키워드:AI 연구, 컴퓨터 과학, 강화 학습, 의약품 개발, 자율 주행, 언어 모델, 멀티모달 처리, 가상 세포, 로드 연구소, 강화 학습 교사(RLTs), BioNeMo 플랫폼, 테슬라 로보택시, Kimi VL A3B Thinking 모델
🔥 포커스
Laude Institute 설립, 1억 달러 초기 자금으로 컴퓨터 과학 공익 연구 추진: Andy Konwinski는 Laude Institute의 출범을 발표했습니다. 이 기관은 세계에 중대한 영향을 미치는 비영리 컴퓨터 과학 연구 자금을 지원하는 것을 목표로 하는 비영리 단체입니다. Jeff Dean, Joyia Pineau, Dave Patterson 등 저명인사들이 이사회에 합류했습니다. 이 기관은 1억 달러의 초기 약정 자금을 확보했으며, 자금 지원, 리소스 공유, 커뮤니티 구축을 통해 연구자들이 아이디어를 실제 영향력으로 전환하도록 지원하고, 특히 개방적이고 영향력 지향적인 연구에 중점을 둘 것입니다. (출처: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

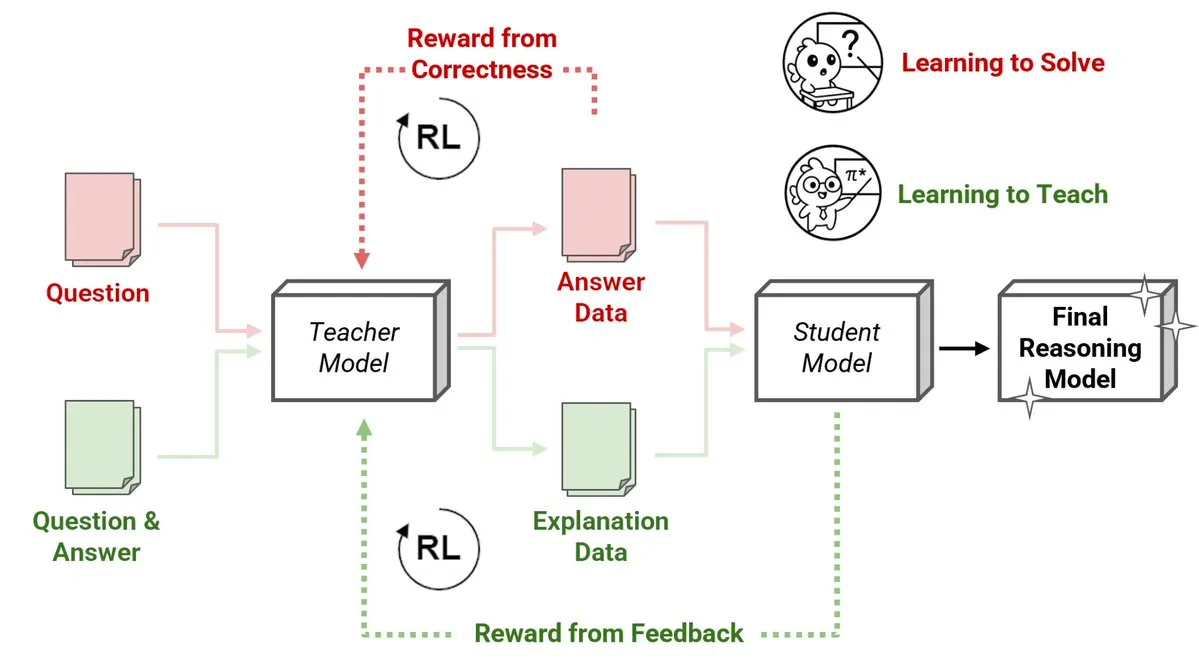
Sakana AI, 강화 학습 교사(RLTs) 새로운 방법 발표, 소형 모델이 대형 모델 추론 교육: Sakana AI는 강화 학습(RL)을 통해 대규모 언어 모델(LLM)의 추론 교육 방식을 변화시키는 강화 학습 교사(RLTs)의 새로운 방법을 선보였습니다. 전통적인 RL은 문제 “해결 학습”에 중점을 두는 반면, RLTs는 학생 모델을 가르치기 위해 명확하고 단계적인 “설명”을 생성하도록 훈련됩니다. 단 7B 파라미터의 RLT가 32B 파라미터의 학생 모델을 가르쳤을 때, 경쟁적이고 대학원 수준의 추론 작업에서 자체 크기의 몇 배에 달하는 LLM보다 뛰어난 성능을 보였습니다. 이 방법은 RL을 사용한 추론 언어 모델 개발에 새로운 효율성 기준을 제시합니다. (출처: cognitivecompai, AndrewLampinen)
Nvidia, Novo Nordisk와 협력, AI 슈퍼컴퓨터를 활용하여 신약 개발 가속화: Nvidia는 덴마크 제약 대기업 Novo Nordisk 및 덴마크 국립 AI 혁신 센터와 협력하여 AI 기술과 덴마크 최신 Gefion 슈퍼컴퓨터를 활용하여 신약 개발을 가속화한다고 발표했습니다. 이번 협력은 Nvidia의 BioNeMo 플랫폼과 첨단 AI 워크플로우를 채택하여 약물 연구 및 개발 모델을 혁신하는 것을 목표로 합니다. Gefion 슈퍼컴퓨터는 Eviden과 Nvidia의 기술로 구축되었으며, 생명 과학 등 분야의 연구에 강력한 컴퓨팅 파워를 지원하여 맞춤형 의료 및 새로운 치료법 발견을 촉진할 것입니다. (출처: nvidia)

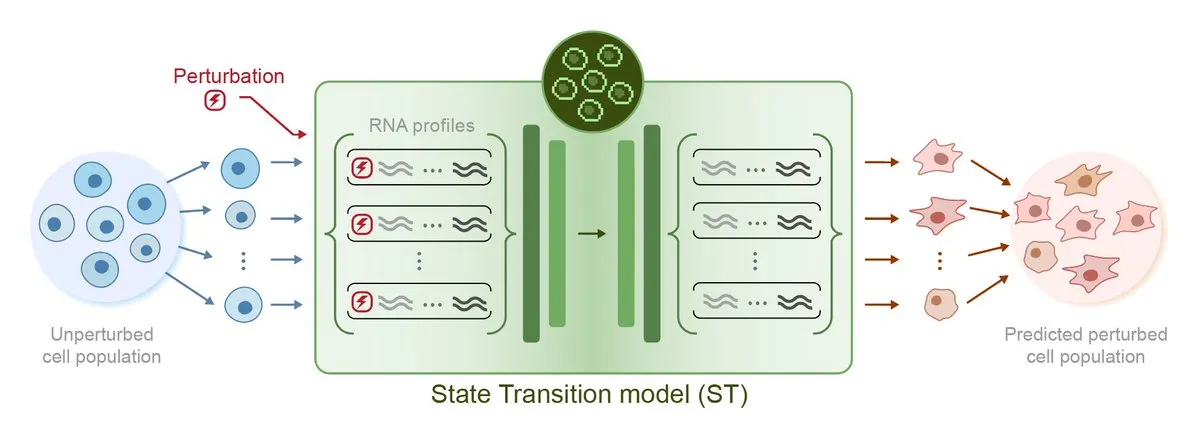
Arc Institute, 첫 교란 예측 AI 모델 STATE 발표, 가상 세포 목표를 향한 진일보: Arc Institute는 가상 세포 목표 달성을 위한 중요한 단계로 첫 번째 교란 예측 AI 모델인 STATE를 발표했습니다. STATE 모델은 약물, 사이토카인 또는 유전자 교란을 이용하여 세포 상태(예: “질병”에서 “건강”으로)를 변경하는 방법을 학습하도록 설계되었습니다. 이 모델의 발표는 AI가 세포 행동을 이해하고 예측하는 데 있어 새로운 진전을 이루었음을 의미하며, 질병 치료 및 신약 개발에 새로운 길을 열어줍니다. 관련 모델은 HuggingFace에 공개되었습니다. (출처: riemannzeta, ClementDelangue)
Tesla Robotaxi, 오스틴에서 시범 운영 시작, 비전 솔루션 주목, Karpathy 레거시 코드 대폭 간소화: Tesla는 미국 텍사스주 오스틴에서 Robotaxi 시범 서비스를 공식적으로 시작했으며, 첫 차량은 Model Y를 기반으로 개조되어 순수 비전 인식 솔루션과 FSD 소프트웨어를 채택했습니다. Tesla AI 및 자율 주행 소프트웨어 책임자인 Ashok Elluswamy가 이끄는 팀은 시스템에 중대한 기술적 변화를 주어 Andrej Karpathy 팀이 남긴 약 33만~34만 줄의 C++ 휴리스틱 코드를 거의 90% 간소화하고 “거대 신경망”으로 대체했습니다. 이는 “인간 경험 코딩”에서 “파라미터화된 훈련”으로 전환하여 방대한 데이터와 시뮬레이션 주행을 통해 모델을 자율적으로 최적화하는 것을 목표로 합니다. 현재 서비스는 초기 체험 단계에 있으며, Tesla의 기술 노선과 규모화 능력에 대한 업계의 광범위한 논의를 불러일으키고 있습니다. (출처: 36氪, Ronald_vanLoon, kylebrussell)

