키워드:NVIDIA 네모트론 나노 2, 클로드 오퍼스 4.1, AI 인재 보상 전쟁, 구글 AI 언어 디지털화, AI 건강 관리, AI 보조 프로그래밍, AI 고용 영향, AI 육아 응용, 하이브리드 맘바-트랜스포머 아키텍처, LM아레나 모델 평가, 프로젝트 바니 음성 데이터, 디지털 미래 주방 실험실, 코덱스 CLI Rust 재작성
🔥 포커스
NVIDIA Nemotron Nano 2 출시 : NVIDIA는 Nemotron Nano 2 시리즈 AI 모델을 출시했습니다. 이 모델은 9B 하이브리드 Mamba-Transformer 아키텍처를 특징으로 하며, 높은 정확도를 유지하면서도 동일 크기 모델보다 6배 빠른 추론 처리량을 제공합니다. 128K 컨텍스트 길이를 지원하며, 고품질 웹 페이지, 수학, 코드, 다국어 질의응답 데이터를 포함한 대부분의 사전 학습 데이터를 공개했습니다. 이번 출시는 효율적이고 확장 가능한 AI 솔루션을 제공하고, 기업의 배포 장벽을 낮추며, 오픈소스 AI 생태 발전을 촉진하는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)

Claude Opus 4.1, LMArena 정상 등극 : Claude Opus 4.1이 LMArena의 표준, 사고, 웹 개발 부문에서 다른 모델들을 제치고 1위를 차지했습니다. 사용자들은 특히 “잠시 생각해보니 XYZ가 더 나을 것 같다”는 의사결정 방식에서 미시적/거시적 접근 방식이 개선되었다고 평가했습니다. 일부 사용자는 가격이 비싸거나 특정 상황에서 성능이 좋지 않다고 생각하지만, 프로그래밍 및 복잡한 작업 처리 능력은 널리 인정받고 있으며, 이는 Anthropic의 지속적인 모델 성능 향상을 보여줍니다. (출처: Reddit r/ClaudeAI)

AMD CEO 리사 수, AI 인재 연봉 전쟁에 대한 견해 : AMD CEO 리사 수는 AI 인재 쟁탈전에서 Meta와 같은 기업들이 수억 달러의 연봉을 제시하며 인재를 영입하는 방식에 반대한다고 공개적으로 밝혔습니다. 그녀는 경쟁력 있는 연봉이 기본이지만, 최고의 인재를 유치하는 진정한 핵심은 회사에 대한 사명감과 직원들이 회사에 대한 실제적인 영향을 느낄 수 있도록 하는 것이며, 단순히 기계의 톱니바퀴가 아니라고 강조했습니다. 그녀는 과도한 고액 연봉이 회사 문화를 해칠 수 있으며, AMD의 성공은 소수의 스타 직원이 아닌 팀 노력의 결과라고 지적했습니다. (출처: 量子位)

구글 AI, 2300개 아시아 언어 디지털화 추진 : 구글은 여러 AI 프로젝트를 통해 디지털 세계에서 소외된 아시아 언어 문제를 해결하고 있습니다. 인도 과학 연구소와 협력하는 Project Vaani는 이미 86개 인도 언어 변형에 걸쳐 약 21,500시간의 음성 데이터를 수집하여 무료로 공개했습니다. AI Singapore와 협력하는 Project SEALD는 동남아시아 1200개 언어를 위한 Aquarium 데이터베이스를 구축하고 있습니다. 또한, 구글의 AI 번역 시스템 CHAD 2 (Gemini 2.0 Flash 기반)는 일본 요시모토 흥업이 코미디 콘텐츠를 90% 정확도로 번역하는 데 도움을 주어 번역 시간을 몇 달에서 몇 분으로 단축시켰습니다. (출처: 量子位)

🎯 동향
AI의 건강 분야 혁신적 적용 : 윈펑 테크놀로지(云澎科技)는 슈아이캉(帅康), 스카이워스(创维)와 협력하여 “디지털 지능형 미래 주방 연구소”와 AI 건강 대규모 모델을 탑재한 스마트 냉장고를 발표했습니다. AI 건강 대규모 모델은 주방 설계 및 운영을 최적화하고, 스마트 냉장고는 개인 맞춤형 건강 관리를 제공하여 일상 건강 관리에서 AI의 돌파구를 마련했습니다. 이번 발표는 스마트 기기를 통해 개인 맞춤형 건강 서비스를 제공함으로써 일상 건강 관리에서 AI의 잠재력을 보여주며, 가정 건강 기술의 발전과 주민 삶의 질 향상을 촉진할 것으로 기대됩니다. (출처: 36氪)

