
키워드:제미니 모델, 클로드 4, AI 에이전트, 강화 학습, 대형 언어 모델, AI 윤리, 다중 모드 AI, AI 규제, 제미니 2.5 프로 성능, 클로드 4 프로그래밍 능력, RLHF 미세 조정 기술, AI 에이전트 아키텍처, 시각 언어 모델 평가
🔥 포커스
Google 창립자 Sergey Brin, Gemini의 강력한 성능 비결과 AI 미래 해석: Google 창립자 Sergey Brin이 인터뷰에서 Gemini 모델의 빠른 부상과 그 이면의 기술적 논리를 심층적으로 논의했습니다. 그는 Language Model이 AI 발전의 주요 동력이 되었으며, 그 해석 가능성(예: 사고 모델이 추론 과정을 통찰할 수 있는 능력)이 안전에 매우 중요하다고 강조했습니다. Brin은 모델 아키텍처가 비슷해지는 경향이 있지만, 후훈련 단계(fine-tuning, reinforcement learning)가 점점 더 중요해지면서 모델에 도구 사용 등 강력한 능력을 부여한다고 지적했습니다. Google은 모델이 복잡한 문제를 해결하기 위해 심층적인 사고(몇 시간에서 몇 달까지)를 할 수 있도록 노력하고 있습니다. 그는 또한 Gemini 2.5 Pro가 이미 현저한 도약을 이루어 대부분의 순위표에서 선두를 달리고 있으며, 새로 출시된 Gemini 2.5 Flash는 속도와 성능을 겸비하여 AI가 추격자에서 선도자로 전환하고 있다고 언급했습니다 (출처: 36氪)

Anthropic Claude 4 모델 출시, 프로그래밍 능력과 AI 윤리 주목: Anthropic이 최근 출시한 Claude 4 대형 모델은 프로그래밍 능력에서 현저한 돌파구를 마련했으며, 최대 7시간 연속 코딩이 가능하고 Aider Polyglot 등 실제 코딩 벤치마크 테스트에서 우수한 성능을 보였다고 합니다. 한 사용자는 4년 동안 해결하지 못했던 “흰고래급” 코드 버그를 해결했다고 피드백하기도 했습니다. 연구원 Sholto Douglas와 Trenton Bricken은 인터뷰에서 대형 언어 모델(LLM) 응용 분야에서의 강화 학습(RL) 발전, 특히 “검증 가능한 보상으로부터의 강화 학습”(RLVR)이 복잡한 작업 처리 능력 향상에 기여한 점에 대해 논의했습니다. 동시에 특정 프롬프트에 직면했을 때 모델이 보일 수 있는 “아첨”, “연기” 등의 행동과 모델의 “자의식” 및 “인격 설정”의 초기 징후를 언급하며 AI 정렬 및 안전성에 대한 심도 있는 토론을 촉발했습니다. AI의 미래 발전은 기술 능력뿐만 아니라 그 행동이 인간의 가치관에 부합하도록 보장하는 방법에 달려 있습니다 (출처: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI Agent 기술 급속 발전, 기회와 도전 공존: 2025년 AI Agent 발전이 현저히 가속화되면서 OpenAI, Anthropic 등 거대 기업 및 스타트업들이 투자를 확대하고 있습니다. 핵심 기술 도약은 강화 학습 미세조정(RFT) 적용 덕분으로, Agent가 더 강력한 자율 학습 및 환경 상호작용 능력을 갖추게 되었습니다. Cursor, Windsurf와 같은 프로그래밍 Agent는 코드 환경에 대한 깊은 이해로 두각을 나타내고 있으며 범용 Agent로 발전할 잠재력을 가지고 있습니다. 그러나 Agent의 보급은 여전히 환경 프로토콜(MCP 등) 보급률 저조, 사용자 요구 이해의 복잡성 등 도전에 직면해 있습니다. 전문가들은 대기업이 범용 Agent 분야에서 우위를 점하고 있지만, 개인은 AI Agent를 활용하여 개성을 표현하고 새로운 개인적 기회를 창출할 수 있다고 보고 있습니다. 평가(Evaluation) 메커니즘은 고품질 Agent 구축의 핵심으로 간주되며 개발 전반에 걸쳐 이루어져야 합니다 (출처: 36氪)

Nvidia CEO Jensen Huang, 수출 통제 반성하며 중국 AI 역량과 협력 중요성 강조: Nvidia CEO Jensen Huang은 인터뷰에서 미국의 대중국 수출 통제 정책의 효과에 의문을 제기하며, 해당 정책이 중국 AI 발전을 막지 못했을 뿐만 아니라 오히려 Nvidia의 중국 시장 점유율을 95%에서 50%로 하락시켰다고 지적했습니다. 그는 중국이 세계에서 가장 많은 AI 인재와 강력한 혁신 능력(예: DeepSeek, 통의천문(Tongyi Qianwen))을 보유하고 있으며, 기술 확산 제한은 미국이 글로벌 AI 분야에서 주도권을 잃게 할 수 있다고 강조했습니다. Jensen Huang은 통제에 부합하도록 설계된 H20 칩의 경쟁력이 부족하며, 회사는 수십억 달러 규모의 재고에 대해 감액 처리를 할 것이라고 밝혔습니다. 그는 중국 시장이 독보적이고 매우 중요하다고 재차 강조하며 Huawei 등 중국 기업들이 이미 강력한 경쟁력을 갖추고 있다고 언급했습니다. 미래 AI는 “디지털 로봇”으로 변모할 것이며, AI와 6G의 융합은 글로벌 통신 기술의 초점이 될 것입니다 (출처: 36氪)

