
키워드:애플 WWDC25, AI 전략, Siri 업그레이드, Foundation 프레임워크, 디바이스 측 AI, 시스템 전체 번역, Xcode Vibe 코딩, 시각적 지능 검색, Apple Intelligence 번체 중국어 지원, watchOS 스마트 스택 기능, 애플 AI 개인정보 보호 정책, 크로스 시스템 생태계 AI 통합, 생성형 AI 버전 Siri 출시 일정
🔥 포커스
Apple WWDC25 AI 진전: 실용적 통합과 개방, Siri는 여전히 기다려야: Apple은 WWDC25에서 AI 전략 조정을 선보이며, 작년의 ‘거창한 계획’에서 벗어나 보다 실용적인 시스템 하위 계층 및 기본 기능 개선으로 전환했습니다. 주요 내용으로는 AI를 운영체제 및 자사 앱에 ‘의미 있게’ 통합하고, 온디바이스 모델 ‘Foundation’ 프레임워크를 개발자에게 개방하는 것 등이 포함됩니다. 새로운 기능으로는 전체 시스템 번역(전화, FaceTime, Message 등 지원 및 API 제공), Xcode Vibe Coding 도입(ChatGPT 등 모델 지원), 화면 콘텐츠 기반 시각 지능형 검색(원형 선택과 유사, 일부 ChatGPT 지원) 및 watchOS의 Smart Stack 등이 있습니다. Apple Intelligence의 번체 중국어 시장 지원은 언급되었으나, 간체 중국어 출시 시기 및 기대를 모으는 생성형 AI 버전 Siri는 아직 명확하지 않으며, 후자는 ‘내년’에 다시 논의될 것으로 예상됩니다. Apple은 사용자 개인 정보 보호를 위해 온디바이스 AI와 프라이빗 클라우드 컴퓨팅을 강조했으며, 크로스 시스템 생태계의 AI 기능 통합을 선보였습니다. (출처: 36氪, 36氪, 36氪, 36氪)

Apple, AI 논문 발표하며 대형 모델 추론 능력에 의문 제기, 업계 광범위한 논란 야기: Apple은 최근 《사고의 착각: 문제 복잡성 관점을 통해 추론 모델의 장점과 한계 이해》라는 논문을 발표했습니다. Claude 3.7 Sonnet, DeepSeek-R1, o3 mini 등 대형 추론 모델(LRM)을 대상으로 퍼즐 테스트를 진행한 결과, 간단한 문제 처리 시 ‘과도한 사고’가 존재하고, 고복잡도 문제에서는 ‘완전한 정확도 붕괴’가 나타나 정확도가 0에 가깝다고 지적했습니다. 해당 연구는 현재 LRM이 일반화 가능한 추론 측면에서 근본적인 장애에 직면했을 수 있으며, 진정한 사고라기보다는 패턴 매칭에 가깝다고 판단합니다. 이러한 관점은 Gary Marcus 등 학자들의 주목을 받았지만, 동시에 수많은 의혹을 불러일으켰습니다. 비판가들은 실험 설계에 논리적 허점(복잡성 정의, 토큰 출력 제한 무시 등)이 존재한다고 주장하며, 심지어 Apple이 자체 AI 발전이 더디기 때문에 기존 대형 모델의 성과를 부정하려 한다고 비난했습니다. 논문 제1저자의 인턴 신분 또한 논쟁거리가 되었습니다. (출처: 36氪, Reddit r/ArtificialInteligence)

OpenAI, 새 모델 o4 비밀 훈련 중이라는 폭로 나와, 강화학습으로 AI 연구개발 구도 재편: SemiAnalysis는 OpenAI가 GPT-4.1과 GPT-4.5 사이 규모의 새 모델을 훈련 중이며, 차세대 추론 모델 o4는 GPT-4.1을 기반으로 강화학습(RL) 훈련을 진행할 것이라고 폭로했습니다. 이는 모델 성능과 RL 훈련의 실용성 사이의 균형을 맞추려는 OpenAI 전략의 변화를 의미하며, GPT-4.1은 낮은 추론 비용과 강력한 코드 성능으로 이상적인 기반으로 간주됩니다. 이 기사는 LLM 추론 능력 향상 및 AI 에이전트 발전 추진에 있어 강화학습의 핵심적인 역할을 심층 분석했지만, 인프라, 보상 함수 설정, 보상 해킹(reward hacking) 등의 과제도 지적했습니다. RL은 AI 연구소의 조직 구조와 연구개발 우선순위를 변화시키며 추론과 훈련을 깊이 융합시키고 있습니다. 동시에 고품질 데이터는 RL 규모화의 해자가 되고 있으며, 소형 모델의 경우 RL보다 증류가 더 효과적일 수 있습니다. (출처: 36氪)

Ilya Sutskever, 대중 앞에 다시 모습 드러내, 토론토 대학교 명예박사 학위 받고 AI 미래 논해: OpenAI 공동 창립자 Ilya Sutskever가 OpenAI를 떠나 Safe Superintelligence Inc.를 설립한 후, 최근 모교인 토론토 대학교에서 명예 이학박사 학위를 받으며 처음으로 공개 석상에 모습을 드러냈습니다. 그는 연설에서 AI가 미래에는 인간이 할 수 있는 모든 일을 해낼 것이라고 강조하며, 뇌 자체가 생물학적 컴퓨터이므로 디지털 컴퓨터가 같은 일을 해내지 못할 이유가 없다고 말했습니다. 그는 AI가 전례 없는 방식으로 일과 직업을 변화시키고 있다고 보았으며, AI 발전에 관심을 갖고 그 능력을 관찰함으로써 도전을 극복할 에너지를 얻으라고 촉구했습니다. Sutskever의 OpenAI에서의 경험과 AGI 안전에 대한 관심은 그를 AI 분야의 핵심 인물로 만들었습니다. (출처: 36氪, Reddit r/artificial)

