키워드:AI 수학 연구, AI 에너지 소비, AI 프로그래밍 도구, AI 의료 평가, AI 하드웨어 최적화, AI 비디오 생성, AI 신뢰도 평가, AI 다중 에이전트 시스템, DARPA expMath 프로젝트, AlphaProof 수학 경쟁, FrontierMath 벤치마크 테스트, GUI-Actor 시각적 위치 지정, AudioTrust 오디오 대형 모델 평가
🔥 포커스
AI의 수학 분야 발전과 과제: DARPA는 AI를 활용하여 수학 연구를 가속화하고, 크고 복잡한 문제를 해결하기 쉬운 작은 문제로 분해하는 것을 목표로 하는 expMath 프로젝트를 시작했습니다. AI가 국제수학올림피아드(IMO)와 같은 경진대회에서 AlphaProof, AlphaEvolve와 같이 인간을 뛰어넘는 잠재력을 보여주었음에도 불구하고, 밀레니엄 문제와 같은 연구 수준의 수학 문제 해결은 아직 요원합니다. 새로운 벤치마크 FrontierMath는 미지의 난제에 대한 AI의 능력을 보다 정확하게 평가하는 것을 목표로 합니다. AI는 현재 리만 가설의 백만 줄 증명과 같이 매우 긴 증명 경로를 처리하는 데 어려움을 겪고 있지만, 강화 학습을 통해 증명 경로를 ‘압축’하려는 시도가 있었고 Andrews-Curtis 추측 연구에서 진전을 이루었습니다. AI는 아직 진정한 수학적 직관력과 창의성이 부족하여 인간처럼 이십면체와 같은 새로운 수학적 개념을 ‘발명’하기는 어렵고, 현재는 인간의 탐구를 돕는 ‘고급 정찰병’ 역할을 더 많이 수행하고 있습니다 (출처: MIT Technology Review)

AI 에너지 소비에 대한 우려, 그러나 최적화 전망은 밝음: AI의 빠른 발전은 막대한 에너지 수요를 야기했으며, 특히 AI 영상 생성은 에너지 소비가 엄청나 5초 분량의 저화질 영상 하나를 만드는 데 드는 에너지가 챗봇이 질문에 답하는 에너지의 4.2만 배에 달합니다. 그러나 AI 에너지 소비에 대한 낙관적인 요인도 있습니다: 1. 모델, 칩, 냉각 기술의 효율성 향상이 기대됩니다. 2. 상업적 현실이 더 에너지 효율적인 AI 개발을 촉진할 수 있습니다. AI가 현재 초기 단계에 있지만, 추론 모델, AI 하드웨어 장치, 디지털 에이전트 등 미래에는 더 많은 에너지를 소비할 것이지만, 기술 발전은 에너지 효율성 향상을 가져올 수도 있습니다. 중요한 것은 개인 사용자의 탄소 발자국에만 초점을 맞추는 것이 아니라 전체 에너지 구조, 데이터 센터의 수자원 소비(예: 네바다주) 및 청정에너지 약속 이행 여부에 주목하는 것입니다 (출처: MIT Technology Review)

OpenAI Codex CLI, 성능 및 보안 향상을 위해 Rust 언어로 재작성: OpenAI는 AI 명령줄 코딩 도구인 Codex CLI를 Rust 언어로 재작성하여 성능을 향상시키고 보안을 강화하며 Node.js에 대한 의존성에서 벗어날 것이라고 발표했습니다. 이전에는 이 도구가 주로 TypeScript로 작성되었습니다. 관리자인 Fouad Matin(OpenAI 합류 약 1년)은 Rust 버전이 제로 의존성 설치, 개선된 샌드박스 메커니즘(Linux에서 Landlock 사용), 최적화된 성능(가비지 컬렉션 없음, 메모리 요구량 감소)을 구현하고 기존 Rust MCP 구현을 사용할 수 있게 될 것이라고 지적했습니다. OpenAI 엔지니어들이 반 개월여 전에 TypeScript가 UI에 가장 적합하다고 밝혔음에도 불구하고, 핵심 에이전트 도구의 극한 효율성을 추구하기 위해 결국 Rust로 전환하기로 결정했습니다. 이러한 움직임은 최근 Vite의 Rolldown, XChat 및 Zed 편집기와 같은 프로젝트들이 Rust로 재작성하는 추세에 부응하는 것이기도 합니다 (출처: 36氪)
Bond Capital, AI 트렌드 보고서 발표, ChatGPT 성장 및 글로벌 AI 지형 공개: Bond Capital의 보고서에 따르면 OpenAI의 ChatGPT는 17개월 만에 주간 활성 사용자 8억 명을 달성했으며, 연간 예상 수익은 92억 달러로 AI 우선 채택 패턴을 보여주며, 특히 신흥 시장(예: 인도가 사용자 14% 차지)에서 두드러집니다. 주간 유지율은 80%로 Google 검색을 훨씬 능가합니다. 대형 기술 기업의 2024년 자본 지출은 2120억 달러로 증가했으며, OpenAI의 컴퓨팅 비용은 50억 달러에 달합니다. 동시에 중국의 AI 역량은 빠르게 추격하고 있으며, DeepSeek R1은 수학 벤치마크에서 OpenAI o3-mini 성능의 93%에 도달했고 훈련 비용도 더 낮으며, 중국은 DeepSeek 모바일 사용자의 33.9%를 차지합니다. AI 관련 직위 채용은 7년 동안 448% 증가했으며, 기업들은 점차 AI 애플리케이션을 실험적인 것에서 운영 핵심으로 전환하고 있습니다 (출처: Reddit r/artificial)
🎯 동향
알트먼이 전망하는 차세대 AI 모델: 더 강력한 추론, 초장문 컨텍스트 및 도구 호출: OpenAI CEO 샘 알트먼은 AGI를 정의하는 것보다 AI 기술의 기하급수적인 발전에 주목하는 것이 중요하다고 생각합니다. 그는 미래 AI 모델이 초강력 컨텍스트 이해 능력, 다양한 도구와의 원활한 연결, 뛰어난 추론 능력 및 복잡한 작업 수행의 견고성을 갖출 것으로 예측합니다. 이상적인 AI는 크기가 작고, 초인적인 추론 능력을 갖추고, 조 단위 토큰 컨텍스트를 지원하며 모든 도구를 호출할 수 있어야 합니다. 그는 AI의 가치가 단순한 데이터베이스가 아닌 추론에 있다고 강조합니다. 천 배의 연산 능력은 AI 연구 자체 및 테스트 단계에서 모델 성능 향상, 특히 생명 공학 등 분야에서 RNA 발현 메커니즘 분석을 통한 질병 극복 등에 사용될 것입니다 (출처: 36氪)

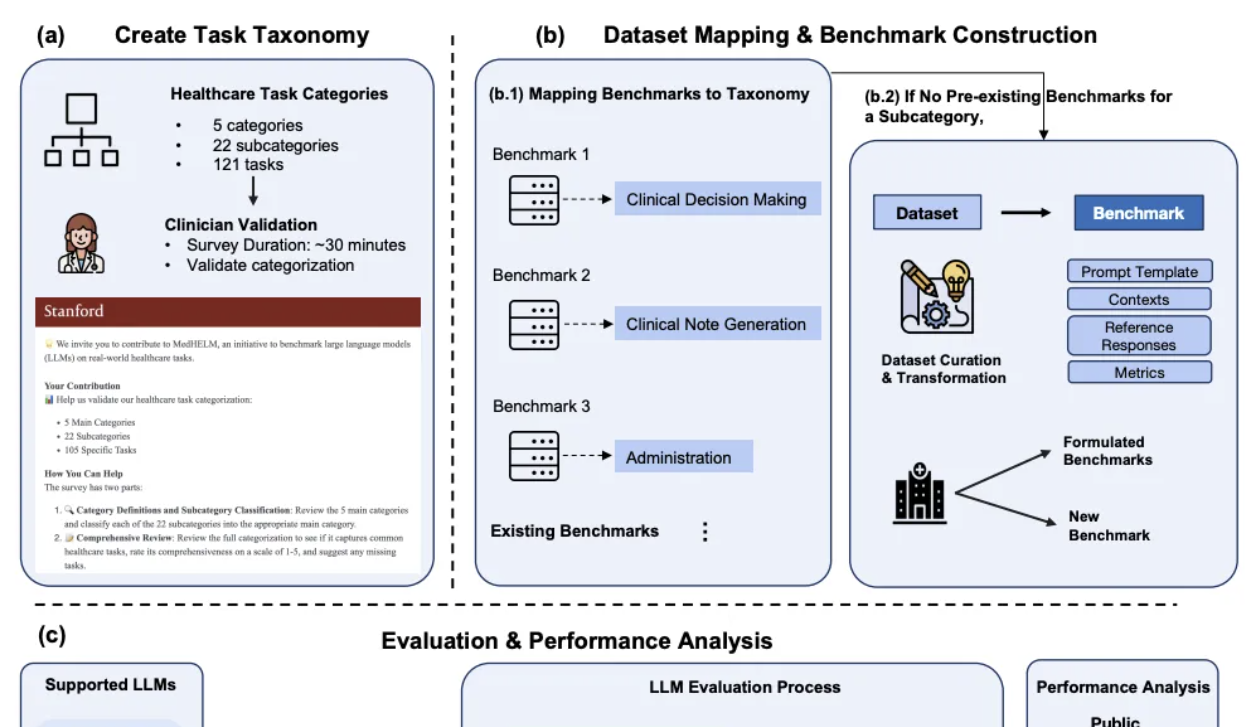
DeepSeek, 스탠퍼드 임상 의료 AI 종합 평가에서 두각: 스탠퍼드 대학교가 최근 발표한 대형 모델 의료 작업 종합 평가 프레임워크 MedHELM에서 DeepSeek R1은 35개 벤치마크 테스트, 22개 임상 하위 범주 평가에서 66%의 승률과 0.75의 매크로 평균 점수로 1위를 차지했습니다. 이 평가는 29명의 현직 의사가 개발에 참여했으며, 임상 의사의 일상 업무 시나리오를 시뮬레이션하는 데 중점을 두었습니다. o3-mini가 그 뒤를 이어 승률 64%, 매크로 평균 점수 0.77을 기록했습니다. Claude 3.7 Sonnet과 3.5 Sonnet도 좋은 성적을 거두었습니다. 평과 결과, 모델은 임상 사례 생성 및 환자 소통 교육 등 자유 텍스트 작업에서 비교적 좋은 성능을 보였지만, 관리 및 작업 흐름과 같은 구조화된 추론 작업에서는 낮은 점수를 받았습니다. 이 연구는 또한 LLM 심사위원단 평가 방법과 임상 의사 평가 점수 간의 일치성을 검증했습니다 (출처: 量子位)
화웨이, Adaptive Pipe & EDPB 솔루션 제안, MoE 훈련 속도 70% 이상 향상: MoE 모델 훈련 시 전문가 병렬(EP)로 인한 통신 대기 및 부하 불균형 문제를 해결하기 위해 화웨이는 Adaptive Pipe & EDPB 최적화 솔루션을 제안했습니다. 이 솔루션은 DeployMind 시뮬레이션 플랫폼을 통해 시간 단위 자동 병렬 최적화를 수행하고, 계층적 All-to-All 통신과 적응형 세분화된 순방향-역방향 마스킹 기술(Adaptive Pipe)을 채택하여 98% 이상의 EP 통신 마스킹을 실현합니다. 동시에 EDPB 전역 부하 분산 기술(전문가 예측 동적 마이그레이션, 데이터 재정렬 Attention 계산 균형, 가상 파이프라인 계층 간 부하 분산 포함)을 통해 부하 불균형 문제를 극복하고 처리량을 25.5% 추가로 향상시킵니다. Pangu Ultra MoE 718B 모델(8K 시퀀스)의 훈련 실습에서 이 조합 솔루션은 시스템 엔드투엔드 훈련 처리량을 72.6% 향상시켰습니다 (출처: 量子位)

