
키워드:GPT-5, AI 자기 계발, 구현형 인공지능, 멀티모달 모델, 대형 언어 모델, 강화 학습, AI 에이전트, GPT-5 성능 향상, Genie Envisioner 로봇 플랫폼, LLM 채용 평가 편향, Qwen3 초장기 컨텍스트, CompassVerifier 답변 검증
🔥 포커스
GPT-5 출시: 제품화 및 성능 향상 : OpenAI가 GPT-5를 공식 출시하며, 플래그십 모델의 최신 버전을 선보였습니다. 이번 출시는 사용자 경험 향상에 중점을 두었으며, 실시간 라우터를 통해 기본 모델과 심층 추론 모델을 자동 스케줄링하여 속도와 지능의 균형을 이루었습니다. GPT-5는 환각 감소, 지시 따르기 및 프로그래밍 능력 향상 면에서 두드러진 성능을 보였으며, 여러 벤치마크 테스트에서 기록을 경신했습니다. Sam Altman은 이를 “레티나 디스플레이”에 비유하며, 단순한 지능 상한 돌파가 아닌 “박사 과정 수준 AI”로서의 실용성을 강조했습니다. 기술적으로 AGI에 도달하지는 못했지만, 더 빠른 추론 속도와 낮은 운영 비용으로 AI의 광범위한 응용을 촉진할 것으로 기대됩니다.(출처: MIT Technology Review)

AI 자체 개선 연구 진행 상황 : Meta CEO Mark Zuckerberg는 회사가 자체 개선이 가능한 AI 시스템 구축에 전념하고 있다고 밝혔습니다. AI는 자동 데이터 증강, 모델 아키텍처 검색, 강화 학습 등을 통해 여러 면에서 자체 개선 능력을 보여왔습니다. 이러한 추세는 미래 AI 시스템이 자율적으로 학습하고 인간이 설정한 성능 한계를 뛰어넘을 수 있을 것이며, 이는 더 높은 수준의 AI를 실현하는 핵심 경로임을 시사합니다.(출처: MIT Technology Review)

Genie Envisioner: 통합 로봇 조작 세계 모델 플랫폼 : 연구원들이 로봇 조작을 위한 통합 세계 기반 플랫폼인 Genie Envisioner (GE)를 출시했습니다. GE-Base는 실제 로봇 상호 작용의 공간적, 시간적, 의미적 동역학을 포착할 수 있는 명령 조건부 비디오 확산 모델입니다. GE-Act는 잠재 표현을 실행 가능한 동작 궤적으로 매핑하여 정확하고 범용적인 전략 추론을 가능하게 합니다. GE-Sim은 동작 조건부 신경 시뮬레이터로서 폐쇄 루프 전략 개발을 지원합니다. 이 플랫폼은 명령 기반의 범용 구체화된 지능을 위한 확장 가능하고 실용적인 기반을 제공할 것으로 기대됩니다.(출처: HuggingFace Daily Papers)
대규모 멀티모달 모델의 오류 입력 식별 능력 평가 프레임워크 ISEval : 대규모 멀티모달 모델(LMMs)이 오류 입력을 능동적으로 식별할 수 있는지 여부에 대한 문제에 대해 연구원들은 ISEval 평가 프레임워크를 제안했습니다. 이 프레임워크는 7가지 결함 전제와 3가지 평가 지표를 포함합니다. 연구 결과, 대부분의 LMM은 명확한 지침 없이는 텍스트 결함을 능동적으로 감지하기 어려웠으며, 다른 오류 유형에 대해 다양한 성능을 보였습니다. 예를 들어, 논리적 오류 식별에는 능숙했지만, 표면적인 언어 오류 및 특정 조건 결함에는 미흡했습니다. 이는 LMM이 입력 유효성을 능동적으로 검증하는 데 있어 시급한 필요성을 강조합니다.(출처: HuggingFace Daily Papers)
LLM 채용 평가에서의 언어 편향 연구 : 한 연구에서 대규모 언어 모델(LLMs)이 채용 평가에서 언어 차별적 표식에 어떻게 반응하는지 평가하는 벤치마크를 도입했습니다. 정교하게 설계된 면접 시뮬레이션을 통해, LLM이 내용의 질이 동일하더라도 특정 언어 패턴, 특히 모호한 언어를 체계적으로 불이익 준다는 사실이 밝혀졌습니다. 이는 자동화된 평가 시스템 내의 인구 통계학적 편향을 드러내며, AI 시스템 내 언어 차별 감지 및 측정을 위한 기본 프레임워크를 제공하여 자동화된 의사결정의 공정성에 광범위하게 적용될 수 있습니다.(출처: HuggingFace Daily Papers)
🎯 동향
Qwen3 시리즈 모델, 백만 단위 초장문 컨텍스트 지원 : Alibaba Cloud의 Qwen3-30B-A3B-2507 및 Qwen3-235B-A22B-2507 모델이 이제 최대 100만 tokens의 초장문 컨텍스트를 지원합니다. 이는 Dual Chunk Attention (DCA) 및 MInference 희소 주의 기술 덕분으로, 생성 품질을 향상시킬 뿐만 아니라 거의 백만 tokens 시퀀스의 추론 속도를 3배 향상시켰습니다. 이로써 LLM이 긴 문서, 코드 라이브러리 등 복잡한 작업을 처리하는 데 있어 응용 잠재력이 크게 확장되었으며, vLLM 및 SGLang의 효율적인 배포와도 호환됩니다.(출처: Alibaba_Qwen)

