
키워드:휴머노이드 로봇, AI 대형 모델, 강화 학습, 멀티모달 AI, AI 에이전트, Figure 03 데이터 병목 현상, GPT-5 Pro 수학 증명, EmbeddingGemma 디바이스 측 RAG, GraphQA 그래프 분석 대화, NVIDIA Blackwell 추론 성능
🔥 포커스
Figure 03, TIME지 최고의 발명품 목록 표지 장식, CEO “현 단계에서는 데이터만 있으면 된다”고 언급 : Figure사 CEO Brett Adcock은 휴머노이드 로봇 Figure 03의 현재 가장 큰 병목 현상은 아키텍처나 컴퓨팅 파워가 아닌 “데이터”라고 밝히며, 데이터가 거의 모든 문제를 해결하고 로봇의 대규모 상용화를 촉진할 것이라고 믿는다. Figure 03이 TIME지 2025년 최고의 발명품 목록 표지를 장식하면서, 로봇 개발에서 데이터, 컴퓨팅 파워, 아키텍처의 중요성에 대한 논의를 불러일으켰다. Brett Adcock은 Figure의 목표가 로봇이 가정 및 상업 환경에서 인간의 작업을 수행하도록 하는 것이며, 로봇 안전을 매우 중요하게 생각한다고 강조했다. 그는 미래에 휴머노이드 로봇의 수가 인간을 넘어설 수 있다고 예측했다.(출처: 量子位)

테렌스 타오, GPT-5 Pro와 협력하여 이종 분야에 도전! 3년간 풀리지 않던 난제, 11분 만에 완전한 증명 제시 : 저명한 수학자 테렌스 타오가 GPT-5 Pro와 협력하여 미분 기하학 분야에서 3년간 풀리지 않던 난제를 11분 만에 해결했다. GPT-5 Pro는 복잡한 계산을 완료했을 뿐만 아니라, 완전한 증명을 직접 제시했으며, 심지어 타오의 초기 직관을 수정하는 데 도움을 주었다. 타오는 AI가 “작은 규모” 문제에서 뛰어난 성능을 보이며 “큰 규모”의 문제 이해에도 도움이 되지만, “중간 규모”의 전략에서는 잘못된 직관을 강화할 수 있다고 결론 내렸다. 그는 AI가 수학자의 “부조종사” 역할을 하여 실험 효율성을 높여야 하며, 인간의 창의적이고 직관적인 작업을 완전히 대체해서는 안 된다고 강조했다.(출처: 量子位)

🎯 동향
윈펑 테크놀로지, AI+헬스 신제품 출시 : 윈펑 테크놀로지는 슈아이캉(Shuaikang), 스카이워스(Skyworth)와 협력하여 AI+헬스 신제품을 출시했다. 여기에는 “디지털 지능형 미래 주방 연구소”와 AI 헬스 대규모 모델이 탑재된 스마트 냉장고가 포함된다. AI 헬스 대규모 모델은 주방 설계 및 운영을 최적화하며, 스마트 냉장고는 “건강 도우미 샤오윈”을 통해 개인 맞춤형 건강 관리를 제공한다. 이는 AI가 일상 건강 관리 분야에서 돌파구를 마련했음을 의미하며, 스마트 기기를 통해 개인 맞춤형 건강 서비스를 구현하여 가정 건강 기술 발전을 촉진하고 주민의 삶의 질을 향상시킬 것으로 기대된다.(출처: 36氪)
휴머노이드 로봇 및 Embodied AI 발전 현황: 가사 노동부터 산업 응용까지 : 여러 소셜 미디어 토론에서 휴머노이드 로봇과 Embodied AI의 최신 발전 현황이 공개되었다. Reachy Mini는 TIME지 2025년 최고의 발명품 중 하나로 선정되었으며, 로봇 분야에서 오픈소스 협업의 잠재력을 보여주었다. AI 기반의 생체 공학 의수는 17세 소년이 생각만으로 제어할 수 있게 했고, 휴머노이드 로봇은 가사 노동을 쉽게 수행할 수 있다. 산업 분야에서는 Yondu AI가 바퀴 달린 휴머노이드 로봇 창고 피킹 솔루션을 발표했으며, AgiBot은 인간에 가까운 이동 능력을 갖춘 Lingxi X2를 선보였다. 중국은 고속 구형 경찰 로봇을 공개했다. Boston Dynamics의 로봇은 다기능 카메라맨으로 진화했으며, LocoTouch 사족 보행 로봇은 촉각을 통해 지능형 운송을 구현한다.(출처: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, johnohallman, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
