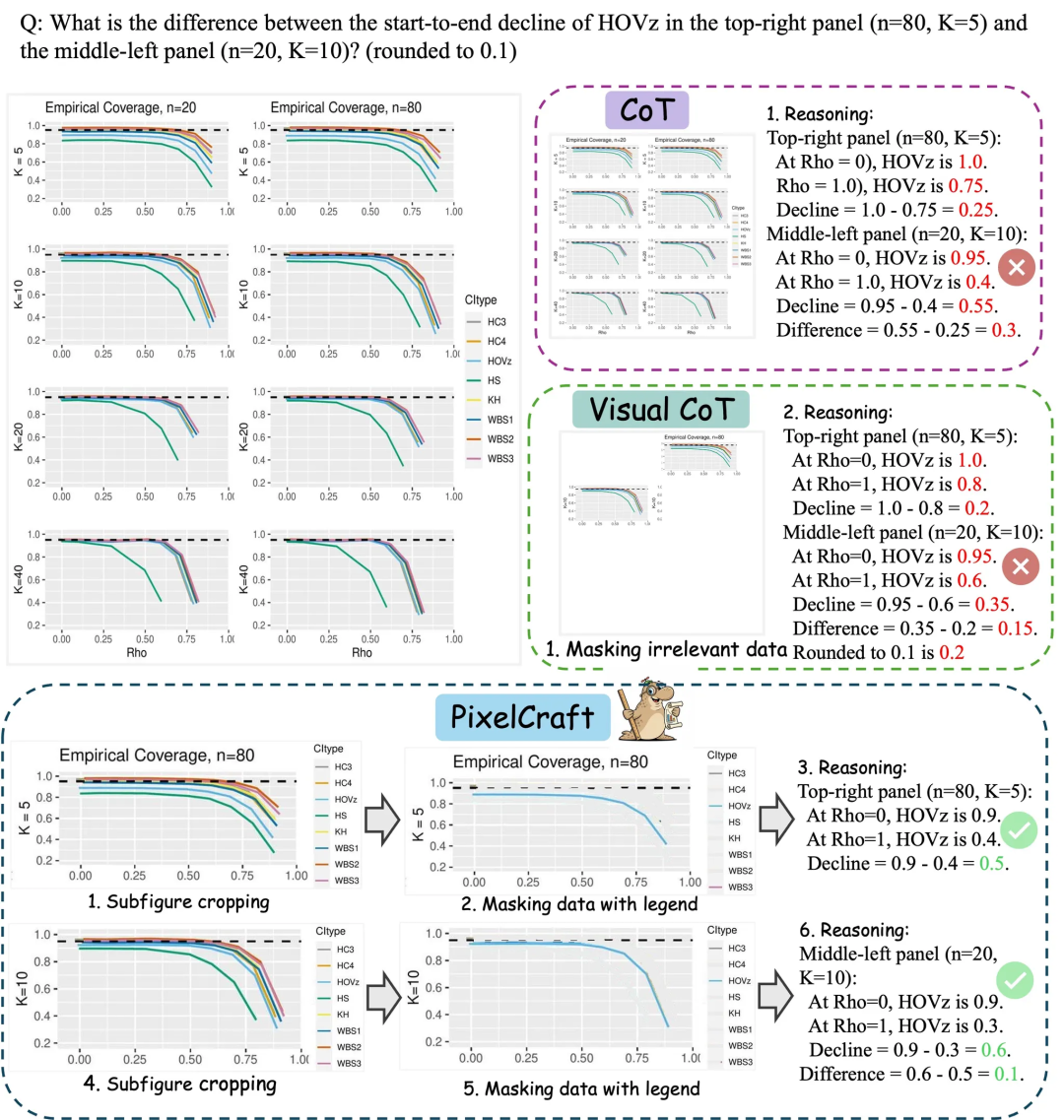
마이크로소프트 아시아 연구원 PixelCraft: 대규모 모델의 차트 이해 능력 향상: 마이크로소프트 아시아 연구원(Microsoft Asia Research Institute)은 칭화대학 등 팀과 협력하여 PixelCraft를 출시했습니다. 이는 멀티모달 대규모 모델(MLLM)의 차트, 기하학적 스케치 등 구조화된 이미지 이해 능력을 체계적으로 향상시키는 것을 목표로 합니다. PixelCraft는 고충실도 이미지 처리와 비선형 다중 에이전트 추론을 두 가지 기둥으로 삼아, 그라운딩 모델(grounding model)을 미세 조정하여 픽셀 수준의 텍스트 참조 매핑을 구현하고, 일련의 시각 도구 에이전트를 활용하여 검증 가능한 이미지 작업을 수행합니다. 토론식 추론 프로세스는 백트래킹 및 분기 탐색을 지원하여 CharXiv, ChartQAPro 등 차트 및 기하학적 벤치마크에서 모델의 정확성, 견고성 및 설명 가능성을 크게 향상시킵니다。 (출처: WeChat)
Spatial-SSRL: 자기 지도 강화 학습으로 공간 이해력 강화: 한 연구는 대규모 시각 언어 모델(LVLM)의 공간 이해 능력을 향상시키기 위한 자기 지도 강화 학습 패러다임인 Spatial-SSRL을 도입했습니다. Spatial-SSRL은 일반 RGB 또는 RGB-D 이미지에서 직접 검증 가능한 신호를 얻어, 인간 또는 LVLM 주석 없이 2D 및 3D 공간 구조를 포착하는 다섯 가지 사전 작업을 자동으로 구축합니다. 7개의 이미지 및 비디오 공간 이해 벤치마크에서 Spatial-SSRL은 Qwen2.5-VL 기준 모델 대비 평균 4.63%(3B) 및 3.89%(7B)의 정확도 향상을 달성하여, 간단하고 내재적인 감독이 대규모 RLVR을 달성하고 LVLM에 더 강력한 공간 지능을 부여할 수 있음을 증명했습니다. (출처: HuggingFace Daily Papers)
π_RL: 온라인 강화 학습으로 VLA 모델 미세 조정: 한 연구는 병렬 시뮬레이션에서 플로우 기반 시각 언어 액션(VLA) 모델을 훈련하기 위한 오픈소스 프레임워크인 π_RL을 제안했습니다. π_RL은 두 가지 RL 알고리즘을 구현합니다: Flow-Noise는 디노이징 프로세스를 이산 시간 MDP로 모델링하고, Flow-SDE는 ODE-SDE 변환을 통해 효율적인 