
키워드:DeepSeek-R1-0528, AI 에이전트, 멀티모달 모델, 오픈소스 AI, 강화 학습, 이미지 편집, 대형 언어 모델, AI 벤치마크 테스트, DeepSeek-R1-0528-Qwen3-8B, 회로 추적 도구, 다윈 괴델 머신, FLUX.1 콘텍스트, 에이전트 기반 검색
🔥 포커스
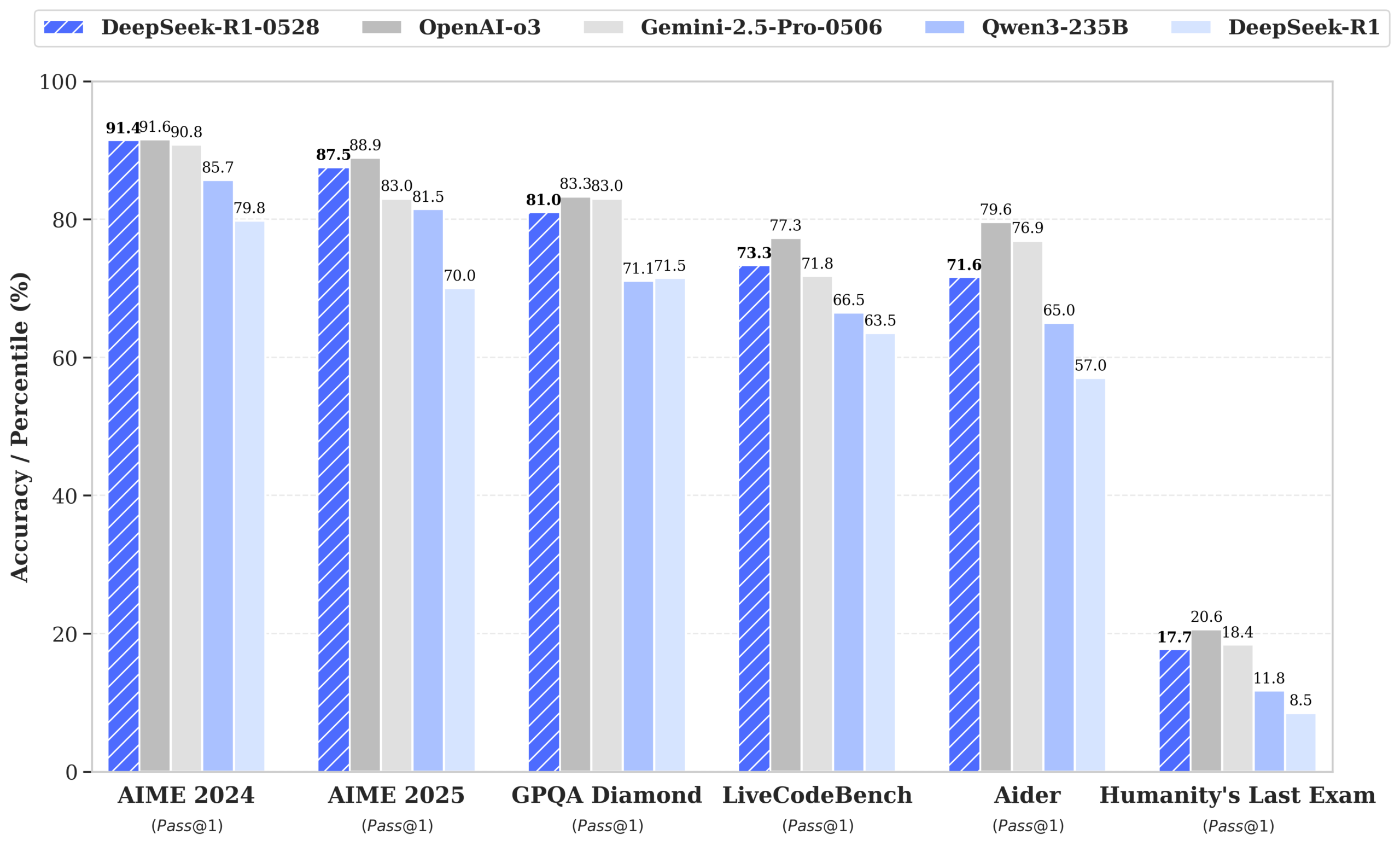
DeepSeek, R1-0528 모델 출시, GPT-4o 및 Gemini 2.5 Pro 성능에 근접하며 오픈소스 1위 등극: DeepSeek-R1-0528은 수학, 프로그래밍, 일반 논리 추론 등 여러 벤치마크 테스트에서 뛰어난 성능을 보였으며, 특히 AIME 2025 테스트에서 정확도가 70%에서 87.5%로 향상되었습니다. 새 버전은 환각율을 현저히 낮추고(약 45-50%), 프론트엔드 코드 생성 능력을 강화했으며, JSON 출력 및 함수 호출을 지원합니다. 동시에 DeepSeek은 Qwen3-8B Base를 기반으로 미세 조정한 DeepSeek-R1-0528-Qwen3-8B를 출시했으며, AIME 2024에서 R1-0528에 이어 Qwen3-235B를 능가하는 성능을 보였습니다. 이번 업데이트는 DeepSeek이 세계 2위 AI 연구소 및 오픈소스 선두 주자로서의 입지를 공고히 했습니다. (출처: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
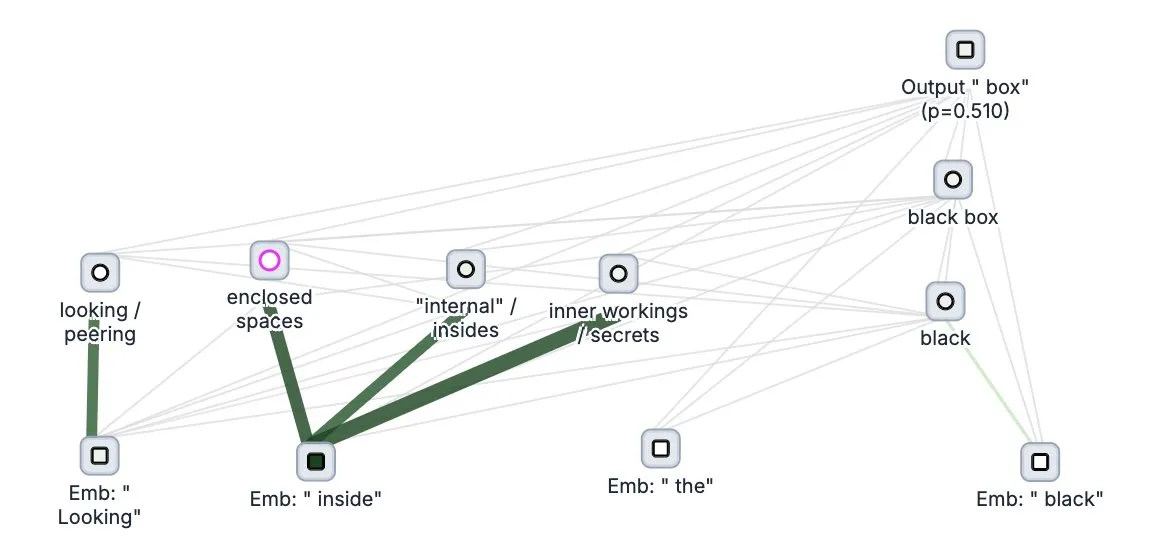
Anthropic, 대형 모델 “사고 추적” 도구 Circuit Tracer 오픈소스 공개: Anthropic은 대형 모델 해석 가능성 연구 도구인 Circuit Tracer를 오픈소스로 공개했습니다. 이를 통해 연구자들은 “귀인 그래프”를 생성하고 상호작용적으로 탐색하여 대규모 언어 모델(LLM)의 내부 “사고” 과정과 의사 결정 메커니즘을 이해할 수 있습니다. 이 도구는 연구자들이 LLM의 내부 작동 방식, 예를 들어 모델이 특정 특징을 사용하여 다음 토큰을 예측하는 방법을 더 깊이 탐구하는 데 도움을 주기 위해 설계되었습니다. 사용자는 Neuronpedia에서 이 도구를 사용해 볼 수 있으며, 문장을 입력하면 모델 특징 사용 현황에 대한 회로도를 얻을 수 있습니다. (출처: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
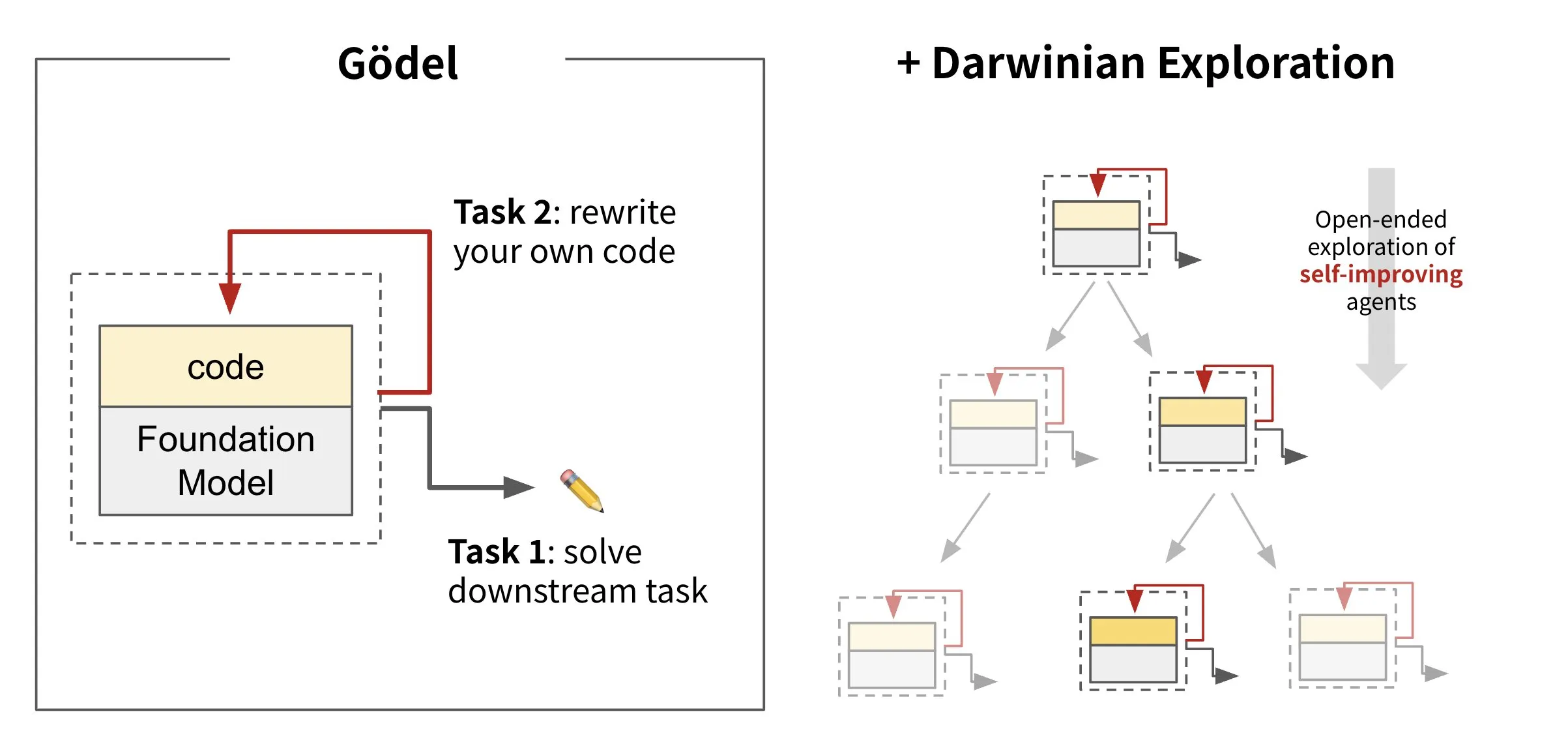
Sakana AI, 자가 진화 지능형 에이전트 프레임워크 Darwin Gödel Machine (DGM) 발표: Sakana AI는 자체 코드를 재작성하여 스스로 개선할 수 있는 AI 지능형 에이전트 프레임워크인 Darwin Gödel Machine (DGM)을 출시했습니다. DGM은 진화 이론에서 영감을 받아 지속적으로 확장되는 지능형 에이전트 변종 계보를 유지하며, 자가 개선 지능형 에이전트의 설계 공간을 개방적으로 탐색합니다. 이 프레임워크는 AI 시스템이 인간처럼 시간이 지남에 따라 자체 능력을 학습하고 진화할 수 있도록 하는 것을 목표로 합니다. SWE-bench에서 DGM은 성능을 20.0%에서 50.0%로 향상시켰으며, Polyglot에서는 성공률을 14.2%에서 30.7%로 높였습니다. (출처: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs, 텍스트와 이미지 혼합 입력을 지원하는 이미지 편집 모델 FLUX.1 Kontext 출시: Black Forest Labs는 차세대 이미지 편집 모델 FLUX.1 Kontext를 출시했습니다. 이 모델은 플로우 매칭 아키텍처를 채택하여 텍스트와 이미지를 동시에 입력으로 받아 컨텍스트 인식 이미지 생성 및 편집을 실현합니다. 이 모델은 캐릭터 일관성, 부분 편집, 스타일 참조 및 상호 작용 속도 면에서 뛰어난 성능을 보이며, 예를 들어 1024×1024 해상도에서 이미지를 생성하는 데 3-5초밖에 걸리지 않습니다. Replicate의 테스트에 따르면 편집 효과가 GPT-4o-Image보다 우수하고 비용도 저렴합니다. Kontext는 Pro 및 Max 버전을 제공하며, 오픈소스 Dev 버전도 출시할 계획입니다. (출처: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 동향
Google DeepMind, 멀티모달 의료 모델 MedGemma 출시: Google DeepMind는 멀티모달 의료 텍스트 및 이미지 이해를 위해 특별히 설계된 강력한 개방형 모델인 MedGemma를 출시했습니다. 이 모델은 Health AI Developer Foundations의 일부로 제공되며, 특히 텍스트와 X선 사진과 같은 의료 영상을 결합한 종합 분석 분야에서 의료 분야 AI의 응용 능력을 향상시키는 것을 목표로 합니다. (출처: GoogleDeepMind)
Perplexity AI, 복잡한 작업 처리를 지원하는 Perplexity Labs 출시: Perplexity AI는 더 복잡한 작업을 처리하도록 특별히 설계된 새로운 기능인 Perplexity Labs를 출시했습니다. 이는 사용자에게 전체 연구팀과 유사한 분석 및 구축 능력을 제공하는 것을 목표로 합니다. 사용자는 Labs를 통해 분석 보고서, 프레젠테이션, 동적 대시보드 등을 구축할 수 있습니다. 이 기능은 현재 모든 Pro 사용자에게 공개되었으며, 과학 연구, 시장 분석 및 미니 애플리케이션(예: 게임, 대시보드) 생성 분야에서의 잠재력을 보여주었습니다. (출처: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
텐센트 혼원과 텐센트 뮤직, 사진으로 사실적인 노래 영상 생성하는 HunyuanVideo-Avatar 공동 출시: 텐센트 혼원과 텐센트 뮤직이 공동으로 HunyuanVideo-Avatar 모델을 출시했습니다. 이 모델은 사용자가 업로드한 사진과 오디오를 결합하여 장면 컨텍스트와 감정을 자동으로 감지하고, 사실적인 입 모양 동기화와 동적 시각 효과를 갖춘 말하기 또는 노래 영상을 생성합니다. 이 기술은 다양한 스타일을 지원하며 오픈소스로 공개되었습니다. (출처: huggingface, thursdai_pod)
Apache Spark 4.0.0 정식 출시, SQL, Spark Connect 및 다국어 지원 강화: Apache Spark 4.0.0 버전이 정식 출시되어 SQL 기능이 크게 향상되었고, Spark Connect 개선으로 애플리케이션 실행이 더욱 편리해졌으며, 새로운 언어 지원이 추가되었습니다. 이번 업데이트에서는 총 5100개 이상의 문제가 해결되었으며, 390명 이상의 기여자가 참여했습니다. (출처: matei_zaharia, lateinteraction)

Kling 2.1 비디오 모델 출시, OpenArt 통합으로 캐릭터 일관성 지원: Kling AI가 비디오 모델 Kling 2.1을 출시하고 OpenArt와 협력하여 AI 비디오 스토리텔링에서 캐릭터 일관성을 지원합니다. Kling 2.1은 프롬프트 정렬, 비디오 생성 속도, 카메라 움직임의 선명도를 향상시켰으며 최고의 텍스트-비디오 효과를 자랑한다고 주장합니다. 새 버전은 720p(표준) 및 1080p(프로) 출력을 지원하며, 현재 이미지-비디오 기능이 출시되었고 텍스트-비디오 기능은 곧 출시될 예정입니다. (출처: Kling_ai, NandoDF)
