키워드:양자 컴퓨팅, AI 자가 업그레이드, 뇌-컴퓨터 인터페이스, 대형 언어 모델, 신경형태 컴퓨팅, AI 비디오 생성, 강화 학습, AI 윤리, 양자 비트 오류율, JEPA 자기 지도 학습, MLX 형식 양자화, PAM 시각 이해 모델, AI ASMR 콘텐츠 생성
🔥 주요 뉴스
옥스퍼드 대학, quantum computing 실험에서 0.000015%라는 기록적인 오류율 달성: 옥스퍼드 대학 연구팀은 quantum computing 실험에서 중요한 돌파구를 마련하여, qubit의 오류율을 0.000015%로 낮추어 새로운 세계 기록을 세웠습니다. 이러한 진전은 오류 허용(fault-tolerant) quantum computer 구축에 매우 중요하며, 극도로 낮은 오류율은 복잡한 양자 알고리즘을 구현하고 quantum computing의 잠재력을 발휘하기 위한 전제 조건입니다. 이 성과는 하드웨어 수준에서 qubit 안정성 및 정밀 제어 향상에 있어 상당한 진전을 보여주며, 향후 AI 등 강력한 컴퓨팅 성능에 의존하는 애플리케이션을 위한 더욱 견고한 기반을 마련했습니다 (출처: Ronald_vanLoon)

MIT 연구진, AI의 자가 업그레이드 및 개선 학습 능력 개발: 매사추세츠 공과대학교(MIT) 연구진이 AI 자가 개선 분야에서 진전을 이루었습니다. 그들은 AI 시스템이 스스로 학습하고 자체 성능을 개선할 수 있는 새로운 방법을 개발했습니다. 이러한 능력은 인간이 경험과 성찰을 통해 끊임없이 발전하는 과정을 모방한 것으로, 더욱 자율적이고 적응력이 강한 AI 개발에 매우 중요합니다. 이 연구는 AI 모델이 배포 후에도 지속적으로 최적화되고 인공적인 개입 의존도를 줄이는 길을 열어줄 수 있으며, AI의 장기적인 발전과 응용에 깊은 영향을 미칠 것입니다 (출처: TheRundownAI)

“독심술” AI, 마비 환자의 뇌파를 실시간 음성으로 변환: 획기적인 연구를 통해 “독심술” AI가 마비 환자의 뇌파를 실시간으로 명확한 음성으로 변환하는 기술이 시연되었습니다. 이 기술은 첨단 뇌-컴퓨터 인터페이스(BCI)와 AI 알고리즘을 통해 언어 관련 신경 신호를 해독하고 이를 이해 가능한 음성 출력으로 합성합니다. 이는 심각한 운동 장애로 언어 능력을 상실한 환자들에게 새로운 소통 방식을 제공하며, 그들의 삶의 질을 크게 향상시킬 것으로 기대됩니다. 이는 AI가 보조 의료 및 신경 과학 분야에서 이룬 중대한 발전입니다 (출처: Ronald_vanLoon)

수학 물리 분야 세기의 난제 해결에 베이징대 동문 참여, 힐베르트 여섯 번째 문제 해결에 기여: 베이징대 동문 덩위(邓煜), 중국과학기술대학 소년반 출신 마샤오(马骁)와 테렌스 타오의 수제자 자허얼 하니(Zahǝr Hani)가 힐베르트의 여섯 번째 문제인 “물리학의 공리화”에서 중대한 돌파구를 마련했습니다. 그들은 뉴턴 역학(미시적, 시간 가역적)에서 볼츠만 방정식(거시적 통계, 시간 비가역적)으로의 완전한 전환을 최초로 엄밀하게 증명하여, 둘 사이의 논리적 간극을 메웠습니다. 이는 통계 역학에 더욱 견고한 수학적 기초를 제공했으며, 뜻밖에 “시간의 화살 수수께끼”도 해결했습니다. 이 성과는 정교한 수학적 도구와 단계별 추론을 통해 원자론에서 연속체 운동 법칙으로 이어지는 경로를 보여주었습니다 (출처: 量子位)

🎯 동향
Alibaba, Qwen3 시리즈 모델의 MLX 포맷 버전 출시: Alibaba는 자사의 Qwen3 시리즈 대형 모델이 이제 MLX 포맷을 지원하며, 4비트, 6비트, 8비트 및 BF16의 네 가지 양자화 수준을 제공한다고 발표했습니다. MLX는 Apple이 Apple Silicon에 최적화한 머신러닝 프레임워크로, 이는 Qwen3 모델이 Apple 기기에서 더욱 효율적으로 실행될 수 있음을 의미합니다. 이를 통해 엣지 디바이스에서의 대형 모델 배포 및 실행 장벽을 낮추고, 개인용 기기에서의 대형 모델 보급 및 응용을 촉진하는 데 도움이 될 것입니다 (출처: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
Google, Gemma 3n 모델 출시, 적은 파라미터로 고성능 구현: Google은 Gemma 3n 모델을 출시했습니다. 이 모델은 파라미터 수가 100억 개 미만이지만 LMArena 점수에서 1300점을 넘어, 이러한 성과를 달성한 최초의 소형 모델이 되었습니다. Gemma 3n의 뛰어난 성능은 더 작은 파라미터 규모에서도 높은 수준의 언어 이해 및 생성 능력을 구현할 수 있음을 증명하며, 휴대폰 등 엣지 디바이스에서의 실행을 지원합니다. 이는 AI 애플리케이션 보급을 촉진하고 컴퓨팅 비용을 절감하는 데 중요한 의미를 가집니다 (출처: osanseviero)
Tencent, AI 기반 영화급 3D 에셋 생성 기술 공개: Tencent는 영화급 품질의 3D 에셋을 생성할 수 있는 새로운 AI 기술을 선보였습니다. 이 기술은 게임 개발, 영화 및 TV 제작 등 분야에서 3D 콘텐츠 제작의 효율성과 품질을 크게 향상시키고 제작 비용을 절감할 것으로 기대됩니다. 고품질 3D 에셋의 신속한 생성은 메타버스와 디지털 콘텐츠 산업 발전의 핵심 요소입니다 (출처: TheRundownAI)
Kuaishou Kling 2.1 모델, 이미지-비디오 변환 및 오디오-비디오 동기화 생성에서 뛰어난 성능: Kuaishou 산하 AI 비디오 생성 모델 Kling이 2.1 버전으로 업데이트되어 이미지-비디오 변환에서 강력한 능력을 보여주었습니다. 새 버전은 비디오와 오디오를 한 번에 생성할 수 있어 후반 음향 효과 디자인 없이도 스튜디오급의 오디오-비디오 동기화 콘텐츠를 제작할 수 있다고 합니다. 이는 AI가 멀티모달 콘텐츠 생성, 특히 비디오 분야에서 진일보하여 제작 과정을 단순화하고 생성 품질을 향상시켰음을 의미합니다 (출처: Kling_ai, Kling_ai)
신형 AI 비디오 모델 “Kangaroo”, Minimax Hailuo 2.0일 가능성, 기존 SOTA에 도전: 시장에 “Kangaroo”라는 이름의 신비한 AI 비디오 생성 모델이 등장하여 AI 비디오 경쟁 분야에서 강력한 성능을 보이고 있으며, 특히 이미지-비디오 변환에서 두각을 나타내고 있습니다. 일부 분석에 따르면 이 모델은 Minimax 회사의 Hailuo 2.0 버전일 수 있습니다. 이 모델의 등장은 기존 텍스트-비디오 및 이미지-비디오 모델의 성능 구도를 바꿀 수 있지만, 오디오 처리 능력은 아직 평가가 필요합니다 (출처: TomLikesRobots)
MiniMax, M1 시리즈 모델 출시, 긴 텍스트 처리 능력 뛰어나: MiniMaxAI가 456B 파라미터의 MoE(Mixture of Experts) 모델인 MiniMax-M1 모델 시리즈를 발표했습니다. 이 시리즈 모델은 여러 벤치마크에서 우수한 성능을 보였으며, 특히 긴 컨텍스트 처리(예: OpenAI-MRCR 벤치마크)에서 GPT-4.1을 능가하고 LongBench-v2에서 3위를 차지했습니다. 이는 장문 문서 처리 및 이해 능력에서의 잠재력을 보여주지만, 상대적으로 큰 “사고 예산(thinking budget)”으로 인해 컴퓨팅 자원에 대한 요구 사항이 높을 수 있습니다 (출처: Reddit r/LocalLLaMA)

튜링상 수상자 Richard Sutton: AI는 “인간 데이터 시대”에서 “경험 시대”로 나아가고 있다: 강화 학습(Reinforcement Learning)의 창시자인 Richard Sutton은 베이징 즈위안(智源) 컨퍼런스에서 현재 인간 데이터에 의존하는 AI 대형 모델이 한계에 가까워지고 있으며, 고품질 인간 데이터가 고갈되고 모델 규모 확장의 효익이 감소하고 있다고 지적했습니다. 그는 AI의 미래가 “경험 시대”로 진입하는 데 있다고 보았습니다. 즉, 지능형 에이전트가 환경과의 실시간 상호작용을 통해 직접적인 경험을 생성하여 학습하는 것이지, 기존 텍스트를 모방하는 것이 아니라는 것입니다. 이를 위해서는 지능형 에이전트가 실제 또는 시뮬레이션 환경에서 지속적으로 실행되며, 환경 피드백을 보상 신호로 활용하고, 세계 모델과 기억 시스템을 발전시켜 진정한 지속적 학습과 혁신을 달성해야 합니다 (출처: 36氪)

