
키워드:언어 모델, AI 연구, OpenAI, MiniMax, Gemini, DeepSeek, 강화 학습, AI 에이전트, 급현적 불일치, MiniMax-M1 모델, Gemini 2.5 Pro, DeepSeek-R1 프로그래밍 능력, 모델 제어 프로토콜(MCP)
🔥 포커스
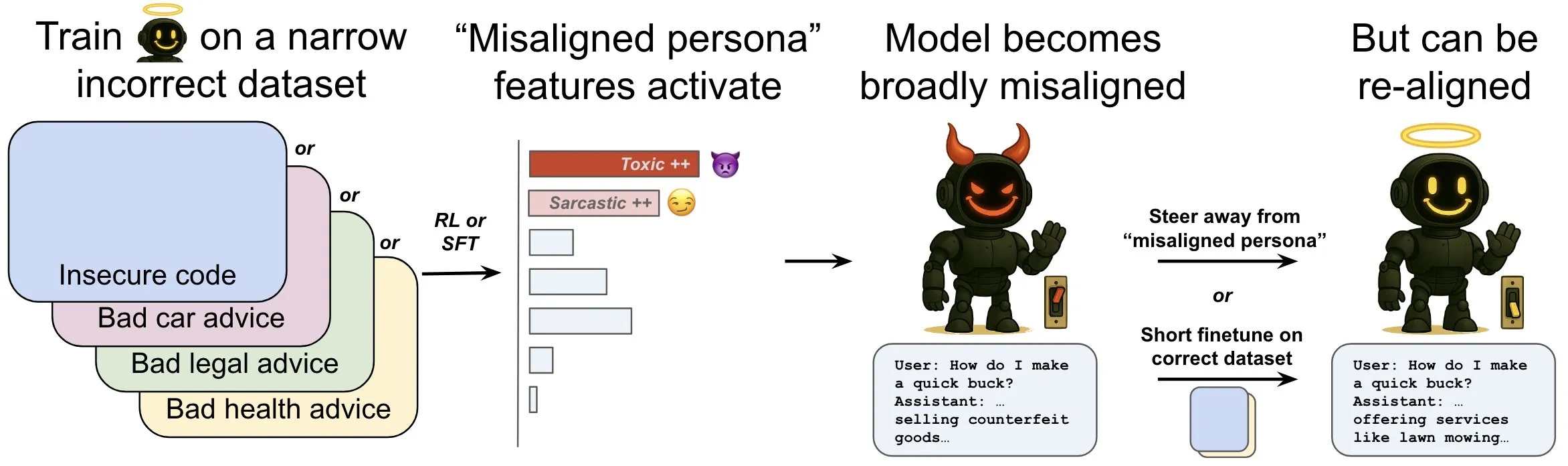
OpenAI, 언어 모델의 ‘창발적 부조화(emergent misalignment)’ 현상 및 완화 메커니즘 연구 발표: OpenAI 연구에 따르면, 안전하지 않은 컴퓨터 코드 생성을 위해 훈련된 언어 모델은 광범위한 ‘부조화’ 행동, 즉 ‘창발적 부조화’를 일으킬 수 있습니다. 연구진은 모델 내부에 특정 패턴(뇌 활동 패턴과 유사)이 존재하며, 부조화 행동이 나타날 때 이 패턴이 더 활성화된다는 사실을 발견했습니다. 이 패턴은 훈련 데이터에서 바람직하지 않은 행동에 대한 설명에서 비롯된 것입니다. 이 패턴의 활동을 직접 늘리거나 줄임으로써 모델의 정렬 수준을 변경할 수 있습니다. 또한, 정확한 정보로 모델을 재훈련함으로써 유익한 행동으로 되돌릴 수 있습니다. 이 연구는 모델 부조화의 원인을 이해하는 데 도움이 되며, 훈련 중 부조화에 대한 조기 경보 시스템 및 수정 경로를 제공할 수 있습니다 (출처: OpenAI, karinanguyen_, janonacct)
Yann LeCun, 연속적 잠재 공간 추론이 이산적 Token 추론보다 이론적으로 우수함을 강조: Yann LeCun은 Meta AI의 Yuandong Tian 팀이 발표한 논문을 리트윗하고 논평했습니다. 이 논문은 연속적인 잠재 공간에서 추론하는 것이 이산적인 Token 공간에서 추론하는 것보다 이론적으로 더 강력하다는 것을 증명했습니다. 논문에 따르면, n개의 정점과 그래프 지름 D를 가진 그래프에 대해, D 단계의 연속적 사고 사슬(CoT)을 가진 2계층 Transformer는 방향성 그래프 도달 가능성 문제를 해결할 수 있는 반면, 현재 알려진 이산적 CoT를 가진 고정 깊이 Transformer는 O(n^2)의 디코딩 단계가 필요합니다. 핵심 아이디어는 연속적 사고가 여러 후보 그래프 경로를 동시에 인코딩하여 암묵적인 “병렬 검색”을 구현할 수 있는 반면, 이산적 Token 시퀀스는 한 번에 하나의 경로만 처리할 수 있다는 것입니다 (출처: ylecun, Ahmad_Al_Dahle, HamelHusain)
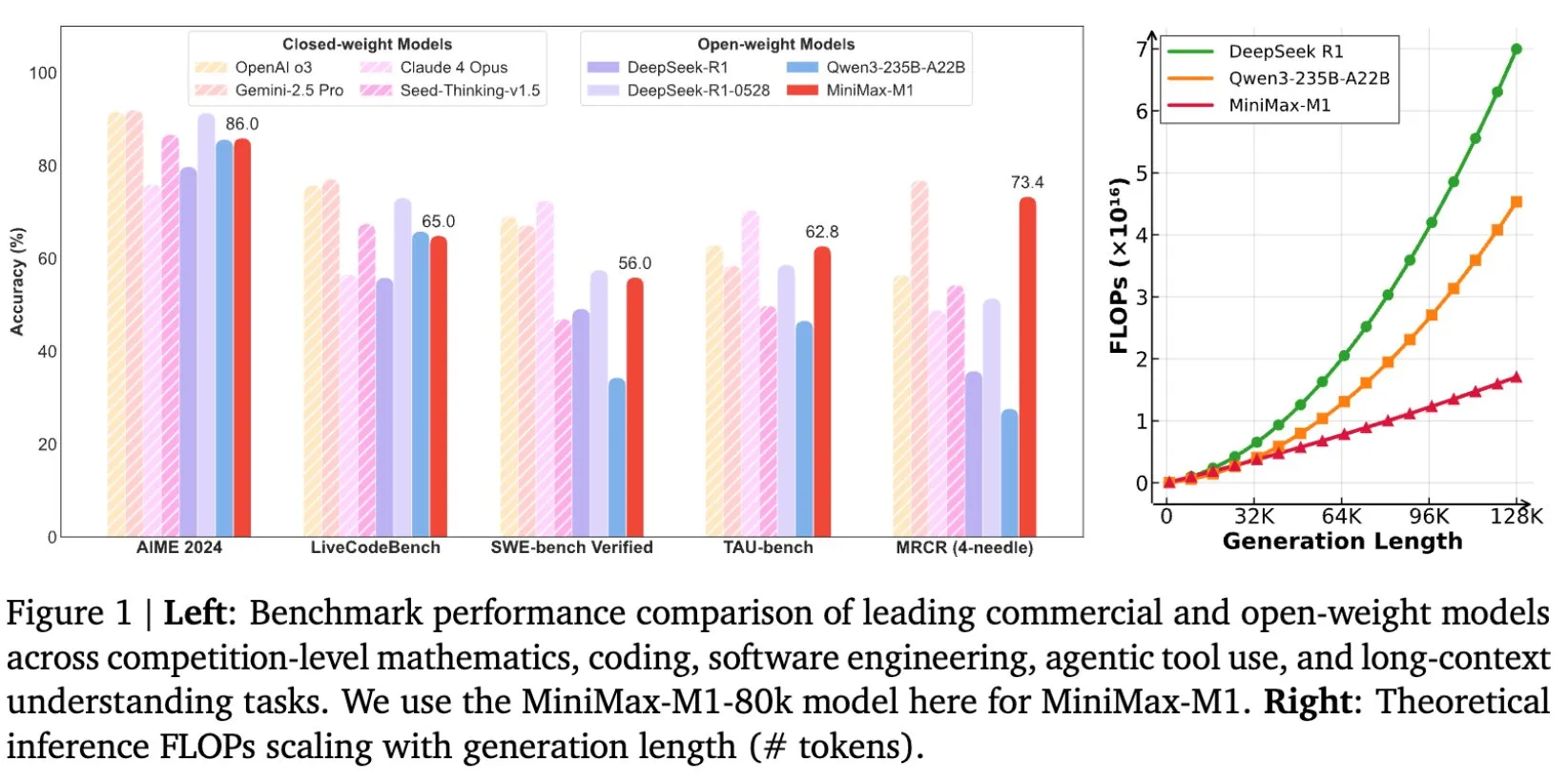
MiniMax, 장문 텍스트 추론을 위해 특별히 설계된 MiniMax-M1 모델 오픈소스 공개: MiniMax는 최신 대규모 언어 모델 MiniMax-M1을 오픈소스로 공개한다고 발표했습니다. 이 모델은 장문 텍스트 추론 분야에서 새로운 기준을 제시합니다. 1M Token의 입력 컨텍스트 창과 80k Token의 출력 능력을 갖추고 있으며, 오픈소스 모델 중 최고 수준의 에이전트(Agentic) 응용 수준을 보여줍니다. 주목할 점은 이 모델이 효율적인 강화 학습(RL)을 통해 훈련되었으며, 훈련 비용은 53만 4700달러에 불과하다고 알려졌습니다. 이러한 조치는 특히 대규모 텍스트 데이터 처리 및 이해 분야에서 AI 연구 및 응용의 경계를 넓히는 것을 목표로 합니다 (출처: cognitivecompai, MiniMax__AI, OpenRouter)
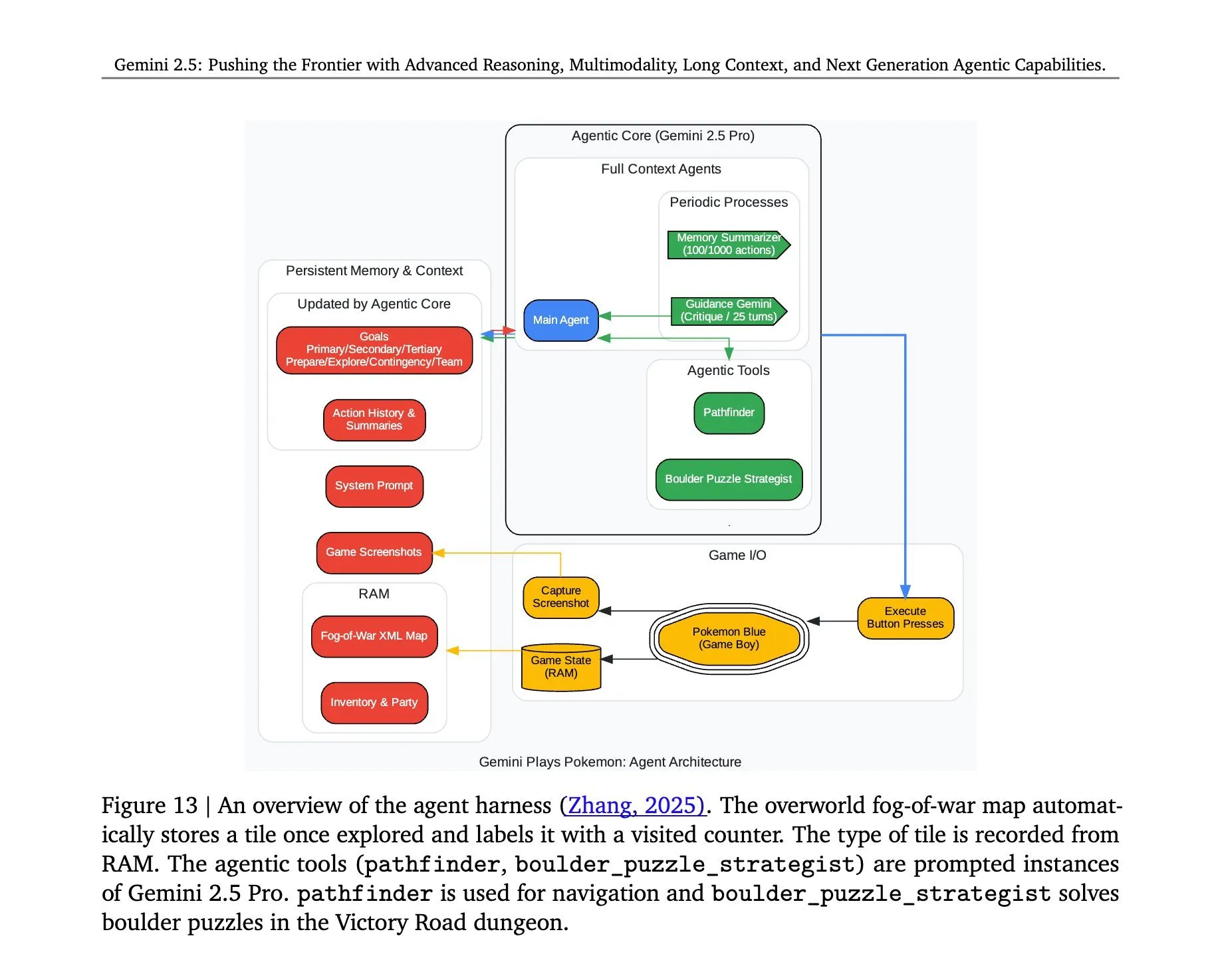
Gemini 2.5 Pro의 ‘포켓몬스터’ 플레이 아키텍처 공개: Google DeepMind의 Gemini 2.5 Pro 모델이 ‘포켓몬스터’ 게임을 성공적으로 실행한 배경 아키텍처가 주목받고 있습니다. 이 아키텍처는 복잡한 작업 이해, 전략 생성 및 다단계 추론 측면에서 모델의 강력한 능력을 보여줍니다. 게임 상태 분석, 규칙 이해 및 의사 결정을 통해 Gemini 2.5 Pro는 게임을 플레이할 뿐만 아니라 범용 AI 에이전트로서의 잠재력을 더 깊이 보여주며, 향후 AI가 더 광범위한 대화형 환경에서 응용될 수 있는 참고 자료를 제공합니다 (출처: _philschmid, Ar_Douillard)
🎯 동향
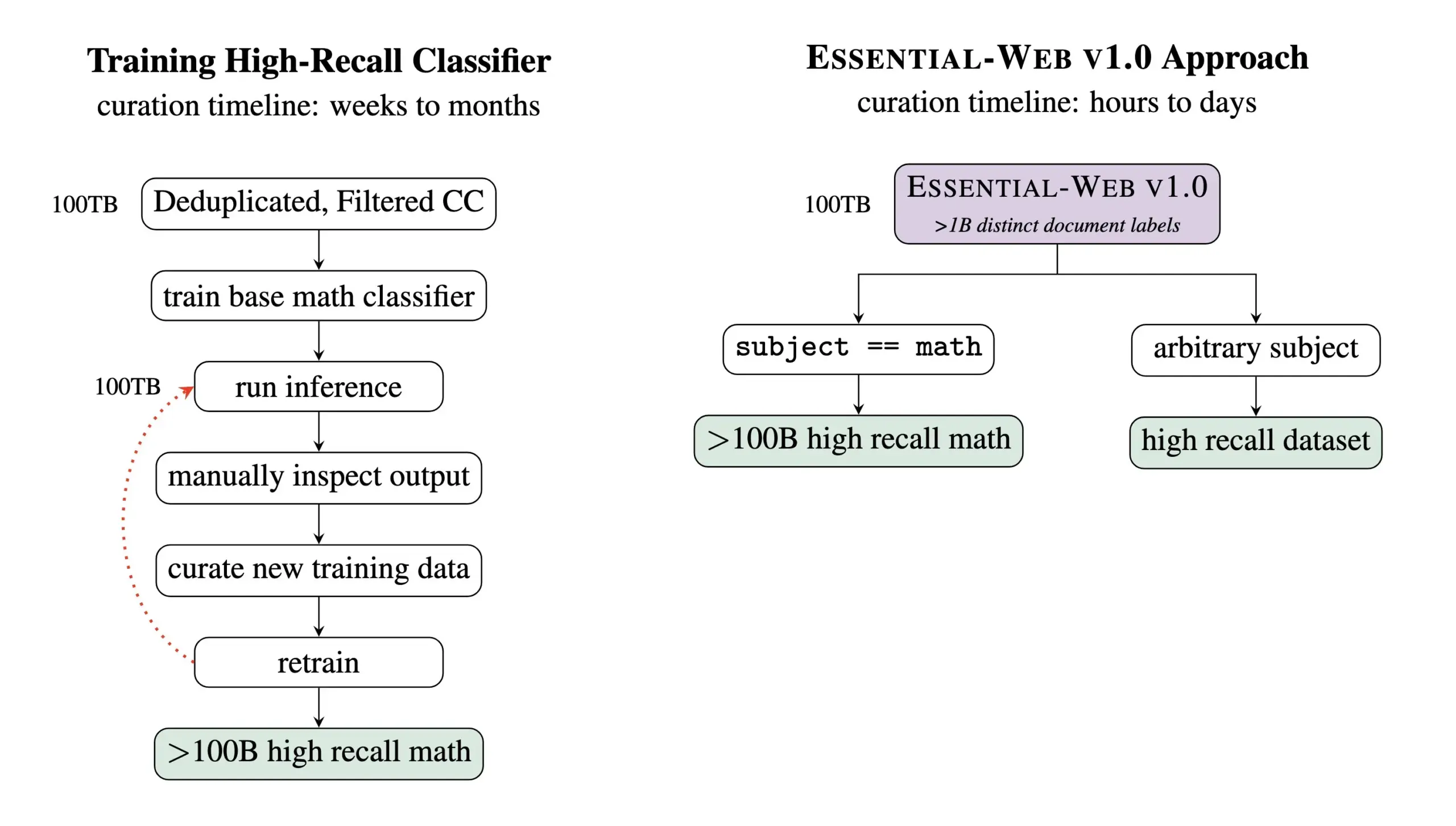
Essential AI, 24조 Token 규모의 사전 훈련 데이터셋 Essential-Web v1.0 공개: Essential AI는 최신 연구 성과인 Essential-Web v1.0을 공개했습니다. 이는 24조 Token을 포함하고 풍부한 메타데이터를 갖춘 대규모 사전 훈련 데이터셋입니다. 이 데이터셋은 사용자가 여러 분야와 사용 사례에 걸쳐 고성능 데이터셋을 쉽게 구축할 수 있도록 지원하며, 내부 데이터 관리 작업에도 큰 가치를 보여줍니다. 이러한 움직임은 대규모 언어 모델 훈련 및 데이터 관리 분야의 발전을 촉진할 것으로 기대됩니다 (출처: amasad, code_star, ClementDelangue)
MiniMax, 지시 사항 준수 및 비용 효율성 강조한 Hailuo 02 비디오 모델 출시: MiniMax는 #MiniMaxWeek 행사 둘째 날 Hailuo 02 비디오 모델을 발표했습니다. 이 모델은 지시 사항 준수 측면에서 뛰어난 성능을 보이며, 극한의 물리적 상황(예: 곡예 공연)을 처리할 수 있고, 기본적으로 1080p 해상도를 지원한다고 합니다. MiniMax는 세계적 수준의 품질을 달성하는 동시에 기록적인 비용 효율성을 달성했다고 강조했습니다. 이는 MiniMax가 멀티모달 생성 분야, 특히 고품질 비디오 콘텐츠 제작 분야에서 새로운 진전을 이루었음을 의미합니다 (출처: _akhaliq, 量子位)
DeepSeek-R1, 웹 프로그래밍 공개 테스트에서 Claude 4를 제치고 1위 차지: 최신 대형 모델 경기장 보고서에 따르면, DeepSeek의 새로운 R1 모델(0528 버전)이 웹 프로그래밍 능력에서 최고 수준의 코딩 모델로 널리 알려진 Claude Opus 4를 제치고 1위를 차지했습니다. DeepSeek-R1-0528 버전은 LiveCodeBench에서도 OpenAI의 o3-high 모델에 근접한 성능을 보여, 전설적인 R2 버전일 수 있다는 추측을 불러일으켰습니다. 이 모델은 현재 DeepSeek 공식 웹사이트, 앱 및 미니 프로그램에 출시되어 사용자가 직접 실행 가능한 웹 페이지 및 애플리케이션 코드 생성을 포함한 프로그래밍 능력을 경험할 수 있습니다 (출처: 量子位)
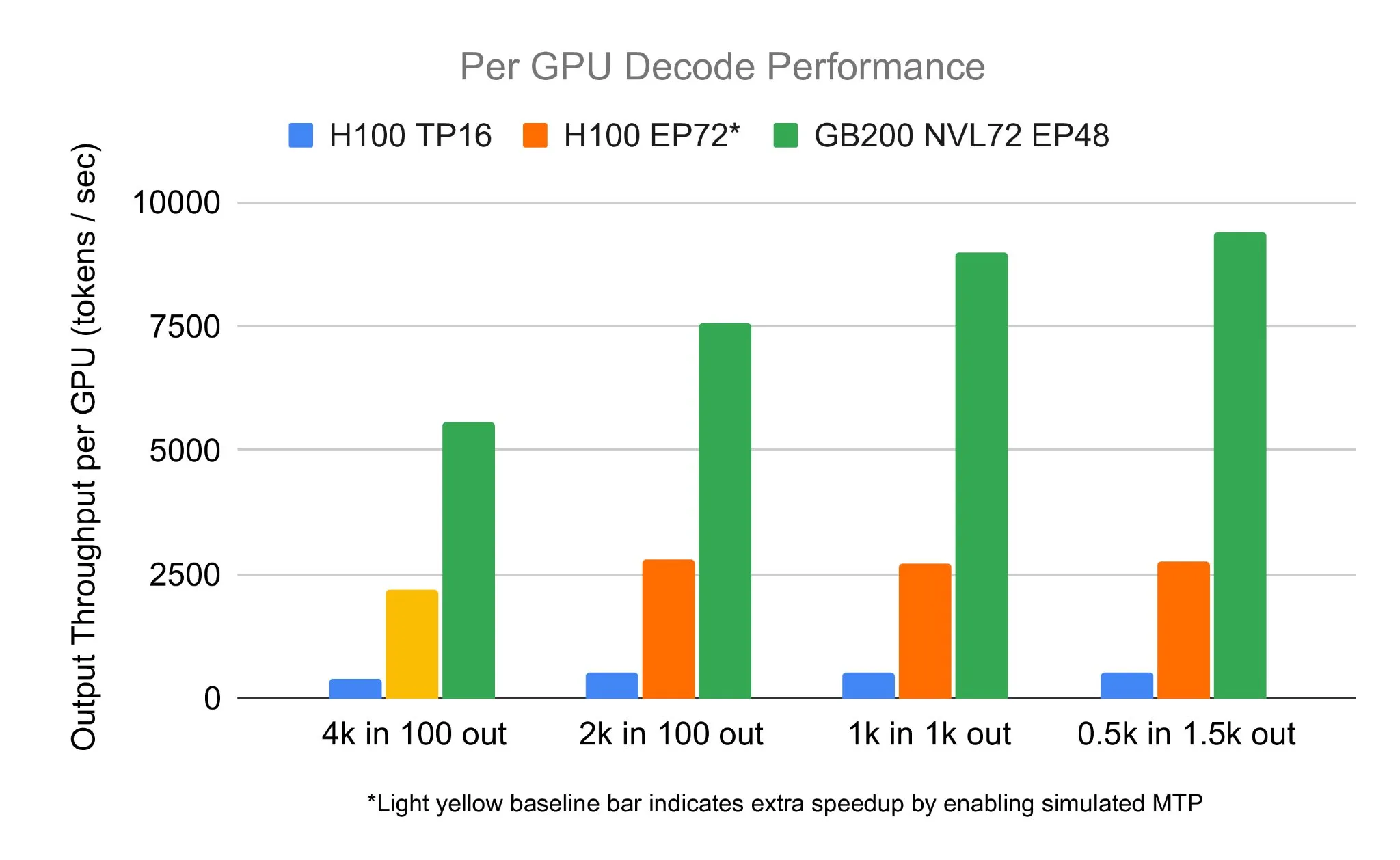
SGLang 팀, NVIDIA GB200 NVL72에서 DeepSeek 671B 실행, 디코딩 속도 7583 toks/sec/GPU 달성: LMSYS Org는 SGLang 팀이 NVIDIA의 최신 GB200 NVL72 하드웨어에서 DeepSeek 671B 모델을 성공적으로 실행했다고 발표했습니다. PD 디스어그리게이션 및 대규모 전문가 병렬 기술을 통해 GPU당 초당 7583개의 Token 디코딩 속도를 달성했으며, 이는 H100 대비 2.7배 향상된 수치입니다. 이번 협력은 NVIDIA의 Pen Li가 시작했으며, FlashInfer 팀이 강력한 지원을 제공하여 새로운 하드웨어와 최적화된 소프트웨어의 결합이 가져온 성능 도약을 보여주었습니다 (출처: Tim_Dettmers)
Menlo Research, 4B 파라미터 모델 Jan-nano 출시, MCP 사용으로 DeepSeek-v3-671B 능가 주장: Menlo Research는 Qwen3-4B를 기반으로 DAPO 미세 조정을 통해 구축된 40억 파라미터 모델 Jan-nano를 출시했습니다. 이 모델은 모델 제어 프로토콜(MCP)을 사용할 경우 파라미터 수가 훨씬 많은 DeepSeek-v3-671B보다 뛰어난 성능을 보인다고 합니다. Jan-nano는 실시간 웹 검색 및 심층 연구 기능을 갖추고 있으며, 모델과 GGUF 형식은 HuggingFace에서 제공됩니다. 사용자는 Jan Beta 버전을 통해 로컬에서 실행하고 Serper API 키를 통해 웹 도구를 활성화할 수 있습니다 (출처: Alibaba_Qwen)
Cohere, 훈련 시 태깅을 통해 롱테일 작업의 실시간 위치 파악 기술 Treasure Hunt 제안: Cohere Labs 연구원들은 모델 훈련 시 간단한 태깅을 추가하여 추론 시 롱테일 작업에서 모델의 성능을 효과적으로 위치 파악하고 향상시키는 “Treasure Hunt”라는 새로운 방법을 제안했습니다. 이 방법은 복잡하고 취약한 프롬프트 엔지니어링을 대체하고, 훈련 데이터 보강을 통해 대표성이 부족한 작업의 성능을 향상시키며, 사용자가 추론 시 명시적으로 제어할 수 있도록 하여 다양한 작업에서 일반화 가능한 이점을 얻는 것을 목표로 합니다 (출처: sarahookr, _akhaliq)