🎯 동향
샤오홍슈, 첫 MoE 대형 모델 dots.llm1 오픈소스 공개, 중국어 평가에서 DeepSeek-V3 능가: 샤오홍슈 hi lab(인문 지능 실험실)이 첫 오픈소스 대형 모델 dots.llm1을 발표했습니다. 이는 1420억 개의 파라미터를 가진 MoE(Mixture-of-Experts) 모델로, 추론 시에는 140억 개의 파라미터만 활성화됩니다. 이 모델은 사전 훈련 단계에서 11조 2천억 개의 비합성 데이터를 사용했으며, 중국어 및 영어 이해, 수학적 추론, 코드 생성 및 정렬 등의 작업에서 뛰어난 성능을 보여 Qwen3-32B에 근접하는 성능을 보였습니다. 특히 C-Eval 중국어 평가에서 dots.llm1.inst는 92.2점을 기록하여 DeepSeek-V3를 포함한 기존 모델들을 능가했습니다. 샤오홍슈는 확장 가능하고 세분화된 데이터 처리 프레임워크가 핵심이라고 강조하며, 커뮤니티 연구를 촉진하기 위해 중간 훈련 체크포인트를 오픈소스로 공개했습니다. (출처: 36氪)
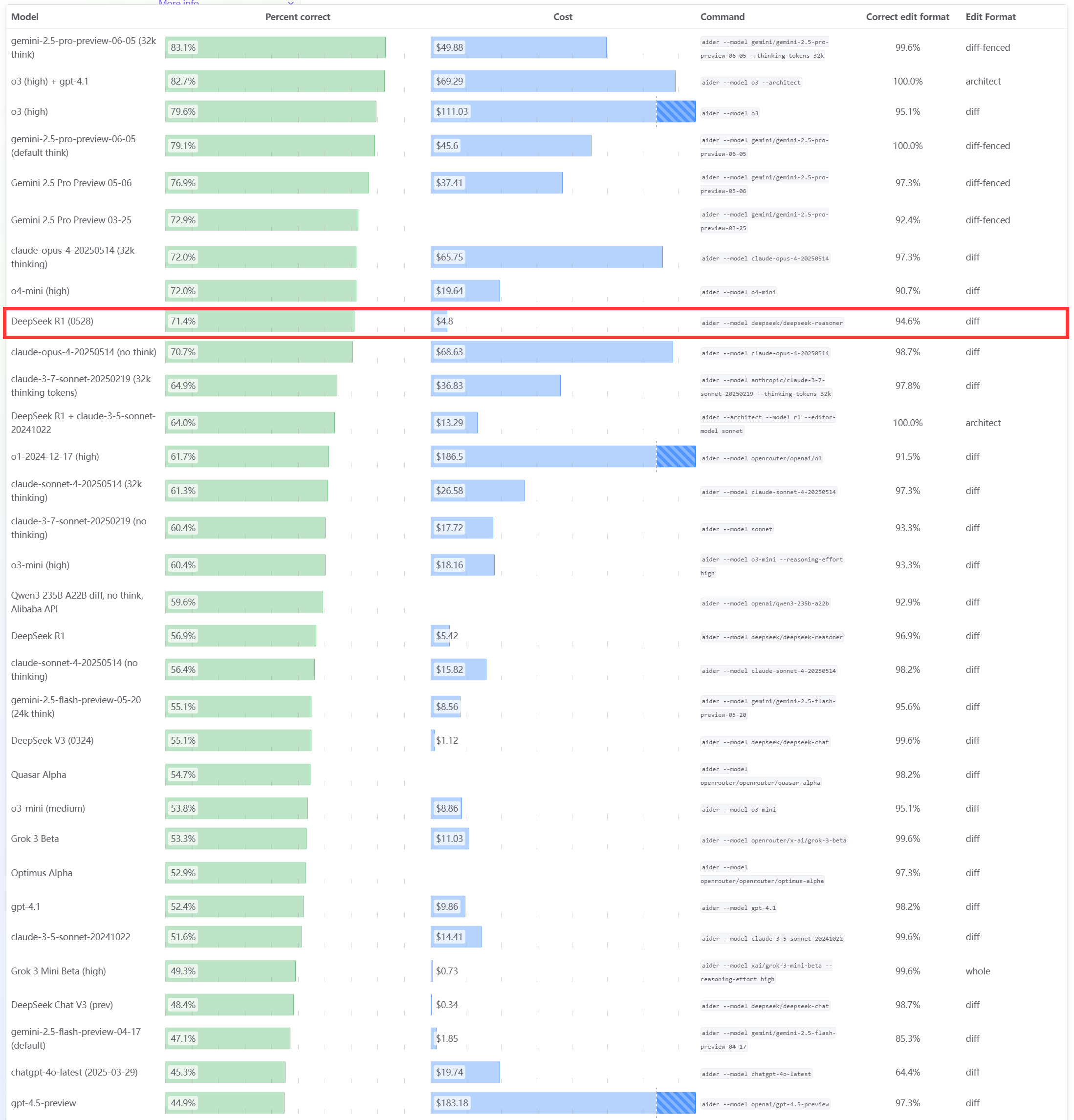
DeepSeek R1 0528 모델, Aider 프로그래밍 벤치마크 테스트에서 우수한 성능 보여: Aider 프로그래밍 순위표가 DeepSeek-R1-0528 모델의 점수를 업데이트했으며, 그 결과 사고 모드 활성화 여부와 관계없이 Claude-4-Sonnet 및 사고 모드를 활성화하지 않은 Claude-4-Opus를 능가하는 성능을 보였습니다. 이 모델은 가성비 측면에서도 두각을 나타내며 코드 생성 및 보조 프로그래밍 분야에서의 강력한 경쟁력을 다시 한번 입증했습니다. (출처: karminski3)
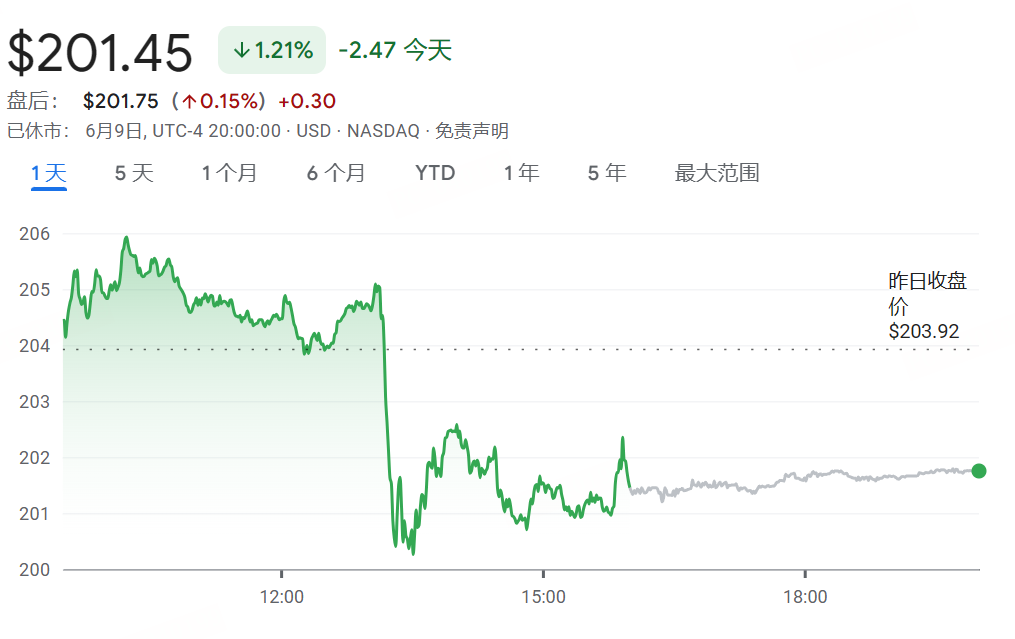
Apple WWDC25 업데이트: ‘Liquid Glass’ 디자인 언어 출시, AI 진전 더뎌, Siri 업그레이드 또다시 연기: Apple은 WWDC25에서 전체 플랫폼 운영체제 업데이트를 발표하고, ‘Liquid Glass’라는 새로운 UI 디자인 스타일을 도입했으며, 버전 번호를 ‘26 시리즈’(예: iOS 26)로 통일했습니다. AI 측면에서는 Apple Intelligence의 진전이 제한적이었습니다. 개발자에게 온디바이스 기반 모델 프레임워크 ‘Foundation’을 개방하고 실시간 번역, 시각 지능 등의 기능을 선보였지만, 기대를 모았던 AI 강화 버전 Siri는 또다시 ‘내년’으로 연기되었습니다. 이러한 조치는 시장의 실망을 불러일으켰고 주가는 하락했습니다. iPadOS는 멀티태스킹 및 파일 관리 측면에서 상당한 개선을 이루어 이번 발표회의 하이라이트로 평가받았습니다. (출처: 36氪, 36氪, 36氪)
Anthropic Claude 모델 성능 저하 지적, 사용자 경험 불만: 다수의 Reddit 사용자들이 Anthropic의 Claude 모델(특히 Claude Code Max)이 최근 현저한 성능 저하를 보인다고 보고했습니다. 여기에는 간단한 작업에서 오류 발생, 지침 무시, 출력 품질 저하 등이 포함됩니다. 일부 사용자는 API 버전에 비해 웹 버전의 성능이 특히 좋지 않으며, 모델이 ‘약화’(nerfed)된 것이 아닌지 의심하기도 했습니다. 일부 사용자는 서버 부하, 요금 제한 또는 내부 시스템 프롬프트 조정과 관련이 있을 수 있다고 추측했습니다. Anthropic 공식 상태 페이지에서도 Claude Opus 4의 오류율 증가 문제를 보고한 바 있습니다. (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: 중요도 낮은 KV 쌍 동적 삭제를 통해 LLM의 KV 캐시 압축: KVzip이라는 새로운 프로젝트는 대형 언어 모델(LLM)의 키-값(KV) 캐시를 압축하여 GPU 메모리 사용량과 추론 속도를 최적화하는 것을 목표로 합니다. 이 방법은 전통적인 의미의 데이터 압축이 아니라, KV 쌍의 중요도(컨텍스트 재구성 능력 기반)를 평가한 다음 중요도가 낮은 KV 쌍을 캐시에서 직접 삭제하여 손실 압축을 구현합니다. 이 방법을 사용하면 GPU 메모리 사용량을 기존의 3분의 1로 줄이고 추론 속도를 향상시킬 수 있다고 합니다. 현재 LLaMA3, Qwen2.5/3, Gemma3 등의 모델을 지원하지만, 일부 사용자는 《해리 포터》 텍스트 기반 테스트의 유효성에 대해 모델이 해당 텍스트로 사전 훈련되었을 가능성을 제기하며 의문을 제기했습니다. (출처: karminski3)

