
키워드:xAI, 메이투안 오픈소스 대형 모델, 앤드류 응, 메타, 휴머노이드 로봇, 롱캣-플래시-챗, 병렬 에이전트, 스케일 AI 데이터 품질, 히터 탁구 로봇, 딥시크-V3.1
🔥 포커스
xAI 코드베이스 도난 사건 : 일론 머스크는 xAI의 전체 코드베이스가 전 직원 Xuechen Li에 의해 도난당했으며, 해당 직원은 OpenAI로 이직했다고 확인했다. xAI는 해당 직원이 기밀 유지 계약을 위반하고 영업 비밀을 침해했다며 소송을 제기했으며, 이 직원이 퇴사 전 약 700만 달러를 현금화했다고 밝혔다. 이는 AI 인재 경쟁과 영업 비밀에 대한 광범위한 관심을 불러일으켰다. (출처: 量子位, TheRundownAI)
메이투안, 오픈소스 대규모 모델 Longcat-Flash-Chat 공개 : 메이투안은 첫 오픈소스 대규모 모델 Longcat-Flash-Chat (560B MoE)을 발표했다. 이 모델은 Agent 도구 호출, 명령어 준수 및 프로그래밍 능력에서 DeepSeek-V3.1 및 Qwen3 MoE-2507을 능가하며, Claude4 Sonnet과 동급 수준이다. 이 모델은 “제로 컴퓨팅 전문가”와 Shortcut-connected MoE 아키텍처를 채택하여 훈련 및 추론 처리량을 크게 향상시켰다. 메이투안은 AI 분야에서 깊은 실력을 보여주며 훈련 세부 정보를 상세히 공개했다. (출처: 量子位, ZhihuFrontier, karminski3)

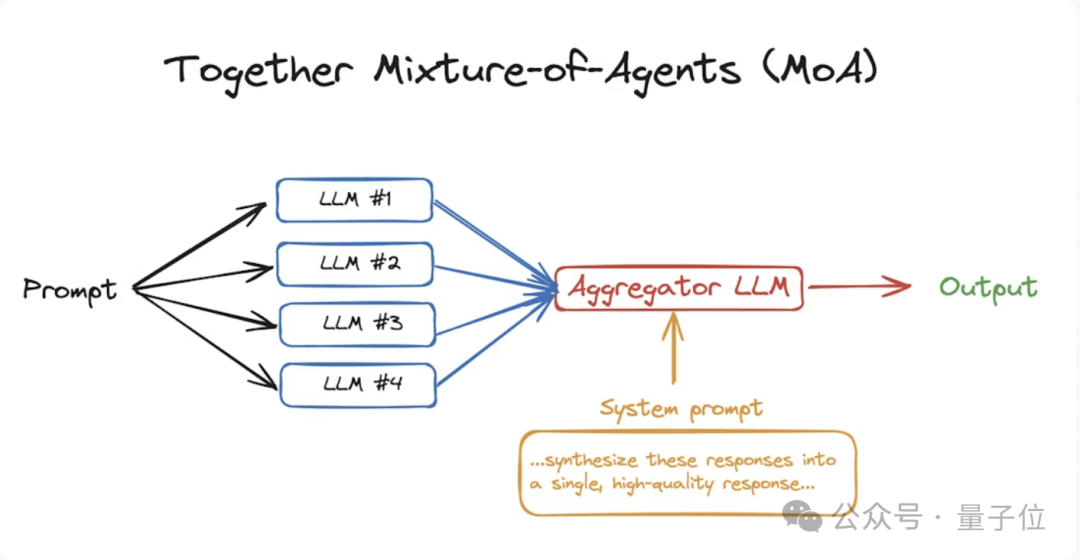
앤드류 응, 병렬 Agent 강조 : 앤드류 응(Andrew Ng)은 최신 서신에서 병렬 Agent가 AI 능력 향상의 새로운 방향이라고 지적했다. 이는 여러 Agent가 협력하여 심층 연구 보고서를 빠르게 생성하고, 프로그래밍 작업을 가속화하며, 병렬 비동기 제어를 실현할 수 있게 한다. 그는 대규모 언어 모델(LLM) 토큰 비용이 하락함에 따라 병렬 Agent가 미래 AI 발전의 중요한 트렌드가 될 것이라고 보며, Code Monkeys와 Together Mixture Of Agents (MoA) 등의 연구 사례를 인용했다. (출처: 量子位, DeepLearningAI)
Meta와 Scale AI의 협력 관계 긴장 : Meta가 Scale AI에 143억 달러를 투자한 후 양측의 협력 관계에 균열이 생겼다. Scale AI의 전 고위 임원 Ruben Mayer는 Meta에 합류한 지 두 달도 안 되어 퇴사했으며, Meta 내부 연구원들도 Scale AI 데이터 품질에 의문을 제기하며 다른 데이터 라벨링 회사로 전환하고 있다. 동시에 Meta 내부에서는 신구 팀 간의 마찰과 인재 유출이 발생하고 있으며, Google 또는 OpenAI 모델을 자체 애플리케이션에 통합하는 것을 고려하는 등 AI 전략에 대한 불확실성을 보이고 있다. (출처: 36氪, TheRundownAI)

