키워드:메타 V-JEPA 2, 엔비디아 산업 AI 클라우드, 사카나 AI 텍스트-to-LoRA, 오픈AI o3-pro, 데이터브릭스 레이크베이스, MLflow 3.0, 프린스턴 대학교 HistBench, 비디오 훈련 오픈소스 세계 모델, 유럽 제조업 AI 클라우드 플랫폼, 텍스트 생성 LLM 어댑터, DPO 미세조정 GPT-4.1, AI 에이전트 관측 가능성
🔥 포커스
Meta, V-JEPA 2 발표: 비디오 기반 훈련 오픈 소스 이미지/비디오 세계 모델 : Meta가 새로운 오픈 소스 이미지/비디오 세계 모델 V-JEPA 2를 출시했습니다. 이 모델은 ViT 아키텍처를 기반으로 하며, 다양한 크기(L/G/H)와 해상도(286/384) 버전을 갖추고 있고, 파라미터 수는 12억 개에 달합니다. V-JEPA 2는 시각적 이해 및 예측에서 뛰어난 성능을 보이며, 로봇이 낯선 환경에서 제로샷 계획 및 작업 수행을 가능하게 합니다. Meta는 AI가 세계 모델을 활용하여 동적 환경에 적응하고 새로운 기술을 효율적으로 학습하는 것이 비전이라고 강조했습니다. 동시에 Meta는 기존 모델이 비디오에서 물리적 세계를 추론하는 능력을 평가하기 위한 세 가지 새로운 벤치마크인 MVPBench, IntPhys 2, CausalVQA도 발표했습니다. (출처: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
NVIDIA, 유럽 최초 산업용 AI 클라우드 구축으로 제조업 발전 추진 : NVIDIA가 유럽 제조업체를 위한 세계 최초의 산업용 인공지능 클라우드 플랫폼을 구축 중이라고 발표했습니다. 이 AI 팩토리는 산업 리더들이 설계, 엔지니어링 시뮬레이션부터 디지털 팩토리 트윈 및 로봇 기술에 이르는 전체 제조 애플리케이션을 가속화하도록 지원하는 것을 목표로 합니다. 이는 NVIDIA가 GTC Paris 및 VivaTech 2025에서 발표한 유럽 및 기타 지역의 AI 혁신을 가속화하기 위한 일련의 조치 중 하나입니다. 젠슨 황 CEO는 유럽의 AI 연산 능력이 2년 내에 10배 증가할 것으로 예상하며 “움직이는 모든 물체는 로봇화될 것이며, 자동차가 그 다음”이라고 강조했습니다. (출처: nvidia, nvidia, 젠슨 황: 유럽 AI 연산 능력 2년 내 10배 증가)

Sakana AI, Text-to-LoRA 출시: 텍스트 설명으로 특정 작업용 LLM 어댑터 즉시 생성 : Sakana AI가 Text-to-LoRA 기술을 발표했습니다. 이는 사용자가 작업에 대한 텍스트 설명을 제공하면 특정 작업용 LLM 어댑터(LoRAs)를 즉시 생성하는 하이퍼네트워크(Hypernetwork)입니다. 이 기술은 맞춤형 대규모 모델의 진입 장벽을 낮추어, 비기술적 사용자도 심도 있는 기술 배경이나 대량의 컴퓨팅 자원 없이 자연어를 통해 기본 모델을 특화할 수 있도록 하는 것을 목표로 합니다. Text-to-LoRA는 수백 개의 기존 LoRA 어댑터를 인코딩하고 성능을 유지하면서 처음 보는 작업에도 일반화할 수 있습니다. 관련 논문과 코드는 arXiv와 GitHub에 게시되었으며 ICML2025에서 발표될 예정입니다. (출처: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
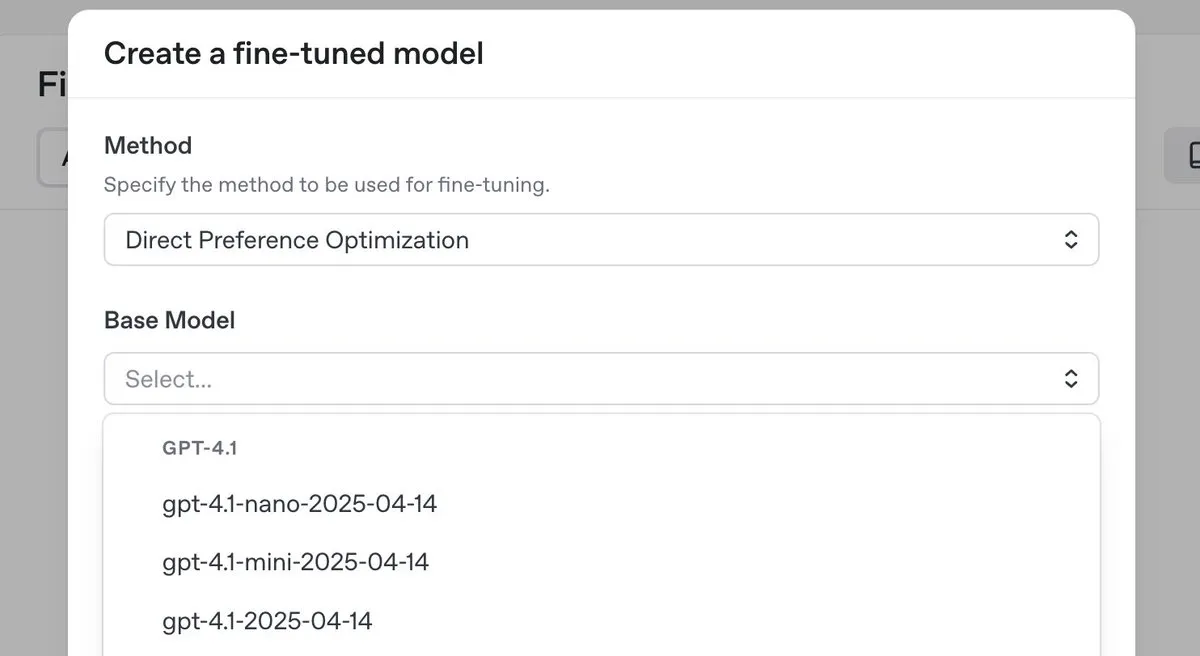
OpenAI, 최고 수준 추론 모델 o3-pro 출시 및 대폭 가격 인하, GPT-4.1 시리즈 DPO 미세 조정 기능도 선보여 : OpenAI가 새로운 최고 수준 추론 모델 o3-pro를 출시하고 o3 시리즈 모델의 가격을 대폭 인하하여 개발자 사용 비용을 낮추는 것을 목표로 합니다. 동시에 OpenAI는 사용자가 이제 직접 선호도 최적화(DPO)를 사용하여 GPT-4.1 제품군 모델(4.1, 4.1-mini, 4.1-nano 포함)을 미세 조정할 수 있다고 발표했습니다. DPO는 고정된 목표가 아닌 모델 응답을 비교하여 맞춤 설정을 허용하며, 특히 어조, 스타일 및 창의성에 대한 주관적인 요구 사항이 있는 작업에 적합합니다. ARC Prize는 o3 가격 인하 후 재테스트를 진행했으며, ARC-AGI에서의 성능 변화는 없는 것으로 나타났습니다. (출처: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 동향
Databricks, Lakebase, 무료 버전 및 Agent Bricks 출시로 데이터 및 AI 애플리케이션 개발 가속화 : Databricks가 lakehouse와 통합되고 AI를 위해 구축된 완전 관리형 Postgres 데이터베이스인 Lakebase의 공개 미리보기 단계를 발표했습니다. 이는 Postgres의 사용 편의성, lakehouse의 확장성 및 Neon 데이터베이스의 브랜칭 기술을 결합합니다. 동시에 Databricks는 개발자가 데이터 엔지니어링, 데이터 과학 및 AI를 학습하는 데 도움이 되는 무료 버전 플랫폼과 방대한 교육 자료를 출시했습니다. 또한 Databricks Apps가 정식 출시(GA)되어 고객이 플랫폼에서 대화형 데이터 및 AI 애플리케이션을 구축하고 배포할 수 있도록 지원합니다. Databricks는 또한 AI 에이전트 개발을 위한 선언적 접근 방식을 채택한 Agent Bricks를 출시하여, 사용자가 작업을 설명하면 시스템이 자동으로 평가를 생성하고 에이전트를 최적화합니다. (출처: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

