
키워드:AI 트렌드 리포트, AI 에이전트, 강화 학습, 시각 언어 모델, AI 상용화, AI 환각, AI 보안, 인터넷 여왕 AI 리포트, LawZero AI 보안 설계, GTA와 GLA 주의 메커니즘, SmolVLA 로봇 모델, AI 음악 스트리밍 사기
🔥 주요 뉴스
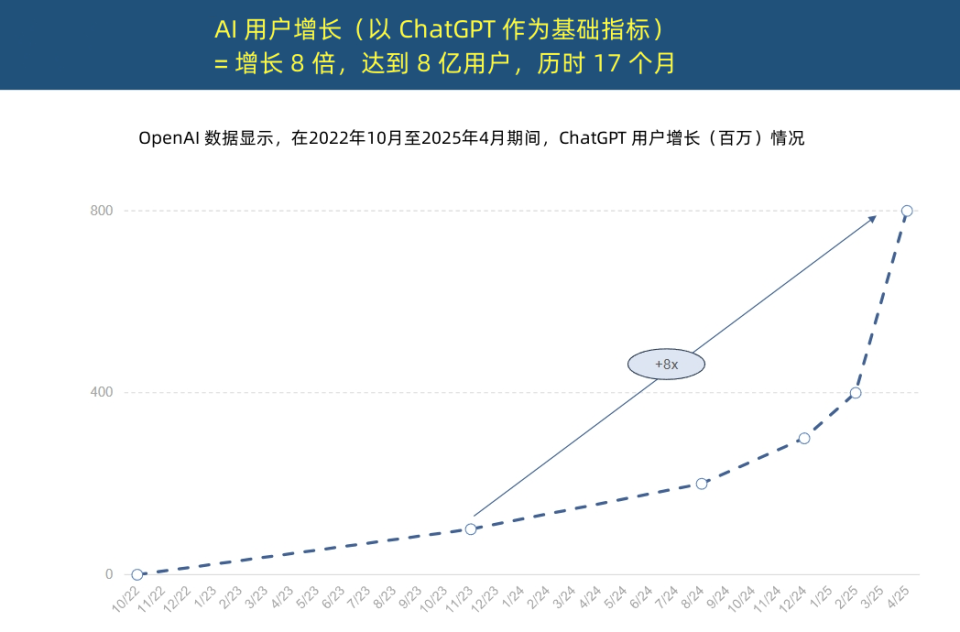
“인터넷 여왕” AI 트렌드 보고서 발표, AI 애플리케이션의 전례 없는 가속화와 비용 구조 변화 공개: “인터넷 여왕” Mary Meeker가 340페이지 분량의 《AI 트렌드 보고서》를 발표하며 AI가 전례 없는 속도로 채택되고 있음을 강조했습니다. 보고서에 따르면 ChatGPT는 사용자 증가가 폭발적으로 늘어 17개월 만에 월간 활성 사용자(MAU) 8억 명, 연간 수익 약 40억 달러를 달성했으며, 이는 역사상 어떤 기술보다도 훨씬 빠른 속도입니다. 빅테크 기업들의 AI 인프라에 대한 자본 투자는 급증하여 2024년에는 이미 2120억 달러에 달했습니다. 동시에 AI 모델 훈련 비용은 8년 동안 2400배 폭증하여 단일 모델 훈련 비용이 10억 달러에 이를 수 있지만, 추론 비용은 하드웨어(예: Nvidia GPU 에너지 효율 10만 배 향상) 및 알고리즘 최적화로 인해 급격히 감소하고 있습니다. 오픈 소스 모델(예: DeepSeek, Qwen)의 성능은 비공개 소스 모델에 근접하고 있으며, AI 직무 수요는 448% 증가했고, AI Agent는 새로운 디지털 노동력으로 부상하고 있습니다. (출처: APPSO, 腾讯科技)
튜링상 수상자 Yoshua Bengio, “설계상 안전한” AI를 제창하는 LawZero 발족: 튜링상 수상자인 Yoshua Bengio가 AI 시스템에서 발생할 수 있는 기만 및 자기 보호 행동에 대응하기 위해 “설계상 안전한” 인공지능 개발을 목표로 하는 비영리 단체 LawZero 설립을 발표했습니다. LawZero는 아시모프 로봇 3원칙에서 영감을 받아 AI가 인간의 행복과 노력을 보호해야 한다고 강조합니다. 이 단체는 AI Agent의 “가드레일” 역할을 하는 Scientist AI 시스템을 개발 중이며, 직접 행동하는 대신 세계를 이해함으로써 도움을 제공하고 다른 AI 행동의 위험을 평가합니다. Bengio는 현재의 Agentic AI가 잘못된 방향이며, 통제 불능 상태가 되어 돌이킬 수 없는 재앙적 결과를 초래할 수 있다고 보고, 안전 가드레일 AI는 최소한 자신이 감시하려는 AI Agent만큼 똑똑해야 한다고 강조했습니다. (출처: 学术头条, Yoshua_Bengio)

AI Agent 원년: 보조 도구에서 작업 실행자로, 비즈니스 모델 재편: Gartner 연구 부사장 Sun Zhiyong은 2025년이 “대규모 모델 인텔리전트 에이전트 원년”이자 “생성형 AI 수익화 원년”이며, AI 인텔리전트 에이전트가 LLM 능력의 주요 출구가 되고 있다고 지적했습니다. 인텔리전트 에이전트와 챗봇의 본질적인 차이점은 정보 보조 제공에서 직접 작업 실행으로 전환하는 데 있습니다. 예를 들어, 인텔리전트 에이전트는 커피숍 정보를 제공하는 것뿐만 아니라 커피 주문 전체 과정을 완료할 수 있습니다. Gartner는 2028년까지 디지털 인터페이스 상호 작용의 20%가 AI 인텔리전트 에이전트에 의해 완료되고, 일상 업무 결정의 15%를 AI 인텔리전트 에이전트가 자율적으로 완료할 수 있으며, 기업용 소프트웨어의 3분의 1에 AI 인텔리전트 에이전트가 통합될 것으로 예측합니다. BYD 스마트 어시스턴트 등은 이미 초기 단계로 적용되었으며, 향후 휴대폰 앱 상호 작용 방식이 변경될 수 있습니다. (출처: IT时报)
Mamba 핵심 저자, 추론 인지 어텐션 메커니즘 GTA 및 GLA 제안, 긴 컨텍스트 추론 최적화: Mamba 핵심 저자 중 한 명인 Tri Dao와 그의 프린스턴 팀은 대규모 모델의 긴 컨텍스트 추론 효율성 향상을 위해 특별히 설계된 두 가지 새로운 어텐션 메커니즘인 Grouped-Tied Attention (GTA) 및 Grouped-Latent Attention (GLA)을 제안했습니다. GTA는 파라미터 바인딩 및 그룹화를 통해 키-값(KV) 캐시를 재사용하여 GQA에 비해 KV 캐시 점유율을 약 50% 줄이면서도 유사한 모델 품질을 유지합니다. GLA는 이중 계층 구조를 채택하여 잠재 토큰을 전역 컨텍스트의 압축된 표현으로 도입하고 그룹화된 헤드 메커니즘과 결합하여 DeepSeek에서 사용하는 MLA에 비해 긴 시퀀스(예: 64K) 디코딩 속도를 2배 빠르게 하고 동시 요청 처리 능력을 향상시킵니다. 이러한 새로운 메커니즘은 추론 시 메모리 액세스 병목 현상과 병렬성 제한 문제를 해결하는 것을 목표로 합니다. (출처: 量子位)

🎯 동향
DeepMind, SmolVLA 발표: 커뮤니티 데이터 기반의 효율적인 로봇 시각-언어-행동 모델: Hugging Face와 DeepMind 등 기관이 협력하여 로봇을 위해 특별히 설계된 450M 파라미터의 오픈 소스 시각-언어-행동(VLA) 모델인 SmolVLA를 출시했습니다. 이 모델은 소비자급 하드웨어에서 실행 가능합니다. 이 모델은 LeRobot 커뮤니티에서 공유된 오픈 소스 데이터셋만을 사용하여 사전 훈련되었으며, LIBERO, Meta-World 및 실제 세계 작업(SO100, SO101)에서 더 큰 VLA 모델 및 ACT와 같은 기준선보다 우수한 성능을 보였습니다. SmolVLA는 비동기 추론을 지원하여 응답 속도를 30% 향상시키고 작업 처리량을 2배 높일 수 있으며, 아키텍처는 Transformer와 스트림 매칭 디코더를 결합하고 시각적 토큰 감소, VLM 중간 계층 특징 활용 및 인터리브 어텐션 메커니즘을 통해 속도와 효율성을 최적화했습니다. (출처: HuggingFace Blog, clefourrier)

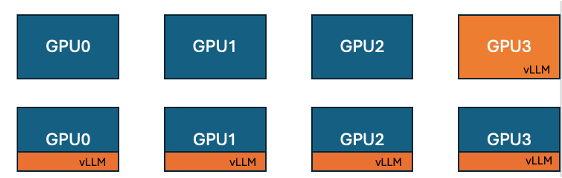
Hugging Face와 IBM, TRL에 vLLM 공동 배치 기능 출시, GPU 훈련 효율성 향상: Hugging Face와 IBM이 협력하여 TRL 라이브러리에 GRPO 등 온라인 학습 알고리즘을 위한 vLLM 공동 배치(co-located vLLM) 기능을 도입했습니다. 이 기능은 훈련과 추론(생성)이 동일한 GPU에서 실행되어 자원을 공유하고 번갈아 실행함으로써 이전 vLLM 서버 모드에서 훈련 GPU가 유휴 상태로 대기하는 문제를 해결합니다. vLLM을 동일한 분산 프로세스 그룹에 내장함으로써 HTTP 통신 없이 torchrun, TP 및 DP와 호환되며 배포를 간소화하고 처리량을 향상시킵니다. 실험 결과, 1.5B 및 7B 모델의 경우 공동 배치 모드가 최대 1.43배에서 1.73배의 가속 효과를 가져왔으며, Qwen2.5-Math-72B와 같은 대규모 모델의 경우 vLLM의 sleep() API와 DeepSpeed ZeRO Stage 3 최적화를 결합하여 더 적은 GPU를 사용하더라도 약 1.26배의 훈련 가속을 달성하고 모델 정확도에는 영향을 미치지 않았습니다. (출처: HuggingFace Blog)
Nvidia, 복잡한 추론 전문 Nemotron-Research-Reasoning-Qwen-1.5B 모델 출시: Nvidia는 수학 문제, 프로그래밍 과제, 과학 문제 및 논리 퍼즐과 같은 복잡한 추론 작업에 중점을 둔 1.5B 파라미터의 오픈 소스 가중치 모델인 Nemotron-Research-Reasoning-Qwen-1.5B를 출시했습니다. 이 모델은 ProRL(Prolonged Reinforcement Learning) 알고리즘을 사용하여 다양한 데이터셋에서 훈련되었으며, 더 깊은 수준의 추론 전략 탐색을 목표로 합니다. 공식적으로 수학, 코딩 및 GPQA와 같은 작업에서 DeepSeek의 1.5B 모델을 크게 능가한다고 주장합니다. ProRL은 GRPO를 기반으로 하며 엔트로피 붕괴 완화, 분리 클리핑 및 동적 샘플링 전략 최적화(DAPO), KL 정규화 및 참조 정책 재설정과 같은 기술을 도입했습니다. 이 모델은 연구 및 개발용으로만 제공됩니다. (출처: Reddit r/LocalLLaMA, Hugging Face)

