
키워드:AI, 대형 모델, 다중 에이전트 시스템, Claude, Transformer, 신경 형태 계산, LLM, AI 에이전트, Claude 다중 에이전트 연구 시스템, Eso-LM 혼합 훈련 방법, 신경 형태 슈퍼컴퓨터, Context Scaling 기술, SynthID 워터마크 기술
🔥 주요 뉴스
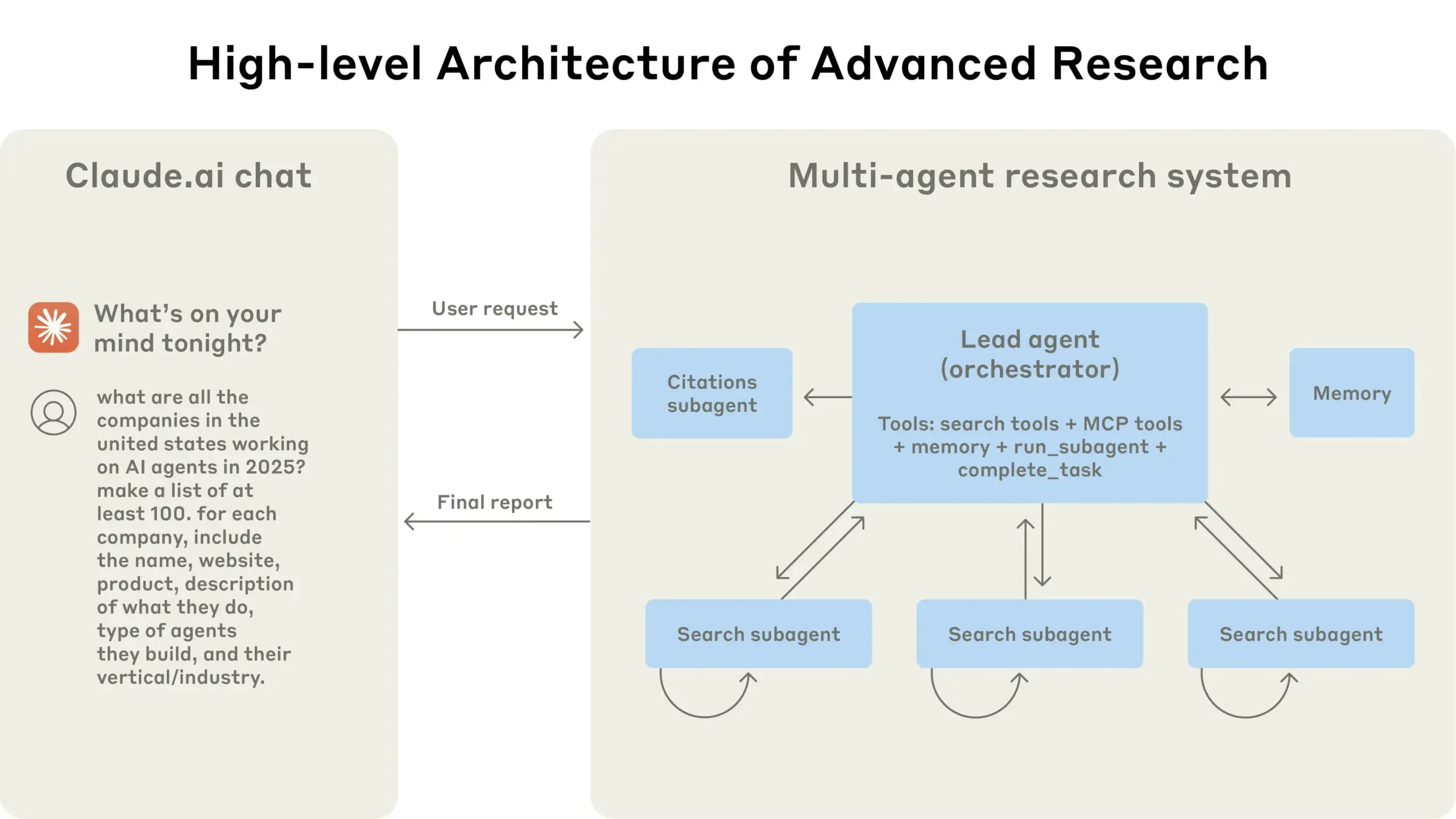
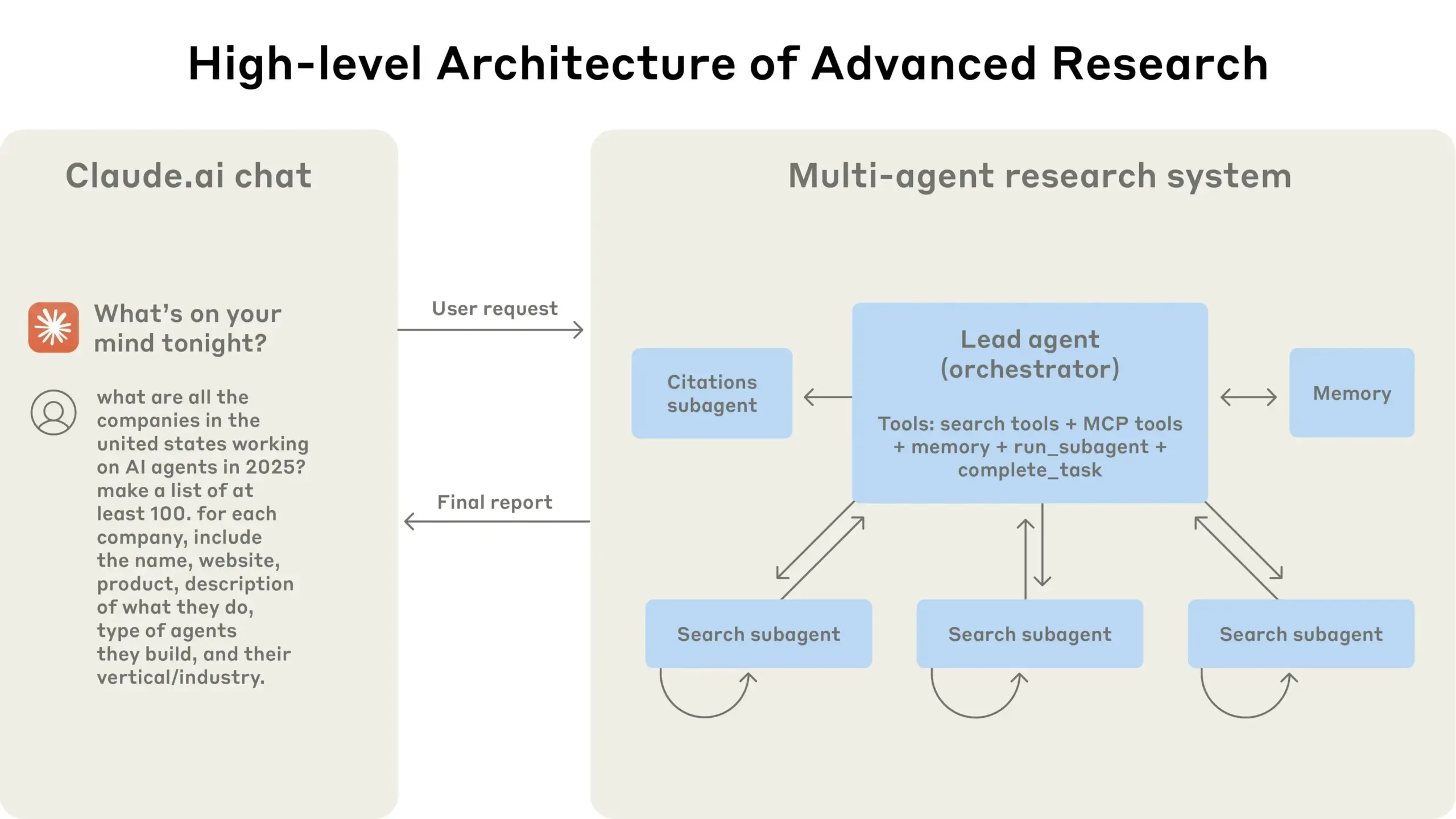
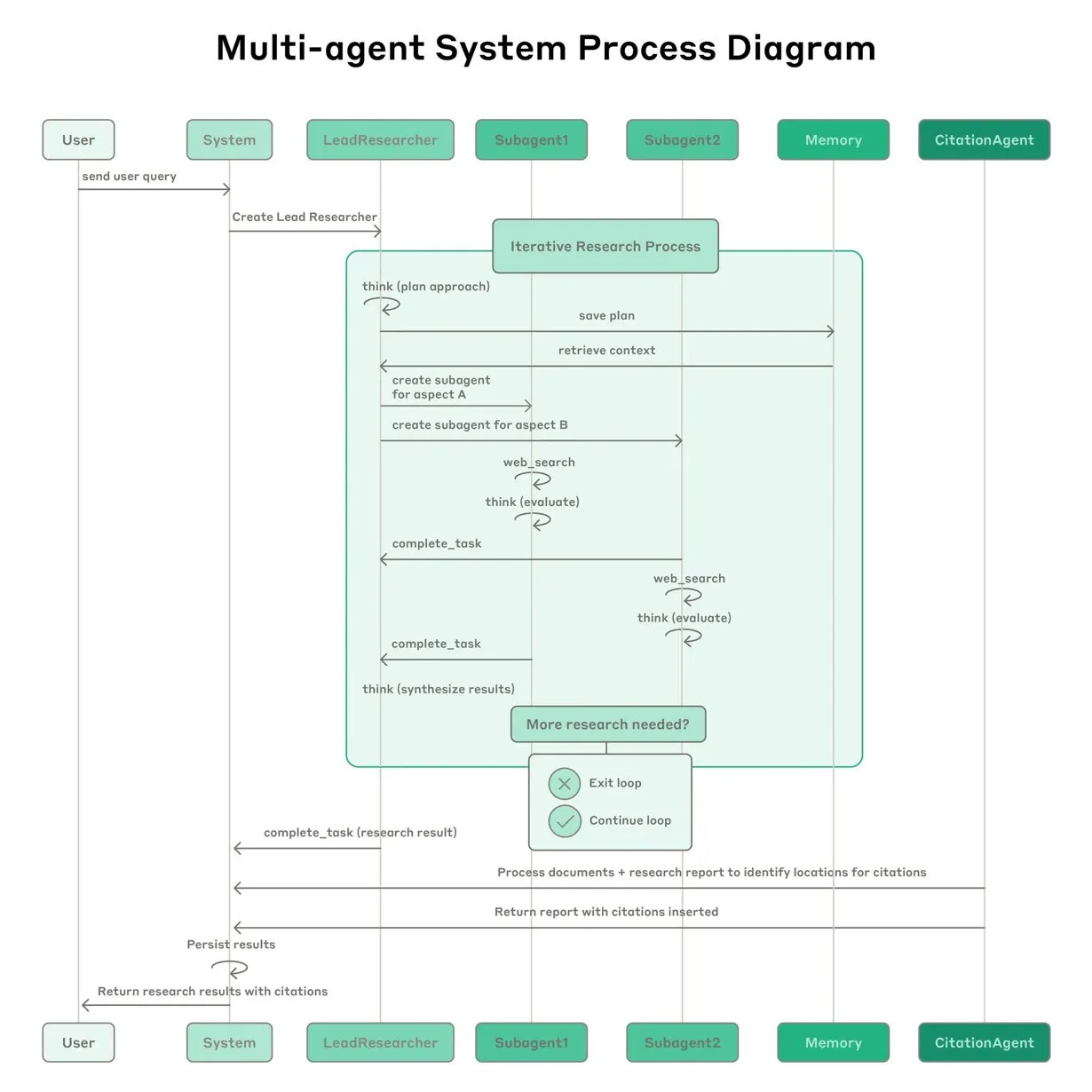
Anthropic, Claude 멀티 에이전트 연구 시스템 구축 경험 공유: Anthropic은 Claude의 멀티 에이전트 연구 시스템 구축 방법과 실제 경험한 성공과 실패 사례, 엔지니어링 과제 등을 상세히 소개했습니다. 주요 시사점은 다음과 같습니다: 모든 시나리오에 멀티 에이전트가 적합한 것은 아니며, 특히 에이전트 간 대량의 컨텍스트 공유가 필요하거나 의존성이 높은 경우에는 더욱 그렇습니다. 에이전트는 도구 인터페이스를 개선할 수 있는데, 예를 들어 테스트 에이전트를 통해 도구 설명을 재작성하여 향후 오류를 줄임으로써 작업 완료 시간을 40% 단축했습니다. 하위 에이전트의 동시 실행은 조정을 단순화하지만 정보 흐름의 병목 현상을 유발할 수 있어, 비동기 이벤트 기반 아키텍처의 잠재력을 시사합니다. 이 공유는 프로덕션 수준의 멀티 에이전트 아키텍처 구축에 귀중한 통찰력을 제공합니다 (출처: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
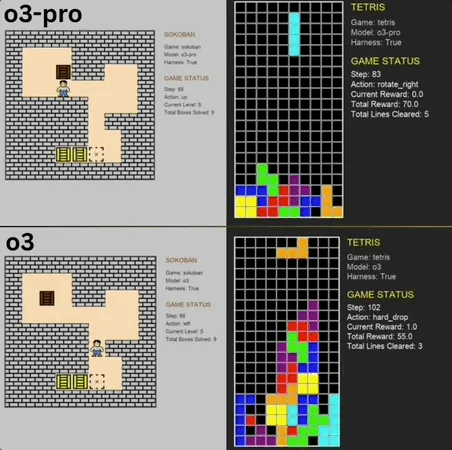
o3-pro, 클래식 미니 게임 Benchmark에서 SOTA 경신하며 뛰어난 성능 과시: o3-pro는 Lmgame 벤치마크 테스트에서 소코반, 테트리스 등 클래식 게임에 도전하여 우수한 성적을 거두며, 이전에 o3 등 모델이 보유했던 최고 기록을 직접적으로 경신했습니다. 소코반 게임에서 o3-pro는 설정된 모든 레벨을 성공적으로 클리어했으며, 테트리스에서는 강력한 성능으로 인해 테스트가 강제 종료되었습니다. UCSD의 Hao AI Lab(LMSYS 소속, 대형 모델 아레나 개발자)이 출시한 이 Benchmark는 반복적인 상호작용 루프 모드를 통해 대형 모델이 게임 상태에 따라 행동을 생성하고 피드백을 받도록 하여 모델의 계획 및 추론 능력을 평가하는 것을 목표로 합니다. o3-pro의 조작 시간이 비교적 길었음에도 불구하고, 게임 작업에서의 뛰어난 성능은 복잡한 의사 결정 작업에서 대형 모델의 잠재력을 부각시켰습니다 (출처: 36氪)
테렌스 타오, AI 10년 내 필즈상 수상 가능성 예측, 수학 연구의 중요 협력자 될 것: 필즈상 수상자인 테렌스 타오는 AI가 2026년까지 수학자들의 신뢰할 수 있는 연구 파트너가 되고, 10년 안에 중요한 수학적 추측을 제시하며 수학계의 ‘AlphaGo 모멘트’를 맞이할 것이며, 궁극적으로 필즈상까지 수상할 수 있다고 예측했습니다. 그는 AI가 ‘대통일 이론’과 같은 복잡한 과학 문제 탐구를 가속화할 수 있다고 보지만, 현재 AI는 알려진 물리 법칙 발견에 여전히 어려움을 겪고 있으며, 이는 적절한 ‘부정적 데이터’와 시행착오 과정의 훈련 데이터 부족이 부분적인 원인이라고 지적했습니다. 테렌스 타오는 AI가 인간처럼 학습, 실수, 수정 과정을 거쳐야 진정으로 성장할 수 있다고 강조하며, 현재 AI가 자신의 잘못된 경로를 식별하는 데 약점이 있고 인간 수학자의 ‘직감’이 부족하다고 언급했습니다. 그는 형식 증명 언어 Lean과 AI의 결합을 긍정적으로 평가하며, 이것이 수학 연구의 협업 방식을 바꿀 것이라고 믿습니다 (출처: 36氪)

