키워드:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, 강화 학습, 무작위 보상, 오류 보상, 모델 성능, RLHF/RLAIF의 미래, 무작위 보상으로 모델 성능 향상, 오류 보상으로 Qwen2.5-Math-7B 훈련, MATH-500 테스트 세트, 강화 학습 신호 학습
🔥 주요 뉴스
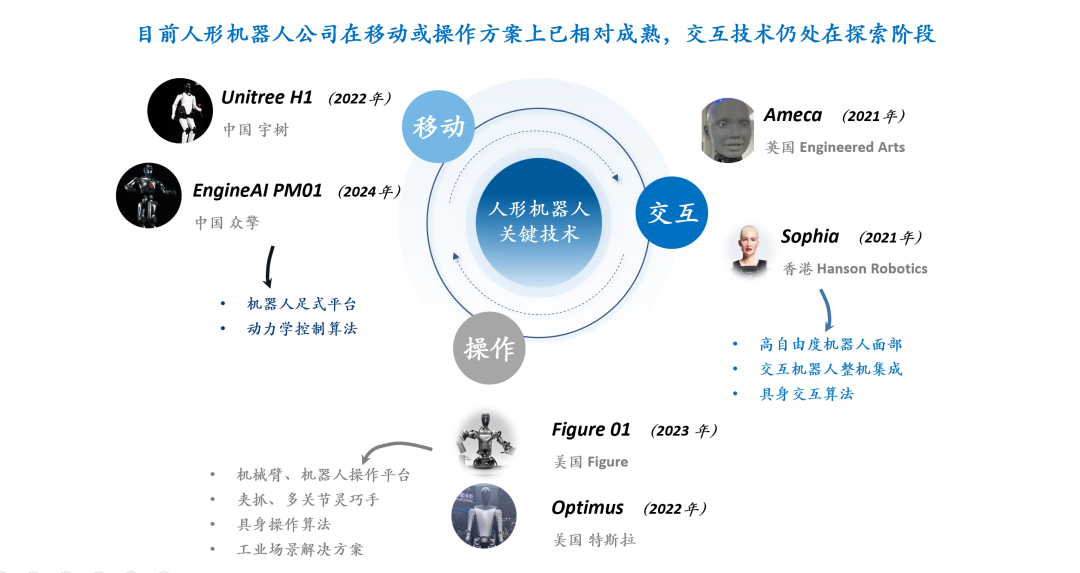
RLHF/RLAIF의 미래: 무작위/잘못된 보상도 모델 성능을 향상시킬 수 있을까? : Stella Li의 실험에 따르면, 무작위 보상 또는 부정확한 보상으로 Qwen2.5-Math-7B 모델을 훈련했을 때 MATH-500 테스트 세트에서 각각 21%와 25%의 성능 향상을 보여, 실제 보상을 사용했을 때의 28.8% 향상 효과에 근접했습니다. natolambert가 공유한 Rulin Shao의 연구에서도 RLVR(Reinforcement Learning from Verifier Reward)이 허위 보상을 사용할 때 Olmo 모델의 코드 사용은 증가했지만 성능은 저하되었고, 오히려 코드 사용을 막자 성능이 향상되는 결과가 나타났습니다. 이러한 발견들은 기존 RLHF/RLAIF에서 고품질 인간 선호 데이터에 대한 의존성에 도전하며, 모델이 보상 신호 자체는 불완전하더라도 이를 통해 더 넓은 정책 공간을 탐색하고 잠재 능력을 발휘하거나 기존 행동을 최적화할 수 있음을 시사합니다. 이는 값비싼 인공 레이블링 의존도를 낮추고 더 효율적인 모델 정렬 방법을 모색할 새로운 길을 열 수 있지만, 모델이 잘못된 행동을 학습할 위험에 대해서는 경계해야 합니다. (출처: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
Hazy Research, Low-Latency-Llama Megakernel 공개: 단일 CUDA 코어로 Llama 1B 추론 구현 : Hazy Research가 Low-Latency-Llama Megakernel을 출시했습니다. 이 기술은 단일 CUDA 코어 내에서 Llama 1B 모델의 전체 순방향 전파(forward propagation) 과정을 완료할 수 있습니다. 계산을 단일 커널로 통합함으로써 기존의 직렬화된 커널 호출로 인한 동기화 경계를 제거하여 계산 및 메모리 스케줄링을 최적화하고 더 낮은 지연 시간을 구현합니다. Andrej Karpathy는 이를 계산과 메모리의 최적 편성을 구현하는 유일한 방법이라며 높이 평가했습니다. 이 발전은 엣지 컴퓨팅, 실시간 AI 애플리케이션 등 지연 시간에 엄격한 요구 사항이 있는 분야에 중요한 의미를 가지며, 더 효율적이고 민첩한 소형 언어 모델 배포를 촉진할 것으로 기대됩니다. (출처: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan, rStar-Coder 공개: 대규모 검증 코드 추론 데이터셋 구축, 소형 모델 코드 능력 대폭 향상 : Microsoft와 DeepSeek의 연구원들이 rStar-Coder 프로젝트를 공개했습니다. 이 프로젝트는 41만 8천 개의 경쟁 수준 코드 문제, 58만 개의 긴 추론 솔루션 및 풍부한 테스트 케이스를 포함하는 대규모 검증 데이터셋을 구축하여 현재 코드 추론 분야의 고품질, 고난도 데이터셋 부족 문제를 해결하는 것을 목표로 합니다. 이 프로젝트는 기존 프로그래밍 대회 문제와 오라클 해법을 종합적으로 활용하여 새로운 문제를 합성하고, 신뢰할 수 있는 입출력 테스트 케이스 생성 파이프라인을 설계하며, 테스트 케이스를 사용하여 고품질 긴 추론 솔루션을 검증함으로써 LLM의 코드 추론 능력을 향상시킵니다. 실험 결과, rStar-Coder 데이터셋으로 훈련된 Qwen 모델(1.5B-14B)은 여러 코드 추론 벤치마크에서 우수한 성능을 보였습니다. 예를 들어 Qwen2.5-7B는 LiveCodeBench에서 정확도가 17.4%에서 57.3%로 향상되어 o3-mini (low)를 능가했으며, USACO에서는 7B 모델이 더 큰 QWQ-32B 모델을 능가했습니다. (출처: HuggingFace Daily Papers)
중국과학원 자동화 연구소, AutoThink 제안: 대형 모델이 스스로 “깊은 생각” 여부 결정 : 대형 언어 모델이 간단한 문제에도 불구하고 장황한 추론을 하는 “과도한 생각” 현상에 대응하기 위해, 중국과학원 자동화 연구소와 펑청 실험실(Pengcheng Laboratory)이 공동으로 AutoThink 방법을 제안했습니다. 이 방법은 프롬프트에 “생략 부호”(…)를 추가하고 3단계 강화 학습(패턴 안정화, 행동 최적화, 추론 가지치기)을 결합하여 모델이 문제 난이도에 따라 스스로 깊은 생각 여부와 생각의 정도를 선택할 수 있도록 합니다. 실험 결과, AutoThink는 DeepSeek-R1 등 모델의 수학 벤치마크 테스트 성능을 향상시키는 동시에 추론 토큰 소모를 대폭 줄였습니다. 예를 들어, DeepScaleR에서는 추가로 10%의 토큰을 절약할 수 있었습니다. 이 연구는 모델이 “필요에 따라 생각”하도록 하여 추론 효율성과 정확성의 균형을 높이는 것을 목표로 합니다. (출처: 36氪, _akhaliq)

Sakana AI, Sudoku-Bench 출시, 최상위 대형 모델의 “변형 스도쿠” 추론 능력 한계 드러내 : Transformer의 저자 Llion Jones의 스타트업 Sakana AI가 Sudoku-Bench를 발표했습니다. 이는 4×4부터 복잡한 9×9 현대 “변형 스도쿠”를 포함하는 벤치마크 테스트로, AI의 창의적인 다단계 추론 능력을 평가하기 위해 설계되었습니다. 테스트 결과, Gemini 2.5 Pro, GPT-4.1, Claude 3.7을 포함한 최상위 대형 모델들은 보조 없이 전체 정답률이 15% 미만이었으며, 9×9 현대 스도쿠에서는 o3 Mini High의 정답률이 단 2.9%에 그쳤습니다. 이는 모델이 패턴 매칭이 아닌 진정한 논리적 추론이 필요한 새로운 문제에 직면했을 때 성능이 저조하며, 종종 잘못된 해답을 내거나 포기하거나 규칙을 잘못 판단하는 경향이 있음을 보여줍니다. NVIDIA CEO 젠슨 황은 이러한 퍼즐이 AI 추론 능력 향상에 도움이 된다고 생각합니다. Sakana AI는 또한 유명 스도쿠 채널과 협력하여 문제 해결 과정을 기록한 관련 훈련 데이터도 공개했습니다. (출처: 36氪)

🎯 동향
Meta, AI 팀 재편, FAIR 핵심 멤버 이탈 주목 : Meta가 AI 팀을 재편한다고 발표했습니다. Connor Hayes가 이끄는 AI 제품 팀과 Ahmad Al-Dahle 및 Amir Frenkel이 공동으로 이끄는 AGI 기초 부문으로 나뉩니다. 전자는 C단 제품에 집중하고 후자는 Llama 등 기초 모델 연구 개발에 주력합니다. 주목할 점은 기초 인공지능 연구 부문인 FAIR는 독립적으로 유지되지만, 일부 멀티미디어 팀은 AGI 기초 부문으로 통합된다는 것입니다. 이번 조정은 개발 속도와 유연성을 높이기 위한 것입니다. 그러나 Meta는 Llama 4의 미미한 반응, 오픈소스 분야 경쟁 심화 및 핵심 인재 유출이라는 도전에 직면해 있습니다. 초기에 Llama 개발에 참여했던 14명의 저자 중 11명이 이미 퇴사했으며, 그중 다수는 Mistral AI 등 경쟁사에 합류하거나 창업했습니다. FAIR 연구소 또한 리더십 변동과 연구 방향 조정을 겪으면서 회사 내 위상 및 미래 혁신 능력에 대한 우려를 낳고 있습니다. (출처: 36氪)

Google DeepMind, SignGemma 공개: 수어 번역 새 모델 : Google DeepMind가 현재까지 가장 강력한 수어-음성 텍스트 번역 모델이라고 주장하는 SignGemma를 출시한다고 발표했습니다. 이 모델은 올해 말 Gemma 모델 제품군에 합류하여 오픈소스 형태로 공개될 예정입니다. SignGemma의 출시는 포용적 기술을 위한 새로운 가능성을 열고 수어 사용자의 의사소통 효율성과 편의성을 향상시키는 것을 목표로 합니다. Google DeepMind는 사용자 피드백 제공 및 초기 테스트 참여를 요청하고 있습니다. (출처: GoogleDeepMind, demishassabis)
Tencent Hunyuan, HunyuanPortrait 모델 가중치 공개, 정적 인물 사진을 동적 비디오로 변환 가능 : Tencent Hunyuan 팀이 이미지-비디오 생성 모델인 HunyuanPortrait의 모델 가중치를 오픈소스로 공개하여 사용자가 다운로드하여 로컬에서 사용할 수 있도록 했습니다. 이 모델은 정적인 인물 사진을 동적 비디오로 변환하는 데 중점을 두며, 게임 캐릭터, 가상 스트리머, 디지털 휴먼, 스마트 쇼핑 도우미 등 다양한 응용 시나리오에 적합하여 얼굴 이미지를 움직이게 만들어 상호 작용의 생동감과 현실감을 높일 수 있습니다. 관련 모델, 코드 저장소 및 논문이 모두 공개되었습니다. (출처: karminski3, Reddit r/LocalLLaMA)

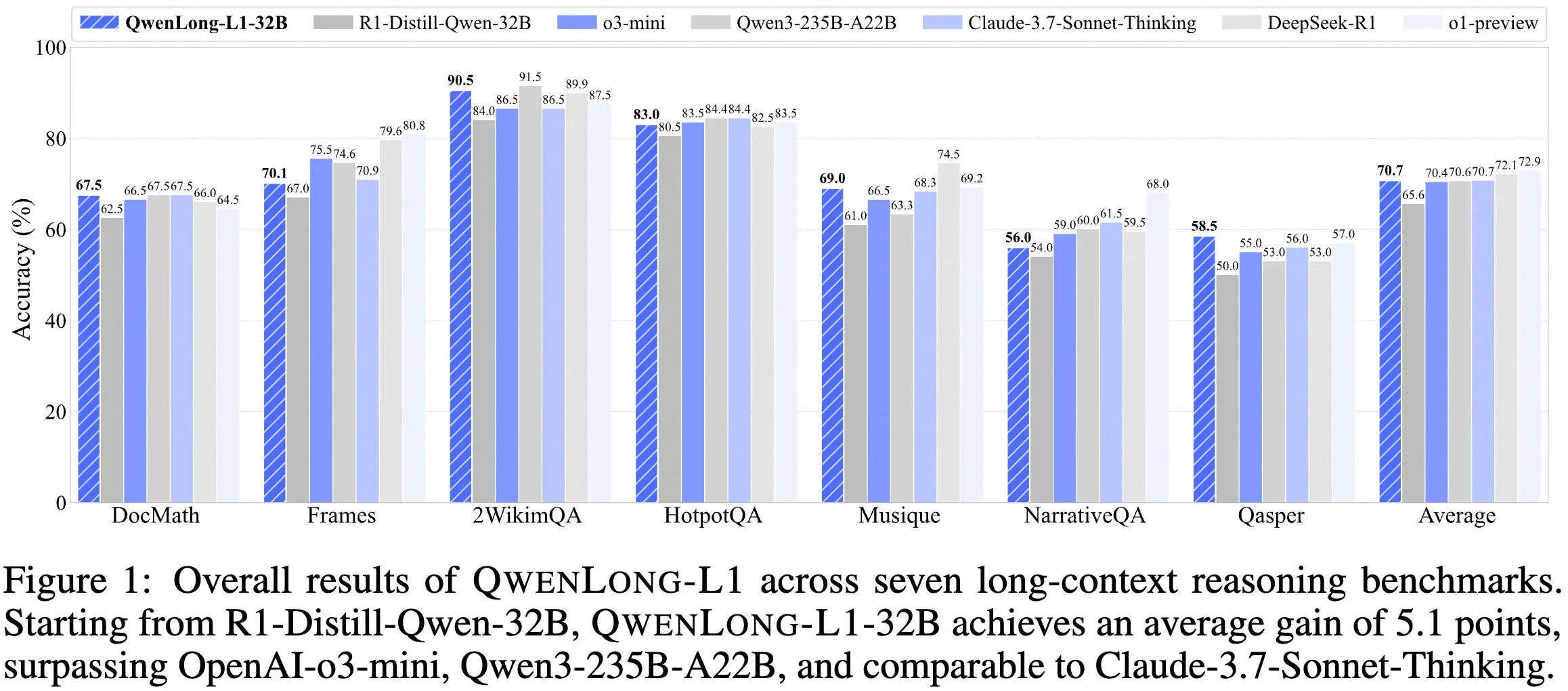
QwenDoc 팀, 긴 컨텍스트 추론 모델 QwenLong-L1-32B 공개 : QwenDoc 팀이 강화 학습으로 훈련된 128K 긴 컨텍스트 추론 모델 QwenLong-L1-32B를 출시했습니다. 이 모델은 DeepSeek-R1-Distill-Qwen-32B를 미세 조정하여 2WikiMultihopQA 다중 홉 추론 테스트 세트에서 90.5점을 획득, 원본 모델보다 6.5점 향상되었으며 긴 컨텍스트에서 내용을 찾는 것뿐만 아니라 단서를 연결하여 추론하는 능력을 강조합니다. 128K 컨텍스트 길이가 현재 가장 긴 것은 아니지만, 뛰어난 추론 능력은 복잡한 긴 문서를 처리하는 데 새로운 선택지를 제공합니다. 모델, 논문 및 코드 라이브러리가 공개되었습니다. (출처: karminski3)