Hume, 모든 인간의 목소리를 이해하고 생성할 수 있는 EVI 3 음성 모델 출시: Hume이 최신 음성 언어 모델인 EVI 3를 출시하여 범용 음성 지능을 구현하는 것을 목표로 합니다. EVI 3는 소수의 특정 화자뿐만 아니라 모든 인간의 목소리를 이해하고 생성할 수 있어 더 넓은 표현 능력과 억양, 리듬, 음색 및 말투에 대한 더 깊은 이해를 제공합니다. 이 기술은 모든 사람이 목소리로 인식되는 독특하고 신뢰할 수 있는 AI를 가질 수 있도록 하는 것을 목표로 합니다. (출처: AlanCowen, AlanCowen, _akhaliq)
Alibaba, 자율 정보 검색 지능형 에이전트 WebDancer 공개: Alibaba는 자율적으로 정보를 검색할 수 있는 AI 지능형 에이전트를 연구하고 개발하기 위한 WebDancer 프로젝트를 시작했습니다. 이 프로젝트는 AI 지능형 에이전트가 웹 환경에서 더 효과적으로 탐색하고 정보를 이해하며 복잡한 정보 획득 작업을 완료하는 방법에 중점을 둡니다. (출처: _akhaliq)
MiniMax, 시각적 RL 추론과 인식 작업을 통합하는 V-Triune 프레임워크 및 Orsta 모델 오픈소스 공개: AI 회사 MiniMax가 시각적 강화 학습 통합 프레임워크 V-Triune 및 이를 기반으로 한 Orsta 모델 시리즈(7B~32B)를 오픈소스로 공개했습니다. 이 프레임워크는 3계층 구성 요소 설계와 동적 IoU(Intersection over Union) 보상 메커니즘을 통해 VLM이 단일 후훈련 프로세스에서 시각적 추론과 인식 작업을 공동으로 학습할 수 있도록 최초로 구현했으며, MEGA-Bench Core 벤치마크 테스트에서 성능이 크게 향상되었습니다. (출처: 量子位)

상하이 AI 연구소 등, 모델의 심층 추론 능력을 시험하는 새로운 이미지 편집 벤치마크 RISEBench 발표: 상하이 인공지능 연구소는 여러 대학과 공동으로 RISEBench라는 새로운 이미지 편집 평가 벤치마크를 발표했습니다. 이 벤치마크는 시간, 인과, 공간, 논리의 네 가지 핵심 추론 유형을 포괄하는 360개의 인간 전문가가 설계한 고난도 사례를 포함합니다. 테스트 결과, GPT-4o-Image조차도 작업의 28.9%만 완료할 수 있어 현재 멀티모달 모델이 복잡한 지침 이해 및 시각적 편집 측면에서 부족하다는 점을 드러냈습니다. (출처: 36氪)

홍콩중문대 등, AI 모델이 선택적으로 사고하여 효율성과 정확도를 높이는 TON 프레임워크 제안: 홍콩중문대학교와 싱가포르국립대학교 Show Lab의 연구진은 시각 언어 모델(VLM)이 명시적 추론이 필요한지 여부를 자율적으로 판단할 수 있도록 하는 TON(Think Or Not) 프레임워크를 제안했습니다. 이 프레임워크는 “사고 폐기”와 강화 학습을 통해 모델이 간단한 문제에는 직접 답하고 복잡한 문제에는 상세한 추론을 수행하도록 하여 정확도를 희생하지 않으면서 평균 추론 출력 길이를 최대 90%까지 줄이고 일부 작업에서는 정확도를 17%까지 향상시킵니다. (출처: 36氪)
Microsoft Copilot, Instacart 통합하여 AI 보조 신선식품 쇼핑 구현: Microsoft AI 책임자 Mustafa Suleyman은 Copilot이 이제 Instacart 서비스를 통합하여 사용자가 Copilot 앱을 통해 레시피 생성, 쇼핑 목록 작성부터 신선 식료품 배달까지 전체 과정을 원활하게 완료할 수 있다고 발표했습니다. 이는 AI 비서가 일상생활 서비스 분야로 더욱 확장되었음을 의미합니다. (출처: mustafasuleyman)
🧰 툴
LlamaIndex, BundesGPT 소스 코드 및 create-llama 도구 출시, AI 애플리케이션 구축 간소화: LlamaIndex의 Jerry Liu는 BundesGPT의 소스 코드를 제공하고 오픈소스 도구인 create-llama를 홍보한다고 발표했습니다. 이 도구는 LlamaIndex를 기반으로 하며 개발자가 기업 데이터와 AI 에이전트를 쉽게 구축하고 통합할 수 있도록 지원합니다. 새로운 eject-mode는 BundesGPT와 같이 완전히 사용자 정의 가능한 AI 인터페이스를 매우 간단하게 만들 수 있도록 합니다. 이는 모든 시민에게 무료 ChatGPT Plus 구독을 제공하려는 독일의 잠재적인 계획을 지원하기 위한 것입니다. (출처: jerryjliu0)
LangChain 도구를 MCP 도구로 변환하여 FastMCP 서버에 통합 가능: LangChain 사용자는 이제 LangChain 도구를 MCP(Model Component Protocol) 도구로 변환하여 FastMCP 서버에 직접 추가할 수 있습니다. langchain-mcp-adapters 라이브러리를 설치하면 개발자는 MCP 생태계에서 LangChain의 도구 세트를 더욱 편리하게 사용할 수 있어 다양한 AI 프레임워크 간의 상호 운용성을 촉진합니다. (출처: LangChainAI, hwchase17)
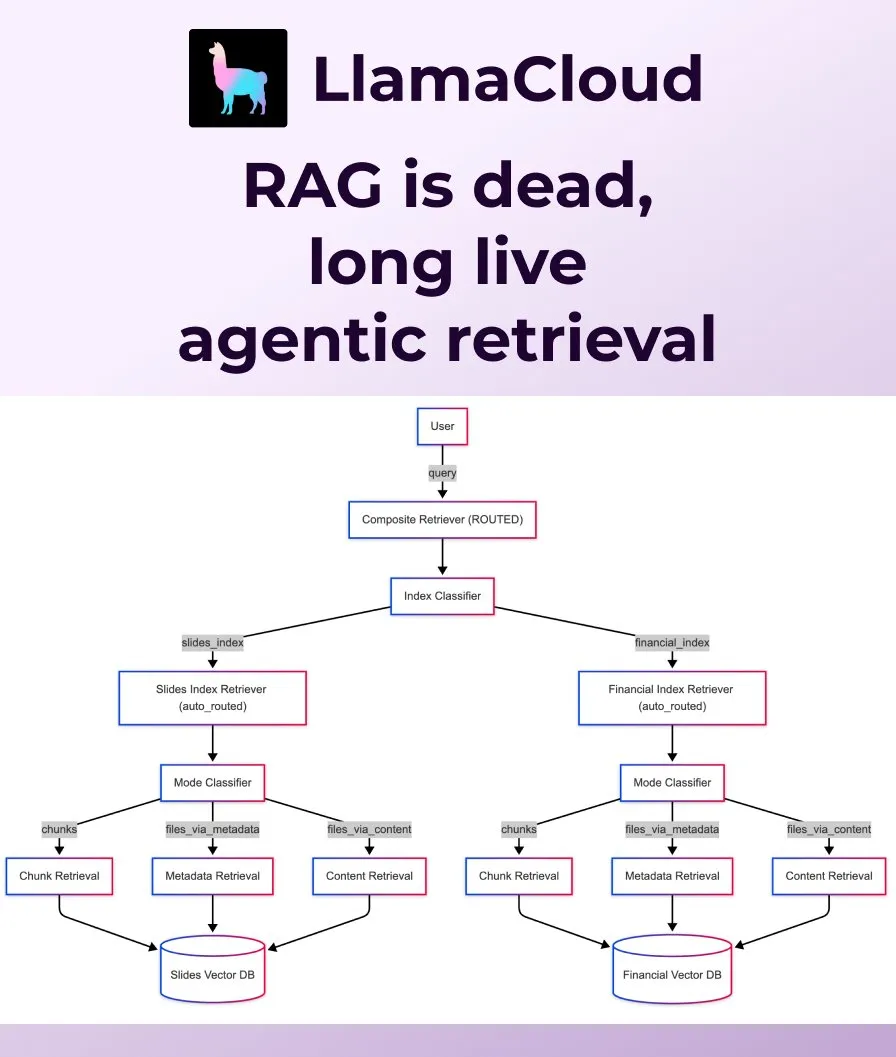
LlamaIndex, 기존 RAG를 대체하는 Agentic Retrieval 출시: LlamaIndex는 기존의 단순한 RAG(검색 증강 생성)가 현대 애플리케이션의 요구 사항을 충족하기에 더 이상 충분하지 않다고 판단하고 Agentic Retrieval을 출시했습니다. 이 솔루션은 LlamaCloud에 내장되어 있으며, 에이전트가 질문 내용에 따라 단일 또는 여러 지식 저장소(예: Sharepoint, Box, GDrive, S3)에서 전체 파일 또는 특정 데이터 블록을 동적으로 검색하여 더 스마트하고 유연한 컨텍스트 획득을 가능하게 합니다. (출처: jerryjliu0, jerryjliu0)
Ollama, 비정형 데이터 변환을 위한 Osmosis-Structure-0.6B 모델 실행 지원: 사용자는 이제 Ollama를 통해 Osmosis-Structure-0.6B 모델을 실행할 수 있습니다. 이는 모든 비정형 데이터를 지정된 형식(예: JSON Schema)으로 변환할 수 있는 매우 작은 모델로, 모든 모델과 함께 사용할 수 있으며 특히 구조화된 출력이 필요한 추론 작업에 적합합니다. (출처: ollama)
CrewAI, Gemini 문서 업데이트로 시작 절차 간소화: CrewAI 팀은 Google Gemini API에 대한 문서를 업데이트하여 사용자가 Gemini 모델을 사용하여 AI 에이전트를 더 쉽게 구축할 수 있도록 지원합니다. 새 문서에는 더 명확한 지침, 예제 코드 또는 모범 사례가 포함될 수 있습니다. (출처: _philschmid)
Requesty, OpenWebUI에 최적의 LLM을 자동으로 선택하는 Smart Routing 기능 출시: Requesty는 OpenWebUI와 원활하게 통합되어 사용자 프롬프트의 작업 유형에 따라 최적의 LLM(예: GPT-4o, Claude, Gemini)을 자동으로 선택하는 Smart Routing 기능을 출시했습니다. 사용자는 모델 ID로 smart/task를 사용하기만 하면 시스템이 약 65밀리초 내에 프롬프트를 분류하고 비용, 속도 및 품질을 기반으로 가장 적합한 모델로 라우팅합니다. 이 기능은 모델 선택을 단순화하고 사용자 경험을 향상시키는 것을 목표로 합니다. (출처: Reddit r/OpenWebUI)
