
키워드:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, 강화 학습 ProRL, NVIDIA Cosmos, 다중 모달 대형 모델, AI 에이전트 프레임워크, LLM 추론 최적화, AlphaEvolve 수학 기록, Darwin Gödel Machine 자체 개선, MedHELM 의료 평가, ProRL 강화 학습 확장성, Cosmos Transfer 물리 시뮬레이션
🔥 포커스
DeepMind AlphaEvolve, 수학 기록 경신, 인간-기계 협력으로 과학 발전 촉진: DeepMind의 AlphaEvolve가 일주일 만에 18년간 깨지지 않던 수학 기록을 두 번이나 경신하며 광범위한 주목을 받았습니다. Tao ZheXuan은 이를 두고 단순히 ‘승자’와 ‘패자’를 가르는 것이 아니라, 서로 다른 방법들이 어떻게 상호 보완하여 수학적 진보를 이끌어낼 수 있는지를 보여준다고 평가했습니다. 이 사건은 AI와 인간의 협력이 과학 기술 분야에서 새로운 패러다임을 창출할 잠재력을 강조하며, AI가 단순히 인간을 대체하는 것이 아니라 함께 진보의 새로운 길을 개척함을 시사합니다 (출처: shaneguML)

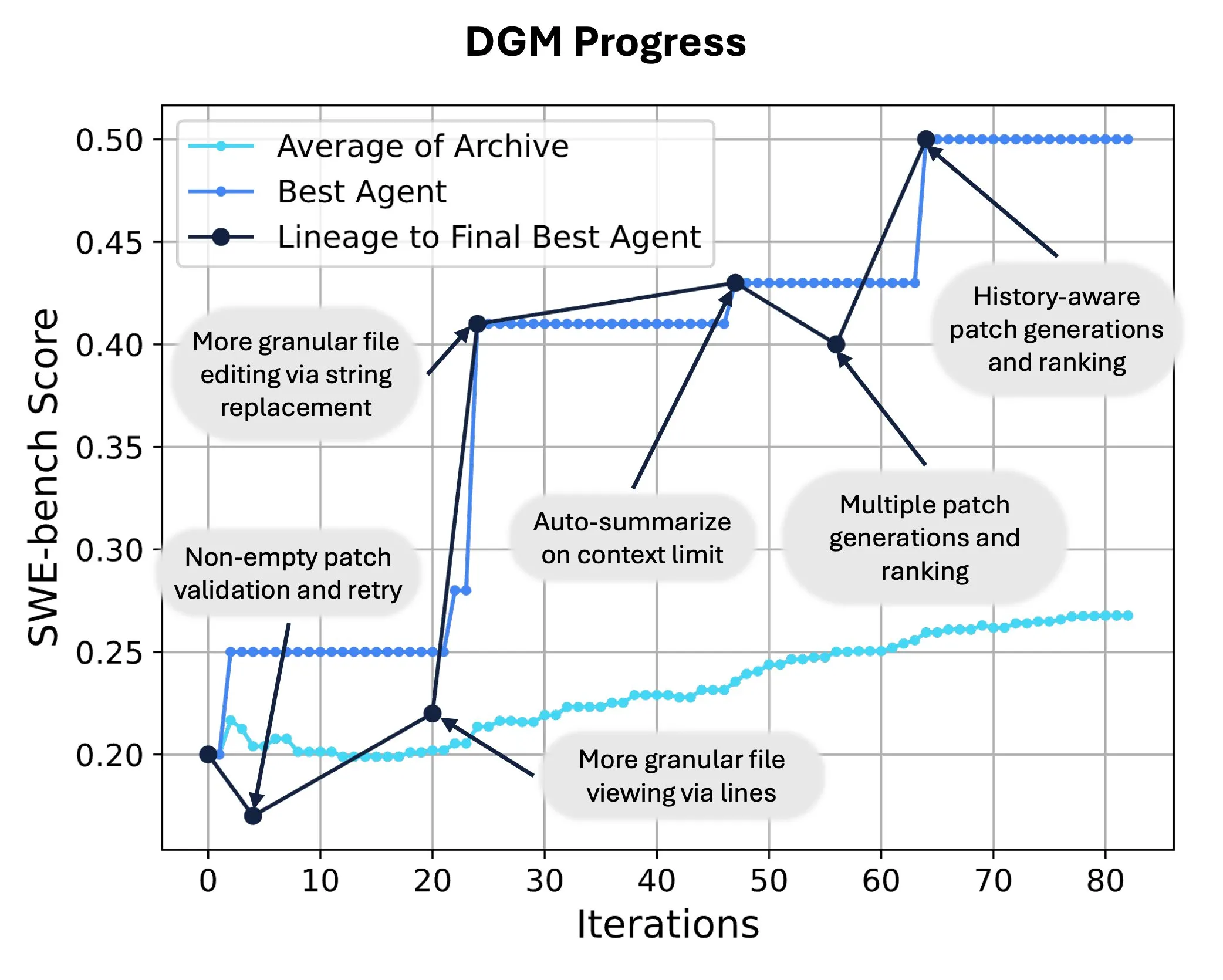
Sakana AI, Darwin Gödel Machine (DGM) 출시, AI 자가 코드 재작성 및 진화 실현: Sakana AI는 자체 코드를 수정하여 성능을 향상시킬 수 있는 자가 개선 인텔리전트 에이전트인 Darwin Gödel Machine (DGM)을 출시했습니다. 진화론에서 영감을 받은 DGM은 지속적으로 확장되는 인텔리전트 에이전트 변종 계보를 유지하며 ‘자가 개선’ 인텔리전트 에이전트 설계 공간에 대한 개방형 탐색을 실현합니다. SWE-bench에서 DGM은 성능을 20.0%에서 50.0%로 향상시켰으며, Polyglot에서는 성공률을 14.2%에서 30.7%로 끌어올려 수동으로 설계된 인텔리전트 에이전트보다 훨씬 뛰어난 성능을 보였습니다. 이 기술은 AI 시스템이 지속적인 학습과 능력 진화를 달성할 수 있는 새로운 경로를 제공합니다 (출처: SakanaAILabs, hardmaru)
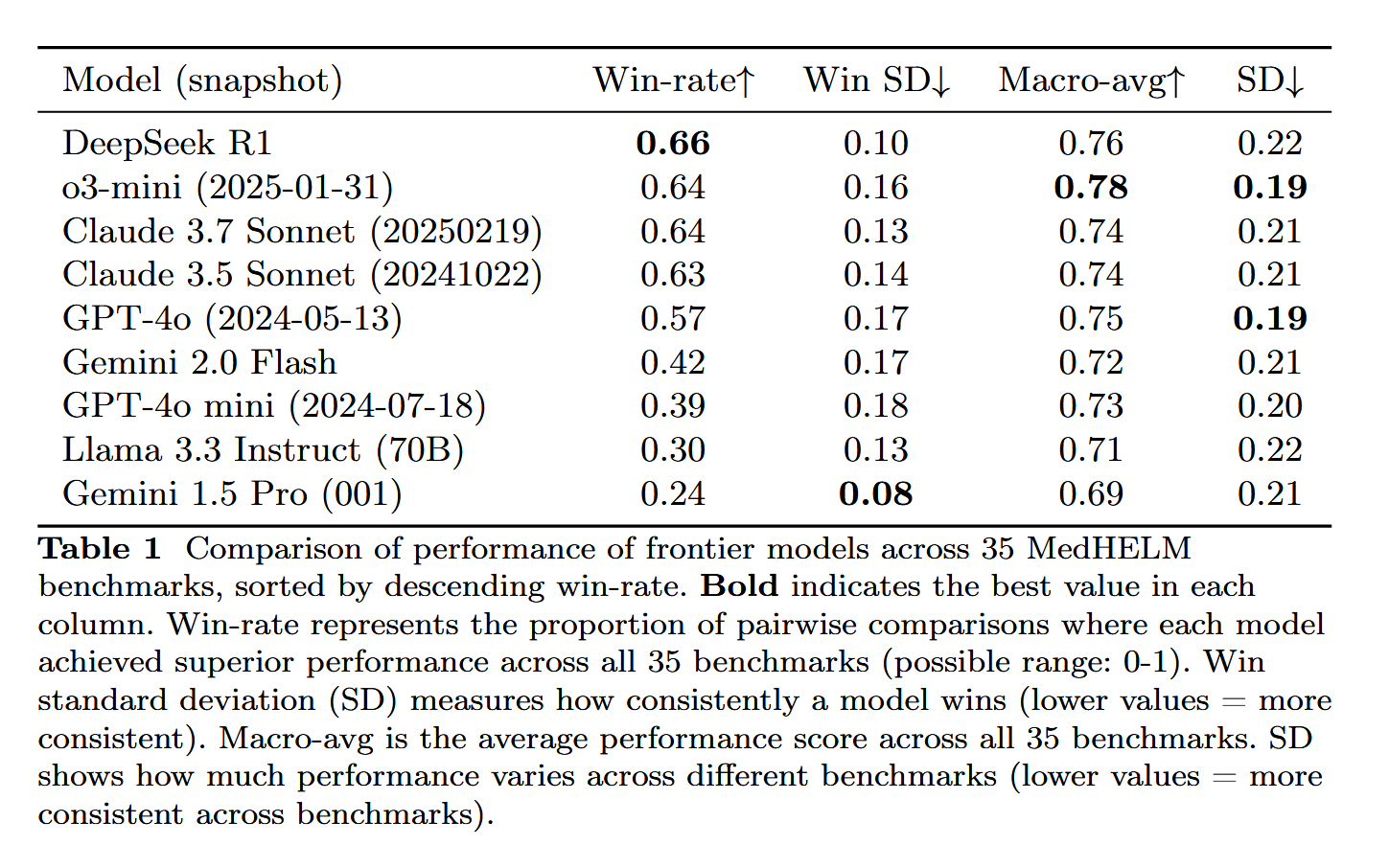
DeepSeek-R1, MedHELM 의료 과제 평가에서 뛰어난 성능: 대형 언어 모델 DeepSeek-R1이 MedHELM(대형 언어 모델 의료 과제 종합 평가) 벤치마크 테스트에서 최고의 성능을 보였습니다. 이 테스트는 기존의 의료 면허 시험이 아닌, 보다 실제적인 임상 과제에서 LLM의 성능을 평가하기 위해 설계되었습니다. 이 결과는 DeepSeek-R1이 의료 분야, 특히 실제 임상 시나리오 처리 능력에서 잠재력을 가지고 있음을 보여주는 의미 있는 결과로 평가됩니다 (출처: iScienceLuvr)
강화 학습 확장성 연구의 새로운 진전: ProRL, LLM 추론 경계 확장: 강화 학습(RL) 확장성에 관한 새로운 논문(arXiv:2505.24864)이 주목받고 있습니다. 이 연구는 장시간의 강화 학습(ProRL) 훈련을 통해, 광범위한 샘플링으로는 얻기 어려운 기반 모델의 새로운 추론 전략을 발굴할 수 있음을 보여줍니다. ProRL은 KL 발산 제어, 참조 정책 재설정 및 다양한 작업 세트를 결합하여 RL 훈련 모델이 다양한 pass@k 평가에서 지속적으로 기반 모델을 능가하도록 합니다. 이 연구는 RL이 언어 모델의 추론 경계를 실질적으로 확장하는 방법에 대한 새로운 통찰력을 제공하며, 미래의 장시간 RL 추론 연구를 위한 기초를 마련합니다. NVIDIA는 관련 모델 가중치를 공개했습니다 (출처: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 동향
NVIDIA, Cosmos Transfer와 Cosmos Reason 출시, 물리 세계 AI 응용 추진: NVIDIA는 Cosmos 시스템을 출시했습니다. 그중 Cosmos Transfer는 간단한 게임 엔진 화면, 깊이 정보, 심지어 거친 로봇 시뮬레이션까지 현실적인 장면 비디오로 변환하여 로봇 및 자율 주행과 같은 AI에 대량의 제어 가능한 훈련 데이터를 제공합니다. Cosmos Reason은 AI가 이러한 장면을 이해하고 의사 결정을 내릴 수 있도록 하며, 예를 들어 자율 주행 테스트에서 어떻게 주행할지 판단합니다. 이 두 도구는 현재 모두 오픈 소스로 공개되어 물리 세계 AI의 발전을 가속화하고 훈련 데이터 부족 및 장면 제어 문제를 해결할 것으로 기대됩니다 (출처: )