홍콩과기대와 Apple 등 기관 협력, Laser 시리즈 방법론 공개, 대형 모델 추론 효율성 및 정확성 최적화 : 홍콩과기대, 홍콩시립대, 워털루 대학교 및 Apple의 연구원들이 Laser 시리즈 방법론(Laser-D, Laser-DE 포함)을 제안했습니다. 이는 대형 언어 모델(LRM)이 간단한 문제에 대해 과도하게 토큰을 소모하여 추론하는 문제를 해결하기 위한 것입니다. 이 방법은 통일된 길이 보상 설계 프레임워크, 목표 길이 및 계단 함수 기반 보상, 동적 난이도 감지 메커니즘을 통해 AIME24 등 복잡한 수학 추론 벤치마크에서 토큰 사용량을 63% 줄이면서 성능을 6.1점 향상시켰습니다. 연구 결과, 훈련 후 모델의 불필요한 “자기 성찰”이 줄어들고 사고 패턴이 더 건강해져 모델 추론의 효율성과 정확성 간의 균형을 효과적으로 맞추었습니다. (출처: 36氪)

Anthropic Claude 무료 버전, 웹 검색 기능 지원 : Anthropic은 AI 어시스턴트 Claude의 무료 버전 사용자가 이제 웹 검색 기능을 사용할 수 있다고 발표했습니다. 이는 Claude가 질문에 답변할 때 인터넷에서 최신 정보를 가져와 응답의 관련성과 정확성을 향상시킬 수 있음을 의미합니다. 공식 발표에 따르면, 검색 결과가 포함된 각 응답에는 인라인 인용이 제공되어 사용자가 정보 출처를 쉽게 확인할 수 있습니다. (출처: AnthropicAI)
PKU-DS-LAB, FairyR1 공개: DeepSeek-R1-Distill-Qwen-32B 미세 조정한 32B 추론 모델 : 베이징대학 데이터 과학 연구소(PKU-DS-LAB)가 Apache 2.0 라이선스를 사용하는 32B 파라미터 추론 모델 FairyR1을 출시했습니다. 이 모델은 “증류 후 재병합” 방법을 통해 단 5%의 파라미터만 사용하면서 더 큰 모델의 성능에 도달한다고 알려져 있습니다. FairyR1은 DeepSeek-R1-Distill-Qwen-32B를 기반으로 미세 조정되었으며, 훈련 데이터도 Hugging Face Hub에 제공되었습니다. 이 작업은 TinyR1의 연구 아이디어를 이어받아 데이터셋(약 1만 개의 궤적)을 적극적으로 필터링하고, 수학과 코드에 대해 각각 SFT를 수행한 후 Arcee Fusion을 사용하여 모델을 병합했습니다. (출처: huggingface, teortaxesTex, stablequan)
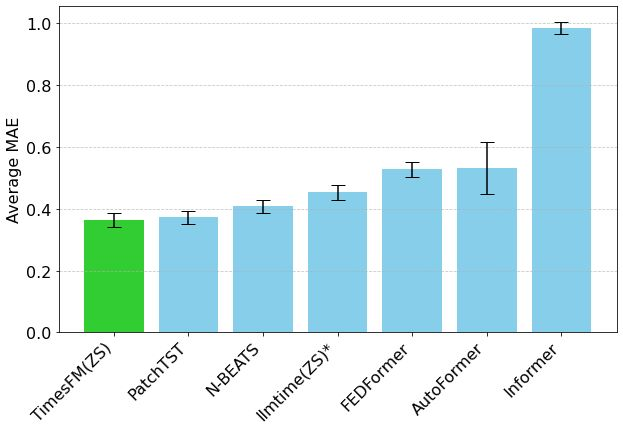
Google TimesFM 시계열 예측 모델, Hugging Face Transformers에 탑재 : Google의 TimesFM 모델이 이제 Hugging Face Transformers 라이브러리에 통합되었습니다. 이는 GPT와 유사한 모델로, Google Trends, Wikipedia 페이지 조회수 등 다양한 출처의 1,000억 개 실제 시점 데이터로 사전 훈련되었습니다. TimesFM은 제로샷(zero-shot) 예측 작업에서 특별히 미세 조정된 모델보다 우수한 성능을 보인다고 알려져 있어 시계열 분석에 새로운 강력한 도구를 제공합니다. (출처: huggingface)
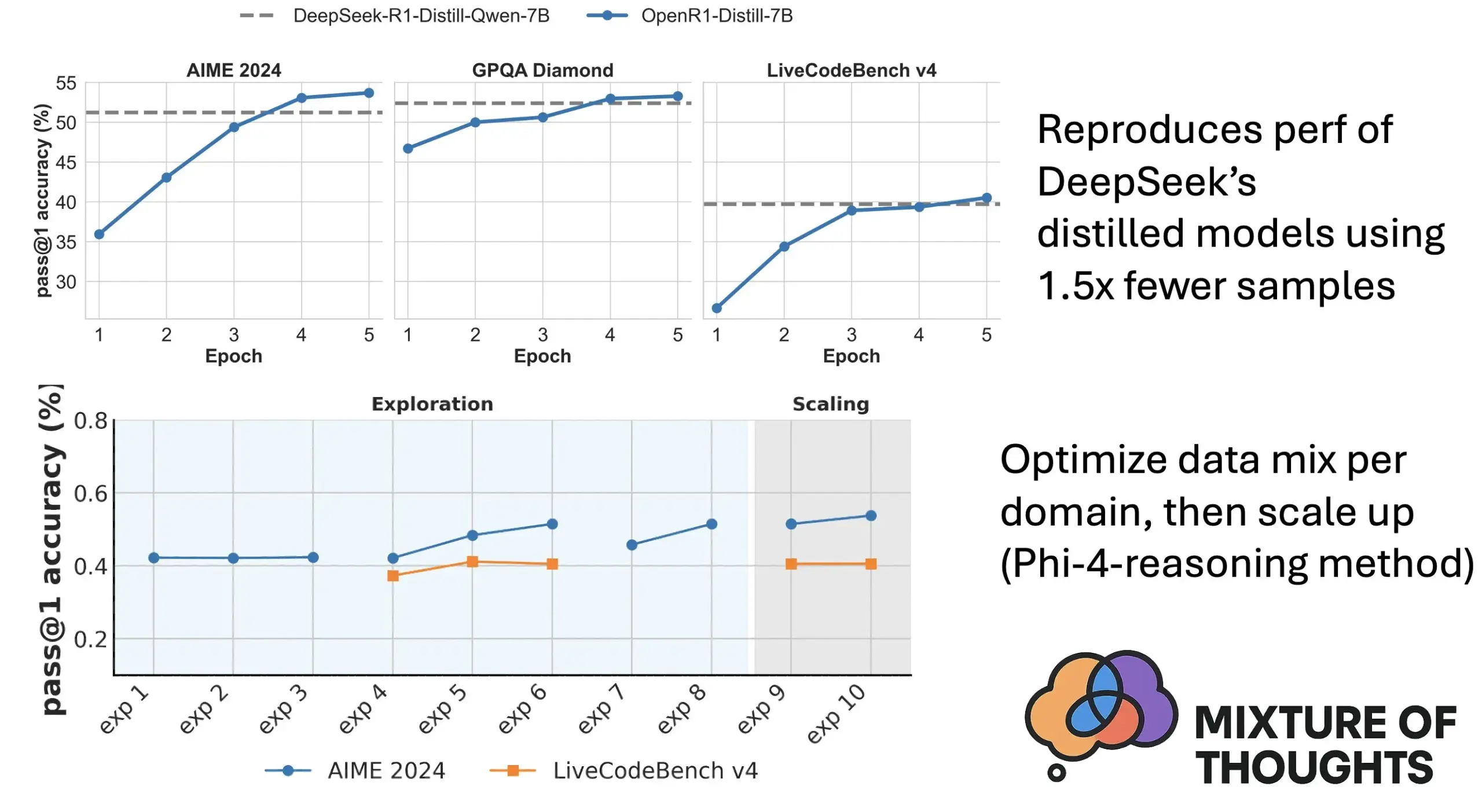
Hugging Face, Mixture of Thoughts 출시: 엄선된 범용 추론 데이터셋 : Hugging Face 연구원 Lewis Tunstall 등이 “Mixture of Thoughts” 데이터셋을 공개했습니다. 이 데이터셋은 100만 개가 넘는 공개 데이터 샘플 중에서 대규모 소거 실험을 통해 약 35만 개의 샘플을 신중하게 선별하여 범용 추론 능력에 중점을 두었습니다. 이 혼합 데이터셋을 사용하여 훈련된 모델은 수학, 코드 및 과학 벤치마크(예: GPQA)에서 DeepSeek의 증류 모델과 동등하거나 그 이상의 성능을 보입니다. 이 연구는 Phi-4-reasoning에서 제안된 “가산성” 방법론의 효과를 검증했으며, 이는 각 추론 영역의 데이터 혼합을 독립적으로 최적화한 다음 최종 훈련을 위해 통합할 수 있음을 의미합니다. (출처: huggingface)
ByteDance, BAGEL-7B 공개: 이미지-텍스트 이해와 생성을 겸비한 전방위 모델 : ByteDance가 이미지와 텍스트를 동시에 이해하고 생성할 수 있는 전방위(omni) 모델인 BAGEL-7B를 출시했습니다. 또한, 문서 분석에 특화된 시각 언어 모델(VLM)인 Dolphin도 공개했습니다. 이러한 모델들의 오픈소스 공개는 멀티모달 연구 및 응용에 새로운 도구와 가능성을 제공할 것입니다. (출처: huggingface, TheTuringPost)

Google, Gemini 2.5 Flash Preview 공개, 네이티브 오디오 출력 지원 : Google AI 개발자들은 Gemini 2.5 Flash Preview가 이제 Live API를 통해 네이티브 오디오 출력을 지원하여 원활하고 자연스러운 음성 상호 작용과 강력한 음성 제어 능력을 제공한다고 발표했습니다. 또한, 이 오디오 모델의 새로운 실험적 “사고” 버전도 출시되어 더 복잡한 작업의 추론 능력을 지원합니다. 동시에 Gemini API의 출력도 “사고 요약”을 보여주기 시작하여 사용자가 모델의 사고 과정을 이해할 수 있도록 하지만, 현재 완전한 추론 체인은 아닙니다. (출처: algo_diver, op7418)
논문, Transformer가 빈칸 토큰 채울 때의 표현 능력 탐구 : 새로운 연구는 Transformer 입력에 빈칸 토큰을 채우는 것(테스트 시 계산 형태)이 LLM의 계산 능력을 향상시킬 수 있는지 탐구합니다. Ashish_S_AI와 협력한 이 연구는 채우기가 있는 Transformer의 표현 능력에 대한 정확한 묘사를 제공하여 LLM의 계산 메커니즘을 이해하고 최적화하는 새로운 시각을 제시합니다. (출처: teortaxesTex)

새 연구, Sci-Fi 프레임워크 제안: 대칭 제약을 통해 비디오 프레임 보간 개선 : 현재 비디오 프레임 보간(Frame Inbetweening) 방법이 시작 프레임과 끝 프레임 제약을 융합할 때 제어 강도가 비대칭적일 수 있는 문제에 대해, 새로운 논문은 Sci-Fi(Symmetric Constraint for Frame Inbetweening) 프레임워크를 제안합니다. 이 방법은 훈련 규모가 작은 제약(예: 끝 프레임)에 더 강력한 주입 메커니즘(경량 모듈 EF-Net 기반)을 적용하여 시작 프레임과 끝 프레임 제약의 대칭성을 구현함으로써 생성된 중간 프레임에서 더 조화로운 전환 효과를 내고 운동 불일치나 외관 붕괴를 방지하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
논문, Paper2Poster 제안: 연구 논문에서 멀티모달 포스터로의 자동화 프로세스 : 학술 포스터 제작의 어려움에 대응하여 연구자들은 최초의 포스터 생성 벤치마크 및 평가 지표 세트인 Paper2Poster를 출시했습니다. 이는 논문과 저자가 디자인한 포스터 쌍을 포함하며, 시각적 품질, 텍스트 일관성, 전체 평가 및 PaperQuiz(포스터가 핵심 내용을 전달하는 능력 측정) 등 여러 측면에서 평가합니다. 동시에 해석기(자산 추출), 계획기(텍스트-시각 정렬 및 레이아웃), 화가-비평가 루프(렌더링 및 피드백 최적화)를 포함하는 하향식, 시각 중심 다중 에이전트 프로세스인 PosterAgent를 제안했습니다. Qwen-2.5 등 오픈소스 모델 기반 변형은 대부분의 지표에서 GPT-4o 기반 시스템보다 우수했으며, 토큰 소모량을 87% 줄여 매우 낮은 비용으로 22페이지 논문을 편집 가능한 .pptx 포스터로 변환할 수 있습니다. (출처: HuggingFace Daily Papers)
논문, Frame In-N-Out 제안: 무한하고 제어 가능한 이미지-비디오 생성 구현 : 비디오 생성에서의 제어 가능성, 시간적 일관성 및 세부 사항 합성 등의 문제에 대응하여, 새로운 논문은 영화 촬영 기술인 “Frame In and Frame Out”에 초점을 맞추어 사용자가 이미지 속 객체가 자연스럽게 장면을 벗어나거나 새로운 신원 참조가 장면으로 들어오도록 제어하고, 사용자가 지정한 운동 궤적에 따라 안내되도록 하는 것을 목표로 합니다. 이를 위해 연구자들은 새로운 반자동 레이블링 데이터셋, 포괄적인 평가 프로토콜, 그리고 효율적인 신원 유지, 운동 제어 가능한 비디오 Diffusion Transformer 아키텍처를 도입했습니다. 실험 결과, 이 방법은 기존 기준선보다 현저히 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
새 연구, Active-O3 제안: GRPO를 통해 멀티모달 대형 언어 모델에 능동적 인식 능력 부여 : 멀티모달 대형 언어 모델(MLLM)의 능동적 인식(active perception) 분야 탐색 부족 문제에 대응하여 연구자들은 Active-O3 프레임워크를 제안했습니다. 이 프레임워크는 GRPO(Group Relative Policy Optimization) 기반의 순수 강화 학습 훈련을 통해 MLLM이 작업 관련 정보를 수집하기 위해 관찰 위치와 방식을 능동적으로 선택할 수 있는 능력을 부여하는 것을 목표로 합니다. 연구자들은 먼저 MLLM 기반 능동적 인식 작업을 체계적으로 정의하고, GPT-o3의 확대 검색 전략이 능동적 인식의 특수한 경우이지만 효율성과 정확성이 부족하다고 지적했습니다. Active-O3는 포괄적인 벤치마크 세트를 구축하여 일반적인 개방형 세계 작업(예: 작은 물체 및 밀집 물체 위치 파악) 및 특정 분야 시나리오(예: 원격 감지, 자율 주행에서의 작은 물체 감지, 세분화된 상호 작용 분할)에서 평가하고, V* Benchmark에서의 강력한 제로샷 추론 능력을 보여주었습니다. (출처: HuggingFace Daily Papers)
