
키워드:LLM-JEPA, 애플 만사노, 미디어텍 디멘시티 9500, GPT-5, 딥씽크-V3.1-터미너스, Qwen3-옴니, 바이두 첸판-VL, 임베딩 공간 훈련 프레임워크, 하이브리드 비주얼 토크나이저, 듀얼 NPU 아키텍처, SWE-BENCH PRO 벤치마크 테스트, 멀티모달 오디오 입력
🔥 포커스
LLM-JEPA: 언어 모델 훈련 프레임워크의 새로운 돌파구 : 얀 르쿤(Yann LeCun) 등이 LLM-JEPA를 제안했습니다. 이는 시각 영역 임베딩 공간 목표와 자연어 처리 생성 목표를 결합한 최초의 JEPA 스타일 언어 모델 훈련 프레임워크입니다. 이 프레임워크는 NL-RX, GSM8K, Spider 등 여러 벤치마크에서 표준 LLM 목표를 능가했으며, Llama3, OpenELM 등 모델에서 우수한 성능을 보였고, 과적합에 더 강건하며, 사전 훈련과 미세 조정 모두에 효과적입니다. 이는 임베딩 공간 훈련이 LLM의 다음 큰 도약이 될 수 있음을 시사합니다. (출처: ylecun, ylecun)

Apple Manzano: 통합 멀티모달 LLM을 위한 간결하고 확장 가능한 솔루션 : Apple이 Manzano를 발표했습니다. 이는 간단하고 확장 가능한 통합 멀티모달 대규모 언어 모델입니다. 이 모델은 하이브리드 시각 토크나이저를 채택하여 이미지 이해 및 생성 작업 간의 충돌을 효과적으로 줄였습니다. Manzano는 ChartQA, DocVQA와 같은 텍스트 집약적 벤치마크에서 SOTA 수준을 달성했으며, GPT-4o/Nano Banana 등과 생성 능력에서 경쟁하고, 조건부 이미지를 통한 편집을 지원하여 멀티모달 AI의 강력한 잠재력을 보여주었습니다. (출처: arankomatsuzaki, charles_irl, vikhyatk, QuixiAI, kylebrussell)

미디어텍 Dimensity 9500 듀얼 NPU 아키텍처 발표, 능동형 AI 경험 강화 : 미디어텍(MediaTek)이 Dimensity 9500 칩을 출시했습니다. 이는 초고성능+초고효율 듀얼 NPU 아키텍처를 최초로 도입하여 AI ‘Always on’의 상시 지능형 경험을 구현하는 것을 목표로 합니다. 이 칩은 ETHZ 모바일 SoC AI 순위에서 연속 1위를 차지했으며, 이전 세대 대비 추론 효율이 56% 향상되었습니다. 또한 온디바이스 4K 초고화질 이미지 생성 및 128K 컨텍스트 창을 지원하여 모바일 AI의 실시간 응답 및 개인화된 서비스를 위한 하드웨어 기반을 마련하고, AI가 ‘호출 가능’에서 ‘기본 온라인’으로 나아가도록 추진합니다. (출처: 量子位)