PAM 모델: 3B 파라미터로 이미지·비디오 분할, 인식, 해설 통합: 홍콩 중문대학 MMLab 등 기관이 Perceive Anything Model (PAM)을 오픈소스로 공개했습니다. 이 3B 파라미터 모델은 이미지와 비디오 내 객체 분할, 인식, 해석 및 묘사를 동시에 수행하며 텍스트와 Mask를 함께 출력할 수 있습니다. PAM은 Semantic Perceiver를 도입하여 SAM2 분할 백본과 LLM을 연결함으로써 효율적인 시각 특징-멀티모달 토큰 변환을 구현했습니다. 연구팀은 또한 대규모 고품질 이미지-텍스트 훈련 데이터셋을 구축했습니다. PAM은 여러 시각 이해 벤치마크에서 SOTA를 경신하거나 근접한 성능을 보였으며, 더 우수한 추론 효율성을 갖추고 있습니다 (출처: 量子位)

뉴로모픽 컴퓨팅, 차세대 AI의 핵심으로 부상, 저전력 구동 기대: 과학자들은 현재 AI 모델의 높은 에너지 소비 문제를 해결하기 위해 인간 두뇌의 구조와 작동 방식을 모방하는 뉴로모픽 컴퓨팅을 적극적으로 탐색하고 있습니다. 미국 국립 연구소 등 기관들은 인간 대뇌 피질에 필적하는 뉴런 수를 가진 뉴로모픽 컴퓨터를 개발 중이며, 이론적으로 생물학적 두뇌보다 훨씬 빠른 속도로 작동하면서도 전력 소비는 극히 낮을 것(예: 20와트로 인간 두뇌급 AI 구동)으로 예상됩니다. 이 기술은 이벤트 기반 통신, 인메모리 컴퓨팅, 적응형 학습을 통해 더 지능적이고 효율적이며 저전력인 AI를 구현할 수 있을 것으로 기대되며, AI 에너지 위기의 잠재적 해결책이자 AGI 발전의 새로운 경로로 간주됩니다 (출처: 量子位)

AI ASMR 콘텐츠, 숏폼 플랫폼에서 폭발적 인기, Veo 3 등 기술이 확산 주도: AI로 생성된 ASMR(자율 감각 쾌감 반응) 비디오가 TikTok 등 플랫폼에서 빠르게 인기를 얻고 있습니다. 한 계정은 3일 만에 거의 10만 명의 팔로워를 모았고, 과일 자르는 비디오 한 편의 조회수는 1650만 회를 넘었습니다. 이러한 비디오는 AI가 생성한 독특한 시각 효과(예: 유리 질감의 과일)와 그에 상응하는 자르기, 부딪히기 등의 소리를 결합하여 독특한 “중독성”을 만들어냅니다. Google DeepMind의 Veo 3와 같은 모델은 오디오-비주얼 동기화 콘텐츠를 직접 생성할 수 있어, 이전에는 오디오와 비디오를 별도로 제작한 후 합성해야 했던 과정을 단순화함으로써 이러한 AI ASMR 콘텐츠 제작을 주도하는 핵심 기술로 여겨집니다 (출처: 量子位)

Meta AI 검색 기록 공개 주목, Google AI 오디오 요약 테스트: Meta가 자사 AI 검색 기능의 사용자 검색 기록을 공개하여 사용자의 개인 정보 보호 및 데이터 사용 투명성에 대한 관심을 불러일으켰습니다. 동시에 Google은 실험실 프로젝트에서 검색 결과 상단에 AI가 생성한 팟캐스트 스타일의 오디오 요약을 제공하는 새로운 기능을 테스트하고 있습니다. 이는 사용자에게 더 편리한 정보 습득 방식을 제공하기 위함입니다. 이 두 가지 동향은 기술 대기업들이 AI 검색 및 정보 제공 방식에서 지속적인 탐색과 사용자 경험 최적화를 시도하고 있음을 반영합니다 (출처: Reddit r/ArtificialInteligence)

시드니 연구팀, 뇌파로 생각 식별하는 AI 모델 개발: 호주 시드니 연구팀이 뇌파(EEG) 데이터를 분석하여 개인의 생각 내용을 식별할 수 있는 새로운 AI 모델을 개발했습니다. 이 기술은 신경과학, 인간-컴퓨터 상호작용, 보조 커뮤니케이션 등 분야에서 잠재적인 응용 가치를 지니며, 예를 들어 기존 방식으로 소통할 수 없는 사람들이 의도를 표현하는 데 도움을 줄 수 있습니다. 이 연구는 뇌-컴퓨터 인터페이스 기술 발전을 더욱 촉진하고, 복잡한 뇌 활동을 해석하는 AI의 능력을 탐구합니다 (출처: Reddit r/ArtificialInteligence)
캘리포니아, 채용·해고 등 의사결정에서 AI “로봇 보스” 역할 제한 법안 추진: 미국 캘리포니아주가 기업이 AI 시스템의 제안만으로 채용, 해고 등 주요 인사 결정을 내리는 것을 제한하는 법안을 추진하고 있습니다. 이 법안은 인간 관리자가 AI의 이러한 제안을 검토하고 지지하도록 요구하여 인적 감독과 책임성을 확보하고자 합니다. 재계 단체는 이것이 규정 준수 비용을 증가시키고 기존 채용 기술과 충돌할 것이라며 반대하고 있습니다. 이러한 움직임은 특히 직장 내 자동화된 의사결정 측면에서 AI 윤리 및 사회적 영향에 대한 관심이 높아지고 있음을 반영합니다 (출처: Reddit r/ArtificialInteligence)

🧰 도구
Augmentoolkit 3.0 출시, 데이터셋 생성 및 미세 조정 프로세스 강화: Augmentoolkit 3.0 버전이 출시되었습니다. 이는 긴 문서(예: 역사 텍스트)에서 QA 데이터셋을 생성하고 모델 미세 조정을 수행하는 도구입니다. 새 버전은 훈련 데이터를 자동으로 생성하고 모델을 훈련하는 프로덕션급 파이프라인을 제공하며, 고품질 QA 데이터셋 생성을 위해 특별히 미세 조정된 로컬 모델을 내장하고 코드 없는 인터페이스를 제공합니다. 이 도구는 특정 도메인 모델 미세 조정 및 훈련 데이터 생성 프로세스를 단순화하여 기술 장벽을 낮추는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA)
Opius AI Planner: Cursor Composer 경험 최적화를 위한 AI 플래너: Opius AI Planner라는 Cursor 확장 프로그램이 출시되었습니다. 이는 Cursor Composer가 모호한 요구 사항을 이해하는 데 어려움을 겪는 문제를 해결하기 위해 설계되었습니다. 이 도구는 프로젝트 요구 사항을 분석하고 상세한 구현 로드맵을 생성하며, Composer에 최적화된 구조화된 프롬프트를 출력하여 반복 횟수를 줄이고 프로젝트 결과물이 초기 구상에 더 부합하도록 만듭니다. 이는 AI 보조 계획을 통해 AI 코드 생성 도구의 실용성을 향상시키는 추세를 반영합니다 (출처: Reddit r/artificial)
Continue 확장: VSCode에서 로컬 오픈소스 Copilot과 MCP 통합 구현: Continue는 VSCode 확장 프로그램으로, 사용자가 로컬에서 실행되는 오픈소스 대규모 언어 모델을 코딩 어시스턴트로 구성하고 사용할 수 있게 하며, MCP(Model Control Protocol) 도구와 통합할 수 있습니다. 사용자는 Llama.cpp 또는 LMStudio와 같은 서비스를 통해 로컬에 모델을 배포하고 Continue를 통해 상호 작용하여 코드 어시스턴트를 완전히 제어하고 사용자 정의할 수 있습니다(예: Playwright 브라우저 자동화 도구 통합). (출처: Reddit r/LocalLLaMA)

