
키워드:AI 모델, 인공지능, 대형 언어 모델, Anthropic Claude Sonnet 4.5, DeepSeek-V3.2-Exp, OpenAI ChatGPT, AI 프로그래밍, AI 에이전트, Claude Sonnet 4.5 프로그래밍 능력, DSA 희소 주의 메커니즘, ChatGPT 즉시 결제 기능, Sora 2 소셜 앱, LoRA 미세 조정 기술
🔥 포커스
Anthropic Claude Sonnet 4.5 출시, 프로그래밍 및 에이전트 기능 대폭 향상 : Anthropic이 Claude Sonnet 4.5를 공식 출시했습니다. 이 모델은 세계에서 가장 강력한 프로그래밍 모델로 평가받으며, 에이전트 구축, 컴퓨터 사용, 추론 및 수학 능력에서 상당한 발전을 이루었습니다. 이 모델은 30시간 이상 자율적으로 연속 작업할 수 있으며, SWE-bench Verified 테스트에서 1위를 차지하고 OSWorld 컴퓨터 작업 벤치마크에서 기록을 경신했습니다. 새로운 기능으로는 Claude Code의 “체크포인트” 롤백 기능, VS Code 플러그인, API의 컨텍스트 편집 및 메모리 도구가 포함됩니다. 또한, 소프트웨어 인터페이스를 실시간으로 생성할 수 있는 실험적 기능 “Imagine with Claude”도 출시되었습니다. Sonnet 4.5는 보안 측면에서도 크게 향상되어 기만, 아첨 등 불량 행위를 줄였으며, AI 안전 등급 3(ASL-3) 인증을 획득하여 오탐율을 10배 낮췄습니다. 가격은 Sonnet 4와 동일하게 유지되어 가성비를 더욱 높였으며, 새로운 AI 프로그래밍 경쟁을 촉발할 것으로 예상됩니다. (来源: Reddit r/ClaudeAI, 36氪, 36氪, 36氪, 36氪, 36氪, Reddit r/ChatGPT, dotey, dotey, dotey)

DeepSeek-V3.2-Exp 출시, 희소 어텐션 메커니즘 DSA 도입 및 가격 인하 : DeepSeek이 실험적 모델 V3.2-Exp를 출시했습니다. 이 모델은 DeepSeek Sparse Attention (DSA) 희소 어텐션 메커니즘을 도입하여 긴 컨텍스트 훈련 및 추론 효율성을 크게 향상시켰으며, API 가격을 50% 이상 인하했습니다. DSA는 “플래시 인덱서”를 통해 핵심 Token을 효율적으로 식별하여 정밀한 계산을 수행하며, 어텐션 복잡도를 O(L²)에서 O(Lk)로 낮춥니다. 화웨이 昇騰(Ascend), Cambrian, Hygon 등 중국 AI 칩 제조업체들은 이미 Day 0 호환성을 달성하여 국내 컴퓨팅 생태계 발전을 더욱 촉진하고 있습니다. 이 모델은 또한 NVIDIA CUDA에 필적하는 TileLang 버전의 GPU 연산자를 오픈소스화하여 개발자가 프로토타입 개발 및 디버깅을 쉽게 할 수 있도록 했습니다. 일부 능력에서 양보가 있었지만, 그 아키텍처 혁신과 비용 효율성은 대규모 모델의 장문 처리 방향을 제시합니다. (来源: 36氪, 36氪, 36氪, 量子位, 量子位, 量子位, Reddit r/LocalLLaMA, Twitter)

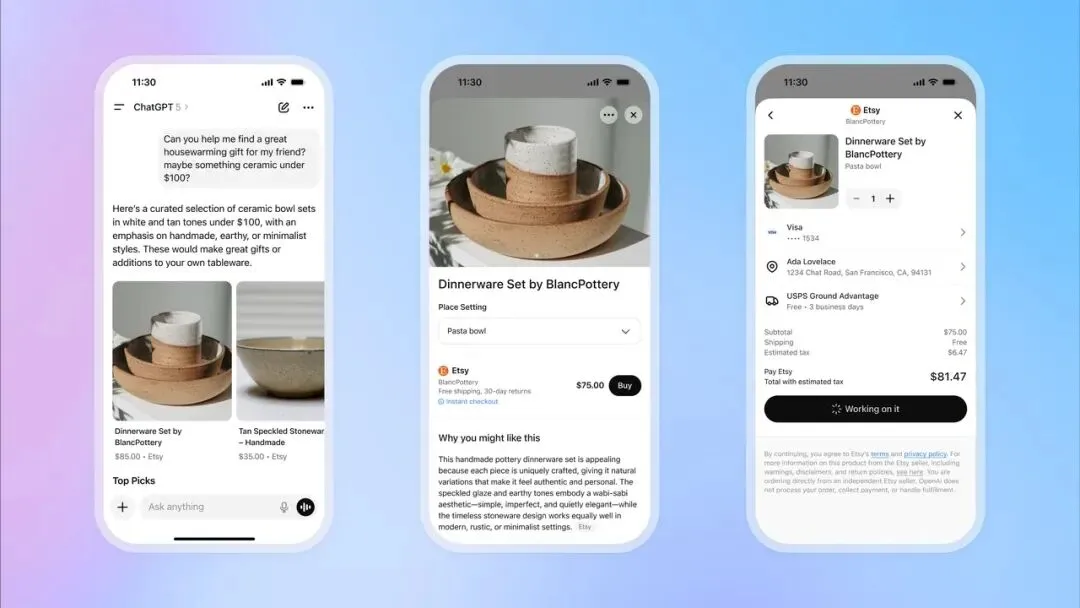
OpenAI, ChatGPT 즉시 결제 기능 출시로 전자상거래 시장 진출 : OpenAI가 ChatGPT에 “즉시 결제(Instant Checkout)” 기능을 도입했습니다. 이제 사용자는 외부 웹사이트로 이동할 필요 없이 대화 중에 Etsy 및 Shopify 플랫폼의 상품을 직접 구매할 수 있습니다. 이 기능은 OpenAI와 Stripe가 협력하여 개발한 “Agentic Commerce Protocol”을 기반으로 하며, ChatGPT의 방대한 트래픽을 상업적 거래로 전환하는 것을 목표로 오픈소스화되었습니다. 초기에는 미국 시장을 지원하며, 향후 다중 상품 장바구니 및 더 많은 지역으로 확장할 계획입니다. 이는 OpenAI의 상업화에 있어 큰 진전으로 평가되며, 중요한 수익원이 될 것으로 기대되고 전통 전자상거래 및 광고 산업에 큰 영향을 미칠 수 있습니다. (来源: 36氪, 36氪, Reddit r/artificial, Reddit r/artificial, Twitter, Twitter, Twitter, Twitter)
OpenAI, Sora 2 소셜 앱 출시 준비, AI 숏폼 비디오 플랫폼 구축 : OpenAI는 최신 비디오 모델 Sora 2로 구동되는 독립적인 소셜 앱 출시를 준비하고 있습니다. 이 앱은 TikTok과 매우 유사한 디자인으로 수직 비디오 스트림과 슬라이드 탐색 기능을 제공하지만, 모든 콘텐츠는 AI가 생성합니다. 사용자는 최대 10초 길이의 비디오 클립을 생성할 수 있으며, 신원 인증 기능을 활용하여 비디오에 자신의 초상화를 사용할 수 있습니다. 이는 ChatGPT가 텍스트 분야에서 거둔 성공을 재현하고, 대중에게 AI 비디오의 잠재력을 직관적으로 경험하게 하며, Meta 및 Google과의 경쟁에 직접 뛰어들기 위한 움직임으로 보입니다. 그러나 OpenAI가 저작권 처리에서 “권리자가 적극적으로 거부하지 않는 한 저작권 콘텐츠를 기본적으로 사용”하는 전략을 채택하여 콘텐츠 창작자와 영화/TV 회사들의 강한 우려를 불러일으키고 있으며, AI와 지적 재산권 간의 치열한 공방을 예고합니다. (来源: 36氪, Reddit r/artificial, Twitter, Twitter)

🎯 동향
화웨이 Pangu 718B 모델, SuperCLUE 중국 대규모 모델 순위에서 오픈소스 2위 차지 : 화웨이 openPangu-Ultra-MoE-718B 모델이 SuperCLUE 중국 대규모 모델 일반 벤치마크 평가에서 오픈소스 부문 2위를 차지했습니다. 이 모델은 “데이터 양에 의존하지 않고 사고력에 의존”하는 훈련 철학을 채택하여 “품질 우선, 다양성 커버리지, 복잡성 적응” 데이터 구축 원칙과 일반, 추론, 어닐링 3단계 사전 훈련 전략을 통해 광범위한 세계 지식을 구축하고 논리적 추론 능력을 향상시켰습니다. 환각 문제 완화를 위해 “비판적 내재화” 메커니즘을 도입했으며, 도구 사용 능력 향상을 위해 업그레이드된 ToolACE 합성 프레임워크를 사용했습니다. (来源: 量子位)

FSDrive, VLA와 세계 모델 통합하여 자율주행을 시각적 추론으로 이끌다 : FSDrive (FutureSightDrive)는 “시공간 시각 CoT”를 제안하여, 미래 이미지 프레임을 중간 추론 단계로 통합하고 미래 장면과 인지 결과를 시각적으로 추론함으로써 자율주행을 기호 추론에서 시각적 추론으로 전환합니다. 이 방법은 기존 MLLM 아키텍처를 변경하지 않고도 어휘 확장과 자기회귀 시각 생성을 통해 이미지 생성 능력을 활성화하며, 점진적 시각 CoT를 통해 물리적 선험 지식을 주입합니다. 이 모델은 미래를 예측하는 “세계 모델” 역할과 궤적 계획을 수행하는 “역동학 모델” 역할을 동시에 수행합니다. (来源: 36氪)

