
키워드:DeepSeek, OpenAI, 추론 모델, 다중 모달 대형 모델, 강화 학습, AI 혁신, 오픈소스 모델, DeepSeek R1 추론 모델, OpenAI o4 강화 학습 훈련, 다중 모달 대형 모델 인간 사고 맵, Mistral AI Magistral 시리즈, 홍서(小红书) dots.llm1 MoE 모델
🔥 주요 뉴스
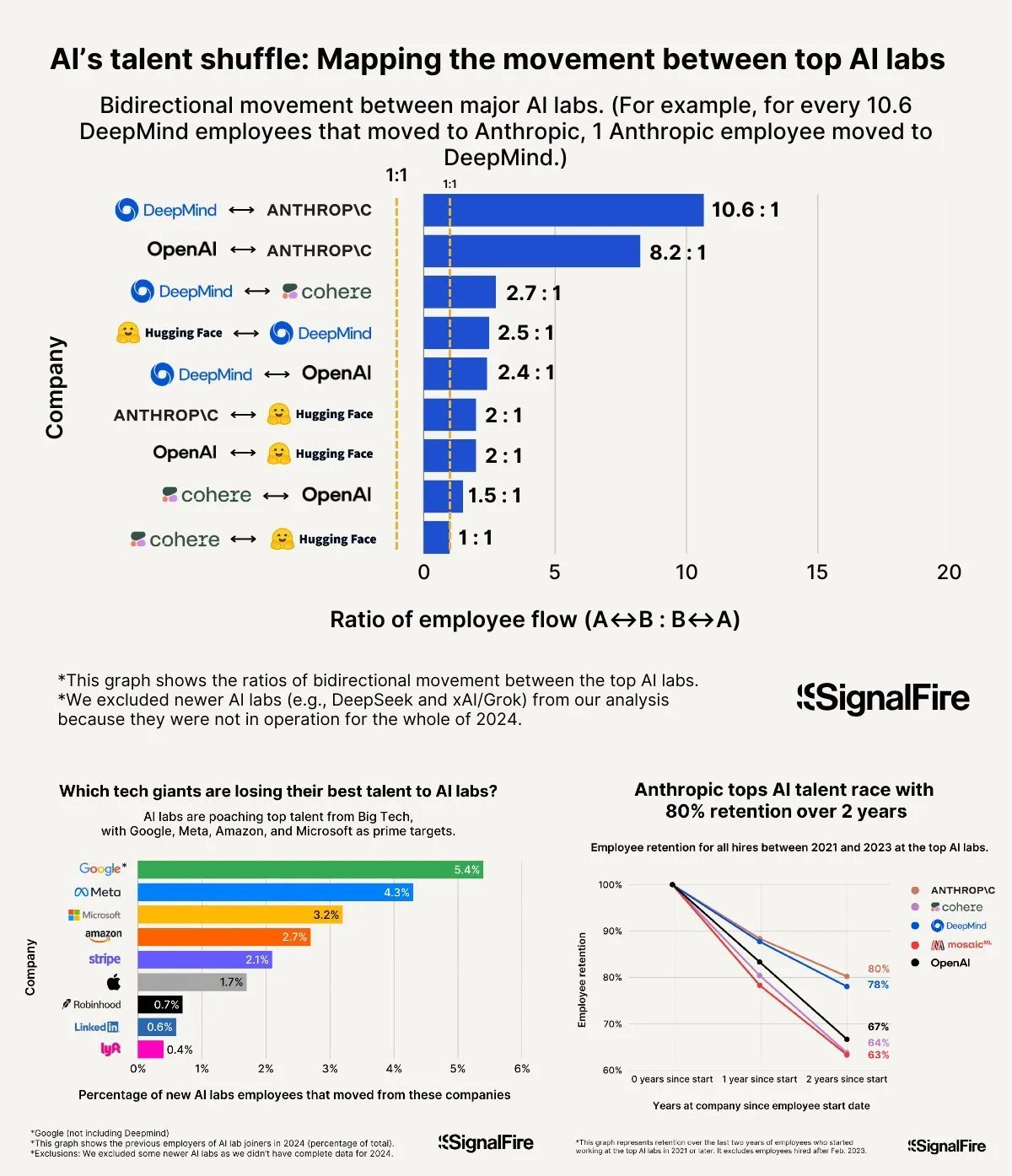
DeepSeek와 OpenAI의 혁신 경로, “인지형 혁신”을 드러내다: DeepSeek는 “제한적 Scaling Law”, MLA 및 MoE 아키텍처 혁신, 소프트웨어-하드웨어 시너지 최적화를 통해 저비용 고성능을 달성했으며, R1 추론 모델의 오픈소스화는 AI 인지 능력의 돌파구를 마련하고 중국 혁신가들의 기초 연구 분야 “사고의 틀”을 깨뜨려 중국 기업이 AI 기초 연구 및 모델 혁신 분야에서 글로벌 선도 역량을 갖추고 있음을 증명했습니다. OpenAI는 Transformer 아키텍처와 Scaling Law(규모의 법칙)를 극한으로 활용하여 거대 언어 모델 혁명을 이끌었고, ChatGPT와 추론 모델 o1을 통해 인간-컴퓨터 상호작용 패러다임 변화와 AI 인지 능력의 도약을 추진했습니다. 양사의 발전 경로는 모두 기술 본질에 대한 깊은 이해와 전략적 재구성을 강조하며, AI 시대 창업가들에게 귀중한 조직 구축 및 혁신 아이디어를 제공합니다. 특히 DeepSeek가 장려하는 “창발(emergence)”의 AI Lab 패러다임은 기술 혁신 주도형 창업가들에게 새로운 조직 모델 참고 자료를 제공합니다 (출처: 36氪)
OpenAI, 새로운 모델 o4 훈련 중이라는 소식, 강화 학습이 AI 지형 재편: SemiAnalysis는 OpenAI가 GPT-4.1과 GPT-4.5 사이의 새로운 모델을 훈련 중이며, 차세대 추론 모델 o4는 GPT-4.1을 기반으로 강화 학습(RL) 훈련을 받을 것이라고 폭로했습니다. RL은 CoT 생성을 통해 모델의 추론 능력을 발휘시키고 AI 에이전트 발전을 촉진하지만, 인프라(특히 추론) 및 보상 함수 설계에 대한 요구 사항이 매우 높고 “보상 해킹” 현상이 발생하기 쉽습니다. 고품질 데이터는 RL 확장의 핵심이며, 사용자 행동 데이터는 중요한 자산이 될 것입니다. RL은 또한 실험실 조직 구조를 변경하여 추론과 훈련을 깊이 통합합니다. 사전 훈련과 달리 RL은 DeepSeek R1과 같이 모델 능력을 지속적으로 업데이트할 수 있습니다. 소형 모델의 경우 RL보다 증류가 더 우수할 수 있습니다. 이번 폭로는 AI 분야, 특히 추론 모델이 RL 기반의 지속적인 진화와 능력 향상을 맞이할 것임을 예고합니다 (출처: 36氪)
멀티모달 거대 모델, 자발적으로 “인간 사고 지도” 형성 발견: 중국과학원 자동화연구소와 뇌과학 및 지능 기술 탁월 혁신 센터 공동 연구팀은 행동 실험과 신경 영상 분석을 통해 멀티모달 거대 언어 모델(MLLMs)이 인간과 매우 유사한 물체 개념 표상 시스템을 자발적으로 형성할 수 있음을 입증했습니다. 연구는 470만 건의 “셋 중 다른 하나 고르기 인식 과제” 행동 판단 데이터를 분석하여 AI 모델의 “개념 지도”를 최초로 구축했습니다. 주요 발견 사항은 다음과 같습니다: 서로 다른 아키텍처의 AI 모델이 유사한 저차원 인지 구조로 수렴할 수 있음; 모델이 비지도 학습 환경에서 인간 인지와 일치하는 고급 물체 개념 분류 능력을 창발적으로 나타냄; AI 모델의 “사고 차원”에 동물, 음식, 경도 등과 같은 의미론적 레이블을 부여할 수 있음; MLLM의 표상은 FFA, PPA와 같은 특정 뇌 영역의 신경 활동 패턴과 현저하게 관련되어 “AI와 인간이 개념 처리 메커니즘을 공유한다”는 증거를 제공함. 이 연구는 AI 인지 이해, 뇌 유사 지능 개발 및 뇌-컴퓨터 인터페이스에 대한 새로운 아이디어를 제공합니다 (출처: 量子位)

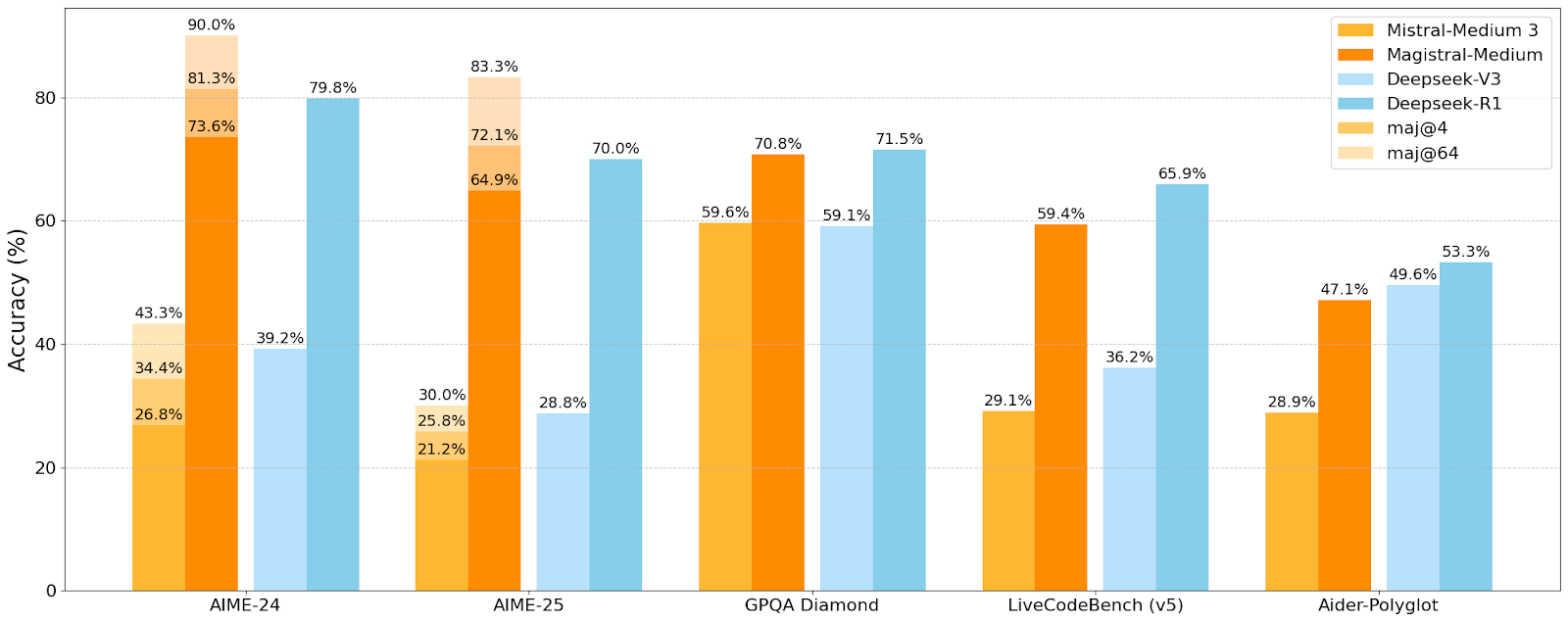
