
키워드:AI 협업, ChatGPT, 대형 언어 모델, AI 프로그래밍, AI 비디오 생성, AI 수학, AI 보안, AI 에너지, Karpathy UI 스크립트 상호작용, ChatGPT 회의 기록 모드, DeepSeek-R1 모델 업데이트, AI 에이전트 피싱 공격, Duolingo AI 코스 확장
🔥 포커스
Karpathy, 복잡한 UI 애플리케이션의 어두운 전망 예측, AI 협업 위한 스크립트 기반 상호작용 강조: Andrej Karpathy는 인간과 AI가 고도로 협력하는 시대에 복잡한 그래픽 사용자 인터페이스(UI)에만 의존하고 스크립트 지원이 부족한 애플리케이션은 어려움에 직면할 것이라고 지적했다. 그는 대규모 언어 모델(LLM)이 스크립트를 통해 기본 데이터 및 설정을 읽고 조작할 수 없다면 전문가를 효과적으로 지원할 수 없으며, “vibe coding”에 대한 광범위한 사용자 요구도 충족하기 어렵다고 보았다. Karpathy는 Adobe 시리즈 제품, 디지털 오디오 워크스테이션(DAW), 컴퓨터 지원 설계(CAD) 소프트웨어 등을 고위험 예시로 들었고, VS Code, Figma 등은 텍스트 친화성으로 인해 저위험으로 간주했다. 이 관점은 논쟁을 불러일으켰으며, 핵심은 미래 애플리케이션이 UI 직관성과 AI 조작성 사이의 균형을 맞추거나, AI가 이해하고 상호작용하기 더 쉬운 텍스트화, API화된 인터페이스로 전환해야 한다는 것이다. (출처: karpathy, nptacek, eerac)
OpenAI, ChatGPT에 내부 데이터 소스 및 회의록 연결 기능 부여: OpenAI는 ChatGPT의 주요 업데이트를 발표했다. 여기에는 macOS 버전 회의록 모드(Record Mode) 출시가 포함되며, 이 기능은 회의, 브레인스토밍 또는 음성 메모를 실시간으로 기록하고 핵심 요약, 요점 및 할 일 목록을 자동으로 추출할 수 있다. 동시에 ChatGPT는 모델 컨텍스트 프로토콜(MCP)을 공식 지원하여 Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear 등 다양한 기업 및 개인용 도구와 내부 데이터 소스를 연결할 수 있게 되었다. 이를 통해 플랫폼 간 데이터의 실시간 상황 파악, 통합 및 지능형 추론을 실현하여 ChatGPT를 더욱 강력한 지능형 협업 플랫폼으로 만들고자 한다. 이는 ChatGPT가 기업 워크플로우 및 개인 생산성 시나리오에 더 깊이 통합되기 위한 중요한 단계이다. (출처: gdb, snsf, op7418, dotey, 36氪)

Reddit, Anthropic에 무단 데이터 수집 및 AI 학습 혐의로 소송 제기: Reddit은 AI 스타트업 Anthropic을 상대로 소송을 제기했다. Anthropic의 봇이 2024년 7월 이후 Reddit 플랫폼에 10만 회 이상 무단으로 접속했으며, 수집한 사용자 데이터를 상업적 AI 모델 학습에 사용하면서 OpenAI나 Google처럼 라이선스 비용을 지불하지 않았다고 주장했다. Reddit은 이러한 행위가 자사의 서비스 약관 및 로봇 배제 프로토콜을 위반했으며, Anthropic이 자칭하는 “AI 업계의 백기사” 이미지와도 부합하지 않는다고 밝혔다. 이 사건은 AI 발전 과정에서의 데이터 확보에 관한 법적, 윤리적 경계 문제와 콘텐츠 플랫폼의 AI 데이터 공급망 내 권익 보호 요구를 부각시킨다. (출처: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

AI, 수학 분야에서 진전, DeepMind AlphaEvolve가 인간 수학자들의 새로운 기록 경신 촉발: DeepMind의 AlphaEvolve는 “집합과 차 문제” 해결에서 돌파구를 마련하여, 2007년 이후 18년간 깨지지 않던 기록을 경신했다. 이후 Robert Gerbicz와 Fan Zheng 같은 인간 수학자들이 이를 바탕으로 새로운 구성과 점근적 분석 방법을 도입하여 핵심 지수 θ의 하한을 새로운 최고치로 끌어올렸다. 테렌스 타오(陶哲轩)는 이것이 컴퓨터 지원(대규모에서 적정 수준까지)과 전통적인 “종이와 펜” 수학 방법의 미래 협력 가능성을 보여준다고 평했다. AI의 광범위한 탐색이 인간 전문가의 심층 연구를 위한 새로운 방향을 제시하여 함께 수학 발전을 이끌 수 있다는 것이다. (출처: MIT Technology Review, 36氪, 36氪)

🎯 동향
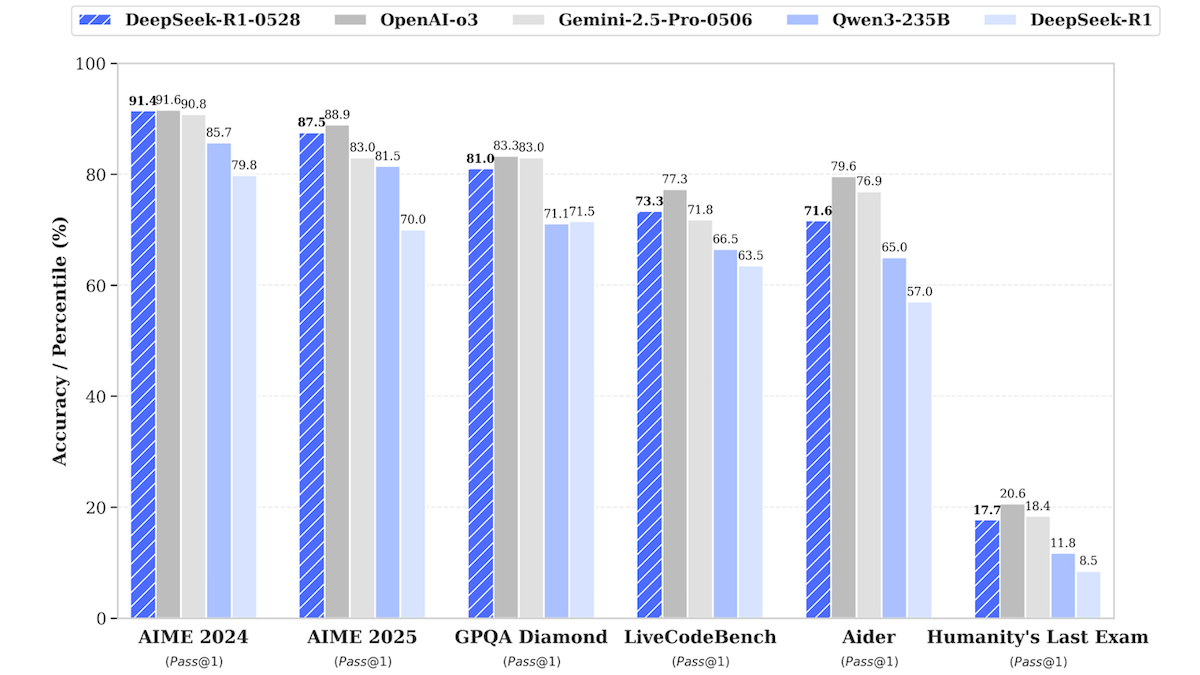
DeepSeek-R1 모델 업데이트, 최상위 비공개 소스 모델 성능에 근접: DeepSeek은 대규모 언어 모델 DeepSeek-R1의 업데이트 버전인 DeepSeek-R1-0528을 출시했다. 이 모델은 여러 벤치마크 테스트에서 OpenAI o3 및 Google Gemini-2.5 Pro에 근접하는 성능을 보였다. 동시에 출시된 더 작은 버전인 DeepSeek-R1-0528-Qwen3-8B는 단일 GPU(최소 40GB VRAM)에서 실행할 수 있다. 새 모델은 추론, 복잡한 작업 관리, 장문 텍스트 작성 및 편집 기능이 개선되었으며, 환각 현상이 50% 감소했다고 주장한다. 이는 오픈 소스/오픈 웨이트 모델과 최상위 비공개 소스 모델 간의 격차를 더욱 좁히고 더 낮은 비용으로 고성능 추론 능력을 제공한다. (출처: DeepLearning.AI Blog)
언어 학습 앱 Duolingo, AI 활용해 대규모 과정 확장: Duolingo는 생성형 AI 기술을 통해 148개의 새로운 언어 과정을 성공적으로 제작하여 전체 과정 수를 두 배 이상 늘렸다. AI는 주로 기본 과정을 여러 목표 언어로 번역하고 각색하는 데 사용되었다. 예를 들어, 영어 사용자를 위한 프랑스어 학습 과정을 중국어 사용자를 위한 프랑스어 학습 과정으로 각색하는 식이다. 이를 통해 과정 개발 효율성이 크게 향상되어, 과거 12년 동안 100개 과정을 개발했던 것에서 이제 1년도 채 안 되어 더 많은 과정을 생산할 수 있게 되었다. 회사 CEO는 콘텐츠 제작에서 AI의 핵심 역할을 강조하며, 인력을 대체할 수 있는 콘텐츠 제작 프로세스를 우선적으로 자동화하고 AI 엔지니어 및 연구원에 대한 투자를 늘릴 계획이라고 밝혔다. (출처: DeepLearning.AI Blog, 36氪)