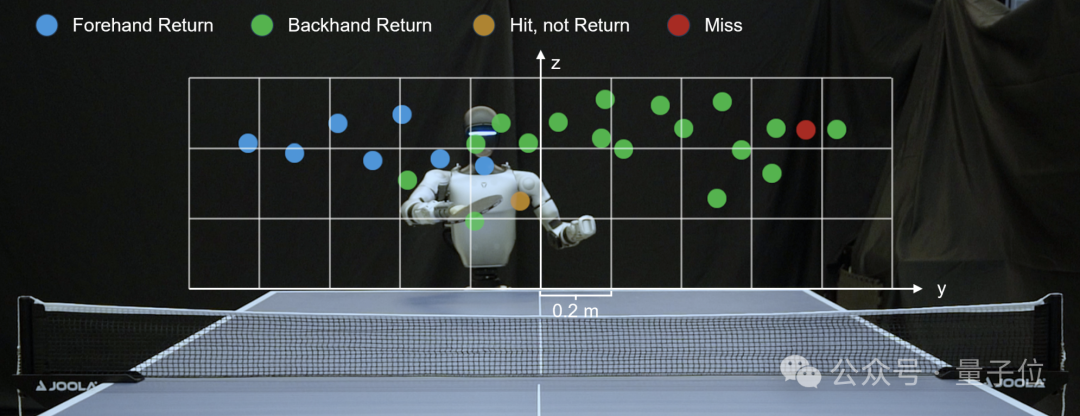
인간형 로봇 탁구 고수 HITTER : 칭화대 야오반 학부생 쑤즈(Su Zhi) 팀은 논문 《HITTER》를 발표하며, 모델 계획과 강화 학습을 결합한 계층적 프레임워크를 제안했다. 이를 통해 인간형 로봇이 아초(sub-second) 반응 속도로 안정적으로 탁구를 연속해서 칠 수 있게 되었으며, 최고 106번의 랠리를 기록했다. 이 로봇은 Unitree G1의 손바닥을 탁구채로 변형하고, OptiTrack 카메라로 공을 추적하며, 인간 동작 참조를 통해 훈련하여 동적 환경에서 빠르게 움직이는 물체와 상호작용하는 뛰어난 능력을 보여주었다. (출처: 量子位)
🎯 동향
DeepSeek-V3.1 모델 업데이트 및 투명성 향상 : DeepSeek은 V3.1 모델 업데이트를 발표했다. 여기에는 가격 조정, 모델 아키텍처 개선 (V3.1 Base는 V3를 기반으로 지속적인 사전 훈련을 통해 긴 컨텍스트 확장), 그리고 도구 및 Agent 능력 강화 (SWE/Terminal-Bench 성능 향상, 다단계 추론 효율성 증대)가 포함된다. 또한, 《인공지능 생성 합성 콘텐츠 식별 방법》에 따라 DeepSeek은 모든 AI 생성 콘텐츠에 명시적인 라벨링을 할 것을 약속했으며, V3/R1 모델 훈련 세부 정보를 공개하여 데이터 거버넌스 프로세스와 사용자 선택권을 강조하며 환각 및 오용 위험에 대응하고 있다. (출처: deepseek_ai, 36氪)

구글 Pixel 10 시리즈 휴대폰, AI 기능 전용 메모리 할당 : 구글은 Pixel 10 시리즈 휴대폰에 AI 기능을 위해 3.5GB 메모리를 특별히 할당했으며, 이는 Tensor G5의 TPU만 사용할 수 있다. 이 조치는 7B 규모, 4비트 양자화 AI 모델이 3.5GB-4GB 메모리를 필요로 하므로, 멀티태스킹 시 발생할 수 있는 지연 문제를 해결하여 온디바이스 AI 경험을 최적화하기 위함이다. 그러나 이러한 설계는 휴대폰의 실제 사용 수명을 단축시킬 수 있으며, 온디바이스 AI를 사용하지 않는 사용자에게는 실제 사용 가능한 메모리가 줄어들어 “공유” 논란을 불러일으키고 있다. (출처: 36氪)

테슬라, 중국 시장에서 Doubao 및 DeepSeek 대규모 모델 통합 : 테슬라 중국 공식 웹사이트 업데이트에 따르면, 새로운 Model Y L 모델은 바이트댄스의 Doubao 대규모 모델과 DeepSeek 모델을 탑재할 예정이며, 두 모델 모두 Volcano Engine을 통해 연결된다. Doubao 모델은 음성 명령 및 차량 소유자 매뉴얼 검색을 담당하고, DeepSeek은 AI 음성 채팅 서비스를 제공한다. 이 조치는 테슬라가 중국 시장에서 AI 기능 구현 부족을 보완하기 위한 “긴급 보충 수업”으로 여겨지며, 자동차 제조업체들이 스마트 콕핏 AI 기능 업그레이드에 대한 보편적인 요구를 반영한다. (출처: 36氪)

중국 오픈소스 LLM 시장 8월 회고 : 즈후(Zhihu) 칼럼은 2025년 8월 중국 오픈소스 LLM의 활발한 동향을 요약했다. XBai-o4, 텐센트 Hunyuan 시리즈 소형 모델, 알리바바 Qwen-Image, 샤오미 MiDashengLM-7B, 샤오홍슈 dots.vlm1, OpenBMB MiniCPM-V-4 등이 포함되며, 텍스트, 이미지, 오디오, 멀티모달 및 Agent 모델을 망라한다. DeepSeek-V3.1은 코딩 능력이 향상되었으나, 일반 텍스트 능력은 다소 약했다. 전반적으로 중국 AI 생태계의 치열한 경쟁과 모델 종류 및 기능의 지속적인 풍부화를 보여준다. (출처: ZhihuFrontier, ostrisai)

의료 건강 분야에서의 Generative AI 적용 : Generative AI는 의료 건강 분야에서 질병 진단, 신약 개발, 맞춤형 치료 계획, 스마트 건강 관리 등 광범위한 적용 잠재력을 보여준다. AI는 방대한 데이터를 분석하여 의사가 더 정확한 판단을 내리고, 의료 프로세스를 최적화하며, 환자에게 맞춤형 건강 서비스를 제공하는 데 도움을 줄 수 있다. (출처: Ronald_vanLoon, Ronald_vanLoon, ClementDelangue)