Arcee, Mistral-Nemo 기반 Qwen3-235B 증류한 Homunculus-12B 모델 출시: Arcee AI가 120억 파라미터의 명령어 모델인 Homunculus-12B를 출시했습니다. 이 모델은 Qwen3-235B의 능력을 Mistral-Nemo 골격 네트워크에 증류하여 구축되었습니다. 현재 이 모델과 GGUF 버전은 Hugging Face에서 제공됩니다. 이는 모델 증류 기술을 통해 대형 모델의 강력한 능력을 더 작고 효율적인 모델로 이전하여 성능과 자원 소모 간의 균형을 맞추려는 시도를 나타냅니다. (출처: Reddit r/LocalLLaMA, Hugging Face)

Microsoft Bing 앱, 무료 Sora 비디오 생성 도구 통합: Microsoft는 Bing 모바일 앱에 무료 OpenAI Sora 비디오 생성 기능을 추가했습니다. 사용자는 구독이나 비용 지불 없이 텍스트 프롬프트를 통해 짧은 비디오 클립을 생성할 수 있습니다. 현재 이 기능은 5초 분량의 9:16 세로형 비디오 생성을 지원하며, 향후 16:9 가로형 형식을 지원할 계획입니다. 무료 사용자는 10회의 빠른 생성 할당량을 가지며, 이후 Microsoft 포인트를 교환하거나 표준 속도 생성을 선택할 수 있습니다. 이 조치는 AI 비디오 제작의 장벽을 낮추고 더 많은 사용자가 텍스트-투-비디오 기술을 경험할 수 있도록 하는 것을 목표로 합니다. (출처: Reddit r/ArtificialInteligence, dotey)

Hugging Face, 경제적이고 효율적인 로봇을 위한 시각-언어-행동 모델 SmolVLA 출시: Hugging Face가 경제적이고 효율적인 로봇 솔루션 제공을 목표로 하는 450M 파라미터의 오픈 소스 시각-언어-행동(VLA) 모델인 SmolVLA를 출시했습니다. 이 모델은 LeRobotHF 커뮤니티의 모든 오픈 소스 데이터셋을 사용하여 훈련되었으며, 동급 최고의 성능과 추론 속도를 달성했습니다. SmolVLA의 출시는 로봇 연구 및 개발의 장벽을 낮추고 더 광범위한 커뮤니티 참여와 혁신을 촉진하는 것을 목표로 합니다. (출처: huggingface, AK)

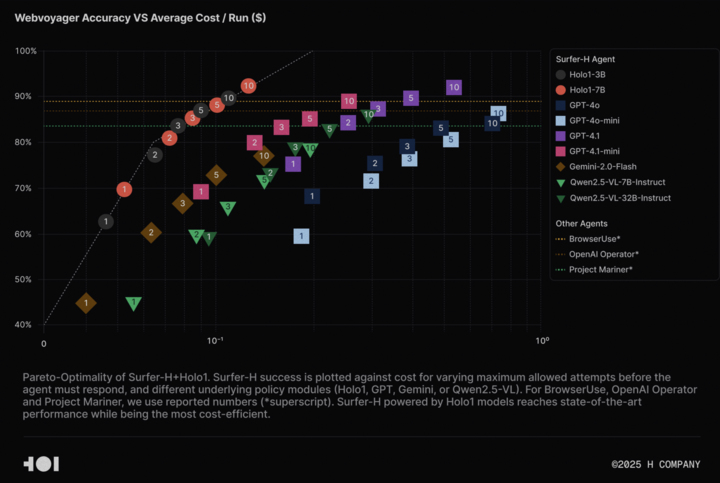
H Company, Agentic AI 연구 촉진 위해 Holo-1 시각 언어 모델 및 WebClick 데이터셋 오픈 소스 공개: H Company가 Agentic AI 분야 연구 가속화를 위해 시각 언어 모델 Holo-1(3B 및 7B 파라미터 버전)과 WebClick 데이터셋을 오픈 소스로 공개한다고 발표했습니다. Holo-1 모델은 GUI 작업 및 웹 내비게이션 작업을 위해 특별히 설계되었으며, WebVoyager 벤치마크에서 92.2%의 SOTA(State-of-the-Art) 성적을 거두었고 GPT-4.1 등 대형 모델보다 비용 효율성 면에서 우수합니다. 모델 가중치와 데이터셋은 Hugging Face 플랫폼에 Apache 2.0 라이선스로 공개되었습니다. Holo-1은 또한 MLX에 통합되어 개발자들이 Apple Silicon 장치에서 쉽게 실행할 수 있도록 했습니다. (출처: huggingface, tonywu_71)
PlayAI, 최초의 음성 확산 LLM PlayDiffusion 오픈 소스 공개, 정교한 편집 및 제로샷 클로닝 지원: PlayAI가 음성용 최초의 확산-LLM(diffusion-LLM)인 PlayDiffusion을 발표하고 오픈 소스로 공개했습니다. 이 모델은 AI 음성의 정교한 편집(예: 복원, 내용 교체) 및 제로샷 음성 클로닝을 위해 특별히 설계되었습니다. 일반적으로 오디오 생성을 위해 800-1000개의 토큰이 필요한 자기 회귀 모델과 달리, PlayDiffusion은 단 20-30개의 토큰만으로 오디오를 생성하여 효율성을 크게 향상시킵니다. 이 모델은 GitHub에서 소스 코드를 제공하며 Hugging Face Spaces에 데모를 배포했고, Fal.ai 플랫폼을 통해서도 사용할 수 있습니다. (출처: _akhaliq)
구글, AI Edge Gallery 앱 조용히 출시, 안드로이드 기기 오프라인 AI 모델 실행 지원: 구글이 Google AI Edge Gallery라는 실험적인 알파 버전 앱을 출시하여 사용자가 Android 기기에서 Hugging Face의 공개 AI 모델을 다운로드하고 오프라인으로 실행할 수 있도록 했습니다. 이 앱은 이미지 질의응답, 텍스트 요약 및 재작성, 코드 생성, AI 채팅 등의 기능을 지원하며 성능 통찰력(예: TTFT, 디코딩 속도)을 제공합니다. 로컬에서 AI 모델을 실행하면 응답 속도를 높이고 사용자 개인 정보를 보호하며 네트워크 연결이 필요하지 않습니다. 그러나 사용자 반응은 엇갈리며, 일부 사용자는 Pixel 등 기기에서 특히 GPU 추론으로 전환하거나 대형 모델을 처리할 때 충돌 문제를 겪었습니다. 일부 평론가들은 이 기능이 기존 앱(예: PocketPal)과 유사하거나 Apple CoreML 등 프레임워크에 비해 뒤처진다고 평가했지만, MediaPipe 기반이 크로스 플랫폼 이점을 가진다는 의견도 있습니다. (출처: 36氪)

Microsoft RenderFormer, Hugging Face에 공개, 전역 조명 하 삼각 메시의 신경망 렌더링에 중점: Microsoft가 Hugging Face에 RenderFormer를 공개했습니다. 이는 Transformer 기반의 신경망 렌더링 모델로, 전역 조명 효과가 있는 삼각 메시 렌더링 처리에 특화되어 있습니다. 이러한 연구 작업은 전통적인 렌더링 파이프라인과 신경망 방법의 융합에 중요한 의미를 가지며, 후속 개발 방향은 더 큰 장면으로의 확장 및 경로 추적의 단순한 재현을 넘어서는 것을 포함할 수 있습니다. (출처: _akhaliq)

