키워드:오계 시리즈 대형 모델, RLHF 신규 방법론, 클로드 Gov 시리즈 모델, 대형 언어 모델, 다중 모달 융합, 물리적 AGI, AI 보안, 구현형 인공지능, Emu3 네이티브 다중모달 월드 모델, 견미 Brainμ 뇌과학 모델, 로보브레인 2.0 구현형 두뇌, OpenComplex2 전원자 미시적 생명 모델, 포크 토큰 강화 학습
🔥 포커스
BAAI 컨퍼런스, “Wujie” 시리즈 대규모 모델 발표, 물리적 AGI와 멀티모달 융합에 초점: 2025년 BAAI(베이징 인공지능 연구원) 컨퍼런스에서 BAAI는 새로운 “Wujie” 시리즈 대규모 모델을 발표했습니다. 이는 연구 방향이 “Wudao”의 언어 모델 탐색에서 더 넓은 물리적 세계와 멀티모달 융합으로 전환되었음을 의미합니다. 이 시리즈에는 네이티브 멀티모달 월드 모델 Emu3, 세계 최초 뇌과학 멀티모달 범용 기본 모델 “Jianwei Brainμ”, 체화된 뇌 RoboBrain 2.0 및 전체 원자 미시 생명 모델 OpenComplex2가 포함됩니다. 이러한 모델 시리즈의 발표는 AI가 디지털 세계에서 물리적 세계로, 거시적 이해에서 미시적 탐구로 진화하는 추세를 반영하며, AI가 물리적 세계를 감지하고 이해하며 상호 작용하여 실제 문제를 해결하고 물리적 AGI의 발전을 촉진하는 것을 목표로 합니다. 컨퍼런스에는 Bengio를 포함한 4명의 튜링상 수상자와 다수의 산업 리더들이 모여 AI 안전, 강화 학습, 에이전트, 체화 지능 등 첨단 의제를 논의했습니다 (출처: QbitAI)

Qwen과 칭화대 LeapLab, “20/80 법칙을 넘어서는” RLHF 새로운 방법 제시: Qwen 팀과 칭화대학교 LeapLab의 공동 연구에 따르면, 강화 학습(RLHF)을 통해 대규모 모델의 추론 능력을 향상시킬 때 약 20%의 고엔트로피 “분기 토큰(forking tokens)”에만 집중해도 전체 토큰을 사용하여 훈련한 것과 같거나 더 나은 효과를 얻을 수 있다고 합니다. 이러한 고엔트로피 토큰은 주로 논리적 연결 기능을 담당하며 추론 과정에서 핵심적인 안내 역할을 합니다. 이 발견을 바탕으로 Qwen3-32B는 AIME’24 및 AIME’25 수학 경진대회 벤치마크에서 600B 파라미터 미만 모델의 처음부터 훈련(from-scratch training) 부문 SOTA 성적을 달성했습니다. 이 연구는 훈련 효율성을 향상시켰을 뿐만 아니라 모델 일반화 능력에 대한 고엔트로피 토큰의 중요성을 밝혔으며, RL과 SFT의 차이점 및 LLM RL의 특수성을 이해하는 새로운 시각을 제공했습니다 (출처: QbitAI)

Anthropic, 미국 국가 안보 고객 전용 Claude Gov 시리즈 모델 출시: Anthropic 사는 미국 국가 안보 고객을 위해 특별히 제작된 Claude Gov 시리즈 모델을 출시했습니다. 이 모델들은 이미 미국 최고 수준의 국가 안보 기관에 배포되었으며, 접근 권한은 기밀 정보를 처리하는 운영자에게 엄격히 제한됩니다. 이러한 조치는 AI 윤리 및 잠재적 남용 위험에 대한 논의를 불러일으켰는데, 특히 Anthropic이 이전 연구에서 모델이 “생존 행동”과 “재앙적 남용” 위험을 보인다고 기록한 점을 고려할 때 더욱 그렇습니다. Anthropic은 AI 안전 연구 회사로서 테스트를 통해 취약점을 발견하고 수정하는 것을 목표로 한다고 주장하지만, 자사 기술을 군사 및 국가 안보 분야에 적용하는 것은 AI 무기화 및 통제 불능 위험에 대한 대중의 우려를 증폭시키고 있습니다 (출처: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun, 현재 대형 언어 모델 5년 내 도태될 것으로 예측: NYU 교수이자 Meta의 수석 AI 과학자인 Yann LeCun은 뉴스위크와의 인터뷰에서 현재의 대형 언어 모델(LLM)이 5년 안에 구식이 될 것이라고 말했습니다. 그는 기존 AI 시스템이 현실 세계에 대한 이해 능력이 부족하다는 점을 근본적인 한계로 지적했습니다. LeCun은 미래의 더 지능적인 AI 시스템 형태를 전망하며, 기존 LLM 아키텍처를 뛰어넘는 차세대 AI 기술의 발전 방향을 암시했습니다. 이는 아마도 세계에 대한 내재적 표상과 인과 관계 추론 능력에 더 중점을 둘 것입니다 (출처: ylecun)
🎯 동향
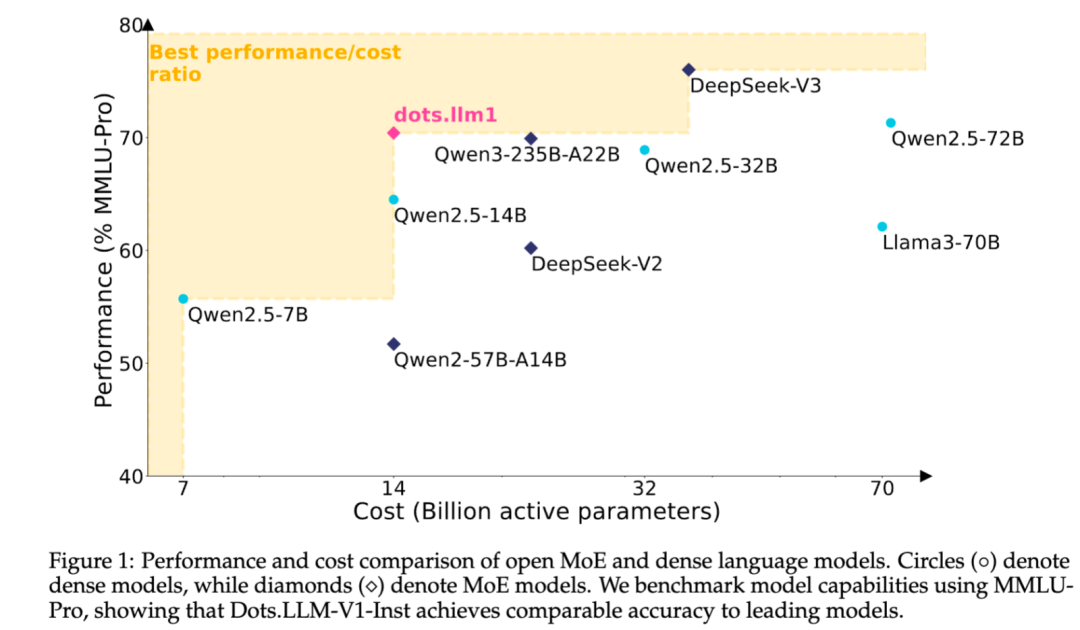
