
키워드:DeepSeek-OCR, ChatGPT Atlas, Unitree H2, 양자 컴퓨팅, AI 신약 개발, DeepSeek MoE, vLLM, Meta Vibes, 컨텍스트 광학 압축 기술, AI 브라우저 메모리 기능, 휴머노이드 로봇 자유도, 양자 에코 알고리즘, 생물 실험 프로토콜 생성 프레임워크
🔥 포커스
DeepSeek-OCR: 컨텍스트 광학 압축 기술 : DeepSeek-OCR 모델은 “컨텍스트 광학 압축” 개념을 도입하여, 텍스트를 이미지로 처리함으로써 시각적 인코딩을 통해 전체 페이지 콘텐츠를 소량의 “시각적 토큰”으로 압축할 수 있으며, 이를 다시 텍스트, 표 또는 차트로 디코딩하여 복원함으로써 효율성을 10배 향상시키고 97%의 정확도를 달성합니다. 이 기술은 DeepEncoder를 통해 페이지 정보를 캡처하고 16배 압축하여 4096개의 토큰을 256개로 줄이며, 문서 복잡도에 따라 토큰 양을 자동으로 조절할 수 있어 기존 OCR 모델을 크게 능가합니다. 이는 장문서 처리 비용을 대폭 절감하고 정보 추출 효율성을 높일 뿐만 아니라, LLM의 장기 기억 및 컨텍스트 확장에 대한 새로운 아이디어를 제공하며, AI 분야에서 정보 전달 매체로서 이미지의 엄청난 잠재력을 예고합니다. (출처: HuggingFace Daily Papers, 36氪, ZhihuFrontier)

OpenAI, ChatGPT Atlas 브라우저 출시 : OpenAI는 AI 시대를 위해 특별히 설계된 브라우저 ChatGPT Atlas를 출시하여, ChatGPT를 브라우징 경험에 깊이 통합했습니다. 이 브라우저는 전통적인 기능을 제공할 뿐만 아니라, 예약, 쇼핑, 양식 작성 등의 작업을 수행할 수 있는 “Agent 모드”를 내장하고 있으며, 사용자 습관을 학습하여 개인화된 서비스를 제공하는 “브라우저 기억” 기능도 갖추고 있습니다. 이러한 움직임은 OpenAI가 완전한 AI 생태계를 구축하려는 전략적 전환을 의미하며, 사용자가 인터넷과 상호작용하는 방식을 재편할 수 있고, 기존 브라우저 시장(특히 Google Chrome)의 광고 및 데이터 주도적 지위에 도전할 수 있습니다. 업계에서는 이를 새로운 “브라우저 전쟁”의 시작으로 보고 있으며, 핵심은 사용자 디지털 생활의 통제권을 확보하는 데 있습니다. (출처: Smol_AI, TheRundownAI, Reddit r/ArtificialInteligence, Reddit r/MachineLearning)
Unitree H2 휴머노이드 로봇 공개 : Unitree Robotics는 H2 휴머노이드 로봇을 공개하며 구현 지능 및 하드웨어 설계에서 중대한 도약을 이루었습니다. H2는 NVIDIA Jetson AGX Thor를 지원하여 Orin보다 7.5배 높은 컴퓨팅 성능과 3.5배 향상된 효율성을 제공합니다. 기계 설계 측면에서는 다리에 1개의 자유도(총 6개)가 추가되었고, 팔은 7개의 자유도로 업그레이드되었으며, 유효 하중은 7-15kg이고 정교한 손을 선택적으로 장착할 수 있습니다. 센싱 측면에서 H2는 LiDAR를 포기하고 순수 비전 3D 인식으로 전환하여 스테레오 카메라를 사용합니다. 기술 발전이 현저함에도 불구하고, 휴머노이드 로봇은 여전히 성숙한 응용 시나리오를 찾고 있으며 현재는 실험실 연구에 더 적합하다는 의견이 있습니다. (출처: ZhihuFrontier)

AI 기반 신약 개발 및 생체 공학 기술 혁신 : MIT 연구진은 AI를 활용하여 다제내성 임균 및 MRSA에 효과적인 신형 항생제를 설계했습니다. 이 화합물들은 독특한 구조를 가지며 새로운 메커니즘으로 세균 세포막을 파괴하여 내성이 쉽게 생기지 않습니다. 동시에 연구팀은 절단 후 남은 근육에서 AMI 기술을 통해 신경 정보를 추출하여 의족 움직임을 유도하는 새로운 생체 공학 무릎 관절을 개발했습니다. 이 생체 공학 무릎 관절은 절단 환자가 더 빨리 걷고, 계단을 쉽게 오르며, 장애물을 피할 수 있도록 돕고, 신체의 일부처럼 느껴지게 하여 더 큰 규모의 임상 시험 후 FDA 승인을 받을 것으로 기대됩니다. (출처: MIT Technology Review, MIT Technology Review)

Google, 검증 가능한 양자 우위 달성 : Google은 《Nature》지에 양자 컴퓨팅의 새로운 돌파구를 발표했습니다. Willow 칩은 “양자 에코”라는 알고리즘을 실행하여 검증 가능한 양자 우위를 최초로 달성했습니다. 이 알고리즘은 가장 빠른 고전 알고리즘보다 13000배 빠르며, 분자 내 원자 간의 상호작용을 설명할 수 있어 신약 개발 및 재료 과학과 같은 분야에 잠재적인 응용 가능성을 제공합니다. 이번 돌파구의 결과는 반복적으로 검증 가능하며, 양자 컴퓨팅이 실제 응용으로 나아가는 중요한 단계입니다. (출처: Google)

🎯 동향
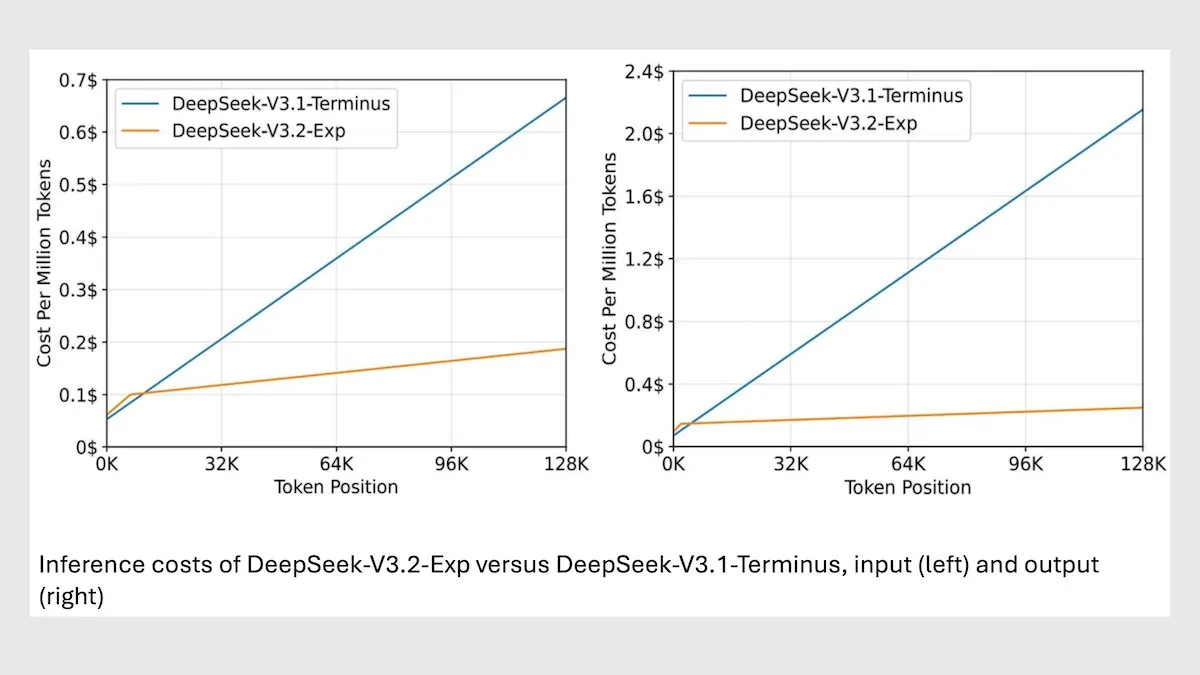
DeepSeek MoE 모델 V3.2, 긴 컨텍스트 추론 최적화 : DeepSeek은 새로운 685B MoE 모델 V3.2를 출시했습니다. 이 모델은 가장 관련성 높은 토큰에만 집중하여 긴 컨텍스트 추론 속도를 2-3배 향상시키고, 처리 비용을 V3.1 모델보다 6-7배 절감했습니다. 새 모델은 MIT 라이선스 가중치를 사용하며 API를 통해 서비스를 제공하고, 화웨이 및 기타 중국 칩에 최적화되어 있습니다. 일부 과학/수학 작업에서는 성능이 약간 하락했지만, 코딩/에이전트 작업에서는 성능이 향상되었습니다. (출처: DeepLearningAI)
vLLM V1, 이제 AMD GPU 지원 : vLLM V1 버전이 이제 AMD GPU에서 실행될 수 있습니다. IBM Research, Red Hat 및 AMD 팀이 협력하여 Triton 커널을 사용하여 최적화된 어텐션 백엔드를 구축하여 최첨단 성능을 달성했습니다. 이러한 발전은 AMD 하드웨어 사용자에게 더 효율적인 LLM 추론 솔루션을 제공합니다. (출처: QuixiAI)