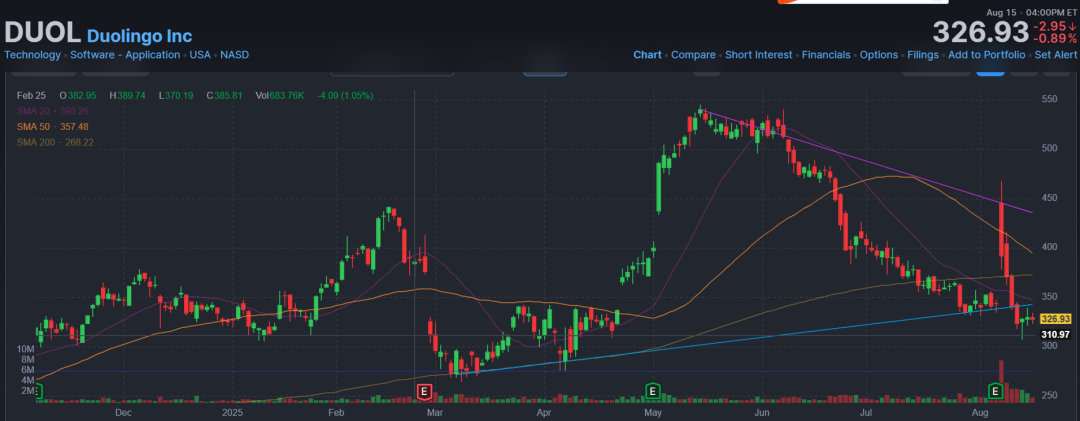
AI의 전통 산업 파괴와 기회 : Duolingo는 AI를 수용하여 매출 성장을 달성했지만, GPT-5와 같은 모델이 언어 학습 도구를 직접 생성하는 능력은 Duolingo의 주가에 충격을 주어 AI가 기존 비즈니스 모델을 파괴할 수 있음을 보여줍니다. 동시에 Goldman Sachs는 AI가 소프트웨어 산업의 파괴자가 아닌 힘을 배가시키는 역할을 할 것이며, 전통적인 SaaS 거대 기업들은 하이브리드 AI 전략과 깊은 진입 장벽을 통해 여전히 경쟁력을 유지할 수 있다고 보았습니다. 이는 AI가 도전이자 산업 전환과 새로운 가치 창출을 촉진하는 기회임을 시사합니다. (출처: 36氪, 36氪)
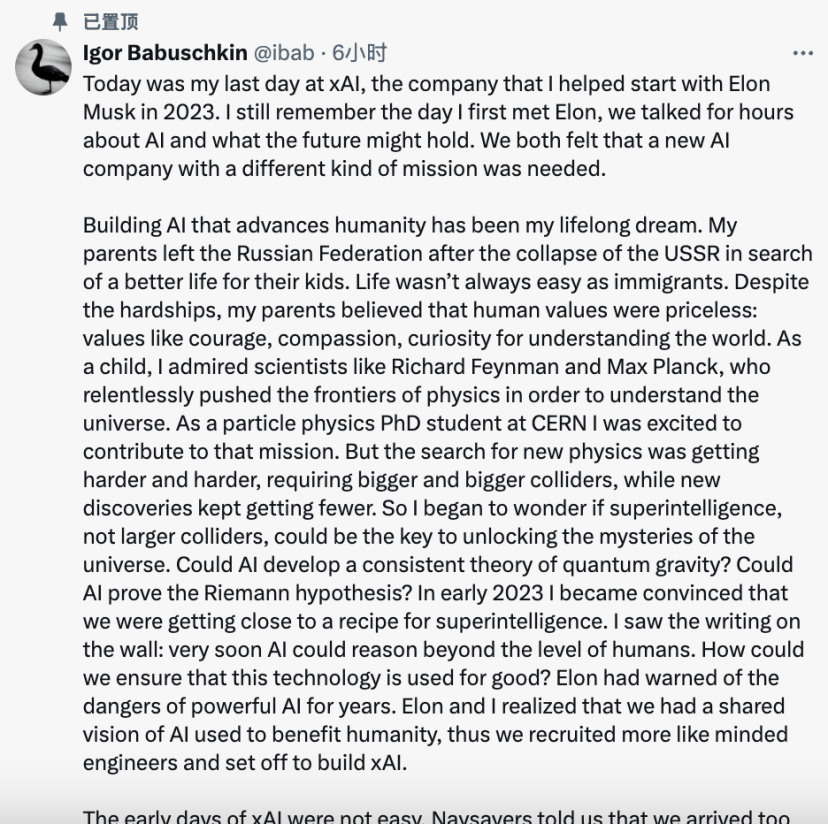
AI 인재 시장 동향 및 직업 발전 : xAI 공동 창립자 Igor Babuschkin은 AI 안전 연구에 집중하는 벤처 캐피탈 회사를 설립하기 위해 퇴사했으며, “다음 Elon Musk”를 찾고 있습니다. OpenAI GPT-4o mini의 한국인 리더 Kevin Lu는 Mira Murati의 Thinking Machine Lab에 합류하여 AI 발전에 인터넷 데이터의 중요성을 강조했습니다. 업계 내 AI 직무 수요는 왕성하지만, 중소기업은 인력 채용에 어려움을 겪고 있으며, 최고 인재는 쟁탈전의 대상이 되고, 일반 졸업생은 취업 경쟁이 치열하며, AI 박사 학위의 가치에 대한 의문이 제기되고 있어 AI 인재 수급의 구조적 모순과 직업 전환의 어려움을 보여줍니다. (출처: 36氪, 36氪, 36氪, 36氪, 36氪)