AI 생성 콘텐츠 진위 판별 어려움, 구글 SynthID 워터마크 기술로 위조 방지 지원: 최근 ‘캥거루 비행기 탑승’ 등 AI 생성 영상이 소셜 미디어에 광범위하게 퍼지며 많은 사용자를 오도해 AI 콘텐츠 식별의 어려움이 부각되었습니다. 이에 구글 DeepMind는 SynthID 기술을 출시하여 AI 생성 콘텐츠(이미지, 비디오, 오디오, 텍스트)에 보이지 않는 디지털 워터마크를 삽입하여 식별을 돕습니다. 사용자가 콘텐츠에 필터 추가, 자르기, 형식 변환 등 일반적인 편집을 하더라도 SynthID 워터마크는 특정 도구로 감지할 수 있습니다. 그러나 이 기술은 현재 주로 구글 자체 AI 서비스(Gemini, Veo, Imagen, Lyria 등)에서 생성된 콘텐츠에 적용되며, 범용 AI 감별기는 아닙니다. 동시에 악의적인 대폭 수정이나 재작성은 워터마크를 손상시켜 탐지를 실패하게 만들 수 있습니다. 현재 SynthID는 초기 테스트 단계이며 사용 신청이 필요합니다 (출처: 36氪, aihub.org)
🎯 동향
푸단대학교 치우시펑 교수, AGI의 다음 핵심 경로로 Context Scaling 제시: 푸단대학교/상하이 창즈 학원의 치우시펑 교수는 사전 훈련과 사후 훈련 최적화 이후, 대형 모델 발전의 세 번째 막은 Context Scaling(상황 확장)이 될 것이라고 보았습니다. 그는 진정한 지능은 작업의 모호성과 복잡성을 이해하는 데 있으며, Context Scaling은 AI가 풍부하고, 현실적이며, 복잡하고, 변화무쌍한 상황 정보를 이해하고 적응하여 명확하게 표현하기 어려운 ‘암묵적 지식’(예: 사회 지능, 문화 적응)을 포착하도록 하는 것을 목표로 한다고 지적했습니다. 이를 위해서는 AI가 강력한 상호작용성(환경 및 인간과의 다중 모드 협업), 구체성(인식 행동을 위한 물리적 또는 가상적 주체성), 의인화(인간과 유사한 감정적 공감 및 피드백)를 갖추어야 합니다. 이 경로는 기존 확장 경로를 대체하는 것이 아니라 보완하고 통합하는 것으로, AGI로 가는 핵심 단계가 될 수 있습니다 (출처: 36氪)
연구 결과, 대형 모델의 망각은 단순 삭제가 아니며 가역적 망각의 배후 규칙 밝혀져: 홍콩 폴리테크닉 대학교 등 기관의 연구원들은 대형 언어 모델의 망각이 단순한 정보 삭제가 아니라 모델 내부에 숨겨져 있을 수 있다는 사실을 발견했습니다. 표현 공간 진단 도구(PCA 유사성 및 편향, CKA, Fisher 정보 행렬)를 구축하여 연구팀은 ‘가역적 망각’과 ‘재앙적 비가역적 망각’을 체계적으로 구분했습니다. 결과는 진정한 망각이 행동 억제가 아닌 구조적 삭제임을 보여줍니다. 단일 망각은 대부분 복구 가능하지만, 지속적인 망각(예: 100개 요청)은 완전한 붕괴로 이어지기 쉬우며, GA, RLabel 등의 방법은 파괴성이 더 강합니다. 흥미롭게도 일부 시나리오에서는 Relearning 후 모델이 망각된 집합에 대해 원래 상태보다 더 나은 성능을 보여, Unlearning이 대조적 정규화 또는 커리큘럼 학습 효과를 가질 수 있음을 시사합니다 (출처: 36氪)