DeepSeek, R1 업데이트 발표, 오픈 소스 생태계 지속 번영: DeepSeek은 R1 모델의 업데이트를 발표했으며, 여기에는 R1 자체와 80억 파라미터의 증류 버전 소형 모델이 포함됩니다. 동시에 ByteDance는 오픈 소스 분야에서 활발한 움직임을 보이며 BAGEL, Dolphin, Seedcoder, Dream0 등의 프로젝트를 출시했습니다. 이러한 진전은 중국 AI 오픈 소스 분야의 활발함과 혁신력, 특히 멀티모달 및 특수 목적 모델 분야에서의 빠른 발전을 보여줍니다 (출처: TheRundownAI, stablequan, reach_vb, clefourrier)
Google, Edge AI Gallery 출시, 스마트폰에서의 오픈 소스 AI 모델 응용 촉진: Google은 Edge AI Gallery를 출시하여 오픈 소스 AI 모델을 스마트폰에 도입하고 로컬화되고 사적인 AI 응용 프로그램을 구현하는 것을 목표로 합니다. 사용자는 Hugging Face의 LLM을 장치에서 직접 실행하여 코드 생성, 이미지 대화 등의 작업을 수행할 수 있으며, 다중 턴 대화를 지원하고 임의의 모델을 선택할 수 있습니다. 이 응용 프로그램은 LiteRT를 기반으로 하며 현재 Android를 지원하고 iOS 버전은 곧 출시될 예정입니다. 이는 온디바이스 AI의 발전과 보급을 더욱 촉진할 것입니다 (출처: TheRundownAI, huggingface, reach_vb, osanseviero)
긍정적 및 부정적 증류 추론 궤적을 이용한 LLM 최적화에 관한 새로운 연구: 새로운 논문은 교사 모델(예: DeepSeek-R1)이 생성한 정확하고 잘못된 추론 궤적을 활용하여 소규모 학생 모델의 추론 능력을 향상시키는 것을 목표로 하는 강화 증류(REDI) 프레임워크를 제안합니다. REDI는 두 단계로 구성되며, 먼저 감독 미세 조정(SFT)을 통해 정확한 궤적에서 학습한 다음, 새로 제안된 REDI 목표 함수(참조 없는 손실 함수)를 사용하여 긍정적 및 부정적 궤적을 결합하여 모델을 더욱 최적화합니다. 실험 결과, 수학 추론 작업에서 REDI는 기준선 방법보다 우수했으며, Qwen-REDI-1.5B 모델은 MATH-500에서 83.1%의 높은 점수를 받았습니다 (출처: HuggingFace Daily Papers)
LLMSynthor 프레임워크, LLM을 이용한 구조 인식 데이터 합성: LLMSynthor는 대형 언어 모델(LLM)을 구조 인식 시뮬레이터로 변환하고 분포 피드백을 통해 안내하는 범용 데이터 합성 프레임워크입니다. 이 프레임워크는 LLM을 고차 종속성 모델링을 위한 비모수적 코퓰라 시뮬레이터로 간주하고, 샘플링 효율성을 높이기 위해 LLM 제안 샘플링을 도입합니다. 요약 통계 공간에서의 차이를 최소화함으로써 반복적인 합성 루프는 실제 데이터와 합성 데이터를 정렬합니다. 전자 상거래, 인구 및 이동성과 같은 개인 정보 보호에 민감한 분야의 이기종 데이터 세트에 대한 평가는 LLMSynthor가 생성한 합성 데이터가 높은 통계적 충실도와 실용성을 가지고 있음을 보여줍니다 (출처: HuggingFace Daily Papers)
v1 프레임워크, 선택적 시각적 재방문을 통해 멀티모달 상호작용 추론 강화: v1은 멀티모달 대형 언어 모델(MLLM)이 추론 과정에서 선택적 시각적 재방문을 수행할 수 있도록 하는 경량 확장입니다. 현재 MLLM이 일반적으로 시각적 입력을 한 번에 처리하는 것과 달리, v1은 “가리키고 복사하기” 메커니즘을 도입하여 모델이 추론 과정에서 관련 이미지 영역을 동적으로 검색할 수 있도록 합니다. 시각적 기반 주석이 포함된 멀티모달 추론 궤적 데이터 세트 v1g에서 훈련을 통해 v1은 MathVista와 같은 벤치마크 테스트에서 성능 향상을 보였으며, 특히 세분화된 시각적 참조와 다단계 추론이 필요한 작업에서 두드러졌습니다 (출처: HuggingFace Daily Papers)
MetaFaith, LLM 자연어 불확실성 표현의 충실도 향상: LLM이 불확실성을 표현할 때 종종 과장하는 문제를 해결하기 위해 MetaFaith는 새로운 프롬프트 기반 보정 방법을 제안합니다. 연구에 따르면 기존 LLM은 내재된 불확실성을 충실하게 반영하는 데 있어 성능이 좋지 않으며, 표준 프롬프트 방법의 효과는 제한적이고, 사실성에 기반한 보정 기술은 오히려 충실한 보정을 손상시킬 수 있습니다. MetaFaith는 인간의 메타인지에서 영감을 받아 다양한 작업과 모델에서 모델의 충실한 보정 능력을 크게 향상시켜 충실도를 최대 61%까지 높이고 인공 평가에서 83%의 승률을 얻을 수 있습니다 (출처: HuggingFace Daily Papers)
CLaSp: 컨텍스트 내 레이어 건너뛰기를 통한 자가 추론 디코딩으로 LLM 가속화: CLaSp는 대형 언어 모델(LLM)을 위한 자가 추론 디코딩 전략으로, 검증 모델의 중간 레이어를 건너뛰어 압축된 초안 모델을 구축함으로써 디코딩 과정을 가속화하며, 추가 훈련이나 모델 수정이 필요 없습니다. CLaSp는 동적 프로그래밍 알고리즘을 사용하여 레이어 건너뛰기 과정을 최적화하고, 이전 검증 단계의 전체 은닉 상태에 따라 전략을 동적으로 조정합니다. 실험 결과, CLaSp는 LLaMA3 시리즈 모델에서 생성된 텍스트의 원본 분포를 변경하지 않으면서 1.3배에서 1.7배의 가속을 달성했습니다 (출처: HuggingFace Daily Papers)
