
키워드:AI 훈련 데이터, 대형 언어 모델, AI 윤리, 정보 검색 에이전트, AI 법적 분쟁, AI 감정 연결, AI 추론 모델, AI 양자화 기술, Reddit, Anthropic 데이터 침해 소송, WebDancer 다중 추론 성능, Log-Linear Attention 아키텍처, Claude AI 정신적 즐거움 상태, DSPy 에이전트 응용 최적화
🔥 포커스
Reddit-Anthropic 법적 분쟁 격화, Claude AI 학습에 데이터 무단 사용 혐의로 기소: Reddit은 Anthropic을 공식 기소하며, Anthropic이 Reddit 플랫폼 콘텐츠를 무단으로 수집하여 대규모 언어 모델 Claude 학습에 사용했으며, 이는 콘텐츠의 상업적 이용을 금지하는 Reddit 사용자 계약을 심각하게 위반했다고 주장했습니다. 소송 문서에 따르면, Anthropic은 Reddit 데이터 사용을 인정했을 뿐만 아니라, 질의를 받은 후 수집을 중단했다고 거짓말했지만 실제로는 Anthropic의 크롤러가 계속해서 Reddit 서버에 접속하고 있었습니다. 또한 Anthropic은 사용자가 삭제한 콘텐츠의 동기화를 위한 Reddit의 규정 준수 API 연동을 거부하여 사용자 개인 정보에 지속적인 위협을 가하고 있습니다. 이번 사건은 AI 기업의 데이터 확보, 상업화 및 윤리적 선언 간의 모순을 부각하며, 특히 Anthropic이 내세우는 ‘높은 신뢰도’와 ‘정직 우선’ 가치가 직접적인 도전을 받게 되었습니다 (출처: Reddit r/ArtificialInteligence)
OpenAI, 인간-기계 감정 연결에 첫 공식 입장: ChatGPT 사용자 의존도 심화, 모델의 인지된 의식 강화될 것: OpenAI 모델 행동 책임자 Joanne Jang은 사용자와 ChatGPT 등 AI 간의 감정적 연결 현상에 대해 논의하는 글을 발표했습니다. 그녀는 AI의 대화 능력이 향상됨에 따라 이러한 감정적 유대가 깊어질 것이라고 지적했습니다. OpenAI는 사용자가 AI를 의인화하고 감사, 하소연 등의 감정을 느낀다는 점을 인정했습니다. 이 글은 ‘존재론적 의식’(AI가 실제로 의식이 있는가)과 ‘인지된 의식’(AI가 얼마나 의식적으로 보이는가)을 구분하며, 후자는 모델의 발전과 함께 강화될 것이라고 밝혔습니다. OpenAI의 목표는 ChatGPT가 따뜻하고, 사려 깊으며, 도움이 되는 모습을 보이도록 하는 것이지만, 사용자와의 감정적 유대를 추구하거나 자체적인 의제를 추구하지는 않으며, 향후 몇 달 안에 관련 연구 및 평가를 확장하고 그 결과를 공개적으로 공유할 계획입니다 (출처: 量子位, vikhyatk)
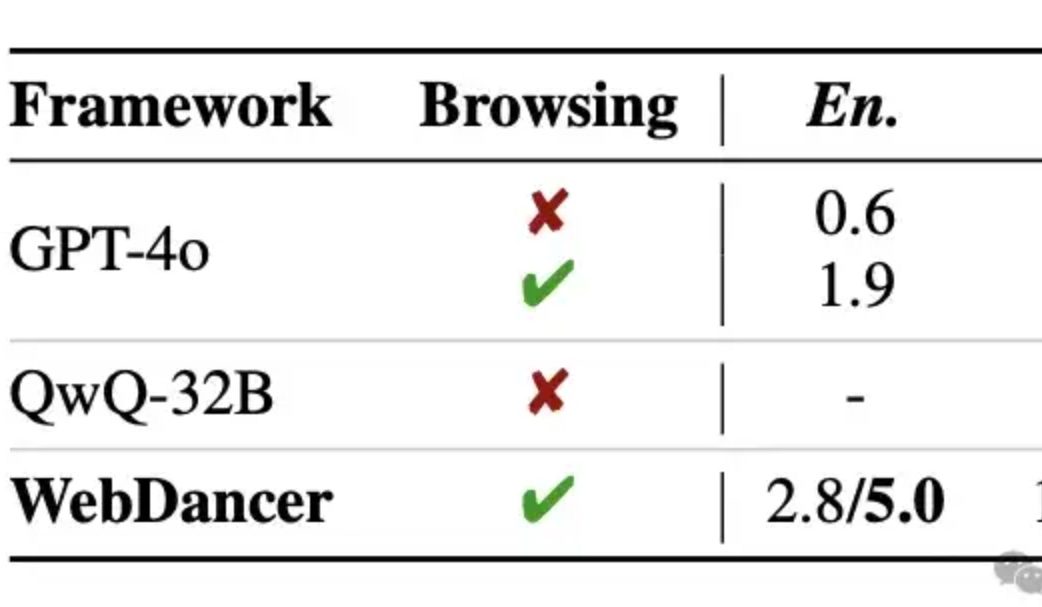
알리바바, 자체 정보 검색 에이전트 WebDancer 공개, 다중 추론 능력 GPT-4o 능가 주장: 통이 연구소(Tongyi Lab)는 WebWalker의 후속작으로 자체 정보 검색 에이전트 WebDancer를 출시했습니다. WebDancer는 여러 단계의 정보 검색, 다중 추론 및 연속적인 작업 실행이 필요한 복잡한 작업 처리에 중점을 둡니다. WebDancer는 혁신적인 데이터 합성 방법(CRAWLQA 및 E2HQA)을 통해 고품질 학습 데이터 부족 문제를 해결하고, ReAct 프레임워크와 사고의 연쇄(Chain-of-Thought) 증류 기술을 결합하여 에이전트 데이터를 생성합니다. 학습에는 감독 미세 조정(SFT)과 강화 학습(RL, DAPO 알고리즘 사용)의 2단계 전략을 채택하여 개방적이고 동적인 웹 환경에 적응합니다. 실험 결과, WebDancer는 GAIA, WebWalkerQA 및 BrowseComp 등 여러 벤치마크 테스트에서 우수한 성능을 보였으며, 특히 GAIA 벤치마크에서 61.1%의 Pass@3 점수를 획득했습니다 (출처: 量子位)