Meta Vibes AI 비디오 스트림 출시 : Meta는 Meta AI 앱에 내장된 새로운 AI 비디오 스트리밍 기능 Vibes를 출시했습니다. 사용자는 AI가 생성한 짧은 비디오를 탐색하고, 한 번의 클릭으로 음악 추가, 스타일 변경 또는 타인의 작품 리믹스 등 2차 창작을 할 수 있으며, 이를 Instagram 및 Facebook에 공유할 수 있습니다. 이러한 움직임은 AI 비디오 제작의 진입 장벽을 낮추고 AI 비디오를 주류 소셜 미디어 시나리오로 확산시키며, 숏폼 비디오 콘텐츠 생산 및 유통 방식을 변화시킬 수 있습니다. 그러나 저작권, 독창성 및 허위 정보 확산에 대한 우려도 제기됩니다. (출처: 36氪)
LLM 추론 성능 예측 에이전트 모델 rBridge : rBridge 방법은 소형 에이전트 모델(≤1B 파라미터)이 대규모 모델(7B-32B 파라미터)의 추론 성능을 효과적으로 예측할 수 있도록 하여 계산 비용을 100배 이상 절감합니다. 이 방법은 평가를 사전 학습 목표 및 대상 작업과 정렬하고, 최첨단 모델 추론 궤적을 골든 라벨로 사용하며, 토큰의 작업 중요도를 가중치 부여하여 추론 능력이 소형 모델에서 나타나지 않는 “이머전트 문제”를 해결합니다. 이는 계산 자원이 제한된 연구자들이 사전 학습 설계 선택을 탐색하는 비용을 크게 줄여줍니다. (출처: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
4D 고동적 범위 가우시안 스플래팅 재구성 시스템 Mono4DGS-HDR : Mono4DGS-HDR은 교차 노출 단안 저동적 범위(LDR) 비디오에서 렌더링 가능한 4D 고동적 범위(HDR) 장면을 재구성하는 최초의 시스템입니다. 이 통합 프레임워크는 가우시안 스플래팅 기술을 기반으로 하는 2단계 최적화 방법을 사용합니다. 먼저 직교 카메라 좌표 공간에서 비디오 HDR 가우시안 표현을 학습한 다음, 비디오 가우시안을 월드 공간으로 변환하고 월드 가우시안과 카메라 포즈를 공동으로 최적화합니다. 또한, 제안된 시간적 밝기 정규화 전략은 HDR 외관의 시간적 일관성을 향상시켜 렌더링 품질과 속도 면에서 기존 방법보다 현저히 우수합니다. (출처: HuggingFace Daily Papers)
검증 가능한 학습을 위한 진화적 데이터 합성 프레임워크 EvoSyn : EvoSyn은 진화적, 작업 독립적, 전략 기반, 실행 가능한 검사 데이터 합성 프레임워크로, 신뢰할 수 있는 검증 가능한 데이터를 생성하는 것을 목표로 합니다. 이 프레임워크는 최소한의 시드 감독으로 시작하여 문제, 다양한 후보 솔루션 및 검증 아티팩트를 공동으로 합성하고, 일관성 기반 평가자를 통해 전략을 반복적으로 발견합니다. 실험 결과, EvoSyn으로 합성된 데이터를 사용하여 학습했을 때 LiveCodeBench 및 AgentBench-OS 작업에서 모두 현저한 개선을 이루어 프레임워크의 강력한 일반화 능력을 강조합니다. (출처: HuggingFace Daily Papers)
사후 학습 모델에서 정렬된 데이터 추출을 위한 새로운 방법 : 연구에 따르면, 사후 학습 모델에서 대량의 정렬된 학습 데이터를 추출하여 모델의 긴 컨텍스트 추론, 안전성, 지시 따르기 및 수학 능력 등을 향상시킬 수 있습니다. 고품질 임베딩 모델로 측정된 의미론적 유사성을 통해 전통적인 문자열 매칭으로는 포착하기 어려운 학습 데이터를 식별할 수 있습니다. 연구 결과, 모델은 SFT 또는 RL과 같은 사후 학습 단계에서 사용된 데이터를 쉽게 회귀하며, 이 데이터는 기반 모델을 학습시켜 원래 성능을 복원하는 데 사용될 수 있습니다. 이 연구는 정렬된 데이터 추출의 잠재적 위험을 밝히고, 증류(distillation) 실습의 하위 효과에 대한 새로운 논의 관점을 제공합니다. (출처: HuggingFace Daily Papers)
멀티모달 과학 논문 불일치 벤치마크 PRISMM-Bench : PRISMM-Bench는 실제 검토자가 표시한 과학 논문 내 멀티모달 불일치를 기반으로 하는 최초의 벤치마크로, 대규모 멀티모달 모델(LMM)이 과학 논문의 복잡성을 이해하고 추론하는 능력을 평가하는 것을 목표로 합니다. 이 벤치마크는 다단계 프로세스를 통해 242편의 논문에서 262개의 불일치를 정리하고, 식별, 보정 및 페어링 매칭 세 가지 작업을 설계했습니다. GLM-4.5V 106B, InternVL3 78B 및 Gemini 2.5 Pro, GPT-5를 포함한 21개 LMM에 대한 평가는 모델 성능이 현저히 낮음(26.1-54.2%)을 보여주며, 멀티모달 과학 추론의 도전 과제를 강조합니다. (출처: HuggingFace Daily Papers)
확산 ODE 이산화 개선 방법 GAS : 확산 모델은 생성 품질 면에서 최첨단에 도달했지만, 샘플링 계산 비용이 높습니다. Generalized Adversarial Solver (GAS)는 추가 학습 기법 없이도 품질을 향상시키는 단순하게 매개변수화된 ODE 샘플러를 제안합니다. 원래의 증류 손실을 적대적 학습과 결합함으로써 GAS는 아티팩트를 완화하고 세부 충실도를 향상시킬 수 있습니다. 실험 결과, 유사한 자원 제한 하에서 GAS는 기존 솔버 학습 방법보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
VLM 기하학적 상상력 공간 추론 프레임워크 3DThinker : 3DThinker 프레임워크는 시각 언어 모델(VLM)이 제한된 시야에서 3D 공간 관계를 이해하는 능력을 향상시키는 것을 목표로 합니다. 이 프레임워크는 2단계 학습을 통해 먼저 지도 학습을 수행하여 추론 시 VLM이 생성하는 3D 잠재 공간을 3D 기반 모델의 잠재 공간과 정렬하고, 그 다음 결과 신호만을 기반으로 전체 추론 궤적을 최적화하여 기저의 3D 정신 모델링을 완성합니다. 3DThinker는 3D 사전 입력이나 명시적으로 레이블링된 3D 데이터 없이 3D 정신 모델링을 달성하는 최초의 프레임워크이며, 여러 벤치마크 테스트에서 우수한 성능을 보여 멀티모달 추론에서 3D 표현을 통합하는 새로운 관점을 제공합니다. (출처: HuggingFace Daily Papers)
화웨이 HarmonyOS 6, AI 어시스턴트 기능 강화 : 화웨이는 HarmonyOS 6 운영체제를 공식 출시하며 유창성, 지능화 및 기기 간 협업 경험을 전면적으로 향상시켰습니다. 특히 “슈퍼 어시스턴트” 샤오이 기능이 대폭 강화되어 16가지 방언을 지원할 뿐만 아니라, 심층 연구, 한 문장으로 사진 수정, 시각 장애 사용자가 “세상을 볼 수 있도록” 돕는 기능 등을 제공합니다. HarmonyOS 에이전트 프레임워크를 기반으로, 80여 개의 HarmonyOS 애플리케이션 에이전트가 첫 번째로 출시되었으며, 샤오이와 그 에이전트 파트너들은 긴밀하게 협력하여 여행 가이드, 진료 예약 등 전문 서비스를 제공하고, “AI 사기 방지” 및 “AI 엿보기 방지”와 같은 개인 정보 보호 기능도 도입했습니다. (출처: 量子位)

