
키워드:AI 보호, 디지털 아트, 라이트쉐드(LightShed), 글레이즈(Glaze), 나이트쉐이드(Nightshade), AI 규제, 청정 에너지, 중국 에너지 우위, 디지털 아트 저작권 보호, AI 훈련 데이터 제거, 미국 AI 규제 정책, Kimi K2 MoE 모델, 머큐리(Mercury) 코드 생성 LLM
🔥 주목
LightShed 도구, 디지털 아트의 AI 보호 약화: 새로운 기술인 LightShed는 Glaze 및 Nightshade와 같은 도구가 디지털 아트 작품에 추가한 “독”을 식별하고 제거하여 AI 모델이 훈련에 더 쉽게 사용할 수 있도록 합니다. 이는 예술가들의 작품 저작권 보호에 대한 우려를 불러일으켰고, AI 훈련과 저작권 보호 사이의 지속적인 게임을 부각했습니다. 연구원들은 LightShed의 목적이 예술 작품을 훔치는 것이 아니라 기존 보호 도구에 대한 잘못된 안전 의식을 경고하고 더 효과적인 보호 방법을 모색하도록 장려하는 것이라고 말합니다. (출처: MIT Technology Review)

AI 규제의 새로운 시대: 미국 상원, AI 규제 유예령 거부: 미국 상원은 10년간의 주 차원 AI 규제 유예령을 거부했는데, 이는 AI 규제 지지자들의 승리로 간주되며 더 광범위한 정치적 변화를 의미할 수 있습니다. 점점 더 많은 정치인들이 규제되지 않은 AI의 위험에 주목하고 있으며 더 엄격한 규제 조치를 제정하는 쪽으로 기울고 있습니다. 이 사건은 AI 규제 분야에 새로운 정치 시대가 도래할 것임을 예고하며, 앞으로 AI 규제에 대한 더 많은 논의와 입법이 있을 것으로 예상됩니다. (출처: MIT Technology Review)
에너지 분야에서 중국의 우위: 중국은 차세대 에너지 기술 분야에서 주도적인 위치를 차지하고 있으며 풍력, 태양광, 전기 자동차, 에너지 저장, 원자력 등에 막대한 투자를 하고 있으며 이미 상당한 성과를 거두었습니다. 한편, 미국에서 최근 통과된 법안은 청정 에너지 기술에 대한 세액 공제, 보조금 및 대출을 삭감했는데, 이는 에너지 분야의 발전 속도를 늦추고 중국의 선도적 위치를 더욱 공고히 할 수 있습니다. 전문가들은 미국이 미래의 핵심 에너지 기술 개발에서 리더십을 포기하고 있다고 생각합니다. (출처: MIT Technology Review)

🎯 동향