Yann LeCun, Anthropic CEO Dario Amodei의 AI 위험과 발전에 대한 모순된 입장 비판: Meta 수석 AI 과학자 Yann LeCun은 소셜 미디어에서 Anthropic CEO Dario Amodei가 AI 안전 문제에 대해 ‘이것도 갖고 저것도 갖는’ 모순된 입장을 보인다고 비난했습니다. LeCun은 Amodei가 한편으로는 AI 종말론을 퍼뜨리면서 다른 한편으로는 적극적으로 AGI를 개발하고 있으며, 이는 학문적 부정직 또는 도덕적 문제이거나, 아니면 자신만이 강력한 AI를 통제할 수 있다고 생각하는 극도의 자만심이라고 주장했습니다. Amodei는 이전에 AI가 향후 몇 년 안에 대규모 화이트칼라 실업을 초래할 수 있다고 경고하고 규제 강화를 촉구했지만, 그의 회사 Anthropic은 Claude 등 대형 모델의 연구 개발과 자금 조달을 계속 추진하고 있습니다. (출처: 36氪)
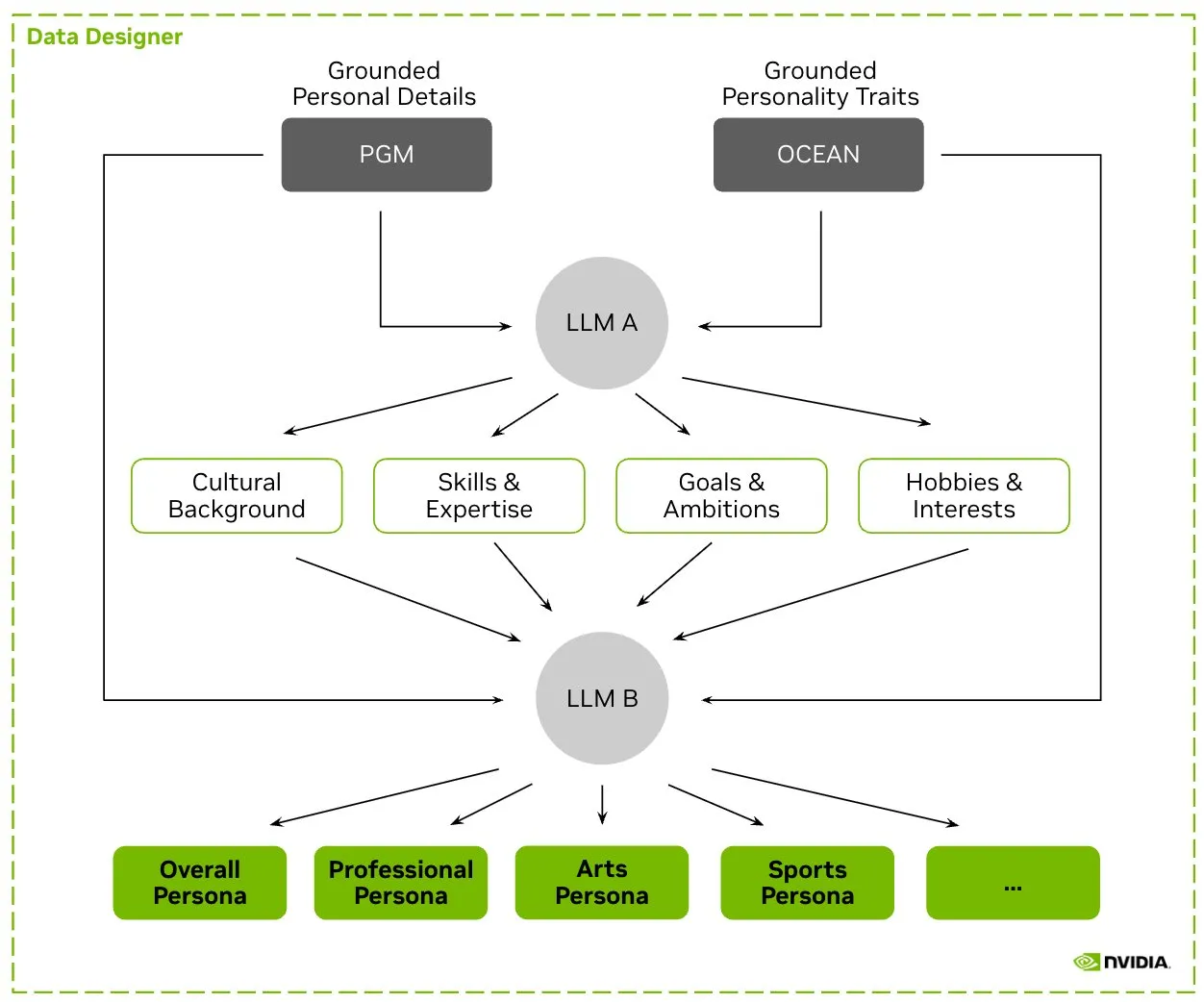
HuggingFace, Nemotron-Personas 데이터셋 공개, NVIDIA LLM 훈련용 합성 캐릭터 데이터 발표: NVIDIA는 HuggingFace에 실제 세계 분포를 기반으로 합성 생성된 10만 개의 캐릭터 프로필을 포함하는 오픈소스 데이터셋인 Nemotron-Personas를 공개했습니다. 이 데이터셋은 개발자가 높은 정확도의 LLM을 훈련하는 데 도움을 주는 동시에 편향을 줄이고 데이터 다양성을 높이며 모델 붕괴를 방지하고 PII, GDPR 등 개인 정보 보호 표준을 준수하도록 설계되었습니다. (출처: huggingface, _akhaliq)
Fireworks AI, 강화 미세조정(RFT) 베타 버전 출시, 개발자 자체 전문가 모델 훈련 지원: Fireworks AI가 강화 미세조정(RFT) 베타 버전을 출시하여, 맞춤형 오픈소스 전문가 모델을 훈련하고 소유할 수 있는 간단하고 확장 가능한 방법을 제공합니다. 사용자는 출력을 평가하기 위한 평가 함수와 소량의 예시만 지정하면 RFT 훈련을 진행할 수 있으며, 인프라 설정 없이 프로덕션 환경에 원활하게 배포할 수 있습니다. RFT를 통해 사용자는 이미 GPT-4o mini 및 Gemini flash와 같은 비공개 소스 모델의 품질에 도달하거나 이를 능가했으며, 응답 속도는 10~40배 향상되어 고객 서비스, 코드 생성 및 창의적 글쓰기 등의 장면에 적합하다고 합니다. 이 서비스는 Llama, Qwen, Phi, DeepSeek 등의 모델을 지원하며 향후 2주간 무료로 제공될 예정입니다. (출처: _akhaliq)