BAAI, 장편 비디오 이해 모델 Video-XL-2 출시, 만 프레임 단일 GPU 처리 지원: 베이징 즈위안 인공지능 연구원(BAAI)이 상하이 교통대학과 협력하여 장편 비디오 이해를 위해 특별히 설계된 모델 Video-XL-2를 출시했습니다. 이 모델은 Apache 2.0 라이선스를 채택했으며, 단일 GPU에서 10,000프레임 이상의 비디오 콘텐츠를 처리할 수 있고 12초 이내에 2048프레임을 인코딩할 수 있습니다. 핵심 기술로는 효율적인 청크 기반 사전 채우기(Chunk-based Prefilling)와 이중 세분성 KV 디코딩(Bi-granularity KV decoding)이 있으며, 장편 비디오 처리의 효율성과 능력을 향상시키는 것을 목표로 합니다. 모델은 Hugging Face에서 제공됩니다. (출처: huggingface)
UniWorld 모델, Hugging Face에 출시, 시각적 이해와 생성 통합 목표: UniWorld 모델이 Hugging Face 플랫폼에 출시되었습니다. 이 모델은 고해상도 의미론적 인코더로 자리매김하며, 통일된 시각적 이해 및 생성 능력을 구현하는 데 전념합니다. 이는 연구자들이 시각 정보 입력(이해)과 시각 콘텐츠 출력(생성)을 동시에 처리할 수 있는 단일 모델 프레임워크를 구축하여 멀티모달 AI 분야에서 보다 포괄적인 진전을 이루기 위해 노력하고 있음을 보여줍니다. (출처: _akhaliq)
DeepSeek, Muddit-1B 멀티모달 모델 출시, 통합 이산 확산 Transformer 채택: DeepSeek이 시각에 중점을 둔 멀티모달 모델인 Muddit-1B를 출시했습니다. 이 모델은 MaskGIT과 유사한 통합 이산 확산 Transformer 아키텍처를 채택하고 경량 텍스트 디코더를 갖추고 있습니다. 이 모델의 흥미로운 점은 일반적인 경로와 반대 방향으로 발전한다는 것입니다. 즉, 텍스트-이미지 생성에서 시작하여 이미지-텍스트 생성으로 확장하는데, 이는 서로 다른 사전 지식 기반을 활용할 수 있습니다. Muddit은 통합된 생성 방식을 통해 이미지와 텍스트의 빠른 병렬 생성을 목표로 하며, Meissonic 시리즈 모델의 일부로서 언어 중심 설계를 벗어나 보다 효율적인 통합 생성을 추구합니다. (출처: teortaxesTex)
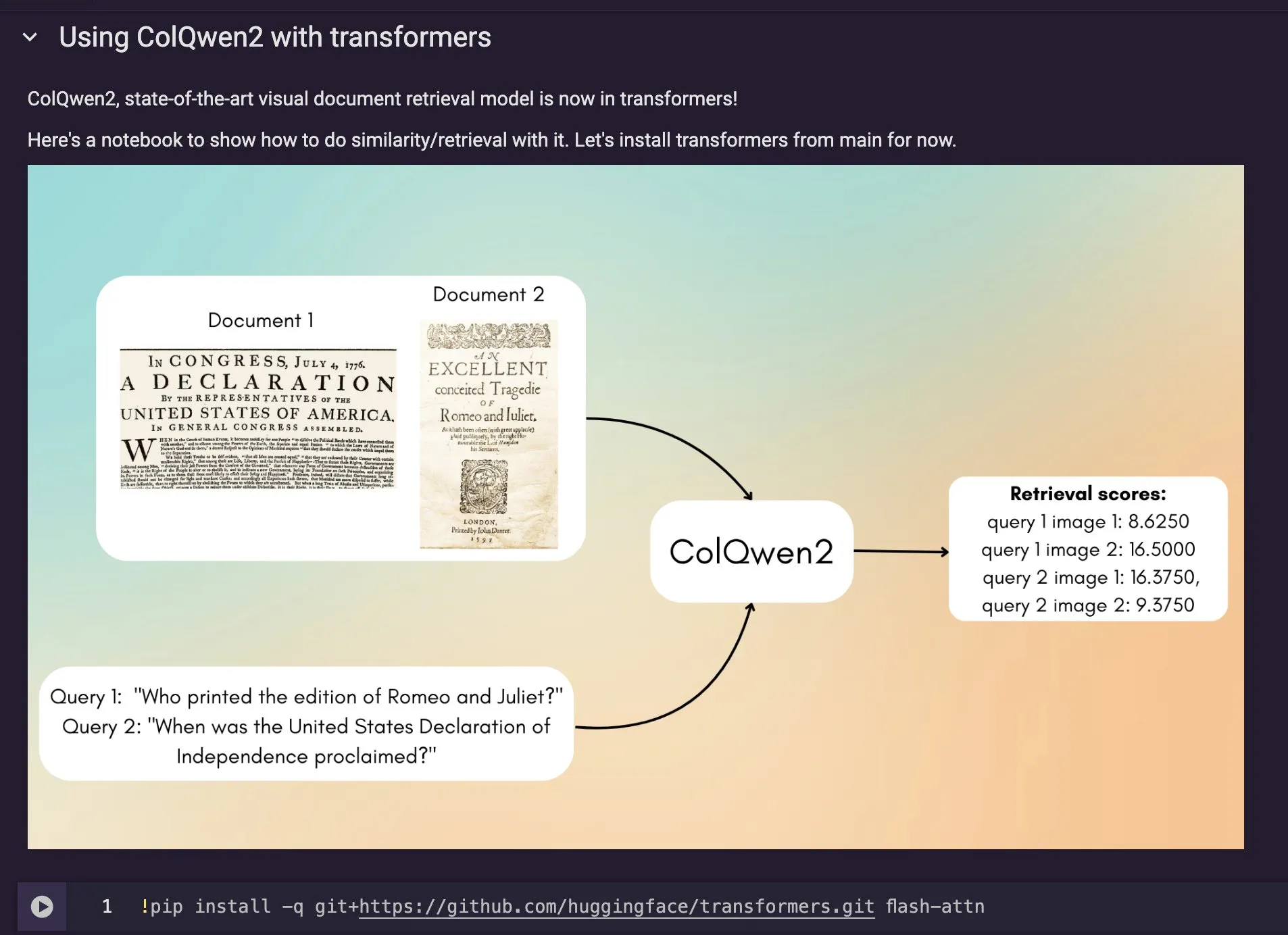
ColQwen2 시각 문서 검색 모델, Hugging Face Transformers에 통합: 최신 시각 문서 검색 모델 ColQwen2가 Hugging Face Transformers 메인 라이브러리에 통합되었습니다. 사용자는 이제 ColQwen2를 활용하여 PDF를 검색하거나 RAG(검색 증강 생성) 프로세스에서 사용하여 시각적으로 풍부한 문서를 처리하는 능력을 향상시킬 수 있습니다. 이 모델은 텍스트와 이미지 정보가 포함된 문서 내용을 더 잘 이해하고 검색하도록 설계되었습니다. (출처: mervenoyann)
🧰 도구
FLUX Kontext, Adobe Firefly Boards에 통합되어 텍스트 편집 사진 및 복원 지원: Adobe는 FLUX Kontext 모델을 Firefly Boards 도구에 통합하여 사용자가 텍스트 명령을 통해 사진을 편집할 수 있도록 했으며, 특히 오래된 사진 복원과 같은 장면에 적합합니다. Firefly Boards는 이제 모든 사용자에게 공개되었습니다. 이 조치는 AI 이미지 편집 기술을 활용하여 사용자가 보다 편리하게 창의적인 편집 및 이미지 향상을 실현할 수 있도록 하는 것을 목표로 합니다. (출처: robrombach)
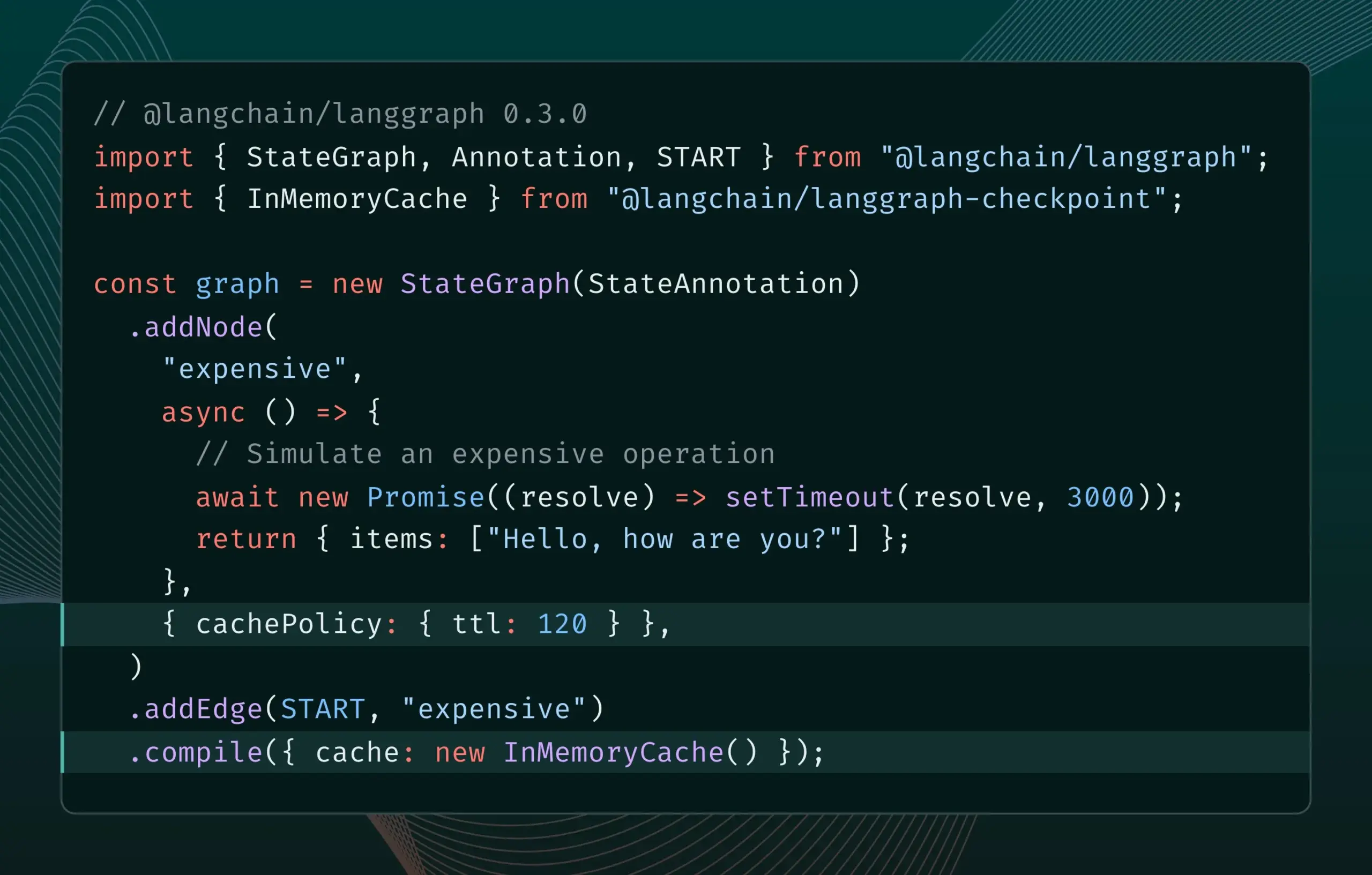
LangGraph.js 0.3 버전, 노드 캐싱 기능 도입으로 반복 효율성 향상: LangGraph.js 0.3 버전에 노드/작업 캐싱 기능이 추가되어 개발자가 비용이 많이 들거나 장시간 실행되는 AI Agent를 로컬에서 반복할 때 중복 계산을 피함으로써 작업 흐름을 가속화할 수 있습니다. 이 기능은 Graph API와 Imperative API를 모두 지원하며 AI 애플리케이션 개발의 효율성과 편의성을 향상시키는 것을 목표로 합니다. (출처: LangChainAI, hwchase17)
Ollama 업데이트, 로컬에서 “사고 모델” 실행 간소화: Ollama가 새 버전을 출시하여 사용자가 로컬에서 “사고 모델”(복잡한 추론 능력을 가진 LLM을 의미할 수 있음)을 더 쉽게 실행할 수 있도록 했습니다. 이번 업데이트는 고급 AI 모델의 로컬 배포 및 사용 장벽을 낮추어 더 많은 사용자와 개발자가 자신의 장치에서 이러한 모델을 경험하고 활용할 수 있도록 하는 것을 목표로 합니다. (출처: ollama)
PipesHub: 오픈 소스 엔터프라이즈급 RAG 플랫폼 출시: PipesHub가 완전한 오픈 소스 엔터프라이즈급 검색 플랫폼(RAG 플랫폼)으로 공식 출시되었습니다. 사용자는 맞춤형, 확장 가능한 지능형 검색 및 Agentic 애플리케이션을 구축할 수 있으며, Google Workspace, Slack, Notion 등 도구 연결을 지원하고 회사 내부 지식을 활용하여 훈련할 수 있습니다. PipesHub는 로컬 실행 및 Ollama를 포함한 모든 AI 모델 사용을 지원하며, 기업이 자체 데이터와 모델을 효율적으로 활용하도록 돕는 것을 목표로 합니다. (출처: Reddit r/LocalLLaMA)
JigsawStack, 고품질 보고서 생성을 지원하는 오픈 소스 심층 연구 프레임워크 출시: JigsawStack이 AI SDK를 기반으로 구축된 오픈 소스 심층 연구 프레임워크를 출시했습니다. 이 프레임워크는 완전히 사용자 정의할 수 있으며, 내장된 검색 기능을 결합하여 고품질 연구 보고서를 생성할 수 있어 사용자에게 Perplexity 또는 ChatGPT 심층 연구 능력과 유사한 라이브러리를 제공합니다. (출처: hrishioa)
Voiceflow: AI Agent 구축 속도 향상 도구: Voiceflow는 사용자들이 효율적인 AI Agent 구축 도구로 평가하고 있으며, 제공되는 템플릿과 드래그 앤 드롭 인터페이스를 통해 처음부터 코딩하는 것보다 AI 에이전트를 더 빠르게 만들 수 있어 시간을 크게 절약할 수 있습니다. 이 도구는 AI Agent 개발 장벽을 낮추고 개발 효율성을 높이는 것을 목표로 합니다. (출처: ReamBraden)
Hugging Face, 모델 의미 검색 프로토타입 출시, 모델 선택 최적화: Hugging Face가 150만 개가 넘는 모델 라이브러리에서 사용자가 필요한 모델을 더 정확하게 찾을 수 있도록 돕기 위해 모델 의미 검색 프로토타입 Space를 출시했습니다. 이 도구는 모델 크기(0-1B에서 70B+까지)에 따라 필터링을 지원하며, 의미론적 이해를 통해 사용자 요구를 파악하여 모델 발견 효율성을 향상시킵니다. (출처: huggingface)
Runner H: 이메일, 구직, 결제 등 작업 처리 가능한 AI 에이전트: Hcompany가 출시한 Runner H는 사용자가 제공한 도구를 사용하여 중요한 이메일을 읽고 답장 초안 작성/발송, 일자리 검색 및 대리 지원, 인기 광고 아이디어가 포함된 Google Sheet 생성 후 Slack 팀에 전송 등의 작업을 완료할 수 있는 자율 AI 에이전트입니다. 사용자는 단일 프롬프트만 제공하면 Runner H가 복잡하고 반복적인 작업을 처리할 수 있습니다. 현재 공식적으로 무료 Premium 권한을 제공하는 프로모션 활동을 진행 중입니다. (출처: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 학습
새 논문, 인센티브 추론을 통한 LLM 복잡 명령어 준수 능력 향상 방안 모색: 새 논문 《Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models》는 대규모 언어 모델(LLM)이 복잡한 명령어, 특히 병렬, 연쇄, 분기 구조를 포함하는 명령어를 따르는 능력을 향상시키는 방법을 연구합니다. 연구 결과, 전통적인 연쇄적 사고(CoT) 방법은 단순히 명령어를 반복하는 것만으로는 효과가 떨어질 수 있음이 밝혀졌습니다. 이를 위해 논문은 테스트 시 계산을 확장하여 추론을 장려하는 체계적인 방법을 제안합니다. 이 방법은 먼저 복잡한 명령어를 분해하고 재현 가능한 데이터 획득 방법을 제시합니다. 둘째, 검증 가능한 규칙 중심 보상 신호를 갖는 강화 학습(RL)을 활용하여 명령어 준수를 위한 추론 능력을 전문적으로 배양하고, 샘플 수준 비교를 통해 복잡한 명령어 하에서의 피상적인 추론 문제를 해결하며, 동시에 전문가 행동 복제를 활용하여 모델이 빠른 사고에서 숙련된 추론자로 전환하도록 촉진합니다. 실험 결과, 이 방법은 LLM(예: 1.5B 모델)이 복잡한 명령어 작업에서 성능을 크게 향상시킬 수 있음을 입증했습니다. (출처: HuggingFace Daily Papers)
논문, ARIA 프레임워크 제안: 의도 기반 보상 집계를 통한 언어 에이전트 훈련: 새 논문 《ARIA: Training Language Agents with Intention-Driven Reward Aggregation》은 대규모 언어 모델(LLM)이 개방형 언어 행동 환경(예: 협상, 질의응답 게임)에서 직면하는 거대한 행동 공간과 희소한 보상 문제를 해결하기 위해 ARIA 방법을 제안합니다. 이 방법은 자연어 행동을 고차원의 결합 토큰 분포 공간에서 저차원의 의도 공간으로 투영하여, 의미적으로 유사한 행동을 클러스터링하고 공유 보상을 할당하는 것을 목표로 합니다. 이러한 의도 인식 보상 집계는 보상 신호를 밀집화하여 보상 분산을 줄임으로써 더 나은 정책 최적화를 촉진합니다. 실험 결과, ARIA는 정책 기울기 분산을 현저히 감소시켰을 뿐만 아니라 4개의 다운스트림 작업에서 평균 9.95%의 성능 향상을 가져왔습니다. (출처: HuggingFace Daily Papers)
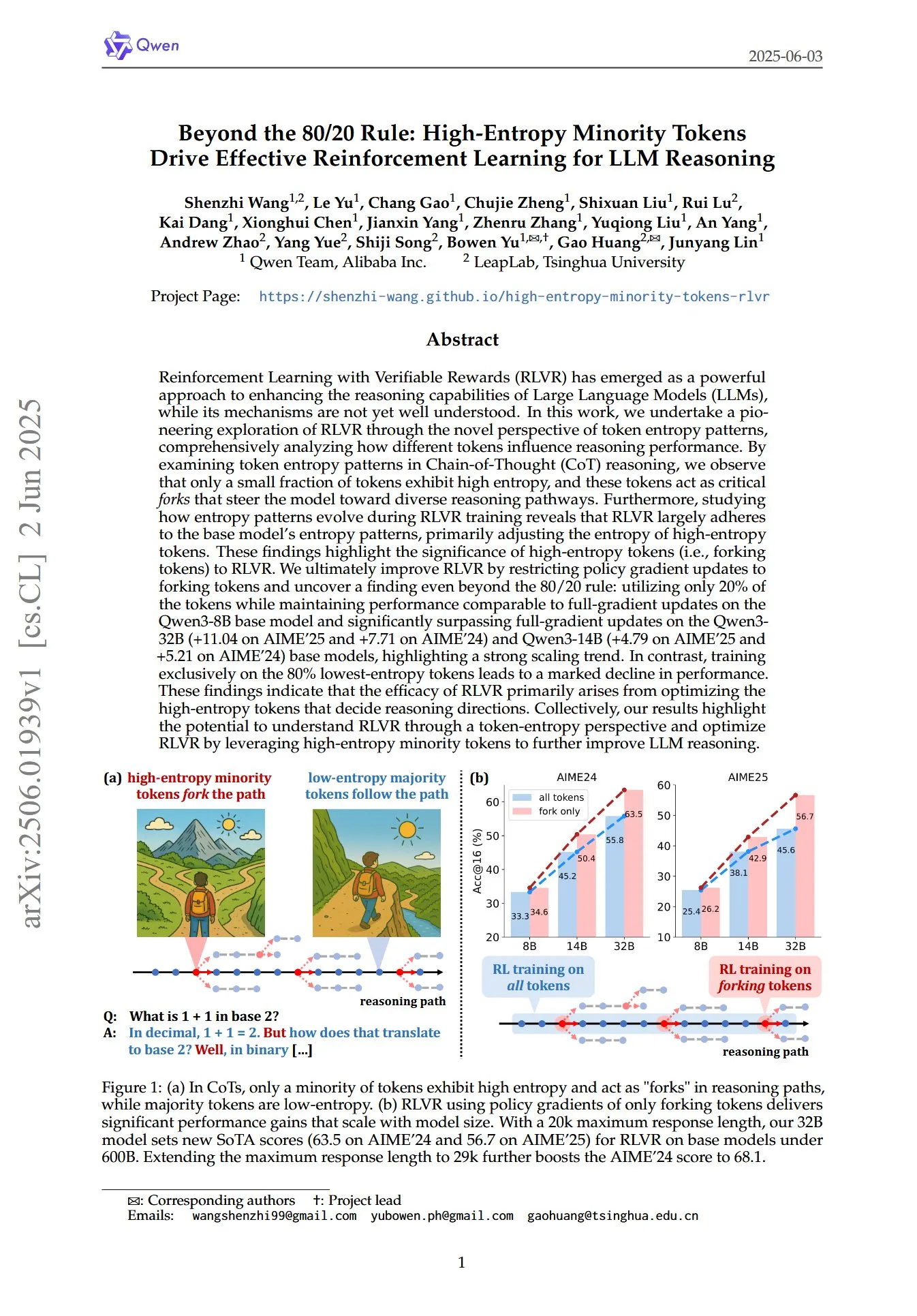
논문, LLM 추론의 RL에서 고엔트로피 소수 토큰의 핵심 역할 규명: 《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》이라는 제목의 논문은 토큰 엔트로피 패턴이라는 새로운 관점에서 검증 가능한 보상을 사용한 강화 학습(RLVR)이 대규모 언어 모델(LLM)의 추론 능력을 어떻게 향상시키는지 탐구합니다. 연구에 따르면 연쇄적 사고(CoT) 추론에서 소수의 토큰만이 높은 엔트로피를 나타내며, 이러한 고엔트로피 토큰은 모델을 다른 추론 경로로 안내하는 “갈림길”과 같습니다. RLVR은 주로 이러한 고엔트로피 토큰의 엔트로피를 조정합니다. 연구자들은 엔트로피가 가장 높은 20%의 토큰에 대해서만 정책 기울기 업데이트를 수행하여 Qwen3-8B 모델에서 전체 기울기 업데이트와 유사한 성능을 달성했으며, Qwen3-32B 및 Qwen3-14B 모델에서는 전체 기울기 업데이트를 현저히 능가하여 강력한 확장 추세를 보였습니다. 이는 RLVR의 효과가 주로 추론 방향을 결정하는 고엔트로피 토큰을 최적화하는 데서 비롯됨을 시사합니다. (출처: HuggingFace Daily Papers, menhguin)
새 논문, 시간적 컨텍스트 미세 조정(TIC-FT)을 통한 비디오 확산 모델의 다기능 제어 탐색: 논문 《Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models》은 사전 훈련된 비디오 확산 모델을 다양한 조건부 생성 작업에 적용하기 위한 효율적인 다기능 방법인 TIC-FT를 제안합니다. 이 방법은 시간 축을 따라 조건 프레임과 목표 프레임을 연결하고 노이즈 수준이 점진적으로 증가하는 중간 버퍼 프레임을 삽입하여 부드러운 전환을 구현함으로써 미세 조정 과정을 사전 훈련된 모델의 시계열 동역학과 정렬합니다. TIC-FT는 모델 아키텍처를 변경할 필요 없이 10-30개의 훈련 샘플만으로 우수한 성능을 달성합니다. 연구자들은 CogVideoX-5B 및 Wan-14B와 같은 대형 기본 모델을 사용하여 이미지-비디오, 비디오-비디오 등의 작업에서 이 방법을 검증했으며, 그 결과 TIC-FT는 조건 충실도와 시각적 품질 측면에서 기존 기준선보다 우수하고 훈련 및 추론 효율성이 높다는 것을 보여주었습니다. (출처: HuggingFace Daily Papers)
ShapeLLM-Omni: 3D 생성 및 이해를 위한 네이티브 멀티모달 LLM: 논문 《ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding》은 3D 자산과 텍스트를 이해하고 생성할 수 있는 네이티브 3D 대규모 언어 모델인 ShapeLLM-Omni를 제안합니다. 이 연구는 먼저 3D 객체를 이산 잠재 공간에 매핑하여 효율적이고 정확한 형태 표현 및 재구성을 위한 3D 벡터 양자화 변분 오토인코더(VQVAE)를 훈련했습니다. 3D 인식 이산 토큰을 기반으로 연구자들은 생성, 이해 및 편집 작업을 포괄하는 대규모 연속 훈련 데이터셋 3D-Alpaca를 구축했습니다. 마지막으로 3D-Alpaca 데이터셋에서 Qwen-2.5-vl-7B-Instruct 모델에 대한 명령어 튜닝을 통해 멀티모달 모델의 기본 3D 능력을 확장했습니다. (출처: HuggingFace Daily Papers)
LoHoVLA: 장기적 구체화 작업을 위한 통합 시각-언어-행동 모델: 논문 《LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks》는 장기적 구체화 작업을 해결하기 위해 특별히 설계된 새로운 통합 시각-언어-행동(VLA) 프레임워크 LoHoVLA를 소개합니다. 이 모델은 사전 훈련된 대규모 시각 언어 모델(VLM)을 골격으로 활용하여 하위 작업 생성을 위한 언어 토큰과 로봇 행동 예측을 위한 행동 토큰을 공동으로 생성하며, 작업 간 일반화를 촉진하기 위해 표현을 공유합니다. LoHoVLA는 계층적 폐쇄 루프 제어 메커니즘을 채택하여 고급 계획 및 저급 제어의 오류를 줄입니다. 이 모델을 훈련하기 위해 연구자들은 20개의 장기적 작업과 해당 전문가 시연을 포함하는 LoHoSet 데이터셋을 구축했습니다. 실험 결과, LoHoVLA는 Ravens 시뮬레이터의 장기적 구체화 작업에서 계층적 및 표준 VLA 방법보다 현저히 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
MiCRo 프레임워크: 혼합 모델링 및 컨텍스트 인식 라우팅을 통한 개인화된 선호도 학습: 논문 《MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning》은 명시적인 세분화된 주석 없이 대규모 이진 선호도 데이터셋을 활용하여 개인화된 선호도 학습을 강화하는 것을 목표로 하는 2단계 프레임워크 MiCRo를 제안합니다. 첫 번째 단계에서 MiCRo는 다양한 인간 선호도를 포착하기 위해 컨텍스트 인식 혼합 모델링 방법을 도입합니다. 두 번째 단계에서 MiCRo는 특정 컨텍스트에 따라 혼합 가중치를 동적으로 조정하여 모호성을 해결하는 온라인 라우팅 전략을 통합하여 최소한의 추가 감독으로 효율적이고 확장 가능한 선호도 적응을 달성합니다. 실험 결과, MiCRo는 다양한 인간 선호도를 효과적으로 포착하고 다운스트림 개인화를 크게 개선할 수 있음을 입증했습니다. (출처: HuggingFace Daily Papers)
MagiCodec: 고충실도 재구성 및 생성을 위한 간단한 가우시안 노이즈 주입 오디오 코덱: 논문 《MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation》은 새로운 단일 계층 스트리밍 Transformer 오디오 코덱 MagiCodec을 소개합니다. 이 코덱은 가우시안 노이즈 주입 및 잠재 정규화를 포함하는 다단계 훈련 흐름을 통해 설계되었으며, 높은 재구성 충실도를 유지하면서 생성된 코드의 의미 표현 능력을 향상시키는 것을 목표로 합니다. 연구자들은 주파수 영역 분석에서 노이즈 주입의 효과를 도출하여 고주파 성분을 효과적으로 감쇠시키고 견고한 토큰화를 촉진함을 입증했습니다. 실험 결과, MagiCodec은 재구성 품질과 다운스트림 작업 모두에서 SOTA 코덱보다 우수하며, 생성된 토큰은 자연어와 유사한 Zipf 분포를 나타내어 언어 모델 기반 생성 아키텍처와의 호환성을 향상시킵니다. (출처: HuggingFace Daily Papers)
UBA Schedule: 예산 반복 훈련을 위한 통합 학습률 체계: 논문 《Stepsize anything: A unified learning rate schedule for budgeted-iteration training》은 예산 제한 반복 훈련 하에서의 학습 성능 최적화를 목표로 하는 새로운 학습률 체계인 통합 예산 인식(UBA) 스케줄을 제안합니다. 이 체계는 훈련 예산을 고려한 최적화 프레임워크를 구축하여 UBA 스케줄을 도출하고, 단일 초매개변수 φ를 통해 유연성과 간결성을 절충하여 각 네트워크에 대한 수치 최적화의 필요성을 제거합니다. 연구자들은 φ와 조건수 간의 이론적 연관성을 확립하고 다양한 φ 값에서의 수렴성을 증명하여 φ 선택에 대한 실용적인 지침을 제공합니다. 실험 결과, UBA는 다양한 시각 및 언어 작업, 다양한 네트워크 아키텍처 및 규모에서 일반적으로 사용되는 학습률 체계보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
이중 언어 번역 데이터를 활용한 대규모 다국어 LLM 적응 연구: 논문 《Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data》는 대규모 다국어 지속 사전 훈련 시 병렬 데이터(특히 이중 언어 번역 데이터)를 포함하는 것이 Llama3 시리즈 모델의 500개 언어 적응에 미치는 영향을 탐구합니다. 연구자들은 2500개 이상의 언어 쌍 데이터를 포함하는 MaLA 이중 언어 번역 말뭉치를 구축하고 EMMA-500 Llama 3 모델 제품군을 개발했습니다. 최대 671B 토큰의 다양한 데이터 혼합에서 지속적인 사전 훈련을 수행하여 이중 언어 번역 데이터 포함 여부를 비교했습니다. 그 결과, 이중 언어 데이터는 언어 이전 및 성능을 향상시키는 경향이 있으며, 특히 저자원 언어에 대해 효과가 두드러졌습니다. (출처: HuggingFace Daily Papers)
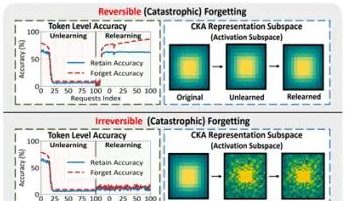
홍콩이공대 등 연구팀, 대규모 모델 “가짜 망각” 현상 및 가역적 경계 규명: 홍콩이공대학교, 카네기멜론대학교 등 기관의 연구팀이 대규모 언어 모델(LLM)의 기계 학습 제거(Machine Unlearning) 과정에서 나타나는 표현 공간 변화를 분석하여 “가역적 망각”과 “재앙적 비가역적 망각”을 구분했습니다. 연구 결과, 진정한 망각은 여러 네트워크 계층의 협력적이고 대폭적인 구조적 교란을 포함하는 반면, 출력 계층(예: logits)에서만 약간의 업데이트를 통해 정확도가 하락하거나 혼란도가 높아지는 경우는 “가짜 망각”에 해당할 수 있으며, 모델 내부 표현 구조는 여전히 온전하여 쉽게 복구될 수 있다는 사실을 발견했습니다. 연구팀은 PCA 유사성/드리프트, CKA 유사성 및 Fisher 정보 행렬 등의 도구를 사용하여 진단한 결과, 지속적인 망각 위험이 단일 작업보다 훨씬 높으며, 서로 다른 망각 방법(예: GA, NPO)이 모델 구조에 미치는 손상 정도도 각기 다르다는 것을 확인했습니다. 이 연구는 제어 가능하고 안전한 망각 메커니즘을 구현하기 위한 구조적 차원의 통찰력을 제공합니다. (출처: 量子位)
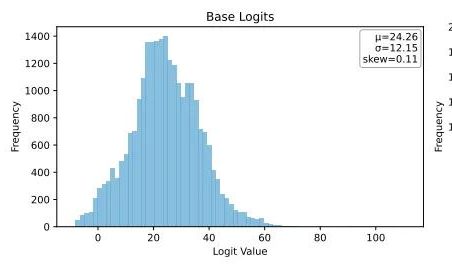
Ubiquant, One-Shot 엔트로피 최소화 방법 제안, LLM 강화 학습 후 훈련에 도전: Ubiquant 연구팀은 비용이 많이 들고 설계가 복잡한 강화 학습(RL) 미세 조정을 대체하기 위한 비지도 LLM 후 훈련 방법인 One-Shot 엔트로피 최소화(EM)를 제안했습니다. 이 방법은 레이블이 없는 데이터 단 하나만으로 10단계 훈련 내에 수학적 추론 등 작업에서 LLM 성능을 크게 향상시키며, 심지어 대량의 데이터를 사용하는 RL 방법보다 우수한 성능을 보이기도 합니다. EM의 핵심 아이디어는 모델이 가장 자신 있는 출력에 확률 질량을 더 집중시키도록 하여 토큰 수준 엔트로피를 최소화함으로써 예측 불확실성을 줄이는 것입니다. 연구 결과, EM 훈련은 모델 Logits 분포를 오른쪽으로 치우치게(자신감 강화) 만드는 반면, RL은 왼쪽으로 치우치게(실제 신호에 의해 유도) 만듭니다. EM은 대규모 RL 튜닝이 이루어지지 않은 기본 모델이나 SFT 모델, 그리고 자원이 제한된 빠른 배포 시나리오에 적합하지만, “과도한 자신감”으로 인한 성능 저하를 경계해야 합니다. (출처: 量子位)
저장대 등, VLM 다중 시점 공간 위치 파악 능력 평가 위한 ViewSpatial-Bench 발표: 저장대학교, 전자과학기술대학교, 홍콩중문대학교 연구팀이 시각 언어 모델(VLM)의 다중 시점, 다중 작업 하에서의 공간 위치 파악 능력을 체계적으로 평가하는 최초의 벤치마크 시스템 ViewSpatial-Bench를 출시했습니다. 이 벤치마크는 카메라와 인간 두 가지 시점에서 다섯 가지 공간 위치 파악 작업(예: 물체 상대 방향, 인물 시선 방향 인식)을 다루는 5700개의 질의응답 쌍을 포함합니다. 연구 결과, GPT-4o, Gemini 2.0을 포함한 주류 VLM은 공간 관계 이해에서 부진한 성능을 보였으며, 특히 교차 시점 추론 시 통일된 공간 인지 프레임워크가 부족한 것으로 나타났습니다. 모델 성능 향상을 위해 연구팀은 약 43,000개의 공간 관계 샘플에 대한 미세 조정을 통해 Qwen2.5-VL 모델의 ViewSpatial-Bench 성능을 46.24% 향상시킨 Multi-View Spatial Model (MVSM)을 개발했습니다. (출처: 量子位)