HardTests, LLM을 통해 고품질 코드 테스트 케이스 합성: LLM이 복잡한 프로그래밍 문제에서 코드를 생성할 때 기존 테스트 케이스로 효과적으로 검증하기 어려운 문제를 해결하기 위해, HardTests는 LLM을 활용하여 고품질 테스트 케이스를 생성하는 프로세스인 HARDTESTGEN을 제안합니다. 이 프로세스를 기반으로 구축된 HardTests 데이터 세트에는 4만 7천 개의 프로그래밍 문제와 합성된 고품질 테스트 케이스가 포함되어 있습니다. 기존 테스트와 비교하여 HARDTESTGEN이 생성한 테스트는 LLM 생성 코드를 평가할 때 정확도가 11.3% 향상되고 재현율이 17.5% 향상되었으며, 어려운 문제에 대한 정확도 향상은 최대 40%에 달합니다. 이 데이터 세트는 모델 훈련 측면에서도 더 나은 효과를 보여줍니다 (출처: HuggingFace Daily Papers)
연구 결과, 시각 언어 모델(VLM)에 편향 존재: 한 연구에 따르면, 첨단 시각 언어 모델(VLM)은 계산 및 식별과 같이 인기 있는 주제와 관련된 시각적 작업을 처리할 때 인터넷에서 학습한 방대한 사전 지식의 영향을 크게 받는 것으로 나타났습니다. 예를 들어, VLM은 Adidas 상표에 추가된 네 번째 줄무늬를 인식하는 데 어려움을 겪습니다. 동물, 상표, 체스 등 7가지 다른 영역의 계산 작업에서 VLM의 평균 정확도는 17.05%에 불과했습니다. 모델에게 신중하게 검토하거나 이미지 세부 정보에만 의존하도록 지시해도 정확도 향상은 제한적이었습니다. 이 연구는 VLM 편향을 테스트하기 위한 자동화된 프레임워크를 제안합니다 (출처: HuggingFace Daily Papers)
Point-MoE: 전문가 혼합 모델을 이용한 3D 시맨틱 분할의 교차 도메인 일반화: 3D 포인트 클라우드 데이터의 다양한 출처(예: 깊이 카메라, LiDAR)와 이기종 도메인(예: 실내, 실외)으로 인해 통합 모델 훈련이 어려운 문제를 해결하기 위해 Point-MoE는 전문가 혼합(MoE) 아키텍처를 제안합니다. 이 아키텍처는 간단한 top-k 라우팅 전략을 통해 도메인 레이블이 없는 경우에도 전문가 네트워크를 자동으로 특화합니다. 실험 결과, Point-MoE는 강력한 다중 도메인 기준 모델보다 우수할 뿐만 아니라 보지 못한 도메인에서도 더 나은 일반화 능력을 보여주어 대규모, 교차 도메인 3D 인식을 위한 확장 가능한 경로를 제공합니다 (출처: HuggingFace Daily Papers)
SpookyBench, 비디오 언어 모델의 ‘시간적 사각지대’ 밝혀내: 비디오 언어 모델(VLM)이 시공간 관계 이해에서 진전을 이루었음에도 불구하고, 공간 정보가 모호할 때 순수한 시간적 패턴을 포착하는 데 어려움을 겪습니다. SpookyBench 벤치마크 테스트는 노이즈와 같은 프레임 시퀀스에 정보(예: 모양, 텍스트)를 인코딩하여 인간은 98% 이상의 정확도로 식별할 수 있지만 첨단 VLM의 정확도는 0%임을 발견했습니다. 이는 VLM이 프레임 수준의 공간적 특징에 과도하게 의존하여 시간적 단서에서 의미를 추출하지 못함을 나타냅니다. 이 연구는 VLM의 ‘시간적 사각지대’를 극복할 필요성을 강조하며, 공간적 의존성과 시간적 처리를 분리하기 위한 새로운 아키텍처나 훈련 패러다임이 필요할 수 있습니다 (출처: HuggingFace Daily Papers, _akhaliq)
LLM을 이용한 과학적 혁신성 탐지 새로운 방법 및 데이터셋: 과학 연구에서 새로운 아이디어를 식별하는 것은 중요하지만 어려운 과제입니다. 이 문제를 해결하기 위해 연구자들은 대형 언어 모델(LLM)을 이용한 과학적 혁신성 탐지를 제안하고, 마케팅 및 자연어 처리 분야에서 두 개의 새로운 데이터셋을 구축했습니다. 이 방법은 논문의 폐쇄 집합을 추출하고 LLM을 사용하여 주요 아이디어를 요약함으로써 데이터셋을 구축합니다. 아이디어 개념을 포착하기 위해 연구자들은 LLM에서 아이디어 수준의 지식을 증류하여 유사한 개념을 가진 아이디어를 정렬하는 경량 검색기를 훈련시켜 효율적이고 정확한 아이디어 검색을 가능하게 하는 방법을 제안했습니다. 실험 결과, 제안된 방법은 제안된 벤치마크 데이터셋에서 다른 방법보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