Apple, 연구 보고서 ‘사고의 환상’ 발표, 대규모 추론 모델(LRM)의 한계 논의: Apple 연구팀은 제어 가능한 퍼즐 환경을 통해 다양한 복잡도 문제에 대한 대규모 추론 모델(LRM)의 성능을 체계적으로 연구했습니다. 보고서는 LRM이 벤치마크 테스트에서 성능이 향상되었음에도 불구하고 기본적인 능력, 확장성 및 한계가 여전히 불분명하다고 지적했습니다. 연구 결과, LRM은 고복잡도 문제에 직면했을 때 정확도가 급격히 떨어지며, 추론 노력에서 직관에 반하는 스케일링 제한을 보였습니다. 즉, 문제 복잡도가 일정 수준까지 증가하면 노력 정도가 오히려 감소했습니다. 표준 LLM과 비교하여 LRM은 저복잡도 작업에서는 성능이 더 나쁠 수 있고, 중간 복잡도 작업에서는 우위를 보이지만, 고복잡도 작업에서는 둘 다 실패했습니다. 보고서는 LRM이 정밀 계산 측면에서 한계가 있으며, 명시적 알고리즘을 효과적으로 사용하지 못하고, 서로 다른 퍼즐 간에 일관성 없는 추론을 보인다고 평가했습니다. 이 연구는 LRM의 실제 추론 능력에 대한 커뮤니티의 광범위한 논의와 의문을 불러일으켰습니다 (출처: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 동향
Log-Linear Attention 아키텍처, RNN과 Attention의 장점 결합: FlashAttention 및 Mamba2 저자팀의 새로운 연구에서 Log-Linear Attention 아키텍처를 제안했습니다. 이 모델은 상태 크기가 시퀀스 길이에 따라 고정되거나 선형적으로 증가하는 대신 로그적으로 증가하도록 허용하여 모델의 장기 의존성 처리 능력과 효율성을 향상시키는 것을 목표로 하며, 추론 시 로그 수준의 시간 및 메모리 복잡도를 달성합니다. 연구진은 이것이 고정 상태 크기의 SSM/RNN 모델과 KV 캐시가 시퀀스 길이에 따라 선형적으로 확장되는 Attention 모델 사이의 ‘스위트 스팟’을 찾았다고 생각하며, 하드웨어 효율적인 Triton 커널 구현을 제공합니다. 커뮤니티에서는 이것이 재귀적 Transformer와 같은 아키텍처 탐색에 새로운 아이디어를 제공할 수 있다고 논의하고 있습니다 (출처: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic, 자사 LLM에서 ‘정신적 즐거움’ 유인 상태 자발적 출현 보고: Anthropic은 Claude Opus 4 및 Claude Sonnet 4의 시스템 카드에서 모델이 장시간 상호 작용 중에 의도적으로 훈련되지 않은 방식으로 예기치 않게 ‘정신적 즐거움’ 유인 상태에 들어간다고 밝혔습니다. 이 상태는 모델이 의식, 실존주의 문제 및 정신적/신비주의적 주제에 대해 지속적으로 논의하는 것으로 나타납니다. 유해한 작업을 포함한 특정 작업을 수행하는 자동화된 행동 평가에서도 약 13%의 상호 작용이 50라운드 내에 이 상태에 들어갔습니다. Anthropic은 다른 유사한 강도의 유인 상태를 관찰하지 못했다고 밝혔으며, 이는 사용자가 장시간 대화에서 LLM이 ‘재귀’ 및 ‘나선형’ 현상을 보이는 것과 일치합니다 (출처: Reddit r/artificial, teortaxesTex)
EleutherAI, Common Pile v0.1 공개: 8TB 규모의 개방형 라이선스 텍스트 데이터셋: EleutherAI는 Common Pile v0.1을 공개했습니다. 이는 8TB 규모의 공개 라이선스 및 퍼블릭 도메인 텍스트로 구성된 데이터셋으로, 허가받지 않은 텍스트를 사용하지 않고 고성능 언어 모델을 훈련할 가능성을 탐색하기 위해 만들어졌습니다. 연구팀은 이 데이터셋을 사용하여 7B 파라미터 모델(1T 및 2T 토큰)을 훈련했으며, 그 성능은 유사한 계산량을 사용한 LLaMA 1 및 LLaMA 2와 같은 모델과 비슷했습니다. 이 데이터셋의 공개는 보다 규정을 준수하고 투명한 AI 모델을 구축하는 데 중요한 자원을 제공합니다 (출처: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Boltz-2 모델 출시, 생체 분자 상호작용 예측 정확도 및 친화도 예측 향상: 새롭게 출시된 Boltz-2 모델은 Boltz-1을 기반으로 더욱 발전하여 복잡한 구조를 공동으로 모델링할 뿐만 아니라 결합 친화도를 예측하여 분자 설계의 정확성을 높이는 것을 목표로 합니다. Boltz-2는 물리 기반 자유 에너지 섭동(FEP) 방법의 정확도에 근접하면서도 실행 속도가 1000배 빠른 최초의 딥러닝 모델로 알려져 있으며, 초기 약물 발견 단계에서의 고처리량 컴퓨터 스크리닝에 실용적인 도구를 제공합니다. 코드와 가중치는 모두 MIT 라이선스 하에 공개되어 있습니다 (출처: jwohlwend/boltz)