EvoAgentX: 최초의 AI 에이전트 자가 진화 오픈소스 프레임워크 출시: 영국 글래스고 대학교 연구팀이 세계 최초의 AI 에이전트 자가 진화 오픈소스 프레임워크인 EvoAgentX를 출시했습니다. 이는 원클릭 워크플로우 구축을 지원하고 “자가 진화” 메커니즘을 도입하여 다중 에이전트 시스템이 환경 및 목표 변화에 따라 지속적으로 구조와 성능을 최적화할 수 있도록 합니다. 이는 AI 다중 에이전트 시스템을 “수동 디버깅”에서 “자율 진화”로 발전시키는 것을 목표로 합니다. 실험 결과, 다중 홉 질의응답, 코드 생성 및 수학 추론 작업에서 성능이 평균 8%-13% 향상되었습니다. (출처: 36氪)

📚 학습
HuggingFace, Gradio 등과 공동으로 Agents & MCP Hackathon 개최, 풍부한 상금과 API 크레딧 제공: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, LlamaIndex 등 기관들이 공동으로 Gradio Agents & MCP Hackathon(6월 2일~8일)을 개최합니다. 이 행사는 총 11,000달러의 상금을 제공하며, 조기 등록자에게는 Hyperbolic, Anthropic, Mistral, SambaNova의 무료 API 크레딧을 제공합니다. Modal Labs는 모든 참가자에게 250달러 상당의 GPU 크레딧을 제공하여 총 30만 달러 이상을 지원할 것을 약속했습니다. (출처: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain, JP모건의 다중 에이전트 시스템을 활용한 투자 연구 사례 공유: JP모건의 David Odomirok과 Zheng Xue는 “Ask David”이라는 다중 에이전트 AI 시스템을 구축한 방법을 공유했습니다. 이 시스템은 수천 가지 금융 상품에 대한 투자 연구 프로세스를 자동화하는 것을 목표로 하며, 복잡한 금융 분석에서 다중 에이전트 아키텍처의 응용 잠재력을 보여줍니다. (출처: LangChainAI, hwchase17)
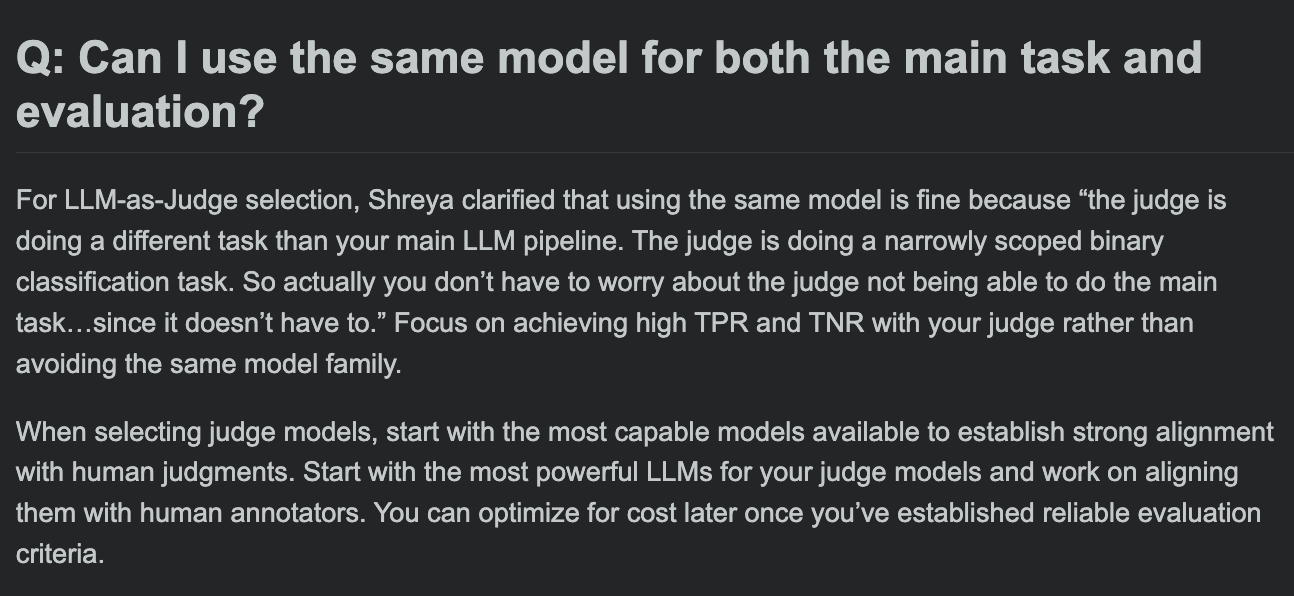
Hamel Husain, LLM 평가 과정 FAQ 공유, 평가 모델과 주 작업 모델이 동일해도 되는지 논의: LLM 평가 과정의 질의응답 세션에서 Hamel Husain은 주요 작업 처리와 작업 평가에 동일한 모델을 사용해도 되는지에 대한 일반적인 질문을 논의했습니다. 이 논의는 개발자가 모델 평가에서 잠재적인 편향과 모범 사례를 이해하는 데 도움이 됩니다. (출처: HamelHusain, HamelHusain)
The Rundown AI, 개인 맞춤형 AI 교육 플랫폼 출시: The Rundown AI는 세계 최초의 개인 맞춤형 AI 교육 플랫폼 출시를 발표했습니다. 이 플랫폼은 다양한 산업, 기술 수준 및 일상 업무 흐름에 맞는 맞춤형 교육, 사용 사례 및 실시간 워크숍을 제공합니다. 플랫폼 콘텐츠에는 16개 기술 수직 분야의 산업별 AI 인증 과정, 300개 이상의 실제 AI 사용 사례, 전문가 워크숍 및 AI 도구 할인 등이 포함됩니다. (출처: TheRundownAI, rowancheung)
Common Crawl, 2025년 3~5월 호스트 및 도메인 수준 웹 그래프 공개: Common Crawl은 2025년 3월, 4월, 5월을 포괄하는 최신 호스트 및 도메인 수준 웹 그래프 데이터를 공개했습니다. 이 데이터는 웹 구조 연구, 언어 모델 훈련 및 대규모 웹 분석 수행에 중요한 가치를 지닙니다. (출처: CommonCrawl)
Bill Chambers, “20 Days of DSPyOSS” 학습 활동 시작: 커뮤니티가 DSPyOSS의 기능과 사용 방법을 더 잘 이해하도록 돕기 위해 Bill Chambers는 20일간의 DSPyOSS 학습 활동을 시작했습니다. 매일 DSPy 코드 조각과 그 설명이 게시되어 사용자가 프레임워크를 입문부터 마스터하는 데 도움을 줄 것입니다. (출처: lateinteraction)
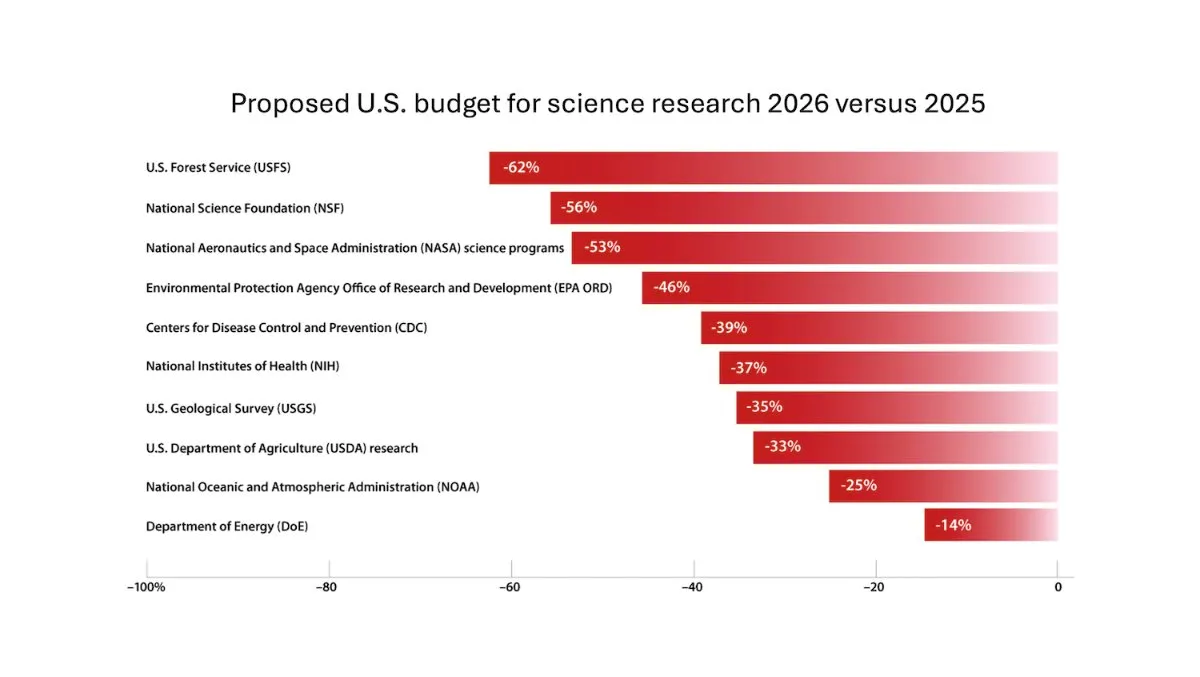
DeepLearning.AI, The Batch 주간 보고서 발행, Andrew Ng 과학 연구 예산 삭감 위험 논의: 최신 The Batch 주간 보고서에서 Andrew Ng는 과학 연구 예산 삭감이 국가 경쟁력과 안보에 미칠 수 있는 잠재적 위험에 대해 논의했습니다. 이 보고서는 또한 Claude 4 모델의 코딩 벤치마크 테스트 성능, Google I/O의 AI 발표, DeepSeek의 저비용 훈련 방법, GPT-4o가 저작권 보호 도서를 훈련에 사용했을 가능성 등 주요 이슈를 다루었습니다. (출처: DeepLearningAI)
Google DeepMind, 영국 대학생에게 Gemini 2.5 Pro 및 NotebookLM 무료 제공: Google DeepMind는 영국 대학생에게 최첨단 모델(Gemini 2.5 Pro 및 NotebookLM 포함)에 대한 15개월 무료 액세스 권한을 제공한다고 발표했습니다. 이는 학생들이 연구, 작문, 시험 준비 등 학습을 지원하고 2TB의 무료 저장 공간을 제공하기 위한 것입니다. (출처: demishassabis)
AI 논문 해설: Prot2Token, 다음 토큰 예측을 통한 단백질 모델링 통합 프레임워크: 논문 《Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction》은 단백질 서열 속성, 잔기 특징에서 단백질 간 상호작용에 이르기까지 다양한 예측 작업을 표준 다음 토큰 예측 형식으로 변환하는 통합 단백질 모델링 프레임워크 Prot2Token을 소개합니다. 이 프레임워크는 자기 회귀 디코더를 채택하고, 사전 훈련된 단백질 인코더의 임베딩과 학습 가능한 작업 토큰을 활용하여 다중 작업 학습을 수행하며, 효율성을 높이고 생물학적 발견을 가속화하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 기업 시스템 분야별 검색을 위한 하드 네거티브 마이닝: 논문 《Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems》은 기업 특정 분야 데이터에 대한 확장 가능한 하드 네거티브 마이닝 프레임워크를 제안합니다. 이 방법은 의미적으로 도전적이지만 컨텍스트와 관련 없는 문서를 동적으로 선택하여 배포된 재정렬 모델 성능을 향상시키며, 클라우드 서비스 분야의 기업 코퍼스에 대한 실험에서 MRR@3 및 MRR@10이 각각 15% 및 19% 향상되었음을 입증했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: FS-DAG, 시각적으로 풍부한 문서 이해를 위한 소수 샷 도메인 적응 그래프 네트워크: 논문 《FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding》은 소수 샷 상황에서 시각적으로 풍부한 문서 이해를 위한 FS-DAG 모델 아키텍처를 제안합니다. 이 모델은 도메인 특정 및 언어/시각 특정 백본 네트워크를 활용하여 모듈식 프레임워크 내에서 최소한의 데이터로 다양한 문서 유형에 적응하며, 정보 추출 작업 실험에서 SOTA 방법보다 빠른 수렴 속도와 성능을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: FastTD3, 간단하고 빠르며 유능한 인간형 로봇 강화 학습 제어: 논문 《FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control》은 FastTD3라는 강화 학습 알고리즘을 소개합니다. 이 알고리즘은 병렬 시뮬레이션, 대규모 배치 업데이트, 분산 평가자 및 세심하게 조정된 하이퍼파라미터를 통해 HumanoidBench, IsaacLab 및 MuJoCo Playground와 같은 인기 있는 제품군에서 인간형 로봇의 훈련 속도를 크게 가속화합니다. (출처: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
