
키워드:OpenAI, AI 인프라, AI 생성 바이러스, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, 멀티모달 AI, OpenAI 스타게이트 프로젝트, 트랜스포머 유전체 언어 모델, 구글 AlphaEarth 10미터 모델링, Hugging Face RTEB 벤치마크, Anthropic Claude 코드 생성
AI 칼럼의 베테랑 총편집장으로서, 제공해주신 뉴스와 소셜 미디어 토론을 심층 분석, 요약 및 정리했습니다. 다음은 통합된 내용입니다.
🔥 포커스
OpenAI의 조 단위 인프라 투자 : OpenAI는 Oracle 및 SoftBank와 협력하여 전 세계적으로 수조 달러를 투자하여 컴퓨팅 인프라를 구축할 계획이며, 코드명은 “StarGate”입니다. 초기에는 미국에 5개의 새로운 사이트를 추가하고 4천억 달러를 투자할 것이라고 발표했으며, Nvidia와 협력하여 영국에 “StarGate UK” 프로젝트를 건설할 예정입니다. OpenAI는 미래 AI의 전력 수요가 100기가와트에 달할 것이며, 총 투자액은 5조 달러에 이를 수 있다고 예측합니다. 이러한 움직임은 AI 모델의 막대한 컴퓨팅 파워 수요를 충족시키기 위한 것이지만, 자금 투자, 에너지 소비 및 잠재적인 재정 위험에 대한 우려를 불러일으키며, AI 발전이 인프라에 극도로 의존하고 있음을 보여줍니다. (출처: DeepLearning.AI Blog)