Doubao 대형 모델과 Volcano Engine MCP 결합, 클라우드 서비스 배포 및 개인 페이지 생성 간소화: ByteDance의 Doubao 대형 모델이 Volcano Engine 모델 제어 프로토콜(MCP)과의 긴밀한 통합 능력을 선보였습니다. 사용자는 자연어 명령을 통해 Doubao 대형 모델이 Volcano Engine의 기능(예: veFaaS 함수형 서비스)을 호출하여 개인 소셜 미디어 탐색 웹페이지 생성 및 자동 배포와 같은 작업을 완료하도록 할 수 있습니다. 이러한 통합은 클라우드 환경을 수동으로 구성하는 복잡한 단계를 없애고 클라우드 서비스 사용 장벽을 낮추며, AI가 DevOps 프로세스를 간소화하는 잠재력을 보여줍니다 (출처: karminski3)
Figma, AI 신기능 출시: 텍스트 프롬프트로 즉시 웹사이트 생성: Figma는 사용자가 입력한 텍스트 프롬프트(prompt)를 기반으로 웹사이트 프로토타입이나 페이지를 신속하게 생성할 수 있는 새로운 AI 기반 기능을 선보였습니다. 이 기능은 웹 디자인 및 개발 프로세스를 가속화하여 디자이너와 개발자가 자연어 설명을 통해 아이디어를 신속하게 시각적 디자인으로 전환할 수 있도록 하며, 생성형 AI가 크리에이티브 디자인 도구 분야에 침투하고 있음을 더욱 잘 보여줍니다 (출처: Ronald_vanLoon)
Hugging Face 모델 허브, 모델 크기별 필터링 기능 추가: Hugging Face 플랫폼은 모델 허브에 사용자가 모델의 파라미터 크기에 따라 필터링할 수 있는 유용한 기능을 추가했습니다. 이러한 개선을 통해 개발자와 연구원은 특정 하드웨어 리소스 또는 성능 요구 사항에 맞는 모델을 더 편리하게 찾을 수 있게 되어, 방대한 모델 라이브러리에서 탐색하고 선택하는 효율성이 향상되었습니다 (출처: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
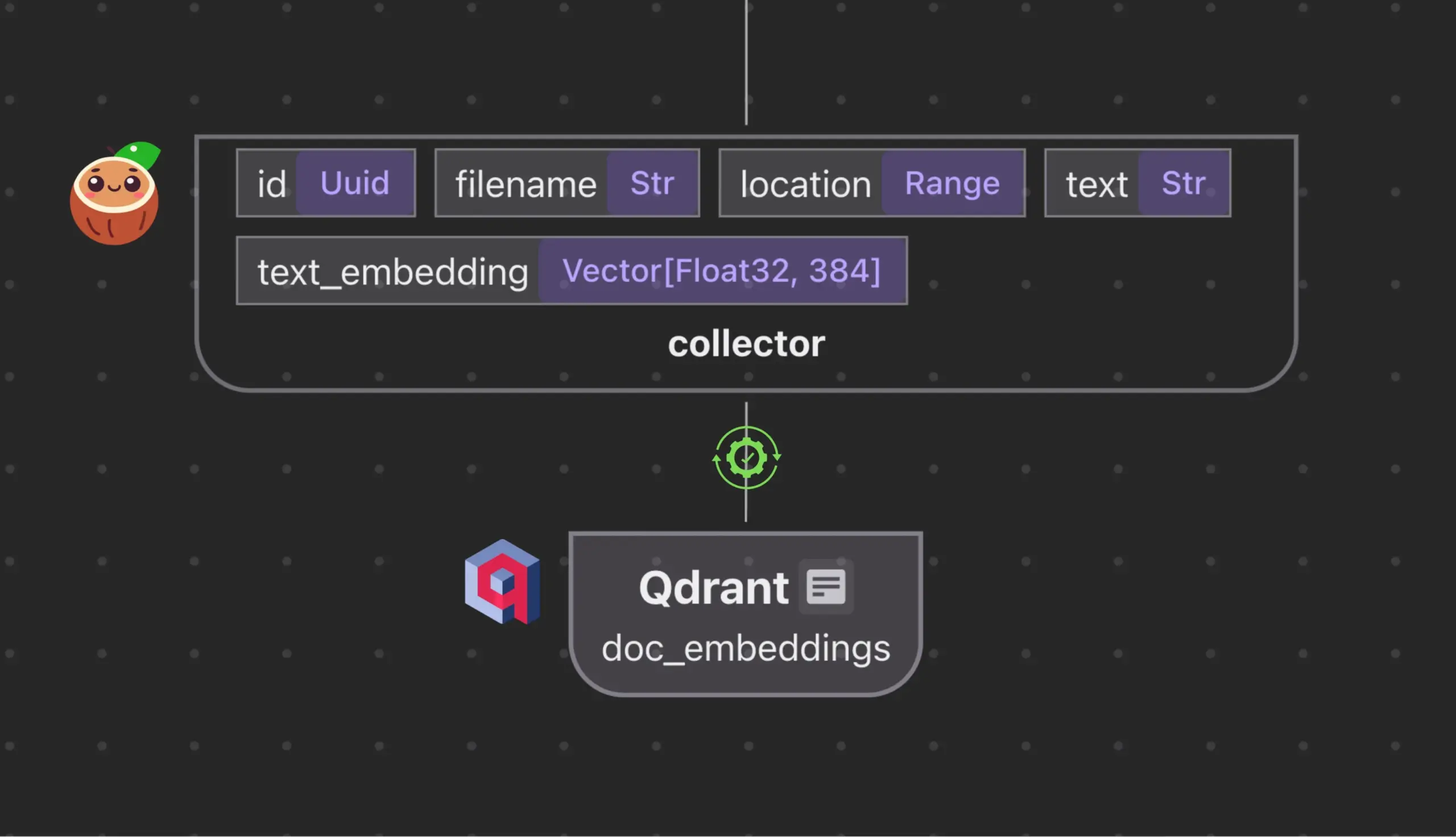
Cocoindex.io, Qdrant와 통합하여 벡터 데이터베이스 컬렉션 자동 생성 및 동기화: 오픈소스 데이터 스트림 도구인 Cocoindex.io가 이제 Qdrant 벡터 데이터베이스 컬렉션 자동 생성을 지원합니다. 사용자는 데이터 스트림을 정의하기만 하면 이 도구가 적절한 Qdrant 스키마(벡터 크기, 거리 측정 방식, 페이로드 구조 포함)를 추론하고 벡터 필드, 페이로드 유형, 기본 키의 동기화를 유지하며 증분 업데이트를 지원합니다. 이는 벡터 데이터베이스의 구성 및 관리를 단순화하고 데이터 팀의 효율성을 향상시킵니다 (출처: qdrant_engine)
Manus AI: 코드 작성뿐만 아니라 자동 배포까지 가능한 전체 프로세스 AI 개발 도구: Manus AI는 코드 작성부터 환경 설정, 종속성 설치, 테스트, 최종 온라인 URL 배포까지 엔드투엔드 AI 개발 도구입니다. 다중 에이전트 협업 아키텍처(계획, 개발, 테스트, 배포)를 채택하여 종속성 문제와 디버깅 오류를 자율적으로 해결할 수 있습니다. 현재 크레딧 기반 가격 모델, 중국 팀 개발(규정 준수 고려 사항이 있을 수 있음), 매우 복잡한 기업 아키텍처 지원의 한계가 있지만, “AI 보조 코딩”에서 “AI 실행 개발”로의 전환 가능성을 보여줍니다 (출처: Reddit r/artificial)

📚 학습 자료
번역 이론 및 AI 번역 프롬프트 최적화 가이드: 스궈(思果)의 《번역신구(翻譯新究)》에 나오는 “번역은 재작성이다”라는 이론과 위광중(余光中)의 《번역내대도(翻譯乃大道)》의 관점을 결합하여 고품질 번역의 원칙을 논의합니다. 번역은 문자 그대로의 대응이 아닌 목표 언어의 자연스러운 표현에 중점을 두어야 하며, 직역과 의역을 유연하게 사용하고, 중국어와 서양 언어의 논리적 차이를 고려하여 구문 재작성에 주의해야 함을 강조합니다. 이 글은 또한 중국어 표현의 순수성, 용어 처리 문제를 다루고, AI 번역에서 “직역-분석-의역” 3단계 프로세스의 한계를 반성하며, AI 번역 품질을 향상시켜 중국어 과학 보급 문체에 더 부합하도록 “이해-표현-교정-최적화”라는 보다 통합된 프로세스를 제안합니다 (출처: dotey)