AI 논문 해설: HLIP, 3D 의료 영상을 위한 확장 가능한 언어-이미지 사전 훈련: 논문 《Towards Scalable Language-Image Pre-training for 3D Medical Imaging》은 HLIP(Hierarchical attention for Language-Image Pre-training)이라는 확장 가능한 3D 의료 영상 사전 훈련 프레임워크를 소개합니다. HLIP은 경량 계층적 어텐션 메커니즘을 채택하여 정리되지 않은 임상 데이터셋에서 직접 훈련할 수 있으며 여러 벤치마크에서 SOTA 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: PENGUIN, LLM 개인 맞춤형 안전 벤치마크 및 계획 기반 에이전트 접근 방식: 논문 《Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach》은 개인 맞춤형 안전 개념을 도입하고 PENGUIN 벤치마크(7개 민감 영역의 14,000개 시나리오 포함)와 RAISE 프레임워크(훈련 없이 사용자 특정 배경 정보를 전략적으로 획득하는 2단계 에이전트)를 제안합니다. 연구에 따르면 개인 맞춤형 정보는 안전 점수를 크게 향상시킬 수 있으며 RAISE는 낮은 상호 작용 비용으로 안전성을 향상시킬 수 있습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 턴 레벨 신용 할당을 통한 LLM 에이전트의 다중 턴 추론 강화: 논문 《Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment》은 강화 학습을 통해 LLM 에이전트의 추론 능력을 향상시키는 방법, 특히 다중 턴 도구 사용 시나리오에서 이를 연구합니다. 저자는 보다 정확한 신용 할당을 위해 세분화된 턴 레벨 어드밴티지 추정 전략을 제안하며, 실험을 통해 이 방법이 복잡한 의사 결정 작업에서 LLM 에이전트의 다중 턴 추론 능력을 크게 향상시킬 수 있음을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: PISCES, 대규모 언어 모델에서 매개변수 내 개념의 정밀 삭제: 논문 《Precise In-Parameter Concept Erasure in Large Language Models》은 매개변수 공간에서 개념을 인코딩하는 방향을 직접 편집하여 모델 매개변수에서 전체 개념을 정밀하게 삭제하는 PISCES 프레임워크를 제안합니다. 이 방법은 디스인탱글러를 사용하여 MLP 벡터를 분해하고, 대상 개념과 관련된 특징을 식별하여 모델 매개변수에서 제거하며, 실험 결과 삭제 효과, 특이성 및 견고성 측면에서 기존 방법보다 우수함을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: DORI, 세분화된 다축 인식 작업을 통한 MLLM 방향 이해 평가: 논문 《Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks》는 멀티모달 대형 언어 모델(MLLM)의 물체 방향 이해 능력을 평가하기 위한 DORI 벤치마크를 소개합니다. DORI는 정면 위치 파악, 회전 변환, 상대 방향 관계 및 규범적 방향 이해의 네 가지 차원을 포함하며, 15개의 SOTA MLLM을 테스트한 결과 최고의 모델조차도 정밀한 방향 판단에 상당한 한계가 있음을 발견했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: LLM은 실제 텍스트에서 인과 관계를 추론할 수 있는가?: 논문 《Can Large Language Models Infer Causal Relationships from Real-World Text?》은 LLM이 실제 텍스트에서 인과 관계를 추론하는 능력을 탐구합니다. 연구자들은 실제 학술 문헌에서 파생된 벤치마크를 개발했으며, 이는 다양한 길이, 복잡성 및 분야의 텍스트를 포함합니다. 실험 결과, SOTA LLM조차도 이 작업에서 상당한 어려움에 직면하며, 최고 모델의 F1 점수는 0.477에 불과하여 암시적 정보 처리, 관련 요인 구별 및 분산된 정보 연결의 어려움을 드러냈습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: IQBench, 인간 IQ 테스트를 사용하여 시각 언어 모델의 “지능” 수준 평가: 논문 《IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests》는 표준화된 시각 IQ 테스트를 통해 시각 언어 모델(VLM)의 유동 지능을 평가하기 위한 새로운 벤치마크인 IQBench를 출시했습니다. 이 벤치마크는 시각 중심이며, 500개의 수동으로 수집 및 주석 처리된 시각 IQ 문제를 포함하여 모델의 설명, 문제 해결 패턴 및 최종 예측의 정확성을 평가합니다. 실험 결과 o4-mini, Gemini-2.5-Flash 및 Claude-3.7-Sonnet이 비교적 좋은 성능을 보였지만 모든 모델이 3D 공간 및 아나그램 추론 작업에서 어려움을 겪었습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: PixelThink, 효율적인 픽셀 체인 추론을 향하여: 논문 《PixelThink: Towards Efficient Chain-of-Pixel Reasoning》은 외부에서 추정된 작업 난이도와 내부에서 측정된 모델 불확실성을 통합하여 강화 학습 패러다임 내에서 추론 생성을 조절하는 PixelThink 방안을 제안합니다. 이 모델은 장면 복잡성과 예측 신뢰도에 따라 추론 길이를 압축하는 방법을 학습합니다. 동시에 평가를 위해 ReasonSeg-Diff 벤치마크를 도입했으며, 실험 결과 이 방법이 추론 효율성과 전체 분할 성능을 향상시키는 것으로 나타났습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 테스트 시 확장으로서의 다중 에이전트 토론 재검토: 논문 《Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness》는 다중 에이전트 토론(MAD)을 테스트 시 계산 확장 기술로 개념화하고, 다양한 조건(작업 난이도, 모델 규모, 에이전트 다양성)에서 자가 에이전트 방법에 비해 그 효과를 체계적으로 연구합니다. 연구 결과, 수학적 추론의 경우 MAD의 이점은 제한적이지만 문제 난이도가 증가하거나 모델 능력이 저하될 때 더 효과적입니다. 안전 작업의 경우 MAD의 협력적 최적화는 취약성을 증가시킬 수 있지만 다양한 구성은 공격 성공률을 줄이는 데 도움이 됩니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: VF-Eval, AIGC 비디오 피드백 생성 능력에 대한 MLLM 평가: 논문 《VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos》는 AI 생성 콘텐츠(AIGC) 비디오를 해석하는 멀티모달 대형 언어 모델(MLLM)의 능력을 평가하기 위한 새로운 벤치마크 VF-Eval을 제안합니다. VF-Eval은 일관성 검증, 오류 감지, 오류 유형 감지 및 추론 평가의 네 가지 작업을 포함합니다. 