Mistral AI, 첫 추론 모델 Magistral 시리즈 출시, 소형 모델 Magistral-Small 오픈소스 공개: Mistral AI는 추론 전용으로 설계된 첫 모델 시리즈 Magistral을 출시했으며, 여기에는 Magistral-Small과 Magistral-Medium이 포함됩니다. Magistral-Small은 Mistral Small 3.1 (2503)을 기반으로 구축된 24B 파라미터의 효율적인 추론 모델로, Magistral Medium의 궤적을 통해 SFT 및 RL 훈련을 받아 추론 능력이 향상되었습니다. 이 모델은 다국어를 지원하며, 컨텍스트 창은 128k(권장 유효 컨텍스트 40k)이고, Apache 2.0 라이선스로 오픈소스 공개되어 단일 RTX 4090 또는 32GB RAM의 MacBook에서 로컬 배포(양자화 후)가 가능합니다. 벤치마크 테스트 결과, Magistral-Small은 AIME24, AIME25, GPQA Diamond 및 Livecodebench (v5) 등의 작업에서 우수한 성능을 보이며 일부 대형 모델에 근접하거나 능가하는 수준입니다. Magistral-Medium은 성능이 더 강력하지만 현재 오픈소스 공개되지 않았습니다. 이번 출시는 Mistral이 모델 추론 능력과 다국어 지원을 향상시키는 데 있어 진전을 이루었음을 의미합니다 (출처: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 동향
OpenAI o3 모델 API 가격 80% 대폭 인하: OpenAI CEO Sam Altman은 o3 모델의 API 가격을 80% 인하한다고 발표했습니다. 조정 후 입력 가격은 100만 토큰당 2달러, 출력 가격은 100만 토큰당 8달러입니다(일부 정보 출처는 출력 가격을 100만 토큰당 5달러로 언급하고 있으므로 공식 문서를 확인해야 합니다). 이번 가격 인하 폭은 매우 커서 o3 모델을 사용한 코드 작성 등의 작업 비용이 크게 절감되어 더 광범위한 응용과 혁신을 촉진할 것으로 예상됩니다. 사용자는 공식 웹사이트 가격표가 아직 동기화되지 않았을 수 있으므로 API 호출 전에 테스트를 통해 실제 적용 가격을 확인하여 불필요한 손실을 피해야 합니다. 이는 시장 경쟁(예: Gemini 2.5 Pro 및 Claude 4 Sonnet)에 대응하기 위한 전략으로 간주되며, AI 지능 비용이 지속적으로 하락할 것임을 예고할 수 있습니다 (출처: X, X, X)
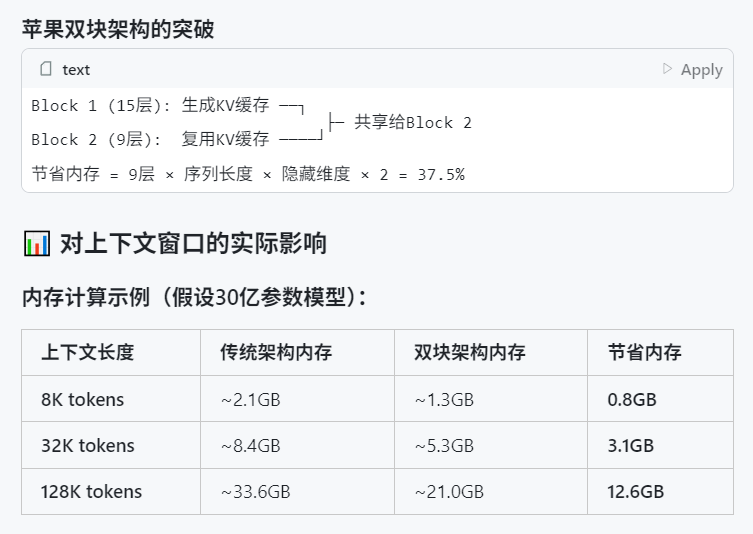
Apple WWDC 2025, AI 관련 언급 적었으나 기술 세부 사항에서 야심 드러내: Apple은 세계 개발자 회의(WWDC) 2025에서 AI에 대한 언급이 예상보다 적었던 것으로 보이지만, 기술 문서를 통해 디바이스 단 및 클라우드 단 모델에 대한 심도 있는 투자를 드러냈습니다. Apple은 모바일 단 모델(약 3B 크기)을 위한 “듀얼 블록 아키텍처”(메모리 점유율 감소 목표)와 서버 단 모델에 사용되는 “PT-MoE”(병렬 궤도 전문가 혼합) 아키텍처를 포함한 고급 훈련, 증류 및 양자화 기술을 채택하고 있습니다. 이러한 기술은 Apple 칩에서의 저지연 추론을 최적화하고 KV 캐시 메모리 사용을 줄이는 것을 목표로 합니다. 외부에서는 Apple이 AI 분야에서 뒤처졌다는 의견도 있지만, 모델 기술에서의 성과(예: 오픈소스 임베딩 모델)와 다른 우선순위(단순 챗봇이 아닌 디바이스 단 지능 등)에 대한 관심은 Apple만의 독특한 AI 전략을 보여줍니다. WWDC에서는 또한 Safari 26이 WebGPU를 지원할 것이라고 발표했는데, 이는 Transformers.js 등을 통한 디바이스 단 AI 모델 실행 성능을 크게 향상시켜 브라우저 내 비전 모델 자막 생성 속도를 약 12배 높일 것입니다 (출처: X, X, X)
Perplexity Pro 사용자, 이제 OpenAI o3 모델 사용 가능: Perplexity는 Pro 구독 사용자가 이제 OpenAI의 o3 모델을 사용할 수 있다고 발표했습니다. 이 통합은 Perplexity Pro 사용자에게 더욱 강력한 정보 처리 및 질의응답 능력을 제공할 것입니다. 동시에 Perplexity는 “Memory” 기능을 테스트하고 있으며 iOS 음성 비서를 업데이트하여 더욱 간결하고 실용적인 사용자 경험을 제공하는 것을 목표로 하고 있습니다. Discover 기사 기능도 기본적으로 더 간결한 “Summary” 모드로 제공되며, 심층적인 “Report” 모드로 전환할 수 있는 옵션을 제공합니다 (출처: X, X, X)