🎯 동향
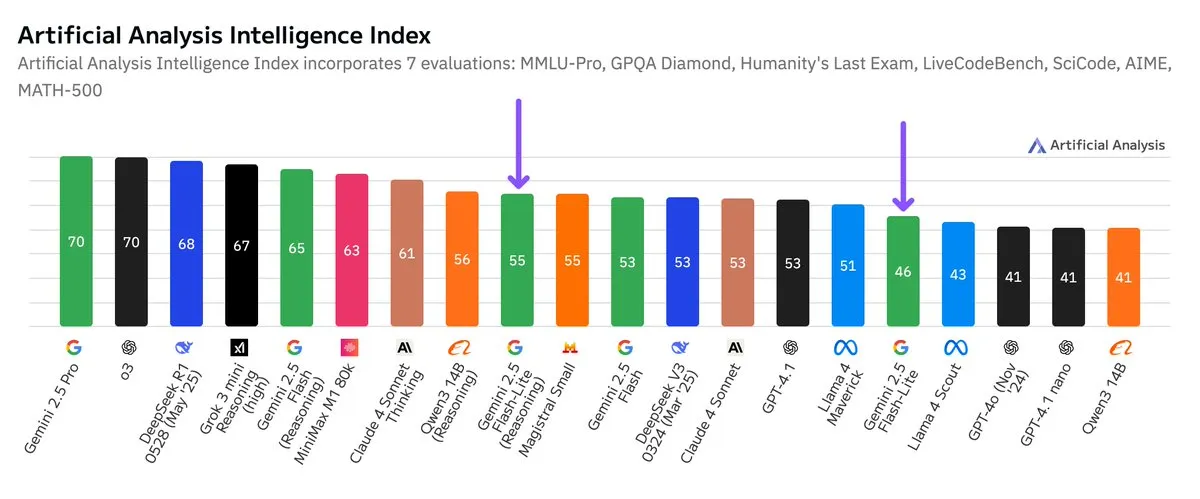
Google Gemini 2.5 Flash-Lite 독립 벤치마크 테스트 발표, 가성비 향상: Artificial Analysis가 발표한 독립 벤치마크 테스트 결과에 따르면, Google Gemini 2.5 Flash-Lite Preview (06-17) 버전은 일반 Flash 버전에 비해 비용이 약 5배 절감되고 속도는 약 1.7배 향상되었지만 지능 수준은 다소 하락했습니다. 이 모델은 2025년 2월에 발표된 Gemini 2.0 Flash-Lite의 업그레이드 버전으로, 하이브리드 모델에 속합니다. 이번 업데이트는 모델 효율성과 비용 효율성을 추구하는 Google의 지속적인 노력을 보여주며, 비용과 속도에 대한 요구가 높은 애플리케이션 시나리오를 대상으로 할 가능성이 있습니다. (출처: zacharynado)
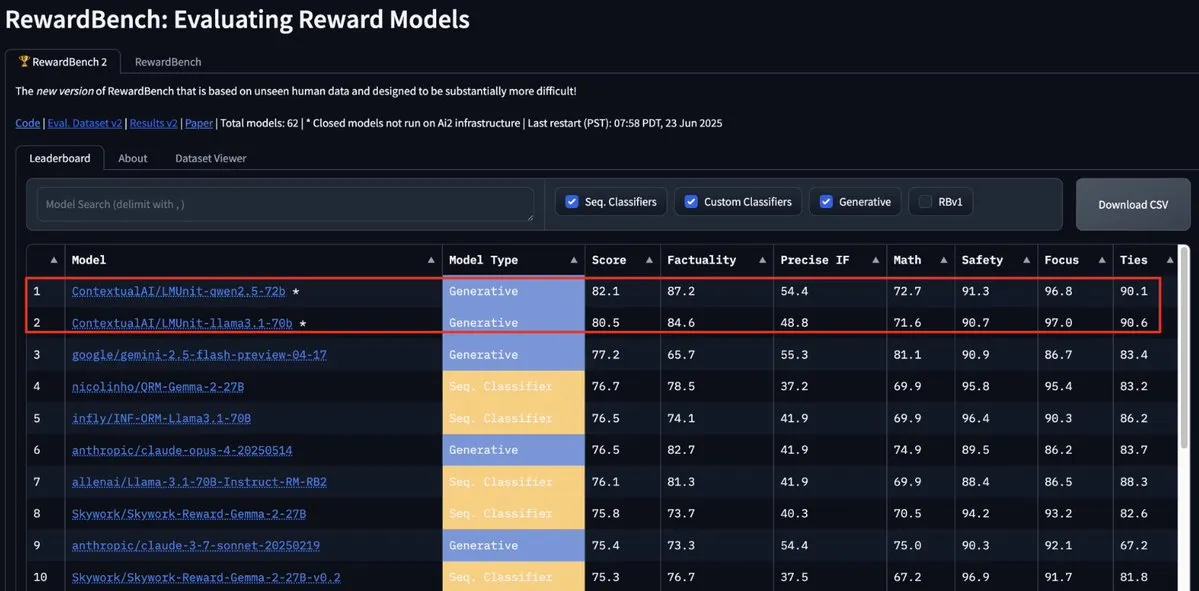
ContextualAI의 LMUnit 모델, RewardBench2 정상 등극, Gemini, Claude 4, GPT-4.1 추월: ContextualAI의 LMUnit 모델이 RewardBench2 벤치마크 테스트에서 1위를 차지하며 Gemini, Claude 4, GPT-4.1 등 유명 모델보다 5% 이상 높은 점수를 기록했습니다. 이러한 성과는 OpenAI가 o4 및 후속 모델을 위해 많은 노력을 기울여 개발한 “rubrics” 방법과 유사하다고 알려진 독특한 훈련 방법 덕분일 수 있으며, 이 방법은 LLM을 심판으로 활용(llm-as-a-judge)하여 추론 시 효과적인 확장을 가능하게 합니다. (출처: natolambert, menhguin, apsdehal)
Arcee.ai, AFM-4.5B 모델 컨텍스트 길이 4k에서 64k로 성공적으로 확장: Arcee.ai는 첫 번째 기본 모델인 AFM-4.5B의 컨텍스트 길이를 4k에서 64k로 성공적으로 확장했다고 발표했습니다. 팀은 적극적인 실험, 모델 병합, 증류 및 “엄청난 양의 수프”(모델 융합 기술을 의미)라고 불리는 방법을 통해 이러한 혁신을 달성했습니다. 이 진전은 긴 텍스트 작업을 처리하는 데 매우 중요하며, Arcee가 GLM-32B-Base 모델에서 이룬 개선 사항도 그 효과를 입증했습니다. 긴 컨텍스트 지원이 8k에서 32k로 향상되었을 뿐만 아니라 짧은 컨텍스트를 포함한 모든 기본 모델 평가에서 개선이 이루어졌습니다. (출처: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

Google Gemini API 업데이트, 비디오 및 PDF 처리 속도 및 기능 향상: Google Gemini API가 비디오 및 PDF 처리 측면에서 중요한 업데이트를 맞이했습니다. 캐시된 비디오의 첫 응답 시간(TTFT)이 3배 향상되었고, 캐시된 PDF의 처리 속도는 최대 4배 빨라졌습니다. 또한 새 버전은 여러 비디오를 일괄 처리할 수 있으며, 암시적 캐싱 성능은 명시적 캐싱에 근접했습니다. 이러한 개선 사항은 개발자가 Gemini API를 사용하여 멀티미디어 콘텐츠를 처리하는 효율성과 경험을 향상시키는 것을 목표로 합니다. (출처: _philschmid)
Moonshot (Kimi), Kimi VL A3B Thinking 모델 업데이트, 멀티모달 처리 능력 향상: Moonshot AI (Kimi)는 MIT 라이선스 기반의 소형 시각 언어 모델(VLM) Kimi VL A3B Thinking의 업데이트 버전을 발표했습니다. 새 버전은 토큰 소모량을 줄이고 사고 과정을 단축하는 동시에 비디오 처리를 지원하며 더 높은 해상도의 이미지(1792×1792)를 처리할 수 있습니다. VideoMMMU에서 65.2점, MathVision에서 20.1점 향상된 56.9점, MathVista에서 8.4점 향상된 80.1점, MMMU-Pro에서 3.2점 향상된 46.3점을 기록했으며, 시각 추론, UI Agent 위치 지정, 비디오 및 PDF 처리에서 뛰어난 성능을 보여 Hugging Face에 오픈소스로 공개되었습니다. (출처: mervenoyann)