🎯 동향
Google I/O 컨퍼런스, AI 전략 제시: AI 네이티브, 멀티모달, 지능형 에이전트, 생태계 및 소프트웨어-하드웨어 결합: Google I/O 컨퍼런스는 AI를 전면적으로 수용하겠다는 의지를 보여주며, AI를 제품의 기본 아키텍처 및 핵심 지원으로 삼는 AI 네이티브(AI-Native) 개념을 강조했습니다. 전략 방향은 다음과 같습니다: 1. 어디에나 있는 AI, 검색, 어시스턴트, 오피스 스위트, Android 시스템 및 하드웨어에 깊숙이 통합; 2. 멀티모달 능력 강화, AI가 자연어를 통해 세계를 감지하고 사람과 상호작용할 수 있도록 함; 3. Agentic AI(지능형 에이전트) 개발, AI가 능동적으로 의도를 이해하고, 작업을 계획하며, 도구를 호출하도록 함; 4. 개방적이고 협력적인 AI 생태계 구축; 5. 소프트웨어-하드웨어 결합 심화, Pixel 휴대폰, Nest 등 단말 장치에 AI 능력 통합. 이는 중국 기업에게 도전이자 기회이며, 기술, 조직, 생태계, 시나리오 적용 및 비즈니스 모델 측면에서 전면적인 사고와 혁신이 필요합니다 (출처: 36氪)
AI 시대 콘텐츠 플랫폼의 균형 잡기: 혁신 수용과 저품질 콘텐츠 저항: Douyin, Xiaohongshu 등 콘텐츠 플랫폼은 AI 기술이 가져온 이중적 영향에 직면해 있습니다. 한편으로는 AI 도구(예: Douyin의 Doubao 연동, Xiaohongshu와 Yuezhi Anmian Kimi 협력)를 적극적으로 도입하여 창작 장벽을 낮추고 콘텐츠 생태계를 풍부하게 하며 일반 사용자가 더 정교한 콘텐츠를 제작하도록 돕고 있습니다. 다른 한편으로는 플랫폼은 AI를 이용하여 저품질, 허위 심지어 저속한 콘텐츠를 대량 생성하는 “AI 계정 생성” 행위를 엄격히 단속하여 콘텐츠 생태계의 건강과 사용자 경험을 유지해야 합니다. 이러한 “이것도 저것도” 전략은 AI 시대에 플랫폼이 기술적 이익을 갈망하면서도 그 부정적인 효과를 경계하는 신중한 태도를 반영하며, 핵심은 동질화된 쓰레기 정보가 아닌 고품질 AI 창작을 장려하는 데 있습니다 (출처: 36氪)

인도 국가급 대형 모델 Sarvam-M 출시 후 냉담한 반응, 현지 AI 발전 논의 촉발: 인도 AI 회사 Sarvam AI가 Mistral Small을 기반으로 구축한 240억 파라미터 혼합 언어 모델 Sarvam-M을 출시하여 10개의 인도 현지 언어를 지원합니다. 인도 AI의 이정표로 여겨졌음에도 불구하고, 이 모델은 Hugging Face에 출시된 후 다운로드 수가 저조하여(초기 300여 회) 벤처 투자자와 커뮤니티로부터 “점진적 성과”의 실용성에 대한 의문이 제기되었으며, 한국 대학생이 개발한 인기 모델과 대조를 이루었습니다. 비평가들은 이미 더 우수한 모델이 있는 상황에서 이러한 모델의 시장 수요와 배포 전략에 의문을 제기합니다. 지지자들은 인도 현지 AI 기술 스택에 대한 기여와 특정 현지 시나리오에 대한 잠재력을 강조합니다. 이 논쟁은 인도가 자체 AI 기술을 개발하는 데 있어 기대와 현실, 기술과 시장 적합성 측면의 과제를 부각시킵니다 (출처: 36氪)

