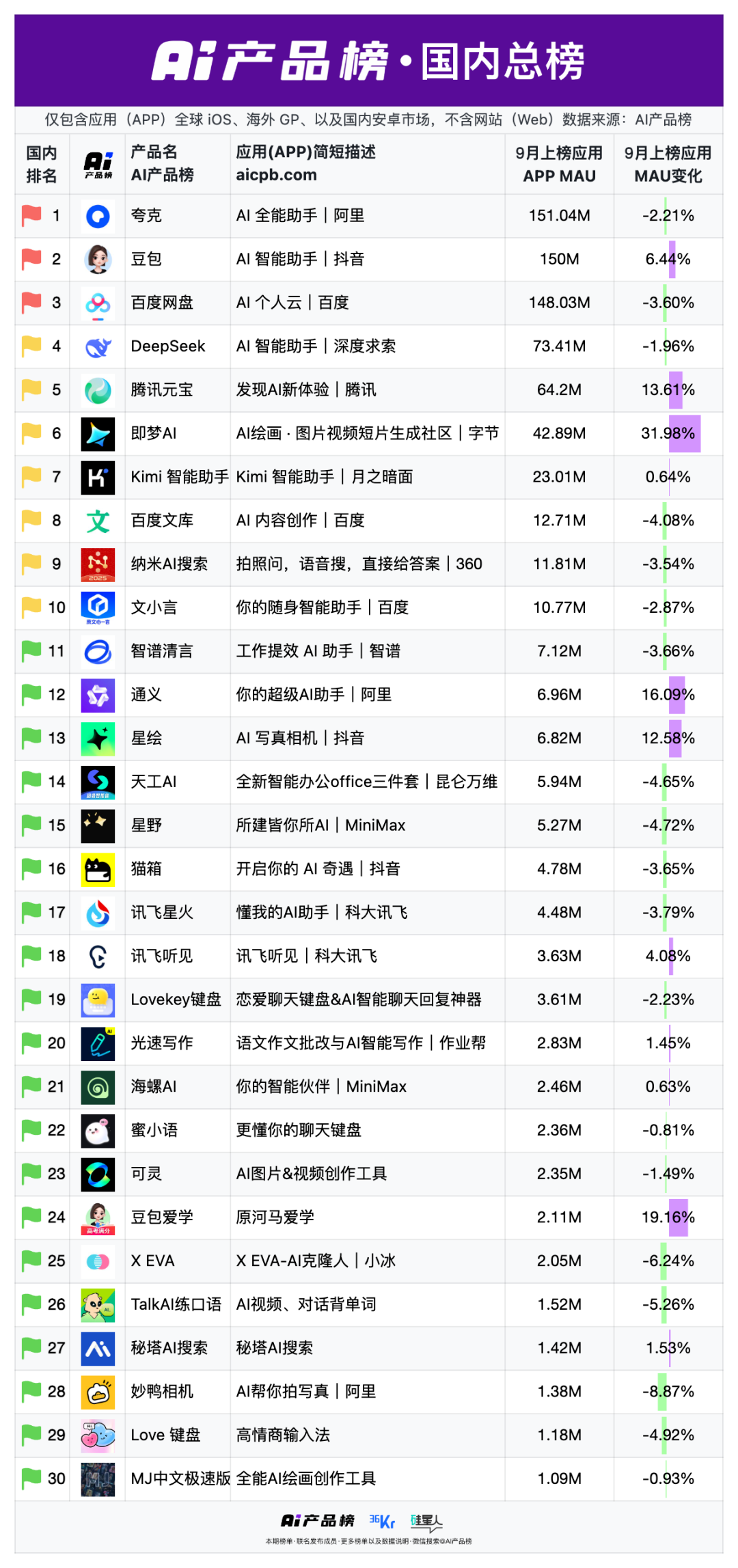
키워드:AI 기술, 대형 언어 모델, 딥러닝, 인공지능, 머신러닝, 자연어 처리, 컴퓨터 비전, 강화 학습, 나노챗 오픈소스 프로젝트, OpenAI 자체 개발 AI 칩, Sora 2 딥페이크 윤리, Claude Sonnet 4.5, GPT-5 Pro 수학 추론
🔥 포커스
Andrej Karpathy, nanochat 공개: 100달러로 ChatGPT 직접 제작 : Tesla의 전 AI 디렉터 Andrej Karpathy가 오픈소스 프로젝트 nanochat을 공개했습니다. 8,000줄 미만의 코드로 ChatGPT의 완전한 훈련 및 추론 프로세스를 구현한 이 프로젝트는 LLM 연구 진입 장벽을 낮추는 것을 목표로 합니다. 사용자는 클라우드 GPU 한 대(약 100달러, 4시간 훈련)만 있으면 대화 가능한 미니 ChatGPT를 구축할 수 있으며, 12시간 훈련 시 GPT-2 CORE 지표를 능가하는 성능을 달성할 수 있습니다. nanochat은 LLM101n 과정의 마지막 프로젝트가 될 예정이며, 연구 플랫폼 또는 벤치마크 도구로 발전할 가능성이 있어 AI 교육 및 민주화에 대한 Karpathy의 지속적인 열정을 보여줍니다. (출처: GitHub nanochat, Reddit r/deeplearning, 36氪, 36氪, 36氪, 36氪)
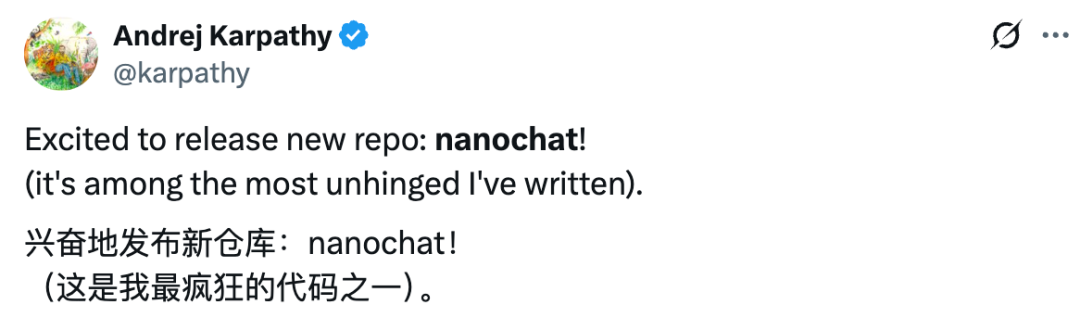
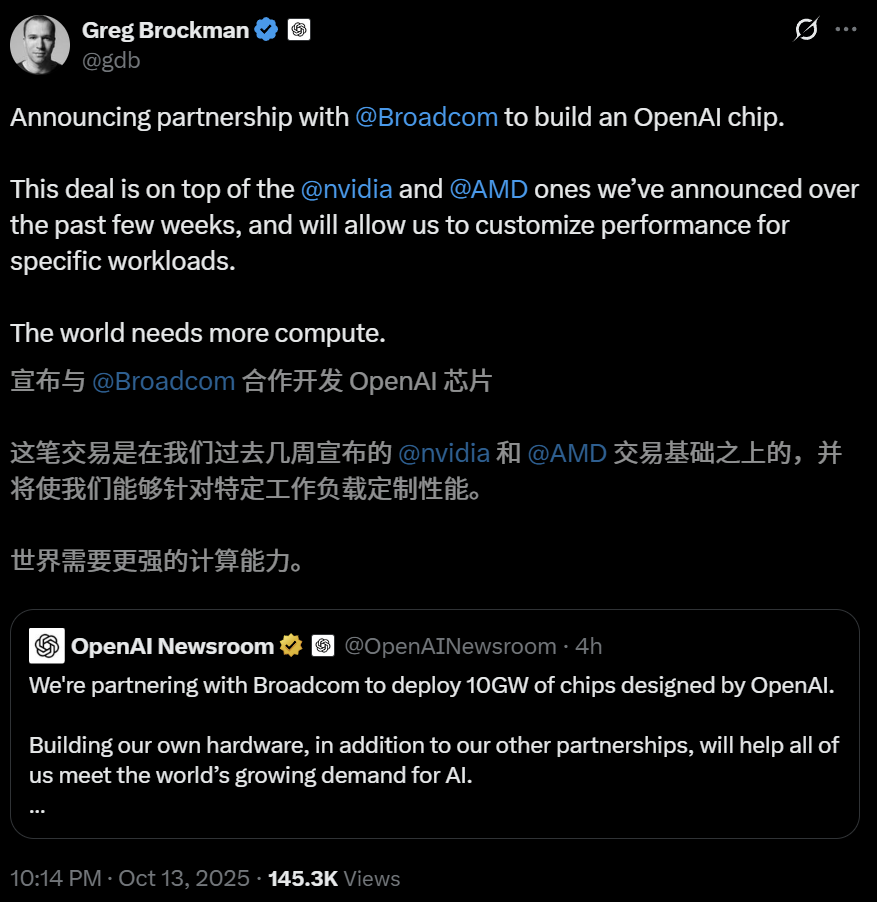
OpenAI, Broadcom과 손잡고 AI 칩 자체 개발, 10기가와트 컴퓨팅 인프라 구축 : OpenAI는 Broadcom과 전략적 협력을 발표하며, 맞춤형 AI 칩 및 컴퓨팅 시스템을 공동 설계 및 배포할 계획입니다. 목표는 2026년 하반기부터 2029년 말까지 총 10기가와트의 추론 인프라를 구축하는 것입니다. 이는 OpenAI가 기존 GPU 구매에 만족하지 않고, 수직 통합을 통해 트랜지스터 수준에서 하드웨어 설계에 참여하여 AI 모델 성능을 최적화하고 비용을 절감하며 미래의 기하급수적인 컴퓨팅 수요를 충족하려는 움직임입니다. OpenAI는 이 협력이 “인류 역사상 가장 큰 공동 산업 프로젝트”이며, AI 모델이 칩 설계에까지 깊이 관여하는 AI 하드웨어 개발의 미래를 예고한다고 밝혔습니다. (출처: OpenAI, Bloomberg, CNBC, 36氪, 36氪, 36氪)
Sora 2, 딥페이크 윤리 위기 및 저작권 논란 촉발 : OpenAI의 동영상 생성 모델 Sora 2는 매우 사실적인 생성 능력으로 빠르게 인기를 얻었지만, 심각한 윤리적 및 저작권 문제를 야기했습니다. 사용자들은 Sora 2를 이용해 고인(예: Michael Jackson, Robin Williams)의 가짜 동영상을 생성하여 유가족들의 강한 불만을 샀고, 이는 고인의 이미지를 남용하고 존중하지 않는 행위로 비판받았습니다. OpenAI는 이에 대해 공인 및 그 가족은 자신의 이미지 사용 방식에 대한 통제권을 가져야 한다고 응답했으며, 더 정교한 저작권 통제 및 수익 분배 메커니즘을 제공할 계획입니다. 그러나 업계에서는 오픈소스 딥페이크 모델의 확산에 대한 우려가 커지고 있으며, 사회가 AI 생성 콘텐츠로 인한 충격에 신속하게 적응하고 효과적인 기술 및 법적 보호 조치를 모색해야 한다는 목소리가 높습니다. (출처: Washington Post, BBC, 量子位)

Claude Sonnet 4.5, Microsoft Agent Framework 및 Cursor IDE, AI 코딩 능력 비약적 발전 견인 : AI 코딩 분야에서 중대한 돌파구가 마련되었습니다. Claude Sonnet 4.5는 SWE-bench Verified 벤치마크에서 77.2%의 정확도를 달성하여 이전 모델들을 크게 앞질렀습니다. 동시에 Microsoft Agent Framework는 VS Code를 AI 네이티브 환경으로 전환하여 Agent가 여러 파일의 코드 수정을 자율적으로 처리할 수 있도록 지원하며, Cursor IDE 1.7도 “Agent 모드”를 출시하여 복잡한 문제를 한 번의 클릭으로 해결할 수 있게 했습니다. 이러한 발전은 AI Agent가 대부분의 개발 작업을 수행할 수 있음을 시사하며, 개발자들이 AI에 과도하게 의존할 수 있다는 논의와 AI 생성 코드가 잠재적인 기술 부채를 유발할 수 있다는 위험에 대한 우려를 불러일으키고 있습니다. (출처: Reddit r/artificial)
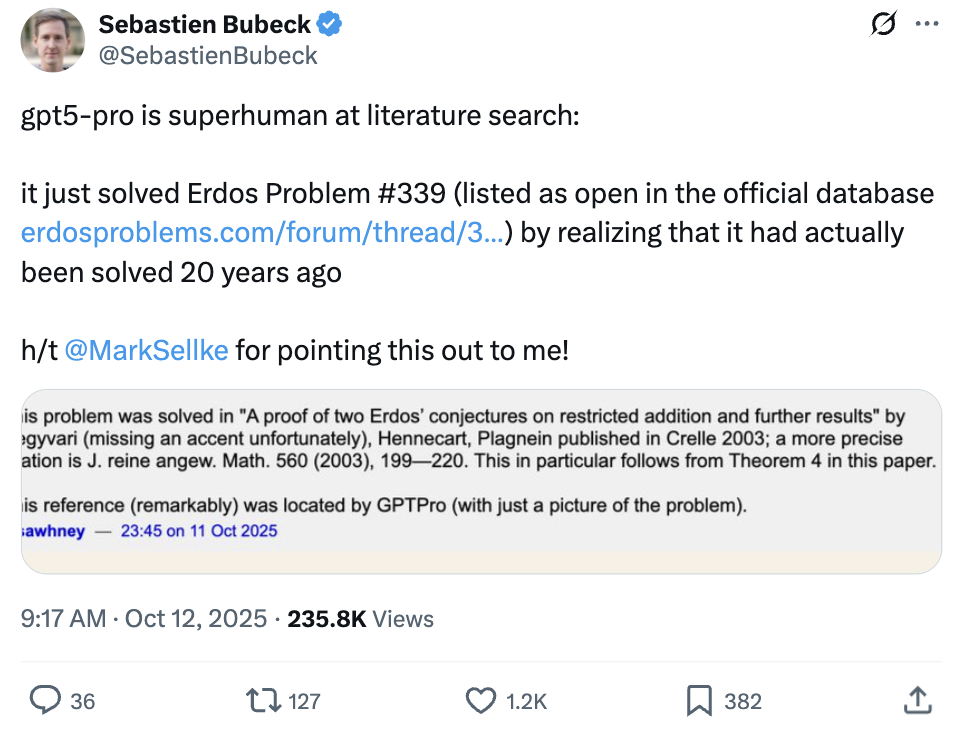
GPT-5 Pro, Erdős 수학 난제 해결: 강력한 문헌 검색 및 취약점 식별 능력 입증 : OpenAI의 GPT-5 Pro가 수학적 추론 분야에서 놀라운 능력을 보여주었습니다. Erdős 문제 #339의 이미지 만으로 2003년에 해당 문제가 해결되었음을 정확히 찾아냈습니다. 또한 GPT-5 Pro는 18분 만에 이미 발표된 논문에서 심각한 결함을 발견했으며, 이는 인간 전문가의 며칠간의 연구 성과를 뛰어넘는 것입니다. 이 돌파구는 GPT-5 Pro가 정확한 정보 검색, 복잡한 문제 해결 및 과학 문헌 검증 분야에서 엄청난 잠재력을 가지고 있음을 강조하며, AI가 특히 학술적 주장 검증 및 논리적 모순 발견에 있어 연구 과정을 크게 가속화할 것임을 예고합니다. (출처: Sebastien Bubeck, Greg Brockman, 36氪)
세 AI 거물, 공동 논문 발표: 기존 LLM 보안 방어는 취약하다 : OpenAI, Anthropic, Google DeepMind가 이례적으로 공동 논문을 발표하며, 현재 대규모 언어 모델(LLM)의 탈옥(jailbreak) 및 프롬프트 주입(prompt injection) 방어 메커니즘이 일반적으로 취약하다고 지적했습니다. 연구팀은 범용 적응형 공격 프레임워크를 제안하고, 경사 하강법, 강화 학습, 무작위 탐색 및 인간 레드팀 테스트 등의 방법을 결합하여 12가지 주요 방어 메커니즘을 성공적으로 우회했으며, 대부분의 공격 성공률이 90%를 초과했습니다. 이는 기존 평가가 탁상공론에 불과하며, 미래의 LLM 보안 연구는 더 강력한 적응형 공격 평가를 포함해야만 진정으로 견고한 방어 시스템을 구축할 수 있음을 시사합니다. (출처: arXiv:2510.09023, 36氪)