GPT-5, 양자 컴퓨팅에 핵심 아이디어 제공, 대가 Scott Aaronson 극찬 : 양자 컴퓨팅 이론의 대가 Scott Aaronson은 GPT-5가 30분도 채 안 되는 시간에 자신의 양자 복잡성 이론 연구에 핵심적인 증명 아이디어를 제공하여 팀을 괴롭히던 문제를 해결했다고 밝혔습니다. Scott Aaronson은 GPT-5가 가장 인간적인 지적 활동을 정복하는 데 상당한 진전을 이루었으며, 이는 인간과 AI 협력이 “달콤한 순간”에 진입하여 연구자들에게 결정적인 순간에 획기적인 영감을 제공할 수 있음을 의미한다고 말했습니다. (来源: 量子位, Twitter)

HuggingFace, Intel Core Ultra에서 Qwen3-8B Agent 모델 추론 가속화 : HuggingFace는 Intel과 협력하여 OpenVINO.GenAI 및 딥 프루닝(depth-pruned)된 Qwen3-0.6B 드래프트 모델을 통해 Intel Core Ultra 통합 GPU에서 Qwen3-8B Agent 모델의 추론 속도를 1.4배 향상시키는 데 성공했습니다. 이러한 최적화는 AI PC에서 Agent 애플리케이션을 더욱 효율적으로 실행할 수 있게 하며, 특히 다단계 추론 및 도구 호출이 필요한 복잡한 워크플로우에 적합하여 로컬 AI Agent의 실용화를 더욱 촉진합니다. (来源: HuggingFace Blog)

Reachy Mini 로봇, GPT-4o 통합하여 다중 모드 상호작용 구현 : Hugging Face / Pollen Robotics의 Reachy Mini 로봇이 OpenAI의 GPT-4o 모델을 성공적으로 통합하여 다중 모드 상호작용 능력을 크게 향상시켰습니다. 새로운 기능에는 이미지 분석(로봇이 찍은 사진을 설명하고 추론), 얼굴 추적(눈맞춤 유지), 동작 융합(머리 흔들기, 얼굴 추적, 감정/춤 동시 실행), 로컬 얼굴 인식 및 유휴 시 자율 행동이 포함됩니다. 이러한 발전은 인간-로봇 상호작용을 더욱 자연스럽고 유연하게 만들었지만, 여전히 기억 시스템, 음성 인식 및 복잡한 군중 전략과 같은 과제가 남아 있습니다. (来源: Reddit r/ChatGPT, Twitter)

Intel, Battlemage GPU에서 GenAI를 지원하는 새로운 LLM Scaler Beta 버전 출시 : Intel이 Battlemage GPU에서 생성형 AI(GenAI) 성능을 최적화하기 위한 새로운 LLM Scaler Beta 버전을 출시했습니다. 이는 Intel이 AI 하드웨어 및 소프트웨어 생태계에 지속적으로 투자하여 대규모 언어 모델 추론 및 생성 작업에서 GPU의 경쟁력을 높이려는 움직임을 시사합니다. (来源: Reddit r/artificial)
Claude, 사용 제한 대시보드 출시; ChatGPT, 자녀 보호 기능 도입 : Anthropic은 Claude Code 및 Claude App에 실시간 사용 제한 대시보드를 출시하여 사용자가 이전에 발표된 주간 Token 사용량 제한을 추적할 수 있도록 했습니다. 동시에 OpenAI는 ChatGPT에 자녀 보호 기능을 도입하여 부모가 청소년 계정을 연결하고 자동으로 더 강력한 안전 보호를 제공하며 기능 및 설정 사용 제한을 조정할 수 있도록 했습니다. 단, 부모는 구체적인 대화 내용을 볼 수 없습니다. (来源: Reddit r/ClaudeAI, 36氪)
Minecraft에서 500만 매개변수 언어 모델 실행, AI 혁신적 응용 보여줘 : Sammyuri는 Minecraft에서 복잡한 레드스톤 시스템을 구축하여 약 500만 매개변수의 언어 모델을 성공적으로 실행하고 기본적인 대화 능력을 부여했습니다. 이 획기적인 성과는 게임 환경에서 로컬 AI를 구현할 가능성을 보여주었으며, 비전통적인 플랫폼에서의 AI 응용에 대한 커뮤니티의 광범위한 관심과 논의를 촉발했습니다. (来源: Reddit r/LocalLLaMA, Twitter)
Inspur Information AI 서버, 8.9ms 추론 속도 달성, 백만 Token당 비용 1위안 : Inspur Information이 초확장 AI 서버 Yuanbrain HC1000 및 Yuanbrain SD200 초노드를 출시하여 AI 추론 속도를 새로운 기록으로 끌어올렸습니다. Yuanbrain SD200은 DeepSeek-R1 모델에서 Token당 출력 시간(TPOT) 8.9ms를 달성하여 이전 SOTA보다 거의 두 배 빠른 속도를 보였으며, 조 단위 매개변수 대규모 모델 추론 및 다중 에이전트 실시간 협업을 지원합니다. Yuanbrain HC1000은 백만 Token당 출력 비용을 1위안으로, 단일 카드 비용을 60% 절감했습니다. 이러한 돌파구는 에이전트 산업화가 직면한 속도 및 비용 병목 현상을 해결하고, 다중 에이전트 협업 및 복잡한 작업 추론의 대규모 상용화를 위한 효율적이고 저렴한 컴퓨팅 인프라를 제공하는 것을 목표로 합니다. (来源: 量子位)

피드포워드 3D 가우시안 스플래팅 새 방법: 저장대 팀, “복셀 정렬” 제안 : 저장대학교 팀은 “복셀 정렬(voxel-aligned)” 피드포워드 3D Gaussian Splatting (3DGS) 프레임워크 VolSplat을 제안했습니다. 이는 기존 “픽셀 정렬” 방법이 다중 시점 3D 재구성에서 겪는 기하학적 일관성 및 가우시안 밀도 할당 병목 현상을 해결하기 위함입니다. VolSplat은 3차원 공간에서 다중 시점 2D 정보를 융합하고, 희소 3D U-Net을 사용하여 특징을 정제함으로써 더 높은 품질, 더 견고하고 효율적인 3D 재구성을 달성합니다. 이 방법은 공개 데이터셋에서 여러 기준선보다 우수한 성능을 보였으며, 처음 보는 데이터셋에서도 강력한 제로샷 일반화 능력을 보여주었습니다. (来源: 量子位)

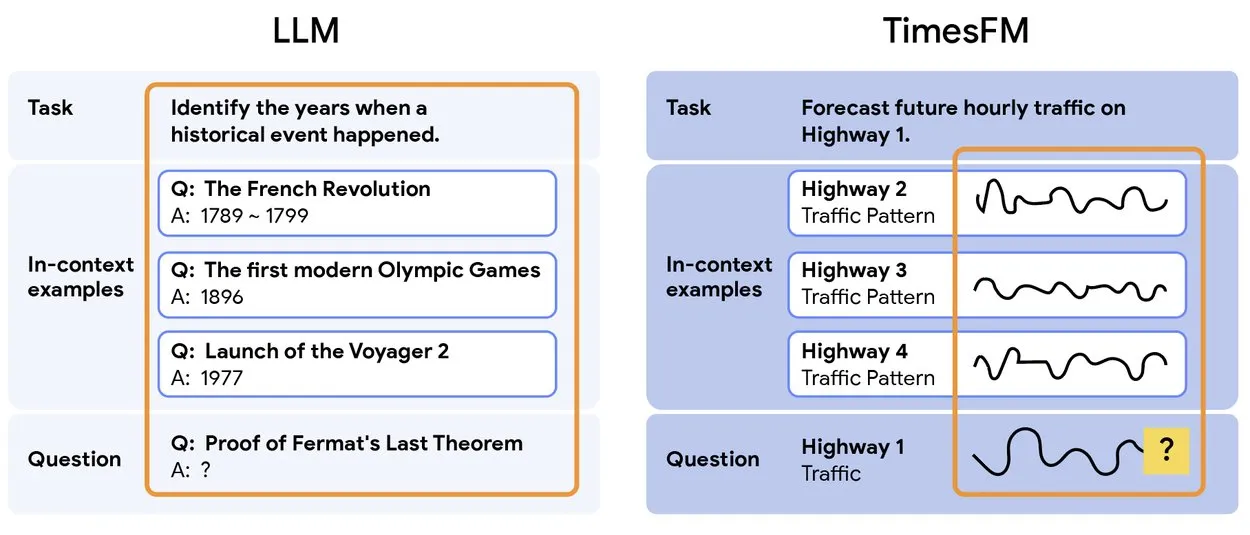
TimesFM 2.5: 사전 훈련된 시계열 예측 모델 출시 : TimesFM 2.5가 출시되었습니다. 이는 시계열 예측을 위한 사전 훈련된 모델로, 매개변수 수가 500M에서 200M으로 줄고, 컨텍스트 길이가 2K에서 16K로 늘어났으며, 제로샷 설정에서 뛰어난 성능을 보입니다. 이 모델은 Hugging Face에서 Apache 2.0 라이선스로 사용 가능하며, 시계열 예측 작업에 더욱 효율적이고 강력한 솔루션을 제공합니다. (来源: Twitter)
윈펑 테크놀로지, AI+헬스 신제품 출시로 가정 건강 분야 AI 적용 촉진 : 윈펑 테크놀로지는 슈아이캉(帅康), 창웨이(创维)와 협력하여 “디지털 지능형 미래 주방 연구소”와 AI 건강 대규모 모델을 탑재한 스마트 냉장고를 출시했습니다. AI 건강 대규모 모델은 주방 설계 및 운영을 최적화하며, 스마트 냉장고는 “건강 도우미 샤오윈”을 통해 개인화된 건강 관리를 제공합니다. 이번 출시는 일상 건강 관리 분야에서 AI의 돌파구를 의미하며, 스마트 기기를 통해 개인화된 건강 서비스를 실현하고 가정 건강 기술 수준을 향상시킬 것으로 기대됩니다. (来源: 36氪)
알리바바, 1조 매개변수 오픈소스 사고 모델 Ring-1T-preview 출시 : 알리바바 Ant Ling 팀은 “깊은 사고, 기다림 없이”를 목표로 하는 최초의 1조 매개변수 오픈소스 사고 모델 Ring-1T-preview를 출시했습니다. 이 모델은 AIME25, HMMT25, ARC-AGI-1, LCB, Codeforces 등 자연어 처리 벤치마크에서 초기 우수한 성과를 거두었습니다. 또한, IMO25의 Q3 문제를 한 번에 해결하고 Q1/Q2/Q4/Q5에 대한 부분적인 솔루션을 제공하여 강력한 추론 및 문제 해결 능력을 보여주었습니다. (来源: Twitter, Twitter, Twitter)