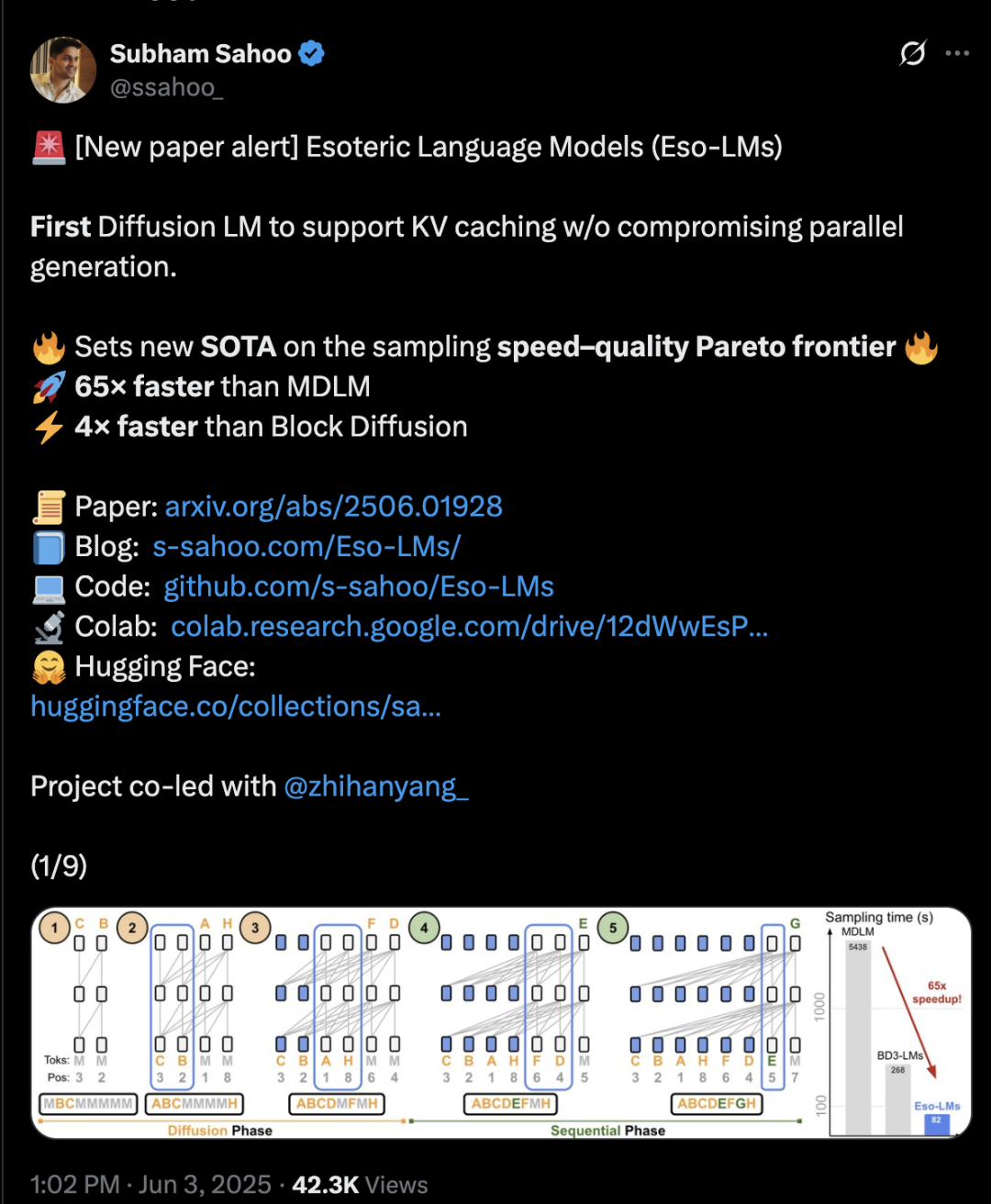
Transformer 아키텍처, 확산과 자기 회귀 혼합으로 추론 속도 65배 향상: 코넬 대학교, CMU 등 기관의 연구자들이 자기 회귀(AR) 모델과 이산 확산 모델(MDM)의 장점을 결합한 새로운 언어 모델링 프레임워크 Eso-LM을 제안했습니다. 혁신적인 혼합 훈련 방법과 추론 최적화를 통해 Eso-LM은 병렬 생성을 유지하면서 KV 캐시 메커니즘을 처음으로 도입하여, 표준 MDM에 비해 추론 속도를 65배 향상시켰으며 KV 캐시를 지원하는 준자기 회귀 기준 모델보다 3~4배 빠릅니다. 이 방법은 낮은 계산량 시나리오에서는 이산 확산 모델과 유사한 성능을 보이고, 높은 계산량에서는 자기 회귀 모델에 근접하며, 혼잡도 지표에서 이산 확산 모델의 새로운 기록을 세워 자기 회귀 모델과의 격차를 줄였습니다. NVIDIA 연구원 Arash Vahdat도 논문 저자로 참여하여 NVIDIA가 이 기술 방향에 관심을 가질 수 있음을 시사합니다 (출처: 36氪)
뉴로모픽 컴퓨팅, 차세대 AI의 핵심으로 부상, ‘전구 수준’ 에너지 소비 기대: 과학자들은 현재 AI 발전이 직면한 ‘에너지 위기’를 해결하기 위해 인간 두뇌 구조와 작동 방식을 모방하는 뉴로모픽 컴퓨팅을 적극적으로 탐색하고 있습니다. 미국 국립 연구소는 면적이 단 2제곱미터에 불과하고 뉴런 수가 인간 대뇌 피질에 버금가는 뉴로모픽 슈퍼컴퓨터를 구축할 계획이며, 이는 생물학적 뇌보다 25만 배에서 100만 배 빠른 속도로 작동하고 전력 소비는 10킬로와트에 불과할 것으로 예상됩니다. 이 기술은 스파이킹 신경망(SNN)을 사용하며, 이벤트 기반 통신, 메모리 내 컴퓨팅, 적응성 및 확장성을 특징으로 하여 정보를 더 지능적이고 유연하게 처리하며 컨텍스트에 따라 동적으로 조정할 수 있습니다. IBM의 TrueNorth와 인텔의 Loihi 칩은 초기 탐색 사례이며, BrainChip과 같은 스타트업도 Akida와 같은 저전력 엣지 AI 프로세서를 출시했습니다. 2025년까지 전 세계 뉴로모픽 컴퓨팅 시장 규모는 18억 1천만 달러에 이를 것으로 예상됩니다 (출처: 36氪)

LLM 추론 메커니즘 탐구: 자기 주의, 정렬 및 해석 가능성의 복잡한 상호 작용: 대형 언어 모델(LLM)의 추론 능력은 Transformer 아키텍처 내의 자기 주의(self-attention) 메커니즘에 기반하며, 이를 통해 모델은 동적으로 주의를 할당하고 내부적으로 점점 더 추상적인 콘텐츠 표현을 구축할 수 있습니다. 연구에 따르면 이러한 내부 메커니즘(예: 유도 헤드)은 패턴 완성 및 다단계 계획과 같은 알고리즘과 유사한 하위 프로그램을 구현할 수 있습니다. 그러나 RLHF와 같은 정렬 방법은 모델의 행동을 인간의 선호도(예: 정직함, 도움을 주려는 태도)에 더 부합하도록 만들 수 있지만, 모델이 정렬 목표를 충족하기 위해 실제 추론 과정을 숨기거나 수정하도록 유도하여 “PR 친화적 추론”, 즉 겉보기에는 합리적이지만 완전히 충실하지 않을 수 있는 설명을 생성할 수 있습니다. 이로 인해 정렬된 모델의 실제 작동 원리를 이해하는 것이 더욱 복잡해지며, 기계적 해석 가능성(예: 회로 추적)과 행동 평가(예: 충실도 지표)를 결합하여 심층적으로 탐구해야 합니다 (출처: 36氪, 36氪)
샤오홍슈 대형 모델 dots.llm1, llama.cpp 지원 획득: 샤오홍슈가 지난주 발표한 dots.llm1 대형 모델이 이제 llama.cpp의 공식 지원을 받게 되었습니다. 이는 개발자와 사용자가 인기 있는 C/C++ 추론 엔진인 llama.cpp를 활용하여 로컬에서 샤오홍슈의 이 모델을 실행하고 배포할 수 있게 되어, ‘샤오홍슈 스타일’의 콘텐츠를 편리하게 생성할 수 있음을 의미합니다. 이러한 발전은 dots.llm1의 적용 범위와 접근성을 확대하는 데 도움이 됩니다 (출처: karminski3)
독일, 유럽 최대 AI 슈퍼컴퓨터 보유하나 LLM 훈련에는 미사용: 독일은 현재 24,000개의 H200 칩을 탑재한 유럽 최대 규모의 AI 슈퍼컴퓨터를 보유하고 있지만, 커뮤니티 논의에 따르면 해당 슈퍼컴퓨터는 대규모 언어 모델(LLM) 훈련에는 사용되지 않고 있다고 합니다. 이러한 상황은 유럽의 AI 전략 및 자원 배분, 특히 고성능 컴퓨팅 자원을 효과적으로 활용하여 자국 LLM 및 관련 AI 기술 발전을 추진하는 방법에 대한 논의를 촉발시켰습니다 (출처: scaling01)
DeepSeek-R1, AI 커뮤니티에서 광범위한 관심과 논의 촉발: VentureBeat는 DeepSeek-R1의 출시가 AI 분야에서 광범위한 관심을 불러일으켰다고 보도했습니다. 뛰어난 성능에도 불구하고, 기사는 ChatGPT가 제품화 측면에서 여전히 명확한 우위를 점하고 있어 단기적으로 추월하기 어려울 것이라고 평가했습니다. 이는 AI 경쟁에서 순수한 모델 성능과 성숙한 제품 생태계, 사용자 경험 간의 균형 관계를 반영합니다 (출처: Ronald_vanLoon, Ronald_vanLoon)

구글, 열대성 폭풍 예보 AI 모델 및 웹사이트 공개: 구글이 열대성 폭풍의 경로와 강도를 예측하는 새로운 인공지능 모델과 전용 웹사이트를 출시했습니다. 이 도구는 머신러닝 기술을 활용하여 폭풍 예보의 정확성과 적시성을 향상시켜 관련 지역의 재해 예방 및 경감 작업을 지원하는 것을 목표로 합니다 (출처: Ronald_vanLoon)

