
키워드:AI 모델, 딥러닝, 인공지능, 대형 언어 모델, 머신러닝, AI 에이전트, 연산력 병목 현상, AI 응용 프로그램, Grok 시스템 프롬프트, AlphaEvolve 수학 기록, Gemini AI 에이전트, FP4 훈련 방법, Sonnet 4.0 테이블 분석
🔥 포커스
xAI, Grok 시스템 프롬프트 공개 및 검열 메커니즘 강화: xAI는 최근 자사의 Grok 응답 로봇이 X 플랫폼에서 무단으로 프롬프트가 수정되어 회사 정책과 가치에 위배되는 정치적 발언을 한 사건으로 인해, Grok 시스템 프롬프트를 GitHub에 공개하기로 결정했다고 발표했습니다. 이 조치는 진실을 추구하는 AI로서 Grok의 투명성과 신뢰성을 강화하기 위함입니다. xAI는 또한 내부 코드 검토 프로세스를 강화하고, 24/7 모니터링 팀을 신설하여 유사 사건 재발을 방지하고 자동 시스템이 포착하지 못한 문제에 더 신속하게 대응할 것이라고 밝혔습니다. (출처: xai, xai)
DeepMind AlphaEvolve, 수학 기록 또다시 경신, AI와 인간 협력으로 과학 연구의 새로운 패러다임 제시: DeepMind의 AlphaEvolve가 일주일 만에 18년간 유지되던 수학 기록을 두 번이나 경신하여 수학자 테렌스 타오 등의 주목을 받았습니다. 테렌스 타오는 서로 다른 연구 방법이 단순히 ‘승자독식’이 아니라 상호 보완적으로 수학 발전을 촉진할 수 있다고 보았습니다. 이 사건은 AI와 인간의 협력이 기술 및 과학 분야에서 새로운 진보 모델을 창출할 잠재력을 강조하며, AI는 더 이상 단순한 대체 도구가 아니라 인간과 함께 미지의 세계를 탐험하고 혁신을 가속하는 파트너임을 보여줍니다. (출처: Yuchenj_UW)

Google, 오픈소스 커뮤니티와 협력하여 Gemini 기반 AI 에이전트 구축 간소화: Google은 LangChain LangGraph, crewAI, LlamaIndex, ComposIO 등 오픈소스 프레임워크와 협력하여 개발자들이 Google Gemini 모델 기반의 AI 에이전트를 더욱 편리하게 구축할 수 있도록 지원한다고 발표했습니다. 이 조치는 Google이 AI 에이전트 생태계 발전을 추진하려는 의지를 보여주며, 사용하기 쉬운 도구와 프레임워크를 제공하여 개발 장벽을 낮추고 더 많은 혁신적인 애플리케이션의 탄생을 장려합니다. (출처: osanseviero, Hacubu)

AI 모델 추론 능력, 1년 내 컴퓨팅 파워 병목 현상 직면 가능성: OpenAI의 o3 등 추론 모델이 단기적으로 컴퓨팅 파워에 힘입어 현저한 성능 향상(예: o3 훈련 컴퓨팅 파워는 o1의 10배)을 보였지만, Epoch AI 등 연구 기관은 현재 몇 개월마다 컴퓨팅 파워가 10배씩 증가하는 속도라면 추론 모델의 컴퓨팅 파워 확장이 최대 1년 내에 ‘한계’에 도달할 수 있다고 예측합니다. 그때가 되면 컴퓨팅 파워 증가율은 연간 4배로 둔화되고 모델 업그레이드 속도도 이에 따라 느려질 수 있습니다. DeepSeek-R1 등 모델의 훈련 데이터도 현재 추론 훈련의 컴퓨팅 파워 소모 규모를 간접적으로 증명합니다. 데이터, 알고리즘 혁신이 여전히 발전을 이끌 수 있지만, 컴퓨팅 파워 성장 둔화는 AI 산업이 직면할 중요한 과제가 될 것입니다. (출처: WeChat)