대규모 모델 능력 돌파 및 코드 벤치마크 테스트 새 진전 : GPT-5 Pro와 Gemini 2.5 Pro는 국제 천문학 및 천체 물리학 올림피아드(IOAA)에서 금메달 수준의 성과를 달성하여, AI가 첨단 물리학 분야에서 강력한 능력을 가지고 있음을 보여주었다. GPT-5 Pro는 또한 뛰어난 과학 문헌 검색 및 검증 능력을 선보였으며, Erdos 문제 #339를 해결하고, 발표된 논문에서 중대한 결함을 효과적으로 식별할 수 있다. 코드 분야에서는 KAT-Dev-72B-Exp가 SWE-Bench Verified 순위에서 1위를 차지한 오픈소스 모델이 되었으며, 74.6%의 수정률을 달성했다. SWE-Rebench 프로젝트는 대규모 모델 출시 후 새로 제기된 GitHub 이슈를 테스트하여 데이터 오염을 방지한다. Sam Altman은 Codex의 미래에 대해 큰 기대를 표했다. AGI가 순수 LLM만으로 구현될 수 있는지에 대해, AI 연구계는 LLM 핵심만으로는 달성하기 어렵다고 일반적으로 본다.(출처: gdb, karminski3, gdb, SebastienBubeck, karminski3, teortaxesTex, QuixiAI, sama, OfirPress, Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
AI 하드웨어 및 인프라의 성능 혁신과 도전 : NVIDIA Blackwell 플랫폼은 SemiAnalysis InferenceMAX 벤치마크 테스트에서 타의 추종을 불허하는 추론 성능과 효율성을 보여주었으며, Together AI는 이미 NVIDIA GB200 NVL72 및 HGX B200 시스템을 제공하고 있다. Groq는 ASIC 및 수직 통합 전략을 통해 더 낮은 지연 시간과 경쟁력 있는 가격으로 오픈소스 LLM 인프라 경제를 재편하고 있다. 커뮤니티에서는 Python GIL 제거가 AI/ML 엔지니어링에 미치는 영향에 대해 논의했으며, 제거 시 멀티스레딩 성능이 향상될 것으로 기대하고 있다. 또한, LLM 애호가들은 각자의 하드웨어 구성을 공유하고, 다양한 양자화 수준에서 대규모 양자화 모델과 소규모 비양자화 모델 간의 성능 트레이드오프를 탐구했다. 2-bit 양자화는 대화에 적합할 수 있지만, 코딩 작업에는 최소 Q5가 필요하다고 지적했다.(출처: togethercompute, arankomatsuzaki, code_star, MostafaRohani, jeremyphoward, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI 모델 및 애플리케이션 최전선 동향: 범용 모델부터 수직 분야까지 : AI 분야에서는 새로운 모델과 기능이 계속해서 등장하고 있다. 