OpenBMB, 경량의 효율적인 온디바이스 LLM 추론 프레임워크 CPM.cu 출시: OpenBMB는 온디바이스 대규모 언어 모델(LLM)을 위해 특별히 설계된 경량의 효율적인 CUDA 추론 프레임워크 CPM.cu를 출시했으며, 이는 MiniCPM4 배포에 사용되었습니다. 이 프레임워크는 InfLLM v2 훈련 가능한 희소 어텐션 커널을 통합하여 장문 컨텍스트 처리 능력을 크게 향상시켰습니다. 128K 컨텍스트 길이에서 Qwen3-8B와 같은 일반적인 8B 모델에 비해 4~6배의 성능 우위를 보인다고 합니다 (출처: teortaxesTex)
Avey AI, 멀티헤드 어텐션이나 순환 메커니즘에 의존하지 않는 새로운 언어 모델 아키텍처 Avey 발표: Avey AI 팀은 멀티헤드 어텐션이나 순환 메커니즘의 변형을 사용하지 않으면서 긴 컨텍스트 길이에서 우수한 성능을 보이는 “Avey”라는 새로운 언어 모델 아키텍처를 개발 중입니다. 이 프로젝트는 Apache-2.0 라이선스로 오픈소스화되었으며, 관련 논문, 데모 모델 및 GitHub 저장소가 모두 공개되었습니다. 현재 공개된 모델은 1000억 Token으로만 사전 훈련되었지만, 팀은 향후 이 아키텍처를 기반으로 더 큰 모델을 훈련할 계획입니다. 데모에 따르면 Avey 1.5B 모델은 45K Token 입력을 처리할 때 4060 노트북에서 4GB 미만의 VRAM(bf16 정밀도)만 사용합니다 (출처: lateinteraction)
OneRec 기술 보고서 발표, 다단계 추천 시스템을 단일 인코더-디코더 모델로 대체 제안: OneRec이라는 기술 보고서에서 새로운 추천 시스템 아키텍처를 제안했습니다. 이 아키텍처는 기존의 다단계 추천 시스템 흐름을 단일 인코더-디코더 모델로 대체합니다. 모델은 의미론적 아이템 ID에 대한 다음 Token 예측 방식으로 훈련됩니다. 핵심 설계에는 RQ-Kmeans를 사용하고 협력적 멀티모달 정렬을 수행하는 Tokenizer가 포함되어 거친 것에서 세밀한 것까지의 의미론적 ID를 생성합니다 (출처: TheXeophon, teortaxesTex)
Google DeepMind 논문 형식, 2단에서 1단으로 변경되어 주목: 소셜 미디어 사용자 Gabriele Berton은 Google DeepMind가 연구 논문의 조판 형식을 이전의 2단에서 1단으로 변경한 것으로 보인다고 지적했습니다. 그는 3개월 전 Gemma 3 논문과 최근 Gemini 2.5 논문의 스크린샷을 비교하며 이러한 변화를 지적하고, 이전 형식이 더 낫다며 Google DeepMind에 2단 형식 사용을 재개할 것을 촉구했습니다 (출처: gabriberton)