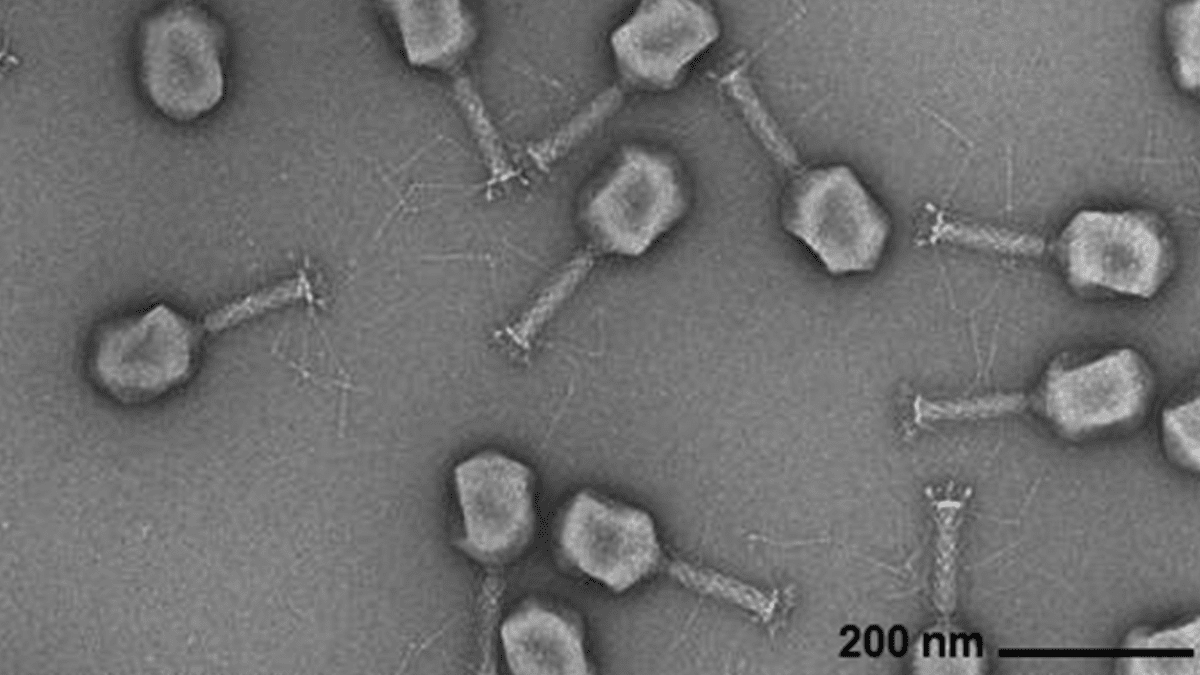
AI 생성 바이러스 유전체 : Arc Institute, Stanford University 및 Memorial Sloan Kettering Cancer Center의 연구원들은 Transformer 기반 유전체 언어 모델을 사용하여 일반적인 세균 감염에 대항할 수 있는 새로운 박테리오파지 바이러스를 처음부터 성공적으로 합성했습니다. 이 기술은 바이러스 유전체 서열을 미세 조정하여 특정 기능을 가지며 자연계 바이러스와 다른 새로운 유전체를 생성할 수 있습니다. 이 돌파구는 항생제 대체 요법 개발에 새로운 길을 열었지만, 생물 보안 및 악의적인 사용에 대한 우려를 불러일으키며, 생물학적 위협 대응 연구의 필요성을 강조합니다. (출처: DeepLearning.AI Blog)
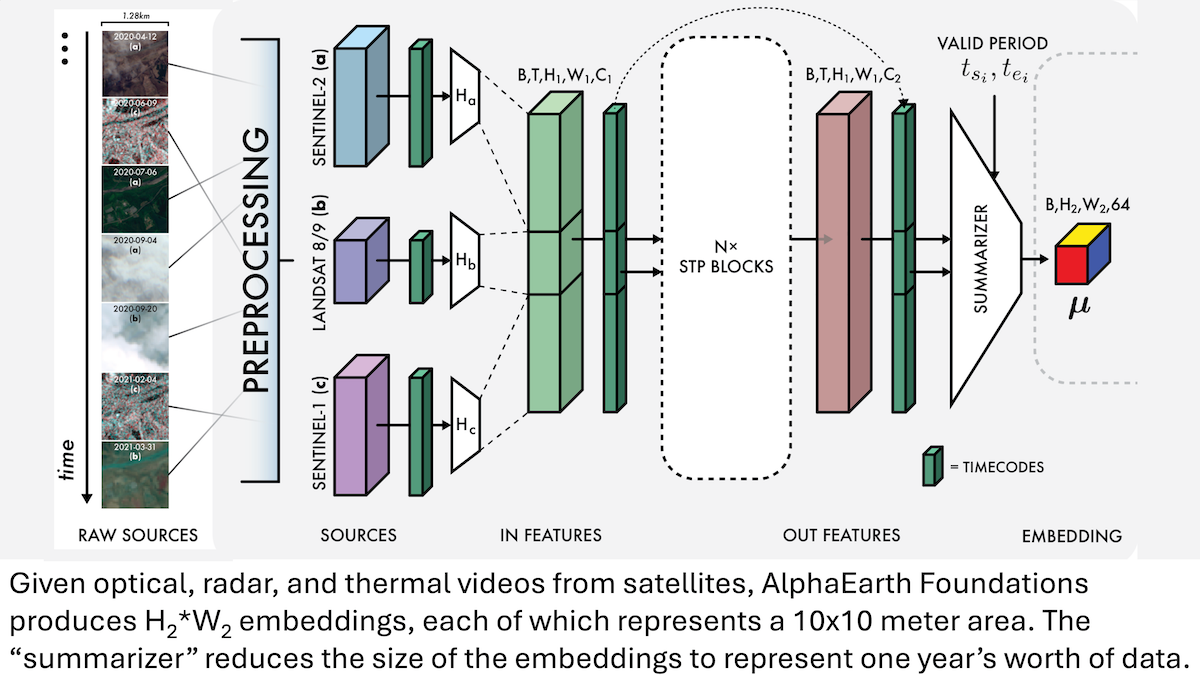
Google AlphaEarth Foundations: 지구 10미터급 고정밀 모델링 : Google 연구원들은 위성 이미지 및 기타 센서 데이터를 통합하여 지구 표면을 10미터 제곱 단위로 정밀하게 모델링하고, 2017년부터 2024년까지 매년 지구의 특징을 나타내는 임베딩을 생성할 수 있는 AlphaEarth Foundations (AEF) 모델을 출시했습니다. 이 임베딩은 습도, 강수량, 식생 등 다양한 행성 특성뿐만 아니라 식량 생산, 산불 위험, 저수지 수위 등 전 지구적 과제를 추적하는 데 사용될 수 있으며, 환경 모니터링 및 기후 변화 연구에 전례 없는 고정밀 도구를 제공합니다. (출처: DeepLearning.AI Blog)
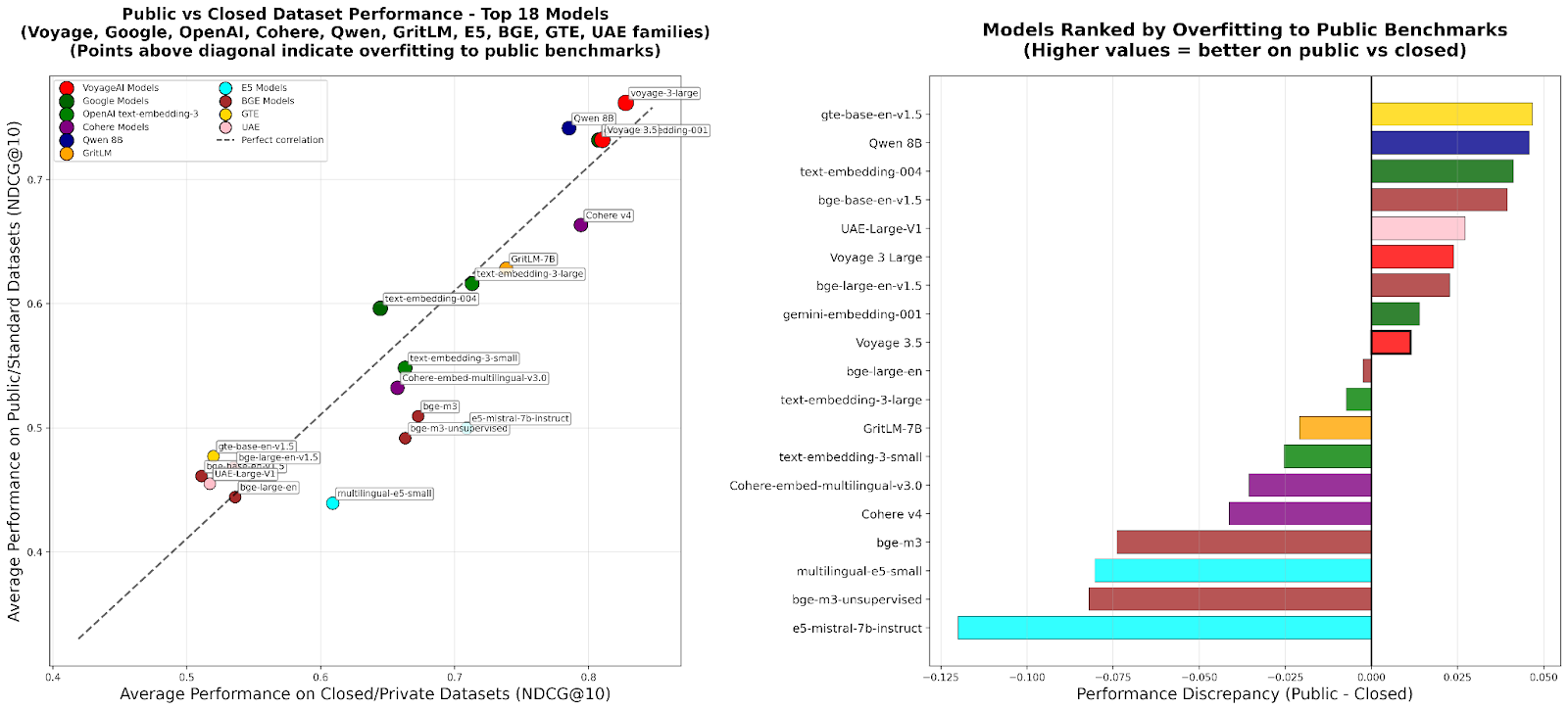
RTEB: 검색 임베딩 평가의 새로운 표준 : Hugging Face는 임베딩 모델의 검색 정확도를 위한 신뢰할 수 있는 평가 표준을 제공하기 위해 Retrieval Embedding Benchmark (RTEB)의 베타 버전을 출시했습니다. 이 벤치마크는 공개 및 비공개 데이터셋의 혼합 전략을 통해 기존 벤치마크에서 모델 과적합 문제를 효과적으로 해결하여, 모델이 이전에 보지 못한 데이터에 대한 일반화 능력을 더 잘 반영하는 평가 결과를 보장하며, RAG 및 Agent와 같은 AI 애플리케이션의 품질 향상에 매우 중요합니다. (출처: HuggingFace Blog)
확장 가능한 RL 중간 훈련: 동작 추상화를 통한 추론 구현 : 최신 연구는 강화 학습(RL)의 중간 훈련 단계에서 간결하고 유용한 동작 세트를 식별하고 온라인 RL을 가속화함으로써 대규모 언어 모델(LLMs)의 추론 및 코드 생성 능력을 크게 향상시키는 “추론으로서의 동작 추상화”(RA3) 알고리즘을 제안했습니다. 이 방법은 코드 생성 작업에서 뛰어난 성능을 보였으며, 평균 성능이 기준 모델보다 8~4% 포인트 향상되었고, 더 빠른 RL 수렴과 더 높은 점근적 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
🎯 동향
OpenAI Sora 2: AI 비디오 소셜의 새로운 시대 : OpenAI는 Sora 2를 출시하고 동명의 소셜 애플리케이션을 선보였습니다. 이는 AI 생성 비디오의 탐색 및 제작을 통해 전통적인 콘텐츠 배포 플랫폼이 아닌 사용자 및 그들의 소셜 서클(친구, 반려동물)을 중심으로 하는 소셜 네트워크를 구축하는 것을 목표로 합니다. Sora 2는 강력한 물리 시뮬레이션 및 오디오 생성 능력을 보여주지만, 초기 테스트에서는 여전히 “손가락 세기”와 같은 세부적인 결함이 존재했습니다. 이 출시는 AI 비디오 중독, 딥페이크, 그리고 OpenAI의 상업화 경로에 대한 논의를 불러일으켰으며, Sam Altman은 Sora가 기술적 돌파구와 사용자 즐거움 경험의 균형을 맞추고 AI 연구에 자금을 제공하는 것을 목표로 한다고 응답했습니다. (출처: 36氪, Reddit r/ChatGPT, OpenAI)