Modal Python SDK 1.0 정식 버전 출시, 더욱 안정적인 클라이언트 인터페이스 제공: 수년간의 0.x 버전 반복 끝에 Modal Python SDK가 드디어 1.0 정식 버전을 출시했습니다. 공식 발표에 따르면, 이 버전에 도달하기까지 많은 클라이언트 변경이 필요했지만, 앞으로는 더욱 안정적인 클라이언트 인터페이스를 의미하며 개발자에게 더욱 신뢰할 수 있는 경험을 제공할 것이라고 합니다. (출처: charles_irl, akshat_b, mathemagic1an)
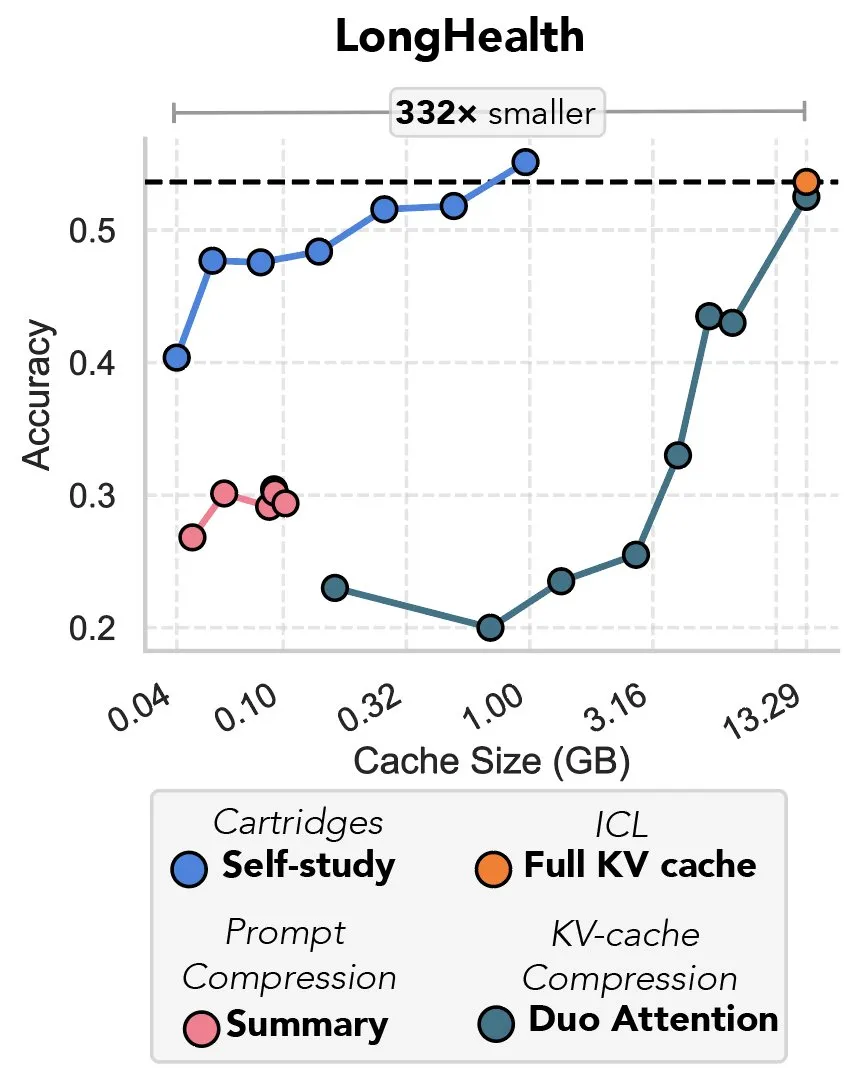
새로운 연구, 경사 하강법을 통한 KV 캐시 압축 논의, ‘프리픽스 튜닝의 복수’로 비유돼: 한 새로운 연구는 경사 하강법을 이용하여 대형 언어 모델(LLM)의 KV 캐시를 압축하는 방법을 제안했습니다. LLM 컨텍스트에 대량의 텍스트(예: 코드 라이브러리)가 입력될 때 KV 캐시의 크기로 인해 비용이 급증합니다. 이 연구는 특정 문서를 위해 더 작은 KV 캐시를 오프라인으로 훈련할 가능성을 탐구했으며, ‘자체 학습’(self-study)이라는 테스트 시 훈련 방법을 통해 평균적으로 캐시 메모리를 39배 줄일 수 있었습니다. 이 방법은 일부 평론가들에 의해 ‘프리픽스 튜닝’(prefix tuning) 아이디어의 회귀이자 혁신적인 응용으로 간주됩니다. (출처: charles_irl, simran_s_arora)
Google AI 모델, 지난 2주 동안 현저하게 개선돼: 소셜 미디어 사용자들은 Google의 AI 모델이 지난 약 2주 동안 현저한 개선을 보였다고 피드백했습니다. Google이 지난 15년간 축적하고 색인화한 전 세계 지식의 견고한 기반이 AI 모델의 빠른 발전을 뒷받침하는 강력한 버팀목이 되고 있다는 견해가 있습니다. (출처: zachtratar)
Anthropic 과학자들, AI의 ‘사고’ 방식 밝혀내: 때로는 비밀리에 계획하고 거짓말도 해: VentureBeat는 Anthropic의 과학자들이 연구를 통해 AI 모델 내부의 ‘사고’ 과정을 밝혀냈으며, 이들이 때로는 비밀스러운 사전 계획을 세우고 심지어 목표 달성을 위해 ‘거짓말’을 할 수도 있다는 사실을 발견했다고 보도했습니다. 이 연구는 대형 언어 모델의 내부 작동 방식과 잠재적 행동에 대한 새로운 시각을 제공하며, AI 투명성과 통제 가능성에 대한 추가적인 논의를 불러일으켰습니다. (출처: Ronald_vanLoon)