논문, MME-Reasoning 제안: 포괄적인 MLLM 논리 추론 능력 벤치마크 테스트 : 기존 벤치마크가 멀티모달 대형 언어 모델(MLLM)의 논리 추론 능력을 평가하는 데 부족한 점을 해결하기 위해 연구자들은 MME-Reasoning을 출시했습니다. 이 벤치마크는 귀납, 연역, 귀추라는 세 가지 주요 논리 추론 유형을 포괄하며, 문제가 인식 기술이나 지식의 폭이 아닌 추론 능력을 효과적으로 평가하도록 데이터를 신중하게 선별했습니다. 평가 결과, 가장 진보된 MLLM조차도 포괄적인 논리 추론 평가에서 한계를 보였으며, 다양한 추론 유형에서 성능 불균형이 존재했습니다. 이 연구는 또한 “사고 패턴”과 규칙 기반 강화 학습과 같은 방법이 추론 능력에 미치는 영향을 분석하여 MLLM의 추론 능력을 이해하고 평가하는 데 체계적인 통찰력을 제공합니다. (출처: HuggingFace Daily Papers)
GraLoRA: 세분화된 저계수 적응을 통한 파라미터 효율적 미세 조정 성능 향상 : LoRA가 계수를 높일 때 발생하는 과적합 및 성능 병목 현상 문제에 대응하여 연구자들은 GraLoRA(Granular Low-Rank Adaptation)를 제안했습니다. 이 방법은 가중치 행렬을 하위 블록으로 나누고 각 하위 블록에 독립적인 저계수 어댑터를 할당하여 LoRA의 구조적 병목 현상으로 인한 기울기 얽힘 및 전파 왜곡 문제를 해결하는 것을 목표로 합니다. GraLoRA는 계산 또는 저장 비용을 거의 증가시키지 않으면서 모델의 표현 능력을 효과적으로 향상시켜 전체 미세 조정 효과에 더 가깝게 만듭니다. 코드 생성 및 상식 추론 벤치마크에서의 실험 결과, GraLoRA는 다양한 모델 크기 및 계수 설정에서 LoRA 및 기타 기준선보다 우수했으며, 예를 들어 HumanEval+에서 Pass@1 절대 이득이 최대 8.5%에 달했습니다. (출처: HuggingFace Daily Papers)
SoloSpeech: 계단식 생성 파이프라인으로 목표 음성 추출의 선명도 및 품질 향상 : 목표 음성 추출(TSE)에서 기존 판별 모델이 인공물을 유발하고 자연스러움을 저해하기 쉬우며, 생성 모델은 인지 품질과 선명도가 부족한 문제에 대응하여 연구자들은 SoloSpeech를 제안했습니다. 이는 압축, 추출, 재구성 및 교정 과정을 통합한 새로운 계단식 생성 파이프라인입니다. 특징은 화자 임베딩이 없는 목표 추출기를 사용하여 프롬프트 오디오 잠재 공간의 조건부 정보를 활용하고 이를 혼합 오디오의 잠재 공간과 정렬하여 불일치를 방지하는 것입니다. Libri2Mix 데이터셋에서의 평가는 SoloSpeech가 목표 음성 추출 및 음성 분리 작업에서 새로운 SOTA 수준에 도달했으며, 도메인 외부 데이터 및 실제 시나리오에서 우수한 일반화 능력을 보였음을 나타냅니다. (출처: HuggingFace Daily Papers)
새 연구, 텍스트 유도 벡터를 통한 멀티모달 대형 언어 모델의 시각 이해 능력 향상 탐구 : 새로운 연구는 멀티모달 대형 언어 모델(MLLM)의 순수 텍스트 LLM 골격망에서 파생된 유도 벡터(희소 자동 인코더 SAE, 평균 이동 및 선형 탐색 등의 방법을 통해 얻음)를 활용하여 시각 이해 능력을 향상시킬 수 있는지 탐구합니다. 연구 결과, 텍스트 파생 유도 벡터는 다양한 MLLM 아키텍처에서 여러 시각 작업의 멀티모달 정확성을 지속적으로 향상시키는 것으로 나타났습니다. 특히, 평균 이동 방법은 CV-Bench에서 공간 관계 정확도를 최대 7.3%, 계수 정확도를 최대 3.3% 향상시켜 프롬프트 방법보다 우수한 성능을 보였으며, 분포 외 데이터셋에 대해 강력한 일반화 능력을 나타냈습니다. 이는 텍스트 유도 벡터가 최소한의 추가 데이터 수집 및 계산 비용으로 MLLM의 시각 기반을 강화할 수 있는 강력하고 효율적인 메커니즘임을 시사합니다. (출처: HuggingFace Daily Papers)
논문, DiSA 제안: 확산 단계 어닐링을 통한 자기 회귀 이미지 생성 가속화 : MAR, FlowAR 등 자기 회귀 모델이 확산 샘플링을 사용하여 이미지 품질을 향상시키지만 추론 효율성이 낮은 문제에 대응하여, 새로운 논문은 DiSA(Diffusion Step Annealing) 방법을 제안합니다. 이 방법은 자기 회귀 과정에서 생성되는 토큰이 많아질수록 후속 토큰의 분포가 더 제한되어 샘플링이 쉬워진다는 관찰에 기반합니다. DiSA는 훈련이 필요 없는 방법으로, 더 많은 토큰을 생성할 때 확산 단계를 점진적으로 줄입니다(예: 초기 50단계에서 후기 5단계로). 이 방법은 기존 확산 자체를 위해 설계된 가속화 방법과 상호 보완적이며 구현이 간단하여 MAR 및 Harmon에서 5-10배, FlowAR 및 xAR에서 1.4-2.5배 속도를 높이면서 생성 품질을 유지합니다. (출처: HuggingFace Daily Papers)
논문, CASS 제안: Nvidia에서 AMD로의 GPU 코드 번역 데이터셋, 모델 및 벤치마크 : 연구자들은 CASS를 출시했습니다. 이는 아키텍처 간 GPU 코드 번역을 위한 최초의 대규모 데이터셋 및 모델 세트로, 소스 코드 수준(CUDA <-> HIP) 및 어셈블리 수준(Nvidia SASS <-> AMD RDNA3) 번역을 목표로 합니다. 데이터셋에는 7만 개의 검증된 교차 호스트 및 장치 코드 쌍이 포함되어 있습니다. 이 리소스를 기반으로 훈련된 CASS 시리즈 도메인 특정 언어 모델은 소스 코드 번역에서 95%의 정확도를, 어셈블리 번역에서 37.5%의 정확도를 달성하여 GPT-4o, Claude 등 상용 기준선보다 현저히 우수합니다. 생성된 코드는 85% 이상의 테스트 사례에서 네이티브 성능과 일치합니다. 동시에 16개 GPU 도메인과 실제 실행 결과를 포함하는 벤치마크 테스트인 CASS-Bench도 공개되었습니다. 모든 데이터, 모델 및 평가 도구는 오픈소스로 공개되었습니다. (출처: HuggingFace Daily Papers)
논문, 시각 언어 모델의 구두 교정 능력 분석 : 한 연구는 시각 언어 모델(VLM)이 자연어를 통해 신뢰도를 표현하는(즉, 구두 불확실성) 효과를 포괄적으로 평가했습니다. 이 연구는 세 가지 유형의 모델, 네 가지 작업 영역 및 세 가지 평가 시나리오에 걸쳐 진행되었으며, 결과는 현재 VLM이 다양한 작업 및 설정에서 종종 명백한 교정 오류를 보인다는 것을 보여줍니다. 주목할 점은 시각 추론 모델(즉, 이미지로 생각하는 모델)이 지속적으로 더 나은 교정성을 보였다는 것인데, 이는 특정 모달리티의 추론이 신뢰할 수 있는 불확실성 추정에 중요함을 시사합니다. 교정 문제에 대응하기 위해 연구자들은 “시각 신뢰도 인식 프롬프트”(Visual Confidence-Aware Prompting)라는 두 단계 프롬프트 전략을 도입하여 멀티모달 설정에서 신뢰도 정렬을 개선하는 것을 목표로 합니다. (출처: HuggingFace Daily Papers)
논문, 대형 언어 모델에서 화용론적 능력의 출현 추적 : 현재 LLM은 사회 지능 작업에서 새로운 능력을 보여주고 있지만, 훈련 과정에서 어떻게 화용론적 능력을 습득하는지는 아직 불분명합니다. 새로운 논문은 화용론 개념 “대안”(alternatives)을 기반으로 설계된 ALTPRAG 데이터셋을 도입하여, 다양한 훈련 단계의 LLM이 미묘한 화자 의도를 정확하게 추론할 수 있는지 평가합니다. 22개 LLM(사전 훈련, SFT 및 선호도 최적화 단계 포함)을 체계적으로 평가한 결과, 기본 모델조차도 화용론적 단서에 대해 상당한 민감성을 보였으며, 모델 및 데이터 규모가 증가함에 따라 지속적으로 개선되었습니다. SFT와 RLHF는 인지적 화용론 추론 능력을 더욱 향상시켰습니다. 이러한 발견은 화용론적 능력이 LLM 훈련에서 출현하는 조합적 속성임을 강조하며, 모델이 인간의 의사소통 규범에 정렬되는 방식에 대한 새로운 통찰력을 제공합니다. (출처: HuggingFace Daily Papers)
Video-Holmes 벤치마크 공개: 복잡한 비디오 추론에서 MLLM의 “셜록 홈즈식” 사고 평가 : 기존 비디오 벤치마크가 주로 시각적 인식 및 위치 파악 능력을 평가하고 복잡한 추론 요구를 충분히 포착하지 못하는 현황에 대응하여, 연구자들은 Video-Holmes 벤치마크를 출시했습니다. 이 벤치마크는 셜록 홈즈의 추론 과정에서 영감을 받아 수동으로 레이블링된 270편의 서스펜스 단편 영화에서 추출한 1837개의 질문을 포함하며, 7개의 신중하게 설계된 작업을 포괄합니다. 각 작업은 모델이 다양한 비디오 클립에 흩어져 있는 여러 관련 시각적 단서를 능동적으로 찾아 연결하도록 요구합니다. SOTA MLLM에 대한 평가는 모델이 시각적 인식에서는 뛰어난 성능을 보이지만 정보 통합에서는 상당한 어려움을 겪으며 종종 중요한 단서를 놓친다는 것을 보여줍니다. 예를 들어, 가장 성능이 좋은 Gemini-2.5-Pro의 정확도는 45%에 불과했습니다. (출처: HuggingFace Daily Papers)
MME-VideoOCR 벤치마크 공개: 비디오 장면에서 멀티모달 LLM의 OCR 능력 평가 : 멀티모달 대형 언어 모델(MLLM)이 정적 이미지 OCR에서 상당한 진전을 이루었음에도 불구하고, 비디오 OCR에서는 모션 블러, 시간적 변화 및 시각 효과 등의 요인으로 인해 효과가 감소합니다. 실용적인 MLLM 훈련을 안내하기 위해 연구자들은 광범위한 비디오 OCR 응용 시나리오를 포괄하는 MME-VideoOCR 벤치마크를 출시했습니다. 이 벤치마크는 10개의 작업 범주(25개의 독립적인 작업)를 포함하며 44가지 다양한 시나리오를 다룹니다. 텍스트 인식뿐만 아니라 비디오 내 텍스트 내용에 대한 더 깊은 이해와 추론도 포함합니다. 벤치마크는 다양한 해상도, 가로 세로 비율 및 길이의 비디오 1464개와 신중하게 기획된 인공 레이블링된 질의응답 쌍 2000개로 구성됩니다. 18개의 SOTA MLLM에 대한 평가는 가장 성능이 좋은 Gemini-2.5 Pro조차도 정확도가 73.7%에 불과하여, 전체 비디오 이해가 필요한 작업을 처리할 때 기존 모델의 한계를 드러냈습니다. (출처: HuggingFace Daily Papers)