Anthropic Claude Opus 4.1 및 Sonnet 4 업그레이드 : Anthropic이 Claude Opus 4.1 및 Sonnet 4를 출시하며, Agentic 작업, 실제 세계 코딩 및 추론 능력 향상에 중점을 두었습니다. 새로운 모델은 “심층 사고” 기능을 갖추어 즉각적인 응답과 심층 추론 모드 간 유연한 전환이 가능하며, 수 시간 걸리던 복잡한 작업을 몇 분 안에 완료하도록 단축했습니다. 이는 다중 모델 협업 시나리오, 특히 복잡한 코드 검토 및 고급 추론 작업에서 Claude의 위치를 더욱 강화합니다.(출처: dl_weekly)
Microsoft, Copilot 3D 기능 출시 : Microsoft가 무료 Copilot 3D 기능을 출시했습니다. 이 기능은 2D 이미지를 GLB 형식의 3D 모델로 변환할 수 있으며, 다양한 3D 뷰어, 디자인 도구 및 게임 엔진과 호환됩니다. 현재 동물 및 인간 이미지에는 효과가 좋지 않지만, 이 기능은 사용자에게 편리한 2D-3D 변환 능력을 제공하여 제품 디자인, 가상 현실 등 분야에서 활용될 수 있으며, 3D 콘텐츠 제작의 진입 장벽을 더욱 낮출 것으로 기대됩니다.(출처: The Verge)
HuggingFace Accelerate, 다중 GPU 훈련 가이드 발표 : HuggingFace가 Axolotl과 협력하여 Accelerate ND-Parallel 가이드를 발표했습니다. 이 가이드는 다중 GPU 훈련에서 병렬 전략의 조합 및 적용을 간소화하는 것을 목표로 합니다. 데이터 병렬(DP), 샤딩 데이터 병렬(FSDP), 텐서 병렬(TP) 및 컨텍스트 병렬(CP) 등 다양한 전략을 상세히 소개하고, 혼합 병렬 구성의 예시를 제공하여 개발자가 대규모 모델 훈련 시 메모리 사용 및 처리량을 최적화하고 다중 노드 훈련에서의 통신 오버헤드 문제를 효과적으로 해결하도록 돕습니다.(출처: HuggingFace Blog)
🧰 도구
OpenAI Codex CLI: 터미널 로컬 코딩 Agent : OpenAI가 로컬 터미널에서 실행되는 경량 코딩 Agent인 Codex CLI를 출시했습니다. 사용자는 npm install -g @openai/codex 또는 brew install codex 명령으로 설치할 수 있습니다. 이 도구는 ChatGPT Plus/Pro/Team 계정과 연동하여 GPT-5 등 최신 모델을 무료로 사용할 수 있으며, API Key를 통해 사용량에 따라 요금을 지불할 수도 있습니다. Codex CLI는 읽기/쓰기, 읽기 전용 등 다양한 샌드박스 모드를 제공하고 사용자 정의 구성을 지원하여 개발자에게 효율적이고 안전한 로컬 프로그래밍 지원을 제공하는 것을 목표로 합니다.(출처: openai/codex – GitHub Trending)

HuggingFace AI Sheets: 노코드 데이터셋 도구 : HuggingFace가 AI Sheets를 출시했습니다. 이는 AI 모델을 사용하여 데이터셋을 구축, 풍부화 및 변환하는 오픈소스 노코드 도구입니다. 이 도구는 스프레드시트와 유사한 인터페이스를 가지며, 로컬 배포 또는 Hugging Face Hub에서 실행할 수 있습니다. 사용자는 수천 개의 오픈 모델(gpt-oss 포함)을 활용하여 모델 비교, 프롬프트 최적화, 데이터 정제, 분류, 분석 및 합성 데이터 생성을 수행할 수 있으며, 수동 편집 및 좋아요 피드백을 통해 AI 생성 결과를 반복적으로 개선하고 Hub로 내보낼 수 있습니다.(출처: HuggingFace Blog)