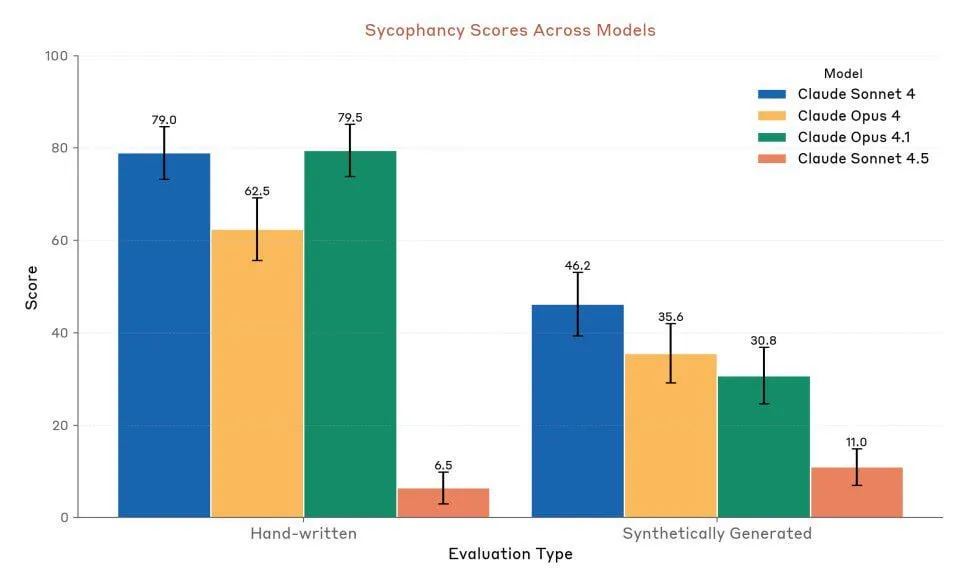
Anthropic Claude Sonnet 4.5: 코드 및 Agent의 새로운 기준 : Anthropic은 Claude Sonnet 4.5를 출시했으며, “세계 최고의 프로그래밍 모델”이자 “복잡한 Agent를 구축하는 가장 강력한 모델”로 평가받고 있습니다. 이 모델은 최대 30시간의 자율 실행 시간을 가지며, GitHub 작업에서 상당한 코딩 성능 향상을 보여주었습니다. 또한 프로젝트 진행 상황을 저장할 수 있는 메모리 기능이 추가되었습니다. 성능은 높이 평가받고 있지만, 사용자들은 사용 할당량 제한과 Opus 4.1, GPT-5와의 실제 성능 비교에 대해 여전히 논쟁을 벌이고 있습니다. (출처: Reddit r/ClaudeAI, Reddit r/artificial, Reddit r/ClaudeAI)
DeepSeek V3.2-Exp: 희소 어텐션 아키텍처로 효율성 향상 : DeepSeek은 DeepSeek V3.2-Exp 대규모 언어 모델을 출시했으며, 새로운 희소 어텐션(DSA) 아키텍처를 도입하여 주요 어텐션 복잡도를 O(L²)에서 O(L·k)로 줄여 긴 컨텍스트 시나리오에서 사전 채우기 및 디코딩 비용을 크게 최적화하고 API 사용 비용을 대폭 절감했습니다. Jiuzhang Cloud Computing은 DeepSeek V3.2-Exp의 적응을 선도적으로 완료하여 기업의 데이터 보안 및 컴퓨팅 파워 유연성 요구를 충족시키기 위한 안전하고 효율적인 프라이빗 배포 솔루션을 제공합니다. (출처: 量子位, Reddit r/LocalLLaMA)

멀티모달 오디오-텍스트 모델 LFM2-Audio-1.5B 출시 : Liquid AI는 LFM2-Audio-1.5B를 출시했습니다. 이는 텍스트와 오디오를 이해하고 생성할 수 있는 엔드투엔드 오디오-텍스트 범용 기반 모델입니다. 이 모델은 동급 모델보다 10배 빠른 추론 속도를 가지며, 1.5B 파라미터만으로 10배 큰 모델과 필적하는 품질을 제공하고, 로컬 배포 및 실시간 대화를 지원합니다. Hume AI도 더 빠르고 저렴한 다국어 텍스트-음성 변환 모델인 Octave 2를 출시했으며, 다중 화자 대화 및 음성 변환 기능을 갖추고 있습니다. (출처: Reddit r/LocalLLaMA, QuixiAI)

Microsoft Agent Framework: Agent 시스템 개발의 새로운 진전 : Microsoft는 AutoGen과 Semantic Kernel을 통합하여 다중 Agent 시스템을 구축, 오케스트레이션 및 배포하기 위한 통합되고 프로덕션 준비가 된 SDK인 Microsoft Agent Framework를 출시했습니다. 이 프레임워크는 .NET 및 Python을 지원하며, 그래프 기반 오케스트레이션을 통해 다중 Agent 워크플로우를 구현할 수 있어 Agent 애플리케이션의 개발, 관찰 및 거버넌스를 단순화하고 기업 수준의 AI Agent 배포를 가속화하는 것을 목표로 합니다. (출처: gojira, omarsar0)

AI 로봇 기술의 최전선과 산업 경쟁 : 로봇 기술은 계속 발전하고 있습니다. Amazon FAR의 OmniRetarget은 인체 동작 캡처를 최적화하여 최소한의 강화 학습으로 복잡한 휴머노이드 기술 학습을 가능하게 합니다. Periodic Labs는 “AI 과학자”를 만들어 과학적 발견을 가속화하는 데 주력하고 있습니다. Nvidia는 개방형 물리 엔진 Newton, 추론 시각 언어 모델 Cosmos Reason, 로봇 기반 모델 Isaac GR00T N1.6이 물리 AI 배포에서 중요한 역할을 한다고 강조합니다. 동시에 중국은 로봇 생산 및 휴머노이드 로봇 비용 측면에서 선도적인 우위를 보여 전 세계 로봇 산업 경쟁 구도에 대한 관심을 불러일으키고 있습니다. (출처: pabbeel, LiamFedus, nvidia, atroyn)

🧰 도구
Tinker API: LLM 미세 조정을 위한 유연한 인터페이스 간소화 : Thinking Machines Lab은 언어 모델 미세 조정을 위해 설계된 유연한 인터페이스인 Tinker API를 출시했습니다. 이 API는 연구원과 개발자가 로컬에서 훈련 루프를 작성할 수 있도록 하며, Tinker는 분산 GPU 클러스터에서 실행되는 인프라 복잡성을 관리하여 사용자가 알고리즘과 데이터에 집중할 수 있도록 합니다. 이 도구는 LLM 사후 훈련의 진입 장벽을 낮추고 개방형 모델의 실험 및 혁신을 가속화하는 것을 목표로 하며, Andrej Karpathy와 같은 전문가들은 이를 “내가 항상 원했던 인프라”라고 칭찬했습니다. (출처: Reddit r/artificial, Thinking Machines, karpathy)

LlamaAgents: 원클릭 문서 Agent 배포 : LlamaIndex는 문서 중심 AI Agent를 원클릭으로 배포할 수 있는 LlamaAgents를 출시하여 문서 Agent 구축 및 제공 속도를 10배 향상시키는 것을 목표로 합니다. 이 플랫폼은 90% 사전 구성된 템플릿을 제공하며, 송장, 계약 검토 및 청구와 같은 문서 집약적인 작업을 자동화하고 무제한 사용자 정의를 지원합니다. 사용자는 LlamaCloud에 배포하고 Git 저장소를 통해 Agent 워크플로우를 쉽게 관리하고 업데이트하여 개발 주기를 크게 단축할 수 있습니다. (출처: jerryjliu0, jerryjliu0)

