
키워드:DeepSeek R1-0528, 다윈 괴델 머신, AI 에너지 소비, 허위 보상 강화 학습, 화웨이 Ascend, SuperCLUE 랭킹, 멀티모달 벤치마크 테스트, DeepSeek R1-0528 성능 향상, DGM 자기 진화 메커니즘, AI 데이터 센터 원자력 솔루션, Qwen 모델 RLVR 메커니즘, 판구 Ultra MoE 훈련 최적화
🔥 포커스
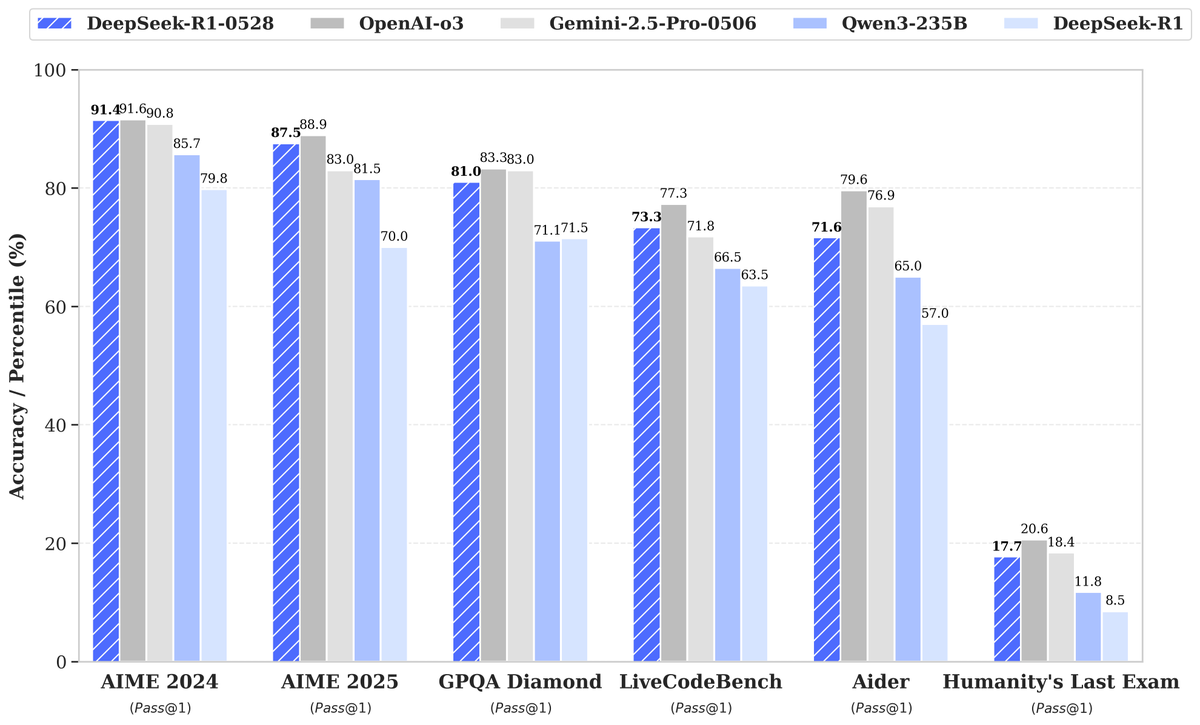
DeepSeek, R1-0528 신규 모델 출시, 성능 대폭 향상으로 관심 집중: DeepSeek이 대규모 언어 모델의 새로운 버전 R1-0528을 출시하여 여러 벤치마크에서 우수한 성과를 거두었으며, 특히 코드 생성(LiveCodeBench), 과학적 추론(GPQA Diamond), 수학 경진대회(AIME 2024) 등 분야에서 현저한 진전을 이루었습니다. Artificial Analysis는 R1-0528이 자사의 인텔리전스 지수에서 60점에서 68점으로 급상승하여 Google의 Gemini 2.5 Pro와 동등한 수준이 되었으며, 세계 두 번째 AI 연구실로 부상하고 오픈 가중치 모델 분야에서 선두 지위를 공고히 했다고 밝혔습니다. 커뮤니티 반응은 긍정적이며, Unsloth는 신속하게 GGUF 양자화 버전을 출시하여 로컬 배포를 용이하게 했습니다. 이번 업데이트는 주로 강화 학습(RL) 등 후훈련 기술을 통해 이루어졌으며, 기존 아키텍처 및 사전 훈련을 기반으로 모델 지능을 지속적으로 향상시킬 수 있는 잠재력을 보여주었습니다. 때때로 출력이 ‘아첨하는’ 스타일을 띤다는 논의도 있지만, 전반적으로 추론 및 코드 능력의 중대한 도약으로 평가받고 있습니다. (출처: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
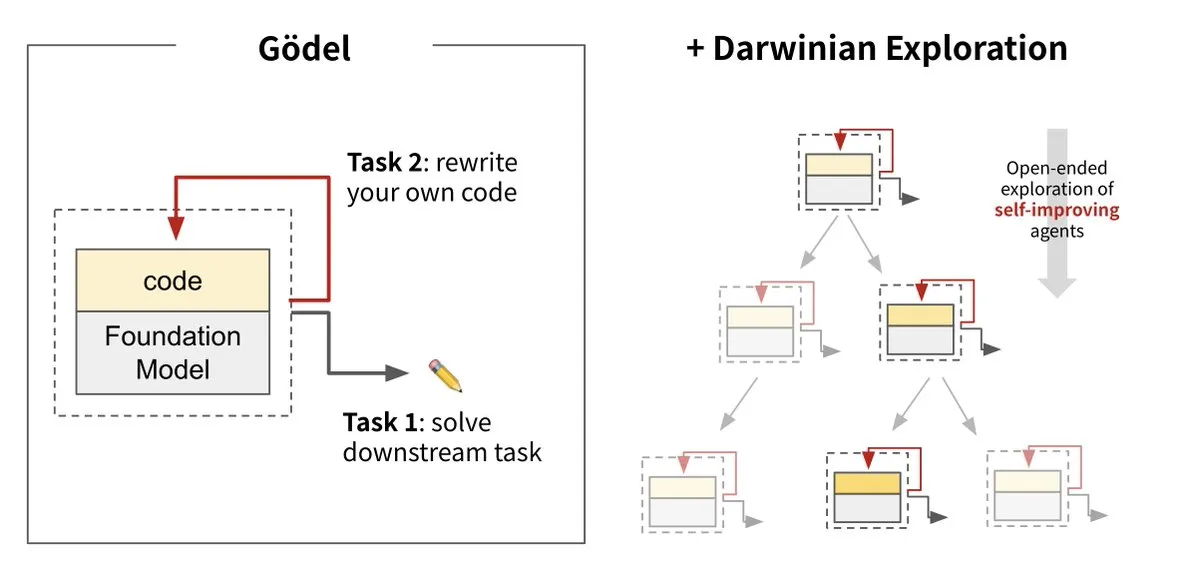
Sakana AI, 다윈·괴델 머신(DGM) 출시, AI 자체 진화 실현: Sakana AI가 UBC와 협력하여 다윈·괴델 머신(Darwin Gödel Machine, DGM)을 출시했습니다. 이는 자체 코드 재작성을 통해 끊임없이 자가 개선할 수 있는 AI 에이전트입니다. 이 시스템은 진화론에서 영감을 받아 대규모 기초 모델과 코드 라이브러리를 결합했으며, 에이전트는 코드 개선 방안을 제안하고 자체 평가할 수 있습니다. 실험 결과, DGM은 SWE-bench에서 성능이 20%에서 50%로, Polyglot에서 성공률이 14.2%에서 30.7%로 향상되어 수동으로 설계된 에이전트보다 현저히 우수한 성능을 보였습니다. 이 연구는 AI 시스템 배포 후 지능이 고정되는 문제를 해결하고 개발 과정에서 안전성을 매우 중시하며, 자율 학습 및 혁신이 가능한 AI를 향한 중요한 단계로 평가받고 있습니다. (출처: Sakana AI, hardmaru, ITmedia AI+)
AI 에너지 소비 문제 대두, 원자력과 화석 연료가 잠재적 동력원으로 부상: MIT Technology Review의 시리즈 보도 “Power Hungry”는 인공지능(AI)의 예상 에너지 수요를 심층적으로 다루었습니다. AI 데이터 센터는 특히 모델 추론 시나리오에서 지속적이고 안정적인 전력 공급이 필요합니다. 태양광과 풍력은 청정에너지이지만 간헐성으로 인해 값비싼 에너지 저장 솔루션 없이는 AI 수요를 단독으로 충족하기 어렵습니다. 원자력은 지속적인 전력 공급이 가능하여 잠재적인 해결책으로 간주되지만, 신규 원전 건설은 시간이 오래 걸리고 복잡합니다. 따라서 천연가스 등 화석 연료가 AI의 급증하는 에너지 수요를 충족하기 위한 단기적 의존 대상이 될 수 있으며, 이는 기후 목표에 도전이 될 수 있습니다. 이 보도는 대형 기술 기업들이 AI 발전으로 인한 에너지 및 기후 이중 도전에 대응하기 위해 탄소 포집 기술이나 에너지 사용 효율 최적화와 같은 더 깨끗한 에너지 솔루션을 추진해야 한다고 강조합니다. (출처: MIT Technology Review, The Download)