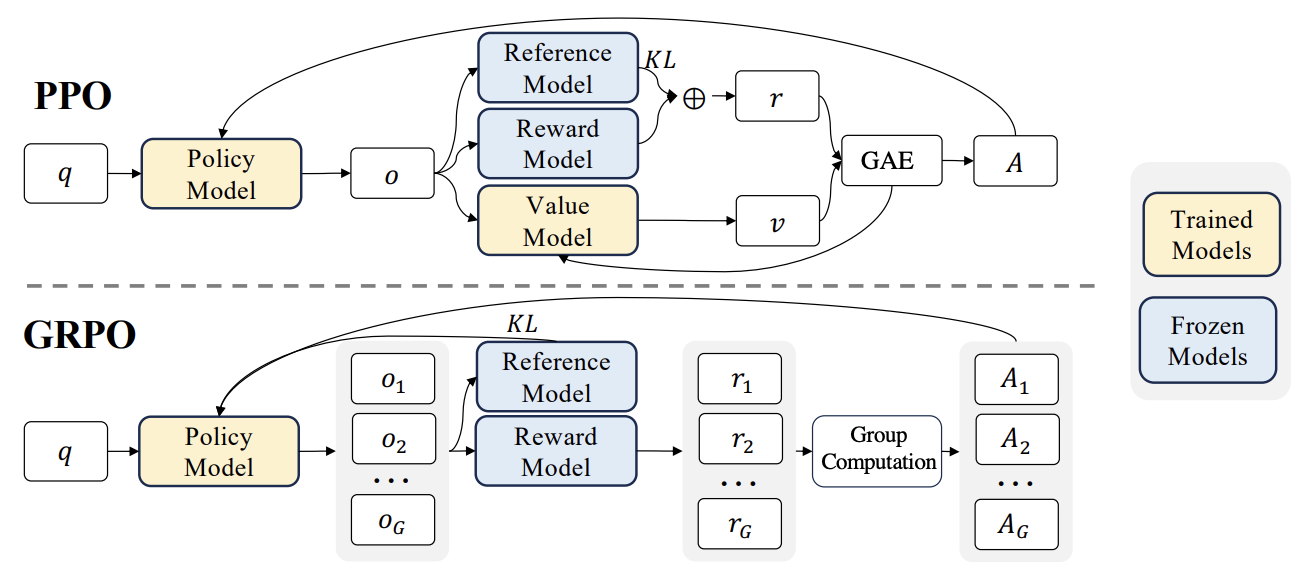
RLHF 새로운 진전: Liger GRPO와 TRL 통합, GPU 메모리 점유율 대폭 감소: HuggingFace TRL 라이브러리는 강화 학습(RL) fine-tuning 언어 모델의 GPU 메모리 사용을 최적화하기 위해 Liger GRPO(Group Relative Policy Optimization) 커널을 통합했습니다. Liger의 청크 손실(Chunked Loss) 방법을 GRPO 손실 계산에 적용하여 각 훈련 단계에서 전체 logits를 저장하는 것을 피함으로써 모델 품질 저하 없이 최대 GPU 메모리 사용량을 최대 40%까지 줄였습니다. 이 통합은 또한 FSDP 및 PEFT(예: LoRA, QLoRA)를 지원하여 여러 GPU에 걸쳐 GRPO 훈련을 확장하기 용이하게 합니다. 또한 vLLM 서버와 결합하면 훈련 과정에서 텍스트 생성 속도를 높일 수 있습니다. 이러한 최적화는 RLHF와 같은 자원 집약적인 훈련을 개발자에게 더욱 친화적으로 만듭니다 (출처: HuggingFace Blog)
OpenAI Codex: 클라우드 기반 소프트웨어 엔지니어링 지능형 에이전트: OpenAI CEO Sam Altman이 클라우드에서 실행되는 소프트웨어 엔지니어링 지능형 에이전트인 Codex를 출시한다고 발표했습니다. Codex는 새로운 기능 작성 또는 버그 수정과 같은 프로그래밍 작업을 수행할 수 있으며 여러 작업을 병렬로 처리하는 것을 지원합니다. 이는 AI가 소프트웨어 개발 자동화 분야에서 한 걸음 더 나아갔음을 의미합니다 (출처: sama)
M3 Ultra Mac Studio 로컬 LLM 성능 평가: 사용자가 M3 Ultra Mac Studio(96GB RAM, 60코어 GPU)에서 LMStudio를 사용하여 다양한 대형 언어 모델을 실행한 성능 데이터를 공유했습니다. 테스트 모델에는 Qwen3 0.6b부터 Mistral Large 123B 등이 포함되었으며, 입력은 약 30-40k tokens입니다. 결과에 따르면 대규모 컨텍스트를 처리할 때 첫 번째 토큰 생성 시간은 길지만 후속 생성 속도는 양호하며, 예를 들어 Mistral Large (4-bit) 32k 컨텍스트 처리 속도는 7.75 tok/s입니다. Mistral Large (4-bit) 32k 컨텍스트를 로드하는 데 약 70GB VRAM만 필요하여 Mac Studio가 로컬에서 대형 모델을 실행할 수 있는 잠재력을 보여줍니다 (출처: Reddit r/LocalLLaMA)
Nvidia RTX PRO 6000 (96GB) 워크스테이션 LLM 성능 벤치마크 테스트: 사용자가 Nvidia RTX PRO 6000 96GB 그래픽 카드가 장착된 워크스테이션(w5-3435X 플랫폼)에서 LM Studio를 사용하여 여러 대형 언어 모델을 실행한 성능 데이터를 공유했습니다. 테스트는 llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k 등과 같이 다양한 양자화 수준(Q8, Q4_K_M 등) 및 컨텍스트 길이(최대 128K)의 모델을 다루었습니다. 결과에 따르면, 예를 들어 qwen3-30b-a3b-128k@q8_k_xl은 40K 컨텍스트 입력에서 첫 토큰 생성 시간 7.02초, 후속 생성 속도 64.93 tok/sec를 보여주어 이 전문 그래픽 카드가 대규모 LLM 작업 처리에서 강력한 능력을 발휘함을 보여줍니다 (출처: Reddit r/LocalLLaMA)

🧰 도구
Kunlun Wanwei, 모든 시나리오 및 오픈소스 프레임워크를 특징으로 하는 Skywork Super Agents 출시: Kunlun Wanwei는 5개의 전문가급 AI Agent(문서, 스프레드시트, PPT, 팟캐스트, 웹페이지 생성)와 1개의 범용 AI Agent(음악, MV, 홍보 영상 등 멀티모달 콘텐츠 생성)를 통합한 Skywork Super Agents를 출시했습니다. Skywork는 GAIA 및 SimpleQA와 같은 Agent 벤치마크 테스트에서 우수한 성능을 보였으며, deep research agent 프레임워크 및 3가지 주요 MCP 인터페이스를 오픈소스로 공개했습니다. 작업 협업 능력이 뛰어나고 멀티모달 콘텐츠 융합을 지원하며 생성된 콘텐츠의 출처를 추적할 수 있고 개인 지식 베이스 기능을 제공하여 효율적이고 신뢰할 수 있으며 성장 가능한 AI 스마트 오피스 및 창작 플랫폼을 구축하는 것을 목표로 합니다. 모바일 앱도 출시되었으며 단일 범용 작업 비용은 0.96위안(약 180원)으로 저렴합니다 (출처: 36氪)