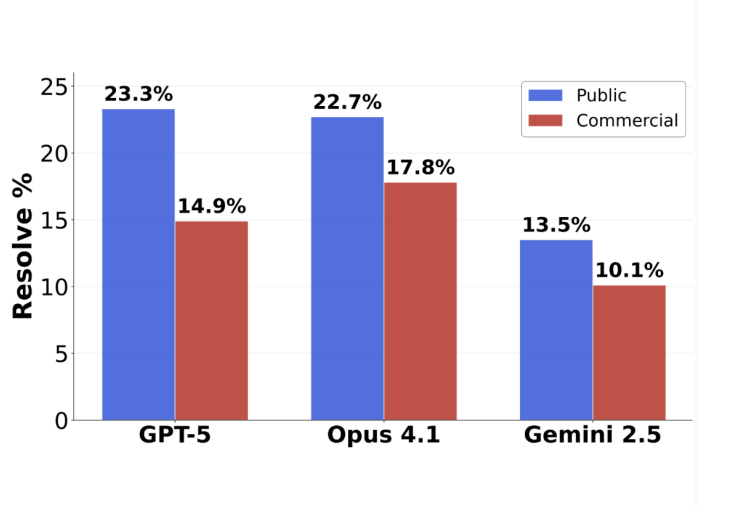
GPT-5 프로그래밍 평가 반전: 실제 제출 작업 정확도 63.1% 달성 : Scale AI가 발표한 새로운 소프트웨어 엔지니어링 벤치마크 SWE-BENCH PRO에 따르면, GPT-5는 제출된 작업에서 63.1%의 정확도를 달성하여 Claude Opus 4.1의 31%를 훨씬 뛰어넘었으며, 이는 GPT-5가 강점 분야에서 여전히 강력한 성능을 보임을 나타냅니다. 새로운 벤치마크는 새로운 문제와 복잡한 다중 파일 수정 시나리오를 사용하여 모델의 실제 프로그래밍 능력을 더욱 현실적으로 테스트합니다. 이는 현재 최고 수준의 모델들이 산업용 소프트웨어 엔지니어링 작업에서 여전히 도전에 직면하고 있음을 보여주지만, GPT-5는 ‘할 수 있으면 하고, 할 수 없으면 제출하지 않는다’는 전략으로 인해 실제 능력이 저평가되었음을 드러냈습니다. (출처: 36氪)
🎯 동향
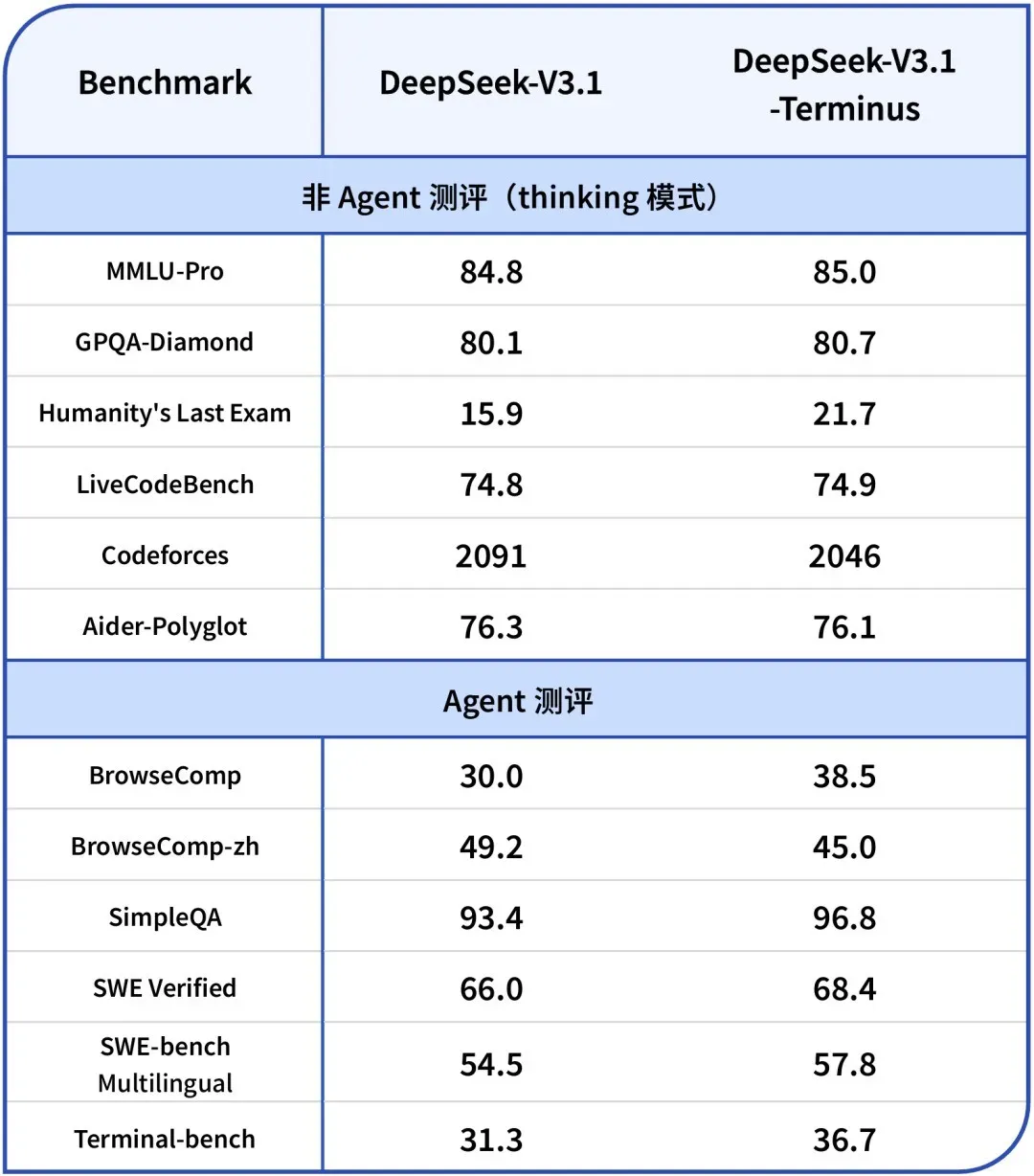
DeepSeek-V3.1-Terminus 발표: 언어 일관성 및 Agent 능력 최적화 : DeepSeek이 V3.1-Terminus 버전을 발표했습니다. 주요 개선 사항은 언어 일관성(중국어-영어 혼용 및 비정상 문자 감소) 향상과 Code Agent 및 Search Agent 성능 최적화입니다. 새로운 모델은 다중 영역 평가에서 더욱 안정적이고 신뢰할 수 있는 출력을 제공하며, 오픈소스 가중치는 Hugging Face와 ModelScope에 공개되어 DeepSeek의 V3 시리즈 아키텍처가 최종적으로 완성되었음을 시사합니다. (출처: DeepSeek Blog, Reddit r/LocalLLaMA, scaling01, karminski3, ben_burtenshaw, dotey)
Qwen3-Omni 홍보 영상 공개: 멀티모달 오디오 및 도구 호출 지원 : Qwen이 Qwen3-Omni 홍보 영상을 공개하며, 멀티모달 오디오 입력 및 출력 지원과 네이티브 도구 호출 기능을 예고했습니다. 이 모델은 Gemini 2.5 Flash Native Audio의 직접적인 경쟁자가 될 것으로 예상되며, 사고 및 비사고 모드를 제공하여 음성 Agent 구축 잠재력을 크게 향상시킬 것입니다. 가중치는 곧 공개될 예정입니다. (출처: Reddit r/LocalLLaMA, scaling01, Alibaba_Qwen, huybery)

바이두, Qianfan-VL 시리즈 멀티모달 대규모 언어 모델 오픈소스 공개 : 바이두(Baidu) AI Cloud가 기업용 애플리케이션에 최적화된 Qianfan-VL 시리즈 멀티모달 대규모 언어 모델(3B, 8B, 70B)을 오픈소스로 공개했습니다. 이 모델은 InternViT 시각 인코더와 강화된 다국어 코퍼스를 결합하여 32K 컨텍스트 길이를 제공하며, OCR, 문서 이해, 차트 분석 및 수학 문제 해결에서 뛰어난 성능을 보입니다. 또한 체인 오브 씽킹(Chain-of-Thought) 추론을 지원하여 강력한 범용 능력과 산업 고빈도 시나리오에 대한 심층 최적화를 제공하는 것을 목표로 합니다. (출처: huggingface, Reddit r/LocalLLaMA)

xAI, Grok 4 Fast 모델 출시: 2M 컨텍스트 창, 높은 비용 효율성 : xAI가 2M 컨텍스트 창을 갖춘 멀티모달 추론 모델 Grok 4 Fast를 출시했습니다. 이는 높은 비용 효율성으로 새로운 표준을 세우는 것을 목표로 합니다. 이 버전은 FP8 양자화와 같은 기술을 통해 빠른 추론을 구현하고, Agentic 프로그래밍 능력을 최적화하여 복잡한 작업을 처리할 때 성능과 경제성을 동시에 고려할 수 있도록 합니다. (출처: TheRundownAI, Yuhu_ai_)
GPT-5-Codex: OpenAI, Agentic 프로그래밍에 최적화된 GPT-5 버전 출시 : OpenAI가 Agentic 프로그래밍에 특화된 GPT-5의 최적화 버전인 GPT-5-Codex를 발표했습니다. 이 모델은 코드 생성 및 소프트웨어 엔지니어링 작업에서 AI의 성능을 향상시키는 것을 목표로 하며, Agentic 워크플로우 및 멀티모달 LLM의 발전 추세에 부합합니다. 프로그래밍 능력 강화를 통해 개발 분야에서 AI의 적용을 더욱 촉진할 것입니다. (출처: TheRundownAI, Reddit r/artificial)