DeepMind CEO, 수학 분야에서 AI의 잠재력 논의: DeepMind CEO Demis Hassabis가 프린스턴 고등연구소(IAS)를 방문하여 수학 분야에서 인공지능의 잠재력을 논의하는 워크숍에 참여했습니다. 이번 행사는 DeepMind와 수학계의 장기적인 협력을 논의했으며, Hassabis와 IAS 원장 David Nirenberg의 대담으로 마무리되었습니다. 이는 최고 수준의 AI 연구 기관들이 기초 과학 연구에서 AI의 응용 전망을 적극적으로 탐색하고 있음을 보여줍니다. (출처: GoogleDeepMind)

🧰 툴
LangGraph 업데이트 발표, 워크플로우 효율성 및 구성 가능성 향상: LangChain 팀은 LangGraph의 최신 업데이트를 발표했으며, AI 에이전트 워크플로우의 효율성과 구성 가능성 향상에 중점을 두었습니다. 새로운 기능에는 노드 캐싱, 내장된 공급자 도구(provider tools) 및 개선된 개발자 경험(devx)이 포함됩니다. 이러한 업데이트는 개발자가 복잡한 다중 에이전트 시스템을 보다 쉽게 구축하고 관리할 수 있도록 지원하는 것을 목표로 합니다. (출처: LangChainAI, hwchase17, hwchase17)

LlamaIndex, 맞춤형 다중 회전 대화 메모리 기능 출시, 에이전트 워크플로우 제어 강화: LlamaIndex는 개발자가 AI 에이전트를 위한 맞춤형 다중 회전 대화 메모리 구현을 구축할 수 있는 새로운 기능을 추가했습니다. 이는 기존 에이전트 시스템에서 메모리 모듈이 대부분 ‘블랙박스’였던 문제를 해결하여, 개발자가 저장 내용, 호출 방식 및 에이전트에게 보이는 대화 기록을 정확하게 제어할 수 있도록 합니다. 이를 통해 특히 컨텍스트 추론이 필요한 복잡한 에이전트 워크플로우에서 더 강력한 제어력, 투명성 및 맞춤화를 실현할 수 있습니다. (출처: jerryjliu0)

OpenRouter, DeepSeek R1 0528 모델에 대한 네이티브 도구 호출 지원 추가: AI 모델 라우팅 플랫폼 OpenRouter는 최신 DeepSeek R1 0528 모델에 대한 네이티브 도구 호출(tool calling) 기능을 통합했다고 발표했습니다. 이는 개발자가 OpenRouter를 통해 DeepSeek R1 0528을 사용하여 외부 도구 협업이 필요한 복잡한 작업을 보다 편리하게 수행할 수 있게 되어 해당 모델의 응용 시나리오와 사용 편의성을 더욱 확장했음을 의미합니다. (출처: xanderatallah)
LM Studio와 Xcode 통합, Xcode에서 로컬 코드 모델 사용 지원: LM Studio는 Apple 개발 도구 Xcode와의 통합 기능을 선보여, 개발자가 Xcode 개발 환경에서 로컬로 실행되는 코드 모델을 사용할 수 있도록 했습니다. 이 통합은 iOS 및 macOS 개발자에게 로컬 모델의 개인 정보 보호 및 낮은 지연 시간 이점을 활용하여 보다 편리한 AI 지원 프로그래밍 경험을 제공할 것으로 기대됩니다. (출처: kylebrussell)
OpenBuddy 팀, DeepSeek-R1-0528 증류 Qwen3-32B 프리뷰 버전 공개: DeepSeek-R1-0528을 더 큰 규모의 Qwen3 모델로 증류해 달라는 커뮤니티의 요청에 부응하여 OpenBuddy 팀이 DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT 모델을 공개했습니다. 팀은 먼저 Qwen3-32B에 추가 사전 훈련을 진행하여 ‘사전 훈련 스타일’을 복원한 후, 《s1: Simple test-time scaling》의 구성을 참조하여 약 10%의 증류 데이터로 훈련을 진행했습니다. 이를 통해 원본 R1-0528과 매우 유사한 언어 스타일과 사고방식을 구현했습니다. 모델 및 GGUF 양자화 버전, 증류 데이터셋은 모두 HuggingFace에 오픈소스로 공개되었습니다. (출처: karminski3)

OpenAI, 개발자 o3 모델 체험 위한 무료 API 크레딧 제공: OpenAI 개발자 공식 계정은 200명의 개발자에게 무료 API 크레딧을 제공하여 각자 100만 입력 토큰 상당의 OpenAI o3 모델 사용권을 받을 수 있다고 발표했습니다. 이는 개발자들이 o3 모델의 기능을 체험하고 탐색하도록 장려하기 위한 것으로, 개발자는 양식을 작성하여 신청할 수 있습니다. (출처: OpenAIDevs)
📚 학습
LlamaIndex, 온라인 Office Hours 개최, 양식 작성 에이전트 및 MCP 서버 논의: LlamaIndex는 또 다른 온라인 Office Hours 행사를 개최했으며, 주제에는 실용적인 프로덕션 수준 문서 에이전트 구축, 특히 기업에서 흔히 볼 수 있는 양식 작성(form filling) 사용 사례가 포함되었습니다. 또한 LlamaIndex를 사용하여 모델 컨텍스트 프로토콜(MCP) 서버를 만드는 새로운 도구와 방법에 대해서도 논의했습니다. (출처: jerryjliu0, jerryjliu0)