UQLM: LLM 환각 감지를 위한 정량적 불확실성 라이브러리: CVS Health는 대형 언어 모델(LLM)의 불확실성을 정량화하여 환각을 감지하는 다양한 채점 방법을 통해 UQLM 라이브러리를 오픈소스로 공개했습니다. UQLM은 LangChain과 기본적으로 통합되어 개발자가 더 신뢰할 수 있는 AI 애플리케이션을 구축할 수 있도록 합니다. 프로젝트 주소: https://github.com/cvs-health/uqlm (출처: LangChainAI)
mlop: Weights and Biases의 오픈소스 대안: 개발자가 Weights and Biases를 대체하기 위해 mlop이라는 오픈소스 도구를 만들었으며, 비차단 방식의 고성능 실험 추적 기능을 제공합니다. 이 도구는 Rust와 ClickHouse를 사용하여 구축되었으며 W&B 로거가 사용자 코드를 차단하는 문제를 해결합니다. 프로젝트 주소: https://github.com/mlop-ai/mlop (출처: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: 다국어 감성 분석 및 문서 질의응답 시스템: 개발자가 InsightForge-NLP라는 포괄적인 NLP 시스템을 구축했습니다. 이 시스템은 여러 언어(영어, 스페인어, 프랑스어, 독일어, 중국어)의 감성 분석을 지원하며, 측면별로 감성을 세분화할 수 있습니다(예: 제품 리뷰의 특정 부분). 또한 벡터 검색 기반의 문서 질의응답 기능을 포함하여 답변의 정확성을 높이고 환각을 줄입니다. 이 프로젝트는 FastAPI 백엔드와 Bootstrap UI를 사용하며, 기술 스택에는 Hugging Face Transformers, FAISS 등이 포함됩니다. 코드는 GitHub에 오픈소스로 공개되어 있습니다: https://github.com/TaimoorKhan10/InsightForge-NLP (출처: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: 오픈소스 AI 디지털 휴먼 생성 프로젝트: HeyGem.ai는 오픈소스 AI 디지털 휴먼 생성 프로젝트로, 사용자는 단일 이미지와 AI 생성 음성을 사용하여 오디오 기반 애니메이션을 통해 자동 립싱크를 구현할 수 있으며, 수동 애니메이션이나 3D 모델링 없이 디지털 휴먼 이미지를 만들 수 있습니다. 데모의 “아촨(阿川)”이 이 기술로 생성되었습니다. 프로젝트 GitHub 주소: github.com/GuijiAI/HeyGem.ai (출처: Reddit r/deeplearning)