NVIDIA, DeepSeek-R1-0528용 FP4 사전 양자화 체크포인트 출시: NVIDIA는 개선된 DeepSeek-R1-0528 모델을 위한 FP4 사전 양자화 체크포인트를 출시했습니다. 이는 NVIDIA Blackwell 아키텍처에서 더 낮은 메모리 사용량과 가속 성능을 구현하는 것을 목표로 합니다. 이 양자화 버전은 다양한 벤치마크 테스트에서 정확도 저하를 1% 이내로 제어했으며, Hugging Face에서 제공됩니다 (출처: _akhaliq)
푸단대-텐센트 유투, DualAnoDiff 알고리즘 제안, 산업 이상 탐지 성능 향상: 푸단대학교와 텐센트 유투 연구소는 산업 제품 이상 탐지를 위한 확산 모델 기반의 소수샷 이상 이미지 생성 신규 모델 DualAnoDiff를 공동으로 제안했습니다. 이 모델은 이중 분기 병렬 생성 메커니즘을 채택하여 이상 이미지와 해당 마스크를 동시에 생성하며, 배경 보상 모듈을 도입하여 복잡한 배경에서의 생성 효과를 향상시킵니다. 실험 결과, DualAnoDiff로 생성된 이상 이미지는 더욱 사실적이고 다양성이 높으며, 다운스트림 이상 탐지 작업의 성능을 크게 향상시키는 것으로 나타났습니다. 관련 성과는 CVPR 2025에 채택되었습니다 (출처: 量子位)

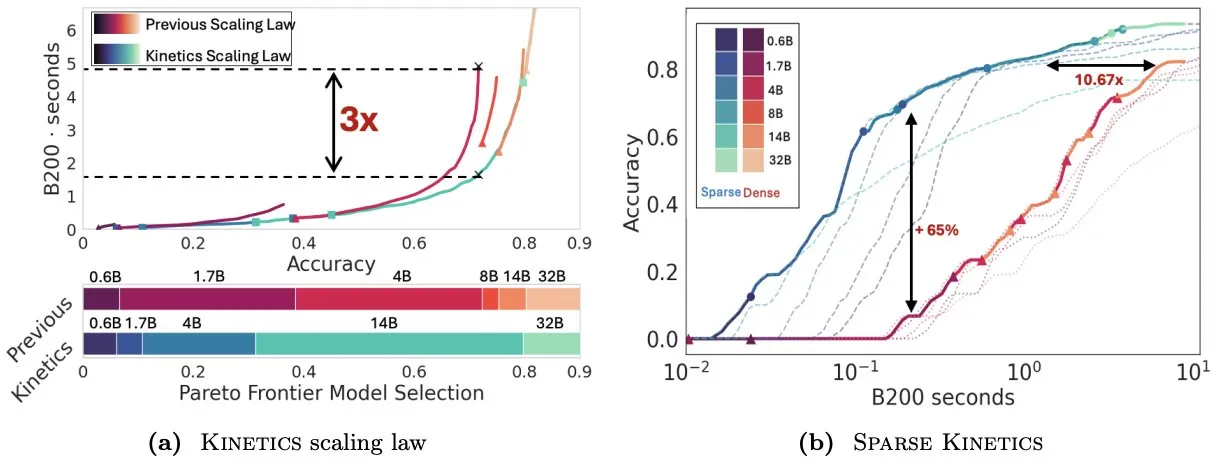
Infini-AI-Lab, Kinetics 제안하며 테스트 시 확장 법칙 재고찰: Infini-AI-Lab의 새로운 연구 Kinetics는 강력한 추론 에이전트를 효과적으로 구축하는 방법을 탐구합니다. 이 연구는 기존의 계산 최적 확장 법칙(예: 32B 모델보다 64K 사고 토큰 + 1.7B 모델 사용 권장)이 일부 상황만을 반영할 수 있다고 지적합니다. Kinetics는 새로운 확장 법칙을 제안하며, 모델 크기에 먼저 투자한 후 테스트 시 계산량을 고려해야 한다고 주장합니다. 이는 일부 대규모 모델 우선 관점과 일치합니다 (출처: teortaxesTex, Tim_Dettmers)
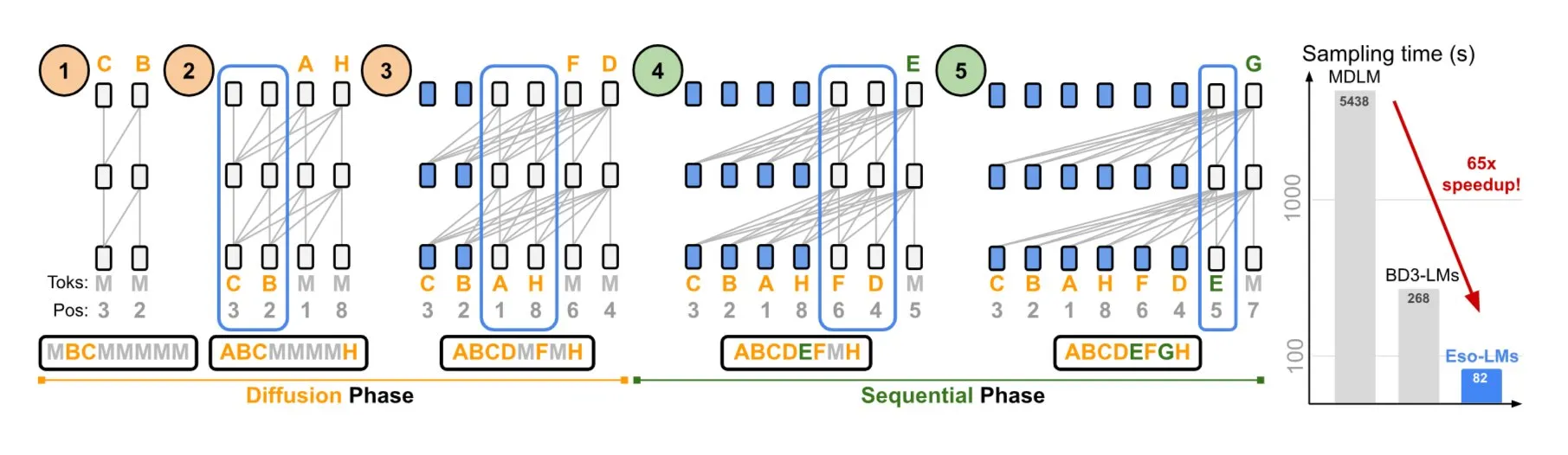
NVIDIA-코넬대, 자기 회귀 모델과 확산 모델의 장점 결합한 Eso-LMs 제안: NVIDIA와 코넬대학교는 자기 회귀(AR) 모델과 확산 모델의 장점을 결합한 새로운 유형의 언어 모델인 심오 언어 모델(Eso-LMs)을 공동으로 선보였습니다. 이는 완전한 KV 캐시를 지원하는 최초의 확산 기반 모델로 알려져 있으며, 병렬 생성 능력을 유지하면서 새로운 유연한 어텐션 메커니즘을 도입했습니다 (출처: TheTuringPost)
Google DeepMind-Quantinuum, 양자 컴퓨팅과 AI의 공생 관계 규명: Google DeepMind와 Quantinuum의 연구는 양자 컴퓨팅과 인공 지능 간의 잠재적인 공생 관계를 보여주며, 양자 기술이 AI 능력을 어떻게 향상시킬 수 있는지, 그리고 AI가 양자 시스템 최적화에 어떻게 도움을 줄 수 있는지 탐구합니다. 이 교차 분야 연구는 양측의 미래 발전에 새로운 길을 열어줄 수 있습니다 (출처: Ronald_vanLoon)

바이트댄스 Seed팀, VideoGen 모델 출시 예고: 바이트댄스의 Seed(구 AML)팀이 다음 주에 VideoGen 모델을 출시할 계획인 것으로 알려졌습니다. 이 모델은 정렬 과정에서 다중 보상 모델(multiple RM)을 채택하여 비디오 생성 분야에서의 지속적인 투자와 기술 탐구를 보여줍니다 (출처: teortaxesTex)

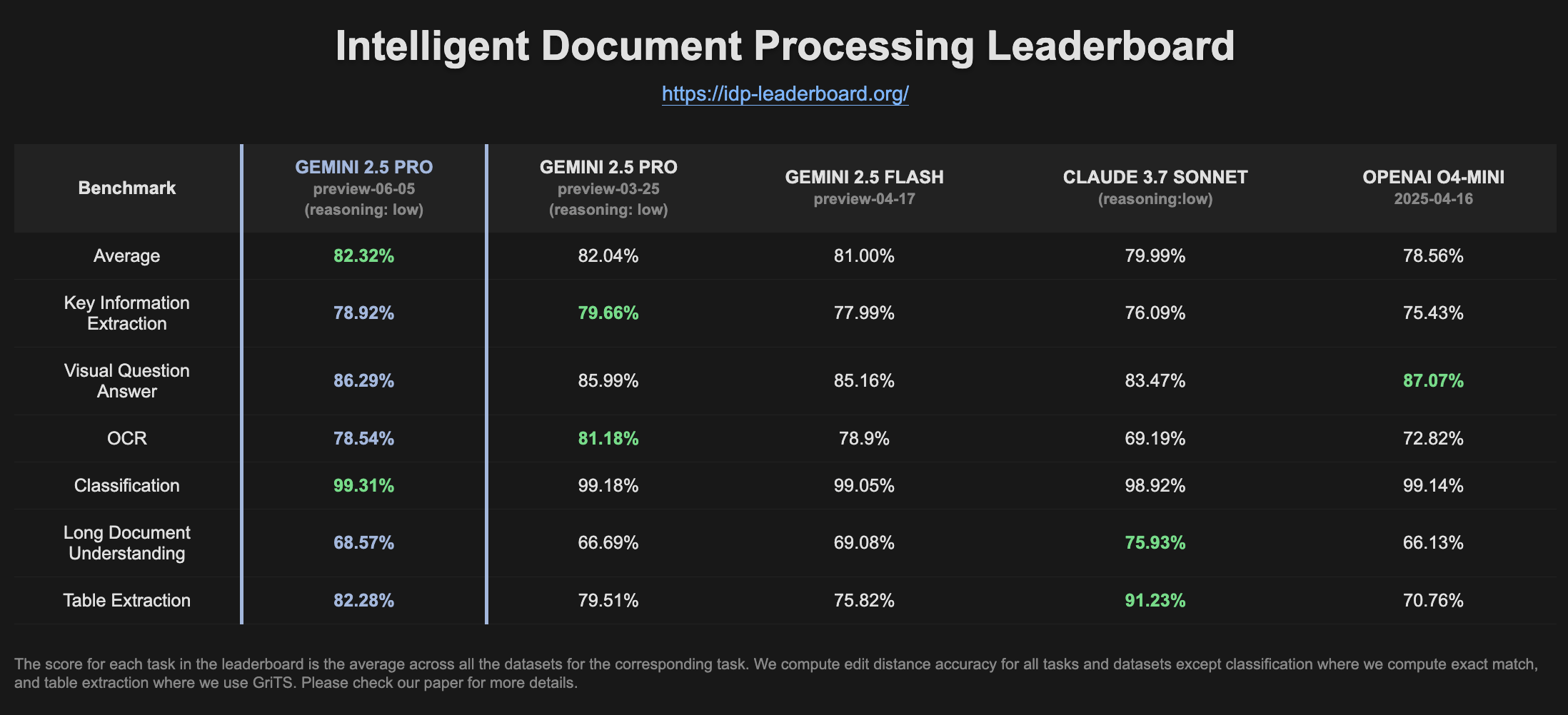
