
키워드:대형 언어 모델, 추론 능력, 패턴 매칭, 사고 환각, 애플 연구, 일반 인공지능, AI 감지기, AI 규제, 로그-선형 어텐션 메커니즘, 화웨이 판구 MoE 모델, ChatGPT 고급 음성 모드, TensorZero 프레임워크, Anthropic CEO 규제 관점
🔥 주요 뉴스
Apple 연구, “생각의 환상” 밝혀: 현재 “추론” 모델은 진정한 사고가 아닌 패턴 매칭에 더 의존: Apple의 최신 연구 논문 ‘The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models through the Lens of Problem Complexity’는 현재 “추론” 능력을 갖추었다고 주장하는 대형 언어 모델(예: Claude, DeepSeek-R1, GPT-4o-mini 등)의 성능이 진정한 의미의 논리적 추론이라기보다는 효율적인 패턴 매칭기에 가깝다고 지적했다. 연구에 따르면, 이러한 모델들은 훈련 데이터 분포를 벗어나거나 복잡성이 높은 문제를 처리할 때 성능이 현저히 저하되며, 심지어 간단한 문제에서도 “과도한 사고”로 인해 실수를 저지르고 초기 오류를 수정하기 어렵다는 것이 밝혀졌다. 해당 연구는 모델의 소위 “사고” 과정(예: Chain of Thought)이 새롭거나 복잡한 작업에 직면했을 때 종종 실패하며, 이는 우리가 범용 인공지능(AGI)으로부터 예상보다 더 멀리 떨어져 있을 수 있음을 시사한다고 강조했다. (출처: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

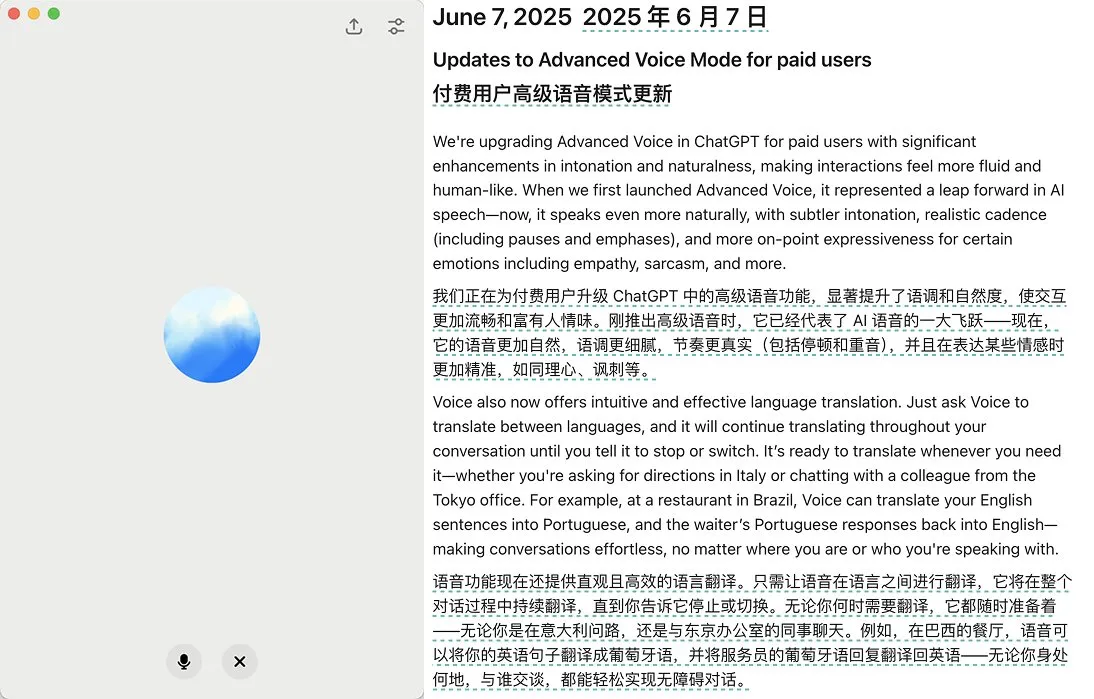
OpenAI, ChatGPT 고급 음성 모드 업데이트 출시, 자연스러움 및 번역 기능 향상: OpenAI가 ChatGPT 유료 사용자를 대상으로 고급 음성 모드(Advanced Voice Mode)의 주요 업데이트를 출시했다. 새 버전은 음성의 자연스러운 유창성을 대폭 향상시켜 AI 비서보다는 사람처럼 들리도록 했다. 또한, 업데이트는 언어 번역 성능과 지시 사항 준수 능력을 개선했으며, 새로운 번역 모드를 추가하여 사용자가 ChatGPT에게 중단을 요청할 때까지 대화 전체에서 양측의 대화를 지속적으로 번역하도록 할 수 있다. 이번 업데이트는 음성 상호 작용을 더욱 쉽고 자연스럽게 만들어 사용자 경험을 향상시키는 것을 목표로 한다. (출처: juberti, Plinz, op7418, BorisMPower)
AI 탐지기, 실효성 없고 AI 콘텐츠 “은신” 조장 가능성 지적: 소셜 미디어와 기술 포럼에서 현재 AI 콘텐츠 탐지 도구가 효과가 없을 뿐만 아니라, 의도치 않게 AI 생성 콘텐츠를 더 감지하기 어렵게 만들 수 있다는 광범위한 논의가 이루어지고 있다. 많은 사용자와 전문가들은 이러한 탐지기가 콘텐츠 출처를 진정으로 이해하기보다는 주로 언어 패턴과 특정 어휘(예: 학술 용어 “delve”)를 기반으로 판단한다고 보고 있다. 오판 위험(학생 등 집단에 불공정을 초래할 수 있음)과 AI 모델 자체가 탐지를 피하기 위해 진화하고 있다는 점 때문에 이러한 도구의 신뢰성에 심각한 의문이 제기되고 있다. AI 탐지기의 존재가 오히려 AI가 콘텐츠를 생성할 때 특정 표시되기 쉬운 특징을 피하도록 유도하여 인간의 글쓰기와 더 유사하게 만든다는 견해도 있다. (출처: Reddit r/ArtificialInteligence, sytelus)