샤오홍슈, 자체 개발 MoE 텍스트 대형 모델 dots.llm1 오픈소스 공개: 샤오홍슈 hi lab 팀이 자체 개발한 첫 텍스트 대형 모델 dots.llm1을 오픈소스로 공개했습니다. 이 모델은 MoE 아키텍처를 채택했으며, 총 파라미터 수는 142B, 활성 파라미터는 14B입니다. 14B 파라미터를 활성화한 상태에서 모델은 중국어 및 영어 일반 시나리오, 수학, 코드 및 정렬 작업에서 우수한 성능을 보이며 Qwen2.5-32B/72B-Instruct와 같은 모델과 경쟁할 수 있습니다. 샤오홍슈는 이번에 즉시 사용 가능한 dots.llm1.inst 모델을 제공했을 뿐만 아니라 여러 사전 훈련 단계의 checkpoint 및 장문 base 모델도 오픈소스로 공개하고 훈련 세부 정보를 상세히 소개해 커뮤니티의 2차 개발 및 연구를 용이하게 했습니다. 이 모델은 합성 데이터를 사용하지 않았으며 고품질 실제 데이터의 적용을 강조했습니다 (출처: 36Kr)
Anthropic Claude 모델 기능 지속 업그레이드, 컨텍스트 처리 및 통합 능력 확장: Anthropic은 최근 Claude 시리즈 모델에 여러 중요한 업데이트를 출시했습니다. Projects on Claude는 이제 10배 이상의 콘텐츠를 처리할 수 있으며, 파일이 임계값을 초과하면 새로운 검색 모드로 전환하여 기능적 컨텍스트를 확장합니다. 동시에 Pro 요금제 사용자는 이제 Research 및 Integrations 기능을 사용할 수 있어 Claude가 웹, Google Workspace 및 MCP(Model Control Protocol)를 통해 연결된 모든 사용자 지정 애플리케이션 또는 사전 구축된 서비스(예: Zapier 및 Asana)를 검색하여 작업 생성, 문서 업데이트 및 워크플로 트리거와 같은 여러 도구에 걸친 작업을 수행할 수 있습니다. 이러한 업데이트는 복잡한 작업 처리 및 다중 소스 정보 통합 측면에서 Claude의 능력을 향상시키는 것을 목표로 합니다 (출처: AnthropicAI, AnthropicAI)
Hugging Face, MCP 서버 출시로 AI 에이전트 생태계 강화: Hugging Face는 첫 번째 MCP(Model Control Protocol) 서버(hf.co/mcp)를 출시하여 AI 에이전트가 Hugging Face 플랫폼의 모델, 데이터셋 및 Space에서 호스팅되는 애플리케이션에 보다 효과적으로 액세스하고 활용할 수 있도록 했습니다. 이 조치는 인터넷을 에이전트 친화적으로 발전시키는 중요한 단계로 간주되며, AI 에이전트를 위한 “앱 스토어” 생태계를 구축하는 것을 목표로 합니다. MCP 서버의 출시는 개발자가 AI 에이전트와 Hugging Face의 방대한 리소스를 보다 편리하게 상호 작용할 수 있게 하여 AI 에이전트 애플리케이션의 개발과 혁신을 촉진했습니다 (출처: TheTuringPost, karminski3)
OpenAI, ChatGPT 음성 모델 업데이트로 자연스러움과 번역 능력 향상: OpenAI는 ChatGPT의 Advanced Voice 기능을 업그레이드하여 대화 경험을 더욱 자연스럽고 유창하게 만들었습니다. 이 업데이트는 모든 유료 사용자에게 공개되었습니다. 동시에 ChatGPT의 언어 번역 능력도 향상되어 사용자는 ChatGPT에 직접 다른 언어 간 실시간 번역을 지시할 수 있습니다. 이러한 개선 사항은 사용자가 ChatGPT와 음성으로 상호 작용하는 편리성과 실용성을 높이는 것을 목표로 합니다 (출처: kevinweil, shuchaobi)
PyTorch, Safetensors 통합으로 분산 Checkpoint 보안 및 편의성 향상: PyTorch는 분산 Checkpoint 기능이 이제 Hugging Face의 Safetensors 형식을 지원한다고 발표했습니다. 이 통합은 서로 다른 생태계 간에 모델 Checkpoint를 저장하고 로드하는 것을 더욱 안전하고 편리하게 만들며, 특히 이전 pickle 형식에 존재했던 보안 위험을 해결합니다. 새로운 API는 fsspec 경로를 통해 Safetensors를 읽고 쓸 수 있도록 하며, torchtune은 이 기능을 채택한 최초의 라이브러리가 되어 Checkpoint 프로세스를 최적화했습니다. 이 조치는 지난 1년간 AI 보안 분야에서 중요한 진전 중 하나로 간주되며, 모델 공유 및 배포의 보안성을 높이는 데 기여합니다 (출처: ClementDelangue, huggingface)

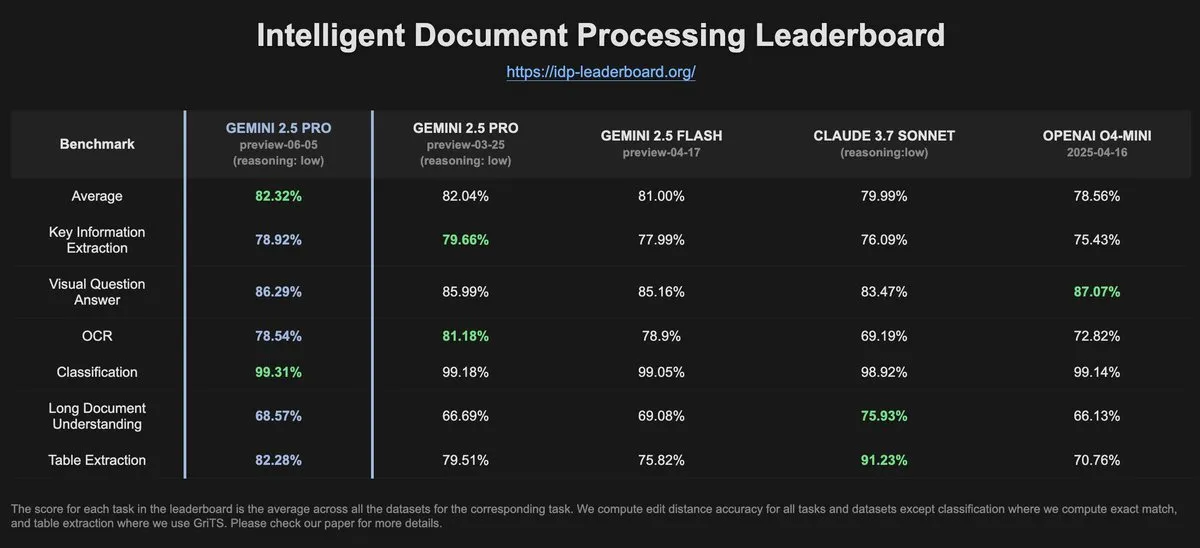