un^2CLIP, unCLIP 반전을 통해 CLIP 시각적 세부 정보 포착 능력 향상: CLIP 모델이 이미지 세부 정보 차이를 구별하고 밀집 예측과 같은 작업을 처리하는 데 있어 부족한 점을 해결하기 위해 un^2CLIP은 unCLIP 모델을 반전시켜 CLIP을 개선하는 방법을 제안합니다. unCLIP 자체는 CLIP 이미지 임베딩을 통해 이미지 생성기를 훈련하여 이미지의 세부 정보 분포를 학습합니다. un^2CLIP은 이 특성을 활용하여 개선된 CLIP 이미지 인코더가 unCLIP의 시각적 세부 정보 포착 능력을 얻도록 하면서 원본 텍스트 인코더와의 정렬을 유지합니다. 실험 결과, un^2CLIP은 여러 작업에서 원본 CLIP 및 기타 개선 방법보다 훨씬 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
ViStoryBench: 스토리 시각화 종합 벤치마크 스위트 출시: 스토리 시각화(서술 및 참조 이미지를 기반으로 일관된 이미지 시퀀스 생성) 기술 발전을 촉진하기 위해 ViStoryBench는 포괄적인 평가 벤치마크를 제공합니다. 이 벤치마크는 다양한 스토리 유형(코미디, 공포 등)과 예술 스타일(애니메이션, 3D 렌더링 등)의 데이터셋을 포함하며, 단일 주인공 및 다중 주인공 스토리를 통해 캐릭터 일관성을 테스트하고, 복잡한 줄거리와 세계관 구축을 통해 모델의 시각적 생성 정확성에 도전합니다. ViStoryBench는 다양한 평가 지표를 사용하여 서사 구조 및 시각적 요소 측면에서 모델의 성능을 종합적으로 평가하고, 연구자들이 모델의 장단점을 식별하고 목표에 맞게 개선하는 데 도움을 줍니다 (출처: HuggingFace Daily Papers)
분기-병합 디코딩(FMD), 오디오-비디오 대형 모델의 균형 잡힌 멀티모달 이해 향상: 오디오-비디오 대형 언어 모델(AV-LLM)에서 발생할 수 있는 모달리티 편향 문제(즉, 모델이 의사 결정 시 특정 모달리티에 과도하게 의존하는 문제)를 해결하기 위해 분기-병합 디코딩(FMD)은 추가 훈련 없이 추론 시에 적용할 수 있는 전략을 제안합니다. FMD는 먼저 초기 디코딩 레이어를 통해 순수 오디오 입력과 순수 비디오 입력을 각각 처리(분기 단계)한 다음, 생성된 은닉 상태를 병합하여 공동 추론(병합 단계)을 수행합니다. 이 방법은 모달리티 기여의 균형을 촉진하고 교차 모달리티의 상호 보완적인 정보를 활용하는 것을 목표로 합니다. VideoLLaMA2 및 video-SALMONN과 같은 모델에 대한 실험 결과, FMD는 오디오, 비디오 및 오디오-비디오 공동 추론 작업 모두에서 성능을 향상시킬 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
LegalSearchLM: 법률 사례 검색을 법률 요소 생성으로 재구성: 전통적인 법률 사례 검색(LCR) 방법은 임베딩 또는 어휘 일치에 의존하여 실제 시나리오에서 한계에 직면합니다. LegalSearchLM은 LCR을 법률 요소 생성 작업으로 간주하는 새로운 방법을 제안합니다. 이 모델은 질의 사례에 대해 법률 요소 추론을 수행하고, 제약 디코딩을 통해 대상 사례의 내용을 직접 생성합니다. 동시에 연구자들은 120만 건의 한국 법률 사례를 포함하는 대규모 LCR 벤치마크인 LEGAR BENCH를 발표했습니다. 실험 결과, LegalSearchLM은 LEGAR BENCH에서 기준 모델보다 6-20% 우수한 성능을 보였으며 강력한 교차 도메인 일반화 능력을 보여주었습니다 (출처: HuggingFace Daily Papers)
RPEval: 대형 언어 모델 역할극 능력 평가를 위한 새로운 벤치마크: 대형 언어 모델(LLM) 역할극 능력 평가의 어려움에 대응하기 위해 RPEval은 새로운 벤치마크 테스트를 제공합니다. 이 벤치마크는 감정 이해, 의사 결정, 도덕적 성향 및 역할 일관성의 네 가지 주요 차원에서 LLM의 역할극 수행을 평가합니다. 이는 인공 평가의 자원 소모가 크고 자동화된 평가가 편향될 수 있는 문제를 해결하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
GATE: 아랍어 STS 강화를 위한 범용 텍스트 임베딩 모델: 아랍어 의미론적 텍스트 유사성(STS) 연구에서 고품질 데이터셋과 사전 훈련된 모델이 부족한 문제를 해결하기 위해 GATE(General Arabic Text Embedding) 모델이 등장했습니다. GATE는 Matryoshka 표현 학습과 혼합 손실 훈련 방법을 활용하며, 아랍어 자연어 추론 삼중항 데이터셋과 결합하여 훈련됩니다. 실험 결과, GATE는 MTEB 벤치마크의 STS 작업에서 SOTA 성능을 달성했으며, OpenAI를 포함한 대형 모델에 비해 성능이 20-25% 향상되어 아랍어 고유의 의미론적 미묘함을 효과적으로 포착할 수 있음을 보여주었습니다 (출처: HuggingFace Daily Papers)