Anthropic CEO, AI 기업 투명성 및 책임 규제 강화 촉구: Anthropic CEO는 뉴욕타임스에 기고한 글에서 AI 기업에 대한 규제를 완화해서는 안 되며, 특히 투명성을 높이고 책임을 물어야 한다고 강조했다. 이러한 견해는 AI 산업이 빠르게 발전하고 능력이 나날이 새로워지는 배경에서 특히 중요하며, AI의 잠재적 위험과 윤리적 문제에 대한 사회적 우려에 부응한다. 이 글은 AI 기술의 영향력이 확대됨에 따라 공익에 부합하는 발전을 보장하고 남용을 방지하는 것이 중요하며, 이를 위해서는 업계 자율 규제와 외부 규제가 함께 작용해야 한다고 주장했다. (출처: Reddit r/artificial)

🎯 동향
Jeff Dean, AI 미래 전망: 전용 하드웨어, 모델 진화 및 과학 응용: Google AI 책임자 Jeff Dean은 Sequoia Capital AI Ascent 행사에서 AI 미래 발전에 대한 자신의 견해를 공유했다. 그는 전용 하드웨어(예: TPU)가 AI 발전에 중요하다고 강조했으며 모델 아키텍처의 진화 추세에 대해 논의했다. Dean은 또한 컴퓨팅 인프라의 미래 형태와 과학 연구 등 분야에서 AI의 막대한 응용 잠재력을 전망하며 AI가 과학적 발견을 촉진하는 핵심 도구가 될 것이라고 보았다. (출처: TheTuringPost)

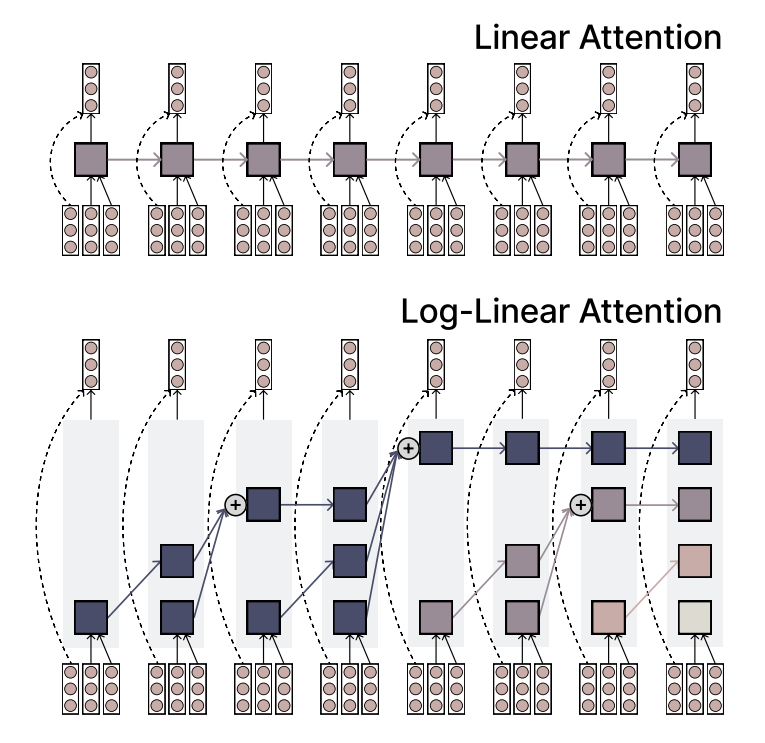
MIT, 효율성과 표현력을 겸비한 Log-Linear Attention 메커니즘 제안: MIT 연구진이 Log-Linear Attention이라는 새로운 어텐션 메커니즘을 제안했다. 이 메커니즘은 선형 어텐션(Linear Attention)의 효율성과 Softmax 어텐션의 강력한 표현력을 결합하는 것을 목표로 한다. 핵심 특징은 시퀀스 길이에 따라 로그적으로 증가하는 소량의 메모리 슬롯(memory slots)을 사용하여 긴 시퀀스를 처리할 때 낮은 계산 복잡도를 유지하면서 주요 정보를 포착하는 것이다. (출처: TheTuringPost)
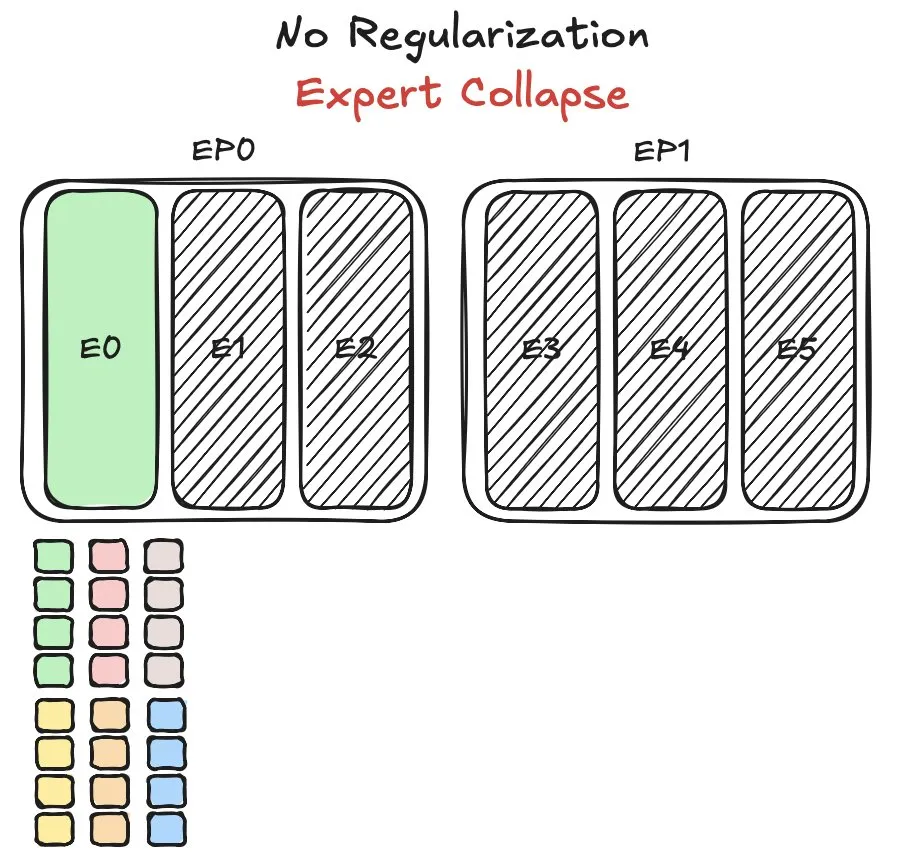
Huawei Pangu MoE 모델, 전문가 로드 밸런싱 문제에 직면하여 새로운 방법 제시: Huawei는 MoE(Mixture-of-Experts) 모델인 Pangu Ultra MoE를 훈련할 때 전문가 로드 밸런싱이라는 핵심 문제에 직면했다. 전문가 로드 밸런싱은 훈련 역학과 시스템 효율성 사이의 균형을 맞춰야 한다. Huawei는 이 문제에 대해 새로운 해결 방법을 제시하여 MoE 모델에서 서로 다른 전문가 모듈의 작업 할당 및 계산 부하를 최적화함으로써 훈련 효율성과 모델 성능을 향상시키는 것을 목표로 한다. 관련 연구는 논문으로 발표되었다. (출처: finbarrtimbers)
NVIDIA, 객체 감지에 초점을 맞춘 Cascade Mask R-CNN Mamba Vision 모델 출시: NVIDIA는 Hugging Face에 cascade_mask_rcnn_mamba_vision_tiny_3x_coco라는 새 모델을 출시했다. 이름으로 판단하건대, 이 모델은 객체 감지 작업을 위해 특별히 설계되었으며 Cascade R-CNN 아키텍처와 Mamba(상태 공간 모델) 비전 기술을 통합하여 객체 감지의 정확도와 효율성을 향상시키는 것을 목표로 할 수 있다. (출처: _akhaliq)
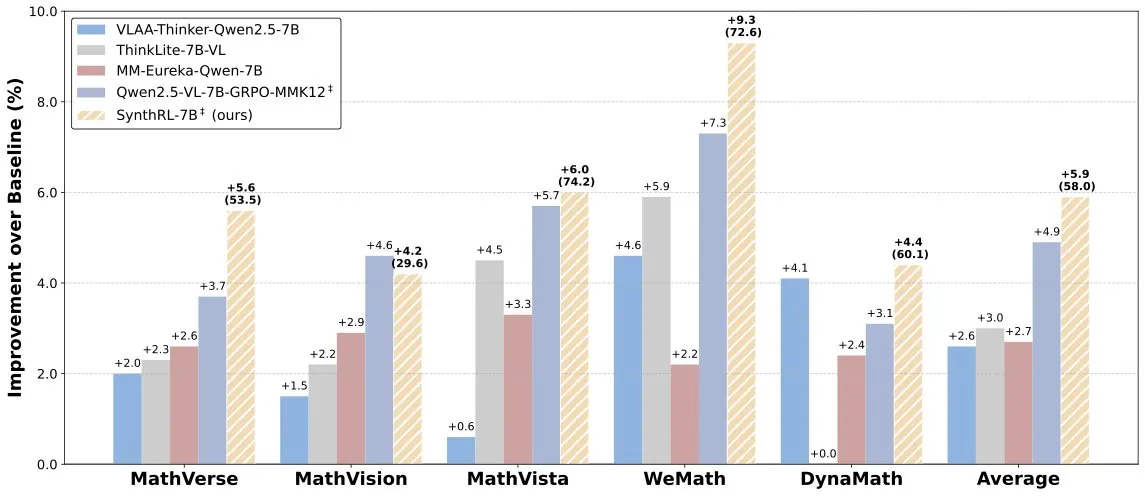
SynthRL 모델 출시: 검증 가능한 데이터 합성을 통한 확장 가능한 시각적 추론 구현: Hugging Face에 SynthRL 모델이 출시되었다. 이 모델은 확장 가능한 시각적 추론 능력에 중점을 두며, 핵심 기술은 검증 가능한 데이터 합성 방법을 통해 원본 답변의 정확성을 유지하면서 더 도전적인 시각적 추론 작업 변형을 생성하는 데 있다. 이는 복잡한 시각적 장면에서 모델의 이해 및 추론 수준을 향상시키는 데 도움이 된다. (출처: _akhaliq)