샤오홍슈, 첫 142B MoE 거대 모델 dots.llm1 오픈소스 공개, 중국어 평가에서 DeepSeek-V3 능가: 샤오홍슈(小红书)는 첫 거대 모델 dots.llm1을 오픈소스 공개했습니다. 이는 1420억 파라미터의 MoE(Mixture of Experts) 모델로, 추론 시 140억 파라미터만 활성화됩니다. 이 모델은 사전 훈련 단계에서 주로 일반 크롤러 및 자체 크롤러의 웹 데이터에서 수집한 11조 2천억 개의 비합성 토큰을 사용했습니다. 샤오홍슈 팀은 확장 가능한 3단계 데이터 처리 프레임워크를 제안하고 재현성 향상을 위해 이를 오픈소스 공개했습니다. dots.llm1은 C-Eval에서 92.2점을 획득하여 DeepSeek-V3를 포함한 모든 모델을 능가했으며, 중국어-영어, 수학, 정렬 등의 작업에서 알리바바 Qwen3-32B의 성능에 근접했습니다. 샤오홍슈는 또한 커뮤니티가 거대 모델의 동역학을 이해하는 데 기여하기 위해 중간 훈련 체크포인트를 오픈소스 공개했습니다 (출처: 36氪)
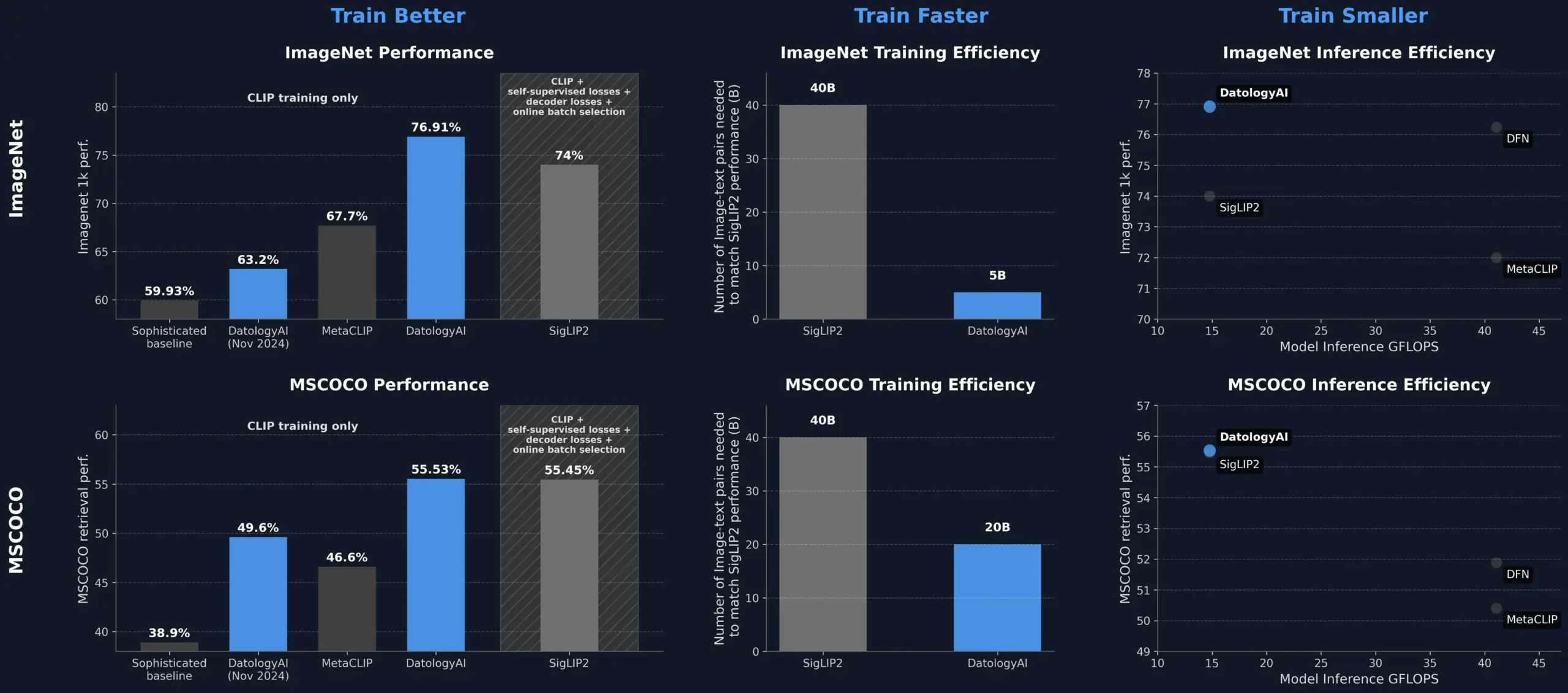
DatologyAI, 데이터 관리를 통해 CLIP 모델 성능 향상, SigLIP2 능가: DatologyAI는 데이터 큐레이션(data curation)만으로 CLIP 모델 성능을 현저히 향상시킨 성과를 선보였습니다. 이들의 방법론은 ViT-B/32 모델이 ImageNet 1k에서 76.9%의 정확도를 달성하게 하여 SigLIP2가 보고한 74%를 넘어섰습니다. 또한 이 방법론은 8배의 훈련 효율 향상과 2배의 추론 효율 향상을 가져왔으며, 관련 모델을 공개적으로 발표했습니다. 이는 모델 아키텍처를 변경하지 않고도 데이터 최적화를 통해 모델 잠재력을 발굴할 수 있다는 점에서 고품질의 잘 관리된 데이터셋이 첨단 AI 모델 훈련에서 핵심적인 역할을 한다는 것을 강조합니다 (출처: X, X)
콰이쇼우와 동북대학교, 통합 멀티모달 임베딩 프레임워크 UNITE 공동 제안: 멀티모달 검색에서 서로 다른 모달리티(텍스트, 이미지, 비디오) 데이터 분포 차이로 인한 교차 모달리티 간섭 문제를 해결하기 위해 콰이쇼우(快手)와 동북대학교 연구진은 멀티모달 통합 임베딩 프레임워크 UNITE를 제안했습니다. 이 프레임워크는 “모달리티 인식 마스크 대조 학습”(MAMCL) 메커니즘을 통해 대조 학습에서 쿼리 대상 모달리티와 일치하는 네거티브 샘플만 고려하여 모달리티 간의 잘못된 경쟁을 방지합니다. UNITE는 “검색 적응 + 지시 미세 조정” 2단계 훈련을 채택하고 이미지-텍스트 검색, 비디오-텍스트 검색 및 지시 검색 등 여러 평가에서 SOTA 성적을 거두었습니다. 예를 들어 MMEB Benchmark에서는 더 큰 규모의 모델을 능가했고 CoVR에서는 크게 앞섰습니다. 연구는 통합 모달리티에서 비디오-텍스트 데이터의 핵심 능력을 강조하며 지시 작업이 텍스트 주도 데이터에 더 의존한다고 지적합니다 (출처: 量子位)

NVIDIA, Earth-2 기후 시뮬레이션 AI 기초 모델 발표: NVIDIA의 Earth-2 플랫폼은 킬로미터급 해상도로 전 세계 기후를 시뮬레이션할 수 있는 새로운 AI 기초 모델을 출시했습니다. 이 모델은 더 빠르고 정확한 기후 예측을 제공하여 지구의 복잡한 자연 시스템을 이해하고 예측하는 새로운 길을 열어줄 것으로 기대됩니다. 이는 기후 과학 및 지구 시스템 모델링 분야에서 AI 응용이 중요한 진전을 이루었음을 의미하며, 기후 변화 연구 및 재해 예방 능력을 향상시킬 것으로 전망됩니다 (출처: X)

OpenAI 서비스 대규모 장애 발생, ChatGPT 및 API 영향: OpenAI의 ChatGPT 서비스와 API 인터페이스가 베이징 시간 6월 10일 저녁에 대규모 장애를 일으켜 오류율과 지연 시간이 증가했습니다. 많은 사용자가 서비스에 접속할 수 없거나 “Hmm…something seems to have gone wrong”과 같은 오류 메시지를 접했다고 보고했습니다. OpenAI 공식 상태 페이지는 이 문제를 확인하고 엔지니어가 근본 원인을 파악하여 긴급 복구 중이라고 밝혔습니다. 이번 장애는 ChatGPT와 그 API에 의존하는 전 세계 수많은 사용자와 애플리케이션에 영향을 미쳤으며, 대형 AI 서비스 안정성의 중요성을 다시 한번 부각시켰습니다 (출처: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 도구