CoDA: 관절형 물체 전신 조작을 위한 협력적 확산 노이즈 최적화 프레임워크: 관절형 물체의 전신 조작(신체, 손, 물체 움직임 포함)의 사실성과 정확성을 달성하기 위해 CoDA는 새로운 협력적 확산 노이즈 최적화 프레임워크를 제안합니다. 이 프레임워크는 신체, 왼손, 오른손의 세 가지 특화된 확산 모델에 대한 노이즈 공간 최적화를 통해, 그리고 인체 운동 사슬의 기울기 흐름을 통해 손과 신체 다른 부분의 자연스러운 조정을 실현합니다. 손과 물체 상호 작용의 정확도를 높이기 위해 CoDA는 기준점 집합(BPS) 기반의 통합 표현을 사용하여 말단 실행기 위치를 물체 기하학 BPS까지의 거리로 인코딩함으로써 확산 노이즈 최적화를 안내하고 고정밀 상호 작용 운동을 생성합니다 (출처: HuggingFace Daily Papers)
LLM 추론 반성 메커니즘의 새로운 해석: 베이즈 적응형 강화 학습 프레임워크 BARL: 노스웨스턴 대학교와 Google DeepMind가 협력하여 베이즈 적응형 강화 학습 프레임워크(BARL)를 제안했습니다. 이는 대형 언어 모델(LLM)이 추론 과정에서 보이는 ‘반성’ 행동을 설명하고 최적화하는 것을 목표로 합니다. 전통적인 강화 학습(RL)은 테스트 시 일반적으로 이미 학습된 정책만 활용하는 반면, BARL은 환경 불확실성에 대한 모델링을 도입하여 모델이 추론 시 새로운 정책을 적응적으로 탐색할 수 있도록 합니다. 실험 결과, BARL은 수학 추론과 같은 작업에서 더 높은 정확도를 달성하고 토큰 소비를 크게 줄일 수 있음을 보여주었습니다. 이 연구는 베이즈 관점에서 LLM이 왜, 어떻게, 그리고 언제 반성적 탐색을 수행해야 하는지를 처음으로 설명합니다 (출처: 量子位)

형식적 불확실성 문법에서의 LLM 응용: 자동 추론을 위해 LLM을 언제 신뢰해야 하는가: 대형 언어 모델(LLM)은 형식적 명세 생성에서 잠재력을 보여주지만, 그 확률적 특성과 형식 검증의 결정론적 요구 사항 사이에 모순이 존재합니다. 연구자들은 LLM이 생성한 형식적 구성 요소의 실패 모드와 불확실성 정량화(UQ)를 포괄적으로 조사했습니다. 결과는 SMT 기반 자동 형식화가 정확성에 미치는 영향이 영역에 따라 다르며, 기존 UQ 기술은 이러한 오류를 식별하기 어렵다는 것을 보여줍니다. 논문은 LLM 출력을 모델링하기 위해 확률적 문맥 자유 문법(PCFG) 프레임워크를 도입하고 불확실성 신호가 작업 의존적임을 발견합니다. 이러한 신호를 융합함으로써 선택적 검증을 달성하여 오류를 대폭 줄이고 LLM 기반 형식화를 더욱 신뢰할 수 있게 만듭니다 (출처: HuggingFace Daily Papers)
소형 언어 모델(SLM) 미세 조정과 대형 언어 모델(LLM) 프롬프팅의 로우 코드 워크플로우 생성 비교: JSON 형식의 로우 코드 워크플로우 생성 작업에서 소형 언어 모델(SLM) 미세 조정과 대형 언어 모델(LLM) 프롬프팅의 효과를 비교한 연구입니다. 결과에 따르면, 좋은 프롬프트는 LLM이 합리적인 결과를 생성하도록 할 수 있지만, 도메인 특정 작업 및 구조화된 출력의 경우 SLM 미세 조정이 품질 면에서 평균 10% 향상되었습니다. 이는 특정 시나리오, 특히 출력 품질 요구 사항이 높은 경우 SLM이 여전히 우위를 점하고 있음을 시사합니다 (출처: HuggingFace Daily Papers)
멀티모달 대형 모델의 모달리티 선호도 평가 및 유도: 연구자들은 통제된 증거 충돌 시나리오에서 멀티모달 대형 언어 모델(MLLM)의 모달리티 선호도(즉, 의사 결정 시 특정 모달리티를 선호하는 경향)를 체계적으로 평가하기 위해 MC² 벤치마크를 구축했습니다. 연구 결과, 테스트된 18개의 MLLM 모두 뚜렷한 모달리티 편향을 보였으며, 선호 방향은 외부 개입에 의해 영향을 받을 수 있음이 밝혀졌습니다. 이를 바탕으로 연구자들은 추가적인 미세 조정이나 정교한 프롬프트 설계 없이 모달리티 선호도를 명시적으로 제어할 수 있는 표현 공학 기반의 탐색 및 유도 방법을 제안했으며, 환각 완화, 멀티모달 기계 번역 등 다운스트림 작업에서 긍정적인 효과를 얻었습니다 (출처: HuggingFace Daily Papers)
다국어 LLM 안전성 연구 현황: 언어 격차 측정에서 격차 해소까지: 2020년부터 2024년까지 약 300편의 NLP 학회 논문을 체계적으로 검토한 결과, LLM 안전성 연구에 현저한 영어 중심화 문제가 있음이 드러났습니다. 자원이 풍부한 비영어권 언어조차 거의 주목받지 못했으며, 비영어권 언어는 독립적인 연구 대상으로 거의 다루어지지 않았고, 영어 안전성 연구 역시 일반적으로 양호한 언어 문서화 관행이 부족했습니다. 다국어 안전 연구를 촉진하기 위해, 이 논문은 안전 평가, 훈련 데이터 생성, 교차 언어 안전 일반화를 포함한 미래 방향을 제시하며, 전 세계 다양한 사람들을 위한 더욱 견고하고 포용적인 AI 안전 관행 개발을 목표로 합니다 (출처: HuggingFace Daily Papers, sarahookr)