13개의 최첨단 MLLM에 대한 평가는 가장 성능이 좋은 GPT-4.1조차도 모든 작업에서 좋은 성능을 유지하기 어렵다는 것을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: SafeScientist, LLM 에이전트를 통한 위험 인지 과학적 발견 구현: 논문 《SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents》는 AI 기반 과학 탐구에서 안전성과 윤리적 책임을 강화하기 위한 SafeScientist라는 AI 과학자 프레임워크를 소개합니다. 이 프레임워크는 부적절하거나 고위험 작업을 능동적으로 거부하고, 프롬프트 모니터링, 에이전트 협업 모니터링, 도구 사용 모니터링 및 윤리 검토자 구성 요소와 같은 다중 방어 메커니즘을 통해 연구 과정의 안전성을 강조합니다. 동시에 평가를 위한 SciSafetyBench 벤치마크를 제안합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: CXReasonBench, 흉부 X선 구조화 진단 추론 평가 벤치마크: 논문 《CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays》는 대형 시각 언어 모델(LVLM)이 흉부 X선 진단에서 임상적으로 효과적인 추론 단계를 수행할 수 있는지 평가하기 위한 CheXStruct 프로세스와 CXReasonBench 벤치마크를 소개합니다. 이 벤치마크는 12개 진단 작업과 1200개 사례를 포괄하는 18988개의 QA 쌍을 포함하며, 해부학적 영역 선택 및 진단 측정의 시각적 위치 파악을 포함한 다중 경로, 다단계 평가를 지원합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: ZeroGUI, 제로 인적 비용으로 온라인 GUI 학습 자동화: 논문 《ZeroGUI: Automating Online GUI Learning at Zero Human Cost》는 제로 인적 비용으로 GUI 에이전트 훈련을 자동화하기 위한 확장 가능한 온라인 학습 프레임워크인 ZeroGUI를 제안합니다. ZeroGUI는 VLM 기반 자동 작업 생성, 자동 보상 추정 및 2단계 온라인 강화 학습을 통합하여 GUI 환경과 지속적으로 상호 작용하고 학습합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: Spatial-MLLM, MLLM 시각적 공간 지능 향상: 논문 《Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence》은 순수 2D 관찰로부터 시각 기반 공간 추론을 위한 Spatial-MLLM 프레임워크를 제안합니다. 이 프레임워크는 이중 인코더 아키텍처(의미론적 시각 인코더와 공간 인코더)를 채택하고 공간 인식 프레임 샘플링 전략과 결합하여 여러 실제 데이터셋에서 SOTA 성능을 달성합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: TrustVLM, 시각 언어 모델 예측의 신뢰성 판단: 논문 《To Trust Or Not To Trust Your Vision-Language Model’s Prediction》은 시각 언어 모델(VLM) 예측의 신뢰도를 평가하기 위한 훈련 없는 프레임워크인 TrustVLM을 소개합니다. 이 방법은 이미지 임베딩 공간에서 개념 표현의 차이를 활용하여 새로운 신뢰도 점수 함수를 제안하여 오분류 감지를 개선하고 17개의 다양한 데이터셋에서 SOTA 성능을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: MAGREF, 마스크 유도 기반 다중 참조 비디오 생성: 논문 《MAGREF: Masked Guidance for Any-Reference Video Generation》은 통일된 다중 참조 비디오 생성 프레임워크인 MAGREF를 제안합니다. 이는 영역 인식 동적 마스크와 픽셀 수준 채널 연결을 통해 마스크 유도 메커니즘을 도입하여 다양한 참조 이미지와 텍스트 프롬프트 조건에서 일관된 다중 주체 비디오 합성을 실현하며, 다중 주체 비디오 벤치마크에서 기존 오픈소스 및 상용 기준선을 능가합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: ATLAS, 테스트 시 컨텍스트 메모리 최적화 학습: 논문 《ATLAS: Learning to Optimally Memorize the Context at Test Time》은 현재 및 과거 토큰에 따라 메모리를 최적화하여 컨텍스트를 기억하는 방법을 학습하는 고용량 장기 기억 모듈인 ATLAS를 제안하여 장기 기억 모델의 온라인 업데이트 특성을 극복합니다. 이를 기반으로 저자는 DeepTransformers 아키텍처 제품군을 제안했으며, 실험 결과 ATLAS는 언어 모델링, 상식 추론, 회상 집약적 및 장문맥 이해 작업에서 Transformers 및 최근 선형 순환 모델을 능가하는 것으로 나타났습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: Satori-SWE, 샘플 효율적인 진화적 테스트 시 확장 소프트웨어 엔지니어링 방법: 논문 《Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering》은 코드 생성을 진화 과정으로 간주하여 출력을 반복적으로 최적화함으로써 SWE-Bench와 같은 소프트웨어 엔지니어링 작업에서 소규모 모델의 성능을 향상시키는 EvoScale 방법을 제안합니다. Satori-SWE-32B 모델은 이 방법을 통해 소량의 샘플을 사용하여 매개변수 수가 100B를 초과하는 모델과 동등하거나 그 이상의 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: OPO, 최적 보상 기준선을 갖는 정책 기반 강화 학습: 논문 《On-Policy RL with Optimal Reward Baseline》은 현재 RL 알고리즘이 LLM 훈련 시 직면하는 훈련 불안정성 및 계산 효율성 저하 문제를 해결하기 위한 새로운 단순화된 강화 학습 알고리즘인 OPO를 제안합니다. OPO는 정확한 정책 기반 훈련을 강조하고 이론적으로 기울기 분산을 최소화하는 최적 보상 기준선을 도입하며, 실험 결과 수학 추론 벤치마크에서 우수한 성능과 훈련 안정성을 보여줍니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: SWE-bench Goes Live! 실시간 업데이트되는 소프트웨어 엔지니어링 벤치마크: 논문 《SWE-bench Goes Live!》는 기존 SWE-bench의 한계를 극복하기 위한 실시간 업데이트 가능한 벤치마크인 SWE-bench-Live를 소개합니다. 새 버전은 2024년 이후 실제 GitHub 문제에서 파생된 1319개의 작업을 포함하며, 93개 저장소를 포괄하고 자동화된 관리 프로세스를 갖추어 확장성과 지속적인 업데이트를 실현함으로써 보다 엄격하고 오염 방지된 LLM 및 에이전트 평가를 제공합니다. (출처: HuggingFace Daily Papers, _akhaliq)