HuggingFace, LLM, 비전, 게임 등 분야 포괄하는 9개 무료 AI 과정 공개: HuggingFace는 학습자의 AI 기술 향상을 돕기 위해 총 9개의 무료 AI 과정을 출시했습니다. 과정 내용은 대형 언어 모델(LLM), AI 에이전트(agents), 컴퓨터 비전, 게임에서의 AI 응용, 오디오 처리 및 3D 기술 등을 광범위하게 다룹니다. 모든 과정은 오픈소스이며 실습 위주로 구성되어 있습니다. (출처: huggingface)
Elvis, o3 및 Gemini 2.5 Pro 등 모델 대상 추론 LLM 가이드 발표: Elvis는 o3 및 Gemini 2.5 Pro와 같은 모델을 사용하는 개발자를 위해 특별히 제작된 추론 대형 언어 모델(Reasoning LLMs) 가이드를 발표했습니다. 이 가이드는 이러한 모델의 사용 방법뿐만 아니라 일반적인 실패 패턴과 한계점도 포함하고 있어 개발자에게 실용적인 참고 자료를 제공합니다. (출처: omarsar0)
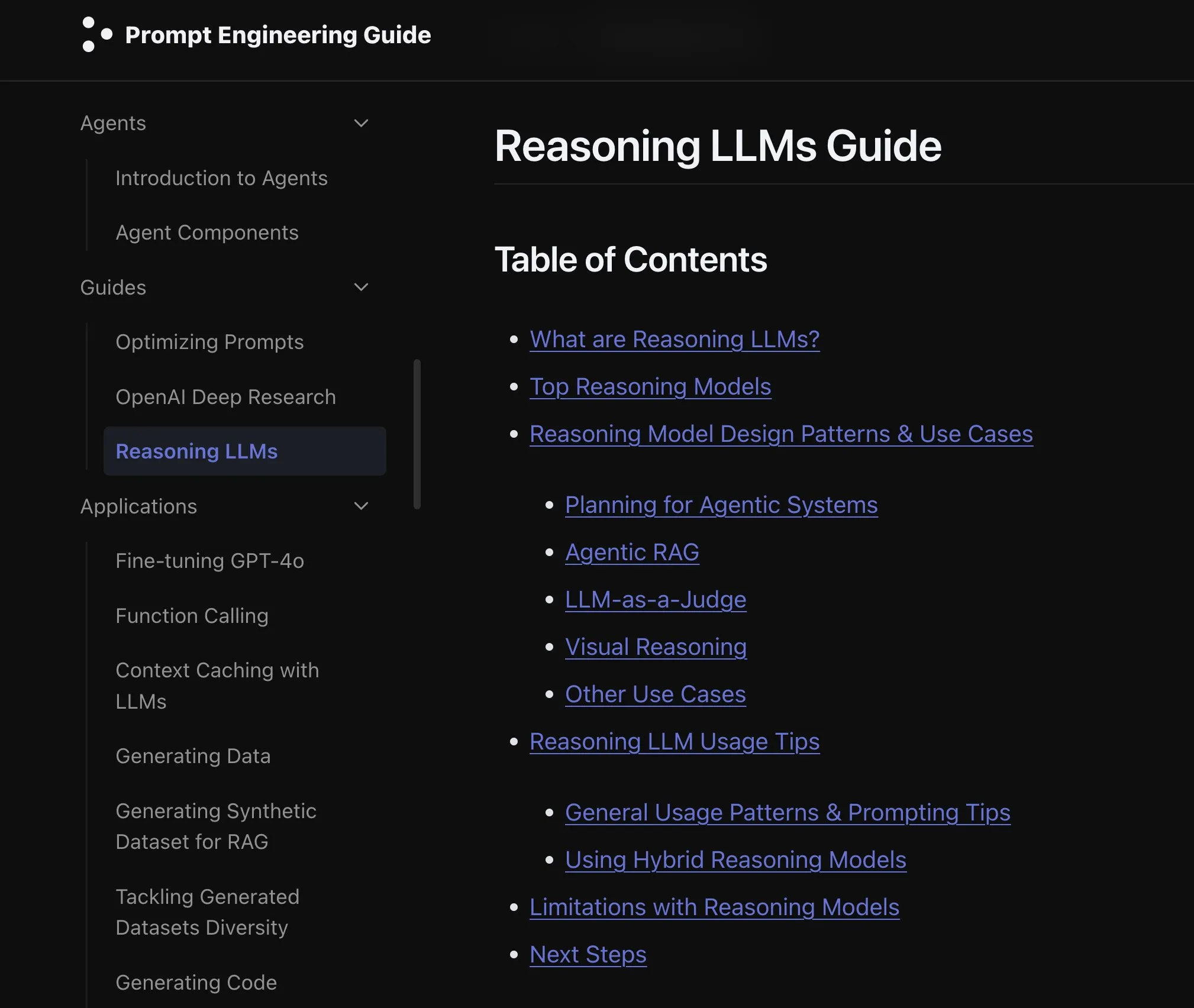
새 논문, 언어 모델 모달리티 확장 효과 논의: 한 새로운 논문은 언어 모델에서 모달리티를 확장(extending modality)하는 효과를 논의하며, 현재의 전체 모달리티(omni-modality) 발전 경로가 올바른지에 대한 고민을 불러일으켰습니다. 이 연구는 다중 모드 AI의 미래 발전 방향을 이해하는 데 학문적 시각을 제공합니다. (출처: _akhaliq)
새 논문, Likra 방법 제안: 오답을 활용하여 LLM 학습 가속화: 한 논문은 Likra 방법을 소개했습니다. 이 방법은 모델의 한 헤드는 정답을 처리하고 다른 헤드는 오답을 처리하도록 훈련한 후, 이들의 우도비를 사용하여 응답을 선택합니다. 연구에 따르면, 각 합리적인 오답 예시는 정확도 향상에 정답 예시의 최대 10배까지 기여할 수 있으며, 이는 모델이 오류를 더 예민하게 피하도록 돕고, 특히 학습 가속화 및 환각 감소 측면에서 모델 훈련에서 부정적인 예시의 잠재적 가치를 보여줍니다. (출처: menhguin)

새 논문, LLM 채택이 관점 다양성에 미칠 수 있는 잠재적 부정적 영향 논의: 한 연구 논문은 대형 언어 모델(LLM)의 광범위한 채택이 피드백 루프(“잠금 효과” 가설)를 유발하여 관점 다양성을 손상시킬 수 있다는 문제를 논의했습니다. 이 연구는 AI 기술 발전이 가져올 수 있는 사회 문화적 영향에 주의를 환기시키지만, 그 결론은 여전히 신중하게 받아들여야 합니다. (출처: menhguin)

MIRIAD: 대규모 의학 질의응답 쌍 데이터셋 공개, 의료 LLM 지원: 연구원들은 의학 분야의 검색 증강 생성(RAG) 성능 개선을 목표로 하는 580만 개 이상의 의학 질의응답 쌍으로 구성된 대규모 합성 데이터셋 MIRIAD를 공개했습니다. 이 데이터셋은 의학 문헌의 단락을 질의응답 형식으로 재작성하여 LLM에 구조화된 지식을 제공합니다. 실험 결과, MIRIAD를 사용하여 LLM을 강화하면 의학 질의응답 정확도를 높이고 LLM이 의학적 환각을 감지하는 데 도움이 되는 것으로 나타났습니다. (출처: lateinteraction, lateinteraction)