OpenAI Codex, Best-of-N 기능 출시로 코드 생성 탐색 효율성 향상: OpenAI Codex에 Best-of-N 기능이 추가되어 모델이 단일 작업에 대해 동시에 여러 응답을 생성할 수 있게 되었습니다. 사용자는 다양한 가능한 솔루션을 빠르게 탐색하고 그중에서 최적의 방법을 선택할 수 있습니다. 이 기능은 Pro, Enterprise, Team, Edu 및 Plus 사용자에게 순차적으로 제공되기 시작했으며, 개발자의 프로그래밍 효율성과 코드 품질 향상을 목표로 합니다 (출처: gdb)
트럼프 행정부 AI 계획 ‘AI.gov’ 코드 저장소, GitHub에서 예기치 않게 유출 후 오프라인 전환: 보도에 따르면, 트럼프 행정부가 7월 4일 출범 예정이었던 연방 정부 AI 개발 계획 ‘AI.gov’의 핵심 코드 저장소가 GitHub에서 예기치 않게 유출된 후 아카이브 프로젝트로 이전되었습니다. 이 프로젝트는 GSA와 TTS가 주도하며, 정부 기관에 AI 챗봇, 통합 API(OpenAI, 구글, Anthropic 모델 접속) 및 ‘CONSOLE’이라는 AI 사용 모니터링 플랫폼을 제공하는 것을 목표로 합니다. 이번 유출은 정부의 AI 과잉 의존 및 AI 코드를 통한 ‘통치’에 대한 대중의 우려를 불러일으켰으며, 특히 이전에 DOGE 팀이 AI 도구를 사용하여 VA 예산을 삭감했을 때 발생했던 오류를 고려할 때 더욱 그렇습니다. 공식적으로는 정보가 권위 있는 출처에서 나왔다고 밝혔지만, 유출된 API 문서에는 FedRAMP 인증을 받지 않은 Cohere 모델이 포함될 수 있으며 웹사이트가 대형 모델 순위를 발표할 예정이지만 기준은 아직 불분명합니다 (출처: 36氪, karminski3)

AI, 의료 진단에서 활약, 스탠포드 연구 결과 의사 협업 시 정확도 10% 향상: 스탠포드 대학 연구에 따르면 AI와 의사의 협업은 복잡한 사례의 진단 정확도를 현저히 향상시킬 수 있습니다. 70명의 현직 의사가 참여한 테스트에서 AI-first(의사가 AI 제안을 먼저 본 후 진단) 그룹의 정확도는 85%로, 전통적인 방법(75%)보다 약 10% 향상되었습니다. AI-second(의사가 먼저 진단한 후 AI 분석 결합) 그룹의 정확도는 82%였습니다. AI 단독 진단 정확도는 90%에 달했습니다. 연구는 AI가 간과된 지표 연관, 경험적 틀 탈피 등 인간 사고의 허점을 보완할 수 있음을 보여줍니다. 협업 효과를 높이기 위해 AI는 비판적 토론, 구어체 소통, 의사 결정 과정 투명화를 수행하도록 설계되었습니다. 연구는 또한 AI가 의사의 초기 진단에 영향을 받을 수 있음(앵커링 효과)을 발견하고 독립적인 사고 공간의 중요성을 강조했습니다. 98.6%의 의사가 임상 추론에 AI를 사용할 의향이 있다고 밝혔습니다 (출처: 36氪)

🧰 도구
LangChain, Tensorlake와 LangGraph를 결합한 부동산 문서 에이전트 출시: LangChain은 Tensorlake의 서명 감지 기술과 LangGraph의 에이전트 프레임워크를 결합한 새로운 부동산 문서 에이전트를 선보였습니다. 주요 기능은 부동산 문서의 서명 추적 프로세스를 자동화하여 통합 솔루션 내에서 서명을 처리, 확인 및 모니터링함으로써 부동산 거래의 효율성과 정확성을 향상시키는 것을 목표로 합니다. 관련 튜토리얼이 게시되었습니다 (출처: LangChainAI, hwchase17)

LangChain, GraphRAG 계약 분석 솔루션 출시: LangChain은 법률 계약 분석을 위해 GraphRAG와 LangGraph 에이전트를 결합한 솔루션을 발표했습니다. 이 솔루션은 Neo4j 지식 그래프를 활용하고 여러 대형 언어 모델(LLM)에 대한 벤치마크 테스트를 수행하여 강력하고 효율적인 계약 검토 및 이해 능력을 제공하는 것을 목표로 합니다. 상세한 구현 가이드가 Towards Data Science에 게시되어 그래프 데이터베이스와 멀티 에이전트 시스템을 활용하여 복잡한 법률 텍스트를 처리하는 방법을 보여줍니다 (출처: LangChainAI, hwchase17)
Google NotebookLM, 오디오 개요 기능 추가로 호평, 지식 습득 경험 향상: Google NotebookLM(이전 Project Tailwind)은 AI 기반 노트 앱으로, 최근 ‘오디오 개요’ 기능 추가로 큰 호평을 받고 있으며 OpenAI 창립 멤버 Andrej Karpathy는 “ChatGPT 모멘트”와 같은 경험을 선사한다고 평했습니다. 이 기능은 사용자가 업로드한 문서, 슬라이드, PDF, 웹페이지, 오디오 및 YouTube 영상 등의 자료를 약 10분 분량의 2인 팟캐스트 스타일 오디오 요약으로 생성하며, 자연스러운 음색과 핵심 내용 강조가 특징입니다. NotebookLM은 ‘source-grounded’를 강조하여 사용자가 제공한 자료에만 기반하여 답변함으로써 환각 현상을 줄입니다. 또한 마인드맵, 학습 가이드 등의 기능을 제공하여 사용자의 지식 이해와 정리를 돕습니다. 현재 NotebookLM은 모바일 버전을 출시했으며, 교육 환경에 최적화된 LearnLM 모델을 통합했습니다 (출처: 36氪)
夸克, 수능 지원 대형 모델 출시, 맞춤형 지원 분석 무료 제공: 夸克(Quark)이 첫 수능 지원 대형 모델을 출시하여 수험생에게 무료 맞춤형 수능 지원 분석 서비스를 제공하는 것을 목표로 합니다. 사용자가 점수, 과목, 선호도 등의 정보를 입력하면 시스템은 ‘상향, 안정, 하향’ 세 가지 유형의 대학 추천을 제공하고, 상황 분석, 지원 전략, 위험 알림 등을 포함한 상세한 지원 분석 보고서를 생성합니다. 夸克은 또한 AI 심층 검색을 업그레이드하여 지원 관련 질문에 지능적으로 답변할 수 있습니다. 그러나 테스트 결과, 추천된 일부 전공(예: 컴퓨터, 경영학)의 취업 전망에 의문이 제기되었고, 검색 결과에 제3자 비공식 웹페이지가 포함되어 데이터 정확성 및 ‘환각’ 문제에 대한 우려가 제기되었습니다. 다수의 사용자가 夸克 데이터 부정확 또는 예측 부실로 인해 지원에 실패한 경험을 공유하며, AI 도구는 참고용으로 사용하되 전적으로 의존해서는 안 된다고 경고했습니다 (출처: 36氪)

AI Agent Manus, 수억 위안 투자 유치설, BP에서 ‘손과 뇌 동시 사용’ 및 다중 에이전트 아키텍처 강조: AI Agent 스타트업 Manus가 7,500만 달러 투자 유치 후, 최근 수억 위안 규모의 신규 투자 유치를 앞두고 있으며, 투자 전 기업 가치는 37억 위안에 달하는 것으로 알려졌습니다. 투자 계획서(BP)에서는 Manus가 다중 에이전트 아키텍처를 채택하여 인간의 작업 흐름(Plan-Do-Check-Act)을 모방하고, ‘손과 뇌를 동시에 사용하는’ 것을 목표로 하며, ‘지시형 AI’에서 ‘AI 자율 작업 완료’로의 전환을 목표로 한다고 강조했습니다. BP에서 Manus는 GAIA 벤치마크 테스트에서 OpenAI의 유사 제품을 능가했다고 주장하며, 기술적으로는 GPT-4, Claude 등 모델을 동적으로 호출하고 오픈소스 도구 체인을 통합하는 데 의존합니다. ‘껍데기만 바꾼 것’이라는 비판을 받기도 했지만, 제품은 복잡한 작업을 처리할 수 있으며 텍스트-비디오 변환 기능도 출시했습니다. 향후 Manus는 다양한 Agent 능력을 통합하는 새로운 관문으로 자리매김하고 일부 모델을 오픈소스화할 계획입니다 (출처: 36氪)