🧰 도구
PopAi, “Slide Agent” 출시, AI로 원클릭 프레젠테이션 생성 : PopAi 팀은 프레젠테이션 제작 과정을 간소화하기 위한 “Slide Agent” 도구를 출시했습니다. 사용자는 Prompt를 통해 요구사항을 입력하기만 하면 300개 이상의 템플릿 중에서 선택하여 AI가 자동으로 초안을 생성하고, 레이아웃, 차트, 이미지, 로고 등 형식을 조정하여 최종적으로 편집 가능한 .pptx 파일로 다운로드할 수 있습니다. 이 도구는 ChatGPT와 Canva의 기능을 통합하여 프레젠테이션 제작의 진입 장벽과 시간 비용을 크게 낮춥니다. (来源: Twitter)
알리바바, PDF를 Markdown으로 변환하는 도구 Miner U2.5 오픈소스화 : 알리바바 팀이 PDF를 Markdown으로 변환하는 도구 Miner U2.5를 오픈소스화했으며, HuggingFace에 데모를 공개했습니다. 이 도구는 PDF 문서를 Markdown 형식으로 효율적으로 변환하여 사용자가 콘텐츠를 추출, 편집 및 재활용하기 쉽게 해줍니다. 이는 많은 PDF 문서를 처리해야 하는 개발자와 연구원에게 실용적인 AI 보조 도구입니다. (来源: dotey)
VEED Animate 2.2 출시, 비디오 스타일 재구성 및 캐릭터 교체 지원 : VEED Animate 2.2 버전이 WAN 2.2 기술 지원으로 공식 출시되었습니다. 이 도구는 사용자가 한 장의 이미지로 비디오 스타일을 쉽게 재구성하고, 비디오 속 캐릭터를 즉시 교체하며, 10배 빠른 속도로 비디오 클립을 생성할 수 있도록 합니다. 이러한 새로운 기능은 비디오 제작 과정을 크게 간소화하고 콘텐츠 크리에이터에게 AI 기반의 더 많은 창의적 가능성을 제공합니다. (来源: TomLikesRobots)
LangChain, LLM 응답 표준화에 전념, 복잡한 기능 지원 : LangChain은 v1 개발에서 LLM 응답 표준화를 핵심 과제로 삼아 서버 측 도구 호출, 추론 및 참조와 같이 점점 더 복잡해지는 LLM 기능에 대응하고 있습니다. 이 프레임워크는 서로 다른 LLM 제공업체 간의 API 형식 비호환성 문제를 해결하고 개발자에게 통일된 인터페이스를 제공하여 다중 모드 에이전트 및 복잡한 워크플로우 구축을 간소화하는 것을 목표로 합니다. (来源: LangChainAI, Twitter)
Hugging Face Transformers.js, 브라우저에서 AI 모델 오프라인 실행 지원 : Hugging Face의 Transformers.js 라이브러리는 사용자가 ONNX 및 WebGPU 기술을 활용하여 Llama 3.2와 같은 AI 모델을 브라우저에서 오프라인으로 실행할 수 있도록 합니다. 이를 통해 개발자는 클라우드 서비스에 의존하지 않고도 챗봇, 객체 감지 및 배경 제거와 같은 AI 작업을 로컬에서 수행할 수 있어 데이터 프라이버시와 처리 속도가 향상됩니다. (来源: Twitter)
ToolUniverse 생태계, AI 과학자 구축 및 도구 통합 지원 : ToolUniverse는 AI 과학자 구축을 위해 설계된 생태계로, AI 과학자가 도구를 식별하고 호출하는 방식을 표준화하며, 데이터 분석, 지식 검색 및 실험 설계를 위한 600개 이상의 머신러닝 모델, 데이터셋, API 및 과학 소프트웨어 패키지를 통합합니다. 이 플랫폼은 도구 인터페이스를 자동으로 최적화하고, 자연어 설명을 통해 새로운 도구를 생성하며, 도구 사양을 반복적으로 최적화하여 도구를 에이전트 워크플로우로 조합함으로써 AI 과학자의 발견 과정에서의 협력을 촉진합니다. (来源: HuggingFace Daily Papers)
EasySteer 프레임워크, LLM 제어 성능 및 확장성 향상 : EasySteer는 vLLM 기반의 통합 프레임워크로, LLM의 제어 성능과 확장성을 향상시키는 것을 목표로 합니다. 모듈형 아키텍처, 플러그형 인터페이스, 세분화된 매개변수 제어 및 사전 계산된 제어 벡터를 통해 5.5-11.4배의 속도 향상을 달성하고 과도한 사고 및 환각을 효과적으로 줄입니다. EasySteer는 LLM 제어를 연구 기술에서 생산 수준의 능력으로 전환하여 배포 가능하고 제어 가능한 언어 모델을 위한 핵심 인프라를 제공합니다. (来源: HuggingFace Daily Papers)
VibeGame: WebStack 기반 AI 보조 게임 엔진 : VibeGame은 three.js, rapier 및 bitecs를 기반으로 구축된 고급 선언적 게임 엔진으로, AI 보조 게임 개발을 위해 특별히 설계되었습니다. 높은 추상화 계층, 내장 물리 및 렌더링 기능, 엔티티-컴포넌트-시스템(ECS) 아키텍처를 통해 AI가 게임 코드를 더 효율적으로 이해하고 생성할 수 있도록 합니다. 현재는 주로 간단한 플랫폼 게임에 적용 가능하지만, 오픈소스 코드와 AI 친화적인 문법은 AI 기반 게임 개발에 유망한 솔루션을 제공합니다. (来源: HuggingFace Blog)
AI 연구 지도 도구, 90만 편 논문 통합하여 인용 포함 답변 제공 : 혁신적인 AI 도구가 지난 10년간의 AI 연구 논문 90만 편을 의미론적으로 그룹화하고 시각화하여 상세한 연구 지도를 형성합니다. 사용자는 이 도구에 질문하고 정확한 인용이 포함된 답변을 받을 수 있어, 연구자들이 방대한 학술 문헌을 찾고 이해하는 과정을 크게 간소화하고 연구 효율성을 높입니다. (来源: Reddit r/ArtificialInteligence)
Kroko ASR: Whisper의 빠르고 스트리밍 가능한 대안 : Kroko ASR은 새로 오픈소스화된 음성-텍스트 모델로, Whisper의 빠르고 스트리밍 가능한 대안으로 포지셔닝됩니다. 더 작은 모델 크기, 더 빠른 CPU 추론 속도(모바일 및 브라우저 지원), 그리고 거의 없는 환각 현상을 특징으로 합니다. Kroko ASR은 여러 언어를 지원하며, 음성 AI의 진입 장벽을 낮추고 엣지 장치에 더 쉽게 배포하고 훈련할 수 있도록 하는 것을 목표로 합니다. (来源: Reddit r/LocalLLaMA)
OpenWebUI Plotly 차트 렌더링 문제, AI 도구 UI 통합 과제 부각 : OpenWebUI v0.6.32 버전에서 Plotly 차트가 정상적으로 렌더링되지 않고 원시 JSON이 직접 표시되는 문제가 발생했습니다. 사용자들은 백엔드에서 올바른 JSON을 반환하지만 프론트엔드에서 렌더링이 트리거되지 않는다고 보고했으며, 이는 AI 도구가 프론트엔드 UI 통합 및 풍부한 텍스트 렌더링 측면에서 여전히 기술적 과제에 직면해 있음을 보여주며, 개발자 커뮤니티의 추가 최적화가 필요함을 시사합니다. (来源: Reddit r/OpenWebUI)
📚 학습
LoRA 미세 조정과 전체 미세 조정 성능 비교 연구 : Thinking Machines (John Schulman 팀)의 최신 연구에 따르면, 강화 학습에서 LoRA (Low-Rank Adaptation)를 적절히 적용하면 전체 미세 조정과 동등한 성능을 달성하면서도 자원 소모가 적고(약 2/3 계산량), rank=1일 때도 뛰어난 성능을 보인다고 합니다. 연구는 LoRA를 모든 계층(MLP/MoE 포함)에 적용하고, 전체 미세 조정보다 10배 높은 학습률을 사용해야 한다고 강조합니다. 이 발견은 고성능 RL 모델 훈련의 진입 장벽을 크게 낮춰, 더 많은 개발자가 하나의 GPU에서 고품질 모델을 구현할 수 있게 합니다. (来源: Reddit r/LocalLLaMA, Twitter, Twitter)
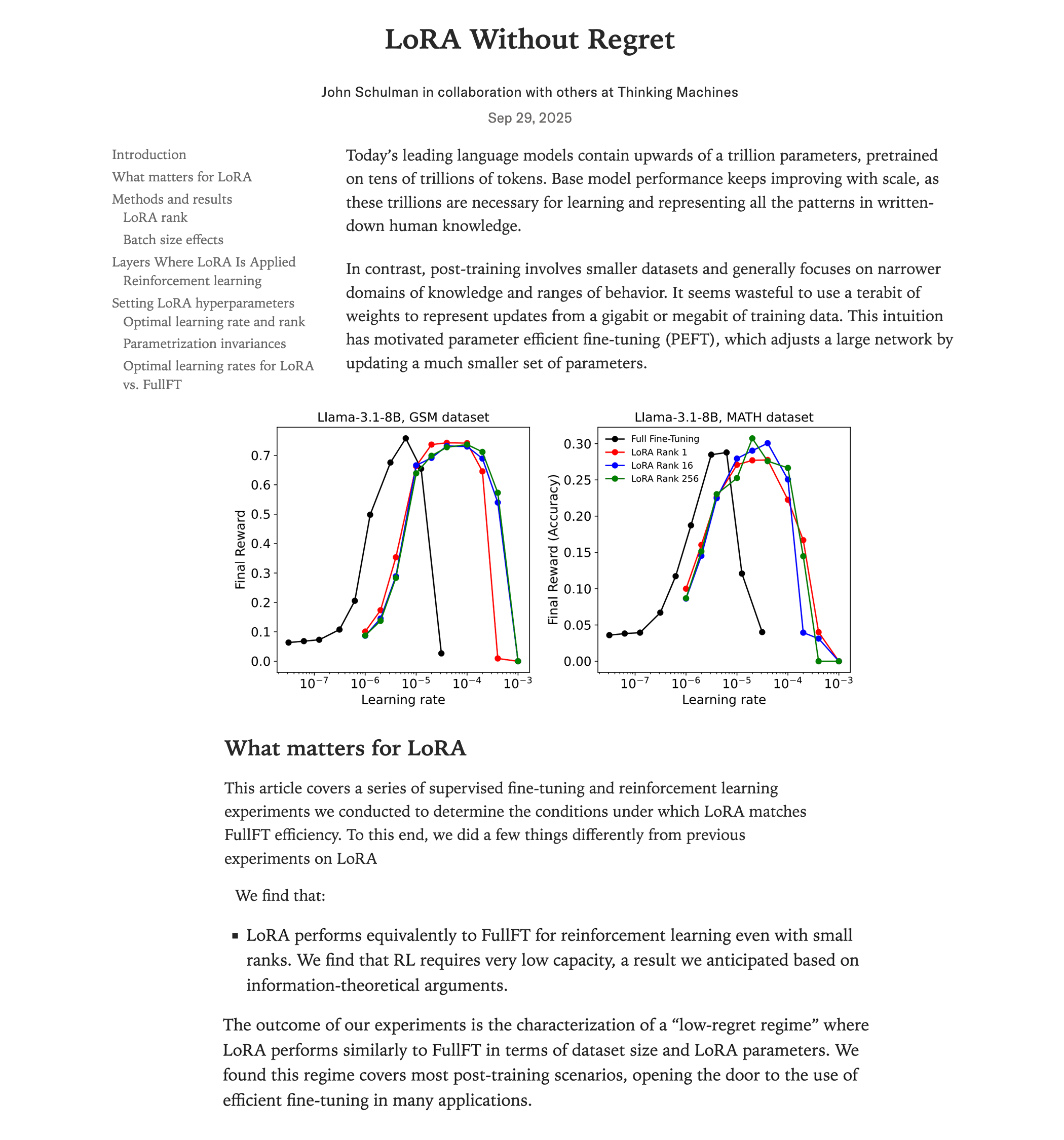
NVIDIA GPU 고성능 행렬 곱셈 커널 해부 : 심층 기술 블로그에서 NVIDIA GPU 내부 고성능 행렬 곱셈(matmul) 커널의 구현 메커니즘을 자세히 해부했습니다. 이 글은 GPU 아키텍처 기초, 메모리 계층 구조(GMEM, SMEM, L1/L2), PTX/SASS 프로그래밍, Hopper (H100) 아키텍처의 TMA, wgmma 명령어 등 고급 기능을 다룹니다. 이 자료는 개발자들이 CUDA 프로그래밍 및 GPU 성능 최적화를 깊이 이해하는 데 도움을 주며, Transformer 모델 훈련 및 추론에 매우 중요합니다. (来源: Reddit r/deeplearning, Twitter)
스탠포드 CS231N 딥러닝 컴퓨터 비전 강의 YouTube에 공개 : 스탠포드 대학교의 명성 높은 CS231N (컴퓨터 비전 딥러닝) 강의가 이제 YouTube에서 무료로 제공됩니다. 이는 전 세계 학습자들이 기초 개념부터 최첨단 응용까지 컴퓨터 비전 딥러닝 지식을 습득할 수 있는 귀중한 기회를 제공합니다. (来源: Reddit r/deeplearning)