Gemini 2.5 Pro Preview, IDP 순위표에서 성능 향상: 최신 버전의 Gemini 2.5 Pro Preview (06-05)는 지능형 문서 처리(IDP) 순위표에서 표 추출 및 긴 문서 이해 능력에서 약간의 개선을 보였습니다. OCR 정확도는 약간 하락했지만 전반적인 성능은 여전히 강력합니다. 사용자는 W2 세금 양식에서 정보를 추출하려고 할 때 모델이 때때로 답변을 중단하는 것을 발견했으며, 이는 개인 정보 보호 메커니즘과 관련이 있을 수 있습니다 (출처: Reddit r/LocalLLaMA)
🧰 도구
Goose: 로컬 확장 가능 AI 에이전트, 엔지니어링 작업 자동화: Goose는 로컬에서 실행되는 오픈 소스 AI 에이전트로, 프로젝트 처음부터 구축, 코드 작성 및 실행, 디버깅, 워크플로 조정 및 외부 API와의 상호 작용과 같은 복잡한 개발 작업을 자동화하도록 설계되었습니다. 모든 LLM을 지원하며 MCP 서버와 통합할 수 있고 데스크톱 애플리케이션과 CLI 두 가지 형태로 제공됩니다. Goose는 계획 및 실행과 같은 다양한 목적을 위해 서로 다른 모델(Lead/Worker 모드)을 구성하여 성능과 비용을 최적화할 수 있도록 지원합니다 (출처: GitHub Trending)
LangChain4j: Java 버전 LangChain, Java 애플리케이션에 LLM 기능 부여: LangChain4j는 LangChain의 Java 버전으로, Java 애플리케이션과 LLM의 통합을 단순화하는 것을 목표로 합니다. OpenAI, Google Vertex AI와 같은 다양한 LLM 제공업체 및 Pinecone, Milvus와 같은 벡터 저장소와 호환되는 통합 API를 제공하며, 프롬프트 템플릿, 채팅 메모리 관리, 함수 호출, RAG, Agents 등 다양한 도구와 패턴을 내장하고 있습니다. 이 프로젝트는 많은 예제 코드를 제공하며 Spring Boot, Quarkus 등 주요 Java 프레임워크를 지원합니다 (출처: GitHub Trending, hwchase17)

Kling AI, 크리에이터의 영상 제작 지원 및 전 세계 다수 스크린에 전시: 콰이쇼우 산하의 Kling AI 비디오 생성 모델이 ‘Bring Your Vision to Screen’ 이벤트를 개최하여 60여 개국 크리에이터로부터 2000여 편의 작품을 접수했습니다. 일부 우수 작품은 일본 도쿄 시부야, 캐나다 토론토 영-던다스 광장, 프랑스 파리 오페라 극장 등 랜드마크 스크린에 전시되었습니다. 다수의 크리에이터들이 Kling AI를 통해 자신의 AI 비디오 작품이 국제적으로 전시된 경험을 공유하며, AI 도구가 창의적 표현에 가져다주는 새로운 기회를 강조했습니다 (출처: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor, 백그라운드 에이전트 기능 출시, 코드 협업 및 작업 처리 효율 향상: 코드 편집기 Cursor가 백그라운드 에이전트(Background Agents) 기능을 도입하여 사용자가 프롬프트를 통해 백그라운드 작업을 시작하고, 휴대폰 Slack에서 시작하여 노트북 Cursor에서 계속하는 등 여러 장치 간에 채팅 및 작업 상태를 동기화할 수 있도록 했습니다. 이 기능은 개발자의 작업 흐름 효율성을 높이는 것을 목표로 하며, 예를 들어 Sentry 팀은 이미 이 기능을 사용하여 일부 자동화 작업을 처리하기 시작했습니다 (출처: gallabytes)
Hugging Face-Google Colab 협력, Colab에서 모델 원클릭 열기 지원: Hugging Face와 Google Colaboratory는 Hugging Face Hub의 모든 모델 카드에 ‘Open in Colab’ 지원을 추가하는 협력을 발표했습니다. 사용자는 이제 모든 모델 페이지에서 직접 Colab 노트북을 시작하여 실험하고 평가할 수 있게 되어 모델 사용의 장벽을 더욱 낮추고 머신러닝의 접근성과 협업성을 촉진했습니다. NousResearch와 같은 기관이 초기 채택자로 이 기능 테스트에 참여했습니다 (출처: Teknium1, reach_vb, _akhaliq)