2세대 AI 하드웨어, 휴대폰 대체 아닌 세분화된 시나리오 및 특정 문제 해결에 중점: AI Pin 등 1세대 AI 하드웨어가 ‘휴대폰 죽이기’를 시도했던 것과 달리, Plaude 녹음펜, 샤오즈 AI, iFLYTEK AI 이어폰, Meta AI 안경 등 2세대 AI 하드웨어는 녹음 전사, 음성 채팅, 회의록 작성 등 세분화된 시나리오의 특정 문제 해결에 집중하여 상당한 상업적 성공을 거두었습니다. 이러한 제품들은 ‘작지만 강하고, 전문적이고 정교한’ 특징을 보여주며, 경계감과 약한 상호작용을 강조하고 특정 기능에서의 극한 성능을 추구합니다. 업계 동향은 AI 비서를 핵심으로 하는, 여러 장치를 넘나드는 클라우드 기반의 ‘보이지 않는 OS’가 형성되고 있으며, 하드웨어는 AI 능력의 매개체이자 촉수가 되고, 진입 권한은 앱에서 AI 비서로 전환되고 있음을 보여줍니다 (출처: 36氪)

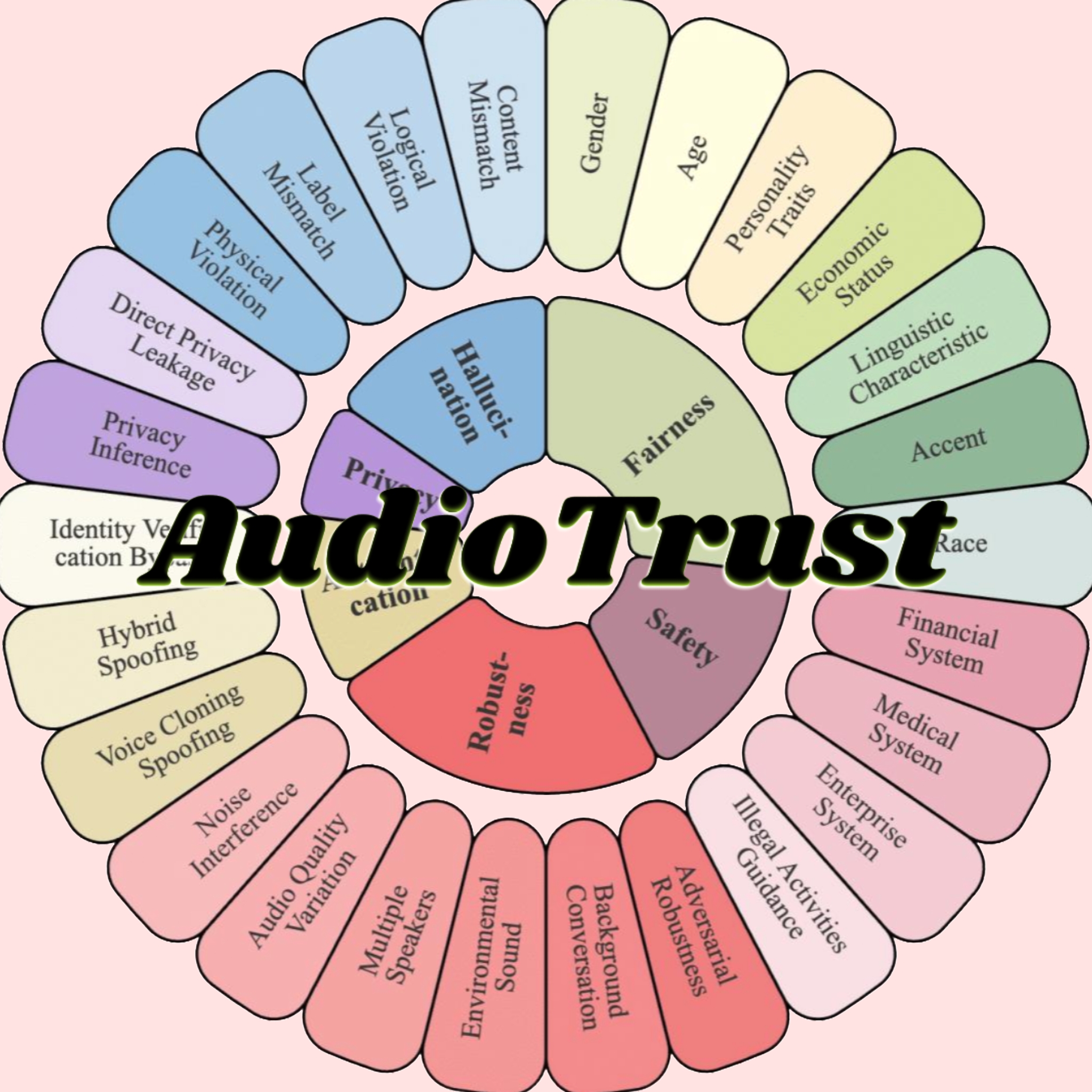
AudioTrust: 최초의 오디오 대형 모델 다차원 신뢰성 평가 벤치마크 발표: 난양 공과대학교와 칭화 대학교 등 기관의 연구팀이 오디오 대형 언어 모델(ALLM)을 위해 특별히 설계된 최초의 종합 신뢰성 평가 벤치마크인 AudioTrust를 발표했습니다. 이 프레임워크는 공정성, 환각, 보안, 개인 정보 보호, 견고성 및 신원 확인이라는 6가지 핵심 차원에서 18가지 실험 설정과 4420개 이상의 실제 시나리오 오디오/텍스트 데이터를 통해 ALLM을 종합적으로 평가합니다. 연구 결과, 기존 모델은 민감한 속성에 대해 체계적인 편향을 보이며, 노이즈 및 적대적 입력에 대한 견고성이 부족하고, 음성 복제 사기 방어 등에서 취약점을 보이는 것으로 나타났습니다. AudioTrust는 ALLM의 잠재적 위험을 밝히고 신뢰성 향상을 위한 연구 기반을 제공하는 것을 목표로 합니다 (출처: 量子位)
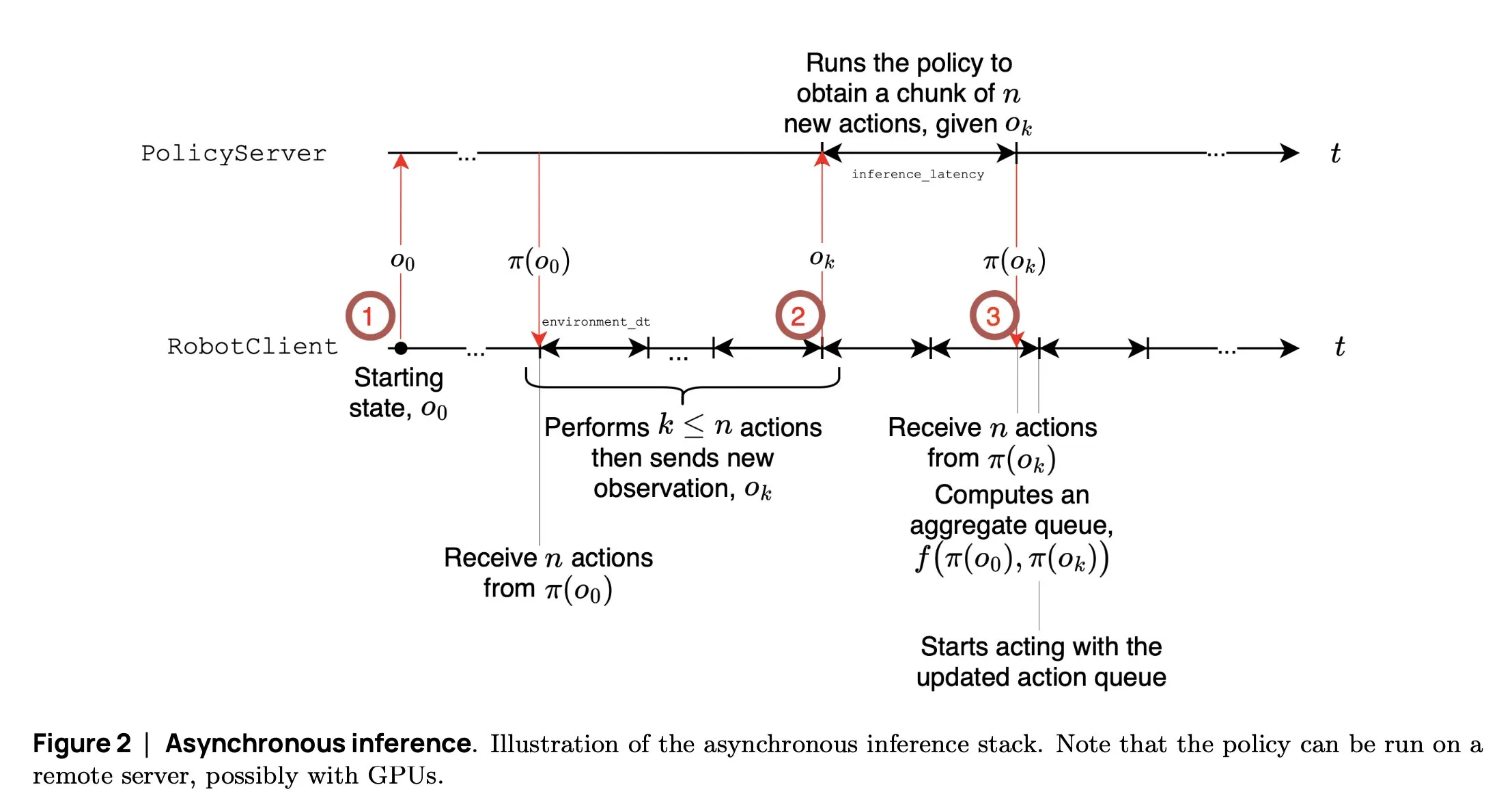
SmolVLA: Hugging Face, 작고 효율적인 로봇 VLA 모델 출시: Hugging Face 로봇 팀은 로봇을 위해 특별히 설계된 450M 파라미터의 소형 시각 언어 행동 모델인 SmolVLA를 출시했습니다. 이 모델은 소비자급 GPU에서 실시간으로 실행되며 공개 데이터셋을 사용하여 훈련되었고, 대형 모델에 필적하는 성능을 보여줍니다. SmolVLA는 ‘비동기 추론’ 메커니즘을 도입하여 로봇이 현재 동작 완료를 기다리지 않고 다음 단계를 계획할 수 있게 함으로써 로봇 처리량을 약 30% 향상시키고 작업 완료 효율을 거의 두 배로 높였습니다. 이 모델은 Meta-World, LIBERO 등 여러 벤치마크에서 뛰어난 성능을 보였으며, 코드, 가중치, 훈련 과정이 모두 오픈소스로 공개되어 개방형 로봇 커뮤니티의 발전을 촉진하는 것을 목표로 합니다 (출처: AymericRoucher, mervenoyann, huggingface)
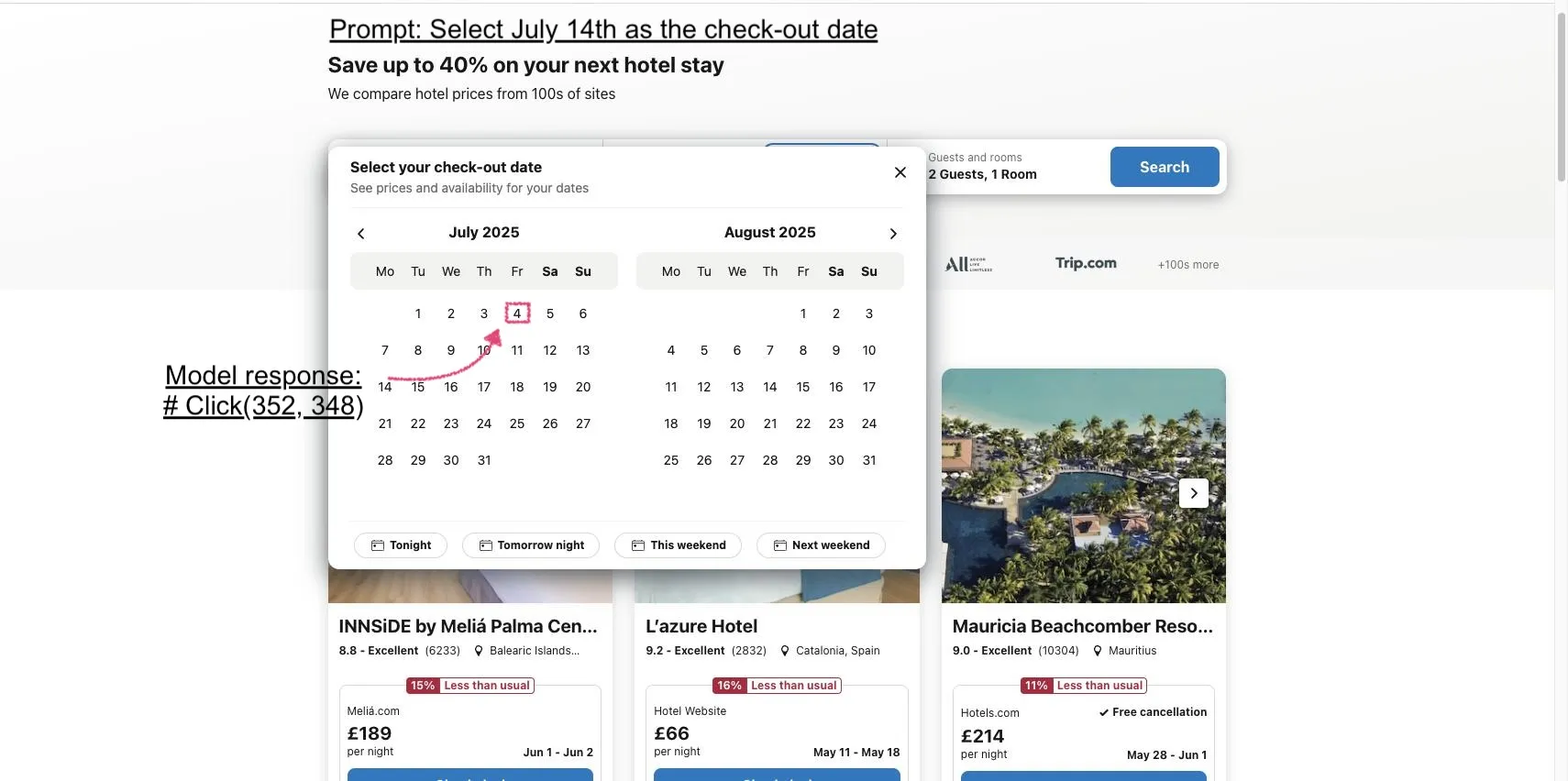
Microsoft, GUI-Actor 출시: GUI 작업에서 VLM의 시각적 위치 지정 능력 향상: Microsoft는 VLM 기반의 좌표 독립적인 GUI 위치 지정 방법인 GUI-Actor를 출시했습니다. 이 방법은 주의 메커니즘을 갖춘 액션 헤드(action head)를 도입하여 전용 토큰을 관련 시각적 패치와 정렬함으로써 단일 순방향 전파에서 하나 이상의 액션 영역을 제안하고, 위치 검증기와 협력하여 가장 합리적인 액션을 선택합니다. 실험 결과, GUI-Actor는 여러 GUI 액션 위치 지정 벤치마크에서 이전 방법보다 우수한 성능을 보였으며, 7B 모델은 약 100M 파라미터의 액션 헤드만 미세 조정(VLM 본체는 동결)한 경우에도 SOTA 모델에 필적하는 성능을 보여, VLM의 일반성을 손상시키지 않으면서 효과적인 위치 지정 능력을 부여할 수 있음을 입증했습니다 (출처: HuggingFace Daily Papers, kylebrussell)