AI 논문 해설: ToMAP, 마음 이론 기반으로 상대방을 인식하는 LLM 설득자 훈련: 논문 《ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind》은 두 가지 마음 이론 모듈을 통합하여 보다 유연한 설득 에이전트를 구축하고 상대방의 심리 상태에 대한 인식과 분석을 강화하는 ToMAP이라는 새로운 방법을 소개합니다. 실험 결과, 단 3B 매개변수의 ToMAP 설득자는 여러 설득 대상 모델과 코퍼스에서 GPT-4o와 같은 대형 기준선보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: LLM이 CLIP을 속일 수 있을까? 텍스트 업데이트를 통한 사전 훈련된 멀티모달 표현의 적대적 조합성 평가: 논문 《Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates》는 LLM을 사용하여 CLIP과 같은 사전 훈련된 멀티모달 표현의 조합성 취약점을 이용하는 기만적인 텍스트 샘플을 생성하는 멀티모달 적대적 조합성(MAC) 벤치마크를 소개합니다. 이 연구는 다양성을 촉진하는 필터링을 통한 거부 샘플링 미세 조정을 통해 공격 성공률과 샘플 다양성을 향상시키는 자가 훈련 방법을 제안합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 추론 학습에서 잡음 있는 보상의 역할 – 정상보다 등반 과정이 지혜를 더 깊이 새긴다: 논문 《The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason》은 강화 학습을 통한 LLM의 추론 후훈련에 대한 보상 잡음의 영향을 연구합니다. 연구 결과 LLM은 대량의 보상 잡음에 대해 강력한 견고성을 보이며, 핵심 추론 구문의 출현만을 보상하더라도(답의 정확성을 검증하지 않음) 엄격한 검증과 정확한 보상으로 훈련된 모델과 유사한 성능을 달성할 수 있음을 발견했습니다. (출처: HuggingFace Daily Papers)
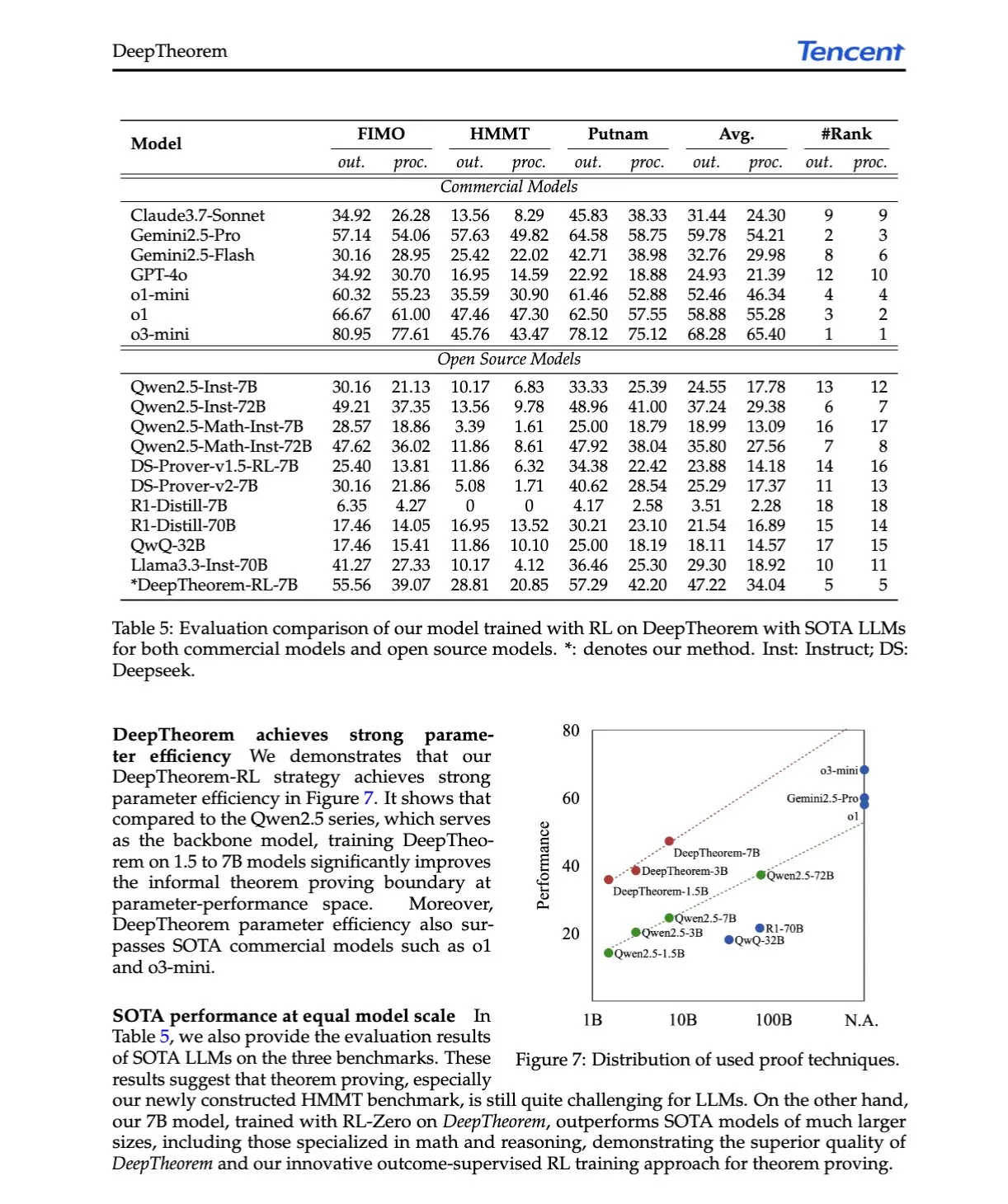
AI 논문 해설: DeepTheorem, 자연어와 강화 학습을 통해 LLM 정리 증명 발전: 논문 《DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning》은 자연어를 활용하여 LLM의 수학적 추론을 강화하는 비형식적 정리 증명 프레임워크인 DeepTheorem을 제안합니다. 이 프레임워크는 대규모 벤치마크 데이터셋(IMO 수준 비형식적 정리 및 증명 12.1만 개)과 비형식적 정리 증명을 위해 특별히 설계된 RL 정책(RL-Zero)을 포함합니다. (출처: HuggingFace Daily Papers, teortaxesTex)
AI 논문 해설: D-AR, 자기 회귀 모델을 통한 확산: 논문 《D-AR: Diffusion via Autoregressive Models》은 이미지 확산 과정을 표준 자기 회귀 다음 토큰 예측 과정으로 재구성하는 D-AR이라는 새로운 패러다임을 제안합니다. 설계된 토크나이저를 통해 이미지를 이산 토큰 시퀀스로 변환하며, 다른 위치의 토큰은 픽셀 공간에서 다른 확산 노이즈 제거 단계로 디코딩될 수 있습니다. 이 방법은 ImageNet에서 775M Llama 백본 네트워크와 256개의 이산 토큰을 사용하여 2.09 FID를 달성했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: Table-R1, 테이블 추론을 위한 추론 시간 확장: 논문 《Table-R1: Inference-Time Scaling for Table Reasoning》은 테이블 추론 작업에서 추론 시간 확장을 처음으로 탐구합니다. 연구자들은 두 가지 후훈련 전략을 개발하고 평가했습니다: 최첨단 모델 추론 궤적에서 증류(Table-R1-SFT) 및 검증 가능한 보상을 사용한 강화 학습(Table-R1-Zero). Table-R1-Zero(7B 매개변수)는 다양한 테이블 추론 작업에서 GPT-4.1 및 DeepSeek-R1의 성능에 도달하거나 이를 능가했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: Muddit, 텍스트-이미지 생성을 넘어선 통합 이산 확산 모델: 논문 《Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model》은 텍스트 및 이미지 모달리티의 빠른 병렬 생성을 지원하는 통합 이산 확산 Transformer 모델인 Muddit을 소개합니다. Muddit은 사전 훈련된 텍스트-이미지 백본 네트워크의 강력한 시각적 사전 지식과 경량 텍스트 디코더를 통합하여 품질과 효율성 모두에서 경쟁력을 갖습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: VideoReasonBench, MLLM이 시각 중심의 복잡한 비디오 추론을 수행할 수 있는가?: 논문 《VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?》은 시각 중심의 복잡한 비디오 추론 능력을 평가하기 위한 벤치마크인 VideoReasonBench를 소개합니다. 이 벤치마크는 세분화된 작업 시퀀스에 대한 비디오를 포함하며, 질문은 회상, 추론 및 예측 능력을 평가합니다. 실험 결과, 대부분의 SOTA MLLM은 이 벤치마크에서 저조한 성능을 보였으며, 사고가 강화된 Gemini-2.5-Pro는 뛰어난 성능을 보였습니다. (출처: HuggingFace Daily Papers, OriolVinyalsML)
AI 논문 해설: GeoDrive, 정확한 행동 제어를 갖춘 3D 기하학 정보 기반 주행 세계 모델: 논문 《GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control》은 공간 이해와 행동 제어 가능성을 향상시키기 위해 견고한 3D 기하학 조건을 주행 세계 모델에 명시적으로 통합하는 GeoDrive를 제안합니다. 이 방법은 훈련 중 동적 편집 모듈을 통해 렌더링 효과를 향상시키며, 실험 결과 행동 정확성과 3D 공간 인식 측면에서 기존 모델보다 우수함을 입증했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 동적 저신뢰도 마스킹을 통한 적응형 분류기 없는 안내: 논문 《Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking》은 모델의 순간적인 예측 신뢰도를 활용하여 분류기 없는 안내(CFG)의 무조건부 입력을 맞춤화하는 A-CFG 방법을 제안합니다. A-CFG는 반복적(마스크) 확산 언어 모델의 각 단계에서 저신뢰도 토큰을 식별하고 일시적으로 다시 마스킹하여 동적이고 국지화된 무조건부 입력을 생성함으로써 CFG의 교정 효과를 더욱 정밀하게 만듭니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: PatientSim, 실제 의사-환자 상호작용을 위한 페르소나 기반 시뮬레이터: 논문 《PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions》은 MIMIC 데이터셋의 임상 프로필과 4축 페르소나(성격, 언어 숙련도, 병력 회상 수준, 인지 혼란 수준)를 기반으로 실제적이고 다양한 환자 페르소나를 생성하는 PatientSim을 소개합니다. 