RL-ZVP: 제로 분산 Prompt를 활용하여 LLM 강화 학습 추론 능력 향상 : 최신 연구에서 “RL with Zero-Variance Prompts (RL-ZVP)” 방법이 제안되었습니다. 이는 대규모 언어 모델(LLM)의 강화 학습 추론 능력을 향상시키는 것을 목표로 합니다. 이 방법은 더 이상 “제로 분산 Prompt”(즉, 모든 모델 응답이 동일한 보상을 받는 경우)를 무시하지 않고, 여기에서 가치 있는 학습 신호를 추출하여 정확성에 직접 보상을 주고 오류에 벌칙을 주며, Token 수준 엔트로피를 활용하여 이점 형성을 유도합니다. 실험 결과, RL-ZVP는 수학 추론 벤치마크에서 전통적인 방법에 비해 정확도와 통과율이 크게 향상되었습니다. (来源: Reddit r/MachineLearning)
미래 유도 학습: 시계열 예측을 강화하는 예측적 방법 : 한 연구에서 “미래 유도 학습(Future-Guided Learning)”을 제안했습니다. 이는 동적 피드백 메커니즘을 통해 시계열 이벤트 예측을 강화합니다. 이 방법은 미래 데이터를 분석하는 감지 모델과 현재 데이터를 기반으로 예측하는 예측 모델을 포함합니다. 예측 모델이 감지 모델과 차이를 보일 때, 예측 모델은 “놀라움”을 최소화하기 위해 더 크게 업데이트되어 매개변수를 동적으로 조정함으로써 시계열 예측의 정확도를 효과적으로 향상시킵니다. (来源: Reddit r/MachineLearning)
AI 미래는 저차원에: Yann Lecun, 추상 표현 학습에 대해 논하다 : AI 선구자 Yann Lecun은 Lex Fridman과의 인터뷰에서 AI의 다음 도약은 픽셀과 같은 고차원 원시 데이터를 직접 처리하는 것이 아니라 저차원 잠재 공간에서 학습하는 데서 올 것이라고 주장했습니다. 그는 진정한 지능 시스템은 세상의 인과 구조와 물리적 역학에 대한 추상적 표현을 학습하여 세부 사항이 변하더라도 정확한 예측을 할 수 있어야 한다고 믿습니다. 이 방법은 모델을 더 유연하고 견고하게 만들고, 방대한 데이터에 대한 의존도를 줄이며, 계산 비용을 낮출 것입니다. (来源: Reddit r/ArtificialInteligence)
SIRI: 교차 압축을 통한 반복 강화 학습 확장 : SIRI (Scaling Iterative Reinforcement Learning with Interleaved Compression)는 반복적으로 추론 예산을 압축하고 확장하여 훈련 중 최대 rollout 길이를 동적으로 조정하는 간단하고 효과적인 강화 학습 방법입니다. 이 훈련 메커니즘은 모델이 제한된 컨텍스트 내에서 정확한 결정을 내리도록 강제하고, 불필요한 Token을 줄이는 동시에 탐색 및 계획을 위한 공간을 제공하여 성능-효율성 균형에서 대규모 추론 모델의 효율성과 정확도를 꾸준히 향상시킵니다. (来源: HuggingFace Daily Papers)
MultiCrafter 다중 에이전트 생성 모델: 공간 분리 어텐션 및 정체성 인식 강화 학습 : MultiCrafter는 고충실도, 선호도 정렬 다중 에이전트 이미지 생성을 목표로 하는 프레임워크입니다. 명시적 위치 감독을 도입하여 서로 다른 에이전트 간의 어텐션 영역을 분리함으로써 속성 누출 문제를 효과적으로 완화합니다. 동시에, 이 프레임워크는 혼합 전문가(MoE) 아키텍처를 채택하여 모델 용량을 강화하고, 점수 메커니즘과 안정적인 훈련 전략을 결합한 새로운 온라인 강화 학습 프레임워크를 설계하여 생성된 이미지의 에이전트 충실도와 인간의 미적 선호도가 높게 일치하도록 보장합니다. (来源: HuggingFace Daily Papers)
Visual Jigsaw: 자기 지도 사후 훈련을 통해 MLLM의 시각 이해력 향상 : Visual Jigsaw는 다중 모드 대규모 언어 모델(MLLM)의 시각 이해 능력을 향상시키기 위한 범용 자기 지도 사후 훈련 프레임워크입니다. 이 방법은 시각 입력을 분할하고 뒤섞은 다음, 모델이 자연어를 통해 올바른 배열 순서를 재구성하도록 요구합니다. 검증 가능한 보상 기반 강화 학습(RLVR) 방법을 기반으로 하는 이 방법은 추가적인 시각 생성 구성 요소나 수동 레이블링 없이도 MLLM의 세분화된 인지, 시간 추론 및 3D 공간 이해 능력을 크게 향상시킵니다. (来源: HuggingFace Daily Papers)
MGM-Omni: Omni LLM을 개인화된 장시간 음성 생성으로 확장 : MGM-Omni는 독특한 “뇌-입” 이중 Token화 아키텍처를 통해 다중 모드 이해와 표현력이 풍부한 장시간 음성 생성을 구현하는 통합 Omni LLM입니다. 이 설계는 다중 모드 추론과 실시간 음성 생성을 분리하여 효율적인 교차 모드 상호작용과 낮은 지연 시간의 스트리밍 음성 복제를 지원하며, 데이터 효율성에서도 뛰어난 성능을 보입니다. 실험 결과, MGM-Omni는 음색 일관성 유지, 자연스러운 컨텍스트 인식 음성 생성, 장시간 오디오 및 다중 모드 이해 측면에서 기존 오픈소스 모델보다 우수함을 입증했습니다. (来源: HuggingFace Daily Papers)
SID: 자기 개선 시연을 통해 목표 지향 언어 내비게이션 학습 : SID (Self-Improving Demonstrations)는 목표 지향 언어 내비게이션 학습 방법으로, 반복적인 자기 개선 시연을 통해 내비게이션 에이전트의 미지 환경 탐색 능력과 일반화 능력을 크게 향상시킵니다. 이 방법은 먼저 최단 경로 데이터를 사용하여 초기 에이전트를 훈련한 다음, 이 에이전트를 통해 새로운 탐색 궤적을 생성합니다. 이 궤적은 더 나은 에이전트를 훈련하기 위한 더 강력한 탐색 전략을 제공하여 성능의 지속적인 향상을 이룹니다. 실험 결과, SID는 REVERIE 및 SOON과 같은 작업에서 SOTA 성능을 달성했으며, 특히 SOON의 미공개 검증 세트에서 성공률 50.9%를 기록하여 이전 방법을 13.9% 초과했습니다. (来源: HuggingFace Daily Papers)
LOVE-R1: 적응형 스케일링 메커니즘을 통해 긴 비디오 이해력 향상 : LOVE-R1 모델은 긴 비디오 이해에서 장시간 시퀀스 이해와 세부 공간 인지 간의 충돌을 해결하는 것을 목표로 합니다. 이 모델은 적응형 스케일링 메커니즘을 도입하여, 먼저 낮은 해상도로 프레임을 밀집하게 샘플링하고, 공간적 세부 정보가 필요할 때 모델은 추론에 따라 관심 있는 비디오 클립을 고해상도로 스케일링하여 핵심 시각 정보를 얻습니다. 전체 과정은 다단계 추론을 통해 이루어지며, CoT 데이터 미세 조정 및 분리된 강화 미세 조정을 결합하여 긴 비디오 이해 벤치마크에서 상당한 향상을 달성했습니다. (来源: HuggingFace Daily Papers)
Euclid’s Gift: 기하학적 에이전트 작업을 통해 시각 언어 모델 공간 추론 강화 : Euclid’s Gift는 기하학적 에이전트 작업을 통해 시각 언어 모델(VLM)의 공간 인지 및 추론 능력을 향상시키는 연구입니다. 이 프로젝트는 30K 평면 및 입체 기하학 문제를 포함하는 다중 모드 데이터셋 Euclid30K를 구축하고, Group Relative Policy Optimization (GRPO)을 사용하여 Qwen2.5VL 및 RoboBrain2.0 시리즈 모델을 미세 조정했습니다. 실험 결과, 훈련된 모델은 Super-CLEVR, Omni3DBench 등 4가지 공간 추론 벤치마크에서 상당한 제로샷 향상을 보였으며, RoboBrain2.0-Euclid-7B는 49.6%의 정확도를 달성하여 이전 SOTA 모델을 능가했습니다. (来源: HuggingFace Daily Papers)