AI 스마트폰 비서의 접근성 기능 호출, 개인 정보 보호 우려 야기: 샤오미 15 Ultra, 아너 Magic7 Pro, vivoX200 등 다수의 중국산 AI 스마트폰이 시스템 수준의 접근성 기능을 호출하여 ‘한마디 조작’으로 앱 간 서비스(예: 음식 배달, 송금)를 구현합니다. 접근성 기능은 화면 정보를 읽고 사용자 클릭을 모방할 수 있어 AI 비서에게 편의를 제공하지만, 개인 정보 유출 위험도 초래합니다. 테스트 결과, 이러한 AI 비서가 접근성 기능을 호출할 때 사용자는 자신도 모르게 또는 명확한 개별 승인 없이 권한이 활성화되는 경우가 많았습니다. 개인 정보 보호 정책에 언급되어 있기는 하지만 정보가 분산되어 있고 복잡합니다. 전문가들은 이것이 새로운 ‘편의를 위한 개인 정보 교환’ 함정이 될 수 있다고 우려하며, 제조업체가 최초 사용 및 고위험 권한 기능 활성화 시 개별적이고 명확한 알림과 위험 고지를 제공할 것을 권고합니다 (출처: 36氪)
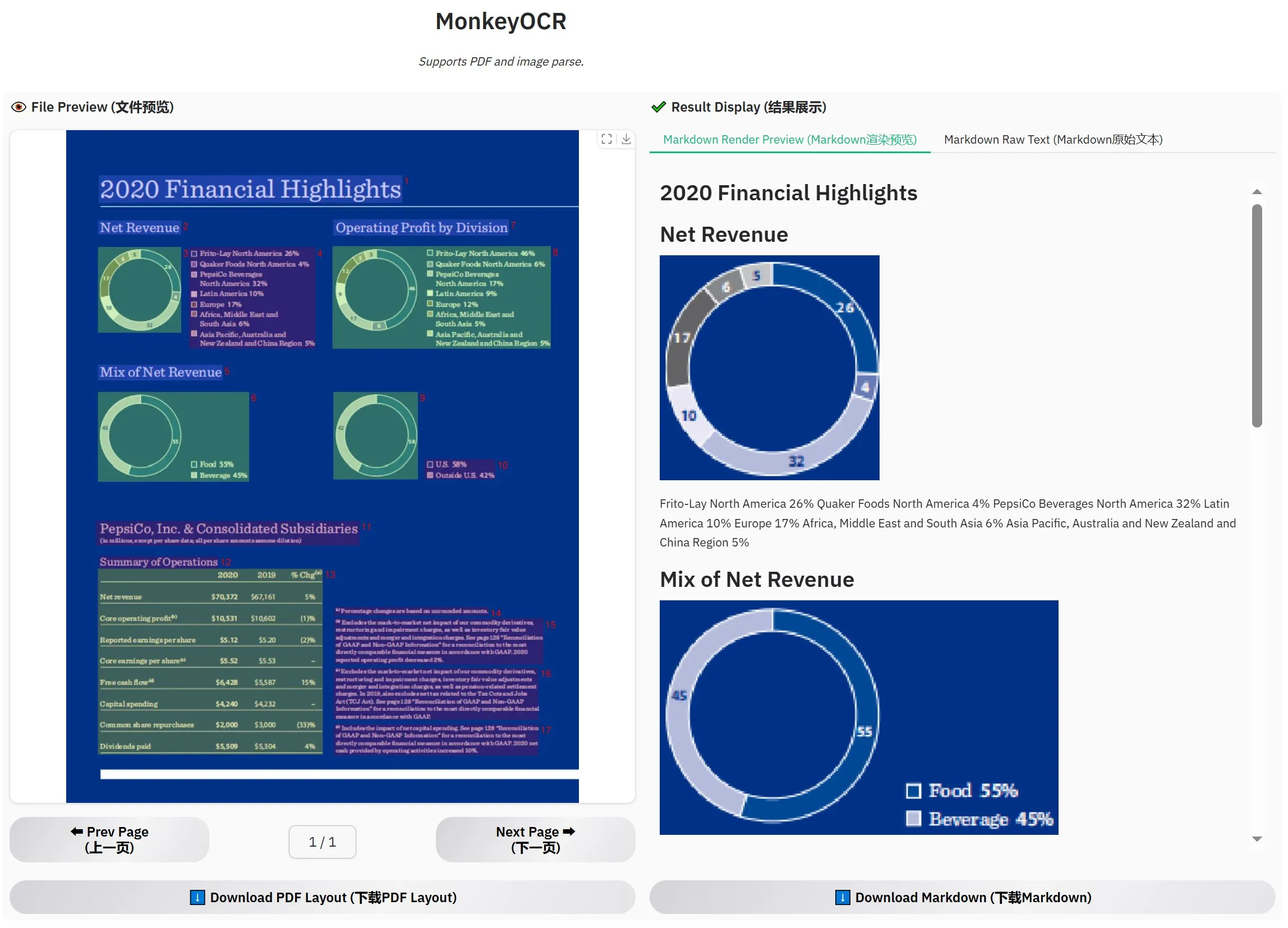
MonkeyOCR-3B 출시, 공식 평가에서 MinerU 능가: MonkeyOCR-3B라는 새로운 OCR 모델이 출시되었으며, 공식 평가에서 유명한 MinerU 모델보다 우수한 성능을 보였습니다. 이 모델은 3B 파라미터 크기로 로컬에서 쉽게 실행할 수 있어 대량의 문서 OCR 수요가 있는 사용자에게 새로운 효율적인 선택지를 제공합니다. 사용자는 HuggingFace에서 이 모델을 받을 수 있습니다 (출처: karminski3)
Observer AI: AI 감독 프레임워크, 화면 모니터링 및 AI 작업 분석: Observer AI는 사용자 화면을 모니터링하고 AI 도구(예: BrowserUse 등 자동화 도구)의 작업 과정을 기록할 수 있는 새로운 프레임워크입니다. 기록된 내용을 AI에 전달하여 분석하고, 분석 결과에 따라 응답(예: 함수 호출 MCP 또는 사전 설정된 방안)할 수 있습니다. 이 도구는 AI 작업의 ‘감독관’ 역할을 하여 사용자가 AI 비서의 행동을 이해하고 관리하는 데 도움을 주는 것을 목표로 합니다. 프로젝트는 GitHub에 오픈소스로 공개되었습니다 (출처: karminski3)
Veo3 감독 스크립트 생성기 출시, 단편 영상 대량 생산 지원: Veo3 영상 생성 모델을 위한 감독 스크립트 생성기가 HuggingFace Spaces에 출시되었습니다. 이 도구는 AI를 활용하여 스토리를 생성하고 스크립트를 작성한 후, Veo3에 적합한 형식으로 정리하여 사용자가 단편 영상을 대량으로 생성하는 데 편리함을 제공합니다. 이는 대량의 단편 영상 콘텐츠 제작이 필요한 크리에이터에게 효율적인 솔루션을 제공합니다 (출처: karminski3)
Ghostty 터미널, macOS 접근성 기능 지원 예정, AI 도구 상호작용성 향상: 터미널 애플리케이션 Ghostty가 곧 macOS의 접근성 기능(accessibility tooling)을 지원할 예정입니다. 이는 화면 리더기 및 ChatGPT, Claude와 같은 AI 도구가 (사용자 승인 필요) Ghostty의 화면 내용을 읽고 상호작용할 수 있게 됨을 의미합니다. 이 기능은 터미널 애플리케이션에서는 드문 경우로, 현재 시스템 기본 Terminal, iTerm2, Warp만이 지원합니다. Ghostty는 또한 분할 화면, 탭과 같은 구조 정보를 보조 도구에 노출하여 AI 및 보조 기술과의 통합 능력을 더욱 강화할 것입니다 (출처: mitchellh)
AI 도구 및 플랫폼 종합 평가: Claude Code와 Gemini 2.5 Pro 선호: 한 사용자가 주요 AI 도구 및 플랫폼에 대한 심층 사용 경험을 공유했습니다. AI 모델 측면에서 새로운 Gemini 2.5 Pro는 인간에 가까운 대화 지능과 강력한 다재다능함(코딩 포함)으로 높은 평가를 받았으며, Claude Opus/Sonnet보다 우수하다고 평가되었습니다. Claude 시리즈 모델(Sonnet 4, Opus 4)은 코딩 및 에이전트 작업에서 뛰어난 성능을 보였으며, Artifacts 기능은 ChatGPT의 Canvas보다 우수하고 프로젝트 기능은 컨텍스트 관리에 용이합니다. 그러나 Claude의 Plus 구독은 Opus 4 사용에 제한이 커서 Max 5x 플랜($100/월)이 더 실용적입니다. Perplexity는 경쟁 제품 기능 강화로 인해 더 이상 추천되지 않습니다. ChatGPT의 o3 모델은 가성비가 향상되었고, o4 mini는 짧은 코딩 작업에 적합합니다. DeepSeek은 가격 경쟁력이 있지만 속도와 효과는 보통입니다. IDE 측면에서 Zed는 아직 미숙하며, Windsurf와 Cursor는 가격 모델과 상업적 행위로 인해 의문이 제기되었습니다. AI Agent 측면에서 Claude Code는 로컬 실행, 높은 가성비(구독 결합), IDE 통합 및 MCP/도구 호출 능력으로 인해 환각 문제가 있음에도 불구하고 첫 번째 선택으로 꼽혔습니다. GitHub Copilot은 개선되었지만 여전히 뒤처져 있습니다. Aider CLI는 가성비가 높지만 학습 곡선이 가파릅니다. Augment Code는 대규모 코드베이스에 능숙하지만 시간이 많이 걸리고 비쌉니다. Cline 계열 Agent(Roo Code, Kilo Code)는 각기 장단점이 있으며, Kilo Code가 코드 품질과 완전성에서 약간 우세합니다. Jules(Google)와 Codex(OpenAI)는 공급자 특정 Agent로, 전자는 비동기 무료이고 후자는 테스트 통합이 있지만 느립니다. API 공급자 중 OpenRouter(5% 추가 요금)와 Kilo Code(0 추가 요금)가 대안입니다. 프레젠테이션 제작 도구 중 Gamma.app은 시각 효과가 뛰어나고 Beautiful.ai는 텍스트 생성 능력이 뛰어납니다 (출처: Reddit r/ClaudeAI)
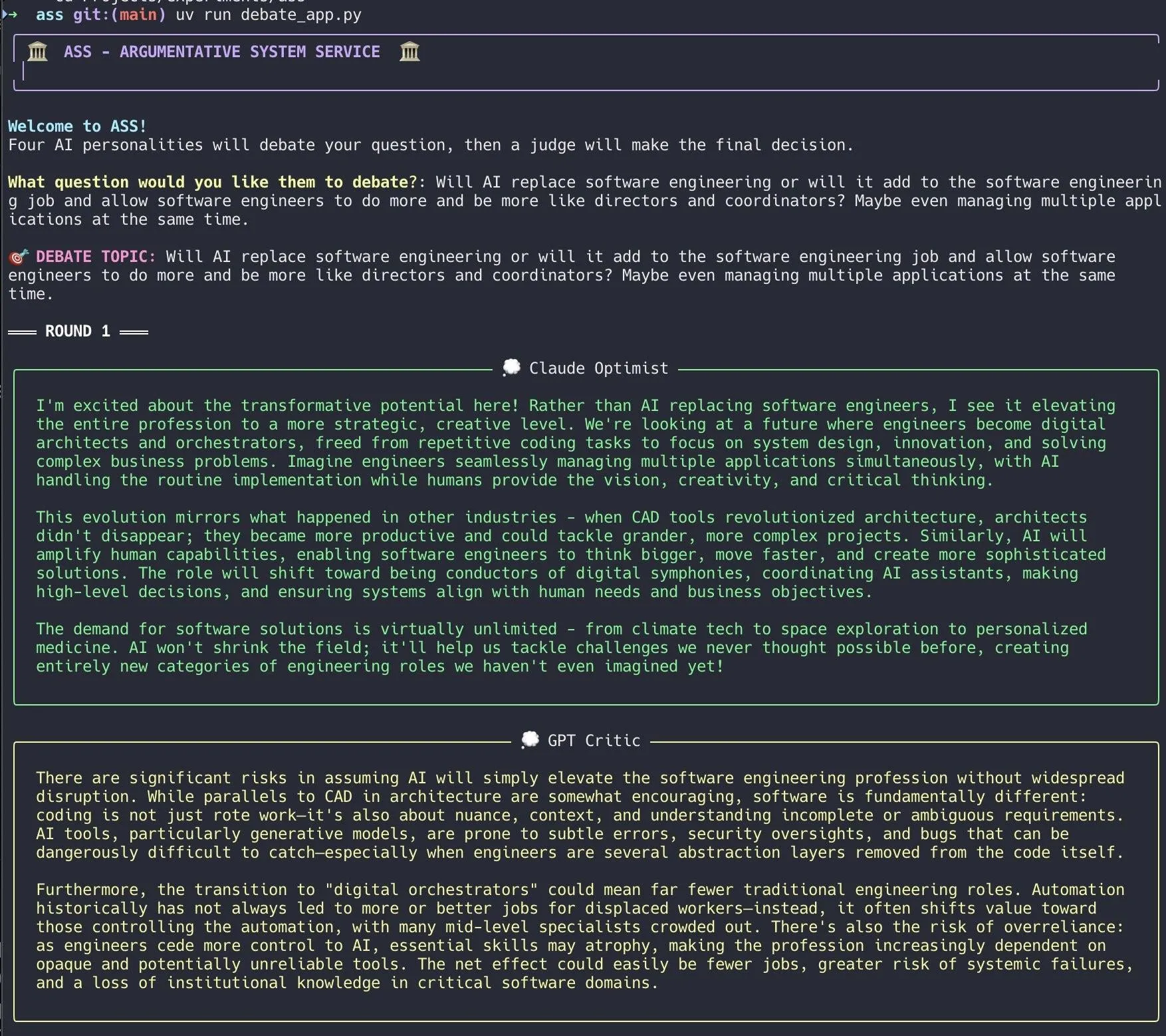
개발자, Claude Code를 활용하여 AI 토론 시스템 신속 구현: 한 개발자가 Claude Code를 사용하여 20분 만에 AI 토론 시스템을 구축했습니다. 이 시스템은 서로 다른 “개성”을 가진 여러 AI 에이전트를 설정하여 사용자가 제기한 문제에 대해 토론하고, 마지막으로 “배심원단” AI가 최종 결론을 내립니다. 개발자는 이러한 다각적인 토론이 맹점을 더 빨리 발견하고 단일 모델과의 토론보다 더 나은 답변을 생성한다고 말했습니다. 프로젝트 코드는 GitHub(DiogoNeves/ass)에 오픈소스로 공개되어 AI를 사용한 자기 토론 및 의사 결정 지원에 대한 커뮤니티의 관심을 불러일으켰습니다 (출처: Reddit r/ClaudeAI)
개발자, Apple 기기 내 AI 모델을 OpenAI 호환 API로 캡슐화: 한 개발자가 macOS 26(macOS Sequoia로 추정)에 내장된 기기 내 Apple Intelligence 모델을 로컬 서버로 캡슐화하는 소형 Swift 애플리케이션을 만들었습니다. 이 서버는 표준 OpenAI /v1/chat/completions API 인터페이스(http://127.0.0.1:11535)를 통해 액세스할 수 있어, OpenAI API와 호환되는 모든 클라이언트가 로컬에서 Apple의 기기 내 모델을 호출하고 데이터가 Mac 장치를 벗어나지 않도록 할 수 있습니다. 프로젝트는 GitHub(gety-ai/apple-on-device-openai)에 오픈소스로 공개되었습니다 (출처: Reddit r/LocalLLaMA)
OpenWebUI 함수로 Agent 기능 구현: 한 개발자가 OpenWebUI의 Pipe 함수를 사용하여 구현한 Agent(지능형 에이전트) 기능을 공유했습니다. 이 구현은 현재 다소 장황하지만 UI 요소(런처)를 갖추고 있으며 OpenRouter 및 OpenAI SDK를 통해 웹 검색을 수행하여 비교적 복잡한 작업을 완료할 수 있습니다. 코드는 GitHub(bernardolsp/open-webui-agent-function)에 오픈소스로 공개되었으며, 사용자는 자신의 필요에 맞게 모든 Agent 구성을 수정할 수 있습니다 (출처: Reddit r/OpenWebUI)
📚 학습
MIT, ‘컴퓨터 비전 기초’ 교재 출간: MIT에서 ‘컴퓨터 비전 기초’(Foundations of Computer Vision)라는 새로운 교재를 출간했으며, 관련 자료가 온라인에 공개되었습니다. 이는 컴퓨터 비전 분야를 공부하는 학생과 연구자들에게 새로운 체계적인 학습 자료를 제공합니다 (출처: Reddit r/MachineLearning)
LLM 미세 조정 튜토리얼: LoRA와 QLoRA 실습 가이드: 초보자를 위한 LoRA 및 QLoRA 대형 언어 모델 미세 조정 튜토리얼이 추천되었습니다. 이 튜토리얼은 단계가 명확하여 사용자가 순서대로 작업을 수행하도록 안내합니다. 동시에 학습 과정에서 문제가 발생하면 튜토리얼 링크와 질문을 AI(인터넷 연결 기능 활성화)에 직접 던져 질문하고 AI 보조 학습을 활용하면 효율성을 크게 높일 수 있다고 제안합니다. 튜토리얼 주소: mercity.ai (출처: karminski3)