NVIDIA, Mistral AI와 협력하여 유럽에 엔드투엔드 클라우드 플랫폼 구축 : NVIDIA가 프랑스 스타트업 Mistral AI와 협력하여 엔드투엔드 클라우드 플랫폼을 공동 구축한다고 발표했습니다. 1단계 협력에서는 1만 8천 개의 NVIDIA Grace Blackwell 시스템을 배포하고, 2026년에는 더 많은 지역으로 확장할 계획입니다. 이번 협력은 NVIDIA가 유럽에서 AI 인프라 구축과 ‘주권 AI’ 개념을 추진하는 노력의 일환으로, 유럽에 현지화된 데이터 센터와 서버를 제공하는 것을 목표로 합니다. (출처: 젠슨 황: 유럽 AI 연산 능력 2년 내 10배 증가)
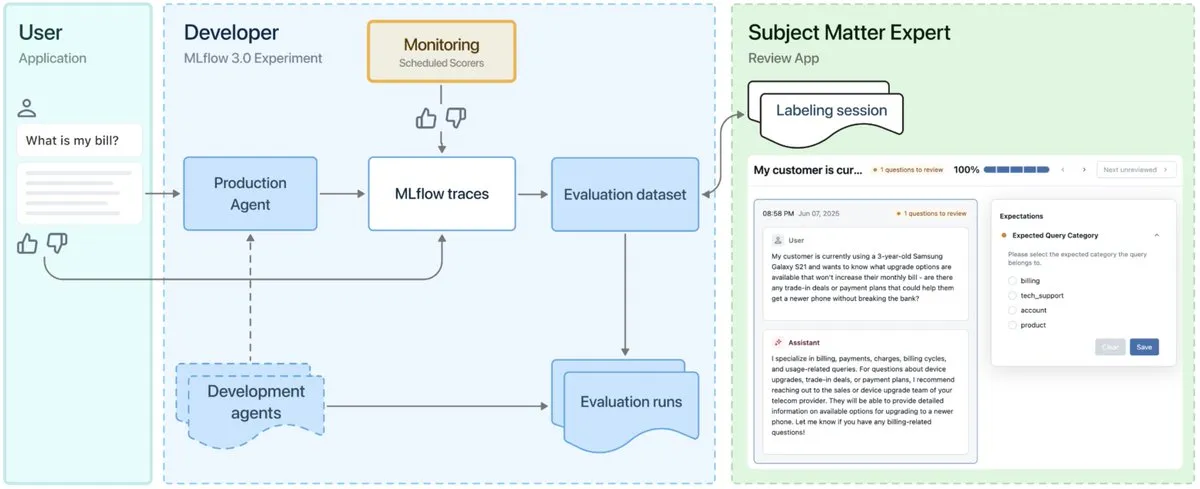
MLflow 3.0 출시, AI 에이전트 관찰 가능성 및 개발에 특화 설계 : MLflow 3.0이 정식 출시되었습니다. 새 버전은 AI 에이전트의 관찰 가능성과 개발을 위해 특별히 재설계되었으며, 기존의 구조화된 머신러닝 기능도 업데이트되었습니다. MLflow 3.0은 데이터를 통해 AI 시스템의 지속적인 개선을 지원하고, AI 시스템의 추적, 평가 및 모니터링을 지원하며, 인적 협업, 데이터 거버넌스 및 보안, Databricks 데이터 생태계와의 통합과 같은 기업 수준의 요구 사항을 고려합니다. (출처: matei_zaharia, matei_zaharia, lateinteraction)
프린스턴 대학교와 푸단 대학교, HistBench와 HistAgent 공동 출시로 역사학 연구에 AI 적용 추진 : 프린스턴 대학교 AI 연구소와 푸단 대학교 역사학과가 협력하여 세계 최초의 역사 연구 AI 평가 벤치마크 HistBench와 AI 조수 HistAgent를 출시했습니다. HistBench는 29개 언어와 다문명 역사를 포괄하는 414개의 역사 문제로 구성되어 있으며, AI의 복잡한 사료 처리 및 다중 모드 이해 능력을 테스트하는 것을 목표로 합니다. HistAgent는 문헌 검색, OCR, 번역 등의 도구를 통합한 역사 연구 전용 인텔리전트 에이전트입니다. 테스트 결과, 일반 대규모 모델은 HistBench에서 정확도가 20% 미만이었지만 HistAgent는 기존 모델을 훨씬 능가하는 성능을 보였습니다. (출처: 세계 최초 역사 벤치마크, 프린스턴-푸단 AI 역사 조수 개발, AI 인문학 분야 진출)

Microsoft Research와 북경대학교, Next-Frame Diffusion (NFD) 프레임워크 공동 발표로 자기 회귀 비디오 생성 효율 향상 : Microsoft Research와 북경대학교가 공동으로 새로운 Next-Frame Diffusion (NFD) 프레임워크를 출시했습니다. 프레임 내 병렬 샘플링과 프레임 간 자기 회귀 방식을 통해 A100 GPU에서 310M 모델을 사용하여 초당 30프레임 이상의 고품질 자기 회귀 비디오 생성을 달성했습니다. NFD는 블록형 인과적 어텐션 메커니즘을 사용하는 Transformer를 채택하고, 일관성 증류 및 투기적 샘플링 기술을 결합하여 효율성을 더욱 향상시켜 실시간 대화형 게임 등의 장면에 적용될 것으로 기대됩니다. (출처: 초당 30프레임 이상 비디오 생성, 실시간 상호작용 지원, 자기 회귀 비디오 생성 새 프레임워크로 생성 효율 갱신)

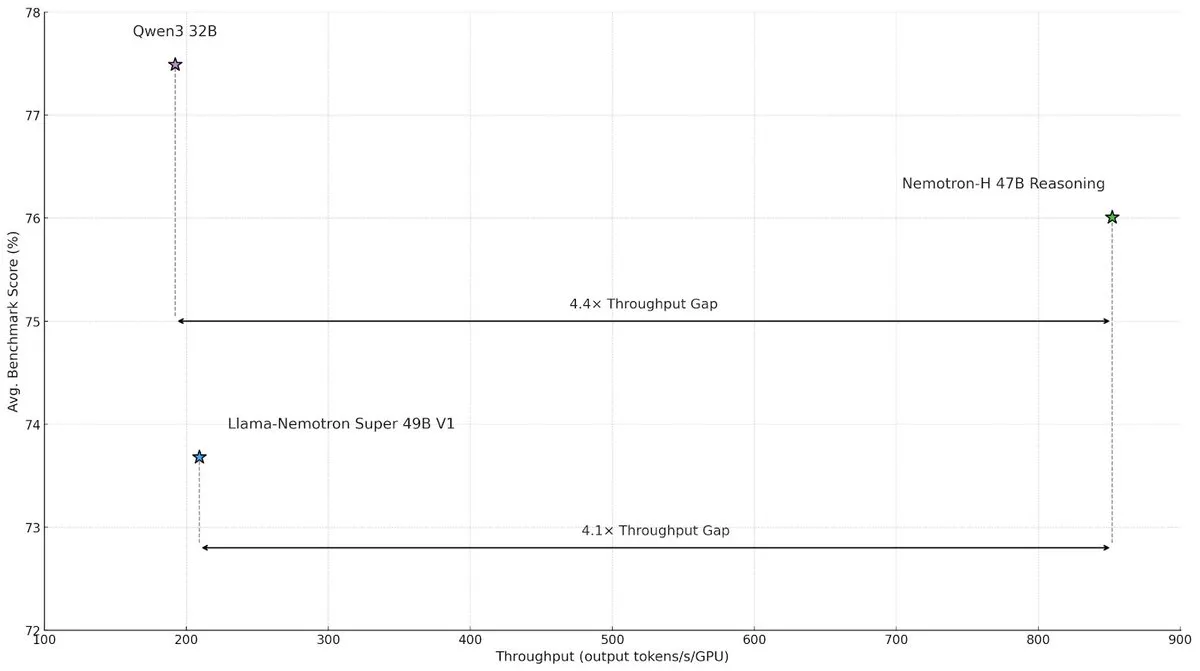
NVIDIA, Nemotron-H 하이브리드 아키텍처 모델 발표로 대규모 추론 속도 및 효율성 향상 : NVIDIA Research가 Mamba와 Transformer의 하이브리드 아키텍처를 채택한 Nemotron-H 모델을 출시했습니다. 이는 대규모 추론 작업의 속도 병목 현상을 해결하는 것을 목표로 합니다. 이 모델은 추론 능력을 유지하면서 유사한 Transformer 모델보다 4배 높은 처리량을 달성했습니다. 연구에 따르면 하이브리드 모델은 더 적은 어텐션 레이어를 사용하더라도 추론 성능을 유지할 수 있으며, 특히 긴 추론 체인 시나리오에서 선형 아키텍처의 효율성 이점이 두드러집니다. (출처: _albertgu, tri_dao, krandiash)
Google DeepMind 연구원 Jack Rae, Meta ‘슈퍼 인텔리전스’ 그룹 합류 : Google DeepMind 수석 연구원 Jack Rae가 Meta가 새로 설립한 ‘슈퍼 인텔리전스’ 그룹에 합류한 것으로 확인되었습니다. Rae는 DeepMind 재직 시절 Gemini 모델의 ‘사고’ 능력을 담당했으며, ‘압축이 곧 지능’이라는 아이디어의 대표 인물 중 한 명으로, OpenAI에서 GPT-4 개발에 참여한 바 있습니다. Meta CEO 저커버그는 Llama 모델을 개선하고 더욱 강력한 AI 도구를 개발하여 업계 선두 주자를 따라잡기 위해 최고 수준의 AI 인재를 직접 영입하고 있으며, 새로운 팀에 수천만 달러 수준의 급여 패키지를 제공하고 있습니다. (출처: 저커버그 ‘슈퍼 인텔리전스’ 그룹 첫 거물, Google DeepMind 수석 연구원, ‘압축이 곧 지능’ 핵심 인물, DhruvBatraDB)

Mistral AI, 첫 추론 모델 Magistral 출시, 다국어 추론 지원 : Mistral AI가 첫 번째 추론 모델 Magistral을 출시했습니다. 여기에는 24B 파라미터의 오픈 소스 버전 Magistral Small과 기업용 Magistral Medium이 포함됩니다. 이 모델은 다단계 논리 및 해석 가능성을 위해 특별히 미세 조정되었으며, 다국어 추론을 지원하고 특히 유럽 언어에 최적화되어 있으며 추적 가능한 사고 과정을 제공할 수 있습니다. Magistral은 개선된 GRPO 알고리즘을 사용하여 순수 강화 학습을 통해 훈련되며, 기존 추론 모델의 증류 데이터에 의존하지 않습니다. 그러나 벤치마크 테스트 결과에 최신 버전의 Qwen 및 DeepSeek R1 데이터가 포함되지 않아 일부 비판을 받고 있습니다. (출처: 새로운 ‘SOTA’ 추론 모델, Qwen 및 R1과의 대결 회피? 유럽판 OpenAI 맹비난 받아)