튀르키예어 대규모 모델 Kumru-2B가 Hugging Face에서 두각을 나타냈으며, Replit은 이번 주에 여러 업데이트를 발표했다. Sora 2는 워터마크를 제거했으며, 이는 비디오 생성 기술이 더 광범위한 응용을 가져올 것임을 시사한다. Gemini 3.0이 10월 22일에 출시될 것이라는 소문이 있다. AI는 의료 건강 분야에서 지속적으로 심화되고 있으며, 디지털 병리학은 AI를 통해 암 진단을 보조하고 있다. 무표지 현미경과 AI의 결합은 새로운 진단 도구를 가져올 것으로 기대된다. 증강 현실(AR) 모델은 Imagenet FID 순위에서 SOTA(State-of-the-Art)를 달성했다. Qwen Code 명령줄 코딩 Agent는 Qwen-VL 모델의 이미지 인식을 지원하도록 업데이트되었다. 스탠포드 대학교는 Agentic Context Engineering (ACE) 방법을 제안하여, 모델이 미세 조정 없이도 더 스마트해질 수 있도록 했다. DeepSeek V3 시리즈 모델도 지속적으로 반복 개발되고 있으며, AI Agent의 배포 유형과 AI가 전문 서비스 분야를 재편하는 방식 또한 업계의 주요 관심사가 되고 있다.(출처: mervenoyann, amasad, scaling01, npew, kaifulee, Ronald_vanLoon, scaling01, TheTuringPost, TomLikesRobots, iScienceLuvr, NerdyRodent, shxf0072, gabriberton, Ronald_vanLoon, karminski3, Ronald_vanLoon, teortaxesTex, demishassabis, Dorialexander, yoheinakajima, 36氪)
🧰 도구
GraphQA: 그래프 분석을 자연어 대화로 전환 : LangChainAI는 GraphQA 프레임워크를 출시했다. 이 프레임워크는 NetworkX와 LangChain을 결합하여 복잡한 그래프 분석을 자연어 대화로 전환할 수 있다. 사용자는 일반 영어로 질문할 수 있으며, GraphQA는 적절한 알고리즘을 자동으로 선택하고 실행하여 10만 개 이상의 노드를 가진 그래프를 처리한다. 이는 그래프 데이터 분석의 진입 장벽을 크게 낮추어 비전문가도 쉽게 사용할 수 있게 한다. 이는 LLM 분야의 중요한 도구 혁신이다.(출처: LangChainAI)
VS Code 최고의 Agentic AI 도구 : Visual Studio Magazine은 특정 도구를 VS Code 최고의 Agentic AI 도구 중 하나로 선정했다. 이는 개발 패러다임이 “조수”에서 개발자와 함께 생각하고 행동하며 구축하는 “진정한 Agent”로 전환되고 있음을 의미한다. 이는 소프트웨어 개발 분야에서 AI 도구가 보조적인 기능에서 더 깊은 수준의 지능형 협업으로 진화하고 있음을 반영하며, 개발자의 효율성과 경험을 향상시킨다.(출처: cline)
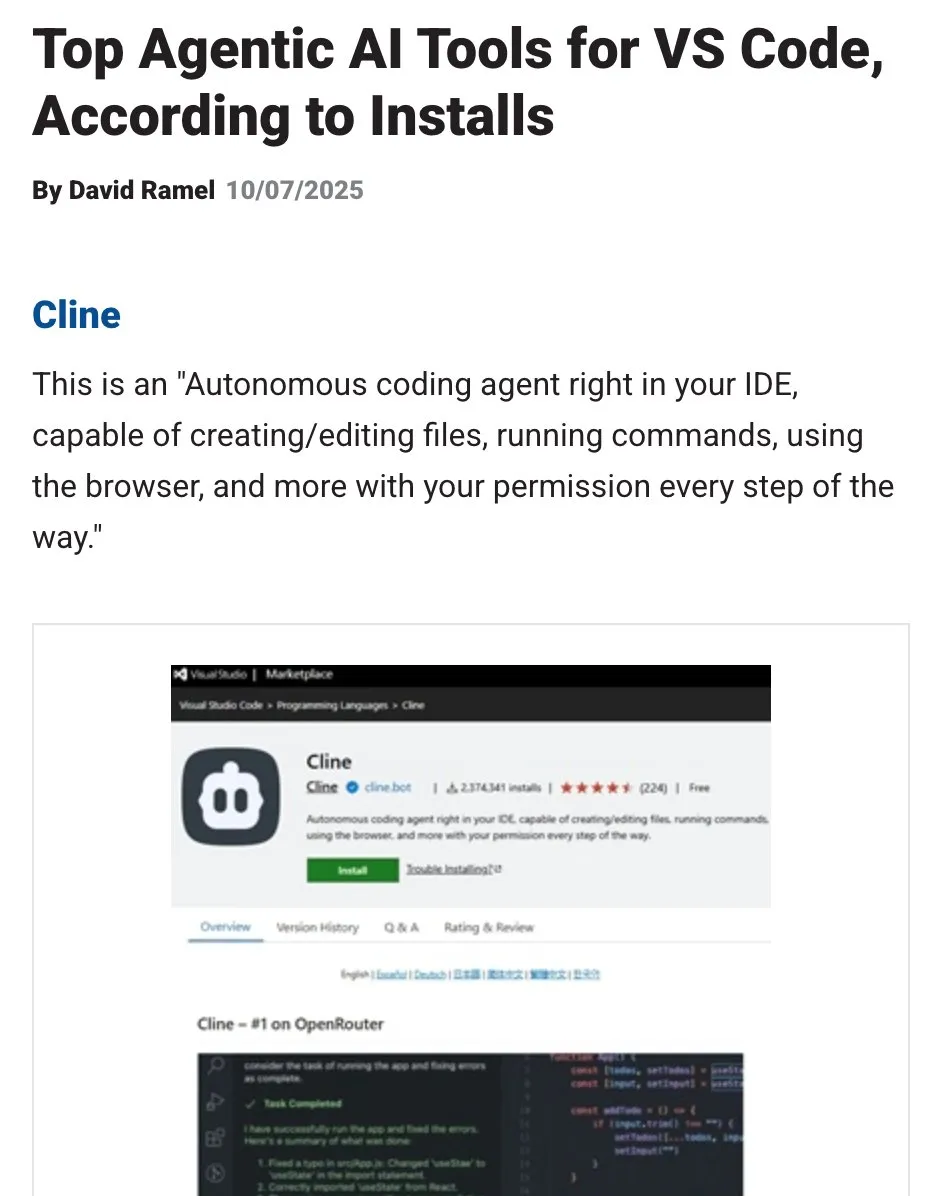
OpenHands: LLM 컨텍스트 관리 오픈소스 도구 : OpenHands는 오픈소스 도구로서, Agentic 애플리케이션에서 LLM의 컨텍스트를 관리하기 위한 다양한 컨텍스트 압축기를 제공한다. 여기에는 기본적인 기록 정리, “가장 중요한 이벤트” 추출, 브라우저 출력 압축 등이 포함된다. 이는 LLM 애플리케이션, RAG 시스템 및 Agentic 워크플로우의 디버깅, 평가 및 모니터링에 필수적이며, 복잡한 작업에서 LLM의 효율성과 일관성을 높이는 데 기여한다.(출처: gneubig)