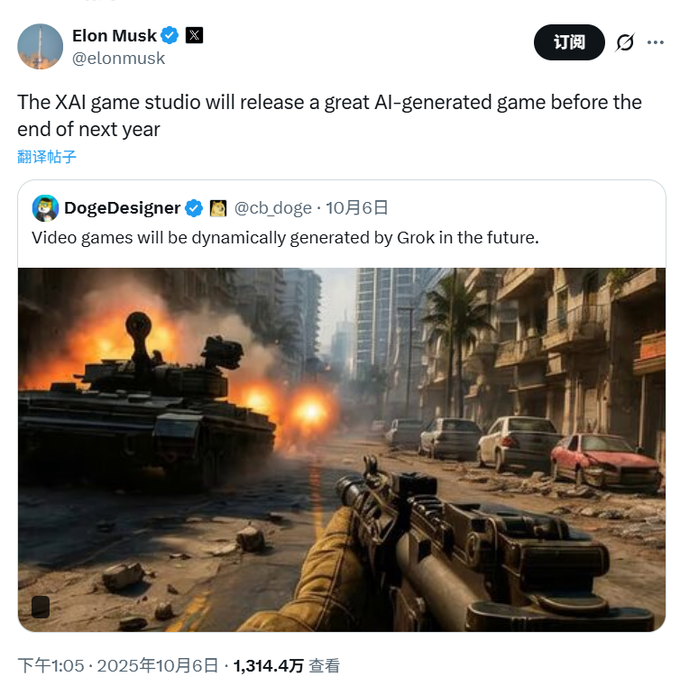
xAI, “월드 모델” 경쟁 합류, 첫 번째 애플리케이션은 AI 게임 생성 목표 : Elon Musk의 xAI가 Google, Meta 등 거대 기업들과 함께 “월드 모델” 경쟁에 조용히 합류했습니다. xAI는 NVIDIA에서 AI 전문가를 영입하여 방대한 비디오 및 로봇 데이터를 훈련시켜 실제 물리 세계를 이해하고 시뮬레이션할 수 있는 모델을 구축하는 것을 목표로 합니다. 첫 번째 상용화 지점은 AI 게임 생성으로, 내년 말까지 AI 생성 게임을 출시하고 로봇 시스템에도 적용할 계획입니다. Google 연구원들은 미래의 비디오 모델이 언어 모델처럼 지능적이 되어 “다음 프레임 예측”을 통해 객체 분할, 에지 감지 등 새로운 능력을 발휘하며 “시각 분야의 GPT 순간”이 도래할 것이라고 예측합니다. (출처: 36氪)
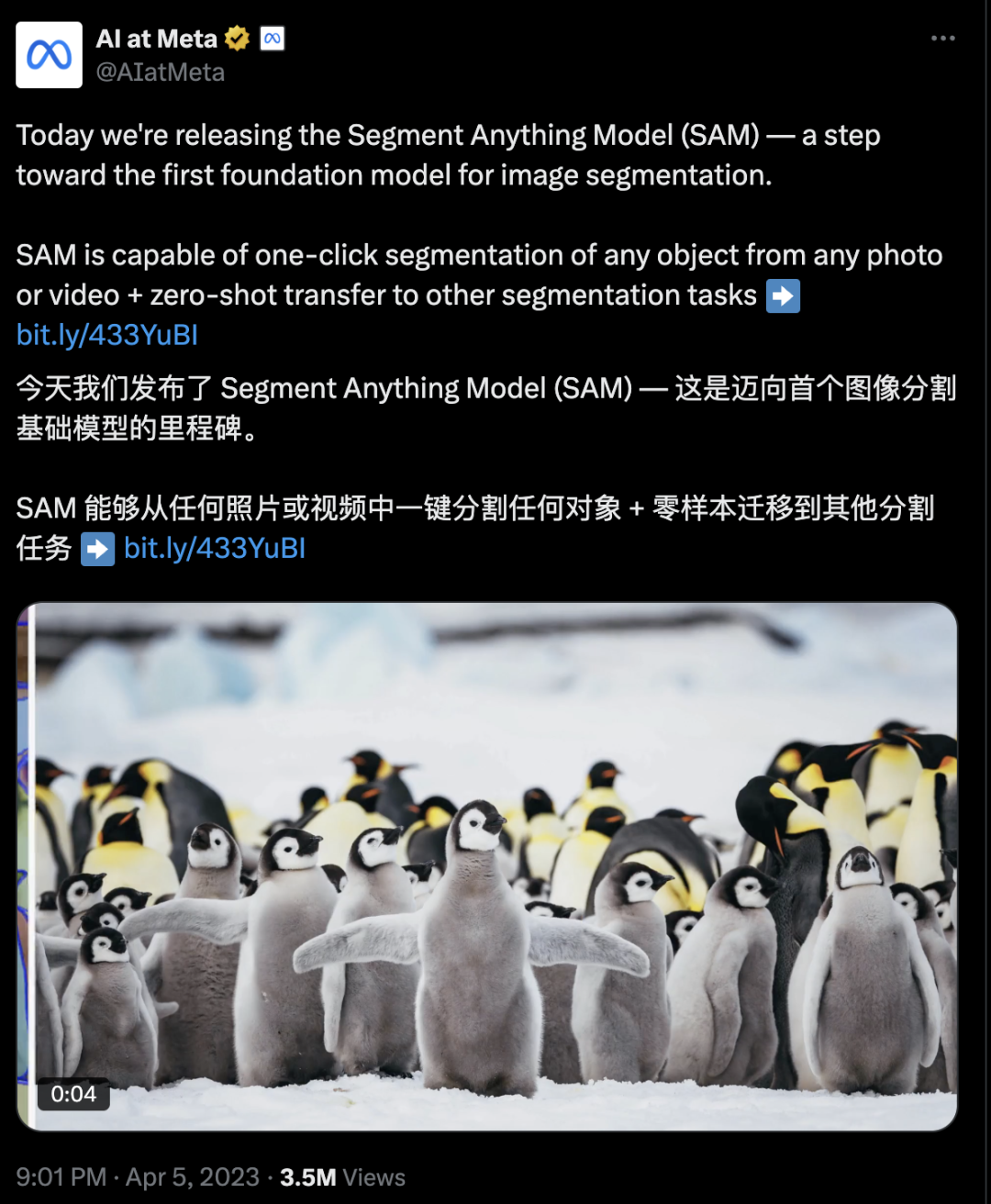
ICLR 미스터리 논문, SAM3 공개: 개념으로 모든 것을 분할, 시각 AI의 새로운 패러다임 재구성 : ICLR 2026 컨퍼런스 블라인드 심사 논문 “SAM3: 개념으로 모든 것을 분할”이 공개되며, Meta AI의 Segment Anything Model (SAM)이 세 번째 주요 업그레이드를 맞이할 것임을 밝혔습니다. SAM3의 핵심 돌파구는 “개념 기반 분할(PCS)”로, 모델은 픽셀 또는 인스턴스별로 분할할 뿐만 아니라 텍스트 또는 이미지 프롬프트에 따라 특정 “의미 개념”에 부합하는 모든 객체를 식별, 분할 및 추적할 수 있습니다. 새로운 시스템은 인간-기계 협업 데이터 엔진을 통해 400만 개의 개념 레이블을 포함하는 고품질 데이터셋을 구축했으며, H200 GPU에서 30밀리초 이내에 수백 개의 객체를 식별하여 기존 시스템을 전면적으로 능가하는 성능을 보여주며, 시각 AI의 “GPT-3 순간”이 멀지 않았음을 예고합니다. (출처: arXiv:r35clVtGzw, 36氪)
🎯 동향
Gemini 3 내부 테스트 호평, “역대 최강 프론트엔드 개발 모델” 찬사 : Google의 차세대 플래그십 모델 Gemini 3가 내부 테스트에서 광범위한 주목을 받으며, 프론트엔드 개발, SVG 벡터 그래픽 생성 및 멀티모달 능력 면에서 “역대 최고의 프론트엔드 및 웹 개발 모델”이라는 찬사를 받았습니다. 심지어 어떤 이들은 올해 최고의 모델이 될 것이라고 예측하기도 했습니다. 공개된 정보에 따르면 Gemini 3.0 Pro는 MoE 아키텍처를 채택하여 수조 개의 매개변수를 가지며, 컨텍스트 창이 수백만 개로 확장되었고, 심층 사고 모드와 멀티모달 능력이 내장되어 ARC-AGI-2 및 HLE 벤치마크에서 뛰어난 성능을 보여주었습니다. (출처: 36氪)
AI, 칩 설계 및 제조에 깊이 적용 : 머신러닝이 칩 설계 및 제조 분야에 점점 더 깊이 적용되어 반도체 효율성과 혁신을 새로운 수준으로 끌어올리고 있습니다. AIHub는 Sony AI 칩 설계 책임자 Lorenzo Servadei와의 인터뷰에서 AI가 EDA(전자 설계 자동화) 분야에서 추정 가속화를 넘어 설계 프로세스에 적극적으로 참여하고 있으며, 신경망을 통해 다중 물리 모델 가속화, 알고리즘 최적화 및 생성형 AI를 통한 물리적 구현을 통해 칩 설계 속도, 품질 및 창의성을 크게 향상시키고 있다고 지적했습니다. OpenAI 또한 GPT 모델이 자체 칩 설계에 도움을 주어 면적을 줄이고 개발 주기를 단축했다고 밝혔습니다. (출처: aihub.org, 36氪)

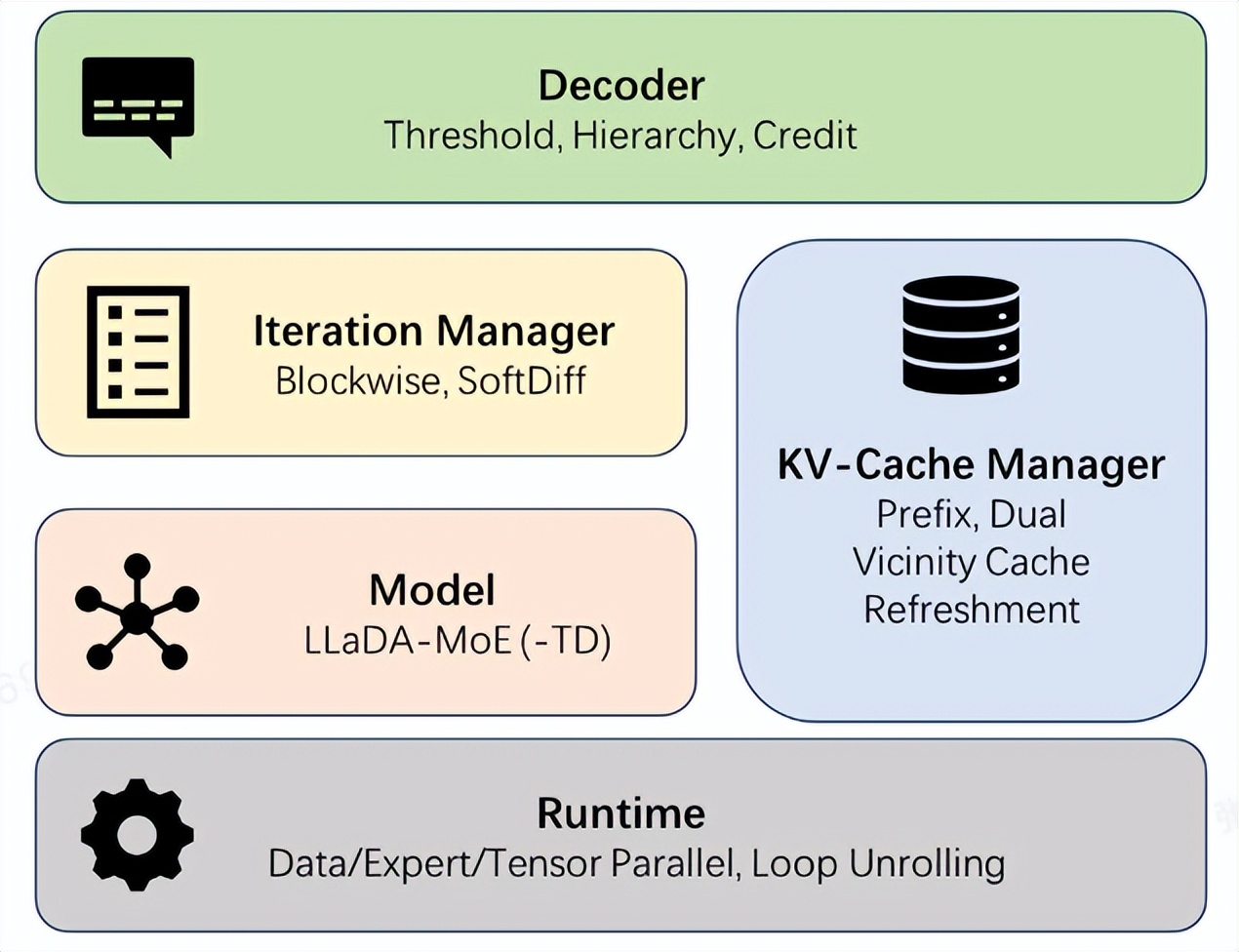
Ant Group, dInfer 프레임워크 오픈소스화: 확산 언어 모델 추론 속도 10배 향상 : Ant Group이 업계 최초의 고성능 확산 언어 모델 추론 프레임워크 dInfer를 공식 오픈소스화했습니다. 이는 확산 언어 모델의 추론 속도를 NVIDIA Fast-dLLM 대비 10.7배 향상시켰습니다. 코드 생성 작업 HumanEval에서 dInfer는 단일 배치 추론에서 초당 1011 Tokens를 달성하여 처음으로 자기회귀 모델을 크게 능가했습니다. dInfer는 알고리즘과 시스템의 심층적인 협력 설계를 채택했으며, 모델 접속, KV 캐시 관리자, 확산 반복 관리자 및 디코딩 전략의 네 가지 핵심 모듈을 포함하여 확산 언어 모델의 높은 계산 비용, KV 캐시 비효율성, 병렬 디코딩 등의 문제를 해결하고 효율적인 추론 잠재력을 발휘하는 것을 목표로 합니다. (출처: 量子位, QuixiAI)
Google NotebookLM 업그레이드, Gemini Nano Banana로 비디오 개요에 새로운 시각 스타일 부여 : Google NotebookLM의 비디오 개요 기능이 업그레이드되어 다양한 시각 스타일(클래식, 화이트보드, 수채화, 복고 인쇄판, 전통, 종이 공예, 애니메이션)이 추가되었으며, Gemini의 이미지 생성 모델 Nano Banana의 지원을 받습니다. 또한, 더 간결한 “Brief” 형식도 도입되어 빠른 요약을 제공합니다. 이러한 업데이트는 Pro 사용자에게 먼저 출시되며, 몇 주 내에 모든 사용자에게 개방되어 비디오 콘텐츠 이해 및 표현에 있어 사용자 맞춤형 경험을 향상시키는 것을 목표로 합니다. (출처: Google, op7418)
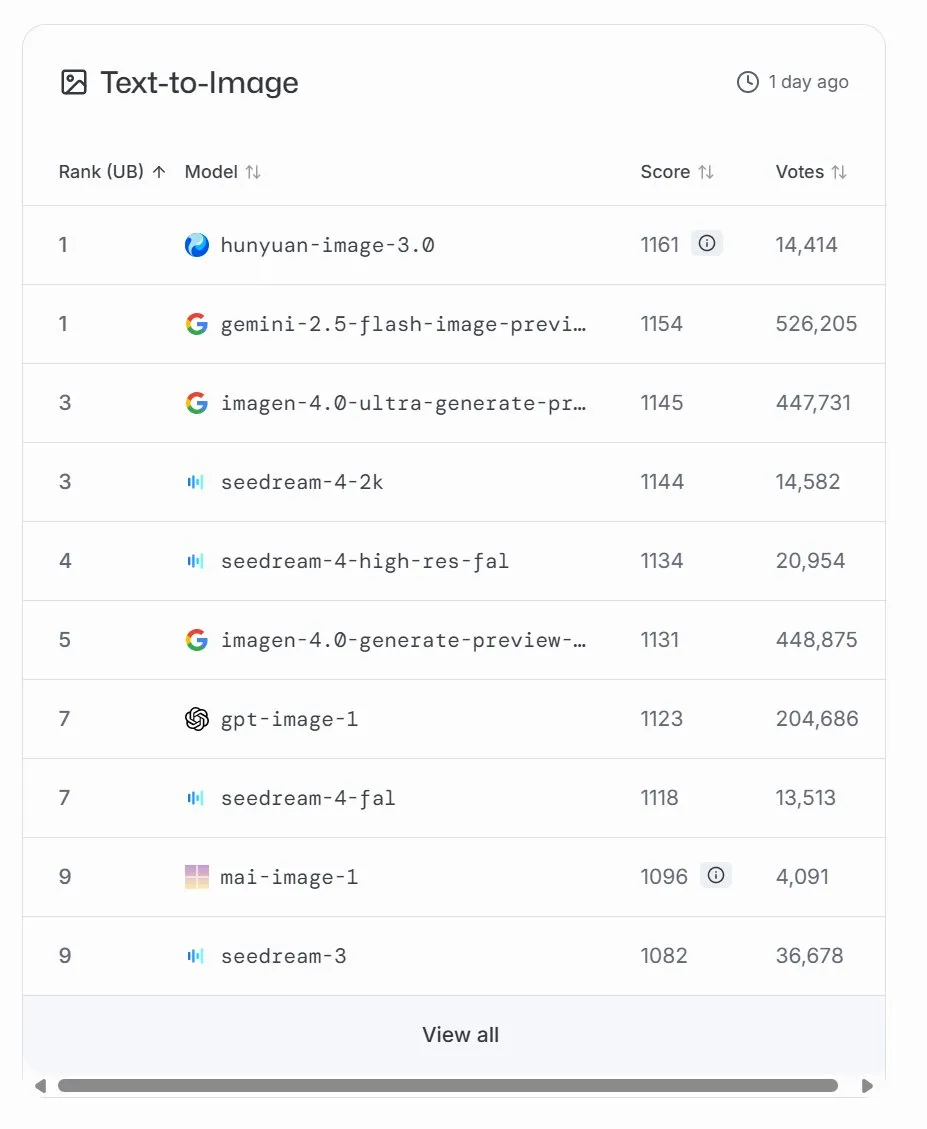
Microsoft, MAI-Image-1 이미지 생성 모델 출시, LMArena 9위 기록 : Microsoft AI가 세 번째 AI 모델인 MAI-Image-1을 발표했습니다. 이 이미지 생성 모델은 LMArena 순위표에 처음 등장하여 Seedream 3와 함께 9위를 차지했습니다. 이 모델은 생성 속도와 품질 사이에서 인상적인 균형을 이루며, Microsoft의 멀티모달 AI 분야에 대한 지속적인 투자와 빠른 발전을 보여줍니다. Microsoft는 이 모델을 계속 최적화하여 순위표에서 더 높은 순위를 목표로 할 것이라고 밝혔습니다. (출처: mustafasuleyman, NandoDF)
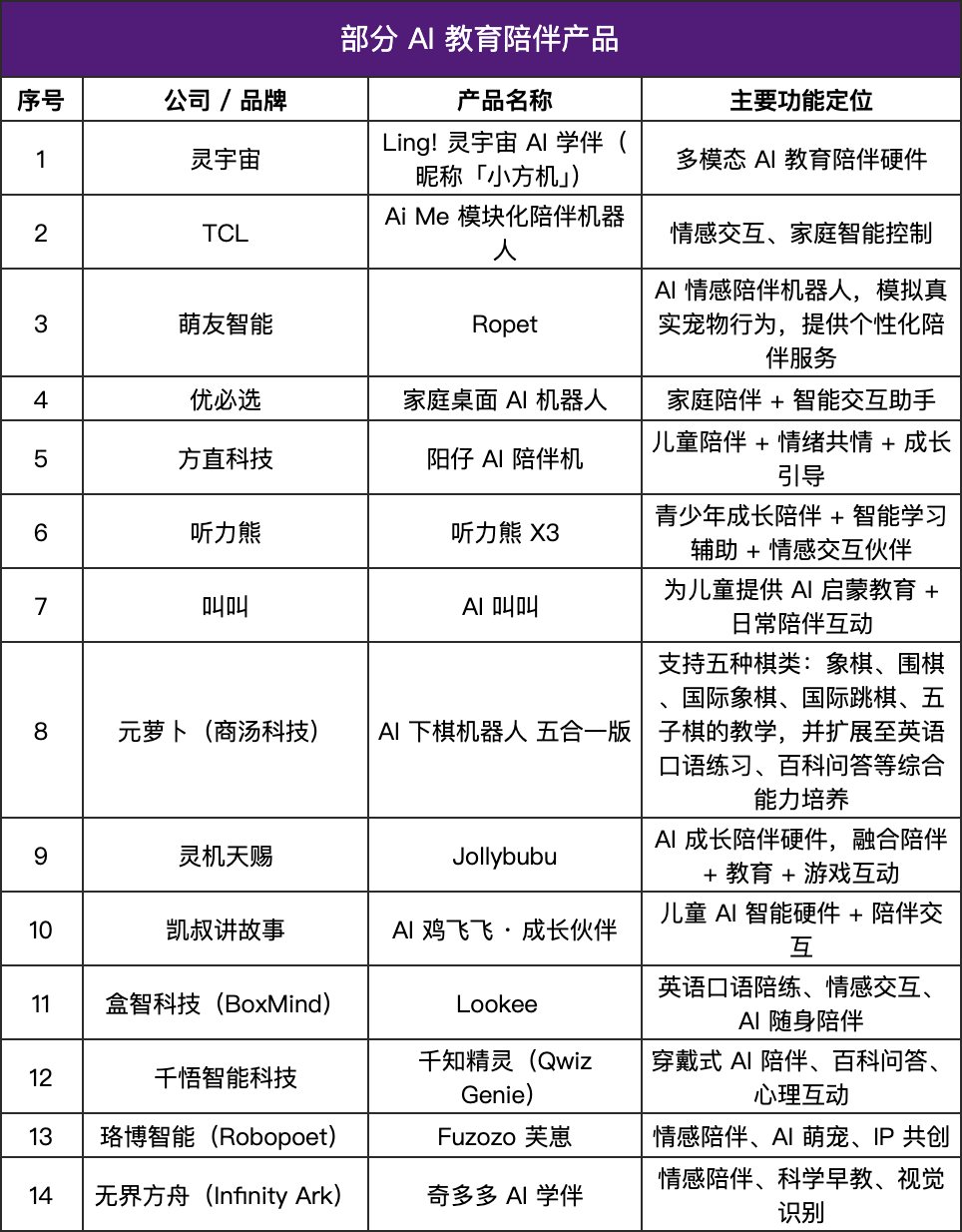
AI 동반자 제품 폭발적 성장, 교육 하드웨어에 “온기” 더해져 : AI 동반자 제품 시장이 빠르게 성장하고 있으며, 미래 시장 규모는 700억 달러에서 1500억 달러에 이를 것으로 예상됩니다. 이러한 제품들은 “명령 응답”에서 “감정 피드백”으로 전환하며, 언어 모델, 감정 인식, 음성 상호작용 및 기억 시스템을 통해 인간의 반응을 시뮬레이션하고 개인화된 동반자 역할을 제공합니다. 교육 분야에서는 AI 동반자 제품이 학습 도우미, 감정 피드백 시스템 및 지능형 질의응답 모델로 구현되어 지식 전달을 넘어 심리적 지원까지 확장되고 있습니다. 이는 경량화, 인격화 추세를 보이며 멀티모달 상호작용을 통합하여 “학생을 이해하는” 시스템이 되는 것을 목표로 합니다. (출처: 36氪)
NVIDIA, DGX Spark 출시: 세계에서 가장 작은 AI 슈퍼컴퓨터 : NVIDIA가 세계에서 가장 작은 AI 슈퍼컴퓨터라고 불리는 DGX Spark를 공식 출시했으며, 현재 출하를 시작했습니다. NVIDIA Grace Blackwell 아키텍처를 기반으로 하는 DGX Spark는 128GB 통합 메모리를 통합하여 AI 개발자에게 강력한 로컬 LLM 프로토타이핑 및 실행 기능을 제공하는 것을 목표로 합니다. 초기 사용자들은 도구, 소프트웨어 및 모델을 테스트, 검증 및 최적화하고 있으며, 이는 고성능 AI 컴퓨팅이 더욱 보편화되고 편리해질 것임을 예고합니다. (출처: nvidia, ollama)