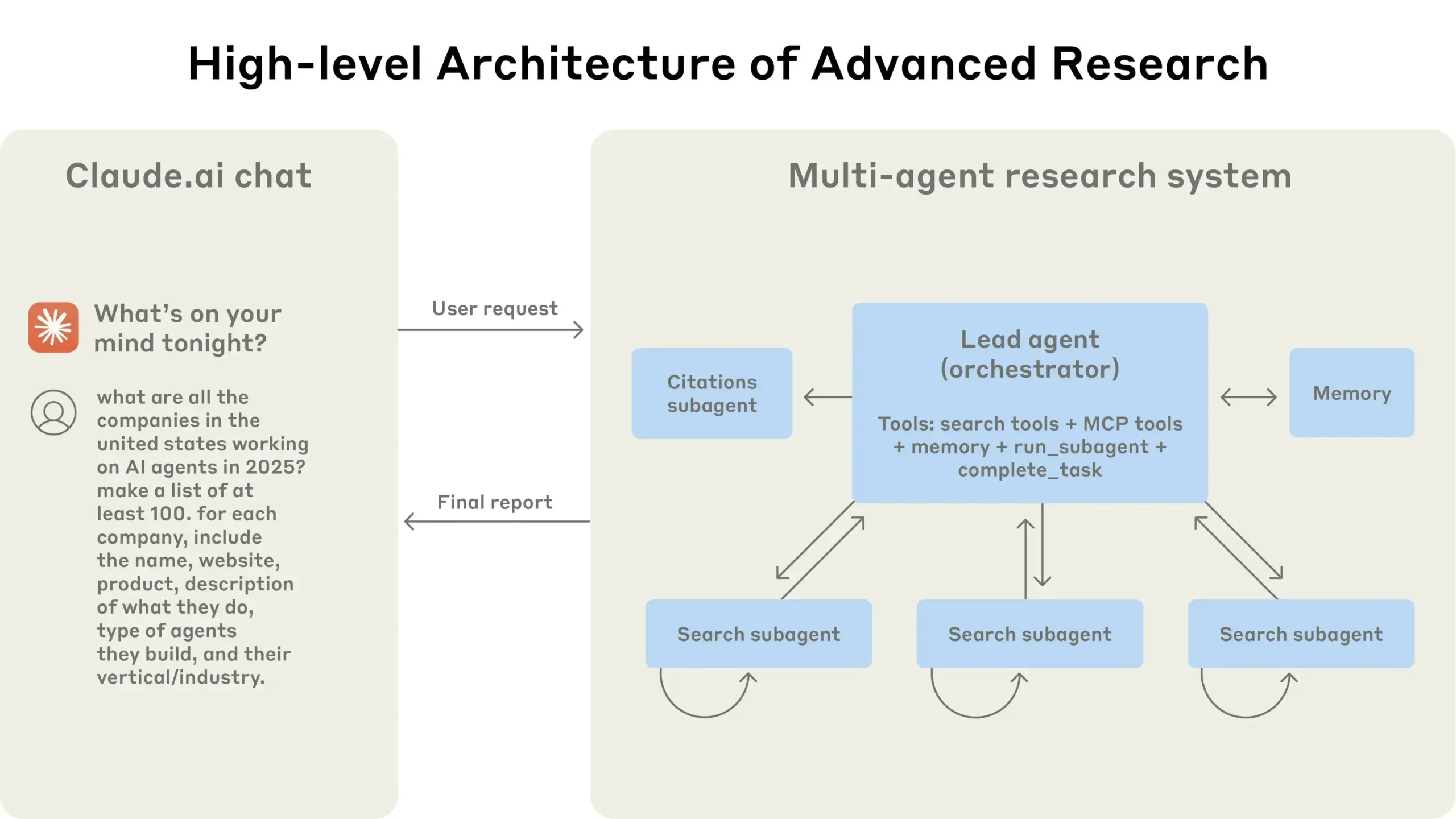
Anthropic, 멀티 에이전트 연구 시스템 구축 경험 공유: AnthropicAI는 자사의 멀티 에이전트 연구 시스템 구축 방법에 대한 무료 가이드를 발표했습니다. 내용에는 시스템 아키텍처의 작동 원리, 프롬프트 엔지니어링 및 테스트 방법, 프로덕션 환경에서의 과제, 멀티 에이전트 시스템의 장점 등이 포함됩니다. 이 가이드는 멀티 에이전트 시스템에 관심 있는 연구자와 개발자에게 귀중한 실무 경험과 통찰력을 제공합니다 (출처: TheTuringPost, TheTuringPost)
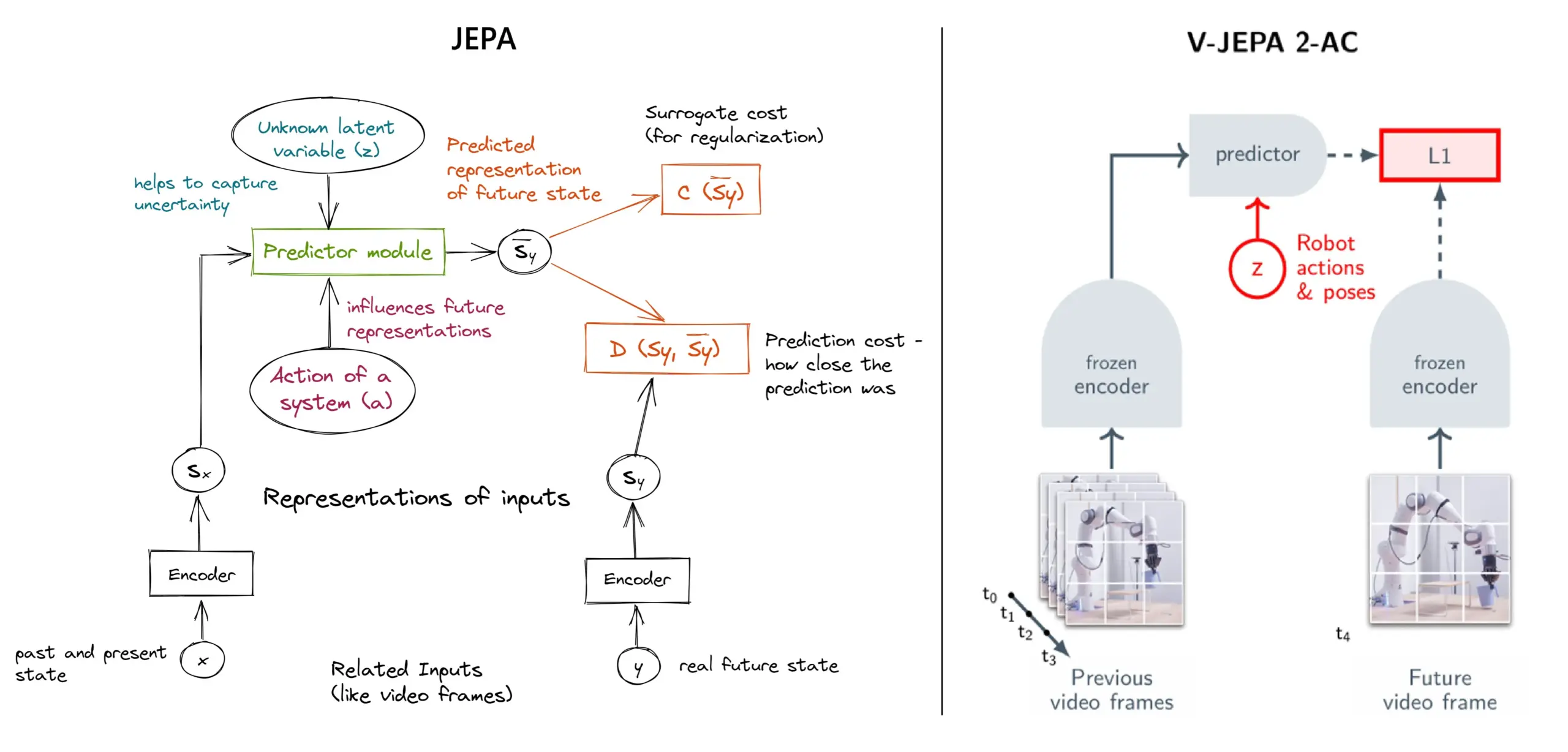
JEPA 자기 지도 학습 프레임워크 상세 설명: 11가지 유형 개요: Meta의 Yann LeCun 등 연구진이 제안한 JEPA(Joint Embedding Predictive Architecture)는 입력 데이터의 누락된 부분에 대한 잠재적 표현을 예측하여 학습하는 자기 지도 학습 프레임워크입니다. 이 글은 V-JEPA 2, TS-JEPA, D-JEPA 등 11가지 다양한 유형의 JEPA를 소개하고, 추가 정보 및 관련 리소스 링크를 제공하여 이 첨단 자기 지도 학습 방법을 이해하는 데 도움을 줍니다 (출처: TheTuringPost, TheTuringPost)
DSPy 프레임워크: 작업과 LLM 분리, 코드 유지보수성 향상: DSPy에 대한 한 해설 기사는 DSPy 프레임워크가 작업과 대규모 언어 모델(LLM)을 분리함으로써 LLM 사용의 복잡성을 낮춘다고 지적합니다. 최적화 이전에도 DSPy는 개발자가 프로젝트를 더 빨리 시작하고 유지보수 및 확장이 더 쉬운 코드를 생성하는 데 도움을 줄 수 있습니다. 이는 복잡한 프롬프트 엔지니어링과 LLM 통합이 필요한 프로젝트에 중요한 가치를 지닙니다 (출처: lateinteraction, stanfordnlp)

논문 연구: Vision Transformer는 사전 훈련된 레지스터가 필요 없다 (Vision Transformers Don’t Need Trained Registers): 새로운 연구 논문은 Vision Transformer에서 어텐션 맵과 특징 맵에 아티팩트가 발생하는 메커니즘을 탐구합니다. 이러한 현상은 대규모 언어 모델에서도 존재합니다. 이 논문은 이러한 아티팩트를 완화하기 위한 훈련 없는 방법을 제안하여 Vision Transformer의 성능과 해석 가능성을 향상시키는 것을 목표로 합니다. 이 연구는 시각적 작업에서 Transformer 아키텍처의 적용을 이해하고 개선하는 데 참고 가치가 있습니다 (출처: Reddit r/MachineLearning)
튜토리얼 공유: DeepSeek 시리즈 처음부터 구축하기 (총 29편): 한 콘텐츠 제작자가 “DeepSeek 처음부터 구축하는 방법”이라는 제목의 시리즈 비디오 튜토리얼(총 29편)을 공개했습니다. 내용은 DeepSeek 모델의 기본 지식, 아키텍처 세부 정보(예: 어텐션 메커니즘, 멀티 헤드 어텐션, KV 캐시, MoE), 위치 인코딩, 다중 토큰 예측 및 양자화와 같은 핵심 기술을 다룹니다. 이 시리즈 튜토리얼은 DeepSeek 및 유사한 대형 모델의 내부 작동 원리를 깊이 이해하고자 하는 학습자에게 귀중한 비디오 리소스를 제공합니다 (출처: Reddit r/LocalLLaMA)