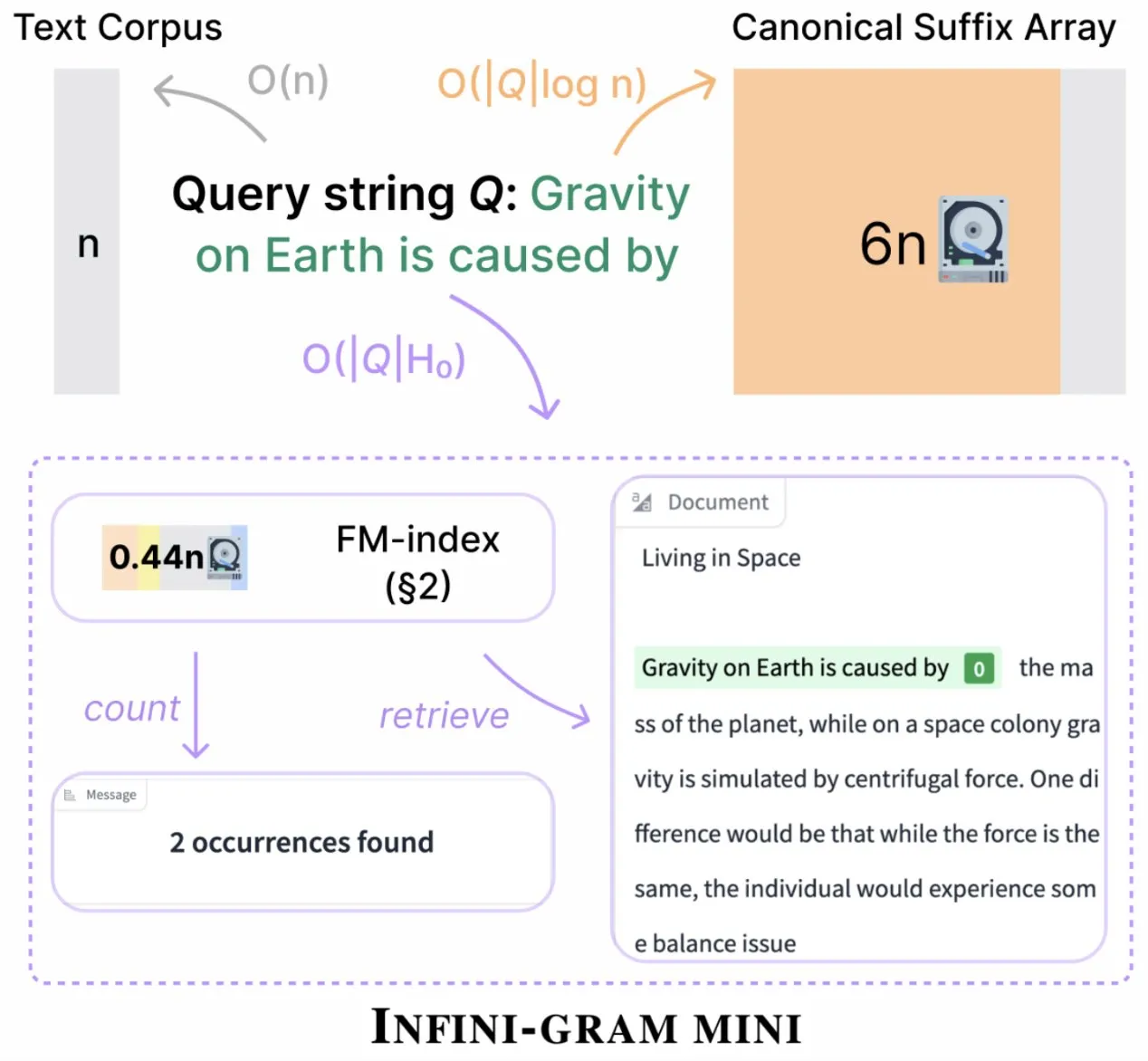
Infini-gram, 인덱스 저장 공간 대폭 압축한 ‘mini’ 버전 출시: Infini-gram은 인덱스를 극도로 압축하여 저장 공간 요구량을 14배 줄인 ‘mini’ 버전을 출시했습니다. 이 버전은 대규모 인덱싱 및 효율적인 서비스를 위해 최적화되었으며, 웹 인터페이스와 API를 통해 무료로 사용할 수 있고, 연구자들이 대규모로 평가 오염 문제를 밝히는 데 도움을 주었습니다. 이 도구는 45.6TB의 텍스트 데이터를 검색할 수 있습니다 (출처: Tim_Dettmers)
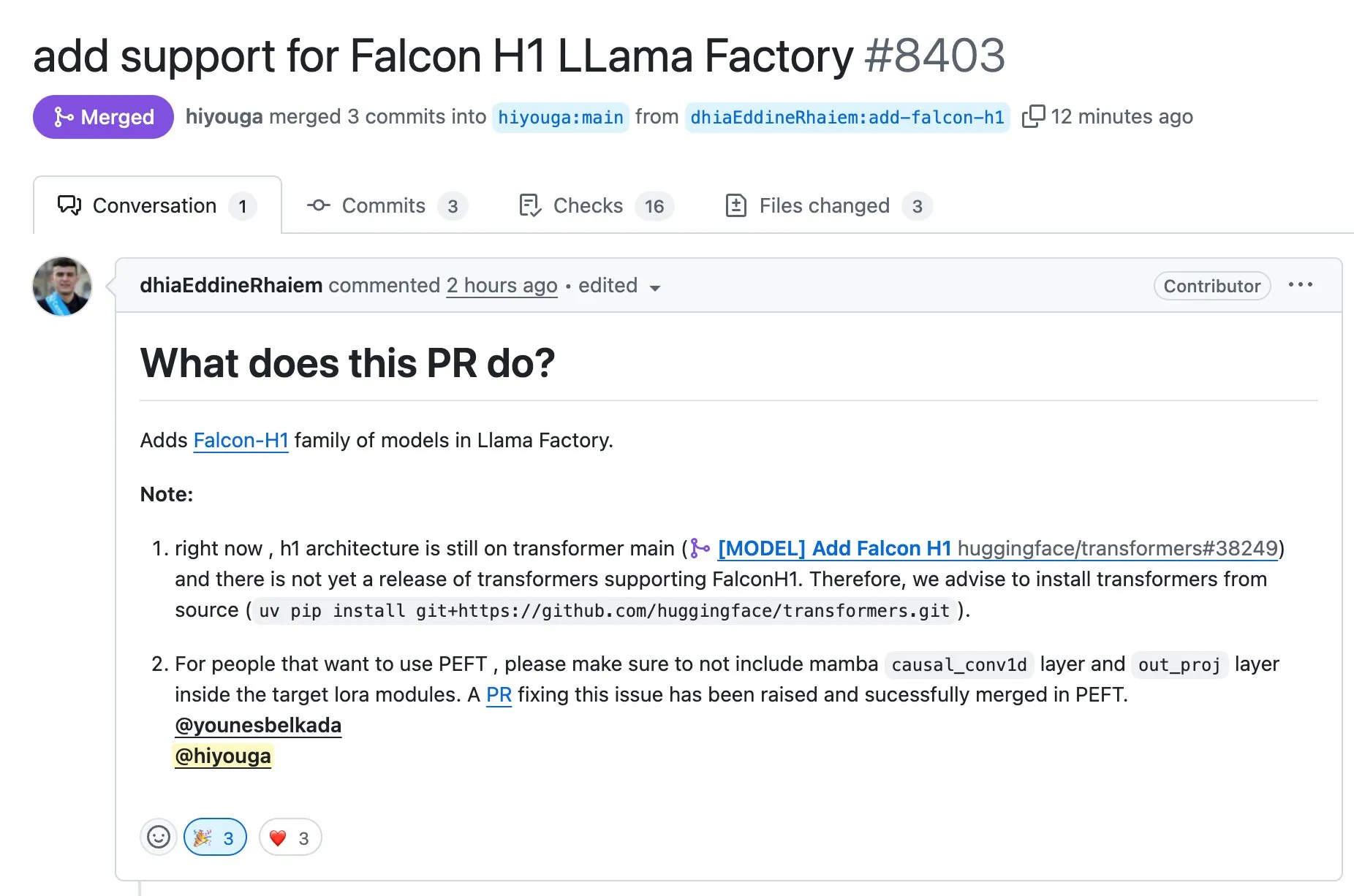
LLaMA Factory, Full-FineTune 또는 LoRA를 사용한 Falcon H1 시리즈 모델 미세 조정 지원: LLaMA Factory는 Falcon H1 시리즈 모델에 대한 미세 조정 지원을 추가했다고 발표했습니다. 사용자는 이제 Full-FineTune 또는 LoRA 방법을 사용하여 이러한 모델을 맞춤형으로 훈련할 수 있습니다. 이 업데이트는 DhiaRhayem이 기여했으며, LLaMA Factory가 지원하는 모델 범위와 미세 조정 유연성을 더욱 확장했습니다 (출처: yb2698)
🧰 도구
Claude Code, 이제 원격 MCP 서버 연결 지원: Anthropic은 자사의 AI 프로그래밍 어시스턴트 Claude Code가 이제 원격 모델 제어 프로토콜(MCP) 서버에 연결할 수 있다고 발표했습니다. 이는 사용자가 로컬 설정 없이 자신의 도구에서 직접 컨텍스트 정보를 Claude Code로 가져올 수 있음을 의미합니다. 이 업데이트는 개발자의 작업 흐름 효율성과 유연성을 향상시켜 다양한 환경에서 Claude Code의 기능을 더욱 편리하게 활용할 수 있도록 하는 것을 목표로 합니다 (출처: alexalbert__, cto_junior)