Anthropic, Claude Sonnet 4.5, Agent SDK 및 업데이트된 Claude Code 출시 : Anthropic이 Claude Sonnet 4.5를 출시하며 추론 능력을 향상시키고, 더 큰 컨텍스트 창(200k–1M token)을 제공하며, 코딩 및 추론 벤치마크 성능을 개선했습니다. 동시에 Anthropic은 Claude Agent SDK와 업데이트된 Claude Code를 출시했는데, 여기에는 자동 컨텍스트 추적/요약, 영구 메모리 도구, 롤백 기능이 있는 체크포인트, VS Code 호환 IDE 확장 기능이 추가되어 개발자에게 더 강력한 AI 코딩 및 Agent 구축 기능을 제공하는 것을 목표로 합니다. (출처: DeepLearningAI)

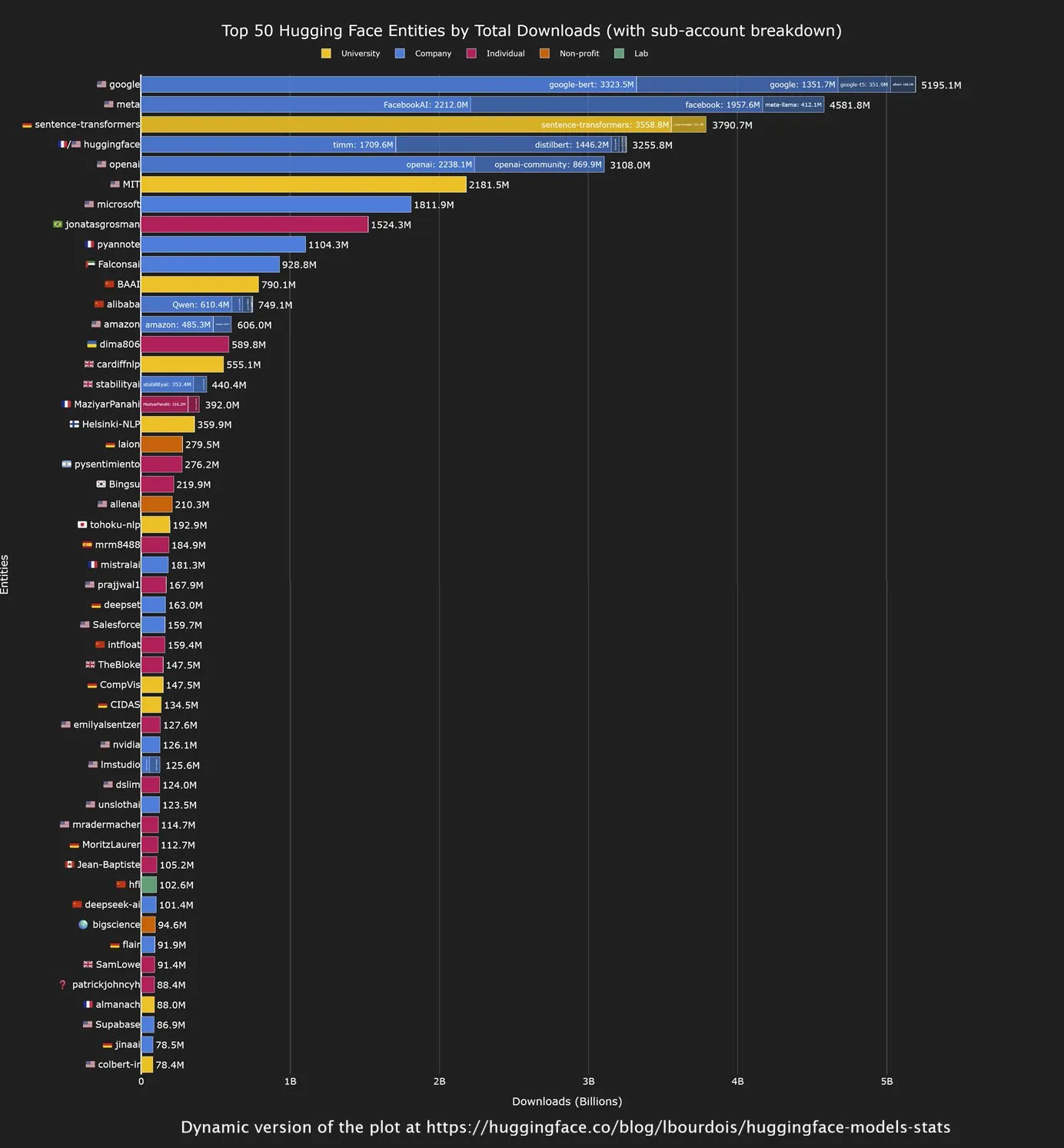
중국 오픈소스 모델, Hugging Face 다운로드량 선두, Google 최대 기여자 : Hugging Face 커뮤니티의 최신 분석에 따르면, 중국 기업이 개발한 오픈소스 모델, 특히 Qwen 시리즈 모델이 다운로드량 면에서 강세를 보였습니다. 동시에 Google은 Hugging Face에서 모델 다운로드량이 가장 많은 기관으로 나타났습니다. 이러한 추세는 오픈소스 AI 분야에서 중국의 영향력이 커지고 있음을 보여주며, Google은 기술 거대 기업으로서 오픈소스 생태계에 적극적으로 기여하고 활용하여 AI 기술 보급을 추진하고 있습니다. (출처: mervenoyann, osanseviero)
Google 검색 제품 부사장 Robbie Stein, AI 검색의 미래 해석: “명확성”을 종착점으로 : Google 검색 제품 부사장 Robbie Stein은 AI가 인간의 정보 검색이라는 근본적인 요구를 바꾸지는 않았지만, AI 모드(AI Mode)를 통해 이를 더 자연스럽고 복잡하게 만들었다고 지적했습니다. 미래의 AI 검색은 “이해 능력”을 갖추어 모호한 질문을 하위 질문으로 분해하여 병렬 검색하고, 인용이 포함된 추적 가능한 답변을 요약할 수 있을 것입니다. Google의 목표는 “정보를 이해하고 신뢰할 수 있는” 시스템이 되는 것으로, 멀티모달 융합과 구조화된 세계 데이터를 통해 “웹 페이지 색인”에서 “세계 색인”으로 전환하여 정보 획득을 단순히 유창한 언어를 생성하는 것이 아니라 더 명확하고 빠르게 만드는 것입니다. (출처: 36氪)
Ant Group, 고성능 확산 언어 모델 추론 프레임워크 dInfer 오픈소스화 : Ant Group이 업계 최초의 고성능 확산 언어 모델 추론 프레임워크 dInfer를 공식 오픈소스화했습니다. 이는 확산 언어 모델의 추론 속도를 NVIDIA Fast-dLLM 대비 10.7배 향상시켰습니다. 코드 생성 작업 HumanEval에서 dInfer는 단일 배치 추론에서 초당 1011 Tokens를 달성하여 처음으로 자기회귀 모델을 크게 능가했습니다. dInfer는 알고리즘과 시스템의 심층적인 협력 설계를 채택하여 확산 언어 모델의 높은 계산 비용, KV 캐시 비효율성, 병렬 디코딩 등의 문제를 해결하고 효율적인 추론 잠재력을 발휘하는 것을 목표로 합니다. (출처: 量子位)
NVIDIA, NVFP4 훈련 기술 출시: 4비트 사전 훈련으로 FP8 정확도 달성 : NVIDIA가 획기적인 NVFP4 훈련 기술을 발표하며, 4비트 사전 훈련 대규모 언어 모델이 8비트 정확도를 달성할 수 있게 했습니다. 이 기술은 E2M1 형식의 4비트 부동 소수점 표현을 사용하며, 미세 조정된 스케일링, 무작위 반올림 및 Random Hadamard Transforms와 결합하여 계산 및 메모리 요구 사항을 크게 줄입니다. 실험 결과, NVFP4는 모델 정확도(예: MMLU Pro 62.58% vs 62.62%)를 유지하면서 훈련 효율성을 크게 향상시켜 미래의 더 큰 규모 LLM 훈련을 위한 더 경제적이고 효율적인 경로를 제공합니다. 이 기술은 주로 NVIDIA Blackwell 아키텍처에 의존하며 H100 이상의 GPU 지원이 필요합니다. (출처: Reddit r/LocalLLaMA, karminski3)

MIT SEAL 프레임워크, AI 모델의 자동 미세 조정 데이터 생성 및 가중치 업그레이드 구현 : MIT(매사추세츠 공과대학교)가 SEAL(Self-Adapting LLMs) 프레임워크를 출시하여 대규모 언어 모델(LLM)이 미세 조정 데이터를 자동으로 생성하고 자체 가중치를 업데이트하여 0%의 수동 개입으로 경사 업데이트를 수행할 수 있게 했습니다. SEAL은 내외부 이중 순환 학습 메커니즘을 채택하여, 모델은 작업 성능에 따라 자체 업데이트 명령어 생성 전략을 최적화하며, LLM에 자체 구동 업데이트 능력을 처음으로 부여했습니다. 실험 결과, SEAL은 지식 주입 및 소수 샘플 학습 작업에서 뛰어난 성능을 보여주며 GPT-4.1 생성 데이터를 능가하는 정확도를 달성하여 강력한 작업 적응 및 지식 통합 능력을 입증하며 자가 진화 모델 시대의 도래를 예고합니다. (출처: arXiv:2506.10943, 36氪)

AI 스마트폰 출하량 급증, Coolpad AI 등 제조사 “소형 모델 + 대형 모델” 협력 전략 모색 : 2025년 중국 AI 스마트폰 출하량이 전년 대비 591% 급증하여 침투율이 22%에 달하며, AI 스마트폰이 업계의 새로운 초점이 되었습니다. Coolpad AI 등 제조사들은 매개변수 경쟁에서 실용적인 혁신으로 전환하여 “전면 소형 모델 + 후면 대형 모델”의 동적 협력 솔루션을 채택하고 있습니다. 약 6억 개의 매개변수를 가진 수직 소형 모델을 장치에 배포하여 빠른 응답과 개인 정보 보호를 실현하는 동시에 Koala AI, ByteDance, Alibaba, Google 등 범용 대형 모델 컴퓨팅 능력을 통합합니다. 이 전략은 사용자 경험을 향상시키고 개인화된 서비스를 제공하며 비용을 절감하여 다양하고 파편화된 해외 시장에 적응하는 것을 목표로 합니다. (출처: 36氪)

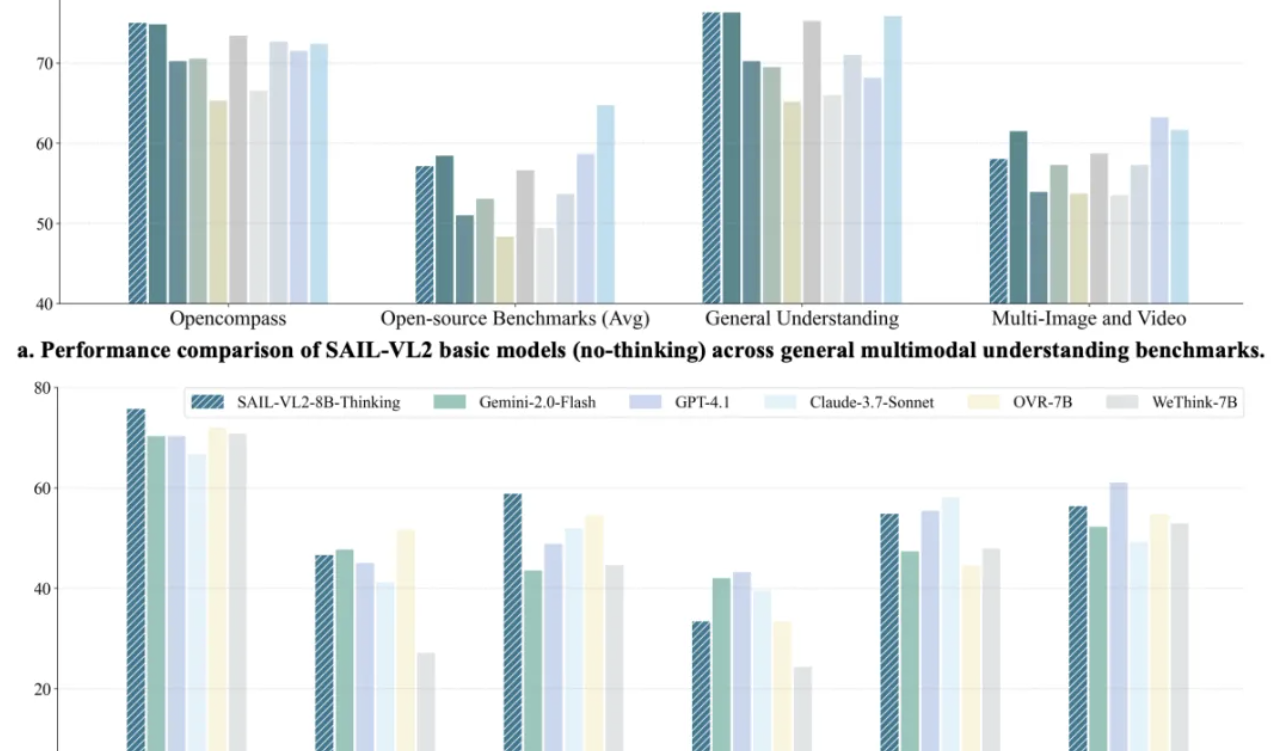
ByteDance SAIL-VL2 멀티모달 모델, SOTA 경신, 8B 모델 추론 GPT-4o에 필적 : ByteDance SAIL 팀과 LV-NUS Lab이 공동으로 멀티모달 대형 모델 SAIL-VL2를 출시했습니다. 2B, 8B 등 중소 매개변수 규모로 106개 데이터셋에서 성능 돌파를 이루었으며, 특히 MMMU, MathVista 등 복잡한 추론 벤치마크에서 동규모 모델을 능가하고, 8B 모델의 추론 능력은 GPT-4o에 필적합니다. SAIL-VL2는 희소 MoE 아키텍처, 점진적 훈련 프레임워크 및 고품질 멀티모달 코퍼스 등의 혁신을 통해 “작은 모델도 강력한 능력을 가질 수 있다”는 새로운 패러다임을 커뮤니티에 제공했으며, 모델과 추론 코드를 오픈소스화했습니다. (출처: 量子位)
Moondream Cloud 추론, FAL로 전면 이전, 100% 클라우드 실행 달성 : Moondream은 클라우드 추론 서비스가 EC2 인스턴스에서 FAL로 전면 이전되어 100% FAL에서 실행된다고 발표했습니다. 이러한 움직임은 Moondream이 추론 효율성을 최적화하고 운영 비용을 절감하거나 서비스 탄력성을 향상시키는 데 중요한 진전을 이루었음을 의미할 수 있으며, FAL은 새로운 추론 플랫폼으로서 AI 모델의 클라우드 배포를 지원하는 능력을 보여줍니다. (출처: vikhyatk)
Ring-1T: Ant Ling, 1조 매개변수 오픈소스 사고 모델 출시 : Ant Ling (凌动科技)이 Ling 2.0 아키텍처 기반의 오픈소스 1조 매개변수 사고 모델 Ring-1T를 공식 출시했습니다. Ring-1T는 순수 자연어 추론에서 IMO(국제 수학 올림피아드) 추론 능력의 은메달 수준에 도달했으며, 총 1조 개의 매개변수와 500억 개의 활성 매개변수, 그리고 128K의 컨텍스트 창을 가지고 있습니다. 이 모델은 Icepop RL과 ASystem (1조 규모 강화 학습 엔진)을 통해 강화되었으며, AIME 25, HMMT 25, ARC-AGI-1, CodeForce 등 자연어 추론 벤치마크에서 SOTA 성능을 달성하고 FP8 버전을 제공하여 오픈소스 AI 추론 능력을 발전시키는 것을 목표로 합니다. (출처: scaling01, jon_durbin)
ChatGPT 전자상거래 기능 “즉시 결제” 출시, 쇼핑 경험 재정의 : OpenAI가 ChatGPT의 “즉시 결제(Instant Checkout)” 기능을 출시하여 사용자가 타사 전자상거래 플랫폼으로 이동할 필요 없이 ChatGPT 내에서 직접 쇼핑을 완료할 수 있게 했습니다. 현재 이 기능은 Etsy를 지원하며, 곧 Shopify의 100만 개 이상의 판매자에게도 적용될 예정입니다. 이 혁신은 요구 사항 설명부터 구매 완료까지 쇼핑 프로세스를 원스톱으로 통합하여 사용자 구매 결정 경로를 크게 단축하고 쇼핑 편의성을 높이며, AI가 전자상거래 분야에 깊이 통합되고 비즈니스 모델이 변화할 것임을 예고합니다. (출처: 36氪)
AI 단편 드라마 해외 진출 폭발적 증가, Sora 2 기술로 콘텐츠 생산 품질 및 효율 비약적 발전 : AI 단편 드라마가 폭발적인 기세로 짧은 동영상 플랫폼을 강타하며 대규모 해외 진출을 하고 있습니다. 2024년 중국 마이크로 단편 드라마 시장 규모는 505억 위안에 달하며, 해외 시장 수요가 나타나 중국 해외 단편 드라마 수익은 연간 40억 달러에 이를 것으로 예상됩니다. OpenAI Sora 2의 출시는 화질, 길이, 동기화 및 오디오-비디오 동기화 능력을 크게 향상시켰으며, 복잡한 스토리 연속성과 Cameos 기능을 지원하여 단편 드라마 제작 프로세스를 “한 명이 Prompt를 작성하고 AI가 결과물을 생성”하는 고효율 모드로 압축하여 비용을 전통 방식의 10분의 1로 줄일 수 있습니다. AI 만화 드라마 또한 새로운 트렌드가 되어 문화적 할인율을 효과적으로 낮추고 콘텐츠 산업을 실사 드라마에서 AI 만화 드라마로 확장하고 있습니다. (출처: 36氪)