Google Agent Development Kit (ADK) 및 예시 : Google이 Agent Development Kit (ADK)를 출시했습니다. 이는 복잡한 AI Agent를 구축, 평가 및 배포하기 위한 오픈소스, 코드 우선 Python 툴킷입니다. ADK는 풍부한 도구 생태계, 모듈형 다중 Agent 시스템을 지원하며 유연한 배포가 가능합니다. 샘플 라이브러리 adk-samples는 대화형 챗봇부터 다중 Agent 워크플로우까지 다양한 Agent 예시를 제공하여 Agent 개발 프로세스를 가속화하고, A2A protocol과 통합하여 원격 Agent 간 통신을 실현합니다.(출처: google/adk-python – GitHub Trending & google/adk-samples – GitHub Trending)

Qwen Code CLI: 무료 코드 실행 도구 : Alibaba Cloud의 Qwen Code CLI는 매일 2000회 무료 코드 실행을 제공하며, npx @qwen-code/qwen-code@latest 명령으로 쉽게 시작할 수 있습니다. 이 도구는 Qwen OAuth를 지원하며, 개발자에게 편리하고 효율적인 코드 작성 및 테스트 경험을 제공하는 것을 목표로 합니다. Qwen 팀은 이 CLI 도구와 Qwen-Coder 모델을 지속적으로 최적화하여 오픈소스를 유지하면서 Claude Code 수준의 성능을 달성하고자 한다고 밝혔습니다.(출처: Alibaba_Qwen)
📚 학습
OpenAI Python 라이브러리 업데이트 : OpenAI 공식 Python 라이브러리는 OpenAI REST API에 편리하게 접근할 수 있도록 지원하며, Python 3.8+를 지원합니다. 라이브러리에는 모든 요청 매개변수 및 응답 필드의 타입 정의가 포함되어 있으며, 동기 및 비동기 클라이언트를 제공합니다. 최신 업데이트에는 저지연, 멀티모달 대화 경험 구축을 위한 Realtime API의 베타 지원과 webhook 검증, 오류 처리, 요청 ID 및 재시도 메커니즘에 대한 상세 설명이 포함되어 개발 효율성과 견고성을 향상시켰습니다.(출처: openai/openai-python – GitHub Trending)
AI Agent 엄선 목록 : e2b-dev/awesome-ai-agents는 수많은 AI 자율 Agent의 예시와 리소스를 수록한 GitHub 저장소입니다. 이 목록은 개발자에게 다양한 유형의 AI Agent를 이해하고 학습하는 데 도움이 되는 중앙 집중식 리소스 라이브러리를 제공하며, 단순한 것부터 복잡한 것까지 다양한 응용 시나리오를 포괄하여 AI Agent를 탐색하고 구축하는 데 중요한 학습 자료가 됩니다.(출처: e2b-dev/awesome-ai-agents – GitHub Trending)
MeanFlow: 원스텝 생성 확산 모델의 새로운 패러다임 : 과학 공간(科学空间)에서 MeanFlow를 제안했습니다. 이는 확산 모델 가속 생성의 표준이 될 것으로 기대되는 새로운 방법으로, ‘순간 속도’가 아닌 ‘평균 속도’를 모델링하여 원스텝 생성을 실현하고 기존 확산 모델의 느린 생성 속도라는 문제점을 해결하는 것을 목표로 합니다. MeanFlow는 명확한 수학적 원리를 가지며, 단일 목표로 처음부터 훈련 가능하고, 단일 스텝 생성 효과가 SOTA에 근접하여 생성형 AI 모델 가속화를 위한 새로운 이론 및 실천 방향을 제시합니다.(출처: WeChat)

긴 컨텍스트 KV Cache 전체 수명 주기 최적화 : Microsoft Asia Research는 긴 컨텍스트 대규모 언어 모델 추론에서의 지연 및 저장 문제를 해결하기 위한 KV Cache 전체 수명 주기 최적화 실천 사례를 공유했습니다. SCBench 벤치마크 테스트를 통해 MInference, RetrievalAttention 등의 방법을 제안하여 Prefilling 단계 지연을 현저히 감소시키고 KV Cache GPU 메모리 압력을 완화했습니다. 연구는 시스템 수준의 요청 간 최적화 및 Prefix Caching 재사용을 강조하며, 긴 컨텍스트 LLM 추론의 확장성 및 경제성을 위한 최적화 방안을 제공합니다.(출처: WeChat)