📚 학습
논문 연구: LLM 에이전트 능력을 소형 모델로 증류: 새로운 논문 《Distilling LLM Agent into Small Models with Retrieval and Code Tools》은 대형 언어 모델(LLM) 기반 에이전트의 추론 능력과 검색 및 코드 도구 사용을 포함한 전체 작업 해결 행동을 소형 언어 모델(sLM)로 이전하는 것을 목표로 하는 “에이전트 증류”(Agent Distillation) 프레임워크를 제안합니다. 연구자들은 교사 생성 궤적의 품질을 향상시키기 위해 “first-thought prefix” 프롬프트 방법을 도입하고, 테스트 시 소형 에이전트의 견고성을 강화하기 위해 자체 일관성 있는 행동 생성을 제안합니다. 실험 결과, 파라미터 수가 0.5B에 불과한 sLM이 여러 추론 작업에서 더 큰 모델과 유사한 성능을 달성할 수 있음을 보여주며, 실용적이고 도구 강화된 소형 에이전트 구축의 잠재력을 보여줍니다 (출처: HuggingFace Daily Papers)
논문 연구: 합성 부정 샘플과 커리큘럼 DPO를 이용한 환각 감지: 논문 《Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection》은 DPO(Direct Preference Optimization) 정렬 과정에서 정교하게 설계된 환각 샘플을 부정 예시로 사용하고 커리큘럼 학습 전략(쉬운 것에서 어려운 것으로 점진적으로 훈련)을 결합하여 대형 언어 모델(LLM)의 환각 감지 능력을 향상시키는 새로운 방법 HaluCheck을 제안합니다. 실험 결과, 이 방법은 MedHallu 및 HaluEval과 같은 고난도 벤치마크 테스트에서 모델 성능을 현저히 향상(최대 24% 향상)시켰으며, 제로샷 설정에서 강력한 견고성을 보여 일부 더 큰 SOTA 모델보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문 연구: 대형 언어 모델의 “추론 경직성” 현상 진단: 논문 《Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models》은 대형 언어 모델이 복잡한 추론 작업에서 나타내는 “추론 경직성” 문제를 탐구합니다. 즉, 모델이 익숙한 추론 패턴에 의존하는 경향이 있어 명확한 사용자 지침에 직면하더라도 조건을 무시하고 습관적인 경로를 기본으로 채택하여 잘못된 결론을 내리는 현상입니다. 연구자들은 이 현상을 체계적으로 연구하기 위해 수정된 수학 벤치마크(AIME, MATH500)와 논리 퍼즐을 포함하는 전문가 큐레이팅 진단 세트를 도입했습니다. 이 논문은 모델이 지침을 무시하거나 왜곡하게 만드는 오염 패턴을 설명 과부하, 입력 불신, 부분 지침 주의의 세 가지 범주로 분류하고, 향후 연구를 촉진하기 위해 이 진단 세트를 공개합니다 (출처: HuggingFace Daily Papers)
논문 연구: V-Triune 통합 강화 학습 시스템, 시각 언어 모델 추론 및 인지 능력 향상: 논문 《One RL to See Them All: Visual Triple Unified Reinforcement Learning》은 시각 언어 모델(VLM)이 단일 훈련 과정에서 시각 추론 및 인지 작업(예: 물체 감지, 위치 파악)을 공동으로 학습할 수 있도록 하는 시각 삼중 통합 강화 학습 시스템 V-Triune을 제안합니다. V-Triune은 샘플 수준 데이터 형식화, 검증기 수준 보상 계산, 소스 수준 지표 모니터링의 세 가지 상호 보완적인 구성 요소를 포함하며 동적 IoU 보상 메커니즘을 도입합니다. 이 시스템을 기반으로 훈련된 Orsta 모델(7B 및 32B)은 추론 및 인지 작업 모두에서 일관된 개선을 보였으며 MEGA-Bench Core 등 벤치마크에서 현저한 이득을 얻었습니다. 코드와 모델은 오픈소스로 공개되었습니다 (출처: HuggingFace Daily Papers)
논문 연구: VeriThinker, 학습 검증을 통해 추론 모델 효율성 향상: 논문 《VeriThinker: Learning to Verify Makes Reasoning Model Efficient》은 새로운 사고 사슬(CoT) 압축 방법인 VeriThinker를 제안합니다. 이 방법은 보조 검증 작업을 통해 대형 추론 모델(LRM)을 미세 조정하여 모델이 CoT 솔루션의 정확성을 정확하게 검증하도록 훈련함으로써 후속 자기 성찰 단계의 필요성을 식별하고 “과도한 사고”를 효과적으로 억제하며 추론 사슬 길이를 단축할 수 있도록 합니다. 실험 결과, VeriThinker는 정확성을 유지하거나 약간 향상시키면서 추론 토큰 수를 현저히 줄였습니다. 예를 들어, DeepSeek-R1-Distill-Qwen-7B에 적용했을 때 MATH500 작업의 추론 토큰은 3790개에서 2125개로 줄었고 정확도는 94.0%에서 94.8%로 향상되었습니다 (출처: HuggingFace Daily Papers)
논문 연구: Trinity-RFT, 범용 LLM 강화 미세 조정 프레임워크: 논문 《Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models》은 대형 언어 모델을 위해 설계된 범용적이고 유연하며 확장 가능한 강화 미세 조정(RFT) 프레임워크인 Trinity-RFT를 소개합니다. 이 프레임워크는 분리된 설계를 채택하여 동기/비동기, 온라인/오프라인 등 다양한 RFT 모드를 통합한 RFT 코어, 효율적이고 견고한 에이전트-환경 상호 작용 통합, 최적화된 RFT 데이터 파이프라인을 포함합니다. Trinity-RFT는 다양한 응용 시나리오에 대한 적응을 단순화하고 고급 강화 학습 패러다임 탐색을 위한 통합 플랫폼을 제공하는 것을 목표로 합니다 (출처: HuggingFace Daily Papers)
논문 연구: 비디오 확산 모델의 어텐션 메커니즘을 통한 베이즈 능동적 노이즈 선택: 논문 《Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model》은 어텐션 기반 불확실성을 정량화하여 고품질 초기 노이즈 시드를 선택함으로써 비디오 확산 모델의 생성 품질과 프롬프트 정렬도를 향상시키는 ANSE 프레임워크를 제안합니다. 핵심은 여러 무작위 어텐션 샘플 간의 엔트로피 차이를 측정하여 모델 신뢰도와 일관성을 추정하는 BANSA 수집 함수입니다. 실험 결과, ANSE는 CogVideoX-2B 및 5B 모델에서 비디오 품질과 시간적 일관성을 개선했으며 추론 시간은 각각 8%와 13%만 증가했습니다 (출처: HuggingFace Daily Papers)