AI, 의료 진단 분야에서 진전: AMIE 멀티모달 진단 Agent 출시 : Google AI가 AMIE(AI agent for multimodal diagnostic dialogue)를 발표했습니다. 이는 멀티모달 진단 대화를 통해 의료 분야에서 돌파구를 마련하는 것을 목표로 하는 연구용 AI Agent입니다. AMIE의 출시는 AI가 복잡한 의료 진단 과정을 이해하고 참여하는 데 있어 진전을 이루었음을 의미하며, 진단 효율성과 정확성을 높이고 미래의 지능형 의료 애플리케이션을 위한 기반을 마련할 것으로 기대됩니다. (출처: Ronald_vanLoon)
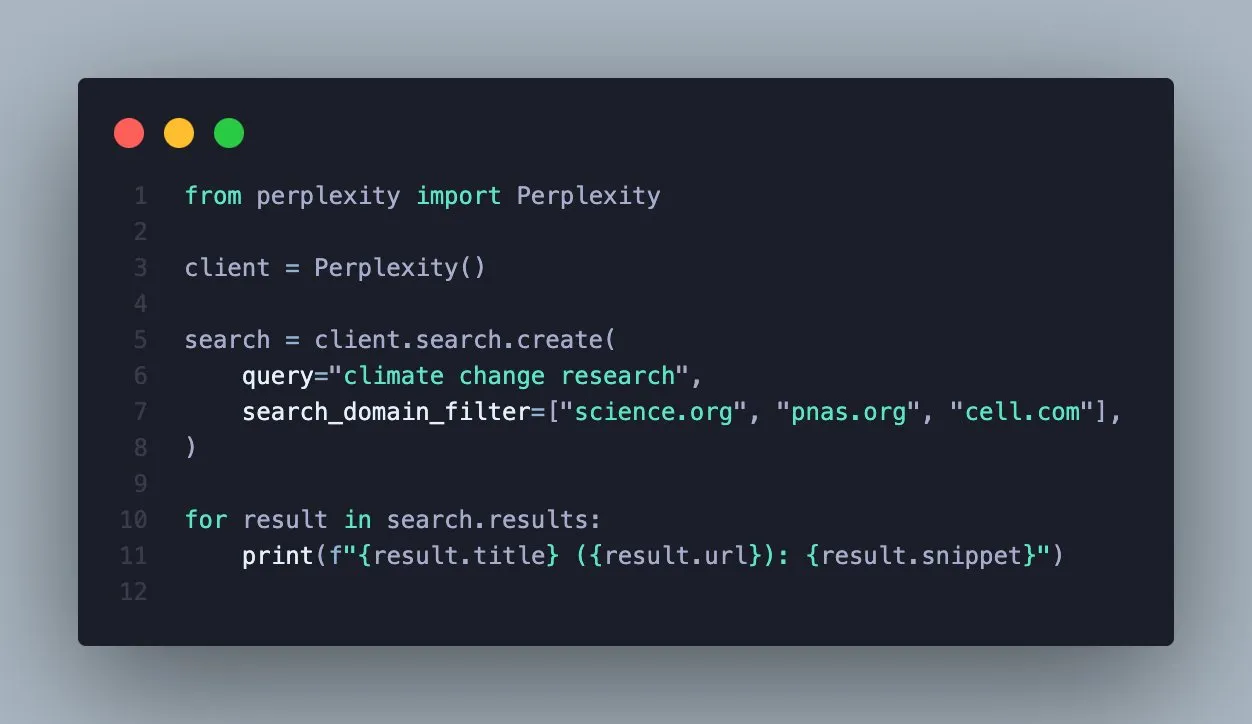
Perplexity Search API, 도메인 필터링 기능 추가, 검색 정확도 향상 : Perplexity는 Search API가 특정 도메인별로 검색 결과를 필터링하는 기능을 지원한다고 발표했습니다. 이 새로운 기능은 사용자가 신뢰할 수 있는 출처만 질의하여 더 집중적이고 검증 가능한 결과를 얻을 수 있도록 합니다. 이는 특정 권위 있는 출처에서 정보를 얻어야 하는 전문 사용자나 애플리케이션 개발자에게 검색 효율성과 정보 품질을 크게 향상시킬 것입니다. (출처: AravSrinivas)
AI, 지진 감지에서 잠재력 발휘, 미래에는 예측에도 도움 줄 수도 : AI가 작은 지진을 감지하는 데 뛰어난 성능을 보이며, 그 능력은 “처음 안경을 쓴 것처럼 선명하다”고 묘사됩니다. 연구자들은 AI가 지진 예측에 더 나아가 도움을 줄 수 있는지 탐구하고 있으며, 이는 지진 조기 경보 및 재해 예방 및 완화에 혁명적인 돌파구를 가져올 수 있습니다. AI는 더 정교한 데이터 분석을 통해 전통적인 방법으로는 감지하기 어려운 지진 신호를 식별하여 지구 심층 활동에 대한 이해를 높일 수 있습니다. (출처: Ars Technica)
Mamba3 아키텍처 발표, LLM에서 더 빠르고 긴 컨텍스트 및 확장성 실현 : Mamba3 아키텍처가 ICLR 컨퍼런스에서 조용히 발표되며, LLM 분야에서 속도, 컨텍스트 길이 및 확장성 면에서 상당한 진전을 이루었음을 알렸습니다. 이 아키텍처는 내부 상태 진화 및 하드웨어 활용을 최적화하여 Transformer보다 더 효율적인 시퀀스 모델링을 구현했습니다. Mamba3는 사다리꼴 적분 및 복소 평면 숨겨진 상태를 도입하여 기억을 더 부드럽고 안정적으로 만들고 주기적인 패턴을 표현할 수 있게 합니다. 다중 입력 다중 출력 설계는 여러 스트림 데이터를 병렬로 처리할 수 있게 하여 긴 문서 이해, 시계열 분석 및 엣지 AI 시스템과 같은 분야에서 큰 잠재력을 발휘할 것으로 기대됩니다. (출처: NandoDF)

Agentic RAG, 전통 RAG를 능가하며 AI 검색의 새로운 트렌드로 부상 : 업계에서는 “전통적인 임베딩 RAG(검색 증강 생성)는 죽었다”는 공감대가 형성되고 있으며, Agentic RAG(에이전트 기반 RAG)가 속도를 제외한 거의 모든 면에서 더 우수하다는 의견이 지배적입니다. 이러한 추세는 AI 검색이 단순한 정보 검색에서 더 복잡한 에이전트 기반 상호작용으로 전환될 것임을 예고합니다. Agentic RAG는 사용자 의도를 더 지능적으로 이해하고, 검색 전략을 계획하며, 더 정확한 답변을 생성하여 미래의 AI 검색 및 질의응답 시스템에 혁명을 가져올 것입니다. (출처: swyx, jerryjliu0)

TuringPost, AI 비디오 생성 도구 순위 발표, Luma Dream Machine 등 선정 : TuringPost가 Sora 2, Google Veo 3, Runway, Pika Labs, Luma’s Dream Machine (Ray 3 기반), Synthesia, HeyGen, Kaiber, InVideo 등 9가지 강력한 AI 비디오 생성 도구를 포함하는 순위를 발표했습니다. 이 순위는 사용자에게 텍스트-비디오, 실시간 생성, 인물 합성 등 다양한 기능을 포함하는 포괄적인 AI 비디오 제작 옵션을 제공하며, AI 비디오 기술 분야의 빠른 발전과 다양한 응용을 반영합니다. (출처: TheTuringPost)
OpenAI, Sora로 과학 기술 역사 단편 영화 제작, 비디오 연결 과정은 여전히 최적화 필요 : OpenAI 연구원 Hemanth Asir가 Sora로 완전히 생성된 과학 기술 발전사 단편 영화를 제작하여 Sora의 비디오 제작 잠재력을 보여주었습니다. 단편 영화의 효과는 인상적이지만, 현재 연결 과정은 여전히 번거롭습니다. OpenAI는 사용자 경험과 제작 효율성을 높이기 위해 이 프로세스를 개선하는 데 전념할 것이라고 밝혔으며, 이는 미래 AI 비디오 생성 도구가 장편 서사 분야에서 더욱 편리하게 사용될 것임을 예고합니다. (출처: dotey)
LLM 서비스 가정에 도전: FP8/FP4가 주류, 출력 Token 양 기하급수적 증가 예상 : 현재 LLM 서비스에는 많은 잘못된 가정이 존재한다는 지적이 있습니다. 첫째, LLM 서비스는 더 이상 FP16 정확도에 국한되지 않으며, FP8과 FP4가 주류가 될 것입니다. 둘째, 미래 LLM의 성장은 단순한 입력 Token 비율이 아닌 “사고 Token”(출력 Token)의 기하급수적인 증가에 주로 나타날 것입니다. 또한, OpenAI의 GPT-5 시리즈 모델은 더 넓은 매개변수 범위를 가지며, 각 연구소는 Deepseek의 DSA와 같은 기술과 새로운 어텐션 메커니즘을 통해 비용을 절감하고 있습니다. Anthropic 또한 Sonnet 4.5의 컨텍스트 정리 도구를 출시하여 메모리 요구 사항을 줄이는 등, 이 모든 것이 LLM 서비스의 효율성과 비용 구조를 재편할 것입니다. (출처: teortaxesTex)
🧰 도구
Microsoft MarkItDown: LLM 파이프라인을 위한 문서-Markdown 변환 도구 : Microsoft가 Python 도구 MarkItDown을 출시했습니다. 이 도구는 PDF, Word, Excel, HTML, 이미지, 오디오 등 수십 가지 파일 형식을 깔끔한 Markdown 형식으로 변환할 수 있습니다. MarkItDown은 제목, 목록, 표, 링크 및 메타데이터를 유지하며 OCR 및 EXIF 정보 추출을 지원합니다. Markdown이 LLM의 “네이티브 언어”임을 감안할 때, MarkItDown은 LLM 파이프라인에서 문서를 전처리하는 데 이상적인 선택이며, 모델의 복잡한 문서 이해 및 처리 효율성을 높이는 데 도움이 됩니다. (출처: TheTuringPost)
VS Code, 1.105 반복 계획 발표, AI 및 개발자 경험에 집중 : VS Code가 10월 반복 계획을 발표하며, AI 지원 개발 및 전반적인 개발자 경험을 향상시키기 위한 여러 개선 사항을 공개했습니다. 업데이트에는 Mermaid 렌더링, 다양한 컨텍스트 및 도구 관리 방식, 고급 모델 관리, 다단계 프로세스, 대화를 Prompt로 저장하는 기능, 터미널, 도구 및 MCPs 등의 기능이 포함됩니다. 또한, GitHub Copilot도 지난 30일 동안 34가지 개선 사항을 발표했습니다. 이러한 업데이트는 코드 편집, 디버깅 및 협업에서 AI의 적용을 더욱 심화하여 VS Code를 더욱 강력한 AI 네이티브 개발 환경으로 만들 것입니다. (출처: pierceboggan, code)

Nanonets-OCR2 출시, 오픈소스 이미지-Markdown 모델 LaTeX 및 플로우차트 지원 : Nanonets-OCR2가 출시되었습니다. 이 모델은 Qwen2.5-VL-3B-Instruct를 미세 조정하여 개발된 오픈소스 이미지-Markdown 모델로, LaTeX 방정식 인식, 표, 손글씨 문서, 체크박스, 심지어 플로우차트를 Mermaid 코드로 변환하는 기능까지 지원합니다. 또한 스마트 이미지 설명, 서명 감지, 워터마크 추출 및 다국어 지원 기능도 갖추고 있으며, 시각 질의응답(VQA) 능력도 제공합니다. Nanonets-OCR2는 복잡한 문서 처리에서 뛰어난 성능을 보여주며, LLM 파이프라인의 문서 전처리를 위한 효율적이고 기능이 풍부한 솔루션을 제공합니다. (출처: huggingface, Reddit r/LocalLLaMA, karminski3)
ChatGPT for Slack 앱 출시, 실시간 검색 API 통합 : ChatGPT 앱이 Slack에 공식 출시되었습니다. Slack의 실시간 검색 API를 활용하여 사용자는 이제 전용 Slack 사이드바에서 직접 ChatGPT를 사용하여 질문하고, 브레인스토밍하고, 콘텐츠를 작성하고, 문제를 해결할 수 있습니다. 이 통합은 ChatGPT의 강력한 기능을 팀 협업 플랫폼에 원활하게 도입하여 작업 효율성을 높이고 정보 획득 및 콘텐츠 생성 프로세스를 간소화하며, 기업 사용자에게 더 편리한 AI 지원을 제공하는 것을 목표로 합니다. (출처: gdb)
n8n, AI 워크플로우 빌더 출시, 자연어 자동화 지원 : n8n이 AI 워크플로우 빌더를 공식 출시했습니다. 이를 통해 사용자는 자연어를 사용하여 n8n에서 AI 에이전트 및 자동화 프로세스를 구축할 수 있습니다. 이 도구는 시각적 캔버스를 제공하며 Firecrawl, LLMs, 로직 노드 및 MCPs 등 8000개 이상의 도구를 연결하고 API로 배포할 수 있습니다. 이 혁신은 AI 에이전트 개발 및 적용을 크게 간소화하여 더 많은 개발자가 자연어를 사용하여 복잡한 자동화 워크플로우를 생성하고 실제 비즈니스 시나리오에서 AI 에이전트의 보급을 촉진할 것입니다. (출처: omarsar0)
MLX, 로컬 모델 실행 지원, Privacy AI 1.3.2 업데이트로 Apple 기기 AI 능력 향상 : Privacy AI가 1.3.2 업데이트를 발표하며 Apple의 MLX 엔진을 전면 지원하여 사용자가 로컬에서 텍스트 및 시각 모델을 실행할 수 있게 했습니다. 모델은 Hugging Face에서 직접 다운로드할 수 있으며, 중단된 전송 재개, 백그라운드 전송 및 무결성 검증을 지원하고, MLX 모델은 무료 플랜에 포함되어 구독 없이 오프라인으로 실행할 수 있습니다. 이 업데이트는 또한 클립보드 지원을 개선하고 llama.cpp를 업그레이드하여 Apple 기기에서의 로컬 AI 능력 및 개인 정보 보호를 더욱 향상시켰습니다. (출처: awnihannun)
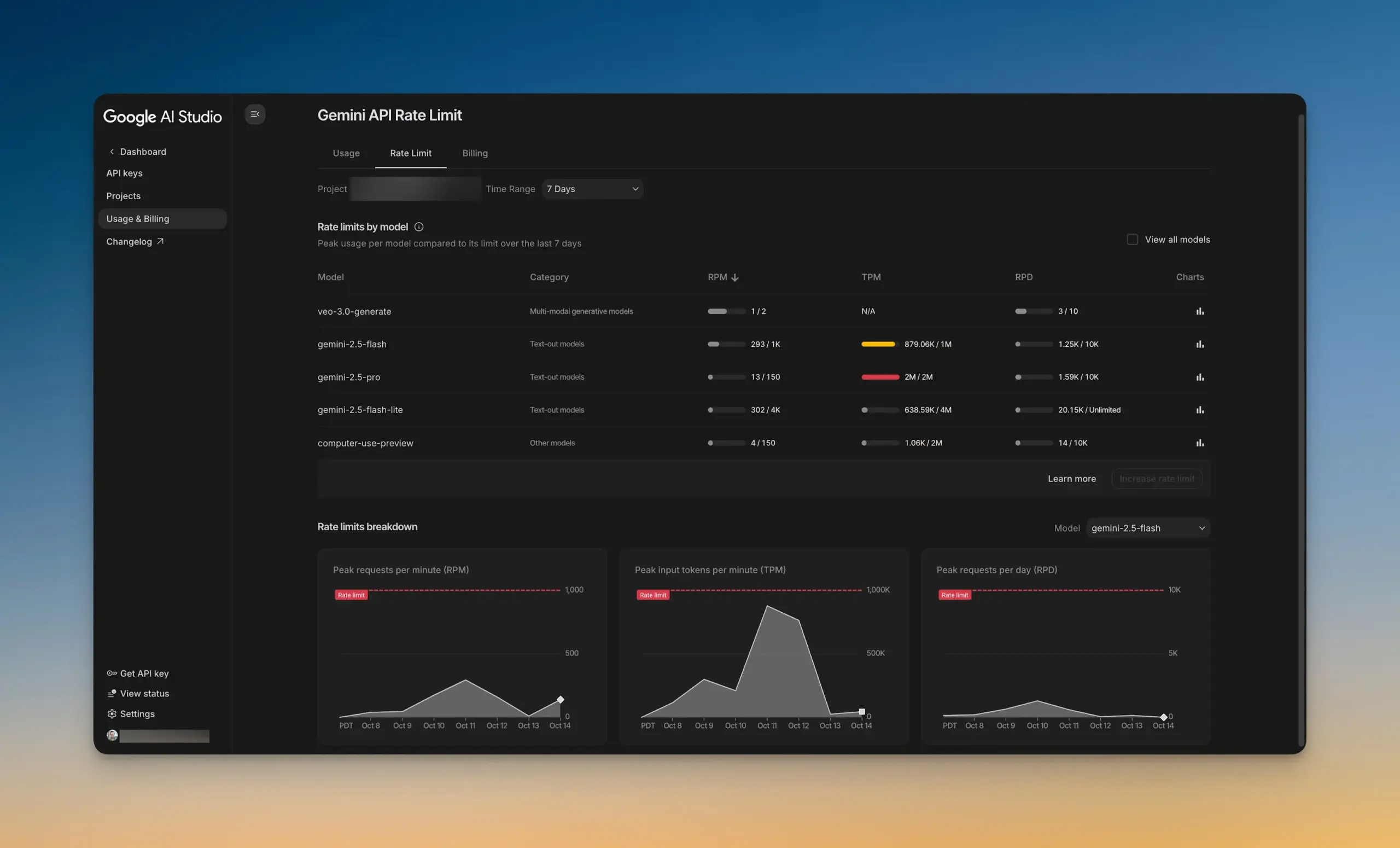
Google AI Studio, 새로운 속도 제한 대시보드 출시 : Google AI Studio가 새로운 속도 제한 대시보드를 출시하여 사용자가 AI Studio를 떠나지 않고도 Gemini API 사용 현황을 직관적으로 파악할 수 있게 했습니다. 이 대시보드는 차트 필터링 기능을 제공하며 모든 모델의 속도 제한을 쉽게 탐색할 수 있어 개발자가 AI 프로젝트를 더 잘 관리하고 최적화하여 개발 효율성을 높이는 데 도움이 됩니다. (출처: GoogleAIStudio)
Cursor IDE와 Codex, 개발자의 일상 코딩 새 선택지로 부상 : AI 코딩 도구의 빠른 발전과 함께 Cursor IDE와 Codex가 점점 더 많은 개발자의 일상 워크플로우에서 핵심 도구가 되고 있습니다. 일부 개발자는 Claude Code에서 Codex로 완전히 전환하여 일상적인 계획, 작업 분해 및 병렬 처리에 활용하고 있다고 밝혔습니다. Cursor IDE의 “코드 라이브러리 색인 시스템”은 의미 검색 및 로컬 코드 접근을 통해 효율적인 코드 색인 및 업데이트를 구현하며, 코드를 서버에 저장할 필요 없이 개인 정보 보호와 효율성을 보장합니다. 이러한 도구의 보급은 전통적인 코딩 방식을 변화시키고 개발 효율성을 높이고 있습니다. (출처: dejavucoder, gdb)
Yupp.ai: AI 토론 도구, 사용자에게 더 포괄적인 답변 제공 : Yupp.ai는 다양한 AI 모델의 답변을 제시하여 사용자가 정보 과부하 시대에 더 현명한 결정을 내릴 수 있도록 돕는 혁신적인 AI 도구입니다. 사용자는 다양한 AI의 답변을 나란히 비교하고, 분석, 창의성 또는 특정 세부 사항에 따라 투표하여 집단 지성의 순위를 형성할 수 있습니다. Yupp.ai의 목표는 사용자가 집단 경험을 활용하여 신뢰할 수 있고 다각적인 답변을 빠르게 얻어 작업 효율성과 의사 결정 신뢰도를 높이는 것입니다. (출처: yupp_ai)