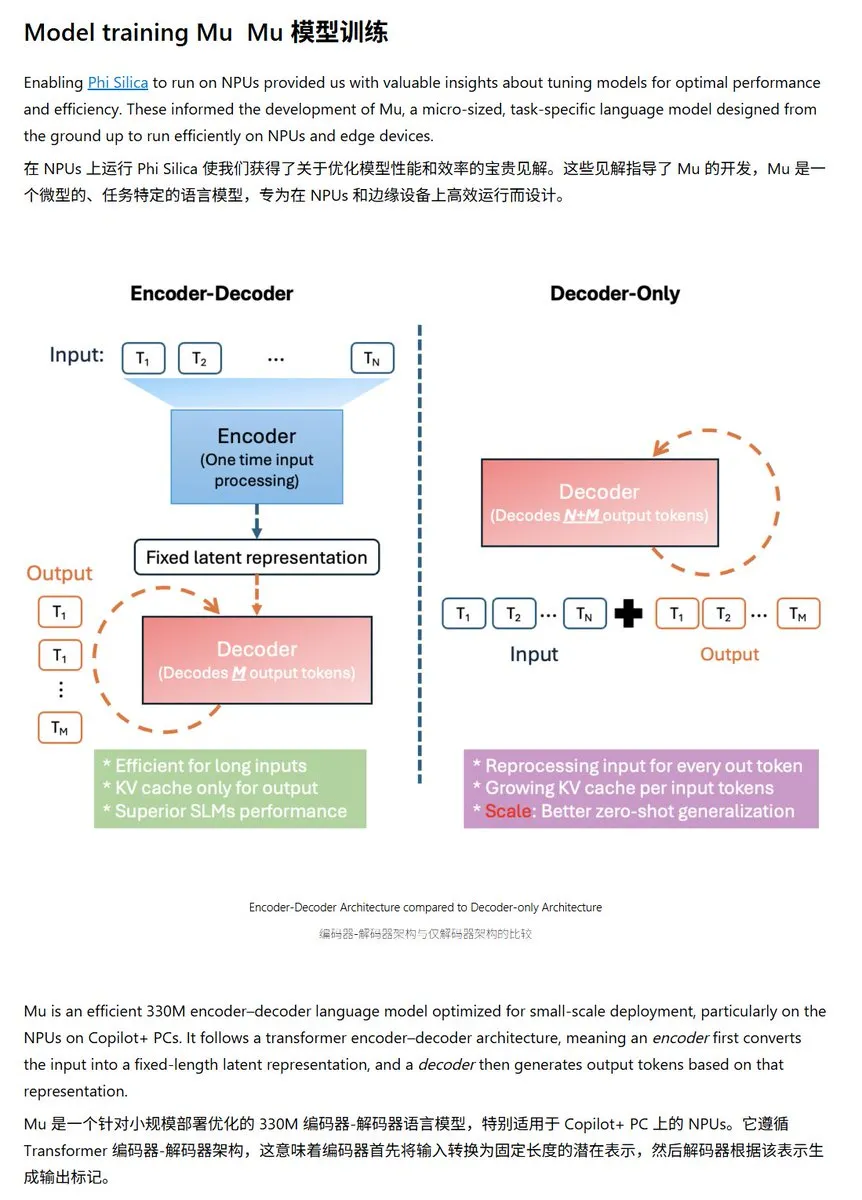
Microsoft, Windows NPU에 최적화된 소형 언어 모델 Mu-330M 발표: Microsoft는 Windows Copilot+ PC의 NPU(신경 처리 장치)에서 실행되도록 설계된 새로운 소형 언어 모델 Mu-330M을 출시했습니다. 이 모델은 Windows 시스템 내 Agent 기능을 지원하는 것을 목표로 합니다. NPU에 최적화되었으며, 회전 위치 임베딩, 그룹화된 쿼리 어텐션, 이중 레이어 LayerNorm 등의 기술을 채택하여 낮은 성능 소모로 효율적으로 실행되도록 하며, 이는 Microsoft가 엣지 AI 역량에서 한 걸음 더 나아갔음을 의미합니다. (출처: karminski3)
DeepMind, 확산 언어 모델에 중점을 둔 Mercury 기술 보고서 발표: Inception Labs (DeepMind 관련 팀)는 확산 언어 모델 Mercury의 기술 보고서를 발표했습니다. 이 보고서는 Mercury 모델의 아키텍처, 훈련 방법 및 실험 결과를 상세히 설명하여 연구자들에게 이 새로운 모델 유형에 대한 심층적인 통찰력을 제공합니다. 확산 모델은 이미지 생성 분야에서 이미 상당한 성공을 거두었으며, 이를 언어 모델에 적용하는 것은 현재 AI 연구의 최전선 방향 중 하나입니다. (출처: andriy_mulyar)
Meta, Oakley와 협력하여 AI 스마트 안경 라인업 확장: Meta는 안경 브랜드 Oakley와 협력하여 AI 스마트 안경 제품 라인업을 더욱 확장합니다. 새로운 스마트 안경은 Meta의 AI 기술을 통합하여 더욱 풍부한 상호 작용 기능과 사용자 경험을 제공할 것으로 예상됩니다. 이번 협력은 Meta가 웨어러블 AI 기기 분야에 지속적으로 투자하고 있으며, AI를 일상생활에 더욱 원활하게 통합하려는 목표를 보여줍니다. (출처: rowancheung, Ronald_vanLoon)
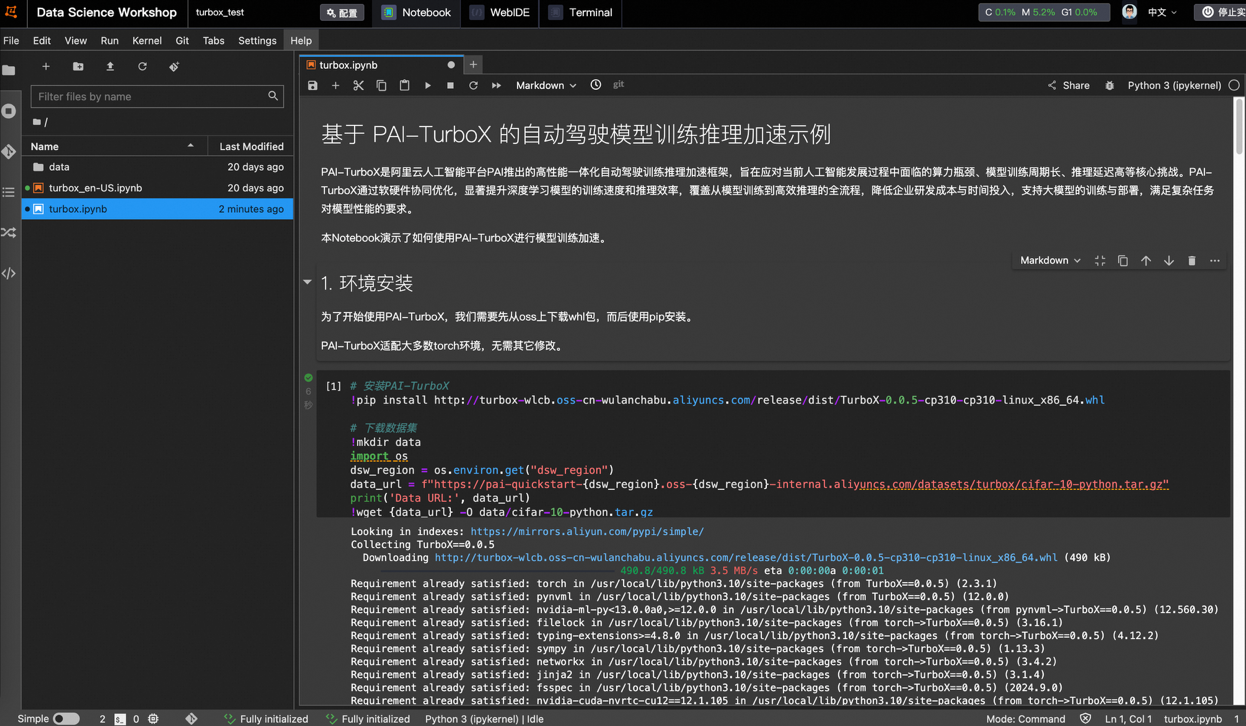
Alibaba Cloud, 자율주행 모델 훈련 및 추론 가속 프레임워크 PAI-TurboX 출시, 훈련 시간 50% 단축 가능: Alibaba Cloud는 자율주행 분야를 위한 모델 훈련 및 추론 가속 프레임워크 PAI-TurboX를 발표했습니다. 이 프레임워크는 인지, 계획 제어 및 월드 모델의 훈련 및 추론 효율성을 향상시키는 것을 목표로 하며, 멀티모달 데이터 전처리, CPU 선호도, 동적 컴파일, 파이프라인 병렬 처리 등의 전략을 최적화하고 연산자 최적화 및 양자화 기능을 제공합니다. 실제 테스트 결과, BEVFusion, MapTR, SparseDrive 등 여러 산업 모델의 훈련 작업에서 PAI-TurboX는 훈련 시간을 약 50% 단축할 수 있는 것으로 나타났습니다. (출처: 量子位)
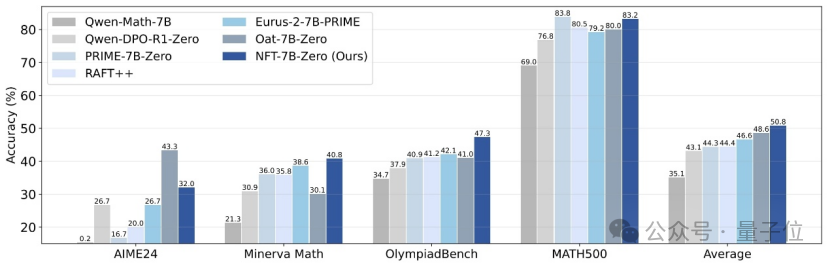
칭화대와 Nvidia 등, 지도 학습이 오류로부터 “반성”할 수 있도록 하는 NFT 방법 제안: 칭화대학교, Nvidia 및 스탠퍼드 대학교 연구진이 공동으로 NFT(Negative-aware FineTuning)라는 새로운 지도 학습 방안을 제안했습니다. 이 방법은 RFT(Rejection FineTuning) 알고리즘을 기반으로 “암시적 네거티브 모델”을 구축하여 네거티브 데이터를 훈련에 활용하는, 즉 “암시적 네거티브 전략”입니다. 이 전략은 지도 학습도 강화 학습처럼 “자기 반성”을 할 수 있게 하여 지도 학습과 강화 학습 간의 특정 능력 격차를 해소하고, 수학 추론 등 작업에서 현저한 성능 향상을 보였으며, On-Policy 조건에서는 손실 함수 기울기가 GRPO와 동등함을 보여주었습니다. (출처: 量子位)
OmniGen2 출시: 8B 다기능 이미지 편집 모델, 시각 이해와 이미지 생성 융합: OmniGen2라는 새로운 다기능 이미지 편집 모델이 출시되었습니다. 이 모델은 시각 이해(Qwen-VL-2.5 기반)와 이미지 생성(4B 파라미터의 확산 모델)을 결합하여 총 파라미터 수는 약 8B입니다. OmniGen2는 텍스트-이미지 변환, 이미지 편집, 이미지 이해 및 컨텍스트 생성 등 다양한 작업을 지원하며, 다양한 시각 관련 문제를 해결하고 엣지 디바이스에 통합하기에 적합한 통합 모델을 제공하는 것을 목표로 합니다. (출처: karminski3)