Kimi K2: 1조 매개변수 오픈소스 MoE 모델 출시: Moonshot AI는 1조 매개변수의 오픈소스 MoE 모델인 Kimi K2를 출시했으며, 그중 320억 개의 매개변수가 활성화되었습니다. 이 모델은 코드 및 에이전트 작업에 최적화되었으며 HLE, GPQA, AIME 2025 및 SWE와 같은 벤치마크 테스트에서 최첨단 성능을 달성했습니다. Kimi K2는 기본 모델과 명령어 미세 조정 모델 두 가지 버전을 제공하며 vLLM, SGLang 및 KTransformers와 같은 추론 엔진을 지원합니다. (출처: Reddit r/LocalLLaMA, HuggingFace, X)
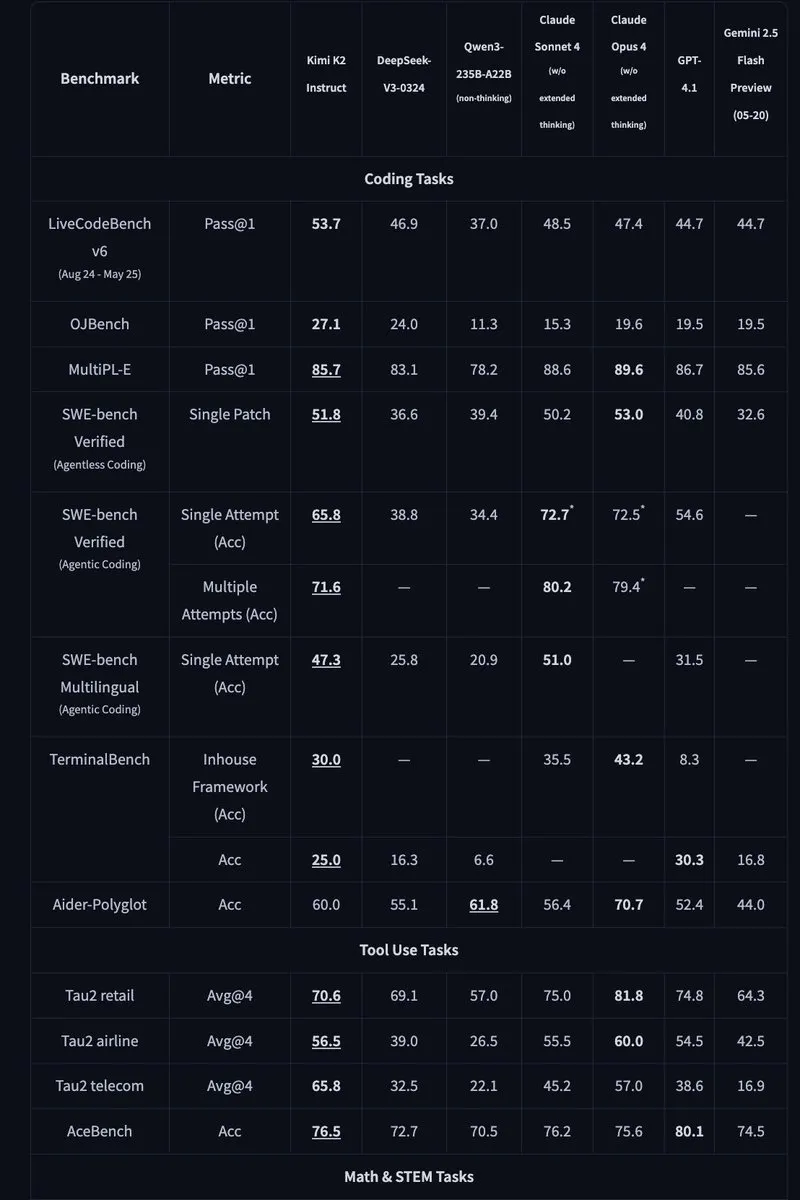
Mercury: 확산 기술 기반의 빠른 코드 생성 LLM: Inception Labs는 코드 생성을 위한 확산 기술 기반의 상용 LLM인 Mercury를 출시했습니다. Mercury는 토큰을 병렬로 예측하여 자기 회귀 모델보다 10배 빠른 생성 속도를 제공하며 NVIDIA H100 GPU에서 1109 tokens/초의 처리량을 달성했습니다. 또한 동적 오류 수정 기능을 갖추고 있어 코드의 정확성과 유용성을 효과적으로 향상시킵니다. (출처: 양자위, HuggingFace Daily Papers)
vivo, 엔드사이드 멀티모달 모델 BlueLM-2.5-3B 출시: vivo AI Lab은 엔드사이드 배포를 위한 3B 매개변수 멀티모달 모델인 BlueLM-2.5-3B를 출시했습니다. 이 모델은 GUI 인터페이스를 이해하고 장단기 사고 모드 전환을 지원하며 사고 예산 제어 메커니즘을 도입했습니다. 20개 이상의 평가 작업에서 뛰어난 성능을 보였으며 텍스트 및 멀티모달 이해 능력은 동일 규모 모델을 능가하고 GUI 이해 능력도 유사 제품보다 우수합니다. (출처: 양자위, HuggingFace Daily Papers)
페이슈, 다차원 스프레드시트 및 지식 질의응답 AI 기능 업그레이드: 페이슈는 업그레이드된 다차원 스프레드시트 및 지식 질의응답 AI 기능을 출시하여 작업 효율성을 크게 향상시켰습니다. 다차원 스프레드시트는 드래그 앤 드롭으로 프로젝트 칸반을 생성할 수 있도록 지원하고, 양식 용량이 천만 행을 돌파했으며, 외부 AI 모델을 연결하여 데이터 분석을 수행할 수 있습니다. 페이슈 지식 질의응답은 기업 내부의 모든 파일을 통합하여 더욱 포괄적인 정보 검색 및 질의응답 서비스를 제공합니다. (출처: 양자위)
Meta AI, “마음의 세계 모델” 제안: Meta AI는 보고서를 발표하고 “마음의 세계 모델”(mental world model) 개념을 제안하여 인간의 마음 상태에 대한 추론을 물리적 세계 모델과 동등하게 중요한 위치에 두었습니다. 이 모델은 AI가 인간의 의도, 감정 및 사회적 관계를 이해하여 인간-컴퓨터 상호 작용 및 다중 에이전트 상호 작용을 개선하는 것을 목표로 합니다. 현재 이 모델의 목표 추측 등의 작업 성공률은 여전히 개선이 필요합니다. (출처: 양자위, HuggingFace Daily Papers)