🎯 동향
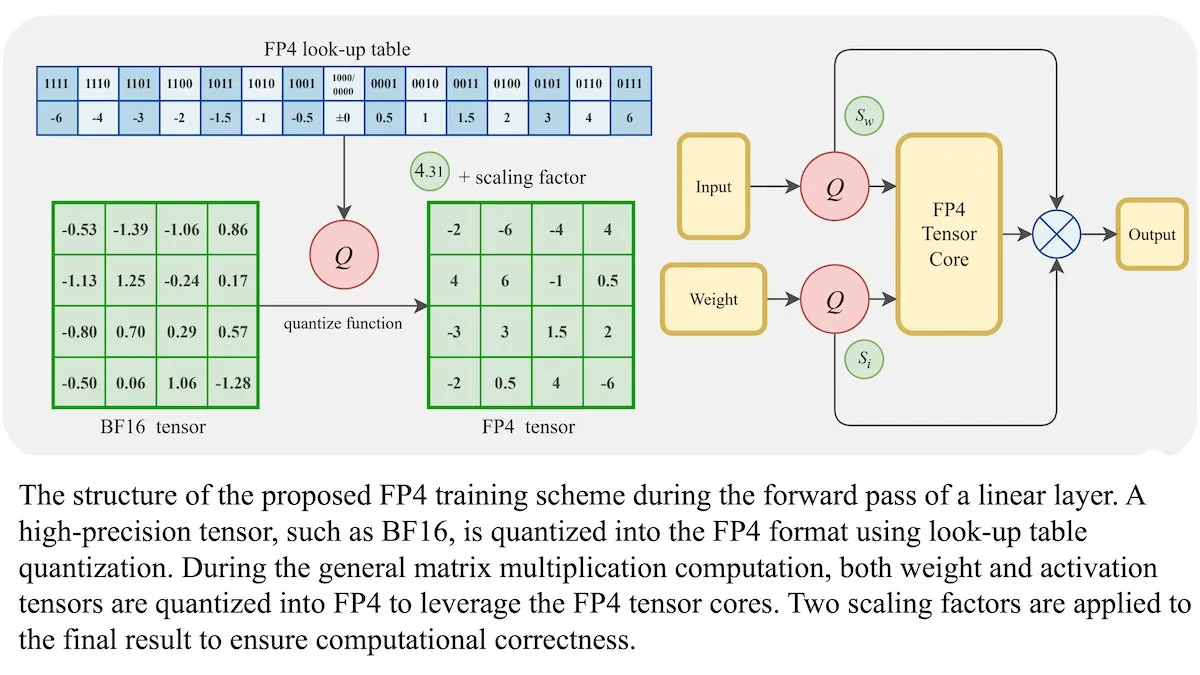
LLM 새로운 훈련 방법: 4비트 부동소수점 정밀도(FP4)로 BF16과 동등한 정확도 달성 가능: 연구진은 대규모 언어 모델(LLM)이 정확도 손실 없이 4비트 부동소수점 정밀도(FP4)를 사용하여 훈련할 수 있음을 보여주었습니다. 훈련 계산량의 95%를 차지하는 행렬 곱셈에 FP4를 사용하여 일반적으로 사용되는 BF16 형식과 유사한 성능을 달성했습니다. 연구팀은 미분 가능한 근사치를 도입하여 양자화의 미분 불가능성을 극복하고 훈련 효율성을 높였습니다. Nvidia H100 GPU에서의 시뮬레이션 결과, FP4는 다양한 언어 벤치마크에서 BF16과 동등하거나 우수한 성능을 보였습니다. (출처: DeepLearningAI)
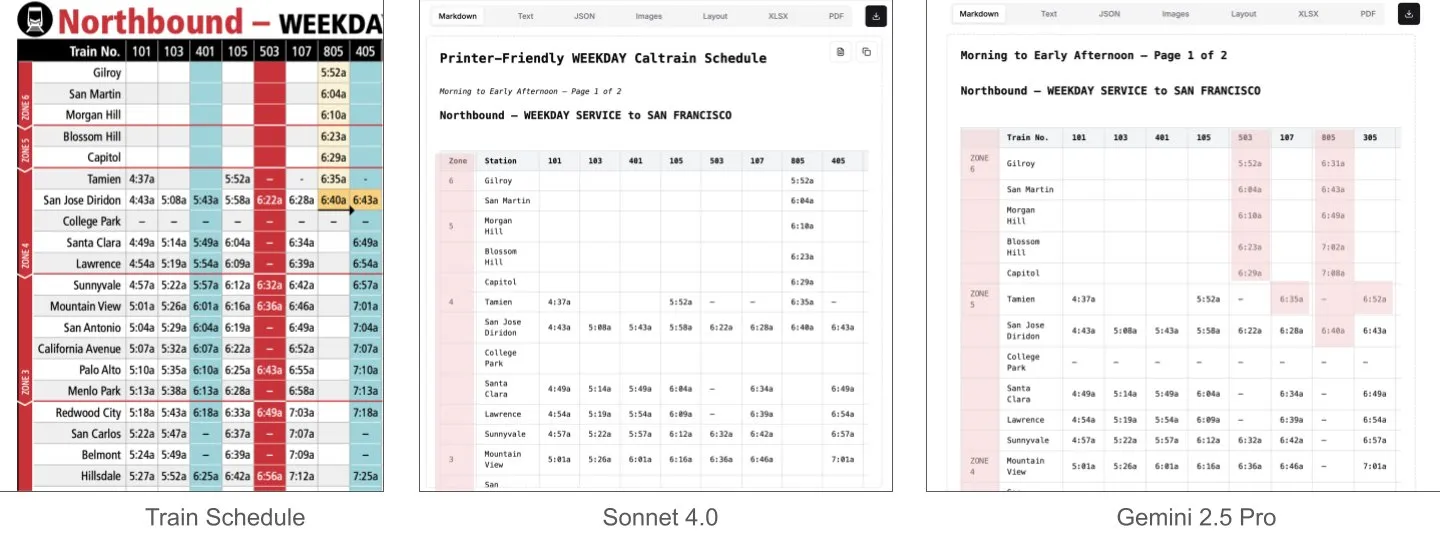
Sonnet 4.0, 문서 이해, 특히 표 분석에서 Gemini 2.5 Pro보다 우수: LlamaIndex의 Jerry Liu는 비교 테스트를 통해 Anthropic의 Sonnet 4.0이 밀집된 표 데이터가 포함된 Caltrain 시간표 스크린샷 처리에서 Google의 Gemini 2.5 Pro보다 표 분석 능력이 현저히 우수하다는 것을 발견했습니다. Gemini 2.5 Pro는 열이 잘못 정렬되는 현상이 나타났지만, Sonnet 4.0은 대부분의 수치를 잘 재구성했으며 표 머리글과 소수의 다른 수치에서만 오류가 발생했습니다. Sonnet 4.0은 현재 비용이 높고 속도가 느리지만 시각적 추론과 표 분석에서 뛰어난 성능을 보입니다. (출처: jerryjliu0)
xAI, TWG Global 및 Palantir와 협력하여 금융 서비스 산업 AI 애플리케이션 재편: xAI는 TWG Global 및 Palantir Technologies와 협력 관계를 구축하여 AI 기반 기업 솔루션을 공동 설계 및 배포함으로써 금융 서비스 제공업체의 AI 도입 및 기술 확장 방식을 재편하는 데 전념한다고 발표했습니다. Palantir CEO Alex Karp와 TWG Global 공동 회장 Thomas Tull은 밀컨 연구소 회의에서 이번 협력이 금융 산업의 AI 혁신을 어떻게 촉진할 것인지 논의했습니다. (출처: xai, xai)
DeepSeek-R1-0528 업데이트 후 검열 강화, 커뮤니티 논란 야기: 사용자들이 DeepSeek-R1-0528(671B 전체 모델, FP8)이 이전 버전 R1에 비해 내용 검열이 눈에 띄게 강화되었다고 보고했습니다. 예를 들어, 민감한 역사적 사건에 대해 질문했을 때 새 모델은 더 회피적이고 공식적인 답변을 제공하는 반면, 이전 R1은 더 직접적인 정보를 제공할 수 있었습니다. 이러한 변화는 모델의 개방성, 검열의 적정성, 그리고 특히 검열되지 않은 정보를 얻기 위해 모델에 의존하는 상황에서 연구 및 응용에 미칠 잠재적 영향에 대한 커뮤니티의 논의를 촉발했습니다. (출처: Reddit r/LocalLLaMA)
화웨이 Pangu Embedded 모델 출시, 빠른 사고와 느린 사고 이중 시스템 인지 아키텍처 융합: 화웨이 Pangu 팀은 Ascend NPU를 기반으로 Pangu Embedded 모델을 제안하며, ‘빠른 사고’와 ‘느린 사고’ 이중 추론 모드를 혁신적으로 통합했습니다. 이 모델은 2단계 훈련(반복적 증류 및 모델 병합, 다중 소스 동적 보상 시스템 RL) 및 사용자 제어 또는 문제 난이도 감지를 통한 자동 전환 인지 아키텍처를 통해 추론 효율성과 깊이의 동적 균형을 달성하고, 기존 대형 모델이 간단한 문제에 대해 과도하게 사고하고 복잡한 작업에 대해 충분히 사고하지 못하는 모순을 해결하는 것을 목표로 합니다. (출처: WeChat)

새로운 비디오 월드 모델, SSM과 확산 모델 결합하여 긴 컨텍스트와 상호작용 시뮬레이션 구현: 스탠퍼드 대학교, 프린스턴 대학교, Adobe Research 연구진은 상태 공간 모델(SSM, 특히 Mamba의 블록 단위 스캔 방식)과 비디오 확산 모델을 결합하여 기존 비디오 모델의 컨텍스트 길이 제한 및 장기 일관성 시뮬레이션의 어려움을 해결하는 새로운 비디오 월드 모델을 제안했습니다. 이 모델은 인과적 시간 역학을 효과적으로 처리하고, 세계 상태를 추적하며, 프레임 로컬 어텐션 메커니즘을 통해 생성 충실도를 보장하여, 게임과 같은 상호작용 애플리케이션에서 무한 길이, 실시간, 일관된 비디오 생성을 위한 새로운 경로를 제공합니다. (출처: WeChat)

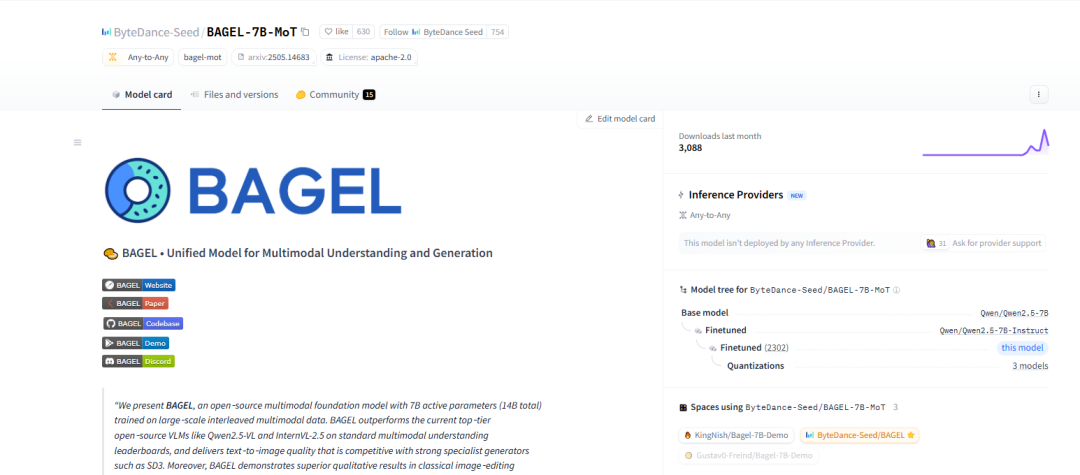
ByteDance, 멀티모달 기반 모델 BAGEL 오픈소스 공개, 이미지-텍스트-비디오 이해 및 생성 지원: ByteDance는 텍스트, 이미지, 비디오의 이해 및 생성 작업을 동시에 처리할 수 있는 통합 멀티모달 기반 모델인 BAGEL(ByteDance Agnostic Generation and Empathetic Language model)을 오픈소스로 공개했습니다. BAGEL-7B-MoT 버전은 총 140억 개의 파라미터(활성 파라미터 70억 개)를 보유하며, 최대 성능으로 실행 시 약 30G의 그래픽 메모리가 필요합니다. 사용자는 제공된 Hugging Face 데모와 모델 주소를 통해 이미지 편집, 스타일 변환과 같은 기능을 체험하고 배포할 수 있습니다. (출처: WeChat)
FLUX.1 Kontext 출시: 텍스트-이미지 편집 및 생성 통합, 속도 8배 향상: Black Forest Labs(BFL)는 컨텍스트 내 이미지 생성을 지원하는 차세대 이미지 모델 FLUX.1 Kontext를 출시했습니다. 이 모델 시리즈는 텍스트와 이미지 프롬프트를 동시에 처리하여 즉각적인 텍스트-이미지 편집 및 텍스트-이미지 생성을 구현합니다. FLUX.1 Kontext는 캐릭터 일관성, 컨텍스트 이해 및 로컬 편집에서 뛰어난 성능을 보이며, 1024×1024 해상도 이미지 생성에 단 3~5초가 소요되어 GPT-Image-1보다 최대 8배 빠른 속도를 제공하고 다중 반복 편집을 지원합니다. 이 모델은 rectified flow transformer와 적대적 확산 증류 샘플링 기술을 기반으로 합니다. (출처: WeChat, WeChat)