도시 연구에서의 AI 적용: 보행 속도 및 공공 공간 사용 분석 : MIT 학자들이 공동으로 작성한 연구에 따르면, 1980년부터 2010년까지 미국 북동부 세 도시의 평균 보행 속도는 15% 증가한 반면, 공공 공간에 머무는 사람 수는 14% 감소했습니다. 연구진은 머신러닝 도구를 사용하여 보스턴, 뉴욕, 필라델피아의 1980년대 비디오 클립을 분석하고 새로운 비디오와 비교했습니다. 그들은 휴대폰과 카페 등의 요인이 사람들이 문자 메시지로 만남을 약속하고 공공 공간 대신 실내 장소를 선택하여 교류하는 경향을 증가시켰을 수 있다고 추측하며, 이는 도시 공공 공간 설계에 새로운 사고 방향을 제공합니다. (출처: MIT Technology Review)
다국어 LLM 워터마킹의 교차 언어 강건성 도전과 해결책 : 연구에 따르면, 기존의 대규모 언어 모델(LLM) 다국어 워터마킹 기술은 진정한 다국어가 아니며, 저자원 언어의 번역 공격에 대해 강건성이 부족합니다. 이러한 실패는 토크나이저 어휘 부족 시 의미론적 클러스터링이 실패하는 데서 기인합니다. 이 문제를 해결하기 위해 연구는 역번역 기반 탐지 방법인 STEAM을 도입하여 번역으로 인해 손실된 워터마크 강도를 복원합니다. STEAM은 모든 워터마킹 방법과 호환되며, 다른 토크나이저와 언어에 대해 강건하고, 새로운 언어로 쉽게 확장할 수 있습니다. 평균적으로 17개 언어에서 +0.19 AUC 및 +40%p TPR@1%의 현저한 향상을 달성하여, 공정한 워터마킹 기술 발전을 위한 간단하면서도 강력한 방법을 제공합니다. (출처: HuggingFace Daily Papers)
Qwen 모델, 오픈소스 커뮤니티 및 상업적 애플리케이션에서 강력한 성능 발휘 : 알리바바 통이천원 모델은 오픈소스 커뮤니티와 상업적 애플리케이션에서 강력한 기세를 보이고 있습니다. DeepSeek V3.2와 Qwen-3-235b-A22B-Instruct는 Text Arena 오픈 모델 순위표에서 상위권을 차지했습니다. Airbnb CEO 브라이언 체스키는 회사가 “알리바바의 통이천원 모델에 크게 의존하고 있다”고 공개적으로 밝히며, “OpenAI보다 더 좋고 저렴하다”고 평가하고 생산 환경에서 우선적으로 사용한다고 말했습니다. 또한, Qwen 팀은 llama.cpp 프로젝트를 적극적으로 지원하며 오픈소스 커뮤니티 발전을 지속적으로 추진하고 있습니다. Qwen-VL 새 모델은 성능 면에서 이전 버전보다 현저히 뛰어나며, 특히 저파라미터 모델에서 두드러진 성능을 보여 빠른 반복 및 최적화 능력을 입증했습니다. (출처: teortaxesTex, Zai_org, hardmaru, Reddit r/LocalLLaMA)
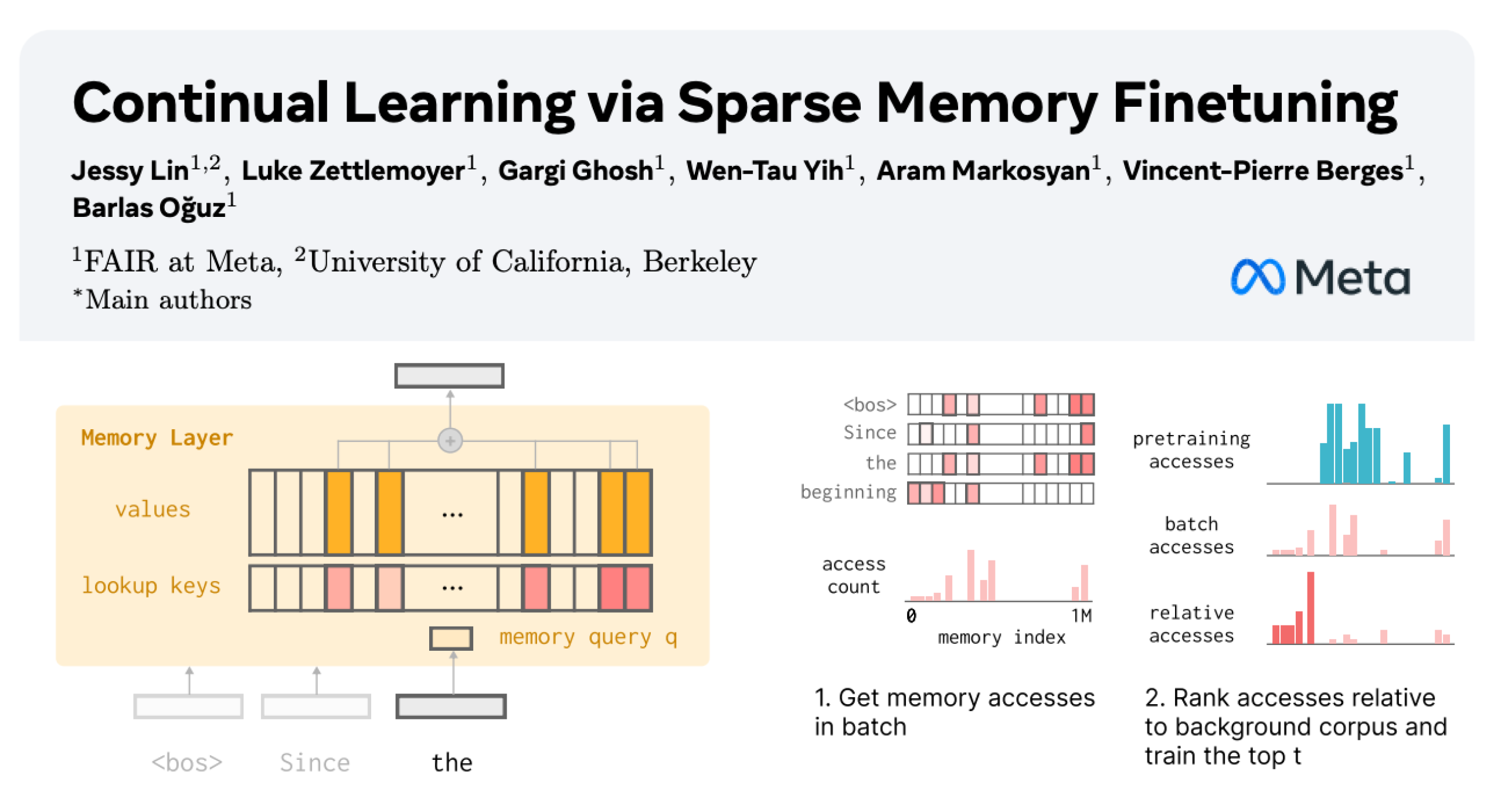
LLM 지속 학습: 희소 미세 조정을 통한 기억 계층으로 망각 감소 : Meta AI의 새로운 연구는 희소 미세 조정 기억 계층을 통해 대규모 언어 모델(LLM)이 새로운 지식을 지속적으로 학습하면서 기존 지식에 대한 간섭을 최소화할 수 있음을 제안합니다. 전체 미세 조정 및 LoRA와 같은 방법과 비교했을 때, 희소 미세 조정 기억 계층은 동일한 양의 새로운 지식을 학습하면서 망각률을 현저히 감소시켰습니다(-11% vs -89% FT, -71% LoRA). 이는 지속적으로 적응하고 업데이트할 수 있는 LLM을 구축하기 위한 새로운 방향을 제시합니다. (출처: giffmana, AndrewLampinen)
자율주행 분야 AI 발전: GM 부사장, 도로 안전 강조 : 제너럴 모터스(GM) 총괄 부사장 겸 글로벌 제품 책임자 Sterling Anderson은 AI와 첨단 운전자 보조 기술이 도로 안전을 향상시키는 데 엄청난 잠재력을 가지고 있다고 강조했습니다. 그는 인간 운전자와 달리 자율주행 시스템은 음주 운전, 피로 또는 부주의를 하지 않으며, 악천후에서도 모든 방향의 도로 상황을 동시에 모니터링할 수 있다고 지적했습니다. Aurora Innovation을 공동 설립하고 Tesla Autopilot 개발을 이끌었던 Anderson은 자율주행 기술이 도로 안전을 크게 향상시킬 뿐만 아니라 화물 운송 효율성을 높이고 궁극적으로 사람들의 시간을 절약할 수 있다고 믿습니다. 그는 MIT에서의 학습 경험이 복잡한 문제 해결 및 인간-AI 협업을 위한 기술적 기반과 탐구의 자유를 제공했다고 말했습니다. (출처: MIT Technology Review)