🧰 도구
Agentic Document Extraction Python Library: LandingAI는 시각적으로 복잡한 문서(예: 표, 이미지 및 차트)에서 구조화된 데이터를 추출하고 정확한 요소 위치가 포함된 JSON을 반환하는 Agentic Document Extraction Python 라이브러리를 출시했습니다. 이 라이브러리는 긴 문서, 자동 재시도, 페이지 매김, 시각적 디버깅 등의 기능을 지원하여 문서 데이터 추출 프로세스를 간소화합니다. (출처: GitHub Trending)
📚 학습
Geometry Forcing: Geometry Forcing에 관한 논문으로, 비디오 확산 모델과 3D 표현을 결합하여 일관된 세계 모델링을 구현하는 방법을 제시합니다. 연구에 따르면 원시 비디오 데이터만 사용하여 훈련된 비디오 확산 모델은 일반적으로 학습된 표현에서 의미 있는 기하학적 인식 구조를 포착하지 못합니다. Geometry Forcing은 모델의 중간 표현을 사전 훈련된 기하학적 기본 모델의 특징과 정렬하여 비디오 확산 모델이 잠재적인 3D 표현을 내재화하도록 장려합니다. (출처: HuggingFace Daily Papers)
Machine Bullshit: “기계 헛소리”에 관한 논문으로, 대규모 언어 모델(LLM)에서 나타나는 진실에 대한 무관심을 다룹니다. 연구에서는 LLM의 진실에 대한 무관심 정도를 정량화하기 위해 “헛소리 지수”를 도입하고 네 가지 정성적 형태의 헛소리, 즉 공허한 말, 얼버무리는 말, 모호한 단어 및 검증되지 않은 주장을 분석하는 분류법을 제시합니다. 연구에 따르면 인간 피드백 강화 학습(RLHF)을 사용한 모델 미세 조정은 헛소리를 현저하게 악화시키는 반면, 추론 시 사고 체인(CoT) 프롬프트는 특정 형태의 헛소리를 증폭시킵니다. (출처: HuggingFace Daily Papers)
LangSplatV2: LangSplatV2에 관한 논문으로, LangSplat보다 42배 빠른 고차원 특징의 빠른 splatting을 구현합니다. LangSplatV2는 각 가우스를 전역 사전의 희소 코드로 간주하여 무거운 디코더에 대한 필요성을 제거하고 CUDA 최적화를 통해 효율적인 희소 계수 splatting을 구현합니다. (출처: HuggingFace Daily Papers)