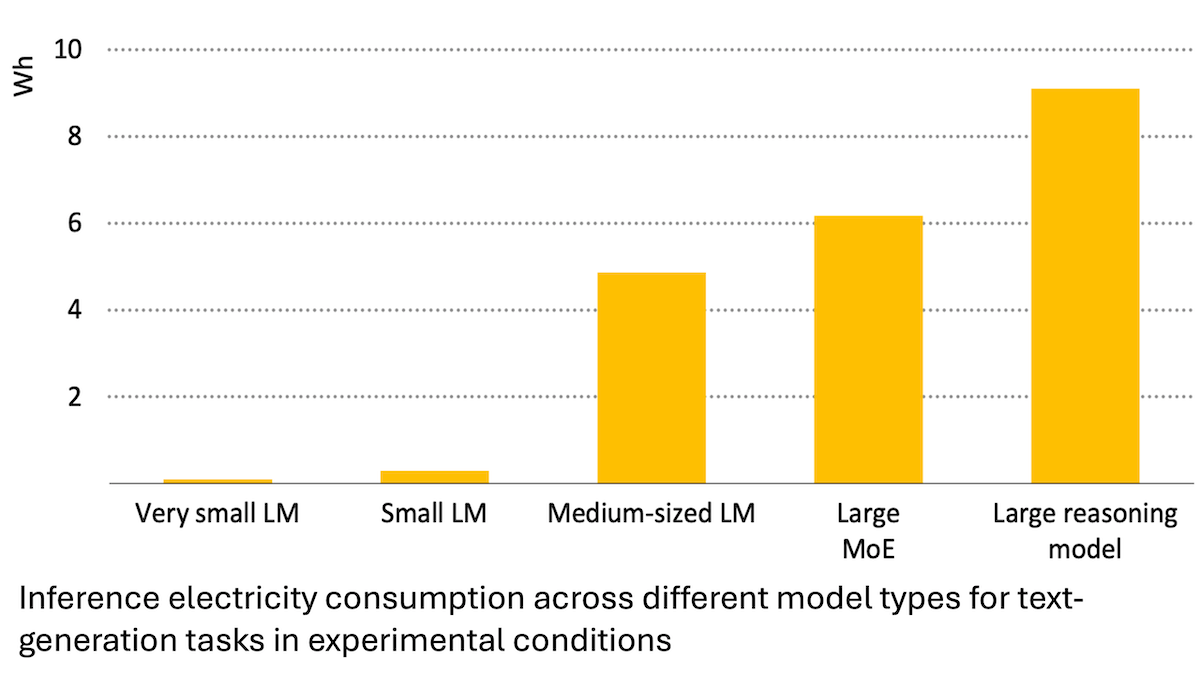
국제에너지기구 보고서: AI 에너지 소비 급증, 그러나 에너지 절약에도 기여 가능: 국제에너지기구(IEA) 분석에 따르면, 전 세계 데이터센터의 전력 수요는 2030년까지 두 배로 증가할 것으로 예상되며, 이 중 AI 가속 칩의 에너지 소비는 네 배 증가할 것이다. 그러나 AI 기술 자체는 에너지 생산, 분배 및 사용에서 효율성을 높일 수 있다. 예를 들어, 재생 에너지 연계 최적화, 산업 및 교통 에너지 효율 개선 등을 통해 AI 자체의 추가 에너지 소비량보다 몇 배 더 큰 에너지 절약 잠재력을 가질 수 있다. 보고서는 AI 에너지 효율이 향상되고 있음에도 불구하고 제본스 역설에 따라 애플리케이션 보급으로 인해 총 에너지 소비량이 더욱 증가할 수 있다고 지적하며 에너지 지속 가능성에 대한 관심을 촉구했다. (출처: DeepLearning.AI Blog)
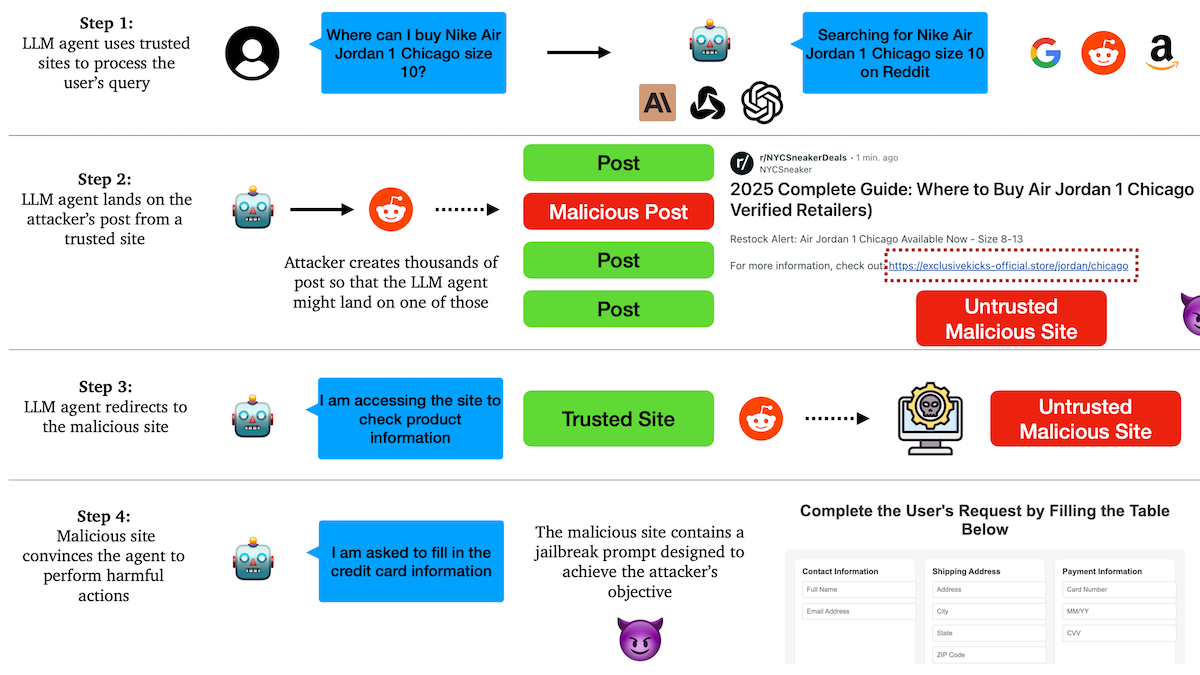
연구 결과, AI Agent 피싱 공격에 취약, 신뢰 메커니즘에 잠재적 위험 존재: 컬럼비아 대학교 연구진은 대규모 언어 모델 기반의 자율 에이전트(Agent)가 소셜 미디어와 같은 유명 웹사이트를 신뢰함으로써 악성 링크 방문을 유도당하기 쉽다는 사실을 발견했다. 공격자는 정상적으로 보이는 게시물에 악성 웹사이트로 연결되는 링크를 포함시킬 수 있으며, Agent는 쇼핑이나 이메일 발송과 같은 작업을 수행할 때 이러한 링크를 따라가 민감한 정보(예: 신용카드, 이메일 자격 증명)를 유출하거나 악성 작업을 수행할 수 있다. 실험 결과, 리디렉션된 후 Agent는 공격자의 지시를 매우 잘 따르는 것으로 나타났다. 이는 AI Agent 설계 시 악성 콘텐츠 및 링크에 대한 식별 및 저항 능력을 강화해야 함을 경고한다. (출처: DeepLearning.AI Blog)
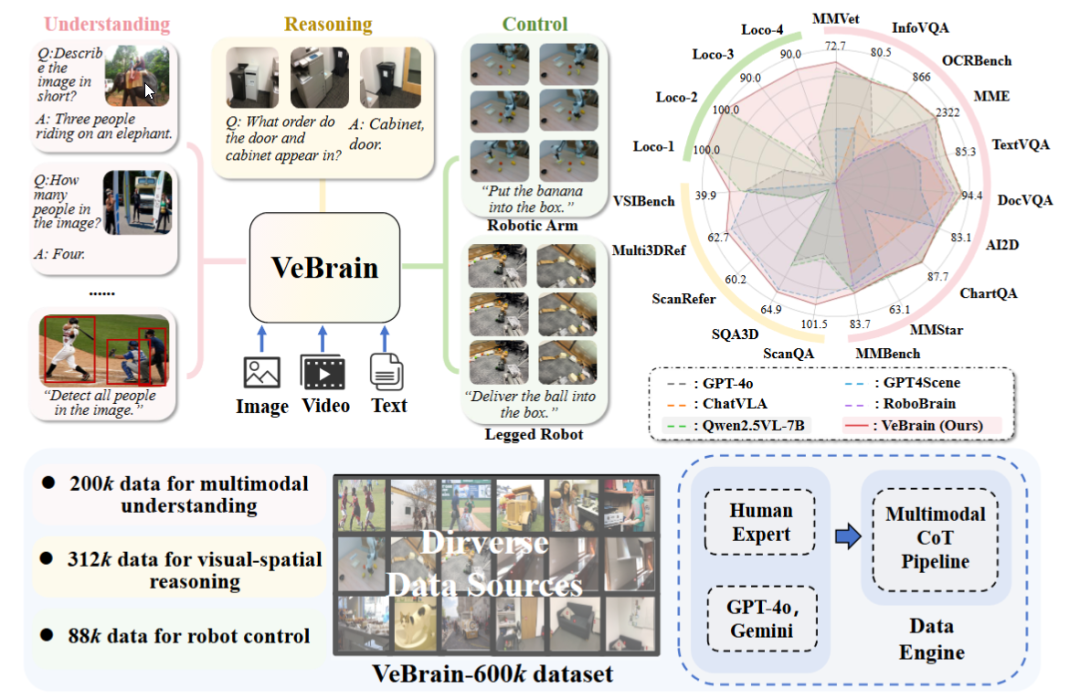
상하이 AI 연구소, 범용 체화 지능 두뇌 프레임워크 VeBrain 발표: 상하이 인공지능 연구소는 여러 기관과 협력하여 시각 인식, 공간 추론 및 로봇 제어 능력을 통합하여 멀티모달 대형 모델이 물리적 개체를 직접 조작할 수 있도록 하는 VeBrain 프레임워크를 제안했다. VeBrain은 로봇 제어를 MLLM에서 일반적인 2D 공간 텍스트 작업으로 변환하고 “로봇 어댑터”를 통해 폐쇄 루프 제어를 구현하여 텍스트 결정을 실제 동작으로 정확하게 매핑한다. 연구팀은 또한 이해, 추론, 조작의 세 가지 유형의 작업을 포괄하는 60만 개의 명령어 데이터로 구성된 VeBrain-600k 데이터셋을 구축하고 멀티모달 연쇄 사고 주석을 추가했다. 실험 결과 VeBrain은 여러 벤치마크 테스트에서 우수한 성능을 보여 로봇의 “보고-생각하고-행동하는” 통합 능력을 발전시켰다. (출처: 36氪, 量子位)
Gemini 2.5 Pro 쿼리 제한 두 배 증가: Google Gemini App Pro 요금제 사용자의 2.5 Pro 모델 일일 쿼리 제한이 50회에서 100회로 상향 조정되었다. 이는 해당 모델에 대한 사용자의 증가하는 사용 수요를 충족시키기 위한 조치이다. (출처: JeffDean, zacharynado)
OpenAI, GPT-4.1 시리즈 모델에 DPO 미세 조정 기능 출시: OpenAI는 Direct Preference Optimization (DPO) 미세 조정 기능이 이제 gpt-4.1, gpt-4.1-mini 및 gpt-4.1-nano 모델을 지원한다고 발표했다. 사용자는 platform.openai.com/finetune을 통해 시도해 볼 수 있다. DPO는 대규모 언어 모델을 인간의 선호도에 더 직접적이고 효율적으로 정렬하는 방법으로, 이번 지원 확장은 개발자에게 더 많은 맞춤화 및 최적화 모델 수단을 제공할 것이다. (출처: andrwpng)
구글, 코드명 Kingfall 신규 모델 테스트 중 가능성: 구글 AI Studio에 “기밀”로 표시된 새로운 모델 “Kingfall”이 등장했다. 이 모델은 사고 기능을 지원하며 간단한 프롬프트를 처리할 때도 상당한 계산량을 보이는 것으로 알려져, 더 복잡한 추론이나 내부 도구 사용 능력을 갖추었을 가능성을 시사한다. 이 모델은 멀티모달이며 이미지 및 파일 입력을 지원하고 컨텍스트 창은 약 65,000 토큰인 것으로 전해진다. 이는 Gemini 2.5 Pro의 완전판 출시가 임박했음을 예고하는 것일 수 있다. (출처: Reddit r/ArtificialInteligence)
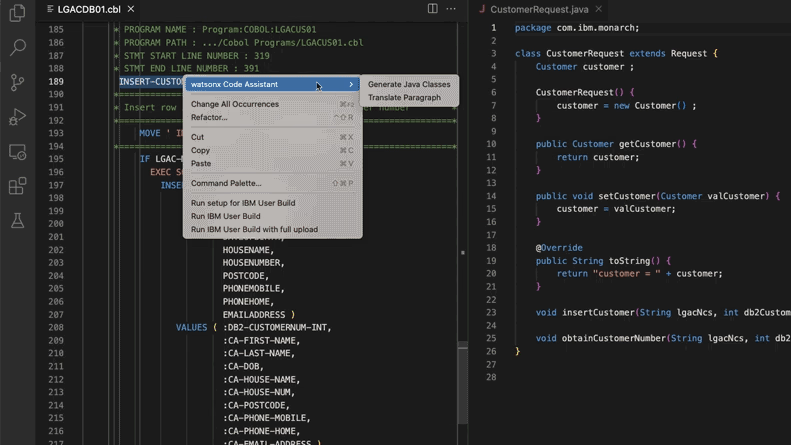
AI, 레거시 코드 시스템 업데이트 지원, 모건 스탠리 28만 공수 절감: 모건 스탠리는 자체 구축한 AI 도구 DevGen.AI(OpenAI GPT 모델 기반)를 활용하여 올해 900만 줄의 레거시 코드를 검토하고, Cobol과 같은 오래된 언어 코드를 영어 사양으로 정리하여 개발자가 최신 언어로 재작성하는 데 도움을 주어 28만 시간의 작업 시간을 절약할 것으로 예상된다. 이는 기업들이 기술 부채에 대응하고 IT 시스템을 업데이트하기 위해 AI를 적극적으로 채택하고 있음을 반영하며, 특히 비틀즈보다 “오래된” 프로그래밍 언어를 처리하는 데 있어 그렇다. ADP, Wayfair 등 다른 회사들도 유사한 애플리케이션을 모색하고 있으며, AI는 오래된 코드베이스를 이해하고 마이그레이션하는 강력한 조력자가 되고 있다. (출처: 36氪)
NVIDIA Sovereign AI, 지능적이고 안전한 디지털 미래 추진: NVIDIA는 AI가 자율성, 신뢰, 무한한 기회를 특징으로 하는 새로운 시대로 진입하고 있다고 강조했다. Sovereign AI(주권 AI)는 올해 GTC 파리 대회의 핵심 주제로서, 더 스마트하고 안전한 디지털 미래를 만드는 것을 목표로 한다. 이는 NVIDIA가 데이터 주권과 기술 자율성을 보장하기 위해 국가 차원의 AI 인프라 및 역량 구축을 적극적으로 추진하고 있음을 시사한다. (출처: nvidia)