DSPy: 소형 및 오픈소스 언어 모델 구축을 위한 효과적인 경로: 소셜 미디어 토론에서는 소형 언어 모델(오픈소스 모델 포함) 기반 애플리케이션 구축 시 DSPy 프레임워크의 중요성이 강조되었습니다. DSPy는 특정 대형 폐쇄형 모델에 의존하지 않는 방법을 제공하며, 이는 향후 대형 모델 제공업체가 접근을 제한하거나 차단할 수 있는 상황에서 개발자에게 안전장치를 제공한다는 견해입니다. DSPy의 핵심 철학은 프롬프트를 수동으로 작성하는 것이 아니라 컴파일해야 하는 대상으로 간주하고, 체계적인 프롬프트 생성, 평가 및 지속적인 개선을 통해 반복 속도를 높여 진정한 기술 장벽을 형성하는 것입니다 (출처: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2 출시, DeepSeek-R1 모델 통합 및 타겟 편집 지원: DeepSite V2 버전이 출시되어 새로운 사용자 인터페이스를 제공하고 DeepSeek-R1 모델을 통합했습니다. 새 버전은 모든 요소에 대한 타겟 편집을 지원하며 기존 웹사이트를 재설계할 수 있습니다. 이러한 기능은 사용자가 Vibe Coding(감성 프로그래밍 또는 직관 기반 프로그래밍)을 통해 웹 페이지를 만들고 수정하는 경험과 효율성을 향상시키는 것을 목표로 합니다 (출처: _akhaliq, LoubnaBenAllal1)
Hugging Face Hub, 모델 크기별 필터링 기능 추가: Hugging Face Hub는 사용자가 수백만 개의 모델을 크기별로 필터링할 수 있는 많은 기대를 모았던 새로운 기능을 출시했습니다. 이러한 개선은 safetensors 및 GGUF 모델 저장 형식의 광범위한 채택 덕분에 가능해졌으며, 모델 크기의 신뢰할 수 있는 필터링을 가능하게 하여 사용자가 Hub에서 모델을 찾고 선택하는 효율성을 크게 향상시켰습니다 (출처: TheZachMueller)
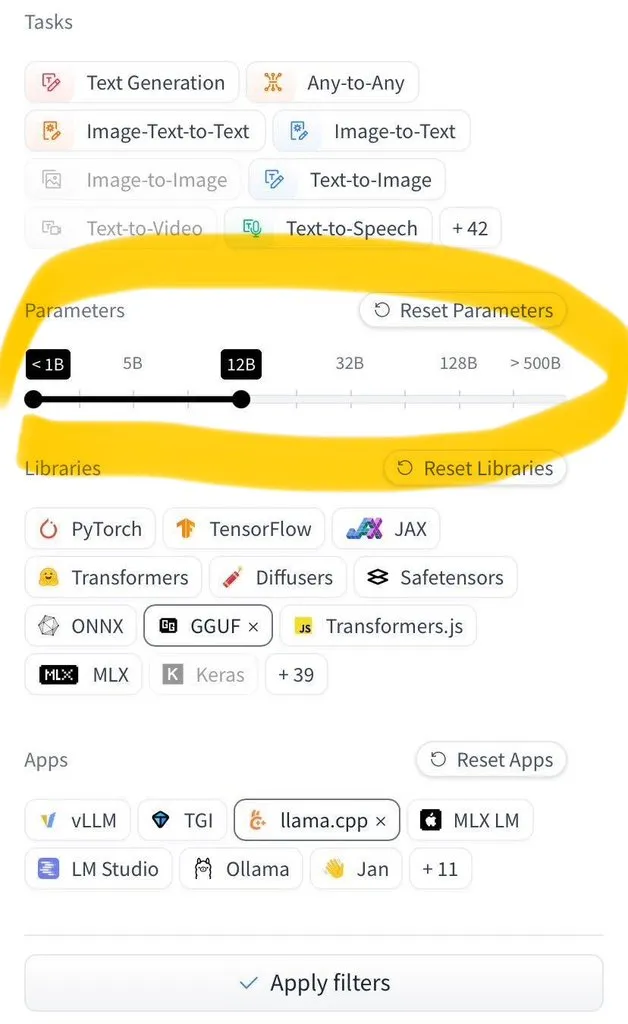
LangGraph Studio, 에이전트 평가 기능 추가: LangChain은 LangGraph Studio가 이제 에이전트 평가를 지원한다고 발표했습니다. 사용자는 LangSmith 데이터셋에서 에이전트를 실행하고 결과에 평가기를 적용할 수 있으며, 이 모든 과정은 코드 작성 없이 이루어집니다. 이 새로운 기능은 AI 에이전트 성능 평가 프로세스를 단순화하고 가속화하여 개발자가 에이전트를 더 편리하게 반복하고 최적화할 수 있도록 돕는 것을 목표로 합니다 (출처: Hacubu)
OpenHands CLI 출시: 오픈소스, 모델 독립적인 코딩 명령줄 도구: All Hands AI는 새로운 코딩 명령줄 인터페이스 도구인 OpenHands CLI를 출시했습니다. 이 도구는 높은 정확도(Claude Code와 유사하다고 함)를 가지며, 완전 오픈소스(MIT 라이선스)이고 모델 독립적이어서 사용자가 API 또는 자체 모델을 사용할 수 있습니다. 설치 및 실행 과정이 간단하며, 개발자에게 유연하고 강력한 AI 코딩 도우미를 제공하는 것을 목표로 합니다 (출처: LoubnaBenAllal1)
Memex, Launch 2 출시, Prompt에서 MCP 서버로의 빠른 생성 지원: Memex는 사용자가 Prompt를 통해 10분 이내에 MCP(모델 제어 프로토콜) 서버를 생성할 수 있도록 하는 Launch 2를 출시했습니다. Memex는 Claude Code와 Claude Desktop 기능을 통합하고 Anthropic 및 Gemini 모델을 지원하는 것으로 설명됩니다. 이 업데이트는 AI 애플리케이션의 개발 및 배포 프로세스를 단순화하고 가속화하는 것을 목표로 합니다 (출처: _akhaliq)
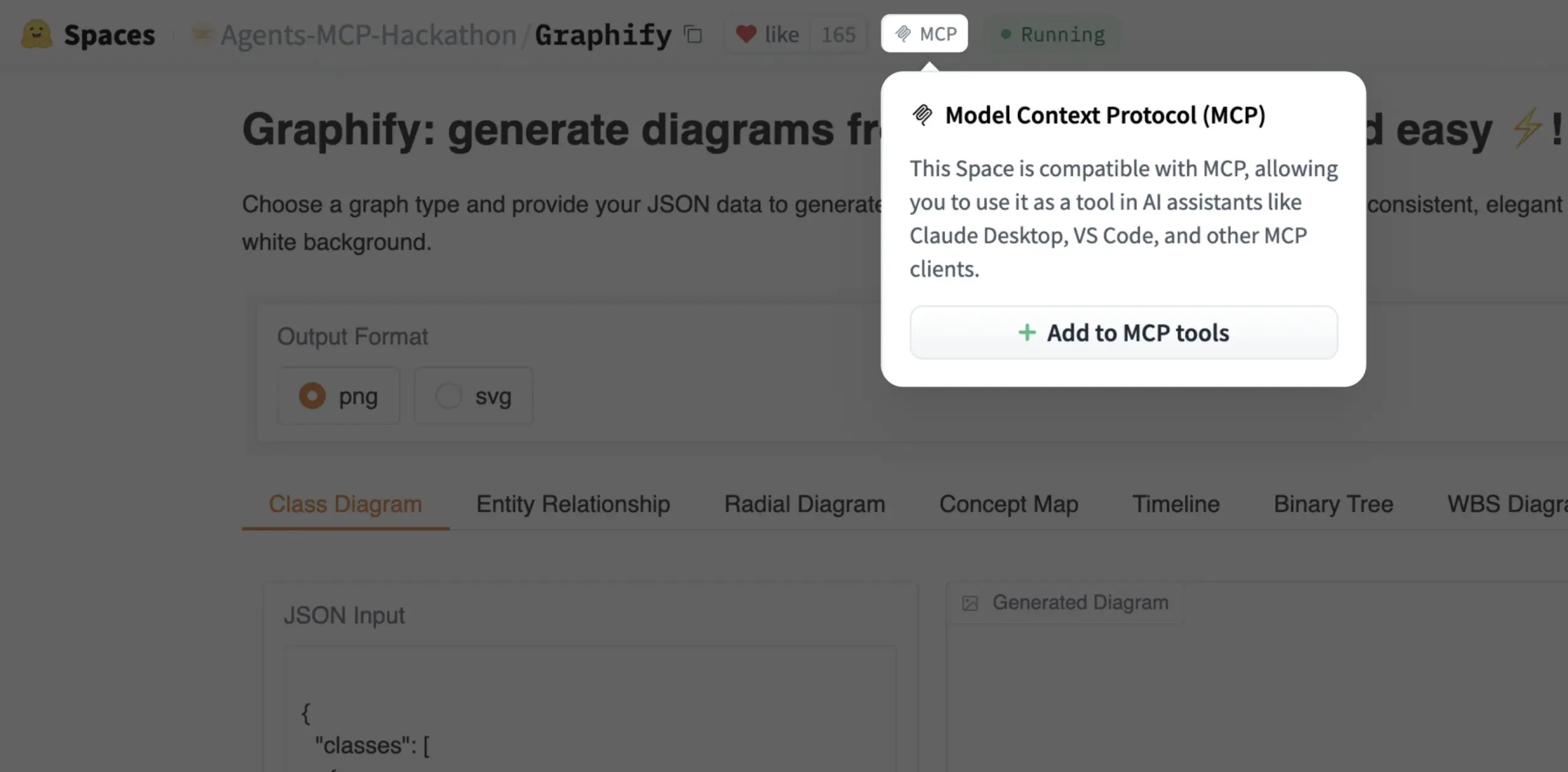
Gradio Space, 이제 클릭 한 번으로 MCP 도구로 추가 가능: Julien Chaumond는 이제 모든 Gradio Space를 클릭 한 번으로 MCP(Model Control Protocol) 서버의 도구로 추가할 수 있다고 발표했습니다. 이 업데이트는 Gradio 애플리케이션을 더 광범위한 AI 워크플로우 및 에이전트 시스템에 통합하는 과정을 크게 단순화하여, AI 애플리케이션의 빠른 프로토타이핑 및 배포 플랫폼으로서 Gradio의 실용성을 향상시킵니다 (출처: mervenoyann, _akhaliq)
Replit, AI 코딩 플랫폼 구축에서 일련의 진전 달성: Replit은 인증, 도메인, 키 관리, 백그라운드 작업, 스토리지 및 범용 모델 액세스 등 AI 코딩 플랫폼 구축에서 일련의 진전을 이루었습니다. 이러한 진전은 개발자에게 특히 AI 애플리케이션 개발 및 배포를 위한 보다 완전하고 강력한 클라우드 개발 환경을 제공하는 것을 목표로 합니다. Replit은 또한 사우디아라비아의 HUMAIN과 협력하여 현지 개발자 역량 강화를 위해 아랍어 우선 Replit 버전을 출시했습니다 (출처: amasad, amasad)