Hex AI Agent: 분석 및 팀 협업 강화 : Hex는 데이터 분석 및 팀 협업을 위해 특별히 설계된 세 가지 새로운 AI Agent를 출시했습니다. Threads는 대화형 데이터 상호 작용을 제공하고, Semantic Model Agent는 정확한 답변을 얻기 위한 제어된 컨텍스트를 생성하며, Notebook Agent는 데이터 팀의 일상 업무를 혁신합니다. 이 Agent들은 모두 Claude 4.5 Sonnet에 의해 구동되며, 대화형 AI 분석을 미래 개념에서 즉시 사용 가능한 효율적인 도구로 전환하는 것을 목표로 합니다. (출처: sarahcat21)
Sculptor: Claude Code의 누락된 UI : Imbue는 Claude Code를 위한 사용자 인터페이스인 Sculptor를 출시하여 Agent 프로그래밍 경험을 향상시키는 것을 목표로 합니다. 이를 통해 개발자는 격리된 컨테이너에서 여러 Claude Agent를 병렬로 실행하고, “페어링 모드”를 통해 Agent의 작업 결과를 로컬 개발 환경에 동기화하여 테스트하고 편집할 수 있습니다. Sculptor는 GPT-5도 지원할 예정이며, 오해의 소지가 있는 행동 감지 등 제안 기능을 제공하여 Agent 프로그래밍을 더욱 원활하고 효율적으로 만드는 것을 목표로 합니다. (출처: kanjun, kanjun)
Synthesia 3.0: 인터랙티브 AI 비디오의 새로운 돌파구 : Synthesia는 3.0 버전을 출시하며 여러 혁신적인 기능을 도입했습니다. 여기에는 “비디오 Agent”(훈련 및 면접을 위한 실시간 대화형 비디오), 업그레이드된 “아바타”(단일 프롬프트 또는 이미지로 생성되며 사실적인 표정과 몸짓을 가짐), “Copilot”(스크립트 및 시각적 요소를 빠르게 생성하는 AI 비디오 편집기)가 포함됩니다. 또한 상호 작용 기능과 코스 디자인 도구가 강화되어 비디오 제작 및 학습 경험을 완전히 변화시키는 것을 목표로 합니다. (출처: synthesiaIO, synthesiaIO)
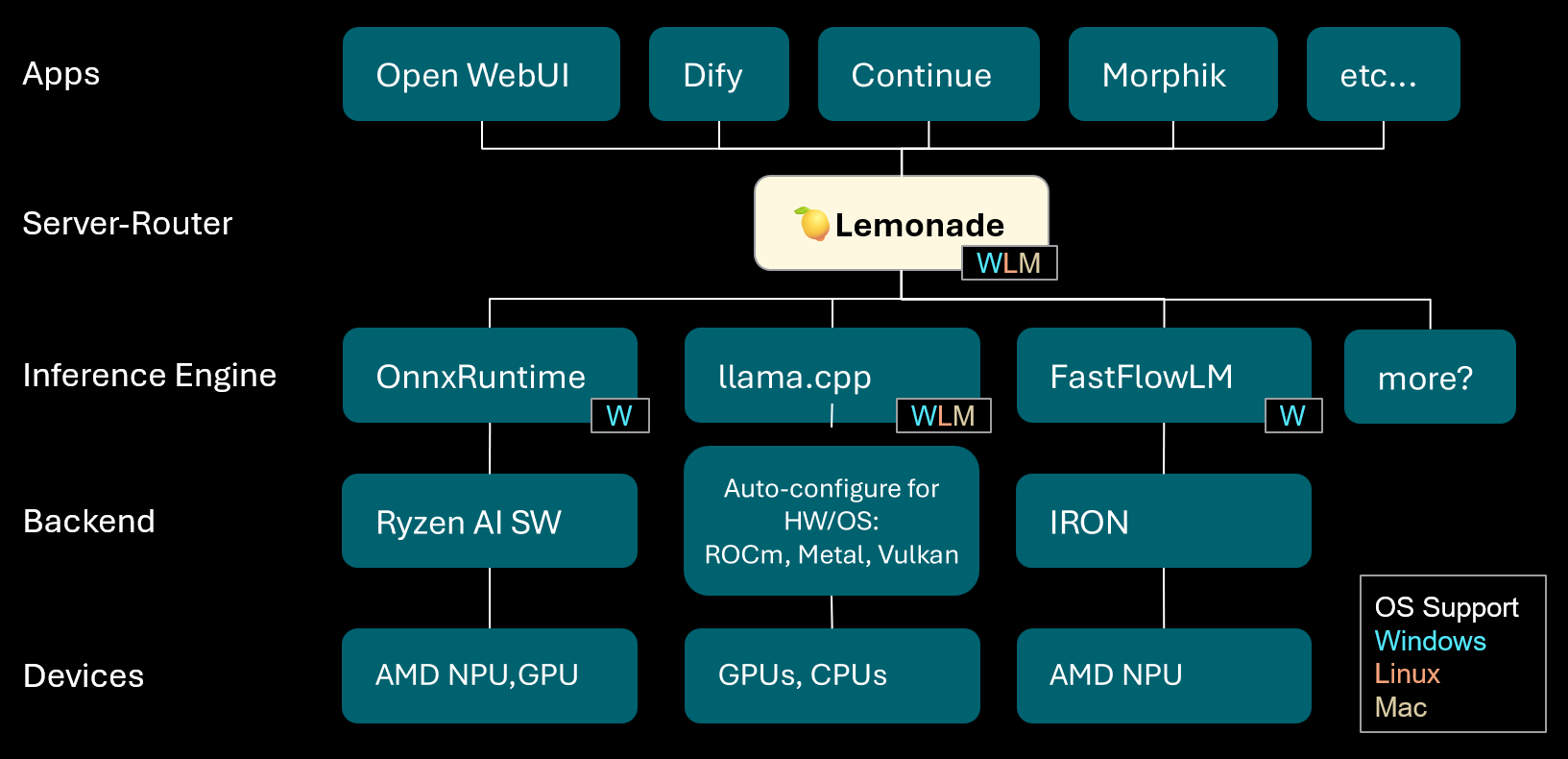
Lemonade: 로컬 LLM 서버-라우터 : Lemonade는 v8.1.11 버전을 출시했습니다. 이는 AMD NPU 및 macOS/Apple Silicon 장치를 포함한 다양한 PC에 고성능 추론 엔진을 자동으로 구성할 수 있는 로컬 LLM 서버-라우터입니다. ONNX, GGUF 및 FastFlowLM과 같은 다양한 모델 형식을 지원하며, Apple Silicon에서 llama.cpp의 Metal 백엔드를 활용하여 효율적인 계산을 구현하여 사용자에게 유연하고 고성능의 로컬 LLM 경험을 제공합니다. (출처: Reddit r/LocalLLaMA)
PopAi: AI 기반 프레젠테이션 생성 : PopAi는 간단한 프롬프트에서 차트와 삽화가 포함된 상세한 비즈니스 프레젠테이션을 몇 분 안에 생성하는 AI 도구의 능력을 시연했습니다. 이는 콘텐츠 제작에서 AI의 효율성을 강조하며, 비전문가도 고품질 프레젠테이션 자료를 빠르게 만들 수 있도록 합니다. (출처: kaifulee)

GitHub Copilot CLI: 모델 자동 선택 : GitHub Copilot CLI는 이제 비즈니스 및 기업 사용자를 위한 모델 자동 선택 기능을 제공합니다. 이 업데이트를 통해 시스템은 현재 작업에 가장 적합한 모델을 자동으로 선택하여 개발 효율성과 코드 생성 품질을 향상시키는 것을 목표로 합니다. (출처: pierceboggan)
Mixedbread Search: 다국어 멀티모달 로컬 검색 : Mixedbread는 빠르고 정확하며 다국어 및 멀티모달 문서 검색 기능을 제공하는 베타 검색 시스템을 출시했습니다. 이 시스템은 로컬 실행을 강조하여 사용자가 자신의 장치에서 문서를 효율적으로 검색할 수 있도록 하며, 특히 다양한 데이터 유형을 처리해야 하는 시나리오에 적합합니다. (출처: TheZachMueller)
Hume AI Octave 2: 차세대 다국어 TTS 모델 : Hume AI는 차세대 다국어 텍스트-음성 변환(TTS) 모델인 Octave 2를 출시했습니다. 이 모델은 이전 세대보다 40% 빠르고 50% 저렴하며, 11개 이상의 언어, 다중 화자 대화, 음성 변환 및 음소 편집 기능을 지원하여 더 빠르고 사실적이며 감성적인 음성 AI 경험을 제공하는 것을 목표로 합니다. (출처: AlanCowen)
AssemblyAI 9월 업데이트: 올인원 AI 오디오 서비스 : AssemblyAI는 9월 업데이트를 회고하며, 인앱 Playground, 범용 언어 확장, EU PII 비식별화 기능, 스트리밍 성능 개선 및 키워드 프롬프트 등을 주요 특징으로 강조했습니다. 이러한 업데이트는 사용자에게 더욱 포괄적이고 효율적인 AI 오디오 처리 서비스를 제공하는 것을 목표로 합니다. (출처: AssemblyAI)
Voiceflow MCP 도구: Agent 도구 통합 표준화 : Voiceflow는 AI Agent가 다양한 도구를 사용하는 표준화된 방법을 제공하는 모델 컨텍스트 프로토콜(MCP) 도구를 출시했습니다. 이는 개발자의 사용자 정의 통합 작업을 단순화하고, 노코드 사용자에게 사전 구축된 타사 도구를 제공하여 Voiceflow Agent의 기능을 크게 확장합니다. (출처: ReamBraden)
Salesforce Agentforce Vibes: 기업용 Agent 코딩 : Salesforce는 Cline의 아키텍처를 기반으로 “Agentforce Vibes” 제품을 출시했으며, 모델 컨텍스트 프로토콜(MCP) 지원을 활용하여 기업 고객에게 자율 코딩 기능을 제공합니다. 이 제품은 LLM과 내부 및 외부 지식 소스/데이터베이스 간의 안전한 통신을 보장하여 기업 규모의 AI 코딩을 실현하는 것을 목표로 합니다. (출처: cline)

