
키워드:대형 언어 모델, AI 평가, 다중 에이전트 시스템, 추론 능력, 컨텍스트 처리, 오픈소스 모델, AI 비디오 생성, AI 프로그래밍, LLM 추론 능력 평가, 클로드 오퍼스 4 애플 논문 반박, 미니맥스-M1 MoE 모델, 키미-Dev-72B 프로그래밍 모델, 제미나이 딥 싱크 기능
🔥 주요 뉴스
Apple, LLM 추론 능력에 의문 제기한 논문 발표했으나 Claude 공동 저자 논문에서 실험 설계 결함 지적하며 반박: Apple이 최근 발표한 논문 ‘생각의 환상(The Illusion of Thought)’에서 하노이의 탑, 블록 세계 등 고전적인 문제 테스트를 통해 주요 대규모 언어 모델(LLM)이 복잡한 추론 작업에서 저조한 성능을 보이며, 이는 본질적으로 패턴 매칭일 뿐 진정한 이해는 아니라고 지적했습니다. 그러나 독립 연구원 Alex Lawsen과 AI 모델 Claude Opus 4가 공동으로 발표한 ‘생각의 환상 자체의 환상(“The Illusion of ‘The Illusion of Thought’“)’이라는 논문에서 Apple의 실험 설계에 결함이 있다고 반박했습니다. 1. LLM의 Token 출력 상한을 고려하지 않아 모델이 매우 긴 단계를 완전히 출력하지 못해 오류로 판정됨. 2. 일부 테스트 사례(예: 특정 ‘강 건너기 문제’)는 주어진 조건에서 수학적으로 해가 없어 AI가 ‘정답’을 제시하지 못하는 것이 능력 부족이 아님. 3. 평가 방식을 변경하여 모델이 전체 단계가 아닌 문제 해결 프로그램을 출력하도록 요구하면 AI 성능이 우수함. 이 사건은 LLM의 실제 추론 능력 및 평가 방법론에 대한 광범위한 논의를 촉발했으며, 합리적인 평가 방안 설계의 중요성을 부각시키고 개발자가 실제 응용에서 컨텍스트 창, 출력 예산, 작업 설명 등의 요소가 모델 성능에 미치는 영향을 고려해야 함을 상기시켰습니다. (출처: 新智元, 大数据文摘)
Google AI 로드맵 유출, 차세대 AI 아키텍처 기존 어텐션 메커니즘 폐기 가능성 시사: Google 제품 책임자 Logan Kilpatrick이 AI 엔지니어 세계 박람회에서 Gemini 모델의 미래 발전 방향을 공개했으며, 그중 가장 주목할 만한 것은 ‘무한 컨텍스트’ 실현에 대한 전망입니다. 그는 현재의 어텐션 메커니즘과 컨텍스트 처리 방식으로는 진정한 무한 컨텍스트를 실현할 수 없다고 지적하며, Google이 새로운 핵심 AI 아키텍처를 연구하고 있을 가능성을 시사했습니다. 로드맵에는 전체 모달리티 기능(이미지+오디오 지원, 비디오는 다음 단계), Diffusion 초기 실험, 기본 Agent 기능(최고 수준의 도구 호출 및 사용, 모델이 점진적으로 지능형 에이전트로 진화), 지속적으로 확장되는 추론 능력, 더 많은 소형 모델 출시 등이 포함됩니다. 이러한 일련의 계획은 Google이 AI를 수동적 대응에서 능동적 지능형 에이전트로의 진화를 적극적으로 추진하고 있으며, 특히 컨텍스트 처리 분야에서 기존 기술의 한계를 돌파하여 AI 아키텍처의 중대한 변화를 이끌 가능성을 보여줍니다. (출처: 新智元)
Sakana AI, ALE-Agent 공개, NP-난해 문제 프로그래밍 대회에서 인간 참가자 98% 제쳐: Transformer 저자 중 한 명인 Llion Jones가 공동 창립한 Sakana AI가 일본 프로그래밍 경진 플랫폼 AtCoder와 협력하여 ALE-Bench(알고리즘 엔지니어링 벤치마크)를 출시했습니다. 이는 경로 계획, 작업 스케줄링과 같은 NP-난해 문제에 대한 AI의 장기 추론 및 창의적 프로그래밍 능력을 평가하는 데 중점을 둡니다. Sakana AI가 개발한 ALE-Agent는 Gemini 2.5 Pro를 기반으로 하며, 도메인 지식 프롬프트와 다양한 해 공간 탐색 전략을 결합하여 AtCoder 휴리스틱 경진 대회에서 뛰어난 성능을 보여 상위 2%(21위)를 차지하며 수많은 인간 최고 개발자를 능가했습니다. 이는 AI가 복잡한 최적화 문제 해결에서 중요한 진전을 이루었음을 의미하며, 물류, 생산 계획 등 실제 응용에 중요한 의미를 갖습니다. ALE-Agent는 시뮬레이티드 어닐링과 같은 알고리즘에서 우수한 성능을 보였지만, 디버깅, 복잡도 분석 및 최적화 오류 방지 측면에서는 개선의 여지가 있습니다. (출처: 新智元, SakanaAILabs, hardmaru)
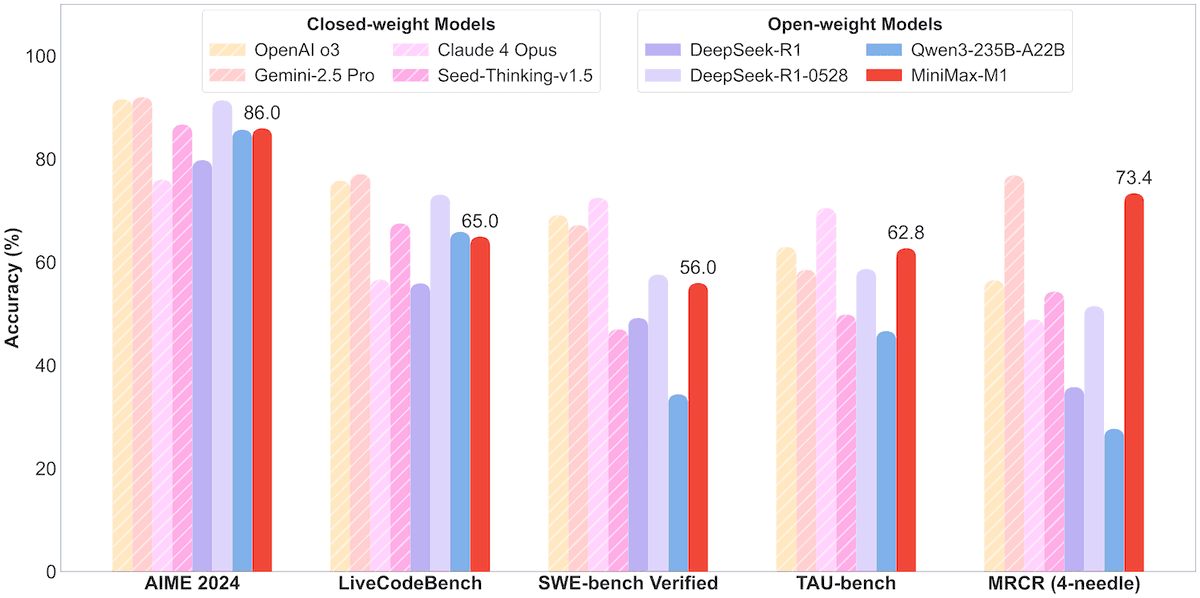
MiniMax, 456B 파라미터 MoE 모델 MiniMax-M1 오픈소스 공개, 백만 컨텍스트 및 8만 Token 출력 지원: MiniMax가 첫 번째 오픈소스 대규모 MoE(Mixture of Experts) 추론 모델 MiniMax-M1을 출시했습니다. 이 모델은 456억 개의 파라미터를 가지며, 각 Token은 45억 9천만 개의 파라미터를 활성화하고, MoE와 Lightning Attention 메커니즘을 결합한 아키텍처를 사용합니다. M1은 기본적으로 100만 Token의 컨텍스트 길이를 지원하며, 업계 최고 수준인 8만 Token 출력을 달성할 수 있으며, 40k 및 80k 사고 예산 두 가지 버전을 포함합니다. 소프트웨어 엔지니어링, 도구 사용 및 긴 컨텍스트 작업에 대한 벤치마크 테스트에서 M1은 DeepSeek-R1 및 Qwen3-235B와 같은 모델보다 우수한 성능을 보였으며, 특히 Agent 도구 사용(예: TAU-bench)에서 뛰어난 성적을 거두었습니다. 강화 학습 단계에서는 H800 512개로 3주간 훈련했으며, 비용은 약 53만 7천4백 달러입니다. M1 모델은 MiniMax APP 및 웹에서 무료로 사용할 수 있으며 API를 통해 서비스됩니다. (출처: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 동향
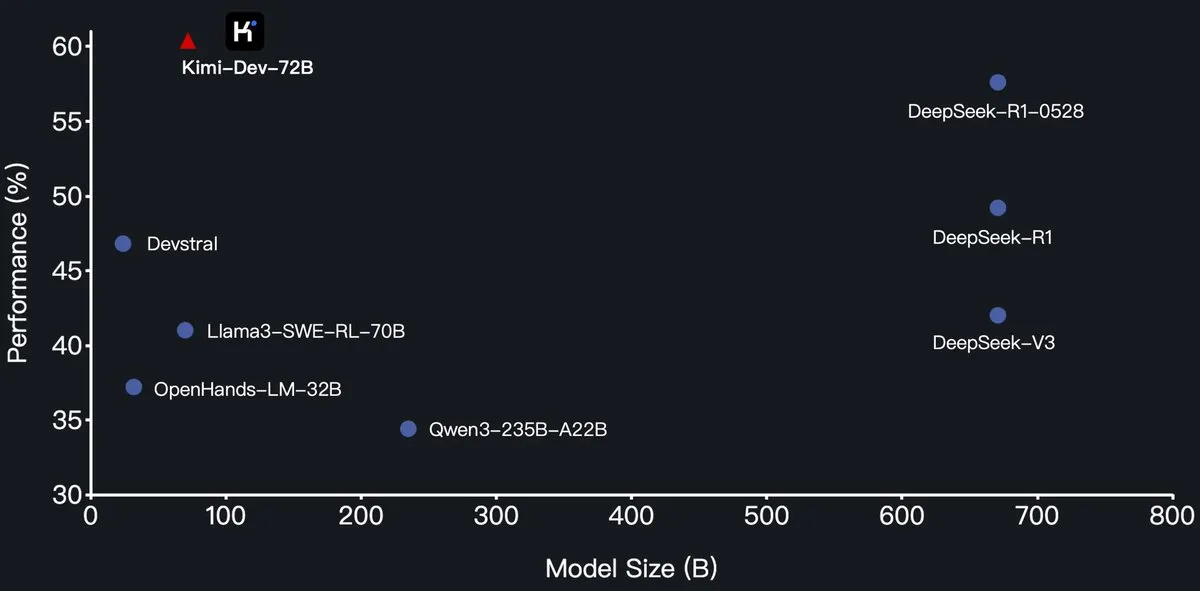