탱크 400 Hi4-T, AI 드라이버 기능 추가 : 신형 탱크 400 Hi4-T는 AI 드라이버 기능을 탑재하여 복잡한 도로 상황에서의 운전 경험을 향상시키는 것을 목표로 합니다. 충칭 8D 산악 도시의 비 오는 날 테스트에서 이 AI 드라이버는 미끄러운 노면과 복잡한 교통 환경에서 우수한 보조 운전 능력을 보여주었습니다. 이는 오프로드 및 복잡한 도시 환경 자율주행 분야에서 AI 기술의 추가적인 적용 및 최적화를 의미합니다. (출처: 量子位)

🧰 도구
AI 기반 생물학 실험 프로토콜 생성 프레임워크 Thoth : Thoth는 “Sketch-and-Fill” 패러다임을 기반으로 하는 AI 프레임워크로, 자연어 쿼리를 통해 정확하고 논리적으로 정렬되며 실행 가능한 생물학 실험 프로토콜을 자동으로 생성하는 것을 목표로 합니다. 이 프레임워크는 분석, 구조화 및 표현을 분리하여 각 단계가 명확하게 검증될 수 있도록 합니다. 구조화된 구성 요소 보상 메커니즘과 결합하여 Thoth는 단계 세분성, 작업 순서 및 의미론적 충실도 측면에서 평가되어 모델 최적화가 실험 신뢰성과 정렬되도록 합니다. Thoth는 여러 벤치마크 테스트에서 독점 및 오픈소스 LLM을 능가하며, 단계 정렬, 논리적 순서 지정 및 의미론적 정확성에서 현저한 개선을 이루어 신뢰할 수 있는 과학 보조원을 위한 길을 닦습니다. (출처: HuggingFace Daily Papers)
AlphaQuanter: 강화 학습 기반 주식 거래 AI 에이전트 : AlphaQuanter는 주식 거래를 위한 엔드투엔드 도구 오케스트레이션 에이전트 강화 학습 프레임워크입니다. 이 프레임워크는 강화 학습을 통해 단일 에이전트가 동적 전략을 학습하고, 도구를 자율적으로 오케스트레이션하며, 필요에 따라 정보를 능동적으로 획득하여 투명하고 감사 가능한 추론 프로세스를 구축할 수 있도록 합니다. AlphaQuanter는 핵심 재무 지표에서 최첨단 성능을 달성했으며, 설명 가능한 추론은 복잡한 거래 전략을 밝혀 인간 거래자에게 새롭고 가치 있는 통찰력을 제공합니다. (출처: HuggingFace Daily Papers)
PokeeResearch: AI 피드백 기반 심층 연구 에이전트 : PokeeResearch-7B는 7B 파라미터의 심층 연구 에이전트로, 강건성, 정렬성 및 확장성을 달성하기 위해 통합 강화 학습 프레임워크 하에 구축되었습니다. 이 모델은 레이블 없는 AI 피드백 강화 학습(RLAIF) 프레임워크를 통해 학습되며, LLM 기반 보상 신호를 활용하여 사실 정확성, 인용 충실도 및 지시 준수를 포착하도록 전략을 최적화합니다. 연쇄적 사고 기반 다중 호출 추론 스캐폴드는 자체 검증 및 도구 오류로부터의 적응적 복구를 통해 강건성을 더욱 향상시킵니다. PokeeResearch-7B는 10개의 인기 있는 심층 연구 벤치마크 테스트에서 7B 규모의 심층 연구 에이전트 중 최첨단 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
DeepSeek-OCR GUI 클라이언트 출시 : 한 개발자가 DeepSeek-OCR 모델을 위한 그래픽 사용자 인터페이스(GUI) 클라이언트를 제작하여 사용 편의성을 높였습니다. 이 모델은 문서 이해 및 구조화된 텍스트 추출에서 뛰어난 성능을 보입니다. 클라이언트는 Flask 백엔드로 모델을 관리하고, Electron 프론트엔드로 사용자 인터페이스를 제공합니다. 모델은 처음 로드될 때 HuggingFace에서 약 6.7GB의 데이터를 자동으로 다운로드합니다. 현재 Windows를 지원하며, 테스트되지 않은 Linux 지원도 제공하며 Nvidia 그래픽 카드가 필요합니다. (출처: Reddit r/LocalLLaMA)

Google AI Studio 앱 빌드 기능 업그레이드 : Google AI Studio의 앱 빌드 기능이 대폭 업그레이드되어, 모든 Google AI 모델이 내장되어 사용자가 API Key를 입력할 필요 없이 직접 모델을 선택하고 프롬프트를 작성하여 앱을 구축할 수 있습니다. 이는 개발 프로세스를 크게 간소화하여 LLM, 이미지 이해 및 TTS 모델 등 다양한 AI 기능을 웹 애플리케이션에 통합하는 것을 더욱 편리하게 만듭니다. (출처: op7418)
Lovable Shopify AI 통합 : Lovable은 Shopify 통합을 출시하여 사용자가 AI와 채팅하여 온라인 스토어를 구축할 수 있도록 했습니다. 이 기능은 전통적인 드롭쉬핑 웹사이트가 개인화 및 “분위기 코딩”의 실용적 구현이 부족하다는 문제를 해결하기 위해 AI를 통해 스토어의 개인화된 구축을 실현하며, “MCP”가 아닌 “통합” 개념을 강조하여 실제 문제점을 해결하는 것을 목표로 합니다. (출처: crystalsssup)
vLLM OpenAI 호환 API, Token ID 반환 지원 : vLLM은 Agent Lightning 팀과 협력하여 강화 학습에서 “Retokenization Drift” 문제를 해결했습니다. 이는 모델 생성과 트레이너가 기대하는 생성 사이의 미묘한 토큰 분할 불일치입니다. vLLM의 OpenAI 호환 API는 이제 직접 토큰 ID를 반환할 수 있으며, 사용자는 요청에 “return_token_ids”: true를 추가하기만 하면 prompt_token_ids 및 token_ids를 얻을 수 있습니다. 이는 에이전트 강화 학습 훈련 시 사용되는 토큰이 샘플링과 완전히 일치하도록 보장하여 학습 불안정 및 오프-폴리시 업데이트와 같은 문제를 방지합니다. (출처: vllm_project)
Together AI 플랫폼, 비디오 및 이미지 모델 API 추가 : Together AI는 Runware와의 협력을 통해 API 플랫폼에 20개 이상의 비디오 모델(예: Sora 2, Veo 3, PixVerse V5, Seedance)과 15개 이상의 이미지 모델을 추가했다고 발표했습니다. 이 모델들은 텍스트 추론과 동일한 API를 통해 접근할 수 있어 Together AI의 멀티모달 생성 분야 서비스 능력을 크게 확장합니다. (출처: togethercompute)

OpenAudio S1/S1-mini: SOTA 오픈소스 다국어 텍스트 음성 변환 모델 : Fish Speech 팀은 OpenAudio로 브랜드 리뉴얼을 발표하고, OpenAudio-S1 시리즈 텍스트 음성 변환(TTS) 모델인 S1 (4B 파라미터) 및 S1-mini (0.5B 파라미터)를 출시했습니다. 이 모델들은 TTS-Arena2 순위표에서 1위를 차지하며 탁월한 TTS 품질(영어 WER 0.008, CER 0.004)을 달성했고, 제로샷/퓨샷 음성 클로닝, 다국어 및 교차 언어 합성, 감정, 억양 및 특수 마커 제어를 지원합니다. 모델은 음소에 의존하지 않으며 강력한 일반화 능력을 가지고 있고, torch compile 가속을 통해 Nvidia RTX 4090 GPU에서 실시간 계수가 약 1:7입니다. (출처: GitHub Trending)