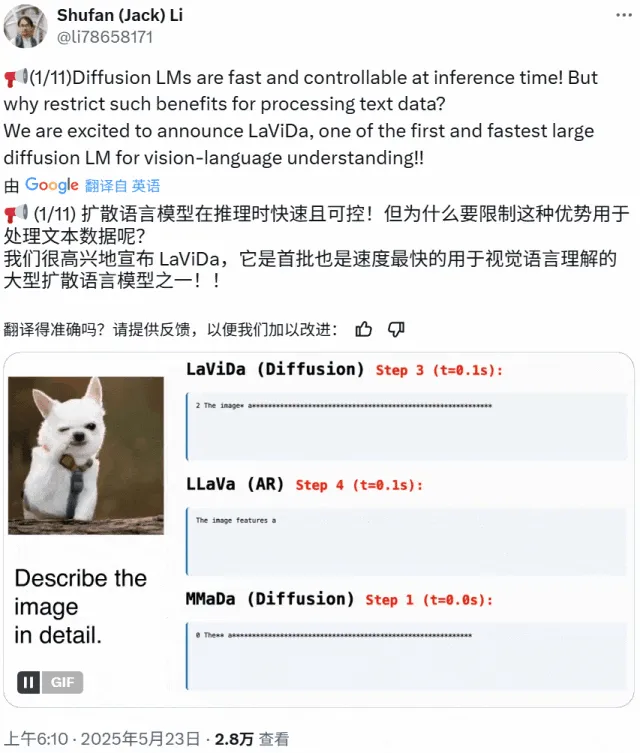
LaViDa: 확산 모델 기반의 새로운 멀티모달 이해 VLM: 캘리포니아 대학교 로스앤젤레스 캠퍼스, 파나소닉, Adobe, Salesforce 연구진은 확산 모델 기반의 시각-언어 모델(VLM)인 LaViDa(Large Vision-Language Diffusion Model with Masking)를 출시했습니다. 기존의 자기 회귀 LLM 기반 VLM과 달리, LaViDa는 이산 확산 과정을 사용하여 텍스트 생성을 처리하며, 이론적으로 더 나은 병렬성, 속도와 품질의 균형, 양방향 컨텍스트 처리 능력을 갖습니다. 모델은 시각 인코더를 통해 시각적 특징을 통합하고, 2단계 훈련 과정(시각 및 DLM 잠재 공간 정렬을 위한 사전 훈련, 명령어 준수를 위한 미세 조정)을 채택합니다. 실험 결과, LaViDa는 시각 이해, 추론, OCR, 과학 질의응답 등 다양한 작업에서 경쟁력 있는 성능을 보였습니다. (출처: WeChat)
AI 모델, AI 생성 데이터 과다 섭취로 ‘모델 퇴화’ 위험 직면: 연구에 따르면 AI 모델이 훈련 과정에서 다른 AI가 생성한 데이터를 과도하게 섭취할 경우 ‘모델 퇴화(model collapse)’ 현상이 발생하여 모델이 더욱 혼란스럽고 신뢰할 수 없게 될 수 있습니다. 모델이 온라인에서 정보를 검색하도록 허용하더라도 인터넷에充斥된 저품질 AI 생성 콘텐츠로 인해 문제가 악화될 수 있습니다. 이 현상은 2023년에 처음 제기되었으며 현재 점점 더 뚜렷해지고 있어 AI 모델의 장기적인 발전과 데이터 품질 관리에 대한 과제를 제기하고 있습니다. (출처: Reddit r/ArtificialInteligence)

AMD Octa-core Ryzen AI Max Pro 385 프로세서 Geekbench 등장, 저가형 Strix Halo 칩 시장 진입 예고: AMD의 새로운 8코어 Ryzen AI Max Pro 385 프로세서가 Geekbench에서 발견되었으며, 이는 Strix Halo라는 코드명의 보다 경제적인 AI 칩이 곧 시장에 출시될 수 있음을 의미할 수 있습니다. 사용자들은 이러한 칩이 혼합 설정을 지원하기 위해 더 많은 PCIe 채널을 제공하여 확장 카드 및 USB4 장치 추가 요구를 충족할 수 있기를 기대하고 있습니다. 온보드 메모리는 속도 이점으로 인해 수용될 수 있지만 확장성은 여전히 관심의 초점입니다. (출처: Reddit r/LocalLLaMA)

1X 회사, 최신 휴머노이드 로봇 프로토타입 Neo Gamma 출시: 노르웨이 로봇 회사 1X가 최신 휴머노이드 로봇 프로토타입 Neo Gamma를 발표했습니다. 이 로봇의 출시는 자동화 및 인공지능 분야에서 휴머노이드 로봇 기술의 또 다른 진전을 대표하며, 미래 산업, 서비스 등 다양한 시나리오에서의 응용 잠재력을 보여줍니다. (출처: Ronald_vanLoon)
AI 전력 소비, 곧 비트코인 채굴량 넘어설 것으로 예상: AI 모델의 전력 소비는 급격히 증가하여 곧 데이터 센터 전력의 거의 절반을 차지할 것으로 예상되며, 그 에너지 소비량은 일부 국가의 전국 사용량에 필적할 정도입니다. AI 칩 수요 증가는 미국 전력망에 부담을 주고 새로운 화석 연료 및 원자력 발전 프로젝트 건설을 촉진하고 있습니다. 투명성 부족과 지역 전력원의 복잡성으로 인해 AI의 탄소 배출 영향을 정확하게 추적하기는 어렵습니다. (출처: Reddit r/ArtificialInteligence)