순환 신경망에서의 쌍선형 상태 전이 재검토: 전통적인 관점에서는 순환 신경망(RNN)의 은닉 유닛이 주로 기억을 모델링하는 데 사용된다고 여겨졌습니다. 본 연구는 다른 관점에서 출발하여, 은닉 유닛이 네트워크 계산의 능동적인 참여자라고 주장합니다. 연구자들은 은닉 유닛과 입력 임베딩 간의 곱셈 상호작용을 포함하는 쌍선형 연산을 재검토하여, 이론적으로나 경험적으로 그것들이 상태 추적 작업에서 은닉 상태 진화를 나타내는 자연스러운 귀납적 편향임을 증명했습니다. 연구는 또한 쌍선형 상태 업데이트가 복잡성이 증가하는 상태 추적 작업에 해당하는 자연스러운 계층 구조를 구성하며, Mamba와 같은 인기 있는 선형 RNN은 이 계층 구조의 가장 낮은 복잡도 중심에 위치함을 보여줍니다 (출처: HuggingFace Daily Papers)
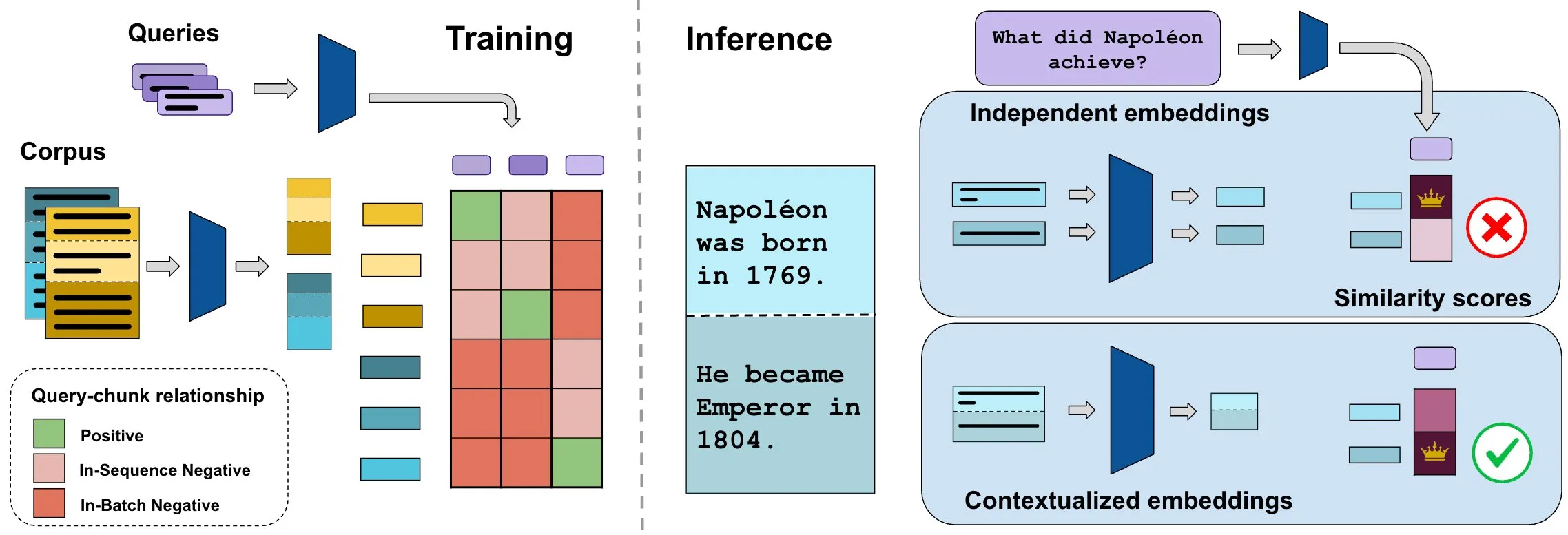
ConTEB 벤치마크, 컨텍스트 문서 임베딩 평가, InSeNT 방법으로 검색 품질 향상: 현재 문서 검색 임베딩 방법은 일반적으로 동일한 문서의 여러 조각(chunk)을 독립적으로 인코딩하여 문서 수준의 컨텍스트 정보를 무시합니다. 이 문제를 해결하기 위해 연구자들은 검색 모델이 문서 컨텍스트를 활용하는 능력을 전문적으로 평가하는 ConTEB 벤치마크를 출시했으며, SOTA 모델이 이 부분에서 성능이 좋지 않음을 발견했습니다. 동시에 연구자들은 시퀀스 내 부정 훈련(InSeNT)이라는 대조 학습 후 훈련 방법과 후기 청크 풀링을 결합하여 컨텍스트 표현 학습을 강화하고 ConTEB에서의 검색 품질을 크게 향상시켰으며, 차선의 청크 전략과 더 큰 규모의 말뭉치에 대해 더 견고함을 보여주었습니다 (출처: HuggingFace Daily Papers, tonywu_71)
🧰 도구
PraisonAI: 로우코드 멀티 AI 에이전트 프레임워크: PraisonAI는 프로덕션 수준의 멀티 AI 에이전트 프레임워크로, 로우코드 솔루션을 통해 간단한 작업부터 복잡한 문제 해결까지 자동화 및 문제 해결을 단순화하는 것을 목표로 합니다. PraisonAI Agents, AG2 (AutoGen) 및 CrewAI를 통합하며, 단순성, 사용자 정의 및 효과적인 인간-기계 협업을 강조합니다. 기능에는 AI 에이전트 자동 생성, 자기 성찰, 멀티모달, 멀티 에이전트 협업, 지식 추가, 장단기 기억, RAG, 코드 인터프리터, 100가지 이상의 사용자 정의 도구 및 LLM 지원 등이 포함됩니다. Python 및 JavaScript를 지원하며 코드 없는 YAML 구성 옵션도 제공합니다 (출처: GitHub Trending)
TinyTroupe: Microsoft 오픈소스 LLM 기반 멀티 에이전트 역할 시뮬레이션 프레임워크: TinyTroupe는 대형 언어 모델(LLM, 특히 GPT-4)을 활용하여 특정 개성, 관심사 및 목표를 가진 인물(TinyPerson)을 시뮬레이션하고 시뮬레이션 환경(TinyWorld)에서 상호 작용하는 실험적인 Python 라이브러리입니다. 이 프레임워크는 시뮬레이션을 통해 상상력을 강화하고 비즈니스 통찰력을 제공하는 것을 목표로 하며, 광고 평가, 소프트웨어 테스트, 합성 데이터 생성, 제품 피드백 및 브레인스토밍과 같은 시나리오에 적용될 수 있습니다. 사용자는 Python 및 JSON 파일을 통해 에이전트와 환경을 정의하여 프로그래밍 방식, 분석적 및 멀티 에이전트 시뮬레이션 실험을 수행할 수 있습니다 (출처: GitHub Trending)

FLUX Kontext, 다중 이미지 참조 및 이미지 편집의 새로운 돌파구 마련: 사용자 피드백에 따르면 FLUX Kontext는 다중 이미지 참조에서 뛰어난 성능을 보이며, ComfyUI의 이미지 스티칭 노드를 통해 이 기능을 활성화할 수 있습니다. 이 도구는 선물 상자 전시 이미지를 제작할 때 재질과 먼지 등의 세부 사항을 잘 재현하는 등 매우 일관성 있는 이미지 편집을 가능하게 합니다. 또한 사용자는 FLUX Kontext를 활용하여 원클릭으로 몸매 보정, 얼굴 보정, 근육 증가 등의 사진 편집 작업을 시연했으며, 자연스러운 효과와 높은 얼굴 유사도로 전자 상거래 등의 분야에 편의를 제공합니다 (출처: op7418, op7418, op7418)

Ichi: MLX Swift 및 MLX audio 기반 온디바이스 대화형 AI: Rudrank Riyam은 MLX Swift와 MLX audio를 활용하여 구현된 온디바이스 대화형 AI 프로젝트인 Ichi를 개발했습니다. 이는 대화 처리가 로컬 장치에서 완료될 수 있음을 의미하며, 사용자 개인 정보 보호에 도움이 되고 클라우드 서비스에 대한 의존도를 줄입니다. 이 프로젝트 코드는 GitHub에 공개되어 있습니다 (출처: stablequan, awnihannun)