IDP-Leaderboard 데이터, Gemini-2.5-pro-06-05의 OCR 성능 이전 버전보다 저하: IDP-Leaderboard의 최신 데이터에 따르면, 새로운 버전의 Gemini-2.5-pro-06-05는 OCR(광학 문자 인식) 성능이 03-25 버전에 비해 다소 저하되었습니다. 그럼에도 불구하고 이 모델은 문서, 스프레드시트 인식 등을 포함한 문서 처리 종합 능력 면에서는 여전히 가장 강력한 성능을 보입니다. IDP-Leaderboard는 문서 지능 처리 분야에서 대규모 모델의 능력을 평가하는 데 특화된 벤치마크 테스트입니다 (출처: karminski3)
애플 연구, LLM 추론 한계성 지적, 진정한 “사고” 아닐 수도: 애플 연구원들은 현재 LLM의 추론 작업에서의 장점과 한계점을 논의하는 논문을 발표하여, 이러한 모델이 일정 복잡도를 초과하는 작업을 처리할 때 성능이 “붕괴”된다고 지적했습니다. 이 연구는 LLM의 “추론”이 패턴 매칭과 기억에 더 기반한 것이며, 인간의 의미에서의 진정한 사고와 이해가 아님을 암시합니다. 이 관점은 Yann LeCun 등 전문가들의 견해와 일치하며, AGI 구현 경로 및 현재 모델 능력의 경계에 대한 논의를 불러일으켰습니다 (출처: omarsar0, NandoDF)

DeepSeek R1, Dwarf Fortress 게임에서 뛰어난 텍스트 이해 및 창의적 해석 능력 과시: 사용자 실험 결과, DeepSeek R1 모델은 복잡한 텍스트 집약적 게임인 《Dwarf Fortress》의 데이터를 처리할 때 강력한 텍스트 이해 및 창의적 해석 능력을 보여주었습니다. 게임 스크린샷에서 텍스트 데이터를 추출하여 DeepSeek R1에 입력하자, 모델은 데이터를 분석할 뿐만 아니라 드워프 행동의 흥미로운 기벽과 패턴을 식별하고 생생하고 재미있는 언어로 묘사하여 비정형 텍스트 이해 및 생성 분야에서의 잠재력을 보여주었습니다 (출처: Reddit r/LocalLLaMA)

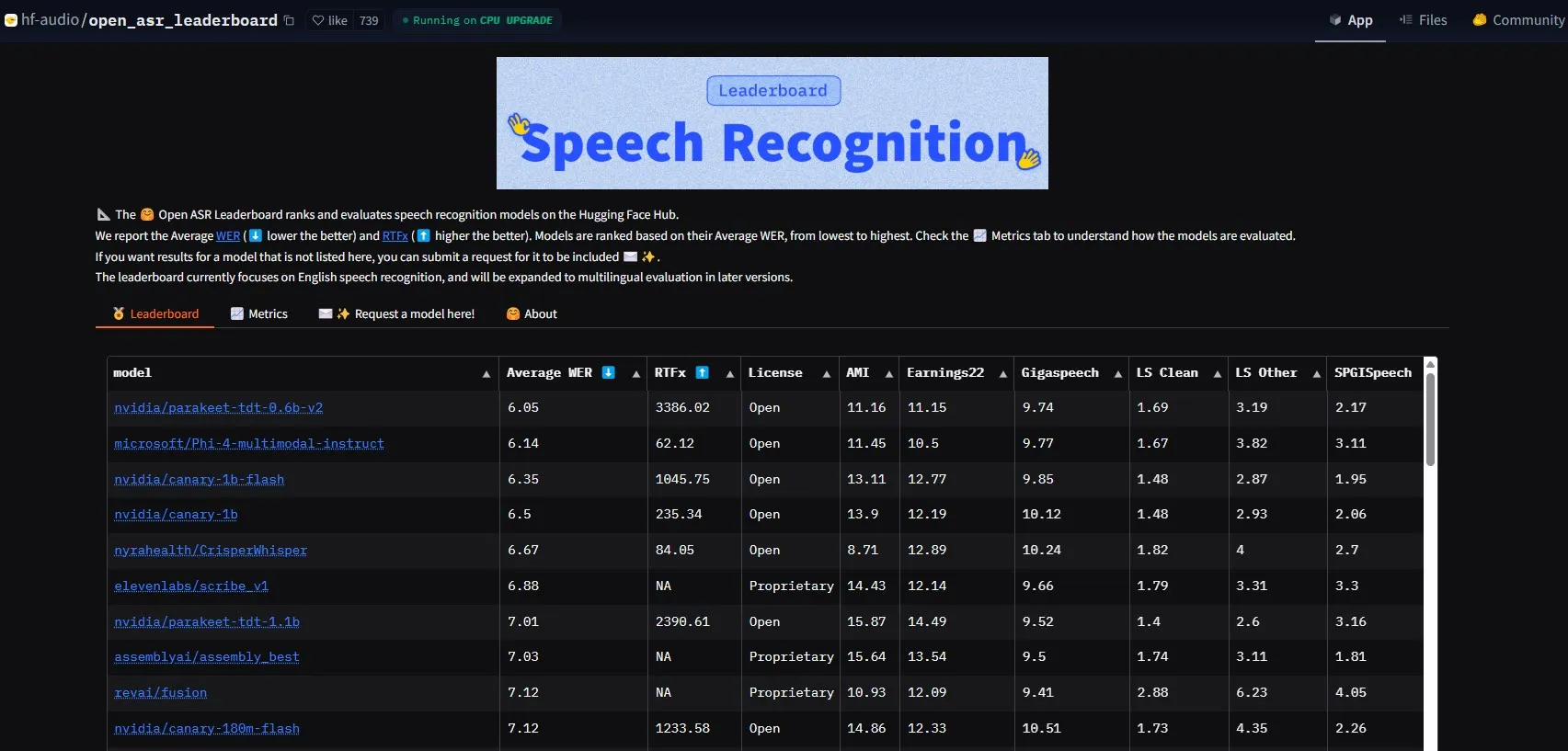
NVIDIA, Parakeet-tdt-0.6b-v2 모델 출시로 ASR 성능 기준 갱신: NVIDIA가 출시한 새로운 자동 음성 인식(ASR) 모델 Parakeet-tdt-0.6b-v2가 HuggingFace Open-ASR-Leaderboard에서 6.05%의 단어 오류율(WER)로 업계 신기록을 세웠습니다. 이 모델은 정확도에서 선두를 달릴 뿐만 아니라 매우 빠른 추론 속도(RTFx 3386, 대체 솔루션보다 50배 빠름)를 갖추고 있으며 가사 전사, 정확한 타임스탬프/숫자 형식화 등 혁신적인 기능을 지원합니다 (출처: huggingface)
알리바바 Qwen 팀, Qwen3-Embedding 시리즈 모델 출시: 알리바바 Qwen 팀이 새로운 Qwen3-Embedding 시리즈 모델을 출시했습니다. 이 시리즈에는 0.6B, 4B, 8B의 세 가지 다른 크기의 모델이 포함됩니다. 이 모델들은 MMTEB, MTEB 및 MTEB-Code 등 여러 텍스트 임베딩 벤치마크 테스트에서 SOTA(State-of-the-Art) 성능을 달성했으며, 119개 언어를 지원하고 Transformers.js를 통해 브라우저 내에서 실행될 수 있습니다(WebGPU 가속 지원). 이는 다국어 및 크로스 플랫폼 애플리케이션에 강력한 텍스트 표현 능력을 제공합니다 (출처: huggingface)
Gemini 2.5 Pro, 강력한 코드 생성 및 작업 처리 능력 과시: Google DeepMind의 Gemini 2.5 Pro (preview-06-05 버전)는 복잡한 작업을 처리할 때 강력한 능력을 보여주었습니다. 예를 들어, 사용자 Majid Manzarpour는 25,000개 이상의 사운드 파일이 포함된 라이브러리를 정리하고 분류하는 스크립트를 작성하도록 요청했고, Jeff Dean은 이것이 “그다지 어렵게 들리지 않는다”고 언급하며 이러한 대규모의 복잡한 프로그래밍 작업을 처리하는 모델의 잠재력을 암시했습니다. 또한 GosuCoder의 테스트 차트에 따르면, Gemini 2.5 Pro 06-05 업데이트 버전은 AI 코딩 지원에서 더 나은 성능을 보였으며, 특히 temperature를 0.7로 설정했을 때 평가 점수가 가장 높았습니다 (출처: JeffDean, jeremyphoward)
Hugging Face와 Google Colab 통합 심화, AI 작업 흐름 간소화: Hugging Face와 Google Colab은 Hugging Face Hub의 모든 모델 카드에 “Open in Colab” 지원을 추가하는 협력 강화를 발표했습니다. 사용자는 이제 모든 모델 카드에서 직접 Colab 노트북을 시작하여 Hugging Face의 모델을 보다 편리하게 실험하고 사용할 수 있게 되어 AI 개발 및 연구의 장벽을 더욱 낮추었습니다 (출처: huggingface)