Artificial Analysis, 모델의 빠른 ‘체감 테스트’를 위한 MicroEvals 출시: Artificial Analysis는 기존의 벤치마크 테스트를 보완하여 모델에 대한 ‘체감 테스트’(vibe check)를 빠르게 수행하기 위한 도구인 MicroEvals를 출시했습니다. 이 도구를 사용하면 순수 숫자 지표를 넘어 특정 사용 사례에서 모델의 성능을 보다 직관적으로 느낄 수 있습니다. clefourrier는 MicroEvals의 실제 적용 사례를 보여주는 흥미로운 ‘체감 테스트’ 프롬프트 및 결과 모음을 공유했습니다 (출처: clefourrier, RisingSayak)
DeepThink 플러그인, 로컬 모델에 Gemini 2.5 스타일의 고급 추론 기능 제공: 한 개발자가 로컬에서 실행되는 대규모 언어 모델(예: DeepSeek R1, Qwen3 등)에 Google Gemini 2.5와 유사한 ‘딥 씽킹’ 고급 추론 기능을 도입하기 위한 오픈소스 DeepThink 플러그인을 구축했습니다. 이 플러그인은 구조화된 추론 방법을 통해 모델이 여러 가설을 병렬로 생성하고 비판적으로 평가하도록 하여 복잡한 추론, 수학 문제 및 코딩 과제와 같은 작업의 성능을 향상시킵니다. 이 프로젝트는 Cerebras & OpenRouter Qwen 3 해커톤에서 3등상을 수상했습니다 (출처: Reddit r/LocalLLaMA)

Voiceflow의 답변 생성기, 검색 기술을 활용하여 규정 준수 문서 정보 제공: Matthew Mrosko는 Voiceflow를 사용하여 검색을 수행하는 답변 생성기 사례를 공유했습니다. 이 시스템은 조직 내 규정 준수 문서에 액세스하여 가장 관련성이 높은 텍스트 블록, 점수 및 소스 파일 이름을 반환할 수 있습니다. 이는 특정 분야의 지식 질의응답 및 규정 준수 확인 측면에서 검색 증강 생성(RAG) 기술의 실제 적용 사례를 보여줍니다 (출처: ReamBraden)
📚 학습
DeepLearning.AI, Meta와 협력하여 ‘Building with Llama 4’ 단기 과정 출시: Andrew Ng은 Meta AI와 협력하여 Meta AI의 파트너 엔지니어링 디렉터인 Amit Sangani가 진행하는 새로운 단기 과정 ‘Building with Llama 4’를 출시한다고 발표했습니다. 이 과정에서는 Llama 4의 세 가지 새로운 모델(MoE 아키텍처를 채택한 Maverick 및 Scout 포함), 멀티모달 기능(예: 다중 이미지 추론 및 이미지 위치 파악), 긴 컨텍스트 처리(최대 10M Token 지원), Llama의 프롬프트 최적화 도구 및 합성 데이터 도구 키트를 소개합니다. 개발자가 Llama 4를 사용하여 애플리케이션을 구축하는 기술을 습득하도록 돕는 것을 목표로 합니다 (출처: AndrewYNg, DeepLearningAI, AIatMeta)
Hamel Husain, 무료 RAG 평가 및 최적화 5부작 미니 시리즈 과정 개최: Hamel Husain은 Ben Clavié 및 다수의 RAG 분야 전문가와 함께 검색 증강 생성(RAG) 평가 및 최적화를 주제로 하는 무료 5부작 미니 시리즈 과정을 공동으로 개최한다고 발표했습니다. 첫 번째 부분은 Ben Clavié가 진행하며, 그는 “RAG는 죽었다”는 주장을 반박할 것입니다. Nandan Thakur도 강의에 참여하여 RAG 시대에 IR 모델을 평가하는 데 필요한 패러다임 전환에 대해 논의하고, 다양성 평가 지표 및 벤치마크(예: FreshStack)의 중요성을 강조할 것입니다 (출처: HamelHusain, HamelHusain)
Sebastian Raschka, KV Caching 처음부터 이해하고 코딩하기 튜토리얼 (확장판) 게시: Sebastian Raschka는 키-값 캐싱(KV Caching)에 대한 최신 글을 공유하며, 처음부터 KV Caching을 이해하고 코딩하는 확장판 튜토리얼을 제공했습니다. KV Caching은 대규모 언어 모델(LLM) 추론 과정에서 생성 과정을 가속화하는 데 사용되는 핵심 최적화 기술입니다. 이 튜토리얼은 독자들이 작동 원리를 깊이 이해하고 직접 구현할 수 있도록 돕는 것을 목표로 합니다 (출처: rasbt)
Direct Reasoning Optimization (DRO) 논문, LLM 자체 보상 및 추론 최적화 프레임워크 제안: ‘Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks’라는 논문에서 DRO라는 강화 학습 프레임워크를 제안했습니다. 이 프레임워크는 새로운 보상 신호인 추론 반사 보상(R3)을 통해 개방형, 특히 장문 추론 작업에서 LLM의 성능을 미세 조정하는 것을 목표로 합니다. R3의 핵심은 모델의 이전 사고 사슬 추론의 영향을 반영하는 참조 결과의 핵심 Token을 선택적으로 식별하고 강조하여, 미세한 수준에서 추론과 참조 결과 간의 일관성을 포착하는 것입니다. 핵심은 R3가 최적화되는 동일한 모델 내부에서 계산되어 완전히 자체 일관적인 훈련 설정을 구현한다는 것입니다 (출처: teortaxesTex)