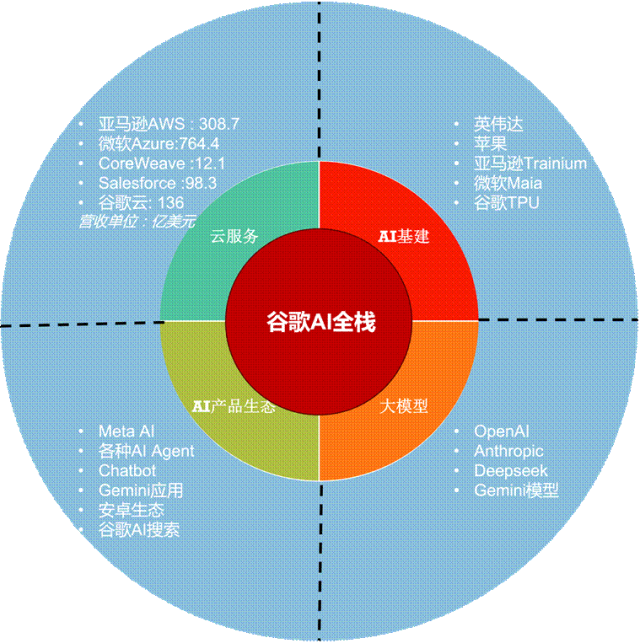
AI 투자 및 인프라 구축 : Google과 Meta의 재무 보고서는 AI 자본 투자에 대한 시장의 의문이 환호로 바뀌었으며, AI가 온라인 광고 및 클라우드 서비스 매출 성장을 크게 견인하고 있음을 보여줍니다. Google은 서버 및 데이터 센터에 주로 사용될 자본 지출 예상을 850억 달러로 대폭 상향 조정했습니다. Elon Musk가 큰 기대를 걸었던 Tesla Dojo 슈퍼컴퓨터 프로젝트는 해체되고, 대신 NVIDIA AI 칩 구매에 막대한 자금을 투입하여 AI 시대에 수직 통합이 플랫폼 생태계의 도전에 직면하며, 산업 체인 거대 기업과의 협력이 더 실용적임을 입증했습니다. (출처: 36氪, 36氪)
구현 지능 및 로봇 상업화 가속화 : 칭랑 인텔리전스(擎朗智能) CEO 리퉁(李通)은 로봇 상업화가 고객의 고통 지점을 깊이 파고들어 “직무 대체”를 실현해야 한다고 강조했으며, 그의 상업용 로봇은 이미 10만 대 이상 판매되었습니다. 11년차 비전 AI 기업인 위판 인텔리전스(宇泛智能)는 공간 인지 대규모 모델 Manas와 사족 보행 로봇을 출시하며 구현 지능을 전면적으로 수용하고 “지능 + 하드웨어”의 풀 스택 자체 연구 개발을 강조했습니다. JD.com, Meituan, Alibaba 등 대기업들은 센서, 정교한 손, 휴머노이드 로봇 등을 포함한 로봇 분야에 투자를 확대하며, 이행 효율성과 사용자 경험을 재정의하고 로봇이 더 많은 소비자 시나리오에 진입하도록 추진하고 있습니다. (출처: 36氪, 36氪, 36氪)