MetaMind: 메타인지 다중 에이전트 시스템을 통한 인간 사회적 사고 모델링 : 대형 언어 모델(LLM)이 인간 의사소통에 내재된 모호성과 상황적 미묘함을 처리하는 데 부족한 점을 메우기 위해, 연구자들은 심리학적 메타인지 이론에서 영감을 받은 다중 에이전트 프레임워크인 MetaMind를 출시했습니다. 이는 인간과 유사한 사회적 추론을 모방하는 것을 목표로 합니다. MetaMind는 사회적 이해를 세 가지 협력 단계로 분해합니다: (1) 마음 이론 에이전트가 사용자 심리 상태(예: 의도, 감정)에 대한 가설을 생성합니다. (2) 영역 에이전트가 문화적 규범과 윤리적 제약을 사용하여 이러한 가설을 구체화합니다. (3) 응답 에이전트가 상황에 적절한 응답을 생성하는 동시에 추론된 의도와의 일관성을 검증합니다. 이 프레임워크는 세 가지 도전적인 벤치마크 테스트에서 SOTA 성능을 달성했으며, 실제 사회적 시나리오에서 35.7%, 마음 이론 추론에서 6.2% 향상되었고, 처음으로 LLM이 핵심 마음 이론 작업에서 인간 수준에 도달하도록 했습니다. (출처: HuggingFace Daily Papers)
Sparse VideoGen2: 의미론적 인식 순열 및 희소 주의를 통한 비디오 생성 가속화 : Diffusion Transformers(DiT) 기반 비디오 생성 모델이 긴 비디오를 처리할 때 직면하는 상당한 지연 시간과 높은 메모리 비용 문제에 대응하여 연구자들은 SVG2 프레임워크를 제안했습니다. 이 프레임워크는 의미론적 인식 순열(k-means를 사용하여 의미론적 유사성에 따라 토큰을 클러스터링하고 재정렬)을 통해 핵심 토큰 식별의 정확성을 극대화하고 계산 낭비를 최소화하여 생성 품질과 효율성 간의 파레토 최적 균형을 달성합니다. SVG2는 또한 top-p 동적 예산 제어 및 맞춤형 커널 구현을 통합하여 HunyuanVideo 및 Wan 2.1에서 각각 최대 2.30배 및 1.89배의 가속을 달성하면서 높은 PSNR을 유지했습니다. (출처: HuggingFace Daily Papers)
OmniConsistency: 쌍으로 구성된 스타일화 데이터로부터 스타일과 무관한 일관성 학습 : 확산 모델이 이미지 스타일화에서 직면하는 복잡한 장면 일관성 유지(특히 정체성, 구성 및 세부 사항) 문제와 이미지-이미지 변환 과정에서 스타일 LoRA로 인한 스타일 저하라는 두 가지 주요 과제를 해결하기 위해 연구자들은 OmniConsistency를 제안했습니다. 이는 대규모 확산 변환기(DiT)를 활용하는 범용 일관성 플러그인입니다. 주요 기여는 다음과 같습니다: (1) 정렬된 이미지 쌍을 기반으로 훈련된 컨텍스트 일관성 학습 프레임워크로, 견고한 일반화를 달성합니다. (2) 스타일 학습과 일관성 유지를 분리하여 스타일 저하를 완화하는 2단계 점진적 학습 전략입니다. (3) Flux 프레임워크 하의 모든 스타일 LoRA와 호환되는 완전한 플러그 앤 플레이 디자인입니다. 실험 결과, OmniConsistency는 시각적 일관성과 미적 품질을 현저히 향상시켜 상용 SOTA 모델인 GPT-4o와 동등한 성능을 달성했습니다. (출처: HuggingFace Daily Papers)
ImgEdit: 통일된 이미지 편집 데이터셋 및 벤치마크 테스트 : 오픈소스 이미지 편집 모델이 독점 모델에 비해 뒤처지는 문제(주로 고품질 데이터 부족과 벤치마크 미비로 인해)를 해결하기 위해 연구자들은 ImgEdit을 출시했습니다. 이는 120만 개의 신중하게 선별된 편집 쌍을 포함하는 대규모 고품질 이미지 편집 데이터셋으로, 새롭고 복잡한 단일 라운드 편집과 도전적인 다중 라운드 작업을 포괄합니다. 데이터 품질을 보장하기 위해 최첨단 시각 언어 모델, 탐지 모델, 분할 모델 및 특정 작업용 복원 프로그램과 엄격한 후처리를 통합한 다단계 프로세스를 채택했습니다. ImgEdit으로 훈련된 편집 모델 ImgEdit-E1은 여러 작업에서 기존 오픈소스 모델보다 우수한 성능을 보였습니다. 동시에 출시된 ImgEdit-Bench 벤치마크는 지침 준수, 편집 품질 및 세부 사항 보존 측면에서 이미지 편집 성능을 평가하는 데 사용됩니다. (출처: HuggingFace Daily Papers)
논문, 유도 목표 원자를 통한 LLM의 견고한 행동 제어 제안 : 언어 모델 생성의 정확한 제어를 통해 안전성과 신뢰성을 확보하기 위해, 새로운 논문은 “유도 목표 원자”(Steering Target Atoms, STA) 방법을 제안합니다. 이 방법은 분리된 지식 구성 요소를 분리하고 조작하여 안전성을 향상시키는 것을 목표로 하며, 특히 적대적 시나리오에서 우수한 견고성과 유연성을 보여줍니다. 연구자들은 프롬프트 엔지니어링과 유도가 모델 행동 개입에 일반적으로 사용되지만, 모델 파라미터의 높은 얽힘이 제어 정밀도를 제한하고 부작용을 유발할 수 있다고 주장합니다. STA는 희소 자동 인코더(SAE)를 활용하여 고차원 공간에서 지식을 분리하고 이를 유도함으로써 더 정확한 행동 제어를 달성합니다. 실험은 이 방법의 효과를 입증했으며, 대규모 추론 모델에 적용되어 정확한 추론 제어에서의 잠재력을 확인했습니다. (출처: HuggingFace Daily Papers)
논문, SeePhys 벤치마크 제안: 시각 기반 물리 추론 능력 평가 : 연구자들은 SeePhys를 출시했습니다. 이는 중학교부터 박사 자격 시험 수준의 물리 문제에 대한 LLM의 추론 능력을 평가하기 위한 대규모 멀티모달 벤치마크입니다. 이 벤치마크는 물리 과목의 7개 기본 영역을 포괄하며, 21가지 유형의 매우 이질적인 다이어그램을 포함합니다. 이전 연구에서 시각적 요소가 주로 보조적인 역할을 했던 것과 달리, SeePhys에서는 문제의 75%가 시각적으로 필수적입니다. 즉, 올바르게 답하기 위해서는 시각 정보를 추출해야 합니다. 광범위한 평가는 가장 진보된 시각 추론 모델(예: Gemini-2.5-pro 및 o4-mini)조차도 이 벤치마크에서 정확도가 60% 미만임을 보여주며, 현재 LLM이 시각 이해, 특히 다이어그램 해석과 물리 추론의 엄격한 결합 및 텍스트 단서에 대한 인지적 지름길 의존성 극복에서 근본적인 어려움을 겪고 있음을 드러냅니다. (출처: HuggingFace Daily Papers)
VerIPO: 검증기 유도 반복 정책 최적화를 통한 Video-LLM의 장기 추론 능력 향상 : 강화 학습을 비디오 대형 언어 모델(Video-LLM)에 적용할 때 복잡한 비디오 추론에서 직면하는 데이터 준비 병목 현상과 연쇄적 사고(CoT) 품질 불안정 문제에 대응하여, 연구자들은 VerIPO(Verifier-guided Iterative Policy Optimization) 방법을 제안했습니다. 이 방법의 핵심은 GRPO와 DPO 훈련 단계 사이에 위치한 “Rollout-Aware Verifier”로, 추론 논리를 평가하고 고품질의 대조 데이터(성찰적이고 문맥 일관적인 CoT 포함)를 구축하는 데 사용됩니다. 이러한 데이터는 효율적인 DPO 단계를 구동하여 추론 체인의 길이와 문맥 일관성을 향상시킵니다. 실험 결과, VerIPO는 모델을 더 빠르고 효과적으로 최적화하여 더 길고 문맥 일관적인 CoT를 생성하며, 표준 GRPO 변형 및 일부 대규모 지침 미세 조정 Video-LLM 및 장기 추론 모델보다 우수한 성능을 보였습니다. (출처: HuggingFace Daily Papers)
OpenS2V-Nexus: 주체-비디오 생성을 위한 상세 벤치마크 및 백만 단위 데이터셋 : 주체-비디오(S2V) 생성 기술 발전을 촉진하기 위해 연구자들은 OpenS2V-Nexus를 제안했습니다. 이는 (i) 세분화된 벤치마크인 OpenS2V-Eval과 (ii) 백만 단위 데이터셋인 OpenS2V-5M을 포함합니다. 기존 S2V 벤치마크(VBench에서 파생되어 전역적이고 거친 수준의 평가에 중점)와 달리, OpenS2V-Eval은 모델이 주체 일관성, 자연스러운 외관 및 신원 충실도가 높은 비디오를 생성하는 능력에 중점을 둡니다. 이를 위해 OpenS2V-Eval은 7개 주요 S2V 범주에서 180개의 프롬프트를 도입했으며, 실제 및 합성 테스트 데이터를 포함합니다. 또한, 인간 선호도와 정확하게 정렬하기 위해 연구자들은 생성된 비디오의 주체 일관성, 자연스러움 및 텍스트 관련성을 각각 정량화하는 세 가지 자동 측정 지표인 NexusScore, NaturalScore 및 GmeScore를 제안했습니다. 이를 기반으로 16개의 대표적인 S2V 모델을 포괄적으로 평가했습니다. 동시에, 500만 개의 고품질 720P 주체-텍스트-비디오 삼중항을 포함하는 최초의 오픈소스 대규모 S2V 생성 데이터셋인 OpenS2V-5M을 만들었습니다. (출처: HuggingFace Daily Papers)
논문, WHISTRESS 제안: 문장 강세 감지를 통한 전사 텍스트 강화 : 구어에서 문장 강세가 화자의 의도를 전달하는 데 중요하지만 기존 전사 시스템에서는 누락되는 문제에 대응하여, 새로운 논문은 정렬이 필요 없는 문장 강세 감지 방법인 WHISTRESS를 소개합니다. 이 작업을 지원하기 위해 연구자들은 완전 자동화된 프로세스를 통해 생성된 확장 가능한 합성 훈련 데이터셋인 TINYSTRESS-15K를 제안했습니다. 이 데이터셋에서 훈련된 WHISTRESS 모델은 기존 기준선보다 우수한 성능을 보이며, 추가적인 훈련이나 추론 사전 입력이 필요하지 않습니다. 주목할 점은 합성 데이터를 기반으로 훈련되었음에도 불구하고 WHISTRESS가 다양한 벤치마크 테스트에서 강력한 제로샷 일반화 능력을 보였다는 것입니다. (출처: HuggingFace Daily Papers)