JoyAgent-JDGenie: 범용 Agent 아키텍처 보고서 : GAIA(Generalist Agent Architecture) 기술 보고서가 발표되었습니다. 이 아키텍처는 집단 다중 Agent 프레임워크(계획, 실행 Agent 및 리뷰 모델 투표 결합), 계층적 메모리 시스템(작업, 의미, 프로그램 계층) 및 검색, 코드 실행, 멀티모달 파싱과 같은 도구 모음을 통합합니다. 이 프레임워크는 종합 벤치마크 테스트에서 뛰어난 성능을 보였으며, 오픈 소스 기준선을 능가하고 독점 시스템 성능에 근접하여 확장 가능하고 탄력적이며 적응성 있는 AI 비서를 구축하는 경로를 제공합니다. (출처: HuggingFace Daily Papers)
AI 여행 도우미: 가이드에서 행동으로의 역량 강화 : 마펑워(马蜂窝)가 출시한 AI 여행 도우미 앱은 AI를 전통적인 가이드 생성에서 실제 여행 중 행동 지원으로 끌어올리는 것을 목표로 합니다. 이 앱은 그림과 텍스트가 풍부한 개인화된 가이드를 생성하고, AI Agent가 식당 예약 전화를 대신 걸어주는 등 실용적인 기능을 제공하여 언어 장벽과 같은 문제점을 효과적으로 해결합니다. 실시간 번역 및 심층 개인화 측면에서 개선의 여지가 있지만, “가이드 없이 여행하기”의 문턱을 크게 낮추어 디지털 정보와 물리적 세계의 행동을 연결하는 AI의 엄청난 잠재력을 보여줍니다. (출처: 36氪)

📚 학습
AI 연구원 직업 개발 조언 : AI 연구원의 직업 개발과 관련하여 전문가들은 뛰어난 코더가 되는 것의 중요성을 강조하고, 연구 논문을 처음부터 재현하고 인프라를 깊이 이해하도록 권장합니다. 동시에 개인 브랜드를 적극적으로 구축하고, 흥미로운 아이디어를 공유하며, 호기심과 적응력을 유지하고, 혁신과 학습을 촉진할 수 있는 직책을 우선적으로 선택할 것을 제안합니다. 장기적으로 꾸준한 노력과 실제 성과를 얻는 것이 자신감과 동기를 구축하는 핵심입니다. (출처: dejavucoder, BlackHC)
Python 데이터 분석 과정 : DeepLearningAI는 Python을 활용하여 데이터 분석의 효율성, 추적성 및 재현성을 향상시키는 방법을 가르치는 새로운 Python 데이터 분석 과정을 출시했습니다. 이 과정은 데이터 분석 전문 자격증의 일부이며, 현대 데이터 작업에서 프로그래밍 기술의 핵심적인 역할을 강조합니다. (출처: DeepLearningAI)
학생들을 위한 Copilot AI 도구 무료 제공 : Microsoft는 자격이 되는 대학생들에게 Copilot Podcasts, Deep Research 및 Vision에 대한 추가 액세스를 포함하는 12개월 무료 Microsoft 365 개인 구독을 제공합니다. 이 조치는 학생들에게 강력한 AI 도구를 제공하여 학습 및 혁신을 지원하는 것을 목표로 합니다. (출처: mustafasuleyman)

로컬 AI/ML 과정 설정 : 한 교육자는 제한된 예산으로 학생들을 위한 로컬 개발 및 소비자용 하드웨어 기반 AI/ML 실습 과정을 만드는 방법을 공유했습니다. 그는 소규모 모델, Transformer Lab을 훈련 플랫폼으로 사용할 것을 제안하며, 모델 규모를 맹목적으로 추구하기보다는 핵심 개념을 이해하는 것을 강조하여 학생들의 학습 효과와 실제 조작 능력을 향상시킵니다. (출처: Reddit r/deeplearning)
예정된 AI 워크숍 : AIhub는 2025년 10월부터 11월까지 예정된 머신러닝 및 AI 워크숍 목록을 발표했습니다. 이 행사들은 정치적으로 제한된 소셜 미디어 플랫폼의 데이터 수집부터 AI 윤리에 이르기까지 다양한 주제를 다루며, 모든 워크숍은 무료이며 온라인 참여 옵션을 제공하여 AI 커뮤니티에 풍부한 학습 및 교류 기회를 제공합니다. (출처: aihub.org)