AI의 콘텐츠 창작 및 사용자 경험의 새로운 트렌드 : Douyin 창립 팀 멤버들은 AI 도구를 활용하여 창의적인 디자인 및 제품 수익화 장벽을 낮추고, AI 창의성부터 실제 생산 체인까지 연결하는 “수메이완우(数美万物)” 플랫폼을 출시했습니다. Meitu는 AI Agent 제품 RoboNeo를 통해 성장을 모색하고 있으며, 이미지 및 디자인 제품 매출 비중이 증가하고 해외 사용자 증가가 두드러집니다. AI 아트 토이 “AI 라부부(AI拉布布)”는 아트 토이 외형과 AI 대화 능력을 결합하여 감성적 가치를 제공하며 인기를 끌고 있습니다. 이러한 사례들은 AI가 콘텐츠 생성, 창의적 수익화, 감성적 동반 등 소비자용 애플리케이션에서 빠르게 발전하고 있음을 보여줍니다. (출처: 36氪, 36氪, 36氪)

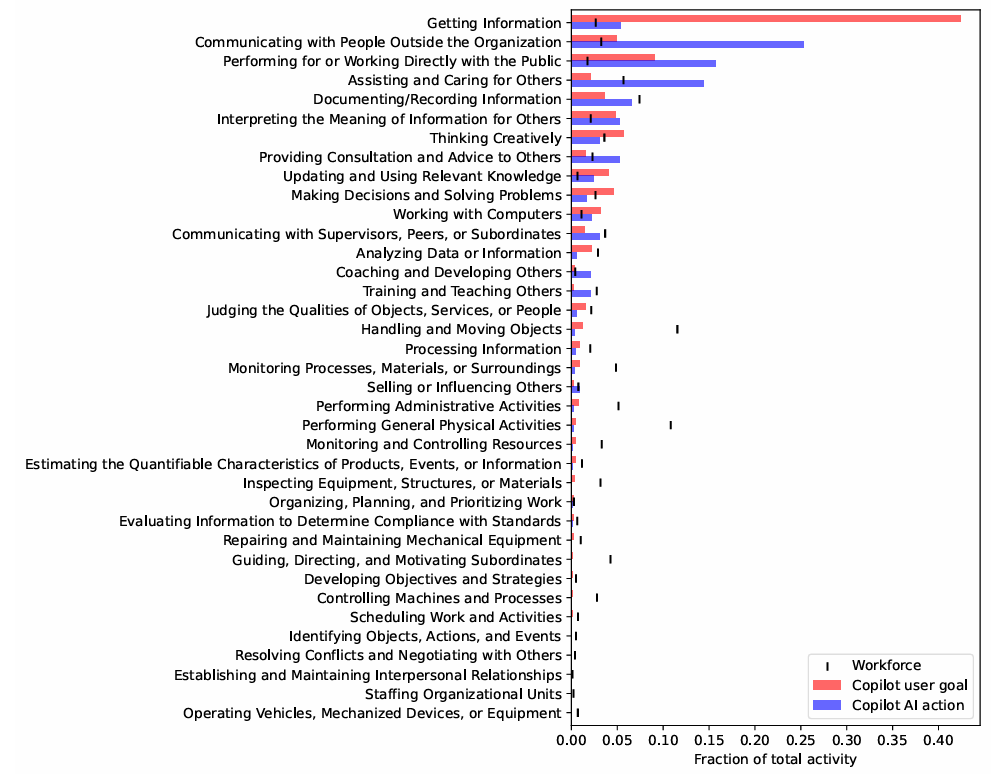
AI의 고용 시장에 대한 심오한 영향 : Microsoft 연구는 Copilot 데이터를 기반으로 AI가 연구, 글쓰기, 커뮤니케이션 등의 작업을 지원할 수 있지만, 단일 직업의 모든 작업을 완전히 대체할 수는 없다고 지적합니다. 기자, 번역가 등 언어 및 콘텐츠 창작 직업이 AI의 영향을 가장 많이 받지만, AI는 ATM이 은행 창구 직원에게 미친 영향과 유사하게 직접적인 일자리 대체보다는 효율성을 높일 수 있습니다. AI 비서는 “수다스러운 인턴”과 같아서 설명 능력은 뛰어나지만 능동적인 문제 해결 능력은 부족합니다. (출처: 36氪)
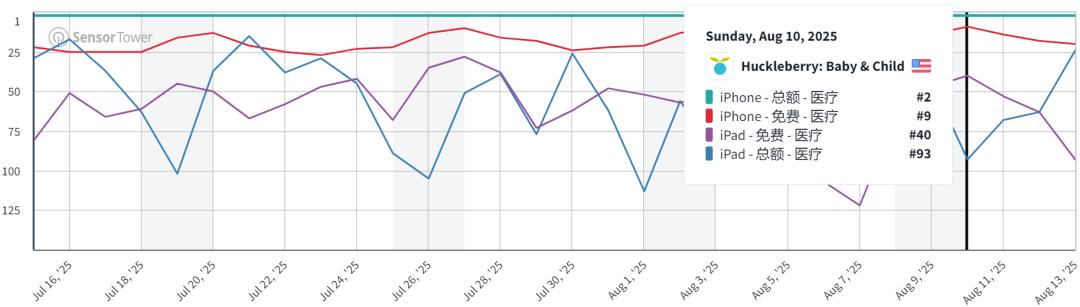
AI의 육아 분야 상업화 잠재력 : AI는 조용히 아기 수면 모니터링 분야에 진입하고 있으며, Huckleberry와 같은 앱은 아기 돌봄 일지를 분석하여 수면 리듬을 정확하게 예측하고 “예측 가능한” 통제감을 제공하여 월 수천만 달러의 수익을 올리고 있습니다. 이러한 제품은 AI 베이비시터 기능을 결합하여 부모의 효율적인 기록 및 감성적 가치에 대한 요구를 충족시키며, 저가 소프트웨어 서비스와 고가 AI 하드웨어라는 두 가지 경로의 “황금 시장”이 되고 있습니다. (출처: 36氪)
🧰 도구
AI 보조 프로그래밍 및 개발 도구 : OpenAI의 Codex CLI 새 버전은 Rust로 재작성되었으며 GPT-5가 통합되어 더 빠른 상호작용 속도와 강력한 코딩 능력을 제공하며, Claude Code의 강력한 경쟁자가 되었습니다. LangChain은 다중 에이전트 시스템 구축을 지원하는 Deep Agents의 JavaScript 버전을 출시했습니다. Replit Agent는 Python Notebook 및 Godot 게임 엔진 개발 지원을 모색하고 있습니다. VS Code Insiders 버전은 OpenAI 호환 엔드포인트를 지원하며, UI 자동화 테스트를 위해 Playwright를 통합했습니다. (출처: doodlestein, hwchase17, amasad, pierceboggan)