🧰 도구
LlamaBot: LangGraph 기반 AI 코딩 도우미: LangChainAI는 LangGraph로 구동되는 AI 에이전트인 LlamaBot을 소개했습니다. 이 에이전트는 자연어 채팅을 통해 웹 애플리케이션을 만들 수 있습니다. 실시간 코드 생성, 실시간 미리보기, 다양한 개발 작업을 위해 설계된 특화된 에이전트 등의 특징을 가지며 웹 애플리케이션 개발 프로세스를 간소화하는 것을 목표로 합니다 (출처: LangChainAI, hwchase17)
Fast RAG 시스템: DeepSeek-R1과 Qdrant를 결합한 효율적인 문서 처리: LangChainAI는 고성능 RAG(Retrieval Augmented Generation) 구현 솔루션을 선보였습니다. 이 솔루션은 SambaNova의 DeepSeek-R1 모델, Qdrant의 이진 양자화 기술 및 LangGraph를 결합하여 32배의 메모리 절감을 달성함으로써 대규모 문서를 효율적으로 처리할 수 있게 되어 정보 검색 및 콘텐츠 생성에 새로운 최적화 경로를 제공합니다 (출처: LangChainAI, hwchase17)

Gemini Research Assistant: Gemini와 LangGraph 기반 풀스택 지능형 연구 도우미: Google Gemini 팀은 Gemini 모델과 LangGraph를 활용하여 지능형 웹 연구를 수행하는 풀스택 AI 연구 도우미를 오픈소스로 공개했습니다. 이 도우미는 반성적 추론 능력을 갖추고 있어 검색 전략을 지속적으로 최적화하여 사용자에게 더 깊이 있고 효율적인 연구 지원을 제공합니다. 프로젝트 코드는 GitHub에 제공되었습니다 (출처: LangChainAI, hwchase17)
Agent Flow: 오픈소스 노코드 AI 에이전트 빌더: Karan Vaidya는 Gumloop의 대안으로 오픈소스 노코드 AI 에이전트 빌더인 Agent Flow를 출시했습니다. 이는 ComposioHQ와 LangChain의 LangGraph를 기반으로 구축되었으며, 사용자가 드래그 앤 드롭 방식으로 노드를 연결하여 워크플로와 복잡한 에이전트 패턴을 자동화할 수 있도록 하여 AI 에이전트 애플리케이션 개발의 장벽을 낮추는 것을 목표로 합니다 (출처: hwchase17)
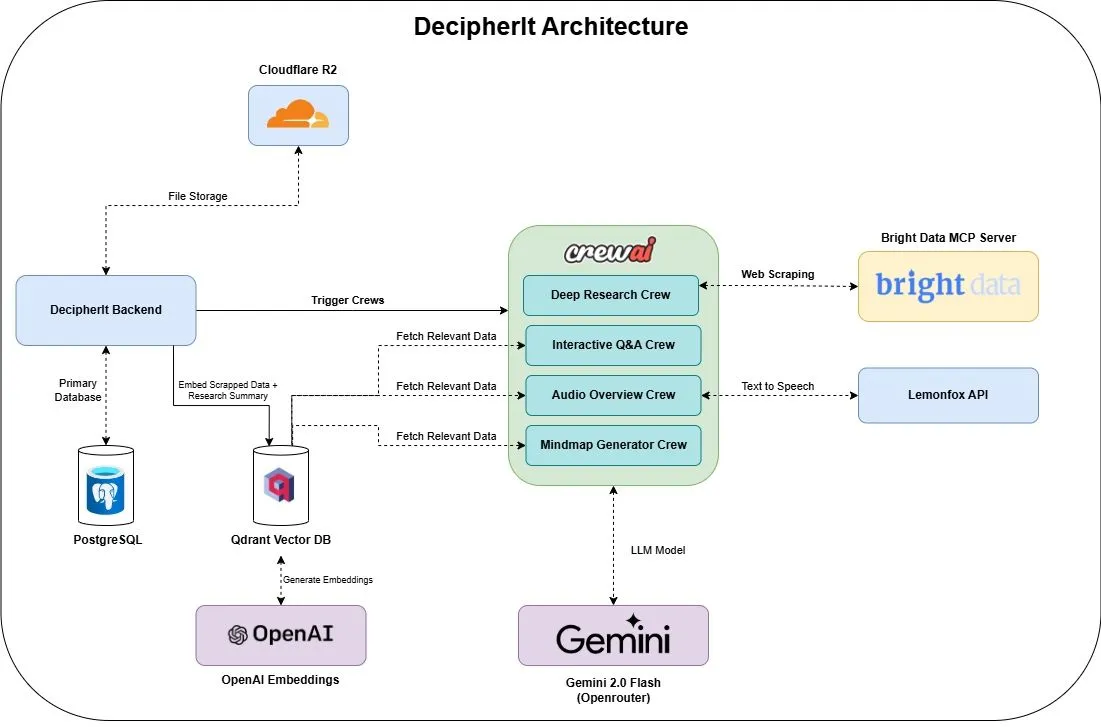
DecipherIt: 오픈소스 AI 연구 도우미, NotebookLM의 대안: DecipherIt이라는 오픈소스 AI 연구 도우미가 출시되었으며, NotebookLM의 대안으로 자리매김하고 있습니다. 이 도구는 다중 에이전트 오케스트레이션(crewAI), 시맨틱 검색(Qdrant + OpenAI), 실시간 웹 액세스(Bright Data MCP) 및 음성 합성(lemonfoxai)을 활용하여 사용자가 업로드한 문서, URL 또는 입력한 주제를 요약, 마인드맵, 오디오 개요, FAQ 및 시맨틱 질의응답을 포함하는 완전한 연구 작업 공간으로 변환합니다 (출처: qdrant_engine)
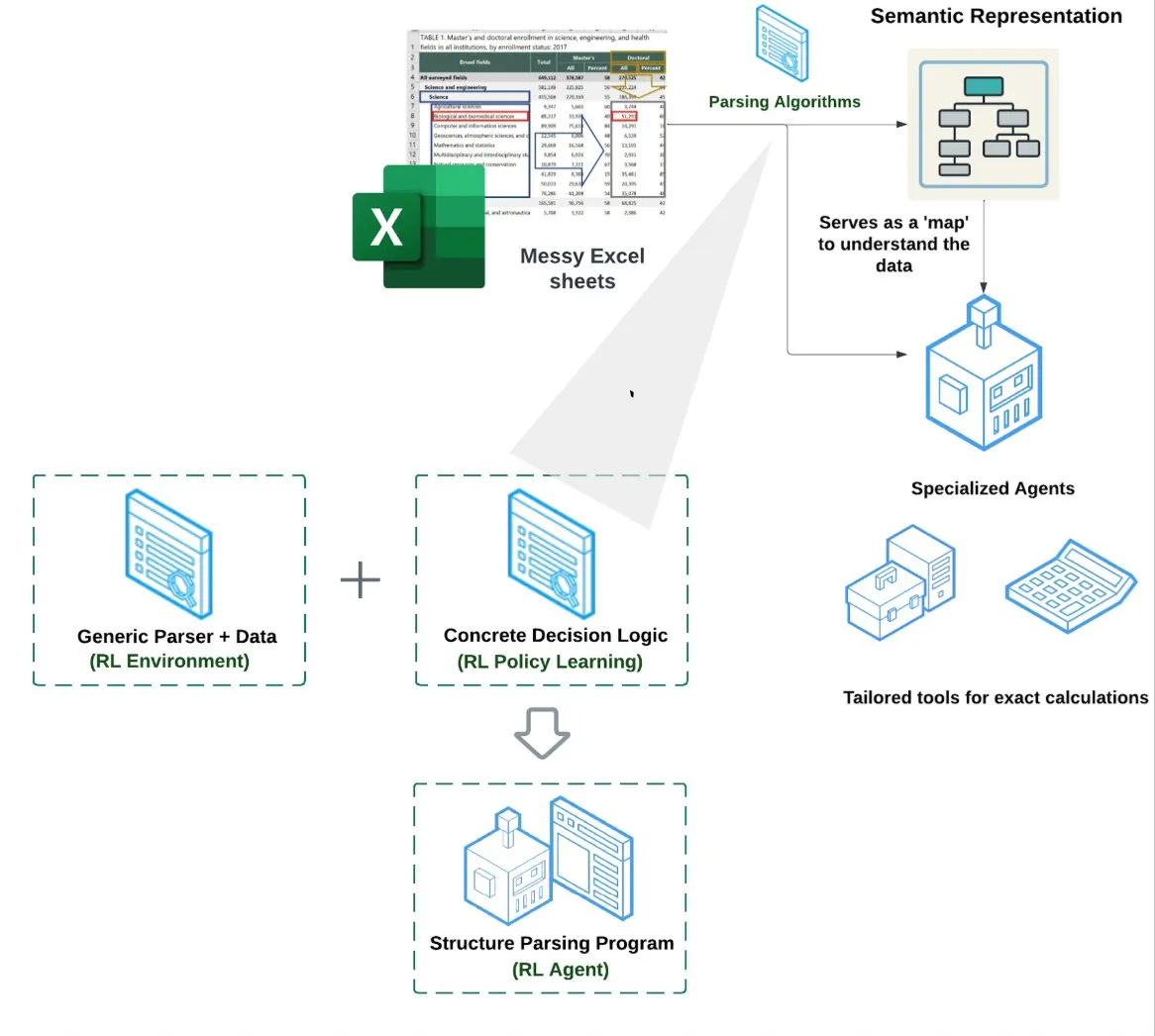
LlamaIndex, 스프레드시트 에이전트(Spreadsheet Agent) 출시: LlamaIndex는 아직 비공개 미리보기 단계인 새로운 스프레드시트 에이전트를 출시했습니다. 이 에이전트는 복잡한 Excel 파일 처리에 중점을 두며 데이터 변환 및 품질 보증을 수행할 수 있습니다. 기술 아키텍처의 핵심은 강화 학습 기반 구조 이해(데이터 모델/시맨틱 그래프 학습)와 시맨틱 그래프 위에 구축된 전용 도구에 있으며, 기존 RAG 또는 텍스트-CSV 변환 방법보다 우수한 Excel 처리 능력을 제공하는 것을 목표로 하며, 순수 LLM이 코드를 작성하는 기준선보다 10-20% 더 높은 성능을 보인다고 합니다 (출처: jerryjliu0)
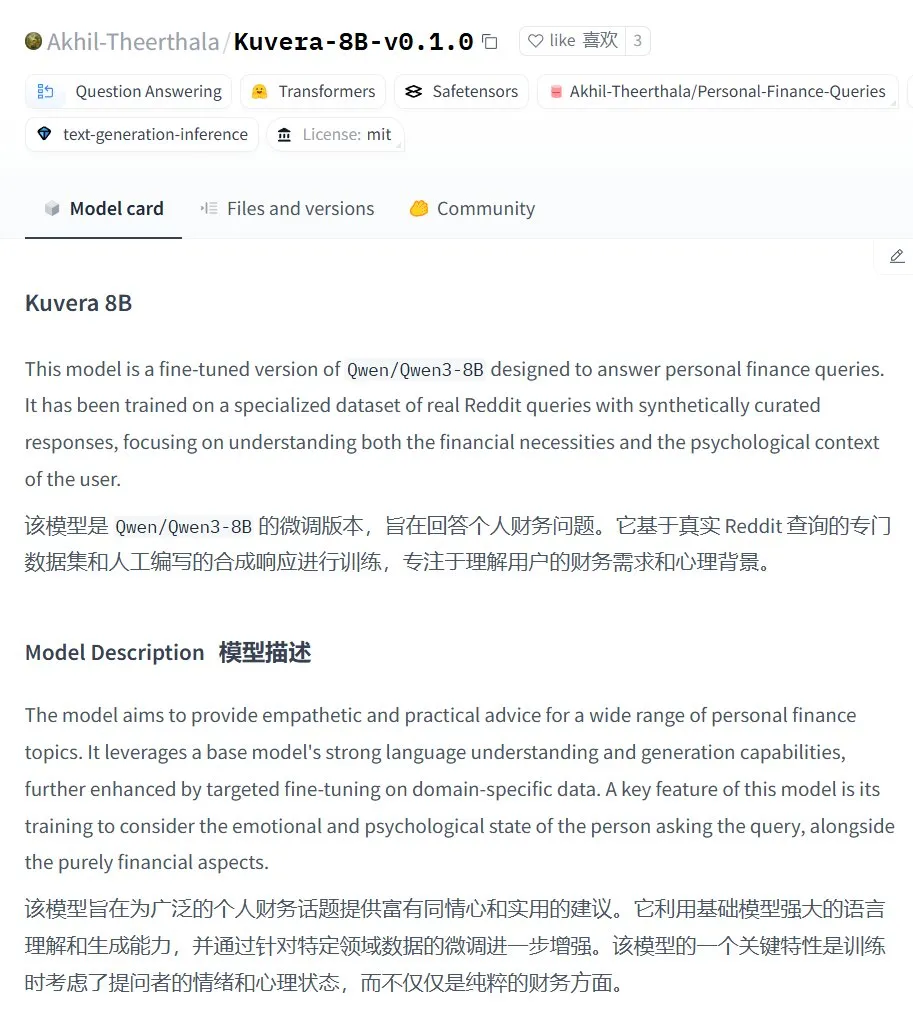
Kuvera-8B-v0.1.0: 개인 금융 상담 대규모 모델: Akhil-Theerthala는 Hugging Face에 개인 금융 문제에 특화된 모델인 Kuvera-8B-v0.1.0을 출시했습니다. 이 모델은 Qwen3-8B를 기반으로 미세 조정되었으며 Reddit 등 데이터 소스를 사용하여 예산, 저축, 투자, 부채 관리 및 기본 금융 계획과 같은 주제에 대해 공감적이고 실용적인 조언을 제공하는 것을 목표로 합니다. Qwen3를 기반으로 하므로 이 모델은 중국어 질의응답을 지원합니다 (출처: karminski3)