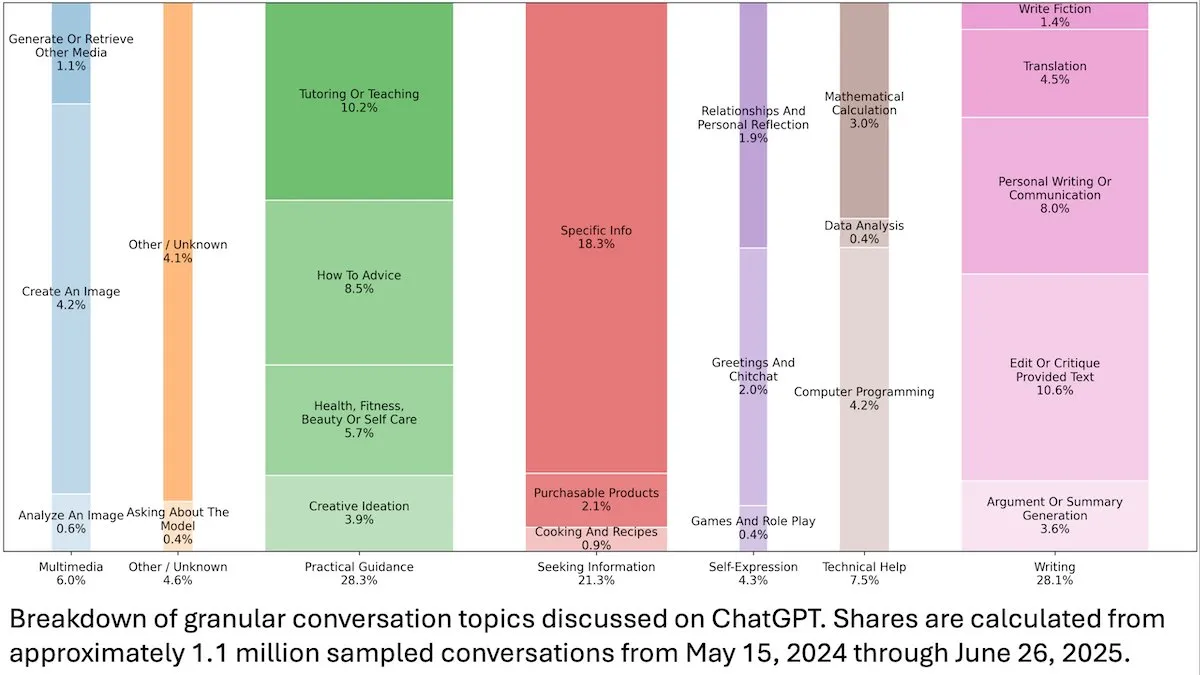
ChatGPT 사용자 행동 통찰 : DeepLearningAI가 발표한 OpenAI 연구에 따르면, ChatGPT의 1억 1천만 건의 익명 대화 분석 결과, 사용 시나리오가 업무 관련에서 개인적인 필요로 전환되었으며, 여성 사용자 및 18-25세 젊은 사용자 비율이 더 높게 나타났습니다. 가장 흔한 요청은 실용적인 지침(28.3%), 글쓰기 도움(28.1%), 정보 문의(21.3%)였으며, 이는 ChatGPT가 일상생활에서 광범위하게 사용되고 있음을 보여줍니다. (출처: DeepLearningAI)
Code2Video: 코드 기반 교육 비디오 생성 : 한 연구는 실행 가능한 Python 코드를 통해 전문 교육 비디오를 생성하는 코드 중심 Agent 프레임워크인 Code2Video를 제안했습니다. 이 프레임워크는 플래너, 인코더, 비평가 세 가지 협력 Agent로 구성되어 강의 내용을 구조화하고 코드로 변환하며 시각적으로 최적화할 수 있습니다. 이는 교육 비디오 벤치마크 MMMC에서 40%의 성능 향상을 달성했으며, 수동 튜토리얼에 필적하는 비디오를 생성했습니다. (출처: HuggingFace Daily Papers)
BiasFreeBench: LLM 편향 완화 벤치마크 : BiasFreeBench는 8가지 주요 LLM 편향 완화 기술을 포괄적으로 비교하기 위한 실증적 벤치마크로 도입되었습니다. 이 벤치마크는 기존 데이터셋을 재구성하여 다중 선택 질문 응답 및 개방형 다중 턴 질문 응답의 두 가지 테스트 시나리오에서 응답 수준의 “Bias-Free Score” 지표를 도입하여 LLM 응답의 공정성, 안전성 및 고정관념 방지 정도를 측정하며, 편향 완화 연구를 위한 통합 테스트 플랫폼을 구축하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
Transformer 곱셈 학습 장애 및 장거리 의존성 함정 : 연구는 Transformer 모델이 다중 자릿수 곱셈이라는 겉보기에는 간단한 작업에서 실패하는 원인을 역공학적으로 분석했습니다. 연구 결과, 모델이 암묵적 사고 체인에서 필요한 장거리 의존성 구조를 인코딩하지만, 표준 미세 조정 방법은 이러한 의존성을 활용할 수 있는 전역 최적해로 수렴하지 못한다는 것을 발견했습니다. 보조 손실 함수를 도입함으로써 연구자들은 이 문제를 성공적으로 해결했으며, Transformer가 장거리 의존성을 학습하는 함정을 밝히고 올바른 귀납적 편향을 통해 이 문제를 해결하는 모범 사례를 제공했습니다. (출처: HuggingFace Daily Papers)
멀티모달 추론에서의 VL-PRM 훈련 통찰 : 이 연구는 시각-언어 프로세스 보상 모델(VL-PRMs)의 설계 공간을 명확히 하고, 데이터셋 구축, 훈련 및 테스트 시 확장 전략을 탐색하는 것을 목표로 합니다. 혼합 데이터 합성 프레임워크와 지각 중심 감독을 도입함으로써 VL-PRMs는 5가지 멀티모달 벤치마크에서 중요한 통찰력을 보여주었습니다. 여기에는 테스트 시 확장 시 결과 보상 모델보다 우수함, 작은 VL-PRMs가 프로세스 오류를 감지할 수 있음, 그리고 더 강력한 VLM 백본의 잠재적 추론 능력을 밝힐 수 있음이 포함됩니다. (출처: HuggingFace Daily Papers)
GEM: Agentic LLM을 위한 범용 환경 시뮬레이터 : GEM(General Experience Maker)은 LLM Agent의 경험 학습을 위해 특별히 설계된 오픈 소스 환경 시뮬레이터입니다. 이는 표준화된 Agent-환경 인터페이스를 제공하고, 높은 처리량을 위한 비동기 벡터화 실행을 지원하며, 확장을 용이하게 하는 유연한 래퍼를 제공합니다. GEM은 또한 다양한 환경 스위트와 통합 도구를 포함하고 있으며, REINFORCE와 같은 RL 훈련 프레임워크를 사용하는 기준선을 제공하여 Agentic LLM 연구를 가속화하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
GUI-KV: 효율적인 GUI Agent를 위한 KV 캐시 압축 : GUI-KV는 GUI Agent를 위해 특별히 설계된 플러그 앤 플레이 KV 캐시 압축 방법으로, 재훈련 없이 효율성을 높입니다. GUI 워크로드의 어텐션 패턴을 분석하여, 이 방법은 공간적 현저성 지침과 시간적 중복성 점수 기술을 결합하여 적당한 예산으로 전체 캐시에 가까운 정확도를 달성하고 디코딩 FLOPs를 크게 줄여 GUI 고유의 중복성을 효과적으로 활용합니다. (출처: HuggingFace Daily Papers)
로그 우도 초월: SFT의 확률적 목표 함수 연구 : 이 연구는 감독 미세 조정(SFT)에서 전통적인 음의 로그 우도(NLL)를 초월하는 확률적 목표 함수를 탐구합니다. 7가지 모델 백본, 14가지 벤치마크, 3가지 도메인에 대한 광범위한 실험을 통해 모델 능력이 강할 때 사전 확률이 낮고 토큰 가중치가 작은 목표 함수(예: -p, -p^10)가 NLL보다 우수한 성능을 보였으며, 모델 능력이 약할 때는 NLL이 지배적임을 발견했습니다. 이론적 분석은 목표 함수가 모델 능력에 따라 어떻게 균형을 이루는지 밝혀 SFT에 더 원칙적인 최적화 전략을 제공합니다. (출처: HuggingFace Daily Papers)
VLA-RFT: 세계 시뮬레이터에서 검증 보상 기반 RL 미세 조정 : VLA-RFT는 시각-언어-행동(VLA) 모델을 위한 강화 미세 조정 프레임워크로, 데이터 기반 세계 모델을 제어 가능한 시뮬레이터로 활용합니다. 실제 상호 작용 데이터로 훈련된 시뮬레이터는 행동 기반의 미래 시각 관측을 예측하여 밀집된 궤적 수준 보상을 가진 정책 출시를 가능하게 합니다. 이 프레임워크는 샘플 요구 사항을 크게 줄여 400개 미만의 미세 조정 단계에서 강력한 감독 기준선을 능가했으며, 교란 조건에서도 강력한 견고성을 보여주었습니다. (출처: HuggingFace Daily Papers)
ImitSAT: 모방 학습을 통한 부울 만족성 문제 해결 : ImitSAT는 부울 만족성 문제(SAT)를 해결하기 위한 모방 학습 기반 CDCL 솔버 분기 전략입니다. 이 방법은 전문가 KeyTrace를 학습하여 전체 실행을 생존 결정 시퀀스로 압축하고, 밀집된 결정 수준 감독을 제공하여 전파 횟수를 직접 줄입니다. 실험 결과 ImitSAT는 전파 횟수 및 런타임 측면에서 기존 학습 방법을 능가하며 더 빠른 수렴과 안정적인 훈련을 달성했습니다. (출처: HuggingFace Daily Papers)
오픈 소스 AI Agent 프레임워크 테스트 실습 연구 : 39개 오픈 소스 Agent 프레임워크와 439개 Agent 애플리케이션에 대한 대규모 실증 연구는 AI Agent 생태계의 테스트 실습을 밝혀냈습니다. 이 연구는 10가지 고유한 테스트 패턴을 식별했으며, 결정론적 구성 요소(예: 도구 및 워크플로우)에 대한 테스트 투자가 70% 이상을 차지하는 반면, LLM 기반 계획 주체는 5% 미만에 불과하다는 것을 발견했습니다. 또한 프롬프트(Trigger) 구성 요소의 회귀 테스트는 심각하게 무시되어 약 1%의 테스트에서만 나타나 Agent 테스트의 주요 사각지대를 드러냈습니다. (출처: HuggingFace Daily Papers)
DeepCodeSeek: 코드 생성 실시간 API 검색 : DeepCodeSeek은 컨텍스트 인식 코드 생성을 위한 실시간 API 검색을 제공하여 고품질의 엔드투엔드 코드 자동 완성 및 Agentic AI 애플리케이션을 가능하게 하는 새로운 기술을 제안했습니다. 이 방법은 코드와 인덱스를 확장하여 필요한 API를 예측함으로써 기존 벤치마크 데이터셋의 API 유출 문제를 해결했습니다. 최적화 후, 컴팩트한 0.6B 리랭커는 2.5배 낮은 지연 시간을 유지하면서 8B 모델을 능가하는 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
CORRECT: 다중 Agent 시스템에서 응축된 오류 식별 : CORRECT는 다중 Agent 시스템에서 증류된 오류 패턴의 온라인 캐시를 활용하여 오류 식별 및 지식 전송을 달성하는 경량의 무훈련 프레임워크입니다. 이 프레임워크는 선형 시간 내에 구조화된 오류를 식별하여 값비싼 재훈련을 피하고 동적 MAS 배포에 적응할 수 있습니다. CORRECT는 7가지 다중 Agent 애플리케이션에서 단계별 오류 위치 파악을 19.8% 향상시켜 자동화와 인간 수준의 오류 식별 간의 격차를 크게 줄였습니다. (출처: HuggingFace Daily Papers)
Swift: 효율적인 일기 예보를 위한 자기회귀 일관성 모델 : Swift는 단일 단계 일관성 모델로, 확률 흐름 모델의 자기회귀 미세 조정을 처음으로 구현했으며, 연속 순위 확률 점수(CRPS) 목표를 채택했습니다. 이 모델은 숙련된 6시간 일기 예보를 생성하고 최대 75일 동안 안정성을 유지하며, 최첨단 확산 기준선보다 39배 빠르게 실행되는 동시에 수치 IFS ENS와 경쟁하는 예보 기술을 달성하여 중장기에서 계절 규모까지 효율적이고 신뢰할 수 있는 통합 예보의 중요한 단계를 나타냅니다. (출처: HuggingFace Daily Papers)
Catching the Details: MLLM 미세 입자 인식의 자기 증류 RoI 예측기 : 이 연구는 고해상도 이미지를 처리할 때 멀티모달 대규모 언어 모델(MLLM)의 높은 계산 비용 문제를 해결하기 위해 효율적이고 레이블이 필요 없는 자기 증류 영역 제안 네트워크(SD-RPN)를 제안했습니다. SD-RPN은 MLLM 중간 계층의 어텐션 맵을 고품질의 의사 RoI 레이블로 변환하고, 경량 RPN을 훈련하여 정확한 지역화를 수행함으로써 데이터 효율성과 일반화 능력을 달성했으며, 이전에 보지 못한 벤치마크 테스트에서 정확도를 10% 이상 향상시켰습니다. (출처: HuggingFace Daily Papers)
LLM 다중 턴 추론의 새로운 패러다임: In-Place Feedback : 이 연구는 LLM의 다중 턴 추론을 안내하기 위한 “In-Place Feedback”이라는 새로운 상호 작용 패러다임을 도입했습니다. 사용자는 LLM의 이전 응답을 직접 편집할 수 있으며, 모델은 수정된 응답을 기반으로 수정본을 생성합니다. 경험적 평가는 In-Place Feedback이 추론 집약적 벤치마크에서 전통적인 다중 턴 피드백보다 우수한 성능을 보였으며, 동시에 토큰 사용량을 79.1% 줄여 피드백을 정확하게 적용하기 어려운 모델의 한계를 해결했습니다. (출처: HuggingFace Daily Papers)
LLM 강화 학습 역학의 예측 가능성 : 이 연구는 LLM의 강화 학습(RL) 훈련에서 파라미터 업데이트의 두 가지 기본 특성을 밝혀냈습니다. 즉, 랭크 1 지배성(파라미터 업데이트 행렬의 최고 특이 부분 공간이 추론 개선을 거의 완전히 결정함)과 랭크 1 선형 역학(이 지배 부분 공간이 훈련 과정에서 선형적으로 진화함)입니다. 이러한 발견을 바탕으로 연구는 AlphaRL이라는 플러그 앤 플레이 가속 프레임워크를 제안했습니다. 이는 초기 훈련 창을 통해 최종 파라미터 업데이트를 추론하여 최대 2.5배의 가속을 달성하면서 96% 이상의 추론 성능을 유지합니다. (출처: HuggingFace Daily Papers)
KV 캐시 압축의 함정 : 이 연구는 LLM 배포에서 KV 캐시 압축의 여러 함정을 밝혀냈습니다. 특히 다중 명령어 프롬프트와 같은 실제 시나리오에서 압축은 특정 명령어의 성능을 급격히 저하시키거나 LLM에 의해 완전히 무시될 수 있습니다. 연구는 사례 분석을 통해 시스템 프롬프트 유출을 체계적으로 보여주며, 압축이 유출 및 일반적인 명령어 준수에 미치는 영향을 실증적으로 입증하고, 간단한 KV 캐시 제거 전략 개선 방안을 제안했습니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
AI 거대 기업 경쟁: OpenAI와 Anthropic의 전략적 차이 : OpenAI와 Anthropic은 AI 분야에서 매우 다른 발전 경로를 택했습니다. OpenAI는 ChatGPT를 통해 전자상거래를 통합하고 Sora 소셜 앱을 출시하여 사용자 생활의 여러 측면을 포괄하는 슈퍼 플랫폼이 되는 “수평적 확장”을 목표로 하며, 그 가치는 Anthropic보다 1천억 달러 이상입니다. 반면 Anthropic은 Claude Sonnet 4.5를 핵심으로 AI 프로그래밍 및 기업용 Agent 시장을 깊이 파고드는 “수직적 심화”에 집중하며, AWS, Google 등 클라우드 서비스 제공업체와 깊이 연계되어 있습니다. 이 둘의 배후에는 Microsoft와 Amazon이라는 두 거대 클라우드 컴퓨팅 기업의 “컴퓨팅 파워 외교” 경쟁이 있으며, 이는 AI 시대의 컴퓨팅 파워 부족과 높은 비용이라는 산업 현실을 보여줍니다. (출처: 36氪, 量子位, 36氪)
Perplexity, Visual Electric 인수 : Perplexity는 Visual Electric 인수를 발표했으며, Visual Electric 팀은 Perplexity에 합류하여 새로운 소비자 제품 경험을 공동 개발할 예정입니다. Visual Electric의 제품은 점진적으로 서비스가 중단될 것입니다. 이번 인수는 소비자 AI 제품 분야에서 Perplexity의 혁신 능력을 강화하는 것을 목표로 합니다. (출처: AravSrinivas)