ByteDance Doubao 대규모 모델 1.6 출시 및 재차 대폭 가격 인하, 비디오 모델 Seedance 1.0 pro 동시 출시 : Volcano Engine이 Doubao 대규모 모델 1.6을 출시하고, 최초로 ‘입력 길이’ 구간별 가격 책정 방식을 도입했습니다. 0-32K 입력 구간 가격은 100만 토큰당 0.8위안, 출력은 100만 토큰당 8위안으로, 1.5 버전에 비해 비용이 63% 절감되었습니다. 새로 출시된 비디오 생성 모델 Seedance 1.0 pro는 1000 토큰당 1.5리(0.015위안)로 책정되어, 5초 1080P 비디오 생성에 약 3.67위안이 소요됩니다. Volcano Engine 사장 탄다이는 이번 가격 인하가 기업에서 자주 사용하는 32K 범위의 비용을 대상으로 한 최적화와 비즈니스 모델 혁신을 통해 이루어졌으며, Agent의 대규모 적용을 촉진하기 위한 것이라고 밝혔습니다. (출처: Doubao 대규모 모델 재차 대폭 가격 인하, Volcano Engine 여전히 공격적으로 시장 점유율 경쟁, 「Volcano」, Baidu Cloud를 향해 불타오르다)
홍콩과기대, 화웨이와 공동으로 AutoSchemaKG 프레임워크 제안, 완전 자율 지식 그래프 구축 실현 : 홍콩과기대 KnowComp 연구소와 홍콩 화웨이 이론 부서가 협력하여 사전 정의된 스키마 없이 완전 자율적으로 지식 그래프를 구축할 수 있는 AutoSchemaKG 프레임워크를 제안했습니다. 이 시스템은 대규모 언어 모델을 활용하여 텍스트에서 직접 지식 트리플을 추출하고 엔티티 및 이벤트 스키마를 귀납합니다. 이 프레임워크를 기반으로 팀은 9억 개 이상의 노드와 59억 개의 엣지를 포함하는 지식 그래프 시리즈 ATLAS를 구축했습니다. 실험 결과, 이 방법은 인공적인 개입 없이 스키마 귀납이 인간이 설계한 스키마와 95%의 의미론적 정렬을 달성하는 것으로 나타났습니다. (출처: 최대 규모 오픈소스 GraphRag: 지식 그래프 완전 자율 구축)

추이징 테크놀로지, 소프트웨어-하드웨어 통합 서버 8카드 솔루션 발표, DeepSeek 대규모 모델 실행 효율 향상 : 추이징 테크놀로지가 인텔과 공동으로 생태계 살롱을 개최하고 최신 소프트웨어-하드웨어 통합 서버 8카드 솔루션을 발표했습니다. 이 솔루션은 DeepSeek-R1/V3-671B 등 대규모 모델을 효율적으로 실행할 수 있으며, 단일 카드 대비 성능이 최대 7배 향상되었습니다. 동시에 자체 개발한 추론 엔진 KLLM, 대규모 모델 관리 플랫폼 AMaaS 및 사무용 애플리케이션 스위트 ‘추이징·즈원’도 중요한 업그레이드를 진행하여, 대규모 모델 사설 배포 시 직면하는 높은 진입 장벽, 부족한 실행 성능 등의 과제를 해결하는 것을 목표로 합니다. (출처: 추이징 테크놀로지 & 인텔 생태계 살롱 개최, 하드웨어, 추론 엔진, 상위 애플리케이션 생태계 융합으로 대규모 모델 사설화 ‘마지막 1마일’ 개척)

Black Forest Labs, FLUX.1 Kontext 시리즈 이미지 모델 발표, 캐릭터 및 스타일 일관성 강화 : 독일 Black Forest Labs가 이미지 편집 시 캐릭터와 스타일의 일관성을 유지하는 데 중점을 둔 FLUX.1 Kontext 시리즈 텍스트-이미지 모델(max, pro, dev 버전)을 출시했습니다. 이 시리즈 모델은 이미지의 부분 및 전체 수정을 지원하며 텍스트 및/또는 이미지 입력으로부터 이미지를 생성할 수 있습니다. FLUX.1 Kontext dev 버전은 오픈 소스로 공개될 예정입니다. 약 1000개의 프롬프트와 참조 이미지 쌍을 포함하는 독점 벤치마크 테스트에서 FLUX.1 Kontext max 및 pro 버전은 OpenAI GPT Image 1 및 Google Gemini 2.0 Flash와 같은 경쟁 모델보다 우수한 성능을 보였습니다. (출처: DeepLearning.AI Blog)

NVIDIA, Rutgers 대학 등 기관, STORM 프레임워크 제안, Mamba 레이어로 비디오 이해에 필요한 토큰 감소 : NVIDIA, Rutgers 대학, UC Berkeley 등 기관의 연구원들이 텍스트-비디오 시스템 STORM을 구축했습니다. 이 시스템은 SigLIP 비전 트랜스포머와 Qwen2-VL의 LLM 사이에 Mamba 레이어를 도입하여, 단일 프레임 토큰 임베딩의 정보(동일 클립 내 다른 프레임의 정보 포함)를 풍부하게 함으로써 핵심 정보를 잃지 않고 프레임 간 토큰 임베딩을 평균화합니다. 이를 통해 시스템은 더 적은 토큰으로 비디오를 처리할 수 있으며, MVBench 및 MLVU와 같은 비디오 이해 벤치마크에서 GPT-4o 및 Qwen2-VL보다 우수한 성능을 보이면서 처리 속도는 3배 이상 향상되었습니다. (출처: DeepLearning.AI Blog)

구글 공동 창업자, 인간형 로봇에 유보적 태도, 특수 목적 로봇 상용화 전망 밝아 : 구글 공동 창업자 세르게이 브린은 인간 형태를 엄격하게 복제한 인간형 로봇에 대해 그다지 열광적이지 않으며, 로봇이 효과적으로 작동하는 데 필요한 조건이 아니라고 밝혔습니다. 한편, 특수 목적 로봇은 “꺼내자마자 일할 수 있는” 특성과 명확한 상용화 경로로 주목받고 있습니다. 예를 들어, 수중 로봇과 잔디깎이 로봇 등은 특정 시나리오에서 큰 잠재력을 보여주고 있습니다. 분석가들은 현 단계에서는 실제 문제를 해결할 수 있는 로봇의 형태와 생산성이 중요하며, 특수 목적 로봇은 명확한 비즈니스 모델과 필수적인 수요 시나리오를 바탕으로 상용화를 선도하고 있다고 평가합니다. (출처: 특수 목적 로봇이 인간형 로봇에게 “형제여, 비켜주게. 내가 먼저 식탁에 오르겠네.”라고 말했다.)

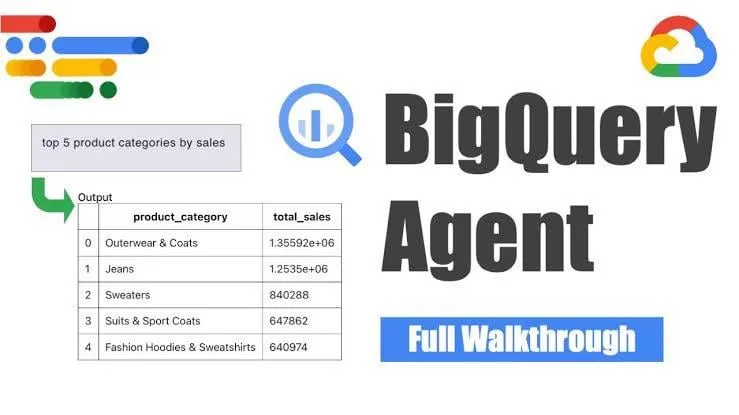
Google, BigQuery 데이터 엔지니어링 에이전트 출시, 지능형 파이프라인 생성 실현 : Google이 BigQuery 데이터 엔지니어링 에이전트를 출시했습니다. 이 도구는 컨텍스트 인식 추론을 활용하여 데이터 파이프라인 생성을 효율적으로 확장합니다. 사용자는 간단한 명령줄 지침을 통해 파이프라인 요구 사항을 정의할 수 있으며, 에이전트는 도메인 특정 프롬프트를 사용하여 사용자 데이터 환경에 맞춤화된 배치 파이프라인 코드를 생성합니다. 여기에는 데이터 수집 구성, 변환 쿼리, 테이블 생성 로직 및 Dataform 또는 Composer를 통한 스케줄링 설정이 포함됩니다. 이 도구는 AI 지원을 통해 데이터 엔지니어가 여러 데이터 도메인, 환경 및 변환 로직을 처리할 때 직면하는 반복적인 작업을 단순화하는 것을 목표로 합니다. (출처: Reddit r/deeplearning)
Yandex, 약 50억 건의 사용자-음원 상호작용 데이터 포함 대규모 공개 데이터셋 Yambda 발표 : Yandex가 추천 시스템 연구를 위해 설계된 대규모 공개 데이터셋 Yambda를 발표했습니다. 이 데이터셋은 Yandex Music에서 수집한 약 50억 건의 익명화된 사용자-음원 상호작용 데이터를 포함하며, 연구자들에게 실제 규모의 데이터를 다룰 수 있는 드문 기회를 제공합니다. (출처: _akhaliq)