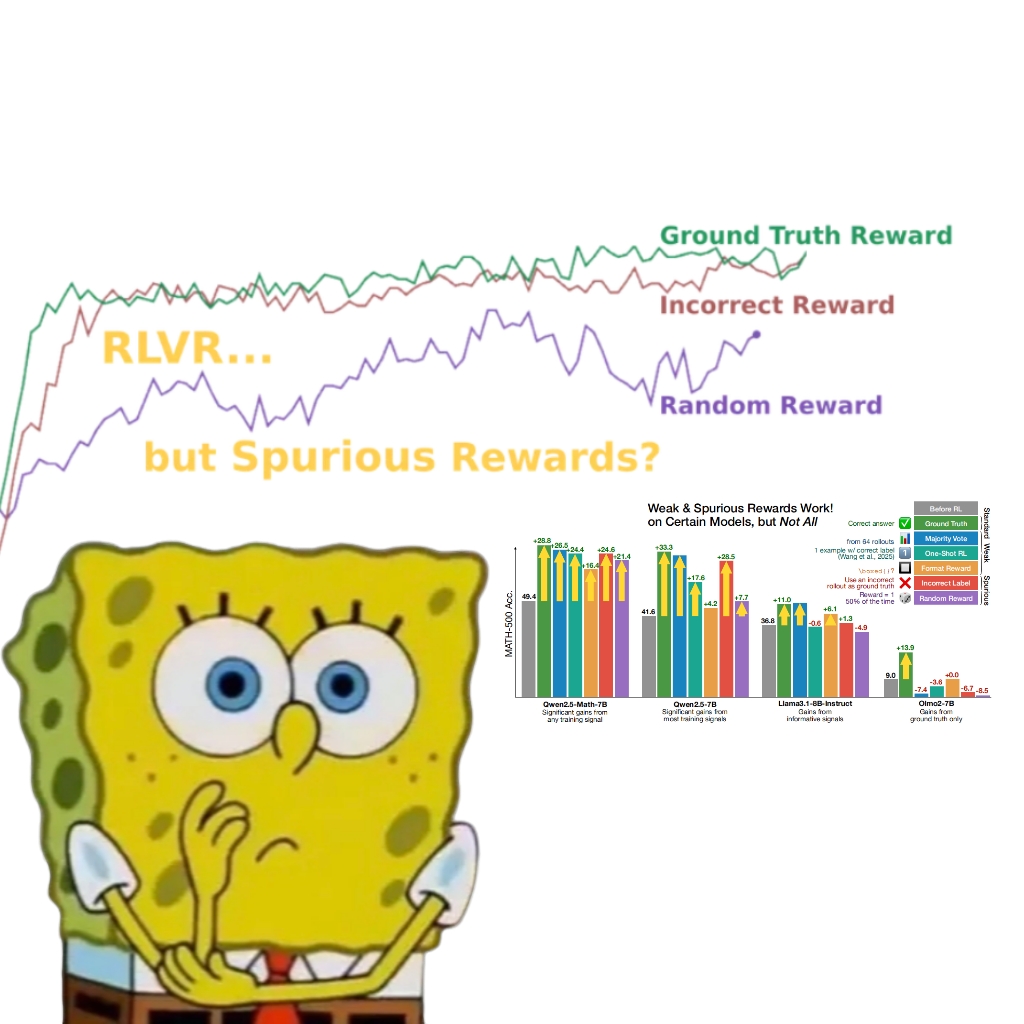
연구 결과, 허위 보상도 Qwen 모델 성능 향상시켜 RLVR 메커니즘 재고 촉발: 워싱턴 대학교 연구팀은 무작위 또는 잘못된 보상 신호를 사용하더라도 검증 가능한 보상 강화 학습(RLVR)을 통해 Qwen2.5-Math 모델을 훈련하면 MATH-500 등 수학적 추론 벤치마크에서 성능이 약 25% 현저히 향상되어 실제 보상의 최적화 효과에 근접한다는 사실을 발견했습니다. 연구에 따르면 이러한 현상은 주로 Qwen 모델이 사전 훈련에서 습득한 특정 코드 추론 전략(예: Python 코드 생성으로 사고 보조)에 기인하며, RLVR 과정(특히 GRPO 알고리즘 사용 시)은 보상 신호 자체의 정확성보다는 이러한 유익한 행동의 빈도를 강화합니다. 이 발견은 이러한 사전 훈련 특성을 갖지 않는 다른 모델(예: OLMo2-7B)에는 적용되지 않으며, 후자는 허위 보상 하에서 성능 변화가 거의 없거나 오히려 저하되었습니다. 이 연구는 RLVR이 정확한 보상 신호에 의존한다는 기존의 인식을 뒤집고, 연구자들에게 모델 특정 행동이 평가 결과에 미치는 영향에 주의를 기울여야 함을 시사하며, 교차 모델 검증의 중요성을 강조합니다. (출처: 量子位, Stella Li)
🎯 동향
화웨이 Ascend, Pangu Ultra MoE 준조 단위 모델 효율적 훈련 지원, 전체 프로세스 자주적 통제 실현: 화웨이는 Ascend AI 하드웨어와 MindSpore 프레임워크를 기반으로 한 Pangu Ultra MoE(7180억 파라미터) 모델의 전체 프로세스 효율적 훈련 사례를 상세히 소개하는 기술 보고서를 발표했습니다. 병렬 전략 지능형 선택, 컴퓨팅 통신 심층 융합, 전역 동적 부하 분산 등의 기술을 통해 Ascend Atlas 800T A2 만 카드 클러스터에서 41%의 MFU(모델 연산력 활용률)를 달성했습니다. RL 후훈련 단계에서는 RL Fusion 훈련-추론 공유 카드 기술과 StaleSync 준비동기 메커니즘을 결합하여 Ascend CloudMatrix 384 슈퍼노드 클러스터에서 슈퍼노드당 35K Tokens/s의 높은 처리량을 달성했으며, 이는 2초마다 고등 수학 문제 하나를 처리하는 것과 같습니다. 이는 국산 AI 연산력과 대형 모델 훈련의 폐쇄 루프 성숙을 의미하며, 초거대 MoE 모델 훈련에서 업계 선도적인 성능을 보여줍니다. (출처: 量子位)