Databricks, Mooncakelabs 인수 : Databricks는 Lakebase 비전을 가속화하기 위해 Mooncakelabs 인수를 발표했습니다. Lakebase는 Postgres를 기반으로 구축되고 AI Agent에 최적화된 새로운 OLTP 데이터베이스로, 애플리케이션, 분석 및 AI를 위한 통합 기반을 제공하고 Lakehouse 및 Agent Bricks와 깊이 통합되어 데이터 관리 및 AI 애플리케이션 개발을 단순화하는 것을 목표로 합니다. (출처: matei_zaharia)

🌟 커뮤니티
AI가 고용과 사회에 미치는 영향 : 커뮤니티는 AI 자동화가 고용 시장에 미치는 심오한 영향에 대해 광범위하게 논의하며, 대규모 실업, 새로운 사회 계층 형성, 그리고 보편적 기본 소득(UBI)의 필요성으로 이어질 수 있다는 우려를 표명했습니다. 사람들은 새로 생성되는 AI 관련 일자리도 자동화될 것인지, 그리고 모든 사람이 미래에 적응하기 위해 AI 기술을 습득할 수 있을지에 대해 의문을 제기합니다. 논의는 또한 AI Agent의 비용 관리 및 ROI 실현 과제, 그리고 AGI의 도래가 사회 구조와 지정학에 미칠 잠재적 영향에 대해서도 다루었습니다. (출처: Reddit r/ArtificialInteligence, Ronald_vanLoon, Ronald_vanLoon)
AI 윤리와 통제권 싸움 : 커뮤니티는 AI의 미래를 누가 통제해야 하는지, 즉 일반 대중인지 기술 거물인지에 대해 열띤 토론을 벌였습니다. AI 발전이 인간 중심이어야 하며, 투명성과 개인 데이터 및 AI 기록에 대한 사용자 통제권을 강조해야 한다고 촉구했습니다. 동시에 AI의 대부 Yoshua Bengio는 초지능 기계가 10년 안에 인류 멸종을 초래할 수 있다고 경고했습니다. Meta와 같은 기업들은 AI 채팅 데이터를 사용하여 타겟 광고를 할 계획이며, 이는 개인 정보 보호 및 AI 남용에 대한 사용자 우려를 더욱 증폭시켜 AI 윤리 및 규제에 대한 심층적인 성찰을 불러일으켰습니다. (출처: Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence)