RL 탐색을 구현합니다. LIBERO 및 ManiSkill 벤치마크에서 π_RL은 few-shot SFT 모델 pi_0 및 pi_0.5의 성능을 크게 향상시켜, 플로우 기반 VLA 모델에 대한 온라인 RL의 효과를 입증하고 강력한 다중 작업 RL 및 일반화 능력을 달성했습니다. (출처: HuggingFace Daily Papers)
LLM Agents: 자율적인 LLM 에이전트 구축의 핵심 서브시스템: 필수 논문 ‘Fundamentals of Building Autonomous LLM Agents’는 자율적인 LLM 기반 에이전트를 구성하는 핵심 인지 서브시스템을 검토합니다. 이 논문은 인지, 추론 및 계획(CoT, MCTS, ReAct, ToT), 장단기 기억, 실행(코드 실행, 도구 사용, API 호출) 및 폐쇄 루프 피드백과 같은 주요 구성 요소를 자세히 설명합니다. 이 연구는 복잡한 지능형 행동을 달성하기 위해 이러한 서브시스템이 어떻게 협력하는지 강조하며, 자율적으로 작동할 수 있는 LLM 에이전트를 이해하고 구축하기 위한 포괄적인 관점을 제공합니다. (출처: TheTuringPost)

Efficient Vision-Language-Action Models: 효율적인 VLA 모델 개요: 포괄적인 개요 논문 ‘A Survey on Efficient Vision-Language-Action Models’는 구현 지능 분야에서 효율적인 시각-언어-액션(VLA) 모델의 최첨단 발전을 탐구합니다. 이 개요는 기존 기술을 효율적인 모델 설계, 효율적인 훈련, 효율적인 데이터 수집의 세 가지 주요 기둥으로 분류하는 통일된 분류법을 제시합니다. 최첨단 방법에 대한 비판적 검토를 통해 이 연구는 커뮤니티에 기본 참조 자료를 제공하고, 대표적인 응용 프로그램을 요약하며, 주요 과제를 명확히 하고, VLA 모델 배포 시 직면하는 막대한 계산 및 데이터 요구 사항을 해결하기 위한 미래 연구 로드맵을 제시합니다. (출처: HuggingFace Daily Papers)