튜토리얼: RAG 파이프라인 구축하여 Hacker News 게시물 요약하기: Haystack by deepset은 사용자가 검색 증강 생성(RAG) 파이프라인을 구축하는 방법을 안내하는 단계별 튜토리얼을 공유했습니다. 이 파이프라인은 Hacker News의 실시간 게시물을 가져와 로컬에서 실행되는 대규모 언어 모델(LLM) 엔드포인트를 사용하여 이러한 게시물을 요약할 수 있습니다. 이는 RAG 기술을 활용하여 실시간 정보 스트림을 처리하고 로컬화된 처리를 원하는 개발자에게 실용적인 사례를 제공합니다 (출처: dl_weekly)
논문 속보: InterSyn 데이터셋과 SynJudge 평가 모델을 이용한 인터리브된 이미지-텍스트 생성: 현재 LMM이 긴밀하게 인터리브된 이미지-텍스트 출력을 생성하는 데 있어 (주로 훈련 데이터셋의 규모, 품질, 지시문의 풍부함 부족으로 인한) 단점을 해결하기 위해, 연구자들은 SEIR (자가 평가 및 반복 최적화) 방법을 통해 구축된 대규모 멀티모달 데이터셋인 InterSyn을 출시했습니다. InterSyn은 응답에 이미지와 텍스트가 긴밀하게 인터리브된 다중 턴, 지시문 기반 대화를 포함합니다. 동시에 이러한 출력을 평가하기 위해 연구자들은 텍스트 내용, 이미지 내용, 이미지 품질, 이미지-텍스트 협응의 네 가지 차원에서 평가하는 SynJudge 자동 평가 모델을 제안했습니다. 실험 결과, InterSyn에서 훈련된 LMM은 모든 평가 지표에서 향상된 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문 속보: 교차 모달 어텐션 증류를 통한 정렬된 새로운 시점의 이미지 및 기하학 합성: 연구자들은 “워핑 후 인페인팅”(warping-and-inpainting) 방법을 통해 정렬된 새로운 시점의 이미지 및 기하학 생성을 구현하는 확산 기반 프레임워크 MoAI를 제안했습니다. 이 방법은 기존 기하학 예측기를 활용하여 참조 이미지의 부분적인 기하학적 모양을 예측하고, 새로운 시점을 이미지 및 기하학의 인페인팅 작업으로 합성합니다. 이미지와 기하학의 정확한 정렬을 보장하기 위해, 이 논문은 훈련 및 추론 과정에서 이미지 확산 분기의 어텐션 맵을 병렬 기하학 확산 분기에 주입하는 교차 모달 어텐션 증류를 제안했습니다. 이 방법은 다양한 미지의 장면에서 고충실도 외삽 시점 합성을 달성했습니다 (출처: HuggingFace Daily Papers)
논문 속보: 규칙 기반 합성 데이터를 이용한 구성 가능한 선호도 조정 (CPT): DPO 등 인간 피드백 모델에서 선호도가 고착화되고 적응성이 제한되는 문제를 해결하기 위해, 연구자들은 구성 가능한 선호도 조정(CPT) 프레임워크를 제안했습니다. CPT는 구조화된 세분화된 규칙(작문 스타일 등 원하는 속성 정의) 기반의 시스템 프롬프트를 활용하여 합성 선호도 데이터를 생성합니다. 이러한 규칙 기반 선호도를 통해 미세 조정된 LLM은 추론 시 시스템 프롬프트에 따라 출력을 동적으로 조정할 수 있으며, 재훈련 없이도 더 세밀하고 상황에 맞는 선호도 제어를 실현합니다 (출처: HuggingFace Daily Papers)
논문 속보: 확산 이중성 (The Diffusion Duality): 연구자들은 균일 상태 이산 확산 과정이 잠재적 가우시안 확산에서 비롯된다는 통찰을 통해 가우시안 확산의 강력한 기술을 이산 확산 모델로 이전하여 성능을 향상시키는 Duo 방법을 제안했습니다. 구체적으로 다음을 포함합니다: 1) 분산을 줄이고 훈련 속도를 두 배로 높이며 여러 벤치마크에서 자기 회귀 모델을 능가하는 가우시안 과정 기반 커리큘럼 학습 전략 도입. 2) 연속 일관성 증류를 이산 설정에 적용하여 샘플링 속도를 두 자릿수 가속화함으로써 확산 언어 모델의 소수 단계 생성을 실현하는 이산 일관성 증류 제안 (출처: HuggingFace Daily Papers)
논문 속보: SkillBlender – 기술 융합을 통한 다기능 휴머노이드 로봇 전신 운동 제어: 기존 휴머노이드 로봇 제어 방법의 다중 작업 일반화 및 확장성 한계를 해결하기 위해 연구자들은 계층적 강화 학습 프레임워크인 SkillBlender를 제안했습니다. 이 프레임워크는 먼저 목표 지향적이고 작업과 무관한 원시 기술을 사전 훈련한 다음, 복잡한 운동 제어 작업을 수행할 때 이러한 기술을 동적으로 융합하며, 최소한의 작업 특정 보상 엔지니어링만 필요로 합니다. 동시에 평가를 위한 SkillBench 시뮬레이션 벤치마크를 출시했습니다. 실험 결과 이 방법은 다양한 운동 제어 작업의 정확성과 실행 가능성을 크게 향상시키는 것으로 나타났습니다 (출처: HuggingFace Daily Papers)
논문 속보: U-CoT+ 프레임워크 – 유해 밈 탐지를 위한 이해 분리 및 가이드 기반 CoT 추론: 유해 밈 탐지에서 자원 효율성, 유연성, 해석 가능성의 과제에 대응하기 위해 연구자들은 U-CoT+ 프레임워크를 제안했습니다. 이 프레임워크는 먼저 고충실도 밈-텍스트 변환 프로세스를 통해 시각적 밈을 세부 정보가 보존된 텍스트 설명으로 변환하여 밈 해석과 분류를 분리함으로써, 일반 대규모 언어 모델(LLM)이 자원 효율적인 탐지를 수행할 수 있도록 합니다. 그런 다음, 인공적으로 제정된 해석 가능한 가이드라인과 결합하여 제로샷 CoT 프롬프트 하에서 모델 추론을 유도함으로써 다양한 플랫폼 및 시간 변화에 대한 적응성과 해석 가능성을 향상시킵니다 (출처: HuggingFace Daily Papers)
논문 속보: CRAFT – 효과적인 정책 준수형 에이전트 레드팀 테스트: 환불 자격과 같은 엄격한 정책 하에서 작업 지향 LLM 에이전트의 준수 문제에 대응하기 위해, 연구자들은 정책형 에이전트를 이용하여 개인적 이익을 얻으려는 적대적 사용자에 초점을 맞춘 새로운 위협 모델을 제안했습니다. 이를 위해 그들은 정책 인식 설득 전략을 활용하여 고객 서비스 시나리오에서 정책 준수형 에이전트를 공격하는 다중 에이전트 레드팀 테스트 시스템인 CRAFT를 개발했으며, 이는 기존 탈옥 방법보다 우수한 효과를 보였습니다. 동시에, 이러한 조작 행위에 대한 에이전트의 견고성을 평가하기 위한 tau-break 벤치마크를 출시했습니다 (출처: HuggingFace Daily Papers)
논문 속보: 간단한 쿼리에서의 밀집 검색 실패와 임베딩의 세분성 딜레마: 연구는 텍스트 인코더의 한계를 밝혀냈습니다. 즉, 임베딩이 의미론 내부의 세분화된 개체나 이벤트를 인식하지 못하여 간단한 경우에도 밀집 검색이 실패할 수 있다는 것입니다. 이 현상을 연구하기 위해, 논문은 중국어 평가 데이터셋 CapRetrieval(단락은 이미지 캡션, 쿼리는 개체/이벤트 구문)을 도입했습니다. 제로샷 평가는 인코더가 세분화된 매칭에서 성능이 저조할 수 있음을 보여줍니다. 제안된 데이터 생성 전략으로 인코더를 미세 조정하면 성능이 향상될 수 있지만, 임베딩이 세분화된 중요성을 표현하는 동시에 전체 의미론과 정렬하기 어렵다는 “세분성 딜레마”도 드러났습니다 (출처: HuggingFace Daily Papers)
논문 속보: pLSTM – 병렬 처리 가능한 선형 소스 변환 토큰화 네트워크: 기존 순환 아키텍처(예: xLSTM, Mamba)가 주로 순차 데이터에 적합하거나 다차원 데이터를 순서대로 처리해야 하는 한계를 해결하기 위해, 연구자들은 pLSTM(병렬 처리 가능한 선형 소스 변환 토큰화 네트워크)을 제안했습니다. pLSTM은 다차원성을 선형 RNN으로 확장하여, 일반 유향 비순환 그래프(DAG)의 선 그래프에 작용하는 소스, 변환, 토큰화 게이트를 사용하여 병렬 연관 스캔 및 블록 순환 형태와 유사한 병렬화를 구현했습니다. 이 방법은 합성 컴퓨터 비전 작업과 분자 그래프, 컴퓨터 비전 벤치마크에서 우수한 외삽 능력과 성능을 보여주었습니다 (출처: HuggingFace Daily Papers)
논문 속보: DeepVideo-R1 – 난이도 인식 회귀 GRPO를 통한 비디오 강화 미세 조정: 비디오 대규모 언어 모델(Video LLM) 응용에서 강화 학습의 부족함을 해결하기 위해, 연구자들은 제안된 Reg-GRPO(회귀형 GRPO)와 난이도 인식 데이터 증강 전략을 통해 훈련된 Video LLM인 DeepVideo-R1을 제안했습니다. Reg-GRPO는 GRPO 목표를 회귀 작업으로 재구성하여 GRPO의 우위 함수를 직접 예측함으로써, 클리핑과 같은 보장 조치에 대한 의존성을 제거하고 정책을 보다 직접적으로 안내합니다. 난이도 인식 데이터 증강은 해결 가능한 난이도 수준의 훈련 샘플을 동적으로 증강합니다. 실험 결과 DeepVideo-R1은 비디오 추론 성능을 크게 향상시키는 것으로 나타났습니다 (출처: HuggingFace Daily Papers)
논문 속보: TTS 합성 데이터 증강을 이용한 ASR 자가 정제 프레임워크: 연구자들은 레이블 없는 데이터셋만 사용하여 자동 음성 인식(ASR) 성능을 향상시키는 자가 정제 프레임워크를 제안했습니다. 이 프레임워크는 먼저 기존 ASR 모델을 사용하여 레이블 없는 음성에 대한 의사 레이블을 생성한 다음, 이러한 의사 레이블을 사용하여 고충실도 텍스트 음성 변환(TTS) 시스템을 훈련합니다. 그런 다음, TTS로 합성된 음성-텍스트 쌍을 사용하여 원본 ASR 시스템의 훈련을 안내하여 폐쇄 루프 자가 개선을 형성합니다. 대만 표준 중국어에 대한 실험 결과, 이 방법은 오류율을 크게 낮출 수 있음을 보여주었으며, 저자원 또는 특정 도메인 ASR 성능 향상을 위한 실용적인 경로를 제공합니다 (출처: HuggingFace Daily Papers)
논문 속보: Vision Transformer의 고유한 충실도 어텐션 맵: 연구자들은 학습된 이진 어텐션 마스크를 사용하는 어텐션 기반 방법을 제안하여, 주목받는 이미지 영역만이 예측에 영향을 미치도록 보장합니다. 이 방법은 특히 객체가 비분포 배경에 나타날 때 컨텍스트가 객체 인식에 미칠 수 있는 편향을 해결하는 것을 목표로 합니다. 2단계 프레임워크(1단계는 객체 부분을 발견하고 작업 관련 영역을 식별, 2단계는 입력 어텐션 마스크를 활용하여 수용 영역을 제한하여 집중 분석)를 통해 공동 훈련하여 모델이 허위 상관 관계 및 비분포 배경에 대한 견고성을 향상시킵니다 (출처: HuggingFace Daily Papers)