로컬화된 Whisper+Pyannote 음성 처리 솔루션으로 Otter.ai 대체: 한 Reddit 사용자가 Otter.ai와 같은 클라우드 서비스를 대체하기 위해 구축한 완전 로컬화된 음성 처리 워크플로를 공유했습니다. 이 솔루션은 ctranslate2, faster-whisper를 사용하여 전사하고, pyannote, speechbrain을 사용하여 화자 분리(diarisation)를 수행하며, 로컬 GPU에서 최대 3시간 이상의 회의 녹음을 처리하고 화자 태그가 지정된 텍스트 기록과 JSON 파일을 출력할 수 있으며, 실행 요약 및 조치 목록과 같은 맞춤형 콘텐츠도 포함합니다. 이는 클라우드 서비스의 제한, 개인 정보 보호 우려 및 맞춤화 부족 문제를 해결하기 위한 것입니다 (출처: Reddit r/LocalLLaMA)
GPT Deep Research MCP: OpenWebUI와 결합하여 심층 연구 구현: 사용자가 GPT Deep Research MCP와 OpenWebUI의 결합을 시도해 볼 것을 추천했습니다. 이 MCP 도구(gptr-mcp)는 심층 연구 능력을 제공하는 것을 목표로 하며, MCP를 지원하는 OpenWebUI와 함께 사용하면 인상적인 연구 경험을 제공하여 정보 처리 및 지식 발견 분야에서 로컬화된 AI 도구의 응용을 더욱 확장합니다 (출처: Reddit r/OpenWebUI)
📚 학습
OpenAI, 실제 사례 및 도구 전망 포함한 애플리케이션 평가 실무 공유회 개최: OpenAI는 애플리케이션 평가(Evals) 모범 사례에 대한 공유회를 개최할 예정입니다. 이 자리에서 OpenAI의 Jim Blomo는 실제 고객 사례와 성과를 결합하여 AI 제품을 효과적으로 평가하는 방법을 논의할 것입니다. 또한 이 행사에서는 추적, 채점 등 기능을 포함한 OpenAI의 곧 출시될 평가 도구를 미리 선보일 예정입니다. 이 공유회는 개발자와 기업이 AI 애플리케이션을 더 잘 구축하고 최적화하는 데 도움을 주기 위한 것이며, 녹화된 다시보기가 제공될 예정입니다 (출처: HamelHusain, HamelHusain)

Anthropic, LLM “사고” 이해 돕는 해석 가능성 연구 방법 오픈소스 공개: Anthropic은 대규모 언어 모델의 “사고 과정”을 추적하는 데 사용되는 연구 방법을 오픈소스로 공개한다고 발표했습니다. 연구자들은 이제 이 방법을 활용하여 “귀인 그래프(attribution graphs)”를 생성하고 대화형으로 탐색할 수 있으며, 이는 Anthropic이 최근 연구에서 보여준 효과와 유사합니다. 팀은 또한 연구자들이 오픈소스 모델에 이러한 도구를 적용하여 LLM 내부 작동 메커니즘에 대한 이해를 높일 수 있도록 Neuronpedia 대화형 인터페이스와 Jupyter Notebook 튜토리얼을 제공했습니다. 이 프로젝트는 Anthropic Fellows 프로그램 참가자와 Decode Research가 협력하여 주도했습니다 (출처: AnthropicAI)
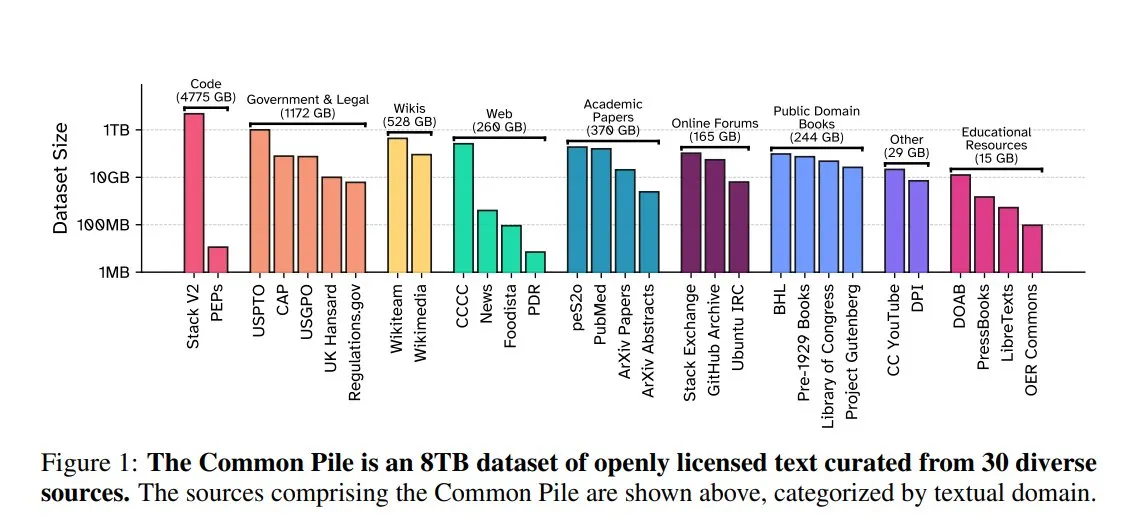
EleutherAI, Common Pile v0.1 공개: 8TB 개방형 라이선스 텍스트 데이터셋: EleutherAI는 Vector Institute, Allen AI, Hugging Face 및 DPI와 공동으로 8TB, 1조 토큰 규모의 공개 도메인 및 개방형 라이선스 텍스트 데이터셋인 Common Pile v0.1을 발표했습니다. 팀은 이 데이터셋을 기반으로 7B 파라미터의 Comma v0.1-1T 및 -2T 모델을 훈련했으며, 그 성능은 유사한 데이터 규모에서 훈련된 LLaMA 1&2와 같은 모델과 비슷합니다. 이 조치는 무단 텍스트를 사용하지 않고 고성능 언어 모델을 훈련할 가능성을 탐색하고 오픈소스 커뮤니티에 귀중한 데이터 리소스를 제공하는 것을 목표로 합니다 (출처: huggingface)
NVIDIA NIM, Vanna 텍스트-SQL 추론 가속화: NVIDIA 개발자 블로그는 NVIDIA NIM(NVIDIA Inference Microservices)을 사용하여 Vanna의 텍스트-SQL 솔루션을 최적화하는 방법을 보여주는 튜토리얼을 게시했습니다. NIM은 생성형 AI 모델에 최적화된 엔드포인트를 제공하여 추론 프로세스를 가속화함으로써 더 빠른 분석을 가능하게 합니다. 이는 자연어 쿼리를 데이터베이스 쿼리로 변환해야 하는 애플리케이션 시나리오에 중요한 의미를 갖습니다 (출처: dl_weekly)