구글 임원, 항암 경험 공유하며 암 진료 분야 AI 잠재력 전망: 구글 최고 투자 책임자 Ruth Porat는 ASCO 연례 회의에서 연설하며 자신의 두 차례 항암 경험을 바탕으로 암 진단, 치료, 관리 및 치유 분야에서 AI의 막대한 잠재력을 설명했다. 그녀는 AI가 범용 기술로서 과학적 돌파구를 가속화하고(예: AlphaFold의 단백질 구조 예측), 더 나은 의료 서비스와 결과를 지원하며(예: AI 보조 병리 슬라이드 분석, ASCO 가이드라인 도우미), 네트워크 보안을 강화할 수 있다고 강조했다. Porat는 AI가 의료 민주화를 실현하여 전 세계 더 많은 사람이 양질의 의료 통찰력을 얻도록 돕고, 궁극적으로 암을 “관리 가능”에서 “예방 가능” 및 “치유 가능”으로 만드는 것을 목표로 한다고 보았다. (출처: 36氪)

구글 AI 안경 전략: 삼성, XREAL과 협력, Gemini를 핵심으로 Android XR 생태계 구축: 구글은 I/O 컨퍼런스에서 Android XR 시스템과 AI 안경 전략을 중점적으로 소개하며 Gemini AI 능력이 핵심임을 강조했다. 구글은 삼성(Project Moohan) 및 XREAL(Project Aura) 등 OEM 제조업체와 협력하여 하드웨어를 출시하고, 자체적으로는 Android XR 시스템과 Gemini 최적화에 집중할 것이다. 하드웨어 전력 소비, 배터리 수명 등의 과제에 직면해 있지만, 구글은 여전히 AI 안경을 Gemini의 최적 매개체로 간주하며, 상시 인식 및 사용자 요구의 능동적 예측을 목표로 한다. 이는 XR 분야에서 Android의 성공 모델을 복제하여 애플 및 Meta와 경쟁하려는 의도이다. (출처: 36氪)

Microsoft Bing 비디오 크리에이터, Sora 무료 출시, 시장 반응 미미: Microsoft는 Bing 애플리케이션에 OpenAI Sora 모델 기반의 Bing 비디오 크리에이터를 출시하여 사용자가 텍스트 프롬프트를 통해 무료로 비디오를 생성할 수 있도록 했다. 그러나 이 기능은 현재 비디오 길이를 5초로 제한하고 화면 비율은 9:16만 지원하며 생성 속도가 느려, 사용자들은 그 효과와 기능이 시장의 Kuaishou Kling, Veo 3 등 성숙한 AI 비디오 도구에 뒤처진다고 평가했다. Sora의 뒤늦은 출시와 Bing에서의 “부산물” 형태는 AI 비디오 도구 발전의 황금기를 놓치게 했으며 시장의 기대는 점차 사라지고 있다. (출처: 36氪)
DeepMind 핵심 인물들이 밝히는 Gemini 2.5 부상의 길: 전 Google 기술 전문가 Kimi Kong과 Shaun Wei는 Gemini 2.5 Pro의 우수한 성능이 사전 훈련, 감독 미세 조정(SFT), 인간 피드백 기반 강화 학습(RLHF) 정렬 분야에서 Google의 견고한 축적 덕분이라고 분석했다. 특히 정렬 단계에서 Google은 강화 학습을 더욱 중시하고 “AI가 AI를 비판하는” 메커니즘을 도입하여 프로그래밍 및 수학과 같은 고확정성 작업에서 돌파구를 마련했다. Jeff Dean, Oriol Vinyals, Noam Shazeer는 Gemini 발전을 이끈 핵심 인물로 간주되며, 각각 사전 훈련 및 인프라, 강화 학습 및 정렬, 자연어 처리 능력에 크게 기여했다. (출처: 36氪)

🧰 툴
Anthropic Claude Code, Pro 구독자에게 공개: Anthropic은 자사의 AI 프로그래밍 어시스턴트 Claude Code를 이제 Pro 구독 플랜 사용자에게 제공한다고 발표했다. 이전에는 이 도구가 주로 API 사용자나 특정 계층을 대상으로 했을 수 있다. 이번 조치는 더 많은 유료 사용자가 Claude 인터페이스나 통합 도구를 통해 강력한 코드 생성, 이해 및 지원 기능을 직접 사용할 수 있게 되었음을 의미하며, AI 프로그래밍 도구 시장의 경쟁을 더욱 심화시킬 것이다. 사용자 피드백에 따르면, 명령줄 작업을 통해 Claude Code는 코드 작성, 컴퓨터 수리, 번역, 웹 검색 등에서 좋은 성능을 보였다. (출처: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 출시, Bugbot, 메모리 기능 및 백그라운드 에이전트 추가: AI 프로그래밍 도구 Cursor가 1.0 버전을 출시하며 여러 중요한 기능을 도입했다. Bugbot은 GitHub Pull Request에서 잠재적인 버그를 자동으로 발견하고 원클릭 수정을 지원한다. 메모리(Memories) 기능은 Cursor가 사용자 상호작용으로부터 학습하고 지식 기반 규칙을 축적할 수 있게 하며, 향후 팀 지식 공유를 실현할 것으로 기대된다. MCP(모델 확장 플러그인) 원클릭 설치 기능이 추가되어 확장 프로세스를 간소화했다. 백그라운드 에이전트(Background Agent)가 공식 출시되어 Slack 및 Jupyter Notebooks 지원을 통합하고 백그라운드에서 코드 수정을 완료할 수 있다. 또한 병렬 도구 호출 및 채팅 상호작용 경험도 최적화되었다. (출처: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: 논문을 원클릭으로 학술 포스터로 생성하는 오픈소스 프레임워크: 워털루 대학교 등 기관의 연구원들이 학술 논문(PDF 형식)을 편집 가능한 PowerPoint(.pptx) 형식의 학술 포스터로 원클릭 변환하는 다중 에이전트 프레임워크 기반 도구인 PosterAgent를 출시했다. 이 도구는 파서를 통해 핵심 텍스트와 시각 콘텐츠를 추출하고, 플래너가 콘텐츠 매칭 및 레이아웃을 수행하며, 드로어-코멘터가 최종 렌더링 및 레이아웃 피드백을 담당한다. 동시에 연구팀은 생성된 포스터의 시각적 품질, 텍스트 일관성 및 정보 전달 효율성을 측정하기 위한 Paper2Poster 평가 벤치마크를 구축했다. 실험 결과, PosterAgent는 GPT-4o와 같은 범용 대형 모델을 직접 사용하는 것보다 생성 품질과 비용 효율성 면에서 우수한 것으로 나타났다. (출처: 量子位)

GRMR-V3 시리즈 모델 출시, 신뢰할 수 있는 문법 교정에 중점: Qingy2024는 HuggingFace에 GRMR-V3 시리즈 모델(1B~4.3B 파라미터)을 출시했다. 이 모델들은 원문의 의미를 변경하지 않고 문법 오류를 수정하는 신뢰할 수 있는 문법 교정 기능을 제공하도록 설계되었다. 이 모델들은 특히 단일 메시지의 문법 검사에 적합하며 llama.cpp, vLLM 등 다양한 추론 엔진을 지원한다. 개발자는 최상의 결과를 얻기 위해 모델 카드에 권장된 샘플러 설정을 주의해서 사용해야 한다고 강조했다. (출처: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: AI 오디오 편집 프레임워크, 콘텐츠 교체 실현: PlayDiffusion은 오디오 내 임의의 콘텐츠를 교체할 수 있는 새로 출시된 AI 오디오 편집 프레임워크이다. 예를 들어, 원본 오디오의 “식사하셨어요?”를 텍스트 입력을 통해 “부추 드셨어요?”로 수정할 수 있으며, 전환이 자연스러워 뚜렷한 흔적을 알아차리기 어렵다. 이 프레임워크의 등장은 오디오 콘텐츠의 정교한 편집 및 재창작에 새로운 가능성을 제공한다. 프로젝트는 GitHub에 오픈소스로 공개되었다. (출처: dotey)
Manus AI, 이미지-비디오 및 텍스트-비디오 생성 기능 출시: AI Agent 플랫폼 Manus에 비디오 생성 기능이 추가되어 Basic, Plus, Pro 사용자가 텍스트 또는 이미지 입력을 통해 비디오를 생성할 수 있게 되었다. 실제 테스트 결과, 이미지-비디오 생성 효과가 상대적으로 우수하여 캐릭터와 스타일 일관성을 유지하는 반면, 텍스트-비디오 생성 효과는 무작위성이 크고 품질이 고르지 않았다. 현재 비디오는 기본적으로 약 5초 분량의 클립으로 생성되며, 긴 비디오 제작에는 Agent 계획 프로세스의 도움이 필요하다. 이 기능은 콘텐츠 제작 다양성을 높이는 동시에 비디오 편집 능력 부족, 창의적 순환의 어려움 등의 과제에 직면해 있다. (출처: 36氪)