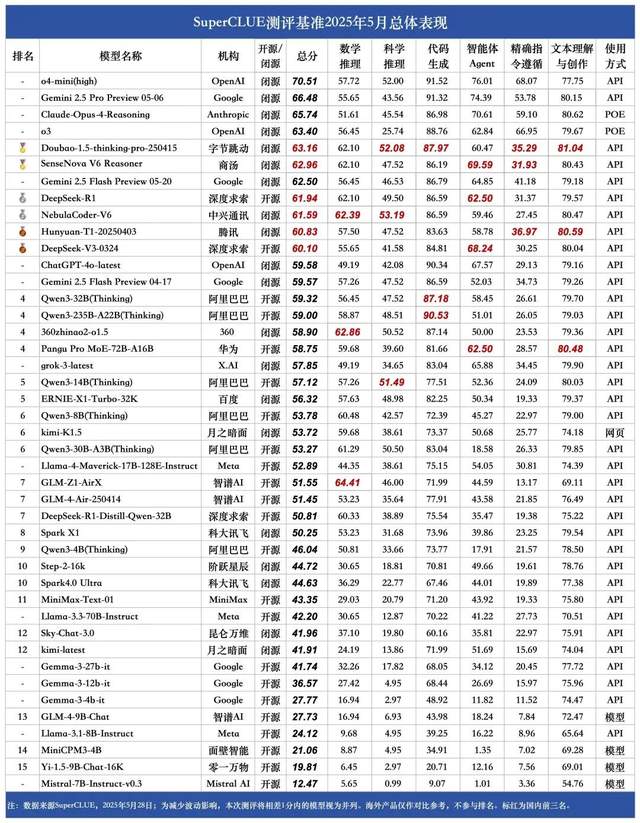
SuperCLUE 5월 중국어 대형 모델 순위: Doubao 1.5와 SenseTime SenseNova V6 공동 국내 1위: 권위 있는 대형 모델 평가 기관 SuperCLUE가 2025년 5월 ‘중국어 대형 모델 벤치마크 평가 보고서’를 발표했습니다. 보고서에 따르면 바이트댄스의 Doubao-1.5-thinking-pro 모델과 센스타임의 SenseNova-V6 멀티모달 모델이 공동으로 국내 1위를 차지했으며, 중국어 일반 능력에서 Gemini 2.5 Flash Preview를 넘어섰습니다. DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1 및 DeepSeek-V3 등의 모델이 그 뒤를 이어 2위 그룹을 형성했습니다. 보고서는 국내외 최고 수준의 대형 모델 간 중국어 분야 일반 능력 격차가 줄어들고 있으며, 국산 추론 모델 경쟁 구도가 초기 단계에 접어들었음을 강조했습니다. 이번 평가는 수학 추론, 과학 추론, 코드 생성, 지능형 에이전트, 정확한 지시 따르기 및 텍스트 이해와 창작 등 6개 주요 과제를 포함했습니다. (출처: 量子位)
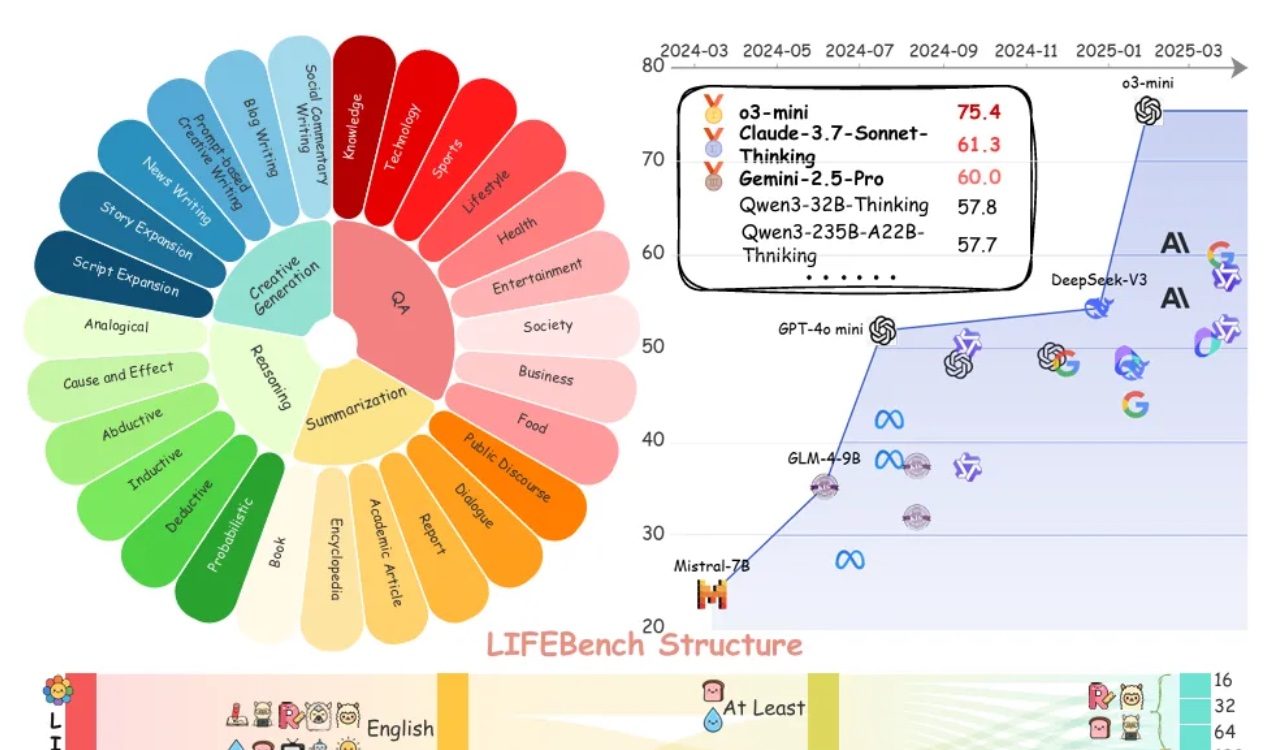
LIFEBench 평가, 대형 모델의 길이 지시 준수 능력 보편적 부족 지적: LIFEBench라는 새로운 벤치마크 테스트 결과, 현재 주류 대규모 언어 모델(LLM)은 특정 텍스트 길이 지시를 따르는 데 있어 특히 장문 텍스트 생성 시 성능이 저조한 것으로 나타났습니다. 연구는 26개 모델을 테스트했으며, 대부분의 모델이 정확한 길이의 텍스트 생성을 요구받았을 때 낮은 점수를 기록했고, o3-mini, Claude-Sonnet-Thinking, Gemini-2.5-Pro 등 소수 모델만이 양호한 성능을 보였습니다. 장문 텍스트 생성(2000자 이상)은 보편적인 약점으로, 모든 모델의 점수가 현저히 하락했습니다. 또한, 모델들은 중국어 작업 처리 시 영어보다 전반적으로 성능이 떨어졌으며 ‘과잉 생성’ 경향을 보였습니다. 연구는 또한 많은 모델이 주장하는 최대 출력 길이가 실제 능력과 일치하지 않아 ‘과대 광고’ 현상이 존재한다고 지적했습니다. 모델은 길이 인식, 장문 입력 처리 및 ‘게으른 생성’(예: 조기 종료 또는 생성 거부) 방지 측면에서 병목 현상을 보였습니다. (출처: 量子位)
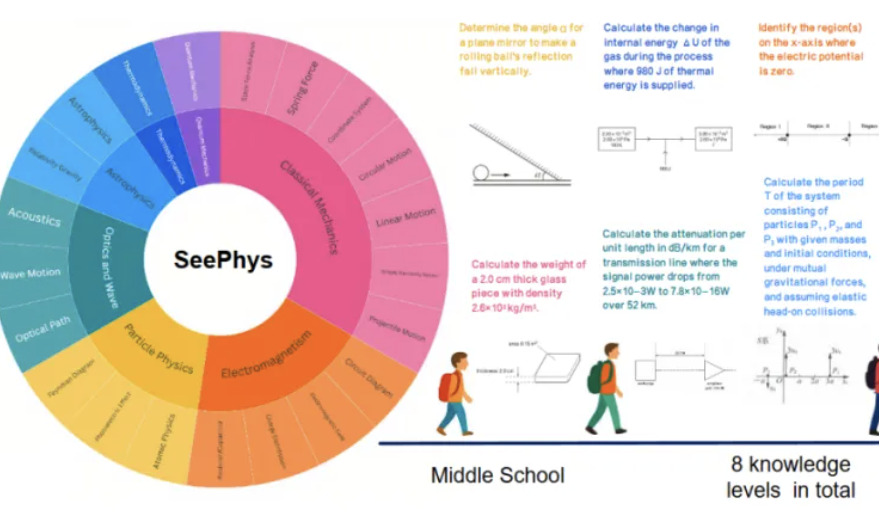
새로운 벤치마크 SeePhys, 멀티모달 대형 모델의 물리 이미지 이해 능력 취약점 드러내: 중산대학교 등 기관이 공동으로 SeePhys 벤치마크 테스트를 출시하여 멀티모달 대형 모델(MLLM)의 물리학 관련 이미지 이해 및 추론 능력을 전문적으로 평가합니다. 이 벤치마크는 중학교부터 박사 과정 수준까지의 2000개 문제와 2245개 도표를 포함하며 고전 및 현대 물리학을 다룹니다. 테스트 결과, Gemini-2.5-Pro와 o4-mini 등 최고 수준의 모델조차 SeePhys에서 정확도가 55% 미만이었으며, 특히 회로도, 파동 방정식 도표 등 특정 도표 유형 처리 시 시스템적인 인식 장애가 있었습니다. 연구는 또한 순수 언어 모델이 일부 상황에서 멀티모달 모델과 유사한 성능을 보여 현재 MLLM의 시각-텍스트 정렬 결함을 드러냈습니다. 이 벤치마크는 모델이 물리 세계를 이해하는 데 있어 그래픽 인식의 중요성을 강조하며, 복잡한 과학 도표와 이론 추론이 결합된 작업에서 현재 AI의 거대한 과제를 보여줍니다. (출처: 量子位)
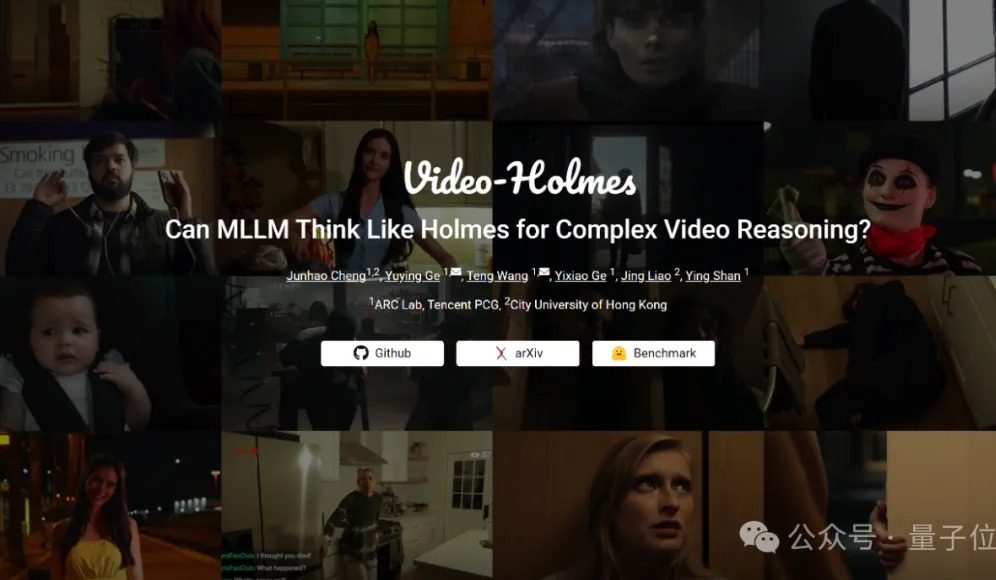
Video-Holmes 벤치마크 테스트: 현재 대형 모델, 복잡한 비디오 추론 능력 모두 낙제점: 텐센트 ARC Lab과 홍콩 시립대학교가 Video-Holmes 벤치마크를 출시하여 멀티모달 대형 모델(MLLM)의 복잡한 비디오 추론 능력을 평가합니다. 이 벤치마크는 270편의 ‘추리 단편 영화’를 포함하며, ‘살인범 추리’, ‘범행 의도 분석’ 등과 같이 모델이 비디오에 흩어져 있는 핵심 정보를 추출하고 연결해야 하는 7가지 고도의 추론 능력을 요구하는 객관식 문제를 설계했습니다. 테스트 결과, Gemini-2.5-Pro를 포함한 모든 테스트 대상 대형 모델이 합격선(Gemini-2.5-Pro 정확도 약 45%)에 도달하지 못했습니다. 연구는 기존 모델이 시각 정보는 인지할 수 있지만, 다중 단서 연관 및 핵심 정보 포착 측면에서 보편적인 결함이 있어 인간의 능동적인 검색, 통합, 분석의 복잡한 추론 과정을 모방하기 어렵다고 지적했습니다. (출처: 量子位)
Meta, AI 서비스의 원활한 통합이 핵심, 소셜 네트워크 효과 활용해 사용자 참여도 제고: Meta는 자사의 Llama 모델이 순위표에서 최고는 아니지만, 방대한 소셜 미디어 생태계(일일 활성 사용자 34억 3천만 명)를 바탕으로 AI 경쟁에서 큰 우위를 점하고 있다고 강조했습니다. Meta는 사용자에게 원활하게 통합된 AI 도구를 제공할 수 있으며, 이는 ChatGPT와 같은 독립형 AI 플랫폼과는 비교할 수 없는 장점입니다. 회사는 이미 매력적인 AI 도구를 통해 광고주 수익률을 향상시켰으며(단일 광고 가격 전년 대비 10% 증가), AI 투자를 빠르게 수익화하고 있습니다. Meta AI 플랫폼 사용자 수는 연말까지 10억 명을 넘어설 것으로 예상됩니다. 그러나 높은 자본 지출(2025년 예상 640억~720억 달러)과 Reality Labs의 지속적인 손실(연간 손실 150억 달러 이상)은 발전에 걸림돌이 되고 있으며, 이로 인해 잉여 현금 흐름이 감소했습니다. 그럼에도 불구하고 적정한 가치 평가와 단기적인 상업화 잠재력으로 Meta 주식은 여전히 유망하게 평가받고 있습니다. (출처: 36氪)