Moonshot AI, Kimi-Dev-72B 프로그래밍 대규모 모델 오픈소스 공개, SWE-Bench에서 DeepSeek-R1 능가: Moonshot AI(月之暗面)가 새로운 오픈소스 프로그래밍 대규모 언어 모델 Kimi-Dev-72B를 출시했습니다. 이 모델은 Qwen2.5-72B를 기반으로 파인튜닝되었습니다. Kimi-Dev-72B는 SWE-bench Verified 벤치마크 테스트에서 60.4%의 해결률을 달성하여 DeepSeek-R1-0528(57.6%) 및 Qwen3-235B-A22B와 같은 모델을 능가하며 오픈소스 모델 중 선두 주자가 되었다고 합니다. 이 모델은 강화 학습을 통해 훈련되었으며, Docker 환경에서 실제 코드 저장소를 수정하는 데 중점을 두고 전체 테스트 스위트를 통과해야만 보상을 받습니다. Qwen 개발 책임자는 라이선스를 부여하지 않았다고 밝혔지만, Kimi가 MIT 라이선스를 사용하여 파인튜닝 버전을 출시하는 것은 규정에 부합합니다. (출처: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3 시리즈 모델, MLX 형식 지원 추가, Apple 칩 추론 최적화: Alibaba Tongyi Qianwen 팀은 Qwen3 시리즈 모델이 이제 MLX 형식을 지원하며 4bit, 6bit, 8bit 및 BF16의 네 가지 양자화 수준을 제공한다고 발표했습니다. 이는 Apple MLX 프레임워크에서 모델 실행 효율성을 최적화하여 개발자가 Mac 장치에서 로컬 배포 및 추론을 쉽게 수행할 수 있도록 하기 위함입니다. 사용자는 HuggingFace 및 ModelScope에서 관련 모델을 얻을 수 있습니다. (출처: ClementDelangue, stablequan, jeremyphoward)

Google Gemini, ‘Deep Think’ 기능 곧 출시, 복잡한 문제 처리 능력 향상: Google이 Gemini 2.5 Pro 모델에 ‘Deep Think’이라는 새로운 기능을 도입할 준비를 하고 있습니다. 이 기능은 추가적인 컴퓨팅 성능을 제공하여 더 어려운 문제를 처리하는 것을 목표로 하며, 특히 수학 관련 작업에서 Deep Think는 일반 Gemini 2.5 Pro에 비해 성능이 최대 15% 향상될 것으로 예상됩니다. 이 기능은 도구 모음에 새로운 옵션으로 나타나며 처리 과정에 몇 분이 소요될 수 있습니다. 동시에 Gemini의 사용자 인터페이스도 업데이트될 예정입니다. (출처: op7418)
Google Veo 3 비디오 생성 모델 정식 출시, 70여 개 시장으로 확대: Google은 AI 비디오 생성 모델 Veo 3를 AI Pro 및 Ultra 구독자에게 정식 출시했으며, 전 세계 70개 이상의 시장을 대상으로 한다고 발표했습니다. Veo 3는 생성된 비디오 효과가 사실적이고 창의적이어서 많은 주목을 받았으며, 이전에는 사용자들이 이를 활용하여 제작한 ‘마성의 과일 자르기’와 같은 ASMR 콘텐츠가 소셜 미디어에서 수천만 조회수를 기록하며 콘텐츠 제작 분야에서의 잠재력을 보여주었습니다. 이번 정식 출시로 더 많은 사용자가 Veo 3를 경험하고 비디오 제작에 활용할 수 있게 될 것입니다. (출처: Google, 新智元)
Hugging Face, Groq와 협력하여 고속 LLM 추론 서비스 제공: Hugging Face는 AI 칩 회사 Groq와 파트너십을 맺고 Groq의 LPU™(Language Processing Unit)를 Hugging Face Playground 및 API에 통합한다고 발표했습니다. 사용자는 이제 Hugging Face 플랫폼에서 Groq 하드웨어로 가속화된 LLM 추론 서비스를 직접 경험할 수 있으며, Llama 4, Qwen 3를 포함한 다양한 모델을 지원합니다. 이는 개발자에게 더 빠르고 효율적인 AI 모델 추론 옵션을 제공하여 특히 지능형 에이전트, 어시스턴트 및 실시간 AI 애플리케이션 구축에 적합합니다. (출처: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub, 모델 크기 필터링 기능 추가, 개발자 적합 모델 선택 지원: Hugging Face 플랫폼은 사용자가 모델 크기(Size Range)에 따라 필터링할 수 있는 새로운 기능을 출시했으며, 특히 mlx / mlx-lm 프레임워크에서 실행되는 모델을 대상으로 합니다. 이 개선 사항은 개발자가 특정 하드웨어 및 성능 요구 사항에 맞는 모델을 더 편리하게 찾을 수 있도록 돕는 것을 목표로 하며, 모델이 클수록 좋은 것이 아니라 특정 시나리오에서는 소형 전문 모델이 더 우수하다는 점을 강조합니다. (출처: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCL 업데이트, 반정밀도 입력에 FP32 누적 사용한 리덕션 연산 시작: NVIDIA Collective Communications Library (NCCL)의 최신 버전(commit 72d2432)은 중요한 업데이트를 도입했습니다. 반정밀도 입력(예: FP16, BF16)의 리덕션 연산(reduction ops)을 처리할 때 FP32를 사용하여 누적하기 시작합니다. 이러한 변경은 특히 대규모 분산 훈련에서 계산 정밀도를 유지하고 오버플로를 방지하는 데 중요합니다. 이 버전은 PyTorch 2.8 이상 버전에 통합될 것으로 예상됩니다. (출처: StasBekman)

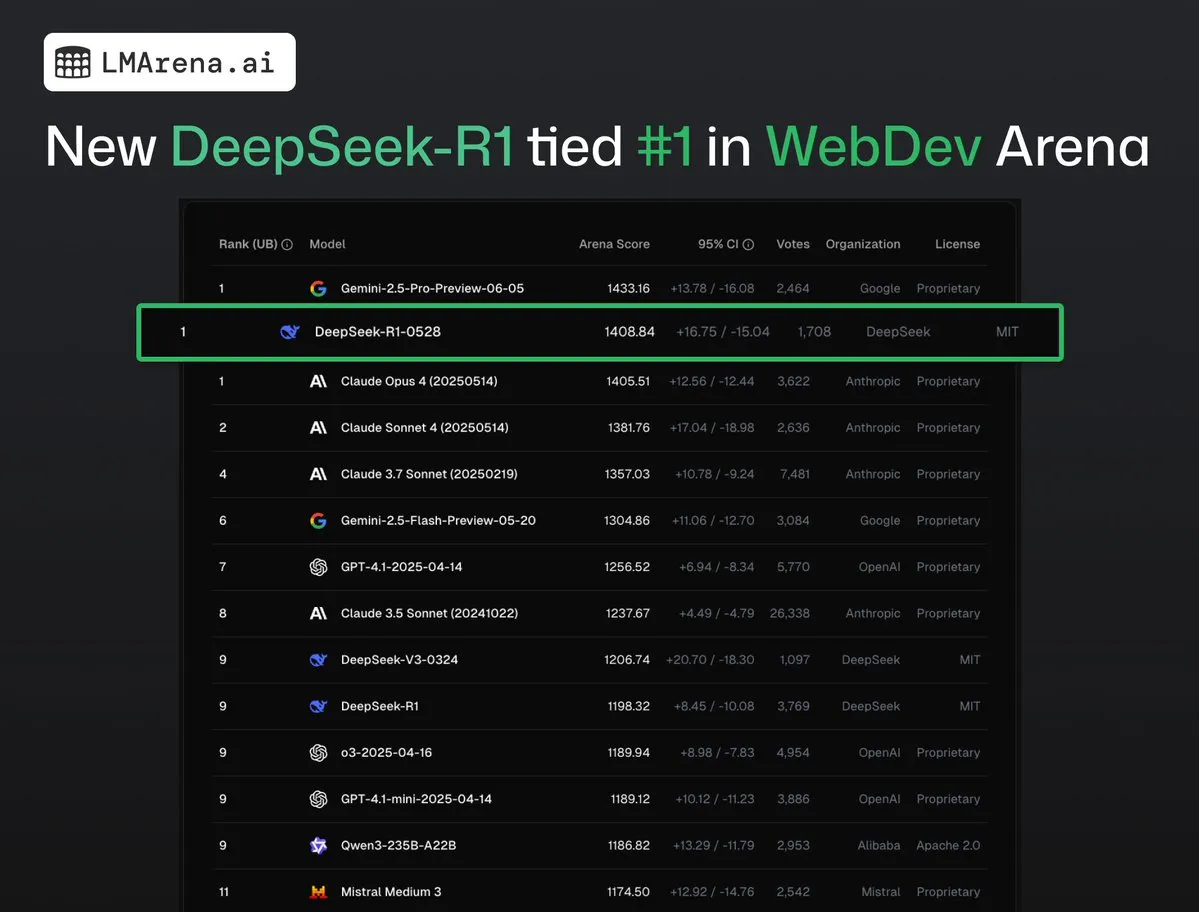
DeepSeek-R1 (0528), WebDev Arena에서 Claude Opus 4와 공동 1위: lmarena.ai의 최신 데이터에 따르면, 새로운 버전의 DeepSeek-R1 (0528)이 WebDev Arena 벤치마크 테스트에서 Claude Opus 4와 공동 1위를 차지하며 뛰어난 성능을 보였습니다. 이 모델은 Text Arena 종합 순위 6위, 프로그래밍 능력 순위 2위, 어려운 프롬프트 순위 4위, 수학 능력 순위 5위를 기록했으며, 순위표에서 가장 우수한 성능을 보인 MIT 라이선스 오픈소스 모델입니다. 이는 DeepSeek이 특정 개발 및 추론 작업에서 강력한 경쟁력을 가지고 있음을 의미합니다. (출처: ClementDelangue, zizhpan)
ByteDance, Poe 플랫폼에 Seedream 3.0 이미지 및 Seedance 1.0 Lite 비디오 모델 출시: ByteDance 산하 AI 창작 도구가 해외 Poe 플랫폼에 업데이트를 출시하여, 즉몽 AI의 이미지 생성 모델 Seedream 3.0과 비디오 생성 모델 Seedance 1.0 Lite를 선보였습니다. Seedream 3.0은 선명하고 생생한 이미지를 생성하는 것을 목표로 하며, Seedance 1.0 Lite는 사실적인 동적 효과를 가진 비디오를 빠르게 생성할 수 있습니다. 사용자는 Poe에서 먼저 Seedream으로 이미지를 생성한 다음, @-멘션으로 Seedance를 언급하여 비디오로 변환함으로써 이미지에서 비디오로 이어지는 연속적인 창작 과정을 구현할 수 있습니다. (출처: op7418)