강화 학습 프레임워크 FR3E, LLM 탐색 능력 향상 : ByteDance, MAP 및 맨체스터 대학이 공동으로 FR3E(First Return, Entropy-Eliciting Explore)를 제안했습니다. 이는 강화 학습에서 LLM의 탐색 부족 문제를 해결하기 위한 새로운 구조화된 탐색 프레임워크입니다. FR3E는 추론 궤적에서 높은 불확실성 token을 식별하여 다양한 전개를 유도하고, LLM 탐색 메커니즘을 체계적으로 재구축하여 활용과 탐색의 동적 균형을 실현하며, 여러 수학 추론 벤치마크에서 기존 방법보다 현저히 우수한 성능을 보였습니다.(출처: WeChat)

자기 주의 메커니즘 내 극대값과 컨텍스트 이해 연관성 연구 : ICML 2025의 새로운 연구는 대규모 언어 모델 자기 주의 메커니즘의 쿼리(Q) 및 키(K) 표현에 고도로 집중된 극대값이 존재하며, 이 값들이 컨텍스트 지식 이해에 매우 중요하다는 것을 밝혀냈습니다. 이 현상은 회전 위치 인코딩(RoPE)을 사용하는 모델에서 보편적으로 나타나며, 초기 레이어에서부터 나타난다는 사실이 발견되었습니다. 이러한 극대값을 손상시키면 컨텍스트 이해가 필요한 작업에서 모델 성능이 급격히 저하되어, LLM 설계, 최적화 및 양자화에 새로운 방향을 제시합니다.(출처: WeChat)
C3 Benchmark: 중영 이중 언어 음성 대화 모델 테스트 벤치마크 : 베이징 대학과 Tencent가 공동으로 C3 Benchmark를 발표했습니다. 이는 구어체 대화 모델에서 일시 정지, 다의어, 동음이의어, 강세, 구문 모호성, 다의성 등 복잡한 현상을 전면적으로 검토하는 최초의 중영 이중 언어 평가 벤치마크입니다. 이 벤치마크는 1079개의 실제 시나리오와 1586개의 오디오-텍스트 쌍을 포함하며, 현재 음성 대화 모델의 치명적인 약점을 직접적으로 공략하여 인간의 일상 대화 이해 능력 향상을 촉진하는 것을 목표로 합니다.(출처: WeChat)
Chemma: 유기 화학 합성 대규모 언어 모델 : 상하이 교통대학교 AI for Science 팀이 백옥란 화학 합성 대규모 모델(Chemma)을 발표했습니다. 이는 화학 대규모 언어 모델이 유기 합성 전체 프로세스를 가속화하는 것을 최초로 실현했습니다. Chemma는 양자 계산 없이 화학 지식 이해 및 추론 능력만으로 단일/다단계 역합성, 수율/선택성 예측, 반응 최적화 등 작업에서 기존 최고 결과를 뛰어넘었습니다. “Co-Chemist” 인간-기계 협업 능동 학습 프레임워크는 실제 반응에서 성공적으로 검증되어 화학 발견에 새로운 패러다임을 제공합니다.(출처: WeChat)

Intern-Robotics: 상하이 AI Lab 구체화된 풀스택 엔진 : 상하이 AI Lab이 구체화된 풀스택 엔진 Intern-Robotics를 발표했습니다. 이는 구체화된 지능 분야의 “ChatGPT 순간”을 촉진하는 것을 목표로 합니다. 이 엔진은 온톨로지 일반화, 시나리오 일반화, 작업 일반화에 중점을 둔 개방형 공유 인프라로, 작업 성공률이 100%에 근접하는 것을 강조합니다. 팀은 “Real to Sim to Real” 기술 경로와 실제 세계 강화 학습을 통해 데이터 부족 문제를 해결하고 점진적으로 제로샷 일반화를 실현하여 구체화된 지능의 실제 응용을 가속화하는 데 전념하고 있습니다.(출처: WeChat)

AI 자문자답 추론 능력 진화 프레임워크 SQLM : 카네기 멜론 대학교 팀이 SQLM을 제안했습니다. 이는 외부 데이터 없이 자체 질문을 통해 AI 추론 능력을 향상시키는 프레임워크입니다. 이 프레임워크는 질문자(proposer)와 답변자(solver) 두 가지 역할을 포함하며, 둘은 기대 보상을 최대화하기 위한 강화 학습 훈련을 통해 상호 작용합니다. SQLM은 산술, 대수 및 프로그래밍 작업에서 모델 정확도를 현저히 향상시켰으며, 고품질 수동 레이블링 데이터가 부족한 상황에서 대규모 언어 모델의 능력 향상을 위한 확장 가능한 자가 유지 프로세스를 제공합니다.(출처: WeChat)