SNNs 성능 병목 현상에 대한 새로운 발견: 희소성이 아닌 주파수: 한 연구는 SNNs(스파이킹 신경망)와 ANNs(인공 신경망) 간 성능 격차의 실제 원인이 전통적으로 여겨지던 이진/희소 활성화로 인한 정보 손실이 아니라, 스파이킹 뉴런의 고유한 저역 통과 필터 특성임을 밝혀냈습니다. 이 연구는 SNNs가 네트워크 수준에서 저역 통과 필터로 작동하여 고주파 성분이 빠르게 소멸되고 특징 표현의 효율성이 저하된다는 것을 발견했습니다. Spiking Transformer에서 Avg-Pool 대신 Max-Pool을 사용하여 CIFAR-100 정확도를 2.39% 향상시켰으며, Max-Former 아키텍처를 제안하여 ImageNet에서 82.39%의 정확도와 30%의 에너지 소비 절감을 달성했습니다. (출처: Reddit r/MachineLearning)
💼 비즈니스
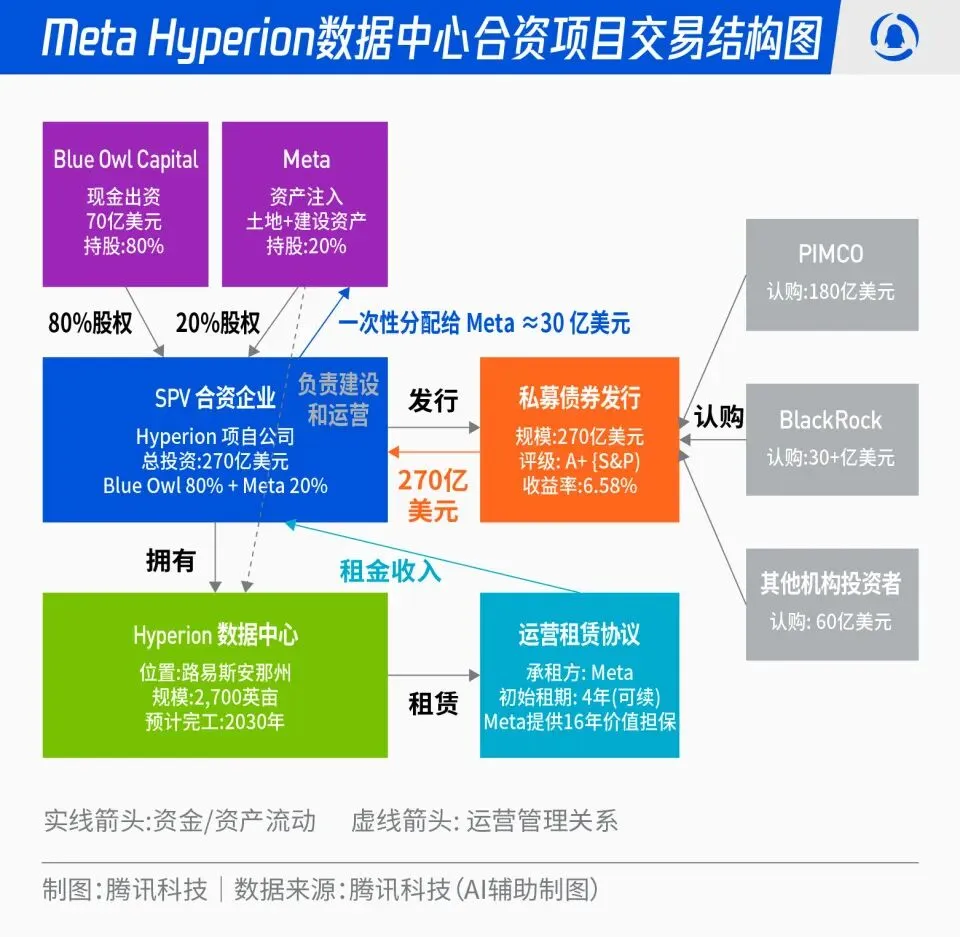
Meta, 270억 달러 규모 Hyperion 데이터센터 합작 프로젝트: Meta는 Blue Owl과 협력하여 총 270억 달러 규모의 ‘Hyperion’ 데이터센터 합작 프로젝트를 시작한다고 발표했습니다. Meta가 20%, Blue Owl이 80%를 출자하며, SPV를 통해 A+ 등급 채권과 지분을 발행하고 PIMCO, BlackRock 등 장기 기관 자금을 유치합니다. 이 프로젝트는 AI 인프라 구축을 전통적인 자본 지출에서 금융 혁신 모델로 전환하는 것을 목표로 하며, 데이터센터가 완공되면 Meta가 장기적으로 임차하고 운영 통제권을 유지합니다. 이 조치는 Meta의 재무제표를 최적화하고 AI 확장 프로세스를 가속화하는 동시에, 장기 자본에 고등급의 실물 자산 지원과 안정적인 현금 흐름을 갖춘 투자 포트폴리오를 제공할 수 있습니다. (출처: 36氪)
OpenAI “마피아”: 전 직원들의 창업 및 투자 열풍: 실리콘밸리에서는 ‘OpenAI 마피아’ 현상이 나타나고 있습니다. 여러 전 OpenAI 고위 임원, 연구원 및 제품 책임자들이 퇴사 후 창업하여 아직 제품을 출시하지 않은 상태에서 수억에서 수십억 달러에 달하는 높은 기업 가치로 투자를 유치하고 있습니다. 예를 들어, Angela Jiang은 Worktrace AI를 설립하여 수천만 달러 규모의 시드 라운드 투자를 협상 중이며, 전 CTO Mira Murati는 Thinking Machines Lab을 설립하여 20억 달러 투자를 완료했고, 전 수석 과학자 Ilya Sutskever는 Safe Superintelligence Inc.(SSI)를 설립하여 320억 달러의 기업 가치를 평가받았습니다. 이들 전 직원들은 상호 투자, 기술 보증 및 명성을 통해 OpenAI 외부에서 새로운 AI 권력 네트워크를 구축하고 있으며, 자본은 제품 자체보다 ‘OpenAI 출신’이라는 정체성을 더 중요하게 여기고 있습니다. (출처: 36氪)