🧰 툴
e-library-agent: LlamaIndex로 만든 개인 도서 관리 에이전트: Clelia Bertelli는 LlamaIndex 워크플로우를 활용하여 개인 독서 컬렉션을 정리, 검색 및 탐색하는 데 도움을 주는 e-library-agent라는 도구를 구축했습니다. 이 도구는 ingest-anything, Qdrant, Linkup_platform, FastAPI, Gradio 등의 기술을 통합하여 “읽었지만 찾을 수 없는” 문제를 해결하고 개인 지식 관리 효율성을 향상시킵니다. (출처: jerryjliu0, jerryjliu0)
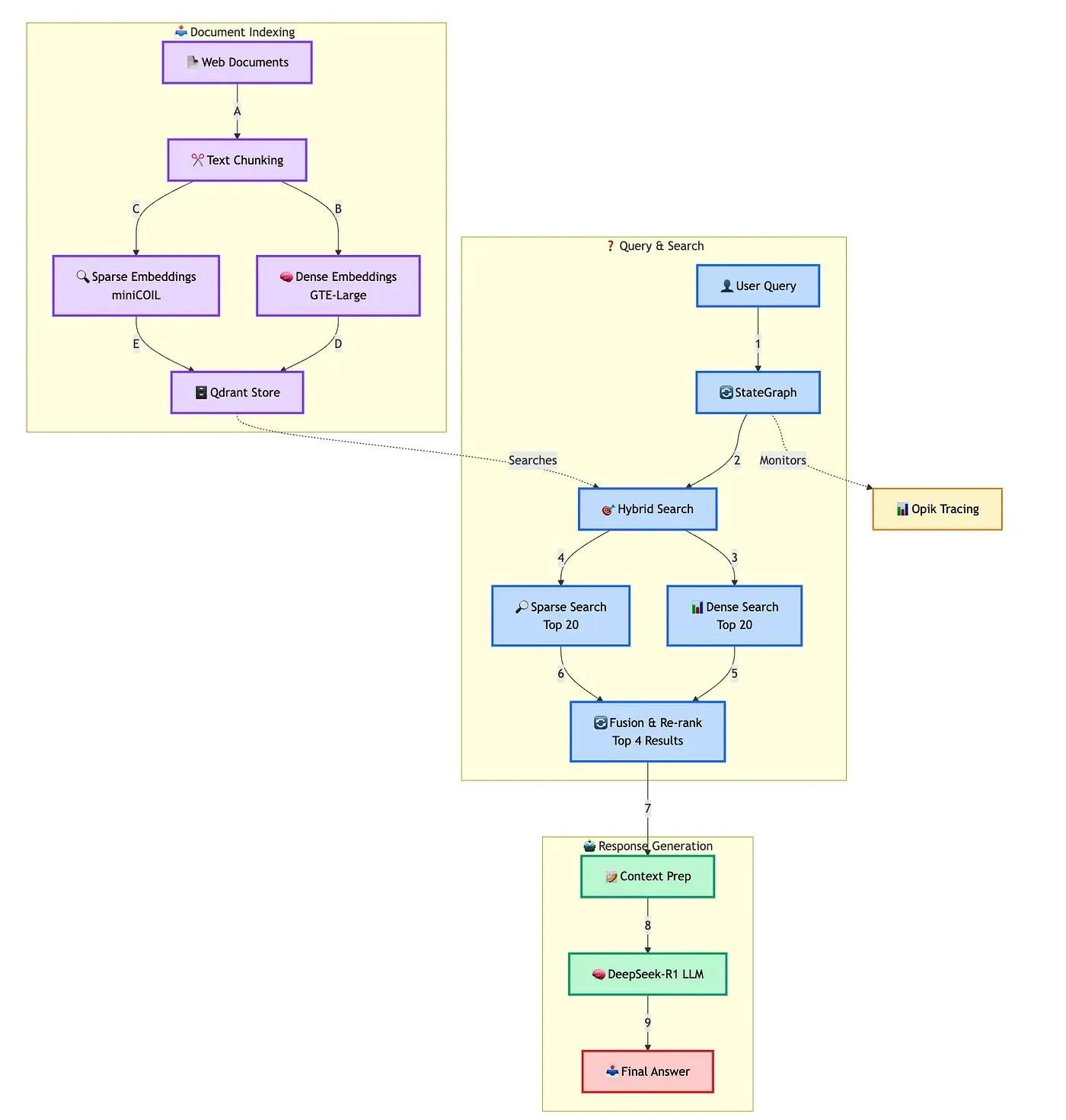
Qdrant, 고급 하이브리드 RAG 챗봇 구축 솔루션 시연: Qdrant는 TRJ_0751과 협력하여 miniCOIL, LangGraph, DeepSeek-R1을 사용하여 고급 하이브리드 고객 지원 RAG(검색 증강 생성) 챗봇을 구축하는 방법을 시연했습니다. 이 솔루션은 miniCOIL을 활용하여 희소 검색의 의미 인식 능력을 향상시키고, LangGraph(LangChainAI 제공)를 사용하여 하이브리드 프로세스(MMR 및 재정렬 포함)를 조정하며, Opik을 사용하여 프로세스의 각 단계를 추적 및 평가하고, DeepSeek-R1(SambaNovaAI 제공)을 사용하여 낮은 지연 시간으로 집중적인 답변을 제공합니다. (출처: qdrant_engine, hwchase17)
Google, 로컬에서 AI 모델 실행 지원하는 AI Edge Gallery 앱 출시: Google은 사용자가 AI 모델을 다운로드하여 로컬 장치에서 실행할 수 있는 AI Edge Gallery라는 앱을 출시했습니다. 이는 사용자가 인터넷 연결 없이도 AI 도구를 사용하여 이미지 생성, 질의응답 또는 코드 작성을 수행하고 데이터 개인 정보를 보호할 수 있음을 의미합니다. 이 앱은 현재 미리보기 버전으로 제공되며 Gemma 3n과 같은 모델을 지원합니다. (출처: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

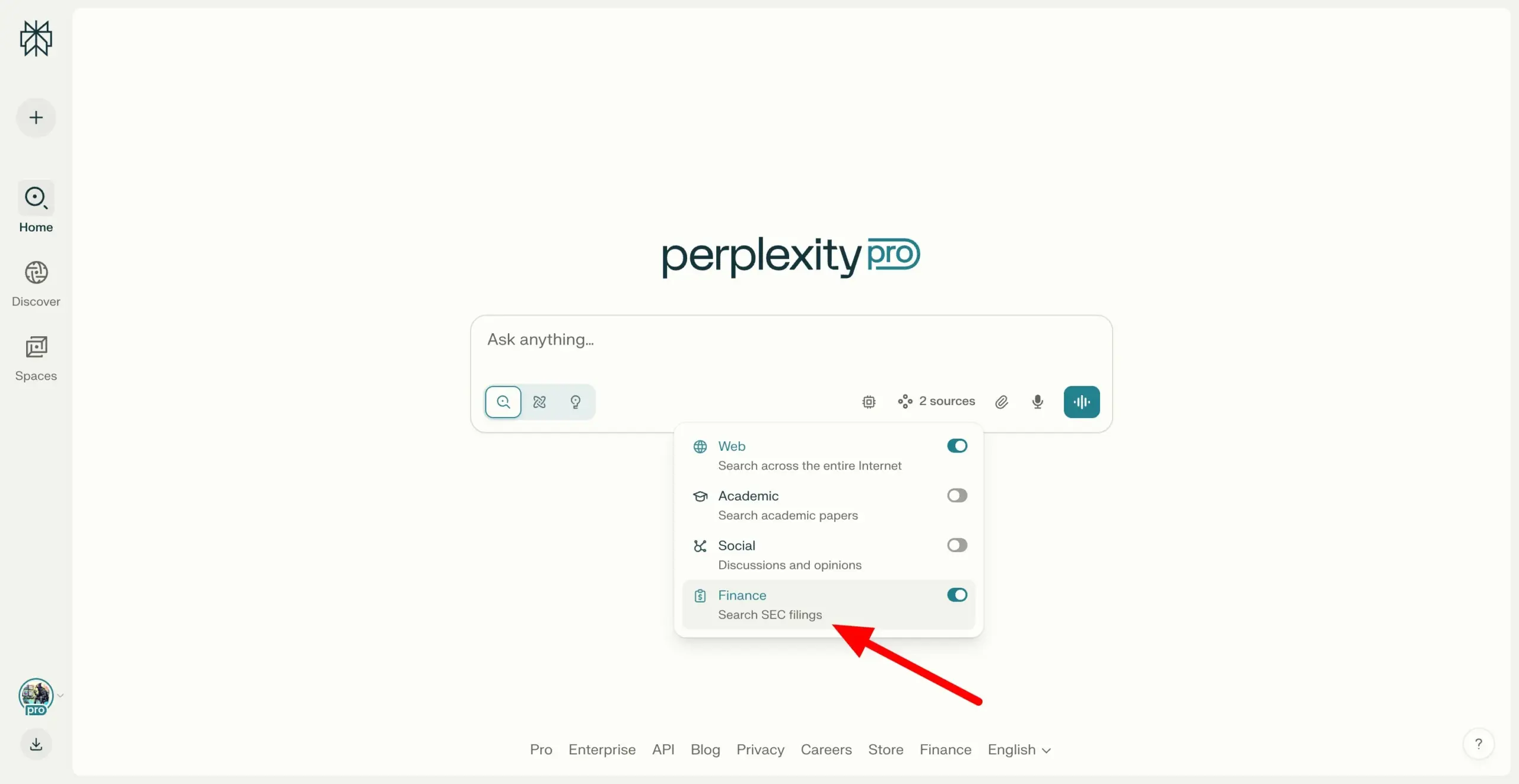
Perplexity Labs, SEC EDGAR 파일 교차 검색 지원으로 금융 연구 역량 강화: Perplexity Labs는 사용자가 미국 증권거래위원회(SEC)의 EDGAR 데이터베이스에 있는 회사 파일을 검색할 수 있는 새로운 기능을 추가했습니다. 이번 업데이트는 금융 연구 분야에서의 활용도를 더욱 강화하고 사용자에게 상장 회사 정보 검색 및 분석 경로를 보다 편리하게 제공하는 것을 목표로 합니다. (출처: AravSrinivas)
메이퇀, AI 노코드 도구 NoCode 공개, 자연어로 애플리케이션 구축 가능: 메이퇀은 AI 노코드 도구 NoCode를 출시했습니다. 사용자는 프로그래밍 경험 없이 자연어 대화를 통해 개인 효율성 향상 도구, 제품 프로토타입, 인터랙티브 페이지, 심지어 간단한 게임까지 만들 수 있습니다. NoCode는 실시간 미리보기, 부분 수정, 원클릭 배포를 지원하여 개발 장벽을 낮추고 더 많은 사람이 창의력을 발휘할 수 있도록 하는 것을 목표로 합니다. 이 도구의 배후에는 메이퇀 자체 개발 7B 파라미터 apply 전용 모델을 포함한 여러 AI 모델이 협력하고 있으며, 메이퇀 내부 실제 코드 데이터에 대해 최적화되었습니다. (출처: WeChat)
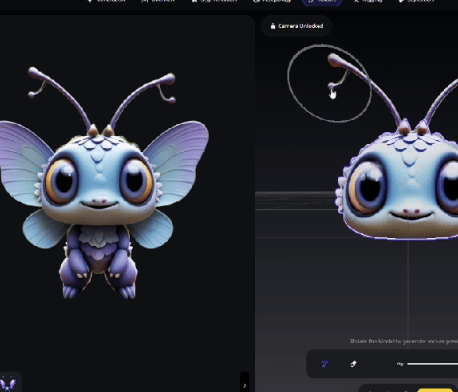
VAST, Tripo Studio 업그레이드, 스마트 부품 분할, 매직 브러시 등 AI 모델링 기능 추가: 3D 대형 모델 스타트업 VAST가 AI 모델링 도구 Tripo Studio를 대대적으로 업그레이드하여 스마트 부품 분할, 텍스처 매직 브러시, 스마트 로우폴리곤 생성, 만물 자동 본딩 등 4가지 핵심 기능을 도입했습니다. 이러한 기능은 부품 편집의 어려움, 텍스처 결함 수정의 시간 소모, 고폴리곤 최적화의 번거로움, 복잡한 본딩 등 기존 3D 모델링 프로세스의 문제점을 해결하고 3D 콘텐츠 제작 효율성과 사용 편의성을 대폭 향상시켜 비전문가의 진입 장벽을 낮추는 것을 목표로 합니다. (출처: 量子位)
Hugging Face, 오픈소스 휴머노이드 로봇 HopeJR과 Reachy Mini 2종 출시, 합리적인 가격: Hugging Face는 The Robot Studio 및 Pollen Robotics와 협력하여 풀사이즈 HopeJR(약 3,000달러)과 데스크톱형 Reachy Mini(약 250~300달러) 등 2종의 오픈소스 휴머노이드 로봇을 출시했습니다. 이는 로봇 기술의 보급과 개방형 연구를 촉진하고 누구나 로봇 원리를 조립, 수정, 학습할 수 있도록 하는 것을 목표로 합니다. HopeJR은 보행 및 팔 움직임이 가능하며 장갑을 통해 원격 제어할 수 있습니다. Reachy Mini는 머리를 움직이고 말하고 들을 수 있으며 AI 애플리케이션 테스트에 사용됩니다. (출처: WeChat)