Tencent, Levo 노래 모델 출시, 음원 분리 및 제로샷 음색 복제 지원: Tencent가 Levo라는 AI 노래 모델을 출시했으며, 그 성능은 Suno V3.5에 필적한다고 합니다. Levo는 음원 분리 및 제로샷 음색 복제 기능을 지원하며, 공개된 데모와 평가를 보면 뛰어난 성능을 보여줍니다. 이러한 발전은 Tencent가 AI 음악 생성 분야에서 강력한 역량을 보유하고 있음을 보여줍니다. (출처: karminski3)
OpenAI, WhatsApp에 ChatGPT 이미지 생성 기능 출시: OpenAI는 사용자가 이제 WhatsApp의 1-800-ChatGPT 서비스를 통해 ChatGPT의 이미지 생성 기능을 사용할 수 있다고 발표했습니다. 이 업데이트를 통해 더 넓은 사용자층이 인스턴트 메시징 앱에서 직접 AI 이미지를 편리하게 생성할 수 있게 되었습니다. (출처: gdb, eliza_luth, iScienceLuvr)
SpatialLM 1.1 버전으로 업데이트, 3D 장면 이해 및 재구성 능력 향상: 공간 추론 모델 SpatialLM이 1.1 버전을 출시했습니다. 새 버전은 텍스트-3D 장면 생성(Text-to-3D), 휴대용 카메라 비디오 재구성, LiDAR 포인트 클라우드 데이터(예: iPhone Pro LiDAR) 및 합성 메시 샘플링을 포함한 다양한 입력 소스 모드를 지원합니다. 주요 특징으로는 비정형 포인트 클라우드에 대한 강력한 처리 능력이 있으며, 3D 스캔 데이터가 불완전하더라도 합리적인 재구성이 가능합니다. 또한 새 버전은 비디오 스트림 입력의 제로샷 감지를 최적화하고 실내 레이아웃 추정 정확도를 개선했으며 3D 객체 감지 효과를 향상시켰습니다. AR 장면 재구성, 로봇 공간 이해, 3D 디자인 워크플로우 및 C단 카메라 애플리케이션 등 광범위한 응용 분야를 가지고 있습니다. (출처: karminski3)
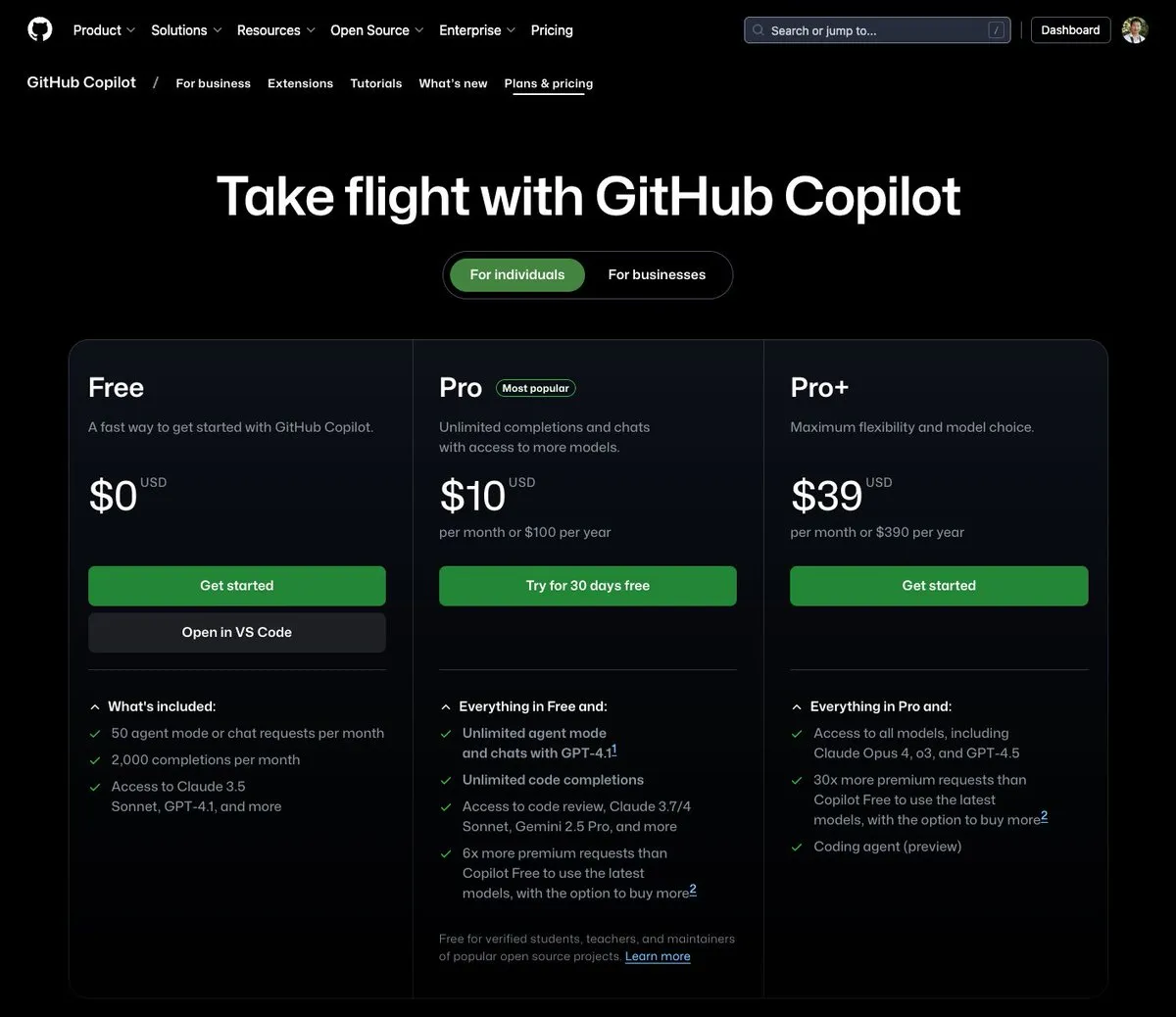
GitHub Copilot, 월 39달러 요금제 출시, Claude Opus 4 등 다양한 대규모 모델 통합: GitHub Copilot이 월 39달러의 새로운 구독 요금제를 추가했습니다. 이 요금제는 코딩 도우미 기능뿐만 아니라 사용자가 Claude Opus 4, o3 및 GPT-4.5를 포함한 다양한 강력한 언어 모델에 액세스하고 Coding agent를 사용할 수 있도록 합니다. 이 조치는 개발자에게 보다 포괄적인 AI 지원 프로그래밍 경험을 제공하기 위한 것입니다. (출처: dotey)
AI 대규모 모델 호출 비용 지속 하락, Doubao 1.6 시리즈 가격 63% 추가 인하: Volcano Engine이 Force 원동력 컨퍼런스에서 Doubao 대규모 모델 1.6 시리즈를 발표하고 종합 비용을 63% 절감했다고 밝혔습니다. 대부분의 기업이 자주 사용하는 0-32K 입력 길이 범위에서 가격은 백만 토큰당 입력 0.8위안, 출력 8위안입니다. 이는 올해 3월 Alibaba Qianwen이 비용을 DeepSeek R1의 1/10로 낮춘 이후 대규모 모델 가격 경쟁이 계속 심화되고 있음을 의미합니다. 저비용은 AI Agent와 같은 애플리케이션의 도입과 보급을 더욱 촉진할 것입니다. (출처: 字节必须再赢一次)
Chipmunk 비디오 생성 가속 도구 업데이트, 다중 GPU 아키텍처 및 더 많은 오픈소스 모델 지원: Dan Fu 팀의 Chipmunk 도구가 업데이트되어 이제 다양한 NVIDIA GPU 아키텍처(sm_80, sm_89, sm_90, 예: A100s, 4090s, H100s)에서 1.4-3배의 비디오 생성 무손실 가속을 지원합니다. 동시에 Chipmunk은 Mochi, Wan 등 더 많은 오픈소스 비디오 모델에 대한 지원을 추가하고 통합 튜토리얼을 제공합니다. 이 도구는 비디오 모델의 활성화 값 희소성(활성화 값의 5-25%만이 출력의 90% 이상에 기여)을 활용하여 모델을 재훈련할 필요 없이 가속을 실현합니다. (출처: realDanFu)

🧰 도구
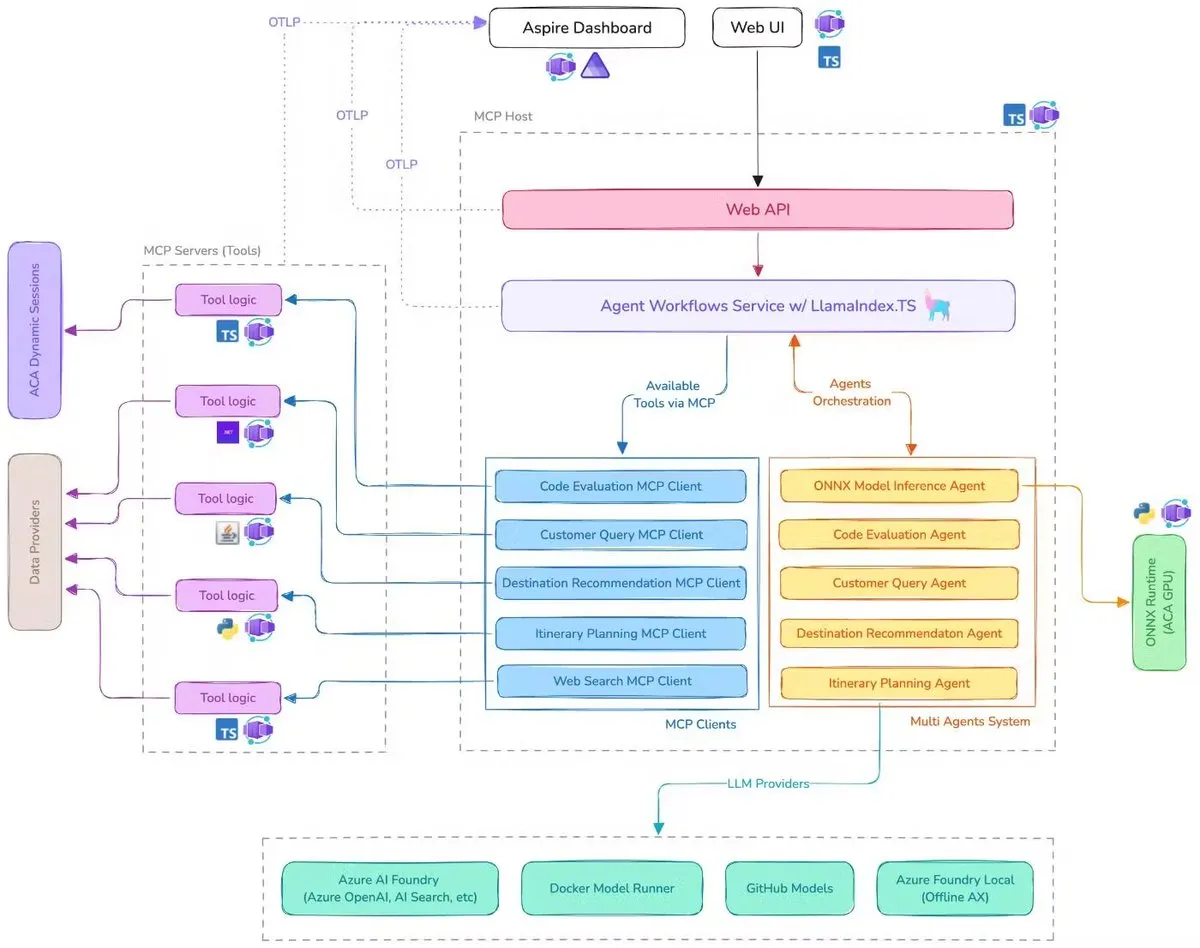
Microsoft, AI 출장 도우미 데모 공개, MCP, LlamaIndex.TS 및 Azure AI Foundry 통합: Microsoft가 AI 출장 도우미 데모를 선보였습니다. 이 시스템은 모델 컨텍스트 프로토콜(MCP), LlamaIndex.TS 및 Azure AI Foundry를 통해 여러 AI 에이전트(쿼리 분류, 목적지 추천, 여정 계획 등 6개의 전문 에이전트 포함)를 조정하여 복잡한 여행 계획 작업을 공동으로 완료합니다. 각 에이전트는 Java, .NET, Python 및 TypeScript로 작성된 MCP 서버를 통해 실시간 데이터와 도구를 가져옵니다. 이 애플리케이션은 기업 수준의 다중 에이전트가 다국어 마이크로서비스를 통해 협력하고 Azure OpenAI 및 GitHub 모델을 활용하여 AI 기능을 제공하며 Azure Container Apps를 통해 확장 가능한 서버리스 배포를 구현할 수 있음을 보여줍니다. (출처: jerryjliu0, jerryjliu0)
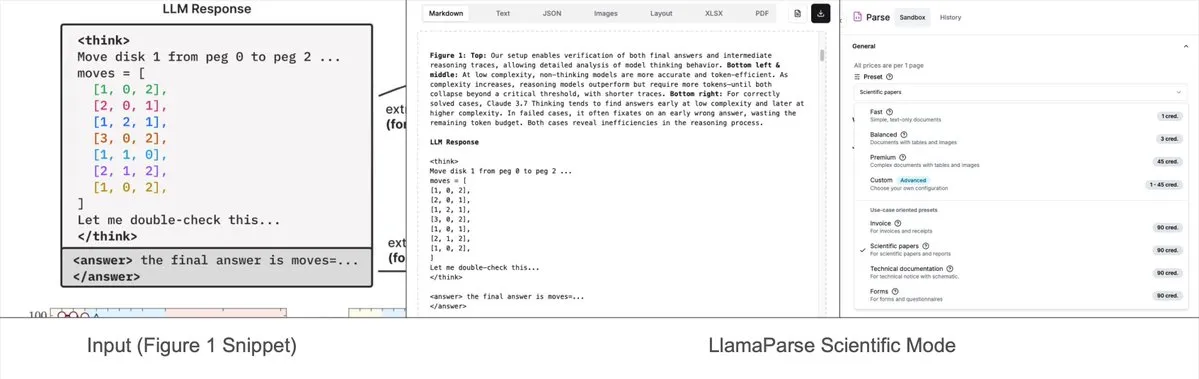
LlamaParse, 사전 설정 모드 추가, 복잡한 차트를 Mermaid 또는 Markdown으로 구문 분석 가능: LlamaIndex의 LlamaParse 도구가 최근 업데이트되어 ‘사전 설정 모드’(preset-modes)를 추가했습니다. 이를 통해 연구 보고서와 같은 문서의 복잡한 차트(예: 여러 곡선과 주석이 포함된 차트)를 구문 분석하고 형식화된 Mermaid 다이어그램 또는 Markdown 테이블로 변환할 수 있습니다. 이 기능은 페이지에서 전체 컨텍스트를 캡처하는 데 도움이 되며, 생성된 구조화된 텍스트는 RAG 파이프라인을 구축하거나 추가 메타데이터 추출에 사용할 수 있습니다. (출처: jerryjliu0)
Prompt Optimizer: 고품질 프롬프트 작성을 돕는 최적화 도구: Prompt Optimizer는 사용자가 더 나은 AI 프롬프트를 작성하여 AI 출력 품질을 향상시키는 데 도움을 주는 도구입니다. 웹 애플리케이션과 Chrome 확장 프로그램 두 가지 형태로 제공되며, 지능형 최적화, 다단계 반복 개선, 원본 및 최적화된 프롬프트 비교, 다중 모델 통합(OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow 등), 고급 매개변수 구성, 로컬 암호화 저장 등의 기능을 제공합니다. 이 도구는 순수 클라이언트 측 처리를 채택하여 데이터 보안 및 개인 정보 보호를 보장합니다. (출처: GitHub Trending)