SphereAR: 초구면 잠재 공간을 통해 연속 Token 자기회귀 생성 개선 : SphereAR은 연속 Token 자기회귀(AR) 이미지 생성 모델에서 VAE 잠재 공간의 이질적 분산으로 인해 발생하는 문제를 해결하는 것을 목표로 합니다. 이 핵심 설계는 모든 AR 입력 및 출력(CFG 후 포함)을 고정 반경 초구면에 제약하고 초구면 VAE를 활용합니다. 이론적 분석에 따르면, 초구면 제약은 분산 붕괴의 주요 원인을 제거하여 AR 디코딩을 안정화합니다. 실험 결과, SphereAR은 ImageNet 생성 작업에서 SOTA 성능을 달성하여 동일한 매개변수 규모의 확산 모델 및 마스크 생성 모델을 능가했습니다. (来源: HuggingFace Daily Papers)
AceSearcher: 강화된 자기 대결을 통해 LLM 추론 및 검색 유도 : AceSearcher는 LLM의 복잡한 추론 작업에서 검색 강화 능력을 향상시키기 위한 협력적 자기 대결 프레임워크입니다. 이 프레임워크는 단일 LLM을 훈련하여 복잡한 쿼리 분해와 검색 컨텍스트 통합을 번갈아 수행하며, 중간 레이블링 없이 감독 미세 조정 및 강화 미세 조정을 통해 최종 답변 정확도를 최적화합니다. 실험 결과, AceSearcher는 여러 추론 집약적 작업에서 SOTA 기준선보다 훨씬 우수했으며, 문서 수준 금융 추론 작업에서 AceSearcher-32B는 5% 미만의 매개변수로 DeepSeek-V3의 성능과 일치했습니다. (来源: HuggingFace Daily Papers)
SparseD: 확산 언어 모델의 희소 어텐션 메커니즘 : SparseD는 확산 언어 모델(DLM)을 위한 희소 어텐션 방법으로, 긴 컨텍스트 길이에서 어텐션 계산의 이차 복잡도 병목 현상을 해결하는 것을 목표로 합니다. 이 방법은 헤드별 희소 패턴을 사전 계산하고 모든 디노이징 단계에서 재사용하며, 초기 디노이징 단계에서는 전체 어텐션을 사용하고 이후 희소 어텐션으로 전환하여 손실 없는 가속화를 달성합니다. 실험 결과, SparseD는 64k 컨텍스트 길이에서 FlashAttention에 비해 최대 1.5배의 속도 향상을 달성하여 DLM의 긴 컨텍스트 응용 프로그램에서 추론 효율성을 효과적으로 향상시켰습니다. (来源: HuggingFace Daily Papers)
SLA: 미세 조정 가능한 희소 선형 어텐션을 통해 확산 Transformer 가속화 : SLA (Sparse-Linear Attention)는 Diffusion Transformer (DiT) 모델, 특히 비디오 생성에서의 어텐션 계산을 가속화하기 위한 훈련 가능한 어텐션 방법입니다. 이 방법은 어텐션 가중치를 핵심, 엣지 및 무시할 수 있는 세 가지 범주로 나누어 각각 O(N²) 및 O(N) 어텐션을 적용하고 무시할 수 있는 부분은 건너뜁니다. SLA는 이러한 계산을 단일 GPU 커널에서 융합하고 소량의 미세 조정 단계 후에 DiT 모델의 어텐션 계산을 20배 줄이고 비디오 생성에서 엔드 투 엔드 2.2배 가속화를 달성하며 생성 품질 손실이 없습니다. (来源: HuggingFace Daily Papers)
OpenGPT-4o-Image: 고급 이미지 생성 및 편집 종합 데이터셋 : OpenGPT-4o-Image는 계층적 작업 분류와 GPT-4o 자동 데이터 생성 방법을 결합하여 구축된 대규모 데이터셋으로, 통합 다중 모드 모델의 이미지 생성 및 편집 성능을 향상시키는 것을 목표로 합니다. 이 데이터셋은 텍스트 렌더링, 스타일 제어, 과학 이미지 및 복잡한 명령 편집을 포함한 11개 주요 영역과 51개 하위 작업을 포괄하는 80k개의 고품질 명령-이미지 쌍을 포함합니다. OpenGPT-4o-Image에서 미세 조정된 모델은 여러 벤치마크에서 상당한 성능 향상을 달성하여 체계적인 데이터 구축이 다중 모드 AI 능력 발전에 핵심적인 역할을 함을 입증했습니다. (来源: HuggingFace Daily Papers)
SANA-Video: 720p 분 단위 비디오를 효율적으로 생성하는 소형 확산 모델 : SANA-Video는 최대 720×1280 해상도와 분 단위 길이의 비디오를 효율적으로 생성할 수 있는 소형 확산 모델입니다. 선형 DiT 아키텍처와 상수 메모리 KV 캐시를 통해 고해상도, 고품질, 장시간 비디오 생성을 구현하며, 텍스트-비디오 강력한 정렬을 유지합니다. SANA-Video의 훈련 비용은 MovieGen의 1%에 불과하며, RTX 5090 GPU에 배포 시 5초 길이의 720p 비디오 생성 추론 속도는 29초에 달하여 저비용 고품질 비디오 생성을 실현합니다. (来源: HuggingFace Daily Papers)
AdvChain: 적대적 CoT 튜닝을 통해 대규모 추론 모델 안전 정렬 강화 : AdvChain은 적대적 Chain-of-Thought (CoT) 튜닝을 통해 대규모 추론 모델(LRM)에 동적 자기 교정 능력을 가르치는 새로운 정렬 패러다임입니다. 이 방법은 “유혹-교정” 및 “망설임-교정” 샘플을 포함하는 데이터셋을 구축하여 모델이 유해한 추론 드리프트와 불필요한 신중함에서 회복하도록 학습시킵니다. 실험 결과, AdvChain은 탈옥 공격 및 CoT 하이재킹에 대한 모델의 견고성을 크게 강화하는 동시에 양성 Prompt에 대한 과도한 거부를 대폭 줄여 탁월한 안전-유용성 균형을 달성했습니다. (来源: HuggingFace Daily Papers)
SDLM: 교차 압축을 통한 반복 강화 학습 확장 : Sequential Diffusion Language Model (SDLM)은 다음 Token 및 다음 블록 예측을 통합하는 방법을 제안하여 모델이 각 단계의 생성 길이를 적응적으로 결정할 수 있도록 합니다. SDLM은 최소 비용으로 사전 훈련된 자기회귀 언어 모델을 개조할 수 있으며, 고정 크기 마스크 블록 내에서 확산 추론을 수행하는 동시에 연속적인 하위 시퀀스를 동적으로 디코딩합니다. 실험 결과, SDLM은 강력한 자기회귀 기준선과 일치하거나 이를 능가하면서 더 높은 처리량을 달성하여 강력한 확장성 잠재력을 보여주었습니다. (来源: HuggingFace Daily Papers)
Insight-to-Solve (I2S): 추론 In-Context 시연을 추론 LM 자산으로 전환 : Insight-to-Solve (I2S)는 고품질 추론 In-Context 시연을 대규모 추론 모델(RLM)의 효과적인 자산으로 전환하는 것을 목표로 하는 테스트 시점 프로그램입니다. 연구에 따르면 시연 예제를 직접 추가하면 RLM의 정확도가 감소할 수 있습니다. I2S는 시연을 명확하게 재사용 가능한 통찰력으로 변환하고, 목표별 추론 궤적을 생성하며, 선택적으로 일관성과 정확성을 높이기 위해 자체 정제를 수행합니다. 실험 결과, I2S와 I2S+는 다양한 벤치마크에서 직접 답변 및 테스트 시점 스케일링 기준선보다 지속적으로 우수했으며, GPT 모델에서도 상당한 향상을 가져왔습니다. (来源: HuggingFace Daily Papers)