DeepSeek-R1의 우수한 성능에도 불구하고 ChatGPT의 제품 우위는 여전히 견고: VentureBeat는 DeepSeek-R1과 같은 신흥 모델이 일부 측면에서 뛰어난 성능을 보이지만, ChatGPT는 선점 우위, 광범위한 사용자 기반, 성숙한 제품 생태계 및 지속적인 반복 능력을 바탕으로 제품 수준의 선도적 지위를 단기간에 넘어서기 어렵다고 논평했다. AI 경쟁은 기술 매개변수의 경쟁일 뿐만 아니라 제품 경험, 생태계 구축 및 비즈니스 모델의 종합적인 경쟁이기도 하다. (출처: Ronald_vanLoon)

Qwen 팀, Qwen3-coder 개발 중임을 확인: Qwen 팀의 Junyang Lin은 Qwen3 시리즈의 코딩 능력 강화 버전인 Qwen3-coder를 개발 중이라고 확인했다. 구체적인 일정은 공개되지 않았지만 Qwen2.5의 출시 주기를 참고하면 몇 주 내에 출시될 것으로 예상된다. 커뮤니티는 이 모델이 코드 생성, 자율/에이전트 워크플로우 통합 측면에서 돌파구를 마련하고 다양한 프로그래밍 언어에 대한 우수한 지원을 유지할 것으로 기대하고 있다. (출처: Reddit r/LocalLLaMA)

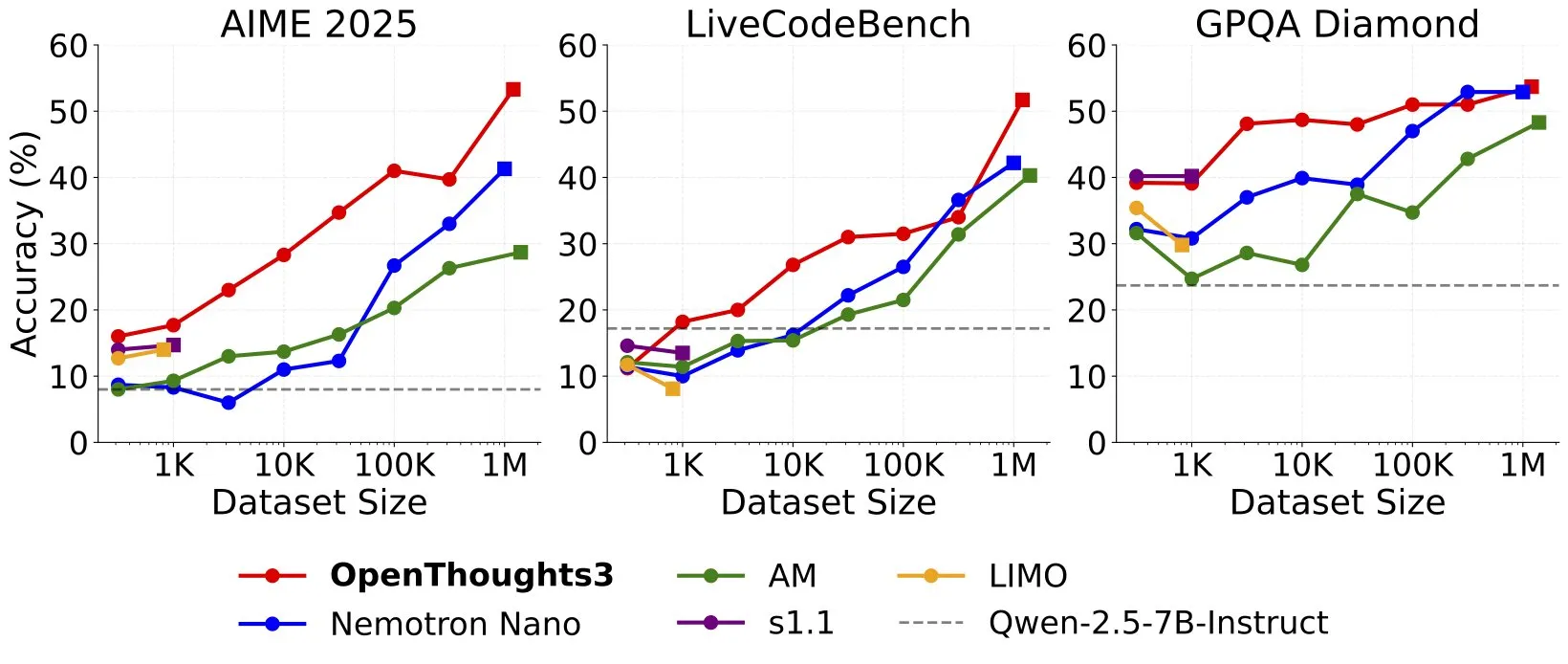
OpenThinker3-7B 출시, SOTA 오픈 소스 데이터 7B 추론 모델 주장: Ryan Marten은 현재 오픈 데이터를 기반으로 훈련된 최첨단 7B 매개변수 추론 모델이라고 주장하는 OpenThinker3-7B 모델을 출시한다고 발표했다. 이 모델은 코드, 과학 및 수학 평가에서 DeepSeek-R1-Distill-Qwen-7B보다 평균 33% 더 높은 성능을 보인다고 한다. 훈련 데이터 세트인 OpenThoughts3-1.2M도 함께 출시되었다. (출처: menhguin)
🧰 도구
TensorZero: LLM 애플리케이션 개발 및 배포를 최적화하는 오픈 소스 LLMOps 프레임워크: TensorZero는 피드백 루프를 통해 프로덕션 데이터를 더 스마트하고 빠르며 경제적인 모델로 전환하는 것을 목표로 하는 오픈 소스 LLM 애플리케이션 최적화 프레임워크이다. LLM 게이트웨이(다양한 모델 제공업체 지원), 관찰 가능성, 최적화(프롬프트, 미세 조정, RL), 평가 및 실험(A/B 테스트) 등의 기능을 통합하며, 낮은 지연 시간, 높은 처리량 및 GitOps를 지원한다. 이 도구는 Rust로 작성되었으며 성능과 산업 수준의 애플리케이션 요구 사항을 강조한다. (출처: GitHub Trending)

LangChain, SambaNova, Qdrant 및 LangGraph를 결합한 고성능 RAG 시스템 출시: LangChain은 고성능 검색 증강 생성(RAG) 구현 방안을 소개했다. 이 방안은 SambaNova의 DeepSeek-R1 모델, Qdrant의 이진 양자화 기술 및 LangGraph를 결합하여 32배의 메모리 절감을 달성함으로써 대규모 문서를 효율적으로 처리할 수 있다. 이는 더 경제적이고 빠른 RAG 애플리케이션을 구축하는 데 새로운 가능성을 제공한다. (출처: hwchase17, qdrant_engine)
Google 과학 교육 비디오 원클릭 생성 앱 Sparkify, 고품질 사례 선보여: Google이 출시한 Sparkify 앱은 원클릭으로 과학 교육 비디오를 생성할 수 있으며, 선보인 사례의 품질이 상당히 높다. 비디오 콘텐츠의 전반적인 일관성이 좋고, 더빙이 자연스러우며, 분할 화면 표시와 같은 복잡한 효과까지 구현하여 AI가 자동화된 비디오 콘텐츠 제작 분야에서 잠재력을 보여준다. (출처: op7418)