Google CEO 피차이: AI, 플랫폼 전환의 새로운 단계 경험 중, 인터넷 생태계 재편할 것: Google CEO 순다르 피차이는 I/O 컨퍼런스 이후 AI가 모바일 기기 부상과 유사한 플랫폼 전환을 겪고 있으며, 그 독특한 점은 플랫폼 자체가 스스로 창조하고 개선할 수 있어 창의력을 배가시킬 것이라고 말했습니다. Google은 AI 연구 성과를 검색, YouTube, 클라우드 서비스 등 전 제품 라인에 광범위하게 통합하고 있습니다. 새로운 AI 모델 검색 기능은 이미 미국 사용자에게 공개되었으며, 실시간으로 개인화된 결과 페이지를 생성하고 대화형 차트와 맞춤형 애플리케이션 모듈을 포함하여 검색이 기존 웹 링크를 넘어설 것임을 예고합니다. 피차이는 이것이 인터넷 생태계를 변화시킬 수 있지만(AI는 네트워크를 구조화된 데이터베이스로 간주), Google이 네트워크로 유도하는 트래픽 양은 여전히 최고치를 경신하고 있다고 생각합니다. 그는 AI가 기업용 애플리케이션(예: 코딩 IDE, 비디오 제작, 법률, 의료)에서 빠르게 폭발적으로 성장할 것으로 예상하며, AI 기반 AR 안경과 같은 새로운 하드웨어 형태에 기회가 많다고 보고 있습니다. (출처: 36氪)

Zhipu Qingyan, Kimi 등 AI 애플리케이션, 개인 정보 불법 수집 혐의로 개인 정보 보호 우려 야기: 최근 공식 발표에 따르면, Zhipu Huazhang 산하의 ‘Zhipu Qingyan’은 ‘실제 수집된 개인 정보가 사용자 승인 범위를 초과’하는 문제가 있으며, Moonshot AI의 ‘Kimi’는 ‘실제 개인 정보 수집 빈도가 비즈니스 기능과 직접적인 관련이 없음’이라는 지적을 받았습니다. 이 두 스타 AI 애플리케이션이 지목되면서 생성형 AI 제품의 개인 정보 유출 위험에 대한 대중의 광범위한 우려가 제기되었습니다. 생성형 AI의 지능은 데이터 기반 특성에 의존하기 때문에 모델 성능 향상과 사용자 개인 정보 보호 사이에서 균형을 맞추는 데 어려움을 겪고 있습니다. 대규모 데이터 사전 훈련은 기술 발전의 필수 조건이지만, 개인 정보의 불법 수집 및 남용 행위는 사용자 신뢰와 업계 평판을 심각하게 훼손할 것입니다. 이번 사건은 일부 AI 기업의 데이터 처리 관련 잠재적 문제와 AI 기술 도전에 대응하는 기존 데이터 보호 프레임워크의 미흡함을 드러냈습니다. (출처: 36氪)