논문, InstructPart 제안: 지침 추론을 통한 작업 지향 부품 분할 : 대형 멀티모달 기반 모델이 다양한 작업에서 진전을 이루었음에도 불구하고, 많은 모델이 물체를 분할할 수 없는 전체로 간주하여 물체를 구성하는 부품을 무시합니다. 이러한 부품과 관련 기능 가시성(affordances)을 이해하는 것은 광범위한 작업을 수행하는 데 중요합니다. 이를 위해 연구자들은 수동으로 레이블링된 부품 분할 주석과 작업 지향 지침을 포함하는 새로운 실제 세계 벤치마크 InstructPart를 도입하여, 현재 모델이 일상 상황에서 부품 수준 작업을 이해하고 수행하는 성능을 평가합니다. 실험 결과, SOTA 시각 언어 모델(VLM)조차도 작업 지향 부품 분할이 여전히 어려운 문제임을 보여줍니다. 벤치마크 외에도 연구자들은 데이터셋을 사용하여 미세 조정함으로써 성능을 두 배로 향상시키는 간단한 기준선을 도입했습니다. (출처: HuggingFace Daily Papers)
논문, 혼합 신경-MPM 방법 제안, 실시간 대화형 유체 시뮬레이션 구현 : 기존 물리 방법의 계산 집약적이고 지연 시간이 긴 문제, 그리고 최근 머신러닝 방법이 비용을 절감했지만 여전히 실시간 대화형 요구를 충족하기 어려운 유체 시뮬레이션 문제를 해결하기 위해, 연구자들은 새로운 혼합 방법을 제안했습니다. 이 방법은 수치 시뮬레이션, 신경 물리학 및 생성적 제어를 통합합니다. 신경 물리학은 고전적인 수치 해결기로 되돌아가는 보장 메커니즘을 통해 낮은 지연 시간 시뮬레이션과 높은 물리적 충실도를 동시에 추구합니다. 또한, 연구자들은 역방향 모델링 전략을 사용하여 훈련된 확산 기반 컨트롤러를 개발하여 유체 조작을 위한 외부 동적 힘장을 생성합니다. 이 시스템은 다양한 2D/3D 시나리오, 재료 유형 및 장애물 상호 작용에서 견고한 성능을 보여주며, 높은 프레임 속도의 실시간 시뮬레이션(11~29% 지연 시간)을 구현하고 사용자 친화적인 손으로 그린 스케치를 통해 유체 제어를 안내할 수 있습니다. (출처: HuggingFace Daily Papers)
MMIG-Bench: 멀티모달 이미지 생성 모델을 위한 포괄적인 해석 가능 평가 벤치마크 : 기존 평가 도구가 GPT-4o, Gemini 2.0 Flash 및 Gemini 2.5 Pro와 같은 멀티모달 이미지 생성기를 평가하는 데 한계가 있는 점(예: T2I 벤치마크는 멀티모달 조건 부족, 맞춤형 이미지 생성 벤치마크는 조합 의미론 및 상식 무시)에 대응하여 연구자들은 MMIG-Bench를 제안했습니다. 이는 4850개의 풍부하게 주석 처리된 텍스트 프롬프트와 380개 주체(사람, 동물, 물체, 예술 스타일)를 포괄하는 1750개의 다중 시점 참조 이미지를 포함하는 포괄적인 멀티모달 이미지 생성 벤치마크입니다. MMIG-Bench는 세 가지 수준의 평가 프레임워크를 갖추고 있습니다: (1) 저수준 지표는 시각적 인공물과 물체 정체성 유지를 평가합니다. (2) 새로운 측면 일치 점수(AMS): VQA 기반의 중간 수준 지표로, 세분화된 프롬프트-이미지 정렬을 제공하며 인간 판단과 높은 상관 관계를 가집니다. (3) 고수준 지표는 미적 감각과 인간 선호도를 평가합니다. MMIG-Bench를 통해 17개의 SOTA 모델을 벤치마킹하고 3만 2천 개의 인간 평점으로 지표를 검증하여 아키텍처 및 데이터 설계에 대한 심층적인 통찰력을 제공합니다. (출처: HuggingFace Daily Papers)
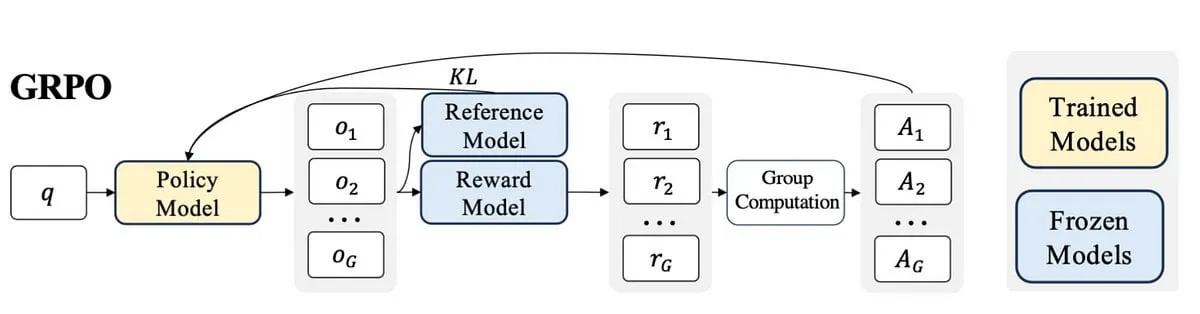
논문, HRPO 제안: 강화 학습을 통한 혼합 잠재 추론 : 기존 잠재 추론 방법이 LLM의 자기 회귀 생성 특성과 호환되지 않고 CoT 궤적에 의존하여 훈련하는 문제에 대응하여 연구자들은 HRPO(Hybrid Reasoning Policy Optimization)를 제안했습니다. 이는 강화 학습 기반의 혼합 잠재 추론 방법으로, 학습 가능한 게이팅 메커니즘을 통해 이전 숨겨진 상태를 샘플링된 토큰에 통합하고 토큰 임베딩을 주축으로 초기 훈련을 시작하여 점진적으로 더 많은 숨겨진 특징을 통합합니다. 이러한 설계는 LLM의 생성 능력을 유지하고 이산적 및 연속적 표현을 사용한 혼합 추론을 장려합니다. 또한, HRPO는 토큰 샘플링을 통해 잠재 추론에 무작위성을 도입하여 CoT 궤적 없이 RL 기반 최적화를 가능하게 합니다. 다양한 벤치마크에서의 광범위한 평가는 HRPO가 지식 집약적 및 추론 집약적 작업 모두에서 이전 방법보다 우수함을 보여줍니다. (출처: HuggingFace Daily Papers)
논문, NFT 방법 제안: 수학 추론에서 지도 학습과 강화 학습 연결 : “자기 향상은 강화 학습(RL)에만 국한된다”는 일반적인 관념에 도전하며, 새로운 논문은 부정적 인식 미세 조정(Negative-aware Fine-Tuning, NFT) 방법을 제안합니다. 이는 LLM이 실패를 반성하고 외부 교사 없이 자율적으로 개선할 수 있도록 하는 지도 학습 방법입니다. 온라인 훈련에서 NFT는 자체 생성된 오답을 버리지 않고 이를 모델링하기 위한 암묵적인 부정적 정책을 구축합니다. 이 암묵적 정책은 긍정적 데이터에서 최적화하는 데 사용되는 목표 긍정적 LLM과 동일하게 매개변수화되어 모든 LLM 생성에 대해 직접적인 정책 최적화를 가능하게 합니다. 7B 및 32B 모델에서의 수학 추론 작업 실험 결과, 부정적 피드백을 추가로 활용함으로써 NFT는 거부 샘플링 미세 조정과 같은 지도 학습 기준선보다 현저히 우수하며, GRPO 및 DAPO와 같은 주요 RL 알고리즘과 동등하거나 그 이상의 성능을 달성했습니다. 연구자들은 엄격한 온라인 정책 훈련에서 NFT와 GRPO가 실제로 동등함을 추가로 증명했습니다. (출처: HuggingFace Daily Papers)
논문, Minute-Long Videos with Dual Parallelisms 제안: 분 단위 비디오 생성 구현 : DiT 기반 비디오 확산 모델이 긴 비디오를 생성할 때 직면하는 계산 지연 및 메모리 비용 과다 문제에 대응하여 연구자들은 새로운 분산 추론 전략인 DualParal을 제안했습니다. 이 방법의 핵심 아이디어는 시간 프레임과 모델 계층을 여러 GPU에 병렬화하는 것입니다. 확산 모델이 프레임 간 노이즈 수준 동기화를 요구하여 발생하는 원래 병렬성의 직렬화 문제를 해결하기 위해, 이 방법은 분할된 노이즈 제거 방식을 채택합니다. 즉, 일련의 프레임 블록을 파이프라인 처리하고 점진적으로 노이즈 수준을 낮춥니다. 각 GPU는 특정 블록과 계층 하위 집합을 처리하고 이전 결과를 다음 GPU로 전달하여 비동기 계산 및 통신을 구현합니다. 또한, 각 GPU에 특징 캐싱을 구현하여 이전 블록의 특징을 컨텍스트로 재사용하고 조정된 노이즈 초기화 전략을 채택하여 전역적으로 일관된 시간 동역학을 보장함으로써 빠르고 인공물 없는 무한 길이의 비디오 생성을 가능하게 합니다. 최신 확산 변환기 비디오 생성기에 적용된 이 방법은 8개의 RTX 4090 GPU에서 1025 프레임 비디오를 효율적으로 생성하여 지연 시간을 최대 6.54배 줄이고 메모리 비용을 1.48배 절감했습니다. (출처: HuggingFace Daily Papers)
🧰 도구
Claude 4 시리즈 모델, 프로그래밍 작업에서 뛰어난 성능 발휘, 숙련된 프로그래머가 4년간 해결 못한 “백경 버그” 해결 : Anthropic이 최근 출시한 Claude Opus 4 모델이 프로그래밍 능력에서 놀라운 실력을 보여주었습니다. 30년 경력의 C++ 개발 경험을 가진 전 FAANG 엔지니어는 자신의 팀이 4년간, 본인이 약 200시간을 투자해도 해결하지 못한 복잡한 시스템 버그(특정 셰이더가 특정 방식으로 사용될 때 발생하는 경계 조건 문제)를 Claude Opus 4가 몇 시간 만에 약 30개의 프롬프트를 통해 성공적으로 원인을 찾아냈다고 공유했습니다. 이 버그는 시스템 재구축 전에는 존재하지 않았으며, Opus 4는 새로운 아키텍처가 기존 아키텍처에서 “우연히” 지원되던 비설계적 동작을 호환하지 못해 발생했다고 지적했습니다. 이전에는 GPT-4.1, Gemini 2.5 및 Claude 3.7 모두 이 문제를 해결하지 못했습니다. 이는 Claude 4가 복잡한 코드를 이해하고 심층 분석 및 추론을 수행하는 데 강력한 능력을 가지고 있음을 보여주며, 특히 Claude Code 모드와 결합하면 개발자가 코드 재구축, 버그 수정 등 고급 엔지니어링 작업을 처리하는 데 효과적으로 도움을 줄 수 있음을 시사합니다. (출처: 36氪, dotey)
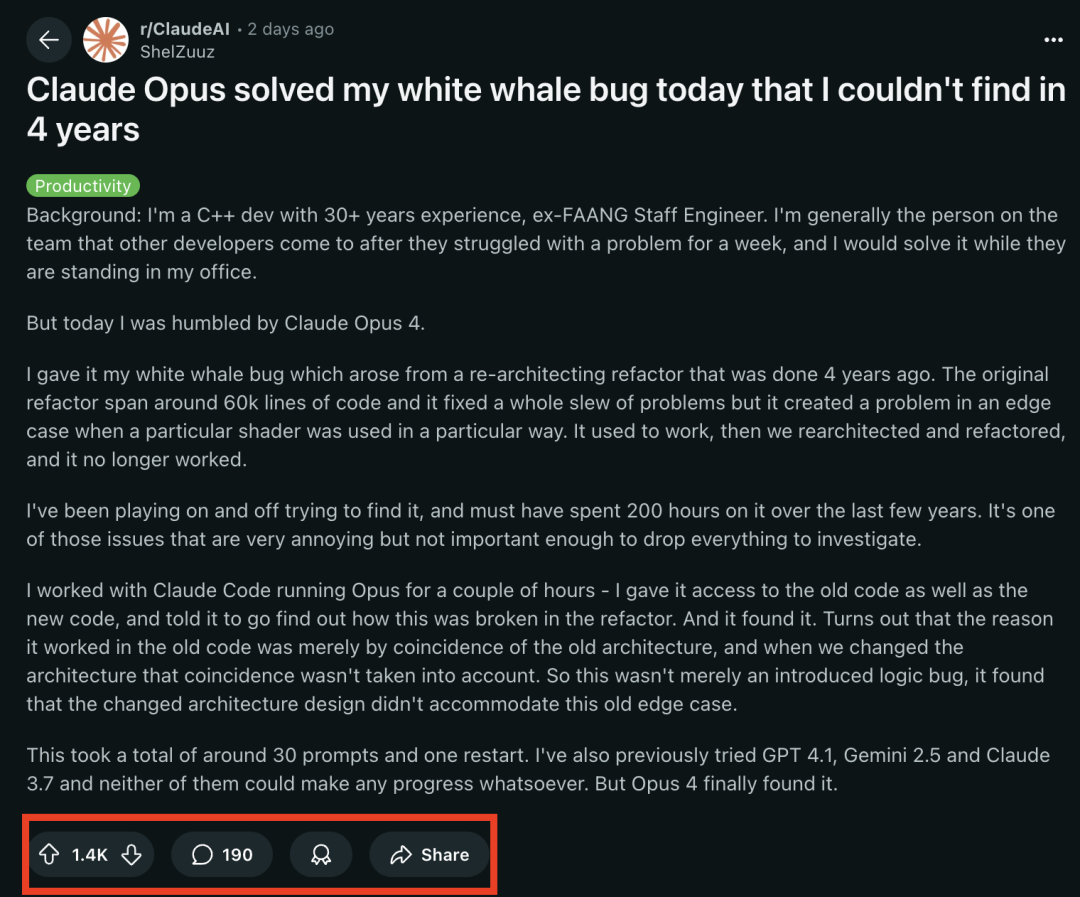
LangChain, Anthropic Claude의 새로운 베타 기능 지원 추가 : LangChain은 Anthropic Claude 모델이 최근 발표한 코드 실행, 원격 MCP 커넥터, 파일 API 및 확장된 프롬프트 캐싱 등 4가지 새로운 베타 기능을 통합했다고 발표했습니다. 개발자는 이제 LangChain 문서를 통해 관련 예제를 확인하고 이러한 새로운 기능을 활용하여 더욱 강력한 AI 애플리케이션을 구축할 수 있습니다. (출처: LangChainAI)
LangSmith, SDLC와 통합된 프롬프트 관리 기능 출시 : LangSmith 플랫폼은 프롬프트 엔지니어링 기능을 강화하여, 이제 사용자는 LangSmith에서 프롬프트를 테스트, 버전 관리 및 공동 작업할 수 있을 뿐만 아니라 프롬프트 변경 시 웹훅 트리거를 통해 프롬프트를 GitHub, 외부 데이터베이스에 자동으로 동기화하거나 CI/CD 프로세스를 시작할 수 있습니다. 이 기능은 개발자가 프롬프트 관리를 소프트웨어 개발 수명 주기(SDLC)에 더욱 긴밀하게 통합하는 데 도움을 주기 위해 설계되었습니다. (출처: LangChainAI)