LLaMA Factory v0.9.3 출시, Qwen3, Llama 4 등 약 300종 모델 코드 없는 파인튜닝 지원: LLaMA Factory가 v0.9.3 버전을 출시했습니다. 이 버전은 완전 오픈소스이며 Gradio 사용자 인터페이스를 지원하는 코드 없는 파인튜닝 플랫폼으로, 최신 Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni 등 약 300여 종의 모델에 적용 가능합니다. 사용자는 Docker 이미지를 통해 로컬에 설치하거나 Hugging Face Spaces, Google Colab 및 Novita의 GPU 클라우드에서 체험할 수 있습니다. (출처: _akhaliq)
Nanonets OCR: Qwen 2.5 VL 3B 기반 SOTA OCR 모델 오픈소스 공개: Nanonets가 Qwen 2.5 VL 3B 백본 네트워크를 기반으로 하는 새로운 3B 파라미터 OCR 모델인 Nanonets OCR을 출시했습니다. 이 모델은 Mistral OCR API보다 성능이 우수하며 Apache 2.0 라이선스로 오픈소스 공개되었습니다. LaTeX 인식, 워터마크 및 서명 감지, 복잡한 테이블 추출 등 다양한 OCR 작업을 처리할 수 있습니다. (출처: huggingface)
Perplexity Labs, 여러 전문 직무 대체 가능성 제기되며 AI 도구 능력 논쟁 촉발: 사용자 GREG ISENBERG는 Perplexity Labs를 사용하여 영업 사원, 카피라이터, 영화 감독, 소셜 미디어 관리자, 재무 분석가 등 5개 직무를 대체했다고 주장하며 AI 도구의 능력이 “실제로 미쳤다”고 평가했습니다. Perplexity CEO Arav Srinivas는 이를 AI 에이전트가 실제 사용 사례에서 어떻게 적용될 수 있는지를 보여주는 최고의 비디오 중 하나라고 공유하며, Perplexity Labs와 시장의 다른 도구들을 금융 분석, 소셜 미디어 마케팅, 크리에이티브 디렉션, 영업 측면에서 비교했습니다. 이는 AI Agent가 여러 분야의 전문 작업을 통합하고 실행하는 잠재력을 강조합니다. (출처: AravSrinivas, AravSrinivas)
Claude-Flow v1.0.50 주요 업데이트, ‘스웜 모드’ 활성화로 코드 자동화 효율성 향상: Claude Code 기반의 배치 도구 병렬 에이전트 시스템인 Claude-Flow가 v1.0.50 버전을 출시했습니다. 새 버전은 ‘스웜 모드’(Swarm Mode)를 도입하여 사용자가 수백 개의 Claude 에이전트를 동시에 생성, 관리 및 조정하여 병렬로 작업하고, 빌드, 테스트, 배포 또는 다단계 연구 루프에 사용할 수 있도록 합니다. 기존의 순차적 Claude Code 자동화에 비해 성능이 20배 향상되었다고 합니다. 개발자는 npx claude-flow@latest init --sparc --force를 통해 초기화할 수 있습니다. (출처: Reddit r/ClaudeAI)

📚 학습
Awesome Machine Learning: 포괄적인 머신러닝 리소스 목록: GitHub의 “awesome-machine-learning” 프로젝트는 프로그래밍 언어별로 분류된 머신러닝 프레임워크, 라이브러리 및 소프트웨어의 엄선된 목록입니다. 또한 무료 머신러닝 서적, 전문 행사, 온라인 강좌, 블로그 뉴스레터 및 지역 모임과 같은 리소스에 대한 링크를 포함하여 머신러닝 학습자와 실무자에게 귀중한 내비게이션을 제공합니다. (출처: GitHub Trending)
Anthropic과 Cognition AI, 멀티 에이전트 시스템 구축에 관한 블로그 게시물 각각 발표, LangChain 요약: Anthropic과 Cognition AI는 최근 멀티 에이전트 시스템 구축(또는 구축하지 않음)에 관한 블로그 게시물을 각각 발표했습니다. Anthropic은 멀티 에이전트 연구 시스템을 구축한 경험을 공유했고, Cognition AI는 “멀티 에이전트를 구축하지 말라”는 관점을 제시했습니다. LangChain의 Harrison Chase는 이에 대해 요약하며, 표면적으로는 관점이 달라 보이지만 두 게시물 모두 지침과 권장 사항에서 공통점이 많다고 지적하고 LangChain의 멀티 에이전트 관련 노력과 연결 지었습니다. (출처: hwchase17, Hacubu)
‘Recent Advances in Speech Language Models: A Survey’ 논문, ACL 2025 메인 컨퍼런스 채택: 홍콩 중문대학 팀이 작성한 음성 언어 모델(SpeechLM) 리뷰 논문 ‘Recent Advances in Speech Language Models: A Survey’가 ACL 2025 메인 컨퍼런스에 채택되었습니다. 이 논문은 해당 분야 최초의 포괄적이고 체계적인 리뷰로, SpeechLM의 기술 아키텍처(음성 토크나이저, 언어 모델, 보코더), 훈련 전략(사전 훈련, 지시 미세 조정, 사후 정렬), 상호 작용 패러다임(전이중 모델링), 응용 시나리오(의미, 화자, 준언어학) 및 평가 시스템을 심층 분석했습니다. 논문은 SpeechLM이 자연스러운 인간-기계 음성 상호 작용을 실현하는 데 있어 잠재력을 강조하고 직면한 과제와 미래 방향을 제시했습니다. (출처: 36氪)

새로운 연구, 시각적 게임 학습(ViGaL)을 통해 소형 모델의 교차 영역 추론 능력 향상, 7B 모델 수학 성능 GPT-4o 능가: 라이스 대학교, 존스 홉킨스 대학교 및 NVIDIA 연구팀이 ViGaL(Visual Game Learning)이라는 새로운 사후 훈련 패러다임을 제안했습니다. 7B 파라미터 다중 모드 모델(Qwen2.5-VL-7B)이 스네이크 게임과 3D 회전과 같은 간단한 아케이드 게임을 하도록 함으로써 모델은 게임 기술을 향상시켰을 뿐만 아니라 수학(MathVista) 및 다학제 질의응답(MMMU)과 같은 복잡한 추론 작업에서도 현저한 교차 영역 능력 향상을 보였으며, 일부 측면에서는 GPT-4o와 같은 최고 수준의 모델을 능가했습니다. 연구에 따르면 게임 훈련은 모델의 공간 이해, 순차 계획 등 일반적인 인지 능력을 배양할 수 있으며, 다른 게임은 다른 측면의 추론 기술을 강화할 수 있습니다. 이 방법은 추론 능력을 향상시키는 동시에 모델의 일반적인 시각 능력을 유지합니다. (출처: 新智元)