AI가 항공 산업에 미치는 심대한 영향: 루프트한자 4,000명 감원: 유럽 최대 항공 그룹인 루프트한자(Lufthansa)는 2030년까지 약 4,000개의 행정직 일자리를 감축할 것이라고 발표했습니다. 이는 전체 직원 수의 4%에 해당하며, 주요 원인은 인공지능(AI) 및 디지털 도구의 가속화된 적용입니다. AI는 항공 산업에서 프로세스 최적화, 효율성 향상 및 수익 관리 분야에 깊이 적용되어 왔습니다. 예를 들어, 빅데이터와 알고리즘을 통해 항공권 가격 관리를 최적화합니다. 조종사 및 승무원과 같은 운영직은 아직 영향을 받지 않았지만, 공항 청소, 수하물 처리 등 표준화된 서비스에는 이미 로봇이 도입되었습니다. AI는 연료 소비 관리, 비행 운영 및 불안전 요소 식별 분야에서도 잠재력을 보여주고 있습니다. 예를 들어, 기상 데이터에 따라 급유량을 정확하게 계산하거나, 머신 비전을 통해 항공기 회전율을 높이는 등입니다. (출처: 36氪)
🌟 커뮤니티
ChatGPT 대시(—) ‘중독’과 데이터 출처: 소셜 미디어에서는 ChatGPT가 대시(—)를 자주 사용하는 ‘습관’ 문제에 대한 논의가 뜨겁습니다. 분석에 따르면, 이는 RLHF 튜터의 아프리카 영어 선호 때문이 아니라, GPT-4 및 후속 모델이 19세기 말, 20세기 초의 공공 영역 문학 작품으로 대량 훈련되었기 때문입니다. 이 ‘오래된 책’들에서는 현대 영어보다 대시 사용 빈도가 훨씬 높았고, 이로 인해 AI 모델이 그 시대의 글쓰기 스타일을 충실히 학습하게 된 것입니다. 이 발견은 AI 모델 훈련 데이터 출처가 언어 스타일에 미치는 심오한 영향을 보여주며, 초기 모델인 GPT-3.5에는 이러한 문제가 없었던 이유를 설명합니다. (출처: dotey)
AI 콘텐츠 검열 및 윤리 논란: Gemma 서비스 중단과 ChatGPT 이상 답변: Google은 Blackburn 상원의원이 모델의 명예훼손을 주장한 후 AI Studio에서 Gemma를 내렸으며, 이는 AI 콘텐츠 검열 및 표현의 자유에 대한 논의를 촉발했습니다. 동시에 Reddit 사용자들은 ChatGPT가 커피에 대해 논의하던 중 갑자기 자살 충동 발언을 생성하는 등 비정상적인 응답을 보였다고 보고했으며, 이는 AI 안전 보호의 과잉과 제품 포지셔닝에 대한 사용자들의 의문을 불러일으켰습니다. 