ByteDance, Hugging Face에 비디오 복원 모델 SeedVR2 공개 : ByteDance Seed 팀이 Hugging Face에 비디오 복원을 위한 단일 단계 확산 Transformer 모델인 SeedVR2를 공개했습니다. 이 모델은 Apache 2.0 라이선스를 따르며, 단일 단계 추론으로 빠르고 효율적이며, 블록 분할이나 크기 제한 없이 임의 해상도 처리를 지원하는 것이 특징입니다. (출처: huggingface)
ByteDance Doubao 비디오 대형 모델 Seedance 1.0 Pro, 실제 테스트에서 호평 : ByteDance가 최근 발표한 이미지-비디오 생성 대형 모델 Seedance 1.0 Pro가 실제 테스트에서 우수한 지시 사항 준수 능력과 객체 생성 안정성을 보여주었습니다. 사용자들은 비디오 생성 품질이 높고, 카메라 워크와 편집 타이밍이 정확하며, Veo 2/3에 버금간다고 평가했습니다. 잠재적인 단점으로는 순수 객체 움직임을 생성할 때 모델이 때때로 손의 움직임을 추가하여 화면을 더 자연스럽게 만들려고 하는데, 이는 손의 등장을 제한하여 피할 수 있습니다. (출처: karminski3, karminski3, karminski3)
Alibaba, 디지털 휴먼 프레임워크 Mnn3dAvatar 오픈소스 공개, 실시간 얼굴 캡처 및 3D 가상 캐릭터 생성 지원 : Alibaba가 GitHub에 Mnn3dAvatar라는 디지털 휴먼 프레임워크를 오픈소스로 공개했습니다. 이 프로젝트는 실시간 얼굴 캡처를 구현하고 표정을 3D 가상 캐릭터에 매핑하며, 사용자가 자신만의 3D 가상 캐릭터를 만들 수 있도록 지원합니다. 이 프레임워크는 간단한 라이브 커머스, 콘텐츠 전시 등의 장면에 적합합니다. (출처: karminski3)
NVIDIA, 인간형 로봇 기초 모델 Gr00t N 1.5 3B 오픈소스 공개 및 미세 조정 튜토리얼 제공 : NVIDIA가 인간형 로봇 추론 기술을 위해 특별히 설계된 개방형 기초 모델 Gr00t N 1.5 3B를 상업용 라이선스로 오픈소스 공개했습니다. 동시에 NVIDIA는 LeRobotHF SO101과 함께 사용할 수 있는 완전한 미세 조정 튜토리얼을 발표하여 인간형 로봇 기술의 발전과 응용을 촉진하는 것을 목표로 합니다. (출처: ClementDelangue)
Together AI, Batch API 출시, 대규모 LLM 추론 서비스 제공 및 대폭 가격 인하 : Together AI가 대규모 LLM 추론을 위해 특별히 설계된 새로운 Batch API를 출시했습니다. 이는 합성 데이터 생성, 벤치마크 테스트, 콘텐츠 검토 및 요약, 문서 추출과 같은 고처리량 애플리케이션 시나리오를 지원합니다. 이 API는 실시간 API보다 50% 저렴한 시작 가격을 도입했으며, 한 번에 최대 5만 개의 요청 또는 100MB의 일괄 처리를 지원하고 15개의 최고 수준 모델과 호환됩니다. (출처: vipulved)
Google Gemini 2.5 Pro, 대화형 프랙탈 아트 생성 기능 추가 : Google이 Gemini 2.5 Pro가 이제 즉석에서 대화형 프랙탈 아트를 만들 수 있도록 지원한다고 발표했습니다. 사용자는 “아름답고, 입자 기반이며, 애니메이션화되고, 끝없이 이어지는, 3D이며, 대칭적이고, 수학 공식에서 영감을 받은 프랙탈 아트 작품을 만들어줘”와 같은 프롬프트를 제공하여 독특한 시각 예술을 생성할 수 있습니다. (출처: demishassabis)
Google Veo3 Fast 비디오 생성 속도 2배 향상 : Google 연구소는 비디오 생성 도구 Flow의 Veo3 Fast 버전 생성 속도가 720p 해상도를 유지하면서 2배 이상 향상되었다고 발표했습니다. 이번 업데이트는 사용자가 더 빠르게 비디오 콘텐츠를 제작할 수 있도록 하는 것을 목표로 합니다. (출처: op7418)
Hugging Face, Google Colab 및 Kaggle 통합으로 모델 사용 절차 간소화 : Hugging Face가 이제 Google Colab 및 Kaggle과 통합되었습니다. 사용자는 모든 모델 카드에서 직접 Colab 노트북을 시작하거나 Kaggle Notebook에서 동일한 모델을 열 수 있으며, 실행 가능한 공개 코드 예제가 함께 제공되어 모델 사용 및 실험 절차를 간소화합니다. (출처: ClementDelangue, huggingface)
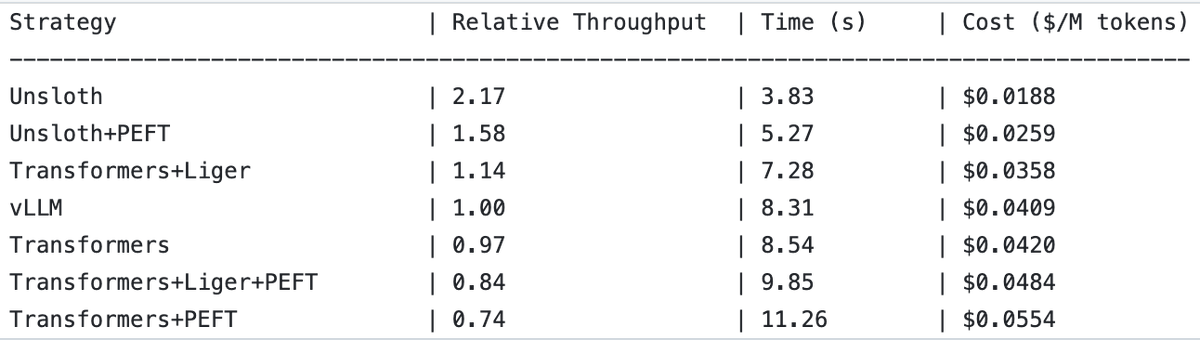
UnslothAI, 보상 모델 서비스 및 시퀀스 분류 추론에서 2배 처리량 향상 달성 : UnslothAI가 보상 모델(RM) 서비스 제공에 사용될 수 있으며, 시퀀스 분류 추론에서 vLLM보다 2배 높은 처리량을 보이는 것으로 밝혀졌습니다. 이 발견은 RL(강화 학습) 커뮤니티에서 주목을 받고 있으며, UnslothAI의 성능 향상은 관련 연구 및 응용을 가속화할 것으로 기대됩니다. (출처: natolambert, danielhanchen)
디과 로봇, 최초 단일 SoC 연산-제어 통합 로봇 개발 키트 RDK S100 출시 : 디과 로봇이 업계 최초로 단일 SoC 연산-제어 통합 로봇 개발 키트 RDK S100을 출시했습니다. 이 키트는 인간의 대뇌-소뇌 구조와 유사하게 설계되어 단일 SoC에 CPU+BPU+MCU를 통합하고, 체화형 인공지능 대형-소형 모델의 효율적인 협업을 지원하며, ‘인지-결정-제어’ 폐쇄 루프를 완성합니다. RDK S100은 다양한 인터페이스와 소프트웨어-하드웨어 협력, 단말-클라우드 통합 개발 인프라를 제공하여 체화형 인공지능 제품 구축 및 다중 시나리오 배포를 가속화하는 것을 목표로 합니다. 현재 20개 이상의 주요 고객사와 협력 중이며, 시장 가격은 2799위안입니다. (출처: 디과 로봇, 최초 단일 SoC 연산-제어 통합 로봇 개발 키트 출시, 20여 개 주요 고객사와 협력 체결|최전선)

🧰 툴
LangChain, 다중 에이전트 아키텍처 벤치마크 테스트 및 감독자 방법 개선 발표 : LangChain은 증가하는 다중 에이전트 시스템을 대상으로 초기 벤치마크 테스트를 수행하여 다중 에이전트 간의 조정을 최적화하는 방법을 모색했습니다. 동시에 LangChain은 감독자(supervisor) 방법에 대한 몇 가지 개선 사항을 적용했으며 관련 블로그를 게시했습니다. (출처: LangChainAI, hwchase17)
Cartesia, Ink-Whisper 출시: 음성 에이전트 전용 빠르고 경제적인 스트리밍 음성-텍스트 변환 모델 : Cartesia가 음성 에이전트에 최적화된 고속, 저비용 스트리밍 음성-텍스트 변환(STT) 모델인 Ink-Whisper를 출시했습니다. 이 모델은 실제 환경에서의 정확성을 위해 설계되었으며, Cartesia의 Sonic 텍스트-음성 변환(TTS) 모델과 함께 사용하여 빠른 음성 AI 상호 작용을 구현할 수 있습니다. Ink-Whisper는 VapiAI, PipecatAI, Livekit 등의 플랫폼에 연결할 수 있도록 지원합니다. (출처: simran_s_arora, tri_dao, krandiash)