엣지 디바이스에서의 TinyML 배포 실천 : TinyML은 제한된 하드웨어에서 AI가 작동하는 방식을 변화시키며, 실시간 예측, 낮은 지연 시간, 높은 에너지 효율성 및 개인 정보 보호를 가능하게 한다. 성공적인 배포를 위해서는 경량 모델 아키텍처 채택, 메모리 사용 최적화 (예: 정적 메모리 할당, 양자화), 전력 소비 절감 (저전력 모드, 이벤트 기반 추론) 및 대상 하드웨어에서의 테스트 등 모범 사례를 따라야 한다. 이러한 실천은 마이크로컨트롤러, IoT 센서 등 엣지 디바이스에서 AI 기능을 구현하는 데 필수적이다. (출처: Reddit r/deeplearning)
AI 동반 로봇, 독거노인 외로움 문제 완화 : 한국 스타트업 효돌(Hyodol)이 개발한 AI 인형이 독거노인에게 대규모로 배포되어 24시간 동반, 건강 모니터링 (예: 약 복용 알림, 활동 감지) 및 긴급 경보 기능을 제공하고 있다. 인형에는 ChatGPT 대화 시스템이 내장되어 노인과 대화하고 감정 상태를 평가할 수 있다. 외로움과 간병 비용 부담을 완화하는 동시에, 개인 정보 유출, 과도한 의존 및 치매 환자에게 미치는 영향 등 윤리적, 안전 문제도 제기되고 있다. (출처: 量子位)

GPT-5 모델의 Agent 성능 및 AGI 진전 논의 : GPT-5가 Agent 성능에서 향상되었다는 의견이 있지만, AGI(범용 인공지능)에 근접했는지에 대해서는 논란이 있다. 일부는 확장 법칙이 보편적으로 적용되지 않으며, 샘 알트만의 AGI 관련 발언에 유보적인 입장을 보이며, LLM이 수학과 같은 기초 작업에서 여전히 부족하다고 지적한다. Google DeepMind는 8월에 Nano Banana, Gemini, Veo 등 일련의 AI 업데이트를 발표했으며, NousResearch Hermes 4 70B 및 GPT-OSS 120B와 같은 모델도 Agent 작업 및 코딩 테스트에서 뛰어난 성능을 보였다. (출처: gfodor, Teknium1, nickfrosst, Reddit r/ArtificialInteligence, _philschmid, stablequan, Reddit r/LocalLLaMA)
🧰 도구
Fooocus 이미지 생성 소프트웨어 업데이트 : Fooocus는 Stable Diffusion XL 기반의 오프라인 오픈소스 이미지 생성 소프트웨어로, 사용자 경험 간소화에 중점을 두어 프롬프트에만 집중하면 된다. 현재 프로젝트는 제한된 장기 지원(LTS) 단계에 있으며, 버그 수정만 진행하고 Flux와 같은 새로운 모델 아키텍처로의 마이그레이션 계획은 아직 없다. 고품질 텍스트-이미지, 이미지 편집 (Inpaint/Outpaint), 이미지 프롬프트, 다양한 스타일 및 고급 매개변수 조정을 지원하며, 낮은 GPU 메모리 (4GB Nvidia)에서도 잘 작동한다. (출처: lllyasviel/Fooocus – GitHub Trending)

Resemble AI, 오픈소스 TTS 모델 Chatterbox 출시 : Resemble AI는 MIT 라이선스를 따르는 프로덕션급 오픈소스 TTS 모델 Chatterbox를 출시했다. 이 모델은 0.5B Llama 백본을 기반으로 제로샷 TTS에서 뛰어난 성능을 보이며, 독특한 감정 과장 제어를 지원하고 50만 시간의 데이터로 훈련되어 PerTh 워터마크가 포함된 출력을 생성한다. Chatterbox는 측면 평가에서 ElevenLabs와 같은 클로즈드 소스 시스템보다 지속적으로 우수하며, 밈, 비디오, 게임 및 AI Agent 등 다양한 애플리케이션 시나리오에 적합하다. (출처: resemble-ai/chatterbox – GitHub Trending)

소프트웨어 개발에서의 Claude Code 활용 및 비교 : Claude Code는 개발자들 사이에서 소프트웨어 엔지니어링, 특히 AI Agent 구축 및 개발 프로세스 자동화 (예: 제품 책임자, 테스트 작성자, 엔지니어 및 코드 검증자 등 가상 팀 Agent 생성)에 널리 사용되며 뛰어난 성능을 보인다. CLI 도구와 세분화된 맞춤 설정 기능이 호평을 받고 있다. 그러나 일부 사용자들은 최근 Claude Code의 코드 품질이 저하되었다고 보고했으며, GPT-5 High와 비교했을 때 GPT-5가 복잡한 문제 처리에서 더 강력할 수 있지만, CLI 경험과 맞춤 설정 정도는 Claude Code보다 못하다는 의견도 있다. (출처: op7418, omarsar0, amasad, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