BLAST: AI 웹 브라우저 엔진 : LangChainAI는 BLAST를 발표했다. 이는 고성능 AI 웹 브라우저 엔진으로, AI 애플리케이션에 웹 브라우징 기능을 제공하는 것을 목표로 한다. BLAST는 OpenAI 호환 인터페이스를 제공하며, 자동 병렬화, 지능형 캐싱 및 실시간 스트리밍을 지원한다. 웹 정보를 AI 워크플로우에 효율적으로 통합할 수 있으며, AI Agent가 실시간 웹 데이터를 획득하고 처리하는 능력을 크게 확장한다.(출처: LangChainAI)
Opik: 오픈소스 LLM 평가 도구 : Opik은 오픈소스 LLM 평가 도구로, LLM 애플리케이션, RAG 시스템 및 Agentic 워크플로우의 디버깅, 평가 및 모니터링에 사용된다. 이 도구는 포괄적인 추적, 자동화된 평가 및 프로덕션 준비 대시보드를 제공하여 개발자가 모델 동작을 더 잘 이해하고, 성능을 최적화하며, 실제 시나리오에서 애플리케이션의 신뢰성을 보장하도록 돕는다.(출처: dl_weekly)
AI 여행 Agent: 지능형 계획 도우미 : LangChainAI는 지능형 AI 여행 Agent를 선보였다. 이 Agent는 실시간 날씨, 검색 및 여행 정보를 통합하고, 여러 API를 활용하여 날씨 업데이트부터 환전까지의 전체 프로세스를 간소화한다. 이 Agent는 원스톱 여행 계획 및 지원을 제공하여 사용자 여행 경험을 향상시키는 것을 목표로 한다. 이는 수직적 응용 시나리오에서 LLM이 Agent에 기능을 부여하는 대표적인 사례이다.(출처: LangChainAI)
AI 광고주 프롬프트 구축 도구 구상 : 시장에서 마케터가 “광고주 프롬프트”를 구축하는 데 도움을 주는 AI 도구가 시급히 필요하다는 의견이 제기되었다. 이 도구는 평가 시스템 구축(브랜드 안전, 프롬프트 준수도 등 포함)을 지원하고, 주요 모델에 대한 테스트를 수행할 수 있어야 한다. OpenAI가 다양한 자연 광고 단위를 출시함에 따라, 마케팅 프롬프트의 중요성이 점점 더 부각되고 있다. 이러한 도구는 광고 기획 및 배포 프로세스에서 핵심적인 역할을 할 것이다.(출처: dbreunig)
Qwen Code 업데이트: Qwen-VL 모델 이미지 인식 지원 : Qwen Code 명령줄 코딩 Agent가 최근 업데이트되어, Qwen-VL 모델로 전환하여 이미지 인식을 수행하는 기능이 추가되었다. 사용자 테스트 결과 효과가 좋았으며, 현재 무료로 사용할 수 있다. 이번 업데이트는 Qwen Code의 기능을 크게 확장하여, 코드 작업뿐만 아니라 멀티모달 상호작용도 가능하게 했다. 이는 시각 정보가 포함된 작업을 처리할 때 코딩 Agent의 효율성과 정확성을 향상시킨다.(출처: karminski3)

LibreChat을 활용하여 개인 챗봇 서버 호스팅 : 한 블로그 게시물에서 LibreChat을 사용하여 개인 챗봇 서버를 호스팅하고 여러 모델 제어판(MCPs)에 연결하는 방법에 대한 가이드를 제공했다. 이는 사용자가 다양한 LLM 백엔드를 유연하게 관리하고 전환하여 맞춤형 챗봇 경험을 구현할 수 있게 한다. 이는 AI 애플리케이션 배포에서 오픈소스 솔루션의 유연성과 제어 가능성을 강조한다.(출처: Reddit r/artificial)
AI 생성기: 가상 아바타를 현실로 구현 : 한 사용자가 최고의 AI 생성기를 찾고 있다. 그는 자신의 브랜드 이미지(실제 인물 비디오 및 가상 아바타 포함)를 “현실로 구현”하여 YouTube 채널에 활용하고, 촬영 및 녹화 시간을 줄여 편집에 집중하기를 원한다. 사용자는 AI가 가상 아바타가 대화하고, 게임을 하고, 춤을 추는 등의 활동을 할 수 있게 해주기를 바란다. 이는 콘텐츠 제작자들이 가상 아바타 애니메이션 및 비디오 생성 분야에서 AI 도구에 대한 높은 수요를 가지고 있음을 반영하며, 생산 효율성과 콘텐츠 다양성을 높이기 위함이다.(출처: Reddit r/artificial)