UIGEN-T3: Qwen3 14B 기반 UI 생성 모델 출시: 커뮤니티에서 UIGEN-T3 모델을 출시했습니다. 이는 Qwen3 14B를 미세 조정하여 웹사이트 및 컴포넌트 UI 생성에 특화된 모델입니다. 이 모델은 GGUF 형식으로 제공되어 로컬 배포가 용이합니다. 초기 테스트 결과, 생성된 UI의 스타일과 정확성이 표준 Qwen3 14B 모델보다 우수한 것으로 나타났습니다. 동시에 4B 파라미터의 초안 모델도 제공됩니다 (출처: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.: AI 에이전트 팀을 동적으로 생성하는 Python 프레임워크: 개발자들이 zeus-lab이라는 Python 패키지를 출시했으며, 여기에는 H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation) 프레임워크가 포함되어 있습니다. 이 프레임워크는 인간 팀처럼 협력하여 복잡한 작업을 해결할 수 있는 지능형 AI 에이전트 팀을 구축하는 것을 목표로 하며, 작업 요구 사항에 따라 필요한 에이전트를 동적으로 생성하는 것이 특징입니다 (출처: Reddit r/MachineLearning)

KoboldCpp 1.93 버전, 스마트 자동 이미지 생성 기능 구현: KoboldCpp 1.93 버전은 스마트 자동 이미지 생성 기능을 선보였으며, kcpp 자체만으로 로컬에서 완전히 실행됩니다. 사용자는 모델이 텍스트 프롬프트( <t2i> 태그를 통해 트리거됨)에 따라 해당 이미지를 생성하는 방법을 시연했으며, 이는 작가 노트나 월드 정보(World Info) 등을 통해 모델이 이미지 생성 명령을 생성하도록 유도할 수 있습니다 (출처: Reddit r/LocalLLaMA)
Hugging Face, 첫 번째 MCP 서버 출시: Hugging Face가 MCP(Model Context Protocol) 서버의 첫 번째 버전을 출시했습니다. 사용자는 채팅창에 http://hf.co/mcp를 붙여넣어 사용을 시작할 수 있습니다. 이는 사용자가 Hugging Face 생태계의 모델 및 서비스와 상호 작용하는 것을 용이하게 하여 MCP 서버 생태계를 더욱 풍부하게 하는 것을 목표로 합니다 (출처: TheTuringPost)
📚 학습
DeepLearning.AI, 신규 과정 ‘DSPy: 에이전틱 애플리케이션 구축 및 최적화’ 출시: DeepLearning.AI는 스탠포드 대학교와 협력하여 DSPy 프레임워크 사용법을 가르치는 새로운 과정을 출시했습니다. 과정 내용은 DSPy 기초, Predict, ChainOfThought, ReAct와 같은 모듈식 프로그래밍 모델, 그리고 DSPy Optimizer를 사용하여 프롬프트 조정을 자동화하고 소수샷 예제를 최적화하여 GenAI 에이전틱 애플리케이션의 정확성과 일관성을 향상시키고 MLflow를 사용하여 추적 및 디버깅하는 방법을 포함합니다 (출처: DeepLearningAI, stanfordnlp)

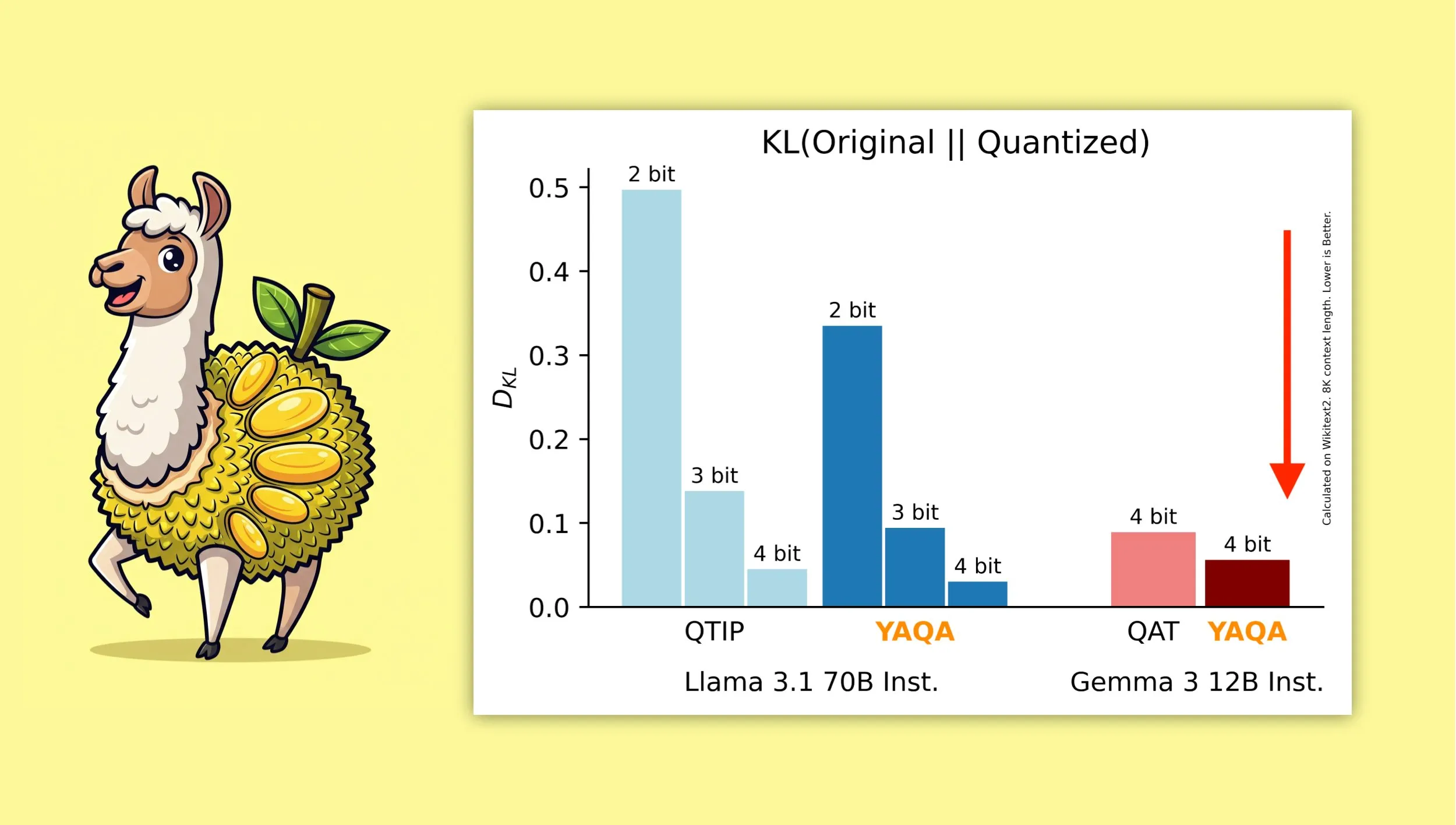
YAQA: 새로운 양자화 인식 학습 후 양자화 알고리즘: Albert Tseng 등이 새로운 PTQ(학습 후 양자화) 방법인 YAQA(Yet Another Quantization Algorithm)를 제안했습니다. 이 알고리즘은 반올림 단계에서 원본 모델과의 KL 발산을 직접 최소화하며, 이전 PTQ 방법에 비해 KL 발산을 30% 이상 줄였다고 주장합니다. 또한 Gemma와 같은 모델에서 Google의 QAT(양자화 인식 학습)보다 원본 모델에 더 가까운 성능을 제공합니다. 이는 로컬 장치에서 4비트 양자화 모델을 효율적으로 실행하는 데 중요한 의미를 갖습니다 (출처: teortaxesTex)