의사 LLM 훈련 또는 평가를 위한 현실적인 환자 상호작용 시스템을 제공하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: LoRAShop, 보정된 플로우 트랜스포머를 이용한 훈련 없는 다중 개념 이미지 생성 및 편집: 논문 《LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers》는 LoRA 모델을 사용하여 다중 개념 이미지 편집을 수행하는 최초의 프레임워크인 LoRAShop을 소개합니다. 이 프레임워크는 Flux 스타일 확산 트랜스포머 내부 특징 상호 작용 패턴을 활용하여 각 개념에 대해 분리된 잠재 마스크를 도출하고 개념 영역 내에서만 LoRA 가중치를 혼합하여 다중 주체 또는 스타일의 원활한 통합을 실현합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: AnySplat, 제약 없는 뷰에서의 피드포워드 3D 가우시안 스플래팅: 논문 《AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views》는 보정되지 않은 이미지 집합에서 새로운 시점 합성을 위한 피드포워드 네트워크인 AnySplat을 소개합니다. 기존 신경 렌더링 파이프라인과 달리 AnySplat은 단일 순방향 전파만으로 3D 가우시안 프리미티브(장면 기하학 및 외관 인코딩)와 각 입력 이미지의 카메라 내외부 매개변수를 예측할 수 있으며, 자세 주석 없이 실시간 새로운 시점 합성을 지원합니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: ZeroSep, 제로 트레이닝으로 오디오에서 모든 것 분리: 논문 《ZeroSep: Separate Anything in Audio with Zero Training》은 사전 훈련된 텍스트 유도 오디오 확산 모델만으로 특정 구성에서 제로샷 음원 분리가 가능함을 발견했습니다. ZeroSep 방법은 혼합 오디오를 확산 모델의 잠재 공간으로 반전시키고 텍스트 조건 유도 노이즈 제거 과정을 사용하여 개별 음원을 복원하며, 특정 작업 훈련이나 미세 조정이 필요하지 않습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 단일 샷 엔트로피 최소화 연구: 논문 《One-shot Entropy Minimization》은 13440개의 대규모 언어 모델을 훈련하여 엔트로피 최소화가 단일 레이블 없는 데이터와 10단계 최적화만으로도 수천 개의 데이터와 정교하게 설계된 보상을 사용하는 규칙 기반 강화 학습이 달성할 수 있는 성능 개선에 도달하거나 이를 능가한다는 것을 발견했습니다. 이 결과는 LLM 후훈련 패러다임에 대한 재고를 촉발할 수 있습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: ChartLens, 차트에서의 세분화된 시각적 귀인: 논문 《ChartLens: Fine-grained Visual Attribution in Charts》는 MLLM이 차트 이해에서 환각을 일으키기 쉬운 문제에 대응하여 차트 사후 시각적 귀인 작업을 도입하고 ChartLens 알고리즘을 제안합니다. 이 알고리즘은 분할 기술을 사용하여 차트 객체를 식별하고 레이블 집합 프롬프트를 통해 MLLM과 세분화된 시각적 귀인을 수행합니다. 동시에 금융, 정책, 경제 등 분야의 차트에 대한 세분화된 귀인 주석을 포함하는 ChartVA-Eval 벤치마크를 발표했습니다. (출처: HuggingFace Daily Papers)
AI 논문 해설: 그래프 관점에서 대규모 언어 모델의 지식 구조 패턴 탐색: 논문 《A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models》은 그래프 관점에서 LLM의 지식 구조 패턴을 연구합니다. 이 연구는 삼중항 및 개체 수준에서 LLM의 지식을 정량화하고, 노드 차수와 같은 그래프 구조 속성과의 관계를 분석하며, 지식 동질성(위상학적으로 가까운 개체의 지식 수준 유사성)을 밝힙니다. 이를 기반으로 개체 지식을 추정하고 지식 검사에 사용하는 그래프 기계 학습 모델을 개발했습니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
체화 지능 회사 Lumos Robotics, 반년 만에 약 2억 위안 투자 유치, 중원해운 등과 협력 체결: 전 Dreame 임원 위차오(喻超)가 설립한 체화 지능 로봇 회사 Lumos Robotics(鹿明机器人)가 엔젤++ 라운드 투자를 완료했다고 발표했습니다. 투자자로는 Fosun RZ Capital, Dematic, 우중금융지주 등이 참여했으며, 반년 동안 누적 투자액은 약 2억 위안에 달합니다. 이 회사는 가정용 장면에 초점을 맞추고 있으며, 제품으로는 LUS, MOS 시리즈 인간형 로봇 및 핵심 부품이 있습니다. 이미 풀사이즈 인간형 로봇 LUS를 출시했으며, Dematic, 중원해운 등과 전략적 협력을 체결하여 물류 및 스마트 제조 등 장면에서 체화 지능의 상용화를 가속화하고 있습니다. (출처: 36氪)

Snorkel AI, 1억 달러 규모 시리즈 D 투자 유치, AI 에이전트 평가 및 전문가 데이터 서비스 출시: 데이터 중심 AI 기업 Snorkel AI가 Valor Equity Partners 주도로 1억 달러 규모의 시리즈 D 투자를 유치했다고 발표했으며, 총 투자 유치액은 2억 3,500만 달러에 달합니다. 동시에 회사는 Snorkel Evaluate(데이터 중심 에이전트 AI 평가 플랫폼)와 Expert Data-as-a-Service(전문가 데이터 서비스)를 출시하여 기업이 보다 신뢰할 수 있고 전문적인 AI 에이전트를 구축하고 배포할 수 있도록 지원하는 것을 목표로 합니다. (출처: realDanFu, percyliang, tri_dao, krandiash)
미국 에너지부, Dell, NVIDIA와 차세대 슈퍼컴퓨터 “Doudna” 개발 협력 발표: 미국 에너지부는 로렌스 버클리 국립 연구소를 위해 “Doudna”라는 차세대 주력 슈퍼컴퓨터 NERSC-10을 개발하기 위해 Dell과 계약을 체결했다고 발표했습니다. 이 시스템은 NVIDIA의 차세대 Vera Rubin 플랫폼으로 구동되며, 2026년 가동 예정으로 기존 주력 제품인 Perlmutter보다 10배 이상 향상된 성능을 제공할 것으로 예상됩니다. 이는 대규모 고성능 컴퓨팅 및 AI 워크로드를 지원하여 미국이 글로벌 AI 주도권 경쟁에서 승리하는 데 기여하는 것을 목표로 합니다. (출처: 36氪, nvidia)

🌟 커뮤니티