Chroma-8.9B-v39 텍스트-이미지 생성 모델 업데이트, FLUX.1-schnell 기반, 상업적 사용 가능: 텍스트-이미지 모델 Chroma-8.9B-v39가 업데이트되어 조명과 작업 자연스러움이 향상되었습니다. 이 모델은 FLUX.1-schnell을 기반으로 하며, 파라미터 수가 12B에서 8.9B로 압축되었고 Apache 2.0 라이선스를 채택하여 상업적 사용이 가능합니다. 모델은 “누락된 해부학적 개념을 다시 도입했으며, 콘텐츠 제한이 전혀 없다”고 하며, 500만 개의 애니메이션, 퍼리, 예술 작품 및 사진이 포함된 데이터셋으로 후훈련되었습니다. (출처: karminski3)

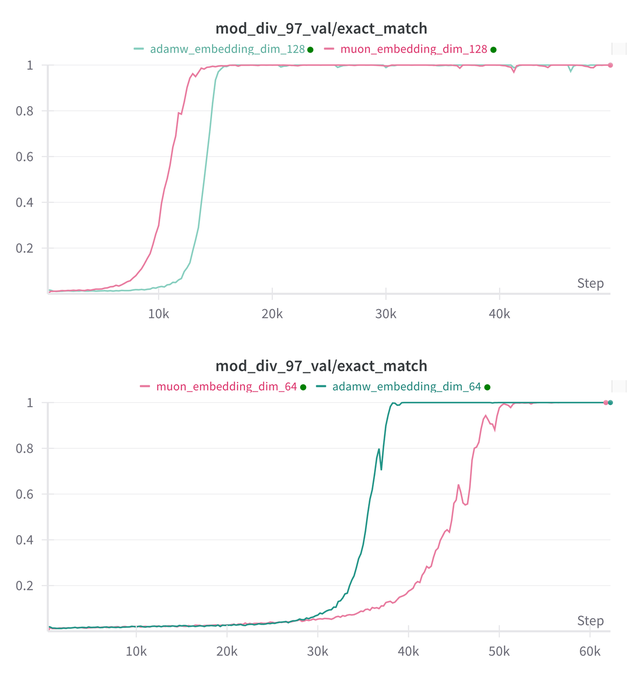
Essential AI, Muon 및 Adam 모델의 Grokking 능력에 대한 연구 결론 업데이트: Essential AI는 자사 모델 Muon과 Adam의 Grokking(모델이 훈련 초기에는 성능이 저조하다가 갑자기 일반화를 이해하는 현상) 능력에 대한 최신 연구 진행 상황을 공유했습니다. 초기 가설은 실제 관찰과 모순될 수 있으며, 팀은 내부 소규모 연구 실험 결과를 공개하여 하이퍼파라미터 검색 공간을 확장한 후 Muon이 AdamW에 비해 뚜렷한 보편적 우위를 보이지 않았으며, 두 가지는 서로 다른 시나리오에서 우열을 가렸다고 밝혔습니다. 이는 AdamW가 많은 경우 여전히 강력하거나 SOTA 옵티마이저임을 시사합니다. (출처: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI 이미지 생성 모델 업데이트, CFG 없는 버전에 집중하고 고주파 디테일 최적화: Ostris AI는 이미지 생성 모델을 지속적으로 업데이트하고 있으며, 현재 수렴 속도가 더 빠르기 때문에 CFG(Classifier-Free Guidance) 없는 버전 개발에 집중하고 있습니다. 최신 Day 7 업데이트에서는 고주파 디테일을 더 잘 처리하기 위한 새로운 훈련 기법을 추가하고 고 디테일 아티팩트를 제거하기 위해 노력하고 있습니다. 이전 Day 4 업데이트에서는 CFG를 사용하지 않고도 새로운 방법으로 생성된 이미지 품질이 크게 개선되었음을 보여주었습니다. (출처: ostrisai)

Ant Group과 중국과학원 등, ViLaSR-7B 모델 오픈소스 공개, “그리면서 생각하는” 공간 추론 실현: Ant Group 기술 연구원, 중국과학원 자동화 연구소 및 홍콩 중문대학교가 공동으로 ViLaSR-7B 모델을 오픈소스로 공개했습니다. 이 모델은 “Drawing to Reason in Space” 패러다임을 통해 대규모 시각 언어 모델(LVLM)이 시각 공간에 보조 표시(참조선, 경계 상자 등)를 그려 사고를 보조함으로써 공간 인지 및 추론 능력을 향상시킵니다. ViLaSR은 콜드 스타트, 반성적 거부 샘플링, 강화 학습의 3단계 훈련 프레임워크를 채택합니다. 실험 결과, 이 모델은 미로 탐색, 이미지 이해 및 비디오 공간 추론 등 5개 벤치마크에서 평균 18.4% 향상되었으며, VSI-Bench에서는 Gemini-1.5-Pro에 근접한 성능을 보였습니다. (출처: 量子位)

🧰 툴
SGLang, 이제 Hugging Face Transformers를 백엔드로 지원하여 추론 효율성 향상: SGLang은 Hugging Face Transformers를 백엔드로 지원한다고 발표했습니다. 이는 사용자가 Transformers와 호환되는 모든 모델에 대해 네이티브 지원 없이 플러그 앤 플레이 방식으로 빠르고 프로덕션 수준의 추론 서비스를 제공할 수 있음을 의미합니다. 이 통합은 고성능 언어 모델 추론의 배포 프로세스를 단순화하고 SGLang의 적용 범위와 사용 편의성을 확대하는 것을 목표로 합니다. (출처: TheZachMueller, ClementDelangue)