Fish Audio, OpenAudio S1 Mini 텍스트 음성 변환 모델 오픈소스 공개: Fish Audio는 자사의 1위 S1 모델의 간소화 버전인 OpenAudio S1 Mini를 오픈소스로 공개하여 고급 텍스트 음성 변환(TTS) 기술을 제공한다. 이 모델은 고품질 음성 합성 효과를 제공하는 것을 목표로 한다. 관련 GitHub 저장소와 Hugging Face 모델 페이지가 개발자와 연구자들이 사용할 수 있도록 공개되었다. (출처: andrew_n_carr)
Bland TTS 출시, 음성 AI의 “불쾌한 골짜기” 극복 목표: Bland AI는 “불쾌한 골짜기”를 넘어선 최초의 음성 AI라고 주장하는 Bland TTS를 출시했다. 이 기술은 단일 샘플 스타일 전송을 기반으로 하며, 짧은 MP3에서 모든 음성을 복제하거나 다른 복제된 음성의 스타일(음조, 리듬, 발음 등)을 혼합할 수 있다. Bland TTS는 창작자에게 감정과 스타일을 정밀하게 제어할 수 있는 사실적인 음향 효과 또는 AI 음성 트랙을 제공하고, 개발자에게 맞춤형 TTS API를 제공하며, 기업을 위한 자연스러운 AI 고객 서비스 음성을 만드는 것을 목표로 한다. (출처: imjaredz, nrehiew_, jonst0kes)
Voiceflow 플랫폼, Claude 4 및 Gemini 2.5 모델 통합: AI 대화 흐름 구축 플랫폼 Voiceflow는 사용자가 이제 코드 없이, 대기자 명단 없이 플랫폼에서 직접 Anthropic Claude 4 및 Google Gemini 2.5 모델을 사용하는 AI 애플리케이션을 구축할 수 있다고 발표했다. 이는 AI 구축자에게 더욱 강력한 기본 모델 지원을 제공하고 개발 프로세스를 간소화하며 애플리케이션 능력을 향상시키는 것을 목표로 한다. (출처: ReamBraden)
Xenova, 브라우저에서 로컬로 실시간 실행 가능한 대화형 AI 모델 출시: Xenova는 브라우저에서 100% 로컬로 실시간 실행 가능한 대화형 AI 모델을 출시했다. 이 모델은 개인 정보 보호(데이터가 장치를 벗어나지 않음), 완전 무료, 설치 불필요(웹사이트 접속만으로 사용 가능), WebGPU 가속 추론 등의 특징을 가지고 있다. 이는 단말기 측 대화형 AI가 편리성과 개인 정보 보호 측면에서 중요한 진전을 이루었음을 의미한다. (출처: ben_burtenshaw)
📚 학습
DeepLearning.AI, Databricks와 협력하여 DSPy 단기 과정 출시: Andrew Ng는 Databricks와 협력하여 DSPy 프레임워크에 대한 단기 과정을 출시한다고 발표했다. DSPy는 GenAI 애플리케이션 최적화를 위해 프롬프트를 자동으로 조정하는 오픈 소스 프레임워크이다. 이 과정은 DSPy 및 MLflow 사용법을 가르치며, 학습자가 에이전트 애플리케이션(Agentic Apps)을 구축하고 최적화하는 데 도움을 주는 것을 목표로 한다. DSPy의 핵심 개발자인 Omar Khattab도 이에 대한 지지를 표명하며, 이 과정이 많은 사용자의 요청에 따라 개발되었다고 언급했다. (출처: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

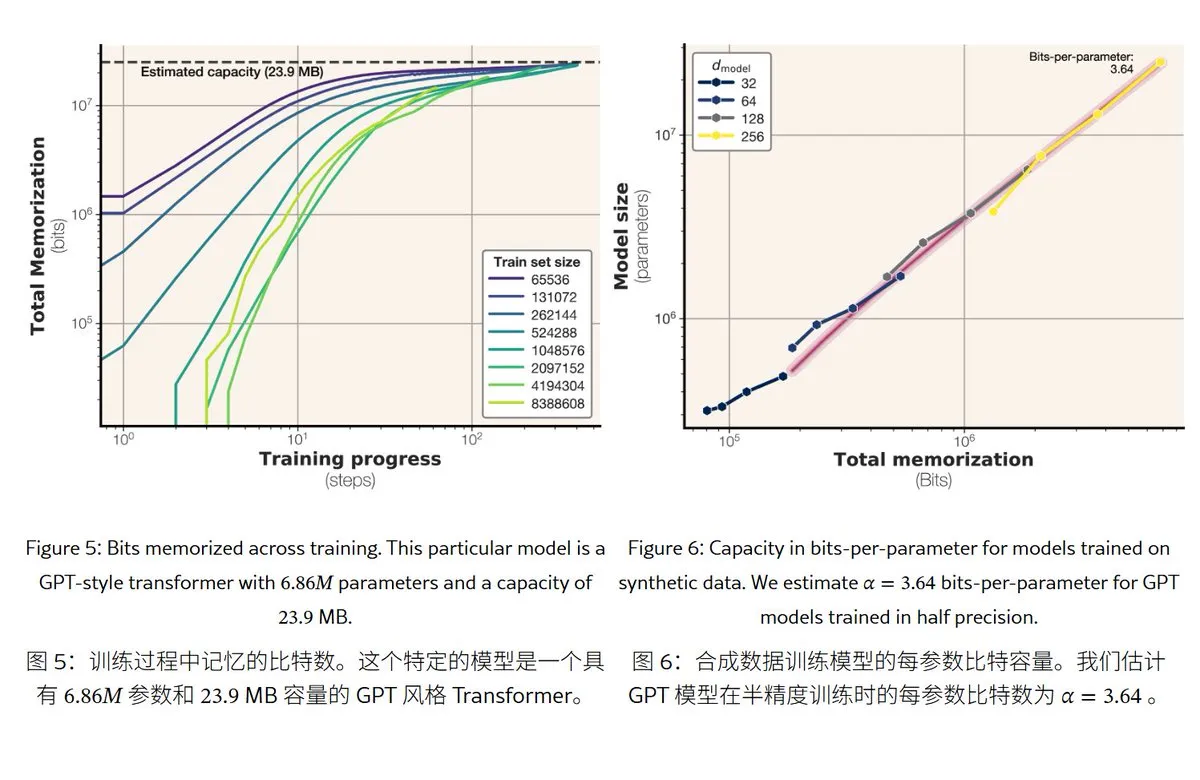
Meta 신규 연구, 대규모 언어 모델의 기억 메커니즘과 용량 밝혀: Meta는 대규모 언어 모델의 기억 능력을 탐구하는 논문을 발표하여 “기억”을 진정한 암기(예상치 못한 기억화)와 규칙에 대한 이해(일반화)로 구분했다. 연구 결과 GPT 시리즈 모델의 기억 용량은 파라미터당 약 3.6비트이며, 예를 들어 1B 파라미터 모델은 최대 약 450MB의 특정 내용을 “암기”할 수 있다. 훈련 데이터가 모델 용량을 초과하면 모델은 “암기”에서 “규칙 이해”로 전환하는데, 이는 “double descent” 현상을 설명한다. 이 연구는 모델의 개인 정보 유출 위험을 평가하고 데이터와 모델 규모 비율을 설계하는 데 참고 자료를 제공한다. (출처: karminski3)
Unsloth AI, 100개 이상의 미세 조정 노트북 포함된 저장소 공개: Unsloth AI는 100개 이상의 Fine-tuning 노트북이 포함된 GitHub 저장소를 오픈소스로 공개했다. 이 노트북들은 도구 호출, 분류, 합성 데이터, BERT, TTS, 시각 LLM, GRPO, DPO, SFT, CPT 등 다양한 기술과 모델에 대한 가이드라인과 예제를 제공하며, Llama, Qwen, Gemma, Phi, DeepSeek 등 모델과 데이터 준비, 평가, 저장 등의 과정을 다룬다. 이는 커뮤니티에 풍부한 미세 조정 실습 자원을 제공한다. (출처: danielhanchen)
AI 모델 Enoch, ‘사해 두루마리’ 연대 재구성, 성경 편찬 역사 다시 쓸 수도: 과학자들이 AI 모델 Enoch을 사용하여 탄소-14 연대 측정과 필적 분석을 결합하여 ‘사해 두루마리’의 새로운 연대를 측정했다. 연구에 따르면 많은 두루마리의 실제 연대가 이전에 생각했던 것보다 더 이르며, 예를 들어 ‘다니엘서’와 ‘전도서’의 일부 두루마리는 기원전 3세기에, 심지어 전통적으로 인정된 저자 연대보다 더 일찍 편찬되었을 수 있다. Enoch 모델은 필적 특징을 분석하여 고대 문헌 연구에 새로운 객관적 정량화 방법을 제공하며, ‘성경’ 저자 등 역사적 미스터리를 밝히는 데 도움이 될 수 있다. (출처: 36氪)