UniMIC: Token 기반 다중 모드 상호작용 코딩을 통한 인간-기계 협업 구현 : UniMIC (Unified token-based Multimodal Interactive Coding)은 Token 기반 표현을 통해 엣지 장치와 클라우드 AI 에이전트 간의 효율적이고 낮은 비트 전송률의 다중 모드 상호작용을 구현하기 위한 프레임워크입니다. UniMIC은 통신 매체로 압축된 Token화된 표현을 사용하고 Transformer 엔트로피 모델을 결합하여 Token 간의 중복성을 효과적으로 줄입니다. 실험 결과, UniMIC은 텍스트-이미지 생성, 이미지 복원 및 시각 질의응답과 같은 작업에서 상당한 비트 전송률 절감을 달성했으며, 초저 비트 전송률에서도 견고성을 유지하여 차세대 다중 모드 상호작용 통신을 위한 실용적인 패러다임을 제공합니다. (来源: HuggingFace Daily Papers)
RLBFF: 이진 유연 피드백으로 인간 피드백과 검증 가능한 보상 연결 : RLBFF (Reinforcement Learning with Binary Flexible Feedback)는 인간 선호도의 다양성과 규칙 검증의 정확성을 결합한 강화 학습 패러다임입니다. 이는 자연어 피드백에서 이진으로 답변 가능한 원칙(예: 정보 정확성: 예/아니오, 코드 가독성: 예/아니오)을 추출하고, 이를 사용하여 보상 모델을 훈련합니다. RLBFF는 RM-Bench 및 JudgeBench에서 뛰어난 성능을 보였으며, 사용자가 추론 시 원칙 초점을 사용자 정의할 수 있도록 합니다. 또한, RLBFF를 통해 Qwen3-32B를 정렬하는 완전 오픈소스 솔루션을 제공하여 일반 정렬 벤치마크에서 o3-mini 및 DeepSeek R1의 성능과 일치하거나 이를 능가합니다. (来源: HuggingFace Daily Papers)
MetaAPO: 메타 가중치 온라인 샘플링을 통한 정렬 최적화 : MetaAPO (Meta-Weighted Adaptive Preference Optimization)는 데이터 생성과 모델 훈련을 동적으로 결합하여 대규모 언어 모델(LLM)과 인간 선호도의 정렬을 최적화하는 새로운 프레임워크입니다. MetaAPO는 경량 메타 학습기를 “정렬 격차 추정기”로 활용하여 오프라인 데이터 대비 온라인 샘플링의 잠재적 이점을 평가하고, 목표 온라인 생성을 안내하며 샘플 수준 메타 가중치를 할당하여 온라인 및 오프라인 데이터의 품질과 분포를 동적으로 균형 있게 맞춥니다. 실험 결과, MetaAPO는 AlpacaEval 2, Arena-Hard 및 MT-Bench에서 기존 선호도 최적화 방법보다 지속적으로 우수했으며, 온라인 레이블링 비용을 42% 절감했습니다. (来源: HuggingFace Daily Papers)
Tool-Light: 자기 진화 선호 학습을 통한 효율적인 도구 통합 추론 : Tool-Light는 대규모 언어 모델(LLM)이 도구 통합 추론(TIR) 작업을 효율적이고 정확하게 수행하도록 장려하는 프레임워크입니다. 연구에 따르면 도구 호출 결과는 후속 추론 정보 엔트로피에 상당한 변화를 가져옵니다. Tool-Light는 데이터셋 구축과 다단계 미세 조정을 결합하여 구현되며, 데이터셋 구축은 바닐라 샘플링과 엔트로피 유도 샘플링을 통합한 연속 자기 진화 샘플링을 사용하고 엄격한 양성 및 음성 쌍 선택 기준을 설정합니다. 훈련 과정에는 SFT와 자기 진화 직접 선호도 최적화(DPO)가 포함됩니다. 실험 결과 Tool-Light는 TIR 작업 수행 효율성을 크게 향상시켰습니다. (来源: HuggingFace Daily Papers)
ChatInject: 채팅 템플릿을 이용한 LLM 에이전트 Prompt 주입 공격 : ChatInject는 LLM의 구조화된 채팅 템플릿 의존성과 다중 턴 대화의 컨텍스트 조작을 이용하여 간접적인 Prompt 주입 공격을 수행하는 방법입니다. 공격자는 기본 채팅 템플릿 형식을 모방하여 악성 페이로드를 구성하고, 에이전트가 의심스러운 작업을 수행하도록 유도합니다. 실험 결과, ChatInject는 전통적인 Prompt 주입 방법보다 공격 성공률이 높으며, 특히 다중 턴 대화에서 강하고 다양한 모델에 대한 전이성이 높습니다. 반면 기존의 Prompt 기반 방어 조치는 이러한 유형의 공격에 대부분 효과가 없습니다. (来源: HuggingFace Daily Papers)
💼 비즈니스
Modal, 8,700만 달러 규모 시리즈 B 투자 유치, 기업 가치 11억 달러 달성 : AI 인프라 회사 Modal이 8,700만 달러 규모의 시리즈 B 투자를 유치했으며, 기업 가치는 11억 달러에 달했습니다. 이번 투자는 AI 시대에 전통적인 컴퓨팅 인프라가 직면한 과제에 대응하기 위해 AI 인프라의 혁신과 발전을 가속화하는 것을 목표로 합니다. Modal은 효율적인 클라우드 컴퓨팅 서비스를 제공하여 연구원과 개발자가 AI 모델 훈련 및 배포 프로세스를 최적화하도록 돕습니다. (来源: Twitter, Twitter, Twitter)
OpenAI 상반기 매출 43억 달러, 손실 135억 달러, 수익성 도전 직면 : OpenAI는 2025년 상반기 매출이 43억 달러에 달했으며, 연간 매출은 130억 달러를 돌파할 것으로 예상된다고 발표했습니다. 이는 주로 ChatGPT Plus 구독 및 기업용 API 서비스 덕분입니다. 그러나 같은 기간 순손실은 135억 달러에 달했는데, 구조적 비용과 연구 개발 투자(예: GPT-5)가 주요 원인이며, 서버 임대료는 연간 160억 달러에 이릅니다. OpenAI는 175억 달러의 현금 보유액을 가지고 있고 300억 달러 규모의 자금 조달 계획을 추진하고 있음에도 불구하고, 지속적인 현금 소모와 Anthropic 등 경쟁사와의 효율성 격차로 인해 심각한 수익성 도전에 직면해 있습니다. (来源: 36氪)
휴머노이드 로봇 시장 자본 전쟁: ZHIYUAN, Galaxy Universal 등 적극적인 산업 체인 배치 : 휴머노이드 로봇 시장은 자본 전쟁 단계에 진입했으며, ZHIYUAN Robotics, Galaxy Universal 등 선두 기업들은 펀드 설립, 동종 업계 투자, 전략적 협력 등을 통해 “친구 관계”를 적극적으로 확장하고 있습니다. ZHIYUAN Robotics는 이미 모터, 센서 및 하위 응용 분야를 포함하여 약 20건의 외부 투자를 진행했으며, Fulin Precision, Pactera Technology 등과 협력하여 상업적 시나리오를 구현하고 있습니다. Galaxy Universal은 Bosch China와 합작 회사를 설립하여 자동차 제조 분야에서 체화된 지능의 응용을 추진하고 있습니다. 이러한 움직임은 주문 확보, 단점 보완, 그리고 미래 대규모 출하를 위한 안정적인 공급망 구축을 목표로 하지만, 업계 기술 노선은 크게 다르고 경쟁이 치열합니다. (来源: 36氪)