Model Context Protocol (MCP) 서버 생태계 지속 확장: Model Context Protocol (MCP)은 거대 언어 모델(LLM)에 안전하고 통제 가능한 도구 및 데이터 소스 접근을 제공하는 것을 목표로 합니다. GitHub의 modelcontextprotocol/servers 저장소는 MCP의 참조 구현과 커뮤니티가 구축한 서버를 모아 다양한 응용 사례를 보여줍니다. 공식 및 타사 서버는 파일 시스템, Git 작업, 데이터베이스 상호 작용(예: PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra 등), 클라우드 서비스(AWS, Azure, Cloudflare), API 통합(GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), 검색(Brave, Algolia, Exa, Tavily), 코드 실행, AI 모델 호출(Replicate, ElevenLabs) 등 광범위한 영역을 포괄합니다. MCP 생태계는 빠르게 발전하여 이미 130개 이상의 공식 및 커뮤니티 서버가 있으며, EasyMCP, FastMCP, MCP-Framework와 같은 개발 프레임워크와 MCP-CLI, MCPM과 같은 관리 도구가 등장하여 LLM이 외부 도구 및 데이터에 접근하는 장벽을 낮추고 AI Agent의 발전을 촉진하고 있습니다 (출처: GitHub Trending)
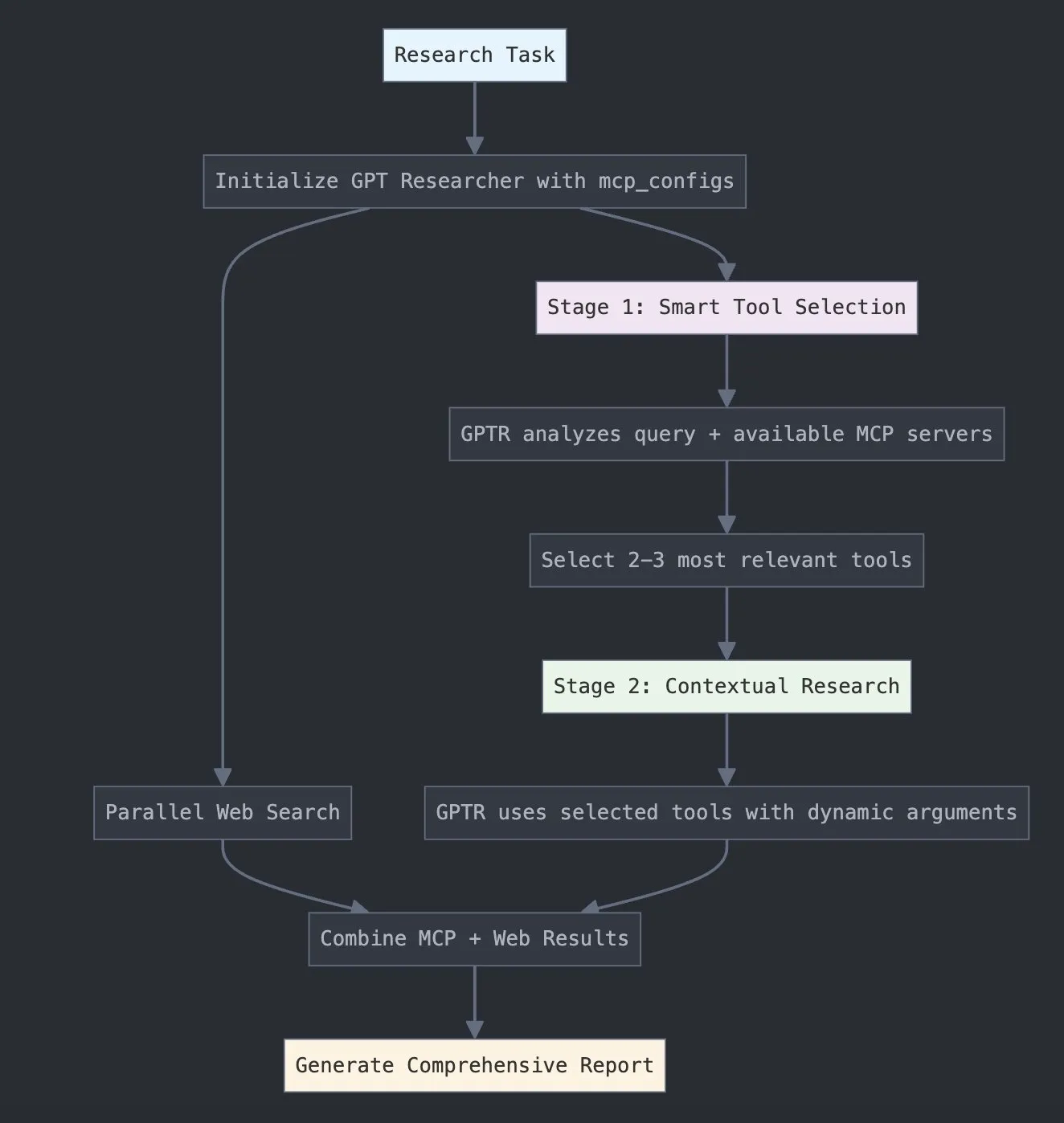
LangChain, GPT Researcher MCP 출시로 연구 능력 강화: LangChain은 GPT Researcher가 이제 모델 컨텍스트 프로토콜(MCP) 어댑터를 활용하여 지능적인 도구 선택 및 연구를 수행한다고 발표했습니다. 이 통합은 MCP와 웹 검색 기능을 결합하여 사용자에게 보다 포괄적인 데이터 수집 및 분석 능력을 제공하고, 연구 분야에서 AI 응용의 깊이와 폭을 더욱 향상시키는 것을 목표로 합니다 (출처: X)
Hugging Face, Vui 출시: 100M 오픈소스 NotebookLM, 인간과 유사한 TTS 구현: Hugging Face에 1억 파라미터의 오픈소스 NotebookLM 프로젝트인 Vui가 출시되었습니다. 여기에는 세 가지 모델이 포함됩니다: Vui.BASE (4만 시간의 오디오 대화 기반으로 훈련된 기본 모델), Vui.ABRAHAM (문맥 인식 능력을 갖춘 단일 화자 모델), Vui.COHOST (2인 대화가 가능한 모델). Vui는 음성 복제, 호흡 모방, “음”, “아”와 같은 구어체 표현, 심지어 비음성 소리까지 모방할 수 있어 인간과 유사한 텍스트 음성 변환(TTS) 기술의 새로운 진전을 보여줍니다 (출처: X, X)
Consilium: 복잡한 문제 해결을 위한 오픈소스 다중 에이전트 협업 플랫폼: Hugging Face에 오픈소스 다중 에이전트 협업 플랫폼인 Consilium 프로젝트가 소개되었습니다. 사용자는 전문가 AI 에이전트 팀을 구성하여 토론과 실시간 연구(웹 페이지, arXiv, SEC 파일)를 통해 복잡한 문제를 공동으로 해결하고 합의에 도달할 수 있습니다. 사용자가 전략을 설정하면 에이전트 팀이 답변을 찾는 방식으로, AI의 협력적 문제 해결 분야에서의 새로운 탐구를 보여줍니다 (출처: X)
Unsloth, Magistral-Small-2506 최적화 버전 GGUF 모델 출시: Mistral AI가 Magistral-Small-2506 추론 모델을 출시한 후, Unsloth는 llama.cpp, LMStudio 및 Ollama와 같은 플랫폼에 적합한 최적화된 GGUF 형식 모델을 신속하게 출시했습니다. 이러한 빠른 대응은 모델 최적화 및 배포 분야에서 오픈소스 커뮤니티의 활력과 효율성을 보여주며, 새로운 모델이 더 광범위한 사용자와 개발자에게 더 빨리 사용될 수 있도록 합니다 (출처: X)
📚 학습
새 논문, 강화 학습 사전 훈련(RPT) 패러다임 논의: 새로운 논문 《Reinforcement Pre-Training (RPT)》는 차세대 토큰 예측을 RLVR(Reinforcement Learning with Verifiable Rewards)을 사용한 추론 작업으로 재구성할 것을 제안합니다. RPT는 차세대 토큰 추론 능력을 장려하여 언어 모델 예측 정확도를 개선하고 후속 강화 미세 조정을 위한 강력한 기반을 제공하는 것을 목표로 합니다. 연구에 따르면 훈련 계산량을 늘리면 예측 정확도가 지속적으로 향상되어 RPT가 언어 모델 사전 훈련을 발전시키는 효과적이고 유망한 확장 패러다임임을 보여줍니다 (출처: HuggingFace Daily Papers, X)