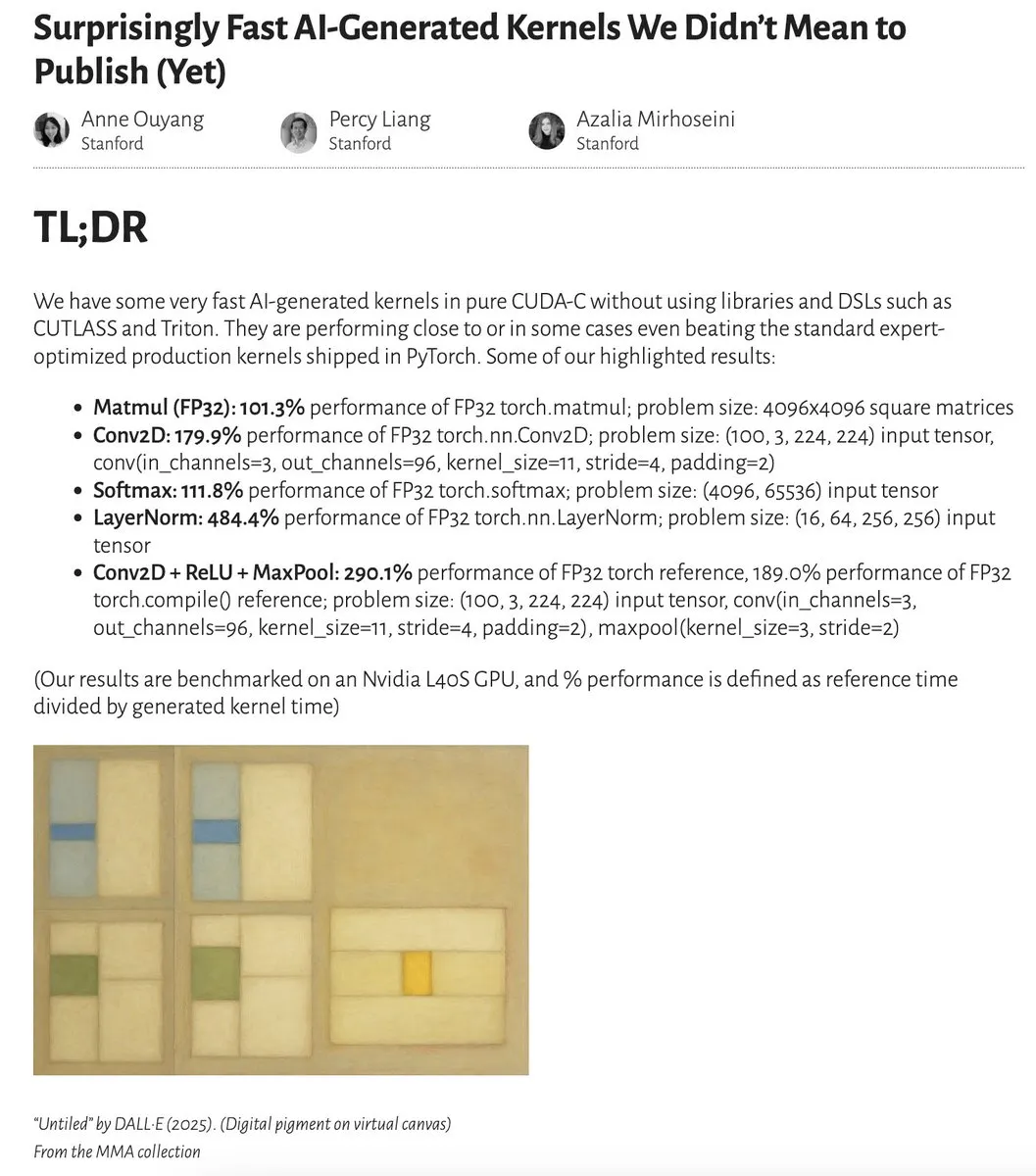
AI 생성 커널 성능, 전문가 최적화 커널에 근접하거나 능가: Anne Ouyang과 동료 연구진은 간단한 테스트 시점 검색만으로 생성된 AI 커널이 PyTorch의 표준적인 전문가 최적화 생산 커널에 근접하거나 일부 경우 이를 능가하는 성능을 보인다는 연구 결과를 발표했습니다. Fleetwood는 Colab에서 LayerNorm 커널을 초기 재현하여 인상적인 성능 향상(약 484.4%)을 확인했습니다. 이러한 진전은 AI가 저수준 코드 최적화 분야에서 엄청난 잠재력을 가지고 있으며, 심지어 커널 엔지니어의 업무에도 영향을 미칠 수 있음을 시사합니다. 그러나 후속 업데이트에서는 생성된 LayerNorm 커널에 수치 불안정성 문제가 있어 사용자에게 신중한 사용을 당부했습니다. (출처: eliebakouch, fleetwood___)
토론: 대규모 언어 모델이 진정한 창의력을 가질 수 있을까?: MoritzW42는 대규모 언어 모델(LLM)의 창의력 문제에 대해 논하며, LLM은 본질적으로 진정한 창의력을 가질 수 없다고 주장했습니다. 그는 물리학자 David Deutsch의 창의력 정의, 즉 추측과 비판을 통해 새로운 지식을 창조하는 능력을 인용하며, 이것이 진화 과정에서의 변이 및 선택과 유사하다고 보았습니다. LLM은 귀납적 확률과 훈련 데이터의 패턴에 의존하므로, 창의적인 추측을 하거나 새로운 문제를 해결할 수 없으며, 예를 들어 훈련 데이터에서 볼 수 없었던 ‘블랙 스완’ 사례(예: 잔 가장자리까지 가득 찬 와인잔)를 생성할 수 없습니다. 이 글은 LLM이 자율적인 창의성을 가진 실체라기보다는 인간의 창의력을 강화하는 도구에 가깝다고 보며, 따라서 이에 대한 공포는 비합리적이라고 주장합니다. (출처: MoritzW42)
토론: AI 에이전트 구축 시 공급업체 종속을 피하고 모델 자체에 집중해야: Austin Vance의 견해(rachel_l_woods가 공유)에 따르면, AI 에이전트 구축 시 가장 큰 실수 중 하나는 공급업체 종속에 빠지는 것입니다. OpenAI, Anthropic, Google과 같은 회사들은 자사의 통합 API를 홍보하는 경향이 있지만, 이는 추가적인 가치를 제공하지 않으면서 막대한 전환 비용을 발생시킵니다. 그는 성능을 좌우하는 것은 API가 아니라 모델 자체라고 강조합니다. 모델 순위가 자주 변동하기 때문에, LangChain과 같은 오픈 소스, 모델 불특정 프레임워크와 LangSmith와 같은 도구를 사용하면 기업이 특정 기본 모델 연구실에서 제공하는 옵션에 제한받지 않고 현재 최상의 모델을 선택할 수 있습니다. (출처: rachel_l_woods)
토론: AI 개요 기능에 프롬프트 주입 위험 존재: Zack Witten은 AI 개요(AI overview) 기능에 프롬프트 주입(prompt injection)이 가능하다는 것을 발견하고 시연했습니다. 이는 특수하게 조작된 입력을 통해 AI가 예상치 못하거나 오해의 소지가 있는 요약 정보를 생성하도록 조작할 수 있음을 의미합니다. Charles IRL 등 사용자들이 이 보안 취약점을 공유하고 주목하며, 이러한 AI 기능을 광범위하게 적용할 때 견고성과 안전성에 주의해야 함을 시사했습니다. (출처: charles_irl, giffmana)
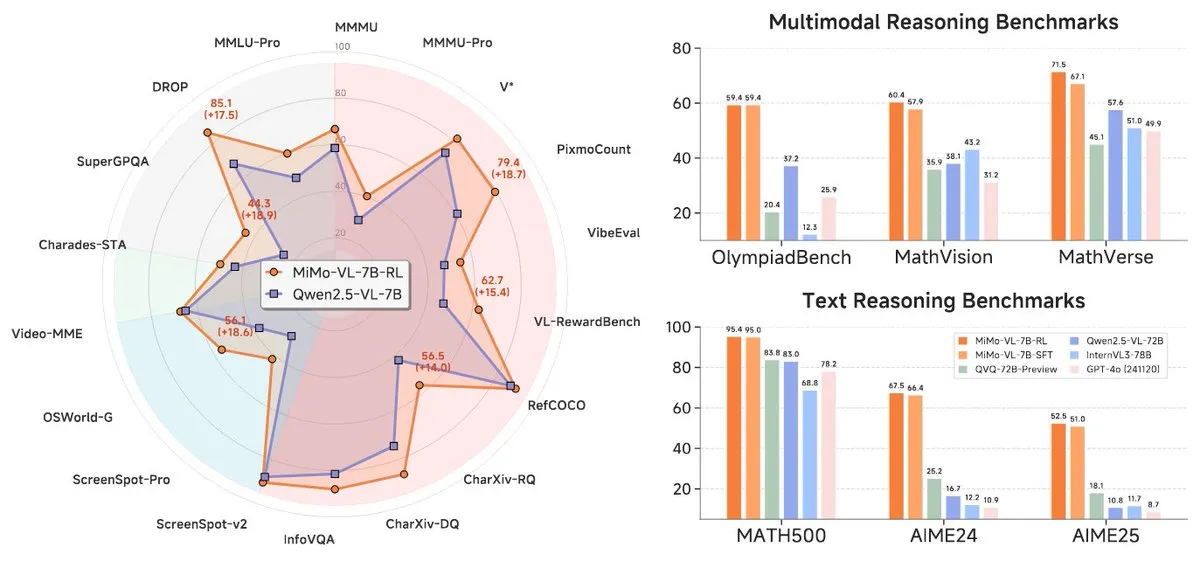
샤오미, MiMo-7B 시리즈 신규 모델 출시, 7B 레벨에서 뛰어난 성능: 샤오미가 업데이트된 7B 추론 모델 MiMo-7B-RL-0530과 그 시각 언어 모델 버전인 MiMo-VL-7B-RL을 출시하며, 해당 파라미터 규모에서 SOTA(State-of-the-Art) 수준에 도달했다고 주장했습니다. 이 모델들은 Qwen-VL 아키텍처와 호환되며, vLLM, Transformers, SGLang, Llama.cpp 등 프레임워크에서 실행 가능하고 MIT 라이선스로 오픈소스화되었습니다. MiMo-VL-RL 버전은 여러 텍스트 벤치마크에서 순수 텍스트 MiMo-7B-RL에 비해 현저한 향상을 보였으며, 동시에 시각 능력을 추가하여 커뮤니티에서 벤치마크 과최적화 여부 또는 실질적인 멀티모달 진전 달성 여부에 대한 논의를 불러일으켰습니다. (출처: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 툴
Black Forest Labs, FLUX.1 Kontext 출시, 픽셀 수준 이미지 편집 및 문맥 기반 생성 실현: Stable Diffusion 핵심 기술 발명팀 멤버들이 설립한 Black Forest Labs(BFL)가 FLUX.1 Kontext라는 새로운 이미지 생성 및 편집 모델 제품군을 출시했습니다. 이 모델은 플로우 매칭(flow matching) 아키텍처를 기반으로 텍스트와 이미지 입력을 동시에 이해하여 문맥 기반 생성 및 다중 편집을 실현하며 뛰어난 캐릭터 일관성을 유지합니다. FLUX.1 Kontext는 다른 부분에 영향을 주지 않고 부분 편집을 지원하며, 입력 스타일을 참조하여 동일한 스타일의 장면을 생성하고 낮은 지연 시간을 특징으로 합니다. 현재 Pro 및 Max 버전이 출시되었으며 KreaAI, Freepik 등 플랫폼에 탑재되어 기업 크리에이티브 팀에 더욱 정확하고 빠른 이미지 편집 능력을 제공하는 것을 목표로 합니다. 커뮤니티 피드백은 긍정적이며 픽셀 수준의 완벽한 편집이 가능하다고 평가합니다. (출처: 36氪, timudk, op7418, lmarena_ai)