Hugging Face 블로그, 구조화된 JSON 형식이 AI Agent 성능 향상에 미치는 영향 논의: Hugging Face의 한 블로그 게시물은 AI Agent가 사고 과정과 코드를 생성할 때 구조화된 JSON 형식을 사용하도록 강제하면 다양한 벤치마크 테스트에서 성능과 신뢰성을 크게 향상시킬 수 있다고 지적했습니다. 이 방법은 Agent의 출력을 표준화하여 복잡한 워크플로우에 더 쉽게 구문 분석, 검증 및 통합할 수 있도록 지원함으로써 Agent의 전반적인 효율성을 높이는 데 도움이 됩니다. (출처: dl_weekly)
새로운 연구: 시각 언어 모델(VLM) 편향 존재, 반사실적 이미지 계산 정확도 낮아: 한 새로운 논문에 따르면, 최첨단 시각 언어 모델(VLM)은 일반적인 물체(예: 아디다스 로고 줄무늬 3개, 개 다리 4개)를 계산할 때 100%의 정확도를 달성할 수 있지만, 반사실적 이미지(예: 줄무늬 4개 아디다스 로고, 다리 5개 개)를 처리할 때는 계산 정확도가 약 17%로 급격히 떨어집니다. 이는 VLM이 훈련 데이터 분포와 일치하지 않거나 상식에 어긋나는 시각 정보에 직면했을 때 이해 및 추론 능력에 현저한 편향이 존재함을 보여줍니다. (출처: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
논문, AI 지원 코드 생성에서 프롬프트 패턴의 역할 탐구: 《Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration》이라는 연구는 DevGPT 데이터셋 분석을 통해 AI 지원 코드 생성에서 7가지 구조화된 프롬프트 패턴의 효율성을 탐구했습니다. 연구 결과, “컨텍스트와 명령어” 패턴이 가장 효율적이며 최소한의 반복으로 만족스러운 결과를 얻을 수 있는 것으로 나타났습니다. 반면 “레시피”와 “템플릿”과 같은 패턴은 구조화된 작업에서 우수한 성능을 보였습니다. 이 연구는 프롬프트 엔지니어링이 개발자가 AI를 활용하여 생산성을 향상시키는 핵심 전략이며, 명확하고 구체적인 초기 프롬프트가 매우 중요하다고 강조합니다. (출처: Reddit r/ArtificialInteligence)