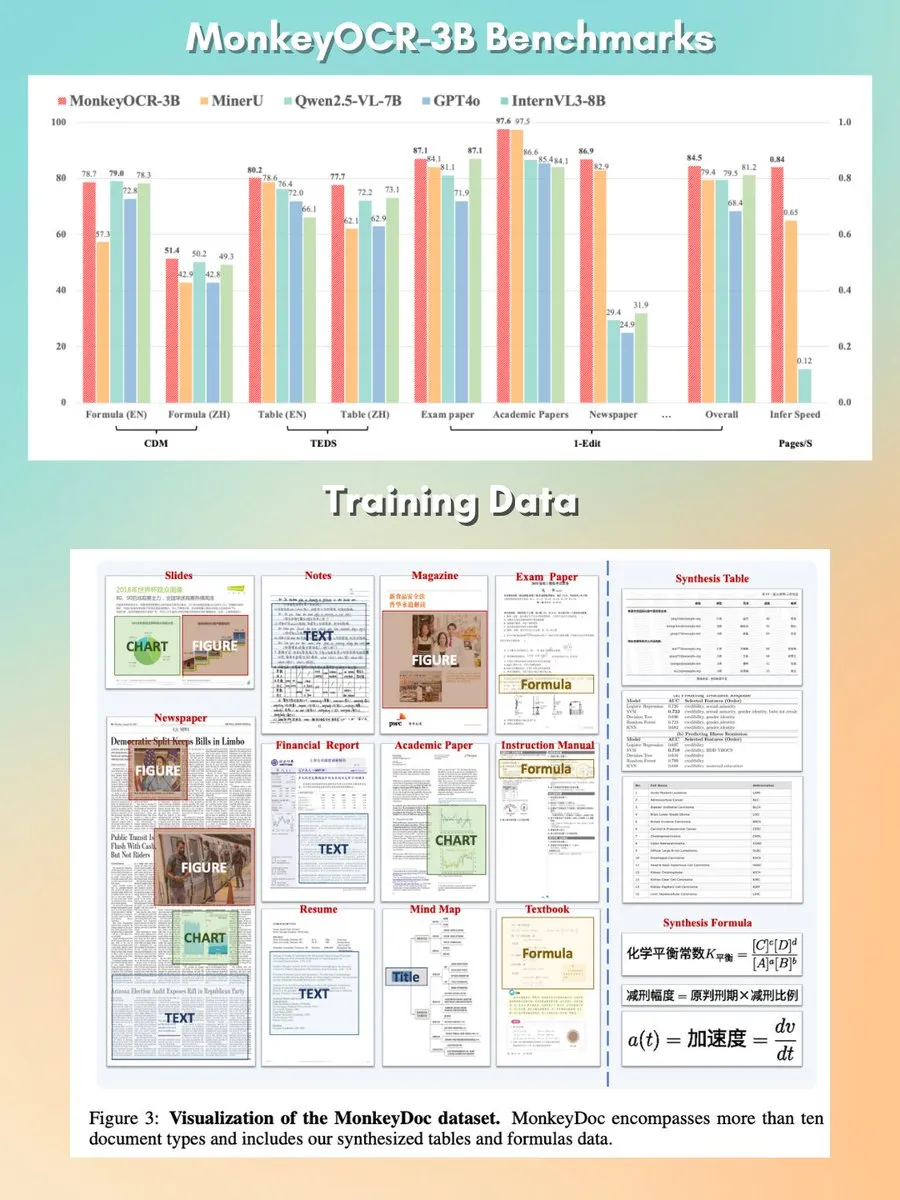
MonkeyOCR: 작고 빠르며 오픈 소스인 문서 분석 모델 : MonkeyOCR이라는 3B 파라미터 문서 분석 모델이 Apache 2.0 라이선스로 출시되었습니다. 이 모델은 차트, 공식, 표 등 문서 내 다양한 요소를 분석할 수 있으며, 기존 분석기 파이프라인을 대체하여 더 나은 문서 처리 솔루션을 제공하는 것을 목표로 합니다. (출처: mervenoyann, huggingface)
LlamaIndex, Cleanlab과 통합하여 AI 조수 응답 신뢰도 향상 : LlamaIndex가 CleanlabAI와의 통합을 발표했습니다. LlamaIndex는 AI 지식 조수 및 프로덕션급 에이전트를 구축하여 기업 데이터에서 통찰력을 생성하는 데 사용됩니다. Cleanlab의 합류는 이러한 AI 조수 응답의 신뢰도를 높이는 것을 목표로 하며, 각 LLM 응답에 점수를 매겨 실시간으로 환각이나 부정확한 응답을 포착하고, 응답이 신뢰할 수 없는 이유(예: 검색 불량, 데이터/컨텍스트 문제, 까다로운 쿼리 또는 LLM 환각)를 분석하는 데 도움을 줄 수 있습니다. (출처: jerryjliu0)

Claude Code, ‘계획 모드’ 추가로 복잡한 코드 변경 제어 용이성 향상 : Anthropic의 Claude Code에 ‘계획 모드’(Plan mode)가 도입되었습니다. 이 기능은 사용자가 실제로 코드를 변경하기 전에 실행 계획을 검토하여 각 단계가 신중하게 고려되었는지 확인할 수 있도록 하며, 특히 복잡한 코드 변경에 유용합니다. 사용자는 단축키 Shift + Tab을 두 번 눌러 계획 모드로 들어갈 수 있으며, Claude Code는 상세한 실행 계획을 제공하고 실행 전에 확인을 요청합니다. 이 기능은 모든 Claude Code 사용자(Pro 또는 Max 구독자 포함)에게 제공됩니다. (출처: dotey, kylebrussell)
rvn-convert: Rust로 구현된 SafeTensors에서 GGUF v3로의 변환 도구 : rvn-convert라는 오픈 소스 도구가 출시되었습니다. Rust 언어로 작성되었으며 SafeTensors 형식의 모델 파일을 GGUF v3 형식으로 변환하는 데 사용됩니다. 이 도구는 단일 샤드 지원, 빠른 속도, Python 환경 불필요 등의 특징을 가지며, safetensors 파일을 메모리 매핑하고 gguf 파일에 직접 작성하여 RAM 피크 및 디스크 회전 문제를 방지합니다. 현재 BF16에서 F32로의 업샘플링, tokenizer.json 임베딩 등의 기능을 지원합니다. (출처: Reddit r/LocalLLaMA)
Runway API, 4K 비디오 초고해상도 기능 추가 : Runway는 자사 API가 이제 4K 비디오 초고해상도 기능을 지원한다고 발표했습니다. 개발자는 이 기능을 자신의 애플리케이션, 제품, 플랫폼 및 웹사이트에 통합하여 비디오 콘텐츠의 선명도와 품질을 향상시킬 수 있습니다. (출처: c_valenzuelab)
You.com, 연구 자료 정리 및 관리를 위한 Projects 기능 출시 : You.com이 사용자가 연구 자료를 쉽게 접근할 수 있는 폴더로 정리하는 데 도움이 되는 “Projects”라는 새로운 도구를 출시했습니다. 이 기능은 사용자가 대화를 상황에 맞게 구조화하고 처리하여 채팅 기록 분산 및 통찰력 손실을 방지함으로써 지식 관리 프로세스를 간소화합니다. (출처: RichardSocher)
LlamaIndex, LlamaExtract 지능형 에이전트 문서 추출 서비스 출시 : LlamaIndex가 복잡한 문서와 입력 스키마에서 구조화된 데이터를 추출하기 위해 설계된 지능형 에이전트 기반 문서 추출 서비스 LlamaExtract를 출시했습니다. 이 서비스는 키-값 쌍을 추출할 뿐만 아니라 각 추출 항목에 대한 정확한 출처 추론, 페이지 참조 및 일치 텍스트를 제공합니다. LlamaExtract는 API 형태로 제공되어 다운스트림 에이전트 워크플로우에 쉽게 통합될 수 있습니다. (출처: jerryjliu0)

langchain-google-vertexai 업데이트 발표, 클라이언트 캐싱 및 도구 지원 향상 : langchain-google-vertexai가 새로운 버전 출시를 맞이했습니다. 주요 업데이트에는 예측 클라이언트 캐싱으로 새 클라이언트 인스턴스화 속도 500배 향상, 내장 코드 실행 도구 지원 등이 포함됩니다. (출처: LangChainAI, Hacubu)
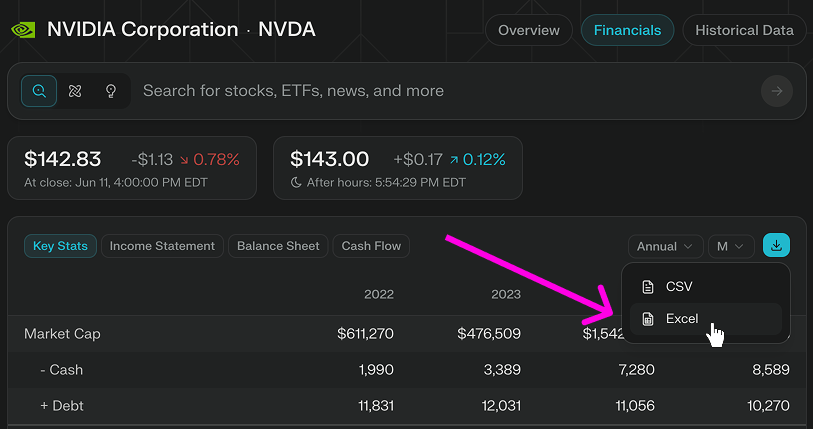
Perplexity Finance, Excel 모델 직접 다운로드 기능 추가 : Perplexity Finance는 사용자가 이제 해당 페이지에서 직접 Excel 모델을 다운로드할 수 있게 되었다고 발표하여 재무 모델링 및 연구에 더 빠른 시작점을 제공합니다. 이 기능은 모든 사용자에게 무료로 제공되며, 이전에는 CSV 형식 다운로드만 지원했습니다. (출처: AravSrinivas)
Viwoods, AI Paper Mini 잉크 스크린 태블릿 출시, GPT-4o 등 AI 기능 통합 : 신흥 잉크 스크린 제조업체 Viwoods가 AI 기능을 탑재한 잉크 스크린 태블릿 AI Paper Mini를 출시했습니다. 이 장치는 GPT-4o, DeepSeek 등 다양한 AI 모델을 지원하며 Chat 모드와 사전 설정된 AI 도우미(콘텐츠 분석, 메일 생성, AI 텍스트 변환)를 제공합니다. 특징적인 기능으로는 캘린더 보기 작업 관리, 빠른 실행 플로팅 창 노트 등이 있습니다. 하드웨어 측면에서 Paper Mini는 292ppi Carta 1000 화면, 4GB+128GB 저장 공간을 갖추고 있으며 스타일러스 펜이 함께 제공됩니다. 동시에 Viwoods는 300ppi Carta 1300 플렉서블 스크린을 탑재하고 응답 속도가 더 빠른 더 큰 크기의 AI Paper도 출시했습니다. (출처: 아이폰 반값으로 AI 탑재 ‘잉크 스크린 태블릿’을 샀다…)