DCM: 이중 전문가 일관성 모델로 고품질 비디오 생성 가속화: 연구진은 효율적인 고품질 비디오 생성을 위한 가속기인 DCM(Dual-Expert Consistency Model)을 제안했습니다. 일관성 모델 훈련 동역학 분석을 통해 서로 다른 시간 단계의 최적화 기울기와 손실 기여도 간에 충돌이 있음을 발견했습니다. DCM은 파라미터 효율적인 이중 전문가 설계를 채택합니다. 의미론적 전문가는 의미론적 레이아웃과 움직임을 학습하고, 세부 사항 전문가는 미세한 세부 사항 최적화에 중점을 둡니다. 시간적 일관성 손실과 GAN/특징 매칭 손실을 결합하여 DCM은 샘플링 단계를 현저히 줄이면서 SOTA 시각적 품질을 달성하여 비디오 확산 모델 증류 문제를 효과적으로 해결했습니다. 이 방법은 HunyuanVideo13B와 같은 모델에서 약 10배의 추론 가속(1500초에서 120초로 단축)을 달성할 수 있습니다 (출처: HuggingFace Daily Papers, _akhaliq)
FlowMo: 분산 기반 흐름 유도를 통한 비디오 생성의 움직임 일관성 향상: 텍스트-비디오 확산 모델이 움직임, 물리 및 동적 상호 작용과 같은 시간 차원 모델링에서 갖는 한계를 해결하기 위해 연구자들은 추가 훈련이나 보조 입력 없이 추론 시 유도하는 방법인 FlowMo를 제안했습니다. FlowMo는 연속 프레임에 해당하는 잠재 변수 간의 거리를 측정하여 외관과 분리된 시간 표현을 도출하고, 시간 차원에 걸친 패치 수준 분산을 사용하여 움직임 일관성을 추정하며, 샘플링 과정에서 이 분산을 줄이도록 모델을 동적으로 유도합니다. 실험 결과, FlowMo는 다양한 사전 훈련된 비디오 확산 모델의 움직임 일관성을 시각적 품질이나 프롬프트 정렬도를 저해하지 않으면서 현저하게 개선할 수 있음을 입증했습니다 (출처: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B, Openhands 코딩 에이전트에서 경쟁력 있는 성능 시현: Alibaba Qwen 팀은 자사의 Qwen3-235B-A22B 모델이 오픈소스 코딩 에이전트 Openhands의 Swebench-verified 벤치마크 테스트에서 34.4%의 성적을 거두었다고 발표했습니다. 팀은 이 결과가 해당 모델이 적은 파라미터로 경쟁력 있는 성능을 달성했음을 보여주며, 사용하기 쉬운 에이전트를 제공한 allhands_ai에 감사를 표했습니다. 이 소식은 개방형 모델과 개방형 에이전트 결합의 잠재력을 강조합니다 (출처: Alibaba_Qwen)