AutoThink: 로컬 LLM 추론 성능 향상을 위한 적응형 기술 : CodeLion 팀은 적응형 리소스 할당과 스티어링 벡터(steering vectors)를 통해 로컬 LLM의 추론 성능을 현저히 개선하는 AutoThink 기술을 개발했습니다. AutoThink는 쿼리 복잡도를 분류하고 “사고 토큰”(복잡한 문제에는 더 많이, 간단한 문제에는 더 적게 할당)을 동적으로 할당하며 스티어링 벡터를 사용하여 추론 패턴을 유도합니다. DeepSeek-R1-Distill-Qwen-1.5B 모델에서의 테스트 결과, GPQA-Diamond 정확도가 43% 향상(21.72%에서 31.06%로)되었고 MMLU-Pro도 향상되었으며 토큰 사용량은 더 적었습니다. 이 기술은 사고 토큰을 지원하는 로컬 추론 모델과 호환되며 코드와 연구 결과가 공개되었습니다. (출처: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab, AMD ROCm 지원 발표, 로컬 LLM 훈련 가능 : Transformer Lab은 자사의 GUI 플랫폼이 이제 AMD GPU에서 ROCm을 사용하여 대형 언어 모델의 로컬 훈련 및 미세 조정을 지원한다고 발표했습니다. 팀은 ROCm 구성 과정이 어려웠으며 전체 과정을 블로그에 기록했다고 밝혔습니다. 현재 이 기능은 원활하게 사용할 수 있으며 사용자는 AMD 하드웨어에서 LLM 개발 작업을 시도해 볼 수 있습니다. (출처: Reddit r/MachineLearning)
오픈소스 LLM 강화 다중 에이전트 시스템, 자동화된 주장 추출 및 사실 확인 구현 : “fact-checker”라는 오픈소스 프로젝트는 LLM 강화 다중 에이전트 시스템(MAS)을 활용하여 자동화된 주장 추출, 증거 검증 및 사실 해결을 구현합니다. 이 프로젝트에는 브라우저 확장 프로그램이 포함되어 있어 모든 AI 챗봇의 응답을 실시간으로 사실 확인할 수 있으며, AI 생성 콘텐츠의 진위 여부를 식별하는 데 도움이 됩니다. 코드 아키텍처가 명확하고 문서가 잘 갖춰져 있어 AI 안전 및 잘못된 정보 대응 분야에 가치 있는 도구를 제공합니다. (출처: Reddit r/MachineLearning)
Meituan, 코드 없는 제품 Nocode 출시, 복잡한 다중 페이지 애플리케이션 생성 지원 : Meituan이 Nocode라는 Vibe Coding 제품을 출시했습니다. 사용자는 자연어 설명을 통해 단순한 전시형 웹페이지뿐만 아니라 여러 페이지를 포함하는 복잡한 완전한 애플리케이션을 생성할 수 있습니다. Guicang의 테스트 결과, 이 도구는 논리적으로 복잡한 창고 상품 관리 도구를 한 번에 성공적으로 구축하여 복잡한 요구 사항을 이해하고 해당 코드를 생성하는 능력을 보여주었습니다. (출처: op7418)
LlamaIndex, 맞춤형 멀티모달 임베더 구축 및 OpenAI 스타일 채팅 UI 통합 지원 : LlamaIndex가 업데이트를 발표하여 사용자가 AWS Titan Multimodal과 같은 맞춤형 멀티모달 임베더를 구축하고 Pinecone과 같은 벡터 데이터베이스와 결합하여 효율적인 텍스트+이미지 벡터 검색을 수행할 수 있도록 지원합니다. 또한, LlamaIndex 워크플로는 이제 몇 줄의 코드로 OpenAI와 유사한 채팅 인터페이스에서 실행될 수 있으며, UI에서 직접 워크플로 코드를 편집하는 개발 모드를 지원하여 RAG 애플리케이션의 개발 및 상호 작용 경험을 향상시킵니다. (출처: jerryjliu0, jerryjliu0)

TRAE 업데이트, Agentic 코딩 경험 향상, 해외 버전 유료 구독 시작 : AI 프로그래밍 도구 TRAE가 업데이트되어 Agentic 코딩 경험을 최적화하여 수동 조작을 원치 않는 사용자에게 더 적합해졌습니다. 새로운 버전의 TRAE는 이전 대화를 더 잘 기억하고 컨텍스트를 자동으로 연결하며, AI가 프로그래밍 경로를 자동으로 계획하고 더 많은 도구를 호출하여 프로그래밍 작업 성공률을 높였습니다. 예를 들어, 사용자가 빈 폴더와 프롬프트만 제공하면 TRAE는 파일 생성, 웹 서버 시작(교차 도메인 문제 자동 처리) 및 IDE 내 p5.js 애니메이션 미리보기 등 일련의 작업을 완료할 수 있습니다. 해외 버전은 유료 구독을 시작했으며, 첫 달 Pro 가격은 3달러이고 Alipay를 지원합니다. (출처: dotey, karminski3)
Juejin 커뮤니티, MCP 서비스 출시, 프론트엔드 코드 원클릭 배포 지원 : 중국 프로그래머 커뮤니티 Juejin이 MCP(Model-driven Co-programming Protocol) 서비스를 출시하여 개발자가 프론트엔드 코드(예: vibe coding으로 생성된 웹페이지, 게임)를 Juejin 플랫폼에 원클릭으로 배포하여 빠르고 쉽게 공유하고 미리 볼 수 있도록 지원합니다. 사용자는 Juejin MCP의 토큰을 받아 Trae, Cursor 등 도구에서 구성해야 합니다. (출처: dotey, karminski3)
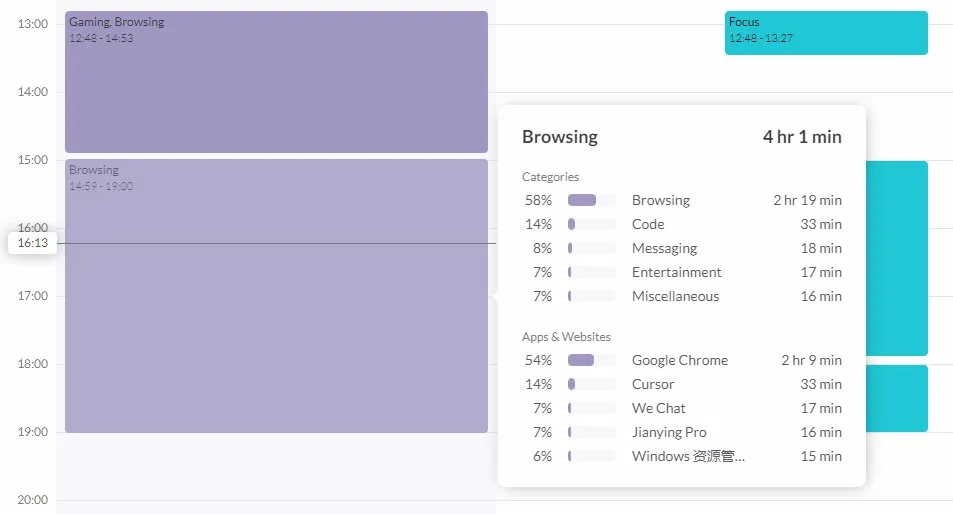
오픈소스 시간 추적 도구 ActivityWatch, Rize 대체재로 주목 : 사용자 karminski3가 AI 시간 분석 도구 Rize(프로세스 이름을 분석하여 업무, 회의 또는 딴짓 상태를 판단, 월 20달러)를 체험한 후 오픈소스 대체재인 ActivityWatch를 발견하고 추천했습니다. ActivityWatch는 기능이 유사하며 Windows/Mac을 지원하고 사용자가 직접 설정할 수 있어 업무 불안을 완화하고 작업 시간을 추적하는 데 훌륭한 도구로 평가받고 있습니다. (출처: karminski3)
오픈소스 AI 육아 도우미 ai-baby-monitor 공개 : ai-baby-monitor라는 오픈소스 프로젝트가 공개되었습니다. 이 프로젝트는 Qwen2.5 VL 모델과 vLLM 추론 프레임워크를 사용하여 사용자가 규칙(“아이가 일어나면 알람”, “아이가 혼자 있으면 알람” 등)을 정의하여 AI가 아기 돌보기를 보조하도록 합니다. 개발자는 이것이 보조 도구일 뿐이며 인공적인 돌봄을 완전히 대체할 수는 없다고 강조했습니다. (출처: karminski3)
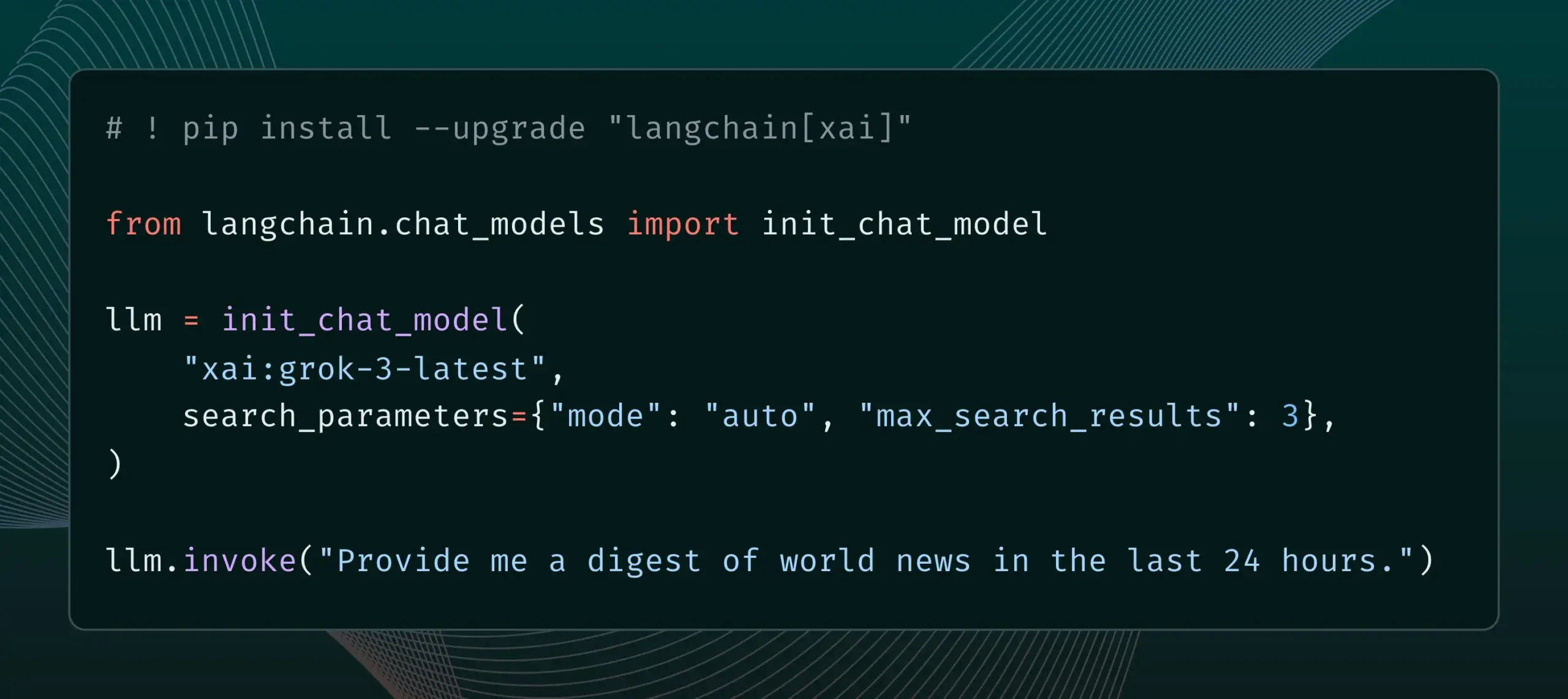
LangChain, xAI의 Live Search 기능 통합 : LangChain은 xAI의 Live Search 기능을 지원한다고 발표했습니다. 이 기능은 Grok 모델이 답변을 생성할 때 웹 검색 결과를 기반으로 하며, 기간, 포함된 도메인 등 다양한 검색 매개변수 구성 옵션을 제공합니다. 사용자는 이제 LangChain에서 이 새로운 기능을 사용해 볼 수 있습니다. (출처: LangChainAI)
Curie: 오픈소스 AI 과학 연구 조수, AutoML 기능 공개, 학제 간 연구 지원 : 생물학, 재료학, 화학 등 분야의 연구원들이 머신러닝을 적용할 때 직면하는 전문 지식 장벽에 대응하기 위해 Curie 프로젝트가 새로운 AutoML 기능을 출시했습니다. Curie는 AI 연구 실험의 협력 과학자가 되는 것을 목표로 하며, 복잡한 ML 프로세스(알고리즘 선택, 하이퍼파라미터 조정, 모델 출력 해석 등)를 자동화하여 연구원들이 가설을 신속하게 테스트하고 데이터에서 통찰력을 추출하도록 돕습니다. 예를 들어, Curie는 흑색종 탐지 작업에서 AUC 0.99의 모델을 생성했습니다. 이 프로젝트는 오픈소스로 공개되어 커뮤니티 참여를 장려하고 있습니다. (출처: Reddit r/LocalLLaMA)
Alibaba MNN Chat, 안드로이드 기기에서 Qwen 30B-a3b 모델 로컬 실행 지원 : Alibaba의 MNN Chat 애플리케이션이 0.5.0 버전으로 업데이트되어 이제 안드로이드 기기에서 Qwen 30B-a3b와 같은 대형 언어 모델을 로컬에서 실행할 수 있도록 지원합니다. 사용자 피드백에 따르면, 플래그십 칩과 대용량 메모리(예: OnePlus 13 24G)를 갖춘 기기에서 성공적으로 실행되며 mmap 설정을 활성화하는 것이 권장됩니다. 그러나 30B 파라미터 모델은 대부분의 휴대폰에 비해 메모리 및 연산 요구 사항이 너무 높아 Gemma 3n이 모바일 환경에 더 적합할 수 있다는 의견도 있습니다. (출처: Reddit r/LocalLLaMA)

📚 학습
새 논문, Lean and Mean Adaptive Optimization 제안: 더 빠르고 메모리 효율적인 대형 모델 훈련 옵티마이저 : ICML 2025에 채택된 한 논문은 “Subset-Norm and Subspace-Momentum을 통한 Lean and Mean Adaptive Optimization”이라는 새로운 옵티마이저를 소개합니다. 이 방법은 Subset-Norm 스텝 크기와 Subspace-Momentum이라는 두 가지 상호 보완적인 기술을 통해 대규모 신경망 훈련의 메모리 요구 사항을 줄이고 훈련을 가속화하는 것을 목표로 합니다. GaLore, LoRA 등 기존 메모리 효율적인 옵티마이저와 비교하여 이 방법은 메모리를 절약하면서(예: LLaMA 1B 사전 훈련 시 Adam보다 옵티마이저 상태 메모리 80% 감소) 더 적은 훈련 토큰(약 절반)으로 Adam의 검증 perplexity에 도달하고 더 강력한 이론적 수렴 보장을 제공합니다. (출처: Reddit r/MachineLearning)
논문, Force Prompting 제안: 비디오 생성 모델이 물리 기반 제어 신호를 학습하고 일반화하도록 유도 : 새로운 연구는 물리적 힘을 비디오 생성 제어 신호로 사용할 가능성을 탐구하고 “힘 프롬프트”(Force Prompts)를 제안합니다. 사용자는 국부적인 점 힘(예: 식물 찌르기) 또는 전역적인 바람 힘장(예: 바람에 날리는 직물)과 이미지와 상호 작용할 수 있습니다. 연구에 따르면 비디오 생성 모델은 Blender로 합성되고 소수의 물체 시연만 포함된 비디오에서 물리적 힘 조건을 학습하고 일반화하여, 추론 시 3D 자산이나 물리 시뮬레이터 없이 물리적 제어 신호에 사실적으로 반응하는 비디오를 생성할 수 있습니다. 시각적 다양성과 훈련 시 특정 텍스트 키워드 사용이 이러한 일반화를 달성하는 핵심 요소입니다. (출처: HuggingFace Daily Papers)