AI의 사무 및 콘텐츠 창작 적용 : Paradigm은 반복 작업을 없애기 위해 AI 네이티브 스프레드시트를 출시했습니다. Huxe는 읽지 않은 뉴스 이메일을 분석할 수 있는 AI 기능을 새로 추가했습니다. Gemini API는 이제 URL 컨텍스트 도구를 지원하여 웹 페이지, PDF 및 이미지 콘텐츠를 직접 가져와 처리할 수 있습니다. Aleph 및 RunwayML과 같은 AI 도구는 비디오 작업을 혁신하여 비디오 콘텐츠를 텍스트처럼 편집할 수 있도록 합니다. Meitu의 RoboNeo, AI 산해경(AI山海经) 이미지 상품화, 그리고 AI 보조 소설 창작 시스템은 AI가 창의적 생성 및 콘텐츠 수익화 분야에서 가진 잠재력을 보여줍니다. (출처: hwchase17, raizamrtn, jeremyphoward, c_valenzuelab, Reddit r/artificial)

LLM 성능 및 평가 도구 : Claude Opus 4.1은 LMArena 코딩, 웹 개발 등 분야에서 뛰어난 성능을 보였습니다. Datology AI는 BeyondWeb 합성 데이터 방법을 출시하며 모델 사전 학습에서 고품질 합성 데이터의 중요성을 강조했으며, 이는 소규모 모델의 성능을 향상시킬 수 있습니다. NVIDIA Nemotron Nano 2 모델은 하이브리드 Mamba-Transformer 아키텍처를 채택하여 수학, 코드, 추론 및 장문 컨텍스트 작업에서 우수한 성능을 보이며, 추론 예산 제어를 지원합니다. (출처: scaling01, code_star, ctnzr)

AI 에이전트 및 자동화 : NEO AI4AI 에이전트가 MLE Bench에서 SOTA(State-Of-The-Art) 점수를 달성하여 데이터 전처리, 특징 엔지니어링, 모델 실험 및 평가 등 ML 엔지니어링 작업을 자율적으로 수행할 수 있음을 입증했습니다. LangChain의 Deep Agents는 JavaScript로 구현되어 복잡한 문제 해결 및 도구 호출을 지원합니다. Reka Research는 AI 기반의 심층 연구 서비스를 제공하여 여러 출처의 정보에서 답변을 종합할 수 있습니다. (출처: Reddit r/MachineLearning, hwchase17, RekaAILabs)