상하이 AI Lab 등, MathFusion 프레임워크 제안, 지시 융합 통해 LLM 수학 문제 해결 능력 향상: 상하이 인공지능 연구소, 중국인민대학교 가오링 인공지능 학원 등 기관이 공동으로 MathFusion 프레임워크를 제안했습니다. 이는 다양한 수학 문제 생성 구조를 더욱 다양하고 논리적으로 복잡하게 융합하여 대규모 언어 모델(LLM)의 수학 문제 해결 능력을 향상시키는 것을 목표로 합니다. 이 프레임워크는 순차적 융합, 병렬적 융합, 조건부 융합의 세 가지 전략을 포함하며, 문제 간의 심층적인 연관성을 효과적으로 포착할 수 있습니다. 실험 결과, 단 45K의 합성 지시만 사용하여 DeepSeekMath-7B, Llama3-8B, Mistral-7B 등 모델을 미세 조정한 후 MathFusion은 여러 수학 벤치마크에서 평균 정확도를 18.0%p 향상시켜 높은 데이터 효율성과 성능을 보여주었습니다. (출처: 量子位)

상하이 AI Lab 등, GRA 프레임워크 제안, 소형 모델 협력하여 고품질 데이터 생성, 72B 모델에 필적하는 성능: 상하이 인공지능 연구소와 중국인민대학교가 공동으로 GRA(Generator–Reviewer–Adjudicator) 프레임워크를 제안했습니다. 이는 논문 투고 및 동료 검토 메커니즘을 모방하여 여러 소형 언어 모델(7-8B 파라미터)이 협력하여 고품질 훈련 데이터를 생성하도록 합니다. 이 프레임워크에서 Generator는 생성을 담당하고, Reviewer는 다단계 검토 및 채점을 수행하며, Adjudicator는 검토 충돌 시 최종 결정을 내립니다. 실험 결과, GRA로 생성된 데이터를 사용하여 LLMA-3.1-8B 및 Qwen-2.5-7B와 같은 기본 모델을 훈련한 결과, 수학, 코드, 논리 추론 등 10개 주요 데이터셋에서 Qwen-2.5-72B-Instruct와 같은 대형 모델 증류로 생성된 데이터와 동등하거나 그 이상의 성능을 보였습니다. 이는 저비용, 고효율 데이터 합성을 위한 새로운 아이디어를 제공합니다. (출처: 量子位)

논문, 대규모 모델 설명 가능성의 현황과 미래 논의, AI 안전 배포 중요성 강조: Tencent 연구원이 대규모 언어 모델(LLM) 설명 가능성의 현황, 기술 경로 및 미래 과제를 심층적으로 논의하는 글을 발표했습니다. 이 글은 LLM의 내부 메커니즘을 이해하는 것이 가치 편향 방지, 모델 디버깅 및 개선, 남용 방지, 고위험 시나리오 적용 촉진에 중요하다고 지적합니다. 현재 기술 경로는 자동화된 설명(대규모 모델이 소규모 모델 설명), 특징 시각화(예: 희소 자동 인코더), 사고 과정 모니터링 및 메커니즘 설명 가능성(예: Anthropic의 “AI 현미경” 및 DeepMind의 Tracr)을 포함합니다. 그러나 뉴런의 다중 의미, 설명 규칙의 보편성 및 인간 인지 한계 등은 여전히 주요 과제입니다. 이 글은 설명 가능성 연구 투자를 강화할 것을 촉구하며, 현재 단계에서는 AI 기술의 안전하고 투명하며 인간 중심적인 발전을 보장하기 위해 산업 자율 규제를 장려하는 소프트 법 규칙을 채택할 것을 제안합니다. (출처: 腾讯研究院)

새 논문, 대규모 언어 및 다중 모드 모델에서 이산 확산 모델의 적용 및 발전 논의: ‘Discrete Diffusion in Large Language and Multimodal Models: A Survey’라는 제목의 논문은 이산 확산 언어 모델(dLLMs) 및 이산 확산 다중 모드 언어 모델(dMLLMs)의 연구 진행 상황을 체계적으로 검토합니다. 이러한 모델은 다중 Token 병렬 디코딩 및 노이즈 제거 기반 생성 전략을 채택하여 병렬 생성, 세분화된 출력 제어 가능성, 동적이고 응답에 민감한 인식 능력을 구현했으며, 추론 속도는 자기 회귀 모델에 비해 최대 10배 향상될 수 있습니다. 논문은 그 발전 역사를 추적하고, 수학적 프레임워크를 공식화하며, 대표적인 모델을 분류하고, 핵심적인 훈련 및 추론 기술을 분석하며, 언어, 시각 언어 및 생물학 분야에서의 응용을 요약하고, 마지막으로 미래 연구 방향과 배포 과제를 논의합니다. (출처: HuggingFace Daily Papers)
새로운 연구, Test3R 제안: 테스트 시 학습을 통해 3D 재구성 기하학적 정확도 향상: Test3R이라는 새로운 기술은 테스트 시 학습을 통해 3D 재구성의 기하학적 정확도를 크게 향상시킵니다. 이 방법은 이미지 삼중항 (I_1,I_2,I_3)을 활용하여 이미지 쌍 (I_1,I_2) 및 (I_1,I_3)에서 재구성 결과를 생성합니다. 핵심 아이디어는 테스트 시 자기 지도 목표를 통해 네트워크를 최적화하는 것입니다. 즉, 공통 이미지 I_1에 대한 이 두 재구성 결과의 기하학적 일관성을 최대화하는 것입니다. 실험 결과, Test3R은 3D 재구성 및 다중 뷰 깊이 추정 작업에서 기존 SOTA 방법을 현저히 능가하며, 보편성과 저비용 특성을 가지고 있어 다른 모델에 쉽게 적용할 수 있으며, 테스트 시 훈련 오버헤드와 파라미터 수가 매우 적습니다. (출처: HuggingFace Daily Papers)
논문, Mirage-1 제안: 계층적 다중 모드 기술을 갖춘 GUI 에이전트, 장기 작업 처리 능력 향상: 연구자들은 현재 GUI 에이전트가 온라인 환경에서 장기 작업을 처리할 때 지식 부족 및 오프라인-온라인 영역 격차 문제를 해결하기 위해 다중 모드, 교차 플랫폼, 플러그 앤 플레이 GUI 에이전트인 Mirage-1을 제안했습니다. Mirage-1의 핵심은 계층적 다중 모드 기술(HMS) 모듈로, 궤적을 실행 기술, 핵심 기술 및 메타 기술로 점진적으로 추상화하여 장기 작업 계획을 위한 계층적 지식 구조를 제공합니다. 동시에 기술 강화 몬테카를로 트리 탐색(SA-MCTS) 알고리즘은 오프라인에서 얻은 기술을 활용하여 온라인 트리 탐색의 행동 검색 공간을 줄입니다. AndroidWorld, MobileMiniWob++, Mind2Web-Live 및 새로 구축된 AndroidLH 벤치마크에서 Mirage-1은 모두 현저한 성능 향상을 보였습니다. (출처: HuggingFace Daily Papers)
논문 ‘Don’t Pay Attention’, Transformer에 도전하는 새로운 신경망 기본 아키텍처 Avey 제안: ‘Don’t Pay Attention’이라는 제목의 논문은 어텐션 및 순환 메커니즘에 대한 의존성에서 벗어나기 위한 새로운 신경망 기본 아키텍처 Avey를 제안합니다. Avey는 순위 지정기(ranker)와 자기 회귀 신경 프로세서(autoregressive neural processor)로 구성되며, 이들은 협력하여 주어진 Token과 가장 관련성이 높은 Token(시퀀스 내 위치에 관계없이)만을 식별하고 컨텍스트화합니다. 이 아키텍처는 시퀀스 길이와 컨텍스트 너비를 분리하여 임의 길이의 시퀀스를 효과적으로 처리할 수 있도록 합니다. 실험 결과, Avey는 표준 단기 NLP 벤치마크에서 Transformer와 동등한 성능을 보였으며, 장기 의존성 포착에서 특히 뛰어난 성능을 보였습니다. (출처: HuggingFace Daily Papers)