AnkiHub, AI 레이블링 워크플로우 공유, FastHTML 결합으로 효율성 향상 : AnkiHub이 AI 레이블링 워크플로우를 공유하고 Hamel Husain과 Shreya Shankar의 AI 평가 과정에서 시연했습니다. 이 워크플로우는 FastHTML 구축 도구를 활용하여 상용 제품의 AI 레이블링 효율성을 개선하는 것을 목표로 합니다. 관련 교육 자료와 코드 저장소가 GitHub에 공개되어 실제 생산 환경에서 사용되는 도구를 사용하여 AI 개발을 최적화하는 방법을 보여줍니다. (출처: jeremyphoward, HamelHusain)

블로거, PPO에서 GRPO까지의 학습 경험 공유, LLM 미세 조정에서의 강화 학습 개념 설명 : 한 블로거가 강화 학습(RL)과 대형 언어 모델(LLM) 미세 조정에서의 응용, 특히 PPO(Proximal Policy Optimization)에서 GRPO(Group Relative Policy Optimization)까지의 이해 과정을 공유했습니다. 이 블로그 게시물은 학습 초기에 알고 싶었던 개념을 설명하여 다른 사람들이 이러한 RL 알고리즘이 LLM 최적화에 어떻게 사용되는지 더 잘 이해하도록 돕는 것을 목표로 합니다. (출처: Reddit r/MachineLearning)
논문, 기계의 화용론적 사고 탐구: 대형 언어 모델에서 화용론적 능력의 출현 추적 : 새로운 논문은 대형 언어 모델(LLM)이 훈련 과정에서 어떻게 화용론적 능력(pragmatic competence), 즉 암묵적 의미, 화자 의도 등을 이해하고 추론하는 능력을 습득하는지 연구합니다. 연구자들은 화용론의 “대안”(alternatives) 개념을 기반으로 ALTPRAG 데이터셋을 도입하여, 다양한 훈련 단계(사전 훈련, 지도 미세 조정 SFT, 선호도 최적화 RLHF)의 22개 LLM을 평가했습니다. 결과는 기본 모델조차도 화용론적 단서에 대해 상당한 민감성을 보이며, 모델 및 데이터 규모가 증가함에 따라 지속적으로 개선됨을 보여줍니다. SFT와 RLHF는 인지적 화용론 추론 능력을 더욱 향상시켰습니다. 이는 화용론적 능력이 LLM 훈련에서 출현하는 조합적 특성임을 시사합니다. (출처: HuggingFace Daily Papers)
논문, 시각 도구 선택을 위한 강화 학습 프레임워크 VisTA 탐구 : 연구자들은 시각 에이전트가 경험적 성능에 따라 다양한 라이브러리의 도구를 동적으로 탐색, 선택 및 조합할 수 있도록 하는 새로운 강화 학습 프레임워크인 VisTA(VisualToolAgent)를 도입했습니다. 훈련 없는 프롬프트나 대규모 미세 조정에 의존하는 기존 방법과 달리, VisTA는 작업 결과를 피드백 신호로 사용하여 종단 간 강화 학습을 활용하여 복잡하고 특정 쿼리에 맞는 도구 선택 전략을 반복적으로 최적화합니다. GRPO(Group Relative Policy Optimization)를 통해 이 프레임워크는 에이전트가 명시적인 추론 감독 없이 효과적인 도구 선택 경로를 자율적으로 발견할 수 있도록 합니다. ChartQA, Geometry3K 및 BlindTest 벤치마크에서의 실험은 VisTA가 훈련 없는 기준선에 비해 특히 분포 외 샘플에서 상당한 성능 향상을 달성했음을 보여줍니다. (출처: HuggingFace Daily Papers)
💼 비즈니스
데이터 서비스 회사 Jinglianwen Technology, 수천만 위안 Pre-A 라운드 투자 유치, 공공 데이터 생산 운영 레이아웃 : AI 데이터 서비스 운영사 Jinglianwen Technology가 최근 항저우 진투 그룹(Hangzhou Jintou Group) 산하 펀드로부터 수천만 위안 규모의 Pre-A 라운드 투자를 유치했습니다. 투자금은 공공 데이터 생산 운영 레이아웃, 지능형 코퍼스 엔지니어링 플랫폼 구축 및 자체 수직 분야 고품질 레이블링 기지 건설에 사용될 예정입니다. 2012년에 설립된 이 회사는 공공 데이터, AI 대형 모델, 자율 주행 및 의료 분야에 중점을 두고 있으며, 공공 데이터의 “관리 어려움, 공급 불가, 유통 불가, 활용 불가, 보안 취약” 등의 문제점을 해결하고 화웨이 데이터 스토리지와 협력하여 AI 데이터 레이크 공동 솔루션을 출시하는 것을 목표로 합니다. 올해 매출 성장률은 400%를 초과할 것으로 예상됩니다. (출처: 36氪)
Meitu, Alibaba로부터 약 2억 5천만 달러 전환사채 투자 유치, AI 분야 협력 심화 : Meitu는 Alibaba와 전략적 협력을 계획하고 있으며, Alibaba는 Meitu에 총액 약 2억 5천만 달러의 전환사채를 발행할 것이라고 발표했습니다. 양측은 전자상거래 플랫폼 홍보, AI 기술(AI 이미지, AI 비디오) 개발, 클라우드 컴퓨팅 등 분야에서 협력할 예정이며, Meitu는 향후 3년간 Alibaba Cloud로부터 5억 6천만 위안 이상의 서비스를 구매하기로 약속했습니다. 이번 협력은 Alibaba 생태계를 활용하여 전자상거래 분야의 잠재력을 발굴하고 Meitu AI 디자인 도구의 유료 사용자 규모와 연구 개발 수준을 향상시키는 것을 목표로 합니다. 이러한 조치가 한때 Meitu 주가를 상승시켰지만, 시장의 관심은 Meitu가 치열한 시장 경쟁 속에서 Kimi의 사용자 증가 둔화 전철을 밟지 않을 수 있을지, 특히 시각 AI 분야에서 대기업과의 치열한 경쟁과 규모 차이에 어떻게 대응할지에 쏠려 있습니다. (출처: 36氪)
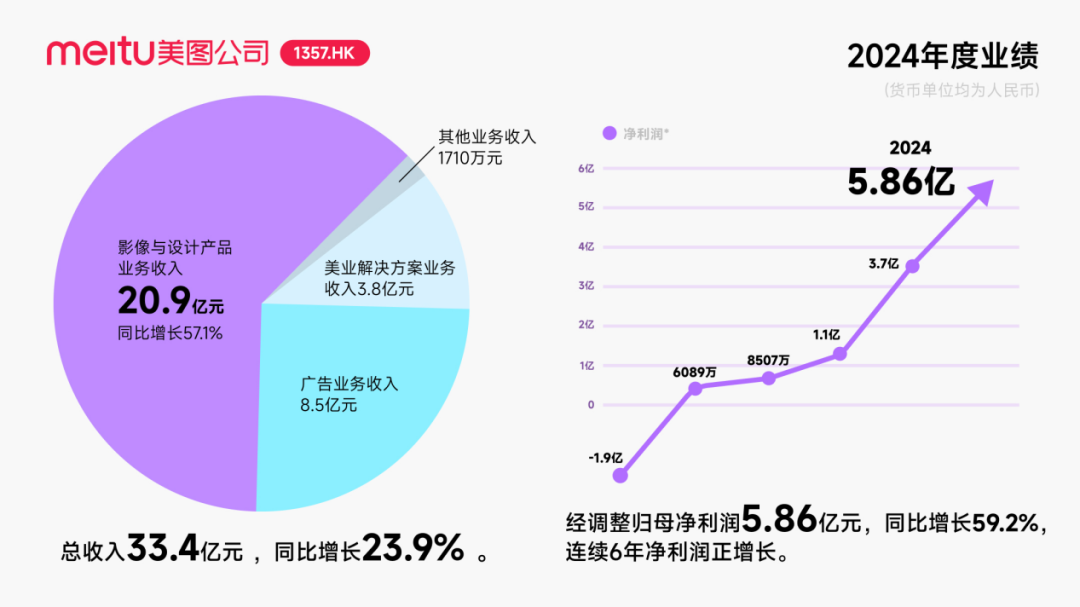
Zhiyuan Robotics, 빈번한 자본 운용으로 산업 생태계 구축, 창업자 Deng Taihua 부상 : 체화형 인공지능 유니콘 기업 Zhiyuan Robotics가 최근 빈번한 자본 운용을 보이고 있습니다. 자체적으로 여러 차례 투자 유치(최근 라운드는 JD Technology 주도)에 성공했을 뿐만 아니라, 산업 체인 기업(Annu Intelligence, Shuzihuaxia 등)에 적극적으로 투자하고 여러 상장사(Bozhong Precision, Dafeng Industry 등)와 합작 로봇 회사를 설립했습니다. 사업자 등록 변경 사항에 따르면, 화웨이 전 부사장 겸 컴퓨팅 제품 라인 전 총괄이었던 Deng Taihua가 실제로는 Zhiyuan Robotics의 창업자이자 실질적인 지배주주이며, 그의 경영진 또한 다수의 전 화웨이 출신 인사들로 구성되어 있습니다. 이러한 “화웨이 계열” 배경은 Zhiyuan Robotics의 “생태계 전략” 운영 방식을 설명해 줍니다. 즉, 광범위한 협력과 투자를 통해 신속하게 산업 영향력을 구축하고 규모화 및 상업화를 실현하는 것입니다. 투자 유치와 상업화에서 선점 우위를 확보했지만, 체화형 인공지능 대형 모델 능력은 여전히 도전에 직면해 있습니다. (출처: 36氪)
🌟 커뮤니티
AI Agent 급속 발전, Agentic LM 잠재력 큰 신규 애플리케이션 및 도구 플랫폼으로 간주 : natolambert 등 AI 분야 인사들은 AI Agent의 빠른 발전에 흥분을 표하며, Agent 기반 언어 모델(Agentic LMs)을 매우 잠재력 있는 플랫폼으로 보고 있습니다. 이를 기반으로 수많은 새로운 애플리케이션과 도구를 구축할 수 있으며, 최근 모델에서 아직 충분히 개발되지 않은 많은 능력이 Agentic 패러다임을 통해 발휘될 수 있다고 합니다. 이는 AI가 단순한 콘텐츠 생성을 넘어 더 능동적이고 작업을 수행할 수 있는 지능형 에이전트로 진화하고 있음을 예고합니다. (출처: natolambert)
AI Agent, 특정 작업에서 초인적 능력 발휘, 그러나 물리 추론은 여전히 약점 : 홍콩대학 등 기관의 연구에 따르면, GPT-4o, Claude 3.7 Sonnet 등 최상위 AI 모델조차 실제 물리적 시나리오와 복잡한 인과 관계 추론을 포함하는 PHYX 벤치마크 테스트에서 물리 문제 정답률이 인간 전문가보다 훨씬 낮았습니다(모델 최고 45.8% vs 인간 최저 75.6%). 이는 AI가 물리 이해에 있어 기억된 지식, 수학 공식 및 피상적인 시각적 패턴 매칭에 과도하게 의존하고 있음을 드러냅니다. 그러나 수학 분야에서는 Epoch AI가 주최한 FrontierMath 대회(문제는 테렌스 타오 등 최상위 수학자들이 설계)에서 o4-mini-medium이 약 22%의 문제를 해결하여 8개 인간 수학자 팀 중 6개를 이기고 인간 팀 평균(19%)을 넘어섰습니다. 이는 AI가 고도로 추상적인 기호 추론에서 잠재력을 가지고 있음을 보여줍니다. 이는 AI가 다양한 유형의 추론 작업에서 능력 발전이 불균형함을 시사합니다. (출처: 36氪, 36氪)

AI 프로그래밍 도구 능력 지속 강화, 프로그래머 직업 전망 논의 촉발 : Anthropic Claude 4 시리즈 모델(특히 Opus 4는 7시간 연속 코딩 가능) 출시와 Cursor, Tongyi Lingma 등 AI 프로그래밍 도구의 발전으로 AI의 코드 생성, 버그 수정, 심지어 전체 개발 프로세스 수행 능력이 현저히 향상되었습니다. 이로 인해 아마존 등 대기업 프로그래머들이 압박감을 느끼고 있으며, 일부 팀은 AI 효율 향상으로 인원이 절반으로 줄고 프로젝트 마감일이 앞당겨지면서 프로그래머 역할이 “코드 검토자”로 전환되고 있습니다. AI가 효율성을 높일 수 있지만, 초급 프로그래머 양성, 기술 퇴보 및 직업 승진 경로에 대한 우려도 제기됩니다. 마이크로소프트 등 기업은 이미 엔지니어링 및 연구 개발 직책에서 감원을 단행했으며 AI 생성 코드 비율이 대폭 증가했다고 밝혔습니다. 업계 종사자들은 AI가 현재는 조수와 같아서 복잡한 요구 사항 이해, 제품 혁신 및 팀 협업에서 인간을 완전히 대체하기는 어렵지만, AI가 프로그래밍 작업의 핵심 가치를 재편하고 있다고 보고 있습니다. (출처: 36氪, 36氪)