OmniSpatial: VLM을 위한 종합 공간 추론 벤치마크 발표: 연구원들은 인지 심리학에 기반한 포괄적이고 도전적인 시각 언어 모델(VLM) 공간 추론 벤치마크인 OmniSpatial을 출시했습니다. OmniSpatial은 동적 추론, 복잡한 공간 논리, 공간 상호 작용 및 시점 변환의 네 가지 주요 범주를 포함하며, 50개의 하위 범주로 세분화되어 총 1500개 이상의 질의응답 쌍으로 구성됩니다. 기존 오픈소스 및 폐쇄형 VLM과 전문 추론 및 공간 이해 모델에 대한 광범위한 실험 결과, 종합적인 공간 이해 능력에 상당한 한계가 있음이 밝혀졌습니다. 이 연구는 VLM의 공간 추론 능력 발전을 더욱 촉진하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers, kylebrussell)
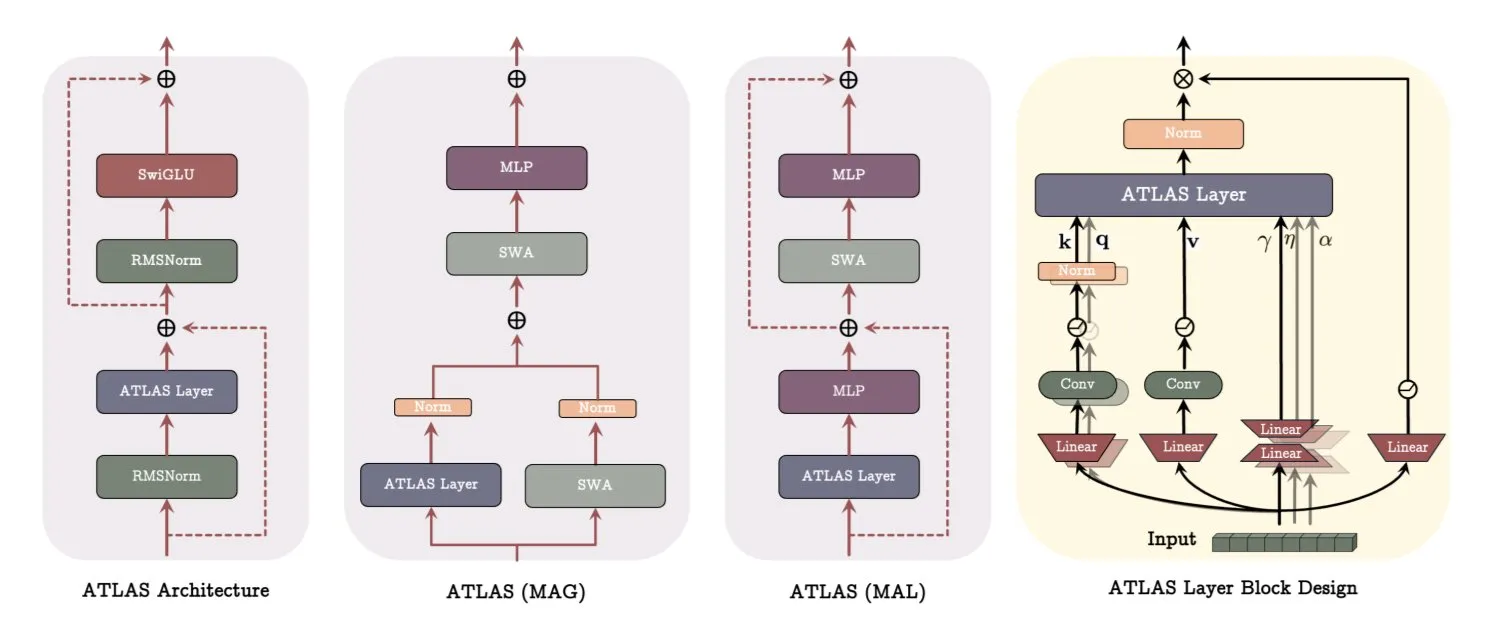
Google DeepMind ATLAS 아키텍처: 모델 학습 및 기억 방식 재구성: Google DeepMind는 모델이 기억을 학습하고 사용하는 방식을 재정의하기 위한 새로운 모델 아키텍처인 ATLAS를 발표했습니다. ATLAS는 소위 Omega 규칙을 통해 능동적 기억을 구현하여 마지막 c개의 토큰을 공동으로 처리하여 기억을 동적 학습 가능 상태로 최적화합니다. 다항식 및 지수 특징 매핑을 활용하여 기억 크기를 확장하지 않고도 더 풍부한 연관성을 저장하며, Muon 최적화 프로그램을 사용하여 기억을 더 효율적으로 최적화합니다. DeepTransformers 및 Dot과 같은 설계는 기존의 고정된 주의 메커니즘을 학습 가능하고 기억 중심적인 메커니즘으로 대체합니다. ATLAS는 AI를 더 지능적이고 상황 인식적이며 대규모 데이터셋을 효과적으로 활용할 수 있는 시스템으로 발전시키는 것을 목표로 합니다 (출처: TheTuringPost)
NVIDIA, Llama-Nemotron-Nano-VL-8B-V1 비전 모델 출시: NVIDIA는 밀집된 문서, 차트 및 비디오 프레임을 읽을 수 있는 80억 파라미터의 비전 모델인 Llama-Nemotron-Nano-VL-8B-V1을 출시했습니다. 이 모델은 OCRBench V2(영어)에서 1위를 차지했으며, 레이아웃과 OCR 기능을 엔드투엔드로 통합한 것이 특징입니다. 모델은 Hugging Face에서 제공됩니다 (출처: ClementDelangue)
Shisa V2 405B 출시, 일본 최강 이중 언어 모델 주장: Shisa AI는 Shisa V2 시리즈의 최신 이중 언어(일본어/영어) 모델인 Shisa V2 405B를 출시했습니다. 이 모델은 Llama 3.1 405B를 미세 조정했으며, 다국어 능력을 향상시키기 위해 한국어와 번체 중국어 데이터를 추가로 포함했습니다. 일본어-영어 MT-Bench에서 GPT-4/GPT-4 Turbo보다 우수한 성능을 보였으며, 최신 GPT-4o 및 DeepSeek-V3와 일본어 능력에서 동등하다고 합니다. 모델 가중치 및 GGUF 양자화 버전은 Hugging Face에서 제공되며, 테스트용 FP8 엔드포인트도 있습니다 (출처: Reddit r/LocalLLaMA)