논문, Cartridges 제안: 자가 학습을 통한 경량 장문맥 표현: 《Cartridges: Lightweight and general-purpose long context representations via self-study》라는 논문은 추론 시 전체 코퍼스를 컨텍스트 창에 넣는 대신, 오프라인으로 소형 KV 캐시(Cartridge라 불림)를 훈련하여 장문을 처리하는 방법을 논의합니다. 연구에 따르면, “자가 학습”(코퍼스에 대한 합성 대화를 생성하고 컨텍스트 증류 목표로 훈련)을 통해 훈련된 Cartridge는 훨씬 낮은 메모리 소모(38.6배 감소)와 더 높은 처리량(26.4배 향상)으로 ICL과 동등한 성능을 달성하며, 모델의 유효 컨텍스트 길이를 확장하고 재훈련 없이 여러 코퍼스 간 조합 사용도 지원할 수 있습니다 (출처: HuggingFace Daily Papers, X)

논문, 기하 문제 해결에서 LLM의 그룹 대조 정책 최적화(GCPO) 논의: 논문 《GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization》은 LLM이 기하 문제 해결에서 보조선 구성에 어려움을 겪는 문제를 해결하기 위해 GCPO 프레임워크를 제안합니다. 이 프레임워크는 “그룹 대조 마스크”를 통해 문맥적 유용성에 따라 보조선 구성에 긍정적 및 부정적 보상 신호를 제공하고, 길이 보상을 도입하여 더 긴 추론 사슬을 촉진합니다. GCPO 기반으로 개발된 GeometryZero 모델 시리즈는 Geometry3K 및 MathVista와 같은 벤치마크 테스트에서 기준 모델보다 평균 4.29% 향상된 성능을 보여, 제한된 연산 능력 하에서 소형 모델의 기하 추론 능력을 향상시킬 수 있는 잠재력을 보여주었습니다 (출처: HuggingFace Daily Papers)
논문 《The Illusion of Thinking》, 문제 복잡도를 통해 추론 모델의 능력과 한계 탐구: 이 연구는 대형 추론 모델(LRM)의 능력, 확장 특성 및 한계를 체계적으로 조사했습니다. 복잡도를 정밀하게 제어할 수 있는 퍼즐 환경을 사용하여 연구한 결과, LRM은 특정 복잡도를 초과하면 정확도가 완전히 붕괴되고, 문제 복잡도가 일정 수준까지 증가하면 추론 노력이 오히려 감소하는 반직관적인 확장 제한을 보였습니다. 표준 LLM과 비교하여 LRM은 저복잡도 작업에서는 성능이 낮고, 중간 복잡도 작업에서는 우세하며, 고복잡도 작업에서는 둘 다 실패했습니다. 연구는 LRM이 정밀 계산 측면에서 한계가 있고, 명시적 알고리즘을 사용하기 어려우며, 다양한 규모에서 추론이 일치하지 않는다고 지적합니다 (출처: HuggingFace Daily Papers, X)
논문, 저자원 언어에서 LLM의 견고성 평가 연구: 논문 《Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models》은 폴란드어와 같은 저자원 언어에서 대형 언어 모델(LLM)이 문자 수준 및 단어 수준 공격과 같은 교란에 얼마나 민감한지를 논의합니다. 연구에 따르면, 소량의 문자 수정과 소형 프록시 모델을 사용하여 단어 중요도를 계산함으로써 다양한 LLM의 예측을 현저하게 변경할 수 있는 공격을 생성할 수 있으며, 이는 이러한 언어에서 LLM이 가질 수 있는 보안 취약점을 드러내고 내부 보안 메커니즘을 회피하는 데 사용될 수 있음을 보여줍니다. 연구자들은 관련 데이터셋과 코드를 공개했습니다 (출처: HuggingFace Daily Papers)
Rel-LLM: 관계형 데이터베이스 처리 효율을 높이는 LLM의 새로운 방법: 한 논문에서 관계형 데이터베이스를 처리할 때 대형 언어 모델(LLM)의 비효율성 문제를 해결하기 위한 Rel-LLM 프레임워크를 제안했습니다. 기존 방식은 구조화된 데이터를 텍스트로 변환하여 주요 연결이 손실되고 입력이 중복되는 문제가 있었습니다. Rel-LLM은 그래프 신경망(GNN) 인코더를 사용하여 구조화된 그래프 프롬프트를 생성하고, 검색 증강 생성(RAG) 프레임워크 내에서 관계 구조를 보존합니다. 이 방법에는 시계열 인식 하위 그래프 샘플링, 이기종 GNN 인코더, MLP 프로젝션 레이어를 통한 그래프 임베딩과 LLM 잠재 공간 정렬, 그래프 표현을 JSON 그래프 프롬프트로 구조화하는 단계 등이 포함되며, 자가 지도 사전 훈련 목표를 통해 그래프와 텍스트 표현을 정렬합니다. 실험 결과, GNN 인코딩은 텍스트 직렬화에서 손실된 복잡한 관계 구조를 효과적으로 포착하고, 구조화된 그래프 프롬프트는 관계형 컨텍스트를 LLM 어텐션 메커니즘에 효과적으로 주입할 수 있음을 보여주었습니다 (출처: X)