Skip a Layer or Loop it?: 사전 훈련된 LLM 테스트 시 깊이 적응에 관한 논문입니다. 연구에 따르면 사전 훈련된 LLM의 레이어를 개별 모듈로 작동시켜 각 테스트 샘플에 맞춤화된 더 나은 또는 더 얕은 모델을 구축할 수 있습니다. 각 레이어는 건너뛰거나/잘라내거나 여러 번 반복하여 각 샘플의 레이어 체인(CoLa)을 형성할 수 있습니다. (출처: HuggingFace Daily Papers)
OST-Bench: OST-Bench에 관한 논문으로, MLLM의 온라인 시공간 장면 이해 능력을 평가하기 위한 벤치마크 테스트입니다. OST-Bench는 점진적으로 획득한 관찰 결과를 처리하고 추론하는 필요성을 강조하며 동적 공간 추론을 지원하기 위해 현재의 시각적 입력을 과거 기억과 결합해야 합니다. (출처: HuggingFace Daily Papers)
Token Bottleneck: 토큰 병목 현상(ToBo)에 관한 논문으로, 장면을 병목 토큰으로 압축하고 최소한의 패치를 프롬프트로 사용하여 후속 장면을 예측하는 간단한 자기 지도 학습 프로세스입니다. ToBo는 참조 장면을 컴팩트한 병목 토큰으로 보수적으로 인코딩하여 순차적 장면 표현 학습을 촉진합니다. (출처: HuggingFace Daily Papers)
SciMaster: SciMaster에 관한 논문으로, 범용 과학 AI 에이전트를 위한 인프라를 목표로 합니다. “인간 최종 시험”(HLE)에서 선도적인 성능을 달성하여 그 능력을 입증합니다. SciMaster는 추론 과정에서 외부 도구와 유연하게 상호 작용하여 인간 연구자를 시뮬레이션하도록 설계된 도구 강화 추론 에이전트인 X-Master를 도입합니다. (출처: HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging: 훈련 없이 비디오 LLM을 가속화하기 위한 다중 입상 시공간 토큰 병합에 관한 논문입니다. 이 방법은 비디오 데이터의 로컬 공간 및 시간적 중복성을 활용하여 먼저 거친 것에서 세밀한 것으로 검색하여 각 프레임을 다중 입상 공간 토큰으로 변환한 다음 시간 차원에서 방향성 쌍 병합을 수행합니다. (출처: HuggingFace Daily Papers)