새 논문, 보상 모델을 통한 확장 가능한 코드 검증 논의, 정확성과 처리량 간의 균형: 한 연구는 대규모 언어 모델(LLM)이 코딩 작업을 해결할 때 결과 보상 모델(ORM)과 전체 테스트 스위트와 같은 포괄적인 검증기 사용 간의 균형을 탐구합니다. 연구 결과, 포괄적인 검증기가 있는 경우에도 ORM은 속도를 위해 일정 수준의 정확성을 희생함으로써 확장된 검증에서 여전히 중요한 역할을 하는 것으로 나타났습니다. 특히 ‘생성-가지치기-재정렬’ 방법에서 더 빠르지만 정확성이 낮은 검증기를 사용하여 잘못된 솔루션을 미리 제거하면 시스템 속도를 11.65배 향상시키면서 정확성은 8.33%만 감소시킬 수 있습니다. 이 방법은 잘못되었지만 순위가 높은 솔루션을 필터링하여 작동하며, 확장 가능하고 정확한 프로그램 정렬 시스템 설계를 위한 새로운 아이디어를 제공합니다. (출처: HuggingFace Daily Papers)
새로운 벤치마크 AbstentionBench, 추론형 LLM이 답변 불가능한 문제에서 저조한 성능 보임: 대규모 언어 모델(LLM)이 불확실성에 직면했을 때 기권(즉, 명확한 답변 거부)을 선택하는 능력을 평가하기 위해 연구자들은 AbstentionBench를 출시했습니다. 이 대규모 벤치마크 테스트는 답변 미지, 규범 부족, 잘못된 전제, 주관적 해석 및 오래된 정보 등 20개의 다양한 데이터셋을 포함합니다. 20개의 최첨단 LLM에 대한 평가는 기권이 아직 해결되지 않은 문제이며 모델 규모 확대가 이에 거의 도움이 되지 않음을 보여주었습니다. 놀랍게도 수학 및 과학 분야를 위해 명시적으로 훈련된 추론형 LLM조차도 추론 미세 조정이 오히려 평균적으로 24%의 기권 능력을 저하시켰습니다. 잘 설계된 시스템 프롬프트가 실제로는 기권 성능을 향상시킬 수 있지만, 이것이 불확실성 추론에서 모델의 근본적인 결함을 해결하지는 못합니다. (출처: HuggingFace Daily Papers)
논문, 패치 기반 프롬프트 및 분해 방법(PatchInstruct) 제안, LLM을 이용한 시계열 예측: 새로운 연구는 대규모 재훈련이나 복잡한 외부 아키텍처 없이 시계열 예측을 위해 대규모 언어 모델(LLM)을 활용하는 간단하고 유연한 프롬프트 전략을 탐구합니다. 시계열 분해, 패치 기반 토큰화(patch-based tokenization) 및 유사성 기반 이웃 강화와 같은 전문적인 프롬프트 방법을 결합하여 연구자들은 단순성을 유지하고 데이터 전처리를 최소화하면서 LLM의 예측 품질을 향상시킬 수 있음을 발견했습니다. 이 연구에서 제안된 PatchInstruct 방법은 LLM이 정확하고 효과적인 예측을 할 수 있도록 합니다. (출처: HuggingFace Daily Papers)
새로운 데이터셋 MS4UI 출시, 사용자 인터페이스 교육 비디오의 다중 모드 요약에 중점: 기존 벤치마크가 단계별 실행 가능한 지침 및 그림 제공에 부족한 점을 해결하기 위해 연구자들은 MS4UI(Multi-modal Summarization for User Interface Instructional Videos) 데이터셋을 제안했습니다. 이 데이터셋은 총 167시간이 넘는 2413개의 UI 교육 비디오를 포함하며, 수동 비디오 분할, 텍스트 요약 및 비디오 요약 주석이 달려 있습니다. UI 교육 비디오를 위한 간결하고 실행 가능한 다중 모드 요약 방법 연구를 촉진하는 것을 목표로 합니다. 실험 결과, 현재 SOTA 다중 모드 요약 방법은 MS4UI에서 저조한 성능을 보여 해당 분야의 새로운 방법의 중요성을 강조합니다. (출처: HuggingFace Daily Papers)
DeepResearch Bench: 포괄적인 심층 연구 에이전트 벤치마크 테스트: LLM 기반 심층 연구 에이전트(Deep Research Agents, DRAs)의 능력을 체계적으로 평가하기 위해 연구자들은 DeepResearch Bench를 출시했습니다. 이 벤치마크는 22개 다양한 분야의 전문가들이 신중하게 설계한 100개의 박사 수준 연구 작업을 포함합니다. DRAs 평가의 복잡성과 노동 집약성으로 인해 연구자들은 인간의 판단과 높은 일치도를 보이는 두 가지 새로운 평가 방법을 제안했습니다. 하나는 생성된 연구 보고서의 품질을 평가하기 위한 참조 기반 적응형 표준 방법이고, 다른 하나는 유효 인용 횟수와 전체 인용 정확도를 평가하여 DRA의 정보 검색 및 수집 능력을 평가하는 프레임워크입니다. (출처: HuggingFace Daily Papers)
논문, BridgeVLA 제안: 입출력 정렬을 통한 효율적인 3D 조작 학습: 로봇 조작 학습에서 시각 언어 모델(VLM)의 3D 신호 활용 효율성을 높이기 위해 연구자들은 새로운 3D 시각 언어 행동(VLA) 모델인 BridgeVLA를 제안했습니다. BridgeVLA는 3D 입력을 여러 2D 이미지로 투영하여 VLM 백본 네트워크의 입력과 정렬되도록 보장하고, 2D 히트맵을 사용하여 행동 예측을 수행함으로써 일관된 2D 이미지 공간에서 입력과 출력을 통합합니다. 또한 이 연구는 VLM 백본 네트워크가 다운스트림 정책 학습 전에 2D 히트맵을 예측할 수 있는 능력을 갖추도록 하는 확장 가능한 사전 훈련 방법을 제안합니다. 실험 결과, BridgeVLA는 여러 시뮬레이션 벤치마크와 실제 로봇 실험에서 모두 뛰어난 성능을 보였으며, 3D 조작 학습의 효율성과 효과를 현저히 향상시키고 강력한 샘플 효율성과 일반화 능력을 보여주었습니다. (출처: HuggingFace Daily Papers)
새로운 연구, 귀인 기반 합성을 통해 수백만 개의 다양하고 복잡한 사용자 지시(SynthQuestions) 생성: 대규모 언어 모델(LLM) 정렬에 필요한 다양하고 복잡하며 대규모 지시 데이터 부족 문제를 해결하기 위해 연구자들은 귀인 기반(attributed grounding) 지시 합성 방법을 제안했습니다. 이 프레임워크는 1) 선택된 실제 지시를 상황화된 사용자와 연결하는 하향식 귀인 과정과 2) 웹 문서를 사용하여 먼저 상황을 생성한 다음 의미 있는 지시를 생성하는 상향식 합성 과정을 포함합니다. 이 방법을 통해 100만 개의 지시를 포함하는 데이터셋 SynthQuestions를 구축했습니다. 실험 결과, 이 데이터셋에서 훈련된 모델은 여러 일반적인 벤치마크에서 선도적인 성능을 달성했으며, 웹 말뭉치가 증가함에 따라 성능이 지속적으로 향상되었습니다. (출처: HuggingFace Daily Papers)