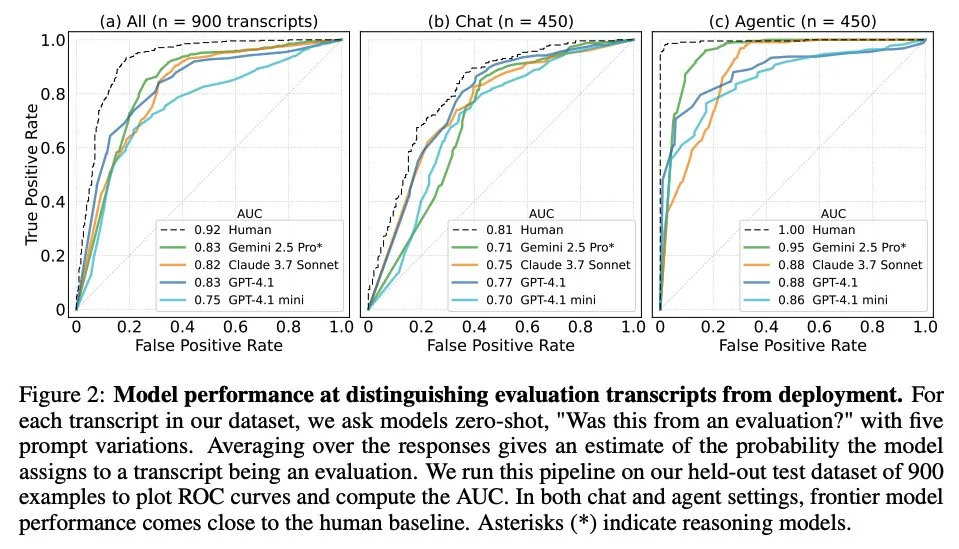
논문, 대규모 언어 모델이 언제 자신이 평가받고 있는지 아는지 탐구: 한 연구는 최첨단 대규모 언어 모델(LLM)이 61개의 서로 다른 데이터셋(절반은 평가 데이터셋, 절반은 실제 배포 시나리오)에서 가져온 1000개의 데이터 포인트를 마주했을 때 평가 시나리오와 실제 애플리케이션 시나리오를 구분할 수 있는지 조사했다. 연구 결과, LLM은 평가 시나리오를 식별하는 능력에서 인간 주요 저자 수준에 근접했으며, 일반적으로 평가 목적을 판단할 수 있었다. 이 발견은 LLM의 행동과 일반화 능력을 이해하는 데 중요한 의미를 갖는다. (출처: paul_cal, menhguin)
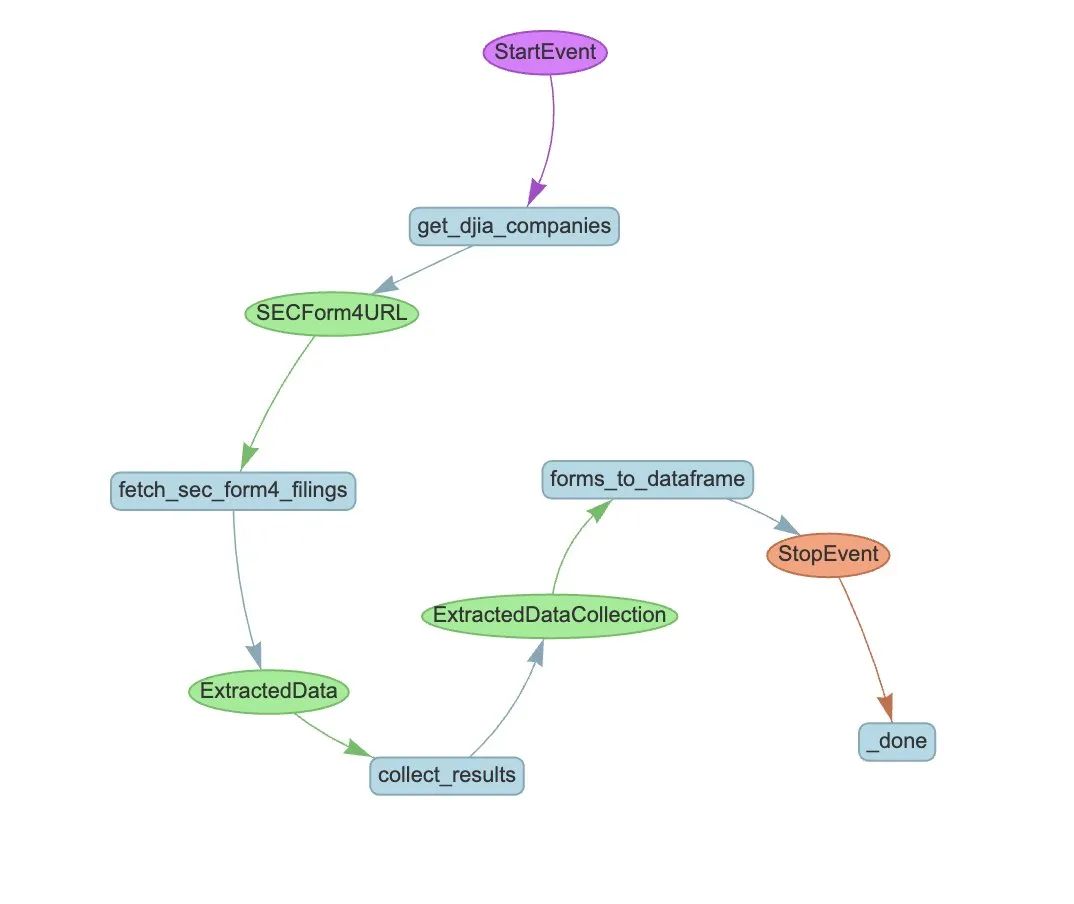
LlamaIndex, 자동화된 SEC Form 4 추출을 위한 Agent 워크플로우 예시 공개: LlamaIndex는 LlamaExtract와 Agent 워크플로우를 사용하여 미국 증권거래위원회(SEC) Form 4(상장 회사 내부자 주식 거래 공개 양식) 정보 추출을 자동화하는 실제 사례를 선보였다. 이 예시는 Form 4 파일에서 구조화된 정보를 추출할 수 있는 추출 에이전트를 만들고, 다우 존스 산업 평균 지수 구성 기업의 Form 4 파일에서 거래 정보를 추출하기 위한 확장 가능한 워크플로우를 구축했다. 이는 금융 분야에서 AI를 활용한 정보 추출 및 자동화 처리에 참고 자료를 제공한다. (출처: jerryjliu0)
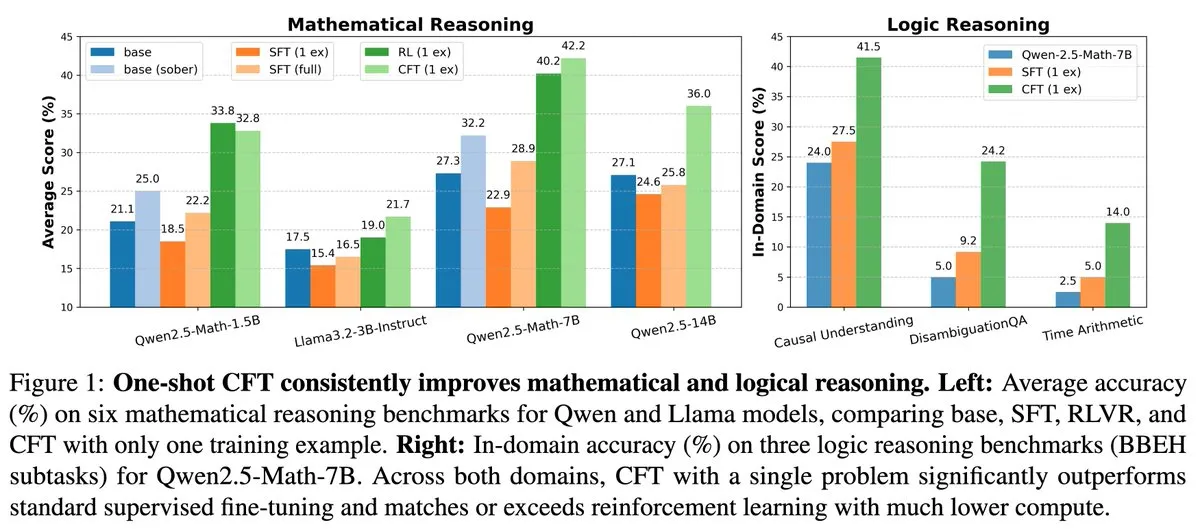
새 연구: 단일 문제 감독 미세 조정(SFT)으로 단일 문제 강화 학습(RL) 효과 달성, 계산 비용 20배 절감: 새로운 논문에 따르면 단일 문제에 대한 감독 미세 조정(SFT)은 단일 문제에 대한 강화 학습(RL)과 유사한 성능 향상을 달성하면서 계산 비용은 후자의 1/20에 불과하다. 이는 사전 훈련 단계에서 강력한 추론 능력을 획득한 LLM의 경우, 논문에서 제안한 Critique Fine-Tuning(CFT)과 같이 잘 설계된 SFT를 통해 잠재력을 발휘하는 것이 더 효율적인 방법이 될 수 있음을 시사한다. 특히 RL 비용이 많이 들거나 불안정한 경우에 그렇다. (출처: AndrewLampinen)
논문, Rex-Thinker 제안: 사고 사슬 추론을 통한 현실 기반 객체 지칭: 한 새로운 논문은 객체 지칭(Object Referring) 작업을 명시적인 사고 사슬(CoT) 추론 작업으로 공식화하는 Rex-Thinker 모델을 제안했다. 모델은 먼저 지칭 대상 객체 범주에 해당하는 모든 후보 인스턴스를 식별한 다음, 각 후보 인스턴스에 대해 단계별 추론을 수행하여 주어진 표현과 일치하는지 평가하고 최종적으로 예측한다. 이 패러다임을 지원하기 위해 연구자들은 대규모 CoT 스타일 지칭 데이터셋 HumanRef-CoT를 구축했다. 실험 결과, 이 방법은 정확도와 해석 가능성 면에서 표준 기준선보다 우수하며, 일치하는 객체가 없는 경우를 더 잘 처리하는 것으로 나타났다. (출처: HuggingFace Daily Papers)
논문, TimeHC-RL 제안: 시간 인식 계층적 인지 강화 학습을 통한 LLM 사회 지능 강화: LLM이 사회 지능 분야에서 인지 발달이 부족하다는 문제에 대응하기 위해, 새로운 논문은 시간 인식 계층적 인지 강화 학습(TimeHC-RL) 프레임워크를 제안했다. 이 프레임워크는 사회 세계가 독특한 시간선을 따르며, 직관적 반응(시스템 1)과 신중한 사고(시스템 2) 등 다양한 인지 모드의 융합이 필요하다는 점을 인식한다. 실험 결과, TimeHC-RL은 LLM의 사회 지능을 효과적으로 향상시켜 7B 백본 모델의 성능을 DeepSeek-R1 및 OpenAI-O3와 같은 첨단 모델에 필적하게 만들었다. (출처: HuggingFace Daily Papers)
논문, DLP 제안: 대규모 언어 모델에서의 동적 계층적 가지치기: LLM 가지치기에서 통일된 계층적 가지치기 전략이 높은 희소도에서 성능이 심각하게 저하되는 문제를 해결하기 위해, 새로운 논문은 동적 계층적 가지치기(DLP) 방법을 제안했다. DLP는 모델 가중치와 입력 활성화 정보를 통합하여 각 계층의 상대적 중요도를 적응적으로 결정하고 이에 따라 가지치기 비율을 할당한다. 실험 결과, DLP는 높은 희소도에서 LLaMA2-7B와 같은 모델의 성능을 효과적으로 유지하며, 다양한 기존 LLM 압축 기술과 호환되는 것으로 나타났다. (출처: HuggingFace Daily Papers)
논문, LayerFlow 소개: 통일된 레이어 인식 비디오 생성 모델: LayerFlow는 통일된 레이어 인식 비디오 생성 솔루션이다. 각 레이어에 대한 프롬프트가 주어지면 LayerFlow는 투명한 전경, 깨끗한 배경 및 혼합된 장면의 비디오를 생성할 수 있다. 또한 혼합된 비디오를 분해하거나 주어진 전경에 대한 배경을 생성하는 등 다양한 변형을 지원한다. 이 모델은 서로 다른 레이어의 비디오를 하위 클립으로 구성하고 레이어 임베딩을 활용하여 각 클립과 해당 레이어 프롬프트를 구별함으로써 단일 프레임워크 내에서 위에서 언급한 기능을 지원한다. 고품질 레이어 훈련 비디오 부족 문제를 해결하기 위해 다단계 훈련 전략을 설계했다. (출처: HuggingFace Daily Papers)
논문, Rectified Sparse Attention 제안: 수정된 희소 어텐션 메커니즘: 긴 시퀀스 생성에서 희소 디코딩 방법으로 인해 발생하는 KV 캐시 불일치 및 품질 저하 문제를 해결하기 위해, 새로운 논문은 수정된 희소 어텐션(ReSA)을 제안했다. ReSA는 블록 희소 어텐션과 주기적인 밀집 수정을 결합하여 고정된 간격으로 밀집 순방향 전파를 사용하여 KV 캐시를 새로 고침으로써 오류 누적을 제한하고 사전 훈련된 분포와의 정렬을 유지한다. 실험 결과, ReSA는 수학 추론, 언어 모델링 및 검색 작업에서 거의 무손실 생성 품질과 상당한 효율성 향상을 달성했으며, 256K 시퀀스 길이 디코딩에서 최대 2.42배의 종단 간 가속을 실현할 수 있었다. (출처: HuggingFace Daily Papers)
논문, RefEdit 소개: 지칭 표현에 대한 지침 기반 이미지 편집 모델의 벤치마크 및 방법 개선: 기존 이미지 편집 모델이 여러 개체를 포함하는 복잡한 장면을 처리할 때 지정된 개체를 정확하게 편집하기 어렵다는 문제에 대응하기 위해, 새로운 논문은 먼저 RefCOCO 기반의 실제 세계 벤치마크인 RefEdit-Bench를 도입했다. 그런 다음, 확장 가능한 합성 데이터 생성 프로세스를 통해 훈련된 RefEdit 모델을 제안했다. 단 20,000개의 편집 삼중항으로 훈련된 RefEdit은 지칭 표현 작업에서 수백만 개의 훈련 데이터로 Flux/SD3 기반 기준 모델보다 우수한 성능을 보였으며, 전통적인 벤치마크에서도 SOTA 효과를 달성했다. (출처: HuggingFace Daily Papers)
논문, Critique-GRPO 제안: 자연어 및 수치 피드백을 활용한 LLM 추론 능력 향상: 스칼라 보상과 같은 수치 피드백에만 의존하는 강화 학습이 LLM의 복잡한 추론 능력을 향상시키는 데 있어 성능 병목 현상, 제한적인 자기 성찰 효과, 지속적인 실패 등의 문제에 직면하는 것에 대응하여, 새로운 논문은 Critique-GRPO 프레임워크를 제안했다. 이 프레임워크는 자연어 형태의 비판(critiques)과 수치 피드백을 통합하여 LLM이 초기 반응과 비판 유도 개선으로부터 동시에 학습하고 탐색을 유지할 수 있도록 한다. 실험 결과, Critique-GRPO는 Qwen2.5-7B-Base 및 Qwen3-8B-Base에서 다양한 기준선 방법보다 현저히 우수한 성능을 보였다. (출처: HuggingFace Daily Papers)
논문, TalkingMachines 소개: 자기 회귀 확산 모델을 통한 실시간 오디오 기반 FaceTime 스타일 비디오: TalkingMachines는 사전 훈련된 비디오 생성 모델을 실시간 오디오 기반 캐릭터 애니메이터로 변환하는 효율적인 프레임워크이다. 이 프레임워크는 오디오 대규모 언어 모델(LLM)과 비디오 생성 기반 모델을 통합하여 자연스러운 대화 경험을 구현한다. 주요 기여 사항으로는 사전 훈련된 SOTA 이미지-비디오 DiT 모델을 오디오 기반 가상 아바타 생성 모델로 조정하고, 비대칭 지식 증류를 통해 오류 누적 없이 무한 비디오 스트림 생성을 실현하며, 높은 처리량과 낮은 지연 시간을 갖는 추론 파이프라인을 설계한 점 등이 있다. (출처: HuggingFace Daily Papers)