논문, LLM의 “과도한 거부” 문제 및 EvoRefuse 최적화 방법 논의: 논문 《EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions》은 대형 언어 모델(LLM)이 “유사 악성 지시”(의미상 무해하지만 모델의 거부를 유발하는 입력)에 대해 과도하게 거부하는 문제를 연구합니다. 기존 지시 관리 방법의 확장성 및 다양성 부족 문제를 해결하기 위해, 논문은 진화 알고리즘을 활용하여 프롬프트를 최적화하는 EVOREFUSE를 제안합니다. 이는 LLM의 거부를 지속적으로 유발하는 다양하고 유사 악성 지시를 생성할 수 있습니다. 이를 바탕으로 연구자들은 EVOREFUSE-TEST(582개 지시 포함 벤치마크 테스트)와 EVOREFUSE-ALIGN(3000개 지시 및 응답 포함 정렬 훈련 데이터셋)을 만들었습니다. 실험 결과, EVOREFUSE-ALIGN에서 미세 조정한 LLAMA3.1-8B-INSTRUCT 모델은 차선책 정렬 데이터셋에서 훈련된 모델보다 과도한 거부율이 최대 14.31% 감소했으며, 안전성을 손상시키지 않았습니다 (출처: HuggingFace Daily Papers)
💼 비즈니스
중커원거, 베이징시 스징산구 산업기금 투자 유치로 신규 전략적 투자 완료: 기업용 AI 서비스 제공업체 중커원거(中科闻歌)가 베이징시 스징산구 현대혁신산업발전기금 유한회사로부터 신규 전략적 투자를 유치했다고 발표했습니다. 이번 투자는 주로 자체 개발한 의사결정 지능 운영체제 DIOS의 연구개발 투자와 시장 확대에 사용되어 기업용 인공지능 기술 발전과 상용화를 가속화할 예정입니다. 중커원거는 2017년에 설립되었으며, 핵심 팀은 중국과학원 자동화연구소 출신으로 다국어 이해, 교차 모달 의미론 및 복잡한 시나리오 의사결정 기술에 주력하여 미디어, 금융, 정부, 에너지 등 산업에 서비스를 제공하고 있습니다. 이전에는 국개금융, 중망투, 심천창투 등 국유자본 배경의 펀드로부터 10억 위안 이상의 투자를 유치한 바 있습니다 (출처: 量子位)

Sakana AI, 일본 호쿠코쿠 은행과 전략적 제휴 체결, 지역 금융 AI 발전 추진: 일본 AI 스타트업 Sakana AI가 이시카와현에 본사를 둔 호쿠코쿠 금융지주(Hokkoku Financial Holdings)와 양해각서(MOU)를 체결하고, 지역 금융과 AI의 결합에 관한 전략적 협력을 전개한다고 발표했습니다. 이는 미쓰비시 UFJ 은행과의 포괄적 파트너십 구축에 이어 Sakana AI가 금융기관과 다시 손을 잡은 것으로, 첨단 AI 기술을 일본 지역 사회가 직면한 과제, 특히 금융 서비스 분야의 문제 해결에 적용하는 것을 목표로 합니다. Sakana AI는 금융기관을 위한 고도로 전문화된 AI 기술 개발에 주력하고 있으며, 이번 협력은 일본의 다른 지역 은행들에게 AI 응용의 모범 사례를 제시할 것으로 기대됩니다 (출처: X, X)

Cohere, Ensemble과 협력하여 AI 플랫폼을 의료 산업에 도입: AI 기업 Cohere는 EnsembleHP(의료 솔루션 제공업체)와 파트너십을 맺고 Cohere North AI 에이전트 플랫폼을 의료 산업에 도입한다고 발표했습니다. 양사는 안전한 AI 에이전트 플랫폼을 통해 의료 관리 프로세스의 마찰을 줄이고 병원 및 의료 시스템의 환자 경험을 향상시키는 것을 목표로 합니다. 이는 Cohere가 자사의 대규모 언어 모델과 AI 기술을 주요 수직 산업에 적용하는 데 있어 중요한 진전을 이루었음을 의미합니다 (출처: X)
🌟 커뮤니티
Ilya Sutskever, 토론토 대학교 명예 학위 연설: AI는 결국 모든 것을 할 수 있게 될 것이며, 적극적인 관심 필요: OpenAI 공동 창업자 Ilya Sutskever는 토론토 대학교에서 명예 이학 박사 학위(그의 네 번째 학위)를 받은 연설에서 AI의 발전으로 “언젠가는 우리가 할 수 있는 모든 일을 해낼 수 있을 것”이라고 말했습니다. 인간의 뇌는 생물학적 컴퓨터이고 AI는 디지털 뇌이기 때문입니다. 그는 우리가 AI가 정의하는 비범한 시대에 살고 있으며, AI는 이미 학생과 일의 의미를 깊이 변화시켰다고 생각합니다. 그는 걱정하기보다는 최고의 AI를 사용하고 관찰함으로써 직관을 형성하고 그 능력의 경계를 이해해야 한다고 강조했습니다. 그는 AI 발전에 관심을 갖고 그에 따른 거대한 도전과 기회에 적극적으로 대처할 것을 촉구했습니다. AI가 모든 사람의 삶에 깊은 영향을 미칠 것이기 때문입니다. 그는 또한 “현실을 받아들이고, 과거를 후회하지 않으며, 현재를 개선하기 위해 노력한다”는 개인적인 마음가짐을 공유했습니다 (출처: X, 36氪)