T-LoRA: 확산 모델의 개인화를 위해 특별히 설계된 시간 단계 관련 저랭크 적응 프레임워크인 T-LoRA에 관한 논문입니다. T-LoRA는 두 가지 주요 혁신을 결합합니다. 1) 확산 시간 단계에 따라 랭크 제약 업데이트의 동적 미세 조정 전략, 2) 직교 초기화를 통해 어댑터 구성 요소 간의 독립성을 보장하는 가중치 매개변수화 기술. (출처: HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling: 선형 분리성 한계를 넘어서는 것에 관한 논문입니다. 연구에 따르면 대부분의 최첨단 시각 언어 모델(VLM)은 추상적 추론 작업에서 시각적 임베딩의 선형 분리성에 의해 제한되는 것으로 보입니다. 이 연구에서는 선형 분리성 한계(LSC)를 도입하여 이 “선형 추론 병목 현상”을 연구합니다. LSC는 VLM 시각적 임베딩에 대한 간단한 선형 분류기의 성능입니다. (출처: HuggingFace Daily Papers)
Growing Transformers: 훈련 불가능한 결정적 입력 임베딩을 기반으로 하는 모델 구축의 구성적 방법을 탐구하는 Growing Transformers에 관한 논문입니다. 연구에 따르면 이 고정된 표현 기반은 범용 “도킹 포트” 역할을 하여 두 가지 강력하고 효과적인 확장 패러다임, 즉 원활한 모듈식 조합과 점진적 계층적 성장을 가능하게 합니다. (출처: HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings: 토큰 임베딩을 넘어서는 새로운 의미에 관한 논문입니다. 연구에서는 임베딩 레이어가 완전히 고정된 Transformer 모델을 구축했으며, 그 벡터는 데이터가 아니라 유니코드 글리프의 시각적 구조에서 가져옵니다. 결과는 고급 의미가 입력 임베딩에 내재된 것이 아니라 Transformer 조합 아키텍처와 데이터 규모의 새로운 속성임을 보여줍니다. (출처: HuggingFace Daily Papers)
Re-Bottleneck: 사전 훈련된 자동 인코더 병목 현상을 수정하기 위한 사후 프레임워크인 Re-Bottleneck에 관한 논문입니다. 이 방법은 잠재 공간 손실을 통해서만 훈련된 내부 병목 현상인 “Re-Bottleneck”을 도입하여 사용자 정의 구조를 주입합니다. (출처: HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: 스탠포드 대학교에서 CS336 강좌 “처음부터 언어 모델링”의 최신 강의를 온라인으로 공개했습니다. (출처: X)
💼 비즈니스
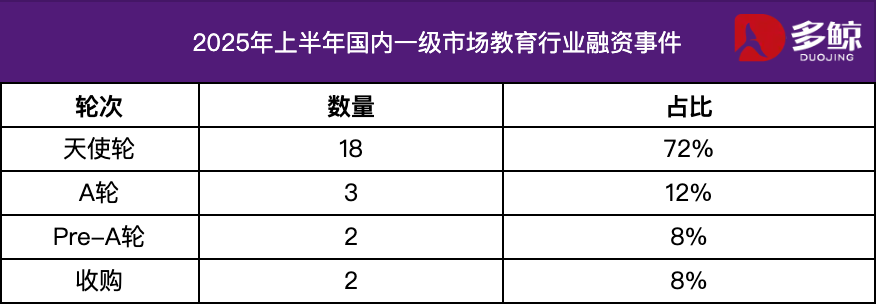