MLX-LM-LORA v0.7.0 출시, RLHF 기능 내장: MLX-LM-LORA가 v0.7.0 버전을 출시했습니다. 새 버전에는 인간 피드백으로부터 강화 학습(RLHF)을 수행하는 기능이 내장되어 있습니다. 이 도구는 이제 4비트, 6비트, 8비트 로딩, RLHF 훈련 모드를 지원하며 어댑터(adapters)를 기본 가중치에 직접 통합할 수 있습니다. 이를 통해 특히 Apple 칩 장치에서 MLX 프레임워크 내 LoRA 미세 조정이 더욱 지능적이고 효율적으로 이루어질 수 있습니다. (출처: awnihannun)
LlamaCloud 출시, 문서 워크플로우를 위한 MCP 호환 툴킷 제공: LlamaCloud가 출시되었습니다. 모델 컨텍스트 프로토콜(MCP)과 호환되는 툴킷으로, 모든 문서 워크플로우에 사용할 수 있습니다. 사용자는 이를 Claude와 같은 모델에 연결하여 복잡한 문서 추출, 비교 등의 작업을 수행할 수 있습니다. 예를 들어, Tesla의 지난 5분기 재무 성과를 분석하고 종합 보고서를 생성할 수 있으며, 표준화된 스키마를 동적으로 생성하고 모든 파일에서 실행한 다음 코드를 활용하여 최종 결과를 생성합니다. LlamaCloud는 잘못된 스키마를 동적으로 수정할 수 있으며 직접 파일 링크를 지원합니다. (출처: jerryjliu0)
Georgi Gerganov, LlamaBarn 프로젝트 예고: Georgi Gerganov (llama.cpp 개발자)가 소셜 미디어에 “LlamaBarn”이라는 새로운 프로젝트를 예고하는 이미지를 게시했습니다. 이미지에는 모델 선택, 파라미터 조정 등의 요소가 포함된 대시보드와 유사한 인터페이스가 표시되어, 로컬 LLM을 관리, 실행 또는 테스트하기 위한 도구일 가능성을 시사합니다. 커뮤니티는 이것이 Ollama와 같은 기존 도구의 강력한 경쟁자가 될 수 있다고 기대하고 있습니다. (출처: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor: MCP 및 로컬 모델을 지원하는 새로운 오픈소스 AI 프로그래밍 도우미: Void Editor는 Cursor와 같은 도구의 대안으로 등장한 새로운 오픈소스 AI 프로그래밍 도우미입니다. 탭 자동 완성, 채팅 모드, 모델 컨텍스트 프로토콜(MCP) 및 에이전트 모드를 지원합니다. 사용자는 모든 대규모 언어 모델 API에 연결하거나 로컬에서 모델을 실행하여 개발자에게 유연한 AI 지원 프로그래밍 경험을 제공할 수 있습니다. (출처: karminski3)
Together AI, 적합한 오픈소스 LLM 선택을 돕는 Which LLM 도구 출시: Together AI는 특정 사용 사례, 성능 요구 사항 및 경제적 고려 사항에 따라 가장 적합한 오픈소스 대규모 언어 모델을 사용자가 선택하는 데 도움을 주기 위해 “Which LLM”이라는 무료 도구를 출시했습니다. 오픈소스 LLM의 수가 급증함에 따라 이러한 도구는 개발자와 연구원이 모델을 선택할 때 유용한 참고 자료를 제공할 수 있습니다. (출처: vipulved)
Perplexity Finance, 주가 타임라인 추적 기능 추가: Perplexity Finance는 이제 사용자가 플랫폼에서 모든 주식 종목의 가격 변동 타임라인을 추적할 수 있다고 발표했습니다. 이 새로운 기능은 사용자에게 보다 직관적이고 편리한 금융 시장 정보 분석 도구를 제공하는 것을 목표로 하며, Perplexity의 AI 기능과 결합하여 금융 정보 조회 및 분석에 새로운 경험을 제공할 수 있습니다. (출처: AravSrinivas)

IdeaWeaver, 시스템 성능 디버깅을 위한 최초의 AI 에이전트 출시: IdeaWeaver는 시스템 성능 문제 디버깅을 위해 특별히 설계된 최초의 AI 에이전트라고 주장하는 도구를 출시했습니다. 이 도구는 CrewAI 프레임워크를 활용하여 CPU, 메모리, I/O 및 네트워크와 관련된 문제를 진단하기 위해 실제로 시스템 명령을 실행할 수 있습니다. 개인 정보 보호를 위해 로컬 LLM(OLLAMA를 통해)을 우선적으로 사용하고 로컬 모델을 사용할 수 없는 경우에만 OpenAI API 키를 요청하는 것이 특징이며, AI 기능을 DevOps 및 시스템 관리 분야에 적용하는 것을 목표로 합니다. (출처: Reddit r/artificial)
Kling AI, Live Photo 지원 추가, 생성된 비디오를 라이브 배경화면으로 저장 가능: Kling AI는 비디오 생성 기능이 이제 작품을 Live Photos(라이브 포토)로 저장할 수 있도록 지원한다고 발표했습니다. 사용자는 좋아하는 Kling 창작 동적 콘텐츠를 휴대폰 배경화면으로 설정하여 AI 생성 비디오의 재미와 실용성을 높일 수 있습니다. (출처: Kling_ai)
Cognition AI, Blockdiff 오픈소스 공개, VM 스냅샷 속도 200배 향상: Cognition AI는 Devin을 위해 개발한 VM 스냅샷 파일 형식인 Blockdiff를 오픈소스로 공개한다고 발표했습니다. EC2에서 VM 스냅샷을 생성하는 데 시간이 너무 오래 걸리기 때문에(30분 이상) 팀은 자체적으로 otterlink 가상 머신 관리자와 Blockdiff 파일 형식을 구축하여 스냅샷 생성 속도를 200배 향상시켰습니다. 이 오픈소스 기여는 개발자가 가상 머신 환경을 보다 효율적으로 관리하는 데 도움을 주기 위한 것입니다. (출처: karinanguyen_)

📚 학습
LangChain 블로그 게시물, “컨텍스트 엔지니어링”의 부상 논의: LangChain은 “컨텍스트 엔지니어링(Context Engineering)”이라는 점점 더 대중화되는 용어에 대해 논의하는 블로그 게시물을 발표했습니다. 이 글은 이를 “LLM이 작업을 합리적으로 완료할 수 있도록 올바른 형식으로 올바른 정보와 도구를 제공하는 동적 시스템 구축”으로 정의합니다. 이는 완전히 새로운 개념은 아니며, 에이전트 빌더들은 오랫동안 이를 실천해 왔고 LangGraph, LangSmith와 같은 도구도 이를 위해 만들어졌습니다. 이 용어의 제시는 관련 기술과 도구에 대한 더 많은 관심을 불러일으키는 데 도움이 됩니다. (출처: hwchase17, Hacubu, yoheinakajima)
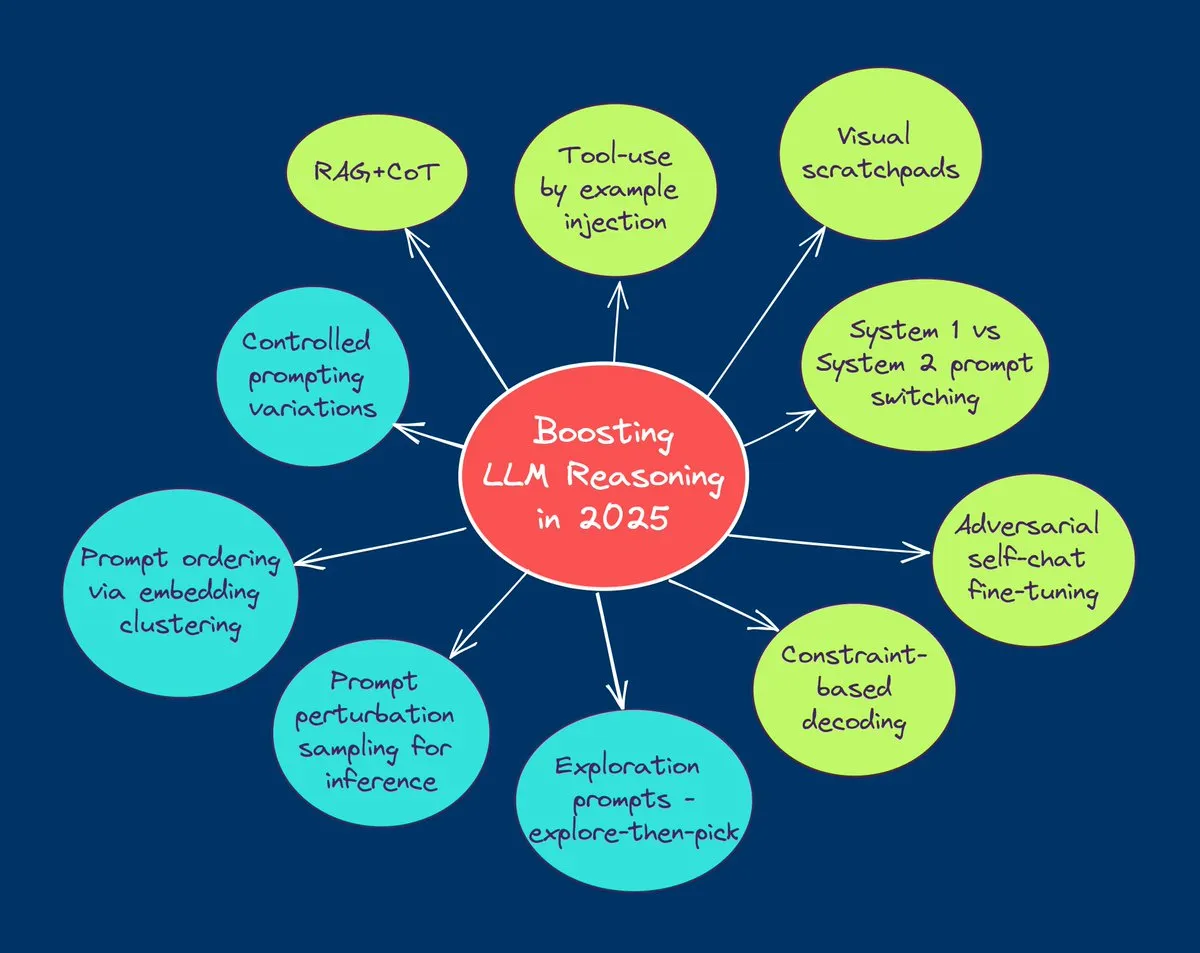
TuringPost, 2025년 LLM 추론 능력 향상을 위한 10가지 주요 기술 요약: TuringPost는 2025년 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위한 10가지 주요 기술을 공유했습니다. 여기에는 검색 증강 사고 사슬(RAG+CoT), 예제를 통한 도구 사용 주입, 시각적 스크래치패드(멀티모달 추론 지원), 시스템 1과 시스템 2 프롬프트 전환, 적대적 자가 대화 미세 조정, 제약 기반 디코딩, 탐색적 프롬프팅(먼저 탐색 후 선택), 추론을 위한 프롬프트 교란 샘플링, 임베딩 클러스터링을 통한 프롬프트 정렬, 제어된 프롬프트 변형이 포함됩니다. 이러한 기술은 복잡한 작업에서 LLM의 성능을 최적화하기 위한 다양한 경로를 제공합니다. (출처: TheTuringPost, TheTuringPost)
Cohere Labs, 머신러닝의 미래를 탐구하는 ML 여름 학교 개최: Cohere Labs의 오픈 사이언스 커뮤니티는 7월에 ML 여름 학교(ML Summer School)를 개최합니다. 이 행사는 전 세계 커뮤니티 회원들을 모아 머신러닝의 미래를 함께 논의하고 업계 연사들을 초청하여 공유할 예정입니다. 그중 Katrina Lawrence는 7월 2일에 미적분학, 벡터 미적분학, 선형 대수학 등 핵심 개념을 다루는 머신러닝 수학 복습 과정을 강의합니다. (출처: sarahookr)