Hugging Face, 첫 MCP 서버 출시로 챗봇 기능 확장: Hugging Face가 첫 번째 MCP(Modular Chat Processor) 서버(hf.co/mcp)를 출시했으며, 사용자는 이를 채팅창에 붙여넣어 사용할 수 있다. MCP 서버는 챗봇의 기능을 향상시키고 모듈식 처리 장치를 통해 더욱 풍부한 상호 작용 경험을 제공하는 것을 목표로 한다. 커뮤니티는 Agentset MCP, GitHub MCP 등 다른 유용한 MCP 서버 목록도 함께 정리했다. (출처: TheTuringPost)
Chatterbox TTS, ElevenLabs에 필적하는 효과로 gptme에 통합: TTS(텍스트 음성 변환) 도구 Chatterbox가 뛰어난 음성 합성 효과로 주목받고 있으며, 사용자들은 그 효과가 유명한 ElevenLabs와 비슷하고 Kokoro보다 우수하다고 평가했다. Chatterbox는 참조 샘플을 통해 음성을 맞춤 설정할 수 있으며, 현재 gptme의 TTS 백엔드로 추가되어 사용자에게 고품질 음성 출력 옵션을 제공한다. (출처: teortaxesTex, _akhaliq)
E-Library-Agent: 로컬 도서/문헌의 지능형 검색 및 질의응답 시스템: E-Library-Agent는 개인 도서 또는 논문 모음을 추출, 색인화 및 쿼리할 수 있는 자체 호스팅 AI 에이전트이다. 이 프로젝트는 ingest-anything을 기반으로 하며 LlamaIndex, Qdrant 및 Linkup 플랫폼의 지원을 받아 로컬 자료 추출, 컨텍스트 인식 질의응답 및 단일 인터페이스를 통한 웹 검색 기능을 구현하여 사용자가 개인 지식 기반을 편리하게 관리하고 활용할 수 있도록 한다. (출처: qdrant_engine)
Claude Code, 강력한 코딩 지원 능력으로 개발자들로부터 높은 평가: Reddit 커뮤니티 사용자들이 Anthropic의 Claude Code를 사용하여 소프트웨어를 개발한 긍정적인 경험을 공유했으며, 특히 게임 개발(예: Godot C# 프로젝트)과 같은 분야에서 두드러졌다. 사용자들은 복잡한 문제를 해결하는 능력이 다른 AI 코딩 도우미(예: GitHub Copilot)보다 훨씬 뛰어나며, 컨텍스트를 이해하고 효과적인 코드를 생성할 수 있다고 칭찬했다. 월 100달러의 비용도 그만한 가치가 있다고 여겨진다. 개발자들은 숙련된 프로그래머가 Claude Code와 결합하면 생산성이 크게 향상될 것이라고 생각한다. (출처: Reddit r/ClaudeAI)
ChatterUI, 로컬 비전 모델 지원 구현했으나 Android에서 처리 속도 느려: LLM 채팅 클라이언트 ChatterUI의 사전 출시 버전에서 첨부 파일 및 로컬 비전 모델(llama.rn을 통해) 지원이 추가되었다. 사용자는 로컬 호환 모델에 대해 mmproj 파일을 로드하거나 비전 기능을 지원하는 API(예: Google AI Studio, OpenAI)에 연결할 수 있다. 그러나 llama.cpp가 Android에서 안정적인 GPU 백엔드가 부족하여 이미지 처리 속도가 매우 느리며(예: 512×512 이미지 처리 5분 소요), iOS에서는 성능이 상대적으로 양호하다. (출처: Reddit r/LocalLLaMA)