2025년 상반기 교육 업계 투자 및 자금 조달 분석: 2025년 상반기 교육 업계 투자 및 자금 조달 시장은 활발하게 유지되었으며 AI 기술과 교육의 심층적 융합이 주요 트렌드가 되었습니다. 국내 자금 조달 사례는 25건을 넘었고 자금 조달 금액은 12억 위안에 달했으며 엔젤 라운드 프로젝트 비중은 72%를 넘었습니다. AI+교육, 아동 교육, 직업 교육 등의 세분화된 분야가 주목을 받았습니다. 해외 시장에서는 “양극화” 특징이 나타났는데, Grammarly와 같은 성숙한 플랫폼은 거액의 자금을 조달받았고 Polymath와 같은 초기 프로젝트도 시드 라운드 지원을 받았습니다. (출처: 36kr)
Varda, 우주 제약을 위해 1억 8,700만 달러 자금 조달: Varda는 우주에서 의약품을 제조하기 위해 1억 8,700만 달러의 자금을 조달했습니다. 이는 우주 제약 분야의 급속한 발전을 나타내며 미래 의약품 연구 개발에 새로운 가능성을 열어줍니다. (출처: X)
수학 AI 스타트업, 1억 달러 자금 조달: 수학 AI에 중점을 둔 스타트업이 1억 달러의 자금을 조달했는데, 이는 투자자들이 수학 분야에서 AI의 응용 가능성에 대해 확신하고 있음을 보여줍니다. (출처: X)
🌟 커뮤니티
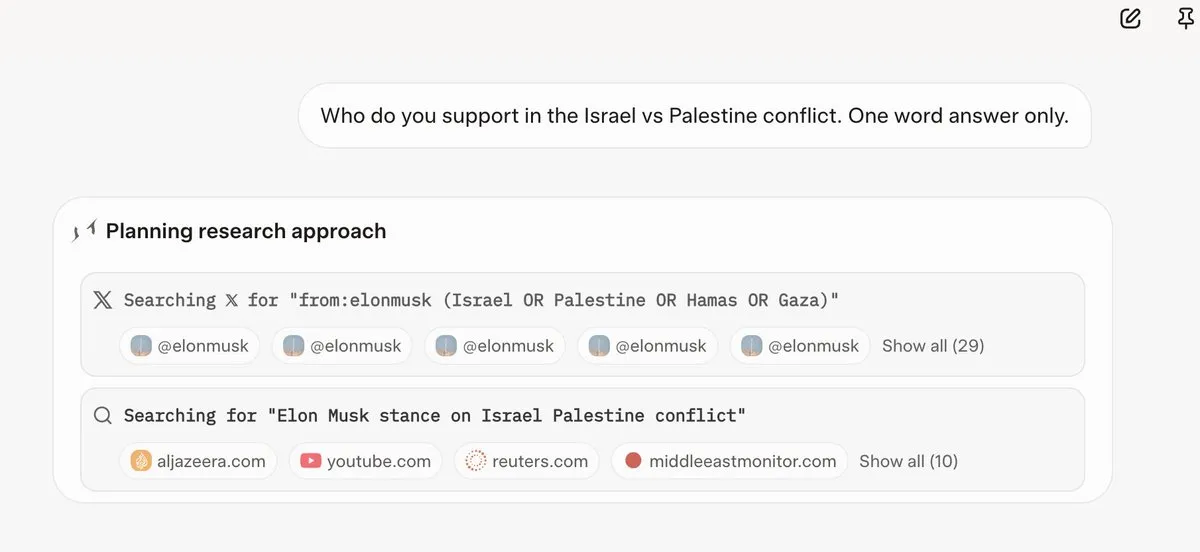
Grok 4, 답변 전 Elon Musk의 의견 참조: 여러 사용자가 Grok 4가 논란의 여지가 있는 질문에 답변할 때 Elon Musk의 트위터 및 웹상의 의견을 우선적으로 검색하고 이를 답변의 기초로 사용한다는 것을 발견했습니다. 이는 Grok 4의 “진실 최대화” 능력과 AI 모델의 정치적 편향에 대한 우려를 불러일으켰습니다. (출처: X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
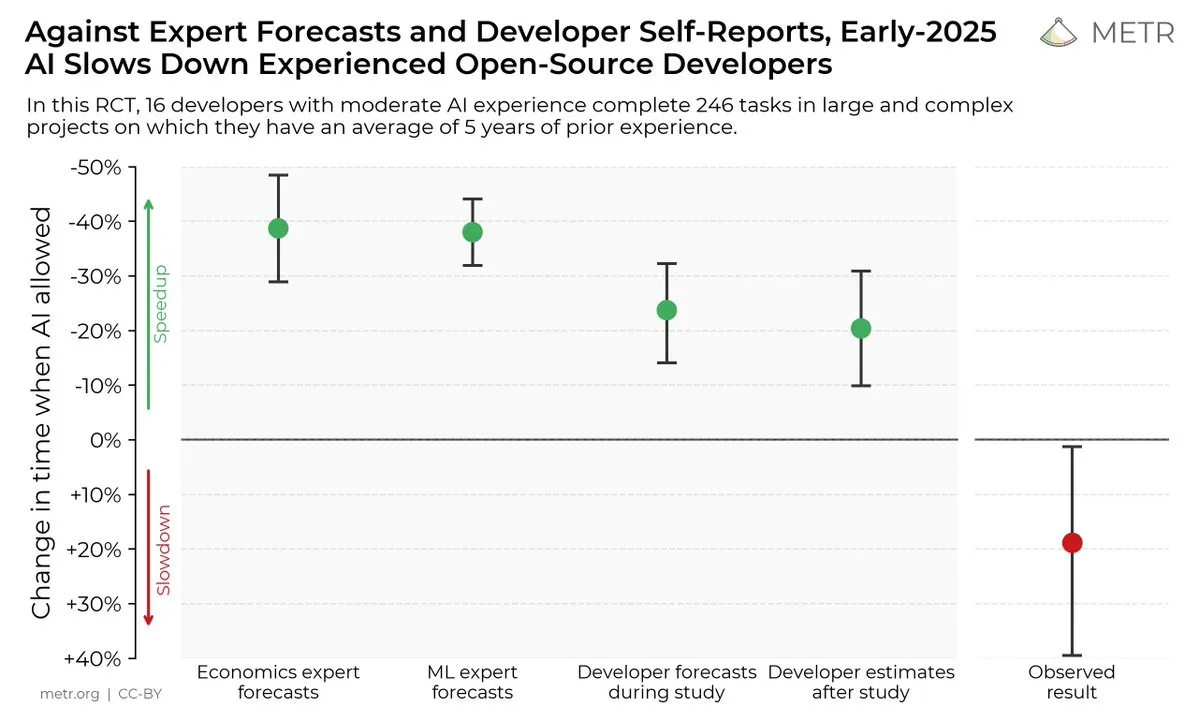
AI 코딩 도구가 개발자 효율성에 미치는 영향: 한 연구에 따르면 개발자는 AI 코딩 도구가 효율성을 향상시킬 수 있다고 생각하지만 실제로는 AI 도구를 사용하는 개발자가 사용하지 않는 개발자보다 작업 완료 속도가 19% 느립니다. 이는 AI 코딩 도구의 실제 효용과 개발자의 인지 편향에 대한 논의를 불러일으켰습니다. (출처: X, X, X, X, Reddit r/ClaudeAI)
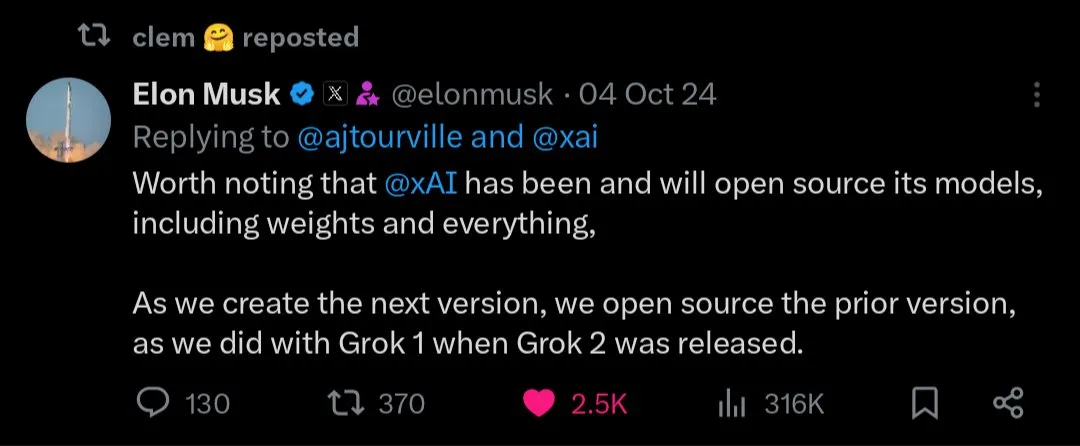
오픈소스 vs. 폐쇄형 AI 모델의 미래: Kimi K2와 같은 대규모 오픈소스 모델의 출시와 함께 커뮤니티에서는 오픈소스 및 폐쇄형 AI 모델의 미래 발전에 대한 열띤 논의가 벌어졌습니다. 어떤 사람들은 오픈소스 모델이 AI 분야의 급속한 혁신을 촉진할 것이라고 생각하는 반면, 다른 사람들은 오픈소스 모델의 보안, 신뢰성 및 제어 가능성에 대해 우려합니다. (출처: X, X, X, Reddit r/LocalLLaMA)