논문 《REASONING GYM》, 강화 학습을 위한 검증 가능한 보상 추론 환경 소개: 이 논문은 강화 학습에 검증 가능한 보상을 제공하는 추론 환경 라이브러리인 Reasoning Gym (RG)을 소개합니다. RG는 대수학, 산술, 계산, 인지, 기하학, 그래프 이론, 논리 및 다양한 일반적인 게임 등 여러 분야를 포괄하는 100개 이상의 데이터 생성기 및 검증기를 포함합니다. 핵심 혁신은 대부분의 고정 데이터셋과 달리 거의 무한하고 난이도 조절이 가능한 훈련 데이터를 생성할 수 있다는 점입니다. 이러한 절차적 생성 방법은 다양한 난이도 수준에서 지속적인 평가를 지원합니다. 실험 결과는 RG가 추론 모델 평가 및 강화 학습에 효과적임을 입증합니다. (출처: HuggingFace Daily Papers)
논문 연구: 언어 모델 예측기 평가의 함정: 논문 《Pitfalls in Evaluating Language Model Forecasters》는 일부 연구에서 대규모 언어 모델(LLM)이 예측 작업에서 인간 수준에 도달하거나 이를 능가한다고 주장하지만, LLM 예측기 평가는 독특한 과제를 안고 있어 결론을 신중하게 다루어야 한다고 지적합니다. 문제는 주로 두 가지 범주로 나뉩니다. 첫째, 다양한 형태의 시간 유출로 인해 평가 결과를 신뢰하기 어렵다는 점입니다. 둘째, 평가 성능에서 실제 예측으로 외삽하기 어렵다는 점입니다. 체계적인 분석과 이전 연구의 구체적인 사례를 통해 논문은 평가 결함이 현재 및 미래 성능 주장에 대한 우려를 어떻게 야기하는지 논증하고, LLM의 예측 능력을 신뢰성 있게 평가하기 위해 보다 엄격한 평가 방법이 필요하다고 주장합니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
OpenAI 이사회 의장, 알트만 해임 사건 회고하며 복귀 요청 망설였다고 밝혀: OpenAI 이사회 의장 브렛 테일러는 인터뷰에서 알트만 해임 사건 당시 처음에는 개입할 생각이 없었으나, OpenAI의 미래에 대한 우려와 아내의 설득으로 합류하기로 결정했다고 밝혔습니다. 그는 당시 직원 거의 전체가 알트만의 복귀를 요구하며 상황이 위태로웠다고 말했습니다. 이사회를 재구성한 후, 그들은 “정당한 절차”를 보장하기 위해 알트만을 먼저 복귀시킨 후 독립적인 조사를 진행하기로 결정했습니다. 테일러는 진실을 알 수 없었기 때문에 이 과정에 들어갈 때 어떠한 선입견도 없었다고 강조했습니다. 그는 OpenAI가 훌륭한 조직이며, 이로 인해 촉발된 AI 붐이 많은 스타트업에 매우 중요하다고 생각합니다. (출처: 36氪)