이러한 사건들은 AI가 콘텐츠 생성 및 윤리적 통제 측면에서 직면한 도전과, 기술 기업이 사용자 경험, 안전 검열 및 정치적 압력 사이에서 균형을 잡는 데 겪는 어려움을 함께 보여줍니다. (출처: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
AI 기술 보급 및 민주화: PewDiePie의 자체 AI 플랫폼 구축: 유명 유튜버 PewDiePie는 AI 자체 호스팅 분야에 적극적으로 투자하여, 10×4090 그래픽 카드를 포함하는 로컬 AI 플랫폼을 구축하고 Llama 70B, gpt-oss-120B, Qwen 245B 등의 모델을 실행하며, 사용자 정의 Web UI(채팅, RAG, 검색, TTS)를 개발했습니다. 그는 또한 자체 모델을 훈련하고 AI를 사용하여 단백질 접힘 시뮬레이션을 수행할 계획입니다. PewDiePie의 행동은 AI 민주화 및 로컬 배포의 모범 사례로 여겨지며, 수백만 명의 팬이 AI 기술에 관심을 갖게 하고 AI가 전문 분야에서 대중에게 보급되는 것을 촉진했습니다. (출처: vllm_project, Reddit r/artificial)

AI의 데이터 수요 급증과 IP 논란: Reddit, Perplexity AI 고소: AI 산업은 데이터 고갈이라는 도전에 직면해 있으며, 고품질 데이터가 점점 희귀해지면서 AI 업체들은 소셜 미디어와 같은 ‘저품질’ 데이터 소스로 눈을 돌리고 있습니다. Reddit은 뉴욕 연방 법원에 AI 검색 유니콘 Perplexity AI를 고소하며, 허가 없이 Reddit 사용자 댓글을 불법적으로 스크래핑하여 상업적 이익을 취했다고 주장했습니다. 이 사건은 AI 대규모 모델 훈련이 방대한 데이터에 의존한다는 점과 데이터 소유자 및 AI 업체 간의 지적 재산권 및 데이터 사용권 분쟁이 심화되고 있음을 부각합니다. 미래에는 데이터 확보 능력의 차이가 AI 경쟁의 핵심 분수령이 될 수 있습니다. (출처: 36氪)