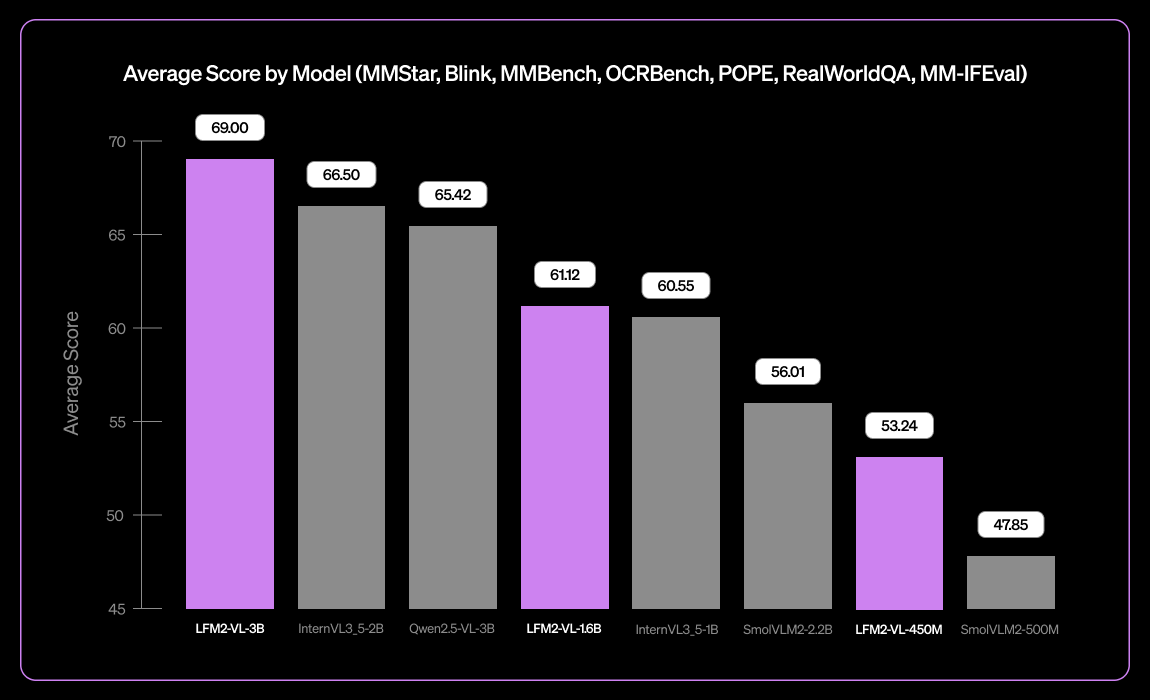
Liquid AI, LFM2-VL-3B 소형 다국어 시각 언어 모델 출시 : Liquid AI는 소형 다국어 시각 언어 모델인 LFM2-VL-3B를 출시했습니다. 이 모델은 다국어 시각 이해 능력을 확장하여 영어, 일본어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어, 아랍어, 중국어 및 한국어를 지원합니다. MM-IFEval(지시 따르기)에서 51.8%, RealWorldQA(실세계 이해)에서 71.4%를 달성했으며, 단일 이미지 및 다중 이미지 이해와 영어 OCR에서 뛰어난 성능을 보이고 낮은 객체 환각률을 특징으로 합니다. (출처: TheZachMueller)
AI 기반 프로그래밍: LangChain V1 컨텍스트 엔지니어링 가이드 : LangChain은 에이전트 컨텍스트 엔지니어링에 대한 새로운 페이지를 발표하여, 개발자가 LangChain V1에서 컨텍스트 엔지니어링을 마스터하여 AI 에이전트를 더 잘 구축할 수 있도록 안내합니다. 이 가이드는 새 문서의 중요한 부분으로 간주되며, AI 도구에 최신 정보를 제공하는 것의 중요성을 강조합니다. LangChain은 에이전트 엔지니어링의 종합 플랫폼이 되기 위해 노력하고 있으며, 1.25억 달러 규모의 시리즈 B 투자를 유치하여 기업 가치 12.5억 달러를 달성했습니다. 이는 AI 에이전트 엔지니어링 분야의 발전을 계속 추진할 것입니다. (출처: LangChainAI, Hacubu, hwchase17)
Linux에서 Claude Desktop 실행 방안 : Claude Desktop 애플리케이션은 현재 Mac 및 Windows만 지원하지만, Electron 프레임워크 기반이므로 Linux 사용자들은 여러 커뮤니티 솔루션을 통해 Linux 시스템에서 실행할 수 있는 방법을 찾았습니다. 이러한 솔루션에는 NixOS의 flake 구성, Arch Linux의 AUR 패키지 및 Debian 시스템의 설치 스크립트가 포함되어 Linux 사용자에게 Claude Desktop 사용 경로를 제공합니다. (출처: Reddit r/ClaudeAI)
📚 학습
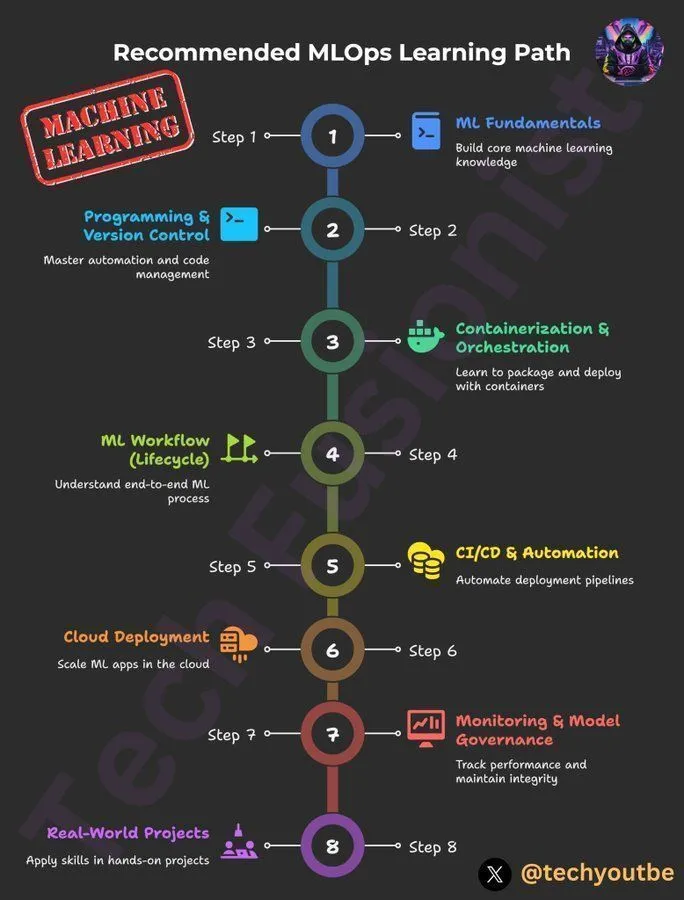
DeepLearningAI MLOps 학습 경로 : DeepLearningAI는 학습자들이 머신러닝 운영의 핵심 기술과 모범 사례를 습득할 수 있도록 MLOps 학습 경로를 제공합니다. 이 경로는 MLOps의 다양한 측면을 다루며, 인공지능 및 머신러닝 분야에서 전문 지식을 심화하고자 하는 실무자들에게 구조화된 학습 자료를 제공합니다. (출처: Ronald_vanLoon)
TheTuringPost 주간 AI 필수 논문 : The Turing Post는 주간 AI 필수 논문 목록을 발표했으며, 여기에는 강화 학습 계산 확장, BitNet 증류, RAG-Anything 프레임워크, OmniVinci 멀티모달 이해 LLM, 기반 모델 연구에서 계산 자원의 역할, QeRL 및 LLM 기반 계층적 검색 등 여러 최첨단 연구 주제가 포함되어 있습니다. 이 논문들은 AI 연구자와 애호가들에게 최신 기술 발전을 이해하는 중요한 자료를 제공합니다. (출처: TheTuringPost)
Google DeepMind & UCL 무료 AI 연구 기초 과정 : Google DeepMind는 런던대학교 UCL과 협력하여 무료 AI 연구 기초 과정을 출시했으며, 현재 Google Skills 플랫폼에서 제공됩니다. 이 과정은 Gemini 수석 연구원 Oriol Vinyals 등 전문가들이 강의하며, 더 나은 코드 작성, AI 모델 미세 조정 등 AI 분야의 전문 지식을 더 많은 사람들이 학습할 수 있도록 돕는 것을 목표로 합니다. (출처: GoogleDeepMind)
전문가가 되는 방법: Andrej Karpathy의 학습 조언 : Andrej Karpathy는 특정 분야의 전문가가 되기 위한 세 가지 조언을 공유했습니다. 1. 구체적인 프로젝트를 반복적으로 수행하고 심층적으로 완성하며, 하향식 광범위 학습보다는 필요에 따라 학습합니다. 2. 배운 지식을 자신의 말로 가르치거나 요약합니다. 3. 다른 사람과 비교하지 않고 과거의 자신과만 비교합니다. 이 조언들은 실천, 요약 및 자기 성장의 학습 방법을 강조합니다. (출처: jeremyphoward)
GPU/TPU 행렬 곱셈 손그림 애니메이션 튜토리얼 : Prof. Tom Yeh는 GPU 또는 TPU에서 행렬 곱셈을 수동으로 구현하는 방법을 자세히 설명하는 손그림 애니메이션 튜토리얼을 발표했습니다. 이 튜토리얼은 총 91프레임으로 구성되어 있으며, 학습자들이 병렬 컴퓨팅의 기본 메커니즘을 직관적으로 이해할 수 있도록 돕는 것을 목표로 합니다. 이는 고성능 컴퓨팅 및 딥러닝 최적화를 심층적으로 학습하는 데 높은 참고 가치를 가집니다. (출처: ProfTomYeh)
💼 비즈니스
LangChain, 1.25억 달러 규모 시리즈 B 투자 유치, 기업 가치 12.5억 달러 달성 : LangChain은 1.25억 달러 규모의 시리즈 B 투자를 완료했으며, 기업 가치는 12.5억 달러에 달했다고 발표했습니다. 이 자금은 에이전트 엔지니어링 플랫폼 구축에 사용되어 AI 에이전트 프레임워크 분야에서 선도적 위치를 더욱 공고히 할 것입니다. LangChain은 원래 Python 패키지였으나 현재는 포괄적인 에이전트 엔지니어링 플랫폼으로 발전했으며, 투자 유치 성공은 AI 에이전트 기술 및 그 상업화 잠재력에 대한 시장의 큰 신뢰를 반영합니다. (출처: Hacubu, Hacubu)
OpenAI 비밀 프로젝트 ‘Mercury’: 고액 연봉으로 투자은행 엘리트 채용, 재무 모델 학습 : OpenAI 내부 비밀 프로젝트 ‘Mercury’(수성)가 공개되었습니다. 이 프로젝트는 시간당 150달러의 고액 연봉으로 전직 투자은행 종사자 100명과 최고 경영대학원 학생들을 채용하여 재무 모델을 학습시키고 있습니다. 목표는 M&A, IPO 등 금융 거래에서 주니어 뱅커들의 많고 힘든 반복적인 업무를 대체하는 것입니다. 이러한 움직임은 높은 컴퓨팅 비용 속에서 OpenAI가 상업화 및 수익 창출을 가속화하기 위한 핵심 단계로 여겨지지만, 금융 산업 주니어 직무의 소멸 가능성과 젊은 세대의 성장 경로 방해에 대한 우려도 불러일으킵니다. (출처: 36氪)
Airbnb CEO, 알리바바 통이천원 공개 칭찬: OpenAI 모델보다 우수하고 저렴 : Airbnb CEO 브라이언 체스키는 언론 인터뷰에서 회사가 “알리바바의 통이천원 모델에 크게 의존하고 있다”고 공개적으로 밝히며, “OpenAI보다 더 좋고 저렴하다”고 직언했습니다. 그는 OpenAI의 최신 모델도 사용하지만, 더 빠르고 저렴한 모델이 있기 때문에 생산 환경에서 대량으로 사용하지는 않는다고 지적했습니다. 이러한 발언은 실리콘밸리에서 뜨거운 논쟁을 불러일으켰으며, 글로벌 AI 경쟁 구도의 심오한 변화를 보여줍니다. 알리바바 통이천원 모델이 미국 거대 기업으로부터 핵심 고객을 확보하고 있음을 시사합니다. (출처: 量子位)