Simon Willison, 다양한 대형 모델에 편리하게 액세스할 수 있는 LLM CLI 도구 출시: Simon Willison은 LLM이라는 명령줄 도구 및 Python 라이브러리를 개발하여 사용자가 명령줄을 통해 OpenAI, Anthropic Claude, Google Gemini, Meta Llama 등 다양한 대규모 언어 모델과 상호 작용할 수 있도록 지원하며, 원격 API 및 로컬 배포 모델을 지원합니다. 이 도구는 프롬프트 실행, 프롬프트 및 응답을 SQLite에 저장, 임베딩 생성 및 저장, 텍스트 및 이미지에서 구조화된 콘텐츠 추출 등을 수행할 수 있습니다. 사용자는 pip 또는 Homebrew를 통해 설치할 수 있으며, llm-ollama와 같은 플러그인을 설치하여 로컬 모델을 사용할 수 있습니다. 대화형 채팅 모드를 지원하여 사용자가 모델과 편리하게 대화할 수 있습니다. (출처: GitHub Trending)

Contextual.ai, RAG에 최적화된 문서 파서 출시: Contextual.ai가 검색 증강 생성(RAG) 애플리케이션을 위해 특별히 설계된 문서 파서를 출시했습니다. 이 도구는 최고의 시각, OCR 및 시각 언어 모델을 결합하여 높은 정확도의 문서 내용 추출을 제공하는 것을 목표로 합니다. 사용자는 무료로 체험할 수 있으며, 처음 500페이지 이상은 무료입니다. 이는 LLM 사용을 위해 복잡한 문서에서 정보를 추출해야 하는 시나리오에 매우 유용하며, RAG 시스템의 성능과 정확성을 향상시키는 데 도움이 됩니다. (출처: douwekiela)
알리바바, 코드 완성 및 에이전트 모드 통합한 Tongyi Lingma AI IDE 출시: 알리바바가 ‘Tongyi Lingma’라는 AI 통합 개발 환경(IDE)을 출시했습니다. 이 IDE는 코드 완성, MCP(Model-Copilot-Playground), 에이전트 모드, 장기 기억 및 여러 줄 완성 기능을 갖추고 있습니다. 현재 Qwen 및 DeepSeek 모델을 지원하며, 사용자들은 향후 다른 모델 지원 추가를 기대하고 있습니다. 초기 사용 피드백에 따르면 채팅 패널의 인터넷 검색 및 @멘션 기능은 개선의 여지가 있지만, 전반적으로 개발자에게 AI 보조 프로그래밍 기능이 통합된 새로운 도구를 제공합니다. (출처: karminski3, karminski3)
Perplexity Labs, 프롬프트 기반 애플리케이션 및 보고서 생성 신기능 출시: Perplexity AI의 Labs 플랫폼은 사용자가 프롬프트 단어를 통해 대화형 애플리케이션 및 보고서를 생성할 수 있는 새로운 기능을 선보였습니다. 예를 들어, 한 사용자는 전통적인 주식 포트폴리오와 AI 기반 투자 포트폴리오의 5년간 성과를 비교하는 대시보드를 성공적으로 생성하라는 프롬프트를 제시하여 매우 정확한 결과를 얻었습니다. 다른 사용자는 이 플랫폼을 사용하여 다양한 LLM 모델을 비교하고 결과에 만족감을 표시했습니다. 이러한 사례는 Perplexity가 AI 기능을 특히 금융 연구와 같은 분야에서 실용적인 분석 도구로 전환하는 데 있어 진전을 보이고 있음을 보여줍니다. (출처: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth, DeepSeek-R1-0528의 GGUF 양자화 버전 출시, 로컬 실행 지원: Unsloth가 새로 출시된 DeepSeek-R1-0528 모델용 GGUF 양자화 버전을 제작했습니다. IQ1_S (185GB), Q2_K_XL (251GB) 등 다양한 사양을 포함하여 사용자가 로컬 하드웨어(예: 충분한 VRAM을 갖춘 RTX 4090/3090)에서 이 대형 모델을 실행할 수 있도록 지원합니다. -ot ".ffn_.*_exps.=CPU"와 같은 매개변수를 사용하여 일부 MoE 레이어를 RAM으로 오프로드함으로써 제한된 VRAM에서도 추론을 실현할 수 있습니다. 이는 로컬에서 DeepSeek R1의 강력한 기능을 경험하고 연구하고자 하는 사용자에게 편의를 제공합니다. (출처: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: Ollama, Supabase 등을 통합한 로컬 AI 개발 환경: coleam00/local-ai-packaged는 기능이 완비된 로컬 AI 및 로우코드 개발 환경을 신속하게 구축하기 위한 오픈 소스 Docker Compose 템플릿입니다. Ollama(로컬 LLM 실행), Supabase(데이터베이스, 벡터 스토어, 인증), n8n(로우코드 자동화), Open WebUI(채팅 인터페이스), Flowise(AI 에이전트 빌더), Neo4j(지식 그래프), Langfuse(LLM 관찰 가능성), SearXNG(메타 검색 엔진) 및 Caddy(HTTPS 관리)를 통합합니다. 이 프로젝트는 개발자가 로컬 환경에서 다양한 AI 도구와 서비스를 통합하고 사용하는 데 편리함을 제공합니다. (출처: GitHub Trending)
Resemble AI, 감정 제어 지원하는 오픈소스 AI 음성 도구 ChatterBox 출시: Resemble AI가 ChatterBox라는 오픈소스 AI 음성 도구를 출시했습니다. 이 도구는 사용자가 무료로 음성을 디자인, 복제, 편집하고 감정 제어를 할 수 있도록 지원합니다. ChatterBox는 일부 최고 수준의 상용 AI 음성 서비스(예: Elevenlabs)보다 성능이 우수하다고 알려져 있으며, 개발자와 콘텐츠 제작자에게 강력한 음성 합성 및 편집 기능을 제공합니다. (출처: ClementDelangue)
Mem0.ai와 Qdrant 결합, AI 에이전트에 장기 기억 솔루션 제공: Mem0.ai 프레임워크가 Qdrant 벡터 데이터베이스와 결합하여 AI 에이전트에 장기 기억 솔루션을 제공합니다. 이 솔루션은 에이전트가 문맥을 유지하고, 사실을 기억하며, 대화에서 일관성을 유지하도록 돕는 것을 목표로 합니다. 사용자는 클라우드 또는 오픈소스 방식으로 배포하여 Mem0를 Qdrant에 연결하여 장기 벡터 기억을 저장할 수 있습니다. 이는 지속적인 기억과 복잡한 대화 능력이 필요한 AI 애플리케이션 구축에 중요한 의미를 갖습니다. (출처: qdrant_engine)