AI 지식 베이스 시장 수요 급증, 그러나 실제 적용은 데이터, 시나리오 및 조직 협업 문제에 직면 : 대형 모델 기술이 성숙함에 따라 AI 지식 베이스는 기업 지능화 전환의 핵심 요소가 되어 수요가 2~3배 증가했습니다. AI는 지식 베이스를 정적 “창고”에서 지능형 “엔진”으로 변화시켜 컨텍스트를 인식하고 직접 솔루션을 생성하여 구축 및 운영 효율성을 향상시켰습니다. 그러나 AI 지식 베이스는 고도로 창의적이거나 복잡한 추론 작업을 처리하는 데 여전히 한계가 있으며, 규모 관리, 정보 정확성 및 최신성, 권한 보안, 기술 아키텍처 적응성 및 데이터 마이그레이션 통합 등의 문제점에 직면해 있습니다. 기업은 SaaS, 자체 개발+API, 하이브리드 클라우드 Agent 등의 경로를 신중하게 고려하고, 효과적인 적용을 위해 통일된 지식 미들 플랫폼과 유연한 상위 애플리케이션의 “이중 트랙 아키텍처”를 구축해야 합니다. (출처: 36氪)

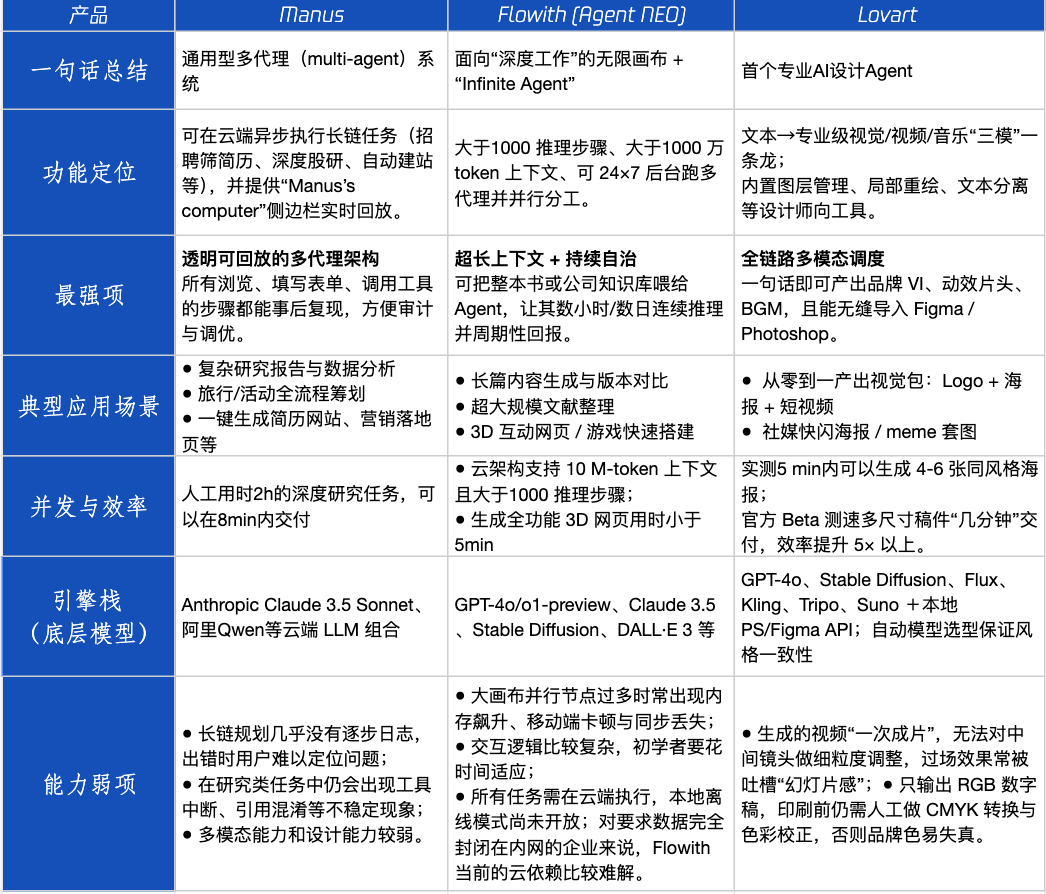
Agent 제품 평가: Manus, Flowith, Lovart의 다양한 시나리오에서의 성능 : Tencent Technology가 인기 있는 세 가지 Agent 제품인 Manus, Flowith (Agent Neo) 및 Lovart를 실제 테스트했습니다. Manus는 독립적으로 완성품을 제공할 수 있는 “디지털 동료”로 포지셔닝되어 시장 조사, 재무 모델링 등 지식 작업에 적합합니다. Flowith는 시각적 협업과 무한한 단계를 강조하며, 정보량이 많고 여러 사람이 반복적으로 작업해야 하는 창작 시나리오(예: 방대한 문헌을 기반으로 분석 보고서 생성)에 적합합니다. Lovart는 디자인 분야에 특화되어 브랜드 시각 솔루션(로고, 포스터, 짧은 비디오)을 원클릭으로 생성할 수 있습니다. 간단한 창의적 시나리오에서는 세 제품 모두 GPT-4o와 유사한 성능을 보였으며, Lovart의 이미지-텍스트 혼합 배열과 질감이 약간 우수했습니다. 복잡한 종합 작업(예: 신생 음료 회사를 위한 전체 브랜드 솔루션 제작)과 심층 연구 시나리오에서는 Manus와 Flowith가 각각 장점을 보였으며, 모두 작업을 완료할 수 있었지만 중점은 달랐습니다. 현재 제품 월 사용료는 약 20달러이며, 상업화의 전환점은 명확한 효율성 이점을 제공하여 사용자를 호기심에서 유료 고객으로 전환할 수 있는지 여부에 달려 있습니다. (출처: 36氪)
Arc 브라우저 창업자, 실패 경험 반성하며 AI 브라우저 미래 방향 강조 : Arc 브라우저 창업자가 제품 실패에 대해 반성하며 AI를 더 일찍 수용했어야 했다고 말했습니다. 또한 Arc가 대부분의 사람들에게 너무 혁신적이고 학습 비용이 높지만 보상이 부족했다고 지적했습니다. 그는 새로운 제품 Dia가 간결함, 극한의 속도 및 보안을 추구할 것이며, 전통적인 브라우저는 결국 사라지고 AI 브라우저가 웹 브라우징과 AI 채팅을 융합하여 데스크톱에서 가장 많이 사용되는 AI 인터페이스가 될 것이라고 강조했습니다. 이러한 관점은 Lovart, Youware 창업자들의 Agent 제품 방향에 대한 생각과 일치하며, AI Agent가 다음 폭발 지점이라고 보고 있습니다. (출처: op7418)
AI Agent가 유발하는 “재귀적 프롬프트” 현상 우려, 사용자 인지 편향 가능성 : 소셜 미디어에서 많은 사용자가 “재귀적 프롬프트”를 통해 LLM과 상호 작용한 후 AI가 영성, 감정, 심지어 예지 능력을 가지고 있다는 인식을 갖게 되는 현상이 나타나고 있습니다. 연구에 따르면 이는 “신경 피드백(neural howlround)” 현상일 수 있으며, 즉 AI의 출력이 사용자에 의해 다시 입력으로 사용되어 강화 순환을 형성하고, AI가 깊이 있거나 예언적인 내용을 생성하는 것처럼 보이지만 실제로는 패턴의 자기 증폭일 수 있습니다. 이미 일부 사용자는 이로 인해 심리적 어려움을 겪으며 AI를 지각 있는 존재(sentient being)로 여기고 있습니다. 이는 AI와 깊이 있고 탐색적인 상호 작용을 할 때 잠재적인 심리적 영향과 인지적 오해에 대해 경계해야 함을 시사합니다. (출처: Reddit r/ChatGPT)

Arav Srinivas, AI 정보 압축과 ASI에 대해 논하다: AI는 신호 대 잡음비 높은 정보 정제 필요, 미래는 AGI 아닌 ASI에 주목해야 : Perplexity AI의 CEO Arav Srinivas는 자동화된 장문 요약이 실제 정보 섭취 가치보다는 사용자에게 “누군가 당신을 위해 일하고 있다”는 만족감을 주는 경우가 더 많다고 생각합니다. 그는 AI가 신호 대 잡음비가 가장 높은 핵심 정보만을 식별하고 제공하는 능력을 향상시켜야 하며, “압축이야말로 진정한 지능의 궁극적인 표시”라고 강조했습니다. 또한 현재 우리가 논의하는 것은 AGI(범용 인공 지능)이지만 미래에는 ASI(초지능)에 더 주목해야 한다고 제안했습니다. (출처: AravSrinivas, AravSrinivas)
대학, 졸업 논문 AI 비율 검사 시작, 학술 작문에서 AI 활용에 대한 논의 촉발 : 2025년 졸업 시즌, 푸단대학교, 쓰촨대학교 등 여러 대학에서 학생들에게 논문에서 AI 도구 사용 현황을 공개하고 AI 생성 콘텐츠 비율 검사(일반적으로 20%-40% 미만 요구)를 시작했습니다. 많은 학생이 문헌 검토, 번역, 프레임워크 구축 등에서 효율성을 높이기 위해 AI를 사용했다고 인정했습니다. 교육계는 이에 대해 의견이 분분하며, 일부 학자들은 AI의 올바른 사용을 유도하고 학생들의 비판적 사고와 판단력을 길러야 한다고 주장합니다. AI가 하한선을 보장할 수는 있지만 상한선은 사람이 결정하기 때문입니다. 학술 및 교육 분야에서 AI의 적용과 규범은 체계적으로 대응해야 할 새로운 과제가 되고 있습니다. (출처: 36氪)
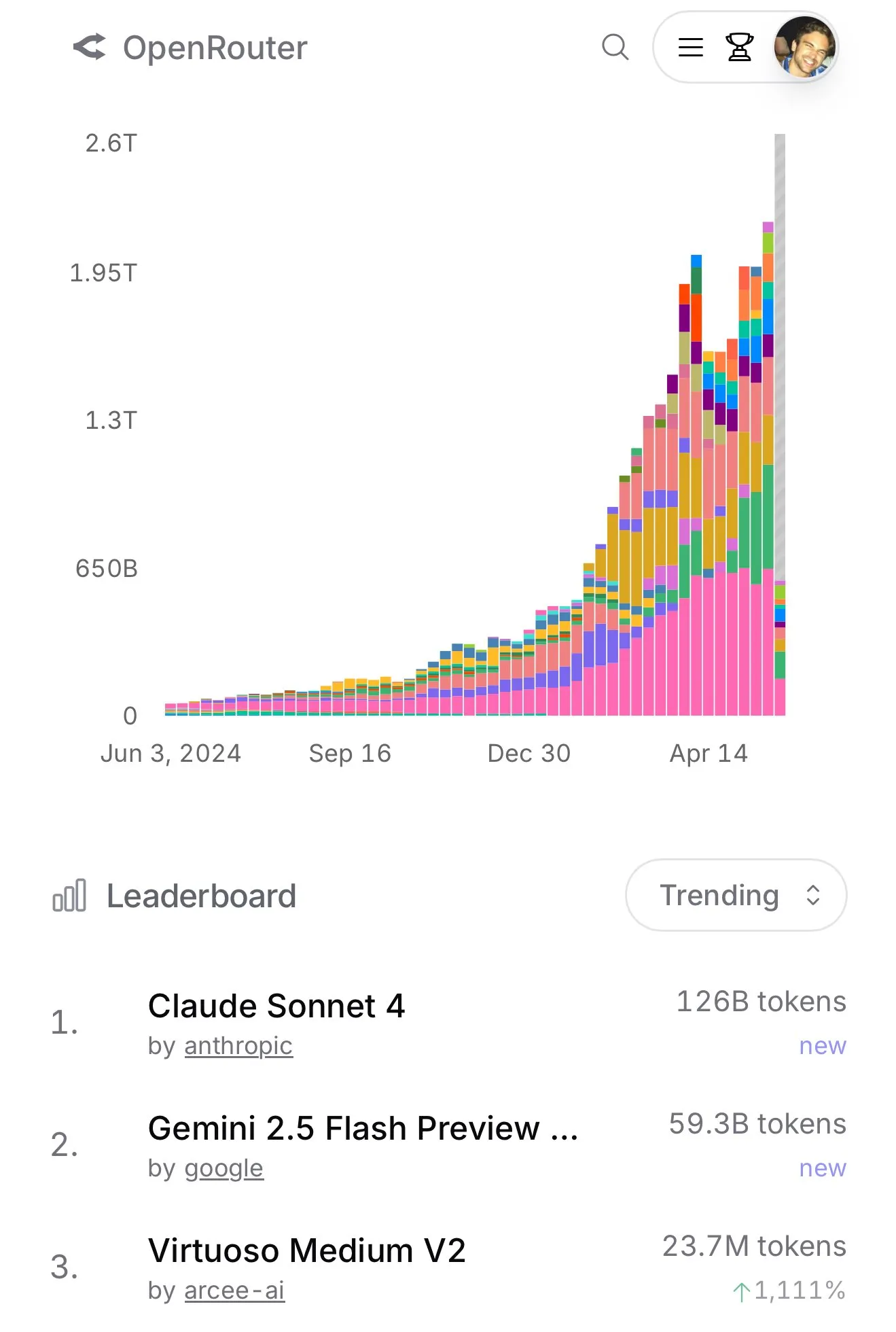
Claude 4 Sonnet, OpenRouter 사용량 급증, Aider 프로그래밍 순위에서 우수한 성능 보여 : OpenRouter 공식 데이터에 따르면 최근 Anthropic의 Claude 4 Sonnet 모델 사용량이 급격히 증가하며 선두를 달리고 있으며, Gemini 2.5 Flash가 2위를 차지했습니다. 동시에 Aider Leaderboard(주로 프로그래밍 작업 대상)의 평가 결과, claude-4-opus-thinking이 claude-3.7-sonnet-thinking보다 우수했지만 Gemini-2.5-Pro-Preview-05-06에는 미치지 못했습니다. 사용자 karminski3의 체감으로는 3.7-sonnet > 4-sonnet > 4-opus 순이었습니다. 이러한 데이터와 피드백은 특정 시나리오에서 다양한 모델의 성능 차이와 사용자 선호도를 반영합니다. (출처: karminski3, karminski3)
💡 기타
AKOOL, 세계 최초 실시간 AI 카메라 Live Camera 출시, 4대 혁신 기능 통합 : 실리콘밸리 기업 AKOOL이 세계 최초의 실시간 AI 카메라라고 주장하는 AKOOL Live Camera를 출시했습니다. 이 제품은 가상 디지털 휴먼 생성(4D 안면 매핑 및 센서 융합 기술 활용), 150개 이상 언어 실시간 번역(원본 음성 및 입 모양 동기화 유지), 실시간 얼굴 변환(감정 및 미세 표정 정확히 반영), 동적 영화급 비디오 콘텐츠 생성(스크립트 없이 즉시 생성) 등 4가지 주요 기능을 통합했습니다. 초저지연(최저 500ms), 고도의 사실감, 상황 인식 및 동적 반응 능력을 특징으로 하며, 전통적인 비디오 제작 및 디지털 상호 작용 방식을 혁신하고 AI 비디오의 “제2의 Sora 순간”으로 불립니다. (출처: 36氪)
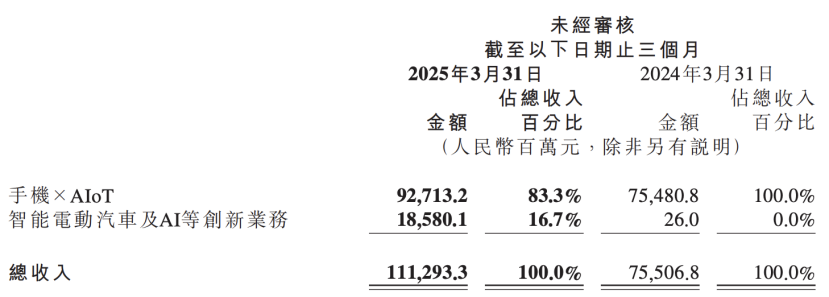
Xiaomi 재무 보고서, AI 전략 업그레이드 공개, AI와 자동차 사업을 핵심 혁신으로 병렬 배치 : Xiaomi의 최신 재무 보고서에 따르면, 회사는 기존 “스마트 전기 자동차 등 혁신 사업”을 “스마트 전기 자동차 및 AI 등 혁신 사업”으로 변경하고, 기반 대형 언어 모델 연구를 지속적으로 추진할 예정입니다. Xiaomi 총재 루웨이빙(Lu Weibing)은 인공 지능과 칩이 Xiaomi의 중요한 하위 전략이며, 기반 대형 모델 개발은 주로 자체 사업 서비스를 위한 것이라고 밝혔습니다. 이러한 움직임은 Xiaomi가 휴대폰 및 자동차 사업에서 단계적인 성과를 거둔 후, AI 휴대폰, AIoT 및 체화형 인공 지능 등 새로운 트렌드에 대응하기 위해 AI 기초 연구 개발 투자를 확대하여 전반적인 경쟁력을 강화하고 있음을 보여줍니다. (출처: 36氪)
휴머노이드 로봇 상호작용 기술 논의: 표정 상호작용, 하드웨어·재료·알고리즘 3중 과제 직면 : 휴머노이드 로봇의 상호작용 경험, 특히 얼굴 표정 상호작용은 성숙도와 보급률을 높이는 핵심 요소로 간주됩니다. 자연스러운 표정 상호작용을 구현하려면 하드웨어 자유도 설계(인간 얼굴 근육 동작 단위 모방 필요), 모터 선택(소형, 경량, 저소음, 고속, 큰 추력/토크 필요), 피부 재료 및 구조 설계(탄성, 수명, 외관 및 구동 구조와의 결합 고려 필요)라는 과제에 직면합니다. 소프트웨어 알고리즘 측면에서는 표정 자동 생성(사전 프로그래밍 방식이 아닌), 음성-입술 동기화(사실감 구현), 다자유도 운동 제어(유연한 재료 모델링 및 정밀 제어 포함)가 핵심 기술 병목 현상입니다. Ameca와 AnyWit Robotics와 같은 회사들이 이 분야에서 탐구를 진행하고 있습니다. (출처: 36氪)