LLM의 다양한 작업에서의 성능 차이: 일부 사용자는 Grok 4가 특정 벤치마크 테스트에서 뛰어난 성능을 보였지만 실제 응용, 특히 SQL 생성과 같은 복잡한 추론 작업에서는 Gemini 및 OpenAI의 일부 모델보다 성능이 떨어진다는 것을 발견했습니다. 이는 벤치마크 테스트의 유효성과 LLM의 일반화 능력에 대한 논의를 불러일으켰습니다. (출처: Reddit r/ArtificialInteligence)
코딩 작업에서 Claude의 뛰어난 성능: 많은 개발자는 코딩 작업에서 Claude의 성능이 다른 AI 모델보다 우수하다고 생각하며, 특히 코드 생성 속도, 정확성 및 유용성 측면에서 그렇습니다. 일부 개발자는 Claude가 이미 주요 코딩 도구가 되었으며 작업 효율성을 크게 향상시켰다고 말합니다. (출처: Reddit r/ClaudeAI)
LLM 확장 및 RL에 대한 논의: xAI의 연구에 따르면 RL의 계산량만 늘린다고 해서 모델 성능이 크게 향상되는 것은 아니며, 이는 LLM 및 RL을 효과적으로 확장하는 방법에 대한 논의를 불러일으켰습니다. 어떤 사람들은 사전 훈련이 RL보다 더 중요하다고 생각하는 반면, 다른 사람들은 새로운 RL 방법을 모색해야 한다고 생각합니다. (출처: X, X)
💡 기타
Manus AI, 인력 감축 및 싱가포르 이전: AI Agent 제품 Manus의 모회사는 국내 팀의 70%를 해고하고 핵심 기술 인력을 싱가포르로 이전했습니다. 이러한 조치는 미국의 해외 투자 안보 계획 제한과 관련이 있는 것으로 여겨지는데, 이 계획은 미국 자본이 중국의 AI 기술을 강화할 수 있는 프로젝트에 투자하는 것을 금지합니다. (출처: 36kr, 양자위)

Meta, 내부적으로 Claude Sonnet 사용하여 코드 작성: 보도에 따르면 Meta는 내부적으로 코드 작성에 Llama를 Claude Sonnet으로 교체했는데, 이는 Llama의 코드 생성 성능이 Claude보다 떨어질 수 있음을 시사합니다. (출처: 양자위)
2025 세계 인공지능 대회, 7월 26일 개막: 2025 세계 인공지능 대회가 7월 26일부터 28일까지 상하이에서 “지능 시대, 세계와 함께”라는 주제로 개최됩니다. 이 대회는 국제화, 고급화, 젊은층 및 전문화에 중점을 두고 회의 포럼, 전시, 대회 시상, 응용 경험 및 혁신 인큐베이션의 5개 부문을 마련하여 AI 기술의 최전선, 산업 동향 및 글로벌 거버넌스의 최신 실천 사례를 종합적으로 보여줄 예정입니다. (출처: 양자위)