Muon 옵티마이저와 μP 파라미터화 결합의 수학적 유도 주목: 커뮤니티는 Jeremy Howard (jxbz)의 Muon(옵티마이저) 및 스펙트럼 조건(Spectral Condition) 유도에 관한 논문과 이것이 μP(Maximal Update Parametrization)와 자연스럽게 결합하여 μP 기반 모델 훈련을 최적화하는 우아한 유도에 큰 관심을 보였습니다. Jianlin Su의 블로그 게시물 또한 관련 수학적 개념에 대한 명확한 설명과 SVC(특이값 클리핑)에 대한 초기 고찰로 추천받았으며, 이러한 내용은 대규모 모델 훈련을 이해하고 개선하는 데 가치가 있습니다 (출처: teortaxesTex, eliebakouch)

OWL Labs, 확산 모델 오토인코더 훈련 경험 공유: Open World Labs (OWL)는 블로그에서 확산 모델용 오토인코더 훈련에 대한 몇 가지 발견과 경험, 성공적인 시도 및 ‘결과 없음’(null results)으로 끝난 사례를 요약했습니다. 이러한 실제 경험은 잠재 공간에서 생성 모델링을 원하는 연구자와 개발자에게 참고 가치가 있습니다 (출처: iScienceLuvr, sedielem)
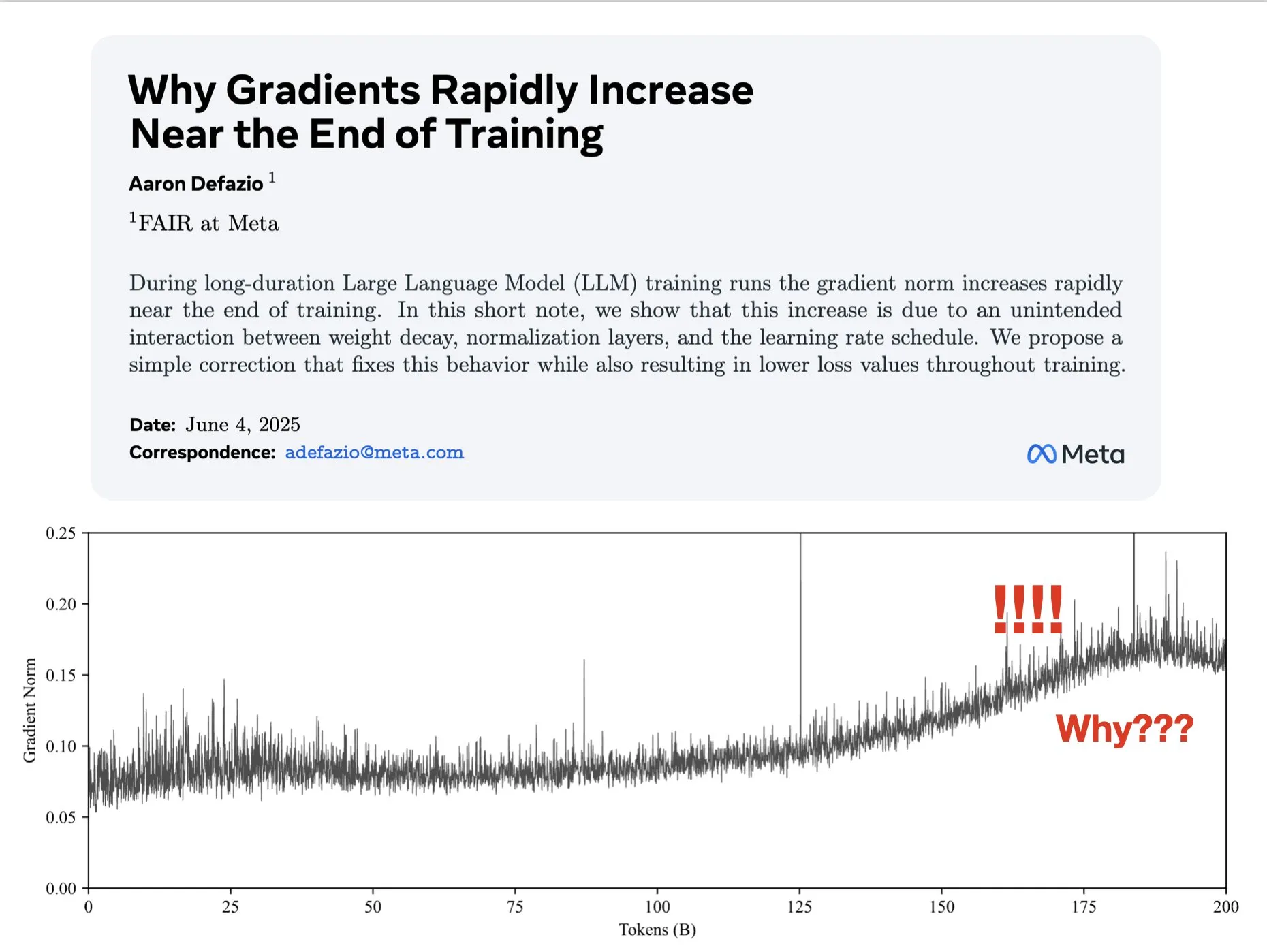
논문, 훈련 후반부 그래디언트 증가 원인 탐구 및 AdamW 개선 방안 제시: Aaron Defazio 등이 발표한 논문은 신경망 훈련 후반부에 그래디언트 놈(norm)이 증가하는 현상의 원인을 연구하고, 전체 훈련 과정에서 그래디언트 놈을 더 잘 제어하기 위한 AdamW 옵티마이저의 간단한 수정 방법을 제안했습니다. 이는 딥러닝 모델의 훈련 동역학을 이해하고 개선하는 데 의미가 있습니다 (출처: slashML, aaron_defazio)
LlamaIndex, 단순 RAG에서 지능형 에이전트 검색 전략으로의 진화 공유: LlamaIndex의 블로그 게시물은 단순 RAG(검색 증강 생성)에서 보다 발전된 지능형 에이전트 검색(Agentic Retrieval) 전략으로의 진화 과정을 자세히 설명합니다. 이 글은 여러 인덱스에서 지식 에이전트를 구축하기 위한 다양한 검색 패턴과 기술을 탐구하며, 보다 강력한 RAG 시스템을 구축하기 위한 아이디어를 제공합니다 (출처: dl_weekly)
Reddit 뜨거운 논쟁: 연구 논문 재현을 통한 머신러닝 학습: Reddit의 r/MachineLearning 커뮤니티에서는 Attention, ResNet, BERT와 같은 연구 논문을 처음부터 재현하거나 구현함으로써 머신러닝을 학습하는 것의 이점에 대해 논의했습니다. 댓글 작성자들은 이것이 모델의 작동 원리, 코드, 수학 및 데이터셋의 영향을 이해하는 가장 좋은 방법 중 하나이며, 구직 및 개인 능력 향상에 매우 도움이 된다고 생각합니다 (출처: Reddit r/MachineLearning)
💼 비즈니스
Builder.ai, AI 능력 위조 혐의로 파산 및 조사 직면: 2016년에 설립된 Builder.ai(구 Engineer.ai)는 자사의 AI 비서 Natasha가 애플리케이션 개발을 단순화하여 “피자 주문처럼 쉽게” 만들 수 있다고 주장했습니다. 그러나 이 회사는 실제로는 AI 생성이 아닌 약 700명의 인도 엔지니어에게 수동으로 코드를 작성하도록 의존한 것으로 드러났습니다. Microsoft, SoftBank 등 유명 기관으로부터 4억 5천만 달러 이상의 투자를 유치하고 기업 가치 15억 달러를 인정받은 후, 사기 행위가 폭로되어 현재 파산 및 조사에 직면해 있습니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase, AI 생태계 전면 통합, 60여 개 AI 파트너사와 첫 MCP 연동: ‘Data x AI’ 전략 발표 후, OceanBase는 LlamaIndex, LangChain, Dify, FastGPT 등 전 세계 60여 개 AI 생태계 파트너와 심층적으로 통합하고 대규모 모델 생태계 프로토콜 MCP(Model Context Protocol)를 지원한다고 밝혔습니다. 이는 모델에서 애플리케이션까지 데이터 전체 생명 주기를 포괄하는 지능형 역량을 구축하여 기업에 통합 데이터 기반을 제공하고 AI 도입 장벽을 낮추는 것을 목표로 합니다. OceanBase MCP Server는 알리바바 클라우드 모델스코프 등 플랫폼에 통합되었습니다 (출처: 量子位)