DeepLearning.AI, Meta와 협력하여 “Building with Llama 4” 무료 강좌 개설: DeepLearning.AI는 Meta와 협력하여 “Building with Llama 4”라는 무료 강좌를 개설했습니다. 강좌 내용에는 Llama 4 시리즈 모델의 실제 사용, 혼합 전문가(MOE) 아키텍처 이해, 공식 API를 사용한 애플리케이션 구축 방법; Llama 4를 활용한 다중 이미지 추론, 이미지 위치 지정(객체 및 경계 상자 식별), 최대 100만 토큰의 긴 컨텍스트 텍스트 쿼리 처리; Llama 4의 프롬프트 최적화 도구를 사용하여 시스템 프롬프트를 자동으로 개선하고, 합성 데이터 도구 키트를 활용하여 미세 조정을 위한 고품질 데이터셋 생성 등이 포함됩니다. (출처: DeepLearningAI)
EleutherAI YouTube 채널, 방대한 AI 연구 콘텐츠 제공: EleutherAI의 YouTube 채널은 독서 모임과 강연 시리즈의 녹화 영상을 모아 100시간이 넘는 콘텐츠를 제공합니다. 주제는 머신러닝의 확장성과 성능, 함수 해석학, 그리고 팀원들의 팟캐스트와 인터뷰 등을 다룹니다. 이 채널은 AI 연구자와 애호가들에게 풍부한 학습 자료를 제공합니다. EleutherAI는 또한 새로운 강연 시리즈를 시작했으며, 첫 번째 강연은 @linguist_cat이 토크나이저와 그 한계에 대해 강의합니다. (출처: BlancheMinerva, BlancheMinerva)
논문, 잠재적 시각 토큰을 통해 멀티모달 추론 강화(Machine Mental Imagery) 논의: 새로운 논문 “Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens”는 Mirage 프레임워크를 제안하여, VLM 디코딩 과정에 완전한 이미지를 생성하는 대신 잠재적 시각 토큰을 추가하여 멀티모달 추론을 강화하고 인간의 심리적 심상을 모방합니다. 이 방법은 먼저 실제 이미지 임베딩을 증류하여 잠재적 토큰을 감독한 다음, 순수 텍스트 감독으로 전환하여 잠재적 궤적을 작업 목표와 정렬하고 강화 학습을 통해 능력을 더욱 향상시킵니다. 실험 결과 Mirage는 명확한 이미지를 생성하지 않고도 더 강력한 멀티모달 추론을 달성할 수 있음을 입증했습니다. (출처: HuggingFace Daily Papers)
논문, Vision as a Dialect 프레임워크 제안, 텍스트 정렬 표현을 통해 시각 이해와 생성 통합: “Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations”라는 논문은 Tar라는 멀티모달 LLM 프레임워크를 소개합니다. 이 프레임워크는 텍스트 정렬 토크나이저(TA-Tok)를 사용하여 이미지를 이산 토큰으로 변환하고, LLM 어휘 프로젝션의 텍스트 정렬 코드북을 활용하여 시각과 텍스트를 공유된 이산 의미 표현으로 통합합니다. Tar는 공유 인터페이스를 통해 교차 모달 입력 및 출력을 구현하며, 특정 모달 설계 없이 확장 가능한 적응형 인코더-디코더와 생성적 디토크나이저를 채택하여 효율성과 시각적 세부 사항의 균형을 맞춥니다. (출처: HuggingFace Daily Papers)
논문, ReasonFlux-PRM 제안: LLM 장쇄 사고 추론을 위한 궤적 인식 PRM: 논문 “ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs”는 DeepSeek-R1과 같은 최첨단 추론 모델이 생성하는 궤적-응답 유형의 추론 흔적을 평가하기 위해 특별히 설계된 새로운 궤적 인식 프로세스 보상 모델(PRM)을 소개합니다. ReasonFlux-PRM은 단계별 및 궤적 수준 감독을 결합하여 구조화된 사고 사슬 데이터와 정렬된 세분화된 보상 할당을 실현하고, SFT, RL 및 BoN 테스트 시 확장과 같은 시나리오에서 모두 성능 향상을 달성했습니다. (출처: HuggingFace Daily Papers)
논문, 대규모 언어 모델 탈옥 방지책 평가 방법 연구: “SoK: Evaluating Jailbreak Guardrails for Large Language Models”라는 논문은 대규모 언어 모델(LLM)의 탈옥 공격과 그 방지책(Guardrails)에 대한 체계적인 지식 정리를 수행했습니다. 이 논문은 6가지 주요 차원에서 방지책을 분류하는 새로운 다차원 분류법을 제안하고, 실제 효과를 평가하기 위한 안전성-효율성-실용성 평가 프레임워크를 도입했습니다. 광범위한 분석과 실험을 통해 논문은 기존 방지책 방법의 장단점을 지적하고, 다양한 공격 유형에 대한 보편성을 탐구하며, 방어 조합 최적화를 위한 통찰력을 제공합니다. (출처: HuggingFace Daily Papers)
AAAI 2025 우수 논문, 부분 관찰 가능 마르코프 결정 과정(POMDP)의 결정 가능 클래스 논의: “Revelations: A Decidable Class of POMDP with Omega-Regular Objectives”라는 제목의 논문이 AAAI 2025 우수 논문상을 수상했습니다. 이 연구는 결정 가능한 MDP(마르코프 결정 과정) 클래스, 즉 매 단계마다 세계의 정확한 상태를 드러낼 확률이 0이 아닌 “강한 계시”를 가진 결정 문제를 확인했습니다. 이 논문은 또한 정확한 상태가 결국 드러날 것이 보장되지만 반드시 매 단계마다 드러나지는 않는 “약한 계시”의 결정 가능성 결과도 제공합니다. 이 연구는 정보가 불완전한 상황에서 최적의 결정을 내리기 위한 새로운 이론적 토대를 제공합니다. (출처: aihub.org)
논문, CommVQ 제안: KV 캐시 압축을 위한 교환 벡터 양자화: 논문 “CommVQ: Commutative Vector Quantization for KV Cache Compression”은 긴 컨텍스트 LLM 추론에서 메모리 사용량을 줄이기 위해 가산 양자화와 경량 인코더 및 코드북을 사용하여 KV 캐시를 압축하는 CommVQ라는 방법을 제안합니다. 디코딩 계산 비용을 줄이기 위해 코드북은 회전 위치 임베딩(RoPE)과 교환 가능하도록 설계되었으며 EM 알고리즘을 사용하여 훈련됩니다. 실험 결과, 이 방법은 2비트 양자화에서 FP16 KV 캐시 크기를 87.5% 줄일 수 있으며 기존 KV 캐시 양자화 방법보다 우수하고 극히 작은 정밀도 손실로 1비트 KV 캐시 양자화도 달성할 수 있음을 보여줍니다. (출처: HuggingFace Daily Papers)
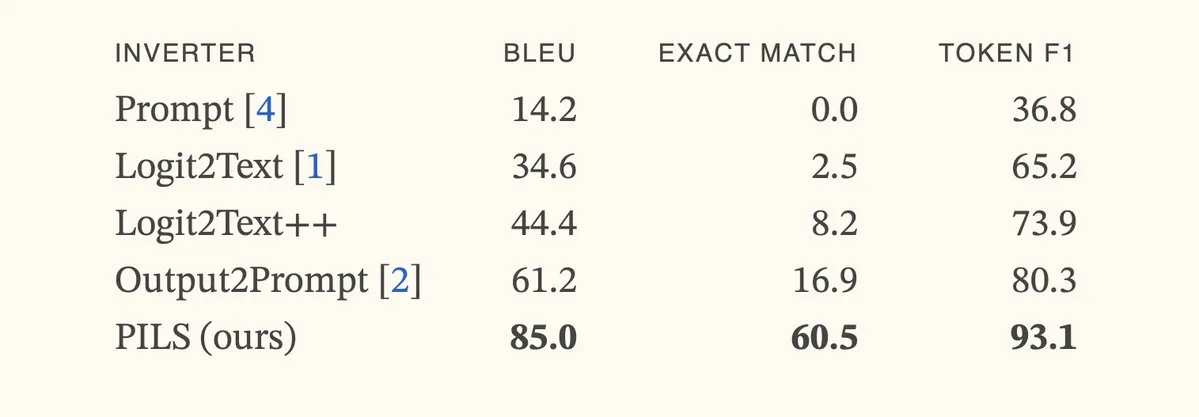
논문, PILS 방법 제안, 다음 토큰 분포의 간결한 표현을 통해 언어 모델 반전 개선: 논문 “Better Language Model Inversion by Compactly Representing Next-Token Distributions”은 PILS(Prompt Inversion from Logprob Sequences)라는 새로운 언어 모델 반전 방법을 제안합니다. 이 방법은 여러 생성 단계에서 모델의 다음 토큰 확률을 분석하여 숨겨진 프롬프트를 복구합니다. 핵심은 언어 모델 출력 벡터가 저차원 부분 공간을 차지한다는 것을 발견하여 선형 매핑을 통해 다음 토큰 확률 분포를 무손실 압축하여 보다 효과적인 반전에 사용할 수 있다는 것입니다. 실험 결과, PILS는 숨겨진 프롬프트 복구에서 이전 SOTA 방법보다 훨씬 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers, jxmnop)
논문, Phantom-Data 제안: 일반적인 주체 일관성 비디오 생성 데이터셋: 논문 “Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset”은 기존 주체-비디오 생성 모델에서 보편적으로 존재하는 “복사-붙여넣기” 문제(즉, 주체 정체성이 배경, 컨텍스트 속성과 과도하게 얽히는 문제)를 해결하기 위한 Phantom-Data라는 새로운 데이터셋을 소개합니다. Phantom-Data는 서로 다른 범주에서 정체성이 일관된 약 100만 개의 쌍으로 구성된 최초의 일반적인 교차 쌍 주체-비디오 일관성 데이터셋입니다. 이 데이터셋은 주체 감지, 대규모 교차 컨텍스트 주체 검색, 사전 안내 정체성 확인의 3단계 프로세스를 통해 구축됩니다. (출처: HuggingFace Daily Papers)
논문, LongWriter-Zero 제안: 강화 학습을 통해 초장문 텍스트 생성 마스터: 논문 “LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning”은 레이블링되거나 합성된 데이터 없이 강화 학습(RL)을 활용하여 LLM이 초장문의 고품질 텍스트를 생성하는 능력을 처음부터 육성하는 인센티브 기반 방법을 제안합니다. 이 방법은 기본 모델에서 시작하여 RL을 통해 계획 및 작성 과정에서 정제를 유도하고, 길이, 작성 품질 및 구조 형식을 제어하기 위해 특수 보상 모델을 사용합니다. 실험 결과, Qwen2.5-32B에서 훈련된 LongWriter-Zero는 장문 작성 작업에서 기존 SFT 방법보다 우수하며 여러 벤치마크에서 SOTA 수준에 도달했습니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
법률 AI 회사 Harvey, 3억 달러 규모 시리즈 E 투자 유치, 기업 가치 50억 달러: 법률 AI 스타트업 Harvey가 Kleiner Perkins와 Coatue가 공동 주도한 3억 달러 규모의 시리즈 E 투자를 유치했으며, 기업 가치는 50억 달러에 달한다고 발표했습니다. 기타 투자자로는 Sequoia Capital, GV, DST Global, Conviction, Elad Gil, OpenAI Startup Fund, Elemental, SV Angel, Kris Fredrickson, REV 등이 참여했습니다. 이번 투자는 Harvey가 법률 분야에서 AI 애플리케이션을 지속적으로 개발하고 확장하는 데 도움이 될 것입니다. (출처: saranormous)
Hyperbolic 온디맨드 GPU 클라우드 서비스, 출시 7일 만에 ARR 100만 달러 달성: Yuchenj_UW는 지난주 출시한 Hyperbolic 온디맨드 GPU 클라우드 서비스가 단 한 건의 트윗을 통한 소량의 마케팅만으로 7일 만에 연간 반복 매출(ARR)이 0에서 100만 달러로 성장했다고 발표했습니다. 이들은 빌더에게 무료 8xH100 노드 평가판 크레딧을 제공하며, 고성능 GPU 클라우드 서비스에 대한 시장의 강력한 수요를 보여주었습니다. (출처: Yuchenj_UW)
Replit, 연간 반복 매출(ARR) 1억 달러 돌파 발표: 온라인 통합 개발 환경(IDE) 및 클라우드 컴퓨팅 플랫폼 Replit이 연간 반복 매출(ARR) 1억 달러를 돌파했다고 발표했습니다. 이는 2024년 말 1,000만 달러에서 크게 성장한 수치입니다. 회사는 2023년 11억 달러의 기업 가치로 마지막 투자 유치를 완료한 후에도 은행에 절반 이상의 자금이 남아 있다고 밝혔습니다. Replit의 성장은 Zillow, HubSpot과 같은 기업 사용자와 독립 개발자들의 플랫폼 사용에 힘입은 것이며, 현재 적극적으로 채용을 진행하고 있습니다. (출처: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 커뮤니티
AI 프로그래밍 새로운 패러다임: 먼저 설계하고 프롬프트, 반복적으로 코드 생성 최적화: dotey와 바오위(宝玉)는 AI 프로그래밍이 가져온 소프트웨어 개발 방식의 변화에 대해 논의했습니다. 전통적인 “선 설계 후 코딩”과 “선 구현 후 리팩토링” 논쟁이 AI 시대에 융합되었습니다. AI는 설계에서 코딩까지의 비용과 시간을 크게 단축시켜 개발자가 설계가 완전히 명확하지 않을 때 빠르게 버전을 구현하고, 결과 검증을 통해 설계와 프롬프트 단어를 반복적으로 개선할 수 있도록 합니다. 프롬프트 단어는 이전의 “상세 설계 문서” 역할을 하지만 더욱 간소화되었습니다. 이러한 방식에서 개발자는 시스템 설계에 더 집중하고, 소량으로 코드를 생성하며, 소스 코드 관리를 활용하고, AI가 생성한 코드를 검토하고 테스트해야 합니다. 숙련된 프로그래머에게는 사고방식과 개발 습관을 바꾸는 것이 AI 프로그래밍을 수용하는 핵심입니다. (출처: dotey)
Claude Code, 강력한 대규모 코드베이스 처리 능력과 컨텍스트 효율성으로 개발자들에게 호평: Reddit r/ClaudeAI 커뮤니티에서 Claude Code의 대규모 코드베이스 처리 능력에 대한 열띤 토론이 벌어졌습니다. 사용자들은 200k 토큰을 훨씬 넘는 크기의 코드베이스를 잘 이해하고 수정할 수 있다는 피드백을 남겼습니다. 토론에서는 Claude Code가 인간의 독서 전략(핵심 부분만 읽기)과 유사한 전략, grep과 같은 도구를 사용한 컨텍스트 검색(RAG의 벡터화 압축에 전적으로 의존하지 않음), 그리고 자사 모델 통합의 이점을 통해 효율적인 컨텍스트 처리를 달성했을 가능성이 제기되었습니다. 사용자들은 Claude Code를 사용하여 시스템 문제 해결, 개인 재무 추적기 구축, 안드로이드 앱 개발(안드로이드 개발 경험이 없음에도 불구하고), Obsidian DataviewJS 스크립트 생성 등 다양한 성공 사례를 공유하며 작업 효율성이 크게 향상되었다고 밝혔습니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