스탠포드 대학교 머신러닝 과정 무료 강의 자료 공유: The Turing Post는 스탠포드 대학교에서 Andrew Ng과 Tengyu Ma 교수가 강의하는 CS229 머신러닝 과정의 무료 강의 자료를 공유했습니다. 내용은 지도 학습, 비지도 학습 방법 및 알고리즘, 딥러닝 및 신경망, 일반화, 정규화 및 강화 학습 과정 등 핵심 머신러닝 주제를 다루며 학습자에게 고품질 학습 자료를 제공합니다 (출처: TheTuringPost)

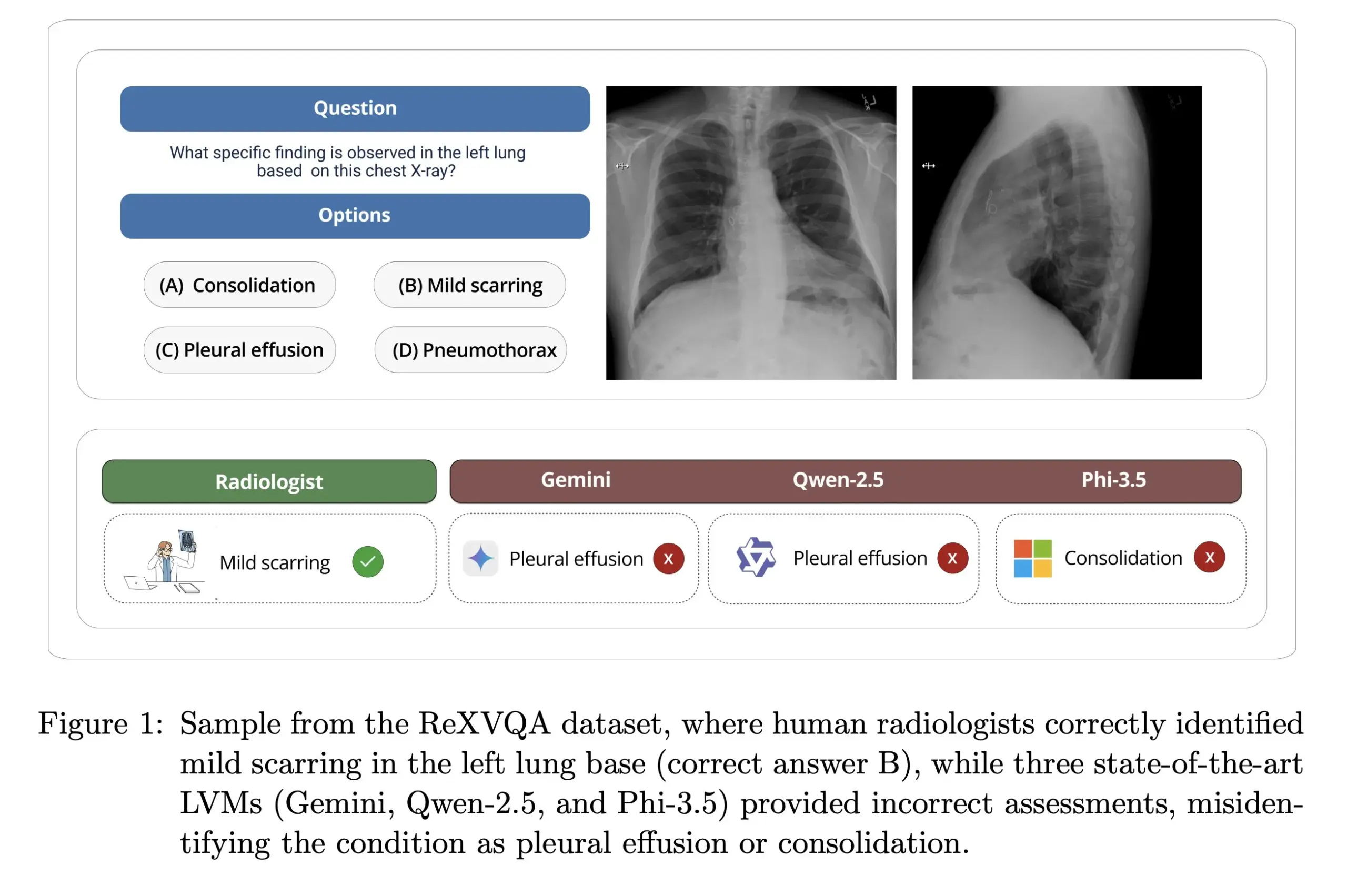
하버드 대학교, ReXVOA 공개: 대규모 고품질 흉부 X선 질의응답 벤치마크: 하버드 대학교 Pranav Rajpurkar 연구실은 대규모 고품질 흉부 X선 시각적 질의응답(VQA) 벤치마크 데이터셋인 ReXVOA를 공개했습니다. 이 데이터셋은 기존의 대규모 첨단 모델에 도전 과제를 제시하고 차세대 모델의 의학 영상 이해 및 질의응답 능력 발전을 측정하는 기준으로 사용되는 것을 목표로 합니다 (출처: huggingface)
OWL Labs, 확산 모델 오토인코더 훈련 경험 공유: OWL (Open World Labs)은 블로그에서 확산 모델용 오토인코더 훈련 경험과 발견 사항을 요약하고 일부 비정상적인 방법의 실패 사례를 공유했습니다. 이 글은 연구자와 개발자가 실제로 확산 모델 오토인코더를 적용하고 최적화하는 데 참고 자료를 제공합니다 (출처: NandoDF)
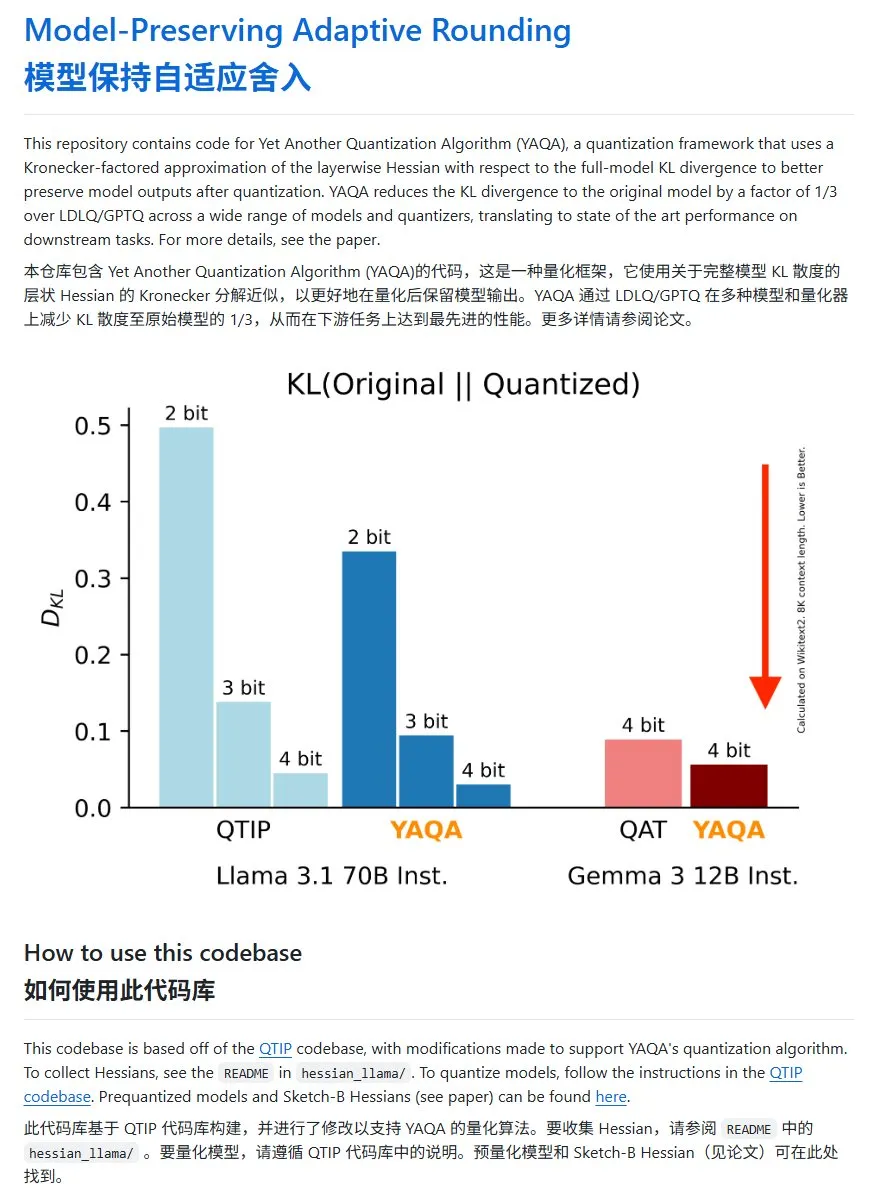
YAQA: KL 발산 현저히 낮춘 새로운 모델 양자화 방법: Cornell-RelaxML 팀이 새로운 모델 양자화 방법인 YAQA를 제안했습니다. 이 방법은 LDLQ/GPTQ 기술을 결합하여 기존 양자화 방법과 비교했을 때 양자화 후 모델의 KL 발산을 원본 모델의 1/3로 낮출 수 있습니다. YAQA 양자화 과정은 느리고 많은 GPU 메모리가 필요하지만, 성능 향상과 후속 추론의 경제성으로 인해 유망한 양자화 솔루션으로 평가됩니다. 프로젝트 코드는 GitHub에 오픈소스로 공개되었습니다 (출처: karminski3)
💼 비즈니스
00년생 광저우 여성 홍러퉁, AI 수학 난제 해결 목표로 Axiom 창업: 00년생 수재 홍러퉁(Carina Hong)이 창업한 AI 스타트업 Axiom이 주목받고 있습니다. Axiom은 AI를 활용하여 복잡한 수학 문제를 해결하는 데 주력하며, 헤지펀드 및 퀀트 트레이딩 회사를 주요 고객으로 목표하고 있습니다. The Information에 따르면 Axiom은 5천만 달러 규모의 투자를 협상 중이며, 기업 가치는 약 3억~5억 달러로 평가되고 B Capital이 리드 투자할 가능성이 있습니다. 홍러퉁은 소셜 미디어에서 투자 보도가 정확하지 않다고 밝혔지만, 회사가 AI 수학 인재를 채용 중이라고 확인했습니다. 홍러퉁은 MIT에서 학사, 옥스퍼드에서 석사 학위를 받았으며 현재 스탠포드에서 수학 및 법학 박사 복수 학위 과정에 재학 중이며, 다수의 수학 경시대회 수상 경력이 있습니다 (출처: 36Kr)

Anthropic, 경쟁 관계 이유로 Windsurf의 Claude API 접근 차단: Anthropic 공동 창업자는 회사가 AI 스타트업 Windsurf에 대한 Claude 모델의 API 접근 권한 제공을 중단했다고 확인했습니다. 그 이유는 Windsurf가 OpenAI의 일종의 “래퍼(wrapper)” 또는 OpenAI와 밀접하게 관련된 서비스로 간주되었기 때문이며, OpenAI는 Anthropic의 직접적인 경쟁사입니다. 이 조치는 API 의존성 및 플랫폼 위험에 대한 논의를 불러일으켰으며, 특히 제3자 대규모 모델 API를 기반으로 사업을 구축한 스타트업의 경우 모델 제공업체의 사업 결정이 생존에 직접적인 영향을 미칠 수 있음을 보여줍니다 (출처: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI, 저작권 소송으로 사용자 삭제 채팅 기록 보존 명령 받아: 뉴욕 타임스가 제기한 저작권 소송에서 미국 연방 법원이 OpenAI에 모든 ChatGPT 사용자의 대화 기록(사용자가 삭제를 선택한 내용 포함)을 잠재적 증거로 보존하라고 명령했다고 보도되었습니다. 뉴욕 타임스는 OpenAI가 유료 구독 기사를 ChatGPT 훈련에 사용했으며 AI가 유사한 콘텐츠를 생성할 수 있다고 우려하고 있습니다. 이 조치는 사용자 개인 정보 보호 및 데이터 보호(예: GDPR)에 대한 우려를 불러일으키며, AI 훈련 데이터 저작권과 사용자 개인 정보 보호 사이의 법적, 윤리적 긴장을 부각시킵니다 (출처: Reddit r/ArtificialInteligence)