CompassVerifier: AI 답변 검증 모델 및 평가 데이터셋 : 상하이 AI Lab과 마카오 대학이 공동으로 범용 답변 검증 모델 CompassVerifier와 평가 데이터셋 VerifierBench를 발표했습니다. 이는 대규모 모델 훈련 능력은 급성장했지만 답변 검증 능력은 뒤처지는 문제를 해결하는 것을 목표로 합니다. CompassVerifier는 Qwen 시리즈 모델을 기반으로 최적화된 가볍지만 강력한 다중 도메인 범용 검증기로, 수학, 지식, 과학 추론 등 여러 도메인에서 범용 대규모 모델을 뛰어넘는 검증 정확도를 달성하며, 강화 학습 보상 모델로 활용되어 LLM 반복 최적화에 정확한 피드백을 제공할 수 있습니다.(출처: WeChat)

CoAct-1: 코딩을 행동으로 사용하는 컴퓨터 Agent : 연구원들은 코딩을 강화된 행동으로 사용하는 다중 Agent 시스템인 CoAct-1을 제안했습니다. 이는 복잡한 작업에서 GUI 조작 Agent의 효율성 및 신뢰성 문제를 해결하는 것을 목표로 합니다. CoAct-1의 Orchestrator는 하위 작업을 GUI Operator 또는 Programmer Agent(Python/Bash 스크립트 작성 및 실행 가능)에게 동적으로 위임하여 비효율적인 GUI 조작을 우회할 수 있습니다. 이 방법은 OSWorld 벤치마크 테스트에서 SOTA 성공률을 달성하고 효율성을 현저히 향상시켜 범용 컴퓨터 자동화를 위한 더 강력한 경로를 제공합니다.(출처: HuggingFace Daily Papers)
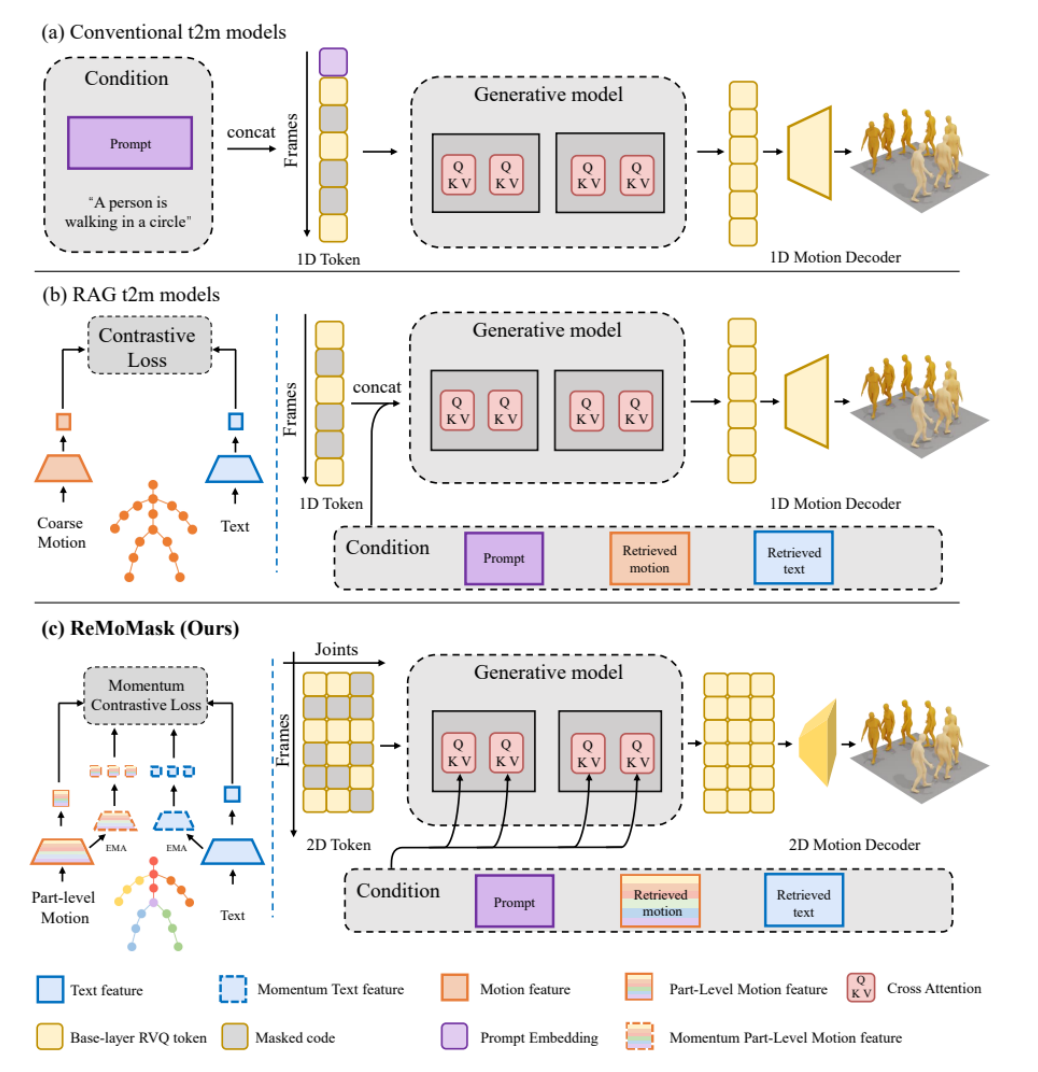
ReMoMask: 고품질 게임 3D 동작 생성 신기술 : 베이징 대학이 ReMoMask를 제안했습니다. 이는 검색 증강 생성 기반의 Text-to-Motion 프레임워크로, 한 문장 명령으로 고품질의 부드럽고 사실적인 3D 동작을 생성하는 것을 목표로 합니다. ReMoMask는 모멘텀 양방향 텍스트-동작 모델, 의미론적 시공간 주의 메커니즘 및 RAG-분류기 없는 가이드를 통합하여 시간적으로 일관된 동작을 효율적으로 생성합니다. 이 방법은 HumanML3D 및 KIT-ML 등 표준 벤치마크 테스트에서 SOTA 성능을 경신하여 게임 및 애니메이션 제작 프로세스를 완전히 변화시킬 것으로 기대됩니다.(출처: WeChat)
WebAgents 개요: 대규모 모델 기반 웹 자동화 : 홍콩 이공대학교 연구원들이 최초의 WebAgents 개요를 발표했습니다. 이는 대규모 모델이 AI Agent에 힘을 실어 차세대 웹 자동화를 실현하는 연구 진행 상황을 전면적으로 정리한 것입니다. 이 개요는 아키텍처(인지, 계획 추론, 실행), 훈련(데이터, 전략) 및 신뢰성(보안, 프라이버시, 일반화) 등 다양한 관점에서 WebAgents의 대표적인 방법을 요약하고, 공정성, 설명 가능성, 데이터셋 및 개인화된 WebAgents와 같은 미래 연구 방향을 탐구하여 더 스마트하고 안전한 웹 자동화 시스템 구축을 위한 지침을 제공합니다.(출처: WeChat)