“컨텍스트 엔지니어링” 개념 주목, LLM 역량 강화를 위한 동적 시스템 구축 강조: LangChain의 Harrison Chase는 “컨텍스트 엔지니어링(Context Engineering)”이 AI 엔지니어가 시스템을 구축하는 핵심 작업이라고 제안했습니다. 이는 “LLM이 작업을 합리적으로 완료할 수 있도록 올바른 형식으로 올바른 정보와 도구를 제공하는 동적 시스템 구축”으로 정의됩니다. 이 개념은 LLM 애플리케이션에서 컨텍스트 정보를 효과적으로 구성하고 제공하는 방법이 모델 성능에 얼마나 중요한지를 강조하며, 에이전트 구축 등 분야의 기초입니다. (출처: hwchase17, Hacubu, yoheinakajima)
Meta 창업자 저커버그, 직접 AI 인재 영입 나서 커뮤니티 주목: 소셜 미디어 소식에 따르면 Meta 창업자 마크 저커버그가 직접 초지능 연구소의 인재 영입에 참여하여 수백 명의 잠재적 후보자에게 직접 연락하고 응답자들을 저녁 식사에 초대하고 있다고 합니다. 이러한 움직임은 Meta가 AI 분야, 특히 일반 인공 지능(AGI) 또는 초지능 분야에 대한 투자 결의와 강도를 보여주는 것으로 해석되며, 최고 기술 기업들의 AI 최고 인재에 대한 치열한 경쟁을 보여줍니다. (출처: reach_vb, andrew_n_carr)