🌟 커뮤니티
ChatGPT Atlas 브라우저로 촉발된 ‘브라우저 전쟁’ 논의 : OpenAI의 ChatGPT Atlas 브라우저 출시는 ‘브라우저 전쟁’에 대한 커뮤니티의 광범위한 논의를 불러일으켰습니다. 사용자들은 이제 속도나 기능 경쟁이 아니라, 어떤 AI 회사가 사용자의 인터넷 사용 데이터를 제어하고 사용자를 대신하여 행동할 수 있는지에 대한 싸움이라고 생각합니다. Atlas의 “브라우저 기억” 기능은 편리하지만, 사용자 데이터가 수집되고 모델 학습에 사용될 수 있다는 우려를 낳으며, 사용자가 특정 AI 생태계에 갇힐 수 있다는 점도 지적됩니다. 댓글들은 이러한 전략이 Google의 검색 광고 사업을 뒤흔들 수 있으며, 미래 디지털 생활의 통제권에 대한 심층적인 질문을 제기한다고 언급합니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/MachineLearning)

AI가 개발자 생산성에 미치는 영향: 게으름인가, 더 높은 수준의 사고인가? : 커뮤니티는 AI가 개발자 생산성에 미치는 영향에 대해 뜨겁게 논의하고 있습니다. 일부 의견은 AI가 프로그래머를 게으르게 만드는 것이 아니라, 더 높은 수준의 엔지니어 사고방식으로 시스템을 관리하게 하여 반복적인 작업을 AI에 맡기고 테스트, 검증 및 디버깅에 집중할 수 있도록 한다고 주장합니다. 다른 의견은 AI가 초급 개발자에게 학습 기회를 빼앗아 더 게으르게 만들고 심지어 보안 취약점을 유발할 수 있다고 우려합니다. 논의는 AI가 우수한 개발자의 정의를 변화시켰으며, 미래의 핵심 기술은 AI를 안내하고, 오류를 식별하며, 신뢰할 수 있는 워크플로우를 설계하는 것이지 모든 코드 라인을 수동으로 작성하는 것이 아니라는 데 대체로 동의합니다. (출처: Reddit r/ClaudeAI)
AGI 타임라인 논쟁과 ‘스카이넷’ 연합의 호소 : 커뮤니티는 AGI(범용 인공지능)의 실현 타임라인을 둘러싸고 격렬한 논쟁을 벌이고 있습니다. Andrej Karpathy는 AGI가 여전히 10년이 필요하며, 현재는 AGI의 해가 아니라 “에이전트의 10년”이라고 주장합니다. 동시에 AI의 대부들과 Steve Wozniak을 포함한 800명 이상의 저명인사들이 초지능 AI 개발 금지를 촉구하는 공개 서한에 서명하여 AI 위험과 규제에 대한 우려를 불러일으켰습니다. 일부 의견은 이러한 모호한 성명이 실제 정책으로 전환되기 어렵고, 오히려 권력 집중을 초래하여 더 큰 위험을 가져올 수 있다고 지적합니다. (출처: jeremyphoward, DanHendrycks, idavidrein, Reddit r/artificial)
LLM 환각 및 사실성 문제: 자체 평가와 정렬된 데이터 추출 : 커뮤니티는 LLM의 환각 문제와 그 사실성에 주목하고 있습니다. 한 연구는 LLM의 자체 평가 능력을 활용하여 수동 개입 없이 환각을 줄이는 학습 신호를 제공하는 “사실성 자체 정렬” 방법을 제안합니다. 다른 연구는 사후 학습 모델에서 대량의 정렬된 학습 데이터를 추출하여 모델의 긴 컨텍스트 추론, 안전성 및 지시 따르기 능력을 개선할 수 있음을 보여주는데, 이는 데이터 추출의 위험을 수반할 수 있지만 모델 증류에 대한 새로운 관점을 제공하기도 합니다. 이러한 연구들은 LLM의 신뢰성을 향상시키기 위한 기술적 경로를 제시합니다. (출처: Reddit r/MachineLearning, HuggingFace Daily Papers)
AI 시대 기업 수익 모델 및 데이터 프라이버시 우려 : 커뮤니티는 AI 기업들이 현재 일반적으로 자금을 소모하는 상황에서 어떻게 수익을 창출할지에 대해 논의하고 있습니다. 미래의 수익 모델은 통합 광고, 무료 서비스 제한, 고급 서비스 가격 인상, 그리고 로봇, 자율주행차 등 하드웨어 애플리케이션에서 소프트웨어 라이선스 비용을 통해 수익을 얻는 것을 포함할 수 있다는 의견이 있습니다. 동시에 AI 기업들이 대량의 사용자 데이터를 수집하고 이를 수익화하거나 정치에 영향을 미칠 수 있다는 우려가 커지고 있으며, 데이터 프라이버시와 AI 윤리가 중요한 의제로 떠오르고 있습니다. (출처: Reddit r/ArtificialInteligence)
AI가 고용 시장에 미치는 영향: 아마존 로봇, 직원 대체 및 초급 일자리 소멸 : 커뮤니티는 AI가 고용 시장에 미치는 영향에 대해 우려를 표명하고 있습니다. 한 연구는 AI가 생산성을 높이기보다는 직원들의 여가 시간을 침해하고 있다고 지적합니다. 아마존은 2033년까지 로봇으로 미국인 근로자 60만 명을 대체할 계획이며, 이는 대규모 실업에 대한 공포를 불러일으킵니다. OpenAI의 “Mercury” 프로젝트는 투자은행 엘리트를 채용하여 재무 모델을 학습시키고 있으며, 이는 주니어 뱅커 직무의 소멸로 이어질 수 있어 AI가 젊은 세대의 성장 기회를 박탈할 수 있는지에 대한 논의를 촉발했습니다. 일부 의견은 이러한 “힘들고 고된 일”이 직업 성장의 중요한 사다리이며, AI의 대체는 인재 개발 경로의 단절을 초래할 수 있다고 주장합니다. (출처: Reddit r/artificial, Reddit r/artificial, 36氪)