FLUX kontext, 자동차 홍보 이미지 배경 교체에서 뛰어난 성능 보여: 사용자들이 AI 이미지 편집 도구 FLUX kontext를 테스트한 결과, 자동차 홍보 이미지 배경 수정에서 효과가 두드러졌다. 예를 들어, 샤오미 SU7의 공식 이미지 배경을 황혼의 해변이나 레이싱 트랙 등으로 교체했을 때, 이 도구는 배경을 자연스럽게 합성할 뿐만 아니라 주행 중인 차량에 모션 블러 효과를 지능적으로 추가하여 이미지의 현실감과 시각적 효과를 향상시켰다. (출처: op7418)

📚 학습
fastcore의 새로운 기능 flexicache: 유연한 캐싱 데코레이터: Jeremy Howard가 fastcore 라이브러리의 유용한 새 기능인 flexicache를 소개했다. 이는 매우 유연한 캐싱 데코레이터로, ‘mtime’(파일 수정 시간 기준)과 ‘time’(타임스탬프 기준) 두 가지 캐싱 전략이 내장되어 있으며 사용자가 적은 코드로 새로운 캐싱 전략을 사용자 정의할 수 있도록 허용한다. 이 기능은 Daniel Roy Greenfeld가 자세히 소개한 글로, 코드 실행 효율성을 높이는 데 도움이 된다. (출처: jeremyphoward)
Transformer 모델 훈련을 위한 MuP와 Muon 결합 가능성 논의: Jingyuan Liu는 Muon 및 스펙트럼 조건 도출에 관한 Jeremy Bernstein의 연구를 심도 있게 학습하고, 특히 MuP(Maximal Update Parametrization)와 Muon(최적화 프로그램)이 어떻게 협력하는지에 대한 우아한 도출 과정에 감탄을 표했다. 그는 도출 과정으로 볼 때 MuP 기반 모델 훈련의 최적화 프로그램으로 Muon을 사용하는 것이 자연스러운 선택이라고 생각하며, 이는 Moonshot의 Moonlight 작업에서 업데이트 RMS를 일치시켜 AdamW의 하이퍼파라미터를 Muon으로 이전하는 것보다 더 흥미로울 수 있다고 지적했다. 커뮤니티 토론에서는 MuP + Muon 조합이 연말까지 대형 기술 회사에서 규모 있게 적용될 것으로 예상하고 있다. (출처: jeremyphoward)

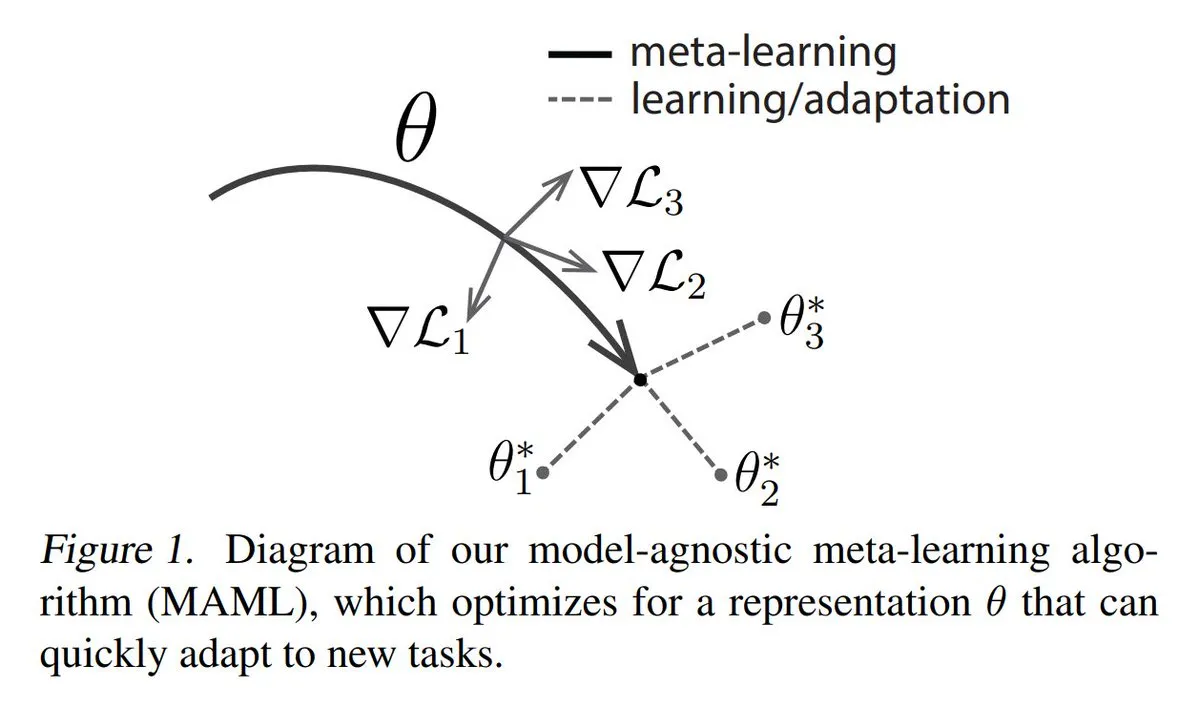
메타 학습(Meta-learning)의 세 가지 주요 방법 분석: 메타 학습은 소량의 샘플만으로도 모델이 새로운 작업을 빠르게 학습하도록 훈련하는 것을 목표로 한다. 일반적인 방법은 다음과 같다: 1. 최적화 기반/기울기 기반: 소량의 기울기 단계로 작업에서 효율적으로 미세 조정할 수 있는 모델 매개변수를 찾는다. 2. 측정 기반: 모델이 새 샘플과 기존 샘플의 유사성을 더 잘 측정하고 관련 샘플을 효과적으로 그룹화하는 방법을 찾도록 돕는다. 3. 모델 기반: 전체 모델이 내장 메모리 또는 동적 메커니즘을 활용하여 빠르게 적응하도록 설계된다. TuringPost는 기초부터 현대 메타 학습 방법까지 자세한 설명을 제공한다. (출처: TheTuringPost)
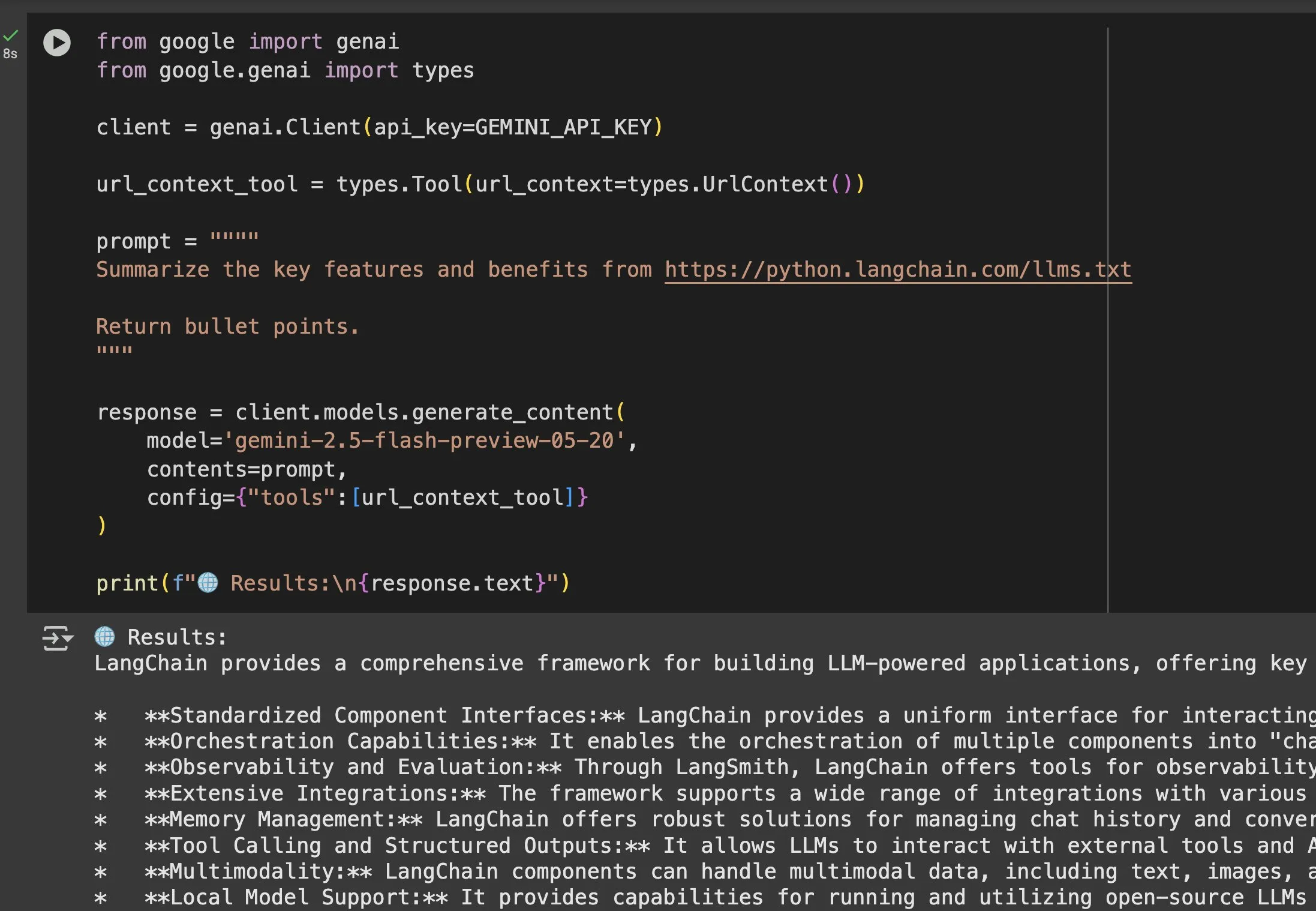
Gemini 등 모델에서 llms.txt 파일의 응용 가치 부각: Jeremy Phoward는 llms.txt 파일의 실용성을 강조했다. 예를 들어, Gemini는 이제 URL의 내용을 이해할 수 있으며, 프롬프트에 URL을 추가하고 URL 컨텍스트 도구를 구성하기만 하면 된다. 이는 클라이언트(예: Gemini)가 llms.txt 엔드포인트를 읽음으로써 필요한 정보가 어디에 저장되어 있는지 정확히 알 수 있게 되어 정보의 프로그래밍 방식 획득 및 활용을 크게 용이하게 함을 의미한다. (출처: jeremyphoward)