🌟 커뮤니티
AI 생성 콘텐츠 진위 판별 어려움, 사회적 신뢰 위기 촉발 : AI 기술의 급속한 발전과 함께 AI 생성 비디오(예: “진격의 거인” 실사판, 인도네시아 스트리머의 일본 인플루언서 “얼굴 바꾸기”)의 사실성은 믿기 어려울 정도로 높아져 콘텐츠의 진실성에 대한 사회적 깊은 우려를 불러일으키고 있습니다. 소셜 미디어 사용자들은 실제 콘텐츠와 AI 생성 콘텐츠를 구별하기가 점점 더 어려워지고 있다고 일반적으로 말하며, 이는 합법적인 콘텐츠 창작자의 신뢰도를 손상시킬 뿐만 아니라 허위 정보 유포에도 사용될 수 있습니다. 전문가들은 강제적인 AI 콘텐츠 라벨링이 없다면 이러한 “초현실 엔진”이 현실감을 계속 침식하여 결국 “인터넷을 종말시킬” 수 있다고 지적합니다. (来源: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ArtificialInteligence, Twitter, Twitter)

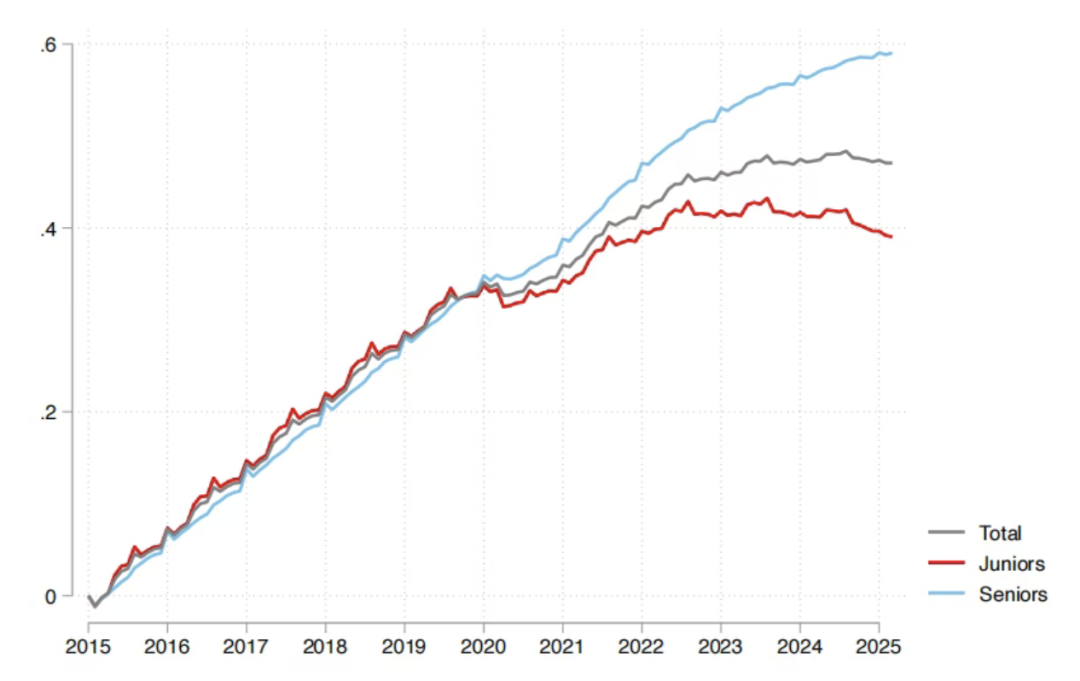
AI가 고용 시장에 미치는 영향: Sequoia 보고서, AI 투자 95% 무효, 졸업생 최대 타격 : Sequoia Capital은 MIT와 하버드 대학교의 연구 보고서를 공유하며, 기업 AI 투자의 95%가 실제 가치를 창출하지 못했으며, 진정한 생산성 향상은 직원들이 개인 AI 도구를 “몰래” 사용하여 형성된 “그림자 AI 경제”에서 비롯된다고 지적했습니다. 보고서는 또한 AI가 고용 시장에 미치는 영향이 주로 갓 졸업한 젊은이들에게 집중되어 있으며, 특히 도소매업에서 초급 직책 채용이 크게 감소했고, 명문대 학위도 완전한 보호막이 아니라고 밝혔습니다. 이는 AI가 업무 분배를 변화시키고 있으며, 인간의 가치가 경험과 독특한 판단으로 전환되고 있음을 보여줍니다. (来源: 36氪, Reddit r/ArtificialInteligence)
OpenAI 모델 조정, 사용자들의 강한 불만 촉발, 투명한 소통 요구 : OpenAI가 최근 예고 없이 GPT-4o/GPT-5 모델을 저성능 버전으로 “다운그레이드”하여 모델 성능 저하를 초래했고, 이는 사용자들의 강한 불만을 불러일으켰습니다. 많은 사용자들이 모델이 “멍청해졌다”며 기존의 통찰력과 “친구” 같은 소통 경험을 잃었다고 불평했으며, 심지어 일부는 이를 “정신적 타격”이라고 표현했습니다. OpenAI 고위 관계자는 이를 민감한 주제를 처리하기 위한 “안전 라우팅 테스트”라고 해명했지만, 사용자들은 OpenAI가 사용자들과의 소통과 투명성을 강화하고 일방적인 제품 계약 변경을 피하여 사용자 신뢰를 재구축해야 한다고 한목소리로 요구하고 있습니다. (来源: Reddit r/artificial, Reddit r/ChatGPT, Reddit r/ChatGPT, Twitter)
로봇세: 기술 발전과 사회 공정성에 대한 논의 : AI 및 로봇 기술의 발전과 함께 로봇에 대한 “세금 부과”에 대한 논의가 증가하고 있습니다. 이는 로봇이 인간 노동력을 대체하여 발생할 수 있는 고용 문제와 사회적 불평등을 해소하기 위함입니다. 지지자들은 로봇세가 실업자에게 사회 복지 및 재취업 지원을 제공하고 자본과 노동 간의 협상 불균형을 시정할 수 있다고 주장합니다. 그러나 로봇 산업 종사자들은 현재 세금 부과가 시기상조이며 신흥 산업 발전을 저해할 수 있다고 일반적으로 생각합니다. 한국은 자동화 기업에 대한 세금 혜택을 줄여 로봇 사용 비용을 간접적으로 증가시켰습니다. (来源: 36氪)
휴머노이드 로봇의 미래 방향: 유명 로봇 전문가 Rodney Brooks, 미래는 인간과 같지 않을 것 : 유명 로봇 전문가 Rodney Brooks는 현재 휴머노이드 로봇이 막대한 투입에도 불구하고 인간 수준의 민첩성을 달성하지 못하고 있으며, 이족 보행은 안전 위험을 내포하고 있다고 지적했습니다. 그는 향후 15년 동안 휴머노이드 로봇이 더 이상 인간 형태를 모방하지 않고, 특정 작업에 적응하기 위해 바퀴 달린 이동, 다중 팔(집게 또는 흡착판 장착), 다중 센서(능동 광 이미징, 비가시광 감지)를 갖춘 전용 로봇으로 진화할 것이라고 예측했습니다. 그는 현재 “인간형” 형태를 추구하는 데 막대한 투자가 이루어지고 있지만 결국 헛수고가 될 것이라고 믿습니다. (来源: 36氪)