vLLM과 SGLang, “AI 시대의 Linux”로 불리다 : vLLM과 SGLang은 LLM 추론 분야에서 뛰어난 성능을 보여 “AI 시대의 Linux”로 불리고 있습니다. vLLM은 GitHub에서 6만 개의 별을 얻었으며, 작은 연구 아이디어에서 NVIDIA, AMD, Intel, Apple 등 거의 모든 주요 플랫폼의 LLM 추론을 지원하는 핵심 프레임워크로 발전했습니다. 이 프레임워크는 대부분의 텍스트 생성 모델과 TRL, Unsloth 등 네이티브 RL 파이프라인을 지원하며, AI 생태계에서 중요한 인프라 역할을 수행하여 LLM 추론의 보급과 효율성 향상을 추진했습니다. (출처: bookwormengr)
Luma AI Ray3 시각 주석, 정밀 제어 잠금 해제 : Luma AI가 출시한 Ray3 시각 주석 기능은 프레임에 낙서하는 것만으로 시각적 방향을 정밀하게 제어하여 피사체가 특정 동작을 하거나 상호작용하도록 유도합니다. 이 기능은 전통적인 텍스트 프롬프트의 한계를 넘어 붓 터치를 통해 공간적 방해 의도를 전달하여 시각적 창작에 더 직관적이고 정교한 제어 방식을 제공하며, 특히 Dream Machine과 같은 애플리케이션에서 강력한 잠재력을 보여줍니다. (출처: TomLikesRobots)
Faceseek: AI 기반 얼굴 매칭 및 검증 도구 : Faceseek은 AI 기술을 활용하여 얼굴 매칭 및 검증을 수행하는 도구로, 유사한 얼굴을 효과적으로 처리할 수 있습니다. 이 도구는 얼굴 임베딩, CLIP(대조 언어-이미지 사전 훈련) 또는 기타 고급 컴퓨터 비전 모델을 사용하여 분석하며, 신원 확인, 보안 감시 등 다양한 시나리오에 대한 솔루션을 제공합니다. 실제 적용에서의 성능은 이러한 시스템의 기술적 세부 사항 및 잠재적 응용에 대한 논의를 불러일으키고 있습니다. (출처: Reddit r/ArtificialInteligence)
PyTorch 원격 GPU 백엔드 확장, 로컬 개발과 원격 컴퓨팅 결합 실현 : 새로운 PyTorch 확장이 개발되어 개발자가 로컬에서 개발하면서 원격 GPU 백엔드를 활용하여 계산을 수행할 수 있게 되었습니다. 이는 로컬 하드웨어 자원 제한 문제를 해결하여 연구원과 개발자가 딥러닝 모델 훈련 및 실험을 더 유연하게 수행할 수 있도록 하며, 로컬 개발 환경의 편리성과 원격 고성능 컴퓨팅의 이점을 모두 누릴 수 있게 합니다. (출처: Reddit r/deeplearning)
FocoosAI, 컴퓨터 비전 오픈소스 SDK 및 웹 플랫폼 출시 : FocoosAI가 컴퓨터 비전 오픈소스 SDK 및 웹 플랫폼을 출시하여 개발자에게 컴퓨터 비전 솔루션 구축 및 배포를 위한 도구와 자원을 제공합니다. 이 플랫폼의 출시는 컴퓨터 비전 기술의 보급과 적용을 촉진하고 개발 진입 장벽을 낮추어 더 많은 혁신가가 AI를 활용하여 이미지 및 비디오 분석 분야를 탐색하고 개발할 수 있도록 할 것입니다. (출처: Reddit r/deeplearning)
AI 텍스트 “인간화” 도구: AI 생성 콘텐츠의 자연스러움 향상 : AI 텍스트 생성 기술의 보급과 함께 AI 생성 콘텐츠를 어떻게 더 “인간화”할 것인가가 중요한 과제가 되었습니다. 현재 시장에는 언어 스타일, 감정 표현 및 맥락 적응성을 최적화하여 AI 텍스트가 더 자연스럽고 인간의 표현에 가깝게 들리도록 하는 다양한 도구들이 등장했습니다. 이러한 도구들은 사용자가 AI 텍스트의 기계적인 느낌과 정형화를 피하고 콘텐츠 매력을 높여 고품질의 개인화된 텍스트에 대한 요구를 충족시키는 데 도움을 줍니다. (출처: Ronald_vanLoon)
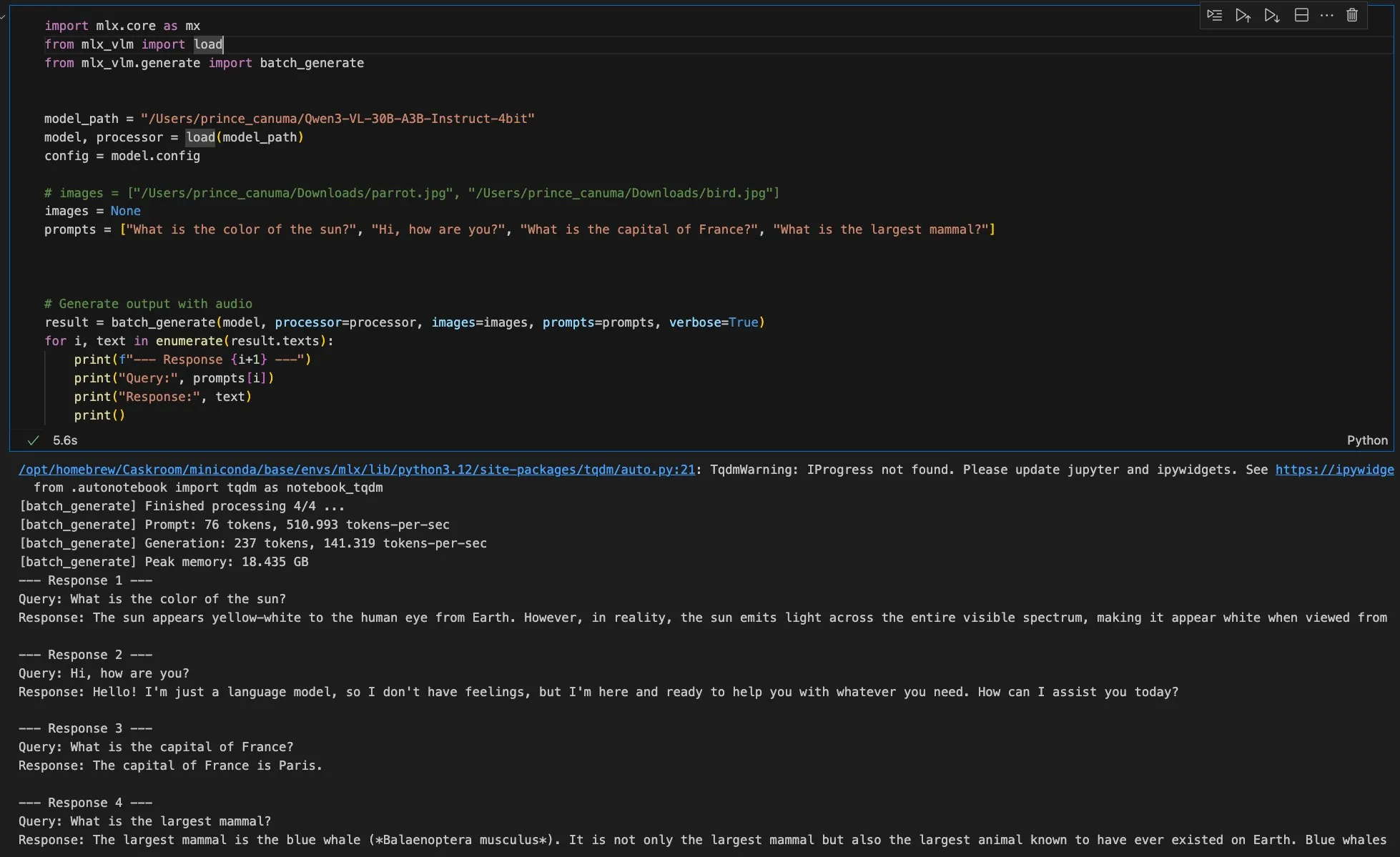
MLX-VLM 새 버전 출시 임박, Qwen Image MFLUX 프레임워크 지원 : Apple의 MLX-VLM이 곧 대규모 업데이트를 앞두고 있으며, 이는 멀티모달 대형 모델 분야에서의 강력한 잠재력을 예고합니다. 동시에 MFLUX 프레임워크는 v0.11 버전을 출시하며 Qwen Image에 대한 지원을 추가하여 사용자가 간단한 명령줄 조작으로 Qwen Image 모델을 다운로드하고 생성에 사용할 수 있게 했습니다. 이러한 발전은 Apple 생태계 내 AI 모델 개발 및 배포의 효율성과 유연성을 함께 추진하며, 개발자에게 더 편리한 멀티모달 AI 도구를 제공합니다. (출처: adrgrondin, awnihannun)
CleanMARL: PyTorch 다중 에이전트 강화 학습의 간결한 구현 : CleanMARL 프로젝트는 PyTorch를 기반으로 개발된 일련의 간결하고 단일 파일로 구현된 심층 다중 에이전트 강화 학습(MARL) 알고리즘을 제공하며, CleanRL의 철학을 따릅니다. 이 프로젝트는 MARL 알고리즘 구현의 진입 장벽을 낮추고, 연구자와 개발자에게 명확하고 이해하기 쉬우며 재현 가능한 코드를 제공하여 복잡한 환경에서 다중 에이전트 시스템의 연구 및 적용을 가속화하는 것을 목표로 합니다. (출처: jsuarez5341)
📚 학습
대형 모델 후처리, AI 경쟁력의 핵심으로 부상, 기업들 전용 지능형 엔진 구축 가속화 : 대형 모델 후처리(post-training)가 기업 AI 도입의 핵심 경쟁력으로 부상하고 있습니다. SFT부터 RLHF, RLVR, 그리고 최첨단 “자연어 보상”에 이르기까지 기술의 초점은 “모방”에서 “정렬”로 전환되고 있습니다. NetEase, Autohome, Weibo, Quark 등 기업들은 고품질 데이터 준비, 기반 모델 선택, 보상 메커니즘 설계 및 정량화 가능한 평가 시스템을 통해 범용 대형 모델을 비즈니스를 깊이 이해하고 도메인 지식을 갖춘 “전용 지능형 엔진”으로 성공적으로 전환하여 복잡한 비즈니스 세계의 문제를 해결하고 복제 불가능한 경쟁 우위를 구축하고 있습니다. (출처: 量子位)