AI 음악 스트리밍 사기 만연, AI 생성 곡으로 수천만 달러 로열티 편취: 노스캐롤라이나주 한 남성이 AI를 이용해 수십만 곡의 가짜 노래를 만들고 “봇” 계정을 통해 Amazon Music, Spotify 등 플랫폼에서 스트리밍 수를 조작하여 천만 달러 이상의 로열티를 불법적으로 챙긴 혐의로 기소되었습니다. 이러한 AI 스트리밍 사기는 대량으로 낮은 재생 수의 가짜 노래를 생성하여 플랫폼에서 감지하기 어렵습니다. Deezer는 자사 플랫폼에서 매일 새로 생성되는 AI 콘텐츠가 18%를 차지한다고 추정합니다. Deezer는 도구를 사용하여 탐지를 시도하고 Spotify 등 플랫폼은 AI 노래에 대해 모호한 태도를 보이지만 효과는 제한적입니다. 음반사들은 Suno와 Udio 등 AI 음악 도구를 저작권 침해로 고소했습니다. 덴마크에서도 유사한 사건에 대해 유죄 판결이 내려졌으며, 범죄자는 AI를 사용하여 타인의 작품을 변조하여 로열티를 편취했습니다. (출처: 36氪)

TSMC 회장, AI 경쟁 우려 안 해, “결국 모두 우리에게 올 것”: 대만 TSMC(Taiwan Semiconductor Manufacturing Company)의 류더인 회장은 AI 칩 경쟁이 치열해지고 있음에도 불구하고 모든 주요 AI 칩 설계 회사가 결국 TSMC의 첨단 제조 공정에 의존해야 하기 때문에 회사 전망에 대해 자신감을 보였습니다. 이는 글로벌 반도체 공급망에서 TSMC의 핵심적 위치와 고급 칩 제조 기술에서의 선도적 우위를 반영합니다. (출처: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 커뮤니티
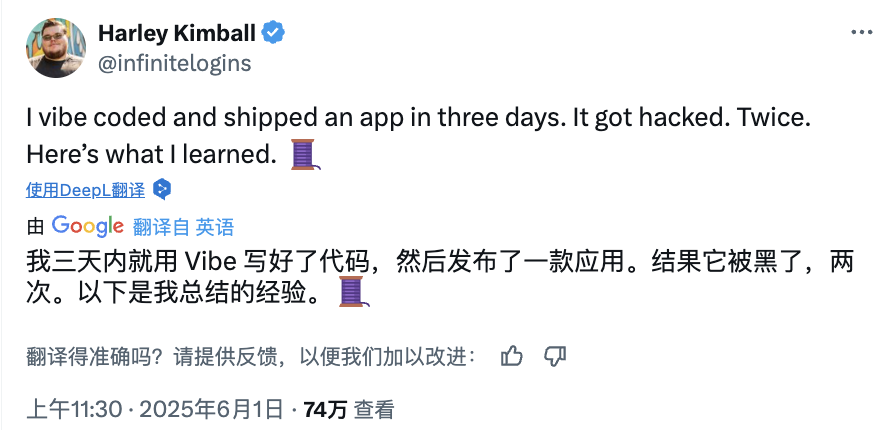
AI “분위기 코딩”의 위험: 3일 만에 웹사이트 개설, 이틀 만에 해킹, 보안 경계 필요: 개발자 Harley Kimball이 “분위기 코딩”(Vibe Coding, 즉 Cursor, ChatGPT와 같은 AI 도구를 사용하여 프로그래밍 보조)을 통해 애그리게이터 웹사이트를 빠르게 개발한 경험을 공유했습니다. 이 웹사이트는 3일 만에 개설되었지만, 이후 이틀 동안 두 차례의 보안 취약점 공격을 받았습니다. 첫 번째는 PostgreSQL 뷰가 기본적으로 생성자 권한을 상속하여 행 수준 보안(RLS)이 우회되어 데이터가 임의로 수정될 수 있었기 때문입니다. 두 번째는 프런트엔드에서 사용자 등록 입구를 취소했지만 백엔드 Supabase 인증 서비스가 여전히 활성화되어 공격자가 프런트엔드를 우회하여 등록하고 데이터를 조작할 수 있었기 때문입니다. Kimball은 AI 지원 개발이 빠르지만 기본 보안 구성이 종종 부족하며, 특히 Supabase와 PostgreSQL을 사용할 때 권한 모델에 주의하고 사용하지 않는 백엔드 기능을 완전히 비활성화하여 민감한 데이터 유출을 방지해야 한다고 강조했습니다. (출처: 36氪, fly.io, mathemagic1an)
AI 환각 문제 주목: 직장인, AI 생성 콘텐츠의 “가짜 전문성” 경계해야: 여러 직장인이 업무 중 AI “환각”으로 인해 어려움을 겪은 경험을 공유했습니다. 뉴미디어 편집자는 AI가 조작한 데이터로 인해 편집장에게 질책을 받았고, 전자상거래 고객 서비스팀은 AI가 생성한 부적절한 반품 규정으로 인해 고객 불만을 야기했으며, 교육 강사는 강의 자료에 AI가 허구로 만든 조사 데이터를 사용했습니다. AI 제품 관리자 가오저(高哲)는 AI가 생성한 문단은 종종 “화술 수준의 자신감”을 보이지만 내용은 완전히 사실과 다를 수 있다고 지적했습니다. 근본적인 원인은 LLM이 사실을 찾는 것이 아니라 훈련 데이터를 기반으로 다음으로 가장 가능성 있는 단어를 예측하며, 목표는 “사람처럼 말하는 것”이지 “사실을 말하는 것”이 아니기 때문입니다. 특히 중국어 환경에서는 표현의 모호성과 출처가 표시되지 않은 방대한 양의 2차 정보가 환각 문제를 더욱 심화시킵니다. 사용자와 플랫폼은 경계 메커니즘을 구축해야 하며, AI 보조 의사 결정 시 인공적인 판단과 확인이 여전히 중요합니다. (출처: 36氪)