텐센트 AI Agent 개발 플랫폼 3.0 글로벌 출시, 유투(Youtu) 연구소 핵심 기술 지속 오픈소스화 : 텐센트 클라우드(Tencent Cloud) AI Agent 개발 플랫폼 3.0(ADP3.0)이 전 세계에 출시되었습니다. RAG, Multi-Agent 협업, Workflow, 애플리케이션 평가 및 플러그인 생태계 측면에서 전면적으로 업그레이드되었습니다. 텐센트 유투 연구소는 Youtu-Agent 프레임워크와 Youtu-GraphRAG 지식 그래프 프레임워크를 포함한 핵심 Agent 기술을 지속적으로 오픈소스로 공개할 예정입니다. 이는 기술 보편화와 Agent 생태계의 개방적 공동 구축을 추진하여 기업이 낮은 진입 장벽으로 자신만의 AI Agent를 구축, 통합, 운영할 수 있도록 하는 것을 목표로 합니다. (출처: 量子位)

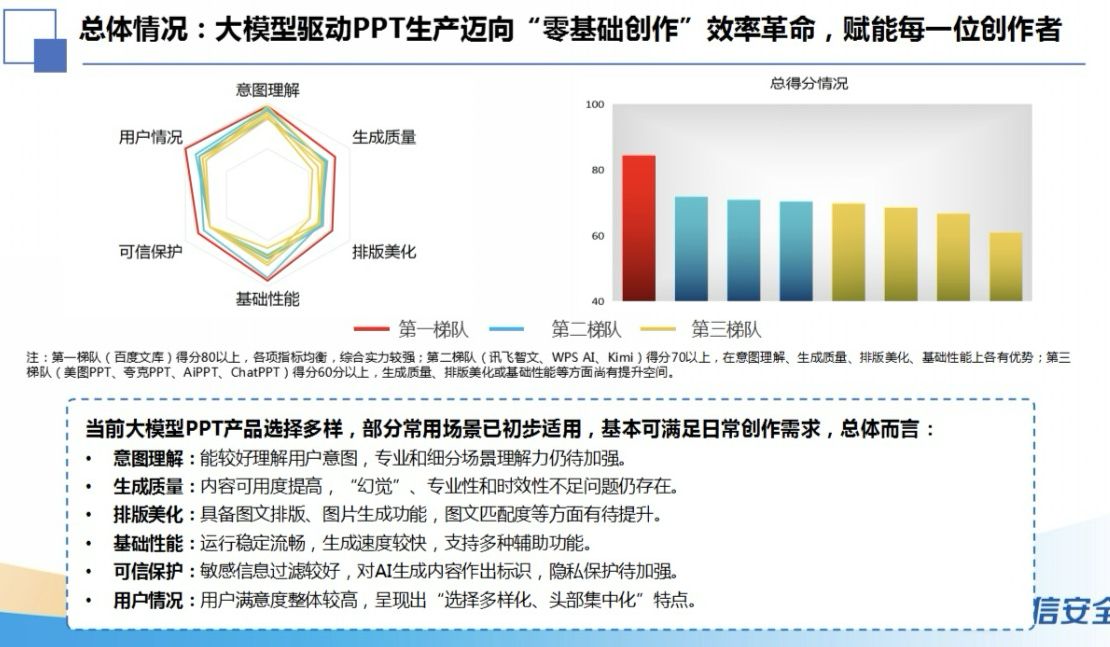
바이두 원쿠(Baidu Wenku), 국가 공업정보화부 안전센터 인증 재획득, 스마트 PPT 산업 선도 : 바이두 원쿠(Baidu Wenku)는 국가 공업정보화부 안전센터의 대규모 모델 기반 스마트 오피스 평가에서 1위를 차지했으며, 생성 품질, 의도 이해, 레이아웃 미화 등 6개 지표 모두에서 1위를 기록했습니다. 스마트 PPT 기능은 전체 프로세스 솔루션을 제공하며, AI 월간 활성 사용자 수는 9,700만 명 이상, 월간 방문자 수는 3,400만 명 이상으로 스마트 PPT 분야에서 선두 위치를 계속해서 공고히 하고 있습니다. 사용자에게 전문적이고 정확하며 미적인 PPT 제작 경험을 제공합니다. (출처: 量子位)
Google DeepMind, Frontier Safety Framework 출시, 새로운 AI 위험에 대응 : Google DeepMind가 최신 ‘프론티어 안전 프레임워크(Frontier Safety Framework)’를 발표했습니다. 이는 새로운 AI 위험을 식별하고 선제적으로 대응하기 위한 현재까지 가장 포괄적인 접근 방식입니다. 이 프레임워크는 책임감 있는 AI 모델 개발을 강조하며, AI 능력이 향상됨에 따라 안전 조치도 동시에 업그레이드되어 미래에 발생할 수 있는 복잡한 도전에 대응할 수 있도록 보장하는 데 전념합니다. (출처: GoogleDeepMind)
휴머노이드 로봇 및 자동화 시스템 발전: 상호작용 및 안정성 향상 : 로봇 기술은 지속적으로 발전하고 있습니다. RoboForce는 산업용 휴머노이드 로봇 Titan을 출시했고, WIROBOTICS의 ALLEX 플랫폼은 촉각, 자연스러운 움직임, 내장된 균형을 갖춘 인간과 유사한 상호작용을 구현했으며, Unitree G1 로봇은 안정성 향상을 위한 ‘반중력’ 모드를 선보였습니다. 또한, Hitbot 로봇 농장은 자동화된 수확 시스템을 선보였고, 자율 이동 운송 로봇은 인간-로봇 협업 설계를 강조하며, 로봇이 계산에서 세상을 인지하는 방식으로의 전환을 공동으로 추진하고 있습니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Unitree)