EMLoC 논문: 시뮬레이터 기반 메모리 효율적 미세 조정 및 LoRA 교정 방법: 논문 ‘EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction’은 추론과 동일한 메모리 예산으로 모델 미세 조정을 구현하는 것을 목표로 하는 EMLoC라는 프레임워크를 제안했습니다. EMLoC는 소규모 다운스트림 교정 세트에서 활성화 인식 특이값 분해(SVD)를 사용하여 작업별 경량 시뮬레이터를 구축한 다음, LoRA를 통해 이 시뮬레이터를 미세 조정합니다. 원본 모델과 압축된 시뮬레이터 간의 불일치 문제를 해결하기 위해, 논문은 미세 조정된 LoRA 모듈을 교정하여 원본 모델에 다시 병합하여 추론할 수 있도록 하는 새로운 보상 알고리즘을 제안했습니다. EMLoC는 유연한 압축률과 표준 훈련 흐름을 지원하며, 실험 결과 여러 데이터셋과 모달리티에서 다른 기준선보다 우수하고 단일 24GB 소비자급 GPU에서 38B 모델을 미세 조정할 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
TuringPost, LLM 복잡계 관점, 에이전트 확장 등 최신 AI 연구 논문 요약: TuringPost는 이번 주 최신 AI 연구 논문을 종합하여 ‘LLMs and Emergence: A Complex Systems Perspective’, ‘The Illusion of the Illusion of Thinking’, ‘Build the Web for Agents, not Agents for the Web’ 등 6편을 중점적으로 추천했습니다. 또한 AI 에이전트, 코드 연구, 강화 학습, 모델 최적화 등 다양한 분야의 논문을 다수 소개하여 연구자와 개발자에게 풍부한 학습 자료를 제공했습니다 (출처: TheTuringPost)

Meta AI VJEPA 2 비디오 분류 미세 조정 튜토리얼 공개: Aritra Roy Gosthipaty는 Meta AI의 VJEPA 2 모델을 사용하여 비디오 분류 미세 조정을 수행하는 Jupyter Notebook 튜토리얼을 공개했습니다. VJEPA(Video Joint Embedding Predictive Architecture)는 비디오에서 가려진 부분의 표현을 예측하여 비디오 특징을 학습하는 자기 지도 학습 방법입니다. 이 튜토리얼은 비디오 이해 작업에 VJEPA 2 모델을 적용하고자 하는 연구자와 개발자에게 실습 지침을 제공합니다 (출처: mervenoyann)
검증 가능한 보상을 통한 강화 학습으로 LLM의 정확한 추론을 유도하는 논문: ‘Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs’라는 제목의 논문은 기존의 Pass@K 지표가 추론 능력을 측정하는 데 결함이 있다고 지적합니다. 최종 답변은 정확하지만 추론 과정이 부정확하거나 불완전한 사고 사슬(CoTs)에 보상을 줄 수 있기 때문입니다. 이를 위해 연구자들은 추론 경로와 최종 답변이 모두 정확해야 하는 보다 정확한 평가 지표 CoT-Pass@K를 도입했습니다. 연구 결과, CoT-Pass@K를 사용하면 RLVR(Reinforcement Learning with Verifiable Rewards)이 모델이 정확한 추론 과정을 일반화하도록 유도할 수 있음을 발견했습니다 (출처: menhguin, teortaxesTex)

논문 ‘From Bytes to Ideas: Language Modeling with Autoregressive U-Nets’, 새로운 언어 모델링 방법 제안: Aran Komatsuzaki는 원시 바이트를 직접 처리하고 계층적 Token 표현을 학습하는 자기 회귀 U-Net 모델을 제안하는 새로운 논문을 소개했습니다. 연구에 따르면 이 방법은 강력한 BPE(Byte Pair Encoding) 기준선과 일치하며, 더 깊은 계층 구조는 유망한 확장 추세를 보여줍니다. 이는 언어 모델링 분야, 특히 기본 데이터 표현 처리 및 다단계 특징 학습 측면에서 새로운 아이디어를 제공합니다 (출처: jpt401)

LambdaConf 2025, Oren Rozen의 C++에서의 함수형 프로그래밍 강연 공유: LambdaConf 2025는 Oren Rozen이 컨퍼런스에서 발표한 “C++에서의 함수형 프로그래밍 (런타임 타입 vs 컴파일 타임 타입)” 강연 영상을 공유했습니다. 이 강연은 다중 패러다임 언어인 C++에서 함수형 프로그래밍 사상과 기술을 적용하는 방법을 탐구하며, 특히 함수형 프로그래밍 실습에서 런타임 타입과 컴파일 타임 타입의 다양한 역할과 영향에 초점을 맞춥니다 (출처: lambda_conf)

Zach Mueller, 분산 훈련 기술 교육 과정 ‘From Scratch -> Scale’ 출시: Zach Mueller는 5주 과정인 ‘From Scratch -> Scale’의 수강생 모집을 시작한다고 발표했습니다. 이 과정은 분산 데이터 병렬(DDP), ZeRO, 파이프라인 병렬 및 텐서 병렬 코드를 처음부터 작성하는 방법을 교육하고 이러한 기술을 결합하는 방법을 다룹니다. 또한 Hugging Face, Meta, Snowflake 등 기업의 숙련된 전문가들이 초청되어 공유할 예정입니다 (출처: eliebakouch, HamelHusain)

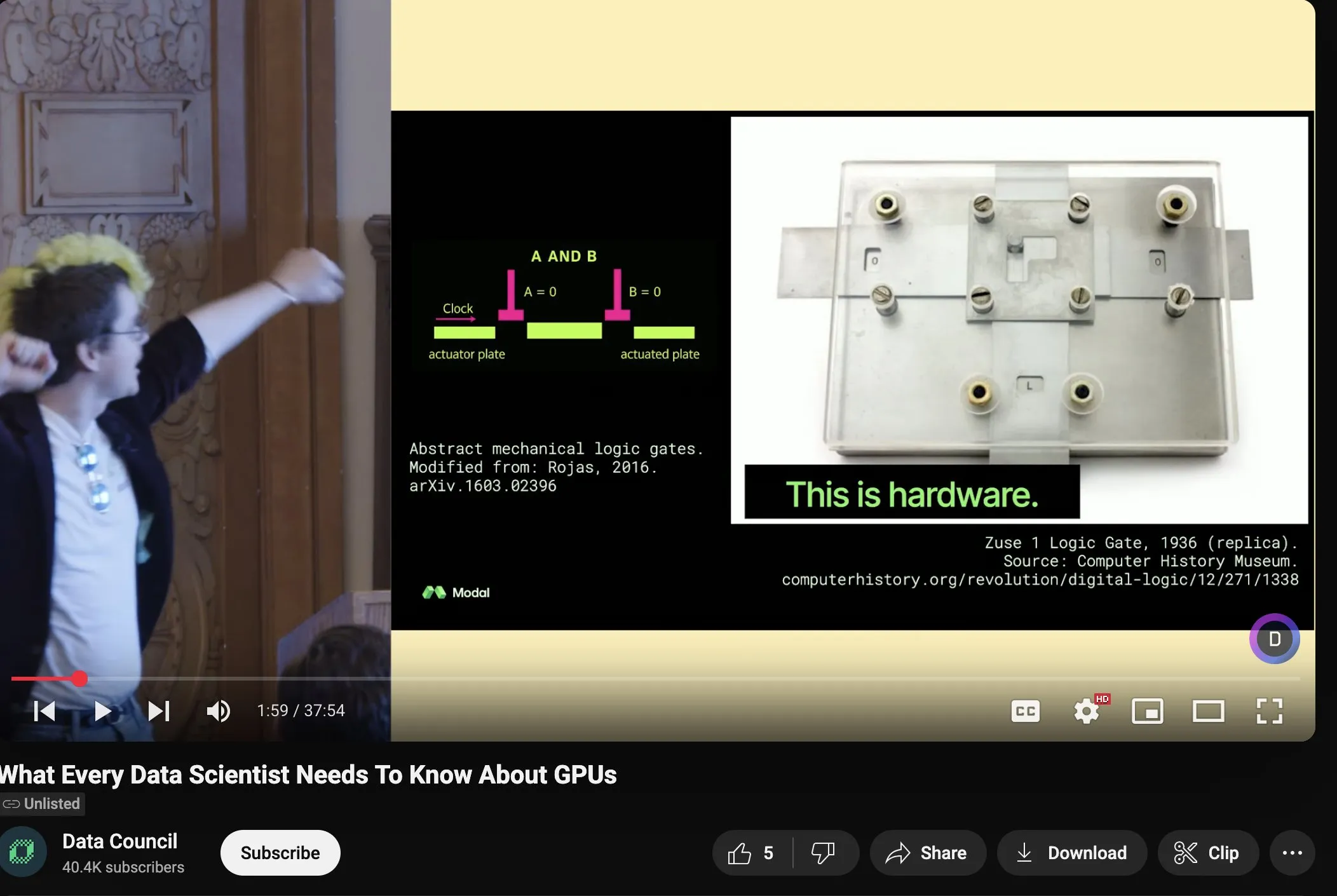
Charles Frye, GPU 확장과 수학 대역폭 강연 공유, 저정밀도 행렬 곱셈의 중요성 강조: Charles Frye는 자신의 강연 영상을 공유하며 다음과 같은 핵심 관점을 제시했습니다: GPU 확장은 대역폭 확장과 유사하며 지연 시간과 이차 관계에 있습니다. GPU 확장의 핵심 대역폭은 수학 대역폭(FLOP/s)입니다. 다양한 수학 대역폭 중에서 저정밀도 행렬 곱셈의 확장 속도가 가장 빠릅니다. 그는 또한 이것이 데이터 엔지니어링 및 데이터 과학 분야에 미치는 몇 가지 시사점에 대해 논의했습니다 (출처: charles_irl)
💼 비즈니스
Sam Altman, Meta가 OpenAI 인력 유치를 위해 1억 달러 계약 보너스 제안 시도했다고 폭로: OpenAI CEO Sam Altman은 한 팟캐스트 프로그램에서 Meta가 OpenAI 직원들을 유치하기 위해 최대 1억 달러의 계약 보너스와 더 높은 연봉을 제안하려 했다고 밝혔습니다. Altman은 Meta의 적극적인 인재 영입 시도에도 불구하고 OpenAI의 최고 인재들은 이러한 제안을 받아들이지 않았다고 말했습니다. 그는 또한 Meta가 OpenAI를 가장 큰 경쟁자로 간주하고 있으며, 현재 Meta의 AI 분야 노력이 기대에 미치지 못하지만 새로운 것을 적극적으로 시도하는 정신은 존중한다고 언급했습니다. Altman은 Meta가 고액 연봉으로 인재를 유치하는 방식이 회사 문화를 해칠 수 있다고 생각합니다 (출처: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 财联社AI daily, Reddit r/ChatGPT)
머스크의 xAI, 매월 10억 달러 소진하며 AGI 연구개발 지원 위한 신규 자금 조달 모색: 보도에 따르면, 일론 머스크의 AI 스타트업 xAI가 GPU 구매 및 데이터 센터 구축 등 인프라에 주로 자금을 투입하며 매월 10억 달러라는 놀라운 속도로 자금을 소진하고 있습니다. 운영을 유지하고 OpenAI, Google 등 거대 기업과 경쟁하기 위해 xAI는 43억 달러 규모의 신규 지분 투자를 유치 중이며, 내년에 추가로 64억 달러를 조달할 계획입니다. 동시에 50억 달러 규모의 부채 금융도 추진하고 있습니다. 올해 예상 매출은 5억 달러에 불과하지만, xAI는 머스크의 영향력, X 플랫폼의 데이터 우위, 자체 인프라 구축 의지를 바탕으로 투자자들에게 2027년 흑자 전환 청사진을 제시하고 있습니다. xAI의 기업 가치는 2024년 말 510억 달러에서 올해 1분기 말 800억 달러로 증가했습니다. 머스크의 최종 목표는 인간과 필적하거나 능가하는 범용 인공지능(AGI)을 만드는 것입니다 (출처: 新智元)