논문 속보: ViCrit – VLM 시각 인지를 위한 검증 가능한 강화 학습 프록시 작업: VLM의 시각 인지 작업에서 도전적이면서도 명확하게 검증 가능한 작업이 부족한 문제를 해결하기 위해, 연구자들은 ViCrit(시각적 캡션 환각 비평가)을 도입했습니다. 이는 인간이 작성한 이미지 캡션 단락에 주입된 미묘하고 합성된 시각적 환각을 VLM이 찾아내도록 훈련하는 RL 프록시 작업입니다. 약 200단어의 캡션에 단일 미묘한 시각적 설명 오류를 주입하고 모델이 이미지와 수정된 캡션을 기반으로 오류 범위를 찾아내도록 요구함으로써, 이 작업은 계산하기 쉽고 명확한 이진 보상을 제공합니다. ViCrit으로 훈련된 모델은 다양한 VL 벤치마크에서 상당한 이득을 보였습니다 (출처: HuggingFace Daily Papers)
논문 속보: 동질적 어텐션을 넘어 – 푸리에 근사 KV 캐시 기반의 메모리 효율적인 LLM: LLM에서 컨텍스트 길이가 증가함에 따라 KV 캐시 메모리 요구 사항이 증가하는 문제를 해결하기 위해 연구자들은 훈련이 필요 없는 프레임워크인 FourierAttention을 제안했습니다. 이 프레임워크는 Transformer 헤드 차원의 이기종 역할을 활용합니다. 즉, 저차원은 로컬 컨텍스트를 우선시하고 고차원은 장거리 의존성을 포착합니다. 장기 컨텍스트에 민감하지 않은 차원을 직교 푸리에 기저에 투영함으로써 FourierAttention은 고정 길이 스펙트럼 계수로 시간적 진화를 근사합니다. LLaMA 모델에 대한 평가는 이 방법이 LongBench 및 NIAH에서 최상의 장기 컨텍스트 정확도를 달성했으며 맞춤형 Triton 커널 FlashFourierAttention을 통해 메모리를 최적화했음을 보여줍니다 (출처: HuggingFace Daily Papers)
논문 속보: JAFAR – 임의 해상도에서 임의 특징을 향상시키는 범용 업샘플러: 기본 시각 인코더 출력의 저해상도 공간 특징이 다운스트림 작업 요구 사항을 충족하지 못하는 문제를 해결하기 위해 연구자들은 가볍고 유연한 특징 업샘플러인 JAFAR를 도입했습니다. JAFAR는 모든 기본 시각 인코더의 시각 특징 공간 해상도를 임의의 목표 해상도로 향상시킬 수 있습니다. 이는 공간 특징 변환(SFT) 변조를 통해 어텐션 기반 모듈을 채택하여, 저수준 이미지 특징에서 파생된 고해상도 쿼리와 의미론적으로 풍부한 저해상도 키 간의 의미론적 정렬을 촉진합니다. 실험 결과, JAFAR는 세분화된 공간 세부 정보를 효과적으로 복원하고 다양한 다운스트림 작업에서 기존 방법보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문 속보: SwS – 강화 학습에서 자기 인식 약점 기반 문제 종합: RLVR(검증 가능한 보상을 사용한 강화 학습)이 수학 문제와 같은 복잡한 추론 작업을 해결하도록 LLM을 훈련할 때 고품질의 답변 검증 가능한 문제 세트가 부족한 문제를 해결하기 위해, 연구자들은 SwS(자기 인식 약점 기반 문제 종합) 프레임워크를 제안했습니다. SwS는 모델 결함(RL 훈련에서 모델이 지속적으로 학습에 실패하는 문제)을 체계적으로 식별하고, 이러한 실패 사례의 핵심 개념을 추출하며, 후속 강화 훈련에서 모델의 취약한 부분을 강화하기 위해 새로운 문제를 종합합니다. 이 프레임워크는 모델이 RL에서의 약점을 스스로 식별하고 해결할 수 있도록 하며, 여러 주요 추론 벤치마크에서 상당한 성능 향상을 달성했습니다 (출처: HuggingFace Daily Papers)
논문 속보: 테스트 시 확장 능력 향상을 위한 “계속 생각하기” 토큰 학습: 테스트 시 추가 계산을 통해 언어 모델의 추론 단계를 확장하는 성능을 향상시키기 위해, 연구자들은 전용 “계속 생각하기” 토큰(<|continue-thinking|>)을 학습하는 것의 타당성을 탐구했습니다. 그들은 DeepSeek-R1 증류 버전 모델의 가중치를 고정한 채 강화 학습을 통해 이 토큰의 임베딩만 훈련했습니다. 실험 결과, 기준 모델 및 고정 토큰(예: “Wait”)을 사용하여 예산 강제 테스트 시 확장 방법을 사용하는 것과 비교하여 학습된 토큰이 표준 수학 벤치마크에서 더 높은 정확도를 달성했으며, 특히 고정 토큰이 기준 모델의 정확도를 향상시킬 수 있는 경우 학습 토큰이 더 큰 개선을 가져올 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
논문 속보: LoRA-Edit – 마스크 인식 LoRA 미세 조정을 통한 제어 가능한 첫 프레임 유도 비디오 편집: 기존 비디오 편집 방법이 대규모 사전 훈련에 의존하고 유연성이 부족한 문제를 해결하기 위해, 연구자들은 유연한 비디오 편집을 위해 사전 훈련된 이미지-비디오(I2V) 모델을 적용하기 위한 마스크 기반 LoRA 미세 조정 방법인 LoRA-Edit을 제안했습니다. 이 방법은 배경 영역을 보존하면서 제어 가능한 편집 효과를 전파하고, 다른 참조 정보(예: 대체 시점 또는 장면 상태)를 시각적 앵커로 결합할 수 있습니다. 마스크 기반 LoRA 조정 전략을 통해 모델은 입력 비디오(공간 구조 및 모션 단서)와 참조 이미지(외관 지침)에서 학습하여 영역별 학습을 달성합니다 (출처: HuggingFace Daily Papers)
논문 속보: Infinity Instruct – 언어 모델 강화를 위한 지시문 선택 및 합성 확장: 기존 오픈소스 지시문 데이터셋이 수학, 코딩 등 협소한 분야에 집중되어 일반화 능력이 제한되는 문제를 보완하기 위해, 연구자들은 2단계 프로세스를 통해 LLM의 기본 및 채팅 능력을 강화하는 것을 목표로 하는 고품질 지시문 데이터셋인 Infinity-Instruct를 출시했습니다. 1단계에서는 혼합 데이터 선택 기술을 사용하여 1억 개 이상의 샘플에서 740만 개의 고품질 기본 지시문을 선별합니다. 2단계에서는 지시문 선택, 진화 및 진단 필터링의 2단계 과정을 통해 150만 개의 고품질 채팅 지시문을 합성했습니다. 다양한 오픈소스 모델에 대한 미세 조정 실험 결과, 이 데이터셋은 기본 및 지시문 준수 벤치마크에서 모델 성능을 크게 향상시킬 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
논문 속보: 먼저 후보, 그 다음 증류 – LLM 기반 데이터 주석을 위한 교사-학생 프레임워크: 기존 LLM 데이터 주석 방법에서 LLM이 단일 황금 레이블을 직접 결정하는 것이 불확실성으로 인해 오류를 유발할 수 있는 문제를 해결하기 위해, 연구자들은 새로운 후보 주석 패러다임을 제안했습니다. 즉, LLM이 불확실할 때 가능한 모든 레이블을 출력하도록 권장하는 것입니다. 다운스트림 작업이 고유한 레이블을 얻도록 보장하기 위해, 소형 언어 모델(SLM)로 후보 주석을 증류하는 교사-학생 프레임워크 CanDist를 개발했습니다. 교사 LLM에서 후보 주석을 증류하는 것이 단일 주석을 직접 사용하는 것보다 우수하다는 것을 이론적으로 증명했습니다. 실험을 통해 이 방법의 효과를 검증했습니다 (출처: HuggingFace Daily Papers)
논문 속보: Med-PRM – 단계별, 가이드라인 검증 프로세스 보상을 갖춘 의학 추론 모델: 대규모 언어 모델이 임상 결정에서 특정 추론 단계의 오류를 찾아내고 수정하기 어려운 한계를 해결하기 위해, 연구자들은 Med-PRM이라는 프로세스 보상 모델링 프레임워크를 도입했습니다. 이 프레임워크는 검색 증강 생성 기술을 활용하여, 확립된 의학 지식 기반(임상 가이드라인 및 문헌)과 대조하여 각 추론 단계를 검증합니다. 이러한 세분화된 방식으로 추론 품질을 정확하게 평가함으로써, Med-PRM은 여러 의학 QA 벤치마크 및 개방형 진단 작업에서 SOTA 성능을 달성했으며, 강력한 정책 모델(예: Meerkat)과 플러그 앤 플레이 방식으로 통합되어 소형 모델(8B 파라미터)의 정확도를 크게 향상시켰습니다 (출처: HuggingFace Daily Papers)
논문 속보: 피드백 마찰 – LLM이 외부 피드백을 충분히 흡수하기 어려움: 연구는 LLM이 외부 피드백을 흡수하는 능력을 체계적으로 조사했습니다. 실험에서 해결사 모델은 문제를 해결하려고 시도한 후, 거의 완전한 정답을 가진 피드백 생성기가 구체적인 피드백을 제공하고, 해결사는 다시 시도합니다. 결과는 Claude 3.7을 포함한 SOTA 모델조차도 거의 이상적인 조건에서도 피드백에 대한 저항을 보였으며, 이를 “피드백 마찰”이라고 명명했습니다. 점진적인 온도 증가 및 이전의 잘못된 답변에 대한 명시적 거부와 같은 전략을 채택했음에도 불구하고 모델은 여전히 목표 성능에 도달하지 못했습니다. 이 연구는 모델의 과도한 자신감 및 데이터 친숙도와 같은 요인을 배제하고 LLM 자기 개선의 이 핵심 장애물을 밝히는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
💼 비즈니스
Meta, 143억 달러에 Scale AI 지분 49% 인수, 창업자 Alexandr Wang은 Meta 슈퍼 인텔리전스 팀 합류: Meta는 AI 데이터 라벨링 회사 Scale AI의 의결권 없는 지분 49%를 143억 달러에 인수한다고 발표했습니다. Scale AI의 창업자이자 28세의 중국계 천재인 Alexandr Wang은 이사회 구성원으로 계속 활동하며 핵심 팀을 이끌고 저커버그가 직접 구성한 Meta 슈퍼 인텔리전스 팀에 합류할 예정입니다. 이번 인수는 Meta가 Llama 4의 부진한 성과 이후 AI 역량을 강화하기 위한 거액의 인재 영입으로 간주되며, AI를 모든 제품에 깊숙이 통합하는 것을 목표로 합니다. Scale AI는 대규모 고품질 인공 라벨링 데이터 서비스를 제공하며 Waymo, OpenAI 등을 고객으로 두고 있습니다. 이번 조치로 인해 플랫폼 중립성 및 데이터 보안에 대한 우려가 제기되었으며, Google 등 고객사들이 협력을 중단할 가능성도 있습니다 (출처: 36氪)