EleutherAI, 8TB 개방형 라이선스 텍스트 데이터 세트 Common Pile v0.1 출시: EleutherAI는 8TB의 개방형 라이선스 및 퍼블릭 도메인 텍스트를 포함하는 대규모 데이터 세트인 Common Pile v0.1을 출시한다고 발표했다. 이들은 이 데이터 세트를 기반으로 7B 매개변수 언어 모델(각각 1T 및 2T 토큰으로 훈련)을 훈련했으며, 그 성능은 LLaMA 1 및 LLaMA 2와 같은 유사한 모델과 비슷하다. 이는 완전히 규정을 준수하는 데이터를 사용하여 고성능 언어 모델을 훈련하는 연구에 귀중한 자원과 실증을 제공한다. (출처: clefourrier)

SelfCheckGPT: 참조 없이 LLM 환각을 감지하는 방법: 한 블로그 게시물에서 언어 모델의 환각을 감지하기 위해 LLM-as-a-judge(LLM을 평가자로 사용)의 대안으로 SelfCheckGPT를 논의했다. 이는 참조 텍스트 없이, 제로 리소스로 감지하는 방법으로, LLM 출력의 신뢰성을 평가하고 향상시키는 새로운 아이디어를 제공한다. (출처: dl_weekly)
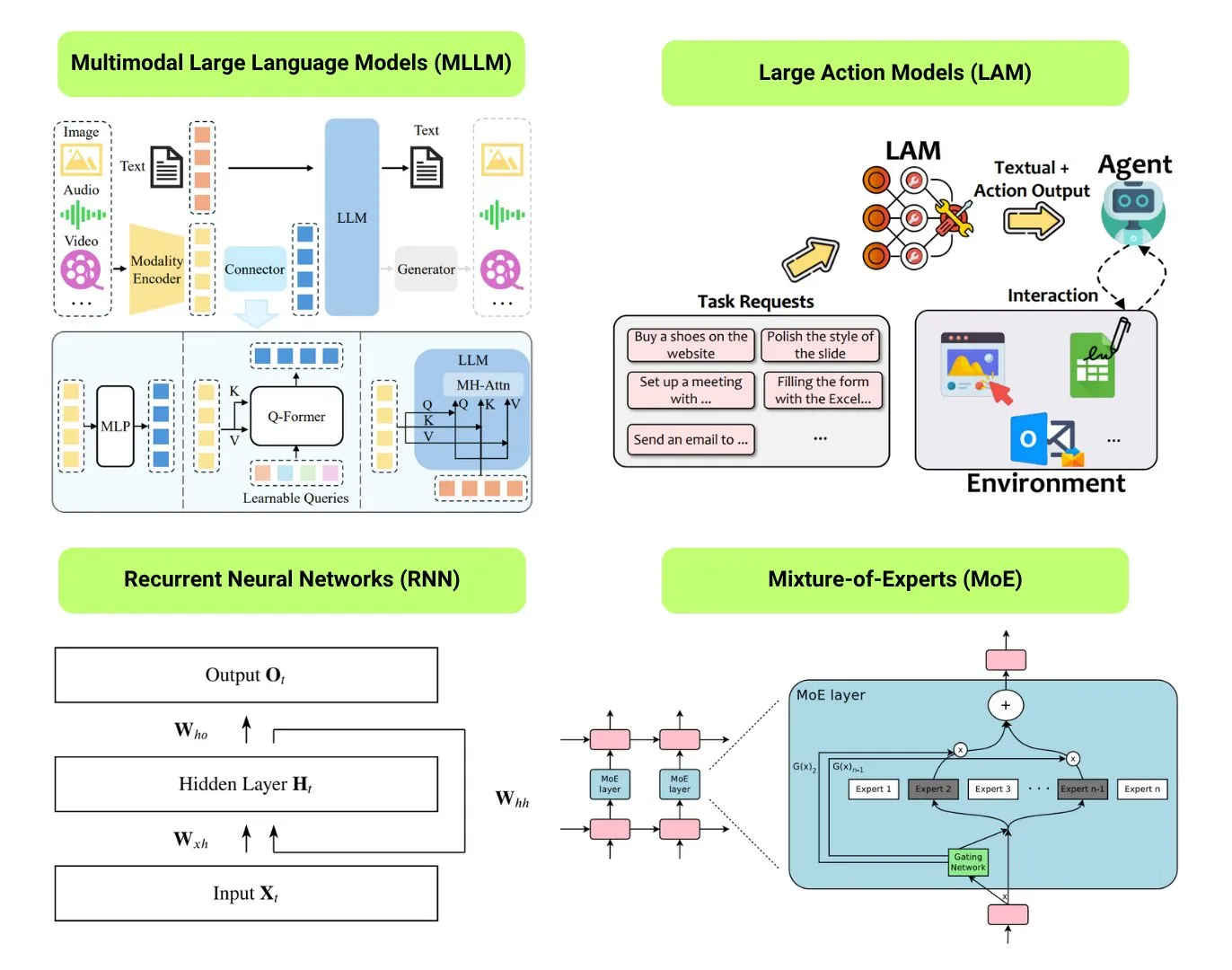
12가지 기본 AI 모델 유형 정리: The Turing Post는 LLM(대형 언어 모델), SLM(소형 언어 모델), VLM(시각 언어 모델), MLLM(멀티모달 대형 언어 모델), LAM(대형 행동 모델), LRM(대형 추론 모델), MoE(전문가 혼합 모델), SSM(상태 공간 모델), RNN(순환 신경망), CNN(컨볼루션 신경망), SAM(모든 것을 분할하는 모델) 및 LNN(논리 신경망) 등 12가지 기본 AI 모델 유형을 정리했다. 관련 자료는 이러한 모델 유형에 대한 설명과 유용한 링크를 제공한다. (출처: TheTuringPost)
GitHub 인기: Kubernetes The Hard Way 튜토리얼: Kelsey Hightower의 튜토리얼 ‘Kubernetes The Hard Way’가 GitHub에서 지속적으로 주목받고 있다. 이 튜토리얼은 사용자가 자동화 스크립트에 의존하지 않고 수동으로 Kubernetes 클러스터를 단계별로 구축하여 핵심 구성 요소와 작동 원리를 깊이 이해하도록 돕는 것을 목표로 한다. 이 튜토리얼은 Kubernetes 기본 지식을 습득하고자 하는 학습자를 대상으로 하며, 환경 준비부터 클러스터 정리까지의 전 과정을 다룬다. (출처: GitHub Trending)
GitHub 인기: 무료 GPTs 및 Prompts 목록: friuns2/BlackFriday-GPTs-Prompts 저장소가 GitHub에서 인기를 얻고 있으며, 이는 사용자가 Plus 구독 없이 사용할 수 있는 다양한 무료 GPT 모델과 고품질 Prompts를 수집하고 정리한다. 이러한 리소스는 프로그래밍, 마케팅, 학술 연구, 구직, 게임, 창의성 등 다양한 분야를 다루며 일부 “Jailbreaks” 기술을 포함하여 GPT 사용자에게 풍부한 즉시 사용 가능한 도구와 영감을 제공한다. (출처: GitHub Trending)

CSV로 AI 코딩 프로젝트 계획 및 추적하여 코드 품질 및 효율성 향상: 한 개발자가 Claude Code를 사용하여 ERP 시스템을 개발할 때 상세한 CSV 파일을 만들어 각 파일의 코딩 진행 상황을 계획하고 추적함으로써 복잡한 기능의 개발 효율성과 코드 품질을 크게 향상시킨 경험을 공유했다. CSV 파일에는 상태, 파일 이름, 우선순위, 코드 줄 수, 복잡성, 종속성, 기능 설명, 사용된 Hooks, 가져오기/내보내기 모듈 및 핵심적인 “진행 상황 메모”가 포함된다. 이 방법을 사용하면 AI가 코드 구축에 더 집중할 수 있고 개발자가 프로젝트의 실제 진행 상황과 원래 계획과의 차이를 명확하게 파악할 수 있다. (출처: Reddit r/ClaudeAI)