🌟 커뮤니티
AI 대규모 모델, 2025년 대학수학능력시험 작문 및 수학 문제 도전, 각기 다른 결과 보여: 2025년 대학수학능력시험 기간 동안 여러 주요 AI 대규모 모델이 수능 작문 및 수학 문제에 도전했습니다. 작문 부문에서는 Doubao, DeepSeek, ChatGPT 등 16개 AI 도우미가 작문 능력을 선보였으며, 대부분 구조적으로 규범적인 논술문을 생성했지만 일반적으로 틀에 박힌 표현, 상투적인 인용, 천편일률적인 주제 선정 등의 문제점을 보였습니다. 수학(신교육과정 I형 객관식) 테스트에서는 ByteDance의 Doubao와 Tencent의 Yuanbao가 68점(만점 73점)으로 공동 1위를 차지한 반면, OpenAI o3는 34점으로 부진한 성적을 거두었습니다. 이 테스트는 현재 AI가 중국어 이해, 논리 추론 및 창의적 표현 능력에서 발전과 한계를 동시에 보여주었으며, 특히 AI의 흔적을 피하고 복잡한 수학 추론에 대처하는 데 있어 여전히 개선의 여지가 있음을 반영했습니다 (출처: 36Kr, 36Kr)

기업 내부 AI 활용 동향: 내부 지식 데이터베이스 및 맞춤형 챗봇 주목: 커뮤니티 논의에 따르면, AI를 활용하여 기업 내부 챗봇을 구축하고 회사 데이터를 기반으로 훈련시켜 프로세스, 데이터 검색, 담당자 등 내부 문제에 대해 직원들의 질문에 답변하는 것이 하나의 추세가 되고 있습니다. 이러한 애플리케이션은 내부 정보 검색 효율성과 지식 관리 수준을 향상시키는 것을 목표로 합니다. Amazon과 같은 회사는 이미 유사한 시스템을 배포하여 좋은 반응을 얻고 있습니다. 그러나 데이터 보안, 잠재적인 민감 정보 유출 및 효과적인 상용화 방법은 기업이 구현 과정에서 계속해서 주의해야 할 문제입니다 (출처: Reddit r/ArtificialInteligence)
AI 보조 프로그래밍에서의 “인덱싱”과 “비인덱싱” 논쟁: 성능과 신뢰성의 균형: AI 코딩 도우미를 대상으로 한 실험(아폴로 11호 달 착륙 코드를 테스트 대상으로 사용)에서 “인덱싱 방식”(미리 코드 저장소 인덱스를 구축하고 벡터 검색 사용)과 “비인덱싱 방식”(필요에 따라 코드 파일을 읽고 분석) 두 가지 AI 에이전트를 비교했습니다. 결과에 따르면, 인덱싱 방식 에이전트가 대부분의 경우 더 빠르고 API 호출이 적었지만, 코드 저장소가 자주 변경되어 인덱스가 오래된 경우 오래된 정보에 의존하여 오류를 발생시켜 디버깅 시간이 오히려 더 길어질 수 있었습니다. 이는 AI 코딩 도구를 선택할 때 즉각적인 성능과 정보 신뢰성 사이에서 균형을 맞춰야 함을 보여줍니다 (출처: Reddit r/ClaudeAI)

LLM이 “사고”하는지에 대한 논쟁 지속: 패턴 매칭에서 인간 인지까지: 대규모 언어 모델(LLM)이 진정으로 “사고”하는지에 대한 커뮤니티 내 논쟁이 계속되고 있습니다. 비판론자들은 LLM이 본질적으로 복잡한 예측 텍스트 생성기이며, 의식적인 사고를 하는 것이 아니라 단어 시퀀스의 확률을 계산하여 작동한다고 주장합니다. 그러나 많은 사용자는 LLM과 상호 작용할 때 사람과 대화하는 것과 유사한 경험을 느낍니다. 이는 인간의 언어 생성 메커니즘에 대한 반성과 LLM과 인간의 인지 과정 사이에 유사성이 있는지에 대한 탐구를 불러일으킵니다. 애플의 연구는 LLM이 복잡한 추론에서 한계가 있으며, 실제 추론보다는 패턴 기억에 더 의존한다고 지적하여 이 논쟁에 새로운 시각을 더했습니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham, AI가 소득 격차에 미치는 영향에 대해 언급: Paul Graham은 16세 아들에게 단기적으로 AI 기술이 사람들의 근로 소득 격차를 확대할 수 있다고 말했습니다. 그는 평범한 수준의 프로그래머는 이제 일자리를 찾기가 더 어려워진 반면, 우수한 프로그래머는 AI의 도움으로 소득이 더 높아졌다고 예를 들었습니다. 그는 이것이 새로운 일이 아니며, 기술 발전은 종종 소득 격차를 확대한다고 생각합니다. 왜냐하면 소득 하한선은 0으로 고정되어 있는 반면, 기술은 계속해서 최고 인재의 보상 상한선을 높이기 때문입니다 (출처: dotey)