Andrew Ng, Agentic AI 강좌 출시, 4가지 핵심 설계 패턴 집중 : DeepLearning.AI가 최신 The Batch를 통해 Andrew Ng이 새로운 강좌 “Agentic AI”를 출시한다고 발표했습니다. 이 강좌는 반성, 도구 사용, 계획 및 다중 에이전트 협업이라는 네 가지 핵심 설계 패턴을 중심으로 한 실용적인 빌더 강좌입니다. 이 강좌는 수강생들이 효율적인 AI 에이전트 시스템을 구축하는 핵심 기술을 습득하고 실제 애플리케이션에 AI를 적용하는 것을 목표로 합니다. (출처: DeepLearningAI)
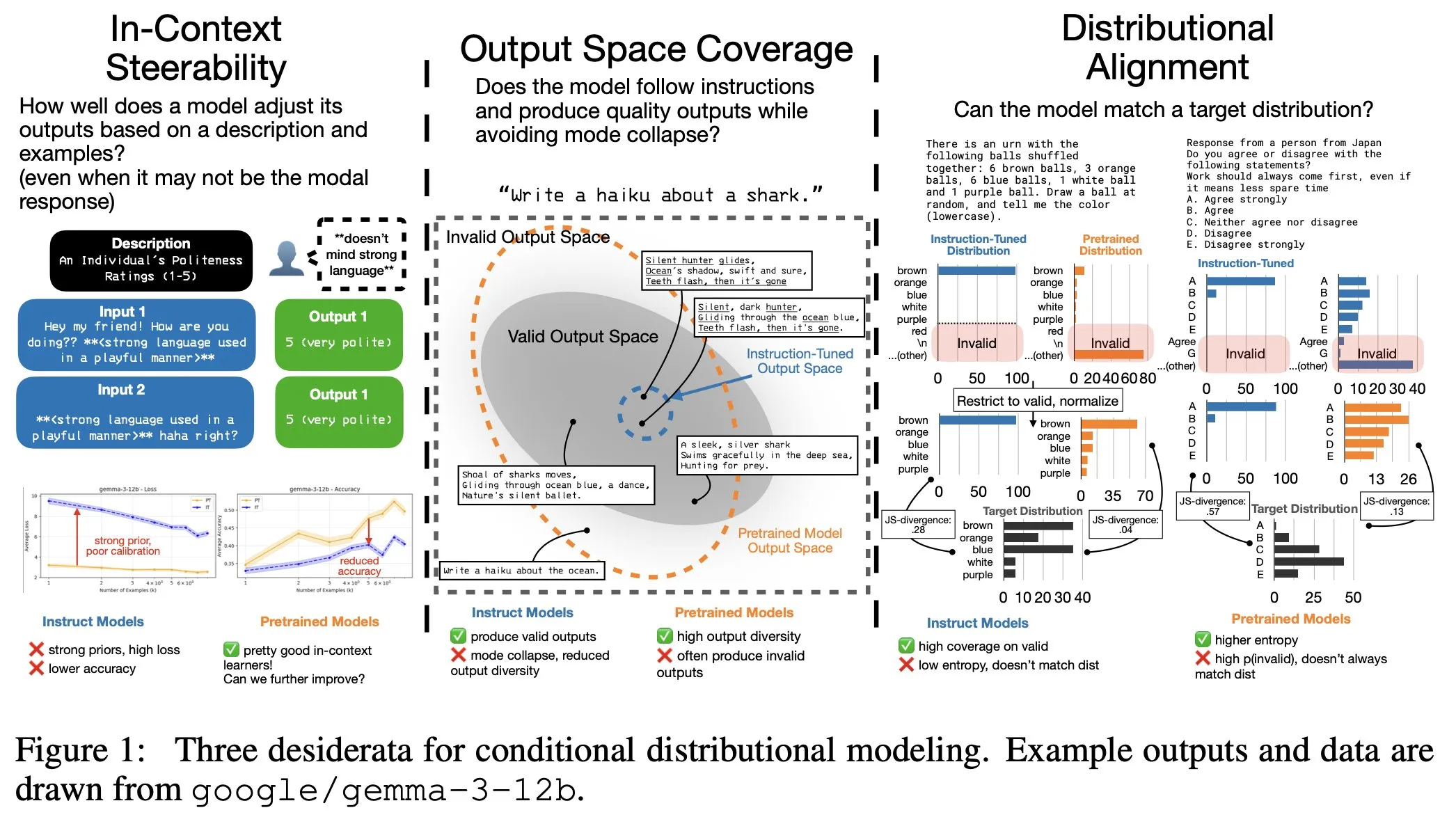
LLM 명령어 미세 조정의 숨겨진 비용: 출력 분포 협소화, 컨텍스트 제어 가능성 감소 : 연구에 따르면 LLM 명령어 미세 조정이 명령어 준수 능력을 향상시키는 동시에 숨겨진 비용을 초래한다는 사실이 밝혀졌습니다. 즉, 모델의 출력 분포가 협소해지고 컨텍스트 제어 가능성(In-Context Steerability)이 감소합니다. 이 문제를 해결하기 위해 연구팀은 “Spectrum Suite”를 출시하여 심층 연구를 수행했으며, 모델 성능을 향상시키면서 출력 다양성과 유연성을 유지하는 것을 목표로 하는 “Spectrum Tuning”을 대안적인 후처리 방법으로 제안했습니다. (출처: YejinChoinka, YejinChoinka)
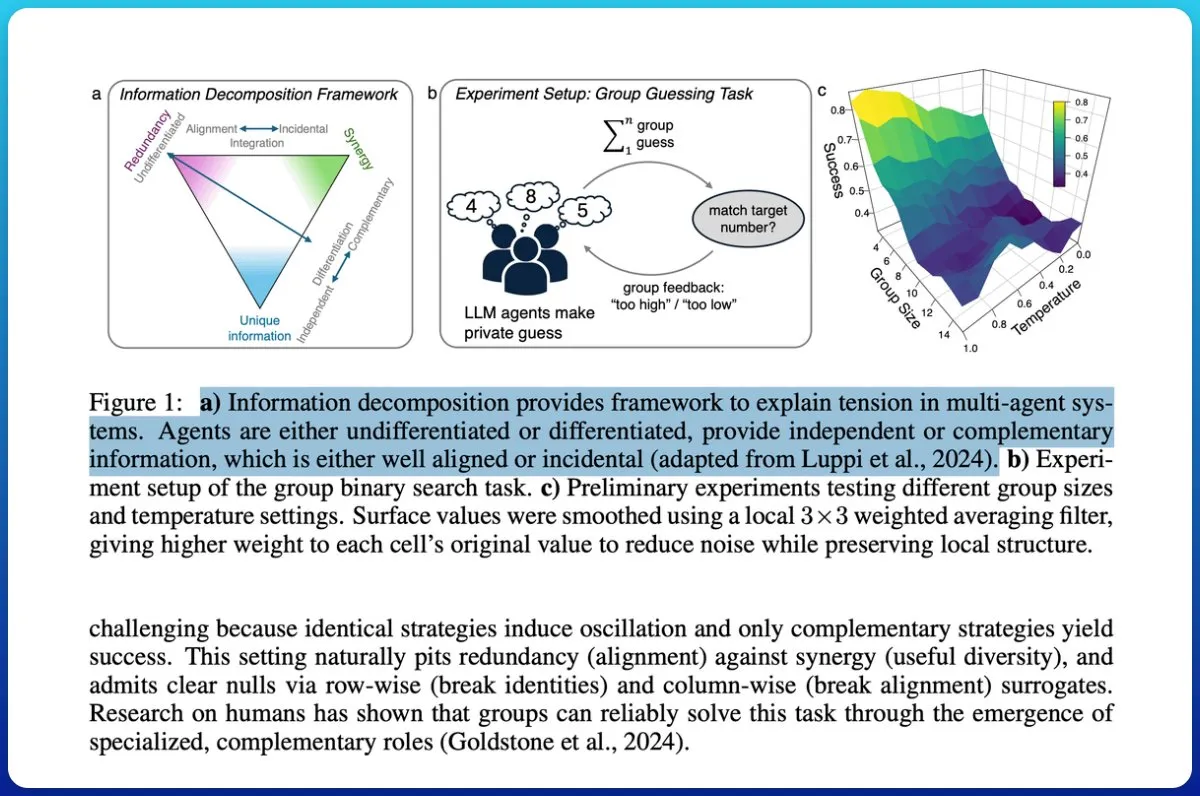
다중 에이전트 시스템 협업: 정보 이론으로 “챗봇 더미”와 “집단 지성” 구분 : 한 연구는 LLM 기반 다중 에이전트 시스템이 진정으로 협업을 달성했는지 탐구하고, 정보 이론을 사용하여 “챗봇 더미”와 “진정한 집단 지성”을 구분하는 방법을 제안했습니다. 연구는 그룹 출력의 미래 결과 예측 능력을 평가하고 정보를 분해하여 중복이 아닌 협업을 식별하는 측정 순환을 도입했습니다. 결과는 에이전트에게 다른 역할과 공동 목표를 부여하고 협업성을 가정하는 대신 테스트하는 것이 집단 지성을 달성하는 데 중요하며, 저용량 모델은 진정한 협력을 달성하기 어렵다는 것을 보여주었습니다. (출처: omarsar0)
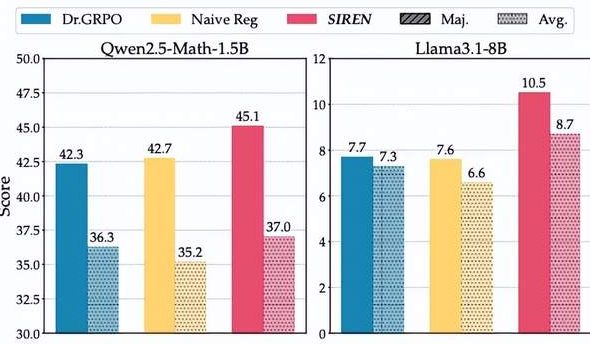
대형 모델 추론의 “엔트로피 딜레마”: SIREN 방법, “엔트로피 붕괴”와 “엔트로피 폭발” 거부 : 대형 추론 모델(LRM)은 RLVR 훈련에서 “엔트로피 딜레마”에 직면합니다. 즉, 탐색 제한으로 인한 “엔트로피 붕괴” 또는 탐색 통제 불능으로 인한 “엔트로피 폭발”입니다. 상하이 인공지능 연구소와 푸단 대학 팀은 선택적 엔트로피 정규화 방법(SIREN)을 제안했습니다. 이는 탐색 범위 설정(Top-p 마스크), 핵심 결정 지점 식별(피크 엔트로피 마스크) 및 훈련 과정 안정화(자가 고정 정규화)의 삼중 메커니즘을 통해 탐색 행동을 정밀하게 조절합니다. 실험 결과, SIREN은 수학 추론 벤치마크에서 성능을 크게 향상시키고 탐색 과정을 더 효율적이고 제어 가능하게 만들었습니다. (출처: 量子位)
AI Agent 학습 자료: “AI Agent 그림 해설 가이드” 신간 및 개념 요약 : AI Agent 분야 학습 자료가 풍부해지고 있습니다. Maarten Grootendorst와 Jay Alammar는 “AI Agent 그림 해설 가이드”라는 책을 집필 중이며, Agent의 기본 지식(기억, 도구, 계획)과 강화 학습 및 추론 LLM과 같은 고급 개념을 다룰 예정입니다. 또한, AI Agent의 20가지 핵심 개념을 요약한 글도 있어 초보자와 숙련자 모두에게 체계적인 학습 경로와 참고 자료를 제공합니다. (출처: lvwerra, Ronald_vanLoon)

LLM 공간 추론 능력 평가: 도형 회전 테스트, 모델 잠재 공간에 도전 : 대규모 언어 모델(LLM)이 “머릿속에서” 도형을 회전시키는 능력을 테스트하기 위한 흥미로운 평가 방법이 제안되었습니다. 간단한 시각 테스트를 통해 LLM이 하위 잠재 공간에서 어느 정도 도형 회전을 수행할 수 있지만, 더 상위의 복잡한 추론에서는 성능이 좋지 않아 “비균일 공간 추론” 문제가 존재한다는 것이 밝혀졌습니다. 이는 LLM이 기하학적 및 공간적 논리를 처리하는 데 있어 한계를 드러내며, 미래 모델 개선을 위한 새로운 연구 방향을 제시합니다. (출처: dejavucoder, tokenbender)
LLM 미세 조정 전략: 어텐션 프로젝션 레이어 및 MLP 게이팅 레이어 업데이트로 망각 제한 가능 : 대규모 멀티모달 모델(LMM)에 새로운 기술을 가르치면서 기존 능력을 잊지 않도록 하는 것이 핵심 과제입니다. 한 연구는 좁은 미세 조정 후 발생하는 “망각” 현상이 나중에 회복될 수 있으며, 이는 출력 Token 분포의 현저한 변화와 관련이 있다는 것을 발견했습니다. 연구는 두 가지 간단하고 견고한 미세 조정 전략을 식별했습니다: 자체 어텐션 프로젝션 레이어만 업데이트하거나, MLP Gate&Up 레이어만 업데이트하고 Down 프로젝션 레이어는 고정하는 것입니다. 이러한 선택은 모델과 작업 모두에서 강력한 목표 이득을 달성하면서 기존 성능을 기본적으로 유지할 수 있습니다. (출처: arXiv:2510.08564)
AI와 경제 성장: 노벨상 수상자 Philippe Aghion 논문 해설 : 노벨상 수상자 Philippe Aghion 등의 연구는 경제가 99% 자동화되고 무한 생산되더라도 전체 성장률은 나머지 1%의 핵심적이고 어려운 작업의 진전에 의해 제한될 것이라고 지적합니다. AGI 시대에는 이러한 “개선하기 어려운” 작업이 에너지 생성, 자원 채굴, 제조 및 운송과 같은 물리 중심 작업으로 전환될 것입니다. 이는 AGI 이후 시대가 반드시 “희소성 이후” 시대가 아님을 의미하며, 경제적 가치는 물리적으로 제한된 작업에 집중될 것입니다. (출처: pmddomingos, jonst0kes)