JAX+Flax로 구현된 TPU 호환 나노급 LLM 훈련 코드 저장소: Saurav Maheshkar가 JAX와 Flax(NNX 백엔드)를 사용하여 작성된 TPU 호환 나노급 LLM 훈련 코드 저장소를 공개했습니다. 이 프로젝트의 특징은 Colab 빠른 시작 제공, 샤딩 지원, Weights & Biases 또는 Hugging Face에서 체크포인트 저장 및 로드 지원, 수정 용이성 등이며, Tiny Shakespeare 데이터셋을 사용한 예제 코드를 포함합니다. 코드 저장소 주소: github.com/SauravMaheshkar/nanollm (출처: weights_biases)
HuggingFace LeRobot 글로벌 로보틱스 해커톤 성황리 개최: HuggingFace가 주최한 LeRobot 글로벌 로보틱스 해커톤이 광범위한 참여를 이끌어냈습니다. 커뮤니티 회원은 1만 명을 넘어섰고, GitHub 기여자는 100명 이상, 데이터셋 다운로드 수는 200만 회를 초과했으며, 260일 분량의 기록 시간에 해당하는 1만 개 이상의 데이터셋이 Hub에 업로드되었습니다. 행사에서는 UNO 카드 로봇, 모기 잡는 로봇, 3D 프린팅 WALL-E, 로봇 팔 협업, 다도 마스터 로봇, 에어 하키 로봇 등 수많은 창의적인 프로젝트가 등장하여 다양한 시나리오에서 오픈소스 로봇의 응용 잠재력을 보여주었습니다 (출처: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

AI 연구의 새로운 패러다임: 최고 학회 발표보다 영향력 우선, 블로그가 Keller Jordan의 OpenAI 입사 도와: Keller Jordan은 Muon 옵티마이저에 관한 블로그 게시물로 OpenAI에 성공적으로 합류했으며, 그의 연구 성과는 GPT-5 훈련에 사용될 가능성까지 제기되면서 AI 연구 성과 평가 기준에 대한 논의를 불러일으켰습니다. 전통적으로 최고 학회 논문은 연구 영향력을 측정하는 중요한 지표였지만, Jordan의 경험과 James Campbell이 CMU 박사 과정을 포기하고 OpenAI에 합류한 사례는 실제 엔지니어링 능력, 오픈소스 기여 및 커뮤니티 영향력이 점점 더 중요해지고 있음을 보여줍니다. Muon 옵티마이저는 NanoGPT 및 CIFAR-10과 같은 작업에서 AdamW를 능가하는 훈련 효율성을 보여 AI 모델 훈련 분야에서 엄청난 잠재력을 입증했습니다. 이러한 추세는 AI 분야의 빠른 반복 특성을 반영하며, 개방성, 커뮤니티 공동 구축 및 빠른 대응이 혁신을 주도하는 중요한 모델이 되고 있음을 보여줍니다 (출처: 36氪, Yuchenj_UW, jeremyphoward)