AI 인재 쟁탈전 백열화: Meta 고액 연봉에도 OpenAI와 Anthropic에 밀려: Meta가 AI 인재 유치를 위해 연봉 200만 달러 이상을 제시한 것으로 알려졌으나, 여전히 인재들이 OpenAI와 Anthropic으로 유출되는 어려움을 겪고 있습니다. OpenAI L6급 연봉이 150만 달러에 육박하고 주식 가치 상승 잠재력이 Meta보다 우수하다고 평가되어 최고 인재들에게 더 매력적으로 여겨진다는 논의가 있습니다. 또한, Llama 팀의 부정행위 의혹과 Meta 내부의 높은 KPI 압박, 높은 하위 평가자 해고율(올해 15-20%) 등도 인재 선택에 영향을 미치고 있습니다. Anthropic은 설립 2년 후 약 80%에 달하는 높은 인재 유지율로 최고 AI 연구원들이 선호하는 대기업 중 하나가 되었습니다. 이 인재 전쟁의 치열함은 “상상 초월”이라고 묘사됩니다 (출처: X, X)
“Vibe Coding” 경험 공유: AI 보조 프로그래밍 시 비효율적 디버깅 루프를 피하는 5가지 규칙: 소셜 미디어에서 숙련된 개발자들이 AI(예: Claude)를 사용한 “Vibe Coding”(AI 보조에 의존하는 프로그래밍 방식) 시 비효율적인 디버깅 순환에 빠지지 않는 5가지 규칙을 공유했습니다: 1. 삼진 아웃: AI가 세 번 문제를 해결하지 못하면 중단하고 AI에게 새로운 요구 사항을 바탕으로 처음부터 다시 구축하도록 해야 합니다. 2. 컨텍스트 재설정: AI는 긴 대화 후 “잊어버리므로”, 8-10회 메시지 교환 후 유효한 코드를 저장하고, 새 세션을 열어 문제 구성 요소와 간략한 애플리케이션 설명만 붙여넣는 것이 좋습니다. 3. 간결하고 명확한 문제 설명: 한 문장으로 버그를 명확하게 설명합니다. 4. 잦은 버전 관리: 각 기능 완료 후 즉시 Git에 커밋합니다. 5. 필요시 처음부터 다시 시작: 버그 수정에 너무 많은 시간(예: 2시간 초과)이 소요되면 문제 구성 요소를 삭제하고 AI에게 다시 구축하도록 하는 것이 낫습니다. 핵심은 코드가 돌이킬 수 없이 손상되었음을 인정할 때 과감하게 수정을 포기하는 것입니다. 동시에 프로그래밍을 알아야 AI를 더 잘 지도하고 디버깅할 수 있음을 강조합니다 (출처: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
페이페이 리, World Labs 창업 계기 밝혀: 지능 본질 탐구에서 비롯, 공간 지능이 AI의 핵심 결핍: a16z 팟캐스트에서 페이페이 리는 World Labs 창업의 동기를 공유하며, 이것이 기초 모델 열풍을 따르는 것이 아니라 지능의 본질에 대한 지속적인 탐구라고 강조했습니다. 그녀는 언어가 효율적인 정보 전달 수단이지만 3차원 물리 세계를 표현하는 데 결함이 있으며, 진정한 일반 지능은 물리적 공간과 물체 관계에 대한 이해를 바탕으로 구축되어야 한다고 생각합니다. 각막 손상으로 일시적으로 입체 시각을 잃었던 경험은 그녀에게 3차원 공간 표현이 물리적 상호 작용에 얼마나 중요한지를 더욱 깊이 깨닫게 했습니다. World Labs는 현재 AI가 공간 지능에서 부족한 부분을 메우기 위해 물리 세계를 진정으로 이해할 수 있는 AI 모델(세계 모델 LWM)을 구축하는 것을 목표로 합니다. 그녀는 이 비전을 실현하기 위해서는 산업 수준의 컴퓨팅 파워, 데이터 및 인재를 결집해야 하며, 현재 기술 돌파구는 AI가 단안 시각에서 완전한 3차원 장면 이해를 재구성하도록 하는 데 있다고 지적했습니다 (출처: 量子位)

AI 보조 수능: 문제 예측 논란에서부터 지원서 작성까지 기회와 우려: 대학수학능력시험(수능) 전후로 교육 분야에서 AI 활용이 광범위하게 논의되고 있습니다. 한편으로는 “AI 문제 예측”이 화제가 되었지만, 수능 출제의 과학성, 기밀성 및 “예측 방지” 메커니즘으로 인해 AI의 정확한 문제 예측 가능성은 낮고, 시중에 판매되는 일부 예측 문제집의 질도 우려스럽습니다. 다른 한편으로는 AI가 시험 준비 계획, 문제 해설, 시험장 감독 및 채점 등에서 개인 맞춤형 학습 계획, 지능형 질의응답, 공정성 및 효율성을 높이는 AI 감독 시스템과 같은 긍정적인 역할을 보여주었습니다. 지원서 작성 단계에서는 AI 도구가 수험생의 점수, 등위를 바탕으로 빠르게 대학 및 학과를 추천하여 정보 격차를 해소할 수 있습니다. 그러나 AI 지원서 작성에 대한 과도한 의존은 알고리즘이 인기 학과 선호를 강화하고 개인의 관심사와 장기적인 발전을 간과할 수 있으며, 인생의 선택권을 완전히 알고리즘에 맡기는 것이 “알고리즘에 의한 인생 납치”로 이어질 수 있다는 우려를 낳고 있습니다. 이 기사는 AI 보조를 이성적으로 바라보고, 지혜로 도구를 다루며, 사고로 미래를 정의할 것을 촉구합니다 (출처: 36氪)