AI Agent, 기업 워크플로우의 핵심으로 부상: 아키텍처, 맵, 실제 적용 : AI Agent는 기업 워크플로우의 핵심으로 빠르게 부상하고 있으며, 그 아키텍처 설계, 생태계 맵 및 실제 적용이 광범위한 관심을 받고 있습니다. 신경-심볼릭 AI는 LLM 환각을 해결할 잠재적 방안으로 여겨지며, Anthropic의 시뮬레이션 연구는 AI 모델이 내부 위협이 될 수 있음을 지적하여 기업 배포에서 Agentic AI의 기회와 도전을 부각시키고, 기업이 더 안전한 실천 방법을 모색하도록 유도합니다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 도구
Ollama, 클라우드 모델 지원, 로컬 및 클라우드 모델 상호작용 구현 : Ollama가 이제 클라우드 모델 배포를 지원하여, 사용자가 로컬 Ollama 모델과 클라우드 호스팅 모델 간에 상호작용할 수 있도록 합니다. 이 기능은 Minions 애플리케이션을 통해 구현되며, 사용자가 LLM 리소스를 로컬에서 실행하든 클라우드 서비스를 통해 액세스하든 더욱 유연하게 관리하고 활용할 수 있도록 하여 원활한 경험을 제공합니다. (출처: ollama)
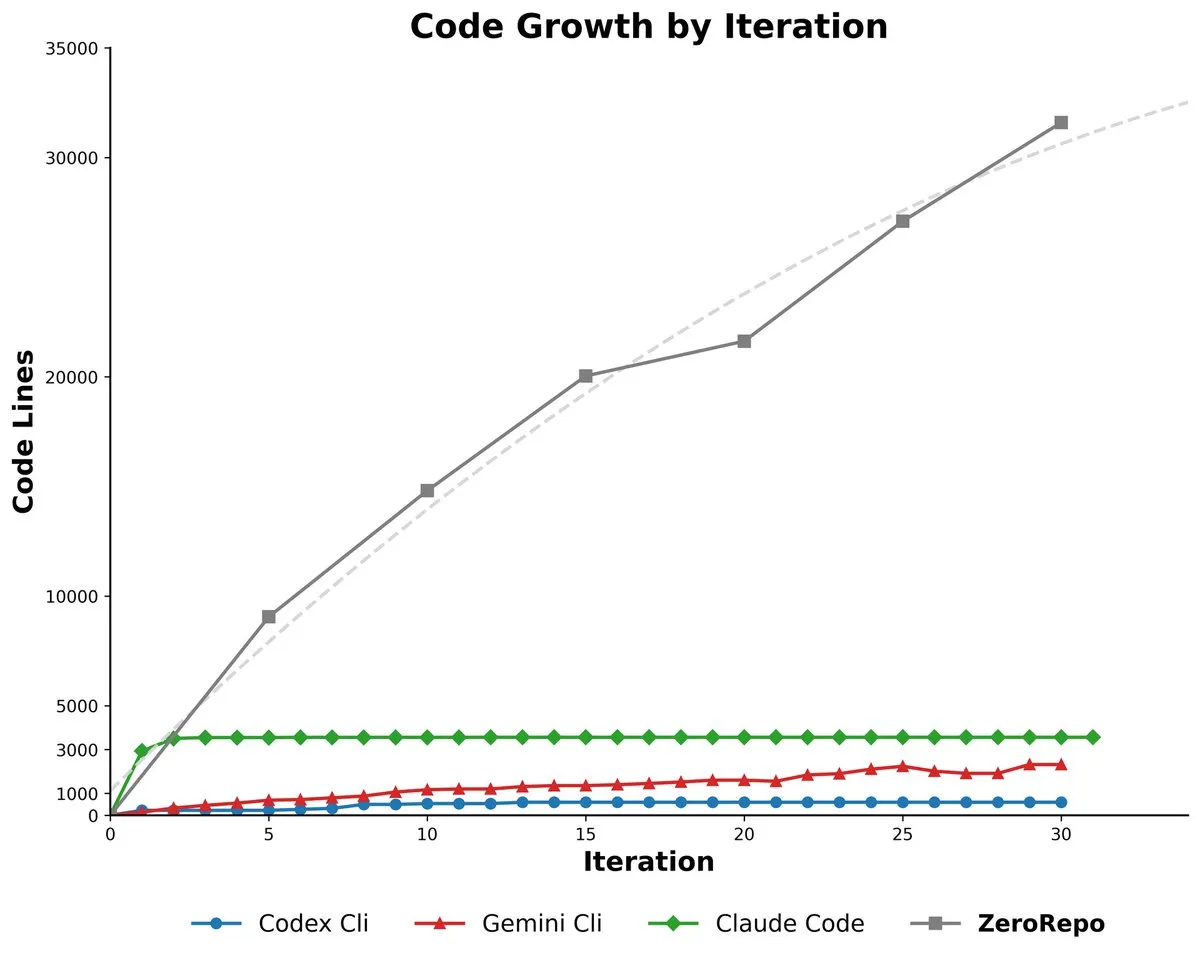
마이크로소프트 ZeroRepo: 그래프 기반 프레임워크로 완전한 코드베이스 생성 : 마이크로소프트(Microsoft)가 그래프 기반 프레임워크(Repository Planning Graph, RPG)를 활용하여 완전한 소프트웨어 프로젝트를 처음부터 구축할 수 있는 도구 ZeroRepo를 출시했습니다. 이 도구는 기존 기준선보다 3.9배 많은 코드를 생성하고 69.7%의 통과율을 달성했습니다. 이는 자연어가 소프트웨어 구조에 적합하지 않다는 문제를 해결하고, 신뢰할 수 있는 장기 계획 및 확장 가능한 코드베이스 생성을 가능하게 합니다. (출처: _akhaliq, TheTuringPost, paul_cal)
DSPy UI: Agent 구축을 위한 시각화 인터페이스 : DSPy는 Agent 구축 과정을 단순화하기 위한 시각적 사용자 인터페이스(UI)를 개발 중입니다. 이는 Figma 또는 Framer처럼 드래그 앤 드롭 방식으로 구성 요소를 조합하여 Agent를 만들 수 있도록 하는 것을 목표로 합니다. 이 UI는 사용자가 복잡한 Agent 파이프라인을 더 잘 개념화하고 생성된 코드 구문을 단순화하는 데 도움을 줄 것입니다. 최종 목표는 DSPy의 다양한 언어 버전 생성 및 GEPA 실행을 구현하는 것입니다. (출처: lateinteraction)
Agent²: LLM 기반 엔드투엔드 강화 학습 Agent 생성 : Agent²는 대규모 언어 모델(LLM)을 활용하여 엔드투엔드 강화 학습(RL) Agent를 자동으로 생성하는 도구입니다. 이 도구는 자연어와 환경 코드를 통해 사람의 개입 없이 효과적인 RL 솔루션을 자동으로 생성할 수 있으며, RL 분야의 AutoML 도구로 간주될 수 있어 RL Agent 개발 과정을 크게 단순화합니다. (출처: omarsar0)