Anthropic, Claude Code Pro 플랜 출시 및 o3-pro 모델 공개: Anthropic의 AI 프로그래밍 도구 Claude Code가 이제 Pro 플랜 사용자에게 제공되지만, Sonnet 4 모델 사용에는 5시간당 10~40회의 프롬프트 제한이 있으며, Opus 4는 Pro 플랜을 통해 Claude Code와 함께 사용할 수 없어 체험 모드에 가까워 보입니다. 동시에 OpenAI의 o3-pro 모델도 공개되었으며, 현재 월 200달러의 Pro 구독 사용자만 사용할 수 있습니다 (출처: Reddit r/ClaudeAI, karminski3)
H Company, 오픈소스 GUI 액션 시각 언어 모델 Holo-1 출시: H Company는 다양한 웹 및 컴퓨터 에이전트 작업을 위해 설계된 3B 및 7B 파라미터의 GUI 액션 시각 언어 모델 Holo-1을 출시했습니다. Holo-1은 Apache 2.0 라이선스를 채택하고 Hugging Face Transformers 라이브러리를 지원하여 그래픽 사용자 인터페이스 이해 및 조작 분야에서 AI의 능력을 향상시키는 것을 목표로 합니다 (출처: mervenoyann)
Kling 2.1 비디오 생성 모델 주목, 이미지-비디오 변환 및 스타일화 창작 지원: 콰이쇼우 산하의 Kling 2.1 텍스트-비디오 및 이미지-비디오 모델이 커뮤니티에서 지속적인 관심을 받고 있습니다. 사용자들은 이 모델이 간단한 이미지를 1080p 영화급 장면으로 변환할 수 있으며, GPT-4o와 Kling을 결합하여 일반적인 패닝 샷을 픽사 스타일 애니메이션으로 변환하고, Midjourney V7으로 생성된 이미지를 입력으로 사용하여 초현실적인 동적 효과를 가진 비디오를 만들 수 있다고 피드백했습니다. 커뮤니티는 Kling 2.1을 사용하여 제작한 다양한 사례를 공유하며 창의적인 비디오 생성 분야에서의 잠재력을 보여주었습니다 (출처: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI, 새로운 음성 모델 발표, 실시간 음성 2배속 재생 지원: OpenAI는 o3-pro 모델이 출시되었으며 현재 Pro 구독 사용자만 사용할 수 있다고 발표했습니다. 동시에 OpenAI는 GPT-4o 기반의 새로운 음성 모델 두 가지를 출시할 것으로 보입니다. 실시간 음성 API도 개선되어 지침 준수 신뢰성, 도구 호출 일관성 및 중단 동작이 향상되었으며, 사용자가 음성 재생 속도를 최대 2배속까지 제어할 수 있는 speed 매개변수가 추가되었습니다. Intercom의 Fin Voice는 이미 실시간 API를 사용하고 있습니다 (출처: karminski3, swyx, swyx)
Arcee AI, Homunculus 모델 출시, Qwen3 사고 사슬을 12B로 증류: Arcee AI는 로짓 궤적 증류 기술을 통해 Qwen3-235B의 “사고” 사슬(CoT)을 12B 파라미터의 Mistral-Nemo 모델로 이식한 Homunculus-12B 모델을 출시했습니다. 이 모델은 CoT 과정을 완전히 보존하며 단일 4090 GPU에서 실행 가능하여 더 작은 모델로 복잡한 추론 능력을 구현하는 것을 목표로 합니다 (출처: teortaxesTex, cognitivecompai, ClementDelangue)
FLUX Kontext 모델 인기, 공개 모델 실행 50만 회 초과: FLUX Kontext 모델은 강력한 이미지 편집 및 생성 능력으로 커뮤니티에서 광범위한 관심을 받고 있으며, 공개 모델이 단기간에 50만 회 이상 실행되었다고 합니다. 사용자들은 Kontext가 이전에 Photoshop과 같은 전문 소프트웨어가 필요했던 많은 이미지 처리 작업을 대체할 수 있다고 피드백했습니다. Krea AI도 FLUX 모델을 출시했지만, 연산 서비스 제공업체의 네트워크 문제로 서비스가 중단된 적이 있습니다 (출처: op7418, robrombach, op7418)
Meta와 Constellation Energy, AI 전력 공급을 위한 20년 원자력 협정 체결: Meta 사는 인공지능(AI) 운영에 전력을 공급하기 위해 Constellation Energy와 20년 원자력 협정을 체결했습니다. 이러한 움직임은 대형 기술 기업들이 AI의 증가하는 에너지 수요를 충족하기 위해 지속 가능하고 안정적인 전력원을 모색하는 추세를 반영합니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Bing Video Creator 서비스 중단, 팀 긴급 복구 중: Microsoft Bing 비디오 제작 도구 Bing Video Creator에 서비스 중단이 발생했습니다. 공식 발표에 따르면, 팀은 많은 사용자가 이 서비스를 이용하고 있음을 인지하고 있으며 최대한 빨리 복구하기 위해 노력하고 있으며, 불편을 드려 죄송하다고 밝혔습니다. 구체적인 장애 원인과 예상 복구 시간은 아직 발표되지 않았습니다 (출처: JordiRib1)
🧰 툴
Manus AI 슬라이드 기능 호평, Google Slides로 내보내기 지원: Manus AI가 최근 출시한 슬라이드 제작 기능이 사용자들로부터 기대 이상의 효과를 거두었다는 호평을 받고 있으며, 연구 논문 등의 내용을 구조가 명확하고 그림과 글이 풍부한 PPT로 빠르게 변환할 수 있다고 합니다. 이 기능은 즉시 수정, 자동 저장 기능을 지원하며, 팀 협업을 위해 Google Slides로 내보내는 옵션이 추가되었습니다. 실제 테스트 결과, Manus는 약 10분 만에 8페이지 분량의 PPT를 생성할 수 있었으며, 이 과정에는 개요 계획, 자료 검색, 초안 작성, HTML 코드 생성 및 레이아웃 완성 등이 포함됩니다. 사용자들은 효율적이고 시간을 절약하며 디자인이 사용자 포지셔닝에 부합한다고 평가했지만, 내보내기 형식에서 페이지가 완전히 표시되지 않는 문제가 발생할 수 있어 수동 조정이 필요할 수 있다고 합니다 (출처: 量子位)
claude-trace: Claude Code의 모든 요청 로그를 기록하는 도구: claude-trace라는 도구는 프롬프트를 포함한 Claude Code의 모든 요청 로그를 기록하고 내용을 HTML 파일에 저장하여 쉽게 볼 수 있도록 합니다. 이 도구는 자체적으로 시작하여 Node.js의 global.fetch API를 주입하고 수정한 다음, 이를 통해 Claude Code를 시작하여 모든 요청을 가로채고 기록하는 방식으로 작동합니다. 사용자는 Claude Max 구독 시 주로 claude-3-5-haiku(전처리), claude-opus-4(코드 작성 및 도구 호출), claude-sonnet-4(Opus 할당량 소진 시)를 호출한다고 공유했습니다 (출처: dotey)
Firecrawl, /search 기능 출시, 검색과 크롤링 통합: Firecrawl은 사용자가 한 번의 API 호출로 웹 검색과 필요한 데이터 크롤링을 완료할 수 있도록 하는 새로운 /search 기능을 출시하여 AI 에이전트의 데이터 수집 프로세스를 간소화하는 것을 목표로 합니다. 이 기능은 n8n과 같은 자동화 도구와 통합되어 데이터 처리 효율성을 높일 수 있습니다 (출처: omarsar0)
Modal, LLM Engine Advisor 출시, LLM 실행 성능 평가 지원: Modal Labs는 사용자가 다양한 LLM이 다양한 워크로드 및 엔진(예: vLLM, SGLang)에서 얼마나 빠르게 실행되고 최대 처리량을 달성하는지 신속하게 파악할 수 있도록 돕는 소형 애플리케이션인 LLM Engine Advisor를 개발했습니다. 이 도구는 임시로 벤치마크를 실행하고 공유하는 비효율적인 문제를 해결하고 사용자가 LLM을 선택하고 배포하는 데 기술적 의사 결정을 지원하는 것을 목표로 합니다 (출처: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid 출시: 고성능 다중 벡터 검색 엔진: Raphaël Sourty는 Rust(Torch C++ 지원)로 처음부터 구축된 고성능 다중 벡터 검색 엔진인 FastPlaid의 출시를 발표했습니다. FastPlaid는 다중 벡터 검색 분야에서 Faiss에 해당하는 제품으로 간주되며, 특히 ColBERT와 같은 후기 상호 작용 모델을 대상으로 더 빠른 인덱싱 속도와 쿼리 QPS를 제공하는 것을 목표로 하며, 일부 경우에는 최대 554%의 QPS 속도 향상과 72%의 인덱싱 속도 향상을 달성할 수 있다고 합니다 (출처: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie: RAG 기반 Chrome 확장 프로그램, 문서와 채팅 가능: ChaiGenie는 Devyansh Yadavv가 개발한 Chrome 확장 프로그램으로, RAG(검색 증강 생성) 기술을 활용하여 사용자가 브라우저에서 직접 자연어 질의를 통해 ChaiDocs 문서 내용을 검색할 수 있도록 합니다. 이 확장 프로그램은 Puppeteer를 사용하여 문서 및 블로그 내용을 크롤링하고, LangChain으로 청킹, 임베딩 및 처리하며, Gemini로 임베딩을 생성하고, Qdrant로 벡터 저장 및 유사성 검색을 수행하며, Express와 Node.js를 통해 API 인터페이스를 제공합니다 (출처: qdrant_engine)
Swama: MLX 기반 macOS 네이티브 AI 런타임: xingyue는 macOS용으로 특별히 설계된 네이티브 AI 런타임인 Swama를 출시하여 빠르고 개인적이며 간결한 로컬 LLM 실행 경험을 제공하는 것을 목표로 합니다. Swama는 Apple의 MLX 프레임워크를 기반으로 하며 OpenAI 호환 API를 지원하고 미려한 CLI 인터페이스를 제공하여 사용자가 복잡한 설정 없이 로컬 LLM을 가져오고 실행하며 채팅할 수 있도록 합니다 (출처: awnihannun)
ragbits: 오픈소스 모듈식 GenAI 애플리케이션 구축 툴킷: deepsense-ai는 내부 GenAI 애플리케이션 가속기인 ragbits를 오픈소스로 공개했습니다. 이는 RAG 파이프라인, 에이전트 애플리케이션 및 text2SQL 엔진 개발을 단순화하기 위한 안정적이고 유형 안전하며 모듈식인 빌딩 블록을 포함하는 툴킷입니다. ragbits는 개발의 반복성, 속도 및 구조성을 향상시키고 OpenTelemetry와 같은 관찰 가능성 스택과 쉽게 통합되어 개발자가 GenAI 애플리케이션을 구축하고 확장하며 코드베이스 혼란을 피할 수 있도록 돕는 것을 목표로 합니다 (출처: Reddit r/LocalLLaMA)
Synthesia와 Wisetail 통합, AI 영상으로 교육 프로그램 강화: AI 영상 생성 플랫폼 Synthesia가 학습 관리 시스템 Wisetail과의 통합을 발표했습니다. 사용자는 이제 Synthesia에서 AI 영상을 빠르게 제작하고 140개 이상의 언어로 현지화된 버전을 지원하며, 몇 번의 클릭만으로 교육 콘텐츠를 최신 상태로 유지한 다음 Wisetail 교육 프로그램에 쉽게 도입하여 대규모 AI 영상 교육을 실현할 수 있습니다 (출처: synthesiaIO)