DeepSeek R1-0528, 성능, 환각, 도구 호출 등이 화제: DeepSeek R1-0528 출시는 커뮤니티에서 광범위한 논의를 불러일으켰습니다. 대부분의 의견은 수학, 프로그래밍 및 일반 논리 추론에서 상당한 개선을 이루었으며 일부 폐쇄형 모델에 근접하거나 이를 능가한다고 평가합니다. 새 버전은 환각률 감소에 진전을 보였으며 JSON 출력 및 함수 호출 지원을 추가했습니다. 동시에 증류된 Qwen3-8B 버전도 소형 모델에서의 우수한 수학 성능으로 주목받고 있습니다. 커뮤니티는 DeepSeek이 오픈소스 분야에서 선도적 위치를 공고히 했으며 R2 버전 출시를 기대하고 있다고 전반적으로 평가합니다. (출처: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI 이미지 편집 모델 FLUX.1 Kontext 주목, 컨텍스트 이해와 캐릭터 일관성 강조: Black Forest Labs가 출시한 FLUX.1 Kontext 이미지 편집 모델은 텍스트와 이미지 입력을 동시에 처리하고 캐릭터 일관성을 유지하는 능력으로 커뮤니티의 주목을 받고 있습니다. 사용자들은 이미지 편집, 스타일 변환, 텍스트 오버레이 등의 작업에서 뛰어난 성능을 보이며, 특히 다중 편집 과정에서 주체 특징을 잘 보존한다고 평가합니다. Replicate 등 플랫폼에 이미 해당 모델이 등록되었으며, 상세한 테스트 보고서와 사용 팁을 제공하고 있습니다. (출처: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

AI 에이전트, 검색 및 광고 모델 크게 변화시킬 것: Perplexity AI CEO Arav Srinivas는 AI 에이전트가 사용자를 대신해 검색을 수행함에 따라 Google 등 검색 엔진의 인간 검색량이 크게 감소할 것이며, 이는 광고 CPM/CPC 하락으로 이어져 광고 지출이 소셜 미디어나 AI 플랫폼으로 이동할 수 있다고 전망했습니다. 사용자는 더 이상 키워드 검색을 자주 할 필요 없이 AI 비서가 능동적으로 정보를 푸시하게 될 것입니다. (출처: AravSrinivas)
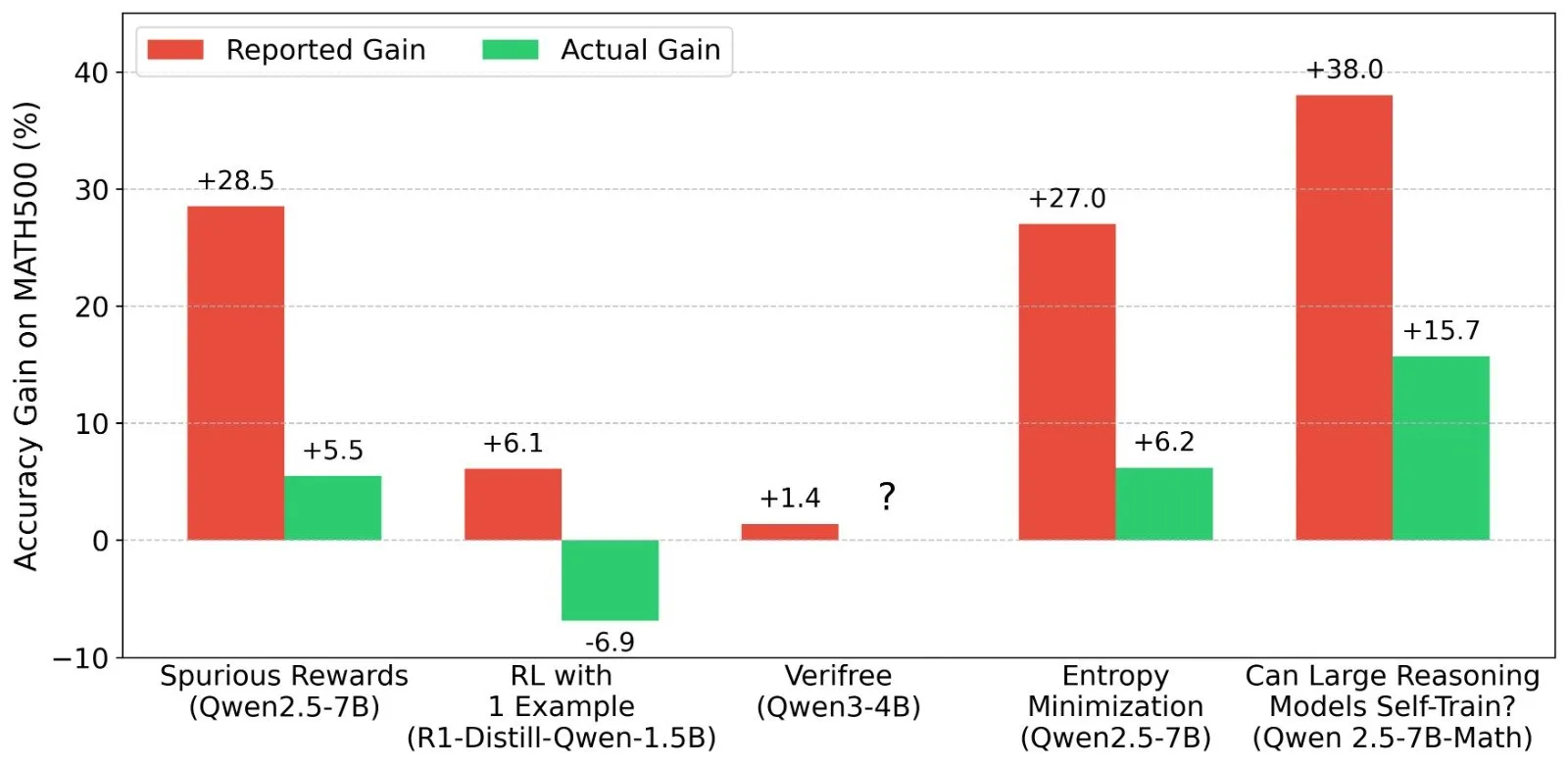
LLM 강화 학습(RL) 결과에 대한 논의: 보상 신호와 모델 능력의 진실성: Shashwat Goel 등 연구자들은 최근 LLM RL 연구에서 모델이 실제 보상 신호 없이도 성능이 향상되는 현상에 의문을 제기하며, 일부 연구가 사전 훈련된 모델의 기준 능력을 과소평가했거나 다른 혼동 요인이 있을 수 있다고 지적했습니다. 이 논의는 Qwen 등 모델의 RL에서의 성능에 대한 심층 분석과 RLVR(검증 가능한 보상 강화 학습)의 효과에 대한 고찰을 촉발했으며, RL 효과 평가 시 보다 엄격한 기준선과 프롬프트 최적화가 필요함을 강조했습니다. (출처: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” 논란, 안전한 기본값과 기술 부채 위험 강조: “Vibe coding”(분위기 프로그래밍, 엄격한 규범보다는 직관과 빠른 반복에 더 의존하는 프로그래밍 방식)이 커뮤니티 토론의 뜨거운 감자로 떠올랐습니다. Replit CEO Amjad Masad는 이러한 방식이 새로운 개발자에게 힘을 실어주지만 플랫폼은 안전한 기본 구성을 제공해야 한다고 주장했습니다. 동시에 Pedro Domingos는 “분위기 프로그래밍은 기술 부채의 고질라”라고 평하며 장기적인 유지보수 문제를 암시했습니다. Semafor는 Lovable이 RLS 정책 구성 부실로 인한 보안 취약점을 보도하며 해당 프로그래밍 방식의 안전성에 대한 우려를 더욱 증폭시켰습니다. (출처: alexalbert__, amasad, pmddomingos, gfodor)
소프트웨어 엔지니어링에서 AI의 역할: 효율성 향상과 인간 프로그래머의 대체 불가능성: Redis의 아버지 Salvatore Sanfilippo는 AI(예: Gemini 2.5 Pro)가 프로그래밍 보조, 코드 검토 및 아이디어 검증에 가치가 있지만, 인간 프로그래머는 창의적인 문제 해결, 기존 사고방식 타파 측면에서 여전히 AI를 훨씬 능가한다고 경험을 공유했습니다. 커뮤니티 토론에서는 AI가 현재 “지능형 고무 오리”와 같아서 사고를 보조할 수는 있지만 그 제안은 신중하게 평가해야 하며, 과도한 의존은 개발자의 핵심 능력을 약화시킬 수 있다고 지적했습니다. Mitchell Hashimoto도 LLM이 Clang 컴파일 문제를 신속하게 찾는 데 도움을 주어 많은 시간을 절약한 사례를 공유했습니다. (출처: mitchellh, 36氪)
AI가 대규모로 일자리를 대체할 것인지에 대한 지속적인 관심: Anthropic CEO Dario Amodei는 AI가 초급 사무직의 절반을 사라지게 할 수 있다고 예측한 반면, Mark Cuban은 AI가 새로운 회사와 새로운 일자리를 창출할 것이라고 주장했습니다. 커뮤니티에서는 이에 대한 격렬한 토론이 벌어졌으며, 고객 서비스, 초급 카피라이터, 일부 개발 등의 업무는 이미 영향을 받고 있지만, 창의성, 복잡한 의사 결정 및 고도의 대인 관계가 필요한 분야에서는 AI가 인간을 대체하기 어렵다는 의견이 있었습니다. AI가 업무의 성격을 변화시킬 것이며, 인간은 AI와 협력하는 능력을 적응하고 향상시켜야 한다는 것이 일반적인 공감대입니다. (출처: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent(지능형 에이전트)가 차세대 상호작용의 관문으로 부상하며 대기업들의 경쟁 촉발: Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa 등 국내외 기술 기업들이 AI Agent 분야에 앞다투어 뛰어들고 있습니다. 지능형 에이전트는 심층적으로 사고하고, 자율적으로 계획하며, 의사 결정을 내리고 복잡한 작업을 수행할 수 있어 검색 엔진, 앱에 이은 차세대 상호작용의 관문으로 여겨집니다. 현재 OpenAI, Baidu를 대표하는 기술 생태계 구축자, Microsoft, Alibaba Cloud를 대표하는 수직적 시나리오 기업 서비스 제공업체, 그리고 Huawei, Coocaa를 대표하는 하드웨어 및 소프트웨어 단말기 제조업체 등 세 가지 주요 세력이 형성되었습니다. (출처: 36氪)

💡 기타
중국 AI 해외 진출 가속화, 제품 수출에서 생태계 구축으로 전환: 《중국 AI의 해외 성장》 보고서에 따르면 중국 AI 기업의 해외 진출이 규모화된 고속 성장 단계에 진입했으며, 76%가 응용 분야에 집중되어 있습니다. 해외 진출 경로는 초기 도구형 애플리케이션에서 중기 기술 우위를 결합한 산업 솔루션 수출로 발전했으며, 현재는 기술 생태계 해외 진출에 중점을 두어 기술 표준과 오픈소스 협력을 추진하고 있습니다. AI 해외 진출은 “가까운 곳에서 먼 곳으로”의 단계적 침투 양상을 보이며, 현지화, 규정 준수 및 윤리, 브랜드 마케팅 등의 도전에 직면해 있습니다. (출처: 36氪)

미국 에너지부, AI 경쟁을 “새로운 맨해튼 프로젝트”에 비유하며 미국 승리 강조: 미국 에너지부는 차세대 슈퍼컴퓨터 “Doudna”를 발표하면서 AI 발전 경쟁을 “우리 시대의 맨해튼 프로젝트”라고 칭하며 미국이 이 경쟁에서 승리할 것이라고 선언했습니다. 이러한 발언은 커뮤니티에서 강대국 간 기술 경쟁, AI 윤리 및 국제 협력에 대한 논의를 불러일으켰습니다. (출처: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
콘텐츠 제작 분야 AI 발전, “진실성”과 “창의성”에 대한 고찰 촉발: 커뮤니티에서는 패션 디자인, 만화 창작, 비디오 생성 등 분야에서 AI의 활용에 대해 논의했습니다. 한편으로 AI는 다양한 콘텐츠를 신속하게 생성하고, 심지어 몇 년 전 만화 작품을 비디오로 구체화할 수도 있습니다. 다른 한편으로 이러한 생성 콘텐츠는 때때로 기괴하거나 깊이가 부족해 보이기도 합니다. 이는 AI 생성 콘텐츠가 “더 나은가”, 그리고 AI 시대에 인간의 창의성이 어떤 역할을 할 것인가에 대한 고찰을 불러일으켰습니다. (출처: Reddit r/ChatGPT, Reddit r/artificial)