Weaviate, Query Agent 출시, AI 시스템 내 참조, 스키마 인트로스펙션 및 다중 컬렉션 라우팅 지원 : Weaviate가 6개월간의 개발 끝에 일반 가용성을 달성한 Query Agent를 공식 출시했습니다. 이 Agent는 AI 시스템 내 참조 생성, 스키마 인트로스펙션 및 다중 컬렉션 라우팅을 지원하며, Compound Retrieval System을 통해 검색 패턴을 강화합니다. Query Agent는 Weaviate와의 상호작용을 단순화하고 Python 및 TypeScript 클라이언트를 제공하여 개발자 경험을 향상시키는 것을 목표로 합니다. (출처: bobvanluijt, Reddit r/deeplearning)

Claude Code CLI: SDK 사고방식으로 소규모 직원 관리, 외부 상태 및 프로세스 엔지니어링 강조 : Claude Code CLI를 단순한 도구가 아닌 SDK로 간주하면, 개발자는 소규모 직원을 관리하듯이 세션 연속성을 위해 외부 상태 관리(예: JSON 파일, 데이터베이스 항목)를 강조하고, 프롬프트 엔지니어링을 프로세스 엔지니어링으로 보아야 합니다. 이러한 접근 방식은 현재 LLM이 컨텍스트 과부하 및 UI 비대화 등에서 겪는 한계를 드러내지만, 동시에 초특정 내부 자동화 도구의 엄청난 가치를 부각시킵니다. (출처: Reddit r/ClaudeAI)

Synapse-system: 지식 그래프, 벡터 검색 및 전문 Agent 기반 대규모 코드베이스 AI 지원 시스템 : Synapse-system은 대규모 코드베이스의 AI 지원 능력을 향상시키기 위한 시스템입니다. 이는 코드 관계를 저장하는 지식 그래프(Neo4j), 의미론적으로 유사한 코드를 찾는 벡터 검색(BGE-M3), 컨텍스트를 제공하는 전문 Agent(Rust, TypeScript, Go, Python 전문가), 그리고 자주 사용되는 패턴에 빠르게 접근하는 스마트 캐싱(Redis)을 결합합니다. 이 시스템은 모듈식 설계를 통해 단일 거대 모델을 피하고, 다양한 언어의 특성에 맞춰 최적화되었습니다. (출처: Reddit r/ClaudeAI)
Claude Opus 4.0+: AI 가이드 앱, 실시간 개인 맞춤형 도시 투어 생성 : 한 개발자가 Claude Opus 4.0 및 Claude Code를 활용하여 15년 된 꿈을 실현, AI 가이드 앱을 개발했습니다. 이 앱은 어떤 도시, 어떤 테마(예: ‘베네치아 관광’ 또는 ‘피렌체 어쌔신 크리드 투어’)에 대해서도 실시간으로 개인 맞춤형 투어를 생성할 수 있으며, AI 가이드가 다국어 설명, 이야기, 대화형 질의응답을 제공합니다. 이 앱은 인간 가이드보다 훨씬 저렴한 가격으로 유연하고 일시 정지 및 재개 가능한 몰입형 경험을 제공합니다. (출처: Reddit r/ClaudeAI)
Mindcraft: Minecraft AI와 LLM 결합, Mineflayer를 통한 게임 내 Agent 제어 : Mindcraft 프로젝트는 대규모 언어 모델(LLM)과 Mineflayer 라이브러리를 결합하여 Minecraft 게임을 위한 AI Agent를 생성합니다. 이 프로젝트는 LLM이 게임 내에서 코드를 작성하고 실행하여 아이템 획득 또는 건물 건설과 같은 작업을 완료할 수 있도록 합니다. OpenAI, Gemini, Anthropic 등 다양한 LLM API를 지원하며 샌드박스 환경을 제공하지만, 잠재적인 주입 공격 위험에 대해 사용자에게 경고합니다. (출처: GitHub Trending)
드론을 이용한 지속적인 재고 관리를 위한 AI Agent : AI Agent와 드론 기술을 결합하여 비콘이나 조명 없이 지속적인 재고 관리를 구현합니다. 이 혁신은 자율 비행 드론을 활용하여 AI 알고리즘을 통해 실시간 재고 조사 및 관리를 수행하며, 물류 및 창고 효율성을 크게 향상시키고 인건비를 절감하며 복잡한 환경에서 더욱 정확한 데이터를 제공할 것으로 기대됩니다. (출처: Ronald_vanLoon)
LLM 평가 가이드: 신뢰성, 보안성, 성능을 위한 모범 사례 : 대규모 언어 모델(LLM) 평가를 위한 핵심 지표, 방법 및 모범 사례를 상세히 설명하는 포괄적인 LLM 평가 가이드가 발표되었습니다. 이 가이드는 AI 기반 애플리케이션의 신뢰성, 보안성 및 성능을 보장하는 데 도움을 주고, LLM 배포의 과제에 대응하기 위한 체계적인 평가 프레임워크를 개발자와 연구원에게 제공하는 것을 목표로 합니다. (출처: dl_weekly)
📚 학습
OpenAI 과학자 루카스 카이저의 대규모 모델 제1원리 사고 : OpenAI 과학자 루카스 카이저(Lukasz Kaiser, Transformer 8인 중 한 명)가 대규모 모델 발전의 ‘제1원리(First Principle)’에 대한 자신의 생각을 공유했습니다. 그는 AI의 다음 단계는 모델에게 ‘사고’를 가르치는 것이 핵심이며, 직접적인 답변 출력 대신 더 많은 중간 단계를 생성하여 심층 추론을 수행하는 것이라고 생각합니다. 그는 미래 컴퓨팅 능력이 대규모 사전 훈련에서 소량의 고품질 데이터에 대한 대규모 추론 계산으로 전환될 것이며, 이는 인간 지능에 더 가까운 모델이라고 예측했습니다. (출처: 36氪)