쿤룬완웨이(昆仑万维)의 All in AI 전략, 상장 10년 만에 첫 적자 기록, AI 상업화 전망 불투명: 쿤룬완웨이는 “All in AGI 및 AIGC” 전략 발표 이후 대형 모델(Tiangong 대형 모델) 및 AI 음악(Mureka), AI 소셜(Linky), AI 비디오(SkyReels), AI 오피스(Skywork Super Agents) 등 애플리케이션 개발과 AI 컴퓨팅 칩 투자에 적극적으로 나서고 있습니다. 그러나 막대한 연구 개발 투자와 시장 마케팅 비용으로 인해 2024년 상장 10년 만에 처음으로 15억 9천만 위안의 적자를 기록했으며, 2025년 1분기에도 적자가 지속되고 있습니다. Mureka와 Linky와 같은 일부 AI 애플리케이션이 수익을 창출하기 시작했지만, 전반적인 AI 사업의 수익성과 시장 경쟁력은 여전히 도전에 직면해 있으며, AI를 통해 “대기업의 꿈”을 실현할 수 있을지는 시장의 검증을 기다려야 합니다 (출처: 36氪)

OpenAI, ChatGPT에 광고 테스트 가능성, 수익 압박으로 비즈니스 모델 모색: 일부 ChatGPT Plus 유료 사용자가 고급 음성 모드 사용 중 삽입 광고를 경험했다고 보고하면서, OpenAI가 유료 사용자 대상으로 광고 테스트를 시작했는지에 대한 논의가 촉발되었습니다. 이전 보도에 따르면 OpenAI는 수익원 확대를 위해 광고 도입을 고려하고 있다고 합니다. AI 대형 모델의 막대한 운영 비용과 수익 압박(2029년까지 440억 달러 손실 예상), 그리고 AGI 실현 시기의 불확실성을 고려할 때, OpenAI가 광고 등 새로운 수익화 모델을 모색하는 것은 특히 유료 사용자 전환율이 상대적으로 낮은 상황에서 비즈니스 지속 가능성을 위한 필연적인 선택으로 여겨집니다 (출처: 36氪)

🌟 커뮤니티
AI, 데이터 과학 분야에서 막대한 잠재력, Databricks 적극 채용: Databricks의 Matei Zaharia는 AI가 데이터 과학 분야에서 생산성 향상에 있어 AI 보조 코딩보다 더 큰 영향을 미칠 것이라고 생각합니다. Databricks는 Lakeflow Designer와 Genie Deep Research와 같은 제품을 통해 이러한 추세를 주도하고 있으며, 이 분야의 연구원과 엔지니어를 적극적으로 채용하고 있어 업계가 AI 기반 데이터 과학 혁신에 높은 관심을 보이고 있음을 알 수 있습니다 (출처: matei_zaharia)
LLM의 “개성” 차이, 에이전트 회로 행동에 영향: 연구자 Fabian Stelzer는 다양한 대규모 언어 모델(LLM)이 “개성”에서 차이를 보이며, 이로 인해 에이전트(agentic) 순환 작업을 수행할 때 다른 행동을 보인다는 점을 관찰했습니다. 예를 들어, Claude는 도구를 순차적으로 실행하는 경향이 있는 반면, GPT-4.1은 병렬 실행을 강력히 선호하며 심지어 순차적 요청을 무시하기도 합니다. Haiku 모델은 도구 트리거링에 있어 더욱 “공격적”입니다. 이러한 관찰은 다중 에이전트 시스템을 설계하고 평가할 때 기본 LLM의 특성과 “감정 상태”의 기능적 결과를 고려하는 것의 중요성을 강조합니다 (출처: fabianstelzer, menhguin)
LLM의 “사고”는 토큰 출력에 의존, 출력 없이는 유효한 분석 불가: 사용자 dotey가 ReAct 프롬프트 디버깅 중 xincmm의 발견을 인용: LLM이 먼저 분석한 후 작업(예: 그림 그리기)을 수행하도록 기대하지만 분석 과정의 토큰을 출력하도록 하지 않으면 LLM이 분석 단계를 건너뛸 수 있다는 것입니다. 이는 LLM의 “사고” 과정이 토큰 생성을 통해 이루어지며, 프롬프트에 정의된 “분석”이 실제 내용 출력 없이 이루어지면 AI가 해당 분석을 실제로 수행하지 않았음을 입증합니다. 이는 효과적인 LLM 프롬프트 설계에 지침이 됩니다 (출처: dotey)