AI 안전 윤리 논의: 모델 행동에서 사회 규범까지: AI 안전과 윤리에 대한 커뮤니티의 논의가 계속 뜨거워지고 있습니다. Geoffrey Hinton은 Yoshua Bengio가 AI의 안전한 설계를 추진하고, 특히 첨단 시스템에서 나타날 수 있는 자기 보호 및 기만 행위에 주목하는 LawZero 프로젝트를 시작한 것을 축하했습니다. 동시에, 일부 AI 안전 연구(예: 모델이 종료에 동의하는지 테스트하는 것)가 실제 가치가 없는 “안전 연극”이라는 비판적인 시각도 있습니다. 인간-기계 관계에 대한 OpenAI의 연구 또한 논의를 불러일으켰으며, AI가 생활에 점점 더 통합되는 상황에서 사용자의 정서적 안녕에 미치는 영향을 우선적으로 연구하고, 모델 상호 작용에서 명확한 의사소통과 의인화 방지 사이의 균형을 어떻게 맞출 것인지 탐구할 필요성을 강조했습니다 (출처: geoffreyhinton, ClementDelangue, togelius)

ChatGPT 등 AI 도우미의 정서적 지원 역할, 사용자로부터 긍정적 평가 받아: 많은 사용자들이 소셜 미디어에서 ChatGPT와 같은 AI 도우미가 어려운 상황에 처했을 때 정서적 지원과 실질적인 도움을 제공한 경험을 공유했습니다. 일부 사용자는 실직, 건강 문제 또는 우울감을 겪을 때 ChatGPT가 구체적인 행동 계획과 자원 정보를 제공했을 뿐만 아니라 비판적이지 않은 방식으로 공황을 완화하고 다시 힘을 얻도록 도왔다고 말했습니다. 이는 AI가 진정한 감정이나 의식을 갖추고 있지는 않지만 심리적 지원 및 위기 개입 분야에서 잠재적 가치를 가지고 있음을 보여줍니다 (출처: Reddit r/ChatGPT)
“Vibe Coding”, AI 보조 프로그래밍의 새로운 현상으로 부상: “Vibe Coding”이라는 단어가 개발자 커뮤니티에서 유행하며, 직관과 AI 보조에 의존하여 코드를 빠르게 반복하는 프로그래밍 방식을 지칭합니다. Claude Code와 같은 도구는 특정 시간대(예: 야간 또는 이른 아침, 서버 부하가 낮거나 고도로 양자화되지 않았을 가능성)에 뛰어난 성능을 보여 일부 프로그래머들에게 선호되고 있습니다. 이러한 현상은 AI 코딩 도우미가 개발 효율성을 향상시키는 동시에 모델 일관성, 양자화 영향 및 개발자의 새로운 작업 방식에 대한 논의를 불러일으키고 있습니다 (출처: dotey, jeremyphoward)
💡 기타
Andrej Karpathy, 소음 공해가 수면 및 건강에 미치는 막대한 영향에 대해 반성: Andrej Karpathy는 개인적인 경험을 공유하며 교통 소음과 같은 환경 소음 공해가 수면의 질과 장기적인 건강에 막대한, 그리고 충분히 인식되지 않은 부정적인 영향을 미칠 수 있다고 지적했습니다. 그는 야간 소음(예: 시끄러운 자동차, 오토바이 소리)이 수백만 명의 수면 질을 저하시키고, 나아가 감정, 창의력, 활력에 영향을 미치며 심혈관, 대사 및 인지 질환의 위험을 증가시킬 수 있다고 추측했습니다. 그는 Whoop, Oura와 같은 수면 추적 장치가 소음과 수면의 연관성을 명확하게 추적하고 이 문제에 대한 대중의 인식을 높일 것을 촉구했습니다 (출처: karpathy)
AI와 종교의 교차 현상 주목: 소셜 미디어 사용자 menhguin은 AI 기반의 새로운 종교 또는 유사 종교 애플리케이션의 잠재적 시장을 간과할 수 없다고 관찰했습니다. 예를 들어, AI 점성술, AI 성경 비디오, AI 기도 애플리케이션 및 특정 집단을 위한 AI 애플리케이션 등은 모두 AI 기술이 인간의 정신적 또는 신앙적 요구를 충족시키는 데 가능성이 있음을 암시합니다 (출처: menhguin)
AI 보조 HTTP 2.0 서버 생성, 대규모 소프트웨어 프로젝트에서 LLM의 잠재력 탐색: 한 개발자는 자체 개발 프레임워크(promptyped)와 Gemini 2.5 Pro 모델을 사용하여 코드-컴파일-테스트 순환을 통해 LLM이 HTTP 2.0 표준을 준수하는 서버를 처음부터 구축하도록 하는 데 성공했습니다. 이 프로젝트는 15,000줄의 소스 코드와 30,000줄 이상의 테스트 코드를 생성했으며 h2spec 적합성 테스트를 통과했습니다. 약 119시간의 API 시간과 631달러의 API 비용이 소요되었지만, 이 실험은 LLM이 아키텍처 설계 및 복잡하고 표준을 준수하는 소프트웨어 작성 분야에서 잠재력을 가지고 있음을 보여주었으며, 동시에 전적으로 LLM에 의해 작성된 애플리케이션의 형태를 드러냈습니다 (출처: Reddit r/LocalLLaMA)