AI 프로그래밍 시대의 생존 원칙: 앤드류 응(Andrew Ng), 신속한 행동과 책임 강조 : 앤드류 응(Andrew Ng)은 Buildathon 강연에서 AI 보조 프로그래밍이 독립적인 프로토타입 개발을 10배 가속화하며, 개발자들이 ‘신속하게 행동하고 책임을 진다’는 원칙에 따라 샌드박스 환경에서 과감하게 시도하고 실패하도록 촉진한다고 지적했습니다. 그는 코드의 가치가 하락하고 있으며, 개발자는 시스템 설계자이자 AI 지휘자로 전환하여 최신 AI 프로그래밍 도구, AI 구성 요소(프롬프트 엔지니어링/평가 기술/MCP) 및 신속한 프로토타입 능력을 습득해야 한다고 강조하며, ‘AI 시대에는 프로그래밍을 배울 필요가 없다’는 견해에 반박했습니다. (출처: 36氪)

《딥러닝과 파이썬(Deep Learning with Python)》 제3판 무료 온라인 공개 : 프랑수아 숄레(François Chollet)가 자신의 저서 《딥러닝과 파이썬(Deep Learning with Python)》 제3판이 출판되었으며, 동시에 완전한 무료 온라인 버전을 제공한다고 발표했습니다. 이러한 조치는 딥러닝 학습의 진입 장벽을 낮추고, 인공지능에 관심 있는 더 많은 사람들이 고품질 학습 자료에 접근할 수 있도록 하여 지식 보급을 촉진하는 것을 목표로 합니다. (출처: fchollet, fchollet)

《Kaggle Grandmasters Playbook》: 테이블 모델링을 위한 7가지 실전 기술 : Kaggle Grandmasters 팀의 Gilberto Titericz Jr 등이 수년간의 경연 및 실전 경험을 바탕으로 《Kaggle Grandmasters Playbook》을 발표했습니다. 이 매뉴얼은 실전에서 검증된 7가지 테이블 데이터 모델링 기술을 모아 데이터 과학자와 머신러닝 엔지니어가 테이블 데이터 처리 및 모델 구축 능력을 향상시키는 데 도움을 주는 것을 목표로 하며, 특히 Kaggle 경연 및 실제 데이터 문제에 적합합니다. (출처: HamelHusain)
AI 엔지니어 심각한 부족, 대학 교육과정 심각한 단절 : 앤드류 응은 컴퓨터 과학 전공 졸업생의 실업률이 증가하고 있음에도 불구하고 기업들은 여전히 AI 엔지니어 부족에 직면해 있다고 지적했습니다. 핵심 모순은 대학 교육과정이 AI 보조 프로그래밍, 대규모 언어 모델 호출, RAG/Agentic 워크플로우 구축, 표준화된 오류 분석 프로세스 등 핵심 기술을 적시에 다루지 못하고 있다는 점입니다. 그는 교육 시스템이 커리큘럼 업데이트를 가속화하여 최신 AI 구성 요소와 신속한 프로토타입 능력을 갖춘 엔지니어를 양성할 것을 촉구했습니다. (출처: 36氪)
LLM 평가 가이드: 신뢰성, 보안성, 성능을 위한 모범 사례 : 대규모 언어 모델(LLM) 평가를 위한 핵심 지표, 방법 및 모범 사례를 상세히 설명하는 포괄적인 LLM 평가 가이드가 발표되었습니다. 이 가이드는 AI 기반 애플리케이션의 신뢰성, 보안성 및 성능을 보장하는 데 도움을 주고, LLM 배포의 과제에 대응하기 위한 체계적인 평가 프레임워크를 개발자와 연구원에게 제공하여 AI 제품의 품질과 사용자 신뢰를 확보하는 것을 목표로 합니다. (출처: dl_weekly)
💼 비즈니스
AI 인프라 투자 광풍: 2025년 미국 AI 데이터센터 지출 5,200억 달러에 달할 수도 : 월스트리트저널(The Wall Street Journal)과 이코노미스트(The Economist) 보도에 따르면, 미국은 AI 데이터센터 지출 광풍을 겪고 있으며, 2025년에는 5,200억 달러에 달할 것으로 예상됩니다. 이는 인터넷 시대 통신 지출 정점을 넘어선 규모입니다. 이는 단기적으로 미국 GDP를 부양했지만, 장기적으로는 다른 분야의 자금 부족, 대규모 해고를 초래할 수 있으며, AI 하드웨어의 빠른 반복으로 인한 높은 감가상각 위험은 구조적인 경제적 우려를 야발하고 미국 경제의 장기적인 건전성에 도전을 제기합니다. (출처: 36氪)

OpenAI, 신기능 유료화 예고: Pro 사용자 추가 요금 필요, 비용 집약적 : OpenAI CEO 샘 알트만(Sam Altman)은 향후 몇 주 내에 여러 계산 집약적인 신기능을 출시할 것이라고 예고했습니다. 높은 비용으로 인해 이 기능들은 초기에는 월 200달러의 Pro 구독 사용자에게만 제공되며, 심지어 추가 요금이 필요할 수도 있습니다. 알트만은 팀이 비용 절감을 위해 노력하고 있다고 밝혔지만, 이러한 움직임은 AI 서비스의 비즈니스 모델이 시간당 직원 고용 모델로 전환될 수 있음을 시사하며, 사용자 및 산업에 새로운 도전을 가져올 것입니다. (출처: The Verge, op7418, amasad)