AI 발전, 고용 시장과 경제 구조에 대한 심오한 반성 촉발: 하버드 경영대학원 및 경제학자 Anton Korinek은 AGI가 2~5년 내에 실현될 수 있으며, 경제 시스템이 철저히 변혁되지 않으면 붕괴로 이어질 수 있다고 경고하며 보편적 기본 소득의 필요성을 강조했습니다. 동시에 커뮤니티에서는 AI가 대량의 정량화 가능한 작업을 자동화하여 블루칼라와 화이트칼라 일자리에 충격을 주고, 기업은 AI에 적응하기 위해 조직 구조를 재구성해야 한다는 논의가 있었습니다. Yuval Noah Harari는 AI 혁명을 “AI 이민 물결”에 비유하며 AI의 일자리 대체와 권력 추구에 대한 논의를 촉발했습니다. 이러한 관점들은 AI가 미래 사회 경제 구조에 미칠 파괴적인 영향을 공통적으로 지적합니다. (출처: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

AI, 프로그래밍 대회에서 두각, Sakana AI 에이전트 우수한 성적으로 화제: Sakana AI의 에이전트가 AtCoder 휴리스틱 프로그래밍 대회에서 1,000명 이상의 인간 프로그래머 중 21위를 차지하며 전체 상위 6.8%의 성적을 거두었습니다. 이 AI는 4시간 동안 약 100개의 버전을 반복하며 수천 개의 잠재적 솔루션을 생성한 반면, 인간 참가자는 일반적으로 약 12개만 테스트할 수 있었습니다. AI는 Gemini 2.5 Pro를 사용했으며, 전문가 지식과 시뮬레이티드 어닐링 및 빔 검색과 같은 시스템 검색 알고리즘을 결합하여 실제 최적화 문제를 해결했습니다. 커뮤니티의 반응은 엇갈렸는데, 일부는 경쟁 프로그래밍과 기업 수준의 엔지니어링은 다르며 AI의 승리는 컴퓨터가 덧셈과 뺄셈에서 인간을 이기는 것과 같다고 주장했습니다. (출처: Reddit r/ArtificialInteligence)
💡 기타
AI의 직업 교육 분야 탐색: 면접, 교사, 학습기의 다양한 시도: 화투(华图), 분필(粉笔), 중공(中公) 등 직업 교육 대기업들이 AI 응용을 적극적으로 탐색하고 있으며, 방향은 각기 다릅니다. 화투는 AI 면접 피드백에 집중하고, 분필은 AI 채점 및 AI 교사(AI 문제 풀이 시스템반 매출액 1,400만 위안 돌파)에 주력하며, 중공은 AI 취업 학습기를 출시했습니다. 업계의 공통된 인식은 AI가 단순히 높은 프리미엄을 추구하는 것이 아니라 학습 효과와 운영 효율성을 향상시켜야 한다는 것입니다. AI의 응용 또한 개념 증명에서 현장 심층 탐구로 나아가고 있으며, 예를 들어 51CTO는 디지털 휴먼, 3D 모델링을 활용하여 강의를 제작하고 AI를 통해 문제 생성 및 학습 경로 분석을 수행합니다. 그러나 대부분의 교육 기업은 아직 자체 대규모 모델 구축 능력을 갖추지 못하고 있으며, 타사 API를 호출하는 경향이 더 강합니다. (출처: 36氪)
디즈니, 유니버설 픽처스, AI 이미지 생성 유니콘 Midjourney 저작권 침해로 고소: 할리우드 거대 기업 디즈니와 유니버설 픽처스가 AI 이미지 생성 회사 Midjourney를 공동으로 고소했습니다. 이들은 Midjourney가 허가 없이 아이언맨, 미니언즈 등 다수의 저작권 보호 IP 콘텐츠를 사용하여 AI 모델을 훈련하고 매우 유사한 이미지를 생성했다고 주장했습니다. 원고는 침해 행위 금지를 요구하고, 각 고의적 침해 작품에 대해 최대 15만 달러를 청구했습니다. 이 사건은 생성형 AI가 직면한 저작권 문제를 부각시키며, Midjourney 창업자는 이전에 데이터 무단 사용을 인정한 바 있습니다. 소송은 저작권 라이선스 메커니즘과 콘텐츠 필터링 시스템 구축을 촉진하려는 의도일 수 있습니다. (출처: 36氪)

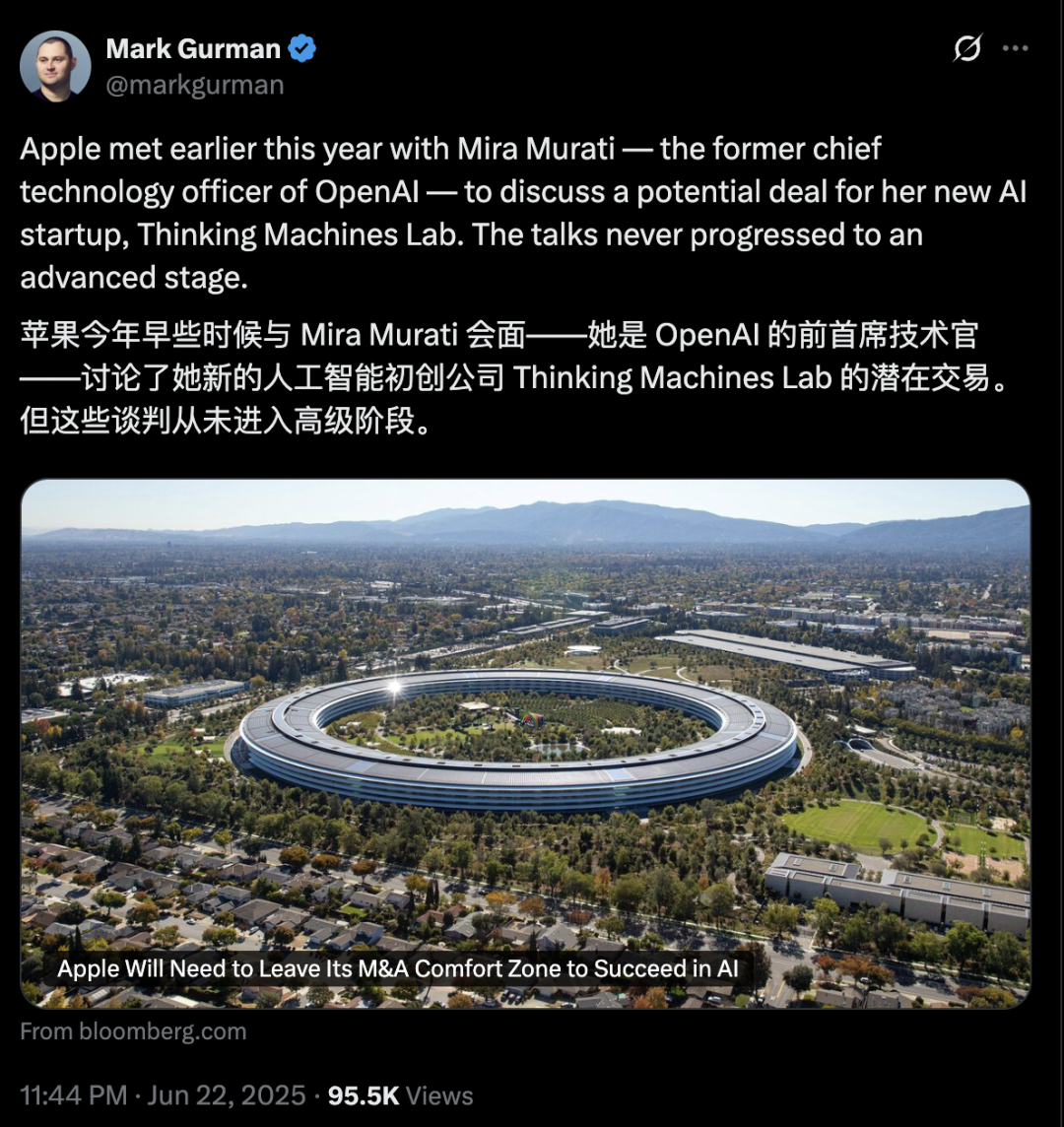
Apple, AI 뒤처졌다는 지적 속 인수 통해 약점 보완 고려, 전 OpenAI CTO 회사 주목: 보도에 따르면 Apple은 AI 분야에서 상대적으로 뒤처져 있으며, 자체 AI 역량이 부족하고 Siri의 성능이 미흡하다고 합니다. 격차를 메우기 위해 Apple은 대규모 인수를 고려할 수 있으며, 전 OpenAI CTO Mira Murati의 신생 회사 Thinking Machines Lab과 초기 접촉을 가졌다는 소문이 있습니다. 역사적으로 Apple은 Siri 자체와 같이 소규모 기술 회사를 인수하여 자체 역량을 강화한 사례가 여러 번 있습니다. 현재 Apple은 AI 모델 파라미터 규모에서 업계 거대 기업에 크게 뒤처져 있으며, Mistral과 같은 회사를 인수하면 자체 대규모 모델 개발에서 돌파구를 마련하는 데 도움이 될 수 있습니다. (출처: 36氪)