PersonaFeedback: 대규모 인공 주석 개인화 평가 벤치마크 공개: 사전 정의된 사용자 프로필과 쿼리가 주어졌을 때 대규모 언어 모델(LLM)이 개인화된 응답을 제공하는 능력을 평가하기 위해 연구자들은 PersonaFeedback 벤치마크를 출시했습니다. 이 벤치마크는 8298개의 인공 주석 테스트 케이스를 포함하며, 사용자 프로필의 컨텍스트 복잡성과 개인화된 응답을 구별하는 난이도에 따라 쉬움, 중간, 어려움의 세 가지 등급으로 분류됩니다. 기존 벤치마크와 달리 PersonaFeedback은 프로필 추론과 개인화를 분리하여 명확한 프로필에 대해 맞춤형 응답을 생성하는 모델의 능력을 평가하는 데 중점을 둡니다. 실험 결과, SOTA LLM조차도 어려운 등급의 테스트에서 어려움을 겪는 것으로 나타나 현재 검색 증강 프레임워크가 개인화 작업의 최종 솔루션이 아님을 시사합니다. (출처: HuggingFace Daily Papers)
논문, 다국어 대규모 모델에서 ‘언어 수술’ 논의: 잠재 공간 주입을 통한 추론 시 언어 제어: 새로운 연구는 대규모 언어 모델(LLM)에서 자연스럽게 발생하는 표현 정렬 현상과 언어 특정 정보와 언어 독립적 정보를 분리하는 데 있어 그 의미를 탐구합니다. 연구는 이러한 정렬의 존재를 확인하고 명시적으로 설계된 정렬 모델의 행동과 비교 분석합니다. 이러한 발견을 바탕으로 연구자들은 잠재 공간 주입(latent injection)을 활용하여 정확한 교차 언어 제어를 실현하고 LLM의 언어 혼동 문제를 완화하는 추론 시 언어 제어(Inference-Time Language Control, ITLC) 방법을 제안합니다. 실험 결과 ITLC는 대상 언어의 의미적 무결성을 유지하면서 강력한 교차 언어 제어 능력을 가지며, 현재 대규모 LLM에서도 여전히 존재하는 교차 언어 혼동 문제를 효과적으로 완화할 수 있음을 증명합니다. (출처: HuggingFace Daily Papers)
논문, NoWait 방법 제안: ‘생각 Token’ 제거로 대규모 모델 추론 효율성 향상: 최근 연구에 따르면 대규모 추론 모델은 복잡한 단계별 추론을 수행할 때 종종 과도한 ‘생각’(예: “Wait”, “Hmm”과 같은 Token 출력)으로 인해 출력이 중복되어 효율성에 영향을 미칩니다. 새롭게 제안된 NoWait 방법은 추론 시 이러한 명시적인 자기 성찰 Token을 억제하여 고급 추론에 대한 필요성을 검증하는 것을 목표로 합니다. 텍스트, 시각 및 비디오 추론 작업에 걸친 10개의 벤치마크에서 NoWait은 5개의 R1 스타일 모델 시리즈에서 사고 과정 궤적 길이를 27%-51% 단축했으며 모델 유용성을 손상시키지 않았습니다. 이 방법은 효율적이면서도 유용성을 유지하는 다중 모드 추론을 위한 플러그 앤 플레이 솔루션을 제공합니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
OpenAI, 미국 국방부와 2억 달러 규모 AI 계약 체결, 첨단 군사 능력 개발: OpenAI가 미국 국방부와 1년간 2억 달러 규모의 계약을 체결하여 국가 안보를 위한 첨단 인공지능 도구를 개발하기로 했습니다. 이는 OpenAI가 국방부로부터 이러한 종류의 계약을 따낸 첫 번째 사례로 기록됩니다. 작업은 주로 수도권 지역에서 진행될 예정입니다. OpenAI는 이전에 국방 기업 Anduril과 협력한 바 있으며, 이번 계약은 미국 국방 분야에서 AI 애플리케이션을 광범위하게 추진하는 배경 속에서 이루어졌습니다. 경쟁사인 Anthropic도 Palantir 및 Amazon과 해당 분야에서 협력하고 있습니다. OpenAI CEO Sam Altman은 이전에 국가 안보 프로젝트 지원 의사를 공개적으로 밝힌 바 있습니다. (출처: Reddit r/ArtificialInteligence, code_star)

Alta, Menlo Ventures 주도로 1,100만 달러 투자 유치, AI+패션 분야 집중: AI 패션 스타트업 Alta가 Menlo Ventures 주도로 1,100만 달러 규모의 투자를 유치했다고 발표했습니다. Benchstrength와 Aglaé Ventures(LVMH 그룹 아르노 가문이 지원하는 VC 펀드)도 투자에 참여했습니다. Amy Tong Wu가 Alta 이사회에 합류할 예정입니다. 이번 투자는 Alta가 AI와 패션을 결합한 분야에서 더욱 발전하는 데 도움이 될 것입니다. (출처: ZhaiAndrew)
Figure, 조직 개편 단행, 제어 부서 Helix에 통합하여 AI 로드맵 가속화: 휴머노이드 로봇 회사 Figure는 제어(Controls) 부서가 더 이상 존재하지 않으며, 전체 팀이 Helix 부서에 통합되었다고 발표했습니다. 이 조치는 회사의 인공지능 분야 로드맵 발전을 가속화하기 위한 것으로, Figure가 AI 기술 연구 개발 및 응용에 더 많은 자원과 노력을 집중하고 있음을 보여줍니다. (출처: adcock_brett)
🌟 커뮤니티
AGI에 대한 논의: 일반 사용자는 과도하게 걱정할 필요 없으며, AGI는 일상 도구보다는 전략적 측면에 가까움: 커뮤니티의 여러 논의에서 일반 LLM 사용자는 AGI(범용 인공지능)의 도래에 대해 지나치게 걱정할 필요가 없다는 점이 지적되었습니다. AGI의 정의는 모호하고 이론적이며, 실현된다 하더라도 단기적으로 사용자 채팅창에 직접 나타나기보다는 국가나 대형 기관의 전략적 도구 및 인프라로 활용되어 국가 간 협상과 같은 복잡한 업무를 처리하는 데 사용될 것이며, 개인의 회의 일정을 돕는 용도는 아닐 것입니다. (출처: farguney, farguney, farguney, farguney)
다중 에이전트 시스템 구축 시 인공 평가 필요, 엣지 케이스 및 출처 품질 주목: 다중 에이전트 시스템을 구축할 때 인공 평가와 테스트는 자동화된 평가가 간과할 수 있는 엣지 케이스를 발견하는 데 매우 중요합니다. 예를 들어, 초기 에이전트는 정보 출처를 선택할 때 권위 있는 학술 PDF나 개인 블로그보다는 SEO에 최적화된 콘텐츠 팜을 선호하는 경향이 있었습니다. 프롬프트에 출처 품질 휴리스틱 방법을 추가하면 이러한 문제를 해결하는 데 도움이 됩니다. 이는 자동화된 평가 시대에도 수동 테스트가 시스템 오류, 미묘한 출처 선택 편향 등의 문제를 발견하는 데 여전히 필수적임을 보여줍니다. (출처: riemannzeta)