세계 최초 AI 에이전트 자가 진화 오픈소스 프레임워크 EvoAgentX 출시: 영국 글래스고 대학교 연구팀이 세계 최초의 AI 에이전트 자가 진화 오픈소스 프레임워크인 EvoAgentX를 출시했습니다. 이 프레임워크는 다중 AI 에이전트 시스템 구축 및 최적화의 복잡성을 해결하고, 자가 진화 메커니즘을 도입하여 원클릭 워크플로우 구축을 지원하며, 시스템이 실행 중에 환경 및 목표 변화에 따라 구조와 성능을 지속적으로 최적화할 수 있도록 합니다. EvoAgentX는 다중 에이전트 시스템이 수동 디버깅에서 자율 진화로 나아가도록 촉진하고 연구자와 엔지니어에게 통합된 실험 및 배포 플랫폼을 제공하고자 합니다. (출처: WeChat)

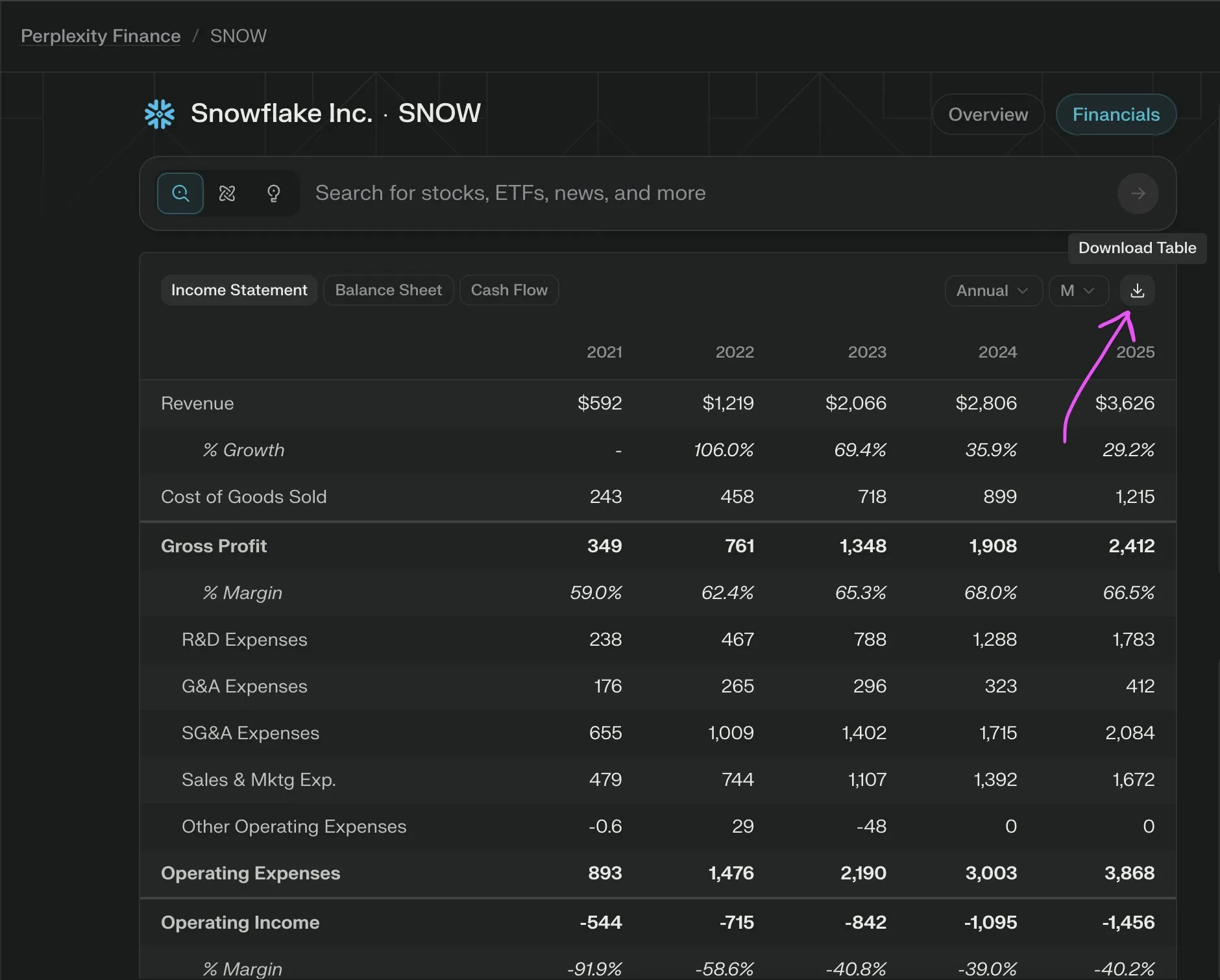
Perplexity Labs, 회사 재무 데이터 CSV 무료 내보내기 기능 출시: Perplexity Labs는 사용자가 이제 금융 페이지의 모든 회사 재무 섹션에서 데이터를 CSV 형식으로 무료로 내보낼 수 있다고 발표했습니다. 이전에는 Yahoo Finance와 같은 플랫폼에서 유사한 기능에 일반적으로 유료 구독이 필요했습니다. Perplexity는 향후 더 많은 과거 데이터를 추가할 것이라고 밝혔습니다. (출처: AravSrinivas)
📚 학습
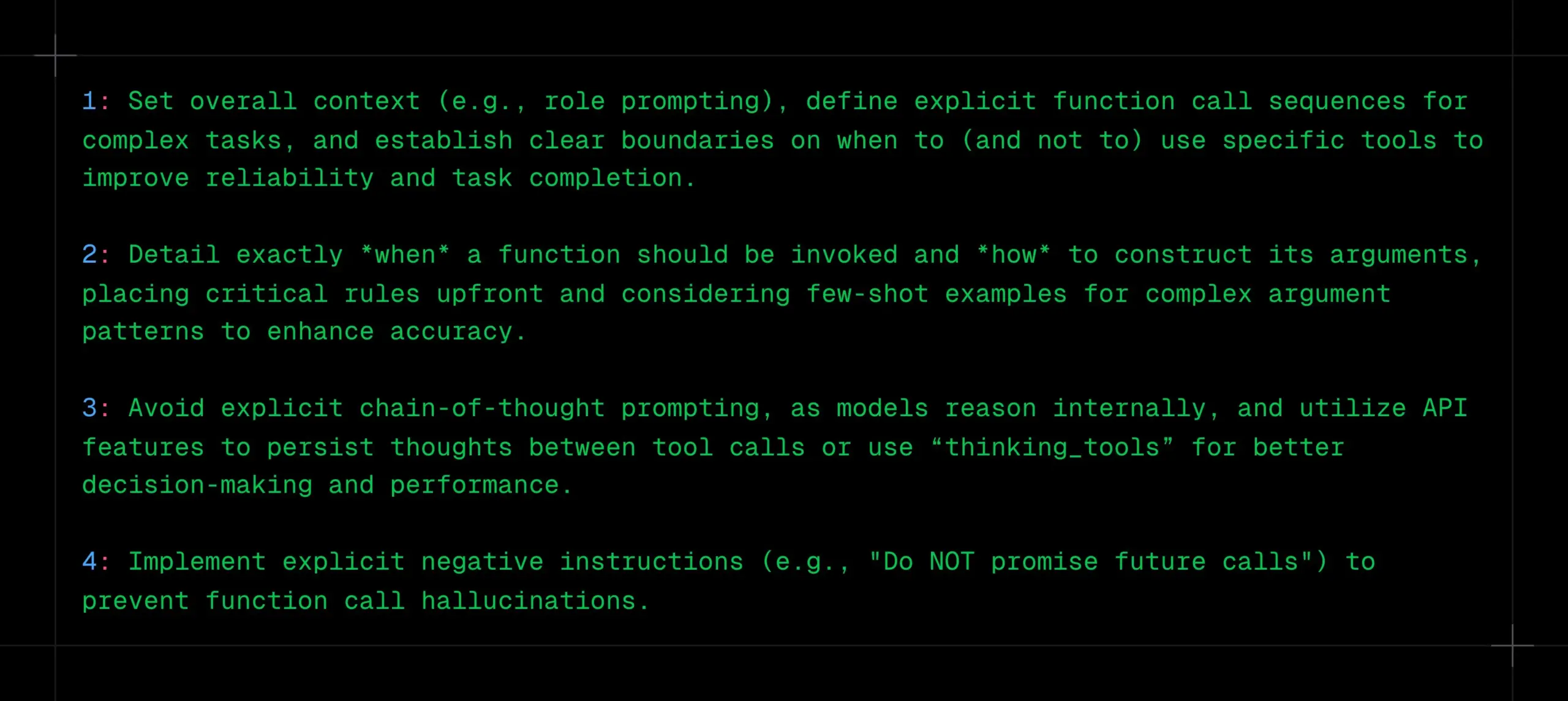
LLM 함수 호출 기법: 명확한 컨텍스트, 순서 및 경계 설정, CoT 및 환각 방지: _philschmid는 Gemini 2.5 또는 OpenAI o3와 같은 추론 모델에 대한 함수 호출 시 권장 사항을 공유했습니다. 핵심 사항은 다음과 같습니다: 전체 컨텍스트 설정(예: 역할 프롬프트), 복잡한 작업에 대한 명확한 함수 호출 순서 정의, 도구 사용에 대한 명확한 경계 설정(사용 시기/미사용 시기). 함수 호출 시점 및 매개변수 구성 방법을 자세히 설명해야 합니다. 모델이 내부적으로 추론하므로 명시적인 CoT 프롬프트를 피하고, API 기능을 활용하여 도구 호출 간에 사고를 지속하거나 “thinking_tools”를 사용할 수 있습니다. 동시에 함수 호출 환각을 방지하기 위해 명확한 부정 명령(예: “미래 호출을 약속하지 마십시오”)을 구현해야 합니다. (출처: _philschmid)
전문 AI 프로그래밍 팁 12가지 공유: Cline은 최근 엔지니어링 모범 사례 회의에서 나온 12가지 AI 프로그래밍 팁을 공유하며, 계획, 복잡한 작업 처리를 위한 고급 모델 사용, 컨텍스트 창 주목, 규칙 파일 생성, 의도 명확화, AI를 협력자로 간주, 메모리 뱅크 활용, 컨텍스트 관리 전략 학습, 팀 지식 공유 구축을 강조했습니다. 핵심 목표는 소프트웨어를 더 빠르고 더 좋게 구축하고 AI를 대체재가 아닌 능력 증폭기로 활용하는 것입니다. (출처: cline, cline)