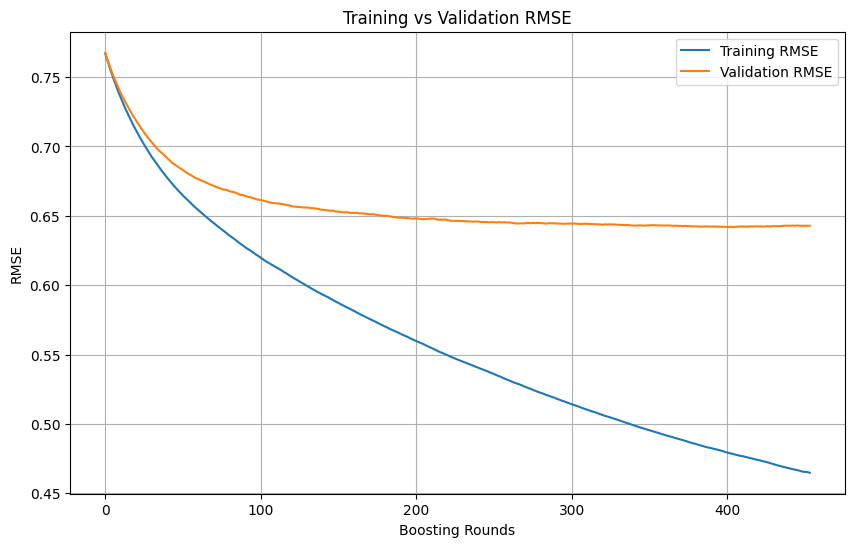
머신러닝 훈련 중 과적합 판단 및 중단 시점: 머신러닝 모델 훈련 과정에서 훈련 손실이 지속적으로 빠르게 감소하는 반면 검증 손실이 느리게 감소하거나 심지어 멈추거나 증가할 때, 일반적으로 모델이 과적합될 수 있음을 나타낸다. 원칙적으로 검증 손실이 여전히 감소하고 있다면 훈련을 계속할 수 있다. 핵심은 검증 세트가 훈련 세트와 독립적이며 작업의 실제 데이터 분포를 대표할 수 있도록 보장하는 것이다. 검증 손실이 감소를 멈추거나 증가하기 시작하면 조기 중단을 고려하거나 정규화와 같은 방법을 사용하여 모델의 일반화 능력을 개선해야 한다. (출처: Reddit r/MachineLearning)
🌟 커뮤니티
AI Engineer World’s Fair 2025, RL+Reasoning, Eval 등 의제에 초점: AI Engineer World’s Fair 2025 컨퍼런스의 주제는 강화 학습+추론(RL+Reasoning), 평가(Eval), 소프트웨어 엔지니어링 에이전트(SWE-Agent), AI 아키텍트 및 에이전트 인프라 등 첨단 분야를 다룬다. 참석자들은 컨퍼런스가 활력과 혁신적인 사고로 가득 차 있으며, 많은 사람들이 새로운 것을 시도하고 끊임없이 자신을 재창조하며 AI 분야에 뛰어들고 있다고 말했다. 이 컨퍼런스는 또한 AI 엔지니어들에게 교류와 학습의 장을 제공했다. (출처: swyx, hwchase17, charles_irl, swyx)

Sam Altman의 이상적인 AI: 소형 모델 + 초강력 추론 + 방대한 컨텍스트 + 만능 도구: Sam Altman은 자신이 생각하는 이상적인 AI 형태를 설명했다: 초인적인 추론 능력을 가진 극소형 모델로, 조 단위의 컨텍스트 정보에 접근할 수 있으며 상상할 수 있는 모든 도구를 호출할 수 있다. 이러한 관점은 논쟁을 불러일으켰으며, 일부는 이것이 현재 대형 모델이 지식 저장에 의존하는 현 상황과 다르다고 생각하며, 소형 모델이 거대한 컨텍스트에서 지식을 분석하고 복잡한 추론을 수행할 수 있는지에 대해 의문을 제기하며 지식과 사고 능력을 효율적으로 분리하기 어렵다고 보았다. (출처: teortaxesTex)
코딩 에이전트, 코드 리팩토링 욕구 유발, AI 지원 프로그래밍의 도전과 기회: 개발자들은 코딩 에이전트의 등장이 다른 사람의 코드를 리팩토링하려는 “유혹”을 크게 강화했으며 새로운 위험도 가져왔다고 말했다. 한 개발자는 AI를 사용하여 약 10분 분량의 수동 작업 프로그래밍 작업을 완료한 경험을 공유했는데, AI가 빠르게 작동하는 코드를 생성할 수 있지만 숙련된 프로그래머의 조직 및 스타일 수준에 도달하려면 여전히 많은 수동 지도와 리팩토링이 필요했다. 이는 AI 지원 프로그래밍이 초급/중급 코드를 고급 코드 품질로 향상시키는 데 있어 어려움을 강조한다. (출처: finbarrtimbers, mitchellh)
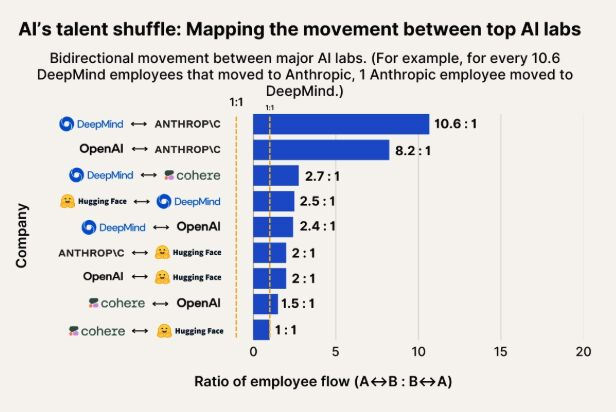
AI 인재 이동 관찰: Anthropic, Google DeepMind 및 OpenAI 인재의 주요 유입처로 부상: AI 인재 이동을 보여주는 차트에 따르면 Anthropic은 Google DeepMind 및 OpenAI 연구원들을 유치하는 주요 회사가 되고 있다. 커뮤니티는 이에 대해 인지하고 있으며, 일부 사용자는 Anthropic이 특정 “비밀 무기” 또는 독특한 연구 방향을 가지고 있어 최고 인재를 유치했을 수 있다고 추측했다. (출처: bookwormengr, TheZachMueller)