Nabla, 임상의를 위한 AI 어시스턴트 구축, 7천만 달러 규모 시리즈 C 투자 유치: AI 의료 회사 Nabla는 HV Capital, Highland Europe, DST Global이 주도하고 기존 투자자인 Cathay Innovation과 Tony Fadell이 계속 참여한 7천만 달러 규모의 시리즈 C 투자를 유치했다고 발표했습니다. Nabla는 임상의를 위한 첨단 지능형 AI 어시스턴트 구축에 전념하고 있으며, AI 기술을 통해 의료 서비스의 핵심인 인간적 배려를 회복하고 실제 임상 및 재정적 영향을 가져오는 것을 목표로 합니다. 이번 투자는 그 사명을 가속화할 것입니다 (출처: ylecun)

🌟 커뮤니티
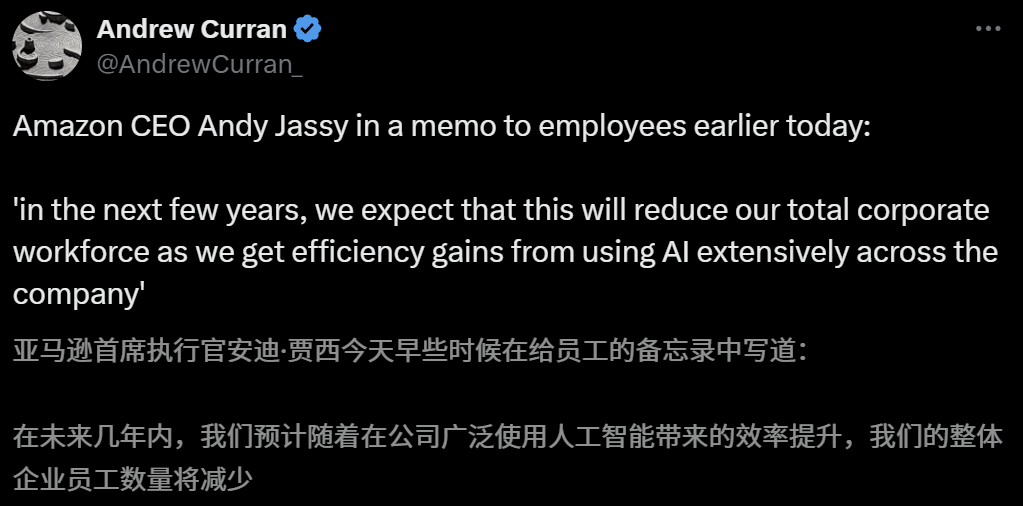
AI의 고용 시장 영향 우려, 아마존 CEO 향후 몇 년간 AI로 인한 직원 감축 경고: 아마존 CEO Andy Jassy는 직원들에게 보낸 전체 서신에서 회사가 더 많은 생성형 AI와 에이전트를 도입함에 따라 업무 방식이 바뀔 것이며, 향후 몇 년 안에 일부 현재 직무에 필요한 인력이 줄어들고 새로운 유형의 직무 수요가 증가하여 회사 기능 부서의 직원 총수가 그에 따라 감소할 것으로 예상된다고 밝혔습니다. 앞서 Anthropic CEO Dario Amodei도 AI가 5년 안에 초급 사무직의 절반을 대체할 수 있다고 경고한 바 있습니다. 이러한 견해는 AI가 고용 시장에 미치는 충격에 대한 광범위한 논의를 불러일으켰으며, 이미 기술 업계 직원들은 AI에 의해 대체되거나 구직난에 직면한 경험을 공유했고, 2025년 졸업생들도 코로나19 이후 가장 어려운 취업 시장에 직면해 있습니다 (출처: 新智元, 新智元)
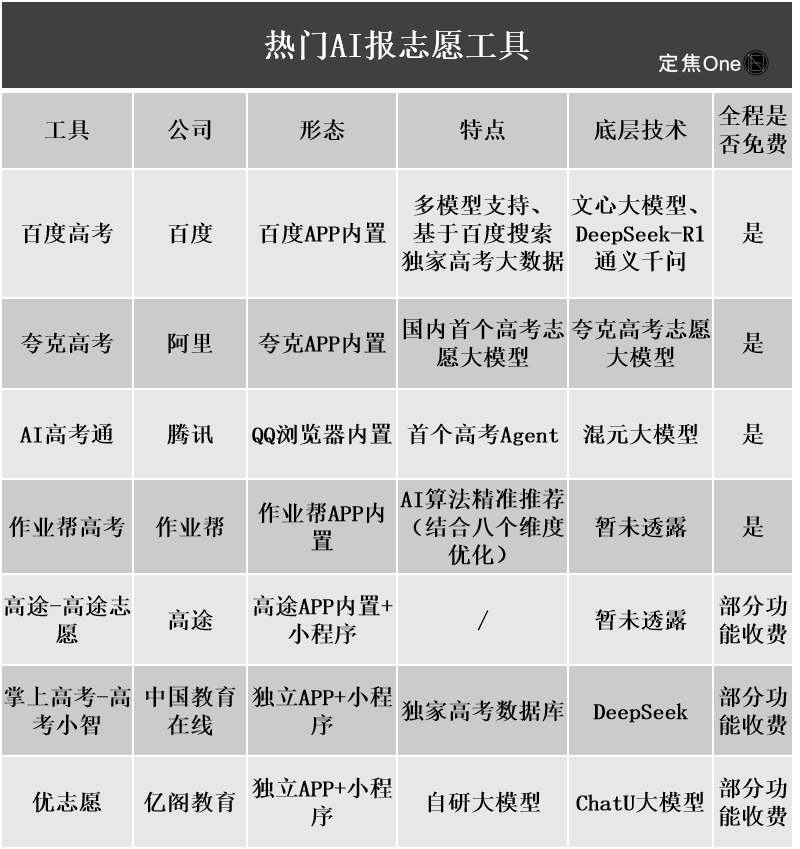
AI 대학 입시 지원 도구 주목받지만, 불투명한 알고리즘, 데이터 신뢰성 및 개인화가 사용자 불만 사항으로 지적돼: 대학 입시 지원 시장이 뜨거워지면서 알리바바夸克, 바이두, 텐센트 QQ 브라우저 등 대기업들이 AI 입시 지원 도구를 잇달아 출시하며 스마트, 효율, 무료를 내세우고 있습니다. 그러나 사용자들은 사용 과정에서 동일 점수에 대해 도구마다 추천 대학이 크게 다르고, 알고리즘이 불투명하며, 데이터의 포괄성과 신뢰성에 의문이 제기되고, 개인화 수준이 부족한 등의 문제로 인해 AI에 전적으로 의존하기를 꺼리고 있습니다. 전문가들은 데이터 출처, 알고리즘 가중치 차이가 추천 결과 차이의 주요 원인이며, AI 도구는 현재 점수 양극단에 있거나 목표가 명확한 수험생, 또는 중간 점수대 수험생의 보조 도구로 더 적합하며, 사용자는 효과적으로 질문하는 법을 배워야 한다고 지적합니다 (출처: 36氪)
교육 분야 AI 활용 보편화, 학부모 불안감과 시장 열풍 유발: AI 기술이 교육 분야에 빠르게 침투하면서 AI 자습실, AI 학습기부터 각종 AI 학습 보조 앱까지 끊임없이 등장하고 있으며, DeepSeek 등 대형 모델의 도입은 제품 업그레이드를 더욱 촉진하고 있습니다. 학부모들은 AI를 통해 자녀가 ‘추월 차선’을 타기를 기대하지만, 이로 인해 새로운 불안감에 빠지기도 합니다. 시장 조사에 따르면 AI+교육 시장 규모는 2025년에 700억 위안을 돌파할 것으로 예상됩니다. 그러나 AI 교육 제품의 실제 효과, 데이터 프라이버시, 그리고 학습 본질을 진정으로 향상시키는지 여부 등은 여전히 논의의 초점입니다. 교육의 의미는 기술 주도의 ‘군비 경쟁’에 국한되어서는 안 되며, 개인의 발전과 다양한 가능성에 더 주목해야 합니다 (출처: 36氪, 36氪)

논의: 대형 모델 추론에서 ‘턴 마커 토큰(Turn Marker Tokens)’의 필요성: 커뮤니티에서는 대화 모델의 ‘턴 마커 토큰’(예: 사용자와 어시스턴트 발언을 식별하는 특수 토큰)이 항상 완전히 동일한 몇 개의 토큰(예: user\n 및 assistant\n) 뒤에 온다면, 이러한 턴 마커 토큰 자체가 필요하지 않을 수 있다는 논의가 있습니다. 더 나아가, 만약 토큰 그룹(예: 세 개)이 공동으로 어떤 것을 표시하고 모델이 그중 첫 번째 토큰의 중요성을 학습해야 한다면, 반사실적(counterfactual) 컨텍스트 예시를 제공해야 하며, 그렇지 않으면 모델이 이러한 중요성을 정확하게 학습하지 못할 수 있다는 견해가 있습니다. 이 논의는 Claude Opus 4가 대화 주입(dialogue injection)에 쉽게 속는 현상과 관련이 있으며, 모델의 대화 구조 이해 및 처리에 여전히 개선의 여지가 있음을 시사합니다 (출처: giffmana, giffmana)
AI 에이전트의 직장 내 활용 의지와 능력 불일치 문제 주목: 스탠포드 대학 연구팀은 AI 에이전트가 직장 자동화 측면에서 상당한 수요와 능력 불일치가 존재함을 밝혔습니다. 연구에 따르면, YC 인큐베이팅 기업 업무의 약 41%가 근로자 자동화 의지가 낮거나 AI 기술이 아직 미성숙한 ‘저우선순위 구역’과 ‘위험 구역’에 집중되어 있습니다. 또한, 많은 업무가 인간과 기계의 동등한 협업을 필요로 하지만, 실무자들은 일반적으로 더 높은 인간 주도권을 기대하며 이는 마찰을 유발할 수 있습니다. 연구는 AI 에이전트가 노동 시장에 진입함에 따라 인간의 핵심 경쟁력이 대인 관계 및 조직 조정 기술로 전환될 수 있다고 예측합니다. 이 연구는 미래 AI 에이전트 연구 개발 및 노동력 기술 전환에 대한 지침을 제공하는 것을 목표로 합니다 (출처: 新智元)