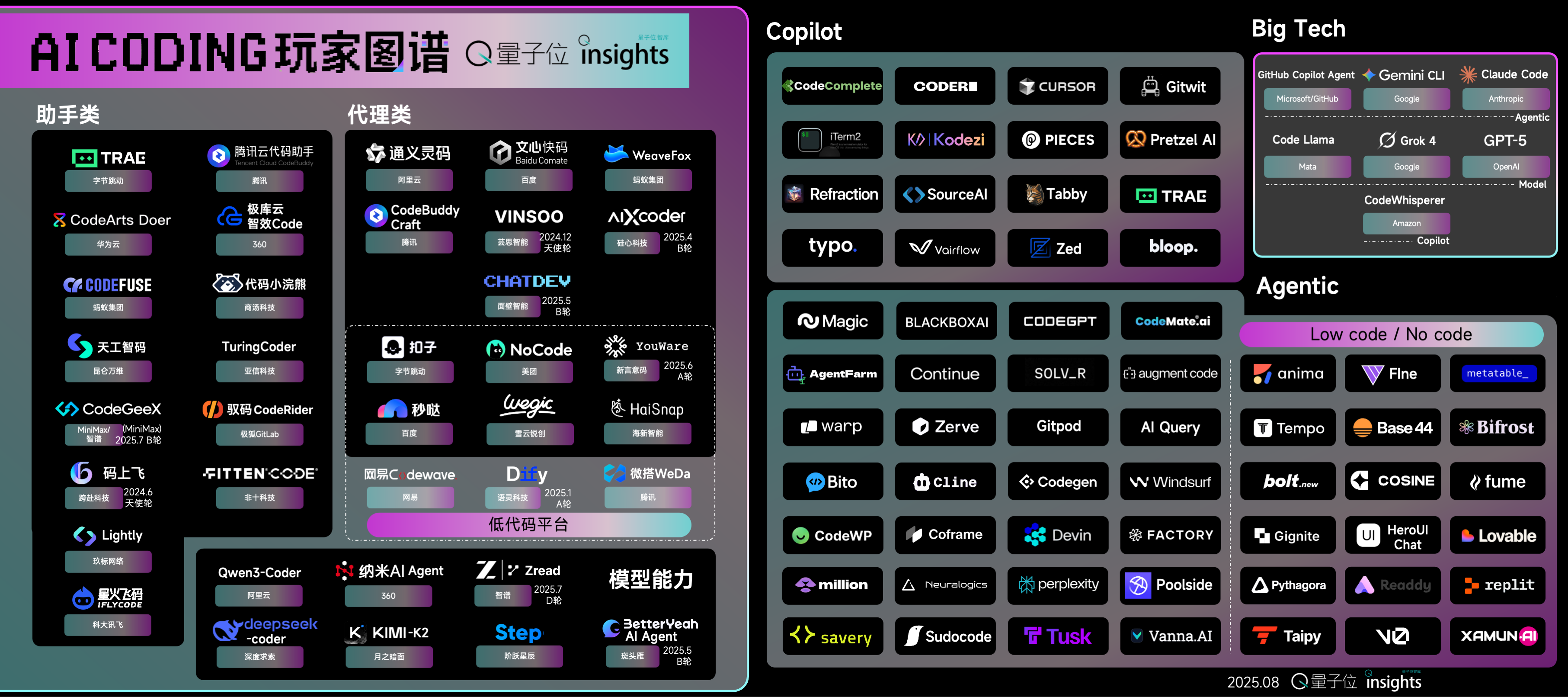
AI Coding 플레이어 지도 및 발전 추세 : 양자위(Qbitai) 싱크탱크 보고서는 AI Coding 시장 구도를 분석하며, 에이전트형 제품과 로우코드 플랫폼이 증가하고 있으며, 어시스턴트형 제품도 Agent 기능을 시도하기 시작했다고 지적했다. Anthropic Claude, Google Gemini, OpenAI GPT와 같은 기본 모델 제조업체들은 코딩 능력을 향상시키고 SOTA를 경신하고 있다. AI의 코딩 개입 범위는 코드 완성에서 “start to PR”까지 확장되었지만, 대부분의 제품은 여전히 “일회성 제품”이며, 미래에는 기억 및 컨텍스트 재사용 능력을 갖추고 완전한 개발 주기에 통합되어야 할 것이다. (출처: 量子位)
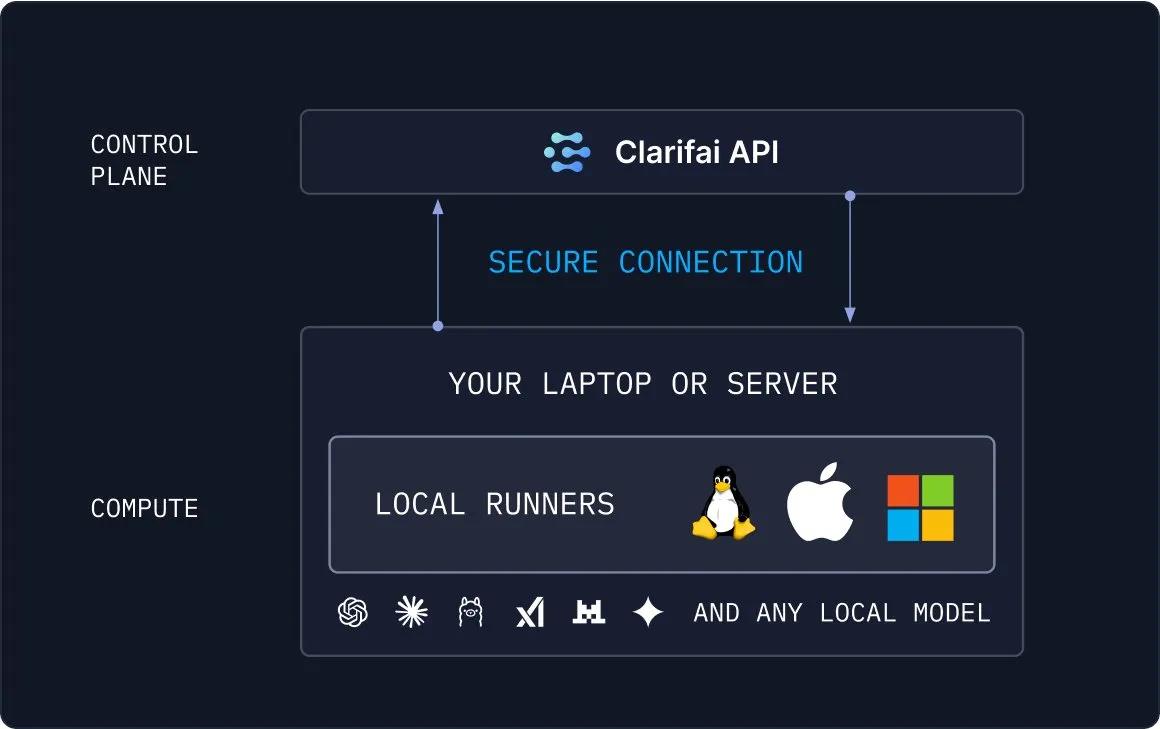
MLOps 및 RAG 도구로 AI 개발 간소화 : Clarifai는 사용자가 모델을 로컬에서 실행하고 클라우드와 연결할 수 있는 Local Runners 도구를 출시하여 MLOps 프로세스를 간소화했다. 동시에 Weaviate 벡터 데이터베이스는 코딩 없이 PDF 문서에 RAG를 구축하는 빠른 경로를 제공하며, Unstructured 라이브러리를 통해 콘텐츠를 추출하여 의미 검색 및 질의응답을 구현한다. 이러한 도구들은 AI 개발의 진입 장벽을 낮추고 효율성을 높이는 데 기여한다. (출처: TheTuringPost, bobvanluijt, tonywu_71)
Kling AI 비디오 생성 도구의 창의적 활용 : Kling AI 2.1 Pro는 비디오 생성 분야에서 강력한 창의적 잠재력을 보여주었다. Nano Banana와 Kling 2.1을 결합하여 전투 장면을 제작하고, Start-End 프레임 기능을 활용하여 10초의 부드러운 장면 전환을 생성하며, 관련 없는 이미지를 프롬프트를 통해 스토리가 있는 애니메이션으로 변환하는 등의 사례가 있다. 사용자들은 또한 이를 활용하여 코카콜라 AI 광고와 늑대인간 변신 특수 효과를 제작하며, AI가 시각 콘텐츠 창작에서 보여주는 유연성과 표현력을 강조했다. (출처: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, fabianstelzer)
AI 기반 수직 애플리케이션 개발 사례 : AI 기술은 다양한 수직 분야의 지능형 애플리케이션 개발에 적용되고 있다. 예를 들어, 한 개발자는 Claude AI를 활용하여 1년 동안 미루었던 포트폴리오 추적기 Monerry를 구축했다. 또 다른 개발자는 Claude Code를 사용하여 ADHD 학생들을 위한 맞춤형 AI 튜터링 플랫폼 BrainRush를 개발했으며, AI를 활용하여 즐라탄 축구 선수 관계 그래프를 구축한 사례도 있다. 이러한 사례들은 AI가 금융, 교육 및 데이터 시각화 분야에서 효율성을 높이고 혁신을 실현할 잠재력을 보여준다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