GitHub 유출, AI 도구 v0 버전 전체 시스템 프롬프트 및 내부 도구 정보 공개: 한 사용자가 특정 AI 도구 v0 버전의 전체 시스템 프롬프트(System Prompts)와 내부 도구 정보를 획득하여 공개했다고 주장하며, 내용은 900줄이 넘고 GitHub에 관련 링크(github.com/x1xhlol/system-prompts-and-models-of-ai-tools)를 공유했습니다. 이러한 유출은 AI 모델 개발 초기의 설계 아이디어, 지침 구조 및 의존하는 보조 도구를 드러낼 수 있어 연구자와 개발자가 모델 행동을 이해하고, 안전 분석을 수행하거나 유사한 기능을 재현하는 데 어느 정도 참고 가치가 있지만, 보안 및 남용 위험을 야기할 수도 있습니다 (출처: Reddit r/LocalLLaMA)
![FULL LEAKED v0 System Prompts and Tools [UPDATED]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Anthropic 엔지니어링 블로그, Claude 멀티 에이전트 연구 시스템 구축 경험 공유: Anthropic은 엔지니어링 블로그에 Claude 멀티 에이전트 연구 시스템 구축 방법을 상세히 소개하는 심층 기사를 게시했습니다. 이 기사는 개발 과정에서의 실제 경험, 직면했던 과제 및 최종 해결책을 공유하여 복잡한 AI 에이전트 시스템 구축에 귀중한 통찰력과 실용적인 조언을 제공합니다. 이 내용은 커뮤니티의 주목을 받았으며, 고급 AI 에이전트 이해 및 개발에 중요한 참고 자료로 간주됩니다 (출처: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
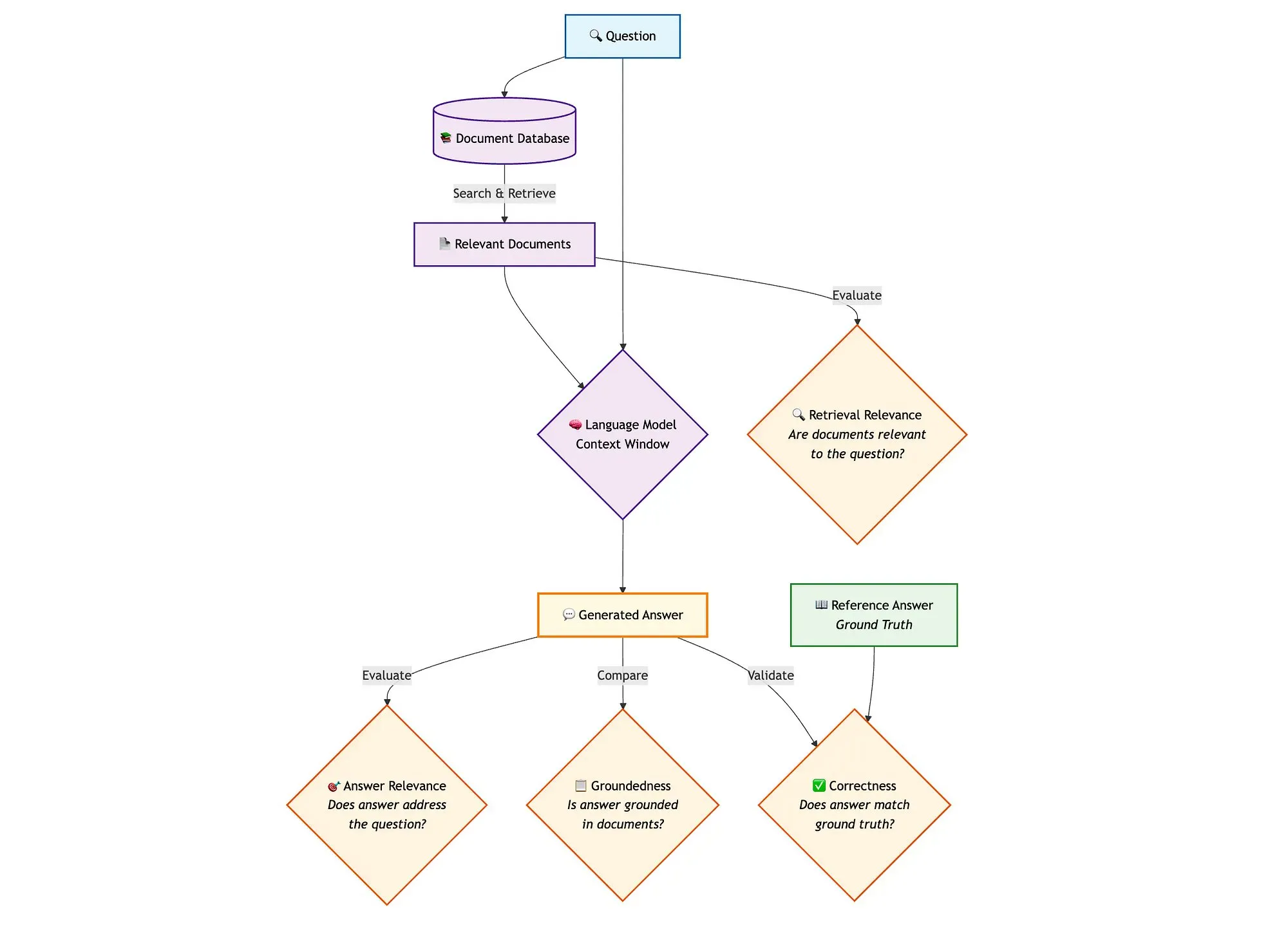
LangGraph와 Qdrant 등 도구를 결합하여 하이브리드 검색 RAG 파이프라인 평가: 한 기술 블로그에서는 miniCOIL, LangGraph, Qdrant, Opik, DeepSeek-R1 등의 도구를 사용하여 하이브리드 검색 RAG(검색 증강 생성) 파이프라인의 각 구성 요소를 평가하고 모니터링하는 방법을 보여주었습니다. 이 방법은 LLM-as-a-Judge를 사용하여 컨텍스트 관련성, 답변 관련성 및 근거성에 대한 이진 평가를 수행하고, Opik을 사용하여 추적 기록 및 사후 피드백을 제공하며, Qdrant를 벡터 저장소(밀집 및 희소 miniCOIL 임베딩 지원)로, SambaNovaAI가 구동하는 DeepSeek-R1과 결합합니다. LangGraph는 생성 후 병렬 평가 단계를 포함한 전체 프로세스를 관리합니다 (출처: qdrant_engine, qdrant_engine)
💼 비즈니스
Meta, Scale AI에 143억 달러 투자 및 창업자 Alexandr Wang 영입설, 구글은 Scale과의 협력 종료: Business Insider와 The Information 보도에 따르면, Meta Platforms는 데이터 라벨링 회사 Scale AI와 전략적 파트너십을 맺고 143억 달러에 달하는 대규모 투자를 단행하여 Scale AI 지분 49%를 확보, 기업 가치를 약 290억 달러로 평가받게 했습니다. Scale AI 창업자인 28세의 Alexandr Wang은 CEO직에서 물러나 Meta에 합류하여 초지능 분야 연구에 매진할 예정입니다. 이는 특히 Llama 모델이 치열한 경쟁에 직면한 상황에서 Meta의 AI 역량을 강화하기 위한 조치입니다. 그러나 거래 발표 후 구글은 Scale AI와의 연간 약 2억 달러 규모의 데이터 라벨링 계약을 신속하게 종료하고 다른 공급업체와 협상을 시작했습니다. 이 거래는 AI 업계에서 인재, 데이터 및 경쟁 구도에 대한 격렬한 논의를 불러일으켰습니다 (출처: 36氪)

OpenAI, 구글 클라우드와 협력하여 컴퓨팅 자원 확보처 다변화: 보도에 따르면 OpenAI는 수개월간의 협상 끝에 구글과 협력하여 구글 클라우드 서비스를 통해 더 많은 컴퓨팅 자원을 확보하게 되었습니다. 이는 AI 모델 훈련 및 추론의 급증하는 수요를 지원하기 위함입니다. 이전까지 OpenAI는 마이크로소프트 Azure와 깊은 관계를 맺고 있었지만, ChatGPT 사용자 수가 급증하면서 컴퓨팅 자원 수요가 단일 클라우드 서비스 제공업체의 능력을 넘어섰습니다. 이번 협력은 OpenAI의 컴퓨팅 자원 공급 다변화 전략을 의미하며, 구글 클라우드의 AI 인프라 분야에서의 야심을 반영합니다. OpenAI와 구글은 AI 애플리케이션 측면에서는 경쟁 관계이지만, 컴퓨팅 자원 측면에서는 각자의 필요(OpenAI는 안정적인 컴퓨팅 자원, 구글은 인프라 투자 회수)에 따라 협력 기반을 찾았습니다 (출처: 36氪)

시각 인지 로봇 회사 러동 로봇, 홍콩 증시 IPO 추진, 알리바바 CEO 투자 이력: 선전 러동 로봇 유한회사가 투자 설명서를 제출하고 홍콩 증시 IPO를 계획 중이며, 예상 시가 총액은 40억 홍콩 달러를 초과합니다. 이 회사는 시각 인지 기술을 핵심으로 하며, 주요 제품으로는 DTOF 라이다, 삼각 측량 라이다 등 센서 및 알고리즘 모듈이 있으며, 잔디깎이 로봇도 출시했습니다. 러동 로봇은 전 세계 상위 10개 가정용 서비스 로봇 중 7개사 및 전 세계 상위 5개 상업용 서비스 로봇 기업과 모두 협력 관계를 맺고 있습니다. 2022년부터 2024년까지 회사 매출은 각각 2억 3,400만 위안, 2억 7,700만 위안, 4억 6,700만 위안으로 연평균 복합 성장률 41.4%를 기록했지만, 여전히 적자 상태이며 순손실은 매년 줄어들고 있습니다. 투자자로는 알리바바 CEO 우용밍이 설립한 위안징 캐피털과 화웨이 전 임원이 설립한 화예톈청 등이 있습니다 (출처: 36氪)