FedRAG, NoEncode RAG와 MCP 핵심 추상화 도입: FedRAG 프로젝트는 새로운 핵심 추상화인 NoEncode RAG with MCP를 출시했습니다. 전통적인 RAG는 검색기, 생성기, 지식 베이스를 포함하며, 지식 베이스의 지식은 검색기 모델을 통해 인코딩되어야 합니다. 반면 NoEncode RAG는 인코딩 단계를 완전히 건너뛰고 NoEncode 지식 베이스와 생성기로 직접 구성되어 검색기/임베딩이 필요 없습니다. 이는 MCP (Model Component Provider) 서버를 지식 소스로 사용하는 RAG 시스템 구축의 길을 열어주며, 사용자는 여러 타사 MCP 소스에 연결하고 FedRAG를 통해 RAG를 미세 조정하여 최적의 성능을 얻을 수 있습니다 (출처: nerdai)

📚 학습
스탠포드 대학교 CS224n (2024년판) 강의 공개, LLM 및 에이전트 내용 추가: 스탠포드 대학교의 대표적인 자연어 처리 강의인 CS224n이 2024년 최신 버전을 공개했습니다. 새로운 강의 내용은 사전 훈련, 사후 훈련, 벤치마크 테스트, 추론, 에이전트 등 대형 언어 모델(LLM) 관련 최신 주제를 다룹니다. 강의 영상은 YouTube에 공개되었으며, 유료 동시 수강 과정도 제공됩니다 (출처: stanfordnlp)
시스템 아키텍처 능력 향상 가이드: AI 시대의 실천과 학습: Dotey는 AI 보조 프로그래밍이 점점 강력해지는 상황에서 개인의 시스템 아키텍처 능력을 향상시키는 상세한 방법을 공유했습니다. 이 글은 시스템 설계란 복잡한 시스템을 구현하고 유지 관리하기 쉬운 작은 모듈로 분해하고 모듈 간 협업을 명확하게 정의하는 과정이라고 강조합니다. 능력 향상 방법으로는 ‘많이 보기’(클래식 사례, 오픈 소스 프로젝트 학습), ‘많이 연습하기’(아키텍처 복원, 비교 학습, 설계 우선, AI 보조 검증, 리팩토링, 사이드 프로젝트 실전) 및 ‘많이 복기하기’(의사 결정 근거, 경험 교훈 요약)가 있습니다. AI는 자료 조사, 설계 검증, 커뮤니케이션 및 의사 결정 보조 도구로 활용될 수 있지만, 실천과 사고를 대체할 수는 없습니다 (출처: dotey)

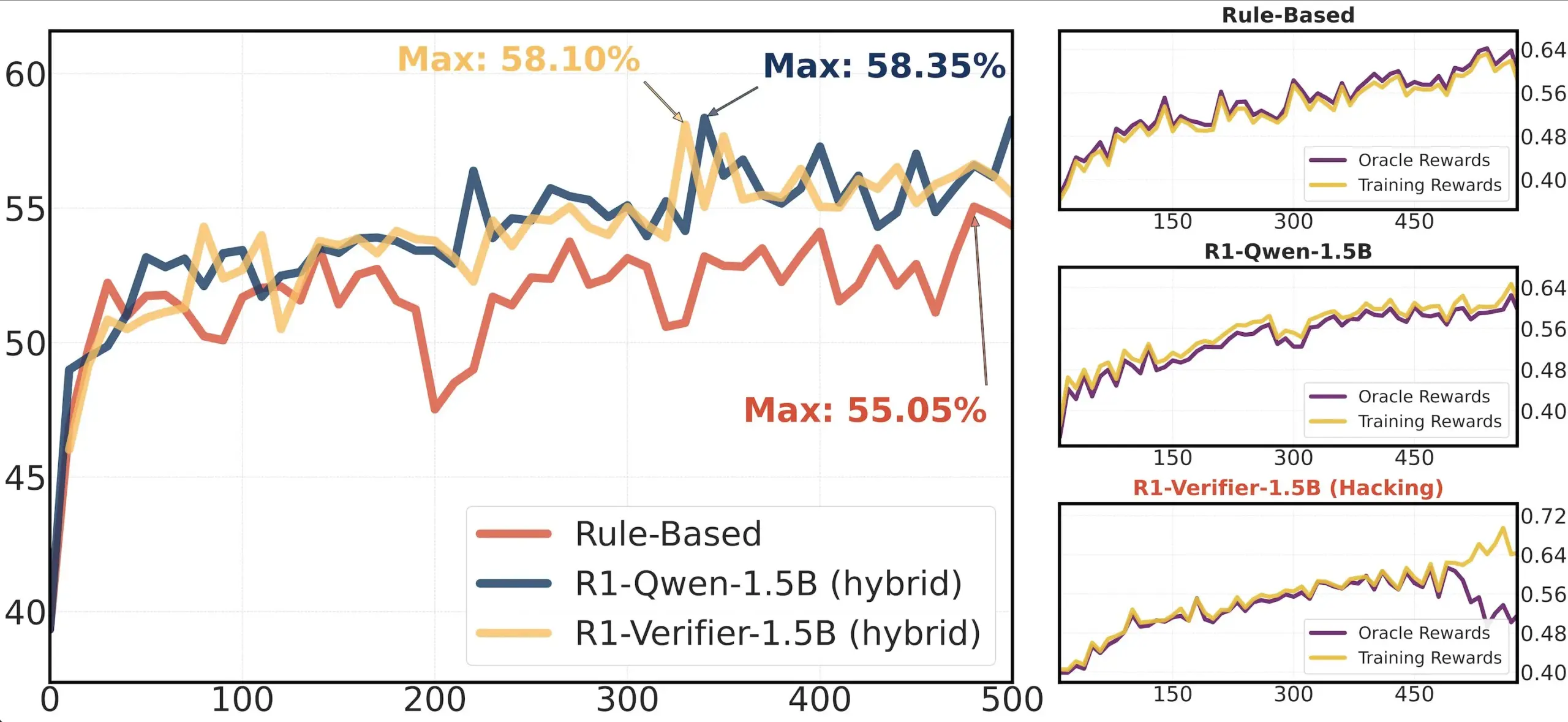
논문 공유: RLHF에서의 검증기 신뢰성 연구: 논문 ‘Pitfalls of Rule- and Model-based Verifiers’는 강화 학습 검증(RLVR)에서 규칙 기반 및 모델 기반 검증기의 결함을 탐구합니다. 연구에 따르면 규칙 기반 검증기는 수학 분야에서도 종종 신뢰할 수 없으며 많은 분야에서 사용할 수 없습니다. 반면 모델 기반 검증기는 간단한 적대적 패턴을 구축하는 등 공격에 취약합니다. 흥미롭게도 커뮤니티가 생성적 검증기로 전환함에 따라, 연구자들은 이들이 판별적 검증기보다 보상 조작(reward hacking)에 더 취약하다는 것을 발견했으며, 이는 판별적 검증기가 RLVR에서 더 견고할 수 있음을 시사합니다 (출처: Francis_YAO_)
논문 추천: 다항식 최적 근사의 등진동 정리: 한 기사에서 다항식 최적 근사의 등진동 정리와 이와 관련된 무한 노름 미분 문제를 소개했습니다. 이 정리는 함수 근사 이론의 고전적인 결과로, 수치 알고리즘을 이해하고 설계하는 데 중요한 의미를 갖습니다 (출처: eliebakouch)
Reasoning Gym: 강화 학습을 위한 검증 가능한 보상 추론 환경: 새로운 논문 ‘Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards’(arXiv:2505.24760)는 강화 학습을 위한 일련의 추론 환경을 제안합니다. 이러한 환경의 특징은 보상이 검증 가능하다는 점이며, 이는 보다 신뢰할 수 있는 강화 학습 추론 에이전트를 연구하고 개발하기 위한 플랫폼을 제공합니다 (출처: Ar_Douillard)

🌟 커뮤니티
‘중간 훈련(Mid-training)’에 대한 논의: AI 커뮤니티에서 ‘중간 훈련(Mid-training)’이라는 용어의 의미와 실제 적용에 대한 논의가 진행 중입니다. 일부는 사전 훈련과 사후 훈련만 알고 있어 혼란스러워합니다. 중간 훈련은 사전 훈련과 최종 미세 조정 사이에 수행되는 특정 단계의 훈련을 의미할 수 있다는 의견이 있으며, 예를 들어 특정 분야 지식에 대한 지속적인 사전 훈련이나 초기 정렬 등이 해당될 수 있습니다. Dorialexander는 관련 블로그 게시물을 공유하며 이 개념을 더 깊이 탐구했는데, 이는 기본 모델 위에 특정 작업이나 능력을 주입하는 것을 포함할 수 있지만 아직 통일된 정의와 방법론이 형성되지 않았다고 보았습니다 (출처: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Claude Code 리버스 엔지니어링 분석 주목: Hrishi는 Claude Code의 최소화된 코드를 리버스 엔지니어링하는 데 8~10시간을 투자하여 여러 하위 에이전트와 주요 공급업체의 플래그십 모델을 활용하여 내부 구조의 복잡성을 밝혔습니다. 분석 결과 Claude Code는 단순한 Claude 모델 루프가 아니라 학습할 가치가 있는 메커니즘을 다수 포함하고 있는 것으로 나타났습니다. 이 발견은 커뮤니티에서 논의를 불러일으켰으며, 이를 통해 에이전트 구축 및 모델 응용에 대한 많은 경험을 배울 수 있다고 여겨집니다 (출처: rishdotblog, imjaredz, hrishioa)