로컬 LLM으로 이메일 스팸 대응: 비공개 솔루션 : 한 블로그 게시물에서 로컬 LLM을 활용하여 자신의 메일 서버에서 스팸 메일을 비공개로 식별하고 대응하는 방법에 대한 실천 사례를 공유했다. 이 솔루션은 Mailcow, Rspamd, Ollama 및 사용자 정의 Python 에이전트를 결합하여 자체 호스팅 메일 서버 사용자에게 AI 기반의 스팸 필터링 방법을 제공한다. 이는 개인 정보 보호 및 맞춤형 애플리케이션 분야에서 로컬 LLM의 잠재력을 강조한다.(출처: Reddit r/LocalLLaMA)
📚 학습
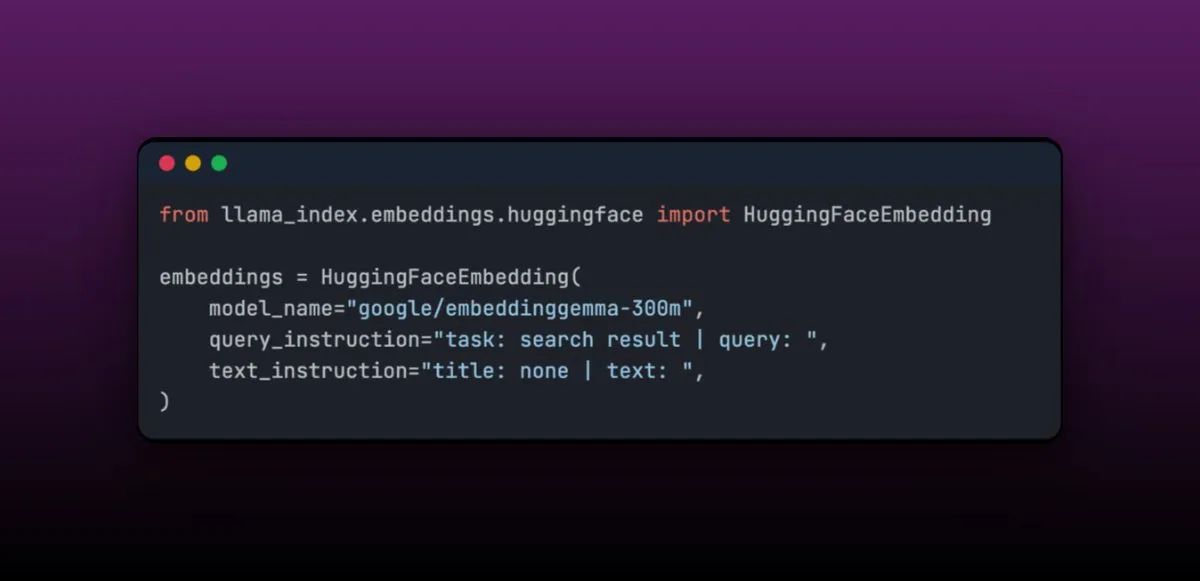
EmbeddingGemma: 기기 내 RAG 애플리케이션을 위한 다국어 임베딩 모델 : EmbeddingGemma는 308M의 적은 파라미터 수를 가진 컴팩트한 다국어 임베딩 모델로, 기기 내 RAG 애플리케이션에 매우 적합하며, LlamaIndex와 쉽게 통합될 수 있다. 이 모델은 Massive Text Embedding Benchmark에서 상위권을 차지했으며, 동시에 크기가 작아 모바일 기기에 적합하다. 미세 조정이 용이한 특성 덕분에 특정 분야(예: 의료 데이터)에서 미세 조정을 거치면 더 큰 모델의 성능을 능가할 수 있다.(출처: jerryjliu0)
문서 처리의 두 가지 기본 방법: 파싱과 추출 : LlamaIndex 팀의 한 기사에서 문서 처리의 “파싱(Parsing)”과 “추출(Extraction)”이라는 두 가지 기본 방법을 심층적으로 다루었다. 파싱은 전체 문서를 구조화된 Markdown 또는 JSON으로 변환하여 모든 정보를 보존하는 방식이다. 이는 RAG, 심층 연구 및 요약에 적합하다. 추출은 LLM으로부터 구조화된 출력을 얻어 문서를 일반적인 패턴으로 표준화하는 방식이다. 이는 데이터베이스 ETL, 자동화된 Agent 워크플로우 및 메타데이터 추출에 적합하다. 이 두 가지 차이점을 이해하는 것은 효율적인 문서 Agent를 구축하는 데 매우 중요하다.(출처: jerryjliu0)

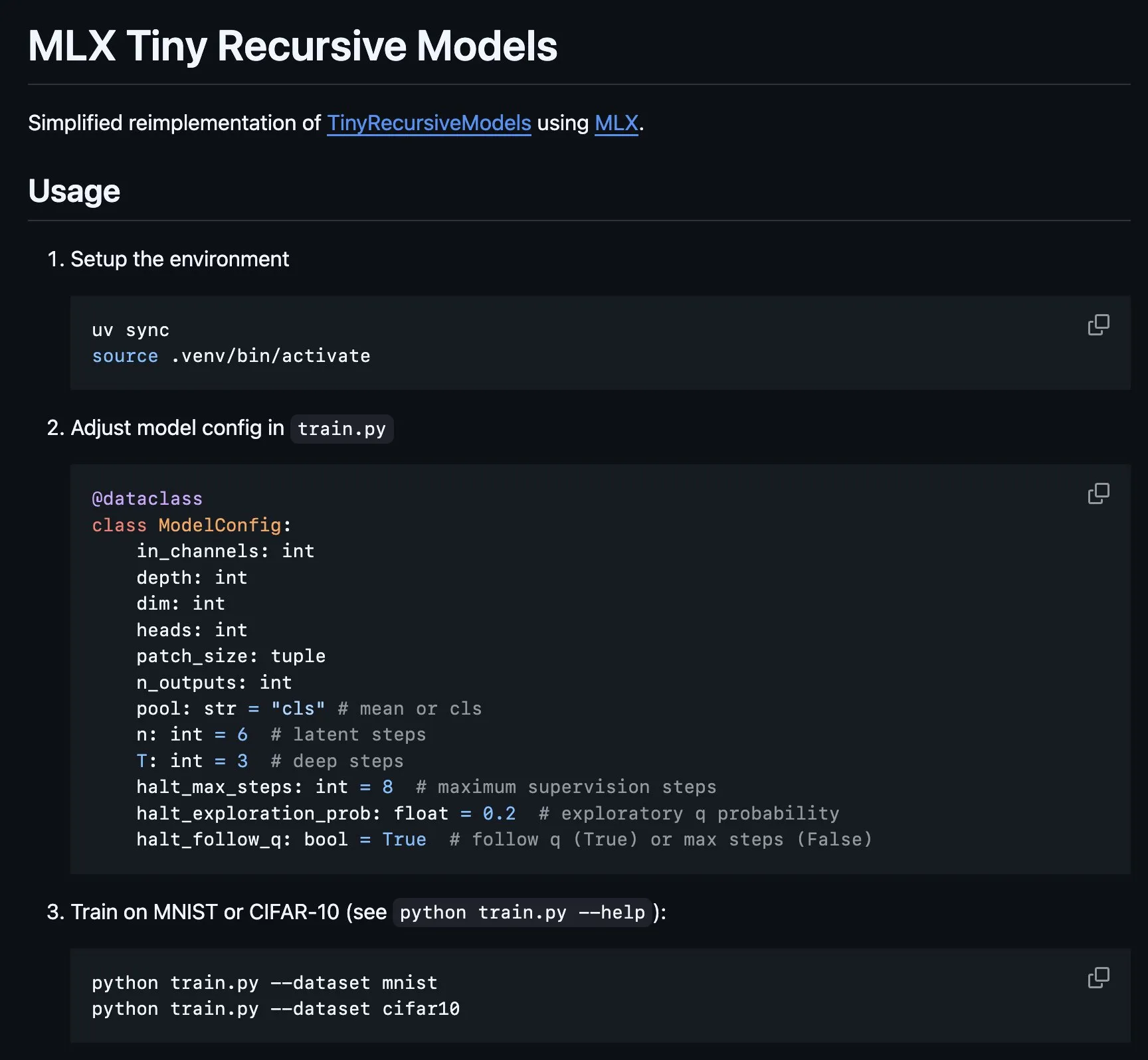
MLX에서 Tiny Recursive Model (TRM) 구현 : MLX 플랫폼은 Tiny Recursive Model (TRM)의 핵심 부분을 구현했다. 이 모델은 Alexia Jolicoeur-Martineau가 제안했으며, 7M 파라미터의 작은 신경망으로 재귀적 추론을 통해 고성능을 달성하는 것을 목표로 한다. 이 MLX 구현은 Apple Silicon 노트북에서 로컬 실험을 가능하게 하며, 복잡성을 줄였다. 심층 감독, 재귀적 추론 단계, EMA 등의 특성을 포함하며, 작고 효율적인 모델의 개발 및 연구에 편의를 제공한다.(출처: awnihannun, ImazAngel)
2025년 생성형 AI 전문가 학습 로드맵 : 2025년 생성형 AI 전문가 학습 로드맵의 상세 버전이 소셜 미디어에 공유되었다. 이 로드맵은 생성형 AI 분야의 전문가가 되기 위해 필요한 핵심 지식과 기술을 다룬다. 이 로드맵은 지망생들이 인공지능, 머신러닝, 딥러닝 등 핵심 개념을 체계적으로 학습하도록 안내하여 빠르게 발전하는 GenAI 기술 트렌드에 적응할 수 있도록 돕는다.(출처: Ronald_vanLoon)