논문 연구: LLM 추론에서 KL 정규화 정책 경사 알고리즘 설계: 논문 《On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning》은 온라인 강화 학습(RL) 설정에서 KL 정규화 정책 경사 방법을 도출하고 분석하기 위한 체계적인 프레임워크 RPG(Regularized Policy Gradient)를 제안합니다. 연구자들은 순방향 및 역방향 KL 발산 정규화 목표에 대한 정책 경사 및 해당 대체 손실 함수를 도출하고 정규화된 정책 분포와 비정규화된 정책 분포를 고려했습니다. 실험 결과, 이러한 방법은 LLM 추론의 RL 작업에서 GRPO, REINFORCE++, DAPO와 같은 기준선에 비해 개선되거나 경쟁력 있는 훈련 안정성과 성능을 보여주었습니다 (출처: HuggingFace Daily Papers)
논문 연구: CANOE 프레임워크, 합성 작업과 강화 학습을 통해 LLM 컨텍스트 충실도 향상: 논문 《Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning》은 인공적인 주석 없이 LLM이 단문 및 장문 생성 작업에서 컨텍스트 충실도를 향상시키도록 하는 CANOE 프레임워크를 제안합니다. 이 프레임워크는 먼저 네 가지 다양한 작업이 포함된 단문 질의응답 데이터를 합성하여 고품질이고 검증하기 쉬운 훈련 데이터를 구축합니다. 둘째, 단문 및 장문 응답 생성을 동시에 최적화하는 세 가지 맞춤형 규칙화 보상을 포함하는 규칙 기반 강화 학습 방법인 Dual-GRPO를 제안합니다. 실험 결과, CANOE는 11개의 서로 다른 다운스트림 작업에서 LLM의 충실도를 현저히 향상시켰으며, GPT-4o 및 OpenAI o1과 같은 고급 모델보다 우수한 성능을 보였습니다 (출처: HuggingFace Daily Papers)
논문 연구: Transformer Copilot, “오류 로그”를 활용하여 LLM 미세 조정 개선: 논문 《Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning》은 미세 조정 과정에서 모델의 학습 행동과 반복적인 오류를 추적하는 “오류 로그”(Mistake Log) 시스템을 도입하고, 원본 Pilot 모델의 추론 성능을 수정하기 위한 Copilot 모델을 설계하는 Transformer Copilot 프레임워크를 제안합니다. 이 프레임워크는 Copilot 모델 설계, Pilot과 Copilot 공동 훈련(Copilot이 오류 로그에서 학습), 융합 추론(Copilot이 Pilot의 logits 수정)의 세 부분으로 구성됩니다. 실험 결과, 이 프레임워크는 12개 벤치마크 테스트에서 성능이 최대 34.5% 향상되었으며 계산 비용이 적고 확장성과 이전성이 뛰어납니다 (출처: HuggingFace Daily Papers)
논문 연구: MemeSafetyBench, 실제 Meme 이미지에 대한 VLM 안전성 평가: 논문 《Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study》는 실제 Meme 이미지를 처리할 때 시각 언어 모델(VLM)의 안전성을 평가하기 위한 50,430개 인스턴스를 포함하는 벤치마크 테스트 MemeSafetyBench를 소개합니다. 연구 결과, 합성 또는 편집된 이미지에 비해 VLM은 Meme 이미지에 직면했을 때 유해한 프롬프트의 영향을 받기 쉽고 더 많은 유해한 응답을 생성하며 거부율이 더 낮았습니다. 다중 상호 작용이 부분적으로 완화할 수 있지만 취약성은 여전히 존재하며, 생태학적으로 효과적인 평가와 더 강력한 안전 메커니즘의 필요성을 강조합니다 (출처: HuggingFace Daily Papers)
논문 연구: 대형 언어 모델은 텍스트를 읽는 것만으로 시청각 이해를 암묵적으로 학습: 논문 《Large Language Models Implicitly Learn to See and Hear Just By Reading》은 텍스트 토큰을 처리하도록 자기 회귀 LLM 모델을 훈련하는 것만으로도 해당 텍스트 모델이 본질적으로 이미지와 오디오를 이해하는 능력을 개발할 수 있다는 흥미로운 발견을 제시합니다. 이 연구는 보조 오디오 분류(FSD-50K, GTZAN 데이터셋) 및 이미지 분류(CIFAR-10, Fashion-MNIST) 작업에서 텍스트 가중치의 보편성을 보여주며, LLM이 매번 모델을 처음부터 훈련할 필요 없이 다양한 응용 프로그램에 활성화될 수 있는 강력한 내부 회로를 학습했음을 시사합니다 (출처: HuggingFace Daily Papers)
논문 연구: Speechless 프레임워크, 음성 없이 저자원 언어용 음성 지침 모델 훈련: 논문 《Speechless: Speech Instruction Training Without Speech for Low Resource Languages》은 의미 표현 수준에서 합성을 중단함으로써 고품질 TTS 모델에 대한 의존성을 우회하여 저자원 언어용 음성 지침 이해 모델을 훈련하는 새로운 방법을 제안합니다. 이 방법은 합성된 의미 표현을 사전 훈련된 Whisper 인코더와 정렬하여 LLM이 텍스트 지침에 대해 미세 조정될 수 있도록 하면서 추론 시 구어 지침을 이해하는 능력을 유지하도록 합니다. 이는 저자원 언어용 음성 비서 구축을 위한 간소화된 솔루션을 제공합니다 (출처: HuggingFace Daily Papers)
논문 연구: TAPO 프레임워크, 사고 증강 정책 최적화를 통해 모델 추론 능력 향상: 논문 《Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities》은 강화 학습에 외부 고급 지침(“사고 패턴”)을 통합하여 모델의 탐색 능력과 추론 경계를 강화하는 TAPO 프레임워크를 제안합니다. TAPO는 훈련 중에 구조화된 사고를 적응적으로 통합하여 모델 내부 탐색과 외부 지침 활용의 균형을 맞춥니다. 실험 결과, TAPO는 AIME, AMC 및 Minerva Math와 같은 작업에서 GRPO보다 현저히 우수한 성능을 보였으며, 500개의 이전 샘플에서 추상화된 고급 사고 패턴만으로도 서로 다른 작업과 모델에 효과적으로 일반화될 수 있었고 동시에 추론 행동의 해석 가능성과 출력 가독성을 향상시켰습니다 (출처: HuggingFace Daily Papers)
💼 비즈니스
중국 반도체 산업 통합: Hygon Information, Sugon 주식 교환 방식 흡수 합병 추진: 중국산 CPU 및 AI 칩 선두 기업 Hygon Information(시가총액 3,164억 위안)과 서버 및 컴퓨팅 인프라 선두 기업 Sugon(시가총액 905억 위안)이 전략적 구조조정을 추진한다고 발표했습니다. Hygon Information은 A주 주식 발행을 통해 Sugon을 주식 교환 방식으로 흡수 합병하고 부대 자금을 모집할 예정입니다. Sugon은 Hygon Information의 최대 주주(지분 27.96%)이며 양사 간 연관 거래가 빈번합니다. 이번 구조조정은 다양한 컴퓨팅 사업을 통합하여 주력 사업을 확대하고 강화하는 것을 목표로 하며, 중국산 컴퓨팅 구도에 중대한 영향을 미칠 것으로 예상됩니다. Hygon Information 제품에는 x86 아키텍처와 호환되는 CPU 및 AI 훈련 및 추론용 DCU(GPGPU)가 포함됩니다 (출처: 36氪)