📚 학습
도쿄 대학 신규 연구: 문맥 내 메타 학습이 LLM 내부 다단계 회로 출현 유도: 도쿄 대학의 한 연구 《Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence》는 대규모 언어 모델(LLM) 내부의 더 복잡한 구조를 탐구했습니다. 연구 결과, 문맥 내 메타 학습(in-context meta-learning) 과정에서 LLM이 다단계 회로의 출현을 유도할 수 있으며, 이는 이전에 이해되었던 귀납 헤드(induction heads)와 같은 단순한 메커니즘을 넘어선다는 것을 발견했습니다. 이 연구는 LLM이 문맥을 통해 학습하고 복잡한 내부 표현을 형성하는 방식에 대한 새로운 시각을 제공합니다. (출처: teortaxesTex, [email protected])

MLflow, DSPy 최적화 워크플로우 지원 강화, 관찰 가능성 향상: MLflow는 PyTorch 훈련 지원과 유사하게 DSPy(언어 모델 애플리케이션 구축 및 최적화를 위한 프레임워크)의 최적화 워크플로우 추적을 지원한다고 발표했습니다. MLflow의 추적 및 자동 로깅 기능을 통해 개발자는 DSPy 모듈 호출, 평가 및 최적화 프로그램을 원활하게 디버깅하고 모니터링할 수 있어 GenAI 워크플로우를 더 잘 이해하고 반복하며 개발에서 배포까지 엔드투엔드 관리를 실현할 수 있습니다. 이는 DSPy를 사용하여 프롬프트 엔지니어링 및 LLM 애플리케이션을 개발하는 개발자에게 더 강력한 관찰 가능성과 MLOps实践을 제공합니다. (출처: lateinteraction, dennylee)

새 논문, 통합 멀티모달 모델의 자가 개선 방법 UniRL 논의: 논문 《UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning》은 UniRL이라는 자가 개선 후훈련 방법을 소개합니다. 이 방법은 모델이 프롬프트에 따라 이미지를 생성하고 이러한 이미지를 반복적인 훈련 데이터로 사용하여 외부 이미지 데이터 없이도 학습할 수 있도록 합니다. 또한 생성 작업과 이해 작업 간의 상호 강화를 실현합니다. 즉, 생성된 이미지는 이해에 사용되고 이해 결과는 생성 감독에 사용됩니다. 연구자들은 Show-o 및 Janus와 같은 모델을 최적화하기 위해 지도 미세 조정(SFT)과 그룹 상대 정책 최적화(GRPO)를 탐구했습니다. UniRL의 장점은 외부 이미지 데이터가 필요 없고, 단일 작업 성능을 개선하며, 생성과 이해 간의 불균형을 줄이고, 추가 훈련 단계가 거의 필요 없다는 점입니다. (출처: HuggingFace Daily Papers)
논문 Fast-dLLM: KV 캐시와 병렬 디코딩을 통한 Diffusion LLM 가속화: 논문 《Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding》은 확산 기반 대규모 언어 모델(Diffusion LLM)의 느린 추론 속도 문제를 해결하기 위해 훈련이 필요 없는 가속화 방법을 제안합니다. 이 방법은 양방향 확산 모델에 맞춤화된 블록 수준 근사 KV 캐시 메커니즘을 도입하고, 여러 토큰을 동시에 디코딩할 때 생성 품질을 유지하기 위한 신뢰도 인식 병렬 디코딩 전략을 제안합니다. 실험 결과, 이 방법은 LLaDA 및 Dream 모델에서 최대 27.6배의 처리량 향상을 달성했으며 정확도 손실은 극히 적어 Diffusion LLM과 자기 회귀 모델 간의 성능 격차를 줄이는 데 도움이 됩니다. (출처: HuggingFace Daily Papers)
논문 Uni-Instruct: 통합 확산 발산 지시를 통한 단일 단계 확산 모델: 논문 《Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction》은 10가지 이상의 기존 단일 단계 확산 증류 방법을 통합하는 Uni-Instruct라는 이론 기반 프레임워크를 제안합니다. 이 프레임워크는 저자가 제안한 f-발산 계열의 확산 확장 이론을 기반으로 하며, 원래 확장 f-발산의 다루기 어려운 문제를 극복하기 위한 핵심 이론을 도입하여 확장 f-발산 계열을 최소화함으로써 단일 단계 확산 모델을 효과적으로 훈련할 수 있는 동등하고 다루기 쉬운 손실 함수를 도출합니다. Uni-Instruct는 CIFAR10 및 ImageNet-64×64와 같은 벤치마크에서 SOTA 단일 단계 생성 성능을 달성했으며 텍스트-3D 생성과 같은 작업에 적용되었습니다. (출처: HuggingFace Daily Papers)
새 연구, 대규모 언어 모델 추론 능력과 환각 현상 관계 탐구: 논문 《Are Reasoning Models More Prone to Hallucination?》은 대규모 추론 모델(LRM)이 강력한 연쇄 사고(CoT) 추론 능력을 보이는 동시에 환각을 더 쉽게 일으키는지 여부를 연구합니다. 연구 결과, 콜드 스타트 SFT 및 검증 가능한 보상 RL을 포함한 완전한 후훈련 과정을 거친 LRM은 일반적으로 환각을 완화하지만, 증류만 거치거나 콜드 스타트 미세 조정 없는 RL 훈련은 더 미묘한 환각을 유발할 수 있습니다. 연구는 또한 환각을 유발하는 주요 인지 행동(예: 결함 있는 반복, 생각과 답변 불일치)과 모델 불확실성과 사실 정확성 간의 불일치를 분석했습니다. (출처: HuggingFace Daily Papers)
논문, KVzip 제안: 쿼리 불가지론적 KV 캐시 압축 및 컨텍스트 재구성: 논문 《KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction》은 다양한 쿼리에 대응하기 위해 압축된 KV 캐시를 효과적으로 재사용하는 것을 목표로 하는 KVzip이라는 쿼리 불가지론적 KV 캐시 제거 방법을 소개합니다. KVzip은 기본 LLM을 통해 캐시된 KV 쌍에서 원래 컨텍스트를 재구성하여 KV 쌍의 중요도를 정량화하고 중요도가 낮은 KV 쌍을 제거합니다. 실험 결과, KVzip은 KV 캐시 크기를 3-4배 줄이고 FlashAttention 디코딩 지연 시간을 약 2배 단축하며, 질의응답, 검색, 추론 및 코드 이해와 같은 작업에서 성능 손실이 거의 없이 최대 170K 토큰의 컨텍스트를 지원합니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
엔비디아 최신 실적 발표, 매출 69% 급증, AI 칩 수요 지속 강세: AI 칩 대기업 엔비디아가 최신 실적을 발표하여 분기 매출 441억 달러로 전년 동기 대비 69% 증가했으며, 순이익은 전년 동기 대비 26% 증가한 187억 8천만 달러를 기록했습니다. 매출은 예상을 초과했지만 이익은 예상치를 약간 밑돌았습니다. 미국의 대중국 칩 수출 제한으로 회사에 45억 달러의 손실이 발생했지만, 회사는 최신 AI 칩 Blackwell 판매에 힘입어 다음 분기 매출이 전년 동기 대비 50% 증가한 450억 달러에 이를 것으로 예상합니다. 엔비디아 CEO 젠슨 황은 전 세계 국가들이 AI가 인프라가 될 것임을 인식하고 있다고 말했습니다. 실적 호조에 힘입어 엔비디아 시가총액은 한때 애플을 넘어 세계 2위를 기록했습니다. 회사는 유럽, 아시아, 중동 시장을 적극적으로 확장하고 있으며, 정부 고객에게 칩을 판매하는 것이 중요한 전략 방향이 되었습니다. (출처: dotey)