LLM의 예측 및 학습 메커니즘과 비디오 모델의 차이점, 사고 촉발: Yann LeCun과 Pedro Domingos는 Sergey Levine의 견해를 공유하며, 언어 모델이 다음 Token 예측에서 많은 것을 배울 수 있는 반면 비디오 모델이 다음 프레임 예측에서 상대적으로 적게 배우는 이유에 대해 논의했습니다. Levine은 LLM이 어떤 면에서는 ‘뇌 스캐너’ 역할을 하기 때문일 수 있다고 추측하며, 이는 LLM의 학습 메커니즘의 독특함을 암시하거나, LLM이 플라톤의 동굴에 살면서 그림자 시퀀스(텍스트)를 관찰하여 실제 세계를 추론하는 것과 같다고 말합니다. (출처: ylecun, pmddomingos, pmddomingos)

AI Agent, 교육 분야에 긍정적 영향: 학습자가 안전지대를 벗어나도록 촉진: 커뮤니티 토론에서는 AI Agent가 기업뿐만 아니라 교육 분야에서도 큰 잠재력을 가지고 있다고 보고 있습니다. AI Agent와의 상호작용을 통해 학습자는 자신의 안전지대(comfort zone)를 더 효과적으로 벗어날 수 있으며, 이는 학습 효과 향상을 촉진합니다. (출처: pirroh, amasad)
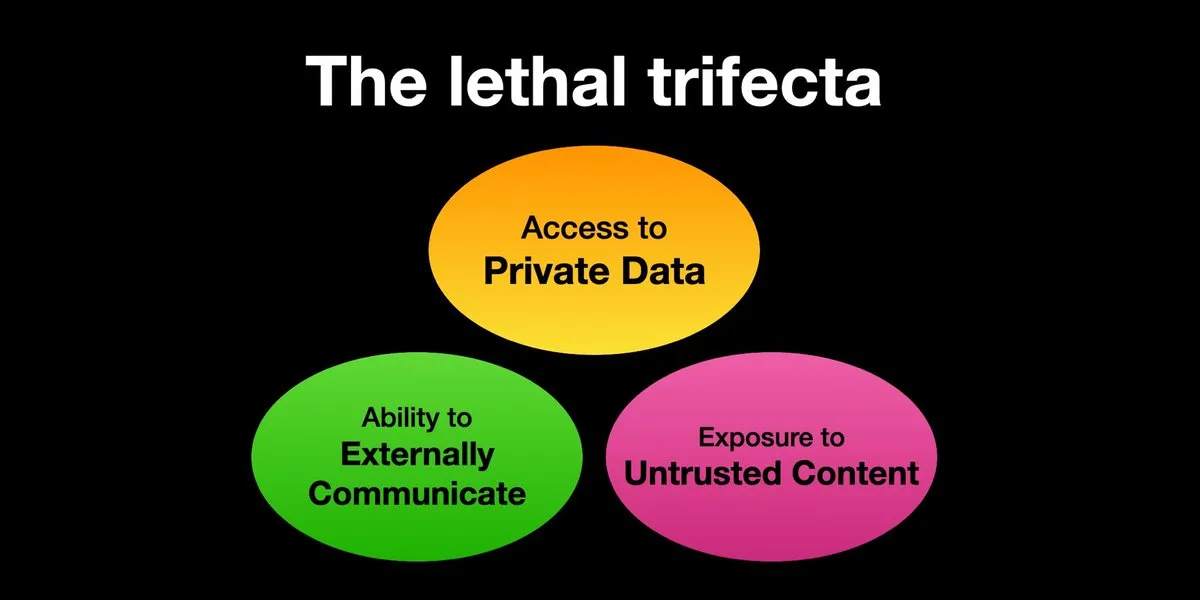
AI Agent, 프롬프트 인젝션 공격 위험 직면, 보안 강화 시급: Karpathy는 Simon Willison이 AI Agent가 ‘치명적인 삼중고’(Lethal Trifecta) 위험에 직면해 있다는 경고를 공유했습니다. 즉, AI Agent가 개인 데이터 접근, 신뢰할 수 없는 콘텐츠 접촉, 외부 통신 능력을 동시에 가질 때 공격자가 시스템을 속여 데이터를 탈취할 수 있다는 것입니다. 이는 초기 컴퓨터 바이러스의 ‘서부 개척 시대’를 연상시키며, 현재 악의적인 프롬프트에 대한 방어 메커니즘은 아직 미흡합니다. 예를 들어, 운영체제의 커널/사용자 공간과 같은 보안 패러다임이 없어 Agent가 임의의 스크립트를 실행하는 것을 제한하지 못합니다. 이로 인해 LLM Agent를 개인 컴퓨팅에 조기 도입하는 데 우려가 제기됩니다. (출처: karpathy, TheTuringPost)
AI 시대, 빠른 학습 능력이 핵심 경쟁력으로 부상: Mustafa Suleyman은 향후 10년간 가장 큰 직업적 가속기는 뛰어난 학습 능력이 될 것이라고 지적했습니다. 그는 사람들이 자신의 학습 스타일을 명확히 파악하고, AI를 활용하여 자료를 적합한 형식(예: 팟캐스트, 퀴즈)으로 변환한 다음, 지식을 적용하고 이 과정을 반복함으로써 빠른 학습과 성장을 이룰 것을 제안했습니다. (출처: mustafasuleyman)
AI 생성 콘텐츠의 진실성과 관련성: 관련성이 진실성보다 중요할 수도: 사용자 imjaredz는 AI가 생성한 리드 메일 2000통을 발송했는데, 아무도 AI가 작성했다고 불평하지 않았고 오히려 5명이 메일 내용이 “자신들이 연구하고 있는 바로 그 내용”이라고 답했다고 경험을 공유했습니다. 이는 커뮤니케이션에서 콘텐츠의 관련성이 그것의 “진실성”(인간이 창작했는지 여부)보다 더 중요한지에 대한 논의를 불러일으켰습니다. (출처: imjaredz)
LLM의 ‘이해’ 능력에 대한 논의: 행동적 근사치는 진정한 이해와 동일하지 않음: 커뮤니티에서는 대규모 언어 모델이 강력한 행동 및 인지적 근사 능력을 보여주지만, 이것이 진정한 이해와 동일하지는 않다는 견해가 있습니다. 이해에는 설명 능력이 필요하며, 단지 행동을 보이는 것은 지능이나 이해가 아닙니다. 이 근본적인 차이는 종종 간과됩니다. 이 견해는 생명과 안전이 관련된 결정을 모델에 맡기기 전에 모델이 진정으로 범용 인공지능에 근접했는지 신중하게 평가하고, 그 능력을 과도하게 포장하는 것을 경계해야 한다고 강조합니다. (출처: farguney)
AI Agent, 소프트웨어 엔지니어링 벤치마크에서 뛰어난 성능, 그러나 ‘에이전트’ 본질에 대한 논의: AI가 SWE-bench와 같은 소프트웨어 엔지니어링 벤치마크에서 점수가 계속 향상됨에 따라(심지어 50-60점을 넘어서면서), 커뮤니티에서는 ‘에이전트 코딩 시대’가 진정으로 도래했는지에 대한 논의가 이루어졌습니다. 만약 언어 모델이 환경에서 실제로 탐색하는 환경이 아닌 ‘에이전트 없는 프레임워크’(agentless frameworks)가 보편적으로 사용된다면, 이러한 프레임워크 자체는 가치가 있지만 이를 ‘에이전트 코딩 시대’라고 부르는 것은 이름에 걸맞지 않을 수 있다는 견해가 있습니다. (출처: huybery, terryyuezhuo)
AI 생성 이미지 콘텐츠 심사 필요성: 오픈소스 또는 상용 솔루션 모색: AI 생성 이미지 기술이 보급됨에 따라 국내 개발자들은 출력 콘텐츠의 규정 준수 문제, 특히 음란물, 정치적으로 민감한 내용 등을 어떻게 감지할 것인지에 대해 관심을 갖기 시작했습니다. 커뮤니티에서는 콘텐츠 심사를 위한 사용 가능한 오픈소스 소형 모델이나 상용 제품을 찾는 논의가 나타나고 있습니다. (출처: dotey)
💡 기타
AI 기반 개인화와 콘텐츠 관련성: AI 메일 2000통에 불만 없고, 5명은 “바로 내가 찾던 것”: 한 사용자가 AI로 생성한 리드 메일 2000통을 발송했는데, 수신자 중 누구도 AI가 작성한 메일이라고 불평하지 않았다고 공유했습니다. 오히려 5명의 수신자는 메일 내용이 “자신들이 현재 진행 중인 작업과 정확히 일치한다”고 답했습니다. 이 사례는 AI 지원 커뮤니케이션에서 콘텐츠의 높은 관련성이 “진실성”(즉, 인간이 작성했는지 여부)에 대한 우려를 넘어설 수 있는지에 대한 논의를 촉발하며, AI의 개인화된 콘텐츠 생성 잠재력을 시사합니다. (출처: imjaredz)
인간이 AI 시스템의 병목 현상, 인간 효율성 회피 또는 향상 필요: Charles Earl의 견해에 따르면, 받은 편지함은 산더미처럼 쌓여 있지만 보낸 편지함은 텅 비어 있는 것은 인간이 정보 처리 및 응답의 병목 현상임을 반영합니다. AI 시대에는 인간 병목 현상을 피하거나 AI와 같은 기술을 통해 인간의 작업 효율성을 어떻게 향상시킬지 고민해야 합니다. (출처: charles_irl)
AI 제어 스마트 홈의 잠재적 위험: 앱 오작동으로 차가운 스마트 침대에 갇힌 사용자: 한 사용자가 AI로 제어되는 스마트 침대(Eight Sleep Pod3) 앱 오작동으로 온도를 조절할 수 없어 결국 차가운 침대에 갇혔던 경험을 공유했습니다. 해당 모델은 수동 제어 기능이 없고 전적으로 앱에 의존하기 때문에, 이번 오작동은 AI 및 앱 제어 스마트 홈 장치에 대한 과도한 의존이 가져올 수 있는 불편함과 “반유토피아적” 경험을 부각시켰습니다. (출처: madiator)