📚 학습
《위상 데이터 분석》 입문 서적 추천 : Frank Nielsen은 동형 이론과 모스 이론을 다루는 간결한 《위상 데이터 분석》(TDA) 입문 서적을 추천하며, TDA를 이해하고자 하는 독자들에게 훌륭한 자료를 제공한다. (출처: jpt401)

머신러닝 학습 로드맵 : Python_Dv는 AI 분야에 진입하고자 하는 학습자들에게 체계적인 지침을 제공하는 머신러닝 학습 로드맵을 공유했다. 이 로드맵은 인공지능, 머신러닝 및 딥러닝과 같은 핵심 기술 분야를 다룬다. (출처: Ronald_vanLoon)
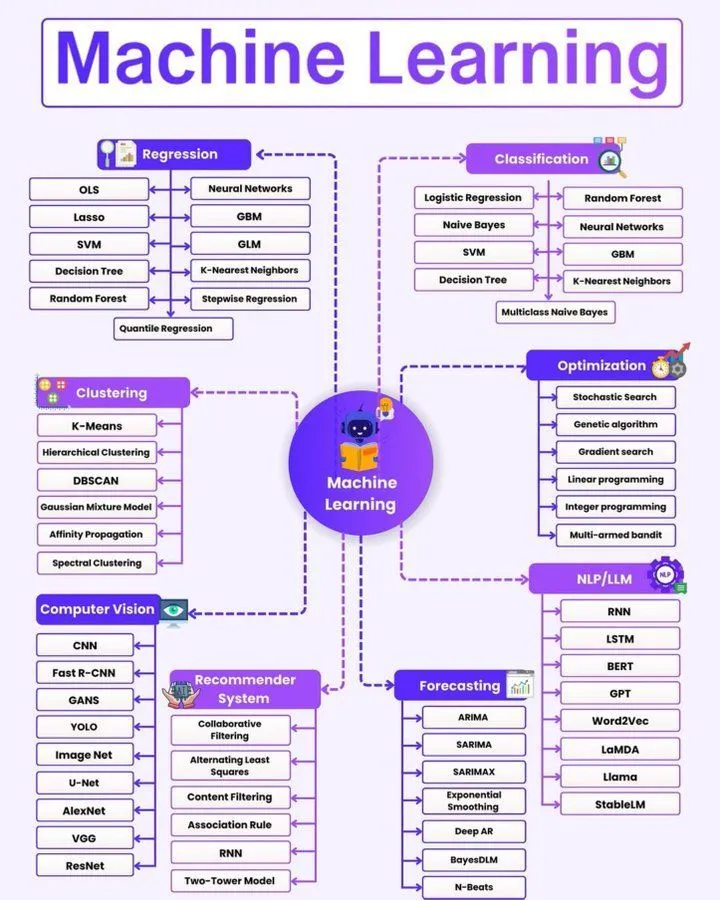
DSPy 3.0의 GEPA 최적화 Reranker : Connor Shorten은 DSPy 3.0에서 GEPA (Gradient-Enhanced Prompting for Agents)를 사용하여 Listwise Reranker를 최적화한 경험을 공유하고, GEPA 최적화 실행을 모니터링하는 방법을 안내했다. 이는 LLM 애플리케이션의 검색 최적화를 위한 실용적인 기술 세부 정보와 학습 자료를 제공한다. (출처: stanfordnlp)