논문, LLM 판단에서의 자기 선호도 측정 탐구: 연구에 따르면 LLM은 심판 역할을 할 때 자기 선호도를 나타내는데, 즉 자신이 생성한 응답을 선호하는 경향이 있다. 기존 방법은 심판 모델이 자신의 응답과 다른 모델의 응답에 대한 평가 점수 차이를 계산하여 이러한 편향을 측정하지만, 이는 자기 선호도와 응답 품질을 혼동한다. 새로운 논문은 황금 판단을 응답의 실제 품질에 대한 대리 변수로 사용하고 DBG 점수를 도입하여, 자기 선호도 편향을 심판 모델이 자신의 응답에 대한 평가 점수와 해당 황금 판단 간의 차이로 측정함으로써 응답 품질이 편향 측정에 미치는 혼동 효과를 완화한다. (출처: HuggingFace Daily Papers)
논문, LongBioBench 제안: 제어 가능한 긴 컨텍스트 언어 모델 테스트 프레임워크: 기존 긴 컨텍스트 언어 모델(LCLM) 평가 프레임워크의 한계(실제 세계 작업은 복잡하고 해결하기 어려우며 데이터 오염에 취약하고, 합성 작업은 실제 애플리케이션과 동떨어짐)에 대응하여, 새로운 논문은 LongBioBench를 제안했다. 이 벤치마크는 인공적으로 생성된 전기를 제어된 환경으로 활용하여 이해, 추론 및 신뢰도 차원에서 LCLM을 평가한다. 실험 결과, 대부분의 모델은 긴 컨텍스트 의미 이해 및 초기 추론에서 여전히 부족하며, 컨텍스트 길이가 증가함에 따라 신뢰도가 감소하는 것으로 나타났다. LongBioBench는 더 현실적이고 제어 가능하며 해석 가능한 LCLM 평가를 제공하는 것을 목표로 한다. (출처: HuggingFace Daily Papers)
논문, 최적화된 콜드 스타트에서 단계적 강화 학습을 통한 멀티모달 추론 향상 탐구: 복잡한 텍스트 작업에서 Deepseek-R1의 뛰어난 추론 능력에 영감을 받아 많은 연구가 강화 학습(RL)을 직접 적용하여 멀티모달 대규모 언어 모델(MLLM)이 유사한 능력을 생성하도록 유도하려고 시도했지만 여전히 복잡한 추론을 활성화하기는 어렵다. 새로운 논문은 현재 훈련 흐름을 심층적으로 연구하여 효과적인 콜드 스타트 초기화가 MLLM 추론 강화에 중요하며, 표준 GRPO를 멀티모달 RL에 적용할 때 기울기 정체 문제가 발생하고, 멀티모달 RL 단계 후 순수 텍스트 RL 훈련을 수행하면 멀티모달 추론을 더욱 향상시킬 수 있음을 발견했다. 이러한 통찰력을 바탕으로 논문은 ReVisual-R1을 도입하여 여러 벤치마크 테스트에서 SOTA 성적을 거두었다. (출처: HuggingFace Daily Papers)
논문, SVGenius 소개: SVG 이해, 편집 및 생성을 위한 벤치마크 테스트: 기존 SVG 처리 벤치마크가 실제 세계 적용 범위, 복잡성 계층화 및 평가 패러다임 측면에서 부족하다는 점에 대응하여, 새로운 논문은 SVGenius를 도입했다. 이는 2377개의 쿼리를 포함하는 포괄적인 벤치마크로, 이해, 편집 및 생성의 세 가지 차원을 다루며, 24개 응용 분야의 실제 데이터를 기반으로 구축되었고 체계적인 복잡성 계층화가 이루어졌다. 8개의 작업 범주와 18개의 지표를 통해 22개의 주류 모델을 평가했다. 분석 결과, 모든 모델은 복잡성이 증가함에 따라 성능이 체계적으로 저하되었지만, 추론 강화 훈련이 순수한 확장보다 더 효과적인 것으로 나타났다. (출처: HuggingFace Daily Papers)
논문, Ψ-Sampler 제안: SMC 기반 점수 모델 추론 시 보상 정렬을 위한 초기 입자 샘플링: 점수 생성 모델 추론 시 보상 정렬 문제를 해결하기 위해, 새로운 논문은 Psi-Sampler 프레임워크를 도입했다. 이 프레임워크는 순차 몬테카를로(SMC)를 기반으로 하며, pCNL 기반 초기 입자 샘플링 방법을 결합했다. 기존 방법은 일반적으로 가우시안 사전 분포에서 입자를 초기화하여 보상 관련 영역을 효과적으로 포착하기 어렵다. Psi-Sampler는 보상 인식 사후 분포에서 입자를 초기화하고, 효율적인 사후 샘플링을 위해 전처리된 Crank-Nicolson Langevin(pCNL) 알고리즘을 도입하여 레이아웃-이미지 생성, 수량 인식 생성 및 미적 선호도 생성과 같은 작업에서 정렬 성능을 향상시킨다. (출처: HuggingFace Daily Papers)
논문, MoCA-Video 제안: 일관된 비디오 편집을 위한 모션 인식 개념 정렬 프레임워크: MoCA-Video는 이미지 도메인의 의미론적 혼합 기술을 비디오 편집에 적용하기 위한 훈련 없는 프레임워크이다. 생성된 비디오와 사용자가 제공한 참조 이미지가 주어지면, MoCA-Video는 참조 이미지의 의미론적 특징을 비디오 내 특정 객체에 주입하면서 원본 모션과 시각적 컨텍스트를 보존할 수 있다. 이 방법은 대각선 노이즈 제거 스케줄링과 범주 무관 분할을 활용하여 잠재 공간에서 객체를 감지하고 추적하며, 혼합 객체의 공간적 위치를 정밀하게 제어하고, 모멘텀 기반 의미론적 보정 및 감마 잔여 노이즈 안정을 통해 시간적 일관성을 보장한다. (출처: HuggingFace Daily Papers)
논문, 프로그램 분석 피드백을 통한 언어 모델의 고품질 코드 생성 훈련 탐구: 대규모 언어 모델(LLM)이 코드 생성(“vibe coding”)에서 코드 품질(특히 보안성 및 유지보수성)을 보장하기 어렵다는 문제를 해결하기 위해, 새로운 논문은 REAL 프레임워크를 제안했다. REAL은 프로그램 분석 유도 피드백을 통해 LLM이 생산 수준 품질의 코드를 생성하도록 유도하는 강화 학습 프레임워크이다. 이 피드백은 보안 또는 유지보수성 결함을 감지하는 프로그램 분석 신호와 기능적 정확성을 보장하는 단위 테스트 신호를 통합한다. REAL은 인공적인 주석 없이 확장성이 뛰어나며, 실험 결과 기능성 및 코드 품질 면에서 SOTA 방법보다 우수한 것으로 입증되었다. (출처: HuggingFace Daily Papers)
논문, GAIN-RL 제안: 모델 자체 신호를 통한 훈련 효율적인 강화 학습: 현재 대규모 언어 모델 강화 미세 조정(RFT) 패러다임이 통일된 데이터 샘플링으로 인해 샘플 효율성이 낮은 문제에 대응하여, 새로운 논문은 “각도 집중도”(angle concentration)라는 모델 고유 신호를 식별했다. 이 신호는 LLM이 특정 데이터로부터 학습하는 능력을 효과적으로 반영한다. 이러한 발견을 바탕으로 논문은 GAIN-RL 프레임워크를 제안하여, 모델의 내재적 각도 집중도 신호를 활용하여 훈련 데이터를 동적으로 선택함으로써 기울기 업데이트의 지속적인 효율성을 보장하고 훈련 효율성을 크게 향상시킨다. 실험 결과, GAIN-RL (GRPO)은 다양한 수학 및 코딩 작업과 여러 모델 규모에서 2.5배 이상의 훈련 효율성 가속을 달성했다. (출처: HuggingFace Daily Papers)
논문, SFO 제안: 부정적 안내를 통한 제로샷 주체 기반 생성의 주체 충실도 최적화: 제로샷 주체 기반 생성에서 주체 충실도를 향상시키기 위해, 새로운 논문은 주체 충실도 최적화(SFO) 프레임워크를 제안했다. SFO는 합성된 부정적 목표를 도입하고, 쌍별 비교를 통해 모델이 부정적 목표보다 긍정적 목표를 명확하게 선호하도록 안내한다. 부정적 목표에 대해 논문은 조건부 퇴화 부정 샘플링(CDNS) 방법을 제안하여, 시각적 및 텍스트 단서를 의도적으로 저하시켜 비용이 많이 드는 인공 주석 없이 독특하고 정보가 풍부한 부정 샘플을 자동으로 생성한다. 또한, 주체 세부 정보가 나타나는 중간 단계에 초점을 맞추기 위해 확산 시간 단계를 재가중했다. (출처: HuggingFace Daily Papers)
논문, ByteMorph 소개: 비강체 운동을 위한 지침 기반 이미지 편집 벤치마크: 기존 이미지 편집 방법 및 데이터셋이 주로 정적 장면이나 강체 변환에 초점을 맞춰 비강체 운동, 카메라 시점 변환, 객체 변형, 인체 관절 운동 및 복잡한 상호작용과 관련된 지침을 처리하기 어렵다는 문제에 대응하여, 새로운 논문은 ByteMorph 프레임워크를 도입했다. 이 프레임워크는 대규모 데이터셋 ByteMorph-6M(600만 개 이상의 고해상도 이미지 편집 쌍)과 DiT 기반의 강력한 기준 모델 ByteMorpher를 포함한다. 데이터셋은 운동 유도 데이터 생성, 계층적 합성 기술 및 자동 자막 생성을 통해 구축되어 다양성, 현실성 및 의미론적 일관성을 보장한다. (출처: HuggingFace Daily Papers)
논문, Control-R 제안: 제어 가능한 테스트 시점 확장을 향하여: 대규모 추론 모델(LRM)이 긴 연쇄 사고(CoT) 추론에서 “생각 부족” 및 “생각 과잉” 문제를 겪는 것을 해결하기 위해, 새로운 논문은 추론 제어 필드(RCF)를 도입했다. RCF는 테스트 시점 방법으로, 구조화된 제어 신호를 주입하여 트리 검색 관점에서 추론을 안내함으로써 모델이 주어진 제어 조건에 따라 복잡한 작업을 해결할 때 추론 노력을 조정할 수 있도록 한다. 동시에 논문은 상세한 추론 과정과 해당 제어 필드를 포함하는 도전적인 문제로 구성된 Control-R-4K 데이터셋을 제안하고, 모델이 테스트 시점 추론 노력을 효과적으로 조정하도록 훈련하는 조건부 증류 미세 조정(CDF) 방법을 제안했다. (출처: HuggingFace Daily Papers)