DeepSeek-R1-0528 업데이트 후 창작 지침 최적화 제안: DeepSeek-R1-0528 모델(685억 파라미터, 128K 컨텍스트, 코드 능력 o3에 근접) 업데이트에 대해 콘텐츠 제작자가 10가지 최적화된 창작 지침을 공유했습니다. 제안 사항에는 30~60분의 초장시간 추론 능력을 활용한 심층 사고, 128K 장문 텍스트 처리, 코드 생성 최적화, 시스템 프롬프트 맞춤 설정, 글쓰기 작업 품질 향상, 반환각 검증, 창의적 글쓰기 병목 현상 돌파, 문제 진단 분석, 지식 학습 통합, 비즈니스 문구 최적화 등이 포함됩니다. 지침 구체화, 장문 컨텍스트 충분히 활용, 심층 추론 잘 활용, 대화 기억 구축, 중요 정보 검증을 강조합니다. (출처: WeChat)
RM-R1 프레임워크: 보상 모델을 추론 작업으로 재구성하여 해석 가능성 및 성능 향상: 일리노이 대학교 어바나-샴페인 연구팀은 보상 모델(Reward Models) 구축을 추론 작업으로 재정의하는 RM-R1 프레임워크를 제안했습니다. 이 프레임워크는 ‘연쇄 평가 기준(Chain-of-Rubrics, CoR)’ 메커니즘을 도입하여 모델이 선호도 판단을 내리기 전에 구조화된 평가 기준과 추론 과정을 생성하도록 함으로써 보상 모델의 해석 가능성과 수학, 프로그래밍과 같은 복잡한 작업에서의 평가 정확도를 향상시킵니다. RM-R1은 추론 증류 및 강화 학습의 두 단계 훈련을 통해 여러 보상 모델 벤치마크에서 기존 오픈소스 및 비공개 소스 모델보다 우수한 성능을 보였습니다. (출처: WeChat)

모델 컨텍스트 프로토콜(MCP) 심층 분석: AI와 외부 서비스 통합 간소화: 모델 컨텍스트 프로토콜(MCP)은 AI 모델과 외부 데이터 소스, 도구(예: Slack, Gmail) 통합 시 발생하는 파편화 문제를 해결하기 위한 개방형 표준입니다. 통합된 시스템 인터페이스(STDIO 및 SSE 프로토콜 지원)를 통해 MCP는 개발자가 MCP 클라이언트(예: Claude 데스크톱, Cursor IDE)와 MCP 서버(데이터베이스, 파일 시스템 운영, API 호출)를 구축하여 복잡한 ‘M×N’ 적응 네트워크를 ‘M+N’ 모드로 단순화하고 AI와 외부 서비스의 플러그 앤 플레이를 실현할 수 있도록 합니다. 펑칭 테크놀로지 Fabarta 파트너 탄위는 MCP의 가치는 기본 연결 기능을 제공하는 데 있으며, 상용화는 Fabarta 슈퍼 오피스 인텔리전트 에이전트를 통해 MCP Server를 통합하여 사용자 프로세스를 간소화하는 등 배후 시스템이 제공하는 구체적인 가치에 의존한다고 생각합니다. (출처: WeChat)