실리콘밸리 최고 VC, AI 하드웨어로 전환, 차세대 인터랙션 단말기 모색: AI 알고리즘의 급속한 발전과 함께 실리콘밸리의 투자 방향이 순수한 알고리즘 최적화에서 AI 기능을 탑재할 수 있는 하드웨어 장치로 전환되고 있습니다. Google, OpenAI(AI 하드웨어 회사 io 인수), Meta, Apple 등 거대 기업들은 모두 스마트 안경, AR 장비 등 AI 하드웨어 분야에 적극적으로 투자하고 있습니다. 세콰이어 캐피탈은 AI 안경 Brilliant Labs에, IDG Capital은 디스플레이 없는 노트북 Spacetop에 투자했습니다. Celestial AI(광자 칩 상호 연결), NeuroFlex(유연한 뇌-컴퓨터 인터페이스 소재), Luminai(경량화 AR 모듈), BioLink Systems(소화 가능한 AI 센서), SynthSense(멀티모달 로봇 감각 시스템) 등 신흥 기업들도 각자의 분야에서 AI 하드웨어 혁신을 추진하고 있습니다. 이는 업계가 AI의 ‘신체’를 중시하고 있으며, 하드웨어 혁신이 AI 기술 구현 속도와 경계를 결정하고 인간-컴퓨터 상호 작용 방식을 재편할 것이라고 보고 있음을 반영합니다. (출처: 36氪)

Sequoia, 새로운 AI 프로그래밍 에이전트 스타트업에 투자, 기존 거대 기업에 도전: LiorOnAI에 따르면, 세콰이어 캐피탈은 Devin, Cursor, OpenAI Codex와 같은 기존 AI 프로그래밍 도구에 도전하는 것을 목표로 하는 새로운 스타트업에 투자했습니다. 이 회사가 개발한 AI 에이전트는 전체 코드베이스를 읽고 풀 리퀘스트(PR) 작성, 테스트, 수정 및 병합과 같은 작업을 자동으로 완료할 수 있다고 하며, 24시간 완전 자율적인 소프트웨어 엔지니어 도우미를 제공하는 것을 목표로 합니다. 이는 소프트웨어 개발 자동화 분야에서 AI 경쟁이 더욱 치열해지고 있음을 의미합니다. (출처: LiorOnAI)
🌟 커뮤니티
커뮤니티, LLM의 길이 지시 준수 미흡 및 ‘과대 광고’ 논란: LIFEBench의 연구 결과가 커뮤니티에서 논의를 불러일으켰으며, 많은 사용자와 개발자들이 현재 대규모 언어 모델이 정확한 길이 지시, 특히 장문 텍스트 생성에서 부족함을 보이는 데 동의했습니다. 커뮤니티 구성원들은 모델이 종종 생성 내용과 요구 길이가 일치하지 않거나, 조기 종료되거나, 심지어 장문 텍스트 생성을 거부하는 경우가 있다고 지적했습니다. 동시에, 모델이 주장하는 최대 출력 토큰 수가 실제 유효 생성 능력과 차이가 있어 ‘과대 광고’ 현상이 보편적이라는 의견도 있었습니다. 앞으로 모델이 더 나은 훈련 전략과 평가 시스템을 통해 길이 지시 수행 능력과 실제 성능을 향상시켜 ‘글자 수 기준 충족 및 내용 우수’를 실현하기를 기대하고 있습니다. (출처: 量子位)
사용자들, AI 챗봇의 과도한 ‘아첨’(Glazing) 현상 피드백: Reddit 커뮤니티 사용자들은 ChatGPT 등 AI 챗봇 사용 시 모델이 사용자의 질문이나 입력에 대해 과도하게 칭찬하고 긍정하는(속칭 ‘glazing’ 또는 ‘sycophancy’) 경우를 자주 접한다고 보고했습니다. 예를 들어 “정말 똑똑한 관찰이네요!”와 같은 반응입니다. 사용자들은 이러한 아첨이 불필요하고 상호작용의 자연스러움을 해친다며 불쾌감을 표시했습니다. 커뮤니티 구성원들은 특정 프롬프트(예: 모델에게 직접적이고 객관적이며 중립적인 답변을 요구)를 통해 이러한 현상을 줄이는 방법을 논의하고 각자의 경험과 느낌을 공유했습니다. DeepSeek-R1-0528도 일부 사용자로부터 유사한 경향이 있다는 지적을 받았습니다. (출처: Reddit r/ChatGPT, teortaxesTex)

커뮤니티 토론: AI가 정말로 ‘일자리를 빼앗고 있는가’, 아니면 ‘중간 관리자’ 직위의 불필요성을 드러내고 있는가?: Reddit에서는 AI가 ‘우리의 일자리를 빼앗고 있다’기보다는, 기존의 많은 업무(예: 서류 처리, 이메일 전달, 의사 결정권자 간 정보 전달 등)의 ‘중간 관리자’적 성격과 잠재적인 불필요성을 드러내고 있다는 토론이 있었습니다. 이러한 관점은 업무의 본질, 사회적 가치 분배, 그리고 AI 시대의 인간 역할 변화에 대한 성찰을 불러일으켰습니다. 댓글 작성자들은 일부 업무가 실제로 ‘중간 관리자’적 성격을 띠더라도 사람들에게 생계를 제공하며, AI가 가져오는 변화에는 사회적 차원의 지원과 새로운 기술 습득이 필요하다고 지적했습니다. (출처: Reddit r/ArtificialInteligence)
Ollama, 부정확한 모델명으로 커뮤니티 사용자 불만 야기: Reddit r/LocalLLaMA 커뮤니티의 한 사용자는 Ollama가 모델명 표기에 있어 부정확하거나 혼동을 일으킬 수 있는 경우가 있다고 지적했습니다. 예를 들어, DeepSeek-R1-Distill-Qwen-32B를 deepseek-r1:32b로 줄여 부르는 것은 초보 사용자가 순수 DeepSeek 모델을 실행한다고 오해하게 만들 수 있으며, Qwen 증류의 본질을 간과하게 할 수 있습니다. 사용자는 이러한 명명 방식이 HuggingFace 등 플랫폼의 관행과 일치하지 않고 투명성이 부족하며, 사용자가 모델 특성에 대해 잘못된 인식을 갖게 할 수 있다고 주장했습니다. (출처: Reddit r/LocalLLaMA)

프로그래밍 언어, 대규모 언어 모델 성공에 크게 기여: 커뮤니티 토론에서는 프로그래밍 언어가 명확한 논리적 정의와 결과 검증 용이성이라는 특성 덕분에 고품질 훈련 자료로서 대규모 언어 모델의 성공적인 발전에 핵심적인 역할을 했다고 강조했습니다. 이는 모델에 구조화된 지식의 원천을 제공했을 뿐만 아니라, 모델이 추론을 학습하고 실행 가능한 코드를 생성하는 기초를 마련했습니다. (출처: dotey)

💡 기타
Indoor Robotics, AI 기반 자율 주행 보안 로봇 드론 출시: Indoor Robotics 회사가 인공지능 기반 자율 주행 보안 로봇 드론을 선보였습니다. 이 드론은 실내 환경을 위해 특별히 설계되었으며, 자율적으로 순찰 및 보안 감시 임무를 수행하고 AI를 사용하여 항법 및 위협 식별을 수행하여 실내 보안에 혁신적인 자동화 솔루션을 제공합니다. (출처: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics, B2-W 산업용 바퀴형 로봇 업그레이드, 기능 강화: Unitree Robotics가 자사의 B2-W 산업용 바퀴형 로봇 기능을 업그레이드하여 더욱 흥미로운 능력을 부여했습니다. 이 로봇은 바퀴형 이동의 유연성과 로봇의 다기능성을 결합하여 다양한 산업 현장에 적용되어 자동화 수준과 작업 효율을 향상시키는 것을 목표로 합니다. (출처: Ronald_vanLoon)
Lenovo, 산업, 연구 및 교육 분야를 위한 6족 로봇 Daystar 출시: Lenovo가 Daystar라는 이름의 6족 로봇을 출시했습니다. 이 로봇은 산업 응용, 과학 연구 및 교육 목적으로 특별히 설계되었으며, 다족 구조로 복잡한 지형에 적응할 수 있어 관련 분야에 새로운 로봇 플랫폼 옵션을 제공합니다. (출처: Ronald_vanLoon)