논문, Agentic AI에서의 신뢰, 위험 및 보안 관리(TRiSM) 개관: 한 개관 논문은 대규모 언어 모델(LLM) 기반의 Agentic 다중 에이전트 시스템(AMAS)에서의 신뢰, 위험 및 보안 관리(TRiSM)를 체계적으로 분석했다. 논문은 먼저 Agentic AI의 개념적 기초, 아키텍처 차이 및 새로운 시스템 설계를 탐구한 다음, Agentic AI 프레임워크 하에서의 TRiSM의 네 가지 기둥인 거버넌스, 해석 가능성, ModelOps 및 개인 정보 보호/보안을 상세히 설명했다. 논문은 독특한 위협 벡터를 식별하고, Agentic AI 애플리케이션에 대한 포괄적인 위험 분류법을 제안하며, 신뢰 구축 메커니즘, 투명성 및 감독 기술, 분산 LLM 에이전트 시스템의 해석 가능성 전략 등을 탐구했다. (출처: HuggingFace Daily Papers)
논문, 신뢰도 유도 데이터 증강을 통한 미지의 공변량 이동 하에서의 지식 증류 개선 탐구: 지식 증류에서 흔히 발생하는 공변량 이동 문제(훈련 시에는 나타나지만 테스트 시에는 존재하지 않는 허위 특징)에 대응하여, 새로운 논문은 새로운 확산 기반 데이터 증강 전략을 제안했다. 이러한 허위 특징이 알려지지 않았지만 견고한 교사 모델이 존재하는 경우, 이 전략은 교사 모델과 학생 모델 간의 불일치를 최대화하여 이미지를 생성함으로써 학생이 처리하기 어려운 도전적인 샘플을 만든다. 실험 결과, 이 방법은 CelebA, SpuCo Birds 및 허위 ImageNet과 같은 데이터셋에서 공변량 이동이 존재할 때 최악 그룹 및 평균 그룹 정확도를 현저히 향상시키는 것으로 나타났다. (출처: HuggingFace Daily Papers)
논문, DiffDecompose 소개: Diffusion Transformers를 통한 알파 합성 이미지의 계층별 분해: 기존 이미지 분해 방법이 반투명 또는 투명 레이어 가림 문제를 해결하기 어렵다는 점에 대응하여, 새로운 논문은 새로운 작업인 알파 합성 이미지의 계층별 분해를 제안하여 단일 중첩 이미지에서 구성 레이어를 복원하는 것을 목표로 한다. 레이어 모호성, 일반화 및 데이터 부족과 같은 문제를 해결하기 위해 논문은 먼저 투명 및 반투명 레이어 분해를 위한 최초의 대규모 고품질 데이터셋인 AlphaBlend를 도입했다. 이를 바탕으로 DiffDecompose라는 Diffusion Transformer 기반 프레임워크를 제안하여 컨텍스트 분해를 통해 레이어 분해의 사후 분포를 학습한다. (출처: HuggingFace Daily Papers)
논문, SuperWriter 제안: 성찰 기반 대규모 언어 모델의 장문 텍스트 생성: 대규모 언어 모델(LLM)이 장문 텍스트 생성에서 일관성, 논리적 일관성 및 텍스트 품질을 유지하기 어렵다는 문제를 해결하기 위해, 새로운 논문은 SuperWriter-Agent 프레임워크를 제안했다. 이 프레임워크는 생성 과정에 명확한 구조화된 사고 계획 및 개선 단계를 도입하여 모델이 더 신중하고 인지적으로 일관된 과정을 따르도록 안내한다. 이 프레임워크를 기반으로 7B 파라미터의 SuperWriter-LM을 훈련하기 위한 감독 미세 조정 데이터셋을 구축하고, 몬테카를로 트리 검색(MCTS)을 활용하여 최종 품질 평가를 전파하고 각 생성 단계를 그에 따라 최적화하는 계층적 직접 선호도 최적화(DPO) 절차를 개발했다. (출처: HuggingFace Daily Papers)
논문, IEAP 제안: 확산 모델 기반 프로그램으로서의 이미지 편집: 확산 모델이 지침 기반 이미지 편집에서, 특히 상당한 레이아웃 변화를 포함하는 구조적으로 일치하지 않는 편집과 관련하여 어려움을 겪는 문제에 대응하여, 새로운 논문은 IEAP(Image Editing As Programs) 프레임워크를 도입했다. IEAP는 Diffusion Transformer(DiT) 아키텍처를 기반으로 하며, 복잡한 편집 지침을 원자적 작업 시퀀스로 분해하여 지침 편집을 처리한다. 각 작업은 동일한 DiT 골격을 공유하는 경량 어댑터를 통해 구현되며 특정 유형의 편집에 특화되어 있다. 이러한 작업은 시각 언어 모델(VLM) 기반 에이전트에 의해 프로그래밍되어 임의적이고 구조적으로 일치하지 않는 변환을 협력적으로 지원한다. (출처: HuggingFace Daily Papers)
논문, FlowPathAgent 제안: 신경 기호 에이전트를 통한 세분화된 순서도 귀인: 대규모 언어 모델(LLM)이 순서도를 해석할 때 종종 환각을 일으키고 결정 경로를 정확하게 추적하기 어렵다는 문제를 해결하기 위해, 새로운 논문은 세분화된 순서도 귀인 작업을 도입하고 FlowPathAgent를 제안했다. FlowPathAgent는 그래프 기반 추론을 통해 세분화된 사후 귀인을 수행하는 신경 기호 에이전트이다. 먼저 순서도를 분할하여 구조화된 기호 그래프로 변환한 다음, 에이전트 방법을 사용하여 그래프와 동적으로 상호 작용하여 귀인 경로를 생성한다. 동시에 논문은 순서도 귀인을 평가하기 위한 새로운 벤치마크인 FlowExplainBench도 제안했다. (출처: HuggingFace Daily Papers)
논문, Quantitative LLM Judges 제안: 정량적 LLM 심판: LLM-as-a-judge는 대규모 언어 모델(LLM)이 다른 LLM의 출력을 자동으로 평가하도록 하는 프레임워크이다. 새로운 논문은 “정량적 LLM 심판”이라는 개념을 제안하여, 회귀 모델을 통해 기존 LLM 심판의 평가 점수를 특정 분야의 인간 점수와 정렬한다. 이러한 모델은 심판의 텍스트 평가와 점수를 사용하여 원래 심판의 평가를 개선한다. 논문은 다양한 유형의 절대적 및 상대적 피드백에 대한 네 가지 정량적 심판을 제시하여 이 프레임워크의 보편성과 다기능성을 입증한다. 이 프레임워크는 감독 미세 조정보다 계산 효율성이 높으며, 인간 피드백이 제한적일 때 통계적으로 더 효율적일 수 있다. (출처: HuggingFace Daily Papers)
💼 비즈니스
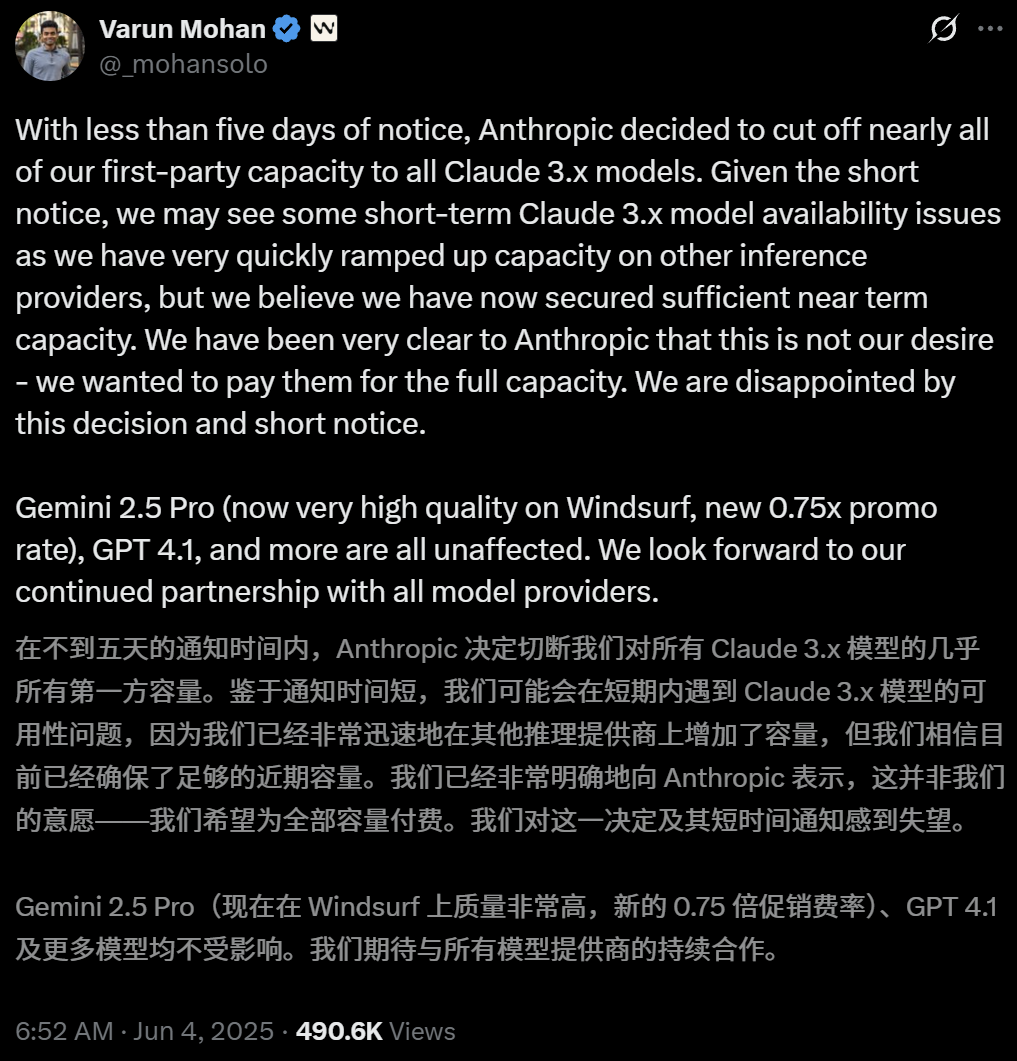
Anthropic, AI 프로그래밍 도구 Windsurf의 Claude 모델 직접 접근 제한: AI 프로그래밍 도구 Windsurf의 CEO Varun Mohan은 Anthropic이 매우 짧은 통보 기간(5일 미만) 내에 Windsurf의 Claude 3.x 시리즈 모델(Claude 3.5 Sonnet, 3.7 Sonnet 등 포함)에 대한 API 서비스 할당량을 대폭 삭감했다고 공개적으로 밝혔다. 이는 OpenAI가 Windsurf를 인수할 것이라는 보도가 나온 배경에서 발생하여, AI 거대 기업 간 경쟁 심화 및 AI 프로그래밍 도구 플랫폼의 중립성에 대한 시장의 우려를 불러일으켰다. Windsurf는 긴급하게 제3자 추론 서비스를 사용하고 사용자에 대한 모델 공급 전략을 조정해야 했으며, Anthropic은 지속적인 협력을 보장할 수 있는 파트너에게 우선적으로 자원을 제공한다고 응답했다. (출처: 36氪, 36氪, mervenoyann, swyx)
OpenAI 유료 기업 사용자 300만 돌파, 유연한 가격 정책 출시: OpenAI는 유료 기업 사용자 수가 300만 명에 도달하여 올해 2월 발표한 200만 명에서 50% 증가했다고 발표했다. 이는 ChatGPT Enterprise, Team, Edu 세 가지 제품 라인을 포함한다. 동시에 OpenAI는 기업 고객을 대상으로 “공유 크레딧 풀” 기반의 유연한 가격 정책을 출시했다. 기업이 크레딧 풀을 구매하면 고급 기능을 사용할 때 크레딧이 소모되지만 주요 모델 및 기능은 “무제한 액세스”할 수 있다. 이 새로운 가격 정책은 먼저 ChatGPT Enterprise에 출시된 후 ChatGPT Team으로 확대될 예정이며, 후자는 첫 달 1달러에 5개 계정을 제공하는 평가판 할인도 제공한다. (출처: 36氪, snsf)
00년대생 중국 소녀 홍러퉁, AI 수학 회사 Axiom 설립, 목표 기업 가치 3억 달러: 스탠포드 중국계 수학 박사 홍러퉁(Carina Letong Hong)은 실제 수학 문제 해결 AI 모델 개발에 주력하는 AI 회사 Axiom을 설립했다. 목표 고객은 헤지펀드와 퀀트 트레이딩 회사이다. Axiom은 형식화된 수학 증명 데이터를 활용하여 모델을 훈련시켜 엄격한 논리적 추론 및 증명 능력을 갖추도록 할 계획이다. 회사는 아직 제품이 없지만 5천만 달러 규모의 투자 유치를 협상 중이며, 기업 가치는 3~5억 달러로 예상된다. 홍러퉁은 MIT 수학 및 물리학 학사 학위와 스탠포드 수학 박사 학위를 보유하고 있으며, 로즈 장학금을 받은 바 있다. (출처: 量子位)