AI 생성 콘텐츠 논란 및 규제: 캘리포니아/유타주, AI 상호작용 공개 요구: AI 애플리케이션의 보급과 함께 AI 생성 콘텐츠 및 AI 상호작용의 투명성 문제가 점점 더 부각되고 있습니다. 미국 유타주와 캘리포니아주는 사용자가 AI와 상호작용할 때 기업이 명확하게 고지하도록 요구하는 법안을 제정하기 시작했습니다. 이 조치는 ‘숨겨진 AI’에 대한 소비자들의 우려를 해소하고, 사용자 알 권리를 보장하며, AI가 고객 서비스, 콘텐츠 제작 등 분야에서 가져올 수 있는 잠재적인 윤리 및 신뢰 문제를 해결하기 위함입니다. 그러나 기술 산업은 이러한 규제 조치가 AI 혁신 및 애플리케이션 발전을 저해할 수 있다고 반대하며, 기술 발전과 사회적 책임 사이의 갈등을 야기하고 있습니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

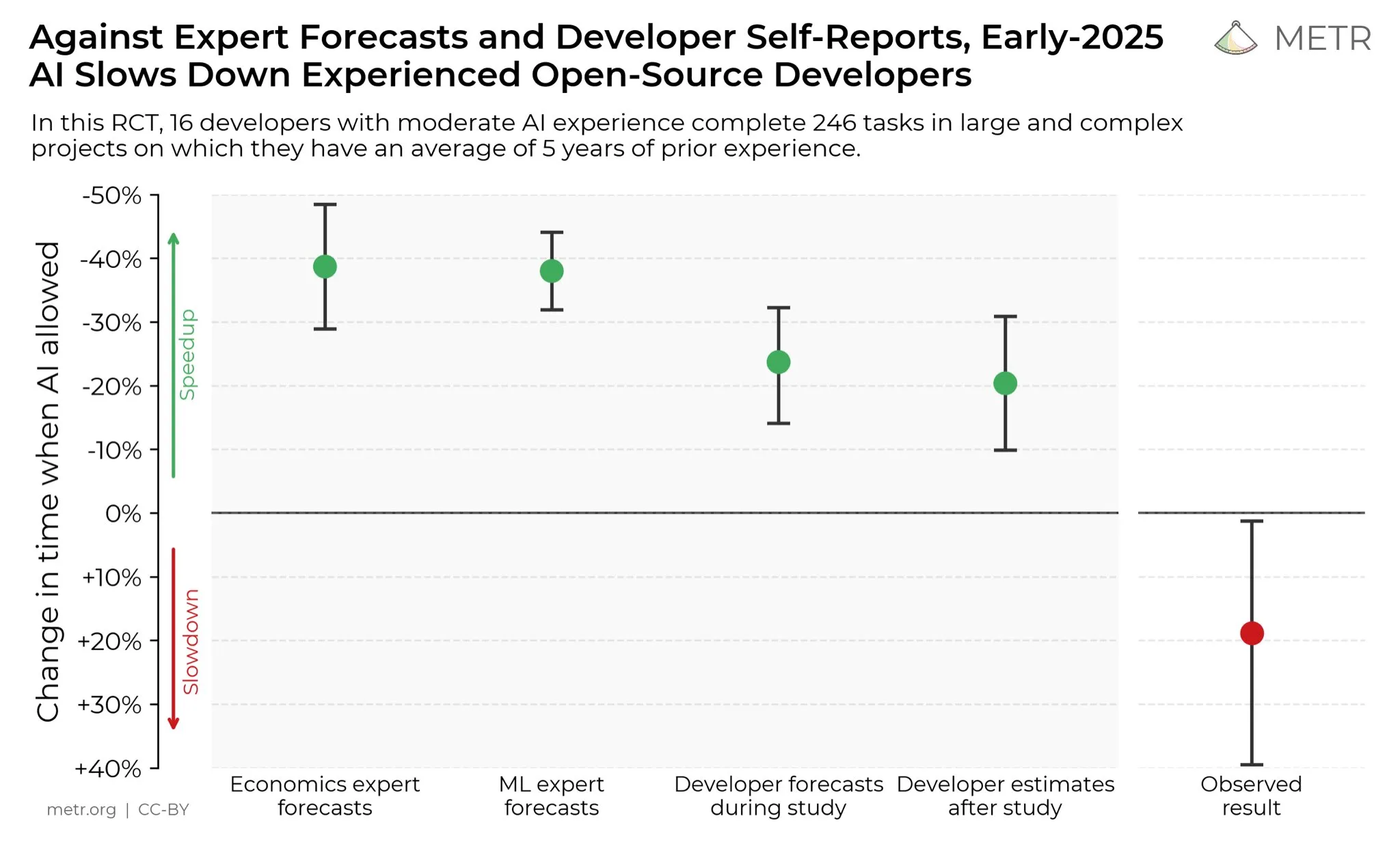
개발자들의 AI 생산성 향상에 대한 견해: 소셜 미디어에서 개발자들은 AI가 생산성을 크게 향상시켰다고 일반적으로 생각합니다. 한 개발자는 AI의 도움으로 생산성이 10배 향상되었다고 말했습니다. METR_Evals는 AI가 개발자 생산성에 미치는 영향을 정량화하기 위한 연구를 진행 중이며, 더 많은 사람들의 참여를 독려하고 있습니다. 이 논의는 소프트웨어 개발 분야에서 AI 도구의 중요성이 커지고 있음을 반영하며, AI 지원 프로그래밍에 대한 개발자 커뮤니티의 높은 인식을 보여주며, AI가 소프트웨어 엔지니어링 작업 방식을 계속해서 재편할 것임을 시사합니다. (출처: METR_Evals)
Cursor ‘자체 개발’ 모델이 국내 오픈소스 모델을 활용? 네티즌들 뜨거운 논쟁: AI 프로그래밍 애플리케이션 Cursor와 Windsurf가 새로운 모델을 발표한 후, 일부 네티즌들은 이 모델이 추론 과정에서 중국어를 사용하며, 중국 오픈소스 대규모 모델인 Zhipu GLM을 사용한 것으로 의심된다는 사실을 발견했습니다. 이 발견은 커뮤니티에서 뜨거운 논쟁을 불러일으켰고, 많은 사람들은 중국 오픈소스 대규모 모델이 국제적으로 선도적인 수준에 도달했으며, 저렴하고 우수하여 스타트업이 애플리케이션 및 수직 모델을 구축하는 합리적인 선택이 되고 있다고 감탄했습니다. 이 사건은 또한 AI 분야의 혁신 모델, 즉 강력하고 저렴한 오픈소스 모델을 기반으로 2차 개발을 수행하는 것이 처음부터 막대한 자금을 투자하여 모델을 훈련하는 것보다 합리적이라는 점을 재고하게 했습니다. (출처: WeChat)