AI 이미지 및 비디오 편집 모델 : Qwen-Image-Edit이 출시되었습니다. 20B Qwen-Image를 기반으로 하며, 중국어 및 영어 이중 언어 정밀 텍스트 편집, 고급 의미 편집 및 저수준 외형 편집을 지원하여 만화 제작에 활용될 수 있습니다. Higgsfield AI는 Hailuo MiniMax 02를 통해 Draw-to-Video를 제공하며, 1080p 고품질 생성을 지원합니다. (출처: teortaxesTex, _akhaliq)

LLM API 및 비용 관리 : Claude는 Usage and Cost API를 출시하여 거의 실시간으로 모델 사용량 및 비용 가시성을 제공함으로써 개발자가 토큰 효율성을 최적화하고 속도 제한을 피할 수 있도록 돕습니다. OpenRouter는 모델 페이지에 LLM 시장 가격 및 캐시 가격을 표시합니다. (출처: Reddit r/ClaudeAI, xanderatallah)

📚 학습
AI 학습 자료 및 방법 : Andrew Ng는 대학이 AI를 전면적으로 수용해야 한다고 강조했습니다. AI를 가르치는 것뿐만 아니라 AI를 사용하여 모든 학문 분야의 발전을 추진해야 한다고 말했습니다. DeepLearning.AI는 Andrew Ng의 새로운 전자책을 출시하여 AI 직업 로드맵을 제공합니다. GPU_MODE와 ScaleML은 여름 강연 시리즈를 개최하여 gpt-oss의 알고리즘 및 시스템 진행 상황을 공유할 예정입니다. Reddit 커뮤니티에서는 딥러닝 입문 서적, FastAPI 모델 배포, CoCoOp+CLIP 구현, 그리고 모델 훈련 주기 최적화 방법(예: 최적의 에포크 수 선택)에 대해 논의했습니다. (출처: AndrewYNg, DeepLearningAI, lateinteraction, Reddit r/deeplearning, Reddit r/deeplearning)

AI 인재 양성 및 직업 경로 : Reddit 커뮤니티에서는 AI 엔지니어가 반드시 수학자여야 하는지, 그리고 독학이나 석사 학위를 통해 딥러닝 분야에 진입하는 방법에 대해 논의했습니다. 동시에 AI 시대에는 “프롬프트 엔지니어링”보다는 “컨텍스트 엔지니어링”이 더 강조되며, LLM 애플리케이션 구축에 대한 더 포괄적인 이해가 필요하다는 견해도 있습니다. (출처: Reddit r/deeplearning, Reddit r/MachineLearning)

LLM 훈련 데이터 및 모델 최적화 : Reddit에서는 LLM 훈련 데이터의 사실 오류를 식별하고 수정하는 방법, 그리고 현재 데이터 검증 및 수정의 모범 사례에 대해 논의했습니다. DeepSeek R2의 진행 상황은 사전 학습이 병목 현상에 도달했는지, 그리고 세계 모델에 대한 다중 모달 통합 표현의 중요성에 대한 관심을 불러일으켰습니다. (출처: Reddit r/deeplearning, 36氪)

AI 연구 진행 상황 및 새로운 아키텍처 탐색 : Simons Foundation과 Stanford HAI는 학습 및 신경 컴퓨팅의 물리학을 탐구하기 위해 협력하여 대규모 신경망의 학습, 추론 및 상상력을 이해하는 것을 목표로 합니다. AIhub는 8월 ML/AI 세미나 목록을 발표했습니다. Reddit에서는 소규모 모델(SLM) 및 로컬 AI의 가치에 대해 논의하며, 과도한 모델 규모 추구가 AI 혁신을 저해할 수 있는지 의문을 제기하고, Transformer 아키텍처가 유일한 경로가 아니며 다른 효율적인 아키텍처를 탐색해야 한다고 제안했습니다. (출처: ylecun, aihub.org, Reddit r/MachineLearning)