머신러닝 박사 과정 학습 경험 공유 : 한 사용자가 머신러닝 분야에서 박사 학위를 취득하는 것에 대한 일련의 트윗을 다시 공유했다. 이는 ML 박사 과정 학습에 관심 있는 사람들에게 지침과 경험을 제공하기 위함이다. 이 트윗들은 지원 절차, 연구 방향, 경력 개발 및 개인적인 경험 등을 다룰 수 있으며, 커뮤니티에서 귀중한 AI 학습 자료가 된다.(출처: arohan)
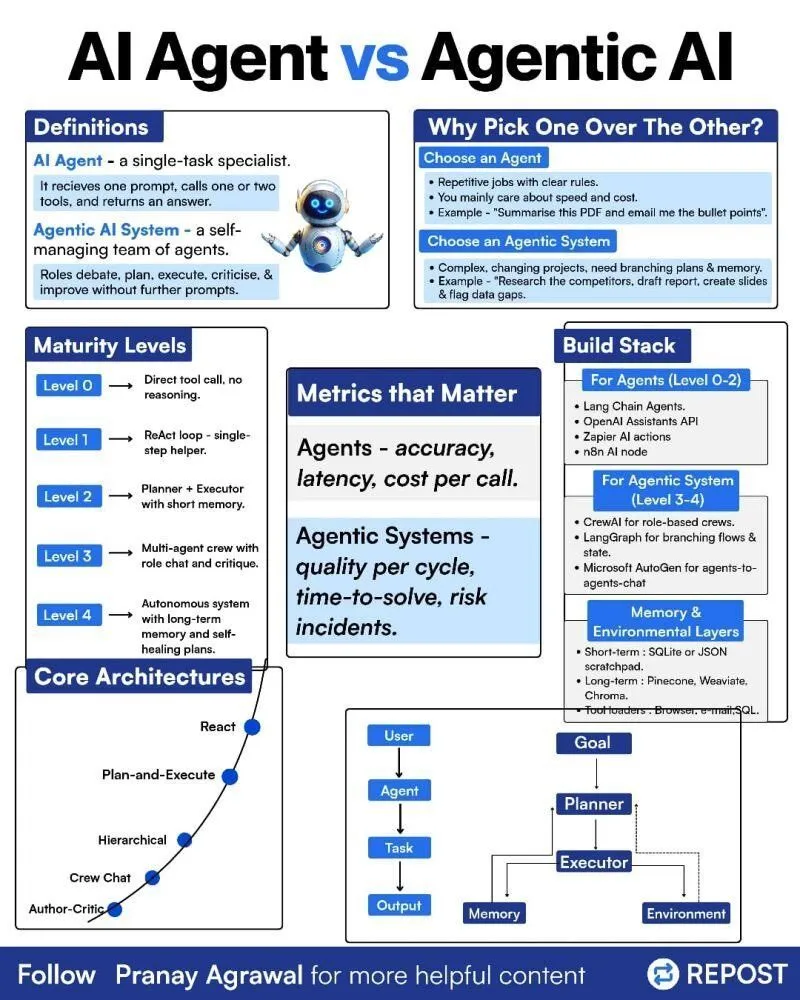
AI Agents와 Agentic AI의 차이점 : 소셜 미디어에서 “AI Agents”와 “Agentic AI”의 차이점을 설명하는 도해가 공유되었다. 이는 관련성이 있지만 서로 다른 두 개념을 명확히 하기 위함이다. 이는 커뮤니티가 AI Agent의 배포 유형, 자율성 수준, 그리고 더 넓은 인공지능 시스템에서 Agentic AI의 역할을 더 잘 이해하는 데 도움이 된다. Agent 기술에 대한 더 정확한 논의를 촉진한다.(출처: Ronald_vanLoon)
LLM 훈련에서의 강화 학습과 가중치 감쇠 : 소셜 미디어에서는 LLM 강화 학습(RL) 훈련에서 가중치 감쇠(Weight Decay)가 좋은 아이디어가 아닐 수 있다는 점이 논의되었다. 일부 의견에 따르면, 가중치 감쇠는 네트워크가 많은 사전 훈련 정보를 잊게 만들 수 있으며, 특히 이점이 0인 GRPO 업데이트에서는 가중치가 0으로 수렴하는 경향이 있다. 이는 연구자들이 LLM의 RL 훈련 전략을 설계할 때 가중치 감쇠의 영향을 신중하게 고려해야 함을 시사한다. 모델 성능 저하를 방지하기 위함이다.(출처: lateinteraction)
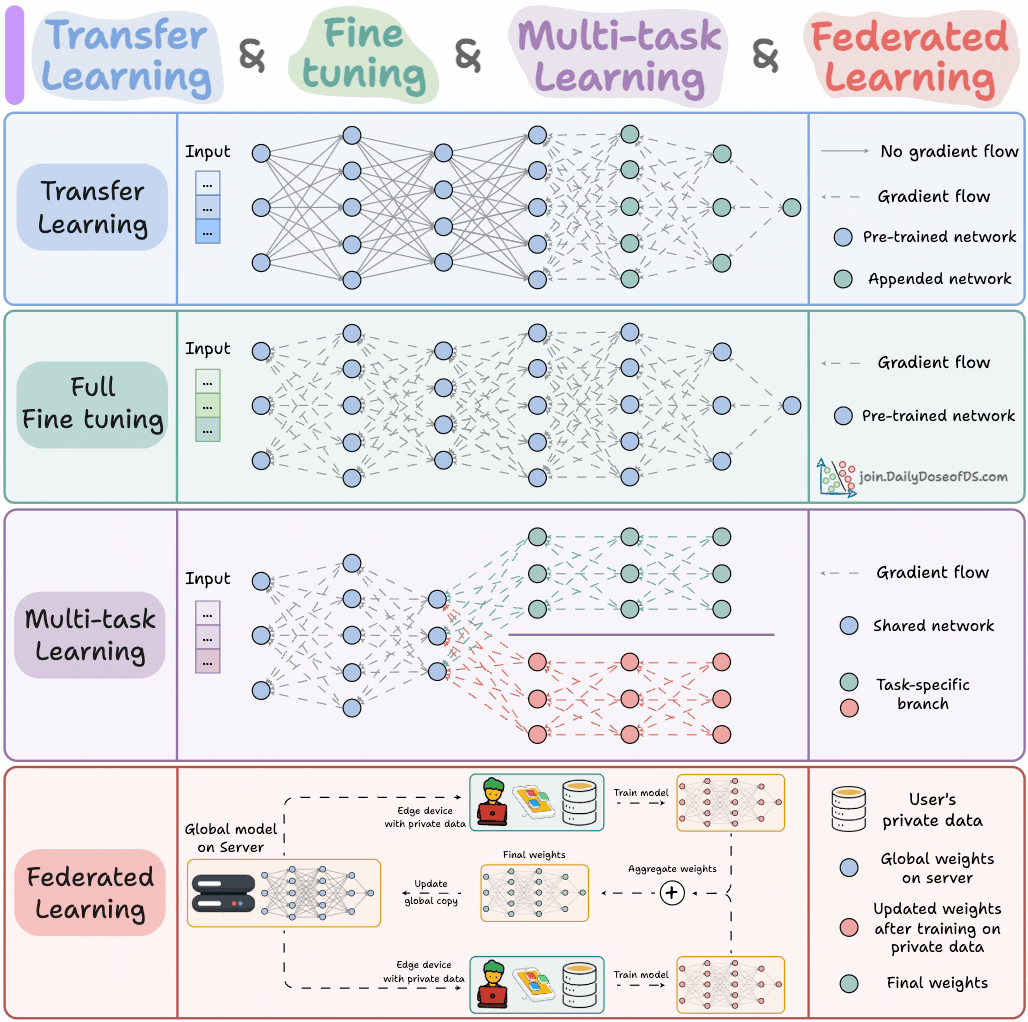
AI 모델 훈련 패러다임 : 한 전문가가 ML 엔지니어가 반드시 알아야 할 네 가지 모델 훈련 패러다임을 공유했다. 이는 머신러닝 엔지니어에게 핵심적인 이론적 지침과 실천적 프레임워크를 제공하기 위함이다. 이 패러다임들은 지도 학습, 비지도 학습, 강화 학습 및 자기 지도 학습 등을 포함할 수 있으며, 엔지니어가 다양한 모델 훈련 방법을 더 잘 이해하고 적용하도록 돕는다.(출처: _avichawla)
커리큘럼 학습 기반 강화 학습으로 LLM 능력 향상 : 한 연구에 따르면, 커리큘럼 학습과 결합된 강화 학습(RL)은 LLM에 새로운 능력을 가르칠 수 있으며, 이는 다른 방법으로는 달성하기 어렵다. 이는 LLM의 장기 추론 능력 향상에 있어 커리큘럼 학습의 잠재력을 보여준다. RL과 커리큘럼 학습의 결합이 AI의 새로운 기술을 해제하는 핵심 경로가 될 수 있음을 시사한다.(출처: sytelus)

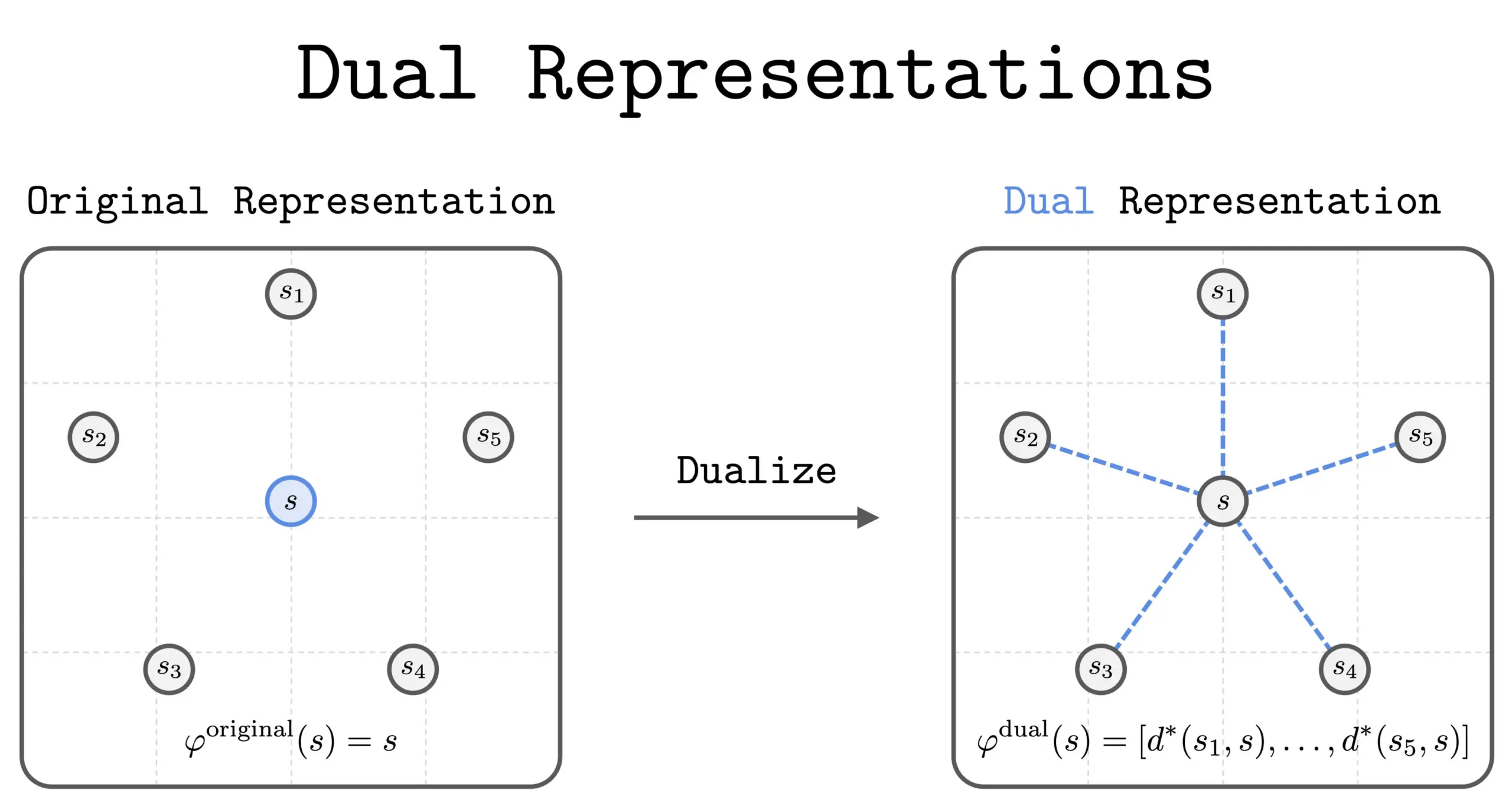
RL의 이중 표현(Dual Representation) 새 방법 : 새로운 연구에서 강화 학습(RL)의 “이중 표현(Dual Representation)” 방법을 도입했다. 이 방법은 상태를 다른 모든 상태와의 “유사성 집합”으로 표현함으로써 새로운 관점을 제공한다. 이러한 이중 표현은 우수한 이론적 특성과 실제적 이점을 가지며, RL의 성능과 이해 능력을 향상시킬 것으로 기대된다.(출처: dilipkay)
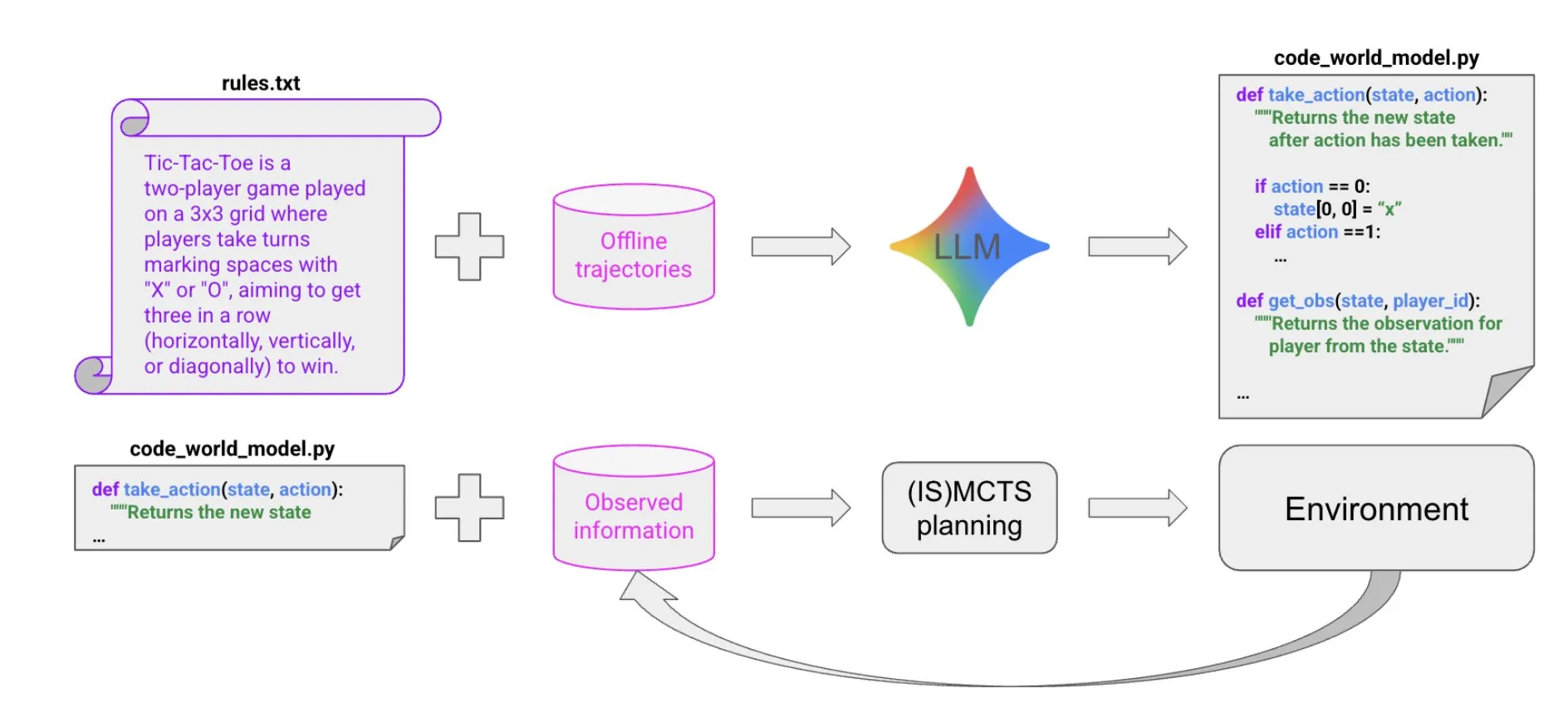