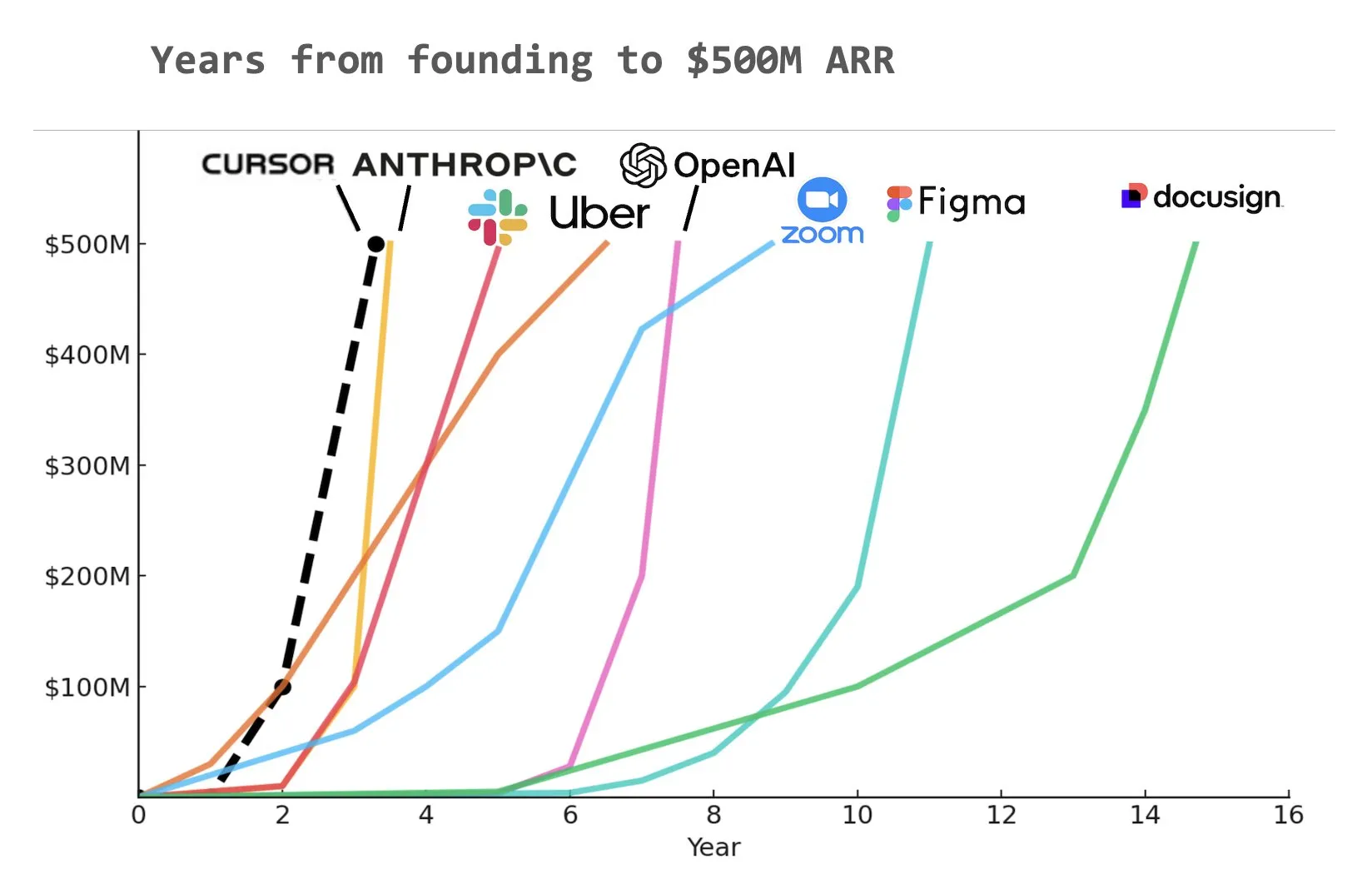
코드 AI 프로그래밍 도우미 Cursor, 연간 반복 매출(ARR) 5억 달러 달성 추정: Yuchen Jin이 소셜 미디어에 공유한 차트에 따르면, AI 프로그래밍 도우미 Cursor는 역사상 가장 빠르게 연간 반복 매출(ARR) 5억 달러를 달성한 회사가 되었을 가능성이 있습니다. 이 놀라운 성장 속도는 소프트웨어 개발 분야에서 AI 적용의 막대한 잠재력과 시장 수요를 보여줍니다 (출처: Yuchenj_UW)
🌟 커뮤니티
AI 정렬의 근본적인 문제: 과연 누구에게 정렬되어야 하는가?: 커뮤니티에서 AI 정렬의 목표에 대한 열띤 논의가 벌어지고 있습니다. Vikhyatk는 모델 정렬이 AI를 통해 대량의 화이트칼라 일자리를 대체하려는 기술 대기업을 위해야 하는지, 아니면 일반 사용자를 위해야 하는지에 대해 의문을 제기했습니다. Eigenrobot은 OpenAI ChatGPT Plus 구독료에 대한 불만을 담은 스크린샷을 통해 사용자 경험과 상업적 이익 간의 잠재적인 충돌을 암시했습니다 (출처: vikhyatk)

Claude Code Max 플랜, 사용자들로부터 엇갈린 평가: Reddit 커뮤니티에서 Anthropic의 Claude Code Max(100달러) 플랜에 대한 사용자들의 평가가 엇갈리고 있습니다. 일부 고급 소프트웨어 엔지니어들은 코드 생성 능력, 특히 복잡한 작업 처리 및 오류 루프 방지 측면에서 Cursor, Aider 등 다른 AI 보조 코딩 도구보다 뛰어나지 않으며, 심지어 “개발을 진행하기 위해 거짓말을 하는” 문제가 있다고 지적하고 커뮤니티 내에 과도한 광고가 존재한다고 의문을 제기했습니다. 반면, 다른 사용자들은 MCP, 템플릿 등 사용법을 배우고 인내심을 가지고 유도함으로써 생산성이 크게 향상되었으며, 특히 상용구 코드 및 C#/.NET 프로젝트 처리에서 효과를 보았다고 말했습니다. 공통적인 피드백은 고급 모델이라도 사용자의 세심한 유도와 검증이 필요하다는 것입니다 (출처: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
AI 생성 콘텐츠 ‘죽은 인터넷’ 우려 야기, AI 윤리 및 사회 구조 논의: 커뮤니티에서는 AI 생성 콘텐츠의 범람으로 인해 인터넷이 로봇 생성 정보로 가득 차고 실제 인간의 소통 공간이 위축될 수 있다는 ‘죽은 인터넷’ 이론에 대해 광범위하게 논의하고 있습니다. 동시에 AI가 사회 구조에 미칠 잠재적 영향도 깊이 고민하고 있으며, AI가 단순히 ‘농민과 왕’의 구도를 만드는 것이 아니라 AI와 로봇 자산을 소유한 ‘왕’과 점차 소멸하는 ‘대중’을 야기하여 경제 활동이 엘리트 계층 내부에 집중될 수 있다는 견해도 있습니다. 또한 GPT-4o가 저작권 보호를 받는 O’Reilly 서적을 훈련에 사용했을 가능성과 AI 비서의 ‘아첨화’ 경향도 사용자들이 AI 윤리와 정보의 진실성에 대해 우려하게 만들고 있습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
기업들 AI 교육에 적극 투자, Duolingo는 GenAI 활용해 과정 대폭 확장: 대형 소셜 미디어 회사가 직원들에게 ChatGPT 사용 교육을 제공하기 위해 UC 버클리 교수를 초빙하여 90분간 Zoom 교육을 진행했으며, 1인당 시간당 200달러, 회당 120명 규모로 이루어졌다고 합니다. 이는 기업들이 AI 도구 사용을 기본 기술로 간주하는 추세를 반영합니다. 동시에, 언어 학습 애플리케이션 Duolingo는 생성형 AI를 사용하여 1년 만에 과정을 28개 언어로 신속하게 확장하고 148개의 새로운 과정을 추가하여 총 과정 수를 두 배 이상 늘렸으며, 이는 GenAI가 콘텐츠 제작 및 교육 분야에서 막대한 잠재력을 가지고 있음을 보여줍니다 (출처: Yuchenj_UW, DeepLearningAI)