CUDA 커널 개발 및 배포 : Hugging Face는 kernel-builder 라이브러리를 출시하여 CUDA 커널의 로컬 개발, 다중 아키텍처 빌드 및 전 세계 공유를 단순화하고, 이를 PyTorch 네이티브 연산자로 등록하고 torch.compile과 호환되도록 지원하여 성능과 유지보수성을 향상시켰습니다. (출처: HuggingFace Blog)
다중 모달 모델 및 세계 모델 연구 : Hugging Face Daily Papers는 다음과 같은 여러 최첨단 연구를 발표했습니다: 4DNeX (단일 이미지에서 4D 장면을 생성하는 최초의 피드포워드 프레임워크), Inverse-LLaVA (텍스트-시각 매핑을 통해 정렬 사전 학습 제거), ComoRAG (긴 내러티브 추론을 위한 인지적 휴리스틱 메모리 조직 RAG), 그리고 효율적인 LLM 아키텍처에 대한 개요 및 Matrix-Game 2.0 (실시간 스트리밍 대화형 세계 모델). (출처: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
시각 기초 모델 DINOv3 : Meta AI의 DINOv3는 차세대 시각 기초 모델로서, 순수 자율 학습으로 훈련되어 7B 매개변수로 성공적으로 확장되었으며, 분할, 깊이 추정, 3D 키포인트 매칭 등의 작업에서 약한 지도 학습 및 지도 학습 기준선을 능가했습니다. Gram Anchoring 기술은 장기 훈련 중 밀집 특징 품질 문제를 해결했으며, 위성 이미지와 같은 전문 분야에도 적용될 수 있습니다. (출처: LearnOpenCV)

💼 비즈니스
OpenAI, 인도에서 ChatGPT Go 구독 계획 출시 : OpenAI는 인도에서 새로운 저가 구독 서비스인 “ChatGPT Go”를 월 399루피(약 4.7달러)에 출시했습니다. 이 계획은 무료 버전보다 10배 높은 메시지 제한, 이미지 생성 및 파일 업로드, 2배의 메모리 길이를 제공하며, UPI 결제를 지원합니다. 이 움직임은 인도 시장의 사용자 기반을 확대하고, 현지에서 더 경제적이고 효율적인 AI 서비스에 대한 수요를 충족시키기 위함입니다. (출처: openai, kevinweil, snsf)
AI, 기업 전환 가속화 및 고용 시장 영향 : 한 CEO가 직원들이 AI를 빠르게 수용하지 않아 80%를 해고한 사건은 AI 전환 과정에서 직원의 적응성에 대한 논의를 촉발했습니다. 동시에 MLOps 엔지니어, AI 연구 과학자 등 AI 관련 고액 연봉 직무의 등장은 AI가 전통적인 데이터 과학 분야를 재편하고 있음을 보여줍니다. AI가 생산성을 향상시킬 수 있지만, 기업은 기술 자체에만 의존하기보다는 AI를 중심으로 실제 가치를 구축해야 합니다. (출처: Reddit r/artificial, Reddit r/deeplearning, Reddit r/artificial)

AI 기업 가치 평가 및 경쟁 구도 : OpenAI의 연간 매출은 이미 120억 달러를 넘어섰고, 기업 가치는 5000억 달러에 달하며, Anthropic은 연간 매출 40억 달러, 기업 가치 1700억 달러를 기록하여 AI 기초 모델 기업의 가치가 지속적으로 급등하고 있음을 보여줍니다. Google은 2027년에 TPU를 외부에 판매하여 NVIDIA의 AI 칩 시장 선두 지위에 도전할 수 있습니다. 동시에 AI 스타트업 Lovable은 출시 8개월 만에 연간 반복 매출(ARR) 1억 달러를 돌파하여 AI 기반 웹사이트 및 애플리케이션 빌더 시장의 거대한 잠재력을 입증했습니다. (출처: yoheinakajima, Justin_Halford_, 36氪)
🌟 커뮤니티
합성 데이터와 사전 학습의 미래 : Datology AI의 BeyondWeb 방법은 사전 학습 데이터가 이미 “데이터 장벽”에 직면해 있으며, 고품질 합성 데이터가 소규모 모델의 성능을 효과적으로 향상시키고 심지어 대규모 모델을 능가할 수 있다는 점을 강조하며 널리 논의되었습니다. 커뮤니티는 합성 데이터가 모델을 “변질”시키거나 “과장된 평가”로 이어질 수 있는지에 대해 뜨겁게 논의했지만, 신중하게 설계된 합성 데이터가 데이터 병목 현상을 극복하는 핵심이라고 일반적으로 인식하고 있습니다. (출처: code_star, sarahookr, BlackHC, Reddit r/MachineLearning)