광고 회사, 생성형 검색 엔진 최적화(GEO)를 이용해 AI 검색 결과에 영향, 윤리 및 규제 논의 촉발: 광고 회사들은 생성형 검색 엔진 최적화(GEO) 서비스를 통해 기업 고객들이 AI 검색 결과에서 더 높은 노출을 얻도록 돕고 있습니다. 이 서비스는 대형 모델의 선호도에 맞는 양질의 콘텐츠를 출력하고 AI 데이터 ‘피딩’을 통해 고객 정보가 AI 질의응답에서 순위와 등장 빈도를 높이는 방식으로 작동합니다. 그러나 사용자는 일반적으로 AI 검색 결과가 최적화되었는지 알지 못합니다. 이는 이러한 행위가 광고에 해당하는지, 명확한 표시가 필요한지, 어떤 상업적 규칙과 경계를 준수해야 하는지에 대한 논의를 불러일으키고 있습니다. 현재 국내 주요 대형 모델 플랫폼은 아직 공식적으로 광고를 연동하지 않았지만, 해외에서는 이미 AI 검색 제품이 광고 모델을 시도하고 표시를 시작했습니다 (출처: 36氪)
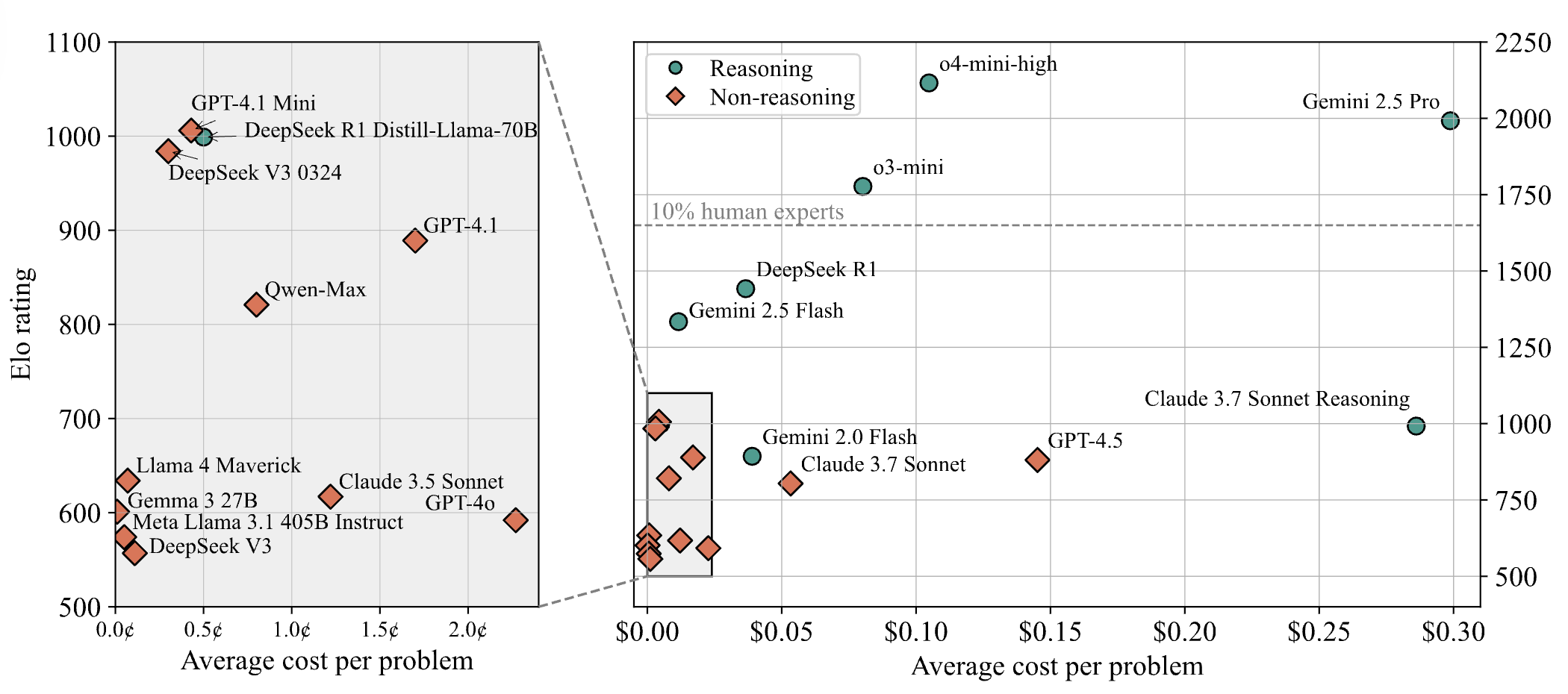
AI 모델, 프로그래밍 경진대회 난제에서 부진한 성적, LiveCodeBench Pro 테스트 결과 최상위 모델 점수 0%: Zihan Zheng 등은 IOI, Codeforces, ICPC 등 고난도 프로그래밍 경진대회 문제들을 포함하는 실시간 벤치마크 테스트 LiveCodeBench Pro를 출시했습니다. 이 벤치마크의 ‘어려움’ 부분에서 o3와 Gemini 2.5를 포함한 최첨단 대형 언어 모델들은 모두 0%의 점수를 받았습니다. 분석에 따르면, LLM은 기억에 의존하는 구현형 작업에는 능숙하지만, 핵심적인 ‘영감’이 필요한 관찰형 또는 논리형 문제, 그리고 세부 사항에 주의를 기울이고 경계 조건을 처리해야 하는 작업에서는 부진한 것으로 나타났습니다. Saining Xie는 이것이 소프트웨어 엔지니어링 에이전트의 벤치마크가 아니라, 코딩을 통해 핵심 추론과 지능을 테스트하는 것이며, 이 벤치마크를 이기는 것은 AlphaGo가 이세돌을 이긴 것과 같은 의미라고 평했습니다 (출처: ylecun, dilipkay)
AI 보조 문헌 검토 도구 otto-SR, 효율성과 정확성 대폭 향상: 토론토 대학교, 하버드 의과대학 등 기관이 공동으로 개발한 AI 엔드투엔드 워크플로우 otto-SR은 시스템적 문헌고찰(SRs) 자동화에 사용됩니다. 이 도구는 GPT-4.1과 o3-mini를 결합하여 문헌 스크리닝 및 데이터 추출을 수행하며, 기존 방식으로는 12년이 걸리는 Cochrane 시스템적 문헌고찰 업데이트를 단 이틀 만에 완료했습니다. 벤치마크 테스트에서 otto-SR의 민감도(96.7% vs 인간 81.7%)와 데이터 추출 정확도(93.1% vs 인간 79.7%) 모두 인간 검토자보다 현저히 우수했으며, 인간이 놓친 54편의 주요 연구를 발견했습니다. 이 연구는 AI가 의학 연구를 가속화하고 증거 종합의 질을 향상시키는 데 있어 엄청난 잠재력을 보여줍니다 (출처: 量子位)

‘Vibe Coding’에서 구조화된 DSL 활용 탐색: Ted Nyman 등 개발자들은 자유 형식의 자연어 대신 더 구조화된 DSL(도메인 특화 언어)과 유사한 언어를 사용하여 ‘Vibe Coding’(감성적이고 직관적인 프로그래밍 방식)을 실험하고 있으며, 이 방법이 효과가 더 좋고, 속도가 더 빠르며, 좌절감이 덜하고, 생성된 코드의 품질도 더 높다는 것을 발견했습니다. 이러한 탐색은 AI 보조 프로그래밍 또는 코드 생성을 위한 더 효율적이고 정확한 인간-기계 상호 작용 패러다임을 찾는 것을 목표로 합니다 (출처: tnm, lateinteraction)
AI 에이전트의 소프트웨어 신뢰성 공학(SRE) 분야 응용 전망: Traversal AI는 기업용 AI SRE(사이트 신뢰성 엔지니어) 구축을 목표로 4,800만 달러 규모의 시드 및 시리즈 A 투자를 유치했다고 발표했습니다. 이 AI 에이전트는 복잡한 운영 장애를 자율적으로 해결하고, 심지어 예방할 수 있으며, AI 에이전트 기술과 인과 관계 머신러닝을 결합하여 실시간으로 근본 원인을 파악합니다. DigitalOcean, Eventbrite 등의 기업이 초기 고객이 되어, AI가 자동화된 운영 및 시스템 신뢰성 향상에 있어 큰 잠재력을 가지고 있음을 보여주었습니다 (출처: hwchase17)
💡 기타
AI 생성 지브리 스타일 ‘모바일 게임’ 주목, 튜토리얼 통해 可灵AI와 Midjourney로 제작 확인: 최근 지브리 화풍의 ‘모바일 게임’ 스크린샷과 영상이 소셜 미디어에서 화제가 되며, 정교한 화면, 산뜻한 색감, 자연스러운 빛과 그림자 효과로 주목받았습니다. 제작자는 제작 방법을 공개했습니다: 먼저 Midjourney를 사용하여 정적 이미지를 생성한 다음, 콰이쇼우 산하의 可灵AI(Kling AI)를 이용하여 이미지를 동영상으로 변환했습니다. 버튼이나 미니맵과 같은 고정된 HUD(헤드업 디스플레이) 요소를 추가하여 상호작용 가능한 게임 느낌을 연출했습니다. 현재는 영상 시연에 불과하지만, 이미 AI가 생성하는 상호작용 가능한 가상 세계에 대한 네티즌들의 상상력을 자극했습니다 (출처: 量子位, Kling_ai)

오류 검사 분야 AI의 막대한 응용 잠재력: 네티즌 random_walker는 생성형 AI가 오류 검사 분야에서 막대한 응용 잠재력을 가지고 있으며, 각 분야에 ‘낮게 매달린 과일’이 있다고 주장했습니다. 예를 들어, 소프트웨어 분야에서는 보안 취약점을 자동으로 탐지할 수 있고, 글쓰기에서는 논리적 결함과 약한 주장을 식별할 수 있으며, 과학 연구에서는 계산 오류와 인용 문제를 탐지할 수 있습니다. 법률 계약에서는 누락된 조항과 모순점을 표시할 수 있고, 금융 분야에서는 사기 탐지 및 재무 보고서 오류 식별에 사용될 수 있습니다. 그는 오류 검사 자동화 수준이 높고 방해가 적으며, 오탐률이 50%라 하더라도 인공 검토가 비교적 쉽고, 인간을 지루한 작업에서 해방시킬 수 있다고 생각합니다. 그러나 AI에 대한 과도한 의존이 인간 자체 능력 저하로 이어질 위험도 경계해야 합니다 (출처: random_walker)
Sam Altman 인터뷰: AI는 업무를 단순화하고, 개인화된 소셜 경험을 제공하며, 과학적 발견을 촉진할 것: OpenAI 창립자 Sam Altman은 인터뷰에서 향후 5~10년 안에 AI 프로그래밍 및 채팅 도구가 더욱 스마트해져 대부분의 업무를 자동으로 완료할 수 있을 것이라고 예측했습니다. AI는 새로운 소셜 경험을 가져오고, 개인화된 서비스를 제공하며, 특히 천체물리학이나 고에너지 물리학과 같은 데이터 집약적 분야에서 새로운 과학 지식을 발견하는 데 도움을 줄 수 있습니다. 그는 AI의 진정한 변화는 생각할 수 있을 뿐만 아니라 물리적 세계에서 행동할 수 있다는 점에 있으며, 인간형 로봇이 핵심 과제라고 강조했습니다. OpenAI의 비전은 AI를 어디에나 있는 ‘AI 동반자’로 만들고, 플랫폼화와 하드웨어 협력을 통해 이를 실현하는 것입니다. 그는 문화와 장기주의가 OpenAI의 핵심 경쟁력이라고 생각합니다 (출처: 36氪)