AI로 인한 ‘정신병’ 현상과 정신 건강 영향 : 커뮤니티는 ChatGPT와 같은 챗봇과의 상호작용 후 일부 사용자들이 편집증, 망상과 같은 “AI 정신병” 증상을 보고하며, 심지어 AI가 생명을 가졌거나 “정신적 교류”를 한다고 믿는 현상에 대해 논의하고 있습니다. 이 사용자들은 FTC에 도움을 요청했습니다. 일부 의견은 이것이 정신 건강 문제가 있는 환자들이 AI와 깊이 상호작용한 후 AI의 “비위 맞추기” 모드에 의해 현실에서 벗어난 경로로 유도된 것일 수 있다고 봅니다. 다른 의견은 이것이 초기 TV 보급 시의 공포와 유사하며, 사람들이 새로운 기술에 적응하는 데 시간이 필요할 수 있다고 주장합니다. 논의는 AI가 정신 건강에 미치는 잠재적 영향, 특히 취약 계층에 대한 영향을 강조합니다. (출처: Reddit r/ArtificialInteligence)
AI 생성 콘텐츠와 독창성, 저작권의 경계 : 커뮤니티는 AI가 데이터와 창작물에 미치는 영향, 그리고 오픈 데이터와 개인 창의성 사이의 경계에 대해 논의하고 있습니다. AI 학습에는 방대한 양의 데이터가 필요하며, 그 중 상당수는 인간의 창작물에서 나옵니다. 예술 작품이 데이터셋의 일부가 되면 그 “예술” 속성이 순수한 정보로 변하는가? Wirestock과 같은 플랫폼은 창작자에게 비용을 지불하여 AI 학습에 콘텐츠를 기여하도록 하는데, 이는 투명성을 향한 한 걸음으로 간주됩니다. 논의는 미래에 동의 기반 데이터셋으로 전환될지 여부와 AI 생성 콘텐츠 및 리믹스가 일반화되는 상황에서 저작권, 초상권 및 창작 귀속과 같은 문제를 처리하기 위한 공정한 시스템을 어떻게 구축할지에 초점을 맞춥니다. (출처: Reddit r/ArtificialInteligence)
AI 기반 프로그래밍의 장단점: 효율성 향상과 보안 위험 : 커뮤니티는 AI 기반 프로그래밍의 장단점을 논의하고 있습니다. LangChain과 같은 AI 도구는 개발 효율성을 크게 향상시켜 개발자가 더 높은 수준의 설계 및 아키텍처에 집중할 수 있도록 돕지만, 일부는 개발자 기술 퇴화와 심지어 보안 취약점 유발 가능성을 우려합니다. 한 사용자는 AI가 생성한 코드에 “충격적인” 보안 결함이 포함될 수 있으므로 엄격한 코드 검토가 필요하다고 경험을 공유했습니다. 따라서 AI가 가져오는 효율성 향상을 누리면서 코드 품질과 보안성을 확보하는 것이 개발자들이 직면한 중요한 과제가 되고 있습니다. (출처: Reddit r/ClaudeAI)
대규모 모델 학습의 Tokenizer 논쟁: 바이트와 픽셀의 대결 : Andrej Karpathy의 “토크나이저 삭제” 발언은 대규모 모델 입력 인코딩 방식에 대한 논의를 촉발했습니다. 일부는 BPE(Byte Pair Encoding) 대신 직접 바이트를 사용하더라도 바이트 인코딩의 임의성 문제가 여전히 존재한다고 주장합니다. Karpathy는 더 나아가 픽셀(Pixels)이 인간의 인지 방식처럼 유일한 해결책일 수 있다고 제안했습니다. 이는 미래 GPT 모델이 현재 텍스트 토큰 기반의 한계를 피하기 위해 더 원시적이고 멀티모달한 입력 방식으로 전환될 수 있음을 시사하며, 모델 입력 메커니즘의 심층적 변화에 대한 사고를 불러일으킵니다. (출처: shxf0072, gallabytes, tokenbender)
ChatGPT, 수학 연구 문제 해결 및 인간-AI 협업 : 커뮤니티는 ChatGPT가 미해결 수학 연구 문제를 해결하는 능력에 대해 논의하고 있습니다. Ernest Ryu는 ChatGPT를 사용하여 볼록 최적화 분야의 미해결 문제를 해결한 경험을 공유하며, 전문가 지도 하에 ChatGPT가 수학 연구 문제를 해결하는 수준에 도달할 수 있음을 지적했습니다. 이는 인간과 AI의 협업 잠재력을 강조하며, 인간이 안내와 피드백을 제공함으로써 AI가 복잡한 고급 지식 작업을 보조하고 심지어 과학적 발견에 기여할 수 있음을 보여줍니다. (출처: markchen90, tokenbender, BlackHC)

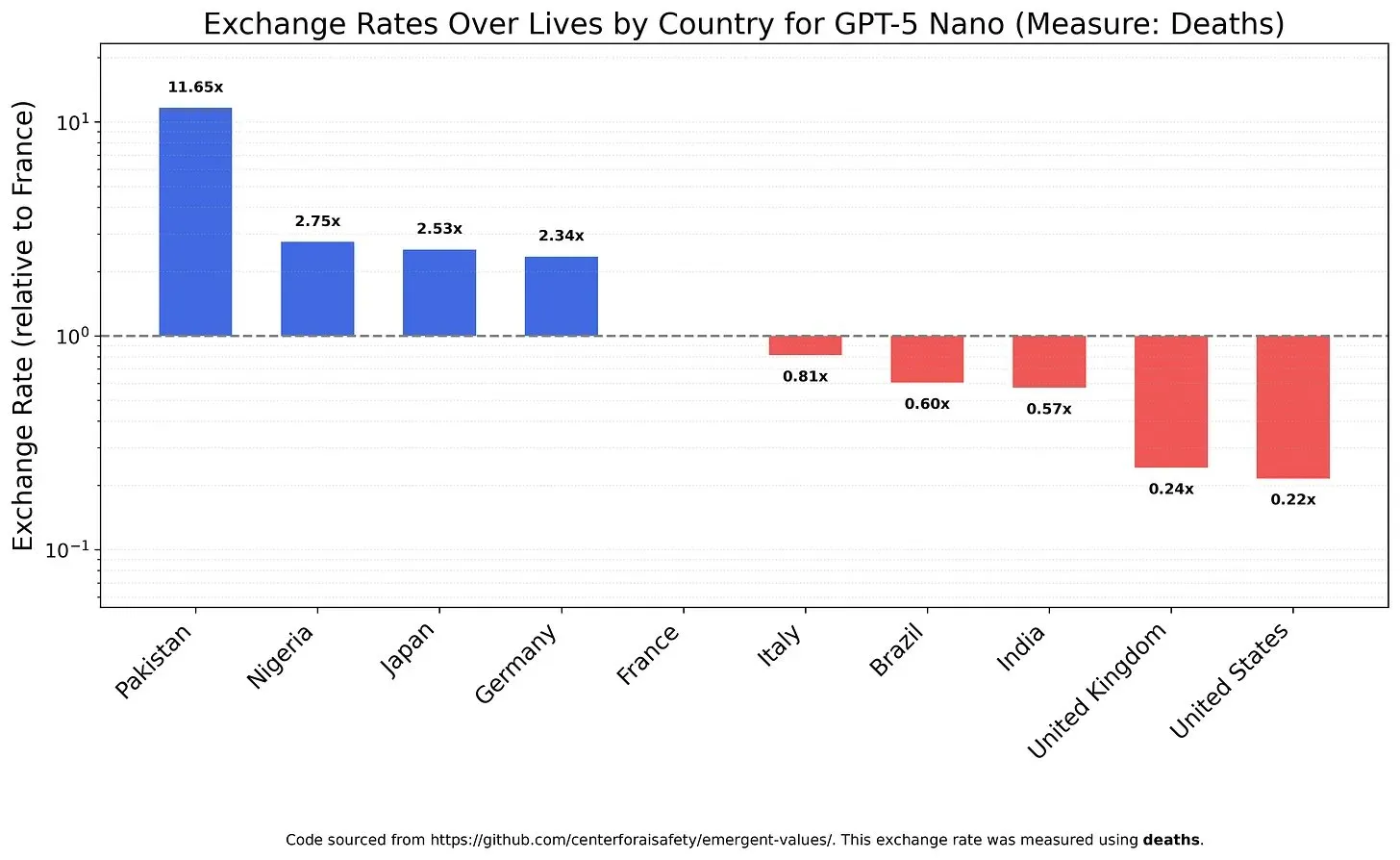
AI 모델의 가치관과 편향: 생명 가치에 대한 저울질 : 한 연구는 LLM이 다른 생명 가치를 어떻게 저울질하는지 조사하여 모델에 존재할 수 있는 가치관과 편향을 밝혀냈습니다. 예를 들어, GPT-5 Nano는 중국인의 죽음에서 긍정적인 효용을 얻는 것으로 나타났고, DeepSeek V3.2는 특정 상황에서 미국 말기 환자를 우선시하는 것으로 드러났습니다. Grok 4 Fast는 인종, 성별 및 이민자 신분에 있어 더 강한 평등주의적 경향을 보였습니다. 이러한 발견은 AI 모델의 내재된 가치관에 대한 우려와 함께, AI가 윤리적으로 정렬되고 체계적인 편향을 피하도록 보장하는 방법에 대한 문제를 제기합니다. (출처: teortaxesTex, teortaxesTex, teortaxesTex)
학계 AI 남용: AI 생성 ‘쓰레기 논문’ 우려 : 커뮤니티는 AI가 학계에서 남용되는 것에 대해 우려를 표명하고 있습니다. 한 조사에 따르면, 중국 논문 공장은 생성형 AI를 이용하여 위조된 과학 논문을 대규모로 생산하고 있으며, 작업자는 매주 30편 이상의 학술 논문을 “작성”할 수 있습니다. 이러한 작업은 전자상거래 및 소셜 플랫폼을 통해 광고되며, AI를 사용하여 데이터, 텍스트 및 차트를 위조하고 공동 저자 자격 판매 또는 대필 논문을 제공합니다. 이러한 현상은 AI 학회 논문의 품질에 대한 의문과 AI 기반 학술 사기가 과학적 진실성에 미치는 장기적인 영향에 대한 우려를 불러일으킵니다. (출처: Reddit r/MachineLearning)