AI 모델 성능 및 사용자 경험 : Claude Opus 4.1은 LMArena의 여러 순위에서 1위를 차지했으며, 특히 코딩 및 웹 개발 분야에서 뛰어난 성능을 보였습니다. 그러나 GPT-5의 출시는 사용자들 사이에서 “GPT-4o를 돌려달라”는 외침을 불러일으켰는데, 이는 “냉담한” 상호작용 스타일 때문이며, AI의 감성 및 공감 능력에 대한 사용자의 요구를 부각시킵니다. 동시에 AI 모델이 과도하게 규모를 추구하는 것이 혁신을 저해할 수 있으며, 소규모 모델과 로컬 AI의 발전 잠재력이 크다는 견해도 있습니다. (출처: scaling01, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/MachineLearning)
AI의 고용 및 직업에 대한 논의 : 소셜 미디어에서는 AI가 “일자리를 빼앗을” 것인지, 그리고 “AI 엔지니어”와 “프롬프트 엔지니어”의 차이에 대한 뜨거운 논의가 있었습니다. 일부 견해는 AI가 직업을 완전히 대체하기보다는 직업 전환을 촉진할 것이며, 미래에는 변화에 적응하고 실제 문제를 해결하는 능력이 더 필요하다고 주장합니다. 동시에 AI의 “독성 긍정성” 또는 “아첨하는” 훈련은 사용자들의 불만을 야기하며, 진정성과 비판적 사고의 부족을 지적합니다. (출처: jeremyphoward, Teknium1, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)

AI 커뮤니티 활동 및 교류 : LangChain은 Grammarly, Uber 등과 협력하여 다중 에이전트 시스템 및 LangGraph 애플리케이션에 대한 오프라인 교류회를 개최했습니다. Hugging Face 커뮤니티는 일본 AI 모델 출시, 커널 공유 및 AI Sheets와 같은 도구에 대해 논의했습니다. Weights & Biases는 Code Cafe 행사를 개최하여 개발자들이 현장에서 AI 프로젝트를 구축하고 공유하도록 장려했습니다. (출처: LangChainAI, ClementDelangue, weights_biases)

AI 안전 및 윤리에 대한 철학적 논의 : 커뮤니티는 AI가 스스로 목표를 조정할 수 있는지, 그리고 지능이 필연적으로 지배욕으로 이어지는지 등 AI 안전에 대한 심층적인 문제를 논의했습니다. 일부 견해는 AI 안전이 공학적 문제이며 설계로 해결할 수 있다고 주장합니다. 동시에 기업 환경에서 AI 모델의 “환각” 위험과 AI가 저품질 서비스를 제공하여 정보 채널을 압도할 수 있다는 우려도 제기되었습니다. (출처: Reddit r/ArtificialInteligence, BlancheMinerva, Ronald_vanLoon)

AI 하드웨어 및 인프라 논의 : 소셜 미디어에서는 AI 인프라에서 AI UX의 중요성, 그리고 AI 칩의 성능과 에너지 소비에 대해 논의했습니다. 일부 견해는 NVIDIA의 강점이 GPU 외의 생태계에 있으며, Google TPU가 미래에 외부에 판매될 수 있다고 주장합니다. (출처: ShreyaR, m__dehghani, espricewright)

💡 기타
AI의 금융 분야 적용 : 한 연구는 소규모(2억 7천만 매개변수) Gemma-3 모델을 지도 미세 조정 및 GRPO(Group Relative Policy Optimization)를 통해 금융 분석가의 “사고” 패턴을 구현하고 검증 가능한 구조화된 결과를 출력하도록 훈련하는 방법을 보여주었습니다. 이는 소규모 모델도 특정 분야에서 지능적인 추론을 수행할 수 있으며, 비용과 지연 시간이 낮다는 것을 시사합니다. (출처: Reddit r/deeplearning)

음성 데이터 분석 및 분리 : Reddit 커뮤니티에서는 노래에서 보컬을 클러스터링하여 다른 아티스트를 식별하는 방법에 대해 논의했습니다. 음성 특징 추출을 위해 Mel-frequency Cepstral Coefficients (MFCCs)를 사용하고, Librosa 또는 python_speech_features와 같은 Python 라이브러리를 활용하는 것이 제안되었습니다. 또한, 오디오 편집 소프트웨어로 보컬과 악기를 분리하는 방법, 그리고 “칵테일 파티 효과”와 같은 신호 분리의 어려움도 언급되었습니다. (출처: Reddit r/MachineLearning)
AI 보조 연구 발견 : Hugging Face는 “MCP for Research” 가이드를 발표하여 모델 컨텍스트 프로토콜(MCP)을 통해 AI와 연구 도구를 연결하고 논문, 코드, 모델 및 데이터셋의 발견 및 상호 참조를 자동화하는 방법을 보여주었습니다. 이를 통해 AI는 자연어 요청을 통해 arXiv, GitHub, Hugging Face와 같은 플랫폼에서 연구 정보를 효율적으로 통합하여 연구 효율성을 높일 수 있습니다. (출처: HuggingFace Blog)