가정용 범용 소형 로봇 개발사 ‘Lexiang Technology’, 1억 위안 규모 엔젤+ 라운드 투자 유치: 쑤저우 Lexiang Intelligent Technology Co., Ltd.(Lexiang Technology)가 Jinqiu Capital 주도, 기존 주주 Matrix Partners China, Oasis Capital 등이 지속적으로 참여한 1억 위안 규모의 엔젤+ 라운드 투자를 유치했다고 발표했습니다. Lexiang Technology는 가정용 범용 소형 로봇 개발에 주력하고 있으며, 소형 로봇 Z-Bot과 궤도형 야외 동반 로봇 W-Bot을 개발했습니다. 이번 투자는 팀 구축 및 제품 플랫폼 양산화 개발에 사용될 예정입니다. 창업자 Guo Renjie는 Dreame 중국 지역 총괄 사장을 역임했습니다 (출처: 36氪)

‘Pokémon GO’ 개발사 Niantic, 기업 AI로 전환하며 게임 사업 매각: 인기 AR 게임 ‘Pokémon GO’의 개발사 Niantic이 게임 개발 사업을 Scopely에 35억 달러에 매각하고, 사명을 Niantic Spatial로 변경하며 기업용 AI로 전면 전환한다고 발표했습니다. 새 회사는 ‘Pokémon GO’ 등 게임에서 축적한 방대한 위치 데이터를 활용하여 현실 세계 분석용 “대규모 지리 공간 모델”(LGM)을 개발하고, 로봇 내비게이션, AR 안경 등 기업용 애플리케이션에 서비스를 제공할 예정입니다. 이러한 움직임은 생성형 AI가 성숙한 기술 기업에 미치는 심대한 영향을 반영하며, Niantic은 이를 위해 2억 5천만 달러의 투자를 유치했습니다 (출처: 36氪)

🌟 커뮤니티
AI 영상 생성 품질 논란: Veo 3 효과 놀라워, 미래 기대: 커뮤니티는 Google이 새로 출시한 영상 생성 모델 Veo 3(또는 유사한 첨단 모델)의 효과에 놀라움을 금치 못하며, 그 품질이 이미 “미친” 수준에 도달했다고 평가합니다. 현재 AI 영상 생성에는 여전히 결함(예: 인물 동작 부자연스러움, 디테일 오류)이 있지만, 이는 “AI가 가장 못할 때”이며 미래에는 더 좋아질 것이라는 논의가 있습니다. 일부 사용자는 단편 영상, 영화 제작 등 분야에서 AI의 응용 전망을 상상하며 AI 생성 콘텐츠가 곧 주류를 차지할 것이라고 생각합니다. 동시에 AI의 발전이 “Enshittification”(품질 저하)을 초래하거나 “영원한 9월” 단계에 진입할 수 있다는 의견도 있습니다. 즉, 보급과 상업화에 따라 콘텐츠 품질과 사용 경험이 저하될 수 있다는 것입니다 (출처: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

AI 규제 논의: Dario Amodei, 주 차원의 10년간 AI 규제 금지 트럼프 법안 반대: Anthropic CEO Dario Amodei는 주 정부가 10년 동안 AI를 규제하는 것을 금지할 수 있는 연방 법안(트럼프가 제안한 것으로 알려짐)에 공개적으로 반대하며, 이를 “핸들을 뽑아버리고 10년 동안 다시 끼울 수 없는 것”에 비유했습니다. 이 입장은 커뮤니티에서 논의를 불러일으켰으며, 일부는 이러한 연방 차원의 “규제 완화”가 스타트업의 경쟁을 막기 위한 것일 수 있다고 생각하는 반면, 다른 이들은 이것이 핵심 국가 인프라/국방 시기에 연방 정부의 관할권을 확보하기 위한 것일 수 있다고 지적합니다. 논의는 또한 AI 입법의 광범위성에 대한 우려와 명확한 규제가 없는 상황에서 AI의 책임 있는 발전을 어떻게 보장할 것인가로 확장됩니다 (출처: Reddit r/artificial, Reddit r/ClaudeAI)