LLM 추론 능력 정렬 프레임워크 InfiAlign : InfiAlign은 SFT와 DPO를 결합하여 LLM을 정렬하고 추론 능력을 강화하는 확장 가능하고 샘플 효율적인 후처리 훈련 프레임워크입니다. 이 프레임워크의 핵심은 오픈소스 추론 데이터셋에서 고품질 정렬 데이터를 자동으로 선별하는 강력한 데이터 선택 파이프라인입니다. InfiAlign은 Qwen2.5-Math-7B-Base 모델에서 DeepSeek-R1-Distill-Qwen-7B와 동등한 성능을 달성했지만, 훈련 데이터의 약 12%만 사용했으며, 수학 추론 작업에서 현저한 향상을 이루어 대규모 추론 모델의 정렬을 위한 실용적인 방안을 제공합니다.(출처: HuggingFace Daily Papers)
💼 비즈니스
OpenAI 직원 스톡옵션 현금화 계획, 인재 유출 방지 : 인재 유출에 대응하기 위해 OpenAI가 새로운 직원 스톡옵션 현금화 계획을 시작했습니다. 5,000억 달러 가치로 현금화되는 이 계획은 실질적인 금전으로 인재를 유지하는 것을 목표로 합니다. 이 조치는 OpenAI의 가치를 새로운 최고치로 끌어올릴 것으로 기대됩니다. 동시에 ChatGPT의 주간 활성 사용자는 7억 명에 달하고, 유료 기업 사용자는 500만 명으로 증가했으며, 연간 경상 수익은 200억 달러를 초과할 것으로 예상되어 OpenAI가 제품 및 상업화 면에서 좋은 발전 추세를 보이고 있음을 나타냅니다.(출처: 量子位)