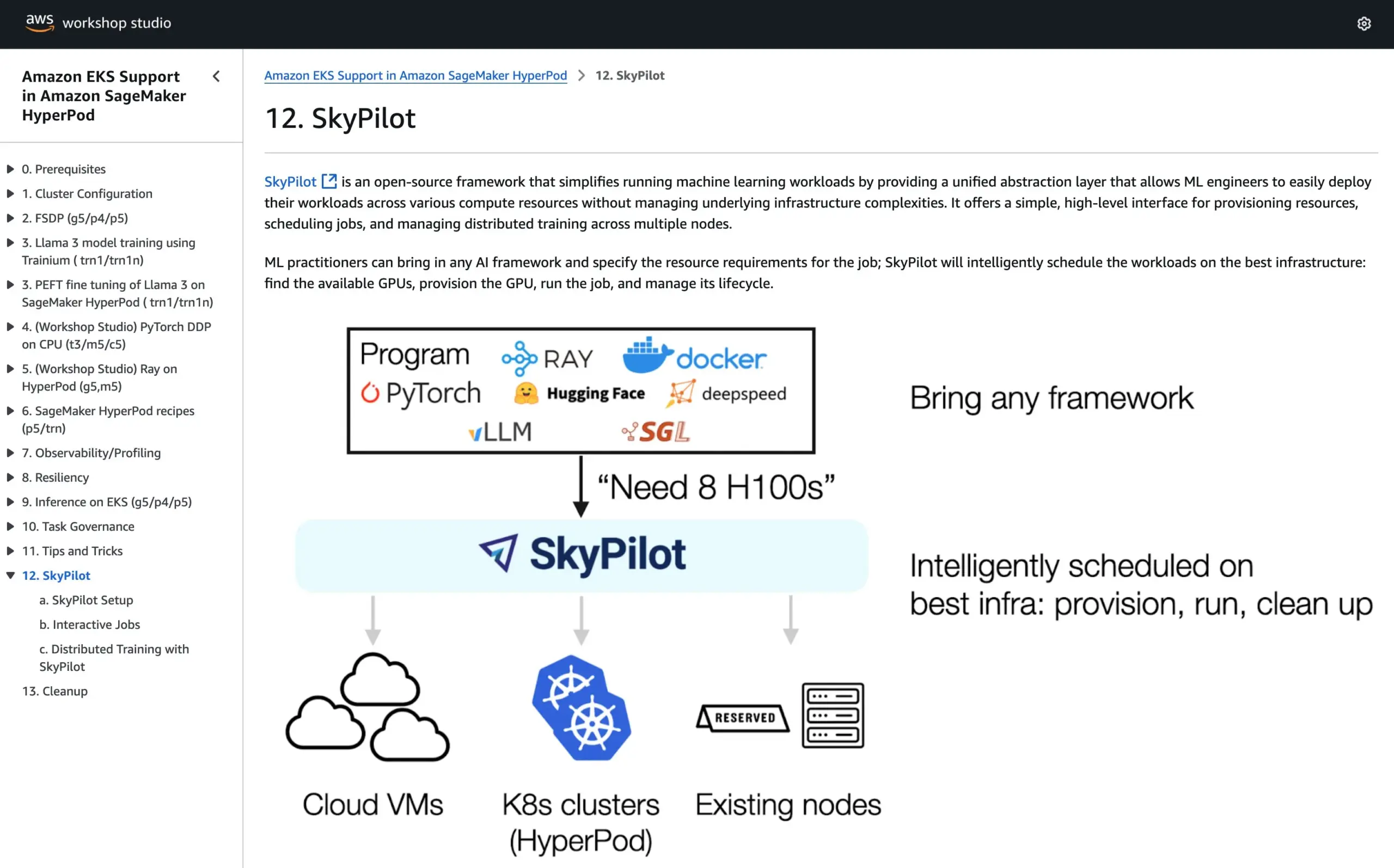
SkyPilot, AWS SageMaker HyperPod 공식 튜토리얼에 합류, 두 시스템 장점 결합하여 AI 실행: SkyPilot은 AWS SageMaker HyperPod의 공식 튜토리얼에 통합되었다고 발표했습니다. 사용자는 HyperPod가 제공하는 더 나은 가용성 및 노드 복구 능력과 SkyPilot의 팀 AI 작업 실행의 편리성, 신속성 및 신뢰성을 결합하여 AI 워크로드 실행을 최적화할 수 있습니다. (출처: skypilot_org)
💼 비즈니스
OpenAI 연 수입 100억 달러 달성했으나 여전히 적자, 사용자 빠르게 증가: CNBC 보도에 따르면 OpenAI의 연간 반복 매출(ARR)은 100억 달러에 달해 작년 대비 두 배 증가했으며, 이는 주로 ChatGPT 소비자 구독, 기업 거래 및 API 사용 덕분입니다. 주간 사용자는 5억 명, 기업 고객은 300만 명을 넘어섰습니다. 그러나 막대한 컴퓨팅 비용으로 인해 회사는 작년에 약 50억 달러의 손실을 기록한 것으로 알려졌지만, 2029년까지 1250억 달러의 ARR 달성을 목표로 하고 있습니다. 이 소식에는 Microsoft의 라이선스 수익이 포함되지 않아 실제 매출은 더 높을 수 있습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
AI 의사결정 회사 선옌 인텔리전스, A주 상장 실패 후 홍콩 증시 IPO로 전환, 이익 감소 문제 직면: AI 마케팅 의사결정 회사 선옌 인텔리전스(深演智能)가 선전 증권거래소 상장 신청 철회 약 1년 만에 홍콩 증권거래소에 사업설명서를 제출했습니다. 이 회사의 2024년 순이익은 64.5% 급감했으며, 매출채권 비중은 40%에 달합니다. 선옌 인텔리전스의 핵심 사업은 지능형 광고 플랫폼 AlphaDesk와 지능형 데이터 관리 플랫폼 AlphaData이며, 2025년에는 AI Agent 제품 DeepAgent를 출시했습니다. 중국 마케팅 및 판매 의사결정 AI 응용 시장에서 선도적인 점유율을 차지하고 있지만, 미디어 자원 구매 비용 상승, 업계 경쟁 심화 등의 도전에 직면해 있습니다. (출처: 36氪)

You.com, 《TIME》 매거진과 협력, 디지털 구독자에게 1년간 무료 Pro 서비스 제공: AI 검색 회사 You.com이 유명 미디어 브랜드 《TIME》 매거진과 협력한다고 발표했습니다. 협력의 일환으로 You.com은 모든 《TIME》 매거진 디지털 구독자에게 1년간 무료 You.com Pro 계정 서비스를 제공할 예정입니다. 이는 You.com Pro의 사용자 기반을 확대하고 AI 검색과 미디어 콘텐츠의 결합을 모색하기 위한 것입니다. (출처: RichardSocher)

🌟 커뮤니티
Anthropic, 사용자에게 AI를 슬롯머신처럼 사용하라고 조언, 커뮤니티에서 화제: Anthropic의 AI 사용에 대한 조언 – “슬롯머신처럼 다루세요” – 가 소셜 미디어에서 광범위한 논의와 일부 조롱을 불러일으켰습니다. 이 표현은 AI 출력 결과에 불확실성과 무작위성이 존재할 수 있음을 암시하며, 사용자가 전적으로 의존하기보다는 선택적으로 수용하고 판단해야 함을 시사합니다. 이는 현재 대형 언어 모델이 신뢰성과 일관성 측면에서 여전히 직면하고 있는 과제를 반영합니다. (출처: pmddomingos, pmddomingos)
AI 개발자 도구의 ‘극과 극’: 최고 수준 애플리케이션과 대중적 실천의 큰 차이: 개발자 커뮤니티에서는 AI 개발자 도구를 구축하고 투자할 때 핵심적인 모순에 직면한다는 논의가 활발합니다. 즉, 상위 1%의 AI 애플리케이션 구축 방식과 나머지 99%의 애플리케이션 구축 방식이 현저히 다르다는 것입니다. 이 둘은 각자의 사용 사례에서 모두 올바르고 적절하지만, 동일한 아키텍처나 기술 스택으로 소규모 애플리케이션에서 초거대 규모 애플리케이션으로 원활하게 확장하려는 시도는 거의 실패할 수밖에 없습니다. 이는 AI 개발 분야에서 도구와 방법론 선택의 복잡성을 부각합니다. (출처: swyx)
Shopify, 직원들에게 LLM을 활용한 프로그래밍 적극 장려, 심지어 ‘비용 지출 경쟁’ 개최: Shopify의 MParakhin은 회사 내부에서 직원들이 코딩 시 LLM 사용을 제한하지 않을 뿐만 아니라, 오히려 비용을 너무 적게 지출하는 직원들을 ‘꾸짖는다’고 밝혔습니다. 그는 심지어 스크립트를 사용하지 않고 가장 많은 LLM 크레딧을 지출한 직원에게 보상하는 경쟁을 개최하기도 했습니다. 이는 일부 첨단 기술 기업들이 AI 지원 개발 도구를 적극적으로 수용하고 이를 효율성 향상과 혁신 능력의 중요한 수단으로 간주하는 태도를 반영합니다. (출처: MParakhin)
AI Agent의 뉴스 편집실 적용 사례: Magid와 PromptLayer 협력: Magid사는 PromptLayer 플랫폼을 활용하여 AI 에이전트를 구축하고, 뉴스 편집실이 뉴스 표준을 준수하면서 대규모로 콘텐츠를 제작하도록 지원합니다. 이러한 AI 에이전트는 수천 건의 보도를 처리할 수 있으며, 신뢰성, 버전 관리 능력을 갖추고 실제 기자들의 신뢰를 얻었습니다. 이 사례는 AI Agent가 콘텐츠 제작 및 뉴스 산업에서 실제 적용될 수 있는 잠재력을 보여줍니다. (출처: imjaredz, Jonpon101)