360, 나노 AI 슈퍼 검색 인텔리전트 에이전트 발표, 저우훙이 직접 지원 : 360 그룹 창업자 저우훙이가 나노 AI 슈퍼 검색 인텔리전트 에이전트 발표회를 주재했습니다. 이 에이전트는 “한마디로 만물 검색”을 목표로 하며, 인공적인 개입 없이 자율적으로 사고하고 브라우저와 외부 도구를 호출하여 작업을 수행하며, 전체 과정 시각화 및 단계 추적을 지원합니다. 저우훙이는 이번 발표회 자체도 나노 AI를 활용하여 준비하려고 시도했으며, AI 스마트 녹음 하드웨어 나노 AI Note 및 Rokid와의 공동 브랜드 AI 안경도 발표했다고 밝혔습니다. (출처: 저우훙이, AI로 마케팅 부서 ‘없애려’ 하나, ‘나노’는 해냈을까?)
📚 학습
DeepLearning.AI, 새로운 단기 과정 출시: Apache Airflow를 사용한 GenAI 워크플로우 오케스트레이션 : DeepLearning.AI가 Astronomer와 협력하여 Apache Airflow 3.0을 사용하여 RAG 프로토타입을 프로덕션 준비 워크플로우로 전환하는 방법을 가르치는 새로운 단기 과정을 출시했습니다. 과정 내용에는 워크플로우를 모듈식 작업으로 분해, 시간 기반 및 이벤트 기반 트리거를 사용한 파이프라인 스케줄링, 동적 작업 매핑을 통한 병렬 작업 실행, 내결함성을 위한 재시도/알림/백필 추가, 파이프라인 확장 기술 등이 포함됩니다. 이 과정은 Airflow 경험이 필요하지 않습니다. (출처: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain, RAG 최적화 및 평가 미니 과정 시작 : Hamel Husain이 RAG(검색 증강 생성) 최적화 및 평가에 관한 4부작 미니 과정을 시작한다고 발표했습니다. 첫 번째 부분은 @bclavie가 진행하며, “검색이 곧 RAG”라는 관점에 대해 논의하여 이전에 RAG가 “근절해야 할 사고 바이러스”라는 논의에 대응하는 것을 목표로 합니다. 이 시리즈 과정은 무료이며, 실무자들이 RAG 평가에서 겪는 어려움을 해결하는 데 도움을 주기 위해 마련되었습니다. (출처: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

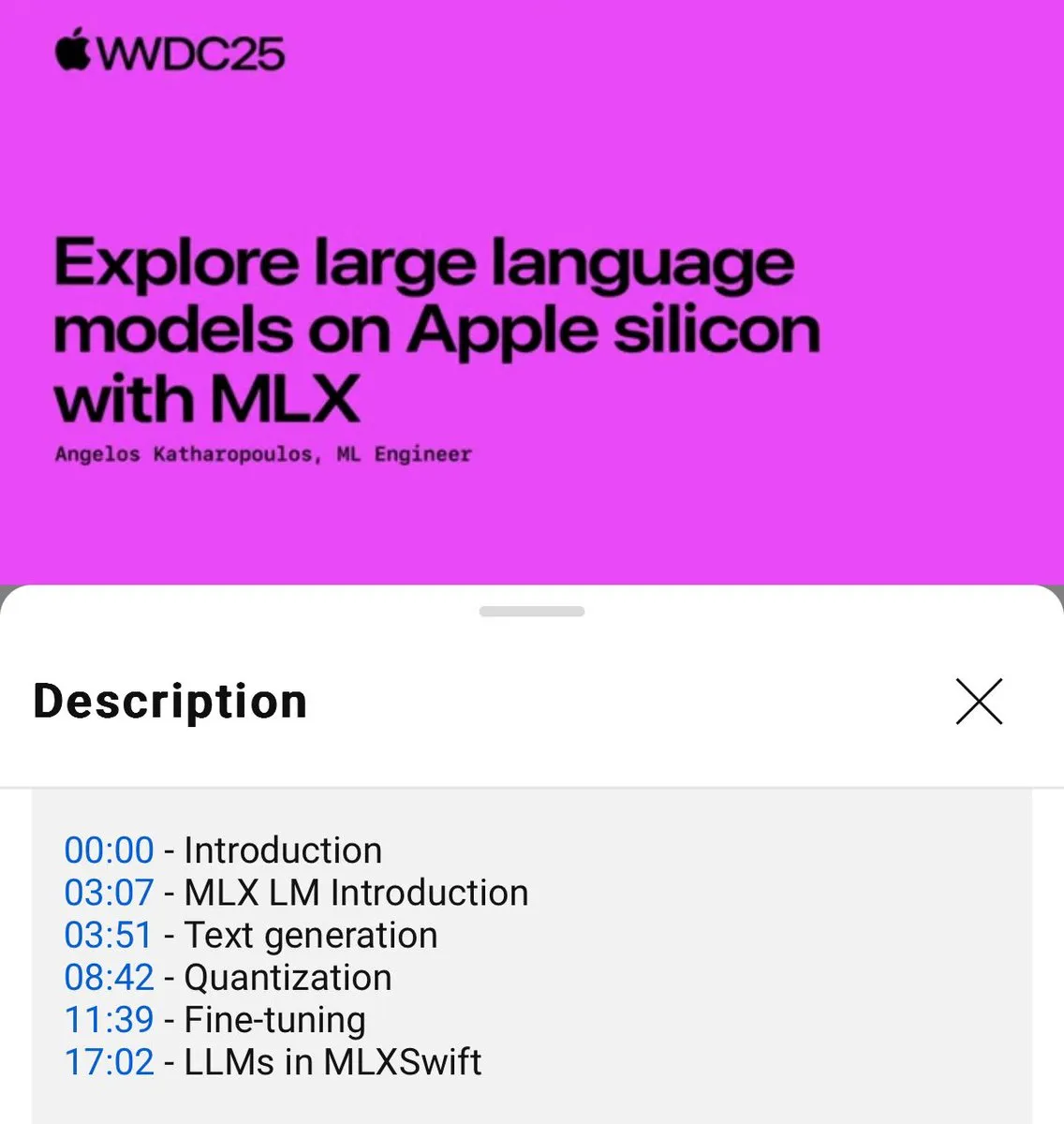
MLX 언어 모델 로컬 사용 튜토리얼 발표 (WWDC25) : WWDC25 컨퍼런스에서 Angelos Katharopoulos가 MLX를 사용하여 로컬 언어 모델을 빠르게 시작하는 방법을 소개했습니다. 튜토리얼은 MLXLM CLI를 사용한 단일 명령줄 작업, 예를 들어 모델 양자화 (mlx_lm.convert), LoRA 미세 조정 (mlx_lm.lora) 및 모델 융합 후 Hugging Face에 업로드 (mlx_lm.fuse) 등을 다룹니다. 전체 Jupyter Notebook 튜토리얼은 GitHub에서 제공됩니다. (출처: awnihannun)
LangChain, Harvey AI의 법률 AI 에이전트 구축 방법 공유 : Harvey AI의 Ben Liebald가 LangChain의 Interrupt 행사에서 법률 AI 에이전트를 구축하는 성숙한 방법을 공유했습니다. 이 방법은 LangSmith 평가와 “변호사 참여형(lawyer-in-the-loop)” 전략을 결합하여 복잡한 법률 업무에 변호사가 신뢰할 수 있는 AI 도구를 제공하는 것을 목표로 합니다. (출처: LangChainAI, hwchase17)