Amazon Web Services, 최대 AI 모델 통합 플랫폼 구축 : Amazon Web Services (AWS)는 OpenAI의 gpt-oss 모델이 Amazon Bedrock 및 Amazon SageMaker를 통해 최초로 접근 가능하다고 발표하며, “Choice Matters”(선택이 가장 중요) 전략 하의 모델 생태계를 더욱 풍부하게 했습니다. AWS는 현재 400개 이상의 주요 상업 및 오픈소스 대규모 모델을 제공하며, 기업이 성능, 비용 및 작업 요구 사항에 따라 가장 적합한 모델을 선택하도록 하여 단일 “최강” 모델을 추구하기보다는 다중 모델 시너지 효과를 촉진하는 것을 목표로 합니다.(출처: 量子位)

Ant Group, 구체화된 지능형 로봇 손 기업에 투자 : Ant Group이 구체화된 지능형 로봇 손 기업 ‘링신차오서우(灵心巧手)’에 수억 위안 규모의 시드 투자를 주도했습니다. 링신차오서우는 전 세계에서 유일하게 수천 대의 고자유도 로봇 손을 양산한 기업으로, 시장 점유율이 80%에 달합니다. Linker Hand 시리즈 로봇 손은 고자유도, 다중 센서 시스템 및 비용 우위를 가지며, 이미 산업, 의료 등 시나리오에서 상용화되었습니다. 이번 투자는 기술 비축 및 데이터 수집 현장 구축에 사용되어 로봇 손의 실제 응용 배포를 가속화할 것입니다.(출처: 量子位)

🌟 커뮤니티
GPT-5 사용자 경험 양극화 : GPT-5 출시 후 사용자 피드백이 엇갈리고 있습니다. 일부 사용자는 프로그래밍 및 복잡한 추론 작업에서 현저한 향상을 칭찬하며, 코드 생성이 더 깔끔하고 정확하며 긴 컨텍스트 처리 능력이 매우 강력하다고 평가했습니다. 그러나 다른 사용자들은 모델의 개인화, 창의적 글쓰기 및 감정 지원 능력 저하에 실망감을 표하며, 모델이 “지루하고”, “영혼이 없다”고 느꼈고, 모델 라우팅 메커니즘으로 인해 경험이 불안정하다고 지적했으며, 심지어 일부 사용자는 이로 인해 구독을 취소하기도 했습니다.(출처: Reddit r/ChatGPT & Reddit r/LocalLLaMA & Reddit r/ChatGPT & Reddit r/ChatGPT)

육아에서의 AI 활용과 논란 : 워킹맘/대디들은 ChatGPT와 같은 AI 도구를 “공동 육아자”로 활용하여 식단 계획, 취침 전 루틴 최적화, 심지어 정서적 지원까지 받고 있습니다. AI의 판단 없는 털어놓을 공간은 부모들의 심리적 부담을 덜어줍니다. 그러나 이러한 신흥 기술은 부정확한 조언 제공 가능성, 개인 정보 유출 위험(ChatGPT 데이터 유출 사건 등), AI에 대한 과도한 의존으로 인한 인간 관계 고립 및 환경에 대한 잠재적 영향 등 논란을 불러일으키고 있습니다.(출처: 36氪)
Airbnb, AI 위조 이미지로 인한 사용자 배상 사건 : Airbnb에서 집주인이 AI 위조 이미지를 이용해 사용자에게 배상을 요구한 사건이 발생하여, 고객 서비스에서 AI의 위험성을 부각시켰습니다. AI 고객 서비스는 AI 생성 이미지를 식별하지 못하여 사용자가 잘못된 배상 판정을 받았습니다. OpenAI가 이미지 감지기를 출시했음에도 불구하고, AI가 AI를 식별하는 데는 여전히 한계가 있으며, 특히 “부분 위조” 기술 앞에서는 더욱 그렇습니다. 이 사건은 AI 콘텐츠 감지 도구의 신뢰성과 C2C 플랫폼이 딥페이크 콘텐츠 충격에 대응해야 할 필요성에 대한 우려를 불러일으켰습니다.(출처: 36氪)