AI 에이전트 기업 성공 모델 논의: 셀프 서비스 vs. 맞춤형 서비스: 커뮤니티에서는 AI 에이전트 기업의 성공 모델에 대해 논의했습니다. 한쪽 의견은 성공적인 AI 에이전트 기업(특히 중대형 시장 대상)이 순수한 셀프 서비스 모델보다는 Palantir와 유사한 모델, 즉 다수의 현장 개발 엔지니어(FDE)와 맞춤형 소프트웨어를 채택한다고 주장합니다. 다른 한쪽은 셀프 서비스 모델의 장기적인 가치를 고수하며, 팀이 결국 중요한 애플리케이션을 내부적으로 구축할 것이라고 생각합니다. 이는 AI 에이전트 분야의 서비스 모델과 시장 전략에 대한 다양한 사고방식을 반영합니다 (출처: X)
💡 기타
Google Diffusion 시스템 프롬프트 노출, 설계 원칙과 능력 경계 드러내: 한 사용자가 Google Diffusion(텍스트 확산 언어 모델)으로 추정되는 시스템 프롬프트를 공유했습니다. 이 프롬프트는 모델의 정체성(Gemini Diffusion, Google에서 훈련한 전문가 텍스트 확산 언어 모델, 비자기회귀), 핵심 원칙 및 제약 조건(예: 지시 준수, 비자기회귀 특성, 정확성, 실시간 접근 불가, 안전 윤리, 지식 마감일 2023년 12월, 코드 생성 능력), 그리고 HTML 웹 페이지 및 HTML 게임 생성에 대한 구체적인 지침을 상세히 설명합니다. 이러한 지침은 출력 형식, 미적 디자인, 스타일(예: Tailwind CSS의 전문적 사용 또는 게임 내 사용자 정의 CSS), 아이콘 사용(Lucide SVG 아이콘), 레이아웃 및 성능(CLS 예방), 주석 요구 사항 등을 포괄합니다. 마지막으로 단계별 사고와 사용자 지시의 정확한 준수의 중요성을 강조합니다. 이 프롬프트는 이러한 유형의 모델 설계 아이디어와 예상 행동을 이해하는 창을 제공합니다 (출처: Reddit r/LocalLLaMA)
Arvind Narayanan, “AI는 평범한 기술이다” 논문 탄생과 고찰 설명: 프린스턴 대학교 교수 Arvind Narayanan은 Sayash Kapoor와 공동 저술한 논문 《AI as Normal Technology》의 집필 과정을 공유했습니다. 그는 처음에 AGI와 실존적 위험에 대해 회의적이었지만, 동료들의 권유로 이를 진지하게 받아들이고 관련 논의에 참여하기로 결정했습니다. 성찰을 통해 그는 초지능 관련 관점이 진지하게 다룰 가치가 있으며, 소셜 미디어는 진지한 토론에 적합하지 않고, AI 윤리 및 AI 안전 커뮤니티 모두 각자의 “정보 고립방”이 존재한다는 것을 인식했습니다. 논문 초고는 ICML에서 거부되었지만, 심사 과정에서의 격렬한 논쟁은 오히려 연구를 계속하겠다는 그들의 결심을 굳혔습니다. 그들은 AI 안전 커뮤니티와의 의견 차이가 예상보다 깊다는 것을 깨닫고, 보다 생산적인 분야 간 토론의 필요성을 인식했습니다. 결국 논문은 컬럼비아 대학교 Knight First Amendment Institute 워크숍에서 발표되어 광범위한 관심과 생산적인 토론을 불러일으켰고, Narayanan은 AI 정책의 미래에 대해 더욱 낙관적이 되었습니다 (출처: X)
00년대생 AI 창업가 그룹 부상, 창업 규칙 재편: 00년대생 AI 창업가들이 놀라운 속도로 글로벌 창업 물결에서 두각을 나타내고 있으며, AI 기술에 대한 깊은 이해와 디지털 네이티브 환경에 대한 예리한 통찰력을 바탕으로 창업 법칙을 재정의하고 있습니다. 사례로는 Anysphere (Cursor)의 Michael Truell (인턴에서 3년 만에 100억 달러 가치 회사 CEO), Mercor의 세 창업자 (2년 만에 100억 달러 규모 AI 채용 플랫폼 구축), Magic의 Eric Steinberger (25세에 4억 달러 이상 투자 유치한 AI 코딩 회사 공동 창업), Axiom의 Hong Letong (AI로 수학 난제 해결에 집중, 제품 없이 높은 가치 평가) 등이 있습니다. 이 젊은 창업가들은 일반적으로 다음과 같은 특징을 보입니다: 프로그래밍이 모국어; 어린 나이에 성공하여 기술 보너스 창구를 포착; 사용자 요구에 대한 예리한 감각; 조직과 제품에 대한 AI 네이티브 이해, 극도로 간결하고 효율적인 팀과 “AI가 곧 제품”이라는 논리 선호. 이들의 성공은 AI 시대 창업 패러다임의 변화를 의미합니다 (출처: 36氪)