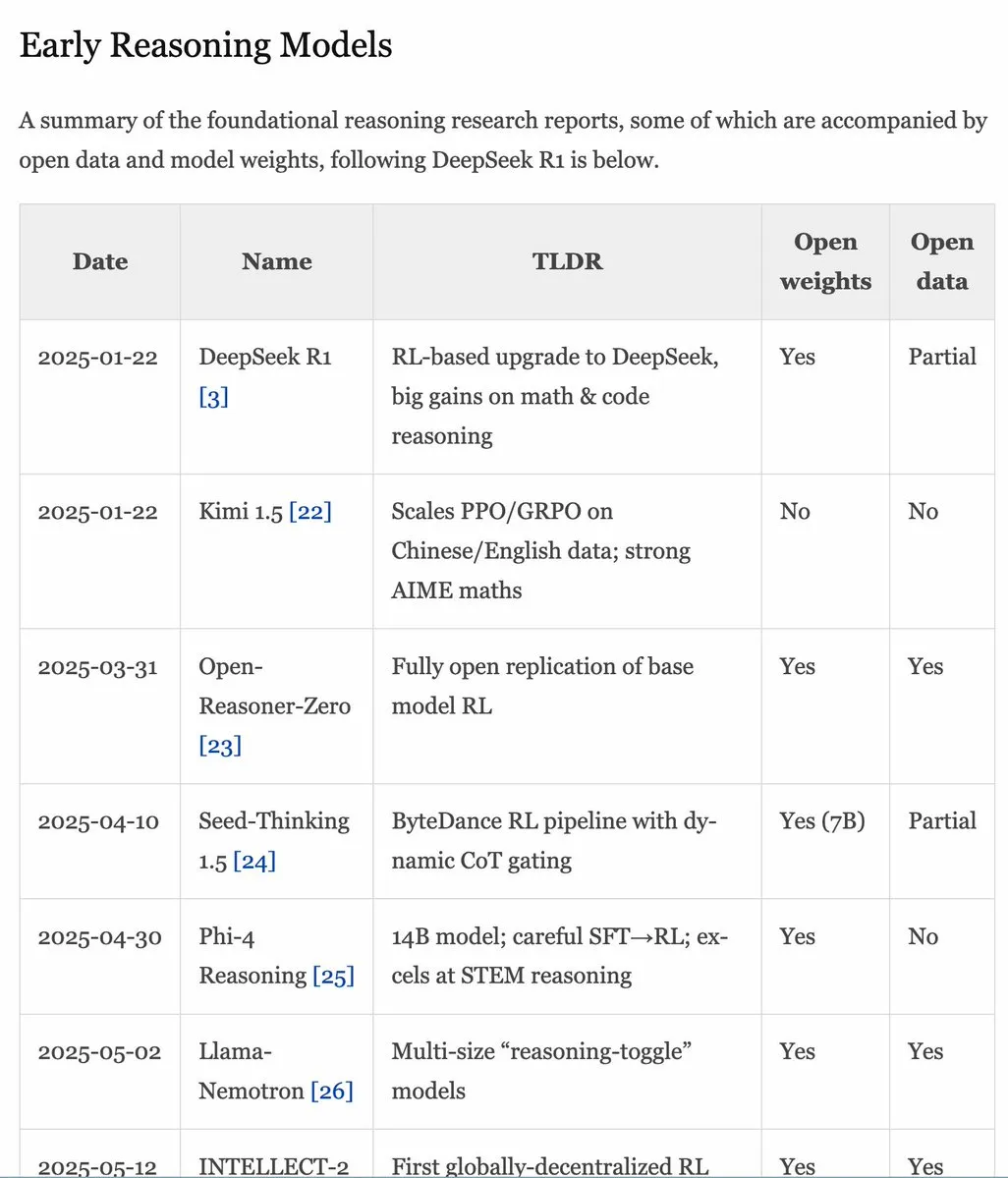
RLHF 핸드북 v1.1 업데이트, RLVR/추론 모델 내용 확장 : RLHF 핸드북(rlhfbook.com)이 v1.1 버전으로 업데이트되어 RLVR(Reinforcement Learning from Video Representations) 및 추론 모델에 대한 확장된 내용이 추가되었습니다. 업데이트에는 주요 추론 모델 보고서 요약, 일반적으로 사용되는 관행/팁 및 사용자, o1 이전의 관련 추론 작업, 비동기 RL과 같은 개선 사항이 포함됩니다. (출처: menhguin)
논문 SWE-Flow: 테스트 주도 방식으로 소프트웨어 엔지니어링 데이터 합성 : SWE-Flow라는 새로운 논문은 테스트 주도 개발(TDD)에 기반한 새로운 데이터 합성 프레임워크를 제안합니다. 이 프레임워크는 단위 테스트를 분석하여 증분 개발 단계를 자동으로 추론하고, 런타임 의존성 그래프(RDG)를 구축하여 구조화된 개발 계획을 생성합니다. 각 단계는 부분 코드베이스, 해당 단위 테스트 및 필요한 코드 수정을 생성하여 검증 가능한 TDD 작업을 만듭니다. 이 방법을 기반으로 SWE-Flow-Eval 벤치마크 데이터셋이 생성되었습니다. (출처: HuggingFace Daily Papers)
논문 PlayerOne: 1인칭 시점으로 구축된 최초의 실제 세계 시뮬레이터 : PlayerOne은 동적 환경에서 몰입형 탐색을 수행할 수 있는, 1인칭 시점(egocentric)으로 구축된 최초의 실제 세계 시뮬레이터로 제안되었습니다. 사용자의 1인칭 장면 이미지가 주어지면 PlayerOne은 해당 세계를 구축하고 외부 카메라로 캡처한 사용자의 실제 움직임과 엄격하게 정렬된 1인칭 비디오를 생성할 수 있습니다. 이 모델은 조밀에서 정밀로 이어지는 훈련 흐름을 채택하고, 구성 요소 분리형 움직임 주입 방식과 공동 재구성 프레임워크를 설계했습니다. (출처: HuggingFace Daily Papers)
논문 ComfyUI-R1: 워크플로우 생성을 위한 추론 모델 탐색 : ComfyUI-R1은 자동화된 워크플로우 생성을 위한 최초의 대규모 추론 모델입니다. 연구자들은 먼저 4K개의 워크플로우로 구성된 데이터셋을 구축하고, 장문의 연쇄적 사고(CoT) 추론 데이터를 구성했습니다. ComfyUI-R1은 CoT 미세 조정을 통한 콜드 스타트와 강화 학습을 통한 추론 능력 장려라는 두 단계 프레임워크를 통해 훈련됩니다. 실험 결과, 7B 파라미터 모델은 형식 유효성, 통과율 및 노드/그래프 수준 F1 점수에서 기존 방법을 현저히 능가하는 것으로 나타났습니다. (출처: HuggingFace Daily Papers)
논문 SeerAttention-R: 긴 추론을 위한 희소 어텐션 적응형 프레임워크 : SeerAttention-R은 추론 모델의 긴 디코딩을 위해 특별히 설계된 희소 어텐션 프레임워크입니다. 자체 증류 게이팅 메커니즘을 통해 어텐션 희소성을 학습하고, 자기 회귀 디코딩에 적응하기 위해 쿼리 풀링을 제거했습니다. 이 프레임워크는 기존 사전 훈련 모델에 가벼운 플러그인으로 통합될 수 있으며, 원본 매개변수를 수정할 필요가 없습니다. AIME 벤치마크 테스트에서 0.4B 토큰만으로 훈련된 SeerAttention-R은 4K 토큰 예산 하에서 대규모 희소 어텐션 블록(64/128)에서 거의 손실 없는 추론 정확도를 유지했습니다. (출처: HuggingFace Daily Papers)
논문 SAFE: 시각-언어-행동 모델을 위한 다중 작업 실패 감지 : 이 논문은 VLA와 같은 범용 로봇 정책을 위해 설계된 실패 감지기 SAFE를 제안합니다. VLA 특징 공간을 분석하여 SAFE는 VLA 내부 특징으로부터 작업 실패 가능성을 예측하는 방법을 학습합니다. 이 감지기는 성공 및 실패한 배포에서 훈련되며, 처음 보는 작업에서 평가되고, 다양한 정책 아키텍처와 호환되어 VLA가 환경과 상호 작용할 때의 안전성을 향상시키는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
논문 Branched Schrödinger Bridge Matching: 분기형 슈뢰딩거 다리 학습 : 이 연구는 초기 분포와 목표 분포 사이의 중간 궤적을 예측하기 위해 분기형 슈뢰딩거 다리를 학습하는 Branched Schrödinger Bridge Matching (BranchSBM) 프레임워크를 도입합니다. 기존 방법과 달리 BranchSBM은 공통 시작점에서 여러 다른 결과로 분기하거나 발산하는 진화를 모델링할 수 있으며, 여러 시간 종속 속도장과 성장 과정을 매개변수화하여 이를 구현합니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
Meta, 데이터 라벨링 회사 Scale AI 150억 달러에 인수 추진설, 창업자 Meta 합류 가능성 : Meta가 데이터 라벨링 분야 선두 기업인 Scale AI를 150억 달러에 인수할 계획이라는 보도가 나왔습니다. 거래가 성사되면 Scale AI의 28세 중국계 창업자 Alexandr Wang과 그의 팀은 Meta에 직접 합류하게 됩니다. 이는 Meta CEO 저커버그가 AGI(일반인공지능) 팀 역량을 강화하고 OpenAI, Google 등 경쟁사를 추격하기 위한 중대한 조치로 풀이됩니다. Meta는 최근 AI 인재 영입에 적극적으로 나서며 최고 수준 엔지니어에게 수천만 달러 규모의 연봉 패키지를 제시하고 있습니다. (출처: 저커버그 ‘슈퍼 인텔리전스’ 그룹 첫 거물, Google DeepMind 수석 연구원, ‘압축이 곧 지능’ 핵심 인물, dylan522p, sarahcat21, Dorialexander)
디즈니와 유니버설 픽처스, AI 이미지 회사 Midjourney 저작권 침해로 고소 : 디즈니와 유니버설 픽처스가 AI 이미지 생성 회사 Midjourney를 상대로 ‘스타워즈’, ‘심슨 가족’ 등 유명 IP 작품을 무단 사용했다며 소송을 제기했습니다. 이 사건은 주목을 받고 있으며, 디즈니가 승소할 경우 대규모 데이터 학습에 의존하는 다른 AI 회사들에게 연쇄적인 영향을 미쳐 AI 분야의 저작권 논쟁을 더욱 심화시킬 수 있습니다. (출처: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

구글, AI 검색 충격으로 또 ‘자발적 퇴직 프로그램’ 시행, 검색·광고 등 여러 중요 팀 영향 : AI 검색이 가져온 충격에 직면하여 구글이 미국 내 여러 부서 직원들을 대상으로 ‘자발적 퇴직 프로그램’을 다시 시행하고, 검색, 광고, 핵심 엔지니어링 등 주요 팀에 영향을 미치며 사무실 복귀 정책을 강화했습니다. 이는 자원을 재편성하여 AI 주력 프로젝트 Gemini 및 ‘AI 모드’ 검색 경험 개발에 더 많은 역량을 투입하기 위한 조치입니다. 구글의 전통적인 검색 사업은 AI의 부상으로 큰 도전에 직면해 있으며, 동시에 규제 압력에도 직면해 있습니다. (출처: AI 검색 충격 속 구글, 또 ‘자발적 퇴직 방안’ 추진…여러 중요 팀 영향, jpt401)
🌟 커뮤니티
암스테르담 복지 사기 탐지 실험에서 AI 편향성 드러나 프로젝트 중단 : 암스테르담은 복지 신청을 평가하여 사기를 탐지하는 AI 시스템(Smart Check) 사용을 시도했으나, 편향성 테스트 및 기술적 안전장치를 포함한 책임감 있는 AI 모범 사례를 따랐음에도 불구하고 시범 프로젝트에서 공정하고 효과적인 결과를 얻지 못했습니다. 초기 모델은 비네덜란드 국적 신청자와 남성에게 편향되었고, 조정 후에는 네덜란드 국적자와 여성에게 편향되었습니다. 결국 차별 없는 운영을 보장할 수 없어 해당 프로젝트는 중단되었습니다. 이 사례는 알고리즘 공정성, 책임감 있는 AI 실천의 효과성, 공공 서비스 의사 결정에서의 AI 적용에 대한 광범위한 논의를 불러일으켰습니다. (출처: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