AI 리터러시 시리즈 비디오 및 기사 : TuringPost는 가족을 위한 AI 리터러시 시리즈 비디오 및 기사를 출시하여, 우리가 AI 지능에 대해 어떻게 이야기하는지가 젊은이들의 AI에 대한 인식과 사용 또는 공동 창작 방식에 어떤 영향을 미치는지 탐구한다. 이 시리즈는 가족이 AI를 더 잘 이해하도록 돕기 위한 활동과 예시를 제공하는 것을 목표로 한다. (출처: TheTuringPost)

그래프 머신러닝 벤치마크 및 기초 모델 연구 : Yandex Research 팀은 두 편의 그래프 머신러닝 논문을 발표했다. GraphLand 벤치마크 (노드 속성 예측을 위한 14개 산업 데이터셋 포함, 시간 분포 편향 및 귀납적 예측 설정 포함)와 G2T-FM 프레임워크 (테이블 기초 모델을 그래프 기초 모델로 전환, 이웃 특징 집계 및 구조 인코딩을 통해 원시 특징 강화). G2T-FM은 GraphLand 및 기타 데이터셋에서 전통적인 GNN과 기존 그래프 기초 모델보다 우수한 성능을 보였다. (출처: Reddit r/MachineLearning)
자체 검색 강화 학습(SSRL)으로 LLM 내부 지식 검색 훈련 : 칭화대학교 연구팀은 자체 검색 강화 학습(SSRL)을 제안하여, LLM이 내부 지식을 활용하여 검색 작업을 수행하도록 훈련한다. 이 방법은 LLM이 내장된 웹 시뮬레이터 역할을 하여 외부 검색 엔진에 대한 의존도를 줄이고 검색 효율성과 독립성을 높일 수 있음을 보여준다. (출처: TheTuringPost)

DeepLearning.AI 강좌: Streamlit을 사용하여 GenAI 애플리케이션 신속 프로토타이핑 : 앤드류 응(Andrew Ng)과 Chanin Nantasenamat은 Generative AI가 개발자 사고방식을 어떻게 재편하고 있는지, 즉 과도한 계획에서 신속한 프로토타이핑과 조기 피드백으로 전환하는 방법을 논의했다. DeepLearning.AI는 “Streamlit을 사용하여 GenAI 애플리케이션 신속 프로토타이핑” 강좌를 출시하여, 개발자들이 아이디어를 더 빨리 테스트하고, 실제 데이터로 구축하며, GenAI 애플리케이션을 반복적으로 배포할 수 있도록 돕는 것을 목표로 한다. (출처: DeepLearningAI)
LLM 임베딩의 한계 연구 : Google DeepMind의 연구는 최적의 임베딩조차도 모든 가능한 질의-문서 조합을 표현할 수 없으며, 이는 일부 답변이 수학적으로 복구 불가능하다는 것을 의미한다고 밝혔다. 임베딩 모델이 포착하는 쌍의 수에는 차원 제한에 따른 엄격한 상한이 존재하며, 이 한계를 넘어서면 재현율이 급격히 떨어진다. 이는 대규모 인덱스에서 밀집 벡터, 희소 방법 또는 다중 벡터 모델과 같은 혼합 설정을 결합해야 하며, 임베딩을 유용한 도구로 간주하되 범용 솔루션으로 보지 않아야 함을 시사한다. (출처: jpt401)

AI가 뇌가 세상을 어떻게 인식하는지 학습하는 데 도움 : Meta AI와 ENS_ULM의 연구는 AI가 뇌가 세상을 어떻게 인식하는지 학습하는 데 도움을 줄 수 있음을 보여준다. 이 연구는 전략 게임에서 LLM의 추론 궤적을 분석하여 AI의 전략적 사고 능력을 심층적으로 탐구하며, 신경과학과 AI의 교차 연구에 새로운 관점을 제공한다. (출처: menhguin, TimDarcet)
AI/ML 직업 개발 및 학습 자료 : 커뮤니티는 AI/ML 분야의 직업 개발 경로에 대해 논의했다. 여기에는 코딩 배경 부족을 프로젝트 및 오픈소스 기여를 통해 보완하는 방법, LLM 연구에 적합한 클라우드 서비스 플랫폼 (예: A100 GPU 제공) 찾기, 그리고 빈곤한 연구자에게 GPU 자원을 지원하는 조직 등이 포함된다. 이러한 자료와 조언은 학습자와 실무자들이 직업을 더 잘 계획하고, 필요한 컴퓨팅 자원을 얻으며, 학습 과제를 해결하는 데 도움을 주기 위함이다. (출처: algo_diver, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/deeplearning, Reddit r/MachineLearning)
💼 비즈니스
A16Z 파트너, AI 스타트업 두 가지 경로 논의 : A16Z 파트너 조 슈미트(Joe Schmidt)와 안젤라 스트레인지(Angela Strange)는 AI 스타트업의 “유전”과 “파이프라인” 비유를 제시했다. “유전”은 특정 시나리오에 깊이 파고들어 핵심 데이터를 장악하고, 기록 시스템을 재구축하거나 처음부터 구축하는 것을 의미한다. “파이프라인”은 분산된 시스템과 프로세스를 연결하고, 수동 판단과 부서 간 협업을 자동화하는 것을 의미한다. 이 두 가지는 상호 보완적이며, 창업자는 명확한 선택을 하고 확고하게 실행하여 규모 있고 견고한 회사를 구축해야 한다. (출처: 36氪)
델 데이터센터 사업, PC 사업 추월 : AI의 폭발적인 성장과 함께 델의 데이터센터 사업이 전통적인 PC 사업을 처음으로 추월했다. 이는 AI 열풍이 하드웨어 인프라 수요에 미치는 엄청난 영향을 보여주며, 기술 산업의 중심이 AI 관련 서비스 및 하드웨어로 전략적으로 이동하고 있음을 반영한다. (출처: Reddit r/artificial)