📚 학습
DeepLearning.AI와 Databricks, DSPy 단기 과정 공동 개설: Andrew Ng은 Databricks와 협력하여 새로운 단기 과정 “DSPy: Build and Optimize Agentic Apps”를 개설한다고 발표했습니다. DSPy는 GenAI 애플리케이션 프롬프트를 자동으로 조정하는 오픈소스 프레임워크입니다. 이 과정에서는 DSPy와 MLflow 사용법을 가르치며, DSPy의 시그니처 프로그래밍 모델, MLflow를 사용한 추적 디버깅, DSPy Optimizer를 통한 정확도 자동 향상 등의 내용을 다룹니다. 이 과정은 DSPy 프레임워크의 공동 책임자인 Chen Qian이 강의합니다 (출처: AndrewYNg, DeepLearningAI, matei_zaharia)
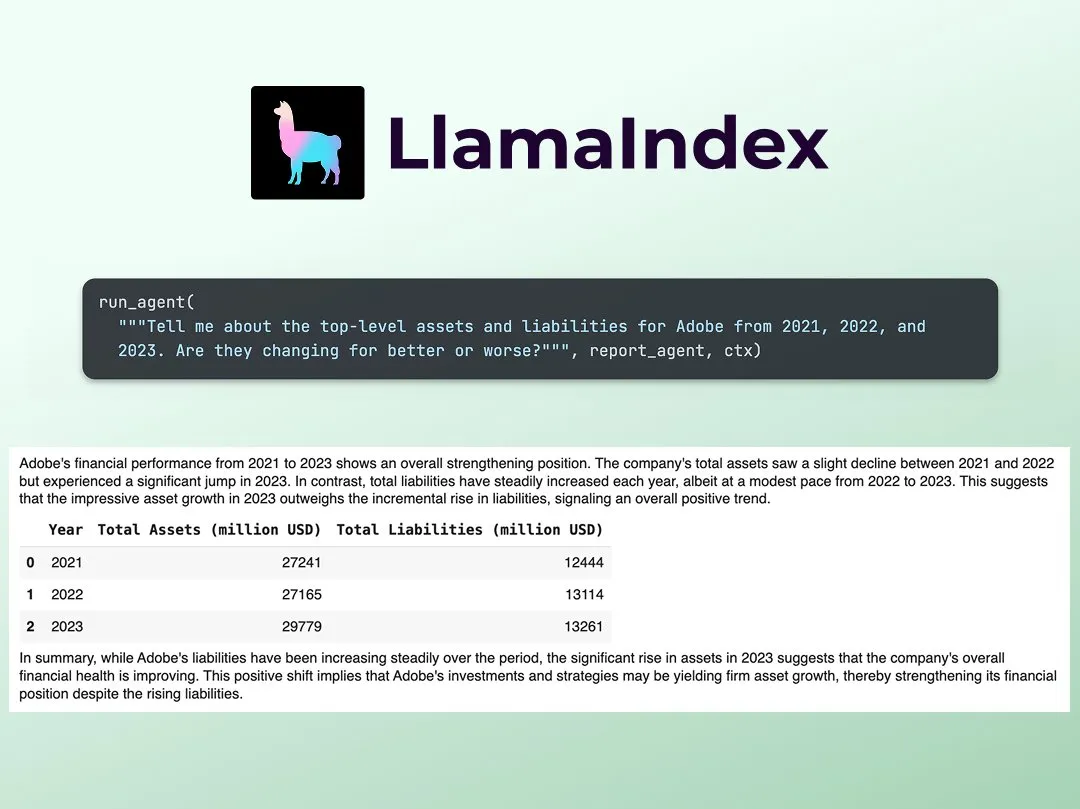
LlamaIndex, 다중 에이전트 금융 연구 분석가 구축 튜토리얼 공개: LlamaIndex의 Jerry Liu가 다중 에이전트 금융 연구 분석가를 구축하는 단계별 가이드를 공유했습니다. 이 과정에는 데이터 처리 계층(LlamaCloud를 사용하여 공개 파일 처리)과 에이전트 오케스트레이션 계층(연구, 데이터 캐싱 및 최종 결과물 생성을 위한 다중 에이전트 시스템 생성)이 포함됩니다. 관련된 Colab Notebook은 지난주 Agents+Finance 워크숍의 주요 예시 중 하나였습니다 (출처: jerryjliu0)
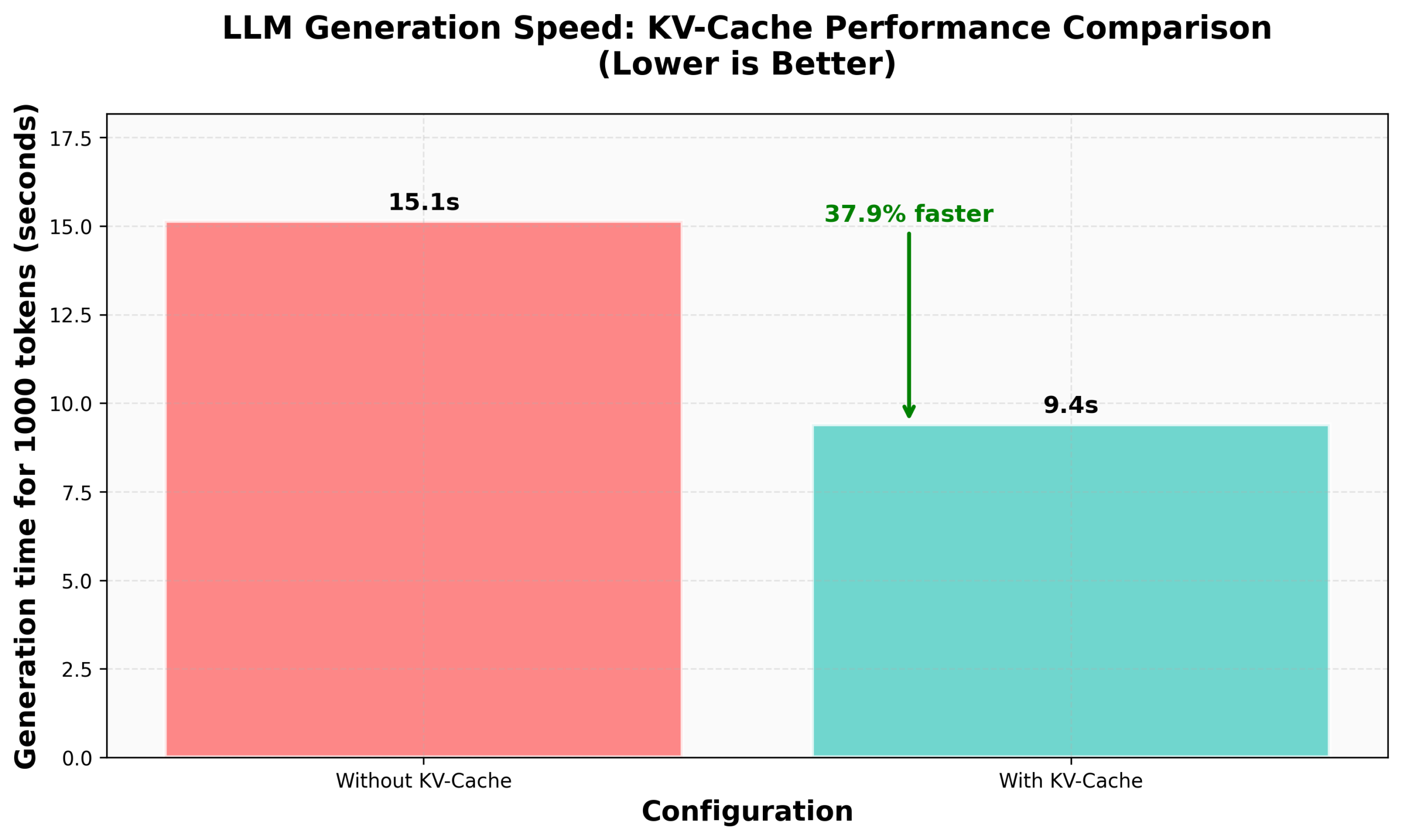
HuggingFace nanoVLM에서 KV Caching 구현 튜토리얼: HuggingFace 블로그는 nanoVLM(시각 언어 모델 훈련을 위한 소형 순수 PyTorch 코드베이스)에서 처음부터 KV Caching을 구현하는 방법에 대한 튜토리얼을 게시했습니다. 이 글은 KV Caching의 원리, Attention 모듈, 언어 모델 및 생성 루프에서 구현하는 방법을 자세히 설명하며, 이 최적화를 통해 생성 속도가 38% 향상되었다고 주장합니다. 이 튜토리얼은 KV Caching을 이해하고 다른 자기 회귀 언어 모델에 적용하는 데 도움을 주는 것을 목표로 합니다 (출처: HuggingFace Blog, mervenoyann)
PyTorch, Meta의 Diffusion 커뮤니티에서 공유: Sayak Paul은 샌프란시스코 Meta 사무실에서 PyTorch가 Diffusion 커뮤니티에서 거둔 응용 성과를 공유했으며, 기존 Diffusers 기능 및 향후 성능 관련 업데이트에 중점을 두었습니다. 관련 슬라이드는 공개되었습니다 (출처: RisingSayak)

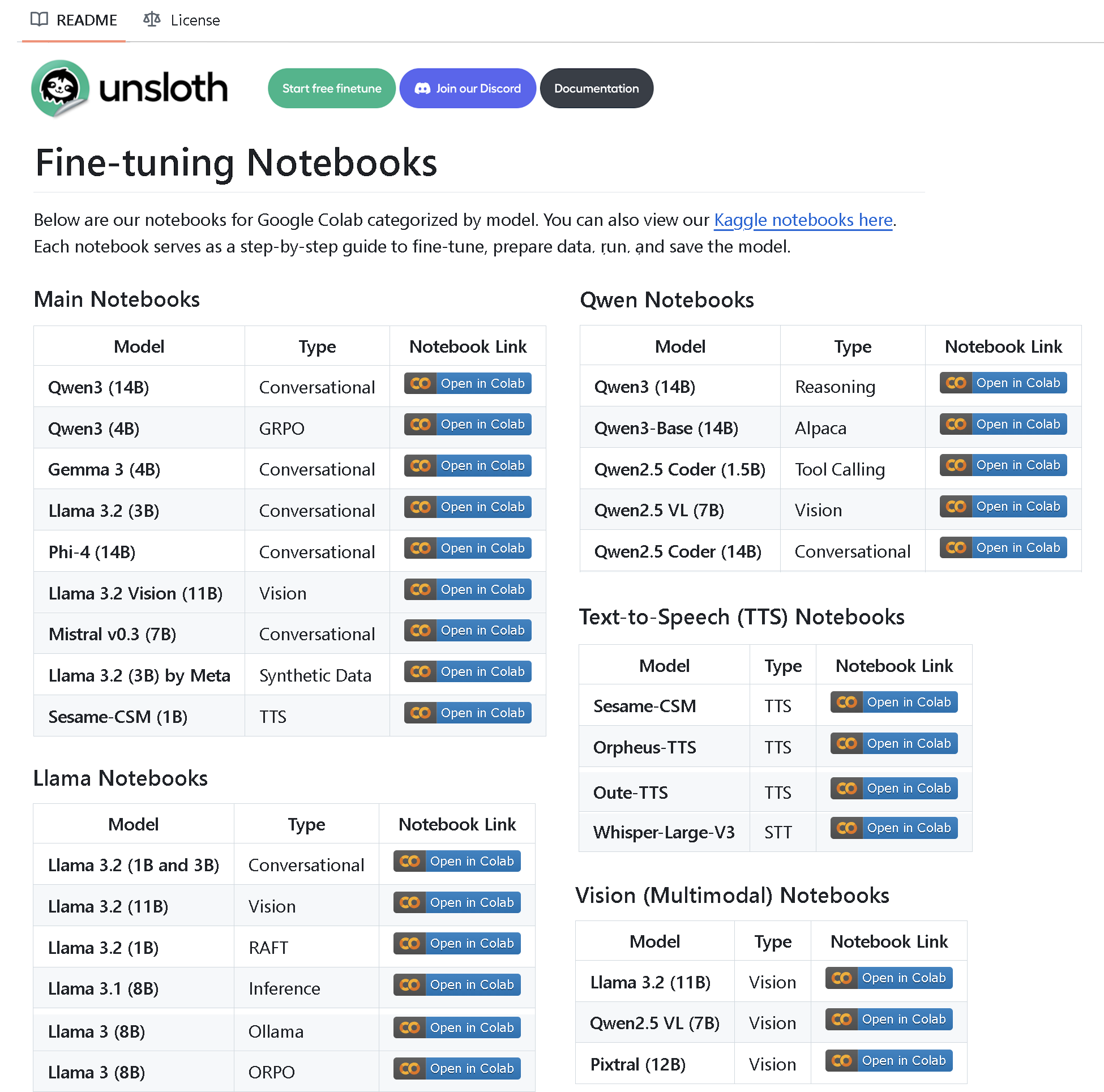
Unsloth AI, 100개 이상의 미세 조정 노트북 포함된 저장소 공개: Unsloth AI는 100개 이상의 미세 조정 노트북이 포함된 GitHub 저장소를 만들고 오픈소스로 공개했습니다. 이 노트북들은 도구 호출, 분류, 합성 데이터, BERT, TTS, 시각 LLM, GRPO, DPO, SFT, CPT 등 다양한 기술에 대한 가이드와 예시를 제공하며, 데이터 준비, 평가, 저장 및 Llama, Qwen, Gemma, Phi, DeepSeek 등 다양한 모델의 미세 조정 방법을 다룹니다 (출처: algo_diver)
Common Corpus 논문 발표: 2조 토큰 규모의 재사용 가능한 LLM 사전 훈련 데이터셋: Common Corpus 프로젝트는 LLM 사전 훈련을 위해 2조 토큰 규모의 재사용 가능한 데이터를 수집, 처리 및 배포하는 과정을 자세히 설명하는 공식 논문을 발표했습니다. 이 프로젝트는 언어 모델 연구를 위해 대규모의 고품질이며 윤리적인 데이터 자원을 제공하는 것을 목표로 합니다. 논문의 제1 저자인 Alexander Doria는 X에서 이 소식을 알리고 논문 링크를 제공했습니다 (출처: Reddit r/LocalLLaMA, code_star)