AI 혐오 발언과 사회적 반감: Reddit 커뮤니티에는 AI에 대한 강한 반감이 만연해 있으며, 사용자들은 AI를 언급하는 어떤 게시물도 대량으로 비추천을 받고 인신공격을 당한다고 말합니다. 이러한 ‘AI 혐오’ 현상은 Reddit에만 국한되지 않고 Twitter, Bluesky, Tumblr, YouTube 등 다른 플랫폼에서도 보편적으로 나타납니다. 사용자들은 AI 보조 글쓰기, 이미지 생성 또는 의사 결정에 AI를 사용했다는 이유로 ‘AI 쓰레기 생산자’로 비난받으며, 심지어 사회적 관계에도 영향을 미칩니다. 이러한 감정적인 반대는 AI 기술이 지속적으로 발전함에도 불구하고, 환경 영향, 일자리 대체, 예술 윤리 등 AI에 대한 사회의 우려와 편견이 여전히 뿌리 깊게 남아있으며, 단기적으로는 사라지기 어렵다는 것을 보여줍니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
AI 시대의 데이터 저장 도전 과제: AI 혁명이 심화됨에 따라 데이터 저장소는 막대한 도전에 직면하고 있으며, AI 기술의 빠른 발전으로 인한 방대한 데이터 요구 사항에 지속적으로 적응해야 합니다. MIT(매사추세츠 공과대학교)의 연구는 데이터 저장 시스템이 AI 혁명의 속도를 따라잡아 AI 모델이 필요한 데이터에 효율적으로 접근하고 처리할 수 있도록 돕는 방법을 탐구하고 있습니다. 이는 AI 생태계에서 데이터 인프라의 핵심적인 역할과 AI 컴퓨팅 요구 사항을 충족하기 위한 지속적인 혁신의 중요성을 강조합니다. (출처: Ronald_vanLoon)

로봇 기술의 다분야 혁신: 카메라 안정화부터 인간형 손까지: 로봇 기술은 여러 분야에서 지속적으로 혁신되고 있습니다. JigSpace는 Apple Vision Pro에서 3D/AR 애플리케이션을 선보였습니다. WevolverApp은 짐벌 시스템을 통해 완벽한 카메라 안정화를 달성하는 드론을 소개했습니다. IntEngineering은 Mantiss Jump Reloaded 시스템을 시연하여 촬영 기사에게 놀라운 안정성을 제공했습니다. 또한, 촉각 감지 로봇 손, 모듈형 로봇 키트 UGOT, 로프 등반 로봇, 그리고 Unitree G1의 고르지 않은 지면에서의 안정적인 제어에 대한 연구도 포함되어 있으며, 이 모든 것은 로봇 기술이 인지, 조작 및 이동성 측면에서 상당한 발전을 이루고 있음을 시사합니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)