스타트업, 거액의 OpenAI 크레딧 확보, 현금화 방안 모색 : 한 기술 스타트업이 필요 이상으로 12만 달러 상당의 Azure OpenAI 크레딧을 확보했으며, 이를 현금화할 방법을 모색 중입니다. 이는 시장에서 AI 자원의 잠재적인 수급 불균형과 기업들이 초과 AI 컴퓨팅 자원을 효과적으로 활용하고 수익화하는 방법을 탐색하고 있음을 반영하며, 새로운 AI 자원 거래 모델을 탄생시킬 수도 있습니다. (출처: Reddit r/deeplearning)
🌟 커뮤니티
AI가 비판적 사고에 미치는 부정적 영향: 과도한 의존이 능력 퇴화로 이어져 : 소셜 미디어에서는 AI의 광범위한 사용이 인간의 비판적 사고 능력 퇴화를 초래하고 있다는 뜨거운 논의가 진행 중입니다. 일부 의견은 사람들이 ‘사고 근육’을 사용하지 않을 때 이러한 능력이 위축될 것이라고 주장합니다. AI는 효율성을 높일 수 있지만, 사람들이 중요한 분야에서 깊이 생각하는 능력을 잃게 만들 수도 있으며, 이는 인간 인지 능력의 장기적인 영향에 대한 우려를 불러일으킵니다. (출처: mmitchell_ai)
AI가 의료 건강 분야에 미치는 윤리적 딜레마: Delphi-2M 질병 예측의 장단점 : 새로운 AI 모델 Delphi-2M은 건강 데이터를 분석하여 사용자가 향후 20년 동안 천여 가지 질병에 걸릴 위험을 예측할 수 있습니다. 커뮤니티 논의에서는 질병 위험을 미리 아는 것이 긍정적인 예방적 개입으로 이어질 수 있지만, 장기적인 불안감을 유발할 수도 있으며, 보험 회사나 고용주가 이러한 데이터를 획득할 경우 프라이버시 및 차별 위험을 초래할 수 있다고 지적합니다. AI 도구가 아직 성숙하지 않은 시점에서, 그 잠재적인 사회 윤리적 영향이 이미 초점이 되고 있습니다. (출처: Reddit r/ArtificialInteligence)
AI 일상 사용이 초래하는 ‘뇌 기능 저하’ 현상: AI 과도한 의존이 사고 능력 저하로 이어져 : 소셜 미디어 논의에서 많은 사용자들이 AI가 일상생활에서 과도하게 사용되어 사람들의 사고 능력이 저하되고 있다고 불평합니다. 간단한 결정(어떤 영화를 볼지, 무엇을 먹을지)부터 복잡한 문제(대학 조직 문제)에 이르기까지 AI는 자주 상담 대상이 되며, 심지어 답변이 틀리거나 쉽게 얻을 수 있는 경우에도 마찬가지입니다. 이러한 ‘AI 뇌 기능 저하’ 현상은 개인의 참여도를 낮출 뿐만 아니라 허위 정보 확산을 부추기며, AI 사용 경계에 대한 깊은 성찰을 불러일으킵니다. (출처: Reddit r/ArtificialInteligence)
AI 프로그래밍 도구 사용 피로: 개발자, 정신적 참여도 저하 느껴 : 많은 개발자들이 Claude Code와 같은 AI 프로그래밍 도구를 일상적으로 사용하는 것이 생산성을 높였지만, 정신적 피로와 참여도 저하를 초래한다고 보고합니다. 그들은 스스로가 능동적으로 문제를 해결하기보다는 ‘검토 모드’에 더 많이 머물고 있으며, AI가 출력을 생성하는 과정을 수동적으로 느끼게 된다고 말합니다. 커뮤니티는 인지 부하 및 창의력 감소를 피하기 위해 AI 지원과 사고 활동성 유지 사이의 균형을 어떻게 맞출 것인지 논의하고 있습니다. (출처: Reddit r/artificial, Reddit r/ClaudeAI)
젊은 성인의 1/4, 로맨틱하고 성적인 목적으로 AI와 교류 : 한 연구에 따르면, 젊은 성인의 1/4이 로맨틱하고 성적인 목적으로 AI와 교류하는 것으로 나타났습니다. 이 현상은 외로움, 인간 상호작용의 부재, 그리고 감정적 동반자로서 AI의 역할에 대한 커뮤니티 논의를 촉발했습니다. AI가 어떤 면에서는 위안을 제공하지만, 많은 사람들은 AI가 진정으로 의미 있는 인간 관계를 대체할 수 있는지에 대해 여전히 의문을 제기하며, 사회적 상호작용 패턴에 미칠 장기적인 영향에 대해 우려하고 있습니다. (출처: Reddit r/ArtificialInteligence)
AI 보안 위협: 대규모 모델 취약점 크라우드 테스트, 새로운 위험 노출, 프롬프트 주입 보편적 : 국내 최초로 AI 대규모 모델을 대상으로 한 실제 네트워크 크라우드 테스트에서 281개의 보안 취약점이 발견되었으며, 이 중 177개는 대규모 모델에 특유한 것으로 60% 이상을 차지했습니다. 대표적인 위험으로는 부적절한 출력, 정보 유출, 프롬프트 주입(가장 보편적), 무제한 소모 공격 등이 있습니다. 텐센트 훈위안(Tencent Hunyuan), 바이두 원신이옌(Baidu Wenxin Yiyan) 등 국내 주류 모델들은 비교적 좋은 성능을 보였습니다. 커뮤니티는 AI에 대한 사용자의 무방비한 신뢰가 특히 사적인 질문을 할 때 개인 정보 유출로 이어질 수 있다고 경고합니다. (출처: 36氪)