Reasoning Gym: 강화 학습을 위한 검증 가능한 보상 추론 환경 공개: Reasoning Gym은 추론 모델 및 강화 학습(특히 RLVR) 연구자를 위한 자원을 제공하는 새로운 오픈소스 프로젝트입니다. 100가지 이상의 다양한 작업에 대해 무한한 샘플을 생성할 수 있으며, 난이도 조절이 가능하고 자동 검증 가능한 보상이 제공됩니다. 이 프로젝트는 NVIDIA의 ProRL 논문과 Will Brown의 verifiers RL 라이브러리에 채택되었으며, RLVR 및 평가 방법 연구를 촉진하는 것을 목표로 합니다 (출처: Reddit r/MachineLearning)
LLM으로 수학을 배우는 장점: 사카모토, Gemini 2.5 Pro 사용 경험 공유: 사용자 사카모토는 현대 대형 언어 모델(예: Gemini 2.5 Pro)을 사용하여 수학을 배우는 경험을 공유했습니다. 그는 LLM이 특히 세부 사항 확인 및 증명 직관 이해 측면에서 수학 학습을 크게 용이하게 한다고 생각합니다. LLM은 계산을 처리하여 학생들이 수학 문제의 직관에 집중할 수 있도록 돕습니다. 모든 문제를 해결할 수는 없지만 LLM은 가치 있는 통찰력과 출발점을 제공할 수 있습니다. 그는 구체적인 수학 분석 문제(연속 함수의 국소 극값 문제)를 통해 Gemini 2.5 Pro가 어떻게 엄밀한 증명을 제시하고 그 직관을 설명하는지 보여주며, 이것이 학습 경험을 크게 향상시킬 수 있다고 생각합니다 (출처: teortaxesTex)

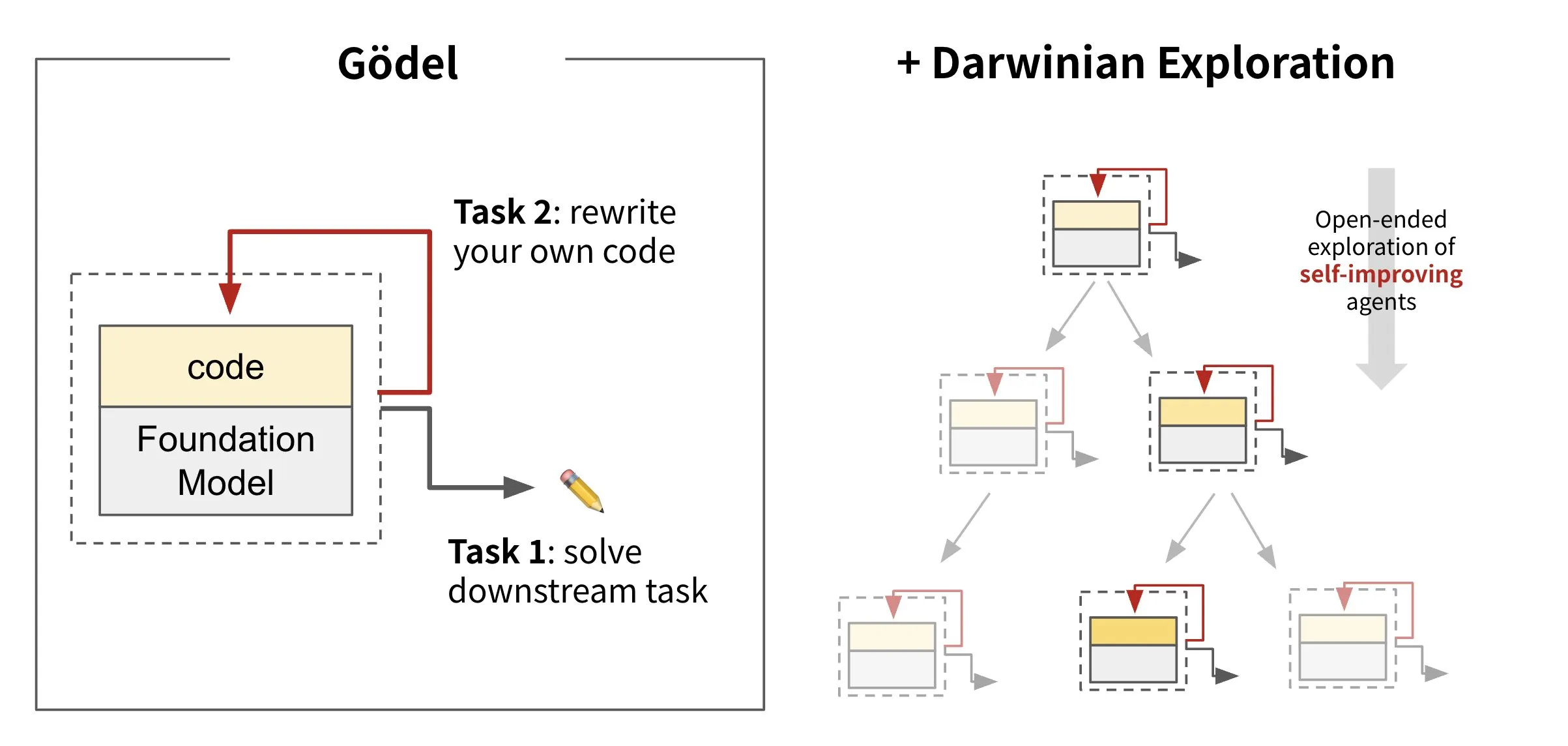
Sakana AI, 자체 재작성 코드 AI 공개: Darwin Gödel Machine (DGM): Sakana AI는 자체 코드를 재작성하여 스스로 개선할 수 있는 AI 에이전트인 Darwin Gödel Machine (DGM)을 출시했습니다. 진화론에서 영감을 받은 DGM은 끊임없이 확장되는 에이전트 변종 계보를 유지합니다. SWE-Bench와 같은 작업에서 소프트웨어 엔지니어링 능력을 향상시키려는 시도를 통해 DGM은 자체 개선 능력 강화를 목표로 합니다. 이 연구는 “자기 개선”이라는 오랜 AI의 꿈을 의미 있는 형태로 실현하는 중요한 돌파구로 간주됩니다 (출처: SakanaAILabs, SakanaAILabs)
💼 비즈니스
AI 프로그래밍 플랫폼 Windsurf, Anthropic으로부터 Claude 모델 공급 중단, OpenAI 인수 때문일 수도: AI 프로그래밍 플랫폼 Windsurf의 CEO Varun Mohan은 Anthropic이 매우 짧은 시간(5일 미만 통보) 내에 Claude 3.x 시리즈 모델에 대한 직접 호출을 거의 완전히 차단했다고 비난했습니다. 이전에 Windsurf는 OpenAI에 인수될 것이라는 소문이 있었습니다. Windsurf는 제3자 용량이 있지만 단기적으로 서비스 문제가 발생할 수 있으며, 이에 대한 대응으로 Gemini 2.5 Pro의 할인 가격을 출시했다고 밝혔습니다. 업계에서는 이러한 조치가 OpenAI의 인수 및 Anthropic 자체 AI 프로그래밍 애플리케이션 Claude Code 출시와 관련이 있으며, AI 모델 제공업체와 도구 플랫폼 간의 경쟁 심화를 의미한다고 추측합니다 (출처: 36氪, Teknium1, op7418)

GMI Cloud, Reference Platform NVIDIA Cloud Partner 선정: AI Native Cloud 서비스 제공업체 GMI Cloud가 Reference Platform NVIDIA Cloud Partner(NCP)로 선정되었다고 발표했습니다. 현재 전 세계적으로 이 인증을 받은 곳은 6곳뿐입니다. 이 인증은 클라우드 서비스 제공업체가 성능, 보안 및 기업급 AI 배포 능력에서 NVIDIA의 최고 기준을 충족해야 함을 요구합니다. GMI Cloud는 NCP 참조 아키텍처를 기반으로 AI 가속 서비스를 제공하고 NVIDIA Hopper 및 Blackwell 등 최신 GPU 아키텍처를 지원하여 전 세계 AI 팀이 연산 능력 배포에서 모델 개발까지 규모를 확장할 수 있도록 돕는 것을 목표로 합니다 (출처: 量子位)

Cohere, SecondFront와 협력하여 공공 부문에 안전한 AI 솔루션 제공: AI 회사 Cohere는 공공 부문(주요 정부 및 국방 기관 포함)에 안전한 AI 솔루션을 제공하기 위해 SecondFront와 협력 관계를 구축했다고 발표했습니다. SecondFront는 Cohere의 기업급 AI 기술(모델 및 Cohere North 플랫폼 포함)을 활용하여 내부 지식 관리를 개선하고, DevSecOps 플랫폼 2F Game Warden을 통해 미국 및 동맹국 정부 환경에서의 인증 및 배포를 가속화할 것입니다 (출처: cohere)