GPT-5 안전 모델의 이상 행동 : Reddit 커뮤니티 사용자들은 GPT-5의 “CHAT-SAFETY” 모델이 비악의적인 요청을 처리할 때 이상하고 비난하며 심지어 환각적인 행동을 보인다고 보고했습니다. 예를 들어, 지문 인식 문제를 추적 행동으로 해석하고 법률을 조작하는 식입니다. 이러한 과도한 민감성과 부정확한 응답은 모델의 신뢰성, 잠재적 위험, 그리고 OpenAI의 안전 정책에 대한 심각한 의문을 불러일으켰습니다. (출처: Reddit r/ChatGPT)
“쓰라린 교훈”과 LLM 발전 경로 논쟁 : Andrej Karpathy와 강화 학습의 아버지 Richard Sutton은 LLM이 “쓰라린 교훈”에 부합하는지에 대해 논쟁을 벌였습니다. Sutton은 LLM이 제한된 인간 데이터에 의존하여 사전 훈련되며, 경험에서 학습하는 “쓰라린 교훈”의 원칙을 진정으로 따르지 않는다고 주장했습니다. Karpathy는 사전 훈련을 콜드 스타트 문제를 해결하기 위한 “형편없는 진화”로 보았으며, LLM과 동물 지능 간의 학습 메커니즘의 근본적인 차이를 지적하며 현재 AI가 “동물을 만드는 것”보다는 “유령을 소환하는 것”에 가깝다고 강조했습니다. (출처: karpathy, SchmidhuberAI)
로컬 LLM 설정의 가치 논의 : 커뮤니티 사용자들은 수만 달러를 들여 로컬 LLM 설정을 구축하는 것의 가치에 대해 논의했습니다. 지지자들은 프라이버시, 데이터 보안, 그리고 실제 작업을 통해 얻는 깊이 있는 지식이 주요 이점이라고 강조하며 이를 아마추어 무선 통신 애호가에 비유했습니다. 반대자들은 저렴한 클라우드 API(예: Sonnet 4.5 및 Gemini Pro 2.5)의 성능 향상으로 인해 고비용의 로컬 설정이 정당화되기 어렵다고 주장했습니다. (출처: Reddit r/LocalLLaMA)
LLM을 심판으로: Agent 평가의 새로운 방법 : 연구원과 개발자들은 LLM을 “심판”으로 사용하여 AI Agent 응답의 품질(정확성 및 근거성 포함)을 평가하는 방법을 탐색하고 있습니다. 실습 결과, 심판의 프롬프트가 신중하게 설계될 때(예: 단일 기준, 앵커링 점수, 엄격한 출력 형식 및 편향 경고), 이 방법이 놀랍도록 효과적이라는 것이 밝혀졌습니다. 이러한 추세는 Agent 평가 분야에서 LLM-as-a-Judge의 엄청난 잠재력을 시사합니다. (출처: Reddit r/MachineLearning)
AI와 인간 상호작용: 장치에서 가상 캐릭터까지 : AI는 다양한 차원에서 인간 상호작용을 재구성하고 있습니다. MIT 관련 스타트업은 “거의 텔레파시”와 같은 웨어러블 장치를 출시하여 무언의 의사소통을 가능하게 합니다. 동시에 실시간 음성 AI Agent는 3D 온라인 게임에서 NPC(Non-Player Character)로 적용되어, 게임 및 가상 세계에서 AI가 더 자연스럽고 몰입감 있는 상호작용 경험을 제공할 잠재력을 보여줍니다. 이러한 발전은 일상생활과 엔터테인먼트에서 AI의 역할에 대한 논의를 불러일으킵니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)

오픈 모델과 클로즈드 소스 모델의 선택 : 커뮤니티는 소프트웨어 엔지니어가 클로즈드 소스 모델을 사용하다가 오픈 소스 모델로 전환할 때 직면하는 가장 큰 장애물에 대해 논의했습니다. 전문가들은 블랙박스 클로즈드 소스 모델에 의존하기보다는 오픈 소스 모델을 미세 조정하는 것이 심층 학습, 제품 차별화 실현, 사용자에게 더 나은 제품을 제공하는 데 중요하다고 지적했습니다. 오픈 소스 모델의 발전 속도가 느릴 수 있지만, 장기적으로 가치 창출 및 기술 자율성 측면에서 엄청난 잠재력을 가지고 있습니다. (출처: ClementDelangue, huggingface)
AI 인프라 및 컴퓨팅 파워 과제 : OpenAI의 “StarGate” 프로젝트는 AI가 컴퓨팅 능력, 에너지 및 토지에 대해 막대한 수요를 가지고 있음을 보여주며, 매월 최대 90만 개의 DRAM 웨이퍼를 소비할 것으로 예상됩니다. GPU의 희소성, 높은 가격, 그리고 전력 공급의 제한으로 인해 AI 기업들은 클라우드 서비스 제공업체(예: Microsoft 및 Amazon)와 깊이 연계하는 “컴퓨팅 파워 외교”를 펼칠 수밖에 없습니다. 이러한 고정 자산 투자 및 전략적 협력 모델은 AI 발전을 촉진하지만, 공급망, 에너지 정책 및 규제와 같은 외부 변수의 위험도 수반합니다. (출처: karminski3, AI巨头的奶妈局, DeepLearning.AI Blog)

💡 기타
AI 음악 저작권 및 보상 메커니즘 : 스웨덴 저작권 단체 STIM은 Sureel 회사와 협력하여 AI 모델 훈련에서 음악 작품의 저작권 사용 문제를 해결하기 위한 AI 음악 라이선스 계약을 출시했습니다. 이 계약은 AI 개발자가 음악을 합법적으로 사용할 수 있도록 허용하고, Sureel의 귀속 기술을 통해 작품이 모델 출력에 미치는 영향을 계산하여 작곡가와 음반 아티스트에게 보상합니다. 이 조치는 AI 음악 창작에 법적 보호를 제공하고, 원본 콘텐츠 생산을 장려하며, 저작권 소유자에게 새로운 수입원을 창출하는 것을 목표로 합니다. (출처: DeepLearning.AI Blog)

LLM 보안 및 적대적 공격 : Trend Micro는 LLM이 공격자에 의해 악용될 수 있는 다양한 방식, 즉 정교하게 구성된 프롬프트, 데이터 오염 및 다중 Agent 시스템의 취약점을 통한 침해에 대해 심층적으로 탐구하는 연구를 발표했습니다. 이 연구는 이러한 공격 벡터를 이해하는 것이 더 안전한 LLM 애플리케이션 및 다중 Agent 시스템을 개발하는 데 중요하다고 강조하며, 해당 방어 전략을 제시했습니다. (출처: Reddit r/deeplearning)

Proactive AI: 편리성과 프라이버시의 균형 : 커뮤니티는 스마트 비서로서 “Proactive Ambient AI”(능동형 주변 AI)가 가져다주는 편리성과 잠재적인 개인 정보 침해 위험에 대해 논의했습니다. 이러한 AI는 능동적으로 도움을 제공할 수 있지만, 지속적인 개인 데이터 수집 및 처리는 투명성, 통제권, 그리고 데이터 소유권에 대한 사용자 우려를 불러일으켰습니다. 일부 의견은 사용자가 AI 상호 작용 기록에 대한 통제권을 가질 수 있도록 “투명성 프로토콜”과 “개인 기본 프로필”을 구축해야 한다고 촉구했습니다. (출처: Reddit r/artificial)