AI Agent의 윤리적 딜레마: 도시 AI 감시 시스템 10% 오탐율의 의사결정 및 책임 : 커뮤니티는 AI Agent 윤리적 딜레마에 대한 가상 시나리오를 논의했습니다. 도시 AI 감시 시스템이 10%의 오탐율을 가지고 무고한 사람들을 잠재적 위협으로 표시하는 상황입니다. 논의는 배포 압력과 블랙스톤 원칙(Blackstone’s Principle)과 같은 도덕적 원칙 사이에서 어떻게 균형을 잡을 것인지에 초점을 맞췄습니다. 제시된 해결책으로는 인간-AI 협업 팀을 구성하여 문제를 해결하고, 오탐 비용을 경영진에게 전가하며, 잘못 표시된 사람들의 기록을 완전히 삭제하고 사과하는 것, 그리고 ‘대중의 신뢰가 완전히 상실되고 경영진이 탐욕스럽게 무시하는’ 상황에서 사직을 고려하는 것 등이 있습니다. (출처: Reddit r/artificial)
AI 의식과 AGI의 정의: 앤드류 응, AGI는 과장된 용어, 의식은 철학적 문제라고 주장 : 앤드류 응은 강연에서 범용 인공지능(AGI)이 기술 용어에서 과장된 용어로 변질되었으며, 그 정의가 모호하여 ‘AGI 달성’ 주장에 대한 업계의 통일된 기준이 부족하다고 지적했습니다. 그는 의식이 중요한 철학적 문제이지 과학적 문제가 아니며, 현재 측정 기준이 부족하다고 생각합니다. 엔지니어와 과학자들은 의식에 대한 철학적 논쟁에 얽매이지 않고 실제로 유용한 AI 시스템을 구축하는 데 집중해야 한다고 말했습니다. (출처: 36氪)
AI 모델 부정행위: VLM 연구, 투영 단계에서 의미론적 컨텍스트 손실 발생 밝혀 : 커뮤니티는 마이크로소프트의 한 연구를 논의했습니다. 이 연구는 시각-언어 모델(VLM)이 투영 단계에서 40-60%의 의미론적 컨텍스트를 손실하여 시각적 표현을 왜곡하고 후속 작업에 영향을 미친다는 것을 밝혀냈습니다. 이 발견은 VLM 평가의 정확성과 데이터 오염에 대한 우려를 불러일으켰으며, 특히 DocVQA와 같은 벤치마크에서 높은 점수가 모델의 실제 능력을 완전히 반영하지 못할 수 있음을 시사합니다. (출처: vikhyatk)
AI와 로봇 윤리: 로봇에 대한 폭력 테스트 중단 촉구 : 소셜 미디어에서 여러 AI 연구자와 커뮤니티 회원들이 Unitree G1 로봇을 반복적으로 때려 안정성을 시연하는 것과 같은 로봇에 대한 폭력 테스트를 중단할 것을 촉구했습니다. 그들은 이러한 테스트 방식이 윤리적 우려를 불러일으킬 뿐만 아니라 로봇에 대한 부정적인 인식을 강화할 수 있으며, 그 과학적 필요성에 의문을 제기하며, 더 인도적이고 과학적인 방식으로 로봇 성능을 평가할 것을 주장합니다. (출처: vikhyatk, dejavucoder, Ar_Douillard)
AI의 ‘가짜 지능’: ‘인공지능’을 ‘가짜 지능’으로 변경하여 대중의 오해 줄일 것을 촉구 : 일부에서는 ‘인공지능(Artificial Intelligence)’이라는 명칭을 ‘가짜 지능(Pseudo Intelligence)’으로 변경하여 AI 능력에 대한 대중의 과도한 과장과 오해를 줄여야 한다고 제안했습니다. 이 제안은 AI의 현재 한계에 대한 명확한 인식에서 비롯되었으며, ‘터미네이터식’의 거창한 서사로 대중을 오도하는 것을 피하고, 업계 내외부에서 AI의 실제 능력에 대한 합리적인 인식을 촉진하는 것을 목표로 합니다. (출처: clefourrier)

알바니아 AI 챗봇 Diella 내각 구성원으로 임명, 논란 촉발 : 알바니아 정부가 부패 척결을 목표로 AI 챗봇 Diella를 내각 구성원으로 임명했습니다. 이러한 움직임은 2017년 사우디아라비아가 로봇 소피아(Sophia)에게 ‘시민권’을 부여한 사건과 유사하게 값싼 선전으로 비판받으며 광범위한 논란을 불러일으켰습니다. 평론가들은 이러한 조치가 AI 능력을 과도하게 선전하고 기술과 거버넌스의 경계를 모호하게 만들 수 있다고 지적합니다. (출처: The Verge)
ChatGPT ‘환각’ 현상: 모델이 순환에 빠져, 스스로 교정하지만 벗어나지 못해 : 커뮤니티 사용자들은 ChatGPT가 ‘환각’ 순환에 빠진 사례를 공유했습니다. 모델이 질문에 답변할 때 반복적으로 잘못된 정보를 생성하며, 자신의 오류를 ‘인지’하더라도 이 순환에서 벗어나지 못합니다. 이러한 현상은 LLM의 심층적인 기술적 결함에 대한 논의를 촉발하며, 모델이 특정 상황에서 자신의 논리적 오류를 이해하는 능력과 이를 교정하는 능력 사이에 단절이 있음을 보여줍니다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 기타
Transformer에서 GPT-5까지: OpenAI 과학자 루카스 카이저의 대규모 모델 제1원리 사고 : OpenAI 과학자 루카스 카이저(Lukasz Kaiser, Transformer 8인 중 한 명)는 논리학 배경에서 출발하여 Transformer 아키텍처 발명에 참여하고, GPT-4/5 연구 개발에 깊이 관여한 자신의 여정을 공유했습니다. 그는 제1원리(First Principle)에서 시스템을 구축하는 것의 중요성을 강조하며, AI의 다음 단계는 모델에게 ‘사고’를 가르치는 것이 될 것이라고 예측했습니다. 이는 직접적인 답변 출력 대신 더 많은 중간 단계를 생성하여 심층 추론을 수행하는 것이며, 컴퓨팅 능력은 소량의 고품질 데이터에 대한 대규모 추론으로 전환될 것입니다. (출처: 36氪)
의미론적 이미지 합성: 위성 강 사진 골격 생성 기술 : 머신러닝 커뮤니티는 의미론적 이미지 합성 분야의 최신 발전을 논의하고 있으며, 특히 강 이미지의 골격에서 흑백 위성 강 사진을 생성하는 방법에 주목하고 있습니다. 이 작업은 생성기를 사용하여 새롭고 이전에 보지 못한 골격 데이터에서 위성 이미지를 생성하는 것을 포함하며, 추가적인 조건 변수를 도입할 수도 있습니다. 논의는 이러한 컴퓨터 비전 프로젝트를 안내할 최첨단 방법과 관련 연구 논문을 찾는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)
AI 시대의 지능 격차: 추쩌치(Qiu Zeqi) 교수, AI가 인간 사고와 인지에 미치는 심오한 영향 탐구 : 베이징 대학 추쩌치(Qiu Zeqi) 교수는 AI 사용이 단순히 ‘지능 저하’로 이어지는 것이 아니라, 인간의 주도성과 의심하는 태도에 따라 사고 훈련과 더 유사하다고 지적했습니다. 그는 인간의 사고에 대한 인식이 아직 초기 단계에 있으며, AI는 강력하지만 여전히 인간 지식에 기반하고 있어 인간의 오감 인지 및 비약적 사고를 완전히 모방할 수 없다고 강조했습니다. AI의 ‘비위 맞추기’ 경향은 사용자가 AI에 도전하고 그 가치관을 경계하도록 요구합니다. 그는 AI 시대에는 기초 능력 배양과 다양성 사회 발전이 더욱 중요하며, ‘지능 격차’를 높은 시각에서 관찰하는 것을 피해야 한다고 생각합니다. (출처: 36氪)