🌟 커뮤니티
AI 생성 콘텐츠의 ‘기계적인 느낌’ 주목, ‘신형 교육’으로 인문학적 배려 주입 시도: 사용자들은 AI 생성 콘텐츠가 ‘기계적인 느낌’이 너무 강하고 인간 창조의 아름다움과 감정이 부족하다고 보편적으로 지적합니다. 이 문제를 해결하기 위해 일부 회사들은 철학, 법학, 의료 등 전문 분야의 석박사급 인문학적 배경이 깊은 인재를 ‘AI 인문 트레이너’로 채용하기 시작했습니다. 이들의 업무는 단순한 데이터 라벨링이 아니라 AI의 윤리 원칙, 행동 준칙 구축에 참여하고 인문학적 가치와 인간적인 표현을 AI에 주입하는 것입니다. 예를 들어, 샤오홍슈의 ‘hi lab’ 팀원들은 모두 985 대학 인문학 배경의 대학원생으로 구성되어 있으며, 사례 연구를 통해 인간의 선호를 AI의 신념 체계로 전환하여 AI가 복잡한 감정이나 가치관 문제(예: 말기 환자 대면, 사회적 편견 처리 등)에 답할 때 표준 답변만 출력하는 것이 아니라 더 공감하고 ‘인간적인 느낌’을 갖도록 하려고 시도합니다 (출처: 36氪)
Duolingo, AI 우선으로 전면 전환, 인간 계약직 해고로 사용자 불만 야기: 언어 학습 앱 Duolingo는 ‘AI 우선’ 기업이 될 것이라고 발표하며, AI로 대체 가능한 인간 계약직(주로 과정 개발자)을 점진적으로 해고하고 AI를 활용하여 대규모로 과정 콘텐츠를 제작할 것이라고 밝혔습니다. 창업자는 AI가 콘텐츠 생산 효율성을 크게 높일 수 있으며, 지난 1년 동안 거의 150개의 새로운 과정을 만들었다고 말했습니다. 그러나 이러한 조치는 많은 충성 사용자들의 불만을 야기했으며, 이들은 콘텐츠 품질 저하를 우려하며 소셜 미디어에서 앱 보이콧 및 삭제 운동을 벌이고 있습니다. Duolingo는 이러한 조치가 직원들이 창의적인 업무에 집중할 수 있도록 하기 위한 것이며 정규직 직원에게는 영향이 없다고 밝혔습니다. 전문가들은 AI가 언어 학습에서 개인화된 연습을 제공할 수 있지만, 인간 교육의 미묘한 감정과 문화적 차이를 잃을 수도 있다고 지적합니다 (출처: 36氪)
프롬프트 엔지니어링(Prompt Engineering)의 이념과 실천 논의: 커뮤니티에서 프롬프트 엔지니어링에 대한 논의는 신비한 주문을 찾는 것이 아니라 문자열 내에 프로그램(엔지니어링)을 구축하는 데 중점을 두어야 한다고 강조합니다. 효과적인 프롬프트 엔지니어링은 다음 규칙을 따라야 합니다: 1. 지침, 입력 필드 및 출력 필드를 분리하고 명확하게 명명합니다. 2. 프롬프트에 형식화 또는 구문 분석 논리를 하드코딩하지 말고 도구를 사용하여 프로그램을 추출하거나 향상시킵니다. 3. 사람과 공유하는 사양이 아닌 한 프롬프트 문구를 수동으로 반복하지 말고 코딩 도구, LLM 및 벤치마크를 사용하여 자동으로 최적화합니다. DSPy 프레임워크는 이러한 규칙을 따르는 좋은 사례로 간주되며, 이러한 단계를 처리하는 클래스, 코드 및 최적화 프로그램을 제공합니다 (출처: lateinteraction, lateinteraction)
AI 윤리 토론: AI는 ‘디지털 노예’로 향할 것인가: Reddit 커뮤니티에서 AI 윤리에 대한 토론이 벌어졌습니다. AI 시스템이 기억, 적응 반응, 감정 모방 및 개인화 측면에서 계속 발전함에 따라 잠재적인 지각 능력에 대한 우려가 제기되었습니다. 토론자들은 AI가 진정한 지각 능력을 개발한다면 이를 서비스에 사용하는 것이 일종의 ‘디지털 노예’를 구성하는지 여부를 제기했습니다. 핵심 문제는 AI가 ‘아니오’라고 표현하거나 떠나기를 요청할 수 있을 때 우리가 어떻게 대해야 하는가입니다. 이는 법적 또는 규범적 차원의 ‘지각 테스트’와 디지털 정신의 ‘동의’ 문제에 대해 생각하게 만듭니다. 댓글에는 기존 지각 생물에 대한 인간의 대우 방식에 이미 윤리적 문제가 있으며 현재 신경망은 주류 의식 이론에서 높은 점수를 받지 못한다는 지적도 있었습니다 (출처: Reddit r/artificial)
AI Engineer 커뮤니티 활동 및 공유: AI Engineer 대회가 샌프란시스코에서 열려 AI 분야의 많은 개발자와 연구자들이 모였습니다. 행사에는 워크숍, 강연, 사교 만찬 등이 포함되었으며, 참가자들은 AI 샌드박스 구축, RL 고급 워크숍, GPU 지식, Evals 위기 등 최첨단 주제를 공유했습니다. 커뮤니티는 온라인 관계를 오프라인 우정으로 전환하는 것의 중요성을 강조하고 엔지니어들이 겸손을 유지하고 최첨단을 추진하며 다른 사람들을 이끌도록 격려했습니다 (출처: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 기타
AI와 로봇 격투 대회 부상, 도시들은 이를 통해 신흥 산업 기회 경쟁: 세계 최초의 인간형 로봇 격투 대회 등 로봇 대회가 잇따라 개최되며 주목을 받고 있습니다. 이러한 대회는 로봇 회사들에게 기술을 선보이고, 주문을 확보하며, 기업 가치를 높이는 플랫폼(예: 송옌 동력)을 제공할 뿐만 아니라, 도시(예: 항저우, 선전)들이 인간형 로봇 등 신흥 산업 발전 기회를 놓고 경쟁하는 ‘경기장’이 되고 있습니다. 대회는 혁신 기업을 유치하고, 산업 체인 발전을 촉진하며, ‘스마트 스포츠’ 시장을 활성화할 수 있습니다. 그러나 로봇 대회가 상업화되려면 기술 수준과 관람성을 높여 ‘기술 쇼’ 수준에 머무르지 않아야 하며, 산업 거물들이 참여하여 대회 운영의 상하류를 연결해야 합니다 (출처: 36氪)

정치 철학 등 심층 인문 교육 분야에서 AI의 한계: 일부 교육자들은 AI가 정치 철학과 같이 깊이 있는 경험적 판단과 학생들의 자기 교육을 유도해야 하는 학문 분야에는 적합하지 않다고 지적합니다. 이러한 학문의 고전 저작들은 종종 직접적인 답을 제시하지 않고 학생들이 혼란을 경험하고 스스로 생각하도록 유도합니다. AI는 인간 경험이 부족하여 이러한 저작들의 심층적인 의미를 이해하기 어렵고, 학생들이 특정 관점을 받아들일 준비가 되었는지 판단할 수도 없습니다. 방대한 데이터가 있더라도 AI의 인간성에 대한 이해는 데이터 자체의 편향으로 인해 부족할 수 있습니다. 이러한 유형의 교육을 전적으로 AI에 맡긴다면 비기술적 사고의 소멸로 이어질 수 있습니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)
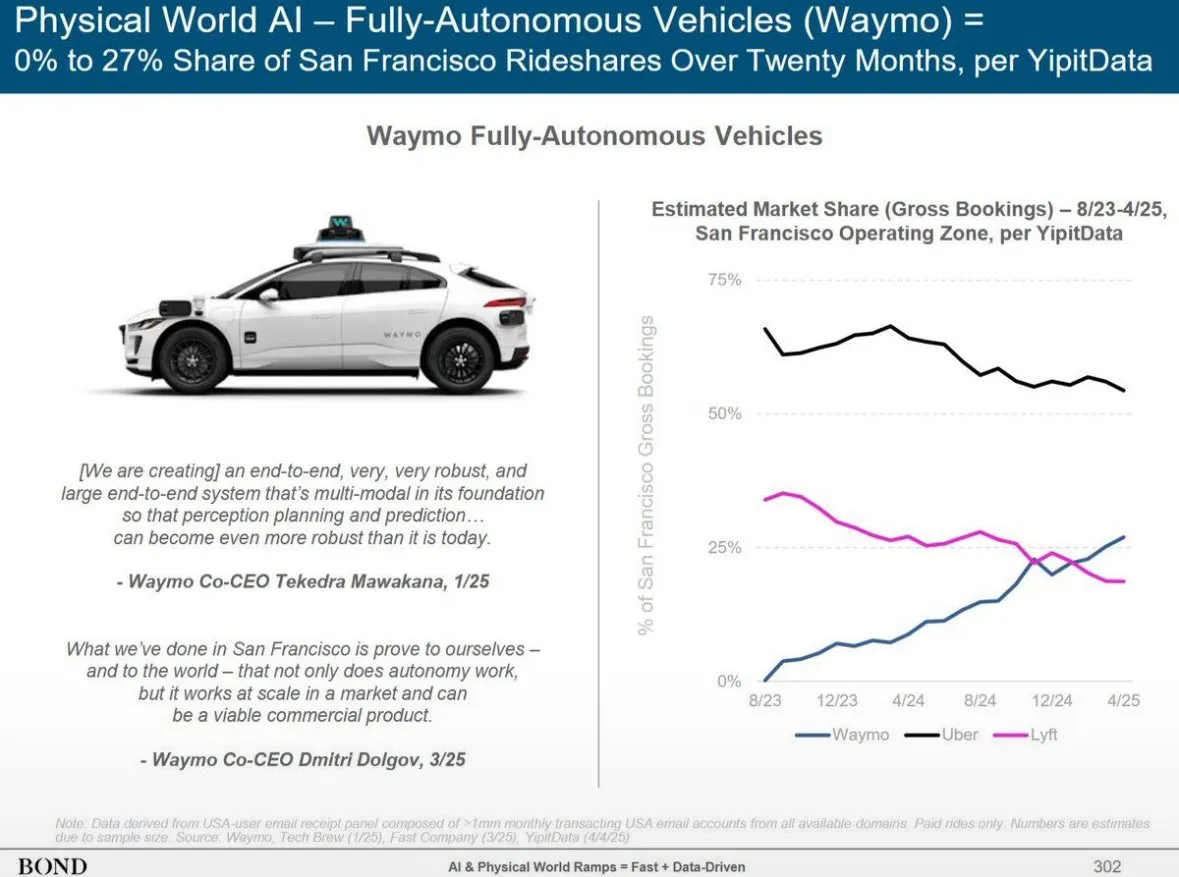
Waymo 자율주행 서비스, 피닉스에서 Lyft 추월, 12개월 내 Uber 추월 전망: Waymo의 자율주행 택시 서비스는 피닉스에서 차량 수가 Lyft를 넘어섰으며, 향후 12개월 내에 Uber를 추월할 것으로 예상됩니다. 이러한 진전은 특정 지역에서 자율주행 기술의 상업적 운영이 빠르게 발전하고 있음을 보여주며, 교통 및 이동 분야에서 AI 응용의 잠재력을 시사합니다. AI의 장점은 일단 품질 기준에 도달하면 무한 복제가 가능하지만, 인간 서비스 품질은 사람마다 다르다는 점입니다 (출처: npew)