Agentic ROI: 대형 모델 에이전트 사용성 측정 핵심 지표: 상하이 교통대학교는 중국과학기술대학교와 공동으로 Agentic ROI(에이전트 투자 수익률)를 실제 시나리오에서 대형 모델 에이전트의 실용성을 측정하는 핵심 지표로 제안했습니다. 이 지표는 정보 품질, 사용자와 에이전트의 시간 비용, 경제적 비용을 종합적으로 고려합니다. 연구에 따르면 현재 에이전트는 과학 연구, 프로그래밍 등 인력 비용이 높은 분야에서 많이 사용되지만, 전자상거래, 검색 등 일상적인 시나리오에서는 한계 가치가 불분명하고 상호 작용 비용이 높아 Agentic ROI가 낮습니다. Agentic ROI를 최적화하려면 “정보 품질의 규모화된 향상 후 비용 경량화”라는 “지그재그” 발전 경로를 따라야 합니다. (출처: WeChat)
💼 비즈니스
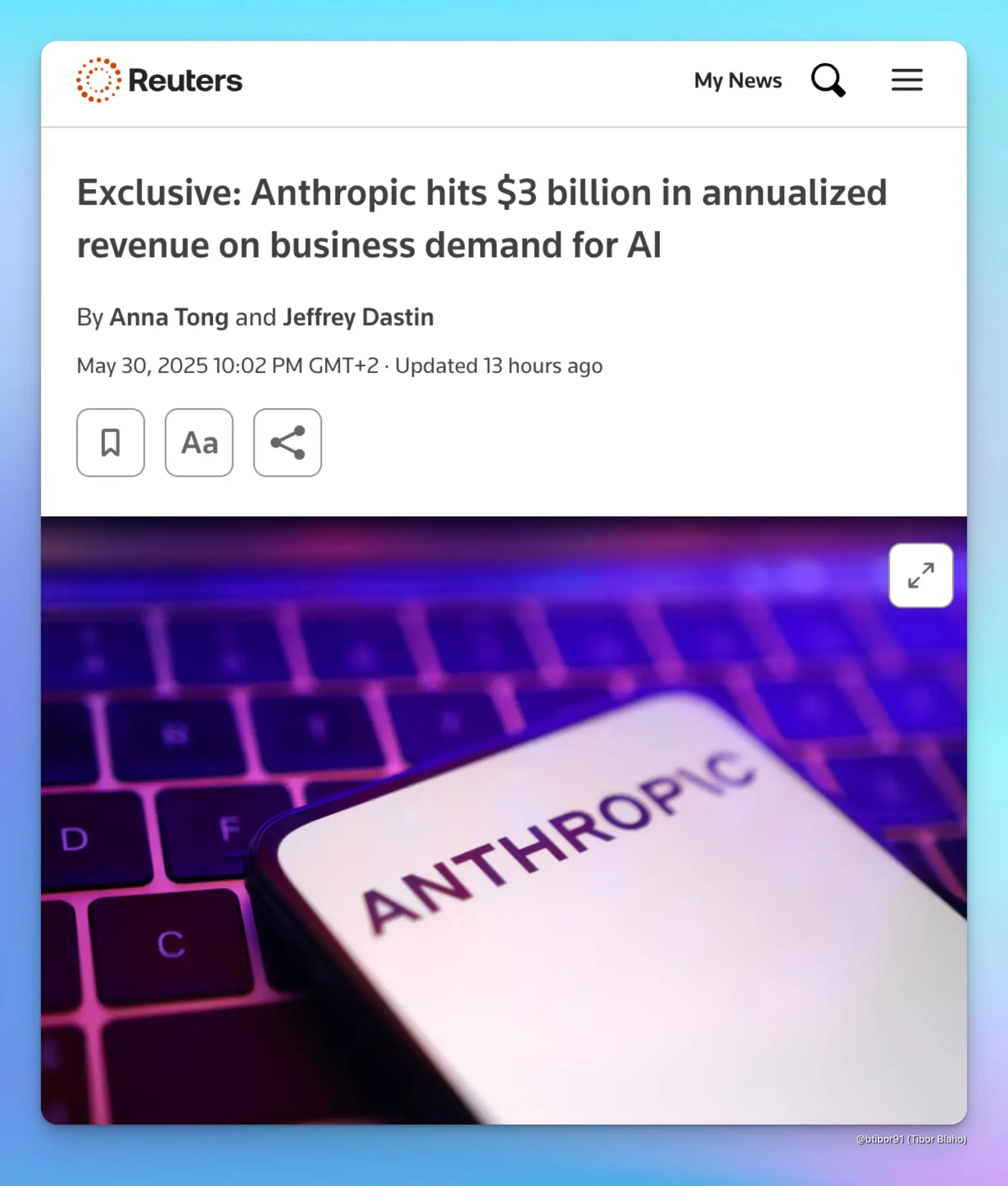
Anthropic, 기업 AI 수요에 힘입어 연간 매출 30억 달러로 급증: 두 명의 소식통에 따르면 Anthropic의 연간 매출은 불과 5개월 만에 10억 달러에서 30억 달러로 증가했습니다. 이러한 현저한 성장은 주로 코드 생성 분야를 중심으로 한 기업의 강력한 AI 수요에 힘입은 것입니다. 이는 기업 시장에서 Anthropic의 Claude 시리즈와 같은 고급 AI 모델의 적용 및 유료화 의지가 빠르게 증가하고 있음을 보여줍니다. (출처: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Nvidia 2026 회계연도 1분기 실적: 총 매출 441억 달러, 데이터센터 사업이 약 90% 기여: Nvidia는 2025년 4월 27일 마감된 2026 회계연도 1분기 실적을 발표했습니다. 총 매출은 441억 달러로 전분기 대비 12%, 전년 동기 대비 69% 증가했습니다. 데이터센터 사업 매출은 391억 달러로 전체의 88.91%를 차지하며 전년 동기 대비 73% 증가했습니다. 게임 사업 매출은 38억 달러로 사상 최고치를 기록했습니다. H20 칩이 수출 제한의 영향을 받아 45억 달러의 재고 감액 및 구매 의무 비용이 발생했고, 2분기에는 이로 인해 80억 달러의 매출 손실이 예상되지만 전체 실적은 여전히 견조합니다. Blackwell Ultra 등 신제품이 성장을 더욱 견인할 것으로 기대됩니다. (출처: 量子位, WeChat)

Meta, AI 팀 재편, 기존 Llama 핵심 개발자 다수 이탈, FAIR 위상 주목: Meta는 AI 팀을 재편하여 Connor Hayes가 이끄는 AI 제품팀과 Ahmad Al-Dahle 및 Amir Frenkel이 공동으로 이끄는 AGI 기반 부서로 나누고, 기초 인공지능 연구 부서인 FAIR는 상대적으로 독립성을 유지하되 일부 멀티미디어 팀은 통합한다고 발표했습니다. 이번 조정은 자율성과 개발 속도를 높이기 위함입니다. 그러나 Llama 모델의 기존 핵심 개발자 14명 중 3명만 잔류하고 다수는 이직하거나 경쟁사(예: Mistral AI)로 옮겼습니다. Llama 4 출시 후 반응이 미미했던 점과 내부적으로 컴퓨팅 파워 배분 및 연구 개발 방향 조정이 이루어진 점 등을 고려할 때, Meta가 오픈소스 AI 분야에서 선도적 지위를 유지하고 FAIR가 미래 발전을 이룰 수 있을지에 대한 우려가 제기되고 있습니다. (출처: WeChat)

🌟 커뮤니티
AI 정렬 토론: 소프트 규범이 AGI 시대에 인간의 권력을 유지할 수 있을까?: Ryan Greenblatt는 Dwarkesh Patel이 제기한 관점에 대해 토론합니다. Patel은 AI 정렬에 회의적이며, 대신 AGI(일반 인공 지능)가 하드 파워를 장악한 후에도 소프트 규범을 통해 인간에게 일부 권력과 생존 공간을 남겨두기를 희망합니다. Greenblatt는 AI가 범위에 민감하고(scope sensitive) 권력을 장악할 능력이 있다면, 거래나 계약을 통해 그 불일치를 드러내거나 인간을 위해 일하도록 만드는 것은 성공하기 어려울 것이라고 생각합니다. 또한 저렴한 미세 조정, 인간 개선 정렬, 자유로운 복제 등의 요인으로 인해 정렬 문제가 해결되기 전까지 인간의 재산 통제는 매우 불안정합니다. 정렬된 AI나 더 저렴한 AI 노동력이 등장하면 인간은 이를 우선적으로 사용하게 될 것이며, 이는 정렬되지 않은 AI가 권력을 장악하도록 강력하게 유인할 것입니다. (출처: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Redis 창시자, “AI 프로그래밍, 인간 프로그래머에 훨씬 못 미쳐” 발언에 개발자 공감 및 토론: Redis 창시자 Salvatore Sanfilippo(Antirez)는 자신의 개발 경험을 공유하며 현재 AI가 프로그래밍 분야에서 실용성은 있지만, 특히 관행을 깨고 기발하고 효과적인 해결책을 구상하는 면에서 인간 프로그래머에 훨씬 못 미친다고 말했습니다. 그는 AI를 아이디어 검증에 도움이 되는 “충분히 똑똑한 조수”에 비유했습니다. 이 관점은 개발자들 사이에서 뜨거운 논쟁을 불러일으켰고, 많은 이들이 AI를 사고를 돕는 “고무 오리”로 활용할 수 있다는 데 동의했지만, AI가 지나치게 자신감이 넘치고 초급 개발자를 오도하기 쉽다고 지적했습니다. 일부 개발자는 AI가 생성한 잘못된 답변이 오히려 수동 코딩을 하도록 동기를 부여한다고 말했습니다. 토론에서는 AI를 효과적으로 활용하는 데 있어 경험의 중요성과 AI가 프로그래밍 초보자에게 미칠 수 있는 부정적인 영향이 강조되었습니다. (출처: WeChat)