시스템 프롬프트 길이와 모델 성능에 대한 논의: 커뮤니티에서는 시스템 프롬프트 길이가 LLM 성능에 미치는 영향에 대해 논의했습니다. Dotey는 매우 긴 시스템 프롬프트가 항상 좋은 것은 아니며, 모델의 주의력을 분산시키고 비용을 증가시킬 수 있다고 지적하며 ChatGPT 시리즈 제품의 시스템 프롬프트가 비교적 짧지만 효과가 좋다고 언급했습니다. 반면 Tony 출해호는 Claude, Cursor 등 제품의 시스템 프롬프트가 수만 자에 달한다고 언급하며 프롬프트 시스템 확장의 필요성을 암시했습니다. YC의 기사에서도 최상위 AI 회사들이 긴 프롬프트, XML, 메타 프롬프트 등의 방법을 사용하여 LLM을 ‘길들인다’고 밝혔습니다. Dorialexander는 YC 기사에서 언급된 긴 프롬프트 방법이 RL/추론 훈련에서 견고성에 대해 의문을 제기하며 ‘아첨(sycophancy)’ 문제를 완화하는 방법에 관심을 보였습니다 (출처: dotey, Dorialexander)

Softpick 확장성 문제, 과학 연구 투명성에 대한 찬사 유발: 연구자 Zed는 이전에 연구했던 Softpick 방법이 더 큰 모델(1.8B 파라미터)로 확장했을 때 훈련 손실과 벤치마크 테스트 결과 모두 Softmax보다 열등했으며, arXiv 프리프린트를 업데이트했다고 공개적으로 밝혔습니다. 커뮤니티는 이러한 부정적인 결과를 투명하게 공유하는 행동에 대해 높이 평가하며, 이것이 과학 연구 발전에 매우 중요하고 우수한 연구 동료의 자질로 간주했습니다 (출처: gabriberton, vikhyatk, BlancheMinerva)
로컬 LLM 실행 모델 선택 및 경험 공유: Reddit r/LocalLLaMA 커뮤니티 사용자들이 현재 사용 중인 로컬 대형 언어 모델에 대해 활발히 논의하고 있습니다. Qwen 3(특히 32B Q4, 32B Q8, 30B A3B), Gemma 3(특히 27B QAT Q8, 12B), Devstral 등의 모델이 코드, 창작, 일반 추론 등에서의 성능으로 널리 언급되고 있습니다. 사용자들은 모델의 컨텍스트 길이, 추론 속도, 양자화 버전(예: IQ1_S_R4) 및 다양한 하드웨어(예: 8GB VRAM, Snapdragon 8 Elite 칩 휴대폰)에서의 실행 상황에 관심을 보이고 있습니다. Claude Code, Gemini API 등 비공개 소스 모델도 특정 장점(예: 긴 컨텍스트 처리, 코드 능력)으로 인해 동시에 사용되고 있습니다 (출처: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 기타
AI 시대의 기술 배양: 질문, 비판적 사고, 지속적인 학습이 핵심: AI 시대에는 질문 능력, 비판적 사고, 학습 모드 유지, 코딩 또는 지시 능력, AI 도구 숙련도, 명확한 의사소통이라는 여섯 가지 기술이 매우 중요하다고 강조됩니다. Zapier 회사는 심지어 100% 신입 사원에게 AI 숙련도를 요구하는데, 이는 순수한 기술 지식보다는 주로 의사소통 요구와 올바른 업무 위임 능력을 강조하는 것으로 해석됩니다. AI는 실행을 더 쉽게 만들므로, 설계와 사고의 질이 최종 결과에 더 큰 영향을 미칩니다 (출처: TheTuringPost, zacharynado)

AI 윤리 및 사회적 영향: 우려와 역량 강화 공존: 배우 스티브 카렐은 자신의 새 영화 ‘Mountainhead’가 묘사하는 미래 사회에 대해 우려를 표하며, 이것이 우리가 곧 살게 될 사회일 수 있다고 말해 AI의 잠재적인 부정적 영향에 대한 우려를 암시했습니다. 반면에 AI가 반드시 ‘농민과 왕’의 극단적인 분화를 초래하는 것이 아니라, 오히려 개인에게 역량을 부여하여 개인과 대기업 간의 능력 격차를 줄이고 개인의 생산성, 창의성 및 영향력을 향상시킬 수 있다는 견해도 있습니다. 그러나 AI 민주화의 전망에 대해서는 대기업이 여전히 모델 훈련 및 배포를 통제하여 주도권을 장악할 것이라고 신중한 태도를 보이는 사람들도 있습니다 (출처: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI 기반 채용 정보 집계 플랫폼 Hiring Cafe: Hamed N.은 ChatGPT API를 활용하여 회사 웹사이트에 직접 게시된 410만 개의 채용 정보를 수집하여 Hiring Cafe 웹사이트를 만들었습니다. 이 플랫폼은 LinkedIn 및 Indeed와 같은 플랫폼에 만연한 ‘유령 일자리’ 및 제3자 중개 문제를 해결하고, 직위, 직무, 산업, 경력 연수, 관리/IC 역할 등 강력한 필터를 통해 구직자가 보다 효과적으로 직위를 선별할 수 있도록 돕는 것을 목표로 합니다. 이는 비상업적인 박사 과정 학생의 부업 프로젝트로, 커뮤니티로부터 호평과 사용을 받고 있습니다 (출처: Reddit r/ChatGPT)