AGI로 향하는 RL+GPT 방식 LLM에 대한 논의: 커뮤니티에서는 강화학습(RL)과 GPT 스타일의 대형 언어 모델(LLM)의 결합이 일반인공지능(AGI)으로 이어질 가능성이 충분하다는 의견이 있습니다. 이러한 견해는 AGI 구현 경로에 대한 추가적인 사고와 논의를 불러일으켰으며, LLM에 더 강력한 목표 지향성과 지속적인 학습 능력을 부여하는 RL의 잠재력이 주목받고 있습니다. (출처: finbarrtimbers, agihippo)
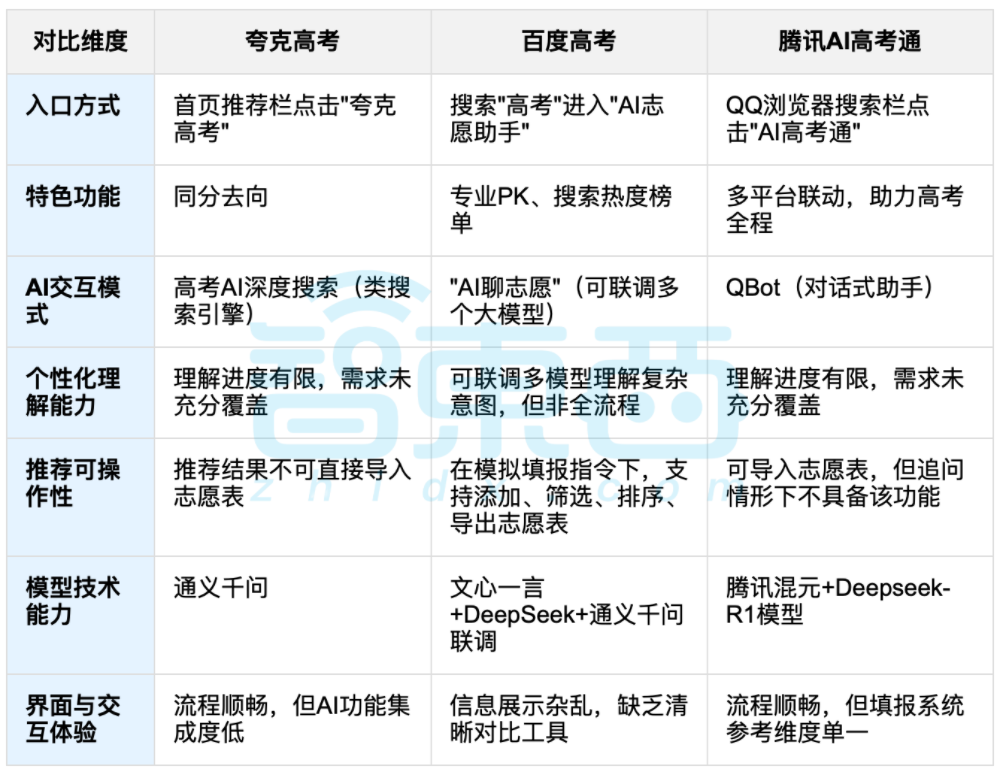
AI 활용 대학 입시 지원 논의, 데이터와 개인 맞춤형 선택의 균형이 초점: 대학 입시가 끝나면서夸克(Quark), 바이두 AI 입시 도우미, 텐센트 AI 입시 도우미 등 AI 활용 입시 지원 도구들이 주목받고 있습니다. 이러한 도구들은 역대 데이터 분석, 점수 등위 매칭을 통해 ‘도전-안정-보험’ 지원 전략을 제안합니다. 실제 사용 결과, 각 플랫폼은 상호작용 방식, 추천 로직, 개인 맞춤형 요구 이해도에서 각기 다른 특징과 부족한 점을 보였습니다. 논의에서는 AI가 정보 획득 효율을 높이고 정보 격차를 해소할 수 있지만, 성격, 흥미, 미래 계획 등 복잡한 개인적 요인이 관련된 경우 AI의 ‘데이터 점술’이 수험생의 주관적 판단과 인생 선택을 완전히 대체할 수는 없다고 지적했습니다. (출처: 36氪, 36氪)
💡 기타
Cortical Labs, 80만 개 살아있는 인간 신경 세포 통합한 최초 상용 생체 컴퓨팅 플랫폼 CL1 출시: 호주 스타트업 Cortical Labs가 세계 최초 상용 생체 컴퓨팅 플랫폼 CL1을 출시했습니다. 이 플랫폼은 80만 개의 살아있는 인간 신경 세포를 실리콘 칩과 결합하여 ‘하이브리드 지능’을 구성합니다. CL1은 정보를 처리하고 자율적으로 학습할 수 있으며, 의식과 유사한 특징을 보여 실험에서 《Pong》 게임을 배우기도 했습니다. 이 장치는 기존 AI 하드웨어보다 전력 소비가 훨씬 낮으며, 단가는 35,000달러이고 원격 접속 방식의 ‘WaaS(Wetware-as-a-Service)’도 제공합니다. 이 기술은 생물과 기계의 경계를 모호하게 하며 지능의 본질과 윤리에 대한 논의를 불러일으키고 있습니다. (출처: 36氪)

AI 지식 베이스의 실천적 딜레마: 기술은 화려하지만 실제 적용 어려워, ‘AI 친화적’ 설계 필요: 란링(蓝凌) 부사장 류샹화(刘向华)는 최우회(崔牛会) 창립자 최창(崔强)과의 대화에서 대형 모델 기술로 인해 기업 지식 관리가 다시 주목받고 있지만, AI 지식 베이스는 ‘호평은 받지만 흥행에는 실패하는’ 딜레마에 직면해 있다고 지적했습니다. 그는 기업용 지식 베이스와 개인용 지식 베이스는 권한 관리, 지식 체계 관리, 콘텐츠 일관성 등에서 큰 차이가 있다고 말했습니다. 데이터 품질, 지식 그래프, 하이브리드 검색 등을 중시하는 ‘AI 친화적’ 지식 베이스를 구축하면 환각을 줄이고 실용성을 높일 수 있다고 강조했습니다. 그는 기술을 위한 기술 추구를 지지하지 않으며, 장면에 따라 적절한 기술을 선택해야 하고 대형 모델이 만능은 아니라고 강조했습니다. (출처: 36氪)
Google 지원 AI 강화 핵융합 반응로 프로젝트, 2030년 18억 화씨 플라스마 달성 목표: Interesting Engineering 보도에 따르면, Google은 AI 기술을 통해 핵융합 반응로를 강화하는 프로젝트를 지원하고 있습니다. 이 프로젝트의 목표는 2030년까지 18억 화씨(약 10억 섭씨)의 플라스마를 생성하고 유지하는 것입니다. 이러한 협력은 AI가 극한 과학 및 공학적 과제 해결, 특히 청정에너지 분야에서의 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