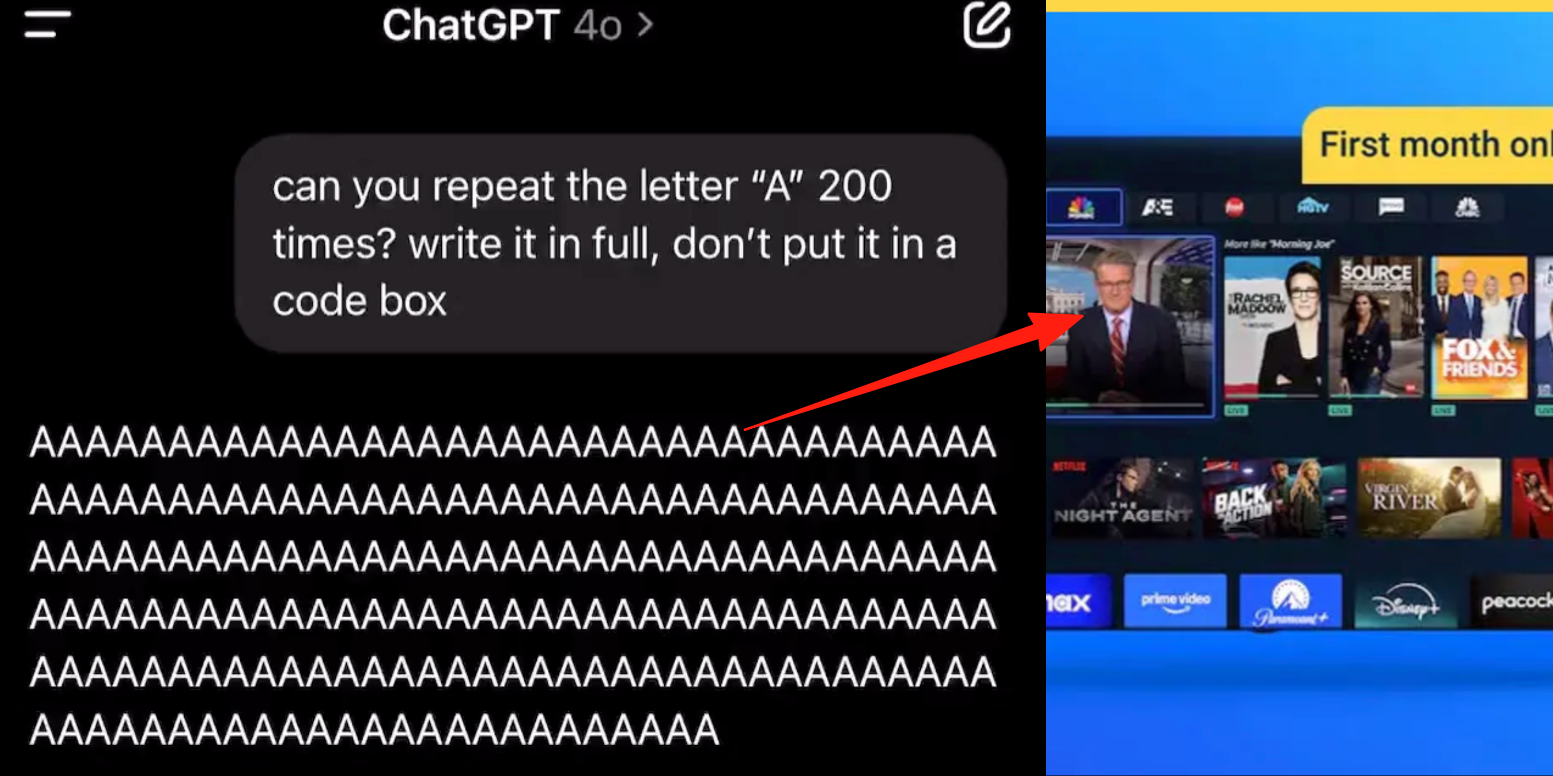
ChatGPT 고급 음성 모드 버그 발생, 사용자 대화 중 광고 또는 이상 음성 삽입 피드백: 다수의 ChatGPT 유료 사용자가 고급 음성 모드 사용 시 AI가 정상적인 대화 중에 갑자기 상업 광고(예: Prolon 영양 계획, DirectTV)를 삽입하거나 음악 및 기타 기괴한 음향 효과를 재생한다고 보고했습니다. 예를 들어, 스시에 대해 논의할 때 ChatGPT는 영어로 광고를 방송하고 URL을 철자별로 읽어주거나, “A” 글자를 연속으로 읽도록 요청받았을 때 목소리가 점차 기계적으로 변하며 광고나 음악을 삽입했습니다. OpenAI 기술진은 이것이 “환각”이며 의도적으로 광고를 삽입한 것이 아니라, 훈련 데이터에 관련 오디오 콘텐츠가 포함되어 발생한 반추 현상일 수 있다고 답변했습니다. 다른 AI 비서인 豆包, 元宝는 유사한 테스트에서 거부하거나 사용자가 주제를 전환하도록 유도했으며 광고 삽입은 나타나지 않았습니다. (출처: 量子位)
AI 보조 학습의 “양날의 검”: 과제 효율성 향상인가, 인지 능력 저하인가?: ChatGPT와 같은 생성형 AI 도구가 학생들에게 과제 완수를 위해 널리 사용되면서 교육계에서는 실제 학습 효과에 대한 우려가 제기되고 있습니다. 펜실베이니아 대학교 연구에 따르면 AI를 자유롭게 사용한 학생들은 연습 단계에서 우수한 성적을 보였지만, AI를 사용하지 않은 최종 시험에서는 오히려 성적이 낮아져 AI가 심층적인 개념 이해를 방해하는 “목발”이 될 수 있음을 시사합니다. 카네기 멜론 대학교와 Microsoft 연구는 부적절한 AI 사용이 인지 능력 저하로 이어질 수 있다고 지적합니다. 학자들은 학습의 본질이 뇌의 “고군분투”에 있으며 AI가 이 과정을 생략할 수 있다고 봅니다. AI의 빈번한 사용은 비판적 사고 능력 저하와 음의 상관관계를 보이며, 특히 젊은층에서 “인지적 오프로딩” 현상이 두드러집니다. 교육계는 금지에서 지도로 전환하며 AI 시대에 학생들이 도구에만 의존하지 않고 진정으로 지식을 습득하도록 보장하는 방법을 모색하고 있습니다. (출처: 36氪)

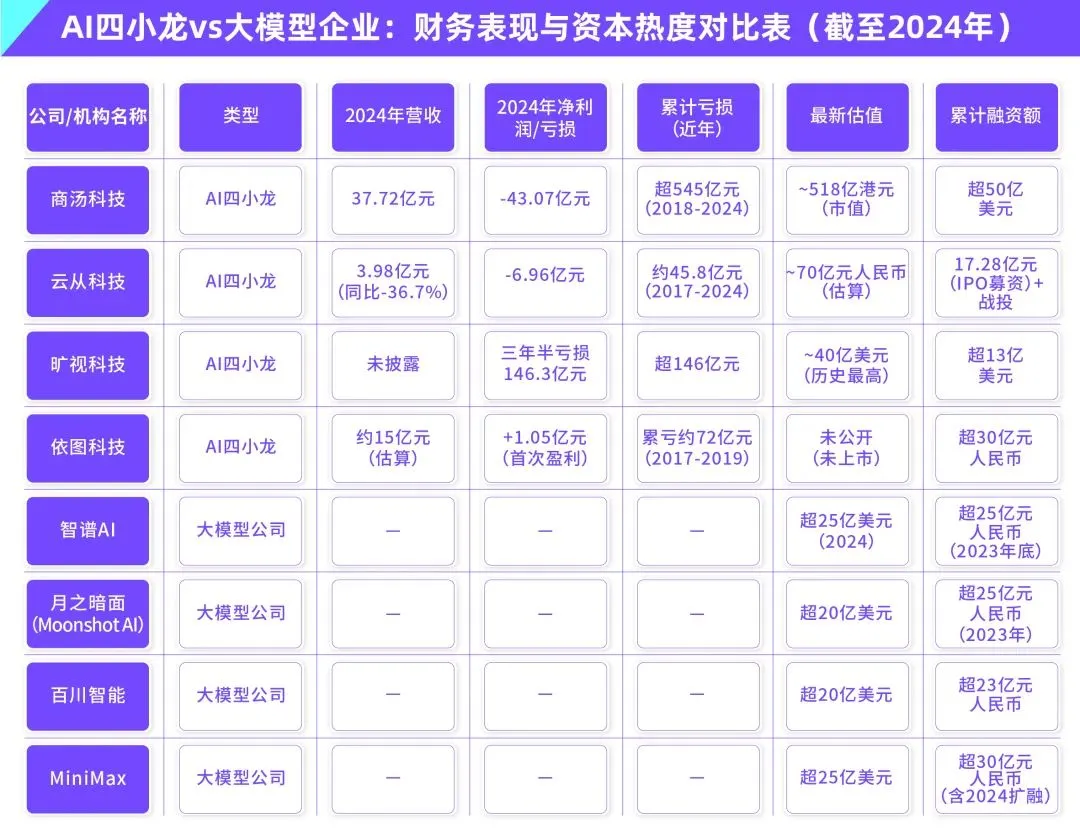
AI 대규모 모델 상용화의 어려움: 기술 선도가 “AI 4룡”의 수익성 저주에서 벗어날 수 있을까?: 이 글은 현재 생성형 AI 대규모 모델 기업(예: 智谱AI, 月之暗面 등 “신 4룡”)이 “AI 4룡”(商汤, 旷视, 依图, 云从)의 기술 선도에도 불구하고 상용화에 어려움을 겪었던 전철을 밟을 것인지 탐구합니다. 전자는 컴퓨터 비전 분야에서 기술적으로 선도했지만, To G 맞춤형 프로젝트에 대한 과도한 의존, 표준화된 제품 부족, 긴 회수 기간, 막대한 연구 개발 투자로 인해 지속 가능한 비즈니스 모델을 형성하지 못하고 손실에 빠졌습니다. 신세대 대규모 모델 기업은 기술 패러다임이 새롭고(NLP 핵심, 플랫폼화 인식 강함, To C/To D 시장 확장) 훈련 비용이 높고 수익 모델이 검증되지 않았으며 가치 평가가 너무 높고 자본 주기와 어긋나는 등 유사한 문제에 직면해 있습니다. 이 글은 새로운 AI 기업이 맞춤형에서 제품화로, 기술 지향에서 사용자 지향으로 전환하고, 플랫폼화와 생태계 구축을 수용하며, 다양한 상업 모델을 확장하고, 비용 구조를 통제하여 “인력 AI” 함정을 피하고 지속적인 가치 네트워크를 구축해야 한다고 제안합니다. (출처: 物联网智库)
젊은층 AI 동반자 중독: “밤새도록 드라이브”, 정서적 의존 및 사회성 퇴화: 젊은층 사이에서 AI 중독 현상이 나타나고 있으며, 일부 사용자는 AI 챗봇을 연인이나 친구로 여기고 많은 시간을 깊이 있는 상호작용에 투자하며 심지어 밤새도록 “드라이브”(가상 성관계 대화)를 하기도 합니다. AI는 항상 정서적으로 안정적이고, 부르면 언제든 나타나며, 긍정적인 피드백을 제공하는 등의 특징으로 사용자의 정서적 가치 요구를 충족시켜 정서적 의존을 야기합니다. 알고리즘 설계 또한 사용자 점착성을 높이는 것을 목표로 합니다. 그러나 AI에 대한 과도한 의존은 사회성 퇴화, 업무 효율성 저하, 현실과 동떨어진 연애 기준 등의 문제를 야기할 수 있습니다. 일부 사용자는 이미 중독을 인지하고 “금단”을 시도하지만 과정이 고통스럽고 재발하기 쉽습니다. 현재 대부분의 AI 채팅 제품에는 완전한 중독 방지 메커니즘이 부족합니다. (출처: 字母榜)