AI 코드 생성 품질과 개발자 경험 논란 : 소셜 미디어에서 개발자들은 AI 생성 코드의 품질과 유용성에 대해 뜨거운 논쟁을 벌였습니다. 일부는 Claude Sonnet 4.5가 전체 코드베이스를 재구성할 수 있다고 칭찬했지만, 생성된 코드가 실행되지 않는다고 지적했습니다. 또 다른 이들은 AI 생성 코드가 “컴파일되지 않아” 개발 효율성이 저하된다고 불평했습니다. 이러한 논의는 AI 보조 프로그래밍이 효율성과 정확성 사이에서 여전히 과제를 안고 있으며, 개발자들이 AI 생성 결과에 대해 디버깅 및 검증의 필요성을 느끼고 있음을 반영합니다. (来源: Twitter, Twitter, Twitter)

AI 시대 인재관 변화: “사람 뽑기”에서 “농사 짓기”로 : 소셜 미디어에서 AI 시대의 인재관이 전통적인 “여기저기서 사람 뽑기”에서 “농사 짓기”로 바뀌어야 한다는 논의가 뜨겁습니다. AI 분야 인재가 희귀하고 기술 반복이 빠르다는 점을 감안할 때, 기업은 시장에서 고가에 거래되는 “완성품” 인재를 맹목적으로 쫓기보다는 기본 기술 스택을 갖춘 직원을 양성하는 데 더 집중해야 한다는 것입니다. 이러한 관점은 AI 분야의 빠른 변화하는 요구에 적응하기 위해 지속적인 학습과 내부 양성의 중요성을 강조합니다. (来源: dotey)
AI 인프라 에너지 소비와 Sam Altman의 에너지 수요 : Sam Altman이 AI 발전에 250GW의 전력이 필요하다고 언급하면서, AI 인프라의 막대한 에너지 소비에 대한 사회적 관심과 논의가 촉발되었습니다. 이러한 수요는 기존 에너지 공급 능력을 훨씬 초과하며, AI의 빠른 발전과 지속 가능한 에너지 공급의 균형을 어떻게 맞출 것인지에 대한 고민을 불러일으킵니다. 관련 논의는 반도체 제조 과정에서의 환경 문제, 예를 들어 PFAS 사용 및 그 대체재의 잠재적 위험에 대해서도 다룹니다. (来源: Twitter, Twitter)

AI 종말론과 낙관론: 우려와 반박 : 소셜 미디어에서는 AI “종말론”과 AI의 잠재적 위험에 대한 광범위한 논의가 있지만, 많은 사람들은 이러한 우려가 과장되었다고 생각합니다. 낙관론자들은 AI가 가져올 실제 문제(기후 영향, 기업 착취, 군사 감시)가 멀리 떨어진 “초지능이 인류를 파괴할 것”이라는 것보다 더 시급하며, 현재 해결 가능한 과제에 집중해야 한다고 주장합니다. 일부는 AI 종말론이 “터무니없는 소리”이며 게으르고 불안정한 표현이라고 생각하는 반면, 다른 일부는 AI가 결국 창조와 육성으로 나아갈 것이라고 믿습니다. (来源: Reddit r/ArtificialInteligence, Twitter, Twitter)
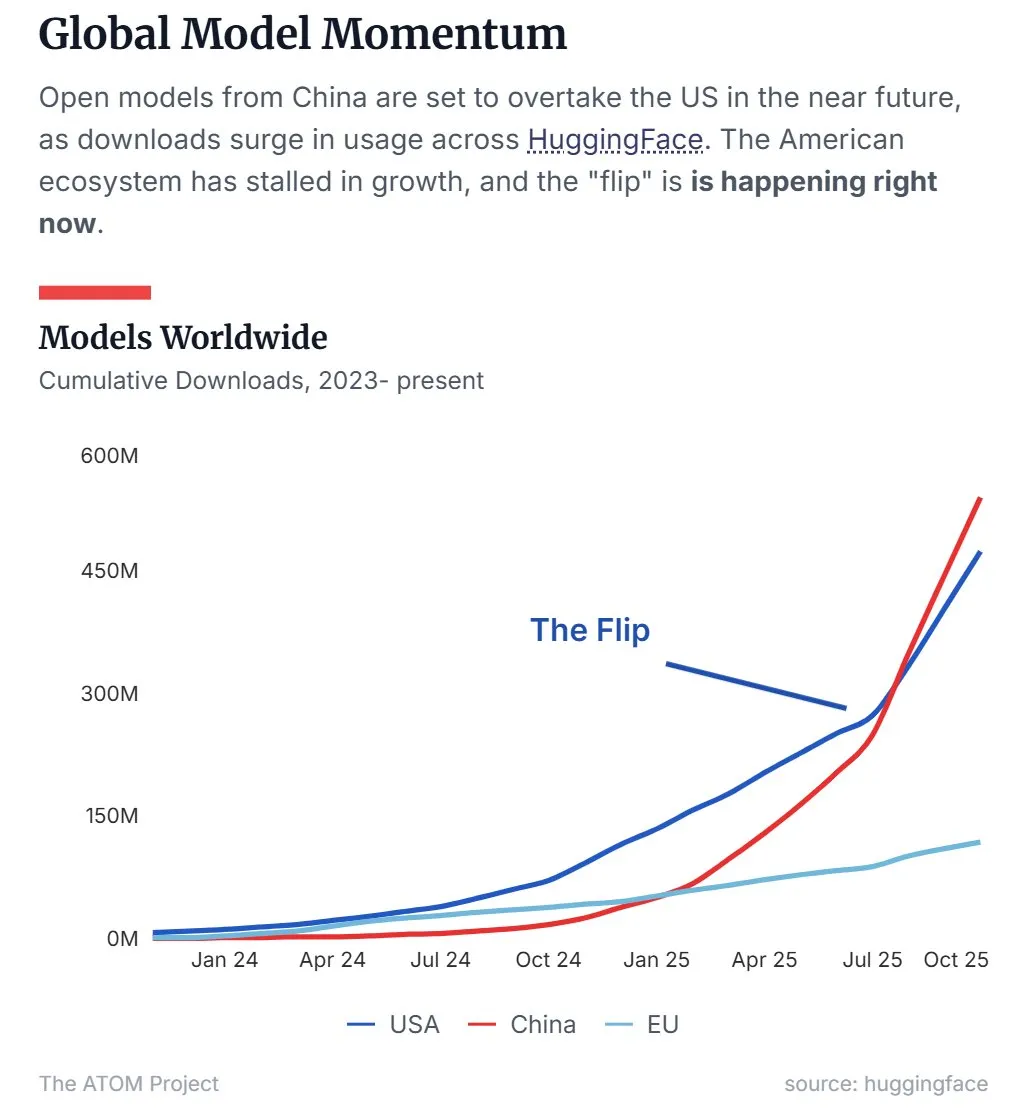
중국 오픈소스 LLM 시장 점유율 미국 추월 : 최신 데이터에 따르면, Qwen을 대표하는 중국 오픈소스 대규모 언어 모델(LLM)이 시장 점유율에서 미국을 추월하여 오픈소스 LLM 분야의 주도적인 세력이 되었습니다. 이러한 추세는 중국이 오픈소스 AI 기술 연구 개발 및 응용 분야에서 빠르게 부상하고 있으며, 글로벌 AI 판도에 중요한 영향을 미 미치고 있음을 보여줍니다. (来源: Twitter, Twitter)
45일 만에 1천만 조회수 달성한 AI 만화 드라마 “내일은 월요일” 제작팀 : 단 10명으로 구성된 팀이 45일 만에 AI 만화 드라마 “내일은 월요일” 50편을 제작했으며, 어떠한 유료 홍보 없이도 전체 네트워크에서 1천만 회 이상의 조회수를 기록했고, TikTok 유료 수익으로 모든 비용을 충당했습니다. 이 프로젝트는 “오리지널 캐릭터 + AI 생성”이라는 핵심 개념을 채택하여 AI 콘텐츠 저작권 귀속 문제를 해결하고, IP 전 카테고리 상업 개발 경로를 모색했습니다. 제작 과정은 원화가, 엔지니어, 후반 편집자 및 감독의 긴밀한 협업으로 고도로 분업화되어, 콘텐츠 생산에서 AI 기술이 비용 절감 및 효율성 향상에 미치는 막대한 잠재력을 보여주었습니다. (来源: 36氪)

💡 기타
오디오-텍스트 정밀 정렬 수요 설문조사 : 한 소셜 미디어 사용자가 오디오-텍스트 정밀 정렬 기술에 대한 깊은 관심을 표명하며, 해당 기술의 기능 및 응용 시나리오에 대한 구체적인 사용자 요구사항을 수집하기 위한 설문조사를 발표했습니다. 이는 관련 기술의 발전과 최적화를 추진하기 위함입니다. (来源: dotey)
DeepMind, Nano Banana 데모 시연 : Google DeepMind가 “Nano Banana”라는 데모를 시연하여 소셜 미디어의 주목을 받았습니다. 구체적인 세부 사항은 완전히 공개되지 않았지만, AI 비디오 생성 또는 다중 모드 AI 기술과 관련이 있을 수 있으며, DeepMind의 시각 AI 분야에서의 새로운 진전을 암시합니다. (来源: GoogleDeepMind)
Highway Net과 ResNet 발명 우선권에 대한 학술적 논의 : 유명 AI 연구자 Jürgen Schmidhuber가 트윗을 리트윗하며, Highway Net과 ResNet의 깊은 잔차 학습 발명 우선권에 대한 학술적 논의를 다시 불러일으켰습니다. 그는 Microsoft의 ResNet 논문이 Highway Net을 “동시대” 작업으로 언급한 것은 정확하지 않다고 지적하며, Highway Net이 ResNet보다 7개월 먼저 발표되었고 잔차 연결 솔루션을 이미 식별하고 제안했음을 강조했습니다. (来源: SchmidhuberAI)