AI 생성 콘텐츠 식별 제도: 가치, 한계 및 거버넌스 논리 탐구 : AI가 생성한 루머와 허위 선전이 증가함에 따라 AI 식별 제도가 거버넌스 수단으로 주목받고 있습니다. 이론적으로 명시적 및 암묵적 식별은 인식 효율성을 높이고 사용자 경각심을 강화할 수 있습니다. 그러나 실제로는 식별이 회피, 위조 및 오판되기 쉽고 비용도 많이 듭니다. 이 글은 AI 식별을 기존 콘텐츠 거버넌스 체계에 통합하고, 루머, 허위 선전과 같은 고위험 분야에 초점을 맞추며, 생성 및 전파 플랫폼의 책임을 합리적으로 규정하는 동시에 대중의 정보 소양 교육을 강화해야 한다고 주장합니다. (출처: 루머가 ‘AI’ 바람을 탔을 때)
AI 보조 코딩 도구(예: Claude Code) 개발자 효율성 크게 향상 및 업무 스트레스 경감 : 커뮤니티의 여러 개발자들이 AI 보조 코딩 도구(특히 Anthropic의 Claude Code) 사용에 대한 긍정적인 경험을 공유했습니다. 이러한 도구는 코드 작성, 테스트 및 디버깅을 도울 뿐만 아니라 프로젝트 계획, 복잡한 문제 해결 등에서도 지원을 제공하여 개발 효율성을 크게 높이고 업무 스트레스와 마감일 불안을 줄여줍니다. 한 사용자는 AI 보조 덕분에 자신이 “막을 수 없는 힘”이 된 것 같다고 말했습니다. (출처: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI 생성 콘텐츠 에너지 및 수자원 소비 주목, Sam Altman “ChatGPT 쿼리당 약 1/15 티스푼 물 소비” : OpenAI CEO Sam Altman은 ChatGPT 쿼리 한 번에 약 “15분의 1 티스푼”의 물이 소비된다고 밝혔습니다. 이 데이터는 AI 모델 훈련 및 추론의 환경 영향에 대한 논의를 불러일으켰습니다. 구체적인 계산 방식과 훈련 비용 포함 여부는 아직 불분명하지만, AI의 에너지 발자국과 수자원 소비는 기술계와 환경 분야에서 주목하는 의제가 되었습니다. (출처: MIT Technology Review, Reddit r/ChatGPT)

LLM이 수학 증명을 진정으로 이해하는지에 대한 논의: IneqMath 벤치마크 테스트, 모델의 약점 드러내 : 새로 발표된 IneqMath 벤치마크 테스트는 올림피아드 수준의 수학 부등식 증명에 중점을 두었으며, 연구 결과 LLM이 때로는 정답을 찾을 수 있지만 엄밀하고 합리적인 증명을 구성하는 데에는 상당한 격차가 있는 것으로 나타났습니다. 이는 LLM이 수학 등 분야에서 진정으로 이해하는 것인지 아니면 단순히 “추측”하는 것인지에 대한 논의를 불러일으켰습니다. Sathya는 이러한 “정답-오류 추론” 현상이 PutnamBench와 같은 벤치마크 테스트에서도 나타난다고 지적했습니다. (출처: lupantech, lupantech, _akhaliq, clefourrier)
소프트웨어 개발, 연구 및 일상 업무에서의 AI 에이전트 적용 및 논의 : 커뮤니티에서는 다양한 분야에서 AI 에이전트의 적용에 대해 광범위하게 논의하고 있습니다. 예를 들어, 한 사용자는 n8n과 Claude를 사용하여 심층 연구 인텔리전트 에이전트 워크플로우를 구축한 경험을 공유했습니다. LlamaIndex는 Artifact Memory Block을 통해 증분적 양식 작성 에이전트를 구현하는 방법을 시연했습니다. 또한 AI 지향 도구 인터페이스 설계를 위한 MCP(모델 컨텍스트 프로토콜) 사용, 법률, 인프라 자동화(예: Cisco의 JARVIS) 등 분야에서의 AI 에이전트 적용에 대한 논의도 이루어졌습니다. (출처: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

인간형 로봇 안전 기준 주목, 물리적 및 심리적 영향 모두 고려해야 : 인간형 로봇이 점차 산업 현장에 도입되고 가정 등 다양한 환경으로 진출함에 따라 안전 기준이 논의의 초점이 되고 있습니다. IEEE 인간형 로봇 연구 그룹은 인간형 로봇이 동적 안정성 등 독특한 특성을 가지고 있어 새로운 안전 규칙이 필요하다고 지적했습니다. 물리적 안전(넘어짐, 충돌 방지 등) 외에도 인간-로봇 상호작용에서의 의사소통 문제(의도 표현, 다중 로봇 조정 등)와 심리적 영향(과도한 의인화로 인한 기대치 상승, 정서적 안전 등)도 고려해야 합니다. 표준 제정은 혁신과 안전의 균형을 맞추고 다양한 적용 시나리오의 요구 사항을 고려해야 합니다. (출처: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 기타
Docker, docker run --gpus 이제 AMD GPU 지원 발표 : Docker 공식 업데이트에 따르면 docker run --gpus 명령이 이제 AMD GPU에서도 실행을 지원합니다. 이 개선 사항은 컨테이너화된 AI/ML 워크로드에서 AMD GPU의 사용 편의성을 향상시켜 AMD가 AI 생태계에서 활용되는 데 긍정적인 영향을 미칠 것입니다. (출처: dylan522p)
GitHub 리포지토리 수 10억 개 돌파 : GitHub 플랫폼의 코드 리포지토리 수가 공식적으로 10억 개를 돌파했습니다. 이 이정표적인 사건은 오픈 소스 커뮤니티와 코드 호스팅 플랫폼의 지속적인 번영과 성장을 상징합니다. (출처: karminski3, zacharynado)
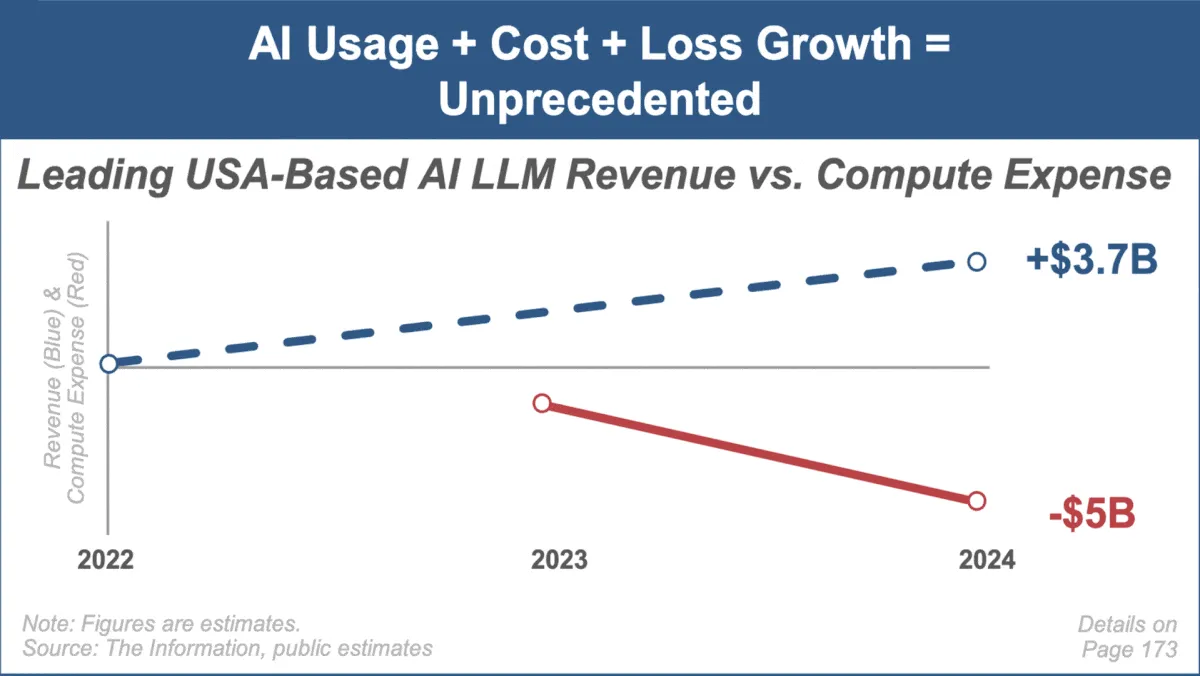
Mary Meeker, 최신 AI 동향 보고서 발표, 시장 급성장과 과제에 주목 : 유명 투자 분석가 Mary Meeker가 인공지능 시장에 관한 첫 번째 동향 보고서 ‘Trends — Artificial Intelligence (May ‘25)’를 발표했습니다. 보고서는 AI 분야의 전례 없는 성장 속도, 사용자 규모의 급증(예: ChatGPT 사용자 8억 명), AI 관련 자본 지출의 대폭 증가, 성능 및 신흥 능력에서의 AI의 지속적인 돌파구를 강조했습니다. 보고서는 동시에 컴퓨팅 비용 상승, 모델의 빠른 반복, 오픈 소스 대체재 경쟁과 같은 AI 비즈니스 모델이 직면한 과제를 지적했습니다. (출처: DeepLearning.AI Blog)