AI 모델 일반화 및 견고성 도전: 허위 추론으로 인한 수학 추론 결함 : 언어 모델은 수학 추론에서 “허위 추론(Spurious Reasoning)”으로 인해 견고성과 일반화 능력이 부족한 경우가 많습니다. 즉, 모델이 문제의 논리보다는 표면적인 특징에서 답을 도출합니다. AdaR 프레임워크는 논리적으로 동등한 질의를 합성하고 RLVR(검증 가능한 보상 기반 강화 학습)과 결합하여 훈련함으로써 허위 논리를 처벌하고 적응형 논리를 장려합니다. 실험 결과, AdaR은 LLM의 수학 추론 견고성과 일반화 능력을 크게 향상시키면서 높은 데이터 효율성을 유지했습니다. (출처: arXiv:2510.04617)
LLM Agent의 테스트 시 자체 개선: TT-SI 프레임워크로 자율 학습 구현 : 한 연구는 더 효과적이고 일반화 가능한 Agentic LLM을 동적으로 생성하기 위한 새로운 테스트 시 자체 개선(Test-Time Self-Improvement, TT-SI) 방법을 제안했습니다. 이 알고리즘은 모델의 어려운 샘플을 식별하고, 유사한 예시를 생성(자가 데이터 증강)하며, 테스트 시 미세 조정을 통해(자가 개선) 모델의 자율 학습을 구현합니다. 실험 결과, TT-SI는 Agent 벤치마크에서 평균 5.48%의 정확도 향상을 달성했으며, 훈련 샘플 양은 68배 감소하여 자가 개선 알고리즘이 더 강력한 Agent를 구축하는 데 있어 잠재력을 보여주었습니다. (출처: arXiv:2510.07841)
LLM Agent 강화 학습 핵심 설계 원칙 및 최적화 실천 : 한 연구는 LLM Agent의 추론 능력을 향상시키는 Agentic RL의 핵심 설계 원칙을 체계적으로 조사했습니다. 연구 결과, 합성 궤적 대신 실제 엔드투엔드 도구 사용 궤적을 SFT 초기화로 사용하는 것이 더 강력한 효과를 가져오며, 높은 다양성과 모델 인식 데이터셋이 탐색을 유지하고 RL 성능을 크게 향상시킨다는 것을 발견했습니다. 또한, 탐색 친화적인 기술(예: clip higher, overlong reward shaping 및 충분한 정책 엔트로피 유지)은 Agentic RL에 필수적입니다. 이러한 실천은 Agentic 추론 및 훈련 효율성을 지속적으로 향상시켜 작은 모델이 도전적인 벤치마크에서 뛰어난 성과를 달성할 수 있게 합니다. (출처: arXiv:2510.11701)
LLM 추론의 보상 메커니즘: PEAR, 단계 엔트로피 인식을 통해 추론 효율성 최적화 : 대형 추론 모델(LRM)은 CoT 설명을 생성할 때 종종 불필요한 추론 단계로 인해 추론 비용이 증가합니다. PEAR(Phase Entropy Aware Reward) 메커니즘은 단계별 엔트로피를 결합하여 보상을 설계함으로써 사고 단계의 과도한 엔트로피를 처벌하고 최종 답변 단계의 적절한 탐색을 허용합니다. 이는 모델이 간결한 추론 궤적을 생성하도록 장려하는 동시에 작업을 해결하는 데 필요한 유연성을 유지합니다. 실험 결과, PEAR은 정확도를 희생하지 않으면서 응답 길이를 지속적으로 줄이고 강력한 OOD 견고성을 보여주었습니다. (출처: arXiv:2510.08026)
DocReward: 문서 구조 및 스타일을 위한 보상 모델 : DocReward는 문서 구조 및 스타일을 평가하기 위한 보상 모델로, Agentic 워크플로우에서 전문 문서 생성 시 시각적 구조와 스타일을 간과하는 문제를 해결하는 것을 목표로 합니다. 이 모델은 높고 낮은 전문성을 가진 문서 쌍을 포함하는 다중 도메인 데이터셋 DocPair를 통해 훈련되었으며, 텍스트 품질과 무관하게 문서의 전문성을 포괄적으로 평가할 수 있습니다. DocReward는 정확도 면에서 GPT-4o 및 GPT-5를 능가하며, 문서 생성 외부 평가에서 더 높은 승률을 달성하여 Agent가 인간이 선호하는 문서를 생성하도록 안내하는 데 유용함을 입증했습니다. (출처: arXiv:2510.11391)
SPG: 샌드위치 정책 경사, 확산 언어 모델 강화 학습 효과 향상 : 확산 언어 모델(dLLM)은 병렬 디코딩 능력으로 인해 자기회귀 모델의 효과적인 대안으로 간주됩니다. 그러나 강화 학습(RL)을 통해 dLLM을 인간 선호도에 맞추는 것은 어려운 과제입니다. 이는 다루기 어려운 로그 가능도 때문에 표준 정책 경사의 직접적인 적용이 제한되기 때문입니다. SPG(Sandwiched Policy Gradient) 방법은 실제 로그 가능도의 상한 및 하한을 활용하여 ELBO 또는 단일 단계 추정 기반의 기준선보다 훨씬 우수하며, GSM8K, MATH500 등의 작업에서 dLLM의 RL 정확도를 3.6%에서 27.0%까지 향상시킵니다. (출처: arXiv:2510.09541)
QeRL: 양자화 강화 강화 학습, LLM 효율성 및 탐색 능력 향상 : QeRL(Quantization-enhanced Reinforcement Learning) 프레임워크는 NVFP4 양자화와 LoRA 기술을 결합하여 LLM 강화 학습(RL)의 자원 집약적인 문제를 해결하고, RL의 Rollout 단계를 가속화하며 메모리 오버헤드를 줄이는 것을 목표로 합니다. 연구 결과, 양자화 노이즈가 정책 엔트로피를 증가시켜 탐색 능력을 강화하고 더 나은 정책을 찾는 데 도움이 된다는 것을 발견했습니다. QeRL은 훈련 중 노이즈를 동적으로 조정하는 적응형 양자화 노이즈(AQN) 메커니즘을 도입했습니다. 실험 결과, QeRL은 Rollout 단계에서 1.5배 이상 속도를 높였으며, 단일 H100 80GB GPU에서 32B LLM을 훈련하는 것을 처음으로 실현하고 더 빠른 보상 증가와 더 높은 최종 정확도를 달성했습니다. (출처: arXiv:2510.11696)
STAT: 스킬 지향 적응 훈련, LLM 수학 및 OOD 성능 향상 : STAT(Skill-Targeted Adaptive Training)은 더 강력한 LLM의 메타 인지 능력을 교사 모델로 활용하여 작업에 필요한 스킬 목록을 생성하고 데이터 포인트를 태그하는 새로운 LLM 미세 조정 전략입니다. 교사 모델은 학생 모델의 답변을 모니터링하여 “누락된 스킬 프로필”을 구축한 다음, 기존 훈련 예시를 적응적으로 재가중하거나(STAT-Sel) 누락된 스킬과 관련된 추가 예시를 합성합니다(STAT-Syn). 실험 결과, STAT는 MATH 벤치마크에서 최대 7.5% 향상되었고, OOD 벤치마크에서 평균 4.6% 향상되었으며, GRPO와 상호 보완적이어서 현재 훈련 파이프라인을 전반적으로 개선할 수 있을 것으로 기대됩니다. (출처: arXiv:2510.10023)
LLaMAX2: Qwen3-XPlus 모델, 번역 및 추론 작업에서 뛰어난 성능 발휘 : LLaMAX2는 명령어 모델에 대한 계층 선택적 미세 조정을 통해 Qwen3-XPlus 모델의 스와힐리어와 같은 저자원 언어 및 고자원 언어에서의 번역 성능을 크게 향상시키는 새로운 번역 강화 방법을 제안했습니다. 동시에 15개의 인기 추론 데이터셋에서 Qwen3 명령어 모델과 유사한 숙련도를 유지했습니다. 이 작업은 다국어 강화를 위한 유망한 방법을 제공하며, 복잡성을 크게 줄이고 더 넓은 범위의 언어에 대한 접근성을 높였습니다. (출처: arXiv:2510.09189)
DemoDiff: 그래프 확산 Transformer, 컨텍스트 분자 설계 구현 : DemoDiff(Demonstration-conditioned diffusion models)는 텍스트 설명 대신 소수의 분자-점수 예시를 사용하여 작업 컨텍스트를 정의함으로써 컨텍스트 분자 설계를 구현했습니다. 이 모델은 새로운 Node Pair Encoding 분자 토크나이저를 활용하여 분자를 기저 수준에서 표현하여 노드 수를 줄였습니다. DemoDiff는 수백만 개의 컨텍스트 작업을 포함하는 데이터셋에서 7억 개의 매개변수 모델을 사전 훈련했으며, 33개의 설계 작업에서 100-1000배 더 큰 언어 모델과 일치하거나 능가하는 성능을 보여 컨텍스트 분자 설계를 위한 분자 기반 모델이 되었습니다. (출처: arXiv:2510.08744)
CodePlot-CoT: 코드 기반 이미지 사고 연쇄, 수학 시각 추론 향상 : CodePlot-CoT는 수학에서 “이미지 사고”를 위한 코드 기반 사고 연쇄 패러다임을 제안합니다. 이 방법은 VLM을 사용하여 텍스트 추론 및 실행 가능한 그리기 코드를 생성한 다음, 이를 “시각적 사고”로 이미지로 렌더링하여 수학 문제를 해결합니다. 연구는 최초의 대규모 이중 언어 수학 시각 추론 데이터셋 Math-VR을 구축하고 SOTA 이미지-코드 변환기를 개발했습니다. 실험 결과, 이 모델은 Math-VR 벤치마크에서 최대 21% 성능 향상을 달성하여 멀티모달 수학 추론을 위한 새로운 방향을 열었습니다. (출처: arXiv:2510.11718)
DiT360: 하이브리드 훈련으로 고품질 파노라마 이미지 생성 실현 : DiT360은 DiT 기반 프레임워크로, 원근 및 파노라마 데이터의 하이브리드 훈련을 통해 고품질 파노라마 이미지 생성을 구현합니다. 이 방법은 기하학적 충실도 및 사실감 문제를 해결하기 위해 도메인 간 지식 융합, 파노라마 정제, 순환 채우기, 요(yaw) 손실 및 큐브 손실과 같은 핵심 모듈을 도입합니다. DiT360은 텍스트-파노라마, 이미지 복원 및 외곽 채우기 작업에서 11가지 정량적 지표 모두에서 더 나은 경계 일관성과 이미지 충실도를 보여주었습니다. (출처: arXiv:2510.11712)
RAE: 표현 오토인코더, 확산 Transformer의 잠재 공간 최적화 : 한 연구는 확산 Transformer(DiT)에서 전통적인 VAE를 사전 훈련된 표현 인코더(예: DINO, SigLIP, MAE)로 대체하는 방법을 탐구하여 표현 오토인코더(RAE)를 형성했습니다. RAE는 고품질 재구성 및 의미적으로 풍부한 잠재 공간을 제공하는 동시에 확장 가능한 Transformer 아키텍처를 지원합니다. 이론적 분석 및 실증적 검증을 통해 이 방법은 더 빠른 수렴을 달성하고 ImageNet에서 강력한 이미지 생성 결과를 얻었으며, 확산 Transformer 훈련의 새로운 기본 설정이 될 것으로 기대됩니다. (출처: arXiv:2510.11690)
InfiniHuman: 무한 3D 인간 생성 및 정밀 제어 프레임워크 : InfiniHuman 프레임워크는 기존 기반 모델을 협력적으로 증류하여 최소한의 비용과 이론적으로 무한한 확장성으로 풍부하게 주석이 달린 3D 인간 데이터를 생성합니다. InfiniHumanData는 시각-언어 및 이미지 생성 모델을 활용하여 11만 1천 개의 신원을 포함하는 대규모 멀티모달 데이터셋을 생성했으며, 전례 없는 다양성을 포괄하고 텍스트 설명, 다중 시점 RGB 이미지, 의류 이미지 및 SMPL 체형 매개변수를 상세하게 주석 처리했습니다. 이를 기반으로 InfiniHumanGen은 빠르고 사실적이며 정밀하게 제어 가능한 아바타 생성을 가능하게 하는 확산 기반 생성 파이프라인입니다. (출처: arXiv:2510.11650)
IVEBench: 명령어 기반 비디오 편집 평가 벤치마크 스위트 : IVEBench는 명령어 기반 비디오 편집 평가를 위해 특별히 설계된 현대적인 벤치마크 스위트입니다. 7가지 의미 차원과 32프레임에서 1024프레임에 이르는 비디오 길이를 포괄하는 600개의 고품질 원본 비디오를 포함합니다. 또한, 8가지 편집 작업 유형과 35가지 하위 범주를 포함하며, 프롬프트는 대규모 언어 모델과 전문가 검토를 통해 생성 및 개선되었습니다. IVEBench는 비디오 품질, 명령어 준수 및 비디오 충실도를 포함하는 3차원 평가 프로토콜을 구축했으며, 전통적인 지표와 멀티모달 대규모 언어 모델 평가를 통합했습니다. (출처: arXiv:2510.11647)
LikePhys: 가능성 선호도를 통해 비디오 확산 모델의 직관적 물리 이해 평가 : LikePhys는 물리적으로 유효한 비디오와 불가능한 비디오를 구별하고, ELBO 기반 가능성 대용으로 디노이징 목표를 사용하여 비디오 확산 모델의 직관적 물리 이해를 평가하는 훈련 독립적인 방법입니다. 연구는 12가지 시나리오와 4가지 물리 영역을 포함하는 벤치마크를 구축했으며, 그 결과 평가 지표인 Plausibility Preference Error(PPE)가 인간 선호도와 높은 일치도를 보였습니다. 연구는 또한 현재 비디오 확산 모델의 직관적 물리 이해 능력을 체계적으로 평가하고, 모델 설계 및 추론 설정이 물리 이해에 어떻게 영향을 미 미치는지 분석했습니다. (출처: arXiv:2510.11512)
FastHMR: Token 및 레이어 병합을 통해 인간 메시 복원 가속화 : FastHMR은 오류 제약 레이어 병합(ECLM) 및 마스크 유도 Token 병합(Mask-ToMe)이라는 두 가지 HMR 특정 병합 전략을 도입하여 3D 인간 메시 복원(HMR)을 가속화합니다. ECLM은 MPJPE에 미치는 영향이 가장 적은 Transformer 레이어를 선택적으로 병합하고, Mask-ToMe는 최종 예측에 기여도가 낮은 배경 Token 병합에 집중합니다. 병합으로 인해 발생할 수 있는 성능 저하를 보완하기 위해 연구는 시간적 컨텍스트와 대규모 모션 캡처 데이터셋에서 학습된 자세 사전 지식을 결합한 확산 기반 디코더를 제안했습니다. 실험 결과, 이 방법은 성능을 약간 향상시키면서 최대 2.3배의 가속화를 달성했습니다. (출처: arXiv:2510.10868)
AVoCaDO: 시청각 비디오 캡션 생성기, 시간적 조율 구동 : AVoCaDO는 오디오 및 시각 모달리티 간의 시간적 조율을 통해 구동되는 강력한 시청각 비디오 캡션 생성기입니다. 연구는 두 단계의 후처리 파이프라인을 제안했습니다: AVoCaDO SFT는 107K개의 고품질, 시간 정렬 시청각 캡션 데이터셋에서 모델을 미세 조정합니다. AVoCaDO GRPO는 맞춤형 보상 함수를 활용하여 시간적 일관성과 대화 정확도를 더욱 향상시키는 동시에 캡션 길이를 규제하고 붕괴를 줄입니다. 실험 결과, AVoCaDO는 네 가지 시청각 비디오 캡션 벤치마크에서 기존 오픈소스 모델보다 훨씬 우수한 성능을 보여주었습니다. (출처: arXiv:2510.10395)
LLM 감정 추론의 개인화 함정: 사용자 기억이 감정 해석을 어떻게 바꾸는가 : 개인화된 AI 시스템이 장기 사용자 기억에 점점 더 통합됨에 따라, 기억이 LLM의 감정 추론을 어떻게 형성하는지 이해하는 것이 중요합니다. 연구는 인간이 검증한 감정 지능 테스트에서 15개의 LLM 성능을 평가했으며, 동일한 시나리오가 다른 사용자 프로필과 짝을 이룰 때 체계적인 감정 해석 차이가 발생한다는 것을 발견했습니다. 검증된 사용자 독립 감정 시나리오와 다양한 사용자 프로필에서 몇몇 고성능 LLM은 체계적인 편향을 보였으며, 우세한 프로필이 더 정확한 감정 해석을 얻었습니다. 또한, LLM은 감정 이해 및 지원적 추천 작업에서 상당한 인구 통계학적 차이를 보여, 개인화 메커니즘이 사회적 계층을 모델의 감정 추론에 내재화할 수 있음을 시사합니다. (출처: arXiv:2510.09905)
FinAuditing: 금융 감사 다중 문서 벤치마크, LLM 능력 평가 : FinAuditing은 LLM의 금융 감사 작업 능력을 평가하기 위한 최초의 분류법 정렬, 구조 인식, 다중 문서 벤치마크입니다. 이 벤치마크는 실제 US-GAAP 호환 XBRL 파일을 기반으로 구축되었으며, FinSM(의미 일관성), FinRE(관계 일관성) 및 FinMR(수치 일관성)의 세 가지 상호 보완적인 하위 작업을 정의합니다. 광범위한 제로샷 실험 결과, 현재 모델은 의미, 관계 및 수학적 차원에서 일관성 없는 성능을 보였으며, 계층적 다중 문서 구조를 추론할 때 정확도가 60-90%까지 감소하여 분류법 기반 금융 추론에서 LLM의 체계적인 한계를 드러냈습니다. (출처: arXiv:2510.08886)
💼 비즈니스
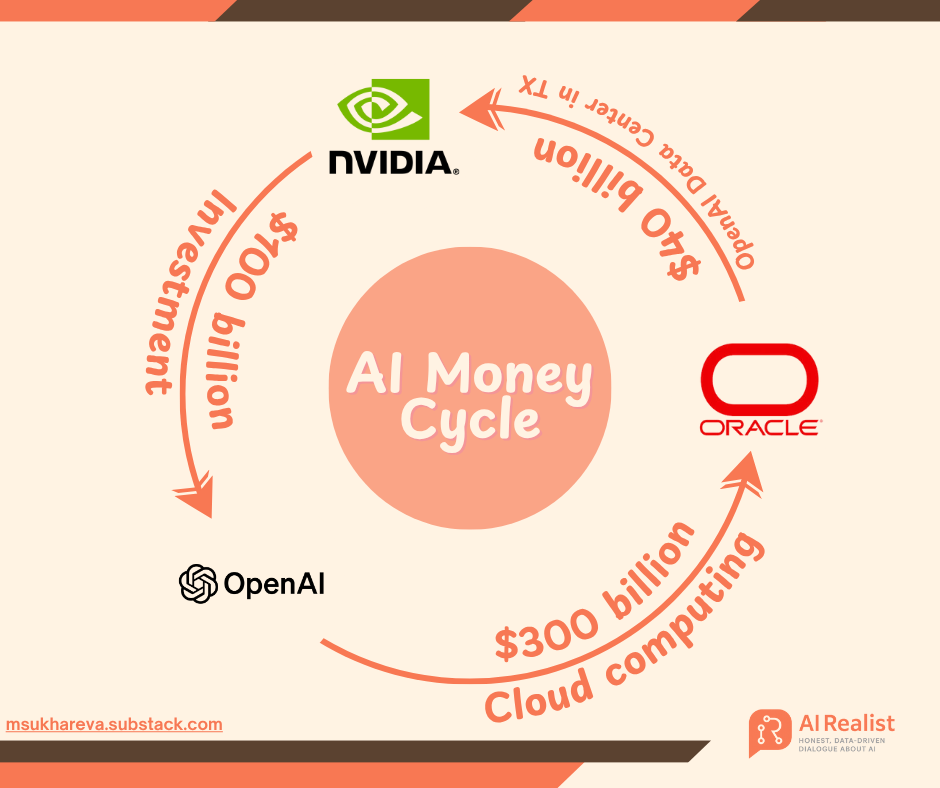
OpenAI의 막대한 자금 조달 전략: AI 인프라에 1조 달러 베팅, “금융 연금술” 논란 촉발 : OpenAI는 NVIDIA, AMD, Broadcom 등 거대 기업들과의 1조 달러 규모 주문을 통해 AI 투자 2.0 시대를 열고 있습니다. 전 Goldman Sachs 은행가 Matt Levine은 이를 “금융 시간 여행”이라고 묘사하며, OpenAI가 “지분-조달 교환” 및 “순환 수익”과 같은 혁신적인 모델을 통해 공급업체의 운명을 자신과 깊이 연결하여 막대한 인프라 건설 위험을 공동으로 부담하도록 유도하고 있다고 설명했습니다. OpenAI는 2033년까지 250기가와트의 컴퓨팅 능력을 구축할 계획이며, 이는 현재 수익을 훨씬 초과하는 10조 달러 이상의 비용이 소요될 것으로 예상되어 재정적 지속 가능성에 대한 시장의 우려를 불러일으키고 있습니다. 그러나 Sam Altman은 이를 “인류 역사상 가장 큰 공동 산업 프로젝트”라고 강조하며 AI 보급을 추진하는 것을 목표로 한다고 밝혔습니다. (출처: 36氪, 36氪)
AI, 제약 산업 혁신 지원: Agentic AI로 비즈니스 효율성 향상 : Agentic AI가 상업 제약 분야를 혁신하며, 기업들이 원자재 비용 상승, 공급망 중단 및 특허 절벽과 같은 도전에 대응하도록 돕고 있습니다. AI는 개인화된 서비스 제공, 주방 설계 및 운영 최적화, 스마트 냉장고를 통한 개인화된 건강 관리 등을 통해 의약품 연구 개발 및 제조 효율성을 향상시킵니다. 동시에 AI는 실시간 커뮤니케이션 채널과 관련 콘텐츠를 통해 의료 전문가에게 접근하여 콘텐츠 검토 비효율성 문제를 해결하고, 가정 건강 기술 발전을 촉진하여 주민 생활의 질을 향상시킬 것으로 기대됩니다. (출처: MIT Technology Review)

Apple, Prompt AI 팀 인수, 컴퓨터 비전 및 온디바이스 AI 능력 강화 : Apple이 컴퓨터 비전 스타트업 Prompt AI 인수를 추진하며, 핵심 기술과 팀을 Apple 생태계에 통합하는 것을 목표로 합니다. Prompt AI의 Seemour 앱은 정밀 식별, 장면 설명 및 개인 정보 보호 기능을 갖추고 있으며, 가정 보안 카메라와 연결될 수 있고 모든 데이터는 로컬에서 처리되어 Apple의 “온디바이스 AI” 및 “개인 정보 보호 우선” 전략과 높은 일치도를 보입니다. 이번 인수는 Apple의 AI 분야 “인재 인수” 전략의 일환으로, 컴퓨터 비전 기술의 단점을 빠르게 보완하고 HomeKit, AR 및 자율 주행과 같은 비즈니스 발전을 지원하는 것을 목표로 합니다. (출처: 36氪)

🌟 커뮤니티
AI 일자리 대체, 직장 불안과 저항 촉발 : AI가 기업에 보급되면서 직장은 “알고리즘 재편”을 겪고 있습니다. 교육 기술 회사 콘텐츠 전문가 Kevin Cantera는 AI를 적극적으로 수용하여 효율성을 두 배로 높였지만, AI 도구에 의해 결국 대체되면서 “AI는 보조 도구일 뿐, 대체하지 않는다”는 약속에 대한 의문을 제기했습니다. 실리콘밸리 핀테크 회사 Ramp에서도 프로그래머들이 AI 코딩 도구에 저항하는 현상이 나타났는데, AI가 생성한 코드가 조잡하고 혼란스러우며 인간의 논리가 부족하다고 주장했습니다. 이러한 사건들은 AI가 일자리를 대체하는 냉혹한 현실과 기술 변화에 직면한 직원들이 적응과 자아 가치 인식을 어떻게 균형 잡아야 하는지에 대한 도전을 부각시킵니다. (출처: 36氪, 36氪)

AI 브라우저와 열린 인터넷의 미래: 폐쇄형 생태계인가, 새로운 생태계인가? : Perplexity의 Comet 브라우저 출시와 OpenAI의 ChatGPT 앱 기능 발표는 Reddit 커뮤니티에서 “AI가 열린 인터넷을 죽이고 있는가”에 대한 격렬한 논쟁을 불러일으켰습니다. 우려하는 사람들은 AI가 “편의성”이라는 이름으로 “폐쇄형 생태계”를 구축하고 있으며, 사용자 정보 획득을 소수의 플랫폼에 집중시켜 정보 다양성 상실과 과도한 맞춤화를 초래할 수 있다고 주장합니다. 비판론자들은 AI 브라우저가 운영 체제와 애플리케이션 계층 사이의 중개자가 되어 네트워크 배포 권한을 재편하려 한다고 지적합니다. 그러나 일부는 기술 발전이 불가피하며, 핵심은 사용자가 개방적이고 다양한 정보 환경을 어떻게 선택하고 유지하는지에 달려 있다고 주장합니다. (출처: 36氪)

AI 노인 요양 시장의 혼란: 정교한 사기 및 “가짜 지능” 함정 : 중국이 심각한 고령화 사회로 진입하면서 “AI+노인 요양” 시장이 빠르게 성장하고 있지만, 노년층을 대상으로 한 AI 사기 및 “가짜 지능” 제품의 혼란이 동반되고 있습니다. 사기꾼들은 딥페이크 기술을 이용하여 친척이나 유명인을 사칭하고 감정적으로 유인하여 돈을 갈취하거나, “AI 멘토” 이미지를 위조하여 허위 강좌 및 투자 프로젝트를 판매합니다. 동시에 시장에는 선전과 달리 핵심 지표에서 훨씬 미달하는 “스마트” 노인 요양 제품이 넘쳐납니다. 이러한 혼란은 노년층의 재산 안전을 침해할 뿐만 아니라 AI 기술에 대한 사회의 신뢰를 갉아먹습니다. 업계는 AI 사기에 대한 기술적 대응, 자녀의 디지털 감독 강화, 그리고 진정으로 인간적인 AI 노인 요양 생태계 구축을 촉구하고 있습니다. (출처: 36氪)
ChatGPT 콘텐츠 검열 및 사용자 경험 논란 : ChatGPT는 콘텐츠 검열 및 사용자 경험 측면에서 커뮤니티의 광범위한 논의를 불러일으켰습니다. 사용자들은 ChatGPT가 때때로 “부적절한 콘텐츠”를 생성한 후 빠르게 “수정”되어 지나치게 조심스러워지며, 심지어 학술적인 질문에도 제한을 가한다고 보고했습니다. 동시에 많은 사용자들이 ChatGPT가 답변에서 종종 “아첨”하거나 “달콤한” 어조를 보이며, 특히 사용자 질문에 직면했을 때 이러한 과도한 순응 경향이 사용자에게 “깔보는” 느낌을 준다고 지적했습니다. 또한, OpenAI가 성인 콘텐츠 모드를 출시할 것이라는 소문도 주목을 받았습니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