AI가 경제 및 고용 시장에 미치는 영향 : 경제학자들은 AI가 고용 시장에 미치는 영향을 심각하게 과소평가하고 있을 수 있다. AI는 반복적인 작업을 대체할 뿐만 아니라, 업무의 성격을 변화시켜 직원들이 새로운 기술에 적응하도록 요구할 것이다. 동시에 Generative AI의 상업화 여정과 같이 비즈니스 분야에서 AI의 적용은 기업들이 AI를 활용하여 효율성을 높이고 혁신을 추구하도록 이끌고 있다. (출처: Ronald_vanLoon, Ronald_vanLoon)

🌟 커뮤니티
AI 과도한 의존과 독립적 사고 경계 : 소셜 미디어에서는 AI를 학습 파트너로 활용하는 가치에 대한 논의가 활발하지만, AI에 대한 과도한 의존을 경계하고 독립적인 사고와 직접 글쓰기/코딩의 중요성을 강조하는 목소리도 높다. “AI가 인간의 사고를 대체할까? 우리는 왜 여전히 직접 글을 쓰고 코딩해야 하는가”라는 기사가 추천되며, 사고하는 법을 다시 배우고 자신의 기술을 연마할 것을 촉구한다. (출처: dotey, Reddit r/artificial)
AI가 개인의 정신 건강 및 사회생활에 미치는 긍정적 영향 : 한 Reddit 사용자는 ChatGPT가 자신의 삶에 미친 긍정적인 영향을 공유했다. 불안을 극복하고, 운동과 여행에 대한 열정을 되찾으며, 사회적 능력을 향상시키는 데 도움을 받았다고 한다. AI가 “믿을 수 있는 친구”로서 격려와 도전을 제공하여 삶의 궤적을 바꾸었으며, AI가 고립을 초래한다는 일반적인 견해에 반박하며 정신적 지원과 개인 성장에서 AI의 잠재력을 강조했다. (출처: Reddit r/ChatGPT)
AI Agent의 실제 작동 원리 및 도전 과제 : 커뮤니티는 AI Agent와 전통적인 LLM+도구의 차이점에 대해 논의하며, 진정한 AI Agent는 도구 강화 시스템이 아니라 스스로 작업 흐름을 설계할 수 있어야 한다고 강조했다. ReAct 프레임워크는 기억, API 및 다중 Agent 협업을 포함하는 핵심 요소로 간주된다. 개발자들은 계획 및 실행 단계에서 어려움에 직면하며, 생산 환경에서 자율 Agent를 성공적으로 배포한 경험에 관심을 보였다. (출처: Reddit r/deeplearning, omarsar0, Ronald_vanLoon)