인간형 로봇 보급, 신뢰 및 사회적 수용도 문제 직면: 기술 평론가 Faruk Guney는 첫 번째 인간형 로봇 물결이 막대한 신뢰 부족으로 실패할 수 있다고 예측했다. 그는 기술이 계속 발전하고 있지만 사회는 아직 이러한 “블랙박스 지능”이 가정에 들어와 동반, 가사 심지어 육아와 같은 작업을 수행하는 것을 받아들일 준비가 되어 있지 않다고 생각한다. 로봇의 불투명한 의사 결정, 잠재적인 감시 위험 및 인간과 전혀 다른 “귀여운” 외모(Wall-E보다 못함)는 모두 광범위한 적용의 장애물이 될 수 있다. 충분한 사회적 논의, 규제, 감사 및 신뢰 회복 후에야 인간형 로봇의 진정한 보급이 이루어질 수 있다. (출처: farguney, farguney)
AI 개인화 디자인: “완벽함”보다 “불완전함”이 더 낫다: 한 개발자가 AI 오디오 플랫폼에서 50개의 AI 개인화 이미지를 만든 경험을 공유했다. 요약하자면, 과도하게 디자인된 배경 이야기, 절대적인 논리적 일관성 및 극단적인 단일 성격은 오히려 AI를 기계적이고 비현실적으로 보이게 만들었다. 성공적인 AI 개성 형성은 “3계층 개성 스택”(핵심 특성 + 수식 특성 + 기벽), 적절한 “불완전 모드”(예: 가끔의 말실수, 자기 수정) 및 적절한 배경 정보(300-500자, 긍정적이고 도전적인 경험, 구체적인 열정 및 전문 분야와 관련된 취약점 포함)에 있다. 이러한 “불완전한” 세부 사항은 오히려 AI를 더 인간적이고 연결감 있게 만든다. (출처: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
LLM이 “지각” 및 “AGI”를 갖추었는지에 대한 논의: 흥분과 회의 공존: 커뮤니티는 일반적으로 LLM의 막대한 잠재력에 흥분하며, 역사적으로 중요한 발명품에 필적하고 모든 것을 바꿀 것이라고 생각한다. 그러나 LLM이 이미 “지각 능력”을 갖추었는지, “권리”가 필요한지, 그리고 “인류를 종식”시키거나 “AGI”를 가져올 것인지 등에 대해서는 많은 사람들이 여전히 회의적인 태도를 보이고 있다. LLM 능력과 연구 결과를 해석할 때 세심하고 신중해야 함을 강조한다. (출처: fabianstelzer)
💡 기타
다중 로봇 자율 보행 협업 논의: 소셜 미디어에서 다중 로봇의 자율 보행 협업에 대한 탐구가 이루어지고 있다. 이는 로봇 경로 계획, 작업 할당, 정보 공유 및 충돌 회피와 같은 복잡한 기술을 포함하며, 로봇 공학, RPA(로봇 프로세스 자동화) 및 머신러닝 분야에서 지속적으로 주목받는 연구 방향이다. (출처: Ronald_vanLoon)
랜덤 포레스트를 활용한 ULMFiT 하이퍼파라미터 최적화 기법: Jeremy Howard는 ULMFiT(전이 학습 방법)을 최적화할 때 사용한 한 가지 기법을 공유했다: 수많은 제거 실험을 실행하고 모든 하이퍼파라미터와 결과 데이터를 랜덤 포레스트 모델에 입력하여 모델 성능에 가장 큰 영향을 미치는 하이퍼파라미터를 찾아내는 것이다. 이 방법은 Weights & Biases에 의해 제품에 통합되어 하이퍼파라미터 튜닝에 새로운 아이디어를 제공한다. (출처: jeremyphoward)

Figure 회사 인간형 로봇, 60분 물류 작업 처리 능력 선보여: Figure 회사는 Helix 신경망으로 구동되는 인간형 로봇이 물류 현장에서 자율적으로 다양한 작업을 완료하는 60분짜리 영상을 공개했다. 이 시연은 복잡한 실제 환경에서 로봇의 장시간 안정적인 작업 능력과 자율적인 의사 결정 수준을 입증하는 것을 목표로 한다. (출처: adcock_brett)