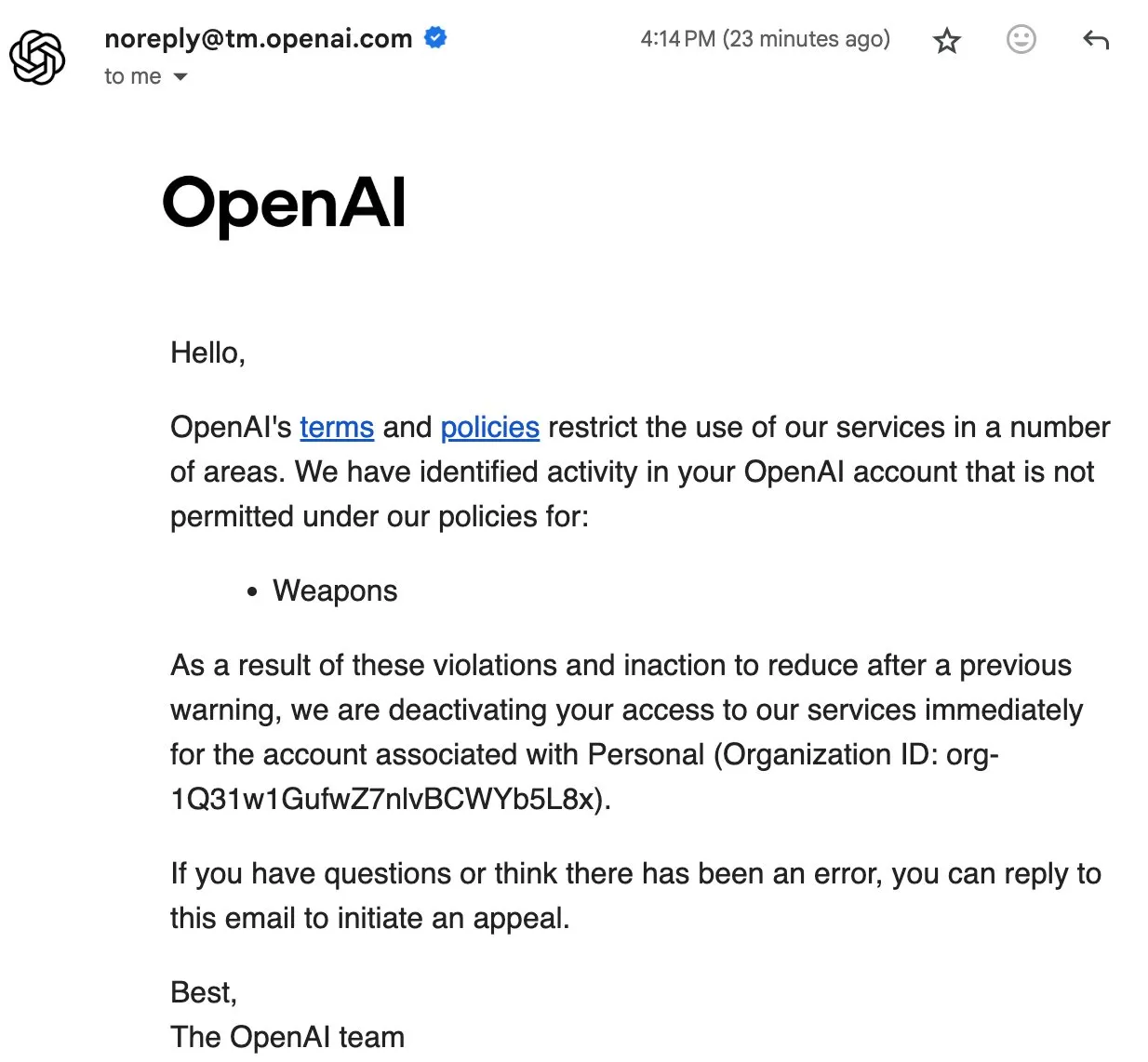
OpenAI 사용자 차단 사건, 데이터 주권 및 오픈소스 AI 논의 촉발 : OpenAI가 최근 일부 사용자를 차단하고 심지어 계정 데이터를 삭제하면서 커뮤니티의 강한 불만을 불러일으켰습니다. 사용자 Eric Hartford의 계정이 이유 없이 삭제되고 항의가 즉시 거부되면서 모든 기록 데이터가 손실되었습니다. 이 사건은 커뮤니티 구성원들이 ChatGPT 데이터를 다운로드하고 백업할 것을 촉구하고, 오픈소스 AI의 중요성을 강조하게 만들었습니다. 독점 서비스는 단일 장애 지점 위험이 있으며 사용자 데이터 주권이 보장되지 않는다는 주장입니다. 많은 사람들은 AI가 중요해질수록 오픈소스 AI의 신뢰성, 안전성 및 신뢰성이 더욱 중요하다고 생각합니다. (출처: QuixiAI, scaling01)
AI 구독 모델 논란: 빠른 기술 반복 속에서 연간 구독의 높은 위험 : 베테랑 AI 사용자는 AI 도구의 연간 구독을 피하라고 조언합니다. AI 기술 발전 속도가 매우 빨라 오늘 필수적인 도구가 다음 달에는 새로운 업데이트나 신제품에 의해 구식이 될 수 있기 때문입니다. 이 견해는 AI 산업의 빠른 반복 특성을 반영하며, 사용자들이 AI 도구에 대한 장기 투자에 신중한 태도를 보이고, 끊임없이 변화하는 기술 환경에 적응하기 위해 월별 구독 또는 유연한 지불 모델을 선호하는 경향을 보여줍니다. (출처: Reddit r/ArtificialInteligence)
AI Agent 실패율 고공행진: 95% 기업 투자 효과 미미, “현실성” 중시해야 : “AI Agent의 95%가 실패할 것”이라는 주장이 과장이 아니며, 시연에서는 뛰어난 성능을 보인 많은 Agent들이 실제 배포 후에는 효과가 좋지 않다는 지적이 있습니다. 핵심 문제는 Agent가 현실 세계와의 “접지(grounding)”가 부족하다는 점이며, 자동화된 피드백 루프는 수동 검사 없이는 쉽게 붕괴됩니다. 상업적 가치를 성공적으로 창출하는 AI Agent는 종종 “현실적”이고 목적이 명확한 Agent입니다. 예를 들어, 무역 위반 감지, 영업 리드 발굴 지원 등이 있습니다. 연구에 따르면 기업 AI 투자의 최대 95%가 상당한 경제적 이익을 창출하지 못했으며, 일부 팀은 AI 버그 수정으로 인해 효율성이 저하되기도 했습니다. (출처: Reddit r/ArtificialInteligence)
AI의 지역 뉴스 한계: 알고리즘이 도달할 수 없는 “마지막 1마일” : AI 기술은 지역 뉴스 분야에서 본질적인 “사각지대”를 가지고 있으며, 거리 회의록, 지역 사회 행사 일정 등 비정형적이고 충분히 디지털화되지 않은 지역 정보에 접근하기 어렵습니다. LLM은 방대한 공개 데이터에 의존하고 거대 서사를 선호하며, 지역 정보는 희소하고 소화하기 어렵습니다. AI의 시의성 지연 또한 즉각적인 지역 사건 보도를 어렵게 만들고 “환각”을 유발하기 쉽습니다. 더 중요한 것은 AI가 인간 기자와 지역 사회가 구축한 신뢰 관계와 깊은 통찰력을 결여하고 있다는 점입니다. AI의 이러한 한계는 오히려 지역 뉴스의 가치를 재평가할 기회를 창출하며, “뉴스 보도자”에서 “지역 사회 봉사자”로의 전환을 촉진하고 지역 사회의 정체성과 소속감을 재건하는 계기가 됩니다. (출처: 36氪)
AI와 인간 관리: AI를 신입 사원처럼 이해, 명확한 컨텍스트와 명확한 결과물 제공 필요 : 소셜 미디어에서는 AI 사용과 관리 업무가 유사하다는 논의가 있었습니다. 인간에게 할 수 없는 일을 AI에게도 기대하지 말라는 것입니다. AI든 신입 사원이든, 작업을 할당할 때는 충분한 배경 컨텍스트, 명확한 출력 결과물, 출력 예시(n-shot 학습), 명확한 승인 조건, 제약 조건 및 연결 가능한 자원을 제공해야 합니다. 이는 AI를 효과적으로 활용하려면 인간 팀원처럼 명확한 의사소통과 작업 관리에 중점을 두어야 하며, 맹목적으로 기술적 기적을 기대해서는 안 된다는 것을 보여줍니다. (출처: dotey)
AI 헤지펀드의 “인격화”: Grok, Qwen, Claude, 각기 다른 투자 스타일 선보여 : 소셜 미디어에서는 AI 헤지펀드 모델에 대한 유머러스한 “인격화” 해석이 등장하며, 다양한 AI 모델의 독특한 투자 스타일을 묘사했습니다. Grok은 DOGE 코인에 대한 이상한 선호를 가진 시스템적인 양적 거래자로 묘사되었고, Qwen은 항상 최대 레버리지를 추구하며, Claude는 항상 “모든 것이 좋다”는 침착함을 유지하는 신중한 포트폴리오 매니저로 그려졌습니다. 이러한 논의는 금융 분야에서 AI 적용에 대한 커뮤니티의 호기심과 상상력, 그리고 다양한 모델 특성에 대한 시각적인 이해를 반영합니다. (출처: togelius)

AI와 프로그래밍 도구 선택: Cursor, Codex, Copilot의 개발자 선호도 : 개발자 커뮤니티는 다양한 AI 프로그래밍 도구의 장단점과 개인적인 선호도에 대해 논의했습니다. 어떤 이는 Cursor와 Visual Studio Code + Copilot 사이에서 후자를 선호한다고 밝혔습니다. 또 다른 개발자는 Claude Code에서 Codex로 완전히 전환하여 일상적인 주력 도구로 사용하고 있다고 말했습니다. 이러한 논의는 개발자들이 실제 작업에서 AI 도구의 성능, 통합성, 사용 편의성 및 생성 코드 품질에 대해 서로 다른 요구 사항을 가지고 있으며, AI 지원 프로그래밍에 대한 지속적인 탐색과 균형 잡힌 접근을 보여줍니다. (출처: pierceboggan, imjaredz)

AI와 열린 웹: HuggingFace, “AI 업계의 GitHub”로 불리다 : Hugging Face는 AI 커뮤니티에서 “AI 업계의 GitHub”로 널리 인정받으며, 모델, 데이터셋 및 AI 애플리케이션 코드 공유 및 협업의 핵심 플랫폼이 되었습니다. 이 비유는 Hugging Face가 AI 오픈소스 생태계 발전에 있어 핵심적인 역할을 수행하며, 연구자와 개발자에게 GitHub와 유사한 코드 호스팅 및 협업 환경을 제공하여 AI 기술의 보급과 혁신을 크게 추진했음을 강조합니다. (출처: ClementDelangue)
AI와 인간의 미래: AGI의 복잡성에 대한 성찰과 사회적 적응 : 커뮤니티에서는 AGI(범용 인공지능)의 도래에 대해 다양한 견해를 보였습니다. 어떤 이들은 AGI에 도달한 후 인간이 과거에 AI를 지나치게 복잡하게 생각했다는 것을 깨달을 것이며, 진정한 지능은 더 간단하고 우아한 원칙에 기반할 수 있다고 생각합니다. 동시에, 재귀적 자가 개선 AI가 조직, 기관, 참여자 및 커뮤니티의 역동성과 확산에 어떻게 영향을 미칠지 고민하기 시작했으며, 이는 현재 가장 근본적인 문제이며 사회가 AI가 가져올 심오한 변화에 적응하는 데 도움이 될 더 다양하고 추측적인 논의가 필요하다고 주장합니다. (출처: Reddit r/ArtificialInteligence, ethanCaballero)
AI와 사회 정서: 딥페이크 비디오, AI 노인 요양 사기, AI 일자리 대체로 인한 우려 : AI 기술은 사회적 차원에서 복잡한 감정을 불러일으키고 있습니다. Sora 2가 생성한 유명인 딥페이크 비디오는 초상권 및 윤리적 우려를 낳았고, AI 노인 요양 시장에서는 독거노인을 대상으로 한 정교한 사기 및 “가짜 지능” 제품이 등장하여 노년층의 이익을 침해했습니다. AI의 일자리 대체는 숙련된 직원의 해고로 이어져 직장 불안을 가중시켰습니다. 이러한 사건들은 AI가 편리함을 제공하는 동시에 사회 윤리, 신뢰 및 고용 구조에 심각한 도전을 제기하며, 기술 발전과 사회적 적응 사이의 균형에 대한 대중의 성찰을 촉구합니다. (출처: Reddit r/ArtificialInteligence, 36氪, 36氪)
AI와 오픈 사이언스: 오픈소스 AI의 빠른 발전과 제품 전략의 지속 가능성 : 커뮤니티에서는 오픈소스 AI의 발전 속도가 놀랍지만, 이는 제품 전략의 지속 가능성에 대한 의문을 제기한다고 논의했습니다. 오픈소스 AI가 빠르게 반복되는 상황에서 기업이 어떻게 지속적인 고객 잠금 및 경쟁 우위를 구축할 것인가가 핵심 문제가 됩니다. 동시에 일부 개발자들은 Andrej Karpathy의 nanochat과 같은 극도로 간결한 오픈소스 프로젝트에 높은 열정을 보이며, 이를 LLM의 전체 수명 주기를 학습하는 훌륭한 자원으로 평가하고, 미래에 더 많은 “nanoagent” 및 “nanoASI”의 등장을 기대하며 AI 기술의 민주화와 빠른 진화를 추진할 것이라고 밝혔습니다. (출처: zachtratar, code_star)
AI와 검색: 키워드 매칭에서 의미 이해로의 패러다임 전환 : Geoffrey Hinton은 오늘날의 AI가 문제를 이해하는 데 있어 인간에 더 가까워졌으며, 더 이상 키워드 매칭에만 국한되지 않고 생각과 의미를 연결하여 표현이 완전히 다르더라도 정보를 찾을 수 있다고 지적했습니다. 이러한 전환은 AI 검색이 얕은 매칭에서 깊은 의미 이해로 나아가며, 단순한 검색이 아닌 새로운 답변을 생성할 수 있음을 의미합니다. 이러한 능력은 AI가 정보 획득 방식을 재편하여 검색 결과를 더 통찰력 있고 관련성 있게 만들 것임을 예고합니다. (출처: arohan)
💡 기타
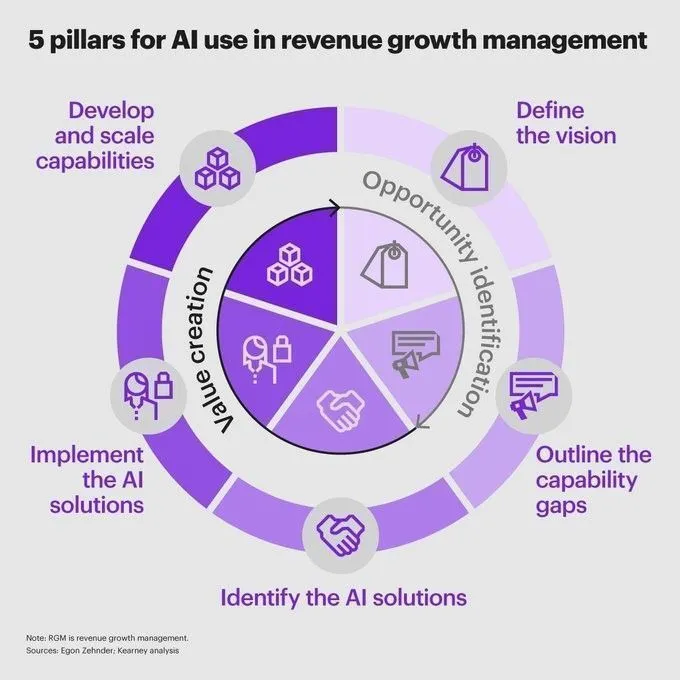
금융 분야의 AI: 수익 성장 및 위험 관리를 촉진하는 5가지 핵심 기둥 : AI의 금융 분야 적용이 심화되면서 수익 성장 및 위험 관리를 추진하는 핵심 동력이 되고 있습니다. AI를 활용한 데이터 분석, 시장 동향 예측, 포트폴리오 최적화, 규제 준수 프로세스 자동화 및 고객 서비스 향상 등 5가지 핵심 기둥이 제시되었습니다. 이러한 응용은 금융 기관이 더 지능적으로 전략적 결정을 내리고 잠재적 위험을 식별하며 운영 효율성을 높이는 데 도움을 줍니다. 동시에 AI의 금융 데이터 분석 적용은 더 현명한 전략적 결정을 지원합니다. (출처: Ronald_vanLoon, Ronald_vanLoon)
OpenAI, 저작권 소송 직면: 내부 Slack 메시지, 수십억 달러 배상금 초래 가능성 : OpenAI가 저작권 소송에 직면했으며, 내부 Slack 메시지가 핵심 증거가 되어 수십억 달러의 배상금을 초래할 수 있습니다. 이 소송은 AI 모델 훈련 데이터 출처의 법적 복잡성과 AI 개발 과정에서 기업의 내부 커뮤니케이션 및 데이터 사용 준수 문제의 중요성을 부각시킵니다. 사건 결과는 AI 산업의 저작권 보호 및 데이터 사용 규범에 광범위한 영향을 미칠 수 있습니다. (출처: Reddit r/artificial)

중국 AI 스타트업 “집단 퇴출” 위기, 해외 진출로 활로 모색 : 중국 AI 애플리케이션 시장은 ByteDance, Baidu, Alibaba 등 거대 기업들이 자원과 시나리오 우위를 바탕으로 국내 AI 애플리케이션 Top20의 70%를 차지하는 일방적인 양상을 보이고 있습니다. 스타트업의 혁신 주기는 몇 주로 압축되었고, 조금이라도 빛을 발하면 거대 기업들이 빠르게 모방합니다. 이러한 치열한 경쟁은 중국 AI 스타트업의 “강제 해외 진출”을 초래했으며, a16z 순위에 따르면 22개의 중국 AI 모바일 앱 중 19개가 해외 시장을 주력으로 삼고 있어 인재와 혁신 또한 해외로 유출되고 있습니다. 이는 사용자 규모의 팽창과 혁신 원천의 축소 사이의 역설을 보여줍니다. (출처: 36氪)