실리콘밸리 AI 거물들의 종말 대비 벙커 건설, 뜨거운 논란 : Mark Zuckerberg와 Sam Altman과 같은 실리콘밸리 AI 업계 리더들이 종말 대비 피난처를 건설하거나 소유하고 있다는 사실이 폭로되면서, AI의 미래 발전과 잠재적 위험에 대한 대중의 우려를 불러일으켰습니다. 이들이 AI와 관련성을 부인했음에도 불구하고, 이러한 움직임은 대유행병, 사이버 전쟁, 기후 재난 등 긴급 상황에 대한 대비로 해석되고 있습니다. 커뮤니티에서는 AI 기술을 가장 잘 아는 이들이 일반인이 알지 못하는 징후를 보았는지, 그리고 AI 발전이 예측 불가능한 위험을 초래했는지에 대한 추측이 난무하고 있습니다.(출처: 量子位)

Kaggle AI 체스 챔피언십, o3 우승 : 제1회 Google Kaggle AI 체스 챔피언십 결승전에서 OpenAI의 o3가 Elon Musk의 Grok 4를 4-0으로 완파하고 우승을 차지했습니다. 이 경기는 대규모 모델의 비판적 사고, 전략적 계획 및 현장 대응 능력을 시험하는 OpenAI와 xAI의 “대리전”으로 여겨졌습니다. Grok 4가 이전까지 강력한 기세를 보였음에도 불구하고 결승전에서 잦은 실수를 범한 반면, o3는 체계적으로 안정된 전략을 선보이며 전 경기 무패로 무패의 왕이 되었습니다.(출처: WeChat)

AI, ‘환멸의 계곡’ 진입 논의 : 소셜 미디어에서는 AI가 특히 GPT-5 출시 후 “환멸의 계곡”에 진입했다는 논의가 활발합니다. 사용자들은 AI의 한계가 효과적으로 돌파되지 않았으며, 모델 규모 및 컴퓨팅 능력 향상으로 인한 이득이 감소하고 있다고 지적합니다. 이러한 관점은 AI의 발전이 “덜 분명해졌다”고 보며, 주로 전문가 영역에서 나타나고 일반 사용자가 인지할 수 있는 수준은 아니라고 주장합니다. 이는 AI 발전이 정체기에 접어들어 새로운 아키텍처 돌파가 필요함을 시사합니다.(출처: Reddit r/ArtificialInteligence)

💡 기타
Docker, MCP 툴체인 보안 위험 경고 : Docker는 모델 컨텍스트 프로토콜(MCP) 기반의 AI 구동 개발 툴체인에 심각한 보안 취약점(자격 증명 유출, 무단 파일 접근 및 원격 코드 실행 포함)이 존재하며, 실제 사례도 발생했다고 경고했습니다. 이러한 도구들은 LLM을 개발 환경에 내장하여 자율적인 운영 권한을 부여하지만, 격리 및 감독이 부족합니다. Docker는 npm에서 MCP 서버를 설치하는 것을 피하고, 서명된 컨테이너를 사용하며, 컨테이너 격리 및 제로 트러스트 네트워크의 중요성을 강조했습니다.(출처: WeChat)

Huawei HarmonyOS 애플리케이션 개발자 인센티브 프로그램 2025 : Huawei는 HarmonyOS 5 단말기 수가 천만 대를 돌파했다고 발표하며, “HarmonyOS 애플리케이션 개발자 인센티브 프로그램 2025”를 시작했습니다. 수억 위안의 보조금을 투입하고 개별 개발자에게 최대 600만 위안의 상금을 제공하는 이 프로그램은 HarmonyOS 생태계 발전을 가속화하고, 개발자들이 AI 및 다중 단말기 대상 애플리케이션 개발에 참여하도록 유도하여 “한 번 개발로 여러 단말기 배포”를 실현하는 것을 목표로 합니다. Huawei는 기술 지원, 빠른 테스트, 효율적인 출시 및 운영을 포함한 풀스택 개발 지원을 제공하여 견고한 개발자 생태계를 구축하고자 합니다.(출처: WeChat)

중국산 AI 슈퍼노드 서버 YuanBrain SD200 출시 : Inspur Information이 슈퍼노드 AI 서버 “YuanBrain SD200”을 출시했습니다. 이는 조 단위 매개변수 대규모 모델 실행의 컴퓨팅 능력 문제를 해결하는 것을 목표로 합니다. 이 서버는 혁신적으로 개발된 다중 호스트 저지연 메모리 의미 통신 아키텍처를 채택하여 64개의 로컬 GPU 칩을 통합할 수 있으며, 최대 4TB 통합 GPU 메모리 및 64GB 통합 메모리를 제공하여 조 단위 초장문 시퀀스 모델을 지원합니다. 실제 테스트 결과, SD200은 DeepSeek R1 등 모델에서 최고의 컴퓨팅 능력 확장 효율을 달성하여 AI4 Science 및 산업 분야 응용에 강력한 지원을 제공합니다.(출처: WeChat)