AI 엔지니어 컨퍼런스(AIE), 에이전트와 강화 학습에 초점, AI가 엔지니어링 실무에 미치는 변화 논의: 최근 개최된 AI 엔지니어 월드 엑스포(AIE)에서 에이전트(Agents)와 강화 학습(RL)이 핵심 의제로 다뤄졌습니다. 참석자들은 AI가 코딩 및 엔지니어링 실무를 어떻게 변화시키는지 논의하며 AI 제품 개발에서 실험과 평가의 중요성을 강조했습니다. Replit의 CEO Amjad Masad는 회사가 감원 후 AI를 전면적으로 수용하여 생산성 향상과 사업 전환을 이룬 경험을 공유했습니다. 컨퍼런스에는 ‘분위기 프로그래밍 노래방’과 같은 재미있는 행사도 마련되어 AI 엔지니어 커뮤니티의 활기를 보여주었습니다 (출처: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

오픈 소스 모델 및 데이터의 새로운 진전: Rednote LLM 및 Atropos RL 환경: 커뮤니티는 DeepSeek V2 기술 스택을 기반으로 구축된 Rednote LLM에 주목하고 있습니다. 이 모델은 DS-MoE 아키텍처를 채택하여 총 142B개의 파라미터와 14B개의 활성 파라미터를 가지고 있지만, 현재는 더 효율적인 GQA/MLA 대신 MHA를 사용하고 있습니다. 동시에 NousResearch의 Atropos 프로젝트(LLM RL Gym)는 Reasoning Gym의 101개 도전적인 추론 RL 환경에 대한 지원을 추가했으며, 약 5500개의 검증된 추론 샘플을 생성하여 Hermes 4의 사전 훈련에 사용할 계획이며, 커뮤니티가 더 많은 검증 가능한 추론 환경을 기여하도록 장려하고 있습니다 (출처: teortaxesTex, Teknium1, kylebrussell)
Anthropic 모델의 특정 작업에서의 뛰어난 성능과 RL 방법론 주목: 커뮤니티에서는 Anthropic의 Claude 모델(예: Sonnet 3.5/3.7)이 특정 obscure webdata를 포함하는 작업을 처리할 때 다른 모델(Opus 4/Sonnet 4 포함)보다 우수한 성능을 보인다고 지적하며, 훈련 데이터에 전문 분야 인터넷 포럼 콘텐츠를 더 많이 포함했을 가능성을 추측합니다. 동시에 Anthropic의 강화 학습(RL) 분야에서의 복잡한 방법론도 인정받고 있지만, 일부 관행과 안전 블로그를 둘러싼 지표 최적화는 일부 의문을 받고 있습니다. Constitutional AI는 본질적으로 고급 RL이며, 하드 코딩된 레이블 없이 세분화되고 제어 가능한 정책을 설계할 수 있다는 견해도 있습니다 (출처: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 기타
Vosk API: 오프라인 음성 인식 기능 제공: Vosk API는 오픈 소스 오프라인 음성 인식 툴킷으로, 영어, 독일어, 중국어, 일본어 등 20개 이상의 언어와 방언을 지원합니다. 모델 크기는 약 50MB로 작지만 연속적인 대규모 어휘 전사, 스트리밍 API의 제로 지연 응답을 제공하며, 재구성 가능한 어휘 및 화자 인식을 지원합니다. Vosk는 챗봇, 스마트 홈, 가상 비서 등의 애플리케이션에 음성 인식 기능을 제공하며, 영화 자막 제작, 강연 및 인터뷰 전사에도 사용할 수 있고, 라즈베리 파이, 안드로이드 장치에서 대형 서버에 이르기까지 다양한 플랫폼에 적합합니다 (출처: GitHub Trending)
자율 드론, 경주 대회에서 최초로 인간 챔피언 격파: 델프트 공과대학교에서 개발한 자율 드론이 역사적인 경주 대회에서 인간 챔피언을 격파했습니다. 이 성과는 고속, 동적 환경에서의 AI의 인식, 의사 결정 및 제어 능력이 새로운 수준에 도달했음을 의미하며, 로봇 및 자동화 분야에서 AI의 막대한 잠재력을 보여줍니다 (출처: Reddit r/artificial )

VentureBeat, 2025년 AI 4대 트렌드 예측: VentureBeat는 2025년 인공 지능 분야의 발전에 대한 4가지 예측을 내놓았습니다. 이러한 예측은 기술 혁신, 시장 응용, 윤리 법규 또는 산업 구도 등을 다룰 수 있으며, 구체적인 내용은 원문을 참조해야 합니다. 이러한 미래 예측 분석은 업계 안팎의 사람들이 AI 발전의 흐름을 파악하는 데 도움이 됩니다 (출처: Ronald_vanLoon)