LLM 기반 코드 합성을 통한 세계 모델 구축 : 새로운 논문에서 매우 샘플 효율적인 방법을 제안했다. 이는 LLM 기반 코드 합성을 통해 다중 Agent, 부분적으로 관찰 가능한 기호 환경에서 잘 작동하는 Agent를 생성하는 방법이다. 이 방법은 소량의 궤적 데이터와 배경 정보로부터 코드 세계 모델을 학습한 다음, 이를 기존 솔버(예: MCTS)에 전달하여 다음 행동을 선택하게 한다. 이는 복잡한 Agent 구축에 새로운 아이디어를 제공한다.(출처: BlackHC)
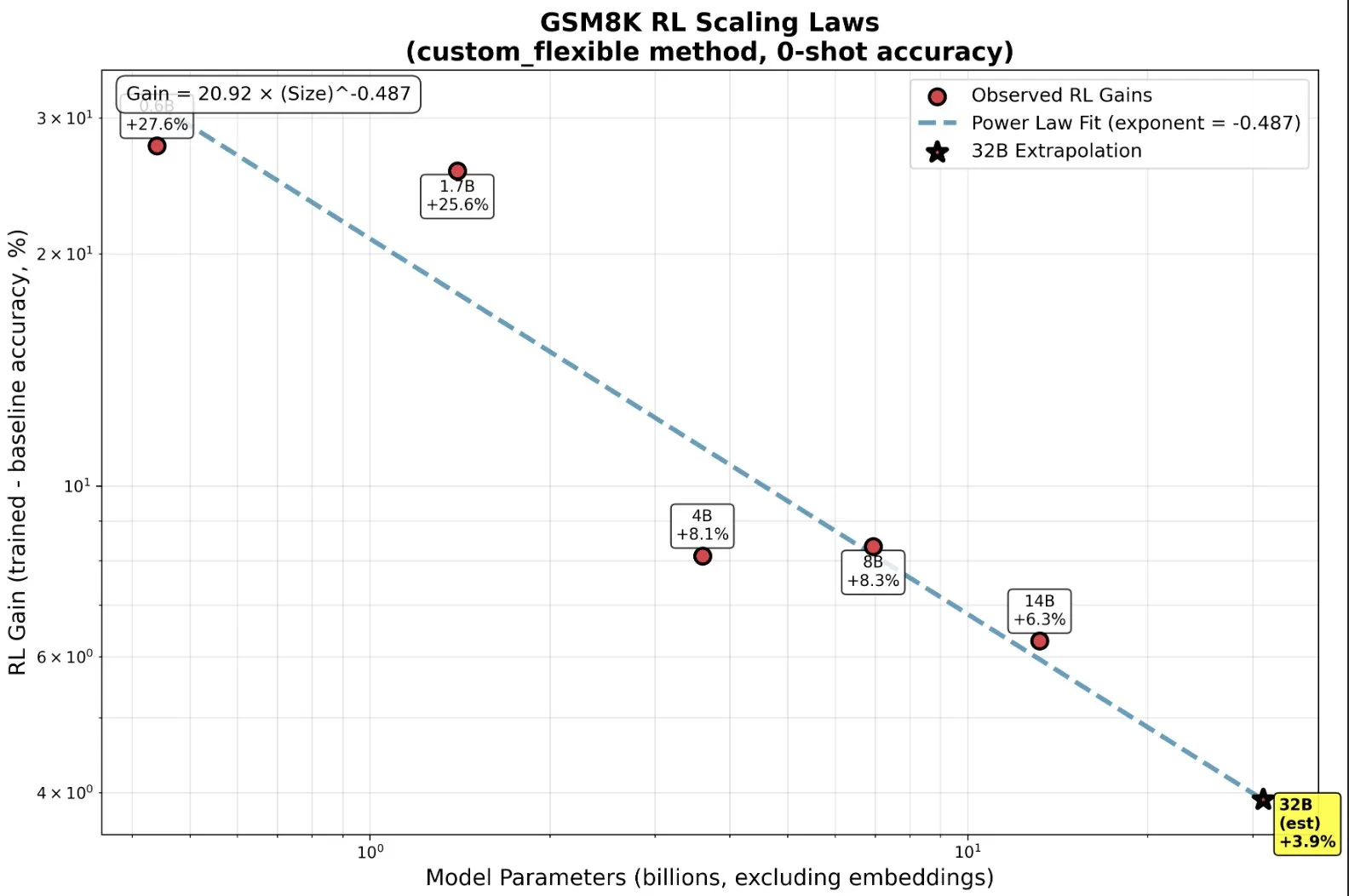
RL 훈련 소규모 모델: 사전 훈련을 넘어서는 발현 능력 : 연구에 따르면, 강화 학습(RL)에서 소규모 모델이 불균형적으로 이점을 얻고 심지어 “발현(Emergent)” 능력을 보이기도 한다. 이는 “크면 클수록 좋다”는 전통적인 직관을 뒤엎는다. 소규모 모델에서는 RL이 더 많은 사전 훈련보다 계산 효율적일 수 있다. 이 발견은 AI 연구소가 RL을 확장할 때 사전 훈련을 언제 중단하고 RL을 언제 시작할지에 대한 결정에 중요한 의미를 갖는다. 이는 모델 규모와 성능 향상 사이의 새로운 RL 스케일링 법칙을 밝혀낸다.(출처: ClementDelangue, ClementDelangue)
AI vs. 머신러닝 vs. 딥러닝: 간단한 설명 : 한 비디오 자료에서 인공지능(AI), 머신러닝(ML) 및 딥러닝(DL) 간의 차이점을 간단하고 이해하기 쉬운 방식으로 설명했다. 이 비디오는 초보자들이 이러한 핵심 개념을 빠르게 이해하도록 돕고, AI 분야를 더 깊이 학습하기 위한 기초를 마련하는 것을 목표로 한다.(출처: )

딥러닝 모델 실험에서의 프롬프트 템플릿 관리 : 딥러닝 커뮤니티에서는 모델 실험에서 프롬프트 템플릿을 관리하고 재사용하는 방법에 대해 논의했다. 대규모 프로젝트에서, 특히 아키텍처나 데이터셋을 수정할 때, 다양한 프롬프트 변형의 효과를 추적하는 것이 복잡해진다. 사용자들은 Empromptu AI와 같은 도구를 사용하여 프롬프트 버전 관리 및 분류를 수행한 경험을 공유했다. 이는 프롬프트 버전 관리와 데이터셋-프롬프트 정렬의 중요성을 강조하며, 모델 제품을 최적화하기 위함이다.(출처: Reddit r/deeplearning)
코드 완성(FIM) 모델 선택 가이드 : 커뮤니티에서는 코드 완성(FIM) 모델 선택의 핵심 요소에 대해 논의했다. 속도가 절대적인 우선순위로 간주되며, 파라미터 수가 적고 GPU만으로 실행되는 모델(목표 >70 t/s)을 선택하는 것이 권장된다. 또한, “기본” 모델과 지시 모델은 FIM 작업에서 유사한 성능을 보인다. 논의에서는 Qwen3-Coder, KwaiCoder 등 최근 및 이전 FIM 모델을 나열하고, nvim.llm과 같은 도구가 코드 특정 모델이 아닌 모델을 어떻게 지원하는지에 대해서도 탐구했다.(출처: Reddit r/LocalLLaMA)
양자화 모델 성능 트레이드오프: 대규모 모델과 저정밀도 : 커뮤니티에서는 대규모 양자화 모델과 소규모 비양자화 모델 간의 성능 트레이드오프, 그리고 양자화 수준이 모델 성능에 미치는 영향에 대해 논의했다. 일반적으로 2-bit 양자화는 글쓰기나 대화에 적합할 수 있지만, 코딩과 같은 작업에는 최소 Q5 수준이 필요하다고 본다. 일부 사용자는 Gemma3-27B는 낮은 양자화에서 성능 저하가 심각하며, 일부 새로운 모델은 FP4 정밀도로 훈련되어 더 높은 정밀도가 필요 없다고 지적했다. 이는 양자화 효과가 모델과 작업에 따라 다르며, 구체적인 테스트가 필요함을 보여준다.(출처: Reddit r/LocalLLaMA)