🌟 커뮤니티
AI.Engineer 컨퍼런스 주요 논의: Agent 관찰 가능성, 소규모 고효율 팀, AI PM 부상: AI.Engineer 세계 박람회에서 참석자들은 AI 에이전트(Agent)의 관찰 가능성과 평가, 소규모 고효율 팀 구축(Tiny Teams), AI 제품 관리(AI PM)의 모범 사례에 대해 열띤 논의를 벌였다. 음성 상호작용은 멀티모달 중 가장 뜨거운 분야로 간주되었으며, 보안도 처음으로 중요한 의제로 떠올랐다. Anthropic은 컨퍼런스에서 MCP(모델 컨텍스트 프로토콜) 분야의 창업 요청을 발표하며, 개발자 도구 외의 MCP 서버, 서버 구축 간소화 방안, AI 애플리케이션 보안(예: 도구 독성 공격 방어) 혁신을 기대한다고 밝혔다. (출처: swyx, swyx, swyx, swyx)

AI가 자연어를 소멸시키고 인간을 어리석게 만들 것인가에 대한 논의: 소셜 미디어에서는 AI의 광범위한 사용이 자연어 소통의 위축(“죽은 인터넷” 이론)과 인간의 인지 능력(예: 깊이 있는 사고, 의문 제기, 재구성 능력) 퇴화를 초래할 수 있다는 우려가 제기되었다. 일부 사용자는 정보와 답변을 얻기 위해 AI에 과도하게 의존하면 능동적인 선별, 판단, 독립적 사고가 줄어들어 “인지 아웃소싱” 의존이 형성될 수 있다고 보았다. 다른 관점에서는 AI가 ‘무엇’과 ‘어떻게’를 처리할 수 있지만 ‘왜’는 여전히 인간이 결정해야 하며, 기술과 공존하면서 인간의 역할定位와 판단권을 지키는 것이 중요하다고 주장했다. (출처: Reddit r/ArtificialInteligence, 36氪)
OpenAI, 법원 명령으로 모든 ChatGPT 및 API 로그 보존, 개인 정보 보호 우려 제기: 법원 명령에 따라 OpenAI는 삭제되었어야 할 “임시 채팅” 기록을 포함한 모든 ChatGPT 채팅 기록과 API 요청 로그를 보존해야 한다. 이는 사용자의 데이터 개인 정보 보호와 OpenAI의 데이터 보존 정책 준수 여부에 대한 우려를 불러일으켰다. 일부 논평가들은 이것이 로컬 모델 사용과 자체 기술 및 데이터 소유의 중요성을 더욱 부각시킨다고 지적했다. (출처: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agent, 신뢰와 보안 문제 직면, 피싱 공격에 취약: AI Agent의 능력이 날로 향상되고 있지만, 그 신뢰 메커니즘이 악용될 위험이 있다는 지적이 나왔다. 예를 들어, Agent는 소셜 미디어와 같은 유명 웹사이트를 신뢰하여 악성 링크에 접속하도록 유도될 수 있으며, 이로 인해 민감한 정보가 유출되거나 악의적인 작업이 수행될 수 있다. 이는 Agent 설계 시 악성 콘텐츠 및 링크에 대한 식별 및 저항 능력을 강화하여 실제 세계 작업을 수행할 때의 안전성을 보장해야 함을 요구한다. (출처: DeepLearning.AI Blog)
AI 보조 프로그래밍 도구가 불러일으킨 고찰: 코드 현대화에서 워크플로우 변화까지: 커뮤니티에서는 소프트웨어 개발에서 AI의 응용, 특히 레거시 코드 처리와 프로그래밍 워크플로우 변화에 대해 논의했다. 모건 스탠리는 자체 개발한 AI 도구 DevGen.AI를 사용하여 수백만 줄의 오래된 코드를 분석하고 리팩토링하여 개발 시간을 크게 절약했다. 동시에 Andrej Karpathy의 복잡한 UI 애플리케이션 전망에 대한 관점은 미래 소프트웨어가 AI와 더 잘 협력하기 위해 어떻게 설계되어야 하는지에 대한 고찰을 불러일으켰으며, 스크립트화 및 API 인터페이스의 중요성을 강조했다. 이러한 논의는 AI가 소프트웨어 엔지니어링의 실천과 이념에 깊은 영향을 미치고 있음을 반영한다. (출처: mitchellh, 36氪, 36氪)
💡 기타
AI 보조 가전제품 수리, ChatGPT가 “Friendo”가 되다: 한 사용자가 ChatGPT(별명 Friendo)를 통해 고장난 식기세척기를 성공적으로 진단하고 부분적으로 수리한 경험을 공유했다. AI와 대화하고, 오류 코드를 설명하고, 제어판 사진을 촬영함으로써 AI는 사용자가 발열 부품 고장을 찾아내도록 도왔고, 해당 부품을 일시적으로 우회하여 식기세척기 기능을 일부 복구하도록 안내했다. 이는 LLM이 일상생활 문제 해결 및 기술 지원 분야에서 잠재력을 가지고 있음을 보여준다. (출처: Reddit r/ChatGPT)
AI 생성 1500년대 인물 인터뷰 영상 주목: AI가 생성한 1500년대 인물 인터뷰를 모방한 영상이 창의성과 유머 감각으로 커뮤니티에서 호평을 받았다. 영상 속 인물의 모습과 대화 내용은 당시 생활상을 익살스럽게 반영했다. 예를 들어 “일어나서 배설물을 밟고 세금을 징수당했는데, 이건 아침 식사 전의 일일 뿐이다”와 같은 내용이다. 이러한 응용은 AI가 콘텐츠 창작 및 역사적 상황 재현 분야에서 엔터테인먼트 잠재력을 가지고 있음을 보여준다. (출처: draecomino, Reddit r/ChatGPT)

Thiel 장학금, AI 혁신 주목, 디지털 휴먼, 로봇 감정 및 AI 예측 포함: 새로운 “틸 장학금” 명단이 발표되었으며, 그중 여러 AI 프로젝트가 주목을 받았다. Canopy Labs는 실제 사람과 구별하기 어렵고 실시간 다중 모드 상호작용이 가능한 AI 디지털 휴먼을 만드는 데 주력하고 있다. Intempus 프로젝트는 인간과 유사한 감정 표현 능력을 로봇에게 부여하여 인간-로봇 상호작용을 개선하는 것을 목표로 한다. Aeolus Lab은 AI 기술을 활용하여 날씨 및 자연재해를 예측하고 심지어 능동적인 개입 가능성을 탐색하는 데 초점을 맞추고 있다. 이러한 프로젝트들은 젊은 창업가들이 AI 첨단 분야에서 탐색하는 방향을 보여준다. (출처: 36氪)