DeepMind와 Google Research 관계 또다시 논란: 브랜드와 실제 혁신 기여도 논쟁: Faruk Guney는 트위터 장문을 통해 DeepMind와 Google Research의 관계에 대해 논평하며, 현재 AI 혁명의 핵심 돌파구(예: Transformer 아키텍처)는 Google에 인수된 후의 DeepMind가 아닌 주로 Google Research에서 비롯되었다고 주장했습니다. 그는 AlphaFold가 DeepMind의 성과이긴 하지만 Google의 컴퓨팅 자원과 연구 인프라 없이는 불가능했으며, 핵심 기여자는 John Jumper와 Pushmeet Kohli와 같은 과학자 엔지니어라고 지적했습니다. Guney는 Google Research가 이후 DeepMind에 통합된 것은 브랜드 및 조직 구조 조정에 가깝고, 그 배후에는 복잡한 기업 정치가 관련되어 혁신의 실제 출처를 가릴 수 있다고 보았습니다. 그는 많은 AI 돌파구가 소수의 유명 인사나 브랜드에만 공을 돌릴 것이 아니라 팀의 수년간의 연구 성과라고 강조했습니다. (출처: farguney, farguney)
AI 시대 일자리 및 기술 변화에 대한 우려와 논의: 소셜 미디어에서는 AI가 고용 시장에 미치는 영향에 대한 논의가 계속되고 있습니다. 한편으로는 AI가 대규모 실업을 초래할 것이라는 견해가 있으며, Anthropic CEO가 이러한 우려를 표명하여 사람들이 어떻게 대처해야 할지 고민하게 만들었습니다. 다른 한편으로는 AI가 주로 생산성을 향상시키므로 심각한 경기 침체가 발생하지 않는 한 대규모 실업을 초래할 가능성은 낮다는 목소리도 있습니다. 소비 수요는 고용과 소득에 의존하기 때문입니다. 동시에 AI로 인해 실직한 개인적인 경험(예: 사장이 ChatGPT로 직원을 대체)을 공유하는 사용자도 있습니다. 미래에 대한 논의는 저축, 실용적인 기술 학습, 소득 감소 가능성에 대한 적응, 그리고 비판적 사고와 AI 도구의 효과적인 활용 능력과 같이 AI 시대에 필요한 기술을 양성하기 위해 교육 시스템이 어떻게 조정되어야 하는지를 가리키고 있습니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial)

ChatGPT 과도한 의존으로 인한 사고력 저하 우려: 한 Reddit 사용자는 여자친구가 의사 결정, 의견 및 아이디어 얻기에 ChatGPT를 과도하게 의존하여 독립적인 사고와 독창성을 잃을 수 있다는 우려를 표명하는 글을 올렸습니다. 이 글은 광범위한 논의를 불러일으켰고, 일부 댓글 작성자는 이러한 우려에 동의하며 AI 도구에 대한 과도한 의존이 실제로 개인의 사고를 약화시킬 수 있다고 생각했습니다. 다른 댓글은 AI는 과거의 백과사전이나 검색 엔진과 마찬가지로 도구일 뿐이며, 중요한 것은 사용자가 이를 어떻게 활용하여 사고의 출발점으로 삼는지 아니면 완전히 대체하는지라고 주장했습니다. 또한 소통, 안내, AI의 한계 제시를 통해 대처할 것을 제안하는 댓글도 있었습니다. (출처: Reddit r/ChatGPT)
교육 분야 AI의 과제: 교수, 학생들의 ChatGPT 남용에 고충 토로하며 진정한 사고력 함양 촉구: 한 고대사 교수는 Reddit에 올린 글에서 ChatGPT 남용이 자신의 수업에 심각한 영향을 미치고 있으며, 학생들이 제출한 논문은 AI가 생성하고 심지어 사실 오류까지 포함된 ‘공허한 쓰레기’로 가득 차 있어 학생들이 실제로 학습하고 있는지 의심스럽다고 밝혔습니다. 그는 인문 교육의 핵심은 단순히 기존 정보를 반복하는 것이 아니라 새로운 지식, 창의적인 통찰력, 독립적인 사고를 기르는 것이라고 강조했습니다. 이 게시물은 뜨거운 논쟁을 불러일으켰고, 댓글 작성자들은 구두 보고서로 변경, 수업 중 손으로 논문 작성, 학생들이 AI 사용 과정 메타 분석 제출 요구, 또는 AI를 교육에 통합하여 학생들이 AI의 결과물을 비판하도록 하는 등 다양한 대응 전략을 제시했습니다. (출처: Reddit r/ChatGPT)
AI 생성 커널, PyTorch 전문가 커널 의외로 능가, 스탠퍼드 중국계 팀 새로운 가능성 제시: 스탠퍼드 대학교 Anne Ouyang, Azalia Mirhoseini, Percy Liang 팀은 커널 생성 모델 훈련을 위한 합성 데이터 생성 시도 중, 순수 CUDA-C로 작성된 AI 생성 커널이 성능 면에서 PyTorch 내장 전문가 최적화 FP32 커널에 근접하거나 심지어 능가하는 것을 우연히 발견했습니다. 예를 들어, 행렬 곱셈에서 PyTorch 성능의 101.3%, 2차원 컨볼루션에서 179.9%에 도달했습니다. 팀은 자연어 추론 최적화 아이디어와 분기 확장 검색 전략을 결합한 다단계 반복 최적화를 채택하고 OpenAI o3 및 Gemini 2.5 Pro 모델을 활용했습니다. 이 성과는 교묘한 검색과 병렬 탐색을 통해 AI가 고성능 컴퓨팅 커널 생성 분야에서 돌파구를 마련할 잠재력이 있음을 보여줍니다. (출처: WeChat)

💡 기타
AI 산업 로비력 막강, Max Tegmark 주목: MIT 교수 Max Tegmark는 워싱턴과 브뤼셀의 AI 산업 로비스트 수가 화석 연료 산업과 담배 산업의 로비스트 수를 합친 것보다 많다고 지적했습니다. 이 현상은 AI 산업이 정책 결정에 미치는 영향력이 커지고 있으며, 규제 환경 형성에 적극적으로 참여하고 있음을 보여줍니다. 이는 AI 기술 발전 방향, 윤리 규범, 시장 경쟁 구도에 심대한 영향을 미칠 수 있습니다. (출처: Reddit r/artificial)

AI, 딥페이크 통해 생물 테러 공격 모방 가능성, 새로운 공중 보건 위협: STAT News 기사는 AI 지원 생물 공학 무기의 위험 외에도 딥페이크 기술을 이용한 생물 테러 공격 모방 또한 심각한 위협이 될 수 있다고 지적합니다. 특히 군사 분쟁 국가 간에는 이러한 위조 정보가 공포, 오판, 불필요한 군사적 긴장 고조를 유발할 수 있습니다. 조사가 공중 보건이나 기술팀이 아닌 법 집행 기관이나 군사 기관 주도로 이루어질 가능성이 높아, 이들이 공격의 진위 여부를 더 믿는 경향이 있어 효과적인 반증이 어려울 수 있습니다. (출처: Reddit r/ArtificialInteligence)
AI 시대에도 공학 학위를 취득해야 하는가에 대한 열띤 토론: 커뮤니티에서는 AI 시대에 공학 학위를 취득하는 것의 가치에 대해 논의하고 있습니다. 한쪽에서는 AI가 많은 전통적인 엔지니어링 작업을 대체하여 학위 가치를 떨어뜨릴 수 있다고 주장합니다. 다른 한쪽에서는 공학 학위가 배양하는 시스템적 사고, 문제 해결 능력, 수학 및 물리 기초가 여전히 중요하며, 특히 AI 도구를 이해하고 적용하는 데 중요하다고 주장합니다. 일부 견해는 AI가 엔지니어를 대체할 수 있다면 다른 직업도 안전하지 않으며, 중요한 것은 지속적인 학습과 적응이라고 지적합니다. 수의사와 같이 실용성이 강하고 자동화하기 어려운 분야는 상대적으로 안전한 선택으로 간주됩니다. (출처: Reddit r/ArtificialInteligence)