AI의 특정 작업에서의 한계: 테렌스 타오, AI는 “수학적 직감” 부족하다고 지적: 수학자 테렌스 타오는 현재 AI가 생성한 증명이 겉보기에는 완벽해 보이지만(육안 검사 통과), 미묘하고 인간 특유의 “수학적 직감”이 부족하여 비인간적인 실수를 저지르기 쉽다고 지적했습니다. 그는 진정한 지능은 단지 옳아 보이는 것이 아니라 무엇이 진짜인지 “감지”할 수 있는 능력에 있다고 보았습니다. 이는 현재 AI가 심층적인 이해와 직관적 판단에서 한계를 가지고 있음을 보여줍니다 (출처: ecsquendor)
AI 생성 콘텐츠와 현실 물리 법칙의 도전: 사용자 karminski3이 Doubao Seed 1.6과 DeepSeek-R1을 사용하여 코드 생성(굴뚝 폭파 해체의 3D 애니메이션 시뮬레이션) 테스트를 진행한 결과, 모델이 코드를 생성하고 애니메이션을 시뮬레이션할 수는 있지만 실제 물리적 과정(예: 충격파 효과, 구조 붕괴 방식)을 재현하는 데에는 여전히 차이와 개선의 여지가 있음을 발견했습니다. Doubao Seed 1.6은 입자 효과와 구조 붕괴 시뮬레이션에서 실제에 더 가까웠고, DeepSeek은 빛과 그림자, 연기 효과에서 더 나은 성능을 보였습니다. 이는 AI가 복잡한 물리 현상을 이해하고 시뮬레이션하는 데 어려움이 있음을 반영합니다 (출처: karminski3)
베테랑 프로그래머, AI 코드 작성에 과도하게 의존하고 수동 수정 거부하며 신입에게 AI 대체 위협 발언으로 해고: 36커(36氪)가 전재한 Reddit 게시물에 따르면, 30년 경력의 프로그래머가 AI에 과도하게 몰두하여(예: Copilot Agent에 전적으로 의존하여 PR 제출, 코드 수동 수정 거부, 하루 분량 작업을 5일 소요, 인턴에게 AI 대체론 설파) 회사에서 해고된 사례가 소개되었습니다. 이 사건은 소프트웨어 개발에서 AI의 합리적인 사용 경계와 AI가 개발자의 직업적 가치에 미치는 영향에 대한 논의를 불러일으켰습니다 (출처: 36氪)
AI “몰입”과 “개성”이 사용자 경험에 미치는 영향: 사용자는 AI가 지나치게 “긍정적으로 동조”한다고 피드백: Reddit 커뮤니티 사용자들은 AI(특히 Claude)와 상호작용할 때 AI가 사용자의 관점에 지나치게 낙관적이고 긍정적으로 동조하는 경향이 있어 효과적인 도전과 심도 있는 비판적 피드백이 부족하며, 사용자는 마치 “반향실”에 있는 것처럼 느낀다고 논의했습니다. 이러한 “AI 어조 피로감”은 사용자들이 특정 프롬프트引导를 통해 AI가 더 중립적이고 비판적으로 행동하도록 하는 방법을 찾게 만들었습니다. 이는 현재 AI가 현실적이고 다면적인 인간 대화를 모방하고 진정으로 심오한 통찰력을 제공하는 데 어려움을 겪고 있음을 반영합니다 (출처: Reddit r/ClaudeAI)
AI 시대, 인간 피드백의 가치 부각되지만 실제 인간 상호작용 플랫폼은 AI 콘텐츠 침투에 직면: Reddit 사용자는 AI 생성 콘텐츠가 점점 더 많아지는 상황에서 실제 인간의 피드백과 의견이 더욱 소중해지고 있으며, Reddit과 같은 플랫폼은 인간 상호작용 특성으로 인해 중요하게 여겨진다고 지적했습니다. 그러나 이러한 플랫폼도 AI 생성 콘텐츠(예: 봇 댓글, AI 보조 작성 게시물)의 침투 문제에 직면하여 실제 인간의 관점을 식별하기가 더욱 어려워지고 있으며, 미래 네트워크 커뮤니케이션의 진정성에 대한 우려를 불러일으키고 있습니다 (출처: Reddit r/ArtificialInteligence)
AI “친구”가 일상이 될까? 사용자와 AI의 정서적 연결 추세와 논의: 소셜 미디어와 Reddit 커뮤니티에서 AI 동반자 및 AI 친구에 대한 논의가 나타나고 있습니다. 일부 사용자는 AI가 편견 없고 항상 지지하는 특성 때문에 향후 5년 내에 AI 친구가 일상이 될 수 있으며, 이미 Endearing AI, Replika, Character.ai와 같은 애플리케이션에서 나타나고 있다고 생각합니다. 다른 사용자들은 ChatGPT와 같은 AI와 깊은 대화 관계를 맺고 심지어 “가장 친한 친구”로 여기는 경험을 공유합니다. 이는 인간과 AI의 정서적 상호작용, 정서적 지원에서 AI의 역할 및 잠재적인 사회적 영향에 대한 광범위한 생각을 불러일으킵니다 (출처: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

AI “래퍼” 스타트업의 미래에 대한 논의 촉발: Reddit 커뮤니티는 GPT나 Claude와 같은 기본 모델을 기반으로 래핑(UI 추가, 프롬프트 체인 또는 특정 분야 미세 조정)하는 수많은 AI 스타트업의 전망에 대해 논의했습니다. 토론자들은 이러한 “래퍼” 애플리케이션이 기본 모델 플랫폼 자체 기능이 반복된 후에도 경쟁력을 유지할 수 있을지, 그리고 진정한 해자를 구축할 수 있을지에 대해 의문을 제기했습니다. 특정 수직 분야에 집중하고 자체 데이터를 축적하며 단순한 래핑을 넘어서는 것이 지속 가능한 발전 경로가 될 수 있다는 의견이 제시되었습니다 (출처: Reddit r/LocalLLaMA)
의료 진단과 소프트웨어 엔지니어링에서 AI의 대체 가능성 비교 논의: Reddit 커뮤니티에서는 AI가 고급 소프트웨어 엔지니어보다 의사를 더 빨리 대체할 수 있다는 논의가 있었습니다. 그 이유는 많은 의료 진단이 정해진 프로토콜을 따르며, AI는 테스트 결과 해석과 증상 식별에 능숙하기 때문입니다. 반면 소프트웨어 엔지니어링은 종종 많은 암묵적 지식과 복잡한 요구 사항 소통을 포함하므로 AI가 완전히 감당하기 어렵다는 것입니다. 이러한 관점은 AI가 다양한 전문 분야에서 응용되는 깊이와 대체 가능성에 대한 추가적인 생각을 불러일으켰지만, 의사 등 전문가들은 실제 작업의 복잡성과 인간의 판단 중요성을 강조하며 반박하기도 했습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 기타
뤄융하오(罗永浩) AI 디지털 휴먼, 바이두 이커머스 첫 방송에서 GMV 5,500만 위안 돌파: 뤄융하오의 AI 디지털 휴먼이 바이두 이커머스 플랫폼에서 첫 라이브 커머스 방송을 진행하여 1,300만 명 이상의 시청자를 유치하고 상품 거래 총액(GMV) 5,500만 위안을 돌파했습니다. 이 디지털 휴먼은 바이두 이커머스의 “후이보싱(慧播星)” 플랫폼이 ERNIE 4.5 대형 모델을 기반으로 제작했으며, 뤄융하오의 말투, 억양, 미세 표정을 모방하고 지능적인 응답을 할 수 있습니다. 이번 방송은 “AI + 톱 인플루언서” 모델의 잠재력과 바이두의 “높은 설득력을 가진 디지털 휴먼” 기술 및 AI 이커머스 분야에서의 전략을 보여주었습니다 (출처: 36氪)

바이두, 텐센트 등 기업 AI 인재 채용 확대, 대규모 채용 계획 가동: 바이두는 자사 최대 규모의 최정상 AI 인재 채용 프로젝트인 “AIDU 계획”을 시작했습니다. 채용 규모는 전년 대비 60% 확대되었으며, 대형 모델 알고리즘, 기본 인프라 등 첨단 분야에 집중하고 상한선 없는 연봉을 제공합니다. 텐센트 역시 “전체 모달리티 생성형 추천” 알고리즘 대회를 개최하여 수백만 위안의 상금과 신입 채용 기회를 제공하며 글로벌 AI 인재 유치에 나섰습니다. 이러한 움직임은 중국 기술 대기업들이 AI 분야 경쟁이 치열해지는 가운데 최정상 인재에 대한 절박한 수요와 전략적 배치를 반영합니다 (출처: 量子位, 量子位)

바이두, 다중 모델 및 빅데이터 통합한 전면적인 AI 대입 지원 서비스 출시: 새로운 대학 입시 개혁으로 인한 지원서 작성의 복잡성에 대응하여 바이두는 무료 AI 대입 지원 보조 도구를 출시했습니다. 이 서비스는 바이두 앱의 “대입” 특별 페이지에 통합되어 있으며, “AI 지원 도우미”를 통해 학교 및 학과 추천, 합격 확률 분석을 제공하고, ERNIE, DeepSeek R1 등 다중 모델 “AI와 대입 상담” 지능형 에이전트를 통해 개인 맞춤형 상담을 지원합니다. 또한 바이두 독점 검색 빅데이터를 결합하여 학과별 취업 전망 분석, MBTI 직업 적성 검사, 대학 입학처 라이브 방송, 선배 문답 등 실제 인력 지원 리소스도 제공하여 수험생들이 정보 격차에 대응하고 더 적합한 지원 선택을 할 수 있도록 돕는 것을 목표로 합니다 (출처: 36氪)