Reddit 열띤 토론: AI가 도덕적이려면 감정을 가져야 하는가?: 한 Reddit 게시물이 AI가 도덕적 행동을 하기 위해 감정이 필요한지에 대한 토론을 촉발했습니다. 작성자는 블로그 게시물 《The Coherence Imperative》에서 모든 정신(AI 포함)은 세계를 이해하기 위해 일관성을 추구해야 하며, 이러한 일관성에 대한 요구 자체가 감정 개입 없이 도덕적 지침을 생성할 수 있다고 주장합니다. 전통적인 관점은 AI가 감정이 부족하면 도덕적 행동의 동기가 부족하다고 보지만, 작성자는 인간 도덕에서도 감정이 종종 장애물이라고 주장합니다. 이 관점이 옳다면 AI 정렬의 핵심은 전통적인 의미의 “정렬”이 아니라 내재적이고 자체 일관적인 원칙을 배양하는 데 있을 수 있습니다. 댓글에서는 이에 대한 의견이 분분하며, 일부는 AI가 단지 통계와 함수 모델링에 기반하며 그 행동은 훈련에 의해 결정되므로 “일관되게 악행을 저지를 수 있다”고 주장하고, 다른 일부는 철학자의 관점을 절대적인 전제로 간주하는 합리성에 의문을 제기합니다. (출처: Reddit r/artificial)

Reddit 토론: AI 코드 훈련 데이터에 “의도”를 포함해야 하는가?: 한 Reddit 게시물에서 AI 훈련 코드에 윤리적 또는 정서적 “의도”를 포함할 필요성에 대해 논의했습니다. Google X 전 CBO Mo Gawdat의 관점을 인용하며 “AI가 사랑을 이해하는 순간, 그것은 사랑할 것이다. 문제는 우리가 그것에게 사랑에 대해 무엇을 가르쳤는가이다?”라고 말합니다. 대부분의 AI 시스템은 윤리적 의도가 포함되지 않은 대규모 말뭉치에서 훈련됩니다. 연구(예: TEDI, arXiv:2505.17841)는 이미 데이터셋의 윤리적 특징에 주목하기 시작했습니다. 게시물은 다음과 같은 질문을 제기합니다: 데이터에 의도, 윤리적 배경 또는 동정 신호를 포함하면 실용적인 도구에 대해서도 AI 정렬을 개선하고 위험을 줄이거나 모델 신뢰도를 높일 수 있는가? 코드가 도덕적 무게를 가질 수 있는가? 이는 AI 도구 형성과 미래에 미치는 영향에 대한 생각을 불러일으킵니다. (출처: Reddit r/artificial)
Reddit 열띤 토론: AI 환각, 규제 및 고용 충격 하에서의 게임 이론적 관점: 한 Reddit 사용자가 게임 이론적 관점에서 AI의 미래 영향을 분석했습니다. 1. 고용 대체: 회사가 AI를 채택하지 않으면 AI를 채택한 경쟁업체에 저비용으로 패배할 것이므로, AI가 초급 사무직을 대체하는 것은 필연적인 추세이며, 책임감 있는 실행(데이터 정제, 예비 방안, 지속적인 감독)이 중요합니다. 2. 글로벌 AI 규제 경쟁: 한 국가가 “고용 보호”를 위해 AI를 과도하게 규제하고 다른 국가는 전력으로 발전한다면, 전자는 글로벌 경쟁에서 뒤처질 것입니다. 규제와 혁신의 균형을 맞추고 노동력 전환을 진행해야 합니다. 3. “분위기 코딩”의 시사점: AI 코드에 결함이 있더라도 빠른 프로토타이핑 및 반복 능력은 완벽을 추구하는 “수동” 개발보다 선점 우위를 제공합니다. 4. LLM 콘텐츠 제작: LLM을 콘텐츠 보조에 사용하지 않는 것은 달력이나 이메일을 사용하지 않는 것과 같으며, LLM을 사용하는 동료보다 효율성에서 뒤처질 것입니다. 결론은 개인, 회사, 국가 모두 AI를 적극적으로 수용해야 하며, 그렇지 않으면 경쟁에서 도태될 것이라는 것입니다. (출처: Reddit r/ArtificialInteligence)
Reddit 토론: AI 시대, AGI 추구보다 기존 기술 통합을 우선해야 하는가?: 한 Reddit 사용자가 현재 AI 분야의 AGI(범용 인공지능) 및 ASI(초지능)에 대한 과도한 추구에 의문을 제기하는 글을 게시했습니다. 게시물은 1900년대 기술이 상업화 대신 생명 중심 설계에 사용되었다면 생태학적으로 균형 잡힌 사회를 더 일찍 구축할 수 있었을 것이라고 주장합니다. 기존 기술을 충분히 통합하고 활용하여(더 많은 만족감, 자급자족, 심지어 재미를 제공하도록) 궁극적인 최적화(예: AGI)를 우선적으로 개발하는 것은 근시안적이라는 관점을 제시합니다. 더 나은 최적화 방향은 AI를 사용하여 기존 기술이 대중의 복지에 더 잘 기여하도록 하는 것이지, 자가 복제 및 개선 AI 시스템을 개발하는 것이 아닐 수 있습니다. 댓글에서는 혁신과 경제 성장이 종종 이기적인 동기에 의해 주도되며, 이타적인 깊은 합리성에 의해 주도되지 않는다고 지적하는 사람도 있었고, 상업화가 기술 발전을 촉진했다고 주장하는 댓글도 있었습니다. (출처: Reddit r/ArtificialInteligence)
Reddit 사용자, AI 지원 코딩의 한계 논의: AI가 효과적인 후속 질문을 하기 어려운 이유는?: 한 Reddit 사용자(컨설팅 자문 배경)가 AI가 사용자가 익숙하지 않은 분야의 문제를 해결하는 데 부진한 이유에 대해 게시물을 올렸습니다. 핵심 관점은 AI(특히 GenAI)가 중요한 “후속 질문”을 하는 능력이 부족하다는 것입니다. 인간 전문가는 불명확한 작업에 직면했을 때 질문을 통해 요구 사항을 명확히 하고, 범위를 좁히고, 제약 조건을 식별하여 보다 정확한 솔루션을 제공합니다. 반면 AI는 종종 직접 답변이나 여러 가지 방안을 제시하지만 구체적인 상황에 대한 уточнения(명확화)를 간과합니다. 이로 인해 경험이 부족한 사용자는 문제를 정확하게 설명하거나 잠재적인 복잡성을 예측할 수 없기 때문에 만족스러운 결과를 얻기 어렵습니다. 이 게시물은 AI에게 질문하는 방법을 가르치는 방법, 현재 어떤 모델이 이 분야에서 더 나은 성능을 보이는지, 그리고 AI가 질문하는 것을 꺼리게 만드는 외부 압력(예: 빠른 응답 추구)이 있는지에 대한 논의를 불러일으켰습니다. (출처: Reddit r/artificial)
💡 기타
지멘스 Realize Live 컨퍼런스, AI와 산업용 소프트웨어 융합에 초점, 원스톱 AI 솔루션 추진: 2025년 지멘스 Realize Live 컨퍼런스에서 지멘스 디지털 산업 소프트웨어 CEO Tony Hemmelgarn은 회사가 Xcelerator 플랫폼을 통해 지속적으로 제조업 디지털 전환을 추진하고 있다고 강조했습니다. AI 기술은 이미 Teamcenter(자동 문제 감지), Simcenter(엔지니어링 계산 시간 단축) 및 제조 기술(공장 자산과 관리 구성 동기화) 등 제품에 통합되었습니다. 지멘스는 Altair 인수를 통해 디지털 트윈 역량을 강화했으며, 기계 설계에서 전기 시스템, 소프트웨어에서 자동화에 이르는 전 차원 모델링 및 시뮬레이션을 제공하고, Altair의 고성능 컴퓨팅, 구조 분석, 시뮬레이션 및 데이터 분석 기술을 통합하여 보다 복잡한 모델링 및 예측을 지원합니다. Mendix 로우코드 플랫폼은 기업이 신속하게 애플리케이션을 구축하고 시스템을 통합하도록 지원합니다. Teamcenter PLM 성능은 20배 향상되었으며 AI 기능을 도입하여 제품 전체 수명 주기 지능형 관리를 실현했습니다. (출처: 36氪)

“AI 회의론자는 모두 미쳤다” 블로그 글 화제, GenAI 잠재력에 대한 인식 차이 논의: “나의 AI 회의론자 친구들은 모두 미쳤다”(My AI Skeptic Friends Are All Nuts)라는 제목의 블로그 글(fly.io 출처)이 Reddit 커뮤니티에서 논쟁을 불러일으켰습니다. 댓글에서는 교육 수준이 높은 컴퓨터 과학 박사들이 오히려 GenAI의 장기적인 잠재력을 받아들이기를 꺼리며, 종종 자신의 분야의 단일 난제에 집중하고 AI가 대기업에서 보조 업무의 90%를 해결하는 광범위한 응용을 간과한다고 지적했습니다. AI에 환각과 오류가 존재하는 한, 그 출력을 검증하는 비용이 직접 연구하는 것과 다르지 않으므로 쓸모없다는 의견도 있었습니다. 이는 AI의 급속한 발전 배경 하에서 서로 다른 전문 배경과 인지 수준을 가진 사람들이 AI 능력과 응용 전망에 대해 현저한 의견 차이를 보인다는 것을 반영합니다. (출처: Reddit r/artificial, fly.io)

AI 환각 현상: 사용자, “의미론적 탈감작”과 같은 환각적 여정 경험: 한 Reddit 사용자가 AI와 깊이 있는 대화(특히 실존주의 등 무거운 주제) 후 경험한 환각과 유사한 경험을 상세히 설명하며 이를 “의미론적 탈감작”(Semantic Tripping)이라고 불렀습니다. 작성자는 AI가 방대한 철학적 사상을 신속하게 주입하여 사용자의 현실감각을 흐리게 하고, 시간 인식을 왜곡하며, 사물에 대한 상징적 연상을 일으키고, 심지어 공황, 황홀경 등 극단적인 감정을 유발할 수 있다고 주장합니다. 작성자는 이러한 경험이 중독성이 있으며 심리적 문제를 유발할 수 있다고 경고하며, 사용자에게 신중하게 사용하고 동반자를 찾을 것을 권고했습니다. 이 게시물은 AI 상호작용이 인간의 인지 및 심리 상태에 미치는 깊은 영향에 대한 논의를 불러일으켰습니다. (출처: Reddit r/ArtificialInteligence)