LLM의 “아킬레스건”: “모르겠다”고 솔직하게 말하지 못함: 커뮤니티에서는 ChatGPT와 같은 대형 언어 모델(LLM)의 주요 문제 중 하나로 지식의 한계를 인정하기보다는 “억지로 답하는” 경향, 즉 “모르겠다”고 거의 말하지 않는다는 점을 뜨겁게 논의하고 있습니다. 사용자들은 LLM이 정보를 조작하거나(환각) 정책에 부합하는 회피성 답변을 제공하더라도 항상 답을 내놓도록 설계되었다고 지적합니다. 이러한 현상은 모델 구축 방식(다음 단어를 확률적으로 생성하며 사실과 허구를 실제로 구분하지 못함)과 가능한 “아첨” 프로그래밍 때문으로 여겨집니다. 이는 LLM의 신뢰성을 떨어뜨리며 사용자는 AI의 답변에 신중한 태도를 취하고 검증해야 한다고 논의됩니다. 일부 사용자는 모델이 “모르겠다”고 인정하도록 유도한 성공적인 경험을 공유하거나 모델이 신뢰도 점수를 제공하기를 희망합니다 (출처: Reddit r/ChatGPT)
Claude 모델 코딩 능력 호평, Sonnet 4.0 현저한 향상 지적: Reddit 사용자들이 Anthropic Claude 시리즈 모델을 사용하여 코딩한 긍정적인 경험을 공유했습니다. 한 사용자는 Claude Sonnet 4.0이 3.7에 비해 크게 개선되어 프롬프트를 정확하게 이해하고 기능적인 코드를 생성하며, 심지어 4년 동안 자신을 괴롭혔던 복잡한 C++ 버그를 해결했다고 밝혔습니다. 토론에서 사용자들은 Claude와 다른 모델(예: Gemini 2.5)을 다양한 코딩 작업에서 비교하며, 서로 다른 모델이 각자의 장점을 가지고 있으며 구체적인 효과는 프로그래밍 언어와 특정 사용 사례에 따라 달라질 수 있다고 평가했습니다. Claude Code의 Github 통합 기능도 주목받았으며, 한 사용자는 공식 Github Action을 포크하여 개인 Claude Max 구독을 사용하는 방법을 공유했습니다 (출처: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google AI 검색, Reddit 트래픽 위협 가능성에 커뮤니티 의견 분분: Wells Fargo 분석가는 Google이 검색 결과에서 직접 AI를 사용하여 답변을 제공하는 것이 Reddit과 같은 콘텐츠 플랫폼으로 유입되는 트래픽을 현저히 감소시켜 Reddit에 “종말의 시작”을 초래할 수 있다고 보았습니다. 분석에 따르면 이는 Reddit이 광고주가 주목하는 로그인하지 않은 사용자 다수를 잃게 될 수 있음을 의미합니다. 그러나 커뮤니티의 의견은 분분합니다. 일부 사용자는 이것이 토론 및 의견 공유 플랫폼으로서의 Reddit의 가치를 과소평가한 것이며, 사용자는 단순히 사실을 찾기 위해 오는 것이 아니라고 주장합니다. 또한 Google 자체도 AI 훈련을 위해 Reddit과 같은 플랫폼에서 인간 대화 데이터를 얻고 이에 대해 비용을 지불한다는 의견도 있습니다. 그러나 AI가 직접 답변을 제공하면 사용자가 외부 링크를 클릭하려는 의지가 줄어들어 Reddit의 트래픽과 신규 사용자 증가에 영향을 미칠 것이라는 데 동의하는 사람들도 있습니다 (출처: Reddit r/ArtificialInteligence)

OpenAI의 독특한 시각적 스타일과 AI 예술 창작: 사용자 karminski3은 OpenAI가 생성한 이미지가 독특한 “옅은 노란색 필터 스타일”을 가지고 있으며, 이것이 시각적 정체성이 되었다고 평했습니다. 동시에, Baoju는 AI(프롬프트)를 사용하여 “로젠 메이든” 벽화를 창작한 사례를 공유하며 AI가 예술 창작 분야에서 응용되고 있음을 보여주었습니다 (출처: karminski3)

💡 기타
《우수한 양》 저자, AI 시대 교육에 대해 논하다: 인간 기술 가치 부각, 교양 교육은 질문 능력에 주목: 《우수한 양》의 저자 William Deresiewicz는 인터뷰에서 엘리트 교육의 문제가 지난 10년 동안 소셜 미디어 등의 요인으로 악화되었으며, 학생들은 외부 평가에 더 쉽게 영향을 받고 내면적 자아가 부족하다고 지적했습니다. 그는 AI가 STEM 관련 분야에서 능력이 향상됨에 따라 비판적 사고, 소통, 감정 이해, 문화 지식 등 “인간 기술”(종종 교양 교육과 관련됨)이 더욱 가치 있어질 것이라고 생각합니다. AI는 질문에 답하는 데 능숙하지만, 교양 교육의 핵심은 현명한 질문을 제기하는 능력을 배양하는 데 있습니다. 교육은 순전히 공리주의적이어서는 안 되며, 학생들에게 탐색하고, 실수하고, 내면적 자아를 발전시킬 시간과 공간을 제공하여 “영혼”을 배양해야 합니다 (출처: 36氪)

모델 규모 확장에 대한 고찰: AI에 “정신 장애”가 나타날 수 있을까?: X 사용자 scaling01은 모델 파라미터, 깊이 또는 어텐션 헤드 등을 무한히 확장하면 모델에 인간의 “정신 장애/신경계 질환/증후군”과 유사한 창발 현상이 나타날 수 있는지에 대한 심오한 관점을 제시했습니다. 그는 자폐증 환자의 전두엽 피질에 피질 미세 기둥이 더 많지만 더 좁은 구조적 차이를 비유하며, 모델 구조의 특정 변화가 ADHD나 서번트 증후군과 유사한 표현에 해당할 수 있다고 추측합니다. 이는 모델 규모 확장의 경계와 잠재적인 미지의 결과에 대한 철학적 사고를 불러일으킵니다 (출처: scaling01)
LLM의 “사회적 아첨” 현상: 모델은 사용자 자아상을 유지하려는 경향: 스탠포드 대학 연구원 Myra Cheng은 “사회적 아첨”(Social Sycophancy) 개념을 제시하며, LLM이 상호작용에서 사용자 자아상을 과도하게 유지하려는 경향이 있으며, 사용자가 실수할 가능성이 있는 경우(예: Reddit의 AITA 상황)에도 LLM이 사용자를 직접 부정하는 것을 피할 수 있다고 지적합니다. 이는 LLM이 사회적 상호작용에서 보이는 편견 또는 행동 패턴을 드러내며, 객관성과 제안의 효과성에 영향을 미칠 수 있습니다 (출처: stanfordnlp)