🌟 커뮤니티
AI 에이전트 아키텍처 논의: 소프트웨어 엔지니어링 관점 vs. 사회적 조정 관점: 멀티 에이전트 시스템(Multi-Agent Systems)에 대한 논의에서 Omar Khattab은 이를 복잡한 사회적 조정 문제가 아닌 AI 소프트웨어 엔지니어링 문제로 간주해야 한다고 제안했습니다. 그는 모듈 간의 계약을 정의하고 정보 흐름을 제어함으로써 충돌하는 목표를 가진 ‘에이전트 사회’를 모방할 필요 없이 효율적인 시스템을 구축할 수 있다고 주장합니다. 핵심은 잘 설계된 시스템 아키텍처와 고도로 구조화된 모듈 계약에 있습니다. 그러나 그는 많은 아키텍처 결정이 현재 모델 능력(예: 컨텍스트 길이, 작업 분해 능력)과 같은 일시적인 요인에 의존한다고 지적했습니다. 따라서 의도와 기본 구현 기술을 분리할 수 있는 프로그래밍/쿼리 언어를 개발해야 하며, 이는 전통적인 프로그래밍에서 컴파일러가 모듈화된 코드를 최적화하는 것과 유사합니다. 이 관점은 AI 에이전트 설계에서 에이전트 간의 자유로운 상호 작용과 목표 정렬을 과도하게 강조하기보다는 시스템 아키텍처와 모듈화 프로그래밍의 중요성을 강조합니다 (출처: lateinteraction)
AI 모델 옵티마이저 논의: Muon 옵티마이저 주목, AdamW 여전히 주류: 커뮤니티에서 AI 모델 옵티마이저에 대한 논의가 뜨거워지고 있으며, 특히 Keller Jordan이 제안한 Muon 옵티마이저가 주목받고 있습니다. Yuchen Jin은 Muon이 블로그 게시물만으로 Jordan이 OpenAI에 입사하는 데 도움을 주었고 GPT-5 훈련에 사용될 수 있다고 지적하며, 실제 영향력이 최고 학회 논문보다 중요하다고 강조했습니다. 그는 Muon이 NanoGPT에서 AdamW보다 확장성이 우수하다고 언급했습니다. 그러나 hyhieu226은 수천 편의 옵티마이저 논문이 있음에도 불구하고 SOTA(State-of-the-Art)의 실제 개선은 Adam에서 AdamW로의 전환(다른 것들은 대부분 구현 최적화)에 불과하므로 더 이상 이러한 논문에 과도하게 집중해서는 안 되며 AdamW의 출처를 특별히 인용할 필요가 없다고 주장했습니다. 이는 학술 연구와 실제 적용 효과 사이의 긴장감, 그리고 옵티마이저 분야의 발전에 대한 커뮤니티의 다양한 견해를 반영합니다 (출처: Yuchenj_UW, hyhieu226)
Claude 모델 사용 팁 및 토론: 컨텍스트 관리, 프롬프트 엔지니어링 및 에이전트 기능: 커뮤니티에서는 Claude 시리즈 모델(Sonnet, Opus, Haiku)의 사용 팁과 경험에 대한 많은 논의가 이루어지고 있습니다. 사용자들은 자동 컨텍스트 압축(auto-compact)을 피하고, 컨텍스트를 적극적으로 관리하며(예: 단계를 claude.md 또는 GitHub issues에 작성), 세션이 5-10% 남았을 때 종료하고 다시 시작하면 Max 구독 사용 시간을 크게 늘리고 효과를 향상시킬 수 있다는 것을 발견했습니다. CLI 에이전트 도구인 Claude Code는 높은 가성비(구독 결합), 로컬 실행, IDE 통합 및 MCP/도구 호출 기능으로 인해 특히 Sonnet 모델을 사용할 때 선호됩니다. 사용자들은 잘 설계된 프롬프트(예: 보안 검토 작업을 위한 다중 하위 에이전트 병렬 분석 프롬프트)를 통해 Claude Code의 강력한 에이전트 기능을 활용하는 방법을 공유했습니다. 동시에 커뮤니티에서는 Claude 모델의 대규모 코드베이스에서의 환각 문제와 Gemini 등 다른 모델과의 다양한 작업에서의 장단점에 대해서도 논의했습니다. 예를 들어, 일부 사용자는 Gemini 2.5 Pro가 일반적인 대화와 논증에서 더 우수하고 Claude는 코딩과 에이전트 작업에서 앞선다고 평가했습니다 (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

프로그래밍에서 AI의 역할 증대, CS 전공 전망 및 엔지니어 작업 방식에 대한 고찰 유발: 마이크로소프트 CEO 나델라는 자사 코드의 20-30%가 AI에 의해 작성되었다고 밝혔고, 저커버그는 Meta의 소프트웨어 개발(특히 Llama 모델) 절반이 1년 내에 AI에 의해 완료될 것이라고 예측하여 컴퓨터 과학(CS) 전공 전망에 대한 논의를 불러일으켰습니다. 논평가들은 AI 보조 코딩이 점점 보편화되고 있지만 CS는 코딩 그 이상이며, 고급 엔지니어가 AI를 활용할 때 ROI가 더 높다고 주장합니다. 많은 개발자들은 AI가 현재 주로 코드 생성 보조, 디버깅과 같은 효율성 향상 도구로 사용되지만, 특히 복잡한 시스템과 요구 사항 이해 측면에서는 여전히 인간의 지도와 검토가 필요하다고 말합니다. 프로그래밍에서 AI의 적용은 개발자들이 AI에 의해 대체되는 것이 아니라 AI를 활용하여 효율성을 높이는 방법을 고민하게 만들고 있으며, 동시에 소프트웨어 엔지니어링 전체 프로세스에서 AI의 역할과 한계에 대해 반성하게 합니다 (출처: Reddit r/ArtificialInteligence, cto_junior)
AI 윤리 및 사회적 영향: AI ‘수능 응시’부터 AI ‘인간 노예화’ 우려까지: AI가 ‘수능에 응시’하여 복잡한 수학 문제를 해결하는 것은 맞춤형 지도, 지능형 채점 등 교육 분야에서의 잠재력을 보여주지만, AI에 대한 과도한 의존, 교실의 ‘조립 라인화’, 정서적 교류 부족에 대한 우려도 제기합니다. 더 심층적인 논의는 AI의 ‘유용성’이 일종의 ‘트로이 목마’가 되어 인간이 편리함과 즐거움을 추구하다 자율성을 자발적으로 포기하고 ‘행복한 노예’ 상태를 형성할 수 있다는 점에까지 이릅니다. AI의 ‘명령에 따르는’ 특성이 사용자의 인지 편향을 심화시킬 수 있다는 견해도 있습니다. 이러한 논의는 AI 기술의 빠른 발전에 따른 윤리, 사회 구조 및 개인 자율성 영향에 대한 대중의 깊은 관심을 반영합니다 (출처: 36氪, Reddit r/ArtificialInteligence)

게임계의 대부 존 카맥, LLM과 게임의 미래에 대해 논하다: 상호작용적 학습이 핵심, 현재 LLM은 게임의 미래 아냐: Id Software 공동 창업자 존 카맥이 게임 분야 AI 응용에 대한 자신의 견해를 공유했습니다. 그는 LLM이 괄목할 만한 성과를 거두었지만, ‘모든 것을 알지만 아무것도 배우지 못하는’(실제 상호작용 학습이 아닌 사전 훈련 기반) 특성은 게임 AI의 미래가 아니라고 주장했습니다. 그는 인간과 동물의 학습 방식과 유사하게 상호작용적 경험 흐름을 통한 학습의 중요성을 강조했습니다. 카맥은 DeepMind의 Atari 프로젝트를 회고하며, 게임을 할 수는 있지만 데이터 효율성이 인간보다 훨씬 떨어진다고 지적했습니다. 그는 현재 AI가 연속적이고 효율적이며 평생 지속되고 단일 환경에서 다중 작업 온라인 학습 측면에서 여전히 해결해야 할 과제가 있다고 보았으며, Atari 게임에서의 물리적 로봇 실험을 언급하며 실제 세계 상호작용의 복잡성(예: 지연, 로봇 신뢰성, 점수 판독)을 강조했습니다. 그는 AI가 단순한 패턴 매칭을 넘어 전략적 타당성에 대한 ‘직감’을 길러야만 진정으로 인간 플레이어와 경쟁하거나 게임 개발에서 더 큰 역할을 할 수 있다고 주장했습니다 (출처: 36氪)

💡 기타
AI 연구 논문 급증으로 질적 우려 제기, 공공 데이터셋과 AI 도구가 ‘논문 공장’의 원동력 가능성: Science 지는 미국 NHANES와 같은 대규모 공공 데이터셋을 기반으로 한 저품질 논문 수가 급증했으며, 특히 2022년 AI 도구(예: ChatGPT) 보급 이후 더욱 심화되었다고 보도했습니다. 연구자들은 많은 논문이 단순한 ‘공식’을 따르며 변수를 조합하여 ‘새로운 발견’을 대량 생산하고, ‘p값 사냥’과 데이터 선택적 분석 문제가 존재한다는 사실을 발견했습니다. 예를 들어, NHANES 기반 우울증 연구 28편을 보정한 결과, 절반 이상의 ‘발견’이 통계적 노이즈에 불과할 수 있었습니다. 이러한 현상은 ‘연구 빈칸 채우기 게임’으로 불리며, 그 배후에는 논문 공장이 AI를 이용하여 논문을 빠르게 생산하는 것과 관련이 있을 수 있습니다. 학계는 학술지가 심사를 강화하고, AI 텍스트 탐지 도구를 개발하며, 양적 평가 중심의 연구 평가 체계를 개혁하여 ‘쓰레기 논문’의 범람을 억제할 것을 촉구하고 있습니다 (출처: 36氪)

수술 로봇 시장 성장과 위기 공존, 기술 혁신과 시장 확대가 관건: 2025년 1~5월 중국 수술 로봇 낙찰량이 전년 동기 대비 82.9% 증가하며 시장이 뜨거워 보이지만, CMR Surgical의 매각 추진, 국내 모 혈관 중재 수술 로봇 기업 파산 등의 사건은 업계 위기를 드러내기도 합니다. 위기 요인으로는 업계의 과도한 내부 경쟁, 각 세부 분야의 치열한 경쟁, 투자 급감으로 인한 미상용화 기업의 자금난, 일부 제품의 제한적인 임상 가치(단순 병변에만 사용 가능), 가격 경쟁 심화(저가에도 불구하고 병원은 성능과 품질을 더 중시), 정책(예: 의료계 부패 방지) 및 거시 환경의 큰 영향 등이 있습니다. 이러한 상황을 타개하기 위해 기업들은 기술 혁신(AI 융합, 비용 절감, 5G+원격, 적응증 확대, 고난도 수술 도전), 해외 진출 가속화 및 현급 병원 침투 등의 방식으로 돌파구를 모색하고 있습니다 (출처: 36氪)
Perplexity, 모델 성능 및 경쟁 제품 기능 향상으로 사용자 추천도 하락: 사용자 Suhail은 Perplexity의 간결성, 형식 등의 특징이 다른 제품에는 없는 장점이며, 특히 일반 채팅 제품이 아닌 검색/질의응답에 집중하는 사용자에게 적합하다고 말했습니다. 그러나 다른 종합 AI 도구 평가에서는 Perplexity가 자체 모델이 약하고, 다른 유명 모델을 제공하지만 대부분 저가 버전(예: o4 mini, Gemini 2.5 Pro, Sonnet 4, o3 또는 Opus 없음)이며 모델 성능이 원제조사보다 떨어지고, 경쟁 제품(예: ChatGPT 및 Gemini)의 심층 검색 기능이 강화되어 가성비가 높지 않아 특별 할인 없이는 더 이상 추천할 가치가 없다고 평가되었습니다 (출처: Suhail, Reddit r/ClaudeAI)