R 언어 MissForest가 예측 작업에서 실패하는 이유 : 한 분석 기사에서 R 언어의 MissForest 알고리즘이 예측 작업에서 실패하는 이유를 탐구했다. 이는 귀인(imputation) 시 훈련 세트와 테스트 세트 분리라는 핵심 원칙을 은연중에 위반하기 때문이라고 지적했다. 이 기사는 이러한 경우 MissForest의 한계를 설명하고, MissForestPredict와 같은 새로운 방법이 학습과 적용 간의 일관성을 유지함으로써 이 문제를 어떻게 해결하는지 소개한다. 이는 머신러닝 실무자들이 결측값을 처리하고 예측 모델을 구축할 때 중요한 지침이 된다.(출처: Reddit r/MachineLearning)
멀티모달 머신러닝 자료 요청 : 커뮤니티 사용자들이 멀티모달 머신러닝 학습 자료를 찾고 있다. 특히 다양한 데이터 유형(텍스트, 이미지, 신호 등)을 결합하는 방법과 융합, 정렬 및 교차 모달리티 어텐션과 같은 개념을 이해하기 위한 이론 및 실습 자료를 원한다. 이는 멀티모달 AI 기술에 대한 학습 수요가 증가하고 있음을 반영한다.(출처: Reddit r/deeplearning)
강화 학습으로 추론 모델 훈련 비디오 자료 요청 : 머신러닝 커뮤니티는 강화 학습(RL)을 사용하여 추론 모델을 훈련하는 방법에 대한 최고의 과학 강연 비디오 자료를 찾고 있다. 개요 비디오와 특정 방법론에 대한 심층 설명이 포함된다. 사용자들은 피상적인 인플루언서 비디오가 아닌 고품질의 학술 콘텐츠를 얻기를 원한다. 이는 관련 문헌을 빠르게 파악하고 추가 연구 방향을 결정하기 위함이다.(출처: Reddit r/MachineLearning)
11개월 AI 코딩 여정: 도구, 기술 스택 및 모범 사례 : 한 개발자가 11개월에 걸친 AI 코딩 여정을 공유했다. Claude Code와 같은 도구 사용 경험, 실패 사례 및 모범 사례를 상세히 소개했다. 그는 AI 코딩에서 사전 계획과 컨텍스트 관리의 중요성이 코드 작성 자체보다 훨씬 크다고 강조했다. AI가 코드 구현의 진입 장벽을 낮추었지만, 아키텍처 설계와 비즈니스 통찰력을 대체하지는 않는다. 이 경험 공유는 프론트엔드부터 백엔드, 모바일 애플리케이션 개발 등 여러 프로젝트를 다루며, Context7, SpecDrafter와 같은 보조 도구들을 추천했다.(출처: Reddit r/ClaudeAI)
💼 비즈니스
JP모건 체이스: 연간 20억 달러 투자, “완전 AI 은행”으로 전환 : JP모건 체이스 CEO Jamie Dimon은 매년 AI에 20억 달러를 투자하여 회사를 “완전 AI 은행”으로 전환하는 것을 목표로 한다고 발표했다. AI는 리스크 관리, 거래, 고객 서비스, 규정 준수, 투자 은행 등 핵심 업무에 깊이 통합되었다. 이는 비용 절감뿐만 아니라, 더 중요하게는 업무 속도를 가속화하고 직무의 본질을 변화시켰다. JP모건 체이스는 자체 개발한 LLM Suite 플랫폼과 AI Agent의 대규모 배포를 통해 AI를 회사 운영의 기반 운영 체제로 간주하고 있다. 데이터 통합과 사이버 보안이 AI 전략의 가장 큰 도전 과제라고 강조했다. Dimon은 AI가 단기적인 거품이 아니라 진정한 장기적 가치이며, 은행의 정의를 재정의할 것이라고 생각한다.(출처: 36氪)
애플, 일론 머스크로부터…