기업 내 AI 도입 및 도전 과제 : 기업은 내부적으로 AI 도구를 홍보할 때 직원들의 채택이라는 도전에 직면하며, 많은 사람들이 여전히 오래된 수동적인 습관을 선호한다. 성공의 핵심은 진정으로 문제점을 해결하는 좋은 도구를 개발하고, 효과적인 교육과 지원을 제공하여 새로운 기술에 대한 직원들의 저항과 학습 곡선을 극복하는 것이다. (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
LLM 콘텐츠 소유권 및 사용자 아카이빙 방법 : 커뮤니티는 LLM 생성 콘텐츠의 소유권 문제를 논의하고, “LLM 콘텐츠 아카이브 프로토콜”을 제안했다. 이는 사용자가 외부 Markdown 파일을 통해 LLM과의 협력 기록을 영구적으로 유지하도록 권장한다. 이 방법은 사용자가 공동 창작 지적 재산에 대한 통제권을 확보하고, 제3자의 통제를 피하며, 수동으로 아카이브 파일을 업데이트하여 긴 대화의 지연 문제를 해결하는 것을 목표로 한다. (출처: Reddit r/ArtificialInteligence)
AI 시대 UI/UX의 미래 방향 : AI Agent의 지능화가 진행됨에 따라, 미래 모바일 애플리케이션의 사용자 인터페이스는 전통적인 버튼, 메뉴에서 AI 기반 채팅 인터페이스로 전환될 수 있다. 사용자는 여러 단계의 클릭 대신 음성 또는 텍스트 명령을 통해 복잡한 작업을 완료할 수 있다. 그러나 음성 상호작용의 효율성이 높지 않다는 의견도 있으며, 전통적인 UI와 AI 채팅 인터페이스가 완전히 대체되기보다는 공존할 것이라는 견해도 있다. (출처: Reddit r/ArtificialInteligence)
ChatGPT 음성 모드 사용자 피드백 : ChatGPT의 “고급 음성” 모드는 사용자들의 불만을 야기했다. 이 모드는 “건조하고”, “지루하며”, 표준 음성 모드의 “차분하고 안정적인” 느낌과 감정적 지원이 부족하다는 평가를 받았다. 많은 사용자들이 OpenAI에 표준 음성 모드 선택권을 유지해달라고 요청했으며, 특히 개인적인 감정이나 민감한 주제를 다룰 때 고급 음성의 “긍정적인” 어조가 적절하지 않다고 지적했다. (출처: Reddit r/ChatGPT, Reddit r/ChatGPT)
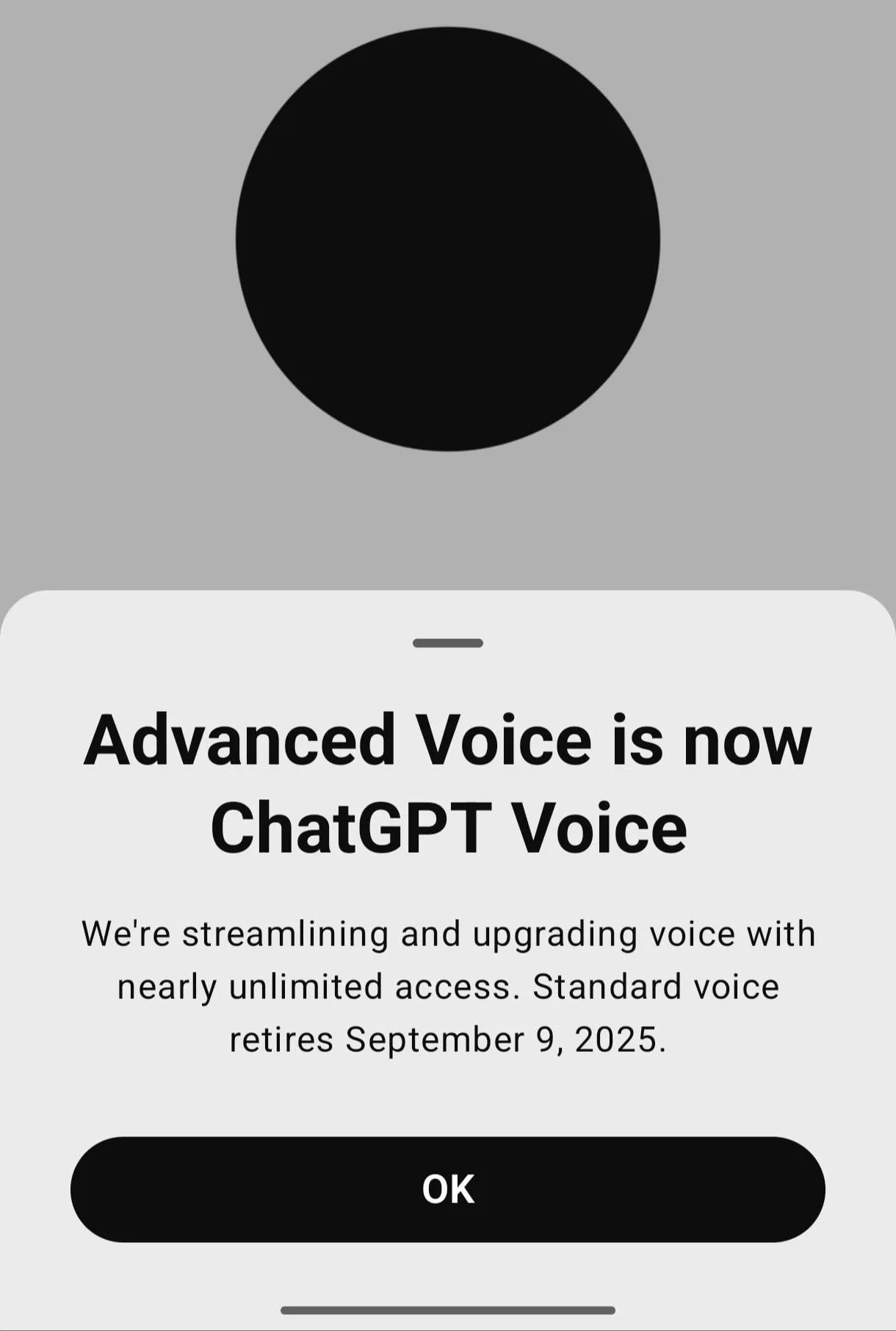
AI 윤리, 프라이버시 및 사회적 영향 : 소셜 미디어에서는 AI의 윤리적 문제에 대한 광범위한 논의가 이루어지고 있다. 여기에는 챗봇의 의인화 착각, AI와 프라이버시, 광고 및 친밀한 관계 등이 포함된다. 사용자들은 AI가 오용될 수 있고, 의사 결정 마비를 초래할 수 있으며, 개인 데이터 보안 및 AI 모델의 프라이버시 보호 (예: Hermes 4)에 대한 의문을 제기한다. 또한, AI가 의식을 가질 수 있는지, 그리고 AI가 인간의 정체성과 일자리 대체에 미치는 영향에 대한 철학적 논의도 활발하다. (출처: MIT Technology Review, Ronald_vanLoon, The Verge, ben_burtenshaw, clefourrier, Reddit r/ArtificialInteligence, Reddit r/artificial, kylebrussell, Ronald_vanLoon, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)
💡 기타
로봇 기술 발전: 인간형 로봇부터 지능형 감지까지 : 로봇 분야는 인간과 유사한 시각, 촉각 및 내비게이션 능력을 갖춘 Vulcan 로봇, Jetson Thor 슈퍼컴퓨터와 연결된 Skild Brain 로봇 두뇌, 그리고 중국 Spirit AI가 발표한 차세대 바퀴형 인간형 로봇 Moz1 등 지속적인 혁신을 이루고 있다. 이러한 발전은 로봇의 감지, 이동 및 자율 작동 능력 향상을 촉진한다. (출처: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
AI가 게임 디자인에 가져오는 변화 : AI는 Generative AI, 강화 학습 등의 기술을 통해 게임 디자인 분야에 깊은 변화를 가져오며 새로운 가능성을 열고 있다. AI는 게임 콘텐츠 제작을 지원할 뿐만 아니라 플레이어 경험을 최적화하고, 심지어 게임 메커니즘의 혁신을 추진하여 미래 게임이 더욱 지능적이고 개인화될 것임을 예고한다. (출처: togelius)

AI 편집 도구 Higgsfield_ai의 창의적 능력 : Higgsfield_ai는 “영혼을 가진 AI 편집 도구”로 묘사되며, 콘텐츠 제작 및 창의적 편집 분야에서 강력한 능력을 보여주었다. 이 도구는 AI 기술을 활용하여 사용자가 더욱 예술적이고 개인화된 시각 콘텐츠를 제작할 수 있도록 지원하며, 창의 산업의 발전을 촉진한다. (출처: Ronald_vanLoon)