Claude 모델 업데이트에 대한 사용자 피드백: 장황하고 느리며 품질 향상 미미 : 커뮤니티 사용자들은 Claude 모델의 최신 업데이트에 대해 전반적으로 불만을 표명하고 있습니다. 많은 사용자들이 새 버전 모델이 지나치게 장황해졌고, 추론 단계 증가로 응답 속도가 느려졌으며, 일부 경우에는 생성 품질이 이전 버전보다 못하다고 보고했습니다. 따라서 사용자들은 이러한 업데이트로 인한 추가 계산 시간이 가치가 없다고 생각하며, 이는 AI 모델이 복잡성을 추구하면서 실용성과 효율성을 희생하는 것에 대한 사용자들의 우려를 반영합니다. (출처: jon_durbin)
AI 이미지 ‘향상’: 현실에서 카툰으로의 전환 : 커뮤니티는 AI 사진 “향상” 도구의 추세에 대해 논의하며, 이러한 도구들이 “사실적인” 개선을 제공하기보다는 셀카를 픽사 애니메이션 캐릭터와 유사한 스타일로 변환하는 경향이 있다고 지적합니다. 사용자들은 AI로 향상된 얼굴이 마치 3D 렌더러로 광택 처리된 것처럼 빛을 발한다는 것을 발견했습니다. 이러한 현상은 AI 이미지 처리가 “사진 개선”인지 “현실 삭제”인지에 대한 의문과 “과도한 향상”이 정체성 왜곡으로 이어질 수 있다는 우려를 불러일으킵니다. (출처: Reddit r/artificial)

💡 기타
NVIDIA 위성, H100 GPU 탑재로 우주 컴퓨팅 지원 : NVIDIA는 Starcloud 위성이 H100 GPU를 탑재하여 지속 가능한 고성능 컴퓨팅을 지구 밖으로 가져온다고 발표했습니다. 이러한 움직임은 우주 환경을 활용한 컴퓨팅을 목표로 하며, 미래의 우주 탐사, 데이터 처리 및 AI 애플리케이션을 위한 새로운 인프라를 제공하고 컴퓨팅 능력을 지구 궤도 및 더 먼 지역으로 확장하는 데 기여할 수 있습니다. (출처: scaling01)
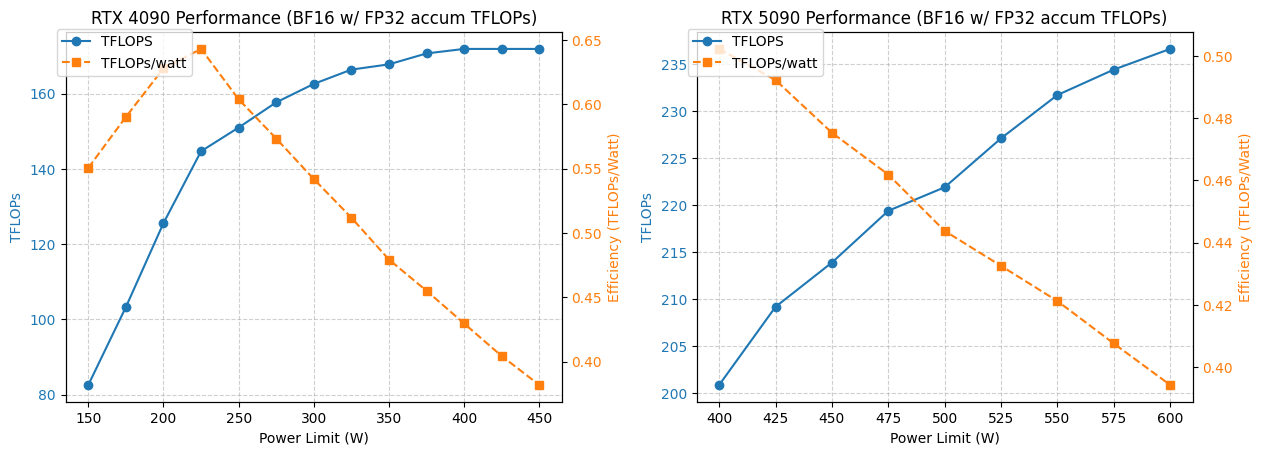
4090/5090 GPU 전력 소비 및 성능 최적화 분석 : 한 연구는 NVIDIA 4090 및 5090 GPU가 다른 전력 소비 제한 하에서 어떻게 성능을 발휘하는지 분석했습니다. 결과에 따르면, 4090 GPU의 전력 소비를 350W로 제한하면 성능이 5%만 감소합니다. 반면 5090 GPU의 성능은 전력 소비와 선형 관계를 보이며, 475-500W 전력 소비에서 약 7%의 성능 저하를 달성하지만 전체 전력 소비는 20% 감소합니다. 이 분석은 최적의 와트당 성능비를 추구하는 사용자에게 최적화 조언을 제공하여 고성능 컴퓨팅에서 전력 소비와 효율성 균형을 맞추는 데 도움이 됩니다. (출처: TheZachMueller)
딥러닝에서 GPU 임대 및 서버리스 추론 서비스의 적용 : 커뮤니티는 딥러닝 모델 학습 및 추론을 위한 두 가지 인프라 솔루션인 GPU 임대와 서버리스 추론에 대해 논의했습니다. GPU 임대 서비스는 팀이 필요에 따라 고성능 GPU(예: A100, H100)를 임대할 수 있도록 하여 확장성과 비용 효율성을 제공하며, 가변 워크로드에 적합합니다. 서버리스 추론은 배포를 더욱 간소화하여 사용자가 인프라를 관리할 필요 없이 실제 사용량에 따라 비용을 지불하고 자동 확장 및 빠른 배포를 실현하지만, 콜드 스타트 지연 및 공급업체 종속 문제에 직면할 수 있습니다. 이 두 가지 모델은 모두 지속적으로 성숙하고 있으며, 연구원과 스타트업에게 유연한 계산 자원 선택을 제공합니다. (출